设计模式
简单工厂模式又叫静态工厂方法模式(Static Factory Method Pattern),是通过专门定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类。 一个简单的实例:要求实现一个计算机控制台程序,要求输入数的运算结果。最原始的解决方法如下:
/**
* @Description:这里使用的是最基本的实现,并没有体现出面向对象的编程思想,代码的扩展性差,甚至连除数可能为0的情况也没有考虑
*/
public static void main(String[] args) {
scanner = new Scanner(System.in);
System.out.print("请输入第一个数字:");
int firstNum = scanner.nextInt();
System.out.print("请输入第二个数字:");
int secondNum = scanner.nextInt();
System.out.print("请输入运算符:");
String operation = scanner.next();
if(operation.equals("+")) {
System.out.println("result:" + (firstNum + secondNum));
} else if(operation.equals("-")) {
System.out.println("result:" + (firstNum - secondNum));
} else if(operation.equals("*")) {
System.out.println("result:" + (firstNum * secondNum));
} else if(operation.equals("/")){
System.out.println("result:" + (firstNum / secondNum));
}
}
上面的写法实现虽然简单,但是却没有面向对象的特性,代码拓展性差,甚至没有考虑除数可能为0的特殊情况。 在面向对象编程语言中,一切都是对象,所以上面运算符号也应当作对象来处理。因此我们首先建立一个运算接口,所有其他的运算都封装成类,并实现该运算接口。
/**
* @Description: 定义一个运算接口,将所有的运算符号都封装成类,并实现本接口
* @author: zxt
* @time: 2018年7月6日 上午10:24:13
*/
public interface Operation {
public double getResult(double firstNum, double secondNum);
}
public class AddOperation implements Operation {
@Override
public double getResult(double firstNum, double secondNum) {
return firstNum + secondNum;
}
}
public class SubOperation implements Operation {
@Override
public double getResult(double firstNum, double secondNum) {
return firstNum - secondNum;
}
}
public class MulOperation implements Operation {
@Override
public double getResult(double firstNum, double secondNum) {
return firstNum * secondNum;
}
}
public class DivOperation implements Operation {
@Override
public double getResult(double firstNum, double secondNum) {
if(secondNum == 0) {
try {
throw new Exception("除数不能为0!");
} catch (Exception e) {
e.printStackTrace();
}
}
return firstNum / secondNum;
}
}
现在的问题的是,如何根据不同的情况创建不同的对象,这里就可以使用简单工厂模式来实现了,客户端只需要提供运算符,工厂类会判断并生成相应的运算类:
/**
* @Description: 简单工厂模式:通过一个工厂类,根据情况创建不同的对象
* @author: zxt
* @time: 2018年7月6日 上午10:50:15
*/
public class OperationFactory {
/**
* @Description:根据运算符得到具体的运算类
* @param operationStr
*/
public static Operation getOperation(String operationStr) {
Operation result = null;
switch(operationStr) {
case "+":
result = new AddOperation();
break;
case "-":
result = new SubOperation();
break;
case "*":
result = new MulOperation();
break;
case "/":
result = new DivOperation();
break;
}
return result;
}
}
// 客户端调用
Operation oper = OperationFactory.getOperation(operation);
double result = oper.getResult(firstNum, secondNum);
System.out.println(result);
简单工厂将对象的创建过程进行了封装,用户不需要知道具体的创建过程,只需要调用工厂类获取对象即可。 这种简单工厂的写法是通过switch-case来判断对象创建过程的。在实际使用过程中,违背了开放-关闭原则(例如,当需要扩展一个新的运算符之后,简单工厂创建的对象也必须多一种,这就需要修改原来的代码了,违背了对修改关闭的原则),当然有些情况下可以通过反射调用来弥补这种不足。
2、工厂方法模式
简单工厂模式的最大优点在于工厂类中包含了必要的逻辑判断,根据客户端的选择条件动态实例化相关的类,对于客户端来说,去除了与具体产品的依赖。但是每扩展一个类时,都需要改变工厂类里的方法,这就违背了开放-封闭原则。于是工厂方法模式来了: 工厂方法模式(Factory Method),定义一个用于创建对象的接口,让子类决定实例化哪一个类,工厂方法使一个类的实例化延迟到其子类。 继续上一个计算器的例子,简单工厂模式由工厂类直接生成相应的运算类对象,判断的逻辑在工厂类中,而工厂方法模式的实现则是定义一个工厂接口,然后每个运算类都对应一个工厂类来创建,然后在客户端判断使用哪个工厂类来创建运算类。
/**
* @Description: 工厂的接口
* @author: zxt
* @time: 2019年2月21日 下午2:49:43
*/
public interface IFactory {
public Operation createOperation();
}
/**
* @Description: 加法类工厂
*/
public class AddFactory implements IFactory {
@Override
public AddOperation createOperation() {
return new AddOperation();
}
}
/**
* @Description: 减法类工厂
*/
public class SubFactory implements IFactory {
@Override
public SubOperation createOperation() {
return new SubOperation();
}
}
/**
* @Description: 乘法类工厂
*/
public class MulFactory implements IFactory {
@Override
public MulOperation createOperation() {
return new MulOperation();
}
}
/**
* @Description: 除法类工厂
*/
public class DivFactory implements IFactory {
@Override
public DivOperation createOperation() {
return new DivOperation();
}
}
工厂方法模式实现时,客户端需要决定实例化哪一个工厂来实现运算类,选择判断的问题还是存在的,也就是说,工厂方法把简单工厂的内部逻辑判断移到了客户端代码来进行。你想要加功能,本来是改工厂类的,而现在是修改客户端。
/**
* @Description: 实现一个简单的计算器功能,使用工厂方法模式
* @author: zxt
* @time: 2018年7月6日 上午10:11:50
*/
public class Computer {
private static Scanner scanner;
public static void main(String[] args) {
scanner = new Scanner(System.in);
System.out.print("请输入第一个数字:");
int firstNum = scanner.nextInt();
System.out.print("请输入第二个数字:");
int secondNum = scanner.nextInt();
System.out.print("请输入运算符:");
String operation = scanner.next();
IFactory operFactory = null;
if(operation.equals("+")) {
operFactory = new AddFactory();
} else if(operation.equals("-")) {
operFactory = new SubFactory();
} else if(operation.equals("*")) {
operFactory = new MulFactory();
} else if(operation.equals("/")){
operFactory = new DivFactory();
}
Operation oper = operFactory.createOperation();
double result = oper.getResult(firstNum, secondNum);
System.out.println("result = " + result);
}
}
增加新功能时,工厂方法模式比简单工厂模式修改的代码量更小,工厂方法克服了简单工厂违背开放封闭原则的缺点,又保持了封装对象创建过程的优点。但是工厂方法的缺点就是每加一个产品,就需要加一个产品工厂的类,增加了额外的开发量。当然这两种模式都还不是最佳的做法。
3、抽象工厂模式
抽象工厂模式是所有形态的工厂模式中最为抽象和最具一般性的一种形态。抽象工厂模式是指当有多个抽象角色时,使用的一种工厂模式。抽象工厂模式可以向客户端提供一个接口,使客户端在不必指定产品的具体的情况下,创建多个产品族中的产品对象。根据里氏替换原则,任何接受父类型的地方,都应当能够接受子类型。因此,实际上系统所需要的,仅仅是类型与这些抽象产品角色相同的一些实例,而不是这些抽象产品的实例。换言之,也就是这些抽象产品的具体子类的实例。工厂类负责创建抽象产品的具体子类的实例。
抽象工厂模式(Abstract Factory):提供一个创建一系列相关或相互依赖对象的接口,而无需指定他们具体的类。
实例场景:对数据库(各种不同的数据库)中的表进行修改,此时,使用工厂模式结构图如下:
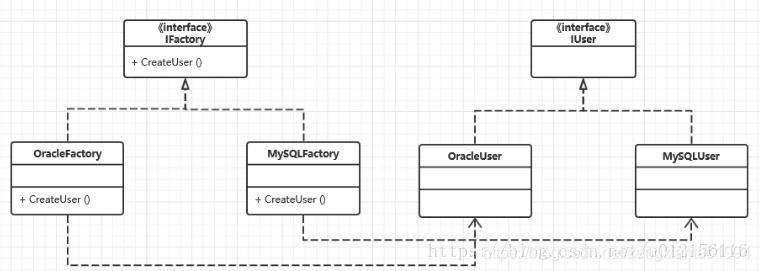 1、User表的定义:
1、User表的定义:
public class User {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
2、定义一个对User表进行操作的接口:
/**
* @Description: 对User类操作的接口
* @author: zxt
* @time: 2019年2月24日 下午7:00:20
*/
public interface IUser {
void insert(User user);
User getUser(int id);
}
3、实现Sql Server数据库对User表的操作:
/**
* @Description: SQL Server数据库中对User表的操作
* @author: zxt
* @time: 2019年2月24日 下午7:04:39
*/
public class SqlServerUser implements IUser {
@Override
public void insert(User user) {
System.out.println("在 SQL Server 中给 User 表增加一条记录!");
}
@Override
public User getUser(int id) {
System.out.println("在 SQL Server 中根据ID得到 User 表的一条记录!");
return null;
}
}
实现Oracle数据库对User表的操作:
/**
* @Description: Oracle数据库中对User表的操作
* @author: zxt
* @time: 2019年2月24日 下午7:05:07
*/
public class OracleUser implements IUser {
@Override
public void insert(User user) {
System.out.println("在 Oracle 中给 User 表增加一条记录!");
}
@Override
public User getUser(int id) {
System.out.println("在 Oracle 中根据ID得到 User 表的一条记录!");
return null;
}
}
4、定义一个抽象工厂接口,用于生成对User表的操作的对象:
/**
* @Description: 得到对User表操作的IUser对象的抽象工厂接口
* @author: zxt
* @time: 2019年2月24日 下午7:06:37
*/
public interface IFactory {
public IUser createUser();
}
5、SQLServerFactory工厂用于生成操作Sql Server数据库的SqlServerUser对象:
public class SQLServerFactory implements IFactory {
@Override
public IUser createUser() {
return new SqlServerUser();
}
}
OracleFactory工厂用于生成操作Oracle数据库的OracleUser对象:
public class OracleFactory implements IFactory {
@Override
public IUser createUser() {
return new OracleUser();
}
}
6、客户端的使用:
public class FactoryMethodTest {
public static void main(String[] args) {
User user = new User();
// 若要改成Oracle数据库,只需要将这句改成OracleFactory即可
IFactory ifactory = new SQLServerFactory();
IUser iu = ifactory.createUser();
iu.insert(user);
iu.getUser(1);
}
}
到此为止,工厂模式都可以很好的解决,由于多态的关系,IFactory在声明对象之前都不知道在访问哪个数据库,却可以在运行时很好的完成任务,这就是业务逻辑与数据访问的解耦。
但是,当数据库中不止一个表的时候该怎么解决问题呢,此时就可以引入抽象工厂模式了,结构图如下:
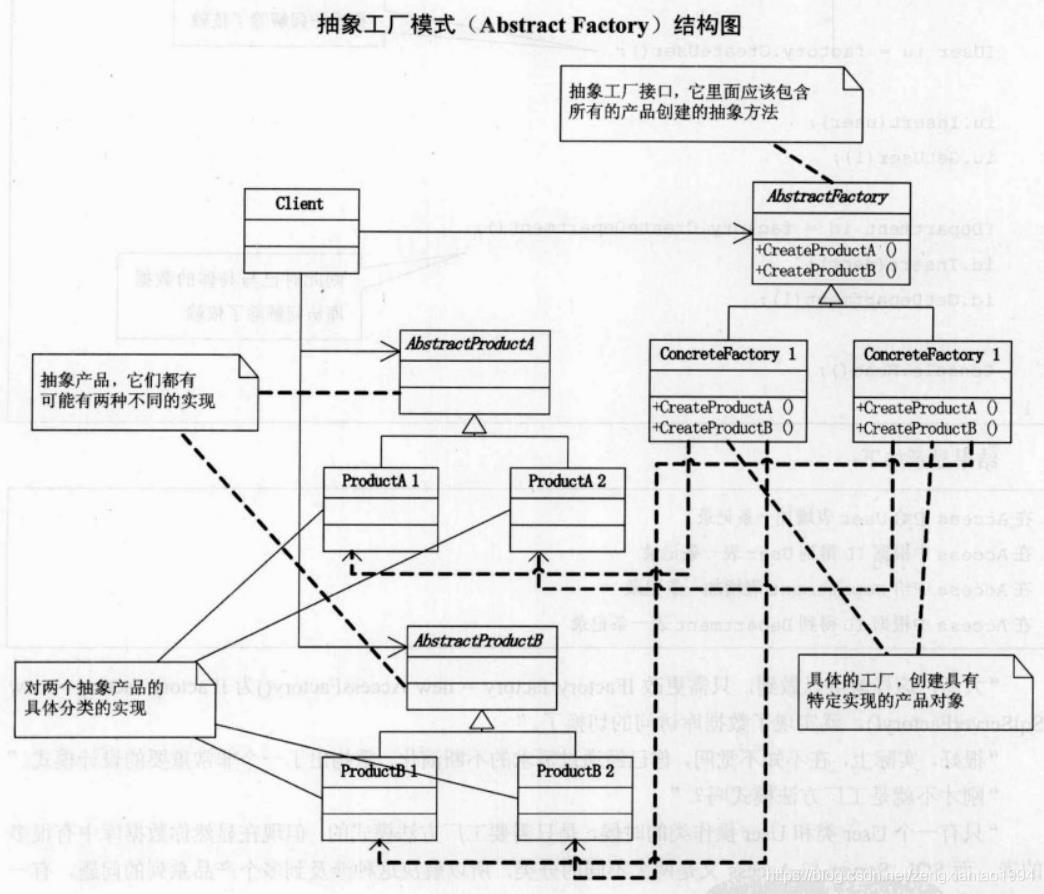 例如增加了部门表Department:
例如增加了部门表Department:
public class Department {
private int id;
private String deptName;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getDeptName() {
return deptName;
}
public void setDeptName(String deptName) {
this.deptName = deptName;
}
}
则增加相应的对Department表操作的接口:
public interface IDepartment {
public void insert(Department department);
public Department getDepartment(int id);
}
实现Sql Server数据库对Department表的操作:
/**
* @Description: SQL Server数据库中对Department表的操作
* @author: zxt
* @time: 2019年2月24日 下午7:04:39
*/
public class SqlServerDepartment implements IDepartment {
@Override
public void insert(Department user) {
System.out.println("在 SQL Server 中给 Department 表增加一条记录!");
}
@Override
public Department getDepartment(int id) {
System.out.println("在 SQL Server 中根据ID得到 Department 表的一条记录!");
return null;
}
}
实现Oracle数据库对Department表的操作:
/**
* @Description: Oracle数据库中对Department表的操作
* @author: zxt
* @time: 2019年2月24日 下午7:05:07
*/
public class OracleDepartment implements IDepartment {
@Override
public void insert(Department user) {
System.out.println("在 Oracle 中给 Department 表增加一条记录!");
}
@Override
public Department getDepartment(int id) {
System.out.println("在 Oracle 中根据ID得到 Department 表的一条记录!");
return null;
}
}
IFactory抽象工厂中增加生成对Department表操作的对象:
/**
* @Description: 得到对User表操作的IUser对象的抽象工厂接口
* @author: zxt
* @time: 2019年2月24日 下午7:06:37
*/
public interface IFactory {
public IUser createUser();
public IDepartment createDepartment();
}
SQLServerFactory工厂增加生成操作Sql Server数据库的SqlServerDepartment对象:
public class SQLServerFactory implements IFactory {
@Override
public IUser createUser() {
return new SqlServerUser();
}
@Override
public IDepartment createDepartment() {
return new SqlServerDepartment();
}
}
OracleFactory工厂增加生成操作Oracle数据库的OracleDepartment对象:
public class OracleFactory implements IFactory {
@Override
public IUser createUser() {
return new OracleUser();
}
@Override
public IDepartment createDepartment() {
return new OracleDepartment();
}
}
客户端的使用:
public class AbstractFactoryTest {
public static void main(String[] args) {
User user = new User();
Department department = new Department();
// 若要改成SQL Server数据库,只需要将这句改成SqlServerFactory即可
IFactory ifactory = new OracleFactory();
IUser iu = ifactory.createUser();
iu.insert(user);
iu.getUser(1);
IDepartment id = ifactory.createDepartment();
id.insert(department);
id.getDepartment(1);
}
}

所以抽象工厂与工厂方法模式的区别在于:抽象工厂是可以生产多个产品的,例如OracleFactory 里可以生产 OracleUser以及 OracleDepartment两个产品,而这两个产品又是属于一个系列的,因为它们都是属于Oracle数据库的表。而工厂方法模式则只能生产一个产品,例如之前的 OracleFactory里就只可以生产一个 OracleUser产品。
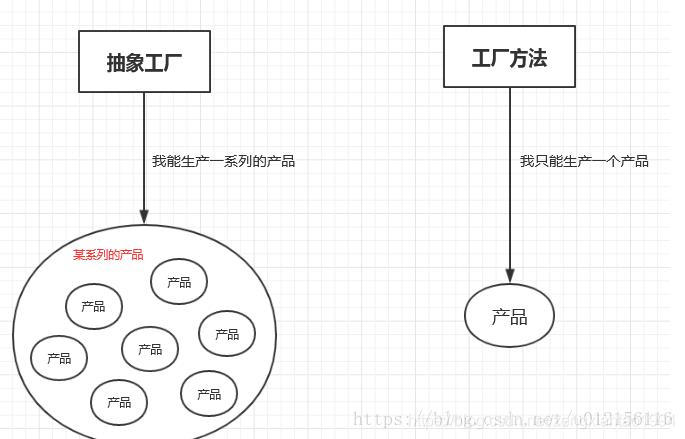 抽象工厂模式的优缺点:
优点:
1、抽象工厂模式最大的好处是易于交换产品系列, 由于具体工厂类,例如 IFactory factory = new OracleFactory(); 在一个应用中只需要在初始化的时候出现一次,这就使得改变一个应用的具体工厂变得非常容易,它只需要改变具体工厂即可使用不同的产品配置。不管是任何人的设计都无法去完全防止需求的更改,或者项目的维护,那么我们的理想便是让改动变得最小、最容易。
2、抽象工厂模式的另一个好处就是它让具体的创建实例过程与客户端分离,客户端是通过它们的抽象接口操作实例,产品实现类的具体类名也被具体的工厂实现类分离,不会出现在客户端代码中。就像我们上面的例子,客户端只认识IUser和IDepartment,至于它是Sql Server里的表还是Oracle里的表就不知道了。
缺点:
1、如果你的需求来自增加功能,比如增加Department表,就有点太烦了。首先需要增加IDepartment,SQLServerDepartment,OracleDepartment。然后我们还要去修改工厂类:IFactory,SQLServerFactory,OracleFactory才可以实现,需要修改三个类,实在是有点麻烦。
2、还有就是,客户端程序肯定不止一个,每次都需要声明IFactory factory = new OracleFactory(),如果有100个调用数据库的类,就需要更改100次IFactory factory = new OracleFactory()。
抽象工厂模式的优缺点:
优点:
1、抽象工厂模式最大的好处是易于交换产品系列, 由于具体工厂类,例如 IFactory factory = new OracleFactory(); 在一个应用中只需要在初始化的时候出现一次,这就使得改变一个应用的具体工厂变得非常容易,它只需要改变具体工厂即可使用不同的产品配置。不管是任何人的设计都无法去完全防止需求的更改,或者项目的维护,那么我们的理想便是让改动变得最小、最容易。
2、抽象工厂模式的另一个好处就是它让具体的创建实例过程与客户端分离,客户端是通过它们的抽象接口操作实例,产品实现类的具体类名也被具体的工厂实现类分离,不会出现在客户端代码中。就像我们上面的例子,客户端只认识IUser和IDepartment,至于它是Sql Server里的表还是Oracle里的表就不知道了。
缺点:
1、如果你的需求来自增加功能,比如增加Department表,就有点太烦了。首先需要增加IDepartment,SQLServerDepartment,OracleDepartment。然后我们还要去修改工厂类:IFactory,SQLServerFactory,OracleFactory才可以实现,需要修改三个类,实在是有点麻烦。
2、还有就是,客户端程序肯定不止一个,每次都需要声明IFactory factory = new OracleFactory(),如果有100个调用数据库的类,就需要更改100次IFactory factory = new OracleFactory()。
3.1、抽象工厂模式的改进1(简单工厂+抽象工厂)
我们将IFactory,SQLServerFactory,OracleFactory三个工厂类都抛弃掉,取而代之的是一个简单工厂类EasyFactory,如下:
public class EasyFactory {
private static String db = "SqlServer";
// private static String db = "Oracle";
public static IUser createUser() {
IUser result = null;
switch (db) {
case "SqlServer":
result = new SqlServerUser();
break;
case "Oracle":
result = new OracleUser();
break;
}
return result;
}
public static IDepartment createDepartment() {
IDepartment result = null;
switch (db) {
case "SqlServer":
result = new SqlServerDepartment();
break;
case "Oracle":
result = new OracleDepartment();
break;
}
return result;
}
}
客户端:
public class EasyClient {
public static void main(String[] args) {
User user = new User();
Department department = new Department();
// 直接得到实际的数据库访问实例,而不存在任何依赖
IUser userOperation = EasyFactory.createUser();
userOperation.getUser(1);
userOperation.insert(user);
// 直接得到实际的数据库访问实例,而不存在任何依赖
IDepartment departmentOperation = EasyFactory.createDepartment();
departmentOperation.insert(department);
departmentOperation.getDepartment(1);
}
}
由于事先在简单工厂类里设置好了db的值,所以简单工厂的方法都不需要由客户端来输入参数,这样在客户端就只需要使用 EasyFactory.createUser(); 和 EasyFactory.createDepartment(); 方法来获得具体的数据库访问类的实例,客户端代码上没有出现任何一个 SqlServer 或 Oracle 的字样,达到了解耦的目的,客户端已经不再受改动数据库访问的影响了。
3.2、抽象工厂的改进2(反射+简单工厂)
使用反射的话,我们就可以不需要使用switch,因为使用switch的话,我添加一个Mysql数据库的话,又要switch的话又需要添加case条件。 我们可以根据选择的数据库名称,如“mysql”,利用反射技术自动的获得所需要的实例:
public class EasyFactoryReflect {
private static String packName = "com.zxt.abstractfactory";
private static String sqlName = "Oracle";
public static IUser createUser() throws Exception {
String className = packName + "." + sqlName + "User";
return (IUser) Class.forName(className).newInstance();
}
public static IDepartment createLogin() throws Exception {
String className = packName + "." + sqlName + "Department";
return (IDepartment) Class.forName(className).newInstance();
}
}
以上我们使用简单工厂模式设计的代码中,是用一个字符串类型的db变量来存储数据库名称的,所以变量的值到底是 SqlServer 还是 Oracle,完全可以由事先设置的那个db变量来决定,而我们又可以通过反射来去获取实例,这样就可以去除switch语句了。
3.3、抽象工厂的改进3(反射+配置文件+简单工厂)
在使用反射之后,我们还是需要进EasyFactory中修改数据库类型,还不是完全符合开-闭原则。我们可以通过配置文件来达到目的,每次通过读取配置文件来知道我们应该使用哪种数据库。 如下是一个json类型的配置文件,也可以使用xml类型的配置文件:
{
"packName": " com.zxt.abstractfactory",
"DB": "Oracle"
}
1234
之后就可以通过这个配置文件去找需要加载的类是哪一个。我们通过反射机制+配置文件+简单工厂模式解决了数据库访问时的可维护、可扩展的问题。
1. Java环境配置
安装完JDK后配置环境变量:计算机→属性→高级系统设置→高级→环境变量。 1、系统变量→新建 JAVA_HOME 变量。变量值填写jdk的安装目录(本人是 D:\Program Java\jdk1.8.0_60); 2、系统变量→寻找 Path 变量→编辑,在变量值最后输入 %JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;(注意原来Path的变量值末尾有没有;号,如果没有,先输入;号再输入上面的代码); 3、系统变量→新建 CLASSPATH 变量,变量值填写:.;%JAVA_HOME%\lib;%JAVA_HOME%\lib\tools.jar(注意最前面有一点)。 4、系统变量配置完毕,检验是否配置成功 运行cmd 输入 java -version (java 和 -version 之间有空格),显示版本信息,则说明安装和配置成功。
2. Java跨平台的原理
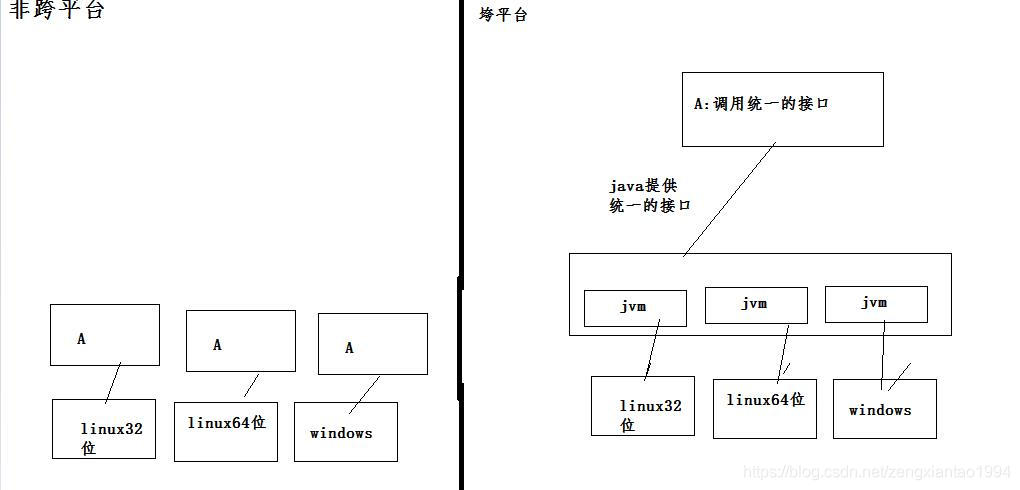
首先什么是平台?
我们把CPU处理器与操作系统的整体叫平台。 CPU的种类很多,除去我们熟知的Intel与AMD外,还有比如SUN的Sparc,比如IBM的PowerPC等等,这些各个公司生产的CPU使用或相同或不同的指令集。指令集就是cpu中用来计算和控制计算机系统的一套指令的集合。指令集又分为精简指令集(RISC)与复杂指令集(CISC), 每种cpu都有其特定的指令集。开发程序,首先要知道该程序在什么CPU上运行,也就是要知道CPU所使用的指令集。
操作系统则是充当用户和计算机之间交互的界面软件,不同的操作系统支持不同的CPU,严格意义上说是不同的操作系统支持不同CPU的指令集。 例如 windows和liunx都支持Intel和AMD的复杂指令集,但并不支持PowerPC所使用的精简指令集,而早期的MAC电脑使用的是PowerPC处理器,所以也就无法在MAC下直接安装windows,直到05年MAC改用了Intel的CPU,才使在MAC下安装windows成为可能。但问题来了,原来的MAC 操作系统也只支持PowerPC,在Intel上也不能安装,怎么办?所以苹果公司也得重写自己的MAC操作系统以支持这种变化。最后总结下,不同的操作系统支持不同的CPU指令集。
由于各操作系统支持的指令集,不是完全一致的。就会让我们的程序在不同的操作系统上要执行不同程序代码。Java开发了适用于不同操作系统及位数的java虚拟机来屏蔽各系统之间的差异,提供统一的接口。 对于我们java开发者而言,你只需要在不同的系统上安装对应的不同java虚拟机、这时你的java程序只要遵循java规范,就可以在所有的操作系统上面运行java程序了。
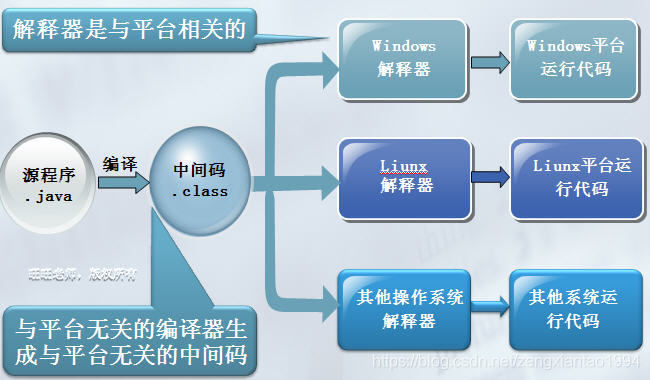 Java通过不同的系统、不同版本、不同位数的java虚拟机(jvm),来屏蔽不同的系统指令集差异而对外体统统一的接口(java API),对于我们普通的java开发者而言,只需要按照接口开发即可。如果我系统需要部署到不同的环境时,只需在系统上面按照对应版本的虚拟机即可。
Java通过不同的系统、不同版本、不同位数的java虚拟机(jvm),来屏蔽不同的系统指令集差异而对外体统统一的接口(java API),对于我们普通的java开发者而言,只需要按照接口开发即可。如果我系统需要部署到不同的环境时,只需在系统上面按照对应版本的虚拟机即可。
 再说下语言根据执行方式的不同分类:第一是编译执行,如C,它把源程序由特定平台的编译器一次性编译为平台相关的机器码, 它的优点是执行速度快,缺点是无法跨平台;第二是解释执行,如HTML,JavaScript,它使用特定的解释器,把代码一行行解释为机器码,类似于同声翻译,它的优点是可以跨平台,缺点是执行速度慢,暴露源程序;第三种是从Java开始引入的“中间码+虚拟机”的方式,它既整合了编译语言与解释语言的优点,同时如虚拟机又可以解决如垃圾回收,安全性检查等这些传统语言头疼的问题,所以其后微软的.NET平台也使用的这种方式。
Java先编译后解释,同一个.class文件在不同的虚拟机会得到不同的机器指令(Windows和Linux的机器指令不同),但是最终执行的结果却是相同的。
再说下语言根据执行方式的不同分类:第一是编译执行,如C,它把源程序由特定平台的编译器一次性编译为平台相关的机器码, 它的优点是执行速度快,缺点是无法跨平台;第二是解释执行,如HTML,JavaScript,它使用特定的解释器,把代码一行行解释为机器码,类似于同声翻译,它的优点是可以跨平台,缺点是执行速度慢,暴露源程序;第三种是从Java开始引入的“中间码+虚拟机”的方式,它既整合了编译语言与解释语言的优点,同时如虚拟机又可以解决如垃圾回收,安全性检查等这些传统语言头疼的问题,所以其后微软的.NET平台也使用的这种方式。
Java先编译后解释,同一个.class文件在不同的虚拟机会得到不同的机器指令(Windows和Linux的机器指令不同),但是最终执行的结果却是相同的。
3. 常见的Java名词
EJB:Enterprise Java Bean:Java企业级容器; JMS:Java Message Service:Java消息服务,主要实现各个应用程序间的通讯,包括点对点和广播; JTA:Java transaction API:Java事务服务,提供分布式事务服务(只需要调用接口); JAF:Java Action Framwork:Java安全认证框架,提供一些安全控制方面的框架; JNDI:Java Naming & Directory Interface:Java命名目录服务; RMI:Remote method Invocation/Internet:对象请求中介协议,主要用于通过远程调用服务。 常用工具: Javac.exe:编译源文件(可以没有main方法); Java.exe:运行class文件,必须要有main方法入口; J2SDK是编译工具,而不是API; Appretriewer.exe:用来解释执行java applet应用程序(没有main函数)。 DOC下的一些命令: Java –version:查看Java开发工具JDK版本; Javac Test.java(Java源文件):编译Java源文件,生成字节码文件Test.class; Java Test.class(后缀名.class可以省略); Javac去编译一个含有package语句的java文件要带参数:javac –d . Java文件名。
4. 面向对象编程的特征
封装 封装是保证软件部件具有优良的模块性的基础,封装的目标就是要实现软件部件的“高内聚、低耦合”,防止程序相互依赖性而带来的变动影响。在面向对象的编程语言中,对象是封装的最基本单位,面向对象的封装比传统语言的封装更为清晰、更为有力。面向对象的封装就是把描述一个对象的属性和行为的代码封装在一个“模块”中,也就是一个类中,属性用变量定义,行为用方法进行定义,方法可以直接访问同一个对象中的属性。把握一个原则:把对同一事物进行操作的方法和相关的方法放在同一个类中,把方法和它操作的数据放在同一个类中。 例如,人要在黑板上画圆,这一共涉及三个对象:人、黑板、圆,画圆的方法要分配给哪个对象呢?由于画圆需要使用到圆心和半径,圆心和半径显然是圆的属性,如果将它们在类中定义成了私有的成员变量,那么,画圆的方法必须分配给圆,它才能访问到圆心和半径这两个属性,人以后只是调用圆的画圆方法、表示给圆发给消息而已,画圆这个方法不应该分配在人这个对象上,这就是面向对象的封装性,即将对象封装成一个高度自治和相对封闭的个体,对象状态(属性)由这个对象自己的行为(方法)来读取和改变。
继承(extend) 1、在定义和实现一个类的时候,可以在一个已经存在的类的基础之上来进行,把这个已经存在的类所定义的内容作为自己的内容,并可以加入若干新的内容,或修改原来的方法使之更适合特殊的需要,这就是继承。继承是子类自动共享父类数据和方法的机制,这是类之间的一种关系,提高了软件的可重用性和可扩展性。 2、子类最多只能继承一个父类。 3、Java所有类都是Object类的子类。 4、构造方法不能被继承,构造方法只能被显式或隐式调用, 如果希望在子类中调用父类的构造方法,要求在子类的构造函数中调用super()方法。且必需放在子类构造函数的第一行。 5、JDK6中有202个包3777个类、接口、异常、枚举、注释和错误。 注意几点: 1、在一个子类继承的时候,实际上会继承父类之中的所有操作(属性、方法),但是需要注意的是,对于所有的非私有(no private)操作属于显式继承(可以直接利用对象操作),而所有的私有操作属于隐式继承(间接完成)。 2、在继承关系之中,如果要实例化子类对象,总是会先调用父类的构造方法,如果子类没有显式地指明使用父类的哪个构造方法,子类则默认调用无参构造方法。(此时若父类自定义了构造方法,则没有无参构造方法,会报错)。 3、关于类加载过程中代码块的执行顺序,首先是静态代码块,是最先执行的,且只在加载的时候执行一次。构造代码块在每次new对象的时候于构造方法执行之前执行,即每次调用构造方法都执行。即首先执行静态代码块、接着执行构造代码块(非静态代码块)、最后执行构造方法。 在实现继承的类被new的过程中,初始化执行顺序如下:1、实现父类的公共静态属性和静态块级代码。2、实现自身的静态属性和静态块级代码。3、实现父类的非静态属性和非静态代码块。4、执行父类的构造函数。5、实现自身的非静态属性和非静态代码块。6、执行自身的构造函数。
多态 所谓多态就是指一个引用(类型)在不同情况下的多种状态。也可以这样理解:多态是通过指向父类的指针,来调用在不同子类中实现的方法。 引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。因为在程序运行时才确定具体的类,这样,不用修改源程序代码,就可以让引用变量绑定到各种不同的类实现上,从而导致该引用调用的具体方法随之改变,即不修改程序代码就可以改变程序运行时所绑定的具体代码,让程序可以选择多个运行状态,这就是多态性。多态性增强了软件的灵活性和扩展性。 1、Java允许父类的引用变量引用它的子类的实例(对象)。这种转化是自动完成的。 2、java实现多态的机制靠的是父类或接口定义的引用变量可以指向子类或具体实现类的实例对象,而程序调用的方法在运行期才动态绑定,就是引用变量所指向的具体实例对象的方法,也就是内存里正在运行的那个对象的方法,而不是引用变量的类型中定义的方法。
5. Java重载和覆盖
重载(overload) 1、简单的说:方法重载就是类的同一种功能的多种实现方式,到底采用哪种方式,取决于调用者给出的参数。 2、方法名相同。方法的参数类型,个数,顺序至少有一项不同。 3、不能通过访问权限、返回类型、抛出的异常进行重载; 4、方法返回类型可以不同。但是只是返回类型不一样,不能够构成重载。我们可以用反证法来说明这个问题,因为我们有时候调用一个方法时也可以不定义返回结果变量,即不要关心其返回结果,例如,我们调用map.remove(key)方法时,虽然remove方法有返回值,但是我们通常都不会定义接收返回结果的变量,这时候假设该类中有两个名称和参数列表完全相同的方法,仅仅是返回类型不同,java就无法确定编程者到底是想调用哪个方法了,因为它无法通过返回结果类型来判断。
覆盖(override) 简单的说:方法覆盖就是子类有一个方法,和父类的某个方法的名称,返回类型,参数一样,那么我们就说子类的这个方法覆盖了父类的那个方法。 1、子类的方法的返回类型,参数,方法名称,要和父类方法的返回类型,参数,方法名称完全一样,否则会编译出错。 2、子类方法不能缩小父类方法的访问权限。子类方法的访问权限只能比父类的更大,不能更小。如果父类的方法是private类型,那么,子类则不存在覆盖的限制,相当于子类中增加了一个全新的方法。 3、子类覆盖父类的方法时,只能比父类抛出更少的异常,或者是抛出父类抛出的异常的子异常,因为子类可以解决父类的一些问题,不能比父类有更多的问题。
6. Java访问修饰符
java中4中修饰符分别为public、protected、default、private,他们这就说明了面向对象的封装性,所以我们要适用他们尽可能的让权限降到最低,从而安全性提高。
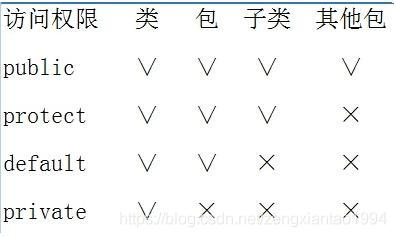 private修饰的属性或方法为该类所特有,在任何其他类中都不能直接访问;
default修饰的属性或方法具有包访问特性,同一个包中的其他类可以访问;
protected修饰的属性或方法在同一个包中的其他类可以访问,同时对于不在同一个包中的子类中也可以访问;(因此也不能说protected修饰的属性与方法,在其他包中绝对访问不到,只要是它的子类就可以)。
public修饰的属性或方法外部类中都可以直接访问。
private修饰的属性或方法为该类所特有,在任何其他类中都不能直接访问;
default修饰的属性或方法具有包访问特性,同一个包中的其他类可以访问;
protected修饰的属性或方法在同一个包中的其他类可以访问,同时对于不在同一个包中的子类中也可以访问;(因此也不能说protected修饰的属性与方法,在其他包中绝对访问不到,只要是它的子类就可以)。
public修饰的属性或方法外部类中都可以直接访问。
7. 抽象类和接口的比较
1、什么是抽象类? 就是对类更高的抽象。抽象类作为多个子类的共同父类。它所体现的是一种模版设计,抽象类作为多个子类的父类,可以把它理解为系统实现过程中的中间产品,这个中间产品已经实现了系统的部分功能,但是不能当成最终产品,还需要进一步的完善。 当父类的一些方法不能确定时,可以用abstract关键字来修饰该方法【抽象方法】,用abstract来修饰该类【抽象类】。 1)、抽象类不能被实例化。 2)、用abstract关键字来修饰一个方法时,这个方法就是抽象方法,抽象方法不能有主体【即不能实现】;用abstract关键字来修饰一个类时,这个类就叫抽象类。 3)、抽象类不一定要包含abstract方法。也就是说抽象类可以没有abstract方法;但是一旦类包含了abstract方法,则这个类必须声明为abstract。
2、什么是接口? 接口是一种规范,就像现实中生产主板和内存条或者网卡的不是同一家产商,但是为何内存或者网卡插入到主板上就能用呢,因为他们都遵守了某种规范。然后就可以使用。虽然他们的内部实现可能完全不同。就好比在java语言中的方法内部实现你不需要关心,只需要知道这个接口是怎样的干嘛的就行了,直接用。既然是一种规范,那他在编程语言中就能在架构中起到非常之大的作用,在一个应用程序之间的时候,接口体现的是一耦合标准。特别是在多个应用程序需要对接的时候。接口是多个应用程序的通信标准。接口就是给出一些没有内容的方法,封装在一起,到某个类要使用的时候,再根据具体情况把这些方法写出来。 接口是更加抽象的抽象的类,抽象类里的方法(非抽象方法,抽象类可以有非抽象方法)可以有方法体,接口里的所有方法都没有方法体。接口体现了程序设计的多态和高内聚低偶和的设计思想。 1)、接口中的所有方法都不能有主体,不能被实例化。 2)、一个类可以实现多个接口。 3)、接口中可以有变量【但变量不能用private和protected修饰】。a、Java接口中的变量是公共的(public),静态的(static),最终的常量(final),相当于全局常量,所以定义接口变量时必须初始化。 b、接口中的变量,本质上都是static的,不管你加不加static修饰。c、在java开发中,我们经常用的变量,定义在接口中,作为全局变量使用。访问形式:接口名.变量名。 4)、一个接口不能继承其它的类,但是可以继承别的接口。 5)、接口没有方法就可以作为一个标志,比如可序列化的接口Serializable,没有方法的接口称为空接口。
7.1. 抽象类与接口的比较
接口和抽象类都不能实例化,他们都位于继承树的顶端,用于被其他类实现和继承。接口和抽象类都可以包含抽象方法,实现接口或继承抽象类的普通子类都必须实现这些抽象方法。 他们的区别: 1、属性:接口没有普通属性,只有静态属性,并且只能用public final static 修饰(并且是默认的,就算你在接口中定义Int i = 0 它也会被隐式的加上public final static);而抽象类可以有普通属性,可以有静态属性(类属性)。 2、方法:接口中的方法都没有方法体并且都是默认使用public abstracrt 修饰,不能定义静态方法。 而抽象类可以有普通方法,也可以没有抽象方法,也可以定义静态方法。 3、构造函数:接口中没有构造器,抽象类中可以有构造器, 但是它不能用于new 对象 而是用于子类调用来初始化抽象类的操作。 4、初始化块:接口中不能包含初始化块,而抽象方法中可以包含初始化块。 5、一个类只能有一个直接父类,包括抽象类,而类可以实现多个接口,弥补了java不能多继承的不足。
7.2.新版本中的修改
1、JDK1.8以前,抽象类中的方法默认访问权限protected,JDK1.8时默认访问权限default。 2、JDK1.8接口,增加了default和static方法,这2个都可以有方法体的,default方法属于实例,static方法属于类(接口),接口的静态方法不会被继承,静态变量会被继承。 3、JDK1.8,如果接口只有一个抽象方法自动变成函数式接口,可以用使用@FunctionInterface注解,接口有FunctionInterface注解只能有一个抽象方法。 4、从java8开始接口里可以有静态方式,用static修饰,但是接口里的静态方法的修饰符只能是public,且默认是public。调用时(接口名.方法名)。 5、java8里,除了可以在接口里写静态方法,还可以写非静态方法,但是必须用default修饰,且只能是public,默认也是public。
8. 构造方法,构造方法重载,什么是复制构造方法?
构造方法是类的一种特殊方法,它的主要作用是完成对新对象的初始化。 1、方法名和类名相同,没有返回值。 2、在创建(new)一个类的新对象时,系统会自动的调用该类的构造方法完成对新对象的初始化。 3、普通方法可以和类名相同,和构造方法唯一的区别在于,构造方法没有返回值(注意是没有不是void)。 4、定义类的时候,若没有自定义构造方法,则会有一个默认的无参构造方法,若自定义了构造方法,则没有无参构造方法。 5、构造方法不能被继承,构造方法只能被显式或者隐式地调用。 6、子类的构造方法总是先调用父类的构造方法,如果子类的构造方法没有显式地指出使用父类的哪个构造方法,子类则默认调用父类的无参构造方法(此时若父类自定义了构造方法,而子类又没有用super则会报错)。 7、Java不支持像C++中那样的复制构造方法(没有这个概念),但是在Object类中有一个clone()方法。 Protected Object clone() throws CloneNotSupportedException:创建并返回此对象的一个副本。“副本”的准确含义可能依赖于对象的类。 这样做的目的是,对于任何对象 x,表达式:x.clone() != x为true,表达式:x.clone().getClass() == x.getClass()也为true,但这些并非必须要满足的要求。一般情况下:x.clone().equals(x)为true,但这并非必须要满足的要求。 首先,使用这个方法的类必须实现java.lang.Cloneable接口,否则会抛出CloneNotSupportedException异常。Cloneable接口中不包含任何方法,所以实现它时只要在类声明中加上implements语句即可。 第二个比较特殊的地方在于这个方法是protected修饰的,覆写clone()方法的时候需要写成public,才能让类外部的代码调用。 按照惯例,返回的对象应该通过调用super.clone获得。如果一个类及其所有的超类(Object除外)都遵守此约定,则 x.clone().getClass() == x.getClass()。 按照惯例,此方法返回的对象应该独立于该对象(正被复制的对象)。要获得此独立性,在super.clone返回对象之前,有必要对该对象的一个或多个字段进行修改。这通常意味着要复制包含正在被复制对象的内部“深层结构”的所有可变对象,并使用对副本的引用替换对这些对象的引用。如果一个类只包含基本字段或对不变对象的引用,那么通常不需要修改 super.clone 返回的对象中的字段。 也就是clone的浅拷贝和深拷贝问题,在具体使用的时候需要特别注意: 浅拷贝:如果一个对象内部还有一个引用类型的基本变量,那么在拷贝该对象的时候,只是在通过clone方法新产生的新对象中拷贝一个该基本类型的引用。换句话说,也就是新对象和原对象他们内部都含有一个指向同一对象的引用。 深拷贝:拷贝对象的时候,如果对象内部含有一个引用类型的变量,那么就会再将该引用类型的变量指向的对象复制一份,然后引用该新对象。 8、实际上,特别需要注意的一点是,Java对象并不是由构造器创建的,而是由new运算符创建的,在程序运行时,是new运算符在堆上开辟一块空间,然后执行对象的初始化(其中包括调用构造器),当对象创建成功,也是new运算符将对象的起始地址返回给应用程序的(并非构造器)。实际上构造器的作用是在对象创建的时候进行类中成员变量的初始化,而绝非创建对象,构造器也没有返回值。因此程序执行的顺序是,先创建对象,然后求解构造器所有形参表达式的值(若形参表达式的计算出现异常,则不会调用构造器方法),最后调用构造器对对象进行初始化。
9. Java内部类
内部类(inner class)是定义在另一个类内部的类。 使用内部类的原因有三个: 1)、内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。 2)、内部类能够隐藏起来,不被同一个包中的其他的类所见。 3)、想要定义一个回调函数,且不想编写大量代码时,使用匿名内部类比较便捷。 4)、内部类有四种:成员内部类、局部内部类、静态内部类、匿名内部类
9.1、成员内部类
成员内部类也是最普通的内部类,它是外围类的一个成员,所以他是可以无限制的访问外围类的所有成员属性和方法,尽管是private的,但是外围类要访问内部类的成员属性和方法则需要通过内部类实例来访问。如果在内部类中定义有和外部类同名的实例变量,访问:OuterClass.this.outerMember; 在成员内部类中要注意两点,第一:成员内部类中不能存在任何static的变量和方法(因为需要先创建外部类,才能创建自己,可以声明static的常量);第二:成员内部类是依附于外围类的,所以只有先创建了外围类才能够创建内部类。
9.2、局部内部类
局部内部类,它是嵌套在方法和作用域内的,对于这个类的使用主要是应用与解决比较复杂的问题,想创建一个类来辅助我们的解决方案,但又不希望这个类是公共可用的,所以就产生了局部内部类,局部内部类和成员内部类一样被编译,只是它的作用域发生了改变,它只能在该方法和属性中被使用,出了该方法和属性就会失效。 局部内部类可以访问的外部类的成员根据所在方法体不同。如果在静态方法中:可以访问外部类中所有静态成员,包含私有;如果在实例方法中:可以访问外部类中所有的成员,包含私有。局部内部类可以访问所在方法中定义的局部变量,但是要求局部变量必须使用final修饰。
9.3、匿名内部类
1、匿名内部类是没有访问修饰符的,也是唯一一种没有构造方法的类。 2、new 匿名内部类,这个类首先是要存在的。 3、注意当所在方法的形参需要被匿名内部类使用,那么这个形参就必须为final。
9.4、静态内部类(静态嵌套类)
使用static修饰的内部类我们称之为静态内部类,或者称之为嵌套内部类。静态内部类与非静态内部类之间存在一个最大的区别,我们知道非静态内部类在编译完成之后会隐含地保存着一个引用,该引用是指向创建它的外围类,但是静态内部类却没有。没有这个引用就意味着: 1、它的创建是不需要依赖于外围类的。 2、它不能使用任何外围类的非static成员变量和方法。
10. 枚举类
(1)、定义一个枚举类,使用的是enum关键字而不是class。 (2)、枚举类的实例一定是有限多个(可枚举的),所有的enum变量必须定义在枚举类的第一行,用逗号隔开,定义完所有的变量后,以分号结束,如果只有枚举变量,而没有自定义变量,分号可以省略。枚举变量最好大写,在其他类中使用enum变量的时候,只需要【类名.变量名】就可以了,和使用静态变量一样。 Enum变量默认添加public static final修饰。 (3)enum类可以把它看成一个普通类,可以有构造器,成员方法,成员变量。当然和普通类也有一定的区别: 枚举类的构造方法默认使用private修饰,且只能使用private修饰; 枚举类默认继承自Enum类,所以不能继承其他类,Enum类实现了Serializable、Comparable接口; 枚举类默认使用final修饰,因此不能派生子类。如果需要扩展enum中的元素,在一个接口的内部,创建实现该接口的枚举,以此将元素进行分组。达到将枚举元素进行分组的目的。 (4)、switch()参数可以使用enum (5)、enum允许程序员为eunm实例编写方法。所以可以为每个enum实例赋予各自不同的行为。 (6)、常用方法
10.1、枚举类方法:
valueOf()方法:它的作用是传来一个字符串,然后将它转变为对应的枚举变量。前提是你传的字符串和定义枚举变量的字符串一模一样,区分大小写。如果你传了一个不存在的字符串,那么会抛出异常。 values()方法:这个方法会返回包括所有枚举变量的数组,可以方便的用来做循环。 name()方法:它和toString()方法的返回值一样,这两个方法的默认实现是一样的,唯一的区别是,你可以重写toString方法。name变量就是枚举变量的字符串形式。
10.2、枚举变量方法:
toString()方法:该方法直接返回枚举定义枚举变量的字符串。 ordinal()方法:默认情况下,枚举类会给所有的枚举变量一个默认的次序,该次序从0开始,类似于数组的下标。而.ordinal()方法就是获取这个次序(或者说下标)。枚举类中枚举变量的次序可以自定义。 compareTo()方法(枚举类实现了Comparable接口):该方法用来比较两个枚举变量的”大小”,实际上比较的是两个枚举变量的次序,返回两个次序相减后的结果,如果为负数,就证明变量1”小于”变量2 (变量1.compareTo(变量2),返回【变量1.ordinal()- 变量2.ordinal()】)。
11. Final关键字
1、final修饰类:当用final修饰一个类时,表明这个类不能被继承。 也就是说,如果一个类你永远不会让他被继承,就可以用final进行修饰。final类中的成员变量可以根据需要设为final,但是要注意final类中的所有成员方法都会被隐式地指定为final方法。 在使用final修饰类的时候,要注意谨慎选择,除非这个类真的在以后不会用来继承或者出于安全的考虑,尽量不要将类设计为final类。 2、final修饰方法:“使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升。在最近的Java版本中,不需要使用final方法进行这些优化了。” 因此,如果只有在想明确禁止该方法在子类中被覆盖的情况下才将方法设置为final的。注:类的private方法会隐式地被指定为final方法。 3、final修饰变量:对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。 当final变量是基本数据类型以及String类型时,如果在编译期间能知道它的确切值,则编译器会把它当做编译期常量使用。也就是说在用到该final变量的地方,相当于直接访问的这个常量,不需要在运行时确定。
关键字final的好处小结
1、final关键字提高了性能。JVM和Java应用都会缓存final变量。 2、final变量可以安全的在多线程环境下进行共享,而不需要额外的同步开销。 3、使用final关键字,JVM会对方法、变量及类进行优化。 4、对于不可变类,它的对象是只读的,可以在多线程环境下安全的共享,不用额外的同步开销。
12. Static关键字
static关键字的用途
《Java编程思想》:“static方法就是没有this的方法。在static方法内部不能调用非静态方法,反过来是可以的。而且可以在没有创建任何对象的前提下,仅仅通过类本身来调用static方法。这实际上正是static方法的主要用途。” 这段话虽然只是说明了static方法的特殊之处,但是可以看出static关键字的基本作用,简而言之,一句话来描述就是: 方便在没有创建对象的情况下来进行调用(方法/变量)。 很显然,被static关键字修饰的方法或者变量不需要依赖于对象来进行访问,只要类被加载了,就可以通过类名去进行访问。 static可以用来修饰类的成员方法、类的成员变量,另外可以编写static代码块来优化程序性能。 1)、static方法 static方法一般称作静态方法,由于静态方法不依赖于任何对象就可以进行访问,因此对于静态方法来说,是没有this的,因为它不依附于任何对象,既然都没有对象,就谈不上this了。并且由于这个特性,在静态方法中不能访问类的非静态成员变量和非静态成员方法,因为非静态成员方法/变量都是必须依赖具体的对象才能够被调用。 但是要注意的是,虽然在静态方法中不能访问非静态成员方法和非静态成员变量,但是在非静态成员方法中是可以访问静态成员方法/变量的。 因此,如果说想在不创建对象的情况下调用某个方法,就可以将这个方法设置为static。我们最常见的static方法就是main方法,至于为什么main方法必须是static的,现在就很清楚了。因为程序在执行main方法的时候没有创建任何对象,因此只有通过类名来访问。 2)、static变量 static变量也称作静态变量,静态变量和非静态变量的区别是:静态变量被所有的对象所共享,在内存中只有一个副本,它当且仅当在类初次加载时会被初始化。而非静态变量是对象所拥有的,在创建对象的时候被初始化,存在多个副本,各个对象拥有的副本互不影响。 static成员变量的初始化顺序按照定义的顺序进行初始化。 3)、static代码块 static关键字还有一个比较关键的作用就是用来形成静态代码块以优化程序性能。static块可以置于类中的任何地方,类中可以有多个static块。在类初次被加载的时候,会按照static块的顺序来执行每个static块,并且只会执行一次。 为什么说static块可以用来优化程序性能,是因为它的特性:只会在类加载的时候执行一次。因此,很多时候会将一些只需要进行一次的初始化操作都放在static代码块中进行。
static关键字的误区
1)、static关键字会改变类中成员的访问权限吗? Java中的static关键字不会影响到变量或者方法的作用域。在Java中能够影响到访问权限的只有private、public、protected(包括包访问权限)这几个关键字。 2)、能通过this访问静态成员变量吗? 虽然对于静态方法来说没有this,那么在非静态方法中能够通过this访问静态成员变量吗?主要考察队this和static的理解。在这里永远要记住一点:静态成员变量虽然独立于对象,但是不代表不可以通过对象去访问,所有的静态方法和静态变量都可以通过对象访问(只要访问权限足够)。 3)、static能作用于局部变量么? 在Java中切记:static是不允许用来修饰局部变量,这是Java语法的规定。 4)、java中是否可以覆盖(override)一个private方法或者static方法? 都不能 覆盖,也就是我们常说的重写,是子类继承父类,且子类中的方法和父类中的方法,方法名相同,参数个数和类型相同,返回值相同。 private修饰的方法,不能被继承,所以也不存在重写(覆盖) static修饰的方法,是静态方法,在编译时就和类名就行了绑定。而重写发生在运行时,动态绑定的。 何况static方法,跟类的实例都不相关,所以概念上也适用。 5)、静态导包 Static还有一种不太常用的用法,即静态导包用法,将类的方法直接导入到当前类中,从而直接使用“方法名”即可调用类方法,更加方便。
常见的笔试面试题
1、下面这段代码的输出结果是什么?
public class TestMain {
static {
System.out.println("static block1");
}
public static void main(String[] args) {
// 在执行main方法之前会首先加载这个类,所以即使main方法中没有语句,静态代码块还是会执行
}
static {
System.out.println("static block2");
}
}

2、下面这段代码的输出结果是什么?
public class Test1 extends Base {
static {
System.out.println("test static");
}
public Test1() {
System.out.println("test constructor");
}
public static void main(String[] args) {
new Test1();
}
}
class Base {
static {
System.out.println("base static");
}
public Base() {
System.out.println("base constructor");
}
}

先来想一下这段代码具体的执行过程,在执行开始,先要寻找到main方法,因为main方法是程序的入口,但是在执行main方法之前,必须先加载Test1类,而在加载Test1类的时候发现Test1类继承自Base类,因此会转去先加载Base类,在加载Base类的时候,发现有static块,便执行了static块。在Base类加载完成之后,便继续加载Test1类,然后发现Test1类中也有static块,便执行static块。在加载完所需的类之后,便开始执行main方法。在main方法中执行new Test1()的时候会先调用父类的构造器,然后再调用自身的构造器。因此,便出现了上面的输出结果。
3、下面这段代码的输出结果是什么?
public class Test2 {
Person person = new Person("Test");
static {
System.out.println("test static");
}
public Test2() {
System.out.println("test constructor");
}
public static void main(String[] args) {
new MyClass();
}
}
class Person {
static {
System.out.println("person static");
}
public Person(String str) {
System.out.println("person " + str);
}
}
class MyClass extends Test2 {
Person person = new Person("MyClass");
static {
System.out.println("myclass static");
}
public MyClass() {
System.out.println("myclass constructor");
}
}

首先加载Test类,因此会执行Test类中的static块。接着执行new MyClass(),而MyClass类还没有被加载,因此需要加载MyClass类。在加载MyClass类的时候,发现MyClass类继承自Test类,但是由于Test类已经被加载了,所以只需要加载MyClass类,那么就会执行MyClass类的中的static块。在加载完之后,就通过构造器来生成对象。而在生成对象的时候,必须先初始化父类的成员变量,因此会执行Test中的Person person = new Person(),而Person类还没有被加载过,因此会先加载Person类并执行Person类中的static块,接着执行父类的构造器,完成了父类的初始化,然后就来初始化自身了,因此会接着执行MyClass中的Person person = new Person(),最后执行MyClass的构造器。
4、下面这段代码的输出结果是什么?
public class Test3 {
// 由于类只加载一次,所以看效果时只能执行一句
public static void main(String[] args) {
/**
* 只输出classB
* 但是当str没有final修饰时,会输出
* A
* B
* classB
*/
// System.out.println(B.str);
/**
* 输出
* A
* C
* classC
*/
// System.out.println(C.str);
/**
* 均输出
* A
* D
* 200
*/
// System.out.println(D.bb);
// System.out.println(D.aa);
/**
* 只输出200
*/
System.out.println(D.cc);
}
}
class A {
static {
System.out.println("A");
}
}
class B extends A {
static {
System.out.println("B");
}
public static final String str = "calssB";
}
class C extends A {
static {
System.out.println("C");
}
public static final String str = new String("classC");
}
class D extends A {
static {
System.out.println("D");
}
public static final int cc = 200;
public static final Integer aa = 100;
public static final Integer bb = new Integer(200);
}
总结:调用类的静态成员或方法,会引起类的初始化,调用类中常量成员则不会引起类的初始化。
13. this和super
1、从本质上讲,this是一个指向本对象的指针,然而super是一个Java关键字,用来对父类进行调用。 2、this:它代表当前对象的引用(在程序中易产生二义性之处,应使用this来指明当前对象;如果函数的形参与类中的成员数据同名,这时需用this来指明成员变量名)。 3、可以使用super关键字来引用父类(最近父类)的成员变量,方法与构造器。(用来访问直接父类中被隐藏的成员数据或函数,基类与派生类中有相同成员定义时,如:super.变量名、super.成员函数名(实参))。 4、super(参数):调用基类中的某一个构造函数(应该为构造函数中的第一条语句)。 调用super()必须写在子类构造方法的第一行,否则编译不通过。每个子类构造方法的第一条语句,都是隐含地调用super(),如果父类没有这种形式的构造函数,那么在编译的时候就会报错。 5、this(参数):调用本类中另一种形成的构造函数(应该为构造函数中的第一条语句)。尽管可以用this调用一个构造器,但却不能调用两个。 super()和this()类似,均需放在构造方法内第一行。区别是,super()从子类中调用父类的构造方法,this()在同一类内调用其它构造方法。 this和super不能同时出现在一个构造函数里面,因为this必然会调用其它的构造函数,其它的构造函数必然也会有super语句的存在,所以在同一个构造函数里面有相同的语句,就失去了语句的意义,编译器也不会通过。(而且从this和super都要求放在构造函数的第一行来看,它们也无法同时存在一个构造方法里面)。 6、this()和super()都指的是对象,所以,均不可以在static环境中使用。包括:static变量,static方法,static语句块。
14. 排序算法总结
冒泡排序:依次比较相邻元素的排序码,若发现逆序则交换。 可以设置一个变量记录,每轮比较的时候是否有元素交换,若没有则已经有序,没有必要再继续了。(对于原本有序的数组比较好,可由平方阶时间复杂度提升至线性阶)。如果两个元素相等,无需改变他们的位置,因此冒泡排序是稳定的。
快速排序:是对冒泡排序的一种改进。通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部数据分别进行快速排序。在选择比较基数时一般有(开头元素、结尾元素、中间元素、随机选择)几种方式,建议随机或者选择中间元素,因为若选择两个边界的则当序列基本有序时快排退化成冒泡。快排在交换元素的时候很可能就打乱了相等元素的相对位置,所以快排是不稳定的。
选择排序法:第一次从 R[0]-R[n-1]中选取最小值,与 R[0]交换,第二次从 R[1]-R[n-1]中选取最小值,与R[1]交换,依次类推。在一趟选择中,如果当前元素比一个元素小,而该小的元素又出现在一个和当前元素相等的元素后面,那么交换后稳定性就被破坏了。例如,序列5 8 5 2 9,我们知道第一个元素是2,那么原序列中两个5的相对顺序就破坏了,所以选择排序是不稳定的。
插入排序:插入排序是在一个已经有序的小序列基础上,一次插入一个元素。当然,刚开始这个有序的小序列只有1个元素。当元素基本有序时,插入排序的比较次数会大大降低,最好情况下时间复杂度降为线性。相等的元素在插入的时候可以不改变顺序,所以插入排序是稳定的。
归并排序:是将两个有序的序列进行合并排序(递归划分,当只有1个元素时则即是有序的)。合并过程中我们可以保证如果两个当前元素相等时,我们把处在前面的序列的元素保存在结果序列的前面,这样就保证了稳定性。(合并的时候需要一个n长度的辅助数组),在Java的集合工具类Collections.sort(list);使用的就是基于归并的排序策略。
希尔排序:改进的插入排序,插入排序每次的增量为1,希尔排序在元素很无序时使用较大的增量,当元素基本有序了,步长很小,插入排序对于有序的序列效率很高。 一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同元素在各自的插入排序中移动,最后其稳定性就会被打乱。所以希尔排序是不稳定的。
堆排序:直接选择排序的改进(将序列创建成堆之后,每次选择的堆顶元素即可)。堆的结构是节点i的孩子为2i和2i+1节点,大顶堆要求父节点大于等于2个子节点,小顶堆要求父节点小于等于其2个子节点。在一个长为n的序列,堆排序的过程从第n/2开始和其子节点共3个值选择最大或最小,这3个值的选择当然不会破坏其稳定性。但当n/2-1,n/2-2,…,1这些父节点选择元素时,就会破坏稳定性。有可能第n/2个父节点交换把后面一个元素交换过去了,而第n/2-1个父节点把后面一个相同的元素没有交换,那么这2个相同的元素之间的稳定性就被破坏了。所以堆排序不是稳定的排序算法。
基数排序:是按照低位先排序,然后收集;再按照高位排序,然后再收集; 依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。基数排序基于分别排序,分别收集,所以是稳定的。
时间复杂度
(1)、平方阶(O(n^2))排序:各类简单排序,直接插入、直接选择和冒泡排序; (2)、线性对数阶(O(nlog2n))排序:快速排序、堆排序和归并排序; (3)、O(n^(1+§)))排序,§是介于 0 和 1 之间的常数:希尔排序; (4)、线性阶(O(n))排序:基数排序,此外还有桶、箱排序。 说明:当原表有序或基本有序时,直接插入排序和冒泡排序将大大减少比较次数和移动记录的次数,时间复杂度可降至O(n); 而快速排序则相反,当原表基本有序时,将蜕化为冒泡排序,时间复杂度提高为O(n^2);原表是否有序,对简单选择排序、堆排序、归并排序和基数排序的时间复杂度影响不大。
稳定性
排序算法的稳定性:若待排序的序列中,存在多个具有相同关键字的记录,经过排序,这些记录的相对次序保持不变,则称该算法是稳定的;若经排序后,记录的相对次序发生了改变,则称该算法是不稳定的。 稳定性的好处:排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。基数排序就是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。另外,如果排序算法稳定,可以避免多余的比较; 稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序; 不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序。 注意:凡是对有序甚至基本有序的序列进行操作时,都可以考虑使用二分策略(二分查找,二分插入)来提升性能。
15. Java反射机制
Java.Lang.Class
在Java中万事万物都被抽象成为类,一个具体的事物则是某个类的实例对象,那么对Java中类的抽象呢(例如,每个类都有成员变量,构造方法,成员方法等)?对类的抽象就是类类型(class type),即Class类。 Class类的实例就是Java中的类,Class类的构造方法是私有的,只能由Java虚拟机创建,并且每个类只有一个与之对应的Class类实例(不管用何种方式获取的都一样)。 当一个类由JVM加载到内存中时,都会生成类对应的一个Class类的对象,(更恰当地说,是被保存在一个同名的.class文件中)。为了生成这个类的对象,运行这个程序的Java虚拟机将使用被称为“类加载器”的子系统。该Class类的对象就保存了运行时Java类的类型信息。 1、getName():一个Class对象描述了一个特定类的属性,Class类中最常用的方法getName,以String的形式返回此Class对象所表示的实体(类、接口、数组类、基本类型或void)名称。 2、newInstance():Class还有一个有用的方法可以为类创建一个实例,这个方法叫做newInstance()。newInstance()方法调用默认构造器(无参数构造器)初始化新建对象。 3、getClassLoader():返回该类的类加载器。 4、getComponentType():返回表示数组组件类型的Class。 5、getSuperclass():返回表示此Class所表示的实体(类、接口、基本类型或void)的超类的Class。 6、isArray():判定此Class对象是否表示一个数组类。
java.lang.reflect.Field
成员变量也是对象,是java.lang.reflect.Field类的对象: * getFields():获取的是所有的public的属性,包括父类继承而来的; * getDeclaredFields():获取的是该类自己声明的属性,不论访问权限。
java.lang.reflect.Method
成员方法也是对象,一个成员方法就是一个Method类的对象: * getMethods():获取的是所有的public的方法,包括从父类继承而来的方法; * getDeclaredMethods():获取的是所有该类自己声明的方法,不论访问权限。 Method类中的如下几种方法: 1、getModifiers():以整数形式返回此 Method 对象所表示方法的 Java 语言修饰符。 2、getReturnType():返回一个 Class 对象,该对象描述了此Method 对象所表示的方法的正式返回类型。 3、getName():以 String 形式返回此 Method 对象表示的方法名称。 4、getParameterTypes():按照声明顺序返回 Class 对象的数组,这些对象描述了此Method 对象所表示的方法的形参类型。 5、getExceptionTypes():返回 Class 对象的数组,这些对象描述了声明将此Method 对象表示的底层方法抛出的异常类型。 在这需要注意的是,利用getModifiers()获取修饰符并不是简单的输出public、static等,而是以整数形式返回所表示的方法的Java语言修饰符。可借助Modifier类的toString()方法来完成。
java.lang.reflect.Constructor
构造函数也是对象,是java.lang.reflect.Constructor类的对象: getConstructors():获取所有的public的构造函数(实际上构造函数也不能被继承,因此所有的也都是自己定义的)。 getDeclaredConstructors():获取自己定义的所有的构造函数。 在Construction,Method,Field三个类中有一个共同的父类AccessibleObject,定义了取消封装的操作:setAccessible(Boolean flag), public void setAccessible(boolean flag) throws SecurityException 该方法默认的参数是false,表示反射的对象应该实施 Java 语言访问检查。值为 true 则指示反射的对象在使用时应该取消 Java 语言访问检查。所谓语言访问检查即不能通过反射来访问类的私有属性与方法,因为这样做会破坏类的封装性。实在要这样做就可以: setAccessible(true);
16. Java异常处理
当出现程序无法控制的外部环境问题(如:用户提供的文件不存在,文件内容损坏,网络不可用…)时,JAVA就会用异常对象来描述。 JAVA中用2种方法处理异常: 1、在发生异常的地方直接处理。 2、将异常抛给调用者,让调用者处理。
Java异常的分类
1、检查性异常:java.lang.Exception(程序正确) 因为外在的环境条件不满足引发。JAVA编译器强制要求处理这类异常,如果不捕获这类异常,程序将不能被编译。 2、运行期异常:java.lang.RuntimeException 意味着程序存在bug,如数字越界,0被除。这类异常需要更改程序来避免,JAVA编译器强制要求处理这类异常。 3、错误:java.lang.Error 一般很少见,也很难通过程序解决。它可能源于程序的bug,但一般更可能源于环境问题,如内存耗尽。错误在程序中无需处理,而由运行环境处理。 java.lang.Exception和java.lang.Error继承自java.lang.Throwable,而java.lang.RuntimeException继承自java.lang.Exception。
异常处理
1、Try…catch:程序运行产生异常时,将从异常发生点中断程序并向外抛出异常信息。 2、Finally:如果把finally块置try…catch…语句后,finally块一般都会得到执行,它相当于一个万能的保险,即使前面的try块发生异常,而又没有对应的catch块,finally块将会马上执行。 若try语句快中存在return语句,则会在finally语句执行完再返回。(若try语句和finally中都有return,则返回的是finally语句块中的)。 以下情形,finally块将不会被执行; 1、finally块中发生了异常。 2、程序所在线程死亡。 3、前面代码使用了System.exit(); 4、关闭CPU。 注意:return要返回的值会存储到一个临时栈,若finally块中只是改变要返回变量的值,而不返回,则临时栈中的值不会改变。
public static int returnTry() {
int a = 0;
try {
a = 1;
return 1;
} finally {
// 只是改变了a的值,但是返回的还是1
System.out.println("改变a的值!!");
a = 2;
}
}
public static int returnFinally() {
int a = 0;
try {
a = 1;
return 1;
} finally {
a = 2;
// 返回2
return a;
}
}
17. String与StringBuffer、StringBulider区别
17.1、可变与不可变
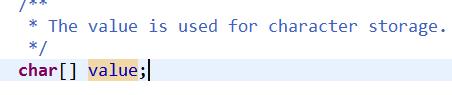
在java中提供三个类String、StringBuillder、StringBuffer来表示和操作字符串。字符串就是多个字符的集合。
String是内容不可变的字符串。String底层使用了一个不可变的字符数组(final char[])。
 StringBuilder与StringBuffer都继承自AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串(没有使用final来修饰),如下就是,可知这两种对象都是可变的。
StringBuilder与StringBuffer都继承自AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串(没有使用final来修饰),如下就是,可知这两种对象都是可变的。
最经典的字符串拼接的例子:
String str = “hello”;
str = str + “world”;
由于String类是不可变的,实际上会在堆内存中会生成“hello”,“world”,“helloworld”三个String对象。当str指向新的“helloworld”时,前两个对象变成垃圾对象。
使用StringBuilder或者StringBuffer 则可以直接拼接:
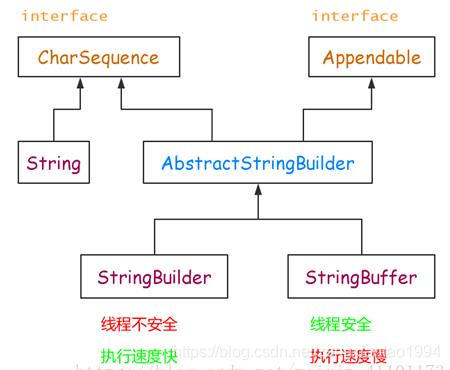
StringBuilder sb = new StringBuilder(); sb.apend(“a”).apend(“b”)
String、StringBuffer、StringBuilder三个类的继承关系如下图所示:
17.2、是否多线程安全
String中的对象是不可变的,也就可以理解为常量,显然线程安全。 AbstractStringBuilder是StringBuilder与StringBuffer的公共父类,定义了一些字符串的基本操作,如expandCapacity、append、insert、indexOf等公共方法。 StringBuffer对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder并没有对方法进行加同步锁,所以是非线程安全的。
17.3、总结
 最后,如果程序不是多线程的,那么使用StringBuilder效率高于StringBuffer。
最后,如果程序不是多线程的,那么使用StringBuilder效率高于StringBuffer。
StringBuffer的容量
首先是两个概念capacity和length,使用str.capacity()得到的时字符串的容量大小,而str.length()得到的时字符串的实际长度。
直接使用new StringBuffer(String str)时,capacity是str.length + 16
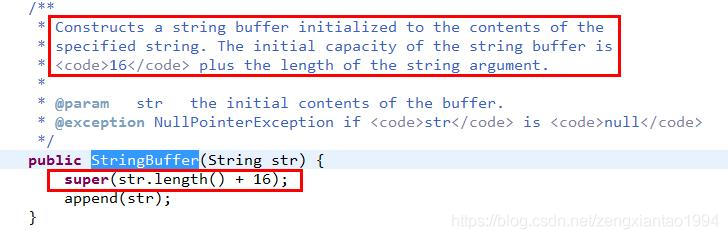 如果直接是new StringBuffer(),则capacity为16
如果直接是new StringBuffer(),则capacity为16
 扩容操作时,容量扩展的规则是把旧的容量(value的长度)2+2
扩容操作时,容量扩展的规则是把旧的容量(value的长度)2+2
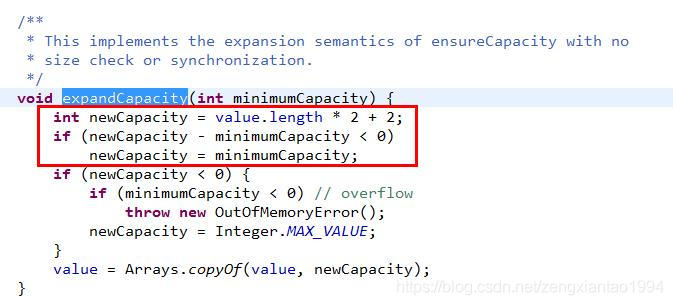 所以第一次append时,小于16则不需扩展,如果大于16则会直接扩展到34(162+2),如果append后的字符串小于34,则容量就为34,如果append后的字符串大于34,则容量为append后的长度(此时capacity和length相等,下一次append势必会扩容)。
即若新的capacity的大小等于append后的长度,则容量为该capacity,如果在append之后,长度大于capacity,则继续使用append后的长度为容量。
所以第一次append时,小于16则不需扩展,如果大于16则会直接扩展到34(162+2),如果append后的字符串小于34,则容量就为34,如果append后的字符串大于34,则容量为append后的长度(此时capacity和length相等,下一次append势必会扩容)。
即若新的capacity的大小等于append后的长度,则容量为该capacity,如果在append之后,长度大于capacity,则继续使用append后的长度为容量。
String对象的不变性
1、String类是final类,也即意味着String类不能被继承,并且它的成员方法都默认为final方法。在Java中,被final修饰的类是不允许被继承的,并且该类中的成员方法都默认为final方法。 2、String类其实是通过char数组来保存字符串的。 String使用private final char value[]来实现字符串的存储,也就是说String对象创建之后,就不能再修改此对象中存储的字符串内容,就是因为如此,才说String类型是不可变的(immutable)。 3、对于改变字符串的操作,无论是sub操、concat还是replace操作都不是在原有的字符串上进行的,而是重新生成了一个新的字符串对象。也就是说进行这些操作后,最原始的字符串并没有被改变。 在这里要永远记住一点:String对象一旦被创建就是固定不变的了,对String对象的任何改变都不影响到原对象,相关的任何change操作都会生成新的对象。
字符串常量池
我们知道字符串的分配和其他对象分配一样,是需要消耗高昂的时间和空间的,而且字符串我们使用的非常多。JVM为了提高性能和减少内存的开销,在实例化字符串的时候进行了一些优化:使用字符串常量池。每当我们创建字符串常量时,JVM会首先检查字符串常量池,如果该字符串已经存在常量池中,那么就直接返回常量池中的实例引用。如果字符串不存在常量池中,就会在堆中创建一份,然后返回堆中的地址。由于String字符串的不可变性我们可以十分肯定常量池中一定不存在两个相同的字符串。 Java中的常量池,实际上分为两种形态:静态常量池和运行时常量池。 所谓静态常量池,即*.class文件中的常量池,class文件中的常量池不仅仅包含字符串(数字)字面量,还包含类、方法的信息,占用class文件绝大部分空间。 而运行时常量池,则是jvm虚拟机在完成类装载操作后,将class文件中的常量池载入到内存中,并保存在方法区中,我们常说的常量池,就是指方法区中的运行时常量池。 当调用String类的intern()方法时,若常量池中已经包含一个等于此String对象的字符串(用Object的equels方法确定),则返回池中的字符串,否则将此String对象添加到池中,并返回此String对象在常量池中的引用。比如:
String s1 = new String(“asd”);
s1 = s1.intern();
String s2 = “asd”;
s1 == s2; // true
1234
其他
1、引用变量与对象:A aa; 这个语句声明一个类A的引用变量aa[我们常常称之为句柄],而对象一般通过new创建。所以aa仅仅是一个引用变量,它不是对象。 2、创建字符串的方式,创建字符串的方式归纳起来有两类: (1)、使用"“引号创建字符串; (2)、使用new关键字创建字符串。结合上面例子,总结如下: A、单独使用”“引号创建的字符串都是常量,编译期就已经确定存储到StringPool中; B、使用new String(”")创建的对象会存储到heap中,是运行期新创建的; new创建字符串时首先查看池中是否有相同值的字符串,如果有,则拷贝一份到堆中,然后返回堆中的地址;如果池中没有,则在堆中创建一份,然后返回堆中的地址(注意,此时不需要从堆中复制到池中,否则,将使得堆中的字符串永远是池中的子集,导致浪费池的空间)! C、使用只包含常量的字符串连接符如"aa"+ “aa"创建的也是常量,编译期就能确定,已经确定存储到StringPool中; D、使用包含变量的字符串连接符如"aa”+ s1创建的对象是运行期才创建的,存储在heap中; 3、使用String不一定创建对象,使用new String,一定创建对象。 在执行到双引号包含字符串的语句时,如String a = “123”,JVM会先到常量池里查找,如果有的话返回常量池里的这个实例的引用,否则的话创建一个新实例并置入常量池里。所以,当我们在使用诸如String str = “abc”;的格式定义对象时,总是想当然地认为,创建了String类的对象str。担心陷阱!对象可能并没有被创建!而可能只是指向一个先前已经创建的对象。只有通过new()方法才能保证每次都创建一个新的对象。
关于final
String中的final用法和理解
final StringBuffer a = new StringBuffer("111");
final StringBuffer b = new StringBuffer("222");
a = b; // 此句编译不通过
final StringBuffer a = new StringBuffer("111");
a.append("222"); // 编译通过
12345
可见,final修饰引用变量只对引用的"值"(即内存地址)有效,它迫使引用只能指向初始指向的那个对象,改变它的指向会导致编译期错误。至于它所指向的对象的变化,final是不负责的。
18. NIO与IO的区别
NIO即New IO,这个库是在JDK1.4中才引入的。NIO和IO有相同的作用和目的,但实现方式不同,NIO主要用到的是块,所以NIO的效率要比IO高很多。在Java API中提供了两套NIO,一套是针对标准输入输出NIO,另一套就是网络编程NIO。 NIO和IO的主要区别,下表总结了Java IO和NIO之间的主要区别:
| IO | NIO |
|---|---|
| 面向流 | 面向缓冲 |
| 阻塞IO | 非阻塞IO |
| 无 | 选择器 |
1、面向流与面向缓冲 Java IO和NIO之间第一个最大的区别是,IO是面向流的,NIO是面向缓冲区的。 Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方。此外,它不能前后移动流中的数据。如果需要前后移动从流中读取的数据,需要先将它缓存到一个缓冲区。Java NIO的缓冲导向方法略有不同。数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。但是,还需要检查是否该缓冲区中包含所有您需要处理的数据。而且,需确保当更多的数据读入缓冲区时,不要覆盖缓冲区里尚未处理的数据。
2、阻塞与非阻塞IO Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write() 时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。线程通常将非阻塞IO的空闲时间用于在其它通道上执行IO操作,所以一个单独的线程现在可以管理多个输入和输出通道(channel)。
3、选择器(Selectors) Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
18.1、NIO和IO适用场景
NIO是为弥补传统IO的不足而诞生的,但是尺有所短寸有所长,**NIO也有缺点,因为NIO是面向缓冲区的操作,每一次的数据处理都是对缓冲区进行的,那么就会有一个问题,在数据处理之前必须要判断缓冲区的数据是否完整或者已经读取完毕,如果没有,假设数据只读取了一部分,那么对不完整的数据处理没有任何意义。**所以每次数据处理之前都要检测缓冲区数据。 那么NIO和IO各适用的场景是什么呢? 如果需要管理同时打开的成千上万个连接,这些连接每次只是发送少量的数据,例如聊天服务器,这时候用NIO处理数据可能是个很好的选择。 而如果只有少量的连接,而这些连接每次要发送大量的数据,这时候传统的IO更合适。使用哪种处理数据,需要在数据的响应等待时间和检查缓冲区数据的时间上作比较来权衡选择。
18.2、Java NIO 总览
Java NIO的三个核心基础组件,Channels、Buffers、Selectors。其余的诸如Pipe,FileLcok都是在使用以上三个核心组件时帮助更好使用的工具类。
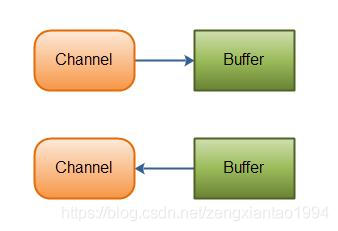
一、Channels和Buffers的关系
所有的IO操作在NIO中都是以Channel开始的。一个Channel就像一个流,NIO Channel和流很近似但是也有一些不同。
1)、你既可以读取也可以写入到Channel,流只能读取或者写入,inputStream和outputStream。
2)、Channel可以异步地读和写。
3)、channel永远都是从一个buffer中读或者写入到一个buffer中去。
 基本的Channel实现有以下这些:
1)、FileChannel:向文件当中读写数据;
2)、DatagramChannel:通过UDP协议向网络读写数据;
3)、SocketChannel:通过TCP协议向网络读写数据;
4)、ServerSocketChannel:以一个web服务器的形式,监听到来的TCP连接,对每个连接建立一个SocketChannel。
涵盖了UDP,TCP以及文件的IO操作。
核心的buffer实现有这些:ByteBuffer、CharBuffer、DoubleBuffer、FloatBuffer、IntBuffer、LongBuffer、ShortBuffer,涵盖了所有的基本数据类型(4类8种,除了Boolean)。也有其他的buffer如MappedByteBuffer。
基本的Channel实现有以下这些:
1)、FileChannel:向文件当中读写数据;
2)、DatagramChannel:通过UDP协议向网络读写数据;
3)、SocketChannel:通过TCP协议向网络读写数据;
4)、ServerSocketChannel:以一个web服务器的形式,监听到来的TCP连接,对每个连接建立一个SocketChannel。
涵盖了UDP,TCP以及文件的IO操作。
核心的buffer实现有这些:ByteBuffer、CharBuffer、DoubleBuffer、FloatBuffer、IntBuffer、LongBuffer、ShortBuffer,涵盖了所有的基本数据类型(4类8种,除了Boolean)。也有其他的buffer如MappedByteBuffer。
一个简单的channel例子:使用一个FileChannel将数据读入一个buffer。
RandomAccessFile aFile = new RandomAccessFile("data/nio-data.txt", "rw");
FileChannel inChannel = aFile.getChannel();
ByteBuffer buf = ByteBuffer.allocate(48);
int bytesRead = inChannel.read(buf);
while (bytesRead != -1) {
System.out.println("Read " + bytesRead);
buf.flip();
while(buf.hasRemaining()){
System.out.print((char) buf.get());
}
buf.clear();
bytesRead = inChannel.read(buf);
}
aFile.close();
buf.flip()的意思是读写转换,首先你读入一个buffer,然后你flip,转换读写,然后再从buffer中读出。
二、NIO buffer
NIO buffer在与NIO Channel交互时使用,数据从Channel中读取出来放入buffer,或者从buffer中读取出来写入Channel。 buffer就是一块内存,你可以写入数据,并且在之后读取它。这块内存被包装成NIO buffer对象,它提供了一些方法来让你更简单地操作内存。 buffer的基本使用,使用buffer读写数据基本上分为以下4部操作: 1)、将数据写入buffer 2)、调用buffer.flip() 3)、将数据从buffer中读取出来 4)、调用buffer.clear()或者buffer.compact() 在写buffer的时候,buffer会跟踪写入了多少数据,需要读buffer的时候,需要调用flip()来将buffer从写模式切换成读模式,读模式中只能读取写入的数据,而非整个buffer。 当数据都读完了,你需要清空buffer以供下次使用,可以有2种方法来操作:调用clear() 或者 调用compact()。 区别:clear方法清空整个buffer,compact方法只清除你已经读取的数据,未读取的数据会被移到buffer的开头,此时写入数据会从当前数据的末尾开始。
// 创建一个容量为48的ByteBuffer
ByteBuffer buf = ByteBuffer.allocate(48);
// 从channel中读(取数据然后写)入buffer
int bytesRead = inChannel.read(buf);
// 下面是读取buffer
while (bytesRead != -1) {
buf.flip(); // 转换buffer为读模式
System.out.print((char) buf.get()); // 一次读取一个byte
buf.clear(); //清空buffer准备下一次写入
}
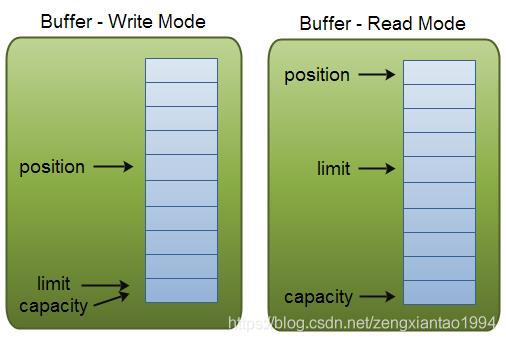
1、buffer的Capacity,Position和Limit
buffer有3个属性需要熟悉以理解buffer的工作原理:
容量(Capacity):缓冲区能够容纳的数据元素的最大数量。容量在缓冲区创建时被设定,并且永远不能被改变。
上界(Limit):写模式中等价于buffer的大小,即capacity;读模式中为当前缓冲区中一共有多少数据,即可读的最大位置。这意味着当调用filp()方法切换成读模式时,limit的值变成position的值,而position重新指向0。
位置(Position):下一个要被读或写的元素的位置。初始化为0,buffer满时,position最大值为capacity-1。切换成读模式的时候,position指向0。Position会自动由相应的 get( )和 put( )函数更新。
position和limit的值在读/写模式中是不一样的。capacity的值永远表示buffer的大小。
下图解释了在读/写模式中Capacity,Position和Limit的意思。
 2、创建一个buffer
获得一个buffer 之前必须先分配一块内存,每个buffer类都有一个静态方法allocate() 来做这件事。
下例为创建一个容量为48byte的ByteBuffer:
ByteBuffer buf = ByteBuffer.allocate(48);
创建一个1024个字符的CharBuffer
CharBuffer buf = CharBuffer.allocate(1024);
2、创建一个buffer
获得一个buffer 之前必须先分配一块内存,每个buffer类都有一个静态方法allocate() 来做这件事。
下例为创建一个容量为48byte的ByteBuffer:
ByteBuffer buf = ByteBuffer.allocate(48);
创建一个1024个字符的CharBuffer
CharBuffer buf = CharBuffer.allocate(1024);
3、将数据写入buffer 写入buffer的方法有2种: 1)、从一个Channel中写入buffer。 2)、调用buffer的put()方法来自行写入数据。 例: int bytesRead = inChannel.read(buf); // 从channel读入buffer buf.put(127); // 自行写入buffer put方法有很多的重载形式。以供你用各种不同的方法写入buffer中,比如从一个特定的position,或者写入一个array。
4、flip() flip方法将写模式切换成读模式,调用flip()方法会将limit设置为position,将position设置回0。 换句话说,position标志着写模式中写到哪里,切换成读模式之后,limit标志着之前写到哪里,也就是现在能读到哪里。
5、从buffer中读取数据 有2种方法可以从buffer中读取数据。 1)、从buffer中读取数据到channel中。 2)、使用buffer的get()方法自行从buffer中读出数据。 例子: // 从buffer中读取数据到channel中 int bytesWritten = inChannel.write(buf); // 使用buffer的get()方法自行从buffer中读出数据 byte aByte = buf.get(); get方法有很多的重载形式。以供你用各种不同的方法读取buffer中的数据。例如从特定位置读取数据,或者读一个数组出来。
6、rewind() rewind()方法将position设置为0,但是不会动buffer里的数据,这样可以从头开始重新读取数据,limit的值不会变,这意味着limit依旧标志着能读多少数据。
7、clear()和compact() 当你读完所有的数据想要重新写入数据时,你可以调用clear或者compact方法。 当你调用clear()方法的时候,position被设置为0,limit被设置为capacity,换句话说,buffer的数据虽然都还在,但是buffer被初始化了,处于可以被重写的状态。这也就意味着如果buffer中还有没被读取的数据,在执行clear之后,你无法知道数据读到哪儿了,剩下的数据还有多少。 如果还有没有读完的数据,但是你想先写数据,可以用compact()方法,这样未读数据会放在buffer前端,可以在未读数据之后跟着写新的数据。compact()会复制未读数据到buffer前端,然后设置position为未读数据单位后面紧跟的位置。limit还是设置为capacity,这和clear是一样的。现在buffer处于可以写的状态,但是不会覆盖之前未读完的数据。
8、mark()和reset() 你可以通过调用buffer.mark()来mark一个buffer中给定的位置。然后你就可以用buffer.reset()方法来将position设置回之前mark的位置。 例子: buffer.mark(); // 调用buffer.get()方法若干次,e.g. 比如在做parsing的时候 buffer.reset(); //set position back to mark.
9、equals() 和 compareTo() 使用这2种方法能够比较2个buffer。 equals()方法:用于判断2个buffer是否相等,2个buffer是equal的,当它们: 1)、是同一种数据类型的buffer。 2)、buffer中未读取的bytes,chars等数据个数是一样的,即(limit-position)相等,capacity不需要相等,剩余数据的索引也不需要相等。 3)、未读取的bytes,chars等内容是一模一样的,即各自[position,limit-1]索引的数据要完全相等。 如你所见,equals()方法只比较buffer的部分内容,而不是buffer中所有的数据,事实上,它只比较buffer中剩余的元素是否一样。
compareTo() compareTo()方法:比较两个buffer的剩余元素(字节,字符等),用于例如: 排序。 在下列情况下,缓冲区被认为比另一个缓冲区“小”: 比较是针对每个缓冲区你剩余数据(从 position 到 limit)进行的,与它们在 equals() 中的方式相同,直到不相等的元素被发现或者到达缓冲区的上界。如果一个缓冲区在不相等元素发现前已经被耗尽,较短的缓冲区被认为是小于较长的缓冲区。
三、NIO Selectors
Selector允许一个线程来监视多个Channel,这在当你的应用建立了多个连接,但是每个连接吞吐量都较小的时候是可行的。例如:一个聊天服务器。图为一个线程使用Selector处理三个Channel。
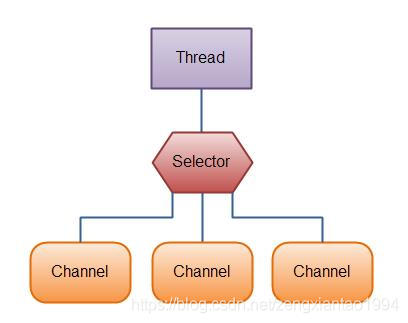 要使用一个Selector,你要先注册这个Selector的Channels。然后你调用Selector的select()方法。这个方法会阻塞,直到它注册的Channels当中有一个准备好了的事件发生了。当select()方法返回的时候,线程可以处理这些事件,如新的连接的到来,数据收到了等。
要使用一个Selector,你要先注册这个Selector的Channels。然后你调用Selector的select()方法。这个方法会阻塞,直到它注册的Channels当中有一个准备好了的事件发生了。当select()方法返回的时候,线程可以处理这些事件,如新的连接的到来,数据收到了等。
19. Java基本数据类型、有了基本数据类型,为什么还需要包装类型?
19.1、Java基本数据类型,数值范围
Java共有4类8种基础数据类型:byte、short、int、long、float、double、char、boolean。
1、四种整数类型(byte、short、int、long):byte:8位,用于表示最小数据单位,如文件中数据,-128127。 short:16位,很少用,-32768 ~ 32767。int:32位,最常用,-231-1231(21亿)。long:64位,次常用。注意事项:int i=5; //5叫直接量(或字面量),即直接写出的常数。整数字面量默认都为int类型,所以在定义的long型数据后面加L或l。小于32 位数的变量,都按int结果计算。强转符比数学运算符优先级高。
2、两种浮点数类型(float、double):float:32位,后缀F或f,1位符号位,8位指数,23位有效尾数。double:64位,最常用,后缀D或d,1位符号位,11位指数,52位有效尾数。注意事项:浮点数字面量默认都为double类型,所以在定义的float型数据后面加F或f;double类型可不写后缀,但在小数计算中一定要写D或X.X。float的精度没有long高,有效位数(尾数)短。float的范围大于long,指数可以很大。浮点数是不精确的,不能对浮点数进行精确比较。
3、一种字符类型(char):char:16位,是整数类型,用单引号括起来的1个字符(可以是一个中文字符),使用Unicode码代表字符,0~2^16-1(65535)。注意事项:不能为0个字符。转义字符:\n 换行、\r回车、\t Tab字符、" 双引号、\表示一个\,两字符char中间用“+”连接,内部先把字符转成int类型,再进行加法运算,char本质就是个数!二进制的,显示的时候,经过“处理”显示为字符。
4、一种布尔类型(boolean):true真和false假。 5、类型转换:char–>自动转换:byte–>short–>int–>long–>float–>double。强制转换:①会损失精度,产生误差,小数点以后的数字全部舍弃。②容易超过取值范围。
19.2、为什么需要包装类型
我们都知道在Java语言中,new一个对象存储在堆里,我们通过栈中的引用来使用这些对象;但是对于经常用到的一系列类型如int,如果我们用new将其存储在堆里就不是很有效——特别是简单的小的变量。所以就出现了基本类型,更加高效。 而为什么还需要包装类型呢?Java是一个面相对象的编程语言,基本类型并不具有对象的性质,为了让基本类型也具有对象的特征,就出现了包装类型(每一种基本的数据类型都有一种对应的包装类型,如我们在使用集合类型Collection时就一定要使用包装类型而非基本类型),它相当于将基本类型“包装起来”,使得它具有了对象的性质,并且为其添加了属性和方法(最大值、最小值、null),丰富了基本类型的操作。 另外,当需要往ArrayList,HashMap中放东西时,像int,double这种基本类型是放不进去的,因为容器都是装object的,这是就需要这些基本类型的包装器类了。
19.3、装箱与拆箱
装箱就是自动将基本数据类型转换为包装器类型;拆箱就是自动将包装器类型转换为基本数据类型。 Integer i = 1;自动装箱,实际上在编译时会调用Integer.valueOf()方法来装箱,在Java5之前,只能通过new的方式创建一个Integer对象,Java5之后实现自动装箱。 Integer i = 1; int j = i; //自动拆箱,实际上也会在编译器调用Integer.intValue(); 其他的也类似,比如Double、Character等。 因此可以用一句话总结装箱和拆箱的实现过程:装箱过程是通过调用包装器的valueOf方法实现的,而拆箱过程是通过调用包装器的 xxxValue方法实现的。(xxx代表对应的基本数据类型)。
19.4、Integer的缓存值
首先看下Integer的valueOf()方法:
public static Integer valueOf(int i) {
if(i >= -128 && i <= IntegerCache.high)
return IntegerCache.cache[i + 128];
else
return new Integer(i);
}
在通过valueOf方法创建Integer对象的时候,如果数值在[-128,127]之间,便返回指向IntegerCache.cache中已经存在的对象的引用;否则创建一个新的Integer对象。这样做主要的目的就是为了提高效率(因为一些小值数据经常使用)。 注意,Integer、Short、Byte、Character、Long这几个类的valueOf方法的实现是类似的。Double、Float的valueOf方法的实现是类似的。这主要是因为在某个范围内的整型数值的个数是有限的,而浮点数却不是。
20. hashCode和equals比较、equals与“==”比较
20.1、equals与“==”
1、基本数据类型,也称原始数据类型。 Byte,short,char,int,long,float,double,boolean,他们之间的比较,应用双等号(==),比较的是他们的值。
int a = 10;
long b = 10l;
double c = 10.0;
System.out.println(a == b); // true
System.out.println(a == c); // true
12345
这里比较的时候存在强制类型的转换,低精度自动向高精度转换,然后比较。
2、复合数据类型(类) 当他们用(==)进行比较的时候,比较的是他们在内存中的存放地址,所以,除非是同一个new出来的对象,他们的比较后的结果为true,否则比较后结果为false。JAVA当中所有的类都是继承于Object这个基类的,在Object中的基类中定义了一个equals的方法,这个方法的初始行为是比较对象的内存地址, 但在一些类库当中这个方法被覆盖掉了,如String,Integer,Date在这些类当中equals有其自身的实现,而不再是比较类在堆内存中的存放地址了。而是比较指向的对象所存储的内容是否相等。 对于复合数据类型之间进行equals比较,在没有覆写equals方法的情况下,他们之间的比较还是基于他们在内存中的存放位置的地址值的,因为Object的equals方法也是用双等号(==)进行比较的,所以比较后的结果跟双等号(==)的结果相同。
20.2、hashCode()是什么
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。 hashCode() 定义在JDK的Object类中,这就意味着Java中的任何类都包含有hashCode() 函数。 虽然,每个Java类都包含hashCode()函数。但是,仅仅当创建并某个“类的散列表”(散列表指的是:Java集合中本质是散列表的类,如HashMap,Hashtable,HashSet)时,该类的hashCode() 才有用(作用是:确定该类的每一个对象在散列表中的位置)。其它情况下(例如,创建类的单个对象,或者创建类的对象数组等等),类的hashCode() 没有作用。 也就是说:hashCode() 在散列表中才有用,在其它情况下没用。在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。 我们都知道,散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码! 散列表的本质是通过数组实现的。 当我们要获取散列表中的某个“值”时,实际上是要获取数组中的某个位置的元素。而数组的位置,就是通过“键”来获取的;更进一步说,数组的位置,是通过“键”对应的散列码计算得到的。 下面,我们以HashSet为例,来深入说明hashCode()的作用。 假设,HashSet中已经有1000个元素。当插入第1001个元素时,需要怎么处理?因为HashSet是Set集合,它不允许有重复元素。 “将第1001个元素逐个的和前面1000个元素进行比较”?显然,这个效率是相等低下的。散列表很好的解决了这个问题,它根据元素的散列码计算出元素在散列表中的位置,然后将元素插入该位置即可。对于相同的元素,自然是只保存了一个。 由此可知,若两个元素相等,它们的散列码一定相等; 但反过来确不一定。在散列表中,1、如果两个对象相等(equals),那么它们的hashCode()值一定要相同;2、如果两个对象hashCode()相等,它们并不一定相等。
20.3、hashCode和equals的关系
“hashCode() 和 equals()的关系”分2种情况来说明。 第一种:不会创建“类对应的散列表” 这里所说的“不会创建类对应的散列表”是说:我们不会在HashSet, Hashtable, HashMap等等这些本质是散列表的数据结构中,用到该类。例如,不会创建该类的HashSet集合。 在这种情况下,该类的“hashCode() 和 equals() ”没有半毛钱关系的!这种情况下,equals() 用来比较该类的两个对象是否相等。而hashCode() 则根本没有任何作用, 第二种:会创建“类对应的散列表” 这里所说的“会创建类对应的散列表”是说:我们会在HashSet, Hashtable, HashMap等等这些本质是散列表的数据结构中,用到该类。例如,会创建该类的HashSet集合。 在这种情况下,该类的“hashCode() 和 equals() ”是有关系的: 1)、如果两个对象相等,那么它们的hashCode()值一定相同。 这里的相等是指,通过equals()比较两个对象时返回true。 2)、如果两个对象hashCode()相等,它们并不一定相等。 因为在散列表中,hashCode()相等,即两个键值对的哈希值相等。然而哈希值相等,并不一定能得出键值对相等。补充说一句:“两个不同的键值对,哈希值相等”,这就是哈希冲突。 总结: 1、如果根据 equals(Object) 方法,两个对象是相等的,那么对这两个对象中的每个对象调用 hashCode 方法都必须生成相同的整数结果。 2、如果两个hashCode()返回的结果相等,则两个对象的equals方法不一定相等。 3、如果根据equals(java.lang.Object)方法,两个对象不相等,那么对这两个对象中的任一对象上调用 hashCode 方法不一定生成不同的整数结果。但是,程序员应该意识到,为不相等的对象生成不同整数结果可以提高哈希表的性能。 因此在重写类的equals方法时,也重写hashcode方法,使相等的两个对象获取的HashCode也相等,这样当此对象做Map类中的Key时,两个equals为true的对象其获取的value都是同一个,比较符合实际。
21. 自增(++)和自减(–)的问题
在java中,a++ 和 ++a的相同点都是给a+1,不同点是a++是先参加程序的运行再+1,而++a则是先+1再参加程序的运行。 举个例子来说:a = 2; b = a++;运行后:b = 2,a = 3; a = 2; b = ++a;运行后:b = 3,a = 3; a– 和 –a情况与 a++ 和 ++a相似,a–为先参加程序运算再-1;–a为先减1后参加运算。
21.1、++和+1的区别
int i = 0;
i = i++;
System.out.println(i);
123
上述程序输出0;
int i = 0;
i = ++i;
System.out.println(i);
123
上述程序输出1;
Java采取了中间变量缓存机制!在java中,执行自增运算时,会为每一个自增操作分配一个临时变量,如果是前缀加(++i),就会“先自加1后赋值(给临时变量)”;如果是后缀加(i++),就会“先赋值(给临时变量)后自加1”。运算最终使用的,并不是变量本身,而是被赋了值的临时变量。
i = i++; | i = a++
int temp = i; //先自增1,再使用i的值 | int temp = a;
i = i + 1; | a = a + 1;
i = temp; | i = temp;
i = ++i; | i = ++a
i = i + 1; //先自增1,再使用i的值 | a = a + 1;
int temp = i; | int temp = a;
i = temp; | i = temp;
21.2、a = a+1和a += 1的区别
我们先看一段代码:
byte b = 2;
b = b + 1;
System.out.println(b);
123
运行结果:错误: 不兼容的类型: 从int转换到byte可能会有损失 报错的原因是short变量在参与运算时会自动提升为int类型,b+1运算完成后变为int,int赋值给short报错。 换成+=的情况:
byte b = 2;
b += 1;
System.out.println(b);
123
编译通过,输出结果3。 这是因为b += 1并不是完全等价于b = b + 1,而是隐含了强制类型转换,相当于b = (short)(b+1)。 注意:+=不会进行溢出检查
byte b = 127;
b += 1;
System.out.println(b);
123
输出结果是-128,开发中要特别注意。
22. 值传递与引用传递
值传递是对基本数据类型变量而言的,传递的是该变量值的一个副本,改变副本不影响原变量。(此时内存中存在两个相等的基本类型,即实际参数和形式参数) 引用传递一般是对于对象类型而言的,传递的是该对象地址的一个副本,并不是原对象本身。也就是说实参和形参同时指向了同一个对象,因此在函数中可以通过形参来修改对象中的数据,但是让形参重新指向另一个对象对实参是没有任何影响的。
程序实例:
public class Parameter {
public static void main(String[] args) {
int real = 5;
Obj obj = new Obj("5", 5);
String str = "5";
StringBuffer bf = new StringBuffer("5");
System.out.println("调用方法前:");
System.out.println("real = " + real);
System.out.println("obj = " + obj);
System.out.println("str = " + str);
System.out.println("bf = " + bf);
method(real);
method(obj);
method(str);
method(bf);
System.out.println("调用方法后:");
System.out.println("real = " + real);
System.out.println("obj = " + obj);
System.out.println("str = " + str);
System.out.println("bf = " + bf);
}
public static void method(int para) {
// 基本数据类型,形参的改变不影响实参
para = 10;
}
public static void method(Obj para) {
// 引用数据类型,可以通过相同的引用修改对象内容
para.age = 10;
}
public static void method(String para) {
// 引用数据类型,形参指向新的对象,不影响实参(String类不可变,+操作会产生新对象)
para = para + 10;
}
public static void method(StringBuffer para) {
// 引用数据类型,可以通过相同的引用修改对象内容
para.append(10);
}
}
class Obj {
String name;
int age;
public Obj(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return "name:" + name + ",age:" + age;
}
}

23. Java集合类的总结
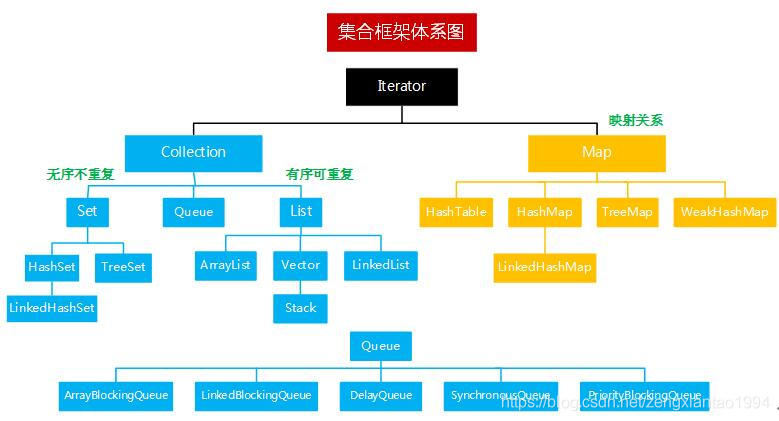 1、Iterator:Collection(值)、Map(键值对);
2、Collection:Set(无序不重复)、List(有序可重复)、Queue;
3、Set:HashSet(基于HashMap实现)、LinkedHashSet(继承自HashSet)、TreeSet(底层基于HashMap实现,升序排列);
4、List:ArrayList(基于数组实现,默认初始容量为10,增速1.5倍 + 1)、Vector(初始容量为10,增速2倍)、Stack(继承自Vector)、LinkedList(基于链表实现);
5、Map:HashMap、HashTable、TreeMap(基于红黑树实现,按key值排序);
6、线程安全的集合类:(喂,SHE),Vector、Stack、HashTable、Enumeration。
7、不论Collection的实际类型如何,它都支持一个iterator()的方法,该方法返回一个迭代子,使用该迭代子即可逐一访问Collection中每一个元素。典型的用法如下:
1、Iterator:Collection(值)、Map(键值对);
2、Collection:Set(无序不重复)、List(有序可重复)、Queue;
3、Set:HashSet(基于HashMap实现)、LinkedHashSet(继承自HashSet)、TreeSet(底层基于HashMap实现,升序排列);
4、List:ArrayList(基于数组实现,默认初始容量为10,增速1.5倍 + 1)、Vector(初始容量为10,增速2倍)、Stack(继承自Vector)、LinkedList(基于链表实现);
5、Map:HashMap、HashTable、TreeMap(基于红黑树实现,按key值排序);
6、线程安全的集合类:(喂,SHE),Vector、Stack、HashTable、Enumeration。
7、不论Collection的实际类型如何,它都支持一个iterator()的方法,该方法返回一个迭代子,使用该迭代子即可逐一访问Collection中每一个元素。典型的用法如下:
Iterator it = collection.iterator(); // 获得一个迭代子
while(it.hasNext()) {
Object obj = it.next(); // 得到下一个元素
}
12345
List还提供一个listIterator()方法,返回一个 ListIterator接口(实现Iterator),和标准的Iterator接口相比,ListIterator多了一些add()之类的方法,允许添加,删除,设定元素,还能向前或向后遍历。 8、快速失败(Fail-Fast)机制:它是Java集合的一种错误检测机制。**当多个线程对集合进行结构上的改变的操作时,有可能会产生fail-fast机制。记住是有可能,而不是一定。**例如:假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构(是结构上面的修改,而不是简单的修改集合元素的内容),那么这个时候程序就会抛出 ConcurrentModificationException 异常,从而产生fail-fast机制。
23.1、Set接口与List接口
List是有序的集合,这里的有序指的是元素插入List的顺序可以控制,Set是无序的。因此List可以允许元素重复,而Set则不可以(只能有一个null)。元素是否重复是根据equals和hashCode判断的,也就是说如果一个对象要存储在Set中,必须重写equals和hashCode方法。
23.2、ArrayList和LinkedList
1、ArrayList和LinkedList都是非线程安全的,都允许null值。ArrayList基于数组数据结构实现,LinkedList基于链表结构实现。 2、ArrayList允许对元素进行快速随机访问,但是想中间插入与移除元素的速率很慢;LinkedList插入与删除的开销不大,随机访问较慢。 3、LinkedList具有下列方法:addFirst(),addLast(),getFirst(),getLast(),removeFirst()和removeLast()这些方法(没有在任何接口或基类中定义过),这些操作使LinkedList可被用作堆栈(stack),队列(queue)或双向队列(deque)。
23.3、ArrayList和Vector
1、ArrayList是线程不安全的,Vector是线程安全的。因此ArrayList的性能要高于Vector; **2、ArrayList和Vector都采用基于数组的方式组织元素,默认初始容量都是10,**如果集合中的元素的数目大于目前集合数组的长度时,Vector扩容为原数组的2倍,而ArrayList扩容为原来1.5倍。Vector还可以设置容量的增量,而ArrayList不可以。
23.4、队列与阻塞队列
队列包含固定长度的队列和不固定长度的队列,先进先出。 固定长度的队列往里放数据,如果放满了还要放,阻塞式队列就会等待,直到有数据取出,空出位置后才继续放;非阻塞式队列不能等待就只能报错了。
23.5、ArrayBlockingQueue
一个由数组支持的有界阻塞队列。此队列按 FIFO(先进先出)原则对元素进行排序。队列的头部是在队列中存在时间最长的元素。队列的尾部是在队列中存在时间最短的元素。新元素插入到队列的尾部,队列获取操作则是从队列头部开始获得元素。 这是一个典型的“有界缓存区”,固定大小的数组在其中保持生产者插入的元素和使用者提取的元素。一旦创建了这样的缓存区,就不能再增加其容量。试图向已满队列中放入元素会导致操作受阻塞;试图从空队列中提取元素将导致类似阻塞。 此类支持对等待的生产者线程和使用者线程进行排序的可选公平策略。默认情况下,不保证是这种排序。然而,通过将公平性 (fairness) 设置为 true 而构造的队列允许按照FIFO 顺序访问线程。公平性通常会降低吞吐量,但也减少了可变性和避免了“不平衡性”。 LinkedBlockingQueue则是一个由链接节点支持的可选有界队列。基于链表实现的阻塞队列。
23.6、PriorityQueue
PriorityQueue是一个基于优先级堆的无界队列,它的元素是按照自然顺序(natural order)排序的。在创建的时候,我们可以给他提供一个负责给元素排序的比较器。PriorityQueue不允许null值,因为他们没有自然顺序,或者说他们没有任何的相关联的比较器。最后,PriorityQueue不是线程安全的,入队和出队的时间复杂度是O(log(n))。 PriorityBlockingQueue是对PriorityQueue的再次包装的阻塞型无界优先级队列。所以在优先阻塞队列上put时是不会受阻的(但是资源耗尽的情况下回导致OutOfMemoryError)。当队列为空,那么取元素的操作take就会阻塞。
23.7、为什么集合类没有实现Cloneable和Serializable接口
克隆(cloning)或者是序列化(serialization)的语义和含义是跟具体的实现类相关的。因此应该由集合类的具体实现来决定如何被克隆或者序列化。当然了,集合框架的接口没有实现克隆和序列化,但是具体的集合类实现了,例如ArrayList类。
24、Array与ArrayList的区别
24.1、存储内容方面:
Array数组可以包含基本类型和对象类型; ArrayList却只能包含对象类型。 但是需要注意的是:Array数组在存放的时候一定是同种类型的元素。ArrayList就不一定了,因为ArrayList可以存储Object。
24.2、空间大小方面:
Array的空间大小是固定的,空间不够时也不能再次申请,所以需要事先确定合适的空间大小。 ArrayList的空间是动态增长的,如果空间不够,它会创建一个空间比原来大1.5倍的新数组,然后将所有元素复制到新数组中,接着抛弃旧数组。而且每次添加新元素的时候都会检查内部数组的空间是否足够。
24.3、方法操作方面:
ArrayList作为Array的增强版,当然是在方法上比Array更多样化,比如添加全部addAll(),删除全部removeAll(),返回迭代器iterator()等。 适用场景: 如果想要保存一些在整个程序运行期间都会存在而且不变的数据,我们可以将它们放进一个全局数组里。如果数据的个数在程序运行时会发生改变,则只能使用ArrayList。但是应该注意到ArrayList增加或者删除数据的时候,都会移动数组中的元素。如果我们需要对元素进行频繁的移动或者删除,或者是处理的是超大量的数据,那么,使用ArrayList就真的不是一个好的选择,因为它的效率很低,使用数组进行这样的动作就会很麻烦,那么,我们可以考虑选择LinkedList。
24.4、Arrays类
Arrays主要是用于方便操作数组的,他的主要方法有,给数组赋值:通过fill方法;对数组排序:通过sort方法,按升序;比较数组:通过equals方法比较数组中元素值是否相等;查找数组元素:通过binarySearch方法能对排序好的数组进行二分查找法操作。
25、HashMap与HashTable以及ConcurrentHashMap的对比
25.1、HashMap和HasheTalbe
相同点:HashMap和HasheTalbe都可以使用来存储key–value的数据。都实现了Map接口; 区别:1、历史原因:HashTable是基于陈旧的Dictionary类的,HashMap是Java1.2引进的Map接口的一个实现。但是两者都实现了Map接口; 2、同步性:**HashTable是线程安全的,也就是说同步的,**这个类中的一些方法包装了HashTable中的对象是线程安全的。**而HashMap则是线程异步的,即不同步的,**因此HashMap中的对象并不是线程安全的。因为同步的要求会影响执行效率,所以HashMap的性能要高于HashTable; 3、HashMap可以将空值(null)做为key和value,而HashTable是不能放入空值的(value为空也不行); 4、HashMap是快速失败机制,HashTable不是; 5、HashTable使用Enumeration,HashMap使用Iterator; 6、HashTable直接使用对象的hashCode值,而HashMap重新计算hash值,并且用“与”运算代替求模。 7、HashMap的初始容量为16,HashTable的初始容量为11。
25.2、Hashtable 和ConcurrentHashMap
效率低下的HashTable容器:HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法时,其他线程访问HashTable的同步方法时,可能会进入阻塞或轮询状态。如线程1使用put进行添加元素,线程2不但不能使用put方法添加元素,并且也不能使用get方法来获取元素,所以竞争越激烈效率越低。
锁分段技术
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是 ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。 java5中新增了ConcurrentMap接口和它的一个实现类 ConcurrentHashMap。ConcurrentHashMap提供了和Hashtable以及SynchronizedMap中所不同的锁机制。Hashtable中采用的锁机制是一次锁住整个hash表,从而同一时刻只能由一个线程对其进行操作;而ConcurrentHashMap中则是一次锁住一个桶。ConcurrentHashMap默认将hash表分为16个桶,诸如put,remove等常用操作只锁当前需要用到的桶。这样,原来只能一个线程进入,现在却能同时有16个写线程执行,并发性能的提升是显而易见的。 而读操作大部分时候都不需要用到锁(读到null值时会上锁)。只有在size等操作时才需要锁住整个hash表。 在迭代方面,ConcurrentHashMap使用了一种不同的迭代方式。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之的是在改变时new新的数据从而不影响原有的数据,iterator完成后再将头指针替换为新的数据,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变。
25.3、为什么我们需要ConcurrentHashMap和CopyOnWriteArrayList
同步的集合类(Hashtable和Vector),同步的封装类(使用Collections.synchronizedMap()方法和Collections.synchronizedList()方法返回的对象)可以创建出线程安全的Map和List。但是有些因素使得它们不适合高并发的系统。它们仅有单个锁,对整个集合加锁,以及为了防止ConcurrentModificationException异常经常要在迭代的时候要将集合锁定一段时间,这些特性对可扩展性来说都是障碍。 ConcurrentHashMap和CopyOnWriteArrayList保留了线程安全的同时,也提供了更高的并发性。ConcurrentHashMap和CopyOnWriteArrayList并不是处处都需要用,大部分时候你只需要用到HashMap和ArrayList,它们用于应对一些普通的情况。
26、Comparable接口和Comparator接口的比较
在实际应用中,我们往往有需要比较两个自定义对象大小的地方。而这些自定义对象的比较,就不像简单的整型数据那么简单,它们往往包含有许多的属性,我们一般都是根据这些属性对自定义对象进行比较的。所以Java中要比较对象的大小或者要对对象的集合进行排序,需要通过比较这些对象的某些属性的大小来确定它们之间的大小关系。 一般,Java中通过接口实现两个对象的比较,比较常用就是Comparable接口和Comparator接口。首先类要实现接口,并且使用泛型规定要进行比较的对象所属的类,然后类实现了接口后,还需要实现接口定义的比较方法(compareTo方法或者compare方法),在这些方法中传入需要比较大小的另一个对象,通过选定的成员变量与之比较,如果大于则返回1,小于返回-1,相等返回0。 1、Comparable和Comparator都是用来实现集合中元素的比较、排序的。 2、Comparable是在类内部定义的方法实现的排序,位于java.lang下。 3、Comparator是在类外部实现的排序,位于java.util下。 4、实现Comparable接口需要覆盖compareTo方法,实现Comparator接口需要覆盖compare方法。
26.1、Comparable接口
1、什么是Comparable接口 此接口强行对实现它的每个类的对象进行整体排序。此排序被称为该类的自然排序,类的 compareTo方法被称为它的自然比较方法 。实现此接口的对象列表(和数组)可以通过 Collections.sort(和 Arrays.sort )进行自动排序。实现此接口的对象可以用作有序映射表中的键或有序集合中的元素,无需指定比较器。 如String、Integer自己就实现了Comparable接口,可完成比较大小操作。自定义类要在加入list容器中后能够排序,也可以实现Comparable接口,在用Collections类的sort方法排序时若不指定Comparator,那就以自然顺序排序。所谓自然顺序就是实现Comparable接口设定的排序方式。 2、实现什么方法 int compareTo(T o) 比较此对象与指定对象的顺序。如果该对象小于、等于或大于指定对象,则分别返回负整数、零或正整数。 参数:o - 要比较的对象。 返回:负整数、零或正整数,根据此对象是小于、等于还是大于指定对象。 抛出:ClassCastException - 如果指定对象的类型不允许它与此对象进行比较。
26.2、Comparator接口
Comparator是一个专用的比较器,当这个对象不支持自比较或者自比较函数不能满足要求时,可写一个比较器来完成两个对象之间大小的比较。Comparator体现了一种策略模式(strategy design pattern),就是不改变对象自身,而用一个策略对象(strategy object)来改变它的行为。 与上面的Comparable接口不同的是: 1)、Comparator位于包java.util下,而Comparable位于包java.lang下。 2)、Comparable接口将比较代码嵌入需要进行比较的类的自身代码中,而Comparator接口在一个独立的类中实现比较。 3)、如果前期类的设计没有考虑到类的Compare问题而没有实现Comparable接口,后期可以通过Comparator接口来实现比较算法进行排序,并且为了使用不同的排序标准做准备,比如:升序、降序。 4)、Comparable接口强制进行自然排序,而Comparator接口不强制进行自然排序,可以指定排序顺序。
27、快速失败与安全失败的区别
27.1、快速失败(fail—fast)
在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。 原理:迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。 注意:这里异常的抛出条件是检测到 modCount!=expectedmodCount 这个条件。如果集合发生变化时修改modCount值刚好又设置为了expectedmodCount值,则异常不会抛出。因此,不能依赖于这个异常是否抛出而进行并发操作的编程,这个异常只建议用于检测并发修改的bug。 JDK中详细的描述: 注意,此实现不是同步的。如果多个线程同时访问一个哈希映射(或者其他集合类),而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。(结构上的修改是指添加或删除一个或多个映射关系的任何操作;仅改变与实例已经包含的键关联的值不是结构上的修改。)这一般通过对自然封装该映射的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedMap 方法来“包装”该映射。最好在创建时完成这一操作,以防止对映射进行意外的非同步访问,如下所示: Map m = Collections.synchronizedMap(new HashMap(…)); 由所有此类的“collection 视图方法”所返回的迭代器都是快速失败的:在迭代器创建之后,如果从结构上对映射进行修改,除非通过迭代器本身的 remove 方法,其他任何时间任何方式的修改,迭代器都将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不冒在将来不确定的时间发生任意不确定行为的风险。 注意,迭代器的快速失败行为不能得到保证,一般来说,存在非同步的并发修改时,不可能作出任何坚决的保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常的程序的做法是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测程序错误。 场景:java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)。
27.2、安全失败(fail—safe)
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。 原理:由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所作的修改并不能被迭代器检测到,所以不会触发ConcurrentModificationException。 缺点:基于拷贝内容的优点是避免了ConcurrentModificationException,**但同样地,迭代器并不能访问到修改后的内容,**即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。 场景:java.util.concurrent包下的容器都是安全失败,可以在多线程下并发使用,并发修改。 ConcurrentHashMap中的迭代器主要包括entrySet、keySet、values方法。它们大同小异,这里选择entrySet解释。当我们调用entrySet返回值的iterator方法时,返回的是EntryIterator,在EntryIterator上调用next方法时,最终实际调用到了HashIterator.advance()方法。这个方法在遍历底层数组。在遍历过程中,如果已经遍历的数组上的内容变化了,迭代器不会抛出ConcurrentModificationException异常。如果未遍历的数组上的内容发生了变化,则有可能反映到迭代过程中。这就是ConcurrentHashMap迭代器弱一致的表现。ConcurrentHashMap的弱一致性主要是为了提升效率,是一致性与效率之间的一种权衡。要成为强一致性,就得到处使用锁,甚至是全局锁,这就与Hashtable和同步的HashMap一样了。
28、Enumeration接口和Iterator接口的区别
package java.util;
public interface Enumeration<E> {
boolean hasMoreElements();
E nextElement();
}
public interface Iterator<E> {
boolean hasNext();
E next();
void remove();
}
(01)、函数接口不同 Enumeration 只有2个函数接口。通过Enumeration,我们只能读取集合的数据,而不能对数据进行修改。 Iterator 只有3个函数接口。Iterator除了能读取集合的数据之外,也能对数据进行删除操作。 (02)、Iterator 支持 fail-fast 机制,而 Enumeration 不支持 Enumeration 是JDK 1.0添加的接口。使用到它的函数包括Vector、Hashtable等类,这些类都是JDK1.0中加入的,Enumeration存在的目的就是为它们提供遍历接口。Enumeration本身并没有支持同步,而在Vector、Hashtable实现Enumeration时,添加了同步。 而Iterator 是JDK 1.2才添加的接口,它也是为了HashMap、ArrayList等集合提供遍历接口。Iterator是支持fail-fast机制的:当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。 总结:Enumeration速度是Iterator的2倍,同时占用更少的内存。但是,Iterator远远比Enumeration安全,因为其他线程不能够修改正在被iterator遍历的集合里面的对象。同时,Iterator允许调用者删除底层集合里面的元素,这对Enumeration来说是不可能的。
29、JVM内存模型(区别Java内存模型)
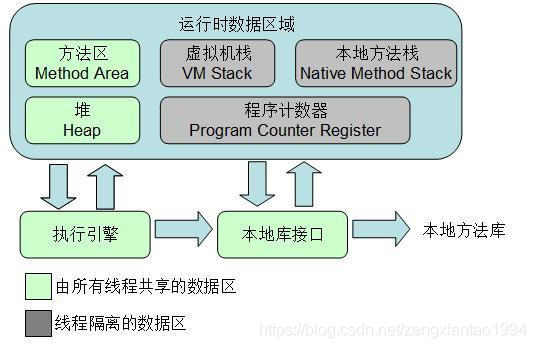 JVM内存主要分为:程序计数器,Java虚拟机栈,本地方法栈,Java堆,方法区。
1、程序计数器: 为了线程切换能恢复到正确的执行位置,每条线程都需要一个独立的程序计数器,各条线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。计数器记录的是正在执行的虚拟机字节码指令的地址。
2、Java虚拟机栈: 每个方法在执行的同时都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接(例如多态就要动态链接以确定引用的状态)、方法出口等信息。局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)和 returnAddress 类型(指向了一条字节码指令的地址)。
其中 64 位长度的 long 和 double 类型的数据会占用 2 个局部变量空间(Slot),其余的数据类型只占用 1 个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
3、本地方法栈: Java 虚拟机栈为虚拟机执行 Java 方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。
4、Java 堆: Java 堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。Java堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC 堆”。
5、方法区: 方法区(Method Area)与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量(final )、静态变量(static)、即时编译器编译后的代码等数据。
一个类中主要有:常量、成员变量、静态变量、局部变量。其中常量与静态变量位于方法区,成员变量位于 Java 堆,局部变量位于 Java 虚拟机栈。
运行时常量池: 是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
Java内存模型:每个线程都有一个工作内存,线程只可以修改自己工作内存中的数据,然后再同步回主内存,主内存由多个线程共享。
JVM内存主要分为:程序计数器,Java虚拟机栈,本地方法栈,Java堆,方法区。
1、程序计数器: 为了线程切换能恢复到正确的执行位置,每条线程都需要一个独立的程序计数器,各条线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。计数器记录的是正在执行的虚拟机字节码指令的地址。
2、Java虚拟机栈: 每个方法在执行的同时都会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接(例如多态就要动态链接以确定引用的状态)、方法出口等信息。局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)和 returnAddress 类型(指向了一条字节码指令的地址)。
其中 64 位长度的 long 和 double 类型的数据会占用 2 个局部变量空间(Slot),其余的数据类型只占用 1 个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
3、本地方法栈: Java 虚拟机栈为虚拟机执行 Java 方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。
4、Java 堆: Java 堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。Java堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC 堆”。
5、方法区: 方法区(Method Area)与 Java 堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量(final )、静态变量(static)、即时编译器编译后的代码等数据。
一个类中主要有:常量、成员变量、静态变量、局部变量。其中常量与静态变量位于方法区,成员变量位于 Java 堆,局部变量位于 Java 虚拟机栈。
运行时常量池: 是方法区的一部分。Class 文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
Java内存模型:每个线程都有一个工作内存,线程只可以修改自己工作内存中的数据,然后再同步回主内存,主内存由多个线程共享。
30、JAVA 内存模型
Java Memory Model (JAVA 内存模型,JMM)描述线程之间如何通过内存(memory)来进行交互。具体说来,JVM中存在一个主存区(Main Memory或Java Heap Memory),对于所有线程进行共享,而每个线程又有自己的工作内存(Working Memory,实际上是一个虚拟的概念),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作并非发生在主存区,而是发生在工作内存中,而线程之间是不能直接相互访问的,变量在程序中的传递,是依赖主存来完成的。具体的如下图所示:
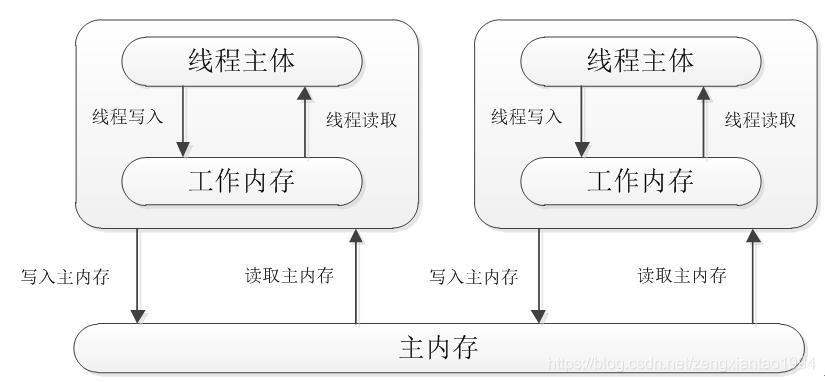 JMM描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存中读取出变量这样的底层细节。
所有的变量都存储在主内存中,每个线程都有自己独立的工作内存,里面保存该线程使用到的变量的副本(主内存中变量的一份拷贝)。
JMM的两条规定
1、线程对共享变量的所有操作都必须在自己的工作内存中进行,不能直接从主内存中读写;
2、不同的线程之间无法直接访问其他线程工作内存中的变量,线程变量值的传递需要通过主内存来完成。
JMM描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量存储到内存中读取出变量这样的底层细节。
所有的变量都存储在主内存中,每个线程都有自己独立的工作内存,里面保存该线程使用到的变量的副本(主内存中变量的一份拷贝)。
JMM的两条规定
1、线程对共享变量的所有操作都必须在自己的工作内存中进行,不能直接从主内存中读写;
2、不同的线程之间无法直接访问其他线程工作内存中的变量,线程变量值的传递需要通过主内存来完成。
31、JVM类加载机制
虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型, 这就是虚拟机的类加载机制。
类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading) 7个阶段。其中验证、准备、解析3个部分统称为连接(Linking)。
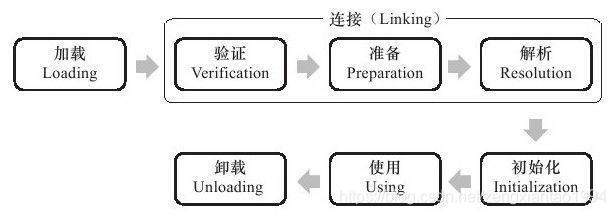 加载、验证、准备、初始化和卸载这5个阶段的顺序是确定的,类的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定(也称为动态绑定或晚期绑定)。注意,这里笔者写的是按部就班地“开始”,而不是按部就班地“进行”或“完成”,强调这点是因为这些阶段通常都是互相交叉地混合式进行的,通常会在一个阶段执行的过程中调用、激活另外一个阶段。
类加载器虽然只用于实现类的加载动作,但它在Java程序中起到的作用却远远不限于类加载阶段。对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类名称空间。 这句话可以表达得更通俗一些:比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等。
加载、验证、准备、初始化和卸载这5个阶段的顺序是确定的,类的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定(也称为动态绑定或晚期绑定)。注意,这里笔者写的是按部就班地“开始”,而不是按部就班地“进行”或“完成”,强调这点是因为这些阶段通常都是互相交叉地混合式进行的,通常会在一个阶段执行的过程中调用、激活另外一个阶段。
类加载器虽然只用于实现类的加载动作,但它在Java程序中起到的作用却远远不限于类加载阶段。对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类名称空间。 这句话可以表达得更通俗一些:比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等。
31.1、双亲委派模型
从Java虚拟机的角度来讲,只存在两种不同的类加载器:一种是启动类加载器(Bootstrap ClassLoader),这个类加载器使用C++语言实现(只限于HotSpot),是虚拟机自身的一部分;另一种就是所有其他的类加载器,这些类加载器都由Java语言实现,独立于虚拟机外部,并且全都继承自抽象类java.lang.ClassLoader。
从Java开发人员的角度来看,类加载器还可以划分得更细致一些,绝大部分Java程序都会使用到以下3种系统提供的类加载器。
启动类加载器(Bootstrap ClassLoader): 这个类加载器负责将存放在<JAVA_HOME>\lib目录中的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机内存中。启动类加载器无法被Java程序直接引用,用户在编写自定义类加载器时,如果需要把加载请求委派给引导类加载器,那直接使用null代替即可。
扩展类加载器(Extension ClassLoader): 这个加载器由sun.misc.Launcher$ExtClassLoader实现,它负责加载<JAVA_HOME>\lib\ext目录中的,或者被java.ext.dirs系统变量所指定的路径中的所有类库,开发者可以直接使用扩展类加载器。
应用程序类加载器(Application ClassLoader): 这个类加载器由sun.misc.Launcher$App-ClassLoader实现。由于这个类加载器是ClassLoader中的getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
我们的应用程序都是由这3种类加载器互相配合进行加载的,如果有必要,还可以加入自己定义的类加载器。这些类加载器之间的关系一般如图所示。
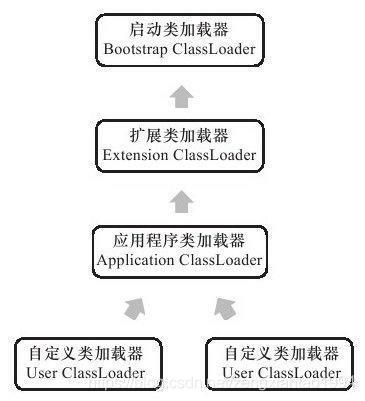 图中展示的类加载器之间的这种层次关系,称为类加载器的双亲委派模型(Parents Delegation Model)。双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器。这里类加载器之间的父子关系一般不会以继承(Inheritance)的关系来实现,而是都使用组合(Composition)关系来复用父加载器的代码。
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
使用双亲委派模型来组织类加载器之间的关系,有一个显而易见的好处就是Java类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存放在rt.jar之中,无论哪一个类加载器要加载这个类,最终都是委派给处于模型最顶端的启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果没有使用双亲委派模型,由各个类加载器自行去加载的话,如果用户自己编写了一个称为java.lang.Object的类,并放在程序的ClassPath中,那系统中将会出现多个不同的Object类,Java类型体系中最基础的行为也就无法保证,应用程序也将会变得一片混乱。
双亲委派模型对于保证Java程序的稳定运作很重要,但它的实现却非常简单,实现双亲委派的代码都集中在java.lang.ClassLoader的loadClass()方法之中,代码清单,逻辑清晰易懂:先检查类是否已经被加载过,若没有加载则调用父加载器的loadClass()方法,若父加载器为空则默认使用启动类加载器作为父加载器。如果父类加载失败,抛出ClassNotFoundException异常后,再调用自己的findClass()方法进行加载。
图中展示的类加载器之间的这种层次关系,称为类加载器的双亲委派模型(Parents Delegation Model)。双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器。这里类加载器之间的父子关系一般不会以继承(Inheritance)的关系来实现,而是都使用组合(Composition)关系来复用父加载器的代码。
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
使用双亲委派模型来组织类加载器之间的关系,有一个显而易见的好处就是Java类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存放在rt.jar之中,无论哪一个类加载器要加载这个类,最终都是委派给处于模型最顶端的启动类加载器进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果没有使用双亲委派模型,由各个类加载器自行去加载的话,如果用户自己编写了一个称为java.lang.Object的类,并放在程序的ClassPath中,那系统中将会出现多个不同的Object类,Java类型体系中最基础的行为也就无法保证,应用程序也将会变得一片混乱。
双亲委派模型对于保证Java程序的稳定运作很重要,但它的实现却非常简单,实现双亲委派的代码都集中在java.lang.ClassLoader的loadClass()方法之中,代码清单,逻辑清晰易懂:先检查类是否已经被加载过,若没有加载则调用父加载器的loadClass()方法,若父加载器为空则默认使用启动类加载器作为父加载器。如果父类加载失败,抛出ClassNotFoundException异常后,再调用自己的findClass()方法进行加载。
31.2、描述 Java类加载器的工作原理及其组织结构。
Java 类加载器的作用就是在运行时加载类。 Java 类加载器基于三个机制:委托性、可见性和单一性。 1、委托机制是指双亲委派模型。 当一个类加载和初始化的时候,类仅在有需要加载的时候被加载。假设你有一个应用需要的类叫作Abc.class,首先加载这个类的请求由Application 类加载器委托给它的父类加载器 Extension 类加载器,然后再委托给Bootstrap 类加载器。Bootstrap类加载器会先看看rt.jar 中有没有这个类,因为并没有这个类,所以这个请求又回到 Extension 类加载器,它会查看 jre/lib/ext 目录下有没有这个类,如果这个类被 Extension 类加载器找到了,那么它将被加载,而Application 类加载器不会加载这个类;而如果这个类没有被 Extension 类加载器找到,那么再由 Application 类加载器从 classpath中寻找,如果没找到,就会抛出异常。 双亲委托机制的优点就是能够提高软件系统的安全性。因为在此机制下,用户自定义的类加载器不可能加载本应该由父加载器加载的可靠类,从而防止不可靠的恶意代码代替由父类加载器加载的可靠代码。如java.lang.Object类总是由根类加载器加载的,其他任何用户自定义的类加载器都不可能加载含有恶意代码的 java.lang.Object 类。 2、可见性原理是子类的加载器可以看见所有的父类加载器加载的类,而父类加载器看不到子类加载器加载的类。 3、单一性原理是指仅加载一个类一次,这是由委托机制确保子类加载器不会再次加载父类加载器加载过的类。 Java 的类加载器有三个,对应 Java 的三种类: BootstrapLoader // 负责加载系统类 (指的是内置类,像String) ExtClassLoader // 负责加载扩展类(就是继承类和实现类) AppClassLoader // 负责加载应用类(程序员自定义的类) Java 提供了显式加载类的API:Class.forName(classname)。
32、JVM编译器优化
32.1、JVM编译的过程
1、解析与填充符号表过程 1)、词法、语法分析 词法分析将源代码的字符流转变为标记集合,单个字符是程序编写过程的最小元素,而标记则是编译过程的最小元素,javac中由com.sun.tools.javac.parser.Scanner类实现。 语法分析是根据token序列构造抽象语法树的过程。抽象语法树(AST)是一种用来描述程序代码语法结构的树形表示方式,语法树中的每一个节点都代表着程序代码中的语法结构,javac中,语法分析过程由com.sun.tools.javac.tree.parser.Parser类实现,这个阶段产生出的抽象语法树由com.sun.tools.javac.tree.JCTree类表示。 2)、填充符号表 enterTree()方法,符号表是由一组符号地址和符号信息构成的表格,符号表中登记的信息在编译的不同阶段都要用到。在语义分析中,符号表所登记的内容将用于语义检查和产生中间代码,在目标代码生成阶段,当对符号进行地址分配时,符号表是地址分配的依据。javac源码中由com.sun.tools.javac.comp.Enter类实现。
2、插入式注解处理器的注解处理过程 注解在运行期间发挥作用,通过插入式注解处理器标准API可以读取、修改、添加抽象语法树种的任意元素,若在处理注解期间对语法树进行修改,编译器将回到解析即填充符号表的过程重新处理,直到所有插入式注解处理器都没有再对语法树进行修改为止,每一次循环称为一个round。javac源码中插入式注解处理器的初始化过程是在initProrcessAnnotation()方法中完成的,而它的执行过程则是在processAnnotation()方法中完成。
3、分析与字节码生成过程 1)、标注检查 attribute()方法,标注检查步骤检查的内容包括诸如变量使用前是否已经被声明、变量与赋值之间的数据类型是否够匹配以及常量折叠。javac中实现类是com.sun.tools.javac.comp.Attr类和com.sun.tools.javac.comp.Check类。 2)、数据及控制流分析 flow()方法,对程序上下文逻辑更进一步的验证,他可以检查出诸如程序局部变量在使用前是否赋值、方法的每条路径是否都有返回值、是否所有的受检查异常都被正确处理了问题。 局部变量在常量池中没有CONSTANT_Fieldref_info的符号引用,自然没有访问标志的信息,甚至可能连名称都不会保存下来。 将局部变量声明为final,对运行期是没有影响的,变量的不变性仅仅由编译器在编译期间保障。 3)、解语法糖 也称糖衣语法,指在计算机中添加某种语法,这种语法对语言的功能没有影响,但是更方便程序员使用,通常来说,使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会。java中最常用的是泛型、变长参数、自动装箱/拆箱等。 4)、字节码生成 javac编译的最后一个阶段,javac源码里面由com.sun.tools.javac.jvm.Gen类来完成,这个阶段不仅仅把前面各个步骤所生成的信息转化成字节码写到磁盘中,编译器还进行少量的代码添加转换工作。 保证一定是按先执行父类的实例构造器,然后初始化变量,最后执行语句块的顺序进行。
32.2、javac语法糖
1、泛型与类擦除 java中的泛型它只在程序源码中存在,在编译后的字节码文件中,就已经替换为原来的原生类型,并在相应的地方插入了强制转换代码,对于运行期的java来说ArrayList与ArrayList就是同一个类,java语言中的泛型实现方法称为类型擦除,基于这种方法的叫伪泛型。 在Class文件格式中,只要描述符不是完全一致的两个方法就可以共存。 Signature是解决伴随泛型而来的参数类型的识别问题中最重要的一项属性,它的作用就是存储一个方法在字节码层面的特征签名,这个属性中保存的参数类型并不是原生类型,而是包括了参数化类型的信息、擦除法所谓的擦除,仅仅是对方法的Code属性中的字节码进行擦除,实际上元数据中还是保留了泛型信息,这也是我们能够通过反射手段取得参数化类型的根本依据。
2、自动装箱、拆箱与循环遍历
3、条件编译 java编译器并非一个个地编译Java文件,而是将所有编译单元的语法树顶级节点输入到待处理列表后再进行编译,因此各个文之间能够互相提供符号信息。 java中根据布尔常量值的真假,编译器会把分支中不成立的代码块擦除掉。这一工作将在编译器解除语法糖阶段完成。
4、常用语法糖 泛型、自动装箱、自动拆箱、遍历循环、变长参数、条件编译、内部类、枚举类、断言语句、对枚举、字符串的switch,try与catch定义和关闭资源。
32.3、运行期JIT编译器
java程序最初是通过解释器进行解释执行的,当虚拟机发现某个方法或者代码块的运行特别频繁时,就好把这些代码认定为“热点代码”,为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器称为即时编译器(JIT编译器),他是虚拟机中最核心且最能体现虚拟机水平的部分。 JIT 是 just in time 的缩写,也就是即时编译器。使用即时编译器技术,能够加速Java 程序的执行速度。 首先,我们大家都知道,通常通过 javac 将程序源代码编译,转换成 java 字节码,JVM 通过解释字节码将其翻译成对应的机器指令,逐条读入,逐条解释翻译。很显然,经过解释执行,其执行速度必然会比可执行的二进制字节码程序慢很多。为了提高执行速度,引入了 JIT 技术。 在运行时 JIT 会把翻译过的机器码保存起来,以备下次使用,因此从理论上来说,采用该 JIT 技术可以接近以前纯编译技术。下面我们看看,JIT 的工作过程。
32.3.1、JIT 编译过程
当 JIT 编译启用时(默认是启用的),JVM 读入.class 文件解释后,将其发给 JIT 编译器。JIT 编译器将字节码编译成本机机器代码,下图展示了该过程。
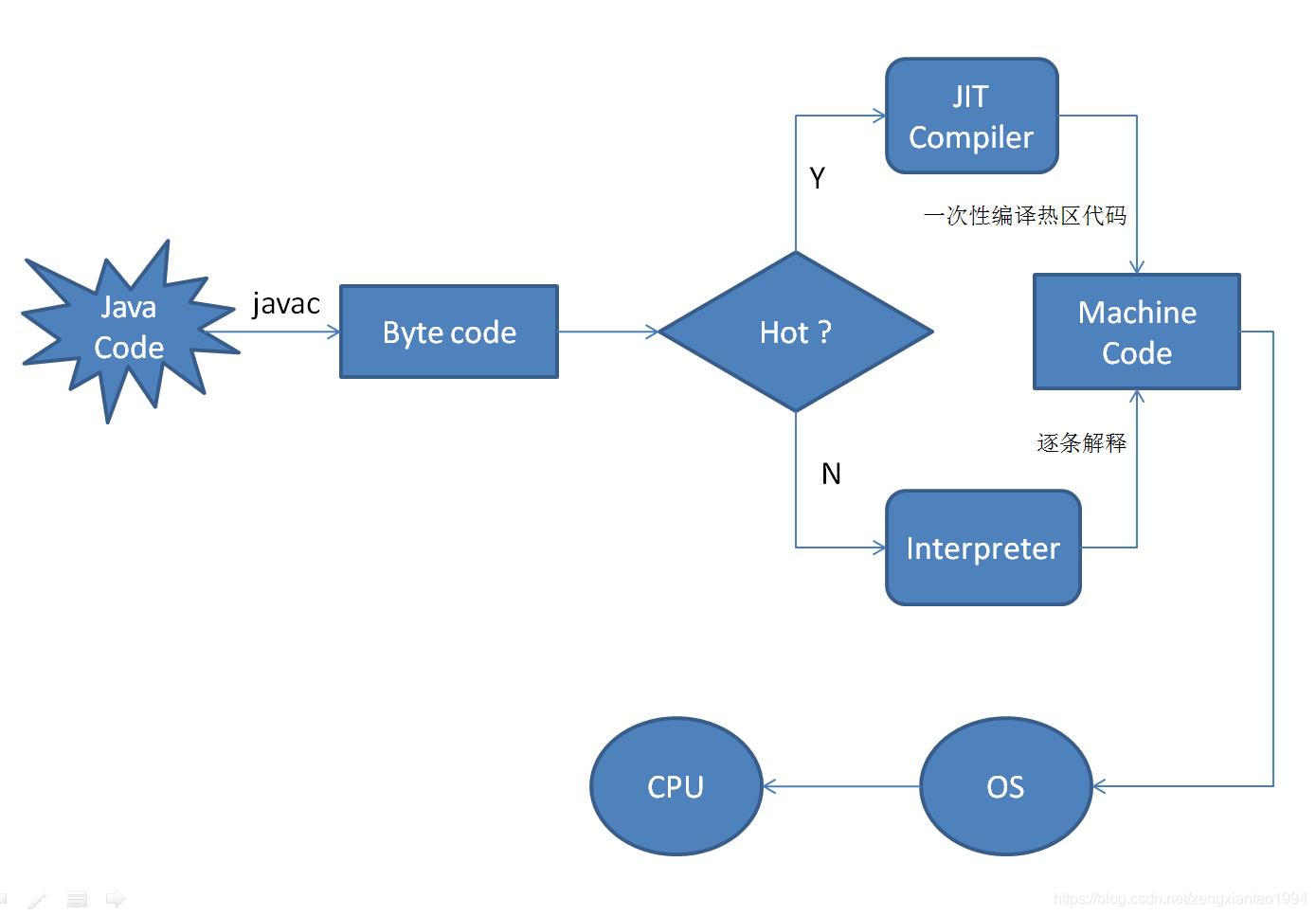
32.3.2、Hot Spot 编译
当 JVM 执行代码时,它并不立即开始编译代码。这主要有两个原因: 首先,如果这段代码本身在将来只会被执行一次,那么从本质上看,编译就是在浪费精力。 因为将代码翻译成 java 字节码相对于编译这段代码并执行代码来说,要快很多。 当然,如果一段代码频繁的调用方法,或是一个循环,也就是这段代码被多次执行,那么编译就非常值得了。因此,编译器具有的这种权衡能力会首先执行解释后的代码,然后再去分辨哪些方法会被频繁调用来保证其本身的编译。其实说简单点,就是 JIT 在起作用,我们知道,对于 Java 代码,刚开始都是被编译器编译成字节码文件,然后字节码文件会被交由 JVM 解释执行,所以可以说 Java 本身是一种半编译半解释执行的语言。Hot Spot VM 采用了 JIT compile 技术,将运行频率很高的字节码直接编译为机器指令执行以提高性能,所以当字节码被 JIT 编译为机器码的时候,要说它是编译执行的也可以。也就是说,运行时,部分代码可能由 JIT 翻译为目标机器指令(以 method 为翻译单位,还会保存起来,第二次执行就不用翻译了)直接执行。 第二个原因是最优化,当 JVM 执行某一方法或遍历循环的次数越多,就会更加了解代码结构,那么 JVM 在编译代码的时候就做出相应的优化。 我们将在后面讲解这些优化策略,这里,先举一个简单的例子:我们知道 equals() 这个方法存在于每一个 Java Object 中(因为是从 Object class 继承而来)而且经常被覆写。当解释器遇到 b = obj1.equals(obj2) 这样一句代码,它则会查询 obj1 的类型从而得知到底运行哪一个 equals() 方法。而这个动态查询的过程从某种程度上说是很耗时的。 例如JVM 注意到每次运行代码时,obj1 都是 java.lang.String 这种类型,那么JVM 生成的被编译后的代码则是直接调用 String.equals() 方法。这样代码的执行将变得非常快,因为不仅它是被编译过的,而且它会跳过查找该调用哪个方法的步骤。 当然过程并不是上面所述这样简单,如果下次执行代码时,obj1 不再是 String 类型了,JVM 将不得不再生成新的字节码。尽管如此,之后执行的过程中,还是会变的更快,因为同样会跳过查找该调用哪个方法的步骤。这种优化只会在代码被运行和观察一段时间之后发生。这也就是为什么 JIT 编译器不会直接编译代码而是选择等待然后再去编译某些代码片段的第二个原因。
32.3.3、寄存器和主存
其中一个最重要的优化策略是编译器可以决定何时从主存取值,何时向寄存器存值。考虑下面这段代码: 清单 1、主存 or 寄存器测试代码
public class RegisterTest {
private int sum;
public void calculateSum(int n) {
for (int i = 0; i < n; ++i) {
sum += i;
}
}
}
在某些时刻,sum 变量居于主存之中,但是从主存中检索值是开销很大的操作,需要多次循环才可以完成操作。正如上面的例子,如果循环的每一次都是从主存取值,性能是非常低的。相反,编译器加载一个寄存器给 sum 并赋予其初始值,利用寄存器里的值来执行循环,并将最终的结果从寄存器返回给主存。这样的优化策略则是非常高效的。但是线程的同步对于这种操作来说是至关重要的,因为一个线程无法得知另一个线程所使用的寄存器里变量的值,线程同步可以很好的解决这一问题。 寄存器的使用是编译器的一个非常普遍的优化。
32.3.4、初级调优:客户模式或服务器模式
JIT 编译器在运行程序时有两种编译模式可以选择,并且其会在运行时决定使用哪一种以达到最优性能。这两种编译模式的命名源自于命令行参数(eg: -client 或者-server)。JVM Server 模式与 client 模式启动,最主要的差别在于:-server 模式启动时,速度较慢,但是一旦运行起来后,性能将会有很大的提升。原因是:当虚拟机运行在-client 模式的时候,使用的是一个代号为 C1 的轻量级编译器,而-server 模式启动的虚拟机采用相对重量级代号为 C2 的编译器。C2 比 C1 编译器编译的相对彻底,服务起来之后,性能更高。
通过 java -version 命令行可以直接查看当前系统使用的是 client 还是 server 模式。例如:
32.3.5、中级编译器调优
大多数情况下,优化编译器其实只是选择合适的 JVM 以及为目标主机选择合适的编译器(-cient,-server 或是-xx:+TieredCompilation)。多层编译经常是长时运行应用程序的最佳选择,短暂应用程序则选择毫秒级性能的 client 编译器。 1)、优化代码缓存 当 JVM 编译代码时,它会将汇编指令集保存在代码缓存。代码缓存具有固定的大小,并且一旦它被填满,JVM 则不能再编译更多的代码。 我们可以很容易地看到如果代码缓存很小所具有的潜在问题。有些热点代码将会被编译,而其他的则不会被编译,这个应用程序将会以运行大量的解释代码来结束。 这是当使用 client 编译器模式或分层编译时很频繁的一个问题。当使用普通server编译器模式时,编译合格的类的数量将被填入代码缓存,通常只有少量的类会被编译。但是当使用 client 编译器模式时,编译合格的类的数量将会高很多。 在 Java 7 版本,分层编译默认的代码缓存大小经常是不够的,需要经常提高代码缓存大小。大型项目若使用 client 编译器模式,则也需要提高代码缓存大小。 现在并没有一个好的机制可以确定一个特定的应用到底需要多大的代码缓存。因此,当需要提高代码缓存时,这将是一种凑巧的操作,一个通常的做法是将代码缓存变成默认大小的两倍或四倍。 可以通过 –XX:ReservedCodeCacheSize=Nflag(N 就是之前提到的默认大小)来最大化代码缓存大小。代码缓存的管理类似于 JVM 中的内存管理:有一个初始大小(用-XX:InitialCodeCacheSize=N 来声明)。代码缓存的大小从初始大小开始,随着缓存被填满而逐渐扩大。代码缓存的初始大小是基于芯片架构(例如 Intel 系列机器,client 编译器模式下代码缓存大小起始于 160KB,server 编译器模式下代码缓存大小则起始于 2496KB)以及使用的编译器的。重定义代码缓存的大小并不会真正影响性能,所以设置 ReservedCodeCacheSize 的大小一般是必要的。 再者,如果 JVM 是 32 位的,那么运行过程大小不能超过 4GB。这包括了 Java 堆,JVM 自身所有的代码空间(包括其本身的库和线程栈),应用程序分配的任何的本地内存,当然还有代码缓存。 所以说代码缓存并不是无限的,很多时候需要为大型应用程序来调优(或者甚至是使用分层编译的中型应用程序)。比如 64 位机器,为代码缓存设置一个很大的值并不会对应用程序本身造成影响,应用程序并不会内存溢出,这些额外的内存预定一般都是被操作系统所接受的。
2)、编译阈值 在 JVM 中,编译是基于两个计数器的:一个是方法被调用的次数,另一个是方法中循环被回弹执行的次数。 回弹可以有效的被认为是循环被执行完成的次数,不仅因为它是循环的结尾,也可能是因为它执行到了一个分支语句,例如 continue。 当 JVM 执行一个 Java 方法,它会检查这两个计数器的总和以决定这个方法是否有资格被编译。如果有,则这个方法将排队等待编译。这种编译形式并没有一个官方的名字,但是一般被叫做标准编译。 但是如果方法里有一个很长的循环或者是一个永远都不会退出并提供了所有逻辑的程序会怎么样呢?这种情况下,JVM 需要编译循环而并不等待方法被调用。所以每执行完一次循环,分支计数器都会自增和自检。如果分支计数器计数超出其自身阈值,那么这个循环(并不是整个方法)将具有被编译资格。 **这种编译叫做栈上替换(OSR),因为即使循环被编译了,这也是不够的:JVM 必须有能力当循环正在运行时,开始执行此循环已被编译的版本。**换句话说,当循环的代码被编译完成,若 JVM 替换了代码(前栈),那么循环的下个迭代执行最新的被编译版本则会更加快。 标准编译是被-XX:CompileThreshold=Nflag 的值所触发。Client 编译器模式下,N 默认的值 1500,而 Server 编译器模式下,N 默认的值则是 10000。改变 CompileThreshold 标志的值将会使编译器相对正常情况下提前(或推迟)编译代码。在性能领域,改变 CompileThreshold 标志是很被推荐且流行的方法。事实上,您可能知道 Java 基准经常使用此标志(比如:对于很多 server 编译器来说,经常在经过 8000 次迭代后改变此标志)。 我们已经知道 client 编译器和 server 编译器在最终的性能上有很大的差别,很大程度上是因为编译器在编译一个特定的方法时,对于两种编译器可用的信息并不一样。降低编译阈值,尤其是对于 server 编译器,承担着不能使应用程序运行达到最佳性能的风险,但是经过测试应用程序我们也发现,将阈值从 8000 变成 10000,其实有着非常小的区别和影响。
3)、检查编译过程 中级优化的最后一点其实并不是优化本身,而是它们并不能提高应用程序的性能。它们是 JVM(以及其他工具)的各个标志,并可以给出编译工作的可见性。它们中最重要的就是–XX:+PrintCompilation(默认状态下是 false)。 如果 PrintCompilation 被启用,每次一个方法(或循环)被编译,JVM 都会打印出刚刚编译过的相关信息。不同的 Java 版本输出形式不一样,我们这里所说的是基于 Java 7 版本的。 编译日志中大部分的行信息都是下面的形式: 清单 2. 日志形式
timestamp compilation_id attributes (tiered_level) method_name size depot
1
这里 timestamp 是编译完成时的时间戳,compilation_id 是一个内部的任务 ID,且通常情况下这个数字是单调递增的,但有时候对于 server 编译器(或任何增加编译阈值的时候),您可能会看到失序的编译 ID。这表明编译线程之间有些快有些慢,但请不要随意推断认为是某个编译器任务莫名其妙的非常慢。
4)、用 jstat 命令检查编译 要想看到编译日志,则需要程序以-XX:+PrintCompilation flag 启动。如果程序启动时没有 flag,您可以通过 jstat 命令得到有限的可见性信息。 Jstat 有两个选项可以提供编译器信息。其中,-compile 选项提供总共有多少方法被编译的总结信息(下面 6006 是要被检查的程序的进程 ID): 清单 3 进程详情
% jstat -compiler 6006
CompiledFailedInvalid TimeFailedTypeFailedMethod
206 0 0 1.97 0
123
注意,这里也列出了编译失败的方法的个数信息,以及编译失败的最后一个方法的名称。 另一种选择,您可以使用-printcompilation 选项得到最后一个被编译的方法的编译信息。因为 jstat 命令有一个参数选项用来重复其操作,您可以观察每一次方法被编译的情况。举个例子: Jstat 对 6006 号 ID 进程每 1000 毫秒执行一次: %jstat –printcompilation 6006 1000,具体的输出信息在此不再描述。
32.3.6、高级编译器调优
这一节我们将介绍编译工作剩下的细节,并且过程中我们会探讨一些额外的调优策略。调优的存在很大程度上帮助了 JVM 工程师诊断 JVM 自身的行为。如果您对编译器的工作原理很感兴趣,这一节您一定会喜欢。
1)、编译线程
从前文中我们知道,当一个方法(或循环)拥有编译资格时,它就会排队并等待编译。这个队列是由一个或很多个后台线程组成,这也就是说编译是一个异步的过程,它允许程序在代码正在编译时被继续执行。如果一个方法被标准编译方式所编译,那么下一个方法调用则会执行已编译的方法。如果一个循环被栈上替换方式所编译,那么下一次循环迭代则会执行新编译的代码。
这些队列并不会严格的遵守先进先出原则:哪一个方法的调用计数器计数更高,哪一个就拥有优先权。所以即使当一个程序开始执行,并且有大量的代码需要编译,这个优先权顺序将帮助并保证最重要的代码被优先编译(这也是为什么编译 ID 在 PrintComilation 的输出结果中有时会失序的另一个原因)。
当使用 client 编译器时,JVM 启动一个编译线程,而 server 编译器有两个这样的线程。当分层编译生效时,JVM 会基于某些复杂方程式默认启动多个 client 和 server 线程,涉及双日志在目标平台上的 CPU 数量。如下图所示:
分层编译下 C1 和 C2 编译器线程默认数量:
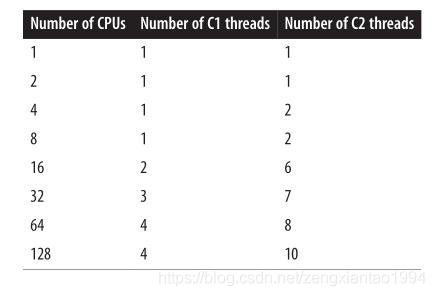 编译器线程的数量可以通过-XX:CICompilerCount=N flag 进行调节设置。这个数量是 JVM 将要执行队列所用的线程总数。对于分层编译,三分之一的(至少一个)线程被用于执行 client 编译器队列,剩下的(也是至少一个)被用来执行 server 编译器队列。
在何时我们应该考虑调整这个值呢?如果一个程序被运行在单 CPU 机器上,那么只有一个编译线程会更好一些:因为对于某个线程来说,其对 CPU 的使用是有限的,并且在很多情况下越少的线程竞争资源会使其运行性能更高。然而,这个优势仅仅局限于初始预热阶段,之后,这些具有编译资格的方法并不会真的引起 CPU 争用。当一个股票批处理应用程序运行在单 CPU 机器上并且编译器线程被限制成只有一个,那么最初的计算过程将比一般情况下快 10%(因为它没有被其他线程进行 CPU 争用)。迭代运行的次数越多,最初的性能收益就相对越少,直到所有的热点方法被编译完性能收益也随之终止。
编译器线程的数量可以通过-XX:CICompilerCount=N flag 进行调节设置。这个数量是 JVM 将要执行队列所用的线程总数。对于分层编译,三分之一的(至少一个)线程被用于执行 client 编译器队列,剩下的(也是至少一个)被用来执行 server 编译器队列。
在何时我们应该考虑调整这个值呢?如果一个程序被运行在单 CPU 机器上,那么只有一个编译线程会更好一些:因为对于某个线程来说,其对 CPU 的使用是有限的,并且在很多情况下越少的线程竞争资源会使其运行性能更高。然而,这个优势仅仅局限于初始预热阶段,之后,这些具有编译资格的方法并不会真的引起 CPU 争用。当一个股票批处理应用程序运行在单 CPU 机器上并且编译器线程被限制成只有一个,那么最初的计算过程将比一般情况下快 10%(因为它没有被其他线程进行 CPU 争用)。迭代运行的次数越多,最初的性能收益就相对越少,直到所有的热点方法被编译完性能收益也随之终止。
33、JVM逃逸分析
逃逸分析(Escape Analysis)是目前Java虚拟机中比较前沿的优化技术。 逃逸分析的基本行为就是分析对象动态作用域:当一个对象在方法中被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他地方中,称为方法逃逸。例如:
public static StringBuffer craeteStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb;
}
StringBuffer sb是一个方法内部变量,上述代码中直接将sb返回,这样这个StringBuffer有可能被其他方法所改变,这样它的作用域就不只是在方法内部,虽然它是一个局部变量,称其逃逸到了方法外部。 甚至还有可能被外部线程访问到,譬如赋值给类变量或可以在其他线程中访问的实例变量,称为线程逃逸。 上述代码如果想要StringBuffer sb不逃出方法,可以这样写:return sb.toString(); 不直接返回 StringBuffer,那么StringBuffer将不会逃逸出方法。 如果能证明一个对象不会逃逸到方法或线程外,则可能为这个变量进行一些高效的优化。
33.1、栈上分配
我们都知道Java中的对象都是在堆上分配的,而垃圾回收机制会回收堆中不再使用的对象,但是筛选可回收对象,回收对象还有整理内存都需要消耗时间。如果能够通过逃逸分析确定某些对象不会逃出方法之外,那就可以让这个对象在栈上分配内存,这样该对象所占用的内存空间就可以随栈帧出栈而销毁,就减轻了垃圾回收的压力。 在一般应用中,如果不会逃逸的局部对象所占的比例很大,如果能使用栈上分配,那大量的对象就会随着方法的结束而自动销毁了。
33.2、标量替换
Java虚拟机中的原始数据类型(int,long等数值类型以及reference类型等)都不能再进一步分解,它们就可以称为标量。相对的,如果一个数据可以继续分解,那它称为聚合量,Java中最典型的聚合量是对象。如果逃逸分析证明一个对象不会被外部访问,并且这个对象是可分解的,那程序真正执行的时候将可能不创建这个对象,而改为直接创建它的若干个被这个方法使用到的成员变量来代替。拆散后的变量便可以被单独分析与优化,可以各自分别在栈帧或寄存器上分配空间,原本的对象就无需整体分配空间了。
33.3、总结
虽然概念上的JVM总是在Java堆上为对象分配空间,但并不是说完全依照概念的描述去实现;只要最后实现处理的“可见效果”与概念中描述的一致就没问题了。所以说,“you can cheat as long as you don’t get caught”。Java对象在实际的JVM实现中可能在GC堆上分配空间,也可能在栈上分配空间,也可能完全就消失了。这种行为从Java源码中看不出来,也无法显式指定,只是聪明的JVM自动做的优化而已。 但是逃逸分析会有时间消耗,所以性能未必提升多少,并且由于逃逸分析比较耗时,目前的实现都是采用不那么准确但是时间压力相对较小的算法来完成逃逸分析,这就可能导致效果不稳定,要慎用。
34、进程与线程的区别
(1)进程概念 进程是表示资源分配的基本单位。 例如,用户运行自己的程序,系统就创建一个进程,并为它分配资源,包括各种表格、内存空间、磁盘空间、I/O设备等。然后,把该进程放入进程的就绪队列。进程调度程序选中它,为它分配CPU以及其它有关资源,该进程才真正运行。所以,进程是系统中的并发执行的单位。 在微内核系统(Mac、Windows NT等)中,真正调度运行的基本单位是线程。因此,实现并发功能的单位是线程。
(2)线程概念 线程是进程中执行运算的最小单位,亦即执行处理机调度的基本单位。 如果把进程理解为在逻辑上操作系统所完成的任务,那么线程表示完成该任务的许多可能的子任务之一。例如,假设用户启动了一个窗口中的数据库应用程序,操作系统就将对数据库的调用表示为一个进程。假设用户要从数据库中产生一份工资单报表,并传到一个文件中,这是一个子任务;在产生工资单报表的过程中,用户又可以输人数据库查询请求,这又是一个子任务。这样,操作系统则把每一个请求――工资单报表和新输人的数据查询表示为数据库进程中的独立的线程。线程可以在处理器上独立调度执行,这样,在多处理器环境下就允许几个线程各自在单独处理器上进行。操作系统提供线程就是为了方便而有效地实现这种并发性。
(3)线程与进程的比较 1、调度:在传统的操作系统中,拥有资源的基本单位和独立调度、分派的基本单位都是进程。而在引入线程的操作系统中,则把线程作为调度和分派的基本单位。而把进程作为资源拥有的基本单位,使传统进程的两个属性分开,线程便能轻装运行,从而可显著地提高系统的并发程度。在同一进程中,线程的切换不会引起进程的切换,在由一个进程中的线程切换到另一个进程中的线程时,将会引起进程的切换。 2、并发性:在引入线程的操作系统中,不仅进程之间可以并发执行,而且在一个进程中的多个线程之间,亦可并发执行,因而使操作系统具有更好的并发性,从而能更有效地使用系统资源和提高系统吞吐量。例如,在一个未引入线程的单CPU操作系统中,若仅设置一个文件服务进程,当它由于某种原因而被阻塞时,便没有其它的文件服务进程来提供服务。在引入了线程的操作系统中,可以在一个文件服务进程中,设置多个服务线程,当第一个线程等待时,文件服务进程中的第二个线程可以继续运行;当第二个线程阻塞时,第三个线程可以继续执行,从而显著地提高了文件服务的质量以及系统吞吐量。 3、拥有资源:不论是传统的操作系统,还是设有线程的操作系统,进程都是拥有资源的一个独立单位,它可以拥有自己的资源。一般地说,线程自己不拥有系统资源(也有一点必不可少的资源),但它可以访问其隶属进程的资源。亦即,一个进程的代码段、数据段以及系统资源,如已打开的文件、I/O设备等,可供同一进程的其它所有线程共享。 4、系统开销:由于在创建或撤消进程时,系统都要为之分配或回收资源,如内存空间、IO设备等。因此,操作系统所付出的开销将显著地大于在创建或撤消线程时的开销。类似地,在进行进程切换时,涉及到整个当前进程CPU环境的保存以及新被调度运行的进程的CPU环境的设置。而线程切换只须保存和设置少量寄存器的内容,并不涉及存储器管理方面的操作。可见,**进程切换的开销也远大于线程切换的开销。**此外,由于同一进程中的多个线程具有相同的地址空间,致使它们之间的同步和通信的实现,也变得比较容易。 1、进程让操作系统的并发成为可能,而线程让进程内部并发成为可能。 2、进程是操作系统进行资源分配的基本单位,而线程是操作系统进行调度的基本单位。
(4)、并发与并行 并发的关键是有处理多个任务的能力,不一定要同时,并行的关键是有同时处理多个任务的能力(可能有多个CPU)。并发和并行都可以是很多个线程,就看这些线程能不能同时被(多个)CPU执行,如果可以,则是并行,而并发是多个线程被(一个)CPU轮流执行。
35、进程间的通信方式(IPC)
1、管道pipe:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。 2、命名管道FIFO:有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。 3、消息队列MessageQueue:消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。 4、共享内存SharedMemory:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量,配合使用,来实现进程间的同步和通信。 5、信号量Semaphore:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。 6、套接字Socket:套接字也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同机器间的进程通信。 7、信号signal:信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
35.1、Java线程间通信方式
1、Object类中的wait()/notify()/notifyAll()方法。 2、使用Condition接口 Condition 是被绑定到 Lock 上的,要创建一个 Lock 的 Condition 对象必须用 newCondition()方法。在一个 Lock 对象里面可以创建多个Condition 对象,线程可以注册在指定的 Condition 对象中,从而可以有选择性地进行线程通知,在线程调度上更加灵活。 在 Condition 中,用 await()替换 wait(),用 signal()替换 notify(),用 signalAll()替换 notifyAll(),传统线程的通信方式,Condition 都可以实现。调用 Condition 对象中的方法时,需要被包含在 lock()和 unlock()之间。 3、管道实现线程间的通信。 实现方式:一个线程发送数据到输出管道流,另一个线程从输入管道流中读取数据。 基本流程: 1)、创建管道输出流 PipedOutputStream pos 和管道输入流PipedInputStream pis。 2)、将 pos 和 pis 连接,pos.connect(pis)。 3)、将 pos 赋给信息输入信息的线程,pis 赋给获取信息的线程,就可以实现线程间的通讯了。 管道流通信的缺点: 1)、管道流只能在两个线程之间传递数据。 2)、管道流只能实现单向发送,如果要两个线程之间互通讯,则需要两个管道流。 4、使用volatile关键字。 volatile关键字能够保证线程对共享变量的修改对其他线程可见,但它不保证操作的原子性。
36、线程的生命周期(状态)
在 Java 当中,线程通常都有五种状态,新建(new)、就绪(runnable)、运行(running)、阻塞(blocked)和死亡(dead)。
第一是新建(new)状态。在生成线程对象,并没有调用该对象的 start 方法,这是线程处于新建状态。
第二是就绪(runnable)状态。当调用了线程对象的 start 方法之后,该线程就进入了就绪状态,**但是此时线程调度程序还没有把该线程设置为当前线程,此时处于就绪状态。**在线程运行之后,从等待或者睡眠中回来之后,也会处于就绪状态。
第三是运行(running)状态。线程调度程序将处于就绪状态的线程设置为当前线程,此时线程就进入了运行状态,开始运行 run 函数当中的代码。
第四是阻塞(blocked) 、timed_waiting、waiting状态。线程正在运行的时候,被暂停,通常是为了等待某个事件的发生(比如说某项资源就绪)之后再继续运行。sleep,wait 等方法都可以导致线程阻塞。
第五是死亡(dead)状态。如果一个线程的 run 方法执行结束或者异常中断后,该线程就会死亡。对于已经死亡的线程,无法再使用 start 方法令其进入就绪。
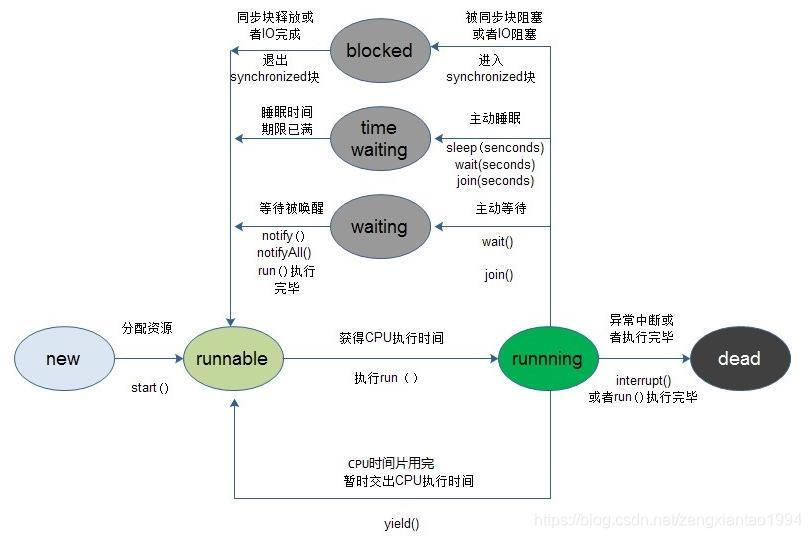
37、创建线程的几种方式
1、继承 Thread类创建线程类 (1)定义 Thread 类的子类,并重写该类的 run 方法,该 run 方法的方法体就代表了线程要完成的任务。因此把 run()方法称为执行体。 (2)创建 Thread 子类的实例,即创建了线程对象。 (3)调用线程对象的 start()方法来启动该线程。 2、通过 Runnable 接口创建线程类 (1)定义 Runnable 接口的实现类,并重写该接口的 run()方法,该 run()方法的方法体同样是该线程的线程执行体。 (2)创建 Runnable 实现类的实例,并以此实例作为 Thread 的 target来创建 Thread 对象,该 Thread 对象才是真正的线程对象。 (3)调用线程对象的 start()方法来启动该线程。 3、通过 Callable 和 Future 创建线程 (1)创建 Callable 接口的实现类,并实现 call()方法,该 call()方法将作为线程执行体,并且有返回值。 (2)创建 Callable 实现类的实例,使用 FutureTask 类来包装 Callable对象,该 FutureTask 对象封装了该 Callable 对象的 call() 方法的返回值。 (3)使用 FutureTask 对象作为 Thread 对象的 target 创建并启动新线程。 (4)调用 FutureTask 对象的 get()方法来获得子线程执行结束后的返回值。 4、通过线程池创建线程 利用线程池不用 new 就可以创建线程,线程可复用,利用 Executors 创建线程池。
38、Java中用户线程和守护线程的区别
当我们在 Java 程序中创建一个线程,它就被称为用户线程。将一个用户线程设置为守护线程的方法就是在调用 start() 方法之前,调用对象的setDamon(true)方法。一个守护线程是在后台执行并且不会阻止 JVM 终止的线程, 守护线程的作用是为其他线程的运行提供便利服务。当没有用户线程在运行的时候,JVM关闭程序并且退出。一个守护线程创建的子线程依然是守护线程。 守护线程的一个典型例子就是垃圾回收器。
代理模式
代理模式的定义:给某一个对象提供一个代理,并由代理对象控制对原对象的引用。
代理(Proxy)是一种设计模式,提供了对目标对象另外的访问方式;即通过代理对象访问目标对象。这样做的好处是:可以在目标对象实现的基础上,增强额外的功能操作,即扩展目标对象的功能。
这里使用到编程中的一个思想:不要随意去修改别人已经写好的代码或者方法,如果需改修改,可以通过代理的方式来扩展该方法。
举个例子来说明代理的作用:假设我们想邀请一位明星,那么并不是直接联系明星,而是联系明星的经纪人,来达到同样的目的。明星就是一个目标对象,他只要负责活动中的节目,而其他琐碎的事情就交给他的代理人(经纪人)来解决。这就是代理思想在现实中的一个例子。
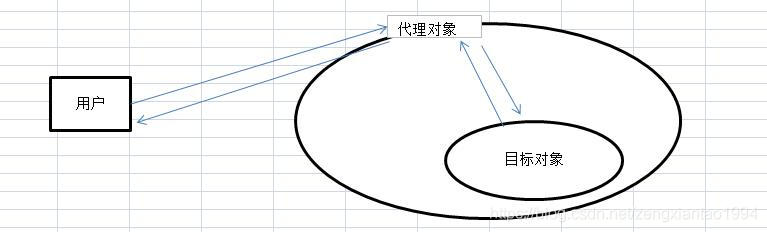 代理模式的关键点是:代理对象与目标对象。代理对象是对目标对象的扩展,并会调用目标对象。
代理模式包含如下角色:
ISubject:抽象主题角色,是一个接口。该接口是对象和它的代理共用的接口。
RealSubject:真实主题角色,是实现抽象主题接口的类。
Proxy:代理角色,内部含有对真实对象RealSubject的引用,从而可以操作真实对象。代理对象提供与真实对象相同的接口,以便在任何时刻都能代替真实对象。同时,代理对象可以在执行真实对象操作时,附加其他的操作,相当于对真实对象进行封装。
代理模式的应用:
远程代理:也就是为一个对象在不同的地址空间提供局部代表。这样可以隐藏一个对象存在于不同地址空间的事实。
虚拟代理:是根据需要创建开销很大的对象。通过它来存放实例化需要很长时间的真实对象。
安全代理:用来控制真实对象访问时的权限。
智能代理:是指当调用真实的对象时,代理处理一些另外的事情。
一般将代理分类的话,可分为静态代理和动态代理两种。
代理模式的关键点是:代理对象与目标对象。代理对象是对目标对象的扩展,并会调用目标对象。
代理模式包含如下角色:
ISubject:抽象主题角色,是一个接口。该接口是对象和它的代理共用的接口。
RealSubject:真实主题角色,是实现抽象主题接口的类。
Proxy:代理角色,内部含有对真实对象RealSubject的引用,从而可以操作真实对象。代理对象提供与真实对象相同的接口,以便在任何时刻都能代替真实对象。同时,代理对象可以在执行真实对象操作时,附加其他的操作,相当于对真实对象进行封装。
代理模式的应用:
远程代理:也就是为一个对象在不同的地址空间提供局部代表。这样可以隐藏一个对象存在于不同地址空间的事实。
虚拟代理:是根据需要创建开销很大的对象。通过它来存放实例化需要很长时间的真实对象。
安全代理:用来控制真实对象访问时的权限。
智能代理:是指当调用真实的对象时,代理处理一些另外的事情。
一般将代理分类的话,可分为静态代理和动态代理两种。
静态代理
静态代理比较简单,是由程序员编写的代理类,并在程序运行前就编译好的,而不是由程序动态产生代理类,这就是所谓的静态。 考虑这样的场景,管理员在网站上执行操作,在生成操作结果的同时需要记录操作日志,这是很常见的。此时就可以使用代理模式,代理模式可以通过聚合和继承两种方式实现:
/**
* @Description: 抽象主题接口
* @author: zxt
* @time: 2018年7月7日 下午2:29:46
*/
public interface Manager {
public void doSomething();
}
/**
* @Description: 真实的主题类
* @author: zxt
* @time: 2018年7月7日 下午2:31:21
*/
public class Admin implements Manager {
@Override
public void doSomething() {
System.out.println("这是真实的主题类:Admin doSomething!!!");
}
}
/**
* @Description: 以聚合的方式实现代理主题
* @author: zxt
* @time: 2018年7月7日 下午2:37:08
*/
public class AdminPoly implements Manager {
// 真实主题类的引用
private Admin admin;
public AdminPoly(Admin admin) {
this.admin = admin;
}
@Override
public void doSomething() {
System.out.println("聚合方式实现代理:Admin操作开始!!");
admin.doSomething();
System.out.println("聚合方式实现代理:Admin操作结束!!");
}
}
/**
* @Description: 继承方式实现代理
* @author: zxt
* @time: 2018年7月7日 下午2:40:39
*/
public class AdminProxy extends Admin {
@Override
public void doSomething() {
System.out.println("继承方式实现代理:Admin操作开始!!");
super.doSomething();
System.out.println("继承方式实现代理:Admin操作结束!!");
}
}
public static void main(String[] args) {
// 1、聚合方式的测试
Admin admin = new Admin();
Manager manager = new AdminPoly(admin);
manager.doSomething();
System.out.println("============================");
// 2、继承方式的测试
AdminProxy proxy = new AdminProxy();
proxy.doSomething();
}
聚合实现方式中代理类聚合了被代理类,且代理类及被代理类都实现了同一个接口,可实现灵活多变。继承式的实现方式则不够灵活。 比如,在管理员操作的同时需要进行权限的处理,操作内容的日志记录,操作后数据的变化三个功能。三个功能的排列组合有6种,也就是说使用继承要编写6个继承了Admin的代理类,而使用聚合,仅需要针对权限的处理、日志记录和数据变化三个功能编写代理类,在业务逻辑中根据具体需求改变代码顺序即可。 缺点: 1)、代理类和委托类实现了相同的接口,代理类通过委托类实现了相同的方法。这样就出现了大量的代码重复。如果接口增加一个方法,除了所有实现类需要实现这个方法外,所有代理类也需要实现此方法。增加了代码维护的复杂度。 2)、代理对象只服务于一种类型的对象,如果要服务多类型的对象。势必要为每一种对象都进行代理,静态代理在程序规模稍大时就无法胜任了。
动态代理
实现动态代理的关键技术是反射。 一般来说,对代理模式而言,一个主题类与一个代理类一一对应,这也是静态代理模式的特点。 但是,也存在这样的情况,有n各主题类,但是代理类中的“前处理、后处理”都是一样的,仅调用主题不同。也就是说,多个主题类对应一个代理类,共享“前处理,后处理”功能,动态调用所需主题,大大减小了程序规模,这就是动态代理模式的特点。动态代理主要有两种:JDK自带的动态代理和CGLIB动态代理。 首先是另一个静态代理的实例: 1、一个可移动接口
public interface Moveable {
public void move();
}
1234
2、一个实现了该接口的Car类
public class Car implements Moveable {
@Override
public void move() {
try {
Thread.sleep(new Random().nextInt(1000));
System.out.println("汽车行驶中----");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
3、现在需要有一个代理类来记录Car的运行时间:
public class CarTimeProxy implements Moveable {
private Moveable m;
public CarTimeProxy(Moveable m) {
super();
this.m = m;
}
@Override
public void move() {
long startTime = System.currentTimeMillis();
System.out.println("汽车行驶前----");
m.move();
long endTime = System.currentTimeMillis();
System.out.println("汽车行驶结束----行驶时间为:" + (endTime - startTime) + "毫秒!");
}
}
4、另一个代理类记录Car的日志:
public class CarLogProxy implements Moveable {
private Moveable m;
public CarLogProxy(Moveable m) {
super();
this.m = m;
}
@Override
public void move() {
System.out.println("日志开始");
m.move();
System.out.println("日志结束");
}
}
5、客户端的调用:
public class CarTest {
public static void main(String[] args) {
Car car = new Car();
// 先写日志,再计时
CarTimeProxy ctp = new CarTimeProxy(car);
CarLogProxy clp = new CarLogProxy(ctp);
clp.move();
System.out.println();
// 先计时,再写日志
CarLogProxy clp1 = new CarLogProxy(car);
CarTimeProxy ctp1 = new CarTimeProxy(clp1);
ctp1.move();
}
}
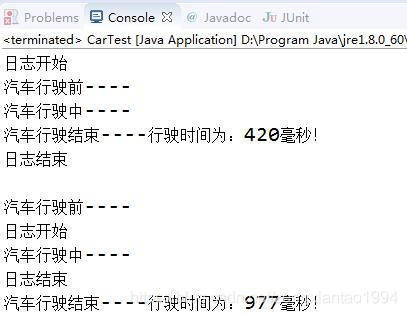
JDK的动态代理
在java的动态代理机制中,有两个重要的类或接口,一个是InvocationHandler(Interface)、另一个则是 Proxy(Class),这一个类和接口是实现我们动态代理所必须用到的。
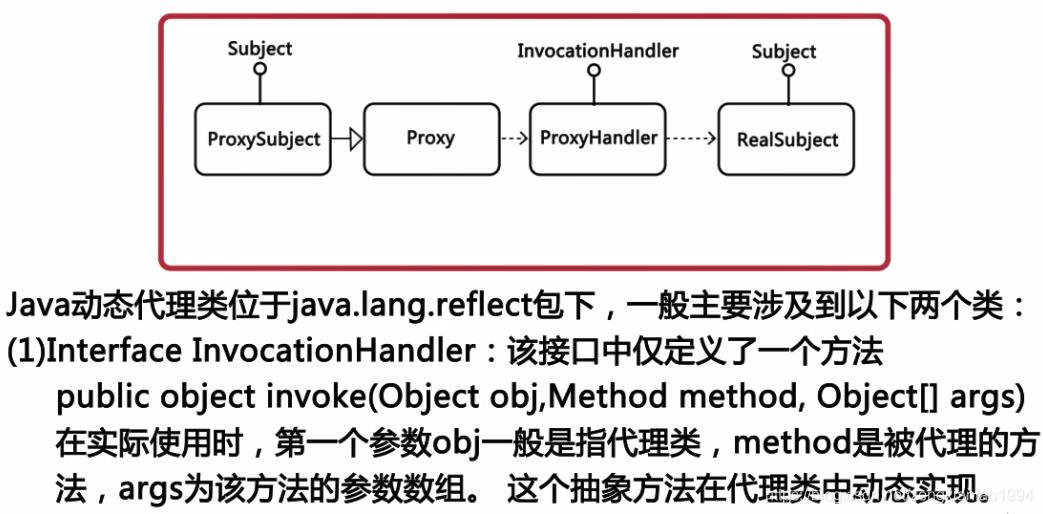
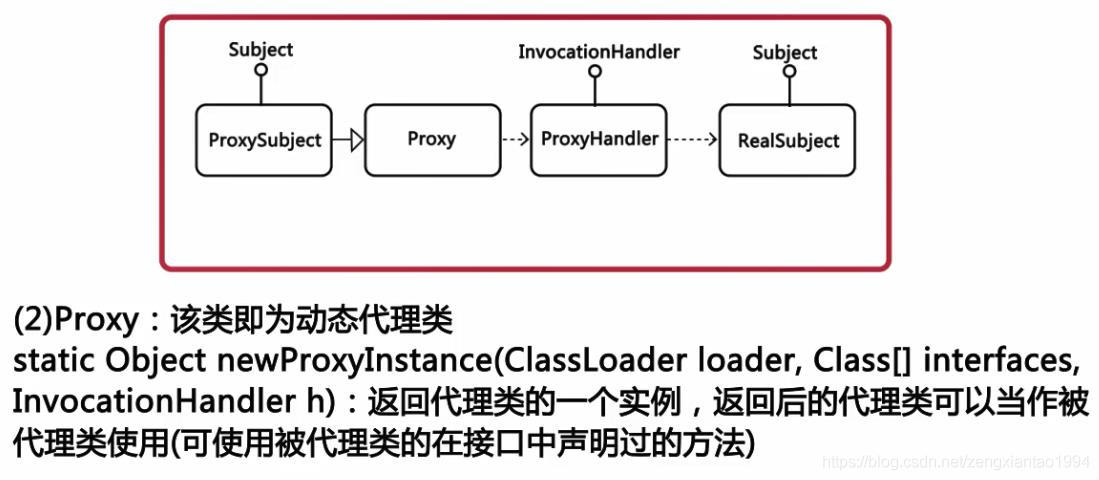
JDK动态代理的实现 1、创建一个实现接口InvocationHandler的类,它必须实现invoke方法。 使用JDK动态代理类时,需要实现InvocationHandler接口,所有动态代理类的方法调用,都会交由InvocationHandler接口实现类里的invoke()方法去处理。这是动态代理的关键所在。 2、创建被代理的类以及接口。 3、调用Proxy的静态方法,创建代理类。 newProxyInstance(ClassLoader loader, Class[] interfaces, InvocationHandler h); 4、通过代理调用方法。 使用JDK动态代理的方式实现上面Car的时间代理: 1、首先是InvocationHandler接口的实现类:
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
public class TimeHandler implements InvocationHandler {
// 被传递过来的要被代理的对象
private Object object;
public TimeHandler(Object object) {
super();
this.object = object;
}
/**
* proxy:被代理的对象
* method:被代理的方法
* args:被代理方法的参数
*
* 函数返回:method的返回
*
*/
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
long startTime = System.currentTimeMillis();
System.out.println("汽车行驶前----");
method.invoke(object, args);
long endTime = System.currentTimeMillis();
System.out.println("汽车行驶结束----行驶时间为:" + (endTime - startTime) + "毫秒!");
return null;
}
}
2、创建动态代理类:
/**
* @Description: JDK动态代理的测试类
* @author: zxt
* @time: 2019年3月1日 下午7:59:29
*/
public class TimeHandlerTest {
public static void main(String[] args) {
// 需要被代理的对象
Car car = new Car();
InvocationHandler h = new TimeHandler(car);
Class<?> clazz = car.getClass();
/**
* 参数一:类加载器
* 参数二:被代理类实现的接口
* 参数三:InvocationHandler实例
*
* 函数返回:返回由InvocationHandler接口接收的被代理类的一个动态代理类对象
*/
Moveable m = (Moveable) Proxy.newProxyInstance(clazz.getClassLoader(), clazz.getInterfaces(), h);
m.move();
}
}
cglib动态代理
JDK动态代理可以在运行时动态生成字节码,主要使用到了一个接口InvocationHandler与Proxy.newProxyInstance静态方法。使用内置的Proxy实现动态代理有一个问题:被代理的类必须要实现某接口,未实现接口则没办法完成动态代理。 如果项目中有些类没有实现接口,则不应该为了实现动态代理而刻意去抽象出一些没有实际意义的接口,通过cglib可以解决该问题。 CGLIB(Code Generation Library)是一个开源项目,是一个强大的,高性能,高质量的Code生成类库,它可以在运行期扩展Java类与实现Java接口,通俗地说cglib可以在运行时动态生成字节码。 使用cglib完成动态代理,大概的原理是:cglib继承被代理的类,重写方法,织入通知,动态生成字节码并运行。对指定目标类产生一个子类,通过方法拦截技术拦截所有父类的方法调用,因为是继承实现所以final类是没有办法动态代理的。
CGLIB动态代理实例:
import java.util.Random;
// 不实现接口的被代理类
public class Train {
public void move() {
try {
Thread.sleep(new Random().nextInt(1000));
System.out.println("火车行驶中----");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
1234567891011121314
import java.lang.reflect.Method;
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
public class CglibProxy implements MethodInterceptor {
private Enhancer enhancer = new Enhancer();
// 得到代理类的方法
public Object getProxy(Class<?> clazz) {
// 设置创建子类的类 (即我们需要为哪个类产生代理类)
enhancer.setSuperclass(clazz);
enhancer.setCallback(this);
return enhancer.create();
}
/**
* 拦截所有目标类方法的调用
*
* object:目标类的实例
* method:目标类的目标方法的反射实例
* args:目标方法的参数
* proxy:代理类的实例
*/
@Override
public Object intercept(Object object, Method method, Object[] args, MethodProxy proxy) throws Throwable {
long startTime = System.currentTimeMillis();
System.out.println("火车行驶前----");
// 代理类调用父类的方法 (由于Cglib动态代理的实现是通过继承被代理类,因此代理类这里需要调用父类的方法)
proxy.invokeSuper(object, args);
long endTime = System.currentTimeMillis();
System.out.println("火车行驶结束----行驶时间为:" + (endTime - startTime) + "毫秒!");
return null;
}
}
123456789101112131415161718192021222324252627282930313233343536373839
public class CglibProxyTest {
public static void main(String[] args) {
CglibProxy cglibProxy = new CglibProxy();
Train train = (Train) cglibProxy.getProxy(Train.class);
train.move();
}
}
JDK动态代理的模拟实现
模拟JDK动态代理的实现,根据Java源代码动态生成代理类。
package com.zxt.jdkproxy;
import java.io.File;
import java.lang.reflect.Constructor;
import java.lang.reflect.Method;
import javax.tools.JavaCompiler;
import javax.tools.JavaCompiler.CompilationTask;
import javax.tools.StandardJavaFileManager;
import javax.tools.ToolProvider;
import org.apache.commons.io.FileUtils;
import com.zxt.staticproxy.Car;
/**
*
* @Description: 模拟JDK动态代理的实现
* 动态代理的实现思路:
* 实现功能:通过自定义的Proxy的newProxyInstance方法返回代理对象
* 1、声明一段源码(动态产生代理)
* 2、编译源码(JDK Compiler API),产生新的类(代理类)
* 3、将这个类load到内存当中,产生一个新的对象(代理对象)
* 4、return 代理对象
*
* @author: zxt
*
* @time: 2019年4月18日 下午3:44:58
*
*/
public class MyProxy {
@SuppressWarnings({ "rawtypes", "unchecked" })
public static Object newProxyInstance(Class<?> inteface) throws Exception {
// 1、声明一段源码(动态产生代理)
String rt = "\r\n";
String methodStr = "";
for(Method m : inteface.getMethods()) {
methodStr += " @Override" + rt
+ " public void " + m.getName() + "() {" + rt
+ " System.out.println(\"日志开始\");" + rt
+ " m." + m.getName() + "();" + rt
+ " System.out.println(\"日志结束\");" + rt
+ " }";
}
String code =
"package com.zxt.jdkproxy;" + rt + "\n"
+ "import com.zxt.staticproxy.Moveable;" + rt + "\n"
+ "public class $MyProxy0 implements " + inteface.getSimpleName() + " {" + rt + "\n"
+ " private " + inteface.getSimpleName() + " m;" + rt + "\n"
+ " public $MyProxy0(" + inteface.getSimpleName() + " m) {" + rt
+ " super();" + rt
+ " this.m = m;" + rt
+ " }" + rt + "\n"
+ methodStr + rt + "\n"
+ "}";
// 由源代码生成java类文件
String filename = System.getProperty("user.dir") + "/bin/com/zxt/jdkproxy/$MyProxy0.java";
File file = new File(filename);
// 使用commons-io里面的简便的工具类来写文件
FileUtils.writeStringToFile(file, code, "UTF-8");
// 2、编译源码(JDK Compiler API),产生新的类(代理类)
// 拿到编译器
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
// 文件管理者
StandardJavaFileManager fileManager = compiler.getStandardFileManager(null, null, null);
// 获取文件
Iterable units = fileManager.getJavaFileObjects(filename);
// 获取编译任务
CompilationTask task = compiler.getTask(null, fileManager, null, null, null, units);
// 编译
task.call();
fileManager.close();
// 3、加载到内存
ClassLoader cl = ClassLoader.getSystemClassLoader();
Class c = cl.loadClass("com.zxt.jdkproxy.$MyProxy0");
// 4、返回代理类
Constructor ctr = c.getConstructor(inteface);
return ctr.newInstance(new Car());
}
public static void main(String[] args) {
}
}
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283848586878889909192
public class MyProxyTest {
public static void main(String[] args) throws Exception {
Moveable m = (Moveable) MyProxy.newProxyInstance(Moveable.class);
m.move();
}
}
可以发现上述实现中的源代码是写死在类中的,因此无法对任意类进行动态代理,所以仿照InvocationHandler接口,定义自己的InvocationHandler接口从而实现对不同的类进行动态代理。
import java.lang.reflect.Method;
public interface MyInvocationHandler {
public void invoke(Object o, Method m);
}
实现该接口的类
import java.lang.reflect.Method;
public class MyLogHandler implements MyInvocationHandler {
// 需要被代理的对象
private Object target;
public MyLogHandler(Object target) {
super();
this.target = target;
}
@Override
public void invoke(Object o, Method m) {
try {
System.out.println("日志开始");
m.invoke(target);
System.out.println("日志结束");
} catch (Exception e) {
e.printStackTrace();
}
}
}
对动态代理MyProxy类进行改进
/**
*
* @Description: 模拟JDK动态代理的实现
* 动态代理的实现思路:
* 实现功能:通过自定义的Proxy的newProxyInstance方法返回代理对象
* 1、声明一段源码(动态产生代理)
* 2、编译源码(JDK Compiler API),产生新的类(代理类)
* 3、将这个类load到内存当中,产生一个新的对象(代理对象)
* 4、return 代理对象
*
* @author: zxt
*
* @time: 2019年4月18日 下午3:44:58
*
*/
public class MyProxy {
@SuppressWarnings({ "rawtypes", "unchecked" })
public static Object newProxyInstance(Class<?> inteface, MyInvocationHandler h) throws Exception {
// 1、声明一段源码(动态产生代理)
String rt = "\r\n";
String methodStr = "";
for(Method m : inteface.getMethods()) {
methodStr += " @Override" + rt
+ " public void " + m.getName() + "() {" + rt
+ " try { " + rt
+ " Method md = " + inteface.getSimpleName() + ".class.getMethod(\""
+ m.getName() + "\");" + rt
+ " h.invoke(this, md);" + rt
+ " } catch (Exception e) { " + rt
+ " e.printStackTrace();" + rt
+ " }" + rt
+ " }";
}
String code =
"package com.zxt.jdkproxy;" + rt + "\n"
+ "import java.lang.reflect.Method;" + rt
+ "import com.zxt.staticproxy.Moveable;" + rt + "\n"
+ "public class $MyProxy0 implements " + inteface.getSimpleName() + " {" + rt + "\n"
+ " private MyInvocationHandler h;" + rt + "\n"
+ " public $MyProxy0( MyInvocationHandler h ) {" + rt
+ " this.h = h;" + rt
+ " }" + rt + "\n"
+ methodStr + rt + "\n"
+ "}";
// 由源代码生成java类文件
String filename = System.getProperty("user.dir") + "/bin/com/zxt/jdkproxy/$MyProxy0.java";
File file = new File(filename);
// 使用commons-io里面的简便的工具类来写文件
FileUtils.writeStringToFile(file, code, "UTF-8");
// 2、编译源码(JDK Compiler API),产生新的类(代理类)
// 拿到编译器
JavaCompiler compiler = ToolProvider.getSystemJavaCompiler();
// 文件管理者
StandardJavaFileManager fileManager = compiler.getStandardFileManager(null, null, null);
// 获取文件
Iterable units = fileManager.getJavaFileObjects(filename);
// 获取编译任务
CompilationTask task = compiler.getTask(null, fileManager, null, null, null, units);
// 编译
task.call();
fileManager.close();
// 3、加载到内存
ClassLoader cl = ClassLoader.getSystemClassLoader();
Class c = cl.loadClass("com.zxt.jdkproxy.$MyProxy0");
// 4、返回代理类
Constructor ctr = c.getConstructor(MyInvocationHandler.class);
return ctr.newInstance(h);
}
}
测试类:
public class MyProxyTest {
public static void main(String[] args) throws Exception {
// 需要被代理的对象
Car car = new Car();
MyInvocationHandler h = new MyLogHandler(car);
Moveable m = (Moveable) MyProxy.newProxyInstance(Moveable.class, h);
m.move();
}
}
39、Synchronized的底层原理
synchronized是JAVA中解决并发编程中最常用的方法。 synchronized的作用如下: 1、确保线程互斥访问同步代码; 2、保证共享变量的修改能够及时可见; 3、有效解决指令重排序问题。 synrhronized关键字简洁、清晰、语义明确,因此即使有了Lock接口,使用的还是非常广泛。其应用层的语义是可以把任何一个非null对象 作为"锁",当synchronized作用在方法上时,锁住的便是对象实例(this);当作用在静态方法时锁住的便是对象对应的Class实例,因为 Class数据存在于永久带,因此静态方法锁相当于该类的一个全局锁;当synchronized作用于某一个对象实例时,锁住的便是对应的代码块。在 HotSpot JVM实现中,锁有个专门的名字:对象监视器。 **每个对象都有一个监视器锁(monitor),同步语句块的实现使用的是monitorenter和 monitorexit 指令,**其中monitorenter指令指向同步代码块的开始位置,monitorexit指令则指明同步代码块的结束位置。当执行monitorenter指令时,当前线程将试图获取 objectref(即对象锁) 所对应的 monitor 的持有权,当 objectref 的monitor 的进入计数器为 0,那线程可以成功取得 monitor,并将计数器值设置为 1,取锁成功;如果当前线程已经拥有 objectref 的 monitor 的持有权,那它可以重入这个monitor,重入时计数器的值也会加 1。倘若其他线程已经拥有 objectref 的 monitor的所有权,那当前线程将被阻塞,直到正在执行线程执行完毕,即monitorexit指令被执行,执行线程将释放 monitor(锁)并设置计数器值为0 ,其他线程将有机会持有 monitor。 值得注意的是编译器将会确保无论方法通过何种方式完成,方法中调用过的每条monitorenter 指令都有执行其对应 monitorexit 指令,而无论这个方法是正常结束还是异常结束。为了保证在方法异常完成时 monitorenter 和 monitorexit 指令依然可以正确配对执行,编译器会自动产生一个异常处理器,这个异常处理器声明可处理所有的异常,它的目的就是用来执行 monitorexit 指令。 总结这两条指令的作用: monitorenter: 每个对象都有一个监视器锁(monitor),当monitor被占用时就会处于锁定状态。线程执行monitorenter命令获取monitor锁的过程如下: 1、如果monitor的进入数为0,则线程获取锁,并设置monitor的进入数为1; 2、如果该线程已经占有该monitor,则进入数+1; 3、如果其他线程占有该monitor,monitor的进入数不为0,则该线程进入阻塞状态,直到monitor为0,重新获取monitor的所有权。 monitorexit: 执行monitorexit的线程必须是monitor的所有者。 当执行该命令时,monitor的进入数-1,当monitor的进入数为0,该线程已经不再是该monitor的所有者,其他被这个monitor阻塞的线程可以尝试获取monitor的所有权。
线程状态及状态转换
当多个线程同时请求某个对象监视器时,对象监视器会设置几种状态用来区分请求的线程:
Contention List:所有请求锁的线程将被首先放置到该竞争队列;
Entry List:Contention List中那些有资格成为候选人的线程被移到Entry List;
Wait Set:那些调用wait方法被阻塞的线程被放置到Wait Set;
OnDeck:任何时刻最多只能有一个线程正在竞争锁,该线程称为OnDeck;
Owner:获得锁的线程称为Owner;
!Owner:释放锁的线程。
下图反映了个状态转换关系:
 新请求锁的线程将首先被加入到Conetention List中,当某个拥有锁的线程(Owner状态)调用unlock之后,如果发现 EntryList为空则从Contention List中移动线程到EntryList,下面说明下ContentionList和EntryList 的实现方式:
新请求锁的线程将首先被加入到Conetention List中,当某个拥有锁的线程(Owner状态)调用unlock之后,如果发现 EntryList为空则从Contention List中移动线程到EntryList,下面说明下ContentionList和EntryList 的实现方式:
ContentionList 虚拟队列
ContentionList并不是一个真正的Queue,而只是一个虚拟队列,原因在于ContentionList是由Node及其next指针逻辑构成,并不存在一个Queue的数据结构。ContentionList是一个先进先出(FIFO)的队列,每次新加入Node时都会在队头进行,通过CAS改变第一个节点的的指针为新增节点,同时设置新增节点的next指向后续节点,而取得操作则发生在队尾。显然,该结构其实是个Lock-Free的队列。
 因为只有Owner线程才能从队尾取元素,也即线程出列操作无争用,当然也就避免了CAS的ABA问题。
因为只有Owner线程才能从队尾取元素,也即线程出列操作无争用,当然也就避免了CAS的ABA问题。
EntryList
EntryList与ContentionList逻辑上同属等待队列,ContentionList会被线程并发访问,为了降低对 ContentionList队尾的争用,而建立EntryList。Owner线程在unlock时会从ContentionList中迁移线程到 EntryList,并会指定EntryList中的某个线程(一般为Head)为Ready(OnDeck)线程。Owner线程并不是把锁传递给 OnDeck线程,只是把竞争锁的权利交给OnDeck,OnDeck线程需要重新竞争锁。这样做虽然牺牲了一定的公平性,但极大的提高了整体吞吐量,在 Hotspot中把OnDeck的选择行为称之为“竞争切换”。 OnDeck线程获得锁后即变为owner线程,无法获得锁则会依然留在EntryList中,考虑到公平性,在EntryList中的位置不发生变化(依然在队头)。如果Owner线程被wait方法阻塞,则转移到WaitSet队列;如果在某个时刻被notify/notifyAll唤醒,则再次转移到EntryList。
自旋锁
那些处于ContetionList、EntryList、WaitSet中的线程均处于阻塞状态,阻塞操作由操作系统完成(在Linxu下通过pthread_mutex_lock函数)。线程被阻塞后便进入内核(Linux)调度状态,这个会导致系统在用户态与内核态之间来回切换,严重影响锁的性能。 缓解上述问题的办法便是自旋,其原理是:当发生争用时,若Owner线程能在很短的时间内释放锁,则那些正在争用线程可以稍微等一等(自旋), 在Owner线程释放锁后,争用线程可能会立即得到锁,从而避免了系统阻塞。但Owner运行的时间可能会超出了临界值,争用线程自旋一段时间后还是无法获得锁,这时争用线程则会停止自旋进入阻塞状态(后退)。基本思路就是自旋,不成功再阻塞,尽量降低阻塞的可能性,这对那些执行时间很短的代码块来说有非常重要的性能提高。自旋锁有个更贴切的名字:自旋-指数后退锁,也即复合锁。很显然,自旋在多处理器上才有意义。 还有个问题是,线程自旋时做些啥?其实啥都不做,可以执行几次for循环,可以执行几条空的汇编指令,目的是占着CPU不放,等待获取锁的机会。所以说,自旋是把双刃剑,如果旋的时间过长会影响整体性能,时间过短又达不到延迟阻塞的目的。显然,自旋的周期选择显得非常重要,但这与操作系统、硬件体系、系统的负载等诸多场景相关,很难选择,如果选择不当,不但性能得不到提高,可能还会下降,因此大家普遍认为自旋锁不具有扩展性。 自旋优化策略 对自旋锁周期的选择上,HotSpot认为最佳时间应是一个线程上下文切换的时间,但目前并没有做到。经过调查,目前只是通过汇编暂停了几个CPU周期,除了自旋周期选择,HotSpot还进行许多其他的自旋优化策略。
40、同步方法与同步代码块的区别
为何使用同步? java允许多线程并发控制,当多个线程同时操作一个可共享的资源变量时(增删改查),将会导致数据的不准确,相互之间产生冲突。类似于在atm取钱,银行数据却没有变,这是不行的,要存在于一个事务中。因此加入了同步锁,以避免在该线程没有结束前,调用其他线程。从而保证了变量的唯一性,准确性。
1、同步方法 即有synchronized (同步) 修饰符修饰的方法。由于java的每个对象都有一个内置锁,当用此关键字修饰方法时,内置锁会保护整个方法。在调用该方法前,要获取内置锁,否则处于阻塞状态。 同步方法(粗粒度锁): A、修饰一般方法: public synchronized void method(){…},获取的是当前调用对象 this 上的锁; B、修饰静态方法: public static synchronized void method (){…},获取当前类的字节码对象上的锁。
2、同步代码块 即有synchronized修饰符修饰的语句块,被该关键词修饰的语句块,将加上内置锁。实现同步。 同步代码块(细粒度锁): synchronized( obj ){…},同步代码块可以指定获取哪个对象上的锁,obj 任意。 同步是高开销的操作,因此尽量减少同步的内容。通常没有必要同步整个方法,同步部分代码块即可。同步方法默认用this或者当前类class对象作为锁。同步代码块可以选择以什么来加锁,比同步方法要更细粒度化,我们可以选择只同步会发生问题的部分代码而不是整个方法。 同步方法锁的是当前对象,当一个线程使用该对象的同步方法时,会获得该对象的锁,其他线程不能访问该对象的同步方法(只有获得该对象的锁才可以访问同步方法,但可以访问该对象的非同步方法),如果并发量大的话,效率很低,因为如果要访问没有冲突的方法时本来不会和之前的操作产生冲突,但因为没有该对象的锁,所以要等待获得该对象的锁,白白地浪费时间。而同步代码块可以选择要同步的代码块,粒度更小,可以避免上面出现的问题。
41、Synchronized和Lock的区别
1)、Lock是一个接口,而 synchronized 是 Java 中的关键字,synchronized 是内置的语言实现; 2)、synchronized 在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而 Lock 在发生异常时,如果没有主动通过 unLock()去释放锁,则很可能造成死锁现象,因此使用 Lock 时需要在 finally 块中释放锁; 3)、Lock 可以让等待锁的线程响应中断(可中断锁),而 synchronized却不行,使用 synchronized 时,等待的线程会一直等待下去,不能够响应中断(不可中断锁); 4)、通过 Lock 可以知道有没有成功获取锁(tryLock()方法:如果获取了锁,则返回true;否则返回false,也就说这个方法无论如何都会立即返回,在拿不到锁时不会一直在那等待。),而 synchronized 却无法办到。 5)、Lock 可以提高多个线程进行读操作的效率(读写锁)。 6)、Lock 可以实现公平锁,synchronized不保证公平性。 在性能上来说,如果线程竞争资源不激烈时,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时 Lock 的性能要远远优于 synchronized。所以说,在具体使用时要根据适当情况选择。
锁的一些种类: 可重入锁, 如果当前线程已经获得了某个监视器对象所持有的锁,那么该线程在该方法中调用另外一个同步方法时也同样持有该锁,即同一个线程调用同锁的多个代码块和方法不会重复加锁,synchronized、ReentrantLock和ReentrantReadWriteLock都是可重入锁。 可重入锁最大的作用是避免死锁。 当锁不具有可重入性,那么在持有当前对象锁的代码块或者方法中调用其他同锁的方法,则另一个方法就会等待当前对象锁的释放,实际上该对象锁已经被当前线程所持有,不可能再次获得,因此就发生死锁。 可中断锁, 在等待的过程中可中断,synchronized 不是可中断锁,lockInterruptibly()获取的就是可中断锁,中断会抛出异常。 如果某一线程 A 正在执行锁中的代码,另一线程 B 正在等待获取该锁,可能由于等待时间过长,线程 B 不想等待了,想先处理其他事情,我们可以让它中断自己或者在别的线程中中断它,这种就是可中断锁。 公平锁, ReentrantLock和ReentrantReadWriteLock两个锁都可以加入Boolean型的构造参数设置成公平锁,但默认是非公平锁,synchronized是非公平锁。 多个线程同时等待,当前线程执行完毕,随机执行下个线程即非公平的,公平锁即先到先执行,尽量以请求锁的顺序来获取锁。 读写锁, 即读锁和写锁是分开的,ReadWriteLock就是读写锁,它是一个接口,ReentrantReadWriteLock实现了这个接口。可以通过readLock()获取读锁,通过writeLock()获取写锁。
42、Volatile与Synchronized的对比
1、volatile不需要加锁,比synchronized更轻量级,不会阻塞线程;并且volatile只能修饰变量,而synchronized可以修饰方法,以及代码块。 2、从内存可见性角度看,volatile读相当于加锁,volatile写相当于解锁。 3、synchronized既能保证可见性,又能保证原子性,而volatile只能保证可见性,无法保证原子性。 4、关键字volatile解决的是变量在多个线程之间的可见性问题,而synchronized关键字解决的是多个线程之间访问资源的同步性。
43、乐观锁和悲观锁的区别
悲观锁: 悲观锁是认为肯定有其他线程来争夺资源,因此不管到底会不会发生争夺,悲观锁总是会先去锁住资源,会导致其它所有需要锁的线程挂起,等待持有锁的线程释放锁。Synchronized 和 Lock 都是悲观锁。 乐观锁: 每次不加锁,假设没有冲突去完成某项操作,如果因为冲突失败就重试,直到成功为止。就是当去做某个修改或其他操作的时候它认为不会有其他线程来做同样的操作(竞争),这是一种乐观的态度,通常是基于 CAS 原子指令来实现的。CAS 通常不会将线程挂起,因此有时性能会好一些。乐观锁的一种实现方式——CAS。 在数据库系统中,悲观锁从数据开始更改时就将数据锁住,直到更改完成才释放。乐观锁直到修改完成准备提交所做的修改到数据库的时候才会将数据锁住。乐观锁不能解决脏读,乐观锁一般使用数据版本或者时间戳来实现。
44、sleep和wait的区别
sleep方法属于Thread类中方法,表示让一个线程进入睡眠状态,等待一定的时间之后,自动醒来进入到可运行状态,不会马上进入运行状态,因为线程调度机制恢复线程的运行也需要时间,一个线程对象调用了sleep方法之后,并不会释放他所持有的所有对象锁,所以也就不会影响其他进程对象的运行。但在sleep的过程中有可能被其他对象调用它的interrupt(),产生InterruptedException异常,如果你的程序不捕获这个异常,线程就会异常终止,进入TERMINATED状态,如果你的程序捕获了这个异常,那么程序就会继续执行catch语句块(可能还有finally语句块)以及以后的代码。 注意sleep()方法是一个静态方法,也就是说他只对当前对象有效,通过t.sleep()让t对象进入sleep,这样的做法是错误的,它只会是使当前线程被sleep 而不是t线程。 wait属于Object的成员方法,一旦一个对象调用了wait方法,必须要采用notify()或notifyAll()方法唤醒该进程;如果线程拥有某个或某些对象的同步锁,那么在调用了wait()后,这个线程就会释放它持有的所有同步资源,而不限于这个被调用了wait()方法的对象。wait()方法也同样会在wait的过程中有可能被其他对象调用interrupt()方法而产生InterruptedException异常。 其实两者都可以让线程暂停一段时间,但是本质的区别是sleep是线程的运行状态控制,wait是线程之间的通讯问题。 sleep()是让某个线程暂停运行一段时间,其控制范围是由当前线程决定,也就是说,在线程里面决定。好比如说,我要做的事情是"点火->烧水->煮面",而当我点完火之后我不立即烧水,我要休息一段时间再烧。对于运行的主动权是由我的流程来控制。 而wait(),首先,这是由某个确定的对象来调用的,将这个对象理解成一个传话的人,当这个人在某个线程里面说"暂停!",也是 thisOBJ.wait(),这里的暂停是阻塞。还是"点火->烧水->煮饭",thisOBJ就好比一个监督我的人站在我旁边,本来该线程应该执行1后执行2,再执行3,而在2处被那个对象喊暂停,那么我就会一直等在这里而不执行3,但正个流程并没有结束,我一直想去煮饭,但还没被允许,直到那个对象在某个地方说"通知暂停的线程启动!",也就是thisOBJ.notify()的时候,那么我就可以煮饭了,这个被暂停的线程就会从暂停处继续执行。 1、sleep是Thread的静态方法、wait是Object的方法; 2、sleep不释放锁对象,wait放弃锁对象; 3、sleep暂停线程,但监控状态仍然保持,结束后自动恢复; 4、wait、notify和notifyAll只能在同步控制方法控制块里面使用,而sleep可以在任意地方使用; 5、wait方法导致线程放弃对象锁,只有针对此对象发出notify(或notifyAll)后才进入对象锁定池准备重新获得对象锁,然后进入就绪状态,准备运行。
45、线程池ThreadPoolExecutor
45.1、创建线程池
Java通过Executors提供四个静态方法创建四种线程池,分别为: newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。 newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。 newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。 newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO,优先级)执行。
45.2、关键参数解析
corepoolsize:核心池的大小,默认情况下,在创建了线程池之后,线程池中线程数为 0,当有任务来之后,就会创建一个线程去执行任务,当线程池中线程数达到 corepoolsize 后,就把任务放在任务缓存队列中。
Maximumpoolsize:线程池中最多创建多少个线程。
Keeplivetime:线程没有任务执行时,最多保存多久的时间会终止,默认情况下,当线程池中线程数 > corepoolsize时,Keeplivetime才起作用,直到线程数不大于 corepoolsize。
workQueue:阻塞队列,用来存放等待被执行的任务。
threadFactory:线程工厂,用来创建线程。

45.3、线程池的状态
1.当线程池创建后,初始为 running 状态; 2.调用 shutdown 方法后,处 shutdown 状态,此时不再接受新的任务,等待已有的任务执行完毕; 3.调用 shutdownnow 方法后,进入 stop 状态,不再接受新的任务,并且会尝试终止正在执行的任务。 4.当处于 shotdown 或 stop 状态,并且所有工作线程已经销毁,任务缓存队列已清空,线程池被设为 terminated 状态。
45.4、当有任务提交到线程池之后的一些操作:
1.若当前线程池中线程数 < corepoolsize,则每来一个任务就创建一个线程去执行。 2.若当前线程池中线程数 >= corepoolsize,会尝试将任务添加到任务缓存队列中去,若添加成功,则任务会等待空闲线程将其取出执行,若添加失败,则尝试创建线程去执行这个任务。 3.若当前线程池中线程数 >= Maximumpoolsize,则采取拒绝策略。 1)、abortpolicy:丢弃任务,抛出 RejectedExecutionException; 2)、discardpolicy:拒绝执行,不抛异常; 3)、discardoldestpolicy:丢弃任务缓存队列中最老的任务,并且尝试重新提交新的任务; 4)、callerrunspolicy:由调用线程处理该任务,有反馈机制,使任务提交的速度变慢。
46、生产者消费者模式实现
1、阻塞队列BlockingQueue实现生产者消费者模式
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ArrayBlockingQueue;
/**
* @Description: 阻塞队列实现生产者消费者模式
*/
public class ProducerConsumerPattern {
public static void main(String[] args) {
BlockingQueue<String> sharedQueue = new ArrayBlockingQueue<String>(2);
// ArrayBlockingQueue:需要设置队列大小,LinkedBlockingQueue不设置的话默认大小为Integer.MAX_VALUE
// BlockingQueue<String> sharedQueue2 = new LinkedBlockingQueue<String>(2);
Producer producer = new Producer(sharedQueue);
Consumer consumer = new Consumer(sharedQueue);
for(int i = 0; i < 5; i++) {
new Thread(producer, "Producer" + (i + 1)).start();
new Thread(consumer, "Consumer" + (i + 1)).start();
}
}
}
// 生产者
class Producer implements Runnable {
private BlockingQueue<String> sharedQueue;
public Producer(BlockingQueue<String> sharedQueue) {
this.sharedQueue = sharedQueue;
}
@Override
public void run() {
try {
String prod = "产品:" + Thread.currentThread().getName();
// 如果队列是满的话,会阻塞当前线程
sharedQueue.put(prod);
System.out.println("我是生产线程,生产了一个产品:" + prod);
} catch (Exception e) {
System.out.println(e);
}
}
}
// 消费者
class Consumer implements Runnable {
private BlockingQueue<String> sharedQueue;
public Consumer(BlockingQueue<String> sharedQueue) {
this.sharedQueue = sharedQueue;
}
@Override
public void run() {
try {
// 如果队列为空,会阻塞当前线程
String prod = sharedQueue.take();
System.out.println("我是消费者,消费产品: " + prod);
} catch (Exception e) {
System.out.println(e);
}
}
}

2、使用Condition实现
import java.util.PriorityQueue;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
/**
* @Description: Condition实现生产者消费者模式
*/
public class ProducerConsumerPattern2 {
private PriorityQueue<String> queue = new PriorityQueue<String>(3);
private Lock lock = new ReentrantLock();
private Condition notFull = lock.newCondition();
private Condition notEmpty = lock.newCondition();
public static void main(String[] args) {
ProducerConsumerPattern2 test = new ProducerConsumerPattern2();
Producer producer = test.new Producer();
Consumer consumer = test.new Consumer();
for(int i = 0; i < 5; i++) {
new Thread(producer, "Producer" + (i + 1)).start();
new Thread(consumer, "Consumer" + (i + 1)).start();
}
}
class Producer implements Runnable {
@Override
public void run() {
lock.lock();
try {
while(queue.size() == 3) {
try {
notFull.await();
} catch (Exception e) {
e.printStackTrace();
}
}
// 每次插入一个元素
String prod = "" + Thread.currentThread().getName();
queue.offer(prod);
System.out.println("我是生产线程,生产了一个产品:" + prod);
// 通知队列不空
notEmpty.signal();
} finally {
lock.unlock();
}
}
}
class Consumer implements Runnable {
@Override
public void run() {
lock.lock();
try {
while(queue.size() == 0) {
try {
notEmpty.await();
} catch (Exception e) {
e.printStackTrace();
}
}
String prod = queue.poll();
System.out.println("我是消费者,消费产品: " + prod);
// 通知队列未满
notFull.signal();
} finally {
lock.unlock();
}
}
}
}

47、struts2的执行流程?
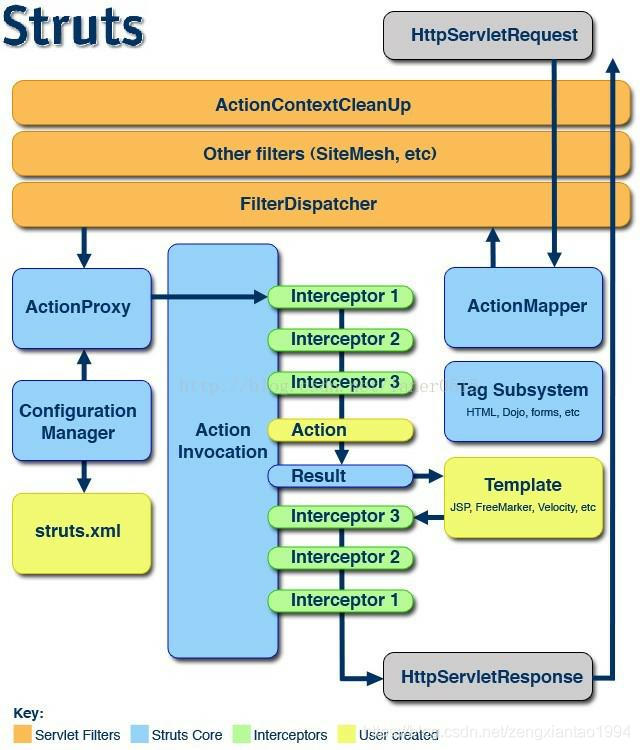 在Struts2框架中的处理大概分为以下的步骤
1、用户发送请求;
2、这个请求经过一系列的过滤器(Filter)(这些过滤器中有一个叫做ActionContextCleanUp的可选过滤器,这个过滤器对于Struts2和其他框架的集成很有帮助,例如:SiteMesh Plugin);
3、接着FilterDispatcher被调用,FilterDispatcher询问ActionMapper来决定这个请求是否需要调用某个Action;
4、如果需要处理,ActionMapper会通知FilterDispatcher,需要处理这个请求,FilterDispatcher会停止过滤器链以后的部分,(这也就是为什么,FilterDispatcher应该出现在过滤器链的最后的原因)。FilterDispatcher把请求的处理交给ActionProxy;
5、ActionProxy通过Configuration Manager询问框架的配置文件struts.xml,找到需要调用的Action类 。(在服务器启动的时候,ConfigurationManager就会把struts.xml中的所有信息读到内存里,并缓存,当ActionProxy带着URL向他询问要运行哪个Action的时候,就可以直接匹配、查找并回答了);
6、ActionProxy创建一个ActionInvocation的实例。
7、ActionInvocation实例使用命名模式来调用,在调用Action的过程前后,涉及到一系列相关拦截器(Intercepter)的调用。
8、一旦Action执行完毕,ActionInvocation负责根据struts.xml中的配置找到对应的返回结果。返回结果通常是(但不总是,也可能是另外的一个Action链)一个需要被表示的JSP或者FreeMarker的模版。在表示的过程中可以使用Struts2 框架中继承的标签。
9、最后,ActionInvocation对象倒序执行拦截器。
10、ActionInvocation对象执行完毕后,响应用户。
注意:2.1.3之后的核心过滤器由FilterDispatcher换成StrutsPrepareAndExecuteFilter。
在Struts2框架中的处理大概分为以下的步骤
1、用户发送请求;
2、这个请求经过一系列的过滤器(Filter)(这些过滤器中有一个叫做ActionContextCleanUp的可选过滤器,这个过滤器对于Struts2和其他框架的集成很有帮助,例如:SiteMesh Plugin);
3、接着FilterDispatcher被调用,FilterDispatcher询问ActionMapper来决定这个请求是否需要调用某个Action;
4、如果需要处理,ActionMapper会通知FilterDispatcher,需要处理这个请求,FilterDispatcher会停止过滤器链以后的部分,(这也就是为什么,FilterDispatcher应该出现在过滤器链的最后的原因)。FilterDispatcher把请求的处理交给ActionProxy;
5、ActionProxy通过Configuration Manager询问框架的配置文件struts.xml,找到需要调用的Action类 。(在服务器启动的时候,ConfigurationManager就会把struts.xml中的所有信息读到内存里,并缓存,当ActionProxy带着URL向他询问要运行哪个Action的时候,就可以直接匹配、查找并回答了);
6、ActionProxy创建一个ActionInvocation的实例。
7、ActionInvocation实例使用命名模式来调用,在调用Action的过程前后,涉及到一系列相关拦截器(Intercepter)的调用。
8、一旦Action执行完毕,ActionInvocation负责根据struts.xml中的配置找到对应的返回结果。返回结果通常是(但不总是,也可能是另外的一个Action链)一个需要被表示的JSP或者FreeMarker的模版。在表示的过程中可以使用Struts2 框架中继承的标签。
9、最后,ActionInvocation对象倒序执行拦截器。
10、ActionInvocation对象执行完毕后,响应用户。
注意:2.1.3之后的核心过滤器由FilterDispatcher换成StrutsPrepareAndExecuteFilter。
48、SpringMVC的执行流程?
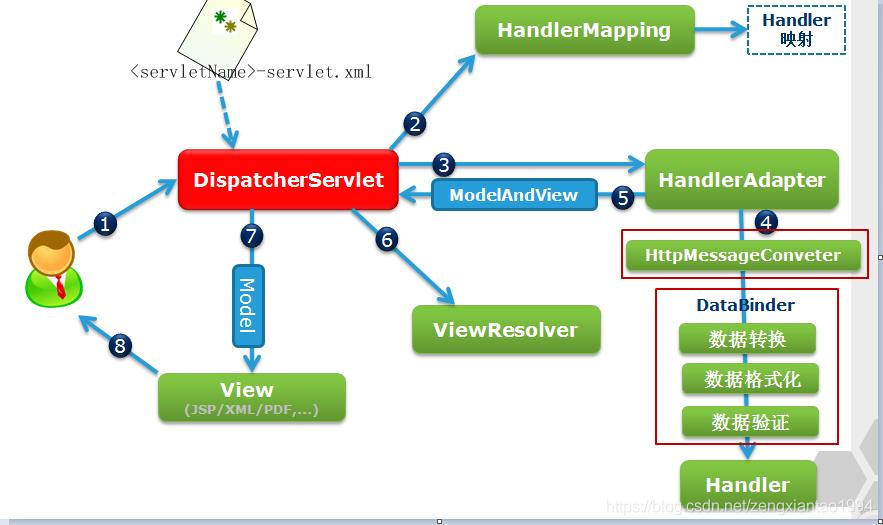 1、用户向服务器发送请求,请求被Spring 前端控制Servelt DispatcherServlet捕获;
2、DispatcherServlet对请求URL进行解析,得到请求资源标识符(URI)。然后根据该URI,调用HandlerMapping获得该Handler配置的所有相关的对象(包括Handler对象以及Handler对象对应的拦截器),最后以HandlerExecutionChain对象的形式返回;
3、DispatcherServlet 根据获得的Handler,选择一个合适的HandlerAdapter。(附注:如果成功获得HandlerAdapter后,此时将开始执行拦截器的preHandler(…)方法);
4、提取Request中的模型数据,填充Handler入参,开始执行Handler(Controller)。在填充Handler的入参过程中,根据你的配置,Spring将帮你做一些额外的工作:
HttpMessageConveter:将请求消息(如Json、xml等数据)转换成一个对象,将对象转换为指定的响应信息;
数据转换:对请求消息进行数据转换。如String转换成Integer、Double等;
数据格式化:对请求消息进行数据格式化。如将字符串转换成格式化数字或格式化日期等;
数据验证:验证数据的有效性(长度、格式等),验证结果存储到BindingResult或Error中;
5、Handler执行完成后,向DispatcherServlet 返回一个ModelAndView对象;
6、根据返回的ModelAndView,选择一个适合的ViewResolver(必须是已经注册到Spring容器中的ViewResolver)返回给DispatcherServlet;
7、ViewResolver 结合Model和View,来渲染视图;
8、将渲染结果返回给客户端。
1、用户向服务器发送请求,请求被Spring 前端控制Servelt DispatcherServlet捕获;
2、DispatcherServlet对请求URL进行解析,得到请求资源标识符(URI)。然后根据该URI,调用HandlerMapping获得该Handler配置的所有相关的对象(包括Handler对象以及Handler对象对应的拦截器),最后以HandlerExecutionChain对象的形式返回;
3、DispatcherServlet 根据获得的Handler,选择一个合适的HandlerAdapter。(附注:如果成功获得HandlerAdapter后,此时将开始执行拦截器的preHandler(…)方法);
4、提取Request中的模型数据,填充Handler入参,开始执行Handler(Controller)。在填充Handler的入参过程中,根据你的配置,Spring将帮你做一些额外的工作:
HttpMessageConveter:将请求消息(如Json、xml等数据)转换成一个对象,将对象转换为指定的响应信息;
数据转换:对请求消息进行数据转换。如String转换成Integer、Double等;
数据格式化:对请求消息进行数据格式化。如将字符串转换成格式化数字或格式化日期等;
数据验证:验证数据的有效性(长度、格式等),验证结果存储到BindingResult或Error中;
5、Handler执行完成后,向DispatcherServlet 返回一个ModelAndView对象;
6、根据返回的ModelAndView,选择一个适合的ViewResolver(必须是已经注册到Spring容器中的ViewResolver)返回给DispatcherServlet;
7、ViewResolver 结合Model和View,来渲染视图;
8、将渲染结果返回给客户端。
49、struts2和springMVC的区别
目前企业中使用SpringMVC的比例已经远远超过Struts2,那么两者到底有什么区别,是很多初学者比较关注的问题,下面我们就来对SpringMVC和Struts2进行各方面的比较: 1、核心控制器(前端控制器、预处理控制器):对于使用过mvc框架的人来说这个词应该不会陌生,核心控制器的主要用途是处理所有的请求,然后对那些特殊的请求(控制器)统一的进行处理(字符编码、文件上传、参数接受、异常处理等等),SpringMVC核心控制器是Servlet,而Struts2是Filter。 2、控制器实例:SpringMVC会比Struts快一些(理论上)。SpringMVC是基于方法设计,而Sturts是基于对象, 每次发一次请求都会实例一个action,每个action都会被注入属性,而Spring更像Servlet一样,只有一个实例,每次请求执行对应的方法即可(注意:由于是单例实例,所以应当避免全局变量的修改,这样会产生线程安全问题)。 3、管理方式:大部分的公司的核心架构中,就会使用到spring,而SpringMVC又是spring中的一个模块,所以spring对于SpringMVC的控制器管理更加简单方便,而且提供了全注解方式进行管理,各种功能的注解都比较全面,使用简单,而struts2需要采用XML很多的配置参数来管理(虽然也可以采用注解,但是几乎没有公司那样使用)。 4、参数传递:Struts2中自身提供多种参数接受,其实都是通过(ValueStack)进行传递和赋值,而SpringMVC是通过方法的参数进行接收。 5、学习难度:Struts有更多的新技术点,比如拦截器、值栈及OGNL表达式,学习成本较高,SpringMVC比较简单,用较少的时间都能上手。 6、intercepter 的实现机制:struts有自己的interceptor机制,SpringMVC用的是独立的AOP方式。这样导致struts的配置文件量还是比SpringMVC大,虽然struts的配置能继承。所以理论使用上来讲,SpringMVC使用更加简洁,开发效率SpringMVC确实比struts2高。**SpringMVC是方法级别的拦截,一个方法对应一个request上下文,**而方法同时又跟一个url对应,所以说从架构本身上SpringMVC就容易实现restful url。**struts2是类级别的拦截,一个类对应一个request上下文;**实现restful url要费劲,因为struts2 action的一个方法可以对应一个url;而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其所属方法了。SpringMVC的方法之间基本上独立的,独享request、response数据,请求数据通过参数获取,处理结果通过ModelMap交回给框架,方法之间不共享变量,而struts2搞的就比较乱,虽然方法之间也是独立的,但其所有Action变量是共享的,这不会影响程序运行,却给我们编码,读程序时带来麻烦。 7、SpringMVC处理ajax请求,直接通过返回数据,方法中使用注解@ResponseBody,SpringMVC自动帮我们对象转换为JSON数据。而struts2是通过插件的方式进行处理。 在SpringMVC流行起来之前,Struts2在MVC框架中占核心地位,随着SpringMVC的出现,SpringMVC慢慢的取代struts2,但是很多企业都是原来搭建的框架,使用Struts2较多。
50. Spring两大核心IOC与AOP
50.1、IoC(Inversion of Control)
IOC的基本概念是:不创建对象,但是描述创建它们的方式。在代码中不直接与对象和服务连接,但在配置文件中描述哪一个组件需要哪一项服务。容器负责将这些联系在一起。 其原理是基于OO设计原则的The Hollywood Principle:Don’t call us, we’ll call you(别找我,我会来找你的)。也就是说,所有的组件都是被动的(Passive),所有的组件初始化和调用都由容器负责。组件处在一个容器当中,由容器负责管理。 简单的来讲,就是由容器控制程序之间的关系,而非传统实现中,由程序代码直接操控。这也就是所谓“控制反转”的概念所在:控制权由应用代码中转到了外部容器,控制权的转移,是所谓反转。 (1)IoC(Inversion of Control)是指容器控制程序对象之间的关系,而不是传统实现中,由程序代码直接操控。控制权由应用代码中转到了外部容器,控制权的转移是所谓反转。对于Spring而言,就是由Spring来控制对象的生命周期和对象之间的关系;IoC还有另外一个名字——“依赖注入(Dependency Injection)”。从名字上理解,所谓依赖注入,即组件之间的依赖关系由容器在运行期决定,即由容器动态地将某种依赖关系注入到组件之中。 (2)在Spring的工作方式中,所有的类都会在spring容器中登记,告诉spring这是个什么东西,你需要什么东西,然后spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。所有的类的创建、销毁都由 spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被spring控制,所以这叫控制反转。 (3)在系统运行中,动态的向某个对象提供它所需要的其他对象。 (4)**依赖注入的思想是通过反射机制实现的,**在实例化一个类时,它通过反射调用类中set方法将事先保存在HashMap中的类属性注入到类中。 总而言之,在传统的对象创建方式中,通常由调用者来创建被调用者的实例,而在Spring中创建被调用者的工作由Spring来完成,然后注入调用者,即所谓的依赖注入or控制反转。 注入方式有两种:依赖注入和设置注入; IoC的优点:降低了组件之间的耦合,降低了业务对象之间替换的复杂性,使之能够灵活的管理对象。
50.2、AOP(Aspect Oriented Programming)
AOP即Aspect-Oriented Programming的缩写,中文意思是面向切面编程,也有译作面向方面编程的,因为Aspect有“方面、见地”的意思。AOP实际上是一种编程思想,由Gregor Kiczales在Palo Alto研究中心领导的一个研究小组于1997年提出。在传统的面向对象(Object-Oriented Progr amming,OOP)编程中,对垂直切面关注度很高,横切面关注却很少,也很难关注。也就是说,我们利用OOP思想可以很好的处理业务流程,却不能把系统中的某些特定的重复性行为封装在某个模块中。比如在很多的业务中都需要记录操作日志,结果我们不得不在业务流程种嵌入大量的日志记录代码。无论是对业务代码还是对日志记录代码来说,今后的维护都是非常复杂的。由于系统种嵌入了这种大量的与业务无关的其它重复性代码,系统的复杂性、代码的重复性增加了,从而使bug的发生率也大大的增加。 在OOP面向对象编程中,我们总是按照某种特定的执行顺序来实现业务流程,各个执行步骤之间是相互衔接、相互耦合的。比如某个对象抛出了异常,我们就必须对异常进行处理后才能进行下一步的操作;又比如我们要把一个学生记录插入到教务管理系统的学生表中去,那么我们就必须按照注册驱动程序、连接数据库、创建 一个statement、生成并执行SQL语句、处理结果、关闭JDBC对象等步骤按部就班的编写我们的代码。可以看到上面的步骤种除了执行SQL和处理结果是我们业务流程所必须的外,其它的都是重复的准备和殿后工作,与业务流程毫无关系,另外我们还得要考虑程序执行过程中的异常。天!我们只是需要向一张表中插入数据而已,可是却不得不和这些大量的重复代码纠缠在一起,我们不得不把大量的精力用在这些代码上而无法专心的设计业务流程。 那么什么可以解决这个问题呢?这时候,我们需要AOP,关注系统的“截面”,在适当的时候“拦截”程序的执行流程,把程序的预处理和后处理交给某个拦截器来完成。比如在操作数据库时要记录日志,如果使用AOP的编程思想,那么我们在处理业务流程时不必再考虑日志记录,而是把它交给一个特定的日志记录模块去完成。这样,业务流程就完全的从其它无关的代码中解放出来,各模块之间的分工更加明确,程序维护也变得容易多了。 正如上所说,AOP不是一种技术,而是编程思想。凡是符合AOP思想的技术,都可以看成是AOP的实现。目前的AOP实现有AspectJ、 JBoss4.0、nanning、spring等项目。其中Spring对AOP进行了很好的实现,同时Spring AOP也是Spring的两大核心之一。
下面介绍一些关于AOP的一些概念: 连接点(join point): 它是指应用中执行的某个点,即程序执行流程中的某个点。如执行某个语句或者语句块、执行某个方法、装载某个类、抛出某个异常……,如下:
public static void main(String[] args) throws Exception {
int i = 0;
i++;
CallMyMethod();
throw new Exception( "哈哈,一个异常!" );
}
注意:这里每一个语句都可以被称作一个连接点。 连接点是有“强弱”的,这种强弱可以用“粒度”来表示,Spring AOP支持到方法级的连接点粒度。 切入点(pointcut): 切入点是连接点的集合,它通常和装备联系在一起,是切面和程序流程的交叉点。比如说,定义了一个pointcut,它将抛出异常ClassNotFoundException和某个装备联系起来,那么在程序执行过程中,如果抛出了该异常,那么相应的装备就会被触发执行。 装备(advice): 也可以叫做“通知”,指切面在程序运行到某个连接点所触发的动作。在这个动作中我们可以定义自己的处理逻辑。装备需要利用切入点和连接点联系起来才会被触发。目前AOP定义了五种装备:前置装备(Before advice)、后置装备(After advice)、环绕装备(Around Advice)、异常装备(After throwing advice)、返回后装备(After returning advice)。 目标对象(target object): 被一个或者多个切面装备的对象。所以它有时候也被称为Advised Object。 引入(introduction): 声明额外的成员字段或者成员方法。它可以给一个确定的对象新增某些字段或者方法。 织入(weaving): 将切面和目标对象联系在一起的过程。这个过程可以在编译期完成,也可以在类加载时和运行时完成。Spring AOP是在运行期完成织入的。 切面(aspect): 一个关注点的模块化。它实际上是一段将被织入到程序流程中的代码。
(1)AOP面向方面编程基于IoC,是对OOP的有益补充; (2)AOP利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其命名为“Aspect”,即方面。所谓“方面”,简单地说,就是将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,比如日志记录,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。 (3)AOP代表的是一个横向的关系,将“对象”比作一个空心的圆柱体,其中封装的是对象的属性和行为;则面向方面编程的方法,就是将这个圆柱体以切面形式剖开,选择性的提供业务逻辑。而剖开的切面,也就是所谓的“方面”了。然后它又以巧夺天功的妙手将这些剖开的切面复原,不留痕迹,但完成了效果。 (4)实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。 (5)Spring实现AOP:JDK动态代理和CGLIB代理 JDK动态代理:其代理对象必须是某个接口的实现,它是通过在运行期间创建一个接口的实现类来完成对目标对象的代理;其核心的两个类是InvocationHandler和Proxy。 CGLIB代理:实现原理类似于JDK动态代理,只是它在运行期间生成的代理对象是针对目标类扩展的子类。CGLIB是高效的代码生成包,底层是依靠ASM(开源的java字节码编辑类库)操作字节码实现的,性能比JDK强;需要引入包asm.jar和cglib.jar。 使用AspectJ注入式切面和@AspectJ注解驱动的切面实际上底层也是通过动态代理实现的。 (6)AOP使用场景: Authentication 权限检查 Caching 缓存 Context passing 内容传递 Error handling 错误处理 Lazy loading 延迟加载 Debugging 调试 Logging,tracing,profiling and monitoring 日志记录,跟踪,优化,校准 Performance optimization 性能优化,效率检查 Persistence 持久化 Resource pooling 资源池 Synchronization 同步 Transactions 事务管理 另外Filter的实现和struts2的拦截器的实现都是AOP思想的体现。
51、Mysql数据库引擎
| 名称 | 事务 | 外键 | 索引 | 适用范围 | 优势、特点 |
|---|---|---|---|---|---|
| Myisam | 不支持 | 不支持 | B+树 | 读操作远多于写操作,不需要事务支持 | 访问速度快,对事务完整性没有要求,保存了表的行数 |
| Innodb | 支持 | 支持 | B+树 | 并发度较高、需要支持事务的场景 | 占用更多的空间以保留数据和索引,不保存表的行数 |
| Memory | B树、HASH | 很快的读写速度,安全性要求较低,表小 | 使用内存来创建表、处理速度快,但安全性不高。 | ||
| Merge | 是一组MyISAM表的组合 |
(1)、ISAM:该引擎在读取数据方面速度很快,而且不占用大量的内存和存储资源;但是ISAM不支持事务处理、不支持外键、不能够容错、也不支持索引。该引擎在包括MySQL 5.1及其以上版本的数据库中不再支持。
(2)、MyISAM存储引擎:mysql默认的引擎(mysql 5.1版本以前),不支持事务、也不支持行级锁和外键。 因此当执行Insert插入和Update更新语句时,即执行写操作的时候需要锁定这个表,所以会导致效率会降低。它优势是访问速度快,对事务完整性没有要求,和Innodb相比,MyIASM引擎是保存了表的行数,于是当进行select count(*) from table语句时,可以直接的读取已经保存的值而不需要进行扫描全表。以select,insert为主的应用基本上可以用这个引擎来创建表。 支持3种不同的存储格式,分别是:静态表;动态表;压缩表。 静态表:表中的字段都是非变长字段,这样每个记录都是固定长度的,优点是存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多(因为存储时会按照列的宽度定义补足空格)ps:在取数据的时候,默认会把字段后面的空格去掉,如果不注意会把数据本身带的空格也会忽略。 动态表:记录不是固定长度的,这样存储的优点是占用的空间相对较少;缺点:频繁的更新、删除数据容易产生碎片,需要定期执行OPTIMIZE TABLE或者myisamchk-r命令来改善性能。 压缩表:因为每个记录是被单独压缩的,所以只有非常小的访问开支。
(3)、InnoDB存储引擎(在新版本的mysql中成为默认存储引擎):Innodb引擎提供了对数据库ACID事务的支持。并且还提供了行级锁和外键的约束,以及自动增长列的支持。 它的设计的目标就是处理大数据容量的数据库系统。它本身实际上是基于Mysql后台的完整的系统。Mysql运行的时候,Innodb会在内存中建立缓冲池,用于缓冲数据和索引。但是,该引擎是不支持全文搜索的。同时,启动也比较的慢,它是不会保存表的行数的。对比MyISAM引擎,写的处理效率会差一些,并且会占用更多的磁盘空间以保留数据和索引。
(4)、MEMORY存储引擎:Memory存储引擎使用存在于内存中的内容来创建表。每个memory表只实际对应一个磁盘文件,格式是.frm。memory类型的表访问非常的快,因为它的数据是放在内存中的,并且默认使用HASH索引,但是一旦服务关闭,表中的数据就会丢失掉。 MEMORY存储引擎的表可以选择使用BTREE索引或者HASH索引,两种不同类型的索引有其不同的使用范围: Hash索引优点:Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree索引需要从根节点到枝节点,最后才能访问到叶节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引; Hash索引缺点:那么不精确查找呢,也很明显,因为hash算法是基于等值计算的,所以对于“like”等范围查找hash索引无效,不支持。 Memory类型的存储引擎主要用于那些内容变化不频繁的代码表,或者作为统计操作的中间结果表,便于高效地对中间结果进行分析并得到最终的统计结果。对存储引擎为memory的表进行更新操作要谨慎,因为数据并没有实际写入到磁盘中,所以一定要对下次重新启动服务后如何获得这些修改后的数据有所考虑。
(5)、MERGE存储引擎:Merge存储引擎是一组MyISAM表的组合,这些MyISAM表必须结构完全相同,merge表本身并没有数据,对merge类型的表可以进行查询,更新,删除操作,这些操作实际上是对内部的MyISAM表进行的。
MyISAM和InnoDB的区别
Mysql5.1之前的默认引擎是MyISAM,mysql5.1之后的默认引擎是InnoDB。 1、事务处理上方面 MyISAM 强调的是性能,查询的速度比 InnoDB 类型更快,但是不提供事务支持。InnoDB 提供事务支持。 2、表主键 MyISAM:允许没有主键的表存在。InnoDB:如果没有设定主键,就会自动生成一个 6 字节的主键(用户不可见)。 3、外键 MyISAM 不支持外键,InnoDB 支持外键。 4、全文索引 MyISAM 支持全文索引,InnoDB 不支持全文索引。innodb 从 mysql 5.6 版本开始提供对全文索引的支持。 5、锁 MyISAM 只支持表级锁,InnoDB 支持行级锁和表级锁,默认是行级锁,行锁大幅度提高了多用户并发操作的性能。innodb 比较适合于插入和更新操作比较多的情况,而 myisam 则适合用于频繁查询的情况。另外,InnoDB 表的行锁也不是绝对的,如果在执行一个 SQL 语句时,MySQL 不能确定要扫描的范围,InnoDB 表同样会锁全表,例如 update table set num=1 where name like “%aaa%”。 6、表的具体行数 MyISAM:select count() from table,MyISAM 只要简单的读出保存好的行数。因为MyISAM 内置了一个计数器,count()时它直接从计数器中读。 InnoDB:不保存表的具体行数,也就是说,执行 select count(*) from table 时,InnoDB要扫描一遍整个表来计算有多少行。
52、数据库范式
数据库的“范式”,指的是设计数据库的规则。按照一定的规则设计出数据库的表和关系,能够避免在一些情况下的查询出错,并具有良好的结构。总的来说,随着范式等级的提高,数据表属性之间的依赖关系越来越小,数据冗余越来越低。但同时,数据关系变得更加复杂, 访问一个具体数据的关系层次增加。所以像设计模式一样,不应盲目追求范式等级,应根据具体需求来选择范式。 几个概念: 1、超键(super key):能够唯一标识一条记录的属性或属性集。 2、候选键(candidate key):能够唯一标识一条记录的最小属性集,候选键是没有多余属性的超键,候选键可能有多个。 3、主键(主码、primary key):某个能够唯一标识一条记录的最小属性集,选取某个候选键为主键。 4、外键(foreign key):子数据表中出现的父数据表的主键,称为子数据表的外键。 5、代理键:当不适合用任何一个候选键作为主键时(如数据太长等),添加一个没有实际意义的键作为主键,这个键就是代理键。(如常用的序号1、2、3)
部分函数依赖:设X,Y是关系R的两个属性集合,存在X→Y,若X’是X的真子集,存在X’→Y,则称Y部分函数依赖于X。 举个例子:学生基本信息表R中(学号,身份证号,姓名)当然学号属性取值是唯一的,在R关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号); 完全函数依赖:设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’!→Y,则称Y完全函数依赖于X。 例子:学生基本信息表R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在R关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级); 传递函数依赖:设X,Y,Z是关系R中互不相同的属性集合,存在X→Y(Y !→X),Y→Z,则称Z传递函数依赖于X。 例子:在关系R(学号,宿舍,费用)中,(学号)->(宿舍),宿舍!=学号,(宿舍)->(费用),费用!=宿舍,所以符合传递函数的要求;
| 范式等级 | 说明 |
|---|---|
| 1NF | 每一列都是原子项,不可分割 |
| 2NF | 非主键属性均完全依赖于主属性,消除部分依赖 |
| 3NF | 所有非主键属性之间没有依赖关系,消除传递依赖 |
| BCNF | 所有属性均不传递依赖于任何候选键 |
| 4NF | 表中不包含超过一个多值属性,消除多值依赖 |
| 5NF | 将表拆分为二元关系,一定会损失信息 |
第一范式(1NF):每一个属性都不能再分割,都是原子项。 说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。减少了数据的冗余,节省存储空间,某些情况下减少了数据访问的层数,提高数据访问速度。 第二范式(2NF):满足第一范式,非主键属性均完全依赖于主键,不能只是部分依赖主键。 2NF消除了属性对主键的部分函数依赖。 可以在一定程度上消除冗余,节省存储空间。如果存在部分函数依赖,则可能存在数据冗余。在多条记录中,主键中的某一个属性可能是一样的,而如果有其他数据项函数依赖于这个不变的属性,则这些数据项也将是一样的。 第三范式(3NF):满足第一、二范式,要求每列都与主键有直接关系,不存在传递依赖。所有非主键属性之间没有函数依赖关系。 既然存在函数依赖,某些数据项就能够通过其他数据项计算得出,很可能存在数据冗余。值得注意的是,在一些情况下,存在这种数据冗余有意义的。如果在表格中存储着某些运算的结果,我们在使用这些结果时就不用进行运算了,节省了运算时间,是一种“空间换时间”的做法。从这里也可以看出,应用范式并不能够保证最好的效果,需要根据应用需求进行合理取舍。 BC范式(boyce-codd范式,BCNF):满足1NF、2NF、3NF,所有属性(包含主键属性和非键主属性)都不传递依赖于任何候选键。 BC范式在3NF的基础上,要求主键属性也不能传递依赖于任何候选键。当主键是复合键时,主键的某个属性可能会依赖于某个候选键。此时,关系能够符合3NF,因为并不是“非主键”属性依赖于某个非主键属性。但此关系并不符合BC范式。 第四范式:要求把同一表内的多对多关系删除。(表中不能包含一个实体的两个或多个多值属性) 所谓多值属性,指的是某个属性可以包含多个值。这个属性的(多个)取值,被另一个属性决定。也就是说,一旦确定了某个属性,另一个属性的多个取值就一起确定了。第四范式在第三范式的基础上,消除多值依赖。(一个表只允许一个多值依赖),消除了多值依赖,可以降低数据冗余,增删改都简单了,减少数据处理复杂度。 第五范式:满足1NF、2NF、3NF、4NF,如果将表中的多元关系分解成一个一个的二元关系,一定会丢失信息。 第五范式在4NF的基础上,进一步消除依赖。第五范式的要求明确,如果不用这个表就不能正确说明数据之间的联系。所以符合5NF的表已经没有任何多余依赖的存在了。所以第五范式是一个比较理想的范式。
53、数据库事务的四大特性(ACID)
如果一个数据库声称支持事务的操作,那么该数据库必须要具备以下四个特性: 1、原子性(Atomicity) 原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚,因此事务的操作如果成功就必须要完全应用到数据库,如果操作失败则不能对数据库有任何影响。 2、一致性(Consistency) 一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。 拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。 3、隔离性(Isolation) 隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。 即要达到这么一种效果:对于任意两个并发的事务T1和T2,在事务T1看来,T2要么在T1开始之前就已经结束,要么在T1结束之后才开始,这样每个事务都感觉不到有其他事务在并发地执行。 4、持久性(Durability) 持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。 例如我们在使用JDBC操作数据库时,在提交事务方法后,提示用户事务操作完成,当我们程序执行完成直到看到提示后,就可以认定事务已经正确提交,即使这时候数据库出现了问题,也必须要将我们的事务完全执行完成,否则就会造成我们看到提示事务处理完毕,但是数据库因为故障而没有执行事务的重大错误。
现在重点来说明下事务的隔离性,当多个线程都开启事务操作数据库中的数据时(并发事务),数据库系统要能进行隔离操作,以保证各个线程获取数据的准确性,在介绍数据库提供的各种隔离级别之前,我们先看看如果不考虑事务的隔离性,会发生的几种问题: 1、更新丢失 两个事务T1和T2读入同一数据并修改,T2提交的结果覆盖了T1提交的结果,导致T1的修改被丢失。 2、脏读 脏读是指在一个事务处理过程里读取了另一个未提交的事务(或者事务由于某种原因被撤销)中的数据。 当一个事务正在多次修改某个数据,而在这个事务中这多次的修改都还未提交,这时一个并发的事务来访问该数据,就会造成两个事务得到的数据不一致。例如:用户A向用户B转账100元,对应SQL命令如下: update account set money = money + 100 where name = ’B’;(此时A通知B) update account set money = money - 100 where name = ’A’; 当只执行第一条SQL时,A通知B查看账户,B发现确实钱已到账(此时即发生了脏读),而之后无论第二条SQL是否执行,只要该事务不提交,则所有操作都将回滚,那么当B以后再次查看账户时就会发现钱其实并没有转。 3、不可重复读 不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。 例如事务T1在读取某一数据,而事务T2立马修改了这个数据并且提交事务给数据库,事务T1再次读取该数据就得到了不同的结果,发送了不可重复读。 不可重复读和脏读的区别是,脏读是某一事务读取了另一个事务未提交的脏数据,而不可重复读则是读取了前一事务提交的数据。 4、虚读(幻读) 幻读是事务非独立执行时发生的一种现象。例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。 幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。 现在来看看MySQL数据库为我们提供的四种隔离级别: ①、Serializable(串行化):可避免脏读、不可重复读、幻读的发生。 ②、Repeatable read(可重复读):可避免脏读、不可重复读的发生。 ③、Read committed(读已提交):可避免脏读的发生。 ④、Read uncommitted (读未提交):最低级别,任何情况都无法保证。 以上四种隔离级别最高的是Serializable级别,最低的是Read uncommitted级别,当然级别越高,执行效率就越低。像Serializable这样的级别,就是以锁表的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。在MySQL数据库中默认的隔离级别为Repeatable read(可重复读)。
54、数据库索引
索引的优缺点
优点: 1、大大加快数据的检索速度; 2、创建唯一性索引,保证数据库表中每一行数据的唯一性; 3、加速表和表之间的连接; 4、在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间。 缺点: 1、索引需要占物理空间; 2、当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,降低数据的维护速度。
索引的分类
1、唯一索引: 是在表上一个或者多个字段组合建立的索引,这个或者这些字段的值组合起来在表中不可以重复。
2、非唯一索引: 是在表上一个或者多个字段组合建立的索引,这个或者这些字段的值组合起来在表中可以重复,不要求唯一。
3、主键索引(主索引): 是唯一索引的特定类型。表中创建主键时自动创建的索引,一个表只能建立一个主索引。
4、聚集索引(聚簇索引、Innodb):表中记录的物理顺序与键值的索引顺序相同。 因为真实数据的物理顺序只有一种,所以一个表只能有一个聚集索引。叶子节点(B+树)存储真实的数据行,不再有另外单独的数据页。
5、非聚集索引(Mylsam):表中记录的物理顺序与键值的索引顺序不同。这也是非聚集索引与聚集索引的根本区别。叶子节点并非数据节点,而是每一个指向真正数据行的指针。 聚集索引与非聚集索引的区别: 1)、聚集索引的优缺点:优点是查询速度快,因为一旦具有第一个索引值的记录被找到,具有连续索引值的记录也一定物理的紧跟其后。缺点是对表进行修改速度较慢,这是为了保持表中的记录的物理顺序与索引顺序的一致,而把记录插入到数据页的相应位置,必须在数据页中进行数据重排,降低了执行速度。在插入新记录时数据文件为了维持 B+Tree 的特性而频繁的分裂调整,十分低效。 建议使用聚集索引的场合为:A.某列包含了小数目的不同值。B.排序和范围查找。 2)、聚集索引和非聚集索引都采用了B+树的结构,但非聚集索引的叶子层并不与实际的数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针的方式。聚集索引的叶节点就是数据节点,而非聚集索引的叶节点仍然是索引节点。 3)、非聚集索引添加记录时,不会引起数据顺序的重组。
看上去聚簇索引的效率明显要低于非聚簇索引,因为每次使用辅助索引检索都要经过两次 B+树查找,这不是多此一举吗?聚簇索引的优势在哪? 1)、由于行数据和叶子节点存储在一起,这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键 Id 来组织数据,获得数据更快。 2)、辅助索引使用主键作为"指针",而不是使用地址值作为指针的好处是,减少了当出现行移动或者数据页分裂时,辅助索引的维护工作,InnoDB 在移动行时无须更新辅助索引中的这个"指针"。也就是说行的位置会随着数据库里数据的修改而发生变化,使用聚簇键索引就可以保证不管这个主键 B+ 树的节点如何变化,辅助索引树都不受影响。
6、组合索引: 基于多个字段而创建的索引就称为组合索引,组合索引的使用要遵从最左前缀。在最左前缀原则中,范围查询会导致组合索引半生效,where子句有or出现还是会遍历全表。
Mysql怎么增加一个索引
创建索引:create index idx1 on table(col1, col2, col3); 添加索引:alter table tablename add index indexname(col1, col2);
55、数据库索引的实现
目前大部分数据库系统及文件系统都采用B-Tree(B树)或其变种B+Tree(B+树)作为索引结构。B+Tree 是数据库系统实现索引的首选数据结构。 在 MySQL 中,索引属于存储引擎级别的概念, 不同存储引擎对索引的实现方式是不同的。
MyISAM 索引实现(非聚集索引)
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。
 图8是一个MyISAM表的主索引(Primary Key)示意,可以看出 MyISAM 的索引文件仅仅保存数据记录的地址。在 MyISAM 中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求 key 是唯一的,而辅助索引的 key 可以重复。如果我们在 Col2 上建立一个辅助索引,则此索引的结构如下图所示:
图8是一个MyISAM表的主索引(Primary Key)示意,可以看出 MyISAM 的索引文件仅仅保存数据记录的地址。在 MyISAM 中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求 key 是唯一的,而辅助索引的 key 可以重复。如果我们在 Col2 上建立一个辅助索引,则此索引的结构如下图所示:
 同样也是一颗 B+Tree,data 域保存数据记录的地址。因此,MyISAM 中索引检索的算法会首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其data 域的值,然后以 data 域的值为地址,读取相应数据记录。
同样也是一颗 B+Tree,data 域保存数据记录的地址。因此,MyISAM 中索引检索的算法会首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其data 域的值,然后以 data 域的值为地址,读取相应数据记录。
InnoDB 索引实现(聚集索引)
MyISAM 索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB 中,表数据文件本身就是按 B+Tree 组织的一个索引结构,这棵树的叶节点data 域保存了完整的数据记录(第一个重大区别)。 这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。
 上图是 InnoDB 主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为 InnoDB 的数据文件本身要按主键聚集。
1、InnoDB 要求表必须有主键(MyISAM 可以没有), 如果没有显式指定,则 MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL 自动为 InnoDB 表生成一个隐含字段作为主键,类型为长整形。
2、尽量在 InnoDB 上采用自增字段做表的主键。 因为 InnoDB 数据文件本身是一棵B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持 B+Tree 的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
第二个与 MyISAM 索引的不同是 InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。 换句话说,InnoDB 的所有辅助索引都引用主键作为 data 域。
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
引申:为什么不建议使用过长的字段作为主键?因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
上图是 InnoDB 主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为 InnoDB 的数据文件本身要按主键聚集。
1、InnoDB 要求表必须有主键(MyISAM 可以没有), 如果没有显式指定,则 MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL 自动为 InnoDB 表生成一个隐含字段作为主键,类型为长整形。
2、尽量在 InnoDB 上采用自增字段做表的主键。 因为 InnoDB 数据文件本身是一棵B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持 B+Tree 的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
第二个与 MyISAM 索引的不同是 InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。 换句话说,InnoDB 的所有辅助索引都引用主键作为 data 域。
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
引申:为什么不建议使用过长的字段作为主键?因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。
总结
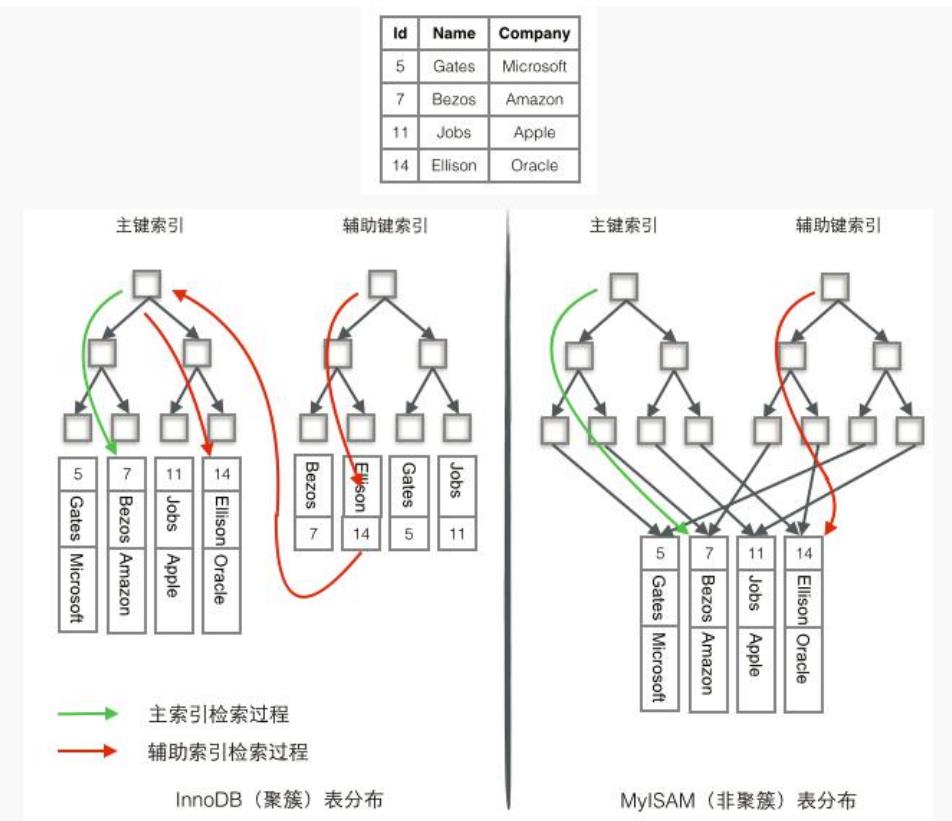 InnoDB使用的是聚簇索引,将主键组织到一棵 B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照 B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对 Name 列进行条件搜索,则需要两个步骤:第一步在辅助索引 B+树中检索 Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树中再执行一次 B+树检索操作,最终到达叶子节点即可获取整行数据。
MyISAM 使用的是非聚簇索引,非聚簇索引的两棵 B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引 B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗 B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
InnoDB使用的是聚簇索引,将主键组织到一棵 B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照 B+树的检索算法即可查找到对应的叶节点,之后获得行数据。若对 Name 列进行条件搜索,则需要两个步骤:第一步在辅助索引 B+树中检索 Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树中再执行一次 B+树检索操作,最终到达叶子节点即可获取整行数据。
MyISAM 使用的是非聚簇索引,非聚簇索引的两棵 B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引 B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗 B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
56、为什么使用B+树作为索引
B/B+ 树性能分析
1、n 个节点的平衡二叉树的高度为 H(即 logn),而 n 个节点的 B/B+树的高度为logt((n+1)/2)+1; 2、若要作为内存中的查找表,B 树却不一定比平衡二叉树好,尤其当 m 较大时更是如此。因为查找操作 CPU 的时间在 B-树上是 O(mlogtn)=O(lgn(m/lgt)),而 m/lgt>1;所以 m较大时O(mlogtn)比平衡二叉树的操作时间大得多。因此在内存中使用B树必须取较小的m。(通常取最小值 m=3,此时 B-树中每个内部结点可以有 2 或 3 个孩子,这种 3 阶的 B-树称为 2-3 树)。
为什么说 B+tree比 B 树更适合实际应用中操作系统的文件索引和数据索引。
B+tree 的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对 B 树更小, 如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对 IO 读写次数就降低了。 由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。 也有人认为数据库索引采用 B+树的主要原因是:B 树在提高了 IO 性能的同时并没有解决元素遍历的效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而 B树不支持这样的操作(或者说效率太低,需要中序遍历)。
57、数据库的锁
锁是一种并发控制技术,锁是用来在多个用户同时访问同一个数据的时候保护数据的。
57.1、有 2 种基本的锁类型
共享(S)锁: 多个事务可封锁一个共享页;任何事务都不能修改该页;通常是该页被读取完毕,S锁立即被释放。在执行 select 语句的时候需要给操作对象(表或者一些记录)加上共享锁,但加锁之前需要检查是否有排他锁,如果没有,则可以加共享锁(一个对象上可以加 n 个共享锁 ),否则不行。共享锁通常在执行完 select 语句之后被释放,当然也有可能是在事务结束(包括正常结束和异常结束)的时候被释放,主要取决于数据库所设置的事务隔离级别。
排它(X)锁: 仅允许一个事务封锁此页;其他任何事务必须等到 X 锁被释放才能对该页进行访问;X 锁一直到事务结束才能被释放。执行 insert、update、delete 语句的时候需要给操作的对象加排他锁,在加排他锁之前必须确认该对象上没有其他任何锁,一旦加上排他锁之后,就不能再给这个对象加其他任何锁。排他锁的释放通常是在事务结束的时候(当然也有例外,就是在数据库事务隔离级别被设置成 Read Uncommitted(读未提交数据)的时候,这种情况下排他锁会在执行完更新操作之后就释放,而不是在事务结束的时候)。
57.2、mysql 锁的粒度(即锁的级别)
MySQL 各存储引擎使用了三种类型(级别)的锁定机制:行级锁定,页级锁定和表级锁定。 1、表级锁, 直接锁定整张表,在你锁定期间,其它进程无法对该表进行写操作。如果你是写锁,则其它进程则读也不允许。特点:开销小,加锁快;不会出现死锁;锁定粒度最大,发生锁冲突的概率最高,并发度最低。 MyISAM 存储引擎采用的是表级锁。 有 2 种模式:表共享读锁和表独占写锁。加读锁的命令:lock table 表名 read;去掉锁的命令:unlock tables。 支持并发插入:支持查询和插入操作并发进行(在表尾并发插入)。 锁调度机制:写锁优先。一个进程请求某个 MyISAM 表的读锁,同时另一个进程也请求同一表的写锁,MySQL 如何处理呢?答案是写进程先获得锁。
2、行级锁, 仅对指定的记录进行加锁,这样其它进程还是可以对同一个表中的其它记录进行操作。特点:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。 InnoDB 存储引擎既支持行级锁,也支持表级锁,但默认情况下是采用行级锁。
3、页级锁, 一次锁定相邻的一组记录。开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
最常用的处理多用户并发访问的方法是加锁。当一个用户锁住数据库中的某个对象时,其他用户就不能再访问该对象。加锁对并发访问的影响体现在锁的粒度上。比如,(表锁)放在一个表上的锁限制对整个表的并发访问;(页锁)放在数据页上的锁限制了对整个数据页的访问;(行锁)放在行上的锁只限制对该行的并发访问。
57.3、按锁的机制分:有悲观锁和乐观锁
悲观锁 ,锁如其名,他对世界是悲观的,他认为别人访问正在改变的数据的概率是很高的,所以从数据开始更改时就将数据锁住,直到更改完成才释放。 一个典型的倚赖数据库的悲观锁调用: select * from account where name=”Erica” for update 这条 sql 语句锁定了 account 表中所有符合检索条件(name=”Erica”)的记录。 本次事务提交之前(事务提交时会释放事务过程中的锁),外界无法修改这些记录。该语句用来锁定特定的行(如果有 where 子句,就是满足 where条件的那些行)。当这些行被锁定后,其他会话可以选择这些行,但不能更改或删除这些行,直到该语句的事务被 commit 语句或 rollback 语句结束为止。需要注意的是,select …for update 要放到 mysql的事务中,即 begin 和commit 中,否则不起作用。 悲观锁可能会造成加锁的时间很长,并发性不好,特别是长事务,影响系统的整体性能。 悲观锁的实现方式: 悲观锁,也是基于数据库的锁机制实现。 传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁 ,他对世界比较乐观,认为别人访问正在改变的数据的概率是很低的,所以直到修改完成,准备提交所做的修改到数据库的时候才会将数据锁住, 当你读取以及改变该对象时并不加锁,完成更改后释放。乐观锁不能解决脏读的问题。 乐观锁加锁的时间要比悲观锁短,大大提升了大并发量下的系统整体性能表现。 乐观锁的实现方式: 1、大多是基于数据版本(Version )记录机制实现, 需要为每一行数据增加一个版本标识(也就是每一行数据多一个字段 version),每次更新数据都要更新对应的版本号+1。 工作原理:读出数据时,将此版本号一同读出,之后更新时,对此版本号加一。 此时,将提交数据的版本信息与数据库表对应记录的当前版本信息进行比对,如果提交的数据版本号大于数据库表当前版本号,则予以更新,否则认为是过期数据,不得不重新读取该对象并作出更改。 假设数据库中帐户信息表中有一个version 字段,当前值为 1;而当前帐户余额字段(balance)为 $100。 1)、操作员 A 此时将其读出(version=1),并从其帐户余额中扣除 $50($100-$50)。 2)、在操作员 A 操作的过程中,操作员 B 也读入此用户信息(version=1),并从其帐户余额中扣除 $20($100-$20)。 3) 操作员 A 完成了修改工作,将数据版本号加一(version=2),连同帐户扣除后余额(balance=$50),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2。 4) 操作员 B 完成了操作,也将版本号加一(version=2)试图向数据库提交数据(balance=$80),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为2,数据库记录当前版本也为 2 ,不满足“提交版本必须大于记录当前版本才能执行更新“的乐观锁策略,因此,操作员 B 的提交被驳回。 这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员 A 的操作结果的可能。 从上面的例子可以看出,乐观锁机制避免了长事务中的数据库加锁开销(操作员 A 和操作员 B 操作过程中,都没有对数据库数据加锁),大大提升了大并发量下的系统整体性能表现。
2、使用时间戳来实现 同样是在需要乐观锁控制的 table 中增加一个字段,名称无所谓,字段类型使用时间戳(timestamp),和上面的 version 类似,也是在更新提交的时候检查当前数据库中数据的时间戳和自己更新前取到的时间戳进行对比,如果一致则 OK,否则就是版本冲突。 悲观锁和乐观锁的适用场景: 如果并发量不大,可以使用悲观锁解决并发问题;但如果系统的并发量非常大的话,悲观锁定会带来非常大的性能问题,所以我们就要选择乐观锁定的方法。
58、数据库存储过程
58.1、存储过程
存储过程:就是一些编译好了的 sql 语句,这些 SQL 语句代码像一个方法一样实现一些功能(对单表或多表的增删改查),然后再给这个代码块取一个名字,在用到这个功能的时候调用他就行了。 优点: 1、存储过程因为 SQL 语句已经预编译过了,因此运行的速度比较快。 2、存储过程在服务器端运行,减少客户端的压力。 3、允许模块化程序设计,就是说只需要创建一次过程,以后在程序中就可以调用该过程任意次,类似方法的复用。 4、减少网络流量,客户端调用存储过程只需要传存储过程名和相关参数即可,与传输 SQL 语句相比自然数据量少了很多。 5、增强了使用的安全性,充分利用系统管理员可以对执行的某一个存储过程进行权限限制,从而能够实现对某些数据访问的限制,避免非授权用户对数据的访问,保证数据的安全。程序员直接调用存储过程,根本不知道表结构是什么,有什么字段,没有直接暴露表名以及字段名给程序员。 缺点: 调试麻烦(至少没有像开发程序那样容易),可移植性不灵活(因为存储过程是依赖于具体的数据库)。
58.2、定义与调用存储过程
create procedure insert_Student (_name varchar(50), _age int, out _id int)
begin
insert into student value(null,_name,_age);
select max(stuId) into _id from student;
end;
call insert_Student('wfz',23,@id);
select @id;
调用存储过程
public class JdbcTest {
public static void main(String[] args) {
// TODO Auto-generated method stub
Connection cn = null;
CallableStatement cstmt = null;
try {
//这里最好不要这么干,因为驱动名写死在程序中了
Class.forName("com.mysql.jdbc.Driver");
//实际项目中,这里应用DataSource数据,如果用框架,这个数据源不需要我们编码创建
cn = DriverManager.getConnection("jdbc:mysql:///test","root","root");
cstmt = cn.prepareCall("{call insert_Student(?,?,?)}");
cstmt.registerOutParameter(3,Types.INTEGER);
cstmt.setString(1, "wangwu");
cstmt.setInt(2, 25);
cstmt.execute();
//get第几个,不同的数据库不一样,建议不写
System.out.println(cstmt.getString(3));
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
try {
if(cstmt != null)
cstmt.close();
if(cn != null)
cn.close();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
59、数据库连接(LEFT)操作
首先定义两个表t1和t2
| ID | NAME |
|---|---|
| 1 | aaa |
| 2 | bbb |
| ID | AGE |
|---|---|
| 1 | 20 |
| 3 | 30 |
内连接(inner join):只显示符合连接条件的记录 select * from t1 inner join t2 on t1.id = t2.id;
| ID | NAME | ID | AGE |
|---|---|---|---|
| 1 | aaa | 1 | 20 |
外连接分为左外连接、右外连接、全外连接三种 1)、左外连接(LEFT JOIN或LEFT OUTER JOIN):即以左表为基准,到右表找到匹配的数据,找不到匹配的用NULL补齐。 最后显示左表的全部记录以及右表符合条件的记录。 select * from t1 left join t2 on t1.id = t2.id;
| ID | NAME | ID | AGE |
|---|---|---|---|
| 1 | aaa | 1 | 20 |
| 2 | bbb | NULL | NULL |
2)、右外连接(RIGHT JOIN 或 RIGHT OUTER JOIN):即以右表为基准,到左表找匹配的数据,找不到匹配的用 NULL 补齐。 显示右表的全部记录及左表符合连接条件的记录。 select * from t1 right join t2 on t1.id = t2.id;
| ID | NAME | ID | AGE |
|---|---|---|---|
| 1 | aaa | 1 | 20 |
| NULL | NULL | 3 | 30 |
3)、全外连接(FULL JOIN 或 FULL OUTER JOIN):除了显示符合连接条件的记录外,在 2 个表中的其他记录也显示出来。
inner join 和 left join的性能比较。 从理论上来分析,确实是 inner join 的性能要好,因为是选出 2 个表都有的记录,而 left join 会出来左边表的所有记录、满足 on 条件的右边表的记录。 1、在解析阶段,左连接是内连接的下一阶段,内连接结束后,把存在于左输入而未存在于右输入的集,加回总的结果集,因此如果少了这一步效率应该要高些。 2、在编译的优化阶段,如果左连接的结果集和内连接一样时,左连接查询会转换成内连接查询,即编译优化器认为内连接要比左连接高效。
60、分组查询
60.1、MySQL对数据表进行分组查询(GROUP BY)
GROUP BY关键字可以将查询结果按照某个字段或多个字段进行分组。字段中值相等的为一组。基本的语法格式如下: GROUP BY 属性名 [HAVING 条件表达式] [WITH ROLLUP] 属性名:是指按照该字段的值进行分组。 HAVING 条件表达式:用来限制分组后的显示,符合条件表达式的结果将被显示。 WITH ROLLUP:将会在所有记录的最后加上一条记录。加上的这一条记录是上面所有记录的总和。 GROUP BY关键字可以和GROUP_CONCAT()函数一起使用。GROUP_CONCAT()函数会把每个分组中指定的字段值都显示出来。 同时,GROUP BY关键字通常与集合函数一起使用。集合函数包括COUNT()函数、SUM()函数、AVG()函数、MAX()函数和MIN()函数等。 COUNT()函数:用于统计记录的条数。 SUM()函数:用于计算字段的值的总和。 AVG()函数:用于计算字段的值的平均值。 MAX()函数:用于查询字段的最大值。 MIN()函数:用于查询字段的最小值。 如果GROUP BY不与上述函数一起使用,那么查询结果就是字段取值的分组情况。字段中取值相同的记录为一组,但是只显示该组的第一条记录。
60.2、单独使用GROUP BY关键字进行分组
如果单独使用GROUP BY关键字,查询结果只显示一个分组的一条记录。
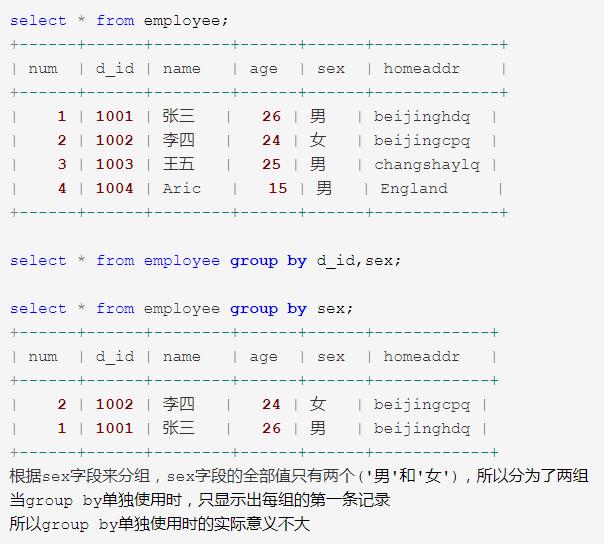 查询结果进行比较,GROUP BY关键字只显示每个分组的一条记录。这说明,GROUP BY关键字单独使用时,只能查询出每个分组的一条记录,这样做的意义不大。因此,一般在使用集合函数时才使用GROUP BY关键字。
查询结果进行比较,GROUP BY关键字只显示每个分组的一条记录。这说明,GROUP BY关键字单独使用时,只能查询出每个分组的一条记录,这样做的意义不大。因此,一般在使用集合函数时才使用GROUP BY关键字。
60.3、GROUP BY关键字与GROUP_CONCAT()函数一起使用
GROUP BY关键字与GROUP_CONCAT()函数一起使用时,每个分组中指定的字段值会全部显示出来。
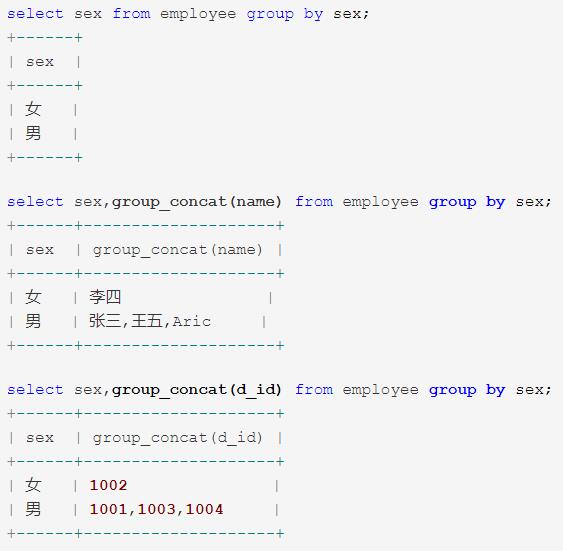
60.4、GROUP BY关键字与集合函数一起使用
GROUP BY关键字与集合函数一起使用时,可以通过集合函数计算分组中的总记录、最大值、最小值等。
 提示:通常情况下,GROUP BY关键字与集合函数一起使用,先使用GROUP BY关键字将记录分组,然后每组都使用集合函数进行计算。在统计时经常需要使用GROUP BY关键字和集合函数。
提示:通常情况下,GROUP BY关键字与集合函数一起使用,先使用GROUP BY关键字将记录分组,然后每组都使用集合函数进行计算。在统计时经常需要使用GROUP BY关键字和集合函数。
60.5、GROUP BY关键字与HAVING一起使用
使用GROUP BY关键字时,如果加上“HAVING 条件表达式”,则可以限制输出的结果。只有符合条件表达式的结果才会显示。
 提示:“HAVING 条件表达式”与“WHERE 条件表达式”都是用于限制显示的。但是,两者起作用的地方不一样。
WHERE 条件表达式:作用于表或者视图,是表和视图的查询条件。
HAVING 条件表达式:作用于分组后的记录(having只能用于group by),用于选择符合条件的组。
提示:“HAVING 条件表达式”与“WHERE 条件表达式”都是用于限制显示的。但是,两者起作用的地方不一样。
WHERE 条件表达式:作用于表或者视图,是表和视图的查询条件。
HAVING 条件表达式:作用于分组后的记录(having只能用于group by),用于选择符合条件的组。
60.6、按照多个字段进行分组
在MySQL中,还可以按照多个字段进行分组。例如,employee表按照d_id字段和sex字段进行分组。分组过程中,先按照d_id字段进行分组,遇到d_id字段的值相等的情况时,再把d_id值相等的记录按照sex字段进行分组。
60.7、GROUP BY关键字与WITH ROLLUP一起使用
使用WITH ROLLUP时,将会在所有记录的最后加上一条记录。这条记录是上面所有记录的总和。
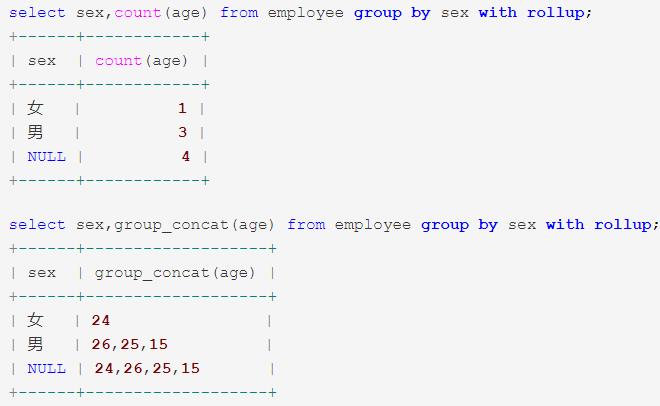
61、数据库查询优化
1、使用索引 应尽量避免全表扫描,首先应考虑在where及order by,group by涉及的列上建立索引。
2、优化SQL语句 1)、通过 explain(查询优化神器)用来查看 SQL 语句的执行效果,可以帮助选择更好的索引和优化查询语句,写出更好的优化语句。通常我们可以对比较复杂的尤其是涉及到多表的 SELECT 语句,把关键字 EXPLAIN 加到前面,查看执行计划。例如:explain select * from news; 2)、任何地方都不要使用 select * from t,用具体的字段列表代替“*”,不要返回用不到的任何字段。 3)、不在索引列做运算或者使用函数。 4)、查询尽可能使用 limit 减少返回的行数,减少数据传输时间和带宽浪费。
3、优化数据库对象 1)、使用procedure analyse()函数对表进行分析,该函数可以对表中列的数据提出优化建议。能小就用小。表数据类型第一个原则是:使用能正确的表示和存储数据的最短类型。这样可以减少对磁盘空间、内存、cpu缓存的使用。 使用方法:select * from 表名 procedure analyse(); 2)、对表进行拆分可以提高访问的效率 垂直拆分:把主键和一些列放在一个表中,然后把主键和另外的列放在另外一个表中。如果一个表中某些列常用,而另外一些不常用,则可以使用垂直拆分。 水平拆分:根据一列或者多列数据的值把数据行放在第二个独立的表中。 3)、创建中间表来提高查询速度:中间表的结构和原表完全相同,转移要统计的数据到中间表,然后在中间表上进行统计,得出想要的结果。
4、硬件优化 1)、CPU优化,选择多核和主频高的CPU; 2)、内存优化,使用更大的内存,将尽量多的内存分配给MYSQL做缓存; 3)、磁盘IO优化,使用磁盘阵列,选择合适的磁盘调度算法,减少磁盘的寻道时间。
5、MYSQL自身优化 对Mysql自身的优化主要是对其配置文件my.cnf中的各项参数进行优化调整。如指定MySQL查询缓冲区的大小,指定MySQL允许的最大连接进程数等。
6、应用层面的优化 1)、使用数据库连接池 2)、使用查询缓存,它的作用是存储select查询的文本及其相应结果。如果随后收到一个相同的查询,服务器会从查询缓存中直接得到查询结果。查询缓存适用的对象是更新不频繁的表,到表中数据更改后,查询缓存中的相关条目就会被清空。
62、大访问量到数据库时,如何优化
1、使用优化查询方法(数据库查询优化)
2、主从复制,读写分离,负载均衡
目前,大部分的主流关系型数据库都提供了主从复制的功能,通过配置两台(或多台)数据库的主从关系,可以将一台数据库服务器的数据更新同步到另一台服务器上。网站可以利用数据库的这一功能,实现数据库的读写分离,从而改善数据库的负载压力。一个系统的读操作远远多于写操作,因此写操作发向 master,读操作发向 slaves 进行操作(简单的轮循算法来决定使用哪个 slave)。
利用数据库的读写分离,Web 服务器在写数据的时候,访问主数据库(Master),主数据库通过主从复制机制将数据更新同步到从数据库(Slave),这样当 Web 服务器读数据的时候,就可以通过从数据库获得数据。 这一方案使得在大量读操作的 Web 应用可以轻松地读取数据,而主数据库也只会承受少量的写入操作,还可以实现数据热备份,可谓是一举两得的方案。
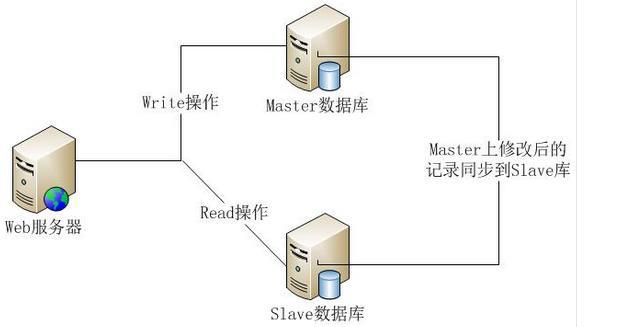
主从复制的原理: 影响 MySQL-A 数据库的操作,在数据库执行后,都会写入本地的日志系统 A 中。假设,实时的将变化了的日志系统中的数据库事件操作,通过网络发给 MYSQL-B。MYSQL-B 收到后,写入本地日志系统 B,然后一条条的将数据库事件在数据库中完成。那么,MYSQL-A 的变化,MYSQL-B 也会变化,这样就是所谓的 MYSQL 的复制。 在上面的模型中,MYSQL-A 就是主服务器,即 master,MYSQL-B 就是从服务器,即slave。 日志系统 A,其实它是 MYSQL 的日志类型中的二进制日志,也就是专门用来保存修改数据库表的所有动作,即 bin log。【注意 MYSQL 会在执行语句之后,释放锁之前,写入二进制日志,确保事务安全】; 日志系统 B,并不是二进制日志,由于它是从 MYSQL-A 的二进制日志复制过来的,并不是自己的数据库变化产生的,有点接力的感觉,称为中继日志,即 relay log。 可以发现,通过上面的机制,可以保证 MYSQL-A 和 MYSQL-B 的数据库数据一致,但是时间上肯定有延迟,即 MYSQL-B 的数据是滞后的。
简化版:
mysql 主(称 master)从(称 slave)复制的原理:
(1)、master 将数据改变记录到二进制日志(binary log)中,也即是配置文件log-bin 指定的文件(这些记录叫做二进制日志事件,binary log events);
PS:从图中可以看出,Slave服务器中有一个I/O线程(I/O Thread)在不停地监听Master的二进制日志(Binary Log)是否有更新:如果没有它会睡眠等待 Master 产生新的日志事件;
如果有新的日志事件(Log Events),则会将其拷贝至 Slave 服务器中的中继日志(Relay Log)。
(2)、slave 将 master 的二进制日志事件(binary log events)拷贝到它的中继日志(relay log);
(3)、slave 重做中继日志中的事件,将 Master 上的改变反映到它自己的数据库中,所以两端的数据是完全一样的。
PS:从图中可以看出,Slave 服务器中有一个 SQL 线程(SQL Thread)从中继日志读取事件,并重做其中的事件,从而更新 Slave 的数据,使其与 Master 中的数据一致。只要该线程与 I/O 线程保持一致,中继日志通常会位于 OS 的缓存中,所以中继日志的开销很小。附简要原理图:
主从复制的几种方式: (1)、同步复制 主服务器在将更新的数据写入它的二进制日志(Bin log)文件中后,必须等待验证所有的从服务器的更新数据是否已经复制到其中,之后才可以自由处理其它进入的事务处理请求。 (2)、异步复制 主服务器在将更新的数据写入它的二进制日志(Bin log)文件中后,无需等待验证更新数据是否已经复制到从服务器中,就可以自由处理其它进入的事务处理请求。 (3)、半同步复制 主服务器在将更新的数据写入它的二进制日志(Bin log)文件中后,只需等待验证其中一台从服务器的更新数据是否已经复制到其中,就可以自由处理其它进入的事务处理请求,其他的从服务器不用管。
3、数据库分表,分区,分库 分表见上面描述(垂直拆分、水平拆分)。 分区就是把一张表的数据分成多个区块,这些区块可以在一个磁盘上,也可以在不同的磁盘上,分区后,表面上还是一张表,但数据散列在多个位置,这样一来,多块硬盘同时处理不同的请求,从而提高磁盘 I/O 读写性能,实现比较简单。包括水平分区和垂直分区。 分库是根据业务不同把相关的表切分到不同的数据库中,比如 web、bbs、blog 等库。
职责链模式(Chain of Responsibility):使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
1、Handler类,定义一个处理请示的接口。
/**
* @Description: 定义一个处理请求的接口
* @author: zxt
* @time: 2019年5月13日 下午9:31:56
*/
public abstract class Handler {
// 设置继任者
protected Handler successor;
public void setSuccessor(Handler successor) {
this.successor = successor;
}
// 处理请求的抽象方法
public abstract void HandleRequest(int request);
}
2、ConcreteHandler类,具体处理者类,处理它所负责的请求,可访问它的后继者,如果可处理该请求,就处理之,否则就将该请求转发给它的后继者。
/**
* @Description: 当请求数在0到10之间则有权处理,否则转到下一位
* @author: zxt
* @time: 2019年5月13日 下午9:49:34
*/
public class ConcreteHandler1 extends Handler {
@Override
public void HandleRequest(int request) {
if (request >= 0 && request < 10) {
System.out.println(this.getClass().getName() + " 处理请求 " + request);
} else if (successor != null) {
// 转移到下一位
successor.HandleRequest(request);
}
}
}
123456789101112131415161718
/**
* @Description: 当请求数在10到20之间则有权处理,否则转到下一位
* @author: zxt
* @time: 2019年5月13日 下午9:49:34
*/
public class ConcreteHandler2 extends Handler {
@Override
public void HandleRequest(int request) {
if (request >= 10 && request < 20) {
System.out.println(this.getClass().getName() + " 处理请求 " + request);
} else if (successor != null) {
// 转移到下一位
successor.HandleRequest(request);
}
}
}
123456789101112131415161718
/**
* @Description: 当请求数在20到30之间则有权处理,否则转到下一位
* @author: zxt
* @time: 2019年5月13日 下午9:49:34
*/
public class ConcreteHandler3 extends Handler {
@Override
public void HandleRequest(int request) {
if (request >= 20 && request < 30) {
System.out.println(this.getClass().getName() + " 处理请求 " + request);
} else if (successor != null) {
// 转移到下一位
successor.HandleRequest(request);
}
}
}
123456789101112131415161718
/**
* @Description: 末端处理器
* @author: zxt
* @time: 2019年5月13日 下午9:49:34
*/
public class ConcreteHandler extends Handler {
@Override
public void HandleRequest(int request) {
System.out.println(this.getClass().getName() + " 处理请求 " + request);
}
}
3、测试
public class Test {
public static void main(String[] args) {
// 设置职责链的上下家
Handler h1 = new ConcreteHandler1();
Handler h2 = new ConcreteHandler2();
Handler h3 = new ConcreteHandler3();
Handler h = new ConcreteHandler();
h1.setSuccessor(h2);
h2.setSuccessor(h3);
h3.setSuccessor(h);
int[] requests = {2, 5, 14, 22, 18, 3, 27, 20, 40};
// 循环给最小处理者提交请求,不同的数额,由不同权限处理者处理
for(int i = 0; i < requests.length; i++) {
h1.HandleRequest(requests[i]);
}
}
}
职责链模式的好处
职责链当中最关键的是当客户提交一个请求时,请求是沿链传递直至有一个ConcreteHandler对象负责处理它。 这就使得接收者和发送者都没有对方的明确信息,且链中的对象自己也并不知道链的结构。结果是职责链可简化对象的相互连接,它们仅需保持一个指向其后继者的引用,而不需要保持它所有的候选者的引用。这也就大大降低了耦合度。 在客户端可以随时地增加或修改处理一个请求的结构,增强了给对象指派职责的灵活性。不过也需要当心,一个请求极有可能到了链的末端都得不到处理,或者因为没有正确配置而得不到处理。
63、JDBC的理解
Jdbc:Java database connection,java数据库连接。数据库管理系统(mysql、oracle等)是很多的,每个数据库管理系统支持的命令是不一样的。 Java只定义接口,让数据库厂商自己实现接口,对于我们开发者而言。只需要导入对应厂商开发的实现即可。然后以接口方式进行调用。(mysql + mysql驱动(实现)+jdbc)。
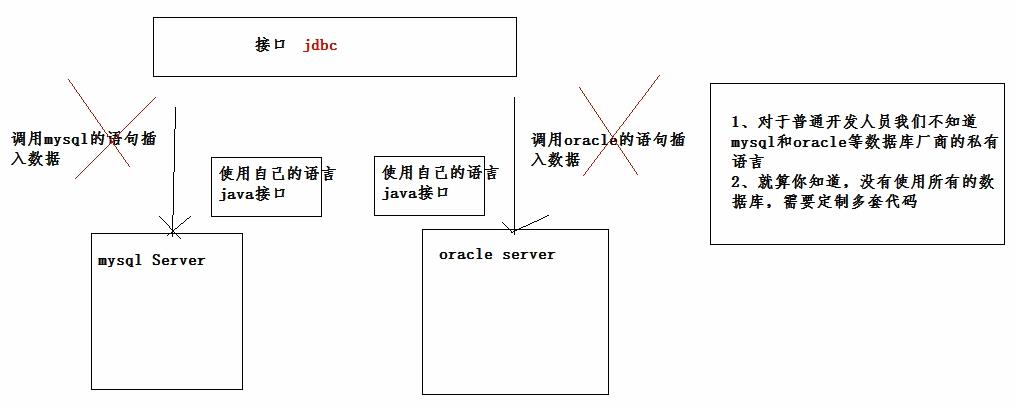
64、数据库连接池
64.1、早期进行数据库操作
1、原理:一般来说,java 应用程序访问数据库的过程是: ①、加载数据库驱动程序; ②、通过 jdbc 建立数据库连接; ③、访问数据库,执行 sql 语句; ④、断开数据库连接。
2、代码
// 查询所有用户
Public void FindAllUsers() {
// 1、装载 sqlserver 驱动对象
DriverManager.registerDriver(new SQLServerDriver());
// 2、通过 JDBC 建立数据库连接
Connection con = DriverManager.getConnection("jdbc:sqlserver://192.168.2.6:1433;DatabaseName=customer", "sa", "123");
// 3、创建状态
Statement state = con.createStatement();
// 4、查询数据库并返回结果
ResultSet result = state.executeQuery("select * from users");
// 5、输出查询结果
while(result.next()) {
System.out.println(result.getString("email"));
}
// 6、断开数据库连接
result.close();
state.close();
con.close();
}
3、分析 程序开发过程中,存在很多问题: 首先,每一次 web 请求都要建立一次数据库连接。建立连接是一个费时的活动,每次都得花费 0.05s~1s 的时间,而且系统还要分配内存资源。这个时间对于一次或几次数据库操作,或许感觉不出系统有多大的开销。可是对于现在的 web 应用,尤其是大型电子商务网站,同时有几百人甚至几千人在线是很正常的事。在这种情况下,频繁的进行数据库连接操作势必占用很多的系统资源,网站的响应速度必定下降,严重的甚至会造成服务器的崩溃。不是危言耸听,这就是制约某些电子商务网站发展的技术瓶颈问题。 其次,对于每一次数据库连接,使用完后都得断开。否则,如果程序出现异常而未能关闭,将会导致数据库系统中的内存泄漏,最终将不得不重启数据库。还有,这种开发不能控制被创建的连接对象数,系统资源会被毫无顾及的分配出去,如连接过多,也可能导致内存泄漏,服务器崩溃。 通过上面的分析,我们可以看出来,“数据库连接”是一种稀缺的资源,为了保障网站的正常使用,应该对其进行妥善管理。其实我们查询完数据库后,如果不关闭连接,而是暂时存放起来,当别人使用时,把这个连接给他们使用。就避免了一次建立数据库连接和断开的操作时间消耗。
64.2、数据库连接池
由上面的分析可以看出,问题的根源就在于对数据库连接资源的低效管理。我们知道,对于共享资源,有一个著名的设计模式:资源池设计模式。该模式正是为了解决资源的频繁分配﹑释放所造成的问题。为解决上述问题,可以采用数据库连接池技术。 数据库连接池的基本思想就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。我们可以通过设定连接池最大连接数来防止系统无尽地与数据库连接。 更为重要的是我们可以通过连接池的管理机制监视数据库的连接的数量、使用情况,为系统开发﹑测试及性能调整提供依据。 我们自己尝试开发一个连接池,来为上面的查询业务提供数据库连接服务: ①、编写 class 实现 DataSource 接口 ②、在 class的构造器一次性创建 10 个连接,将连接保存 LinkedList 中 ③、实现 getConnection, 从 LinkedList 中返回一个连接 ④、提供将连接放回连接池中的方法
1、连接池代码
public class MyDataSource implements DataSource {
// 因为 LinkedList 是用链表实现的,对于增删实现起来比较容易
LinkedList<Connection> dataSources = new LinkedList<Connection>();
// 初始化连接数量
public MyDataSource() {
// 问题:每次new MyDataSource 都会建立 10 个链接,可使用单例设计模式解决此类问题
for(int i = 0; i < 10; i++) {
try {
// 1、装载 sqlserver 驱动对象
DriverManager.registerDriver(new SQLServerDriver());
// 2、通过 JDBC 建立数据库连接
Connection con =DriverManager.getConnection("jdbc:sqlserver://192.168.2.6:1433;DatabaseName=customer", "sa", "123");
// 3、将连接加入连接池中
dataSources.add(con);
} catch (Exception e) {
e.printStackTrace();
}
}
}
@Override
public Connection getConnection() throws SQLException {
// 取出连接池中一个连接
final Connection conn = dataSources.removeFirst(); // 删除第一个连接返回
return conn;
}
// 将连接放回连接池
public void releaseConnection(Connection conn) {
dataSources.add(conn);
}
}
2、使用连接池重构我们的用户查询函数
// 查询所有用户
Public void FindAllUsers() {
// 1、使用连接池建立数据库连接
MyDataSource dataSource = new MyDataSource();
Connection conn = dataSource.getConnection();
// 2、创建状态
Statement state = conn.createStatement();
// 3、查询数据库并返回结果
ResultSet result = state.executeQuery("select * from users");
// 4、输出查询结果
while(result.next()){
System.out.println(result.getString("email"));
}
// 5、断开数据库连接
result.close();
state.close();
// 6、归还数据库连接给连接池
dataSource.releaseConnection(conn);
}
64.3、连接池的工作原理
连接池的核心思想是连接的复用,通过建立一个数据库连接池以及一套连接使用、分配和管理策略,使得该连接池中的连接可以得到高效,安全的复用,避免了数据库连接频繁建立和关闭的开销。 连接池的工作原理主要由三部分组成,分别为连接池的建立,连接池中连接的使用管理,连接池的关闭。 第一、连接池的建立。 一般在系统初始化时,连接池会根据系统配置建立,并在池中建立几个连接对象,以便使用时能从连接池中获取。java 中提供了很多容器类,可以方便的构建连接池,例如 Vector(线程安全类),linkedlist 等。 第二、连接池的管理。 连接池管理策略是连接池机制的核心,连接池内连接的分配和释放对系统的性能有很大的影响。其策略是: 当客户请求数据库连接时,首先查看连接池中是否有空闲连接,如果存在空闲连接,则将连接分配给客户使用并作相应处理(即标记该连接为正在使用,引用计数加 1);如果没有空闲连接,则查看当前所开的连接数是否已经达到最大连接数,如果没有达到最大连接数,就重新创建一个连接给请求的客户;如果达到,就按设定的最大等待时间进行等待,如果超出最大等待时间,则抛出异常给客户。 当客户释放数据库连接时,先判断该连接的引用次数是否超过了规定值,如果超过了就从连接池中删除该连接,并判断当前连接池内总的连接数是否小于最小连接数,若小于就将连接池充满;如果没超过就将该连接标记为开放状态,可供再次复用。 第三、连接池的关闭。 当应用程序退出时,关闭连接池中所有的链接,释放连接池相关资源,该过程正好与创建相反。
64.4、连接池的主要优点
1)、减少连接的创建时间。连接池中的连接是已准备好的,可以重复使用的,获取后可以直接访问数据库,因此减少了连接创建的次数和时间。 2)、更快的系统响应速度。数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而缩减了系统整体响应时间。 3)、统一的连接管理。如果不使用连接池,每次访问数据库都需要创建一个连接,这样系统的稳定性受系统的连接需求影响很大,很容易产生资源浪费和高负载异常。连接池能够使性能最大化,将资源利用控制在一定的水平之下。连接池能控制池中的链接数量,增强了系统在大量用户应用时的稳定性。
65、PreparedStatement相比Statement的好处
大多数时候我们都使用PreparedStatement代替Statement 1、PreparedStatement是预编译的,比Statement速度快; 2、代码的可读性和可维护性更好 虽然用PreparedStatement来代替Statement会使代码多出几行,但这样的代码无论从可读性还是可维护性上来说,都比直接用Statement的代码高很多档次: stmt.executeUpdate(“insert into tb_name (col1,col2,col2,col4) values (’”+var1+"’,’"+var2+"’,"+var3+",’"+var4+"’)"); perstmt = con.prepareStatement(“insert into tb_name (col1,col2,col2,col4) values (?,?,?,?)”); perstmt.setString(1,var1); perstmt.setString(2,var2); perstmt.setString(3,var3); perstmt.setString(4,var4); perstmt.executeUpdate(); 不用多说,对于第一种方法,别说其他人去读你的代码,就是你自己过一段时间再去读,都会觉得伤心。 **3、安全性 PreparedStatement可以防止SQL注入攻击,而Statement却不能。**比如说: String sql = “select * from tb_name where name= ‘”+varname+"’ and passwd=’"+varpasswd+"’"; 如果我们把[’ or ‘1’ = ‘1]作为varpasswd传入进来,用户名随意,看看会成为什么? select * from tb_name where name = ‘随意’ and passwd = ‘’ or ‘1’ = ‘1’; 因为’1’=‘1’肯定成立,所以可以任何通过验证,更有甚者: 把[’;drop table tb_name;]作为varpasswd传入进来,则: select * from tb_name where name = ‘随意’ and passwd = ‘’;drop table tb_name;有些数据库是不会让你成功的,但也有很多数据库就可以使这些语句得到执行。 而如果你使用预编译语句你传入的任何内容就不会和原来的语句发生任何匹配的关系,只要全使用预编译语句你就用不着对传入的数据做任何过虑。而如果使用普通的statement,有可能要对drop等做费尽心机的判断和过虑。
66、Truncate与delete的区别
TRUNCATE table:删除内容、不删除定义、释放空间 DELETE table:删除内容、不删除定义、不释放空间 DROP table:删除内容和定义,释放空间 1、truncate table:只能删除表中全部数据;delete from table where……,可以删除表中全部数据,也可以删除部分数据。 2、delete from记录是一条条删的,所删除的每行记录都会进日志,而truncate一次性删掉整个页,因此日志里面只记录页的释放。 3、truncate的执行速度比delete快。 4、delete执行后,删除的数据占用的存储空间还在,还可以恢复数据;truncate删除的数据占用的存储空间不在,不可以恢复数据。也因此truncate 删除后,不能回滚,delete可以回滚。
67、OSI 与 TCP/IP 的网络分层
 (1)、物理层—-定义了为建立、维护和拆除物理链路所需的机械的、电气的、功能的和规程的特性,其作用是使原始的数据比特流能在物理媒体上传输。具体涉及接插件的规格、“0”、“1”信号的电平表示、收发双方的协调等内容。
(2)、数据链路层—-比特流被组织成数据链路协议数据单元(通常称为帧),并以其为单位进行传输,帧中包含地址、控制、数据及校验码等信息。数据链路层的主要作用是通过校验、确认和反馈重发等手段,将不可靠的物理链路改造成对网络层来说无差错的数据链路。数据链路层还要协调收发双方的数据传输速率,即进行流量控制,以防止接收方因来不及处理发送方来的高速数据而导致缓冲器溢出及线路阻塞。
(3)、网络层—-数据以网络协议数据单元(分组)为单位进行传输。网络层关心的是通信子网的运行控制,主要解决如何使数据分组跨越通信子网从源传送到目的地的问题,这就需要在通信子网中进行路由选择。另外,为避免通信子网中出现过多的分组而造成网络阻塞,需要对流入的分组数量进行控制。当分组要跨越多个通信子网才能到达目的地时,还要解决网际互连的问题。
(4)、传输层—-是第一个端–端,也即主机–主机的层次。传输层提供的端到端的透明数据运输服务,使高层用户不必关心通信子网的存在,由此用统一的运输原语书写的高层软件便可运行于任何通信子网上。传输层还要处理端到端的差错控制和流量控制问题。
(5)、会话层—-是进程–进程的层次,其主要功能是组织和同步不同的主机上各种进程间的通信(也称为对话)。会话层负责在两个会话层实体之间进行对话连接的建立和拆除。在半双工情况下,会话层提供一种数据权标来控制某一方何时有权发送数据。会话层还提供在数据流中插入同步点的机制,使得数据传输因网络故障而中断后,可以不必从头开始而仅重传最近一个同步点以后的数据。
(6)、表示层—-为上层用户提供共同的数据或信息的语法表示变换。为了让采用不同编码方法的计算机在通信中能相互理解数据的内容,可以采用抽象的标准方法来定义数据结构,并采用标准的编码表示形式。表示层管理这些抽象的数据结构,并将计算机内部的表示形式转换成网络通信中采用的标准表示形式。数据压缩和加密也是表示层可提供的表示变换功能。
(7)、应用层是开放系统互连环境的最高层。不同的应用层为特定类型的网络应用提供访问 OSI 环境的手段。网络环境下不同主机间的文件传送访问和管理(FTAM)、传送标准电子邮件的文电处理系统(MHS)、使不同类型的终端和主机通过网络交互访问的虚拟终端(VT)协议等都属于应用层的范畴。
(1)、物理层—-定义了为建立、维护和拆除物理链路所需的机械的、电气的、功能的和规程的特性,其作用是使原始的数据比特流能在物理媒体上传输。具体涉及接插件的规格、“0”、“1”信号的电平表示、收发双方的协调等内容。
(2)、数据链路层—-比特流被组织成数据链路协议数据单元(通常称为帧),并以其为单位进行传输,帧中包含地址、控制、数据及校验码等信息。数据链路层的主要作用是通过校验、确认和反馈重发等手段,将不可靠的物理链路改造成对网络层来说无差错的数据链路。数据链路层还要协调收发双方的数据传输速率,即进行流量控制,以防止接收方因来不及处理发送方来的高速数据而导致缓冲器溢出及线路阻塞。
(3)、网络层—-数据以网络协议数据单元(分组)为单位进行传输。网络层关心的是通信子网的运行控制,主要解决如何使数据分组跨越通信子网从源传送到目的地的问题,这就需要在通信子网中进行路由选择。另外,为避免通信子网中出现过多的分组而造成网络阻塞,需要对流入的分组数量进行控制。当分组要跨越多个通信子网才能到达目的地时,还要解决网际互连的问题。
(4)、传输层—-是第一个端–端,也即主机–主机的层次。传输层提供的端到端的透明数据运输服务,使高层用户不必关心通信子网的存在,由此用统一的运输原语书写的高层软件便可运行于任何通信子网上。传输层还要处理端到端的差错控制和流量控制问题。
(5)、会话层—-是进程–进程的层次,其主要功能是组织和同步不同的主机上各种进程间的通信(也称为对话)。会话层负责在两个会话层实体之间进行对话连接的建立和拆除。在半双工情况下,会话层提供一种数据权标来控制某一方何时有权发送数据。会话层还提供在数据流中插入同步点的机制,使得数据传输因网络故障而中断后,可以不必从头开始而仅重传最近一个同步点以后的数据。
(6)、表示层—-为上层用户提供共同的数据或信息的语法表示变换。为了让采用不同编码方法的计算机在通信中能相互理解数据的内容,可以采用抽象的标准方法来定义数据结构,并采用标准的编码表示形式。表示层管理这些抽象的数据结构,并将计算机内部的表示形式转换成网络通信中采用的标准表示形式。数据压缩和加密也是表示层可提供的表示变换功能。
(7)、应用层是开放系统互连环境的最高层。不同的应用层为特定类型的网络应用提供访问 OSI 环境的手段。网络环境下不同主机间的文件传送访问和管理(FTAM)、传送标准电子邮件的文电处理系统(MHS)、使不同类型的终端和主机通过网络交互访问的虚拟终端(VT)协议等都属于应用层的范畴。
67.1、网络各层常用的协议
物理层:RJ45、CLOCK、IEEE802.3 数据链路:PPP、FR、HDLC、VLAN、MAC 网络层:IP、ICMP、ARP、RARP、OSPF、IPX、RIP、IGMP 传输层:TCP、UDP、SPX 会话层:RPC 、SQL、NETBIOS、NFS 表示层:JPEG、MPEG、ASCII、MIDI 应用层:RIP、BGP、FTP、DNS、Telnet、SMTP、HTTP、WWW、NFS 常见协议的端口:http 80,ftp 20、21,telnet 23,SMTP 25。
68、IP地址
68.1、IP地址的分类
整个的因特网就是一个单一的、抽象的网络。IP地址就是给因特网上的每一个主机(或路由器)的每一个接口分配一个在全世界范围内唯一的32位的标识符。 所谓分类的IP地址,就是将IP地址划分为若干固定类,每一类地址都由两个固定长度的字段组成,其中一个字段是网络号 net-id,它标志主机(或路由器)所连接到的网络,一个网络号在整个因特网范围内必须是唯一的。而另一个字段则是主机号 host-id,它标志该主机(或路由器),一个主机号在它前面的网络号所指明的网络范围内必须是唯一的。由此可见,一个IP地址在整个因特网范围内是唯一的。 由于一个路由器至少应当连接到两个网络(这样它才能将 IP 数据报从一个网络转发到另一个网络),因此一个路由器至少应当有两个不同的 IP 地址。路由器只根据目的站的IP 地址的网络号进行路由选择。 用转发器或网桥连接起来的若干个局域网仍为一个网络,因此这些局域网都具有同样的网络号。 两级的 IP 地址可以记为:IP 地址 :: = { <网络号>, <主机号>}
 上图中的A类、B类、C类地址都是单播地址(一对一通信),是最常用的。网络号字段的最前面有1-4位的类别位,A类、B类、C类地址的类别位分别为0、10、110。为了提高可读性,我们常常把32位的IP地址中的每8位用其等效的十进制数字表示。
IP地址的取值范围:
A类:1.0.0.0到127.255.255.255
B类:128.0.0.0到191.255.255.255
C类:192.0.0.0到223.255.255.255
D类:224.0.0.0到239.255.255.255
E类:240.0.0.0到247.255.255.255
私有地址有:
A类:10.0.0.0到10.255.255.255
B类:172.16.0.0到172.31.255.255
C类:192.168.0.0到192.168.255.255
A类地址的网络号字段占一个字节,只有7位可供使用(第一位已固定为0),但是可指派的网络号是126个(2^7-2),减2的原因:第一,IP地址中全为0的地址是个保留地址,表示“本网络”;第二,网络号为127(01111111)保留作为本地软件环回测试本主机的进程间的通信。
A类地址的主机号占3字节,因此每一个A类网络中的最大主机数是2^24-2。减2的原因:第一,全为0的主机号字段表示该IP地址是本主机所连接到的单个网络地址,第二,全为1的主机号字段表示该网络上的所有主机。
B类地址的网络号字段有2字节,但是前两位已经固定为10,只剩下14位可以进行分配,因为前面两位是10,不会出现全为0或全为1的网络号,但实际上,B类网络地址128.0.0.0是不指派的。所以最大网络数为2^14-1。最大主机数为2^16-2。
C类地址有3字节的网络号字段,前三位固定位110,还有21位可以进行分配。但实际上192.0.0.0是不指派的,因此C类地址可指派的网络总数为2^21-1,最大主机数为2^8-2。
上图中的A类、B类、C类地址都是单播地址(一对一通信),是最常用的。网络号字段的最前面有1-4位的类别位,A类、B类、C类地址的类别位分别为0、10、110。为了提高可读性,我们常常把32位的IP地址中的每8位用其等效的十进制数字表示。
IP地址的取值范围:
A类:1.0.0.0到127.255.255.255
B类:128.0.0.0到191.255.255.255
C类:192.0.0.0到223.255.255.255
D类:224.0.0.0到239.255.255.255
E类:240.0.0.0到247.255.255.255
私有地址有:
A类:10.0.0.0到10.255.255.255
B类:172.16.0.0到172.31.255.255
C类:192.168.0.0到192.168.255.255
A类地址的网络号字段占一个字节,只有7位可供使用(第一位已固定为0),但是可指派的网络号是126个(2^7-2),减2的原因:第一,IP地址中全为0的地址是个保留地址,表示“本网络”;第二,网络号为127(01111111)保留作为本地软件环回测试本主机的进程间的通信。
A类地址的主机号占3字节,因此每一个A类网络中的最大主机数是2^24-2。减2的原因:第一,全为0的主机号字段表示该IP地址是本主机所连接到的单个网络地址,第二,全为1的主机号字段表示该网络上的所有主机。
B类地址的网络号字段有2字节,但是前两位已经固定为10,只剩下14位可以进行分配,因为前面两位是10,不会出现全为0或全为1的网络号,但实际上,B类网络地址128.0.0.0是不指派的。所以最大网络数为2^14-1。最大主机数为2^16-2。
C类地址有3字节的网络号字段,前三位固定位110,还有21位可以进行分配。但实际上192.0.0.0是不指派的,因此C类地址可指派的网络总数为2^21-1,最大主机数为2^8-2。
68.2、IP地址与硬件地址
硬件地址是数据链路层和物理层使用的地址,而IP地址是网络层和以上各层使用的地址,是一种逻辑地址。
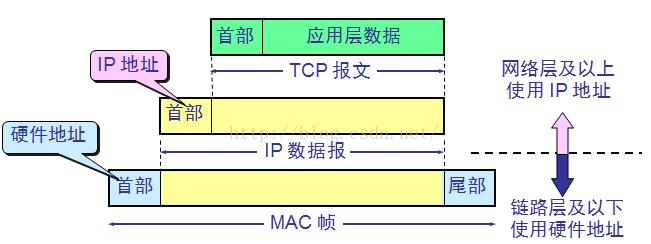 发送数据时,数据从高层下到低层,然后才到通信链路上传输。使用IP地址的IP数据报一旦交给了数据链路层,就被封装成了MAC帧。MAC帧在传送时使用的源地址和目的地址都是硬件地址,这两个硬件地址都写在MAC帧的首部。
连接在通信链路上的设备在接受MAC帧时,其根据是MAC帧首部中的硬件地址。在数据链路层看不见隐藏在MAC帧的数据中的IP地址。只有在剥去了MAC帧的首部和尾部后把MAC层的数据上交给网络层后,网络层才能在IP数据报的首部中找到源IP地址和目的IP地址。
发送数据时,数据从高层下到低层,然后才到通信链路上传输。使用IP地址的IP数据报一旦交给了数据链路层,就被封装成了MAC帧。MAC帧在传送时使用的源地址和目的地址都是硬件地址,这两个硬件地址都写在MAC帧的首部。
连接在通信链路上的设备在接受MAC帧时,其根据是MAC帧首部中的硬件地址。在数据链路层看不见隐藏在MAC帧的数据中的IP地址。只有在剥去了MAC帧的首部和尾部后把MAC层的数据上交给网络层后,网络层才能在IP数据报的首部中找到源IP地址和目的IP地址。
68.3、划分子网
一个拥有许多物理网络的单位,可将所属的物理网络划分为若干个子网(subnet)。划分子网纯属一个单位内部的事情。单位对外仍然表现为一个网络。 划分子网的方法是从主机号借用若干个位作为子网号 subnet-id,而主机号 host-id 也就相应减少了若干个位。于是两级IP地址在本单位内部就变为三级IP地址:网络号、子网号和主机号。 IP地址 ::= {<网络号>, <子网号>, <主机号>} 凡是从其他网络发送给本单位某个主机的 IP数据报,仍然是根据 IP 数据报的目的网络号 net-id,先找到连接在本单位网络上的路由器。然后此路由器在收到 IP 数据报后,再按目的网络号 net-id 和子网号 subnet-id 找到目的子网。最后就将 IP 数据报直接交付目的主机。 下面通过一个例子来展示划分子网的方法与效果。 下图表示某单位拥有一个B类IP地址,网络地址是145.13.0.0(网络号是145.13)。
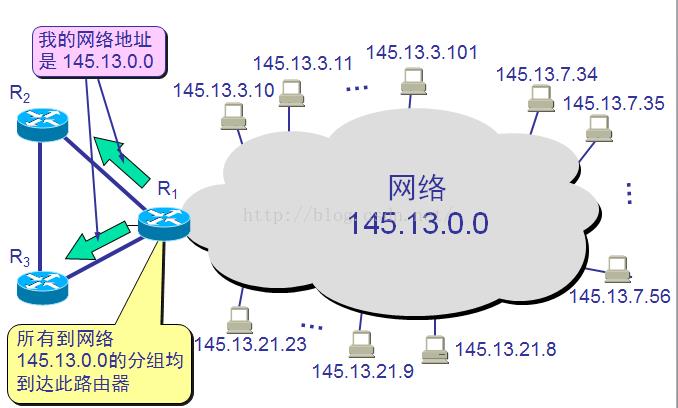 现把上图中的网络划分为三个子网,这里假定子网号占用8位,因此主机号只剩8位。所划分的子网分别是:145.13.3.0、145.13.7.0、145.13.21.0。
现把上图中的网络划分为三个子网,这里假定子网号占用8位,因此主机号只剩8位。所划分的子网分别是:145.13.3.0、145.13.7.0、145.13.21.0。
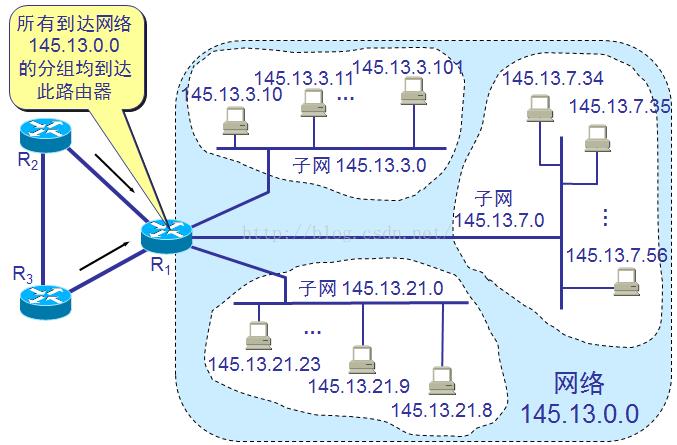 划分子网后,整个网络对外仍表现为一个网络,其网络地址仍为145.13.0.0,但是路由器R1在收到外来的数据报后,再根据数据报的目的地址把它转发到相应的子网。
假定有一个数据报的目的地址是145.13.3.10已经到达路由器R1,那么这个路由器如何把它转发到子网145.13.3.0呢?这就需要借助子网掩码(subnetmask)来实现了。
路由器会把子网掩码和收到的数据报地址的目的IP地址145.13.3.10进行按位“与”操作,得出所要找的子网的网络地址。
划分子网后,整个网络对外仍表现为一个网络,其网络地址仍为145.13.0.0,但是路由器R1在收到外来的数据报后,再根据数据报的目的地址把它转发到相应的子网。
假定有一个数据报的目的地址是145.13.3.10已经到达路由器R1,那么这个路由器如何把它转发到子网145.13.3.0呢?这就需要借助子网掩码(subnetmask)来实现了。
路由器会把子网掩码和收到的数据报地址的目的IP地址145.13.3.10进行按位“与”操作,得出所要找的子网的网络地址。
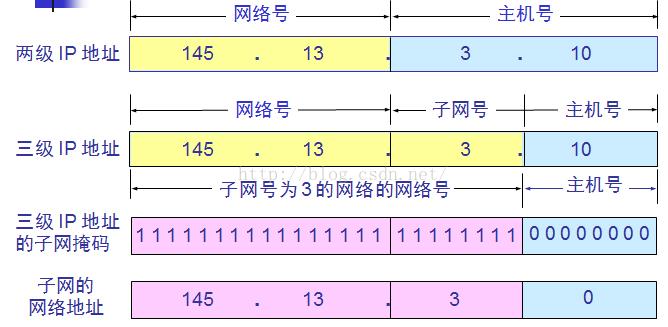 子网掩码与IP地址进行“与”操作之后,就将主机号“过滤”掉了,只剩下了网络号与子网号。
实际上,因特网的标准规定:所有网络必须使用子网掩码。即便一个网络没有划分子网,也要使用默认子网掩码。默认子网掩码中1的位置和IP地址中的网络号字段正好相对应,因此,两者进行“与”操作后,就能得出该IP地址的网络地址。A类、B类、C类地址的默认子网掩码是固定的:
子网掩码与IP地址进行“与”操作之后,就将主机号“过滤”掉了,只剩下了网络号与子网号。
实际上,因特网的标准规定:所有网络必须使用子网掩码。即便一个网络没有划分子网,也要使用默认子网掩码。默认子网掩码中1的位置和IP地址中的网络号字段正好相对应,因此,两者进行“与”操作后,就能得出该IP地址的网络地址。A类、B类、C类地址的默认子网掩码是固定的:
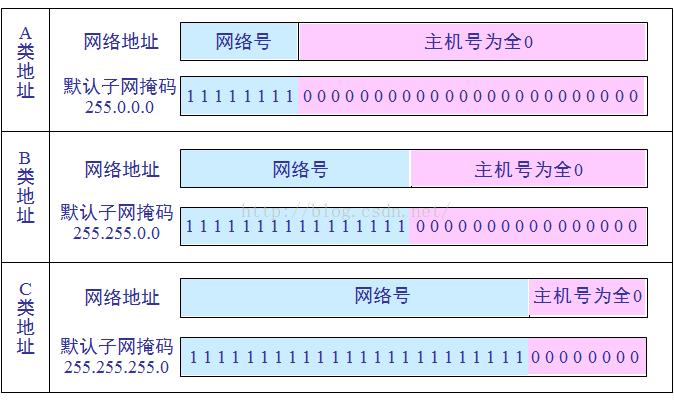 例,已知 IP 地址是141.14.72.24,子网掩码是 255.255.192.0。试求网络地址。
例,已知 IP 地址是141.14.72.24,子网掩码是 255.255.192.0。试求网络地址。
 应当注意,划分子网后,路由表必须包含以下三项内容:目的网络地址、子网掩码和下一跳地址。
应当注意,划分子网后,路由表必须包含以下三项内容:目的网络地址、子网掩码和下一跳地址。
68.4、路由器转发分组算法
在划分子网的情况下路由器转发分组的算法: (1)、从收到的分组的首部提取目的IP 地址 D。 (2)、先用各网络的子网掩码和 D逐位相“与”,看是否和相应的网络地址匹配。若匹配,则将分组直接交付。否则就是间接交付,执行(3)。 (3)、若路由表中有目的地址为 D的特定主机路由,则将分组传送给指明的下一跳路由器;否则,执行(4)。 (4)、对路由表中的每一行的子网掩码和 D 逐位相“与”,若其结果与该行的目的网络地址匹配,则将分组传送给该行指明的下一跳路由器;否则,执行(5)。 (5)、若路由表中有一个默认路由,则将分组传送给路由表中所指明的默认路由器;否则,执行(6)。 (6)、报告转发分组出错。
68.5、地址解析协议ARP
已知主机的IP地址,如何获取其相应的硬件地址。地址解析协议ARP是在主机ARP高速缓存中存放一个从IP地址到硬件地址的映射表,并且这个表还经常动态更新(新增或超时删除)。每个主机都设有一个ARP高速缓存(ARP cache)。里面有本局域网上的各主机和路由器的IP地址到硬件地址的映射表。
ARP 解决的是同一个局域网内,主机或路由器的 IP 地址和 MAC 地址的映射问题。如果源主机和目的主机在同一个局域网内(目标 IP 和本机 IP 分别与子网掩码相与的结果相同,那么它们在一个子网 ),就可以用 ARP 找到目的主机的 MAC 地址;如果不在一个局域网内,用 ARP 协议找到本网络内的一个路由器的 MAC 地址,剩下的工作由这个路由器来完成。
ARP 协议的具体内容是:
01、每个主机都会有ARP高速缓存,存储本局域网内IP地址和MAC地址之间的对应关系。
02、当源主机要发送数据时,首先检查 ARP 高速缓存中是否有对应 IP 地址的目的主机的MAC 地址,如果有,则直接发送数据,如果没有,就向本网段的所有主机发送 ARP 请求分组,该数据包包括的内容有:(源主机 IP 地址,源主机 MAC 地址,目的主机的 IP 地址)。
03、当本网络的所有主机收到该 ARP 请求分组时,首先检查数据包中的 IP 地址是否是自己的 IP 地址,如果不是,则忽略该数据包;如果是,则首先从数据包中取出源主机的 IP 地址和 MAC 地址写入到 ARP 高速缓存中,如果已经存在,则覆盖,然后将自己的MAC 地址写入 ARP 响应包中,告诉源主机自己是它想要找的 MAC 地址。
04、源主机收到 ARP 响应分组后,将目的主机的 IP 和 MAC 地址写入 ARP 高速缓存中,并利用此信息发送数据。如果源主机一直没有收到 ARP 响应分组,表示 ARP 查询失败。
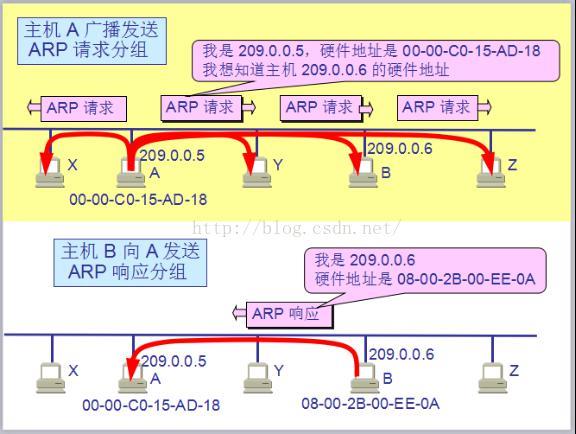 注意:主机的用户对这种地址解析的过程是不知道的,ARP协议会自动解析所需要的硬件地址。
问题:为什么不直接使用硬件地址通信,而是要使用抽象的IP地址,并调用ARP来寻址相应的硬件地址?
由于全世界存在着各式各样的网络,它们使用不同的硬件地址。要使这些异构的网络能够互相通信就必须进行非常复杂的硬件地址转换工作,因此由用户或用户主机来完成这项工作几乎是不可能的事。但是统一的IP地址把这个复杂的问题解决了。
注意:主机的用户对这种地址解析的过程是不知道的,ARP协议会自动解析所需要的硬件地址。
问题:为什么不直接使用硬件地址通信,而是要使用抽象的IP地址,并调用ARP来寻址相应的硬件地址?
由于全世界存在着各式各样的网络,它们使用不同的硬件地址。要使这些异构的网络能够互相通信就必须进行非常复杂的硬件地址转换工作,因此由用户或用户主机来完成这项工作几乎是不可能的事。但是统一的IP地址把这个复杂的问题解决了。
69、路由协议
69.1、基本概念
网络层主要做的是通过查找路由表确定如何到达服务器,期间可能经过多个路由器,这些都是由路由器来完成的工作,通过查找路由表决定通过那个路径到达服务器,其中用到路由选择协议。 路由主要分为两类:即静态路由和动态路由。从管理层面来说,静态路由比较容易部署/修改(小网络),动态路由协议一般路由的体积比较大,管理相对比较复杂(大网络)。但是从技术层面来说,动态路由协议能够适应各种网络结构的拓扑,能够智能检测网络状态;静态路由技术无法实现,需要人工干预,包括后面我们学习的RIP,EIGRP,OSPF,ISIS,BGP这些路由协议都是动态路由。
69.2、算法特征
距离矢量:距离矢量就是路由协议会根据路由距离的远近来判断到达目的网络的最佳路径选择,例如在RIP路由协议中,数据报每经过一个路由器,就是一跳,到达目标网络最少需要经过几跳被认为是最佳路径,矢量是用于指明目的网络方向。另外还有EIGRP、BGP这几个也是基于距离矢量的路由协议。
链路状态:链路状态就是根据链路的一个带宽的状态来决定链路路径的选择,基于链路状态的路由协议有OSPF、ISIS。
关于距离矢量和链路状态:
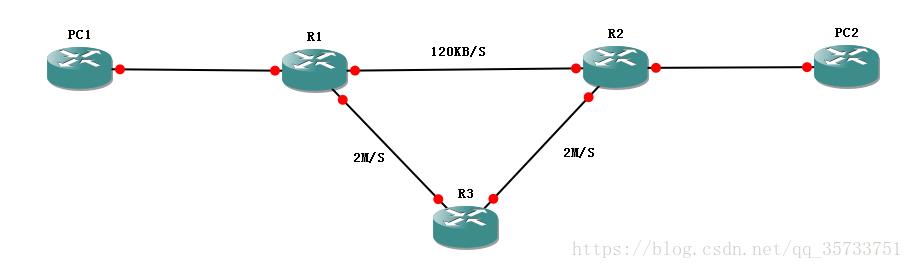 基于距离矢量的路由选择:
假设pc1到pc2有两条路径可选
路径1:pc1–>R1–>R2–>pc2
路径2:pc1–>R1–>R3–>R2–>pc2
如果是按距离矢量来选择路由路径的话,显然路径1对于pc1来说无疑是最佳的路由路径。
基于链路状态的路由选择:但是如果此时再根据链路的带宽状态来选择路由路径的话,路径1中R1–>R2的带宽是120KB/s,而路径2中R1–>R3–>R2的带宽是2M/s,显然是路径2的带宽速度比路径1要快几十倍不止,也就是说,路径2从带宽的速度上弥补了路由距离上的不足,甚至可以忽略路由路径的距离,根据链路状态选择路径2是最佳路由路径。
基于距离矢量的路由选择:
假设pc1到pc2有两条路径可选
路径1:pc1–>R1–>R2–>pc2
路径2:pc1–>R1–>R3–>R2–>pc2
如果是按距离矢量来选择路由路径的话,显然路径1对于pc1来说无疑是最佳的路由路径。
基于链路状态的路由选择:但是如果此时再根据链路的带宽状态来选择路由路径的话,路径1中R1–>R2的带宽是120KB/s,而路径2中R1–>R3–>R2的带宽是2M/s,显然是路径2的带宽速度比路径1要快几十倍不止,也就是说,路径2从带宽的速度上弥补了路由距离上的不足,甚至可以忽略路由路径的距离,根据链路状态选择路径2是最佳路由路径。
69.3、运行范围
按基于运行范围来看,主要有IGP和EGP两个协议:
IGP是内部网关协议(internal gateway protocol)的简称, 一般是由一个组织控制或管理的网络。比如:RIP,EIGRP,OSPF,ISIS等都是内部网关协议的一种。
EGP是外部网关协议(external gateway protocol)的简称, 一般是用于两个不同组织控制或管理的网络之间通信,BGP是边界网关协议,是外部网关协议的一种。
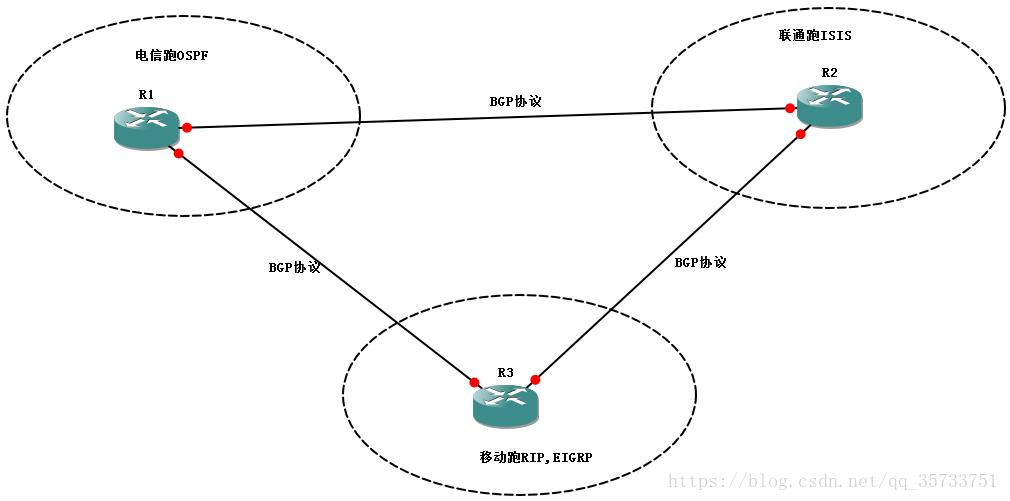 如图所示,移动,联通,电信三大运营商部使用的都是不同的内部网关协议,移动内部跑的是RIP,EIGRP协议;电信内部跑的是OSPF路由协议;联通内部跑的是ISIS协议。但是他们相互之间想要进行通信资源的整合,就必须把网络连接起来,而BGP协议就是相当于把互联网中的资源进行连接,相当于连接不同网络的一个边界一样。
如图所示,移动,联通,电信三大运营商部使用的都是不同的内部网关协议,移动内部跑的是RIP,EIGRP协议;电信内部跑的是OSPF路由协议;联通内部跑的是ISIS协议。但是他们相互之间想要进行通信资源的整合,就必须把网络连接起来,而BGP协议就是相当于把互联网中的资源进行连接,相当于连接不同网络的一个边界一样。
69.4、内部网关协议
1、RIP(Routing Information Protocol,应用层协议,基于 UDP) RIP 是一种基于距离向量的路由选择协议。RIP 协议要求网络中的每一个路由器都要维护从它自己到其他每一个目的网络的距离记录。这里的“距离”实际上指的是“最短距离”。RIP 认为一个好的路由就是它通过的路由器的数目少,即“距离短”。RIP 允许一条路径最多只能包含 15 个路由器。“距离”的最大值为 16 时即相当于不可达。RIP 选择一个具有最少路由器的路由(即最短路由),哪怕还存在另一条高速(低时延)但路由器较多的路由。 2、OSPF(Open Shortest Path First,网络层协议) “最短路径优先”是因为使用了 Dijkstra 提出的最短路径算法。使用洪泛法向本自治系统中所有路由器发送信息。发送的信息就是与本路由器相邻的所有路由器的链路状态(“链路状态”就是说明本路由器都和哪些路由器相邻,以及该链路的“度量”),但这只是路由器所知道的部分信息。只有当链路状态发生变化时,路由器才用洪泛法向所有路由器发送此信息。
69.5、外部网关协议
1、BGP 协议(应用层协议,基于 TCP的)
BGP是不同自治系统的路由器之间交换路由信息的协议。边界网关协议 BGP 只能是力求寻找一条能够到达目的网络且比较好的路由(不能兜圈子),而并非要寻找一条最佳路由。
BGP发言人:每一个自治系统的管理员要选择至少一个路由器作为该自治系统的“BGP发言人”。一般说来,两个 BGP 发言人都是通过一个共享网络连接在一起的,而 BGP 发言人往往就是 BGP 边界路由器,但也可以不是 BGP 边界路由器。
BGP 交换路由信息:
一个 BGP 发言人与其他自治系统中的 BGP 发言人要交换路由信息,就要先建立 TCP连接,然后在此连接上交换 BGP 报文以建立 BGP 会话(session),利用 BGP 会话交换路由信息。使用 TCP 连接能提供可靠的服务也简化了路由选择协议。使用 TCP 连接交换路由信息的两个 BGP 发言人,彼此成为对方的邻站或对等站。BGP 所交换的路由信息就是到达某个网络所要经过的一系列 AS 。
69.6、路由器分组转发算法
(1)、首先从 IP 数据报首部提取出目的主机的 IP地址D,得出其所在的网络 N。 (2)、若 N 就是与此路由器直接相连的某个网络,则进行 直接交付,直接把数据报交付给目的主机。否则就执行(3)。 (3)、若路由表中有目的地址为 D 的特定主机路由,则把数据报传给路由表中所指明的下一跳路由器。否则执行(4)。 (4)、若路由表中有到达网络 N 的路由,则把数据报传给路由表中所指明的下一跳路由器。否则执行(5)。 (5)、若路由表中有一个 默认路由,则把数据报传给默认路由所指明的默认路由器。否则执行(6)。 (6)、报告转发分组出错。
70、TCP协议的三次握手与四次挥手
70.1、TCP报文结构
 1、源端口号:表示发送端端口号,字段长为16位。
2、目标端口号:表示接收端口号,字段长为16位。
3、序列号:表示发送数据的位置,字段长为32位。每发送一次数据,就累加一次该数据字节数的大小。
注意:序列号不会从0或1开始,而是在建立连接时由计算机生成的一个随机数作为其初始值,通过SYN包发送给接收端主机。然后再将每次转发过去的字节数累加到初始值上表示数据的位置。
4、确认应答号:表示下一次应该收到的数据的序列号,字段长为32字节。发送端收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收。
序号的优点:
(1)保证报文按序到达。
(2)保证可靠性。
(3)保证效率。
(4)精准的报告哪些报文已经收到,哪些需要重传。
5、首部长度:该字段长度为4位,单位为4字节(32位)。TCP首部长度不包括选项的话,是20个字节,20/4=5,5的二进制序列:0101,报头长度也叫数据偏移,所以该字段可以设置为5,选项字段最大的是40字节,所以,TCP首部长度为最大为20+40=60字节,该字段可以设置的最大长度为60/4=15。
6、保留:该字段主要是为了以后扩展时使用,其长度为4位。一般设置为0,即使收到的包在该字段不为0,此包也不会丢弃。
7、控制位:字段长为6,每一位从左到右分别为:URG、ACK、PSH、RST、SYN、FIN。当对应的值为1,表示有具体含义。
1、源端口号:表示发送端端口号,字段长为16位。
2、目标端口号:表示接收端口号,字段长为16位。
3、序列号:表示发送数据的位置,字段长为32位。每发送一次数据,就累加一次该数据字节数的大小。
注意:序列号不会从0或1开始,而是在建立连接时由计算机生成的一个随机数作为其初始值,通过SYN包发送给接收端主机。然后再将每次转发过去的字节数累加到初始值上表示数据的位置。
4、确认应答号:表示下一次应该收到的数据的序列号,字段长为32字节。发送端收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收。
序号的优点:
(1)保证报文按序到达。
(2)保证可靠性。
(3)保证效率。
(4)精准的报告哪些报文已经收到,哪些需要重传。
5、首部长度:该字段长度为4位,单位为4字节(32位)。TCP首部长度不包括选项的话,是20个字节,20/4=5,5的二进制序列:0101,报头长度也叫数据偏移,所以该字段可以设置为5,选项字段最大的是40字节,所以,TCP首部长度为最大为20+40=60字节,该字段可以设置的最大长度为60/4=15。
6、保留:该字段主要是为了以后扩展时使用,其长度为4位。一般设置为0,即使收到的包在该字段不为0,此包也不会丢弃。
7、控制位:字段长为6,每一位从左到右分别为:URG、ACK、PSH、RST、SYN、FIN。当对应的值为1,表示有具体含义。
| 字段 | 含义 |
|---|---|
| URG | 紧急指针是否有效。为1,表示某一位需要被优先处理。 |
| ACK | 确认号是否有效,一般置为1。 |
| PSH | 提示接收端应用程序立即从TCP缓冲区把数据读走。 |
| RST | 对方要求重新建立连接,复位。 |
| SYN | 请求建立连接,并在其序列号的字段进行序列号的初始值设定。建立连接,设置为1。 |
| FIN | 希望断开连接。 |
8、窗口大小:接收缓冲区的大小,TCP不允许发送超过此处所示大小的数据。 9、校验和:发送端填充,CRC校验,接收校验不通过,则认为数据有问题。和UDP的区别是,UDP校验的是数据本身,TCP校验的不仅包含TCP首部,而且包含TCP数据部分。 10、紧急指针:只有在URG为1时有效,该字段为1表示本报文的段中的紧急数据的指针。 11、选项:用于提高TCP的传输性能。需要根据首部长度进行控制,其最大长度为40字节。
70.2、TCP三次握手以及四次挥手用到的字段
1、序列号seq 占4个字节,用来标记数据段的顺序,TCP把连接中发送的所有数据字节都编上一个序号,第一个字节的编号由本地随机产生,给字节编上序号后,就给每一个报文段指派一个序号,序列号seq就是这个报文段中的第一个字节的数据编号。 2、确认号ack 占4个字节,期待收到对方下一个报文段的第一个数据字节的序号,序列号表示报文段携带数据的第一个字节的编号,而确认号指的是期望接受到下一个字节的编号,因此当前报文段最后一个字节的编号+1即是确认号。 3、确认ACK 占1个比特位,仅当ACK=1,确认号字段才有效。ACK=0,确认号无效。 4、同步SYN 连接建立时用于同步序号。当SYN=1,ACK=0表示:这是一个连接请求报文段。若同意连接,则在响应报文段中使用SYN=1,ACK=1。因此,SYN=1表示这是一个连接请求,或连接接收报文,SYN这个标志位只有在TCP建立连接才会被置为1,握手完成后SYN标志位被置为0。 5、终止FIN 用来释放一个连接。
70.3、TCP三次握手
 step1:第一次握手
建立连接时,客户端发送SYN包到服务器,其中包含客户端的初始序号seq=x,并进入SYN_SENT状态,等待服务器确认。(其中,SYN=1,ACK=0,表示这是一个TCP连接请求数据报文;序号seq=x,表明传输数据时的第一个数据字节的序号是x)。
step2:第二次握手
服务器收到请求后,必须确认客户的数据包。同时自己也发送一个SYN包,即SYN+ACK包,此时服务器进入SYN_RECV状态。(其中确认报文段中,标识位SYN=1,ACK=1,表示这是一个TCP连接响应数据报文,并含服务端的初始序号seq(服务器)=y,以及服务器对客户端初始序号的确认号ack(服务器)=seq(客户端)+1=x+1)。
step3:第三次握手
客户端收到服务器的SYN+ACK包,向服务器发送一个序列号(seq=x+1),确认号为ack(客户端)=y+1,此包发送完毕,客户端和服务器进入ESTAB_LISHED(TCP连接成功)状态,完成三次握手。
未连接队列
在三次握手协议中,服务器维护一个未连接队列,该队列为每个客户端的SYN包(syn=j)开设一个条目,该条目表明服务器已收到SYN包,并向客户发出确认,正在等待客户的确认包时,删除该条目,服务器进入ESTAB_LISHED状态。
step1:第一次握手
建立连接时,客户端发送SYN包到服务器,其中包含客户端的初始序号seq=x,并进入SYN_SENT状态,等待服务器确认。(其中,SYN=1,ACK=0,表示这是一个TCP连接请求数据报文;序号seq=x,表明传输数据时的第一个数据字节的序号是x)。
step2:第二次握手
服务器收到请求后,必须确认客户的数据包。同时自己也发送一个SYN包,即SYN+ACK包,此时服务器进入SYN_RECV状态。(其中确认报文段中,标识位SYN=1,ACK=1,表示这是一个TCP连接响应数据报文,并含服务端的初始序号seq(服务器)=y,以及服务器对客户端初始序号的确认号ack(服务器)=seq(客户端)+1=x+1)。
step3:第三次握手
客户端收到服务器的SYN+ACK包,向服务器发送一个序列号(seq=x+1),确认号为ack(客户端)=y+1,此包发送完毕,客户端和服务器进入ESTAB_LISHED(TCP连接成功)状态,完成三次握手。
未连接队列
在三次握手协议中,服务器维护一个未连接队列,该队列为每个客户端的SYN包(syn=j)开设一个条目,该条目表明服务器已收到SYN包,并向客户发出确认,正在等待客户的确认包时,删除该条目,服务器进入ESTAB_LISHED状态。
70.4、四次挥手过程(关闭客户端到服务器的连接)
step1:第一次挥手 首先,客户端发送一个FIN,用来关闭客户端到服务器的数据传送,然后等待服务器的确认。其中终止标志位FIN=1,序列号seq=u。 step2:第二次挥手 服务器收到这个FIN,它发送一个ACK,确认ack为收到的序号加一。 step3:第三次挥手 关闭服务器到客户端的连接,发送一个FIN给客户端。 step4:第四次挥手 客户端收到FIN后,并发回一个ACK报文确认,并将确认序号seq设置为收到序号加一。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。 客户端发送FIN后,进入终止等待状态,服务器收到客户端连接释放报文段后,就立即给客户端发送确认,服务器就进入CLOSE_WAIT状态,此时TCP服务器进程就通知高层应用进程,因而从客户端到服务器的连接就释放了。此时是“半关闭状态”,即客户端不可以发送给服务器,服务器可以发送给客户端。 此时,如果服务器没有数据报发送给客户端,其应用程序就通知TCP释放连接,然后发送给客户端连接释放数据报,并等待确认。客户端发送确认后,进入TIME_WAIT状态,但是此时TCP连接还没有释放,然后经过等待计时器设置的2MSL(2倍报文最大生存时间)后,才进入到CLOSE状态。 【注意】中断连接端可以是 Client 端,也可以是 Server 端。 假设 Client 端发起中断连接请求,也就是发送 FIN 报文。Server 端接到 FIN 报文后,意思是说"我 Client 端没有数据要发给你了",但是如果你还有数据没有发送完成,则不必急着关闭 Socket,可以继续发送数据。所以你先发送 ACK,“告诉 Client 端,你的请求我收到了,但是我还没准备好,请继续你等我的消息”。这个时候 Client 端就进入FIN_WAIT 状态,继续等待 Server 端的 FIN 报文。当 Server 端确定数据已发送完成,则向 Client 端发送 FIN 报文,“告诉 Client 端,好了,我这边数据发完了,准备好关闭连接了”。Client 端收到 FIN 报文后,“就知道可以关闭连接了,但是他还是不相信网络,怕 Server 端不知道要关闭,所以发送 ACK 后进入 TIME_WAIT 状态,如果 Server端没有收到 ACK 则可以重传。”Server 端收到 ACK 后,“就知道可以断开连接了”。Client端等待了 2MSL 后依然没有收到回复,则证明 Server 端已正常关闭,那好,我 Client 端也可以关闭连接了。Ok,TCP连接就这样关闭了!
70.5、为什么需要三次握手,两次不可以吗?或者四次、五次可以吗?
我们来分析一种特殊情况,假设客户端请求建立连接,发给服务器SYN包等待服务器确认,服务器收到确认后,如果是两次握手,假设服务器给客户端在第二次握手时发送数据,数据从服务器发出,服务器认为连接已经建立,但在发送数据的过程中数据丢失,客户端认为连接没有建立,会进行重传。假设每次发送的数据一直在丢失,客户端一直SYN,服务器就会产生多个无效连接,占用资源,这个时候服务器可能会挂掉。这个现象就是我们听过的“SYN的洪水攻击”。 总结:第三次握手是为了防止:如果客户端迟迟没有收到服务器返回确认报文,这时会放弃连接,重新启动一条连接请求,但问题是:服务器不知道客户端没有收到,所以他会收到两个连接,浪费连接开销。如果每次都是这样,就会浪费多个连接开销。 也是为了防止失效的连接请求报文段突然又传送到服务器,因而产生错误。
70.6、为什么是四次挥手,而不是三次或是五次、六次?
确保数据能够完成传输。 关闭连接时,当收到对方的 FIN 报文通知时,它仅仅表示对方没有数据发送给你了;但未必你所有的数据都全部发送给对方了,所以你可以未必会马上会关闭 SOCKET,也即你可能还需要发送一些数据给对方之后,再发送 FIN 报文给对方来表示你同意现在可以关闭连接了,所以它这里的 ACK 报文和FIN 报文多数情况下都是分开发送的。 TCP 协议是一种面向连接的、可靠的、基于字节流的运输层通信协议。TCP 是全双工模式,这就意味着,当主机 1 发出 FIN 报文段时,只是表示主机 1 已经没有数据要发送了,主机 1 告诉主机 2,它的数据已经全部发送完毕了;但是,这个时候主机 1 还是可以接受来自主机 2 的数据;当主机 2 返回 ACK 报文段时,表示它已经知道主机 1 没有数据发送了,但是主机 2 还是可以发送数据到主机 1 的;当主机 2 也发送了 FIN 报文段时,这个时候就表示主机 2 也没有数据要发送了,就会告诉主机 1,我也没有数据要发送了,之后彼此就会愉快的中断这次 TCP 连接。
70.7、time_wait 状态产生的原因?
1)、可靠地实现 TCP 全双工连接的终止 我们必须要假想网络是不可靠的,你无法保证你最后发送的 ACK 报文会一定被对方收到,因此对方处于 LAST_ACK 状态下的 SOCKET 可能会因为超时未收到 ACK 报文,而重发 FIN报文,client 必须维护这条连接的状态(保持 time_wait,具体而言,就是这条TCP 连接对应的(local_ip, local_port)资源不能被立即释放或重新分配)以便可以重发丢失的 ACK,如果主动关闭端不维持 TIME_WAIT 状态,而是处于 CLOSED 状态,主动关闭端将会响应一个 RST,结果 server 认为发生错误,导致服务器端不能正常关闭连接。**所以这个TIME_WAIT 状态的作用就是用来重发可能丢失的 ACK 报文。**所以,当客户端等待 2MSL(2倍报文最大生存时间)后,没有收到服务端的 FIN 报文后,他就知道服务端已收到了 ACK报文,所以客户端此时才关闭自己的连接。 2)、允许老的重复分节在网络中消逝 2MSL可以使本连接持续的时间内所有所产生的报文段都从网络中消失。这样就可以使下一个新的连接中不会出现旧的连接的请求报文段。 如果 TIME_WAIT 状态保持时间不足够长 (比如小于2MSL),第一个连接就正常终止了。第二个拥有相同四元组(local_ip, local_port, remote_ip,remote_port)的连接出现(建立起一个相同的 IP 地址和端口之间的 TCP 连接),而第一个连接的重复报文到达,干扰了第二个连接。TCP 实现必须防止某个连接的重复报文在连接终止后出现,所以让TIME_WAIT 状态保持时间足够长 (2MSL),连接相应方向上的 TCP 报文要么完全响应完毕,要么被丢弃。建立第二个连接的时候,不会混淆。
70.8、如果网络连接中出现大量 TIME_WAIT 状态所带来的危害?
如果系统中有很多 socket 处于 TIME_WAIT 状态,当需要创建新的 socket 连接的时候可能会受到影响,这也会影响到系统的扩展性。 之所以 TIME_WAIT 能够影响系统的扩展性是因为在一个 TCP 连接中,一个 Socket如果关闭的话,它将保持 TIME_WAIT 状态大约 1-4分钟。如果很多连接快速的打开和关闭的话,系统中处于 TIME_WAIT 状态的 socket 将会积累很多,由于本地端口数量的限制,同一时间只有有限数量的 socket 连接可以建立,如果太多的socket 处于TIME_WAIT状态,你会发现,由于用于新建连接的本地端口太缺乏,将会很难再建立新的对外连接。
70.9、TCP如何保证传输的可靠性?
0、在传递数据之前,会有三次握手来建立连接。 1、应用数据被分割成 TCP 认为最适合发送的数据块(按字节编号,合理分片)。这和UDP完全不同,应用程序产生的数据报长度将保持不变。(将数据截断为合理的长度) 2、当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。(超时重发) 3、当 TCP 收到发自 TCP 连接另一端的数据,它将发送一个确认。这个确认不是立即发送,通常将推迟几分之一秒 。(对于收到的请求,给出确认响应) (之所以推迟,可能是要对包做完整校验)。 4、TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。(校验出包有错,丢弃报文段,不给出响应,TCP 发送数据端,超时时会重发数据) 5、既然 TCP 报文段作为 IP 数据报来传输,而 IP 数据报的到达可能会失序,因此TCP 报文段的到达也可能会失序。如果必要,TCP 将对收到的数据进行重新排序,将收到的数据以正确的顺序交给应用层。(对失序数据进行重新排序,然后才交给应用层) 6、既然 IP 数据报会发生重复,TCP 的接收端必须丢弃重复的数据。(对于重复数据,能够丢弃重复数据) 7、TCP 还能提供流量控制。TCP 连接的每一方都有固定大小的缓冲空间。TCP 的接收端只允许另一端发送接收端缓冲区所能接纳的数据。这将防止较快主机致使较慢主机的缓冲区溢出。(TCP 可以进行流量控制,防止较快主机致使较慢主机的缓冲区溢出) TCP 使用的流量控制协议是可变大小的滑动窗口协议。 8、TCP 还能提供拥塞控制。当网络拥塞时,减少数据的发送。
70.10、TCP 建立连接之后怎么保持连接(检测连接断没断)?
有两种技术可以运用。一种是由 TCP 协议层实现的 Keepalive 机制,另一种是由应用层自己实现的 HeartBeat 心跳包。 1、在 TCP 中有一个 Keep-alive 的机制可以检测死连接,原理很简单,当连接闲置一定的时间(参数值可以设置,默认是 2 小时)之后,TCP 协议会向对方发一个 keepalive探针包(包内没有数据),对方在收到包以后,如果连接一切正常,应该回复一个 ACK;如果连接出现错误了(例如对方重启了,连接状态丢失),则应当回复一个 RST;如果对方没有回复,那么,服务器每隔一定的时间(参数值可以设置)再发送 keepalive 探针包,如果连续多个包(参数值可以设置)都被无视了,说明连接被断开了。 2、心跳包之所以叫心跳包是因为:它像心跳一样每隔固定时间发一次,以此来告诉服务器,这个客户端还活着。事实上这是为了保持长连接,至于这个包的内容,是没有什么特别规定的,不过一般都是很小的包,或者只包含包头的一个空包。由应用程序自己发送心跳包来检测连接的健康性。客户端可以在一个 Timer 中或低级别的线程中定时向服务器发送一个短小精悍的包,并等待服务器的回应。客户端程序在一定时间内没有收到服务器回应即认为连接不可用,同样,服务器在一定时间内没有收到客户端的心跳包则认为客户端已经掉线。
71、TCP流量控制(滑动窗口机制)
滑动窗口协议的基本原理就是在任意时刻,发送方都维持了一个连续的允许发送的帧的序号,称为发送窗口;同时,接收方也维持了一个连续的允许接收的帧的序号,称为接收窗口。发送窗口和接收窗口的序号的上下界不一定要一样,甚至大小也可以不同。不同的滑动窗口协议窗口大小一般不同。 所谓滑动窗口协议,自己理解有两点:1)、“窗口”对应的是一段可以被发送者发送的字节序列,其连续的范围称之为“窗口”;2)、“滑动”则是指这段“允许发送的范围”是可以随着发送的过程而变化的,方式就是按顺序“滑动”。在此之前要先了解以下前提: 1、TCP 协议的两端分别为发送者 A 和接收者 B,由于是全双工协议,因此 A 和 B 应该分别维护着一个独立的发送缓冲区和接收缓冲区,由于对等性(A发B收 和 B发A收),我们以 A 发送 B 接收的情况作为例子; 2、发送窗口是发送缓存中的一部分,是可以被 TCP 协议发送的那部分,其实应用层需要发送的所有数据都被放进了发送者的发送缓冲区; 3、发送窗口中相关的有四个概念:已发送并收到确认的数据(不在发送窗口和发送缓冲区之内)、已发送但未收到确认的数据(位于发送窗口之中)、允许发送但尚未发送的数据以及发送窗口外发送缓冲区内暂时不允许发送的数据; 4、每次成功发送数据之后,发送窗口就会在发送缓冲区中按顺序移动,将新的数据包含到窗口中准备发送;
71.1、流量控制
流量控制方面主要有两个要点需要掌握。一是TCP利用滑动窗口实现流量控制的机制;二是如何考虑流量控制中的传输效率。
1、流量控制
所谓流量控制,主要是接收方传递信息给发送方,使其不要发送数据太快,是一种端到端的控制。主要的方式就是返回的ACK中会包含自己的接收窗口的大小,并且利用大小来控制发送方的数据发送:
 这里面涉及到一种情况,如果B已经告诉A自己的缓冲区已满,于是A停止发送数据;等待一段时间后,B的缓冲区出现了富余,于是给A发送报文告诉A我的rwnd大小为400,但是这个报文不幸丢失了,于是就出现A等待B的通知||B等待A发送数据的死锁状态。为了处理这种问题,TCP引入了持续计时器(Persistence timer),当A收到对方的零窗口通知时,就启用该计时器,时间到则发送一个1字节的探测报文,对方会在此时回应自身的接收窗口大小,如果结果仍为0,则重设持续计时器,继续等待。
2、传递效率
一个显而易见的问题是:单个发送字节单个确认,和窗口有一个空余即通知发送方发送一个字节,无疑增加了网络中的许多不必要的报文(请想想为了一个字节数据而添加的40字节头部吧!),所以我们的原则是尽可能一次多发送几个字节,或者窗口空余较多的时候通知发送方一次发送多个字节。对于前者我们广泛使用Nagle算法,即:
1)、若发送应用进程要把发送的数据逐个字节地送到TCP的发送缓存,则发送方就把第一个数据字节先发送出去,把后面的字节先缓存起来;
2)、当发送方收到第一个字节的确认后(也得到了网络情况和对方的接收窗口大小),再把缓冲区的剩余字节组成合适大小的报文发送出去;
3)、当到达的数据已达到发送窗口大小的一半或已达到报文段的最大长度时,就立即发送一个报文段;
对于后者我们往往的做法是让接收方等待一段时间,或者接收方获得足够的空间容纳一个报文段或者等到接受缓存有一半空闲的时候,再通知发送方发送数据。
这里面涉及到一种情况,如果B已经告诉A自己的缓冲区已满,于是A停止发送数据;等待一段时间后,B的缓冲区出现了富余,于是给A发送报文告诉A我的rwnd大小为400,但是这个报文不幸丢失了,于是就出现A等待B的通知||B等待A发送数据的死锁状态。为了处理这种问题,TCP引入了持续计时器(Persistence timer),当A收到对方的零窗口通知时,就启用该计时器,时间到则发送一个1字节的探测报文,对方会在此时回应自身的接收窗口大小,如果结果仍为0,则重设持续计时器,继续等待。
2、传递效率
一个显而易见的问题是:单个发送字节单个确认,和窗口有一个空余即通知发送方发送一个字节,无疑增加了网络中的许多不必要的报文(请想想为了一个字节数据而添加的40字节头部吧!),所以我们的原则是尽可能一次多发送几个字节,或者窗口空余较多的时候通知发送方一次发送多个字节。对于前者我们广泛使用Nagle算法,即:
1)、若发送应用进程要把发送的数据逐个字节地送到TCP的发送缓存,则发送方就把第一个数据字节先发送出去,把后面的字节先缓存起来;
2)、当发送方收到第一个字节的确认后(也得到了网络情况和对方的接收窗口大小),再把缓冲区的剩余字节组成合适大小的报文发送出去;
3)、当到达的数据已达到发送窗口大小的一半或已达到报文段的最大长度时,就立即发送一个报文段;
对于后者我们往往的做法是让接收方等待一段时间,或者接收方获得足够的空间容纳一个报文段或者等到接受缓存有一半空闲的时候,再通知发送方发送数据。
71.2、拥塞控制
网络中的链路容量和交换结点中的缓存和处理机都有着工作的极限,当网络的需求超过它们的工作极限时,就出现了拥塞。拥塞控制就是防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不致过载。常用的方法就是: 1、慢开始、拥塞控制; 2、快重传、快恢复; 一切的基础还是慢开始,这种方法的思路是这样的: 1)、发送方维持一个叫做“拥塞窗口”的变量,该变量和接收端口共同决定了发送者的发送窗口; 2)、当主机开始发送数据时,避免一下子将大量字节注入到网络,造成或者增加拥塞,选择发送一个1字节的试探报文; 3)、当收到第一个字节的数据的确认后,就发送2个字节的报文; 4)、若再次收到2个字节的确认,则发送4个字节,依次递增2的指数级; 5)、最后会达到一个提前预设的“慢开始门限”,比如24,即一次发送了24个分组,此时遵循下面的条件判定: *1、cwnd < ssthresh,继续使用慢开始算法; *2、cwnd > ssthresh,停止使用慢开始算法,改用拥塞避免算法; *3、cwnd = ssthresh,既可以使用慢开始算法,也可以使用拥塞避免算法; 6)、所谓拥塞避免算法就是:每经过一个往返时间RTT就把发送方的拥塞窗口+1,即让拥塞窗口缓慢地增大,按照线性规律增长; 7)、当出现网络拥塞,比如丢包时,将慢开始门限设为原先的一半,然后将cwnd设为1,执行慢开始算法(较低的起点,指数级增长);
 上述方法的目的是在拥塞发生时循序减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够的时间把队列中积压的分组处理完毕。慢开始和拥塞控制算法常常作为一个整体使用,而快重传和快恢复则是为了减少因为拥塞导致的数据包丢失带来的重传时间,从而避免传递无用的数据到网络。快重传的机制是:
1)、接收方建立这样的机制,如果一个包丢失,则对后续的包继续发送针对该包的重传请求;
2)、一旦发送方接收到三个一样的确认,就知道该包之后出现了错误,立刻重传该包;
3)、此时发送方开始执行“快恢复”算法:
*1、慢开始门限减半;
*2、cwnd设为慢开始门限减半后的数值;
*3、执行拥塞避免算法(高起点,线性增长);
上述方法的目的是在拥塞发生时循序减少主机发送到网络中的分组数,使得发生拥塞的路由器有足够的时间把队列中积压的分组处理完毕。慢开始和拥塞控制算法常常作为一个整体使用,而快重传和快恢复则是为了减少因为拥塞导致的数据包丢失带来的重传时间,从而避免传递无用的数据到网络。快重传的机制是:
1)、接收方建立这样的机制,如果一个包丢失,则对后续的包继续发送针对该包的重传请求;
2)、一旦发送方接收到三个一样的确认,就知道该包之后出现了错误,立刻重传该包;
3)、此时发送方开始执行“快恢复”算法:
*1、慢开始门限减半;
*2、cwnd设为慢开始门限减半后的数值;
*3、执行拥塞避免算法(高起点,线性增长);
 TCP 滑动窗口协议,窗口过大或过小有什么影响?
滑动窗口的大小对网络性能有很大的影响。
如果滑动窗口过小,极端的情况就是停止等待协议,发一个报文等一个 ACK,会造成通信效率下降。
如果滑动窗口过大,网络容易拥塞,容易造成接收端的缓存不够而溢出,容易产生丢包现象,则需要多次发送重复的数据,耗费了网络带宽。
TCP 滑动窗口协议,窗口过大或过小有什么影响?
滑动窗口的大小对网络性能有很大的影响。
如果滑动窗口过小,极端的情况就是停止等待协议,发一个报文等一个 ACK,会造成通信效率下降。
如果滑动窗口过大,网络容易拥塞,容易造成接收端的缓存不够而溢出,容易产生丢包现象,则需要多次发送重复的数据,耗费了网络带宽。
72、TCP与UDP的对比
TCP、UDP 都是传输层协议,他们的通信机制与应用场景不同。 TCP(Transmission Control Protocol),又叫传输控制协议,UDP(User Datagram Protocol),又叫用户数据报协议,它们都是传输层的协议,但两者的机制不同,它们的区别如下:
| 特点 | TCP | UDP |
|---|---|---|
| 连接性 | 面向连接 | 面向非连接 |
| 可靠性 | 可靠 | 不可靠 |
| 传输效率 | 慢 | 快 |
TCP的优点:可靠,稳定。TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源。TCP的缺点:慢,效率低,占用系统资源高,易被攻击。TCP在传递数据之前,要先建连接,这会消耗时间,而且在数据传递时,确认机制、重传机制、拥塞控制机制等都会消耗大量的时间,而且要在每台设备上维护所有的传输连接,事实上,每个连接都会占用系统的CPU、内存等硬件资源。而且,因为TCP有确认机制、三次握手机制,这些也导致TCP容易被人利用,实现DOS、DDOS、CC等攻击。 UDP的优点:快,比TCP稍安全。UDP没有TCP的握手、确认、窗口、重传、拥塞控制等机制,UDP是一个无状态的传输协议,所以它在传递数据时非常快。没有TCP的这些机制,UDP较TCP被攻击者利用的漏洞就要少一些。但UDP也是无法避免攻击的,比如:UDP Flood攻击……;UDP的缺点:不可靠,不稳定,因为UDP没有TCP那些可靠的机制,在数据传递时,如果网络质量不好,就会很容易丢包。 基于上面的优缺点,那么: 什么时候应该使用TCP: 当对网络通讯质量有要求的时候,比如:整个数据要准确无误的传递给对方,这往往用于一些要求可靠的应用,比如HTTP、HTTPS、FTP等传输文件的协议,POP、SMTP等邮件传输的协议。在日常生活中,常见使用TCP协议的应用如下: 浏览器,用的HTTP FlashFXP,用的FTP Outlook,用的POP、SMTP Putty,用的Telnet、SSH QQ文件传输…………;什么时候应该使用UDP:当对网络通讯质量要求不高的时候,要求网络通讯速度能尽量的快,这时就可以使用UDP。 比如,日常生活中,常见使用UDP协议的应用如下:QQ语音、QQ视频、TFTP ……。 TCP与UDP区别总结: 1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接; 2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付; 3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的,UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等); 4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信; 5、TCP首部开销20字节;UDP的首部开销小,只有8个字节; 6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道;
72.1、可靠性补充
在通信的角度来看,可靠即要确保通信双方的通信信息不会丢失,若丢失了保证能够对其进行恢复,并且收到的信息内容与原发送内容一样。 在 TCP 中,传输报文都是通过建立的虚拟连接来进行传输,发送端传输的每一个 TCP报文,都会对其进行编号(编号是由于网络传输的原因,发送的报文可能会乱序到达,因此需要根据编号对报文进行重排),并且开启一个计时器;当接收端收到报文后,并且通过校验和对收到的报文数据进行校验,若校验成功则会返回一个确认报文,告知发送端我已经成功收到该报文了;若发送端在计时器结束前仍未收到确认报文,则认为接收端接收失败,则会重传该报文;服务端若收到重复报文(根据编号发现已经是收到了),则会将该报文丢弃。 UDP不需要确保服务端一定能收到或收到完整的数据。它仅仅提供了校验和机制来保障一个报文是否完整,若校验失败,则直接丢弃报文,不做任何处理。 基于TCP协议的应用层协议:http、ftp、telnet、smtp; 基于UDP协议的应用层协议:dns、rip、tftp;
73、HTTP协议请求过程
大致的流程:输入地址 –> DNS域名解析 –> 发起TCP的三次握手 –> 建立TCP连接后发起http请求 –> 服务器响应http请求,浏览器得到html代码 –> 浏览器解析html代码,并请求html代码中的资源(如javascript、css、图片等) –> 浏览器对页面进行渲染呈现给用户。
第一步:输入地址 当我们开始在浏览器中输入网址的时候,浏览器其实就已经在智能的匹配可能的url了,他会从历史记录,书签等地方,找到已经输入的字符串可能对应的 url,然后给出智能提示,让你可以补全 url 地址。对于 google 的 chrome 的浏览器,他甚至会直接从缓存中把网页展示出来,就是说,你还没有按下 enter,页面就出来了。
第二步:浏览器查找域名的 IP 地址
1、请求一旦发起,浏览器首先要做的事情就是解析这个域名,一般来说,浏览器会首先查看本地硬盘的 hosts 文件,看看其中有没有和这个域名对应的规则,如果有的话就直接使用 hosts 文件里面的 ip 地址。
2、如果在本地的 hosts 文件没有能够找到对应的 ip 地址,浏览器会发出一个 DNS请求到本地 DNS 服务器。本地 DNS 服务器一般都是你的网络接入服务器商提供,比如中国电信,中国移动。
3、查询你输入的网址的 DNS 请求到达本地 DNS 服务器之后,本地 DNS 服务器会首先查询它的缓存记录,如果缓存中有此条记录,就可以直接返回结果,此过程是递归的方式进行查询。如果没有,本地 DNS 服务器还要向 DNS 根服务器进行查询。
4、根 DNS 服务器没有记录具体的域名和 IP 地址的对应关系,而是告诉本地 DNS 服务器,你可以到域服务器上去继续查询,并给出域服务器的地址。这种过程是迭代的过程。
5、本地 DNS 服务器继续向域服务器发出请求,在这个例子中,请求的对象是.com域服务器。.com 域服务器收到请求之后,也不会直接返回域名和 IP 地址的对应关系,而是告诉本地 DNS 服务器,你的域名的解析服务器的地址。
6、最后,本地 DNS 服务器向域名的解析服务器发出请求,这时就能收到一个域名和IP 地址对应关系,本地 DNS 服务器不仅要把 IP 地址返回给用户电脑,还要把这个对应关系保存在缓存中,以备下次别的用户查询时,可以直接返回结果,加快网络访问。
第三步:浏览器向 web 服务器发送一个 HTTP 请求 拿到域名对应的IP地址之后,浏览器会以一个随机端口(1024<端口<65535)向服务器的WEB程序(常用的有httpd,nginx等)80端口发起TCP的连接请求。这个连接请求到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的TCP/IP协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过Netfilter防火墙(属于内核的模块)的过滤,最终到达WEB程序,最终建立了TCP/IP的连接。 建立了TCP连接之后,发起一个http请求。一个典型的 http request header 一般需要包括请求的方法,例如 GET 或者 POST 等,不常用的还有 PUT 和 DELETE 、HEAD、OPTION以及 TRACE 方法,一般的浏览器只能发起 GET 或者 POST 请求。
第四步:服务器的永久重定向响应 服务器给浏览器响应一个 301 永久重定向响应,这样浏览器就会访问"http://www.google.com/" 而非"http://google.com/"。为什么服务器一定要重定向而不是直接发送用户想看的网页内容呢?其中一个原因跟搜索引擎排名有关。如果一个页面有两个地址,就像 http://www.yy.com/ 和 http://yy.com/, 搜索引擎会认为它们是两个网站,结果造成每个搜索链接都减少从而降低排名。而搜索引擎知道301 永久重定向是什么意思,这样就会把访问带 www的和不带 www的地址归到同一个网站排名下。还有就是用不同的地址会造成缓存友好性变差,当一个页面有好几个名字时,它可能会在缓存里出现好几次。 扩展知识**** 1)301 和 302 的区别 301 和 302 状态码都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到一个新的 URL 地址,这个地址可以从响应的 Location 首部中获取(用户看到的效果就是他输入的地址 A 瞬间变成了另一个地址 B)——这是它们的共同点。他们的不同在于。301 表示旧地址 A 的资源已经被永久地移除了(这个资源不可访问了),搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址; 302 表示旧地址 A 的资源还在(仍然可以访问),这个重定向只是临时地从旧地址 A跳转到地址 B,搜索引擎会抓取新的内容而保存旧的网址。 2)重定向原因: (1)网站调整(如改变网页目录结构); (2)网页被移到一个新地址; (3)网页扩展名改变(如应用需要把.php 改成.html 或.shtml)。这种情况下,如果不做重定向,则用户收藏夹或搜索引擎数据库中旧地址只能让访问客户得到一个 404 页面错误信息,访问流量白白丧失;再者某些注册了多个域名的网站,也需要通过重定向让访问这些域名的用户自动跳转到主站点等。 3)什么时候进行 301 或者 302 跳转呢? 当一个网站或者网页 24—48 小时内临时移动到一个新的位置,这时候就要进行 302跳转,而使用 301 跳转的场景就是之前的网站因为某种原因需要移除掉,然后要到新的地址访问,是永久性的。 清晰明确而言:使用 301 跳转的大概场景如下: 1、域名到期不想续费(或者发现了更适合网站的域名),想换个域名。 2、在搜索引擎的搜索结果中出现了不带 www 的域名,而带 www 的域名却没有收录,这个时候可以用 301 重定向来告诉搜索引擎我们目标的域名是哪一个。 3、空间服务器不稳定,换空间的时候。 扩展知识****
第五步:浏览器跟踪重定向地址 现在浏览器知道了 “http://www.google.com/"才是要访问的正确地址,所以它会发送另一个 http 请求。这里没有啥好说的。
第六步:服务器处理请求 经过前面的重重步骤,我们终于将我们的 http 请求发送到了服务器这里,其实前面的重定向已经是到达服务器了,那么,服务器是如何处理我们的请求的呢?后端从在固定的端口接收到 TCP 报文开始,它会对 TCP 连接进行处理,对 HTTP 协议进行解析,并按照报文格式进一步封装成 HTTP Request 对象,供上层使用。一些大一点的网站会将你的请求到反向代理服务器中,因为当网站访问量非常大,网站越来越慢,一台服务器已经不够用了。于是将同一个应用部署在多台服务器上,将大量用户的请求分配给多台机器处理。此时,客户端不是直接通过 HTTP 协议访问某网站应用服务器,而是先请求到 Nginx,Nginx 再请求应用服务器,然后将结果返回给客户端,这里 Nginx的作用是反向代理服务器。同时也带来了一个好处,其中一台服务器万一挂了,只要还有其他服务器正常运行,就不会影响用户使用。
第七步:服务器返回一个 HTTP 响应 经过前面的 6 个步骤,服务器收到了我们的请求,也处理我们的请求,到这一步,它会把它的处理结果返回,也就是返回一个 HTTP 响应。
第八步:浏览器显示 HTML 在浏览器没有完整接受全部 HTML 文档时,它就已经开始显示这个页面了,浏览器是如何把页面呈现在屏幕上的呢?不同浏览器可能解析的过程不太一样。
第九步:浏览器发送请求获取嵌入在 HTML 中的资源(如图片、音频、视频、CSS、JS 等等) 其实这个步骤可以并列在步骤 8 中,在浏览器显示 HTML 时,它会注意到需要获取其它地址内容的标签。这时,浏览器会发送一个获取请求来重新获得这些文件。这些地址都要经历一个和 HTML 读取类似的过程。所以浏览器会在 DNS 中查找这些域名,发送请求,重定向等等…不像动态页面,静态文件会允许浏览器对其进行缓存。有的文件可能会不需要与服务器通讯,而从缓存中直接读取,或者可以放到 CDN 中。
74、HTTP1.1与HTTP1.0的比较(HTTP1.1的四个新特性)
1、默认持久连接和流水线 HTTP/1.1 默认使用持久连接,只要客户端服务端任意一端没有明确提出断开 TCP 连接,就一直保持连接,在同一个 TCP 连接下,可以发送多次 HTTP 请求。同时,默认采用流水线的方式发送请求,即客户端每遇到一个对象引用就立即发出一个请求,而不必等到收到前一个响应之后才能发出下一个请求,但服务器端必须按照接收到客户端请求的先后顺序依次回送响应结果,以保证客户端能够区分出每次请求的响应内容,这样也显著地减少了整个下载过程所需要的时间。 HTTP/1.0 默认使用短连接,要建立长连接,可以在请求消息中包含Connection:Keep-Alive 头域,如果服务器愿意维持这条连接,在响应消息中也会包含一个 Connection:Keep-Alive 的头域。Connection 请求头的值为 Keep-Alive 时,客户端通知服务器返回本次请求结果后保持连接;Connection 请求头的值为 close 时,客户端通知服务器返回本次请求结果后关闭连接。
2、分块传输数据 HTTP/1.0 可用来指定实体长度的唯一机制是通过 Content-Length 字段。静态资源的长度可以很容易地确定,但是对于动态生成的响应来说,为获取它的真实长度,只能等它完全生成之后,才能正确地填写 Content-Length 的值,这便要求缓存整个响应,在服务器端占用大量的缓存,从而延长了响应用户的时间。 HTTP/1.1 引入了被称为分块(chunked)的传输方法。该方法使发送方能将消息实体分割为任意大小的组块(chunk),并单独地发送他们。在每个组块前面,都加上了该组块的长度,使接收方可确保自己能够完整地接收到这个组块。更重要的是,在最末尾的地方,发送方生成了长度为零的组块,接收方可据此判断整条消息都已安全地传输完毕。这样也避免了在服务器端占用大量的缓存。Transfer-Encoding:chunked 向接收方指出:响应将被分组块,对响应分析时,应采取不同于非分组块的方式。
3、状态码 100 Continue HTTP/1.1 加入了一个新的状态码 100 Continue,用于客户端在发送 POST 数据给服务器前,征询服务器的情况,看服务器是否处理 POST 的数据。 当要 POST 的数据大于 1024 字节的时候,客户端并不会直接就发起 POST 请求,而是会分为 2 步: 1)、发送一个请求,包含一个 Expect:100-continue,询问 Server 是否愿意接受数据。 2)、接收到 Server 返回的 100 continue 应答以后,才把数据 POST 给 Server。 这种情况通常发生在客户端准备发送一个冗长的请求给服务器,但是不确认服务器是否有能力接收。如果没有得到确认,而将一个冗长的请求包发送给服务器,然后包被服务器给抛弃了,这种情况挺浪费资源的。
4、Host 域 HTTP1.1 在 Request 消息头里多了一个 Host 域,HTTP1.0 则没有这个域。在HTTP1.0中认为每台服务器都绑定一个唯一的 IP 地址,这个 IP 地址上只有一个主机。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机,并且它们共享一个 IP 地址。