这些高阶的函数技术,你掌握了么
在 JavaScript 中,函数为一等公民(First Class),所谓的 “一等公民”,指的是函数与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或作为其它函数的返回值。
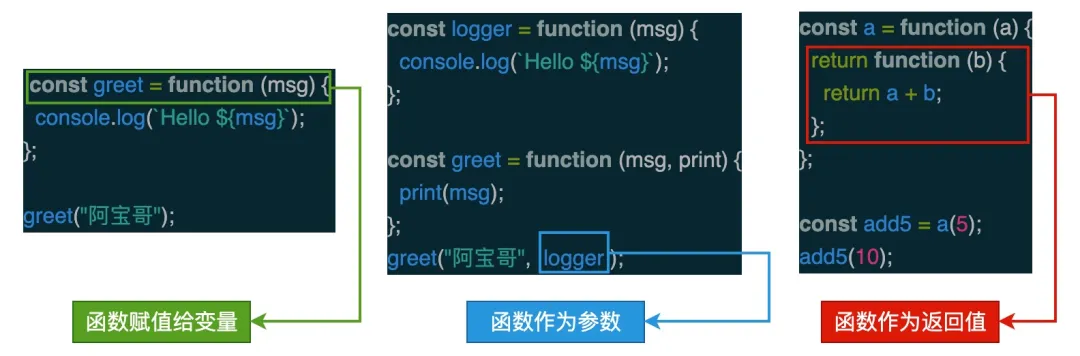
接下来阿宝哥将介绍与函数相关的一些技术,阅读完本文,你将了解高阶函数、函数组合、柯里化、偏函数、惰性函数和缓存函数的相关知识。
一、高阶函数
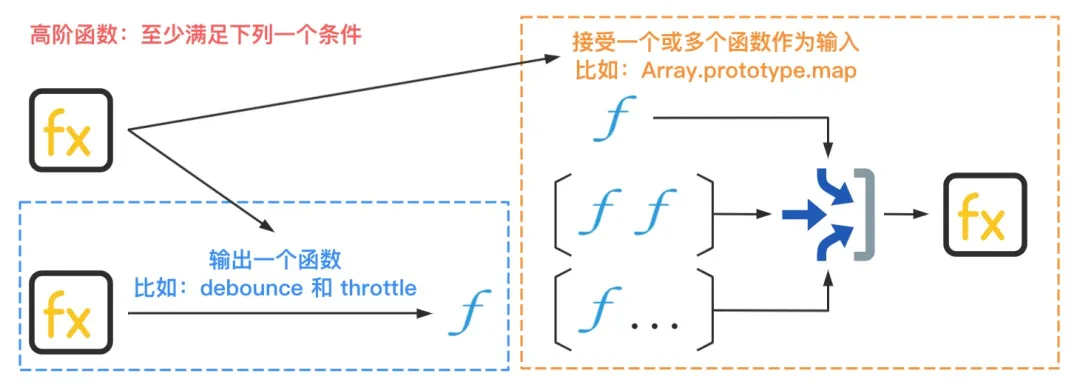
在数学和计算机科学中,高阶函数是至少满足下列一个条件的函数:
- 接受一个或多个函数作为输入;
- 输出一个函数。
接收一个或多个函数作为输入,即函数作为参数传递。这种应用场景,相信很多人都不会陌生。比如常用的 Array.prototype.map() 和 Array.prototype.filter() 高阶函数:
// Array.prototype.map 高阶函数
const array = [1, 2, 3, 4];
const map = array.map(x => x * 2); // [2, 4, 6, 8]
// Array.prototype.filter 高阶函数
const words = ['semlinker', 'kakuqo', 'lolo', 'abao'];
const result = words.filter(word => word.length > 5); // ["semlinker", "kakuqo"]
而输出一个函数,即调用高阶函数之后,会返回一个新的函数。我们日常工作中,常见的 debounce 和 throttle 函数就满足这个条件,因此它们也可以被称为高阶函数。
二、函数组合
函数组合就是将两个或两个以上的函数组合生成一个新函数的过程:
const composeFn = function (f, g) {
return function (x) {
return f(g(x));
};
};
在以上代码中,f 和 g 都是函数,而 x 是组合生成新函数的参数。
2.1 函数组合的作用
在项目开发过程中,为了实现函数的复用,我们通常会尽量保证函数的职责单一,比如我们定义了以下功能函数:

在拥有以上功能函数的基础上,我们就可以自由地对函数进行组合,来实现特定的功能:
function lowerCase(input) {
return input && typeof input === "string" ? input.toLowerCase() : input;
}
function upperCase(input) {
return input && typeof input === "string" ? input.toUpperCase() : input;
}
function trim(input) {
return typeof input === "string" ? input.trim() : input;
}
function split(input, delimiter = ",") {
return typeof input === "string" ? input.split(delimiter) : input;
}
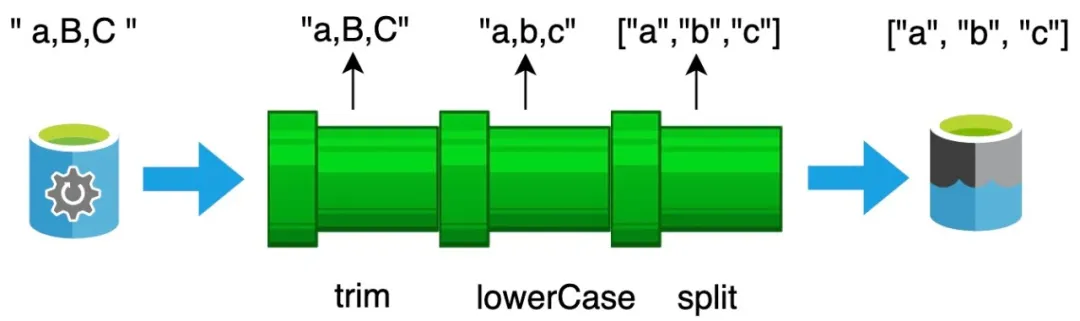
const trimLowerCaseAndSplit = compose(trim, lowerCase, split); // 参考下面compose的实现
trimLowerCaseAndSplit(" a,B,C "); // ["a", "b", "c"]
在以上的代码中,我们通过 compose 函数实现了一个 trimLowerCaseAndSplit 函数,该函数会对输入的字符串,先执行去空格处理,然后在把字符串中包含的字母统一转换为小写,最后在使用 , 分号对字符串进行拆分。利用函数组合的技术,我们就可以很方便的实现一个 trimUpperCaseAndSplit 函数。
2.2 组合函数的实现
function compose(...funcs) {
return function (x) {
return funcs.reduce(function (arg, fn) {
return fn(arg);
}, x);
};
}
在以上的代码中,我们通过 Array.prototype.reduce 方法来实现组合函数的调度,对应的执行顺序是从左到右。这个执行顺序与 Linux 管道或过滤器的执行顺序是一致的。
不过如果你想从右往左开始执行的话,这时你就可以使用 Array.prototype.reduceRight 方法来实现。
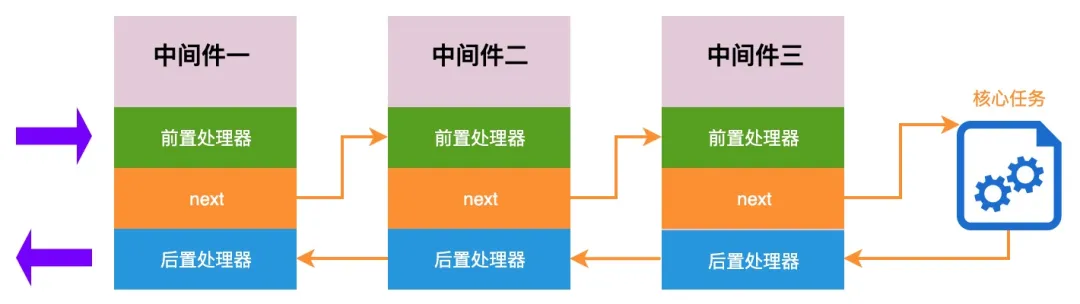
其实每当看到 compose 函数,阿宝哥就情不自禁想到 “如何更好地理解中间件和洋葱模型” 这篇文章中介绍的 compose 函数:
function compose(middleware) {
// 省略部分代码
return function (context, next) {
let index = -1;
return dispatch(0);
function dispatch(i) {
if (i <= index)
return Promise.reject(new Error("next() called multiple times"));
index = i;
let fn = middleware[i];
if (i === middleware.length) fn = next;
if (!fn) return Promise.resolve();
try {
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)));
} catch (err) {
return Promise.reject(err);
}
}
};
}
利用上述的 compose 函数,我们就可以实现以下通用的任务处理流程:
三、柯里化
柯里化(Currying)是一种处理函数中含有多个参数的方法,并在只允许单一参数的框架中使用这些函数。这种转变是现在被称为 “柯里化” 的过程,在这个过程中我们能把一个带有多个参数的函数转换成一系列的嵌套函数。它返回一个新函数,这个新函数期望传入下一个参数。当接收足够的参数后,会自动执行原函数。
在理论计算机科学中,柯里化提供了简单的理论模型,比如:在只接受一个单一参数的 lambda 演算中,研究带有多个参数的函数的方式。与柯里化相反的是 Uncurrying,一种使用匿名单参数函数来实现多参数函数的方法。比如:
const func = function(a) {
return function(b) {
return a * a + b * b;
}
}
func(3)(4); // 25
Uncurrying 不是本文的重点,接下来我们使用 Lodash 提供的 curry 函数来直观感受一下,对函数进行 “柯里化” 处理之后产生的变化:
const abc = function(a, b, c) {
return [a, b, c];
};
const curried = _.curry(abc);
curried(1)(2)(3); // => [1, 2, 3]
curried(1, 2)(3); // => [1, 2, 3]
curried(1, 2, 3); // => [1, 2, 3]
_.curry(func, [arity=func.length])
创建一个函数,该函数接收 func 的参数,要么调用func返回的结果,如果 func 所需参数已经提供,则直接返回 func 所执行的结果。或返回一个函数,接受余下的func 参数的函数,可以使用 func.length 设置需要累积的参数个数。
这里需要特别注意的是,在数学和理论计算机科学中的柯里化函数,一次只能传递一个参数。而对于 JavaScript 语言来说,在实际应用中的柯里化函数,可以传递一个或多个参数。好的,介绍完柯里化的相关知识,接下来我们来介绍柯里化的作用。
3.1 柯里化的作用
3.1.1 参数复用
function buildUri(scheme, domain, path) {
return `${scheme}://${domain}/${path}`;
}
const profilePath = buildUri("https", "github.com", "semlinker/semlinker");
const awesomeTsPath = buildUri("https", "github.com", "semlinker/awesome-typescript");
在以上代码中,首先我们定义了一个 buildUri 函数,该函数可用于构建 uri 地址。接着我们使用 buildUri 函数构建了阿宝哥 Github 个人主页 和 awesome-typescript 项目的地址。对于上述的 uri 地址,我们发现 https 和 github.com 这两个参数值是一样的。
假如我们需要继续构建阿宝哥其他项目的地址,我们就需要重复设置相同的参数值。那么有没有办法简化这个流程呢?答案是有的,就是对 buildUri 函数执行柯里化处理,具体处理方式如下:
const _ = require("lodash");
const buildUriCurry = _.curry(buildUri);
const myGithubPath = buildUriCurry("https", "github.com");
const profilePath = myGithubPath("semlinker/semlinker");
const awesomeTsPath = myGithubPath("semlinker/awesome-typescript");
3.1.2 延迟计算/运行
const add = function (a, b) {
return a + b;
};
const curried = _.curry(add);
const plusOne = curried(1);
在以上代码中,通过对 add 函数执行 “柯里化” 处理,我们可以实现延迟计算。好的,简单介绍完柯里化的作用,我们来动手实现一个柯里化函数。
3.2 柯里化的实现
现在我们已经知道了,当柯里化后的函数接收到足够的参数后,就会开始执行原函数。而如果接收到的参数不足的话,就会返回一个新的函数,用来接收余下的参数。基于上述的特点,我们就可以自己实现一个 curry 函数:
function curry(func) {
return function curried(...args) {
if (args.length >= func.length) { // 通过函数的length属性,来获取函数的形参个数
return func.apply(this, args);
} else {
return function (...args2) {
return curried.apply(this, args.concat(args2));
};
}
}
}
四、偏函数应用
在计算机科学中,偏函数应用(Partial Application)是指固定一个函数的某些参数,然后产生另一个更小元的函数。而所谓的元是指函数参数的个数,比如含有一个参数的函数被称为一元函数。
偏函数应用(Partial Application)很容易与函数柯里化混淆,它们之间的区别是:
- 偏函数应用是固定一个函数的一个或多个参数,并返回一个可以接收剩余参数的函数;
- 柯里化是将函数转化为多个嵌套的一元函数,也就是每个函数只接收一个参数。
了解完偏函数与柯里化的区别之后,我们来使用 Lodash 提供的 partial 函数来了解一下它如何使用。
4.1 偏函数的使用
function buildUri(scheme, domain, path) {
return `${scheme}://${domain}/${path}`;
}
const myGithubPath = _.partial(buildUri, "https", "github.com");
const profilePath = myGithubPath("semlinker/semlinker");
const awesomeTsPath = myGithubPath("semlinker/awesome-typescript");
_.partial(func, [partials])
创建一个函数。该函数调用 func,并传入预设的 partials 参数。
4.2 偏函数的实现
偏函数用于固定一个函数的一个或多个参数,并返回一个可以接收剩余参数的函数。基于上述的特点,我们就可以自己实现一个 partial 函数:
function partial(fn) {
let args = [].slice.call(arguments, 1);
return function () {
const newArgs = args.concat([].slice.call(arguments));
return fn.apply(this, newArgs);
};
}
4.3 偏函数实现 vs 柯里化实现

五、惰性函数
由于不同浏览器之间存在一些兼容性问题,这导致了我们在使用一些 Web API 时,需要进行判断,比如:
function addHandler(element, type, handler) {
if (element.addEventListener) {
element.addEventListener(type, handler, false);
} else if (element.attachEvent) {
element.attachEvent("on" + type, handler);
} else {
element["on" + type] = handler;
}
}
在以上代码中,我们实现了不同浏览器 添加事件监听 的处理。代码实现起来也很简单,但存在一个问题,即每次调用的时候都需要进行判断,很明显这是不合理的。对于上述这个问题,我们可以通过惰性载入函数来解决。
5.1 惰性载入函数
所谓的惰性载入就是当第 1 次根据条件执行函数后,在第 2 次调用函数时,就不再检测条件,直接执行函数。要实现这个功能,我们可以在第 1 次条件判断的时候,在满足判断条件的分支中覆盖掉所调用的函数,具体的实现方式如下所示:
function addHandler(element, type, handler) {
if (element.addEventListener) {
addHandler = function (element, type, handler) {
element.addEventListener(type, handler, false);
};
} else if (element.attachEvent) {
addHandler = function (element, type, handler) {
element.attachEvent("on" + type, handler);
};
} else {
addHandler = function (element, type, handler) {
element["on" + type] = handler;
};
}
// 保证首次调用能正常执行监听
return addHandler(element, type, handler);
}
除了使用以上的方式,我们也可以利用自执行函数来实现惰性载入:
const addHandler = (function () {
if (document.addEventListener) {
return function (element, type, handler) {
element.addEventListener(type, handler, false);
};
} else if (document.attachEvent) {
return function (element, type, handler) {
element.attachEvent("on" + type, handler);
};
} else {
return function (element, type, handler) {
element["on" + type] = handler;
};
}
})();
通过自执行函数,在代码加载阶段就会执行一次条件判断,然后在对应的条件分支中返回一个新的函数,用来实现对应的处理逻辑。
六、缓存函数
缓存函数是将函数的计算结果缓存起来,当下次以同样的参数调用该函数时,直接返回已缓存的结果,而无需再次执行函数。这是一种常见的以空间换时间的性能优化手段。
要实现缓存函数的功能,我们可以把经过序列化的参数作为 key,在把第 1 次调用后的结果作为 value 存储到对象中。在每次执行函数调用前,都先判断缓存中是否含有对应的 key,如果有的话,直接返回该 key 对应的值。分析完缓存函数的实现思路之后,接下来我们来看一下具体如何实现:
function memorize(fn) {
const cache = Object.create(null); // 存储缓存数据的对象
return function (...args) {
const _args = JSON.stringify(args);
return cache[_args] || (cache[_args] = fn.apply(fn, args));
};
};
定义完 memorize 缓存函数之后,我们就可以这样来使用它:
let complexCalc = (a, b) => {
// 执行复杂的计算
};
let memoCalc = memorize(complexCalc);
memoCalc(666, 888);
memoCalc(666, 888); // 从缓存中获取
Array 中的高阶函数 —- map, filter, reduce
map() - 映射
var newArr = array.map((currentValue, index, array) => { return ... }, thisValue);
- currentValue, 必须,当前的元素值;
- index, 可选,当前元素值的索引;
- array, 可选,原数组;
- thisValue, 可选,对象作为该执行回调时使用,传递给函数,用作 “this” 的值;
- return 新数组;
栗子:
var array1 = [1,4,9,16];
const map1 = array1.map(x => x *2);
console.log(array1); // [1,4,9,16]
console.log(map1); // [2,8,18,32]
注意:
- map() 不会对空数组进行检测;
filter() - 过滤,筛选
var newArr = array.filter((currentValue, index, array) => { return ... }, thisValue);
- currentValue, 必须,当前的元素值;
- index, 可选,当前元素值的索引;
- array, 可选,原数组;
- thisValue, 可选,对象作为该执行回调时使用,传递给函数,用作 “this” 的值;
- return 新数组;
栗子:过滤不符合项
var arr = [20,30,50, 96,50]
var newArr = arr.filter(item => item>40)
console.log(arr) // [20,30,50, 96,50]
console.log(newArr) // [50, 96, 50]
高频用途:
-
上例中的过滤不符合项;
-
去掉数组中的 空字符串、0、undefined、null;
var arr = ['1', '2', null, '3.jpg', null, 0]
var newArr = arr.filter(item => item)
// 也可以写成
// var newArr = arr.filter(Boolean);
console.log(newArr) // ["1", "2", "3.jpg"]
- 数组去重;
注意:
- filter() 不会对空数组进行检测;
reduce - 累计
var result = array.reduce((total, currentValue, currentIndex, array) => { return ... }, initialValue);
- total, 必须,初始值,第一次循环之后是计算后的返回值;
- currentValue, 必须,当前的元素值;
- currentIndex, 可选,当前元素值的索引;
- array, 可选,原数组;
- initialValue, 可选,传递给函数的初始值,即此值会在第一次循环之前赋值给 total;
- return 经过处理过的 total;
栗子:统计字符串中每个字符出现的次数
const str = '9kFZTQLbUWOjurz9IKRdeg28rYxULHWDUrIHxCY6tnHleoJ'
const obj = {}
Array.from(str).reduce((accumulator, current) => {
current in accumulator ? accumulator[current]++ : accumulator[current] = 1
return accumulator;
}, obj)
当然,非 reduce 的写法是:
const str = '9kFZTQLbUWOjurz9IKRdeg28rYxULHWDUrIHxCY6tnHleoJ'
const obj = {}
str.split('').forEach(item => {
obj[item] ? obj[item]++ : obj[item] = 1
})
reduce 的用途很广泛,可以说,js 中有关数组循环的模块都可以使用 reduce 来实现,这里不一一列举,详见 reduce-MDN
js 实现 map
原生 js 实现
Array.prototype.myMap = function(fn, context = window) {
if (typeof fn !== 'function') return;
let newArr = [];
for(let i = 0, len = this.length; i < len; i++) {
newArr.push(fn.call(context, this[i], i, this))
}
return newArr;
}
// 使用
[1,2,3].myMap(function(v, i, arr) {
console.log(v, i, arr);
return v * 2;
})
有一点奇怪的是,需要先在 Array 上挂 myMap() 这个方法,然后回车后才能使用,如果将上述代码全部复制进浏览器控制台,回车运行会报错,这是为什么?
使用 reduce 实现
Array.prototype.reduceMap = function(fn, context = window) {
if (typeof fn !== 'function') return;
// or if (typeof fn !== 'function') throw new TypeError(fn + 'is not a function') ;
let _this = this;
let newArr = _this.reduce(function(total, cV, cI, _this) {
return total.concat([fn.call(context, cV, cI, _this)])
}, [])
return newArr
}
上面的示例是挂载在 Array 上的,下面这个示例是函数式编程示例:
let fpReduceMap = (fn, context = window) => {
return targetArr => {
if (typeof fn !== 'function') throw new TypeError(fn + 'is not a function')
if (!Array.isArray(targetArr)) throw new TypeError('targetArr must be a Array')
if (targetArr.length == 0) return [];
return targetArr.reduce((total, cV, cI, targetArr) => {
return total.concat([fn.call(context, cV, cI, targetArr)])
}, [])
}
}
// 使用
fpReduceMap(function(v) {
console.log(this);
return v + 1;
}, {msg: 'mapping'})([1,2,3])
手写十种Promise!
前言:这篇文章应该会和你见到的大部分手写Promise文章都不一样,文中不会讲到Promises/A+规范,也不会提到Promise.race / race等语法糖。在本文中,我会大量使用到面向对象的思维方式,并且只关注Promise的核心思想及其实现,相信在您认真看完之后,会对Promise产生一个更加结构性的理解。
好的,屁话说完,进入正题。对于Promise,MDN中对它的解释为:Promise 对象用于表示一个异步操作的最终完成 (或失败)及其结果值。在本文中,我以面向对象编程的思想作为出发点,给它下了另一个定义:Promise 对象是一个可用于存储异步操作结果状态和数据的容器。
围绕这个概念,我用UML类图对Promise对象做了一个整理,以便阁下更好地理解我所说的容器概念,图示如下:
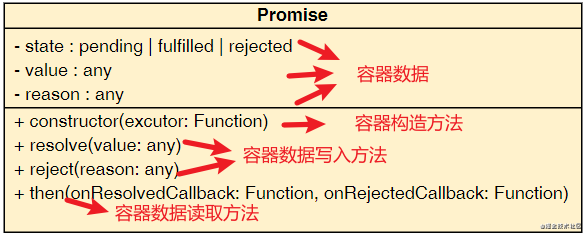
其实上述类图只能用于描述一个用于管理 同步操作 结果状态和数据的容器对象结构。因为实际的Promise容器对象需要支持管理 异步操作 所产生的结果状态和数据,所以它的类图需要加上两个用于暂存回调函数的内部属性(原因下文会说),此时它的类图会是这样:

下文中对Promise的所有探讨和实现都会围绕这幅图,如果您有兴趣继续往下看下去,我希望您能在这幅图上的理解上多花一些时间,以更好地阅读下文。
好的,接下来我就以用面向对象编程的编程实现步骤作为思路,分成以下几个部分来达到手写Promise的目的:
- 以容器概念作为切入点,实现Promise对象的基本结构。
- 分析Promise容器和异步操作的关系,实现Promise的构造方法constructor。
- 理清Promise容器中数据的写入方式,实现Promise的resolve和reject方法。
- 理清Promise容器中数据的读取方式,实现Promise的then方法。
- 给then方法加个需求,支持链式调用,方便处理异步操作流。
碰到需要手写Promise的笔试面试场景时,个人也会围绕上图并按照上述思路步骤来实现。
一:以容器概念作为切入点,设计并实现Promise对象的基本结构
在分析给出答案前,我希望您能根据上幅图,预先思考一下以下两个问题:
- Promise容器里面装的是什么数据?
- Promise容器里面的数据如何读写?
在往前,我把这里的容器读写操作称之为填充和取出,后来考虑到Promise容器中的数据是支持一次填充,无数次取出的,就像磁盘数据一样,所以之后我都称这些操作为读写。
1.容器中存储的数据(对象属性)
- state:容器状态,分为三种,即容器未就绪状态pending和容器已就绪状态fulfilled、rejected
- value:容器fulfilled状态下的数据
- reason:容器rejected状态下的数据
- onResolvedTodoList:容器fulfilled状态下的回调行为数组,pending状态时暂存,fulfilled状态后消费
- onRejectedTodoList:容器rejected状态后的回调行为数组,pending状态时暂存,rejected状态后消费
为了让变量名字更加统一和见名知意,下面的手写Promise实现中我们以resolved状态代替fulfilled状态(换个名而已,无需纠结)。
2.容器中数据的读写(对象方法)
- 写入数据:容器内部定义并暴露一个可以设置内部状态和数据的resolve和reject方法,以供外部调用为容器写入数据(state、value / reason)。
- 读取数据:容器内部定义并暴露一个可以读取内部状态和数据的then方法,以供外部调用读取容器中的数据,根据容器状态触发传入的相应回调行为。
3.容器对象代码实现
理解了Promise对象的封装组成(属性、方法)之后,根据上文的UML类图,我们做出以下代码实现:
温馨提示:请确保理解以下代码结构,这是Promise的大局,我们以大局为重。
class Container {
state = undefined;
value = undefined;
reason = undefined;
onResolvedTodoList = [];
onRejectedTodoList = [];
constructor(excutor) { // 构造容器 }
resolve = value => { // 写容器数据 }
reject = reason => { // 写容器数据 }
then(onResolved, onRejected) { // 读容器数据 }
}
Container.PENDING = 'pending';
Container.RESOLVED = 'resolved';
Container.REJECTED = 'rejected';
为了更加突出容器概念,我这里给我们要手写的Promise类取了个Container类名。
二:分析Promise容器和异步操作的关系,实现Promise的构造方法constructor
在具体实现Promise的构造方法constructor之前,我们先分析一波Promise容器和异步操作的关系:
- Promise容器:它是一个异步操作容器,可以存储数据并管理它们的读写。
- 异步操作:一些同步、异步语句的结合体,是我们真正的代码逻辑。
- Promise容器和异步操作的关系:异步操作把其执行结果 托付 给Promise容器对象代为管理。
托付这个词,能够非常好地表示异步操作和Promise容器之间的关系。
1.从托付这个词来理解异步操作和Promise之间的联系
从UML类图中,我们阐述了Promise的对象结构,现在我们再以托付这个动作为中心,彻底理解异步操作和Promise容器之间的联系:
- 建立托付关系:外部意愿,外部选择Promise容器管理异步操作后的结果。(ps:ES6之前就是回调函数一把梭)。
- 托付数据给容器:外部意愿,外部在异步操作中调用resolve和reject方法决定具体托付给容器什么状态和数据。需要注意的是,我们经常在某个异步语句的回调中托付数据。
- 索要容器中数据:外部意愿,外部决定什么时候索要数据以及索要数据之后做什么行为。需要注意的是,在外部读取容器内数据时,托付数据经常是异步的,所以很容易造成容器数据读写的时序错乱问题。
从需求出发,根据以容器对象管理异步操作结果的思路,你完全可以设计出一个你自己的Promise,一百个人会写出一百种Promise。
好的,在取得外部将异步操作的结果托付给Promise容器管理这个核心认识之后,我们就可以理解官方Promise的设计逻辑了。接下来我们实现官方版Promise容器的构造方法constructor,这其中涉及到异步操作和Promise的托付关系建立以及托付数据给容器两个过程。
至于为什么是官方版Promise设计成这样,这是由需求决定的,我们是要把 异步操作结果交由容器管理才会创建这个容器(你品,你细品),所以它把这两个过程都放在了构造方法中实现(当然,我们自己设计的promise可能不会是这样,但是也能实现目的,但我相信从封装后的易用性来看肯定不如官方版的友好)。
2.实现Promise的构造方法constructor
(1): 代码实现示例
class Container {
state = undefined;
value = undefined;
reason = undefined;
onResolvedTodoList = [];
onRejectedTodoList = [];
// 接收excutor函数作为构造参数并立即调用,根据excutor函数形参约定进行实参传递。
constructor(excutor) {
try {
excutor(this.resolve, this.reject);
this.state = Container.PENDING;
} catch (e) {
this.reject(e)
}
}
resolve = value => { // 写容器数据 }
reject = reason => { // 写容器数据 }
then(onResolved, onRejected) { // 读容器数据 }
}
Container.PENDING = 'pending';
Container.RESOLVED = 'resolved';
Container.REJECTED = 'rejected';
(2): 调用构造示例
// 外部定义excutor函数,约定形参resolve和reject
const p1 = new Container((resolve, reject) => {
// 外部决定什么时候写入容器数据,写入什么数据
setTimeout(() => {
resolve(0)
})
})
(3): 函数式编程思想看excutor
根据上面分析官方版实现方式的构造方法需要建立异步操作和Promise容器之前的托付关系以及托付数据给容器这两个职责来来看,excutor函数它要实现两个功能:
- 异步操作载体:函数对象形式
- 授权外部设置容器中管理的数据和状态:容器数据写入方法resolve和reject
根据函数职责,剖析一下的它的函数输入输出以加深理解和印象:
- 函数输入:向容器内部写入数据的方法,即resolve和reject
- 函数输出:副作用形式,写入容器数据
- 映射逻辑:在异步操作的执行过程中,根据调用者需要,向容器写入数据
三:理清Promise容器中数据的写入方式,实现Promise的resolve和reject方法
所谓的写入容器数据,实质上也就是表现为容器内方法为容器内数据赋值。如果仅仅是简单赋值那自然没什么学问可以探讨,但在官方版Promise中却有几个细节需要注意,先来看看仿官方版Promise的实现示例吧:
1.实现示例和调用示例
官方版Promise是把容器数据划分为互斥存在的value和reason两个数据,并且对应于已就绪状态fullfilled和rejected,如果我们自己设计,也许不会这样。
class Container {
// ...attr
constructor(excutor) {}
resolve = value => {
if (this.state != Container.PENDING) return
this.status = Container.RESOLVED;
this.value = value;
while (this.onResolvedTodoList.length) this.onResolvedTodoList.shift()() // 取出第一个
}
reject = reason => {
if (this.state != Container.PENDING) return
this.status = Container.REJECTED;
this.reason = reason;
while (this.onRejectedTodoList.length) this.onRejectedTodoList.shift()()
}
then(onResolved, onRejected) {}
}
封装完,再看看调用示例吧:
const p1 = new Promise((resolve, reject) => {
// 同步方式往容器中写入数据
// resolve(0)
// 异步方式往容器中写入数据
setTimeout(() => {
resolve(1)
})
})
2.问题:为什么写入数据时非pending状态什么也不做?
Promise容器管理的异步数据是操作后的结果数据,操作执行结束后,数据就不应该再变化。这正好与它的命名强对应,Promise意为承诺,只有操作后的数据不再变化,外部才能托付并信任这个容器中的数据。
这也意味着我们在日常使用Promise时,只能调用一次resolve方法和一次rejected方法,多次调用时,只有第一次有效。
3.问题:为什么在写入数据后还需要消费暂存回调队列?
消费暂存回调队列中存储的是容器在pending状态时,外部向容器添加的回调行为。很多情况下,外部在调用then方法读取容器中的状态和数据去做一些行为时,由于异步的原因,容器的状态和数据尚未被写入,所以容器并不能马上响应外部的读取后回调行为。但Promise是可靠的,它向我们承诺,一旦自身状态和数据被定下来就会马上去做我们给它安排的事情,一件也不会落下。
4.问题:为什么resolve方法和reject方法需要被设置为箭头函数?
有些朋友曾经问过我这个问题,他问为什么resolve和reject函数被要求设置为箭头函数而不能是function声明。其实以function声明的方式也未尝不可,之所以设置为箭头函数,是因为以箭头函数形式声明的函数,调用者调用时就不能通过任何方式去改变其内部的this指向,即使使用call、apply、bind函数也是一样。
所以说,这里设置为箭头函数只是对外部的一种约束,让外部不能更改resolve和reject函数中this的指向,强制约定resolve方法和reject方法只能用来写入当前容器对象的数据。
四:理清Promise容器中数据的读取方式,实现Promise的then方法
所谓的读取Promise容器中的数据,按照我们常规的理解,其实也就是定义一个get方法返回容器内部数据。从then方法的命名中也可以看出,它可不仅仅只是get数据这么简单,它的中文含义是然后,也就是异步操作的下一步操作该做什么。下面我们先写一个最简单的then方法,以加深对then方法概念的理解:
const obj = {
value: 1,
then: function (fn) {
fn(this.value)
}
}
obj.then(console.log);
学过函子的朋友,可以对比一下Promise的then方法与函子map方法的区别。思考一下同样是容器,为什么函子适合用来做数据转换流,Promise适合用来做异步操作流。
有认真在思考的朋友可能会说到promise的then函数中的回调函数参数是以微任务的方式执行的呀。很高兴您能提出这个问题,没错,上述示例中的then方法明显是同步执行的,不符合promise的then方法要求,下面我们把它再改造一下,让它的回调函数参数以微任务的形式执行,代码如下:
const obj = {
value: 1,
then: function (fn) {
process.nextTick(() => {
fn(this.value);
});
},
};
obj.then(console.log);
温馨提示:process是node环境下的api,在bom环境下是不能用的哦!
好的,屁话说的又多了,下面我们直接先来看一个在不支持链式调用情况下(第五点支持),如何实现一个仿官方版Promise的then方法示例吧。
1.实现示例和调用示例
在无需支持链式调用的情况下,then函数功能及其实现都非常简单,它负责接收用户给定的两个回调参数,而后容器内存储的数据在就绪后就会根据容器状态来决定调用哪个回调函数,同时以容器内存储的数据作为参数来具体调用该函数。在实现一个函数之前,我们先用函数式的编程思想来分析一下这个then方法。
- then函数输入:接收value/reason数据作为参数的onResolved/onRejected回调函数。
- then函数输出:副作用形式,某个参数回调函数的调用。
- then函数映射逻辑:判断容器是否就绪,未就绪时把回调参数函数暂存起来,已就绪时则根据状态来决定执行哪个回调函数。
下面是超简单超短以致于一看就懂的then函数实现示例和调用示例:
实现示例:
class Container {
state = undefined;
value = undefined;
reason = undefined;
onResolvedTodoList = [];
onRejectedTodoList = [];
constructor(excutor) {}
resolve = value = >{}
reject = reason = >{}
then(onResolved, onRejected) {
// 问题:为什么对参数onResolved和onRejected做缺省处理?
onResolved = onResolved ? onResolved: value => value;
onRejected = onRejected ? onRejected: reason => { // 问题:为什么onRejected回调缺省处理逻辑不是reason => reason?
throw reason
};
switch (this.state) {
// 问题:为什么需要判断pending状态,,这个状态下的代码逻辑为什么是暂存回调函数而不是调用回调函数?
case Container.PENDING:
// 问题:为什么将回调函数onResolved和onRejected放入暂存队列中时用箭头函数包裹后传入而不是直接传入onResolved或者onRejected?
this.onResolvedTodoList.push(() = >{
// 问题:then函数的回调函数参数不是以微任务形式调用吗,为什么你这里写成宏任务的形式呢?
setTimeout(() => {
// 问题:为什么回调函数的调用不做异常处理?
onResolved(this.value);
});
});
this.onRejectedTodoList.push(() = >{
setTimeout(() => {
onRejected(this.reason);
});
});
break;
case Container.RESOLVED:
setTimeout(() => {
onResolved(this.value);
});
break;
case Container.REJECTED:
setTimeout(() => {
onRejected(this.reason);
});
break;
}
}
}
调用示例:
p1.then((value) => {
console.log(value)
}, (reason) => {
console.log(reason)
})
下面我们对代码中的几个核心逻辑和问题展开探讨。
2.问题:为什么对参数onResolved和onRejected做缺省处理?
个人认为主要是出于以下两个方面考虑:
- 避免onResolved和onRejected回调函数调用时大量的判空逻辑。
- 在链式调用时,支持在不传入某一个回调函数或者都不传的情况下,可以把结果状态和数据穿透下去。(原因会在第五点说明)
3.问题:为什么onRejected回调缺省处理逻辑不是reason => reason?
onRejected回调缺省处理逻辑设计为reason => { throw reason }是有道理的,个人认为这个主要是受到需求方面的影响。因为promise容器用于管理一个操作后的结果,而操作常常意味着成功或者失败,所以我们在使用时常常就会把resolve状态视为成功来读写容器内数据,reject状态视为失败来读写容器内数据。同时我们在执行一段同步或者异步操作代码逻辑时,有时候并不需要关注它成功后的值,但是操作失败我们是必须要知道的,因为这意味着托付给它的操作可能没有成功,也没有产生我们希望它产生的副作用。
reason状态和reject状态并不一定是代表成功或者失败状态,对应的数据也未必一定是代表成功数据或者失败数据。promise仅仅是一个容器,其中管理的状态和数据的含义一直都是由调用者决定的。
4.问题:为什么需要判断pending状态,这个状态下的代码逻辑为什么是暂存回调函数而不是调用回调函数?
promise的pending状态设计的目的就是用来解决异步操作导致时容器数据读写时序混乱的问题。这个pending状态我们可以称之为容器已构造但未就绪状态,此时容器内的状态为pending,数据为undefined,外部在调用该promise容器的then方法以执行下一步操作时,无法拿到容器中存储的上一步操作的状态和数据,所以无法调用。
可靠的是,虽然无法立即调用,但是promise并不会把外部在此时添加的回调函数视为无效,它会把这些回调函数暂存起来,然后等待着容器就绪时消费,消费具体表现为resolve方法和reject方法中的onResolvedTodoList数组和onResolvedTodoList数组的遍历有序调用。
5.问题:为什么将回调函数onResolved和onRejected放入暂存队列中时用箭头函数包裹后传入而不是直接传入onResolved或者onRejected?
首先明确需求:暂存队列遍历调用回调函数时是需要携带value或者reason作为参数调用的,也就是带参回调函数的执行。至于为什么不在resolve或者reject函数内遍历调用时传入呢?我觉得在此处这样做也并没有什么不妥。
如果阁下对这个问题有不同的见解,欢迎评论处告知,谢谢!
具体要不要用箭头函数再包裹一层闭包结构,我觉得可以从以下三个方面来考虑:
- 你希望这个回调函数在什么时间执行?
- 你希望这个回调函数在什么作用域环境下执行?
- 你希望这个回调函数中的this指向什么?(函数this指向与函数调用密切相关)
6.问题:then函数的回调函数参数不是以微任务形式调用吗,为什么你这里写成宏任务的形式呢?
很高兴您能提出这个问题,您说的对,按照官方版promise的做法,我们确实不应该用以setTimeout注册成宏任务的形式来执行then方法的回调函数参数。但是这也无可奈何,如果希望我们手写的promise能够在bom环境下使用,那么就不能使用process.nextTick方法,另外又找不到能够在bom环境下使用并且合适的微任务api,所以这个以及下面的示例中我都写成了宏任务的形式(手写node环境下使用的promise就没这个问题啦)。问题不大啦,手写promise你尽管使用setTimeout,面试官问为什么的时候您能答出个所以然就行。
有些朋友可能还会问到,为什么官方版的promise可以做到呢,它的then方法的回调函数参数就是以微任务的形式调用的呀。那没得办法呀,人家的promise是内置类(也可以叫对象,看你怎么理解),都不是用JavaScript写的,自然不会受限于JavaScript和bom。
如果这篇文章还骗不到你的赞的话,我就退出掘金了o( ̄ヘ ̄o#)!
7.问题:为什么回调函数的调用不做异常处理?
有的朋友在看完链式then方法的实现后,可能会产生这个问题。我想说的是,我们做异常处理并不是为做而做。只有做异常处理真正有价值时才做。这里做不做异常处理有什么区别吗?在这里捕捉或者在由全局捕捉这个回调函数的调用异常都是一样的。我们并不需要像链式时一样,碰到异常就告知下下次操作,下次操作出现了问题,所以下下个操作应该走错误回调函数。
如果阁下对此有什么高见,还请告知,谢谢!
五:给then方法加个需求,支持链式调用,方便处理异步操作流
promise的最大魅力就是它将以往对异步操作流的实现,从回调嵌套编码形式转变现如今的then“同步调用”的编码形式,彻底解决了折磨前端开发者好多年的回调地狱编码问题。
这里先提一提我瞎扯的异步操作流是什么意思,操作流可以理解为操作 -> 下步操作 -> 下下步操作 -> 下下下步操作 -> …这么一个过程,异步操作流也就是指上述操作流中有一些操作带有异步逻辑啦。形象点说,就是我们通过多个then方法先把生产车间拼好(你品,你细品)。
then的链式调用特性让promise能够支持处理异步操作任务流式处理,如果从需求方面理解then的链式调用,我建议大家始终围绕这异步操作流这五个字来理解。
如果要为理解Promise贴上几个标签的话,我会给它贴上三个,它们分别是:容器、异步、操作流。
那么如何实现呢,对于then的链式调用,用屁股想一下就知道在then方法中return一个新的promise容器对象即可。不过这里有几个关键问题需要明确,我们先看链式then方法的示例实现和调用示例吧。
1.链式then方法实现示例和调用示例
温馨提示:建议对比一下未链式调用的then方法实现示例,在对比的过程中,找出为了实现链式调用,then方法发生的变化。
class Container {
constructor(excutor) {}
resolve = value => {}
reject = reason => {}
onResolvedTodoList = [];
onRejectedTodoList = [];
then(onResolved, onRejected) {
onResolved = onResolved ? onResolved : value => value;
onRejected = onRejected ? onRejected : reason => { throw reason };
let containerBack = new Container((resolve, reject) => {
switch (this.state) {
case Container.PENDING:
this.onResolvedTodoList.push(() => {
setTimeout(() => {
// 问题:为什么这里又开始异常处理了呢?
try {
const value = onResolved(this.value);
// 问题:为什么不直接把新的value作为新容器管理的数据,而是封装一个resolveContainer函数?
resolveContainer(containerBack, value, resolve, reject);
} catch (e) {
reject(e);
}
})
});
this.onRejectedTodoList.push(() => {
setTimeout(function () {
try {
const value = onRejected(this.reason);
resolveContainer(containerBack, value, resolve, reject);
} catch (e) {
reject(e);
}
})
});
break;
case Container.RESOLVED:
setTimeout(() => {
try {
const value = onResolved(this.value);
resolveContainer(containerBack, value, resolve, reject);
} catch (e) {
reject(e);
}
})
break;
case Container.REJECTED:
setTimeout(function () {
try {
const value = onRejected(this.reason);
resolveContainer(containerBack, value, resolve, reject);
} catch (e) {
reject(e);
}
})
break;
}
});
return containerBack
}
}
function resolveContainer(containerBack, value, resolve, reject) {
if (!(value instanceof Container)) {
resolve(value)
} else {
if (value !== containerBack) {
value.then(resolve, reject);
} else {
reject(new TypeError('Chaining cycle detected for promise #<Promise>'));
}
}
}
调用示例:
const p2 = p1.then((value) => {
console.log(value)
}, (reason) => {
console.log(reason)
})
p2.then((value) => {
console.log('p2', value)
}, (reason) => {
console.log('p2', reason)
}).then((value) => {
console.log('p3', value)
}, (reason) => {
console.log('p3', reason)
})
2.问题:为什么这里又开始异常处理了呢?
那是因为在链式调用的情况下,我们可以把回调函数的内部操作视为下一个promise所托管的异步操作的核心部分(下一点会说特殊情况),如果这个新的异步操作出现异常,我们就认为新的promise的状态为reject,并且reason数据为异常对象。为什么不直接不捕捉而让外部报错呢?这是因为在链式调用情况下,从需求上说,用户是可以把reject状态和数据也当作一种状态来处理的,promise无权中断(从需求上你品,你细品)。
3.问题:为什么不直接把新的value作为新容器管理的数据,而是封装一个resolveContainer函数?
我们直接来看resolveContainer函数:
function resolveContainer(containerBack, value, resolve, reject) {
if (!(value instanceof Container)) { // 回调函数返回一个非promise容器对象,这时候回调函数基本上等同于外部构造新容器时传入该回调函数作为异步操作
resolve(value)
} else {
if (value !== containerBack) {
value.then(resolve, reject); // 回调函数返回一个promise容器对象,非自身,新的promise接管这个回调函数返回的promise容器对象的状态和数据
} else { // 回调函数返回一个promise容器对象,并且是新容器自身,这时新的promise接管新的promise容器对象的状态和数据(无限套娃)
reject(new TypeError('Chaining cycle detected for promise #<Promise>'))
}
}
}
这一点听我说可能不如直接从上述代码以及注释中自己找答案。为什么会是这样?我是这样理解的,从需求上说,我们并不能简单把回调函数简单地作为新的promise的异步操作核心部分来处理,这一点认识很关键,很多人就是没有搞清楚新的promise所管理的异步操作主体是什么,它与then函数的回调函数参数是什么关系(你品,你细品),然后导致不知到如果构造这个新的promise容器对象。
JavaScript中的apply()和call()
1、call,apply都属于Function.prototype的一个方法,它是JavaScript引擎内在实现的,因为属于Function.prototype,所以每个Function对象实例(就是每个方法)都有call,apply属性。既然作为方法的属性,那它们的使用就当然是针对方法的了,这两个方法是容易混淆的,因为它们的作用一样,只是使用方式不同。
2、语法:foo.call(this, arg1,arg2,arg3) == foo.apply(this, arguments) == this.foo(arg1, arg2, arg3);
3、相同点:两个方法产生的作用是完全一样的。
4、不同点:方法传递的参数不同。
实例代码
代码如下:
<script type="text/javascript">
function A(){
this.flag = 'A';
this.tip = function(){
alert(this.flag);
};
}
function B(){
this.flag = 'B';
}
var a = new A();
var b = new B();
//a.tip.call(b);
a.tip.apply(b);
</script>
三、代码解释(即说明apply和call作用)
1、实例代码定义了两个函数A和B,A中包含flag属性和tip属性(这个属性赋值一个函数),B中有一个flag属性。
2、分别创建A和B的对象a和b。
3、无论是a.tip.call(b);和a.tip.apply(b);运行的结果都是弹出B。
4、从结果中可以看出call和apply都可以让B对象调用A对象的tip方法,并且修改了this的当前作用对象。
JavaScript中的apply()方法和call()方法使用介绍
1、每个函数都包含两个非继承而来的方法:apply()和call()。 2、他们的用途相同,都是在特定的作用域中调用函数。 3、接收参数方面不同,apply()接收两个参数,一个是函数运行的作用域(this),另一个是参数数组。 call()方法第一个参数与apply()方法相同,但传递给函数的参数必须列举出来。
例1:
代码如下:
window.firstName = "diz";
window.lastName = "song";
var myObject = { firstName: "my", lastName: "Object" };
function HelloName() {
console.log("Hello " + this.firstName + " " + this.lastName, " glad to meet you!");
}
HelloName.call(window); //huo .call(this);
HelloName.call(myObject);
运行结果为:
Hello diz song glad to meet you!
Hello my Object glad to meet you!
例2:
代码如下:
function sum(num1, num2) {
return num1 + num2;
}
console.log(sum.call(window, 10, 10)); //20
console.log(sum.apply(window,[10,20])); //30
分析:在例1中,我们发现apply()和call()的真正用武之地是能够扩充函数赖以运行的作用域,如果我们想用传统的方法实现,请见下面的代码:
代码如下:
window.firstName = "diz";
window.lastName = "song";
var myObject = { firstName: "my", lastName: "Object" };
function HelloName() {
console.log("Hello " + this.firstName + " " + this.lastName, " glad to meet you!");
}
HelloName(); //Hello diz song glad to meet you!
myObject.HelloName = HelloName;
myObject.HelloName(); //Hello my Object glad to meet you!
见加红的代码,我们发现,要想让HelloName()函数的作用域在对象myObject上,我们需要动态创建myObject的HelloName属性,此属性作为指针指向HelloName()函数,这样,当我们调用myObject.HelloName()时,函数内部的this变量就指向myObjecct,也就可以调用该对象的内部其他公共属性了。 通过分析例2,我们可以看到call()和apply()函数的真正运用之处,在实际项目中,还需要根据实际灵活加以处理! 一个小问题:再看一看函数中定义函数时,this变量的情况
代码如下:
function temp1() {
console.log(this); //Object {}
function temp2() {
console.log(this); //Window
}
temp2();
}
var Obj = {};
temp1.call(Obj); //运行结果见上面绿色的注释!!!!
执行结果与下面的相同:
代码如下:
function temp1() {
console.log(this);
temp2();
}
function temp2() {
console.log(this);
}
var Obj = {};
temp1.call(Obj);
4、bind()方法 支持此方法的浏览器有IE9+、Firefox4+、Safari5.1+、Opera12+、Chrome。它是属于ECMAScript5的方法。直接看例子:
代码如下:
window.color = "red";
var o = { color: "blue" };
function sayColor(){
alert(this.color);
}
var OSayColor = sayColor.bind(o);
OSayColor(); //blue
这里,sayColor()调用bind()方法,并传入o对象,返回了OSayColor()函数,在OSayColor()中,this的值就为o对象。
JavaScript call() 方法
call() 方法是预定义的 JavaScript 方法。
它可以用来调用所有者对象作为参数的方法。
通过 call(),您能够使用属于另一个对象的方法。
本例调用 person 的 fullName 方法,并用于 person1:
var person = {
fullName: function() {
return this.firstName + " " + this.lastName;
}
}
var person1 = {
firstName:"Bill",
lastName: "Gates",
}
var person2 = {
firstName:"Steve",
lastName: "Jobs",
}
person.fullName.call(person1); // 将返回 "Bill Gates"
本例调用 person 的 fullName 方法,并用于 person2:
var person = {
fullName: function() {
return this.firstName + " " + this.lastName;
}
}
var person1 = {
firstName:"John",
lastName: "Doe",
}
var person2 = {
firstName:"Mary",
lastName: "Doe",
}
person.fullName.call(person2); // 将返回 "Steve Jobs"
带参数的 call() 方法
call() 方法可接受参数:
var person = {
fullName: function(city, country) {
return this.firstName + " " + this.lastName + "," + city + "," + country;
}
}
var person1 = {
firstName:"Bill",
lastName: "Gates"
}
person.fullName.call(person1, "Seattle", "USA");
call() 和 apply() 之间的区别
不同之处是:
call() 方法分别接受参数。
apply() 方法接受数组形式的参数。
如果要使用数组而不是参数列表,则 apply() 方法非常方便。
带参数的 apply() 方法
apply() 方法接受数组中的参数:
var person = {
fullName: function(city, country) {
return this.firstName + " " + this.lastName + "," + city + "," + country;
}
}
var person1 = {
firstName:"John",
lastName: "Doe"
}
person.fullName.apply(person1, ["Oslo", "Norway"]);
与 call() 方法对比:
var person = {
fullName: function(city, country) {
return this.firstName + " " + this.lastName + "," + city + "," + country;
}
}
var person1 = {
firstName:"John",
lastName: "Doe"
}
person.fullName.call(person1, "Oslo", "Norway");
在数组上模拟 max 方法
您可以使用 Math.max() 方法找到(数字列表中的)最大数字:
Math.max(1,2,3); // 会返回 3
Math.max.apply(null, [1,2,3]); // 也会返回 3
第一个参数(null)无关紧要。在本例中未使用它。
这些例子会给出相同的结果:
Math.max.apply(Math, [1,2,3]); // 也会返回 3
Math.max.apply(" ", [1,2,3]); // 也会返回 3
Math.max.apply(0, [1,2,3]); // 也会返回 3
向服务器发送请求
如需向服务器发送请求,我们使用 XMLHttpRequest 对象的 open() 和 send() 方法:
xhttp.open("GET", "ajax_info.txt", true);
xhttp.send();
| 方法 | 描述 |
|---|---|
| open(method, url, async) | 规定请求的类型method:请求的类型:GET 还是 POSTurl:服务器(文件)位置async:true(异步)或 false(同步) |
| send() | 向服务器发送请求(用于 GET) |
| send(string) | 向服务器发送请求(用于 POST) |
GET 还是 POST?
GET 比 POST 更简单更快,可用于大多数情况下。
不过,请在以下情况始终使用 POST:
- 缓存文件不是选项(更新服务器上的文件或数据库)
- 向服务器发送大量数据(POST 无大小限制)
- 发送用户输入(可包含未知字符),POST 比 GET 更强大更安全
GET 请求
一条简单的 GET 请求:
xhttp.open("GET", "demo_get.asp", true);
xhttp.send();
在上面的例子中,您可能会获得一个缓存的结果。为了避免此情况,请向 URL 添加一个唯一的 ID:
xhttp.open("GET", "demo_get.asp?t=" + Math.random(), true);
xhttp.send();
如果您需要用 GET 方法来发送信息,请向 URL 添加这些信息:
xhttp.open("GET", "demo_get2.asp?fname=Bill&lname=Gates", true);
xhttp.send();
POST 请求
一条简单的 POST 请求:
xhttp.open("POST", "demo_post.asp", true);
xhttp.send()
如需像 HTML 表单那样 POST 数据,请通过 setRequestHeader() 添加一个 HTTP 头部。请在 send() 方法中规定您需要发送的数据:
xhttp.open("POST", "ajax_test.asp", true);
xhttp.setRequestHeader("Content-type", "application/x-www-form-urlencoded");
xhttp.send("fname=Bill&lname=Gates");
| 方法 | 描述 |
|---|---|
| setRequestHeader(header, value) | 向请求添加 HTTP 头部header:规定头部名称value:规定头部值 |
url - 服务器上的文件
open() 方法的 url 参数,是服务器上文件的地址:
xhttp.open("GET", "ajax_test.asp", true);
该文件可以是任何类型的文件,如 .txt 和 .xml,或服务器脚本文件,如 .asp 和 .php(它们可以在发送回响应之前在服务器执行操作)。
异步 - ture 还是 false?
如需异步发送请求,open() 方法的 async 参数必须设置为 true:
xhttp.open("GET", "ajax_test.asp", true);
发送异步请求对 web 开发人员来说是一个巨大的进步。服务器上执行的许多任务都非常耗时。在 AJAX 之前,此操作可能会导致应用程序挂起或停止。
通过异步发送,JavaScript 不必等待服务器响应,而是可以:
- 在等待服务器响应时执行其他脚本
- 当响应就绪时处理响应
onreadystatechange 属性
通过 XMLHttpRequest 对象,您可以定义当请求接收到应答时所执行的函数。
这个函数是在 XMLHttpResponse 对象的 onreadystatechange 属性中定义的:
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
document.getElementById("demo").innerHTML = this.responseText;
}
};
xhttp.open("GET", "ajax_info.txt", true);
xhttp.send();
您将在稍后的章节学到更多有关 onreadystatechange 的知识。
如需执行同步的请求,请把 open() 方法中的第三个参数设置为 false:
xhttp.open("GET", "ajax_info.txt", false);
有时 async = false 用于快速测试。你也会在更老的 JavaScript 代码中看到同步请求。
由于代码将等待服务器完成,所以不需要 onreadystatechange 函数:
xhttp.open("GET", "ajax_info.txt", false);
xhttp.send();
document.getElementById("demo").innerHTML = xhttp.responseText;
我们不推荐同步的 XMLHttpRequest (async = false),因为 JavaScript 将停止执行直到服务器响应就绪。如果服务器繁忙或缓慢,应用程序将挂起或停止。
同步 XMLHttpRequest 正在从 Web 标准中移除,但是这个过程可能需要很多年。
现代开发工具被鼓励对使用同步请求做出警告,并且当这种情况发生时,可能会抛出 InvalidAccessError 异常。
onreadystatechange 属性
readyState 属性存留 XMLHttpRequest 的状态。
onreadystatechange 属性定义当 readyState 发生变化时执行的函数。
status 属性和 statusText 属性存有 XMLHttpRequest 对象的状态。
| 属性 | 描述 |
|---|---|
| onreadystatechange | 定义了当 readyState 属性发生改变时所调用的函数。 |
| readyState | 保存了 XMLHttpRequest 的状态。0: 请求未初始化1: 服务器连接已建立2: 请求已接收3: 正在处理请求4: 请求已完成且响应已就绪 |
| status | 200: “OK"403: “Forbidden"404: “Page not found"等 |
| statusText | 返回状态文本(例如 “OK” 或 “Not Found”) |
每当 readyState 发生变化时就会调用 onreadystatechange 函数。
当 readyState 为 4,status 为 200 时,响应就绪:
function loadDoc() {
var xhttp = new XMLHttpRequest();
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
document.getElementById("demo").innerHTML =
this.responseText;
}
};
xhttp.open("GET", "ajax_info.txt", true);
xhttp.send();
}
**注释:**onreadystatechange 被触发五次(0-4),每次 readyState 都发生变化。
使用回调函数
回调函数是一种作为参数被传递到另一个函数的函数。
如果您的网站中有多个 AJAX 任务,那么您应该创建一个执行 XMLHttpRequest 对象的函数,以及一个供每个 AJAX 任务的回调函数。
该函数应当包含 URL 以及当响应就绪时调用的函数。
loadDoc("url-1", myFunction1);
loadDoc("url-2", myFunction2);
function loadDoc(url, cFunction) {
var xhttp;
xhttp = new XMLHttpRequest();
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
cFunction(this);
}
};
xhttp.open("GET", url, true);
xhttp.send();
}
function myFunction1(xhttp) {
// action goes here
}
function myFunction2(xhttp) {
// action goes here
}
服务器响应属性
| 属性 | 描述 |
|---|---|
| responseText | 获取字符串形式的响应数据 |
| responseXML | 获取 XML 数据形式的响应数据 |
服务器响应方法
| 方法 | 描述 |
|---|---|
| getResponseHeader() | 从服务器返回特定的头部信息 |
| getAllResponseHeaders() | 从服务器返回所有头部信息 |
responseText 属性
responseText 属性以 JavaScript 字符串的形式返回服务器响应,因此您可以这样使用它:
实例
document.getElementById("demo").innerHTML = xhttp.responseText;
responseXML 属性
XML HttpRequest 对象有一个內建的 XML 解析器。
ResponseXML 属性以 XML DOM 对象返回服务器响应。
使用此属性,您可以把响应解析为 XML DOM 对象:
请求文件 music_list.xml,并对响应进行解析:
xmlDoc = xhttp.responseXML;
txt = "";
x = xmlDoc.getElementsByTagName("ARTIST");
for (i = 0; i < x.length; i++) {
txt += x[i].childNodes[0].nodeValue + "<br>";
}
document.getElementById("demo").innerHTML = txt;
xhttp.open("GET", "music_list.xml", true);
xhttp.send();
您将在本教程的 DOM 章节学到更多有关 XML DOM 的知识。
getAllResponseHeaders() 方法
getAllResponseHeaders() 方法返回所有来自服务器响应的头部信息。
var xhttp = new XMLHttpRequest();
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
document.getElementById("demo").innerHTML = this.getAllResponseHeaders();
}
};
getResponseHeader() 方法
getResponseHeader() 方法返回来自服务器响应的特定头部信息。
var xhttp = new XMLHttpRequest();
xhttp.onreadystatechange = function() {
if (this.readyState == 4 && this.status == 200) {
document.getElementById("demo").innerHTML = this.getResponseHeader("Last-Modified");
}
};
xhttp.open("GET", "ajax_info.txt", true);
xhttp.send();