内容提要
本书主要介绍如何通过ECMAScript 6将函数式编程技术应用于代码来降低代码的复杂性。
本书共三部分内容。第一部分“函数式思想”是为第二部分的学习作铺垫的,这一部分引入了对函数式JavaScript的描述,从一些核心的函数式概念入手,介绍了纯函数、副作用以及声明式编程等函数式编程的主要支柱;第二部分“函数式基础”重点介绍函数式编程的核心技术,如函数链、柯里化、组合、Monad等;第三部分“函数式技能提升”则是介绍使用函数式编程解决现实问题的方法。
本书循序渐进地将函数式编程的相关知识铺陈开来,以理论作铺垫,并辅以实例,旨在帮助读者更好地掌握这些内容。如果读者是对面向对象软件有一定的了解,且对现代Web应用程序挑战有一定认识的JavaScript开发人员,那么可以从中提升函数式编程技能。如果读者是函数式编程的初学者,那么可以将本书作为入门书籍仔细阅读,为今后的学习夯实基础。
序
在本科和研究生阶段,我的课程安排专注于面向对象设计,并将其作为软件系统规划与架构设计的唯一方法。像许多开发人员一样,我的职业生涯也是从编写面向对象代码开始的,并且基于该编程范式来构建整个系统。
在整个职业生涯中,我密切关注并学习编程语言,不仅是因为想要学习一些很酷的知识,也因为我对每种语言的设计决策和设计哲学都很感兴趣。新的语言会对如何解决软件问题提供不同的观点,新的范式可以达到相同的效果。虽然面向对象的方法仍然是软件设计的主流工作方式,但是学习函数式编程能够拓宽视野,因为该技术既能够单独使用,也可以与其他设计范例并用。
函数式编程已经存在多年。尽管我听说过Haskell、Lisp、Scheme以及近年流行的Scala、Clojure和F#在表现力方面以及高效的平台上拥有优势,但起初我对此并不是很关心。随着时间的流逝,即使是传统上一直被认为很啰嗦的语言Java,也具有了一些让代码更简洁的函数式特性。最终,这项不起眼的技术变得让我无法抵挡。更令人难以置信的是,JavaScript这种大家都当成面向对象的语言,也可以作为函数式语言来使用了。事实证明,这正是JavaScript更强大、更高效的使用方法。我花了很长时间才发现这一点,所以希望能通过本书让你也意识到这一点,如此一来,你的JavaScript代码就不会变得过于复杂。
作为开发人员,我学会了如何使用函数式编程原则来创建模块化、表达性强且易于理解和测试的代码。毫无疑问,作为一名软件工程师,函数式编程让我脱胎换骨,所以我想记录下这些经验,将其放到一本书中。于是,我联系了Manning出版社,打算以Dart编程语言为基础来编写这本函数式编程的书。当时我正在使用Dart,并认为如果将它与我的函数式背景相结合,会产生一个非常有趣的未知领域。因此,我拟定了一个写作方案,并在一个星期后与出版社的人进行了沟通——我了解到Manning正在寻找人写一本关于JavaScript函数式编程的书。因为JavaScript也是我非常痴迷的语言,所以我毫不犹豫地抓住了这个机会。通过这本书,我希望能帮助你提升这方面的技能,并为你的发展带来新的方向。
前言
复杂性是一头需要驯服的巨兽,我们永远无法完全摆脱它,而它也将永远是软件开发的一部分。我曾尝试花费无数小时和无法估量的脑力试图了解一段特定的代码。函数式编程能够帮助你控制代码的复杂性,使其不会与代码库的大小成正比。我们正在编写越来越多的JavaScript代码。我们已经经历了小型客户端事件处理程序的构建、富客户端架构以及同构(服务器+客户端)JavaScript应用程序的实现。函数式编程不是一种工具,而是一种可以同时适用于任何环境的思维方式。
本书旨在说明如何通过ECMAScript 6将函数式编程技术应用于代码。本书以渐进、稳定的速度呈现,涵盖了函数式编程的理论和实践两个方面,还为高级读者提供了更多信息,以帮助他们深入了解一些更高级的概念。
本书内容结构
本书分为三部分内容,指导读者学习从基础到函数式编程的更先进的应用。
第一部分“函数式思想”描绘了函数式JavaScript的高层次景观。它还讨论了如何像函数式程序员一样函数式地使用和思考JavaScript的核心。
- 第1章介绍了后续章节包含的一些核心的函数式概念(便于跨越到函数式),介绍了函数式编程的几个主要支柱,包括纯函数、副作用和声明式编程。
- 第2章为初级和中级JavaScript开发人员准备了练习场,高级的读者也可借此机会复习。本章还介绍了基本的函数式编程概念,为第二部分讨论的技术作铺垫。
第二部分“函数式基础”着重于核心函数式编程技术,包括函数链、柯里化、组合、Monad等。
- 第3章介绍了函数链,并探讨了如何使用递归和高阶函数组合成程序,如map、filter和reduce。其过程会使用到Lodash.js。
- 第4章介绍流行的提高代码模块化程度的技巧和组合。使用诸如Ramda.js之类的函数式框架。组合是编排整个JavaScript解决方案的黏合剂。
- 第5章带读者深入了解函数式编程的更多理论领域,并在错误处理的上下文中对Functor和Monad进行了全面并循序渐进的讨论。
第三部分“函数式技能提升”讨论了使用函数式编程解决现实世界挑战的优势。
- 第6章揭示了函数式程序易于进行单元测试的原因,还引入了一种严密的自动测试模式(称为基于属性测试 )。
- 第7章介绍了JavaScript函数求值的内存模型。本章还讨论了有助于优化函数式JavaScript应用程序执行时间的技术。
- 第8章介绍了JavaScript开发人员在处理事件驱动和异步行为时经常遇到的一些主要挑战,讨论了函数式编程如何提供优雅的解决方案,以通过使用RxJS实现的称为响应式编程 的相关范例,来降低现有命令式解决方案的复杂性。
本书面向的读者
本书是针对对面向对象软件有基本了解,以及对现代Web应用程序挑战具有一定认识的JavaScript开发人员编写的。JavaScript是一种无处不在的语言,如果你需要函数式编程的介绍,并喜欢熟悉的语法,那么完全可以充分利用本书,而不是去学习Haskell(如果想要以更轻松的方式入门Haskell,本书不是最好的资源,因为每种语言都有自己的特性,直接学习其实是最好的理解)。
本书通过对高阶函数、闭包、函数调用、组合以及新的JavaScript ES6特性(如lambda表达式、迭代器、生成器和Promise)的介绍,帮助初级和中级程序员提高他们的JavaScript技能。高级开发人员也将从中领略到Monad和响应式编程的解读,从而可以运用创新的方法,来完成处理事件驱动和异步代码的艰巨任务,并充分地使用JavaScript平台。
如何使用本书
如果读者是初级或中级JavaScript开发人员,并且刚刚接触函数式编程,请从第1章读起。如果读者是一名高级JavaScript程序员,那么可以简要阅读第2章,然后从第3章的函数链和整体函数式设计读起。
函数式JavaScript的更高级用户通常已经理解纯函数、柯里化和组合,因此可以快速浏览第4章,并从第5章开始学习Functor与Monad。
示例和源代码
本书中的代码示例使用ECMAScript 6 JavaScript编写,它可以在服务器(Node.js)或客户端上运行。一些示例需要IO和浏览器DOM API,但没有考虑浏览器的兼容性。期望读者已经有在HTML页面和控制台的基础级互动的经验。代码对浏览器没有特定要求。
本书大量使用了诸如Lodash.js、Ramda.js等函数式的JavaScript库。读者可以在附录中找到文档和安装信息。
本书包含大量用于展示函数式技术的代码清单,并在适当的情况下比较了命令式和函数式设计。读者可以在Manning官方网站和GitHub上找到所有代码示例。
本书体例
本书中使用了以下约定:
粗体字 用于引用重要术语。
Courier 字体用于表示代码清单,以及元素和属性、方法名称、类、函数和其他编程工件。
代码清单中会有一些代码注释,以突出重要的概念。
第一部分 函数式思想
也许读者构建专业应用程序的大部分经验都与面向对象语言有关。读者可能通过阅读其他书籍、博客、论坛和杂志文章听说过函数式编程,但却从来没有编写过任何函数式代码。别担心,这正是笔者所想到的。笔者也曾在面向对象的环境中完成了大部分开发工作。编写函数式代码并不困难,但学会函数式的思考、放弃旧习惯才是真正的挑战。本书第一部分的主要目标是为第二部分和第三部分讨论的函数式技术奠定基础。
第1章讨论了什么是函数式编程,以及需要以什么样的心态来迎接它,同时还介绍了基于纯函数、不可变性、副作用和引用透明性等概念的一些重要技术。这些技术能够形成函数式代码的主干,并将帮助读者更轻松地走近函数式编程。此外,这也将成为后面章节中许多代码设计的指导原则。
第2章揭示了JavaScript作为函数式语言的另一面。由于Javascript是主流语言且广泛存在,因此这是一门理想的、可用来教授函数式编程的语言。如果读者不是一名高级JavaScript开发人员,本章将帮助你快速了解学习函数式JavaScript的必备基础,例如高阶函数、闭包和作用域规则。
第1章 走近函数式
本章内容
- 函数式思想
- 什么是函数式编程以及为什么要进行函数式编程
- 不变性和纯函数的原则
- 函数式编程技术及其对程序设计的影响
面向对象编程(OO)通过封装变化使得代码更易理解。
函数式编程(FP)通过最小化变化使得代码更易理解。
——Michael Feathers (Twitter)
如果你正在阅读这本书,那么很可能你已经是一名拥有面向对象或结构化设计工作经验的JavaScript软件开发人员,但你对函数式编程很感兴趣。或许你曾经尝试过学习它,但并不能在工作或个人项目中成功地应用它。这样的话,你的主要目标是增强开发技能,提高代码质量,那么本书可以帮助你实现这一目标。
Web平台的快速演进和浏览器的不断进化以及最重要的——用户的需求,给如今的Web应用的设计带来了意想不到的变化。人们期望Web应用给人的感觉应该更像本地的桌面应用,或是具有丰富且响应式的部件的移动应用。这样的期望自然而然地迫使JavaScript开发人员能够更广泛地去思考各种解决方案,并适时地采用那些可能提供最优解决方案的编程范式和最佳实践。
作为开发人员,我们总是更喜欢那些拥有简洁应用结构并可以增强软件扩展性的框架。然而代码库的复杂性仍然超出预期,这使得我们去重新审视这些代码的基本设计原则。此外,互联网对于JavaScript开发人员来说已今非昔比,因为今天的我们可以实现很多以前技术上不可行的东西了。我们可以用Node.js来编写大型的服务器端应用程序,还可以将大量的业务逻辑放到客户端去实现,使得服务端非常轻巧。这就需要与外部存储的交互、创建异步进程、处理事件,等等。
面向对象设计有助于解决一部分问题,但由于JavaScript是一种拥有很多共享状态的动态语言,用不了多久,代码就会积累足够的复杂性,变得笨拙而难以维护。面向对象设计的确能够一定程度地缓解这个问题,但我们需要的比缓解更多。也许最近几年你听说过响应式编程 这个术语。这种编程范式有助于数据流的处理和变化的传递。而在处理JavaScript中的异步或事件响应时,这一点至关重要。总之,我们需要一个能够引发我们对数据及其交互的函数深入思考的编程范式。当考虑应用设计时,你应该问问自己是否遵从了以下的设计原则。
- 可扩展性—— 我是否需要不断地重构代码来支持额外的功能?
- 易模块化—— 如果我更改了一个文件,另一个文件会不会受到影响?
- 可重用性—— 是否有很多重复的代码?
- 可测性—— 给这些函数添加单元测试是否让我纠结?
- 易推理性—— 我写的代码是否非结构化严重并难以推理?
如果对于这些问题,你的回答是“是”或是“不知道”,那么本书就能够指导你提高生产效率。函数式编程就是你需要的编程范式。尽管函数式编程基于一些简单的概念,但它还需要你换一种思考问题的方式。函数式编程不是一种新工具或新的API,而是另一种解决问题的方式,一旦你了解了它的基本原则,所要解决的问题将变得很直观。
本章将解释函数式编程的概念,并告诉你它那么有用和重要的原因,以及让其发挥作用的方法。我们将了解不变性和纯函数的核心原则,探讨函数式编程的技术,以及这些技术能够怎样影响程序的设计。这些技术能够使你更加轻松地学习响应式编程,并解决复杂的JavaScript任务。但在了解这一切之前,你需要知道为什么函数式思维方式如此重要的,以及它如何帮助解决JavaScript程序的复杂性。
1.1 函数式编程有用吗?
函数式编程的学习从未像今天这样重要。开发社区和各大软件公司都开始意识到使用函数式编程给其业务应用带来的好处。如今,大多数主流编程语言(如Scala、Java 8、F#、Python 和 JavaScript 等)都提供原生的或基于API的函数式支持。因此,行业对函数式编程技能的需求量很大,同时将在未来的几年不断增长。
在 JavaScript 的上下文中,函数式思想可以用来塑造令人难以置信的语言特性,帮助你编写干净的、模块化的、可测试的并且简洁的代码,使你在开发过程中更加高效。多年来,一个一直被忽略的事实是,JavaScript可以用函数式风格写得更加高效。部分原因是由于对JavaScript语言的整体理解偏差,另外也由于JavaScript缺乏一些能够妥当管理状态的原生结构——这种动态语言将管理状态的职责交给了开发人员(也是在程序中引入bug的原因之一)。这个问题并不会影响规模较小的脚本代码,但随着代码量的不断增长,会变得越来越难以控制。所以从某种程度上而言,我认为函数式编程能够在 JavaScript 中保护你不受该问题的影响。这个问题将在第2章进一步探讨。
编写函数式的 JavaScript 代码能够克服以上提到的大部分问题。通过使用一整套基于纯函数式的已被科学证明的技术与实践,即便复杂性日益提高,你也可以编写出易于推理和理解的代码。编写函数式的 JavaScript 是一件一举两得的事情,因为它不仅能够提高整个应用程序的质量,也能够更好地了解并精通 JavaScript 语言本身。
因为函数式编程是一种编写代码的方式,而不是一种框架或工具,函数式的思维方式与面向对象的思维方式完全不同。但如何迈向函数式呢?如何开始使用函数式去思考呢?一旦你掌握了它的本质,函数式编程将是直观的。摒弃旧习是最难的部分,对于一个有面向对象背景的人来说,将是一个巨大的编程范式转变。在学习如何使用函数式思考之前,首先你必须知道函数式编程到底是什么。
1.2 什么是函数式编程?
简单来说,函数式编程是一种强调以函数使用为主的软件开发风格。你可能会说,“就这样啊,我早就在日常的基本工作中使用函数了。有什么不一样么?”正如之前提到的,函数式编程需要你在思考解决问题的思路时有所变化。其实使用函数来获得结果并不重要,函数式编程的目标是使用函数来抽象作用在数据之上的控制流与操作 ,从而在系统中消除副作用 并减少对状态的改变 。我知道这听起来很拗口,但我将在书中进一步逐个地解释这些贯穿全书的术语。
通常情况下,函数式编程一类的书都会以斐波那契数列的计算为例开始讲解,但我更愿意以一个在HTML页面上显示文字的简单 JavaScript 程序作为开始。还有什么例子比输出一句经典的“Hello World”更好的呢?
document.querySelector('#msg').innerHTML = '<h1>Hello World</h1>';
注意
就像之前提到的,函数式编程不是一种具体的工具,而是一种编写代码的方式。因此,你既可以用它来编写客户端(基于浏览器的)程序,也可以用它来编写服务器端的应用程序(如Node.js)。打开浏览器、直接输入一段代码,这应该是让JavaScript运行起来的最简单的方式,而这也是本书需要你准备的所有东西。
这个程序很简单,但因为所有代码都是写死的,所以不能动态地显示消息。如果想改变消息的格式、内容或者目标DOM元素,就需要重写整个表达式。也许你决定用一个函数来封装这段代码,用参数来表明可变的部分。这样就可以只定义一遍,并通过不同的参数配置来使用它:
function printMessage(elementId, format, message) {
document.querySelector(`#${elementId}`).innerHTML =
`<${format}>${message}</${format}>`;
}
printMessage('msg', 'h1','Hello World');
这样确实有所改进,但它仍然不是一段可重用的代码。假设要将文本写入文件,而非 HTML 页面。你要形成一种简单的思维过程,即在另一个层面来创建参数化的函数,其参数不再只是量值,也可以是可以提供更多功能的函数。函数式编程就像是给函数打了激素,唯一目的就是执行并组合各种函数来实现更强大的功能。先展示一下函数式解决该问题的部分代码,如清单1.1所示。
清单 1.1 函数式的printMessage
var printMessage = run(addToDom('msg'), h1, echo);
printMessage('Hello World');
毫无疑问,这段代码与之前的完全不同。首先,h1 不再是一个量值了,它与 addToDom 和 echo 一样都是函数。这样看上去好像是用一些较小的函数构建了一个新的函数。
代码写成这样是有原因的。清单1.1将程序分解为一些更可重用、更可靠且更易于 理解的部分,再将它们组合起来,形成一个更易推理的程序整体。所有的函数式程序都遵循这一基本原则。从目前来看,要用一个神奇的函数run [1] 来序列地调用一系列的函数,例如addToDom 、h1 和echo 。后面会详细解释 run 函数。在后台,run 函数基本上是通过将一个函数的返回值作为下一个函数的输入这种方式将各个函数链接起来。这样,由 echo 返回的字符串“Hello World”被传递到 h1 中,而结果又最终被传递到 addToDom 里。
为什么函数式的解决方案是这样的呢?笔者更喜欢将其想成将代码本身参数化,这样以一种非侵入式的方式修改它 —— 例如修改一个算法的初始条件。基于这种方式,开发者可以轻松地增强 printMessage 来输出两遍文本,再换个 h2 的标题,最终将文本信息写入到控制台,而非 DOM 元素,而所有这些都无须重写任何内部的逻辑。代码如清单1.2所示。
清单1.2 扩展 printMessage
var printMessage = run(console.log, repeat(3), h2, echo);
printMessage('Get Functional');
这种视觉上不同的做法并非偶然。通过比较函数式和非函数式的解决方案,你会发现它们在代码风格上存在着根本区别。尽管它们的打印输出相同,但它们看起来却截然不同。这是源于函数式编程开发中固有的声明模式。为了充分理解函数式编程,读者首先必须知道它所基于的一些基本概念。
- 声明式编程。
- 纯函数。
- 引用透明。
- 不可变性。
1.2.1 函数式编程是声明式编程
函数式编程属于声明式 编程范式:这种范式会描述一系列的操作,但并不会暴露它们是如何实现的或是数据流如何穿过它们。目前,更加主流的是命令式 的或过程式 的编程范式,如Java、C#、C++ 和其他大多数结构化语言和面向对象语言都对其提供支持。命令式编程将计算机程序视为一系列自上而下的断言,通过修改系统的各个状态来计算最终的结果。
我们来看一个命令式的程序样例。假设你需要计算一个数组中所有数的平方,命令式的程序应有如下步骤:
var array = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9];
for(let i = 0; i < array.length; i++) {
array[i] = Math.pow(array[i], 2);
}
array; //-> [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
命令式编程很具体地告诉计算机如何 执行某个任务(在本例中是通过数组循环并将平方公式应用在每个数上)。这是编写代码的最常见方式,你在第一次实现该功能时很有可能也是这样写的。
而声明式编程是将程序的描述与求值分离开来的。它关注于如何用各种表达式 来描述程序逻辑,而不一定要指明其控制流或状态的变化。你可以在SQL语句中找到声明性编程的例子。SQL语句是由一个个描述查询结果应是什么的断言组成,对数据检索的内部机制进行了抽象。在第3章中,我们会看到一个使用类似SQL语句的模式组织起来的函数式代码,它能够同时描述应用程序及运行于其中的数据的意义。
如果使用函数式来解决相同的问题,只需要对应用在每个数组元素上的行为予以关注,将循环交给系统的其他部分去控制。完全可以让 Array.map() 去做这种繁重的工作:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9].map(
function(num) {
return Math.pow(num, 2); <--- map接收一个计算平方的函数
});
//-> [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
与之前的命令式代码相比,可以看到函数式的代码让开发者免于考虑如何妥善管理循环计数器以及数组索引访问的问题。简单地说,代码量越大,存在bug的地方就会越多。同时,标准的代码循环是很难被重用的东西,除非将它们抽象为函数。而这正是我们要去做的。在第3章中,我们将阐述如何使用如 map 、reduce 和 filter 这样的一等高阶函数来从代码中去除循环,它们都以函数为参数,可以增强代码的可重用性、可扩展性和声明性。这就是那个神奇的 run 函数在清单1.1和清单1.2中所做的事。
你可以发挥 ES6 JavaScript 的lambda表达式 以及箭头函数 的优势来将循环抽象成函数。lambda 表达式提供了一种匿名函数的简写方式,并可以作为函数类型的参数来传递,以减少代码的书写:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9].map(num => Math.pow(num, 2));
//-> [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
将 lambda 转换为常规函数
lambda 表达式提供了一种比常规函数更具语法优势的特性,因为它简化了常规函数的结构,使人关注于函数的那些真正重要的部分。下面的ES6 lambda表达式:
num => Math.pow(num, 2)等同于以下函数:
function(num) { return Math.pow(num, 2); }
为什么要去掉代码循环?循环是一种重要的命令控制结构,但很难重用,并且很难插入其他操作中。此外,它意味着为响应新的迭代,代码会不断变化。你马上就会知道,函数式编程旨在尽可能地提高代码的无状态性 和不变性 。无状态的代码不会改变或破坏全局的状态。但要做到这一点,开发者要学会使用那些没有副作用和状态变化的函数——也称为纯函数 。
1.2.2 副作用带来的问题和纯函数
函数式编程基于一个前提,即使用纯函数构建具有不变性的程序。纯函数具有以下性质。
- 仅取决于提供的输入,而不依赖于任何在函数求值期间或调用间隔时可能变化的隐藏状态和外部状态。
- 不会造成超出其作用域的变化,例如修改全局对象或引用传递的参数。
直观地看,任何不符合以上条件的函数都是“不纯的”。编写不可变的程序起初会令人感到陌生。毕竟,我们所习惯的命令式程序设计的本质,就是声明一些从一个状态变为下一个状态的变量(毕竟它们是“变量”)。这是我们做起来很自然的事。考虑以下函数:
var counter = 0;
function increment() {
return ++counter;
}
这个函数是不纯的,因为它读取并修改了一个外部变量,即函数作用域外的 counter 。一般来说,函数在读取或写入外部资源时都会产生副作用,如图1.1所示。另一个例子是经常见到的函数 Date.now() ,它的输出肯定是不可预见的并且不一致的,因为它总是依赖于一个不断变化的因素——时间。
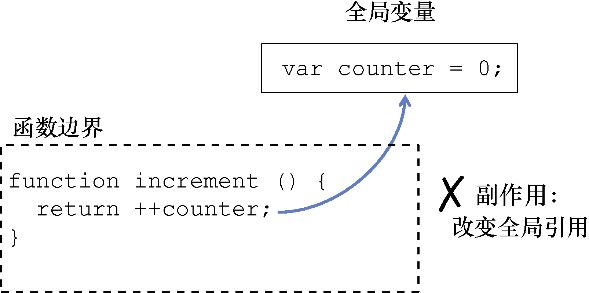
图1.1 函数 increment() 通过读取 / 修改一个外部变量 counter 而产生副作用。其结果是不可预见的,因为 counter 可以在调用间隔的任何时间发生改变
在这个例子中,counter 可以通过一个隐式全局变量被访问到(在浏览器的 JavaScript 环境中,这个变量是window 对象)。另一种常见的副作用发生在通过this 关键字访问实例数据时。this 在JavaScript中的行为与其他编程语言中的不同,因为它决定了一个函数在运行时的上下文。而这往往就导致很难去推理代码,这就是为什么要尽可能地避免。我们将在下一章重温这个话题。在很多情况下,以下副作用都有可能发生。
- 改变一个全局的变量、属性或数据结构。
- 改变一个函数参数的原始值。
- 处理用户输入。
- 抛出一个异常,除非它又被当前函数捕获了。
- 屏幕打印或记录日志。
- 查询 HTML 文档、浏览器的 cookie或访问数据库。
如果无法创建和修改对象,或是打印到控制台,这样的程序会有什么实用价值?事实上,在一个充满了动态行为与变化的世界里,纯函数确实是很难使用的。但是,函数式编程在实践上并不限制一切 状态的改变。它只是提供了一个框架来帮助管理和减少可变状态,同时让你能够将纯函数从不纯的部分中分离出来。之前列出的那些不纯的代码都会产生外部可见的 副作用,而本书会探索处理该问题的方法。
为了更具体地讨论这些问题,假设你是一名开发人员,而你的团队正在实现一个用来管理学校学生数据的应用程序。清单1.3是一个短小的命令式程序,它能通过社会安全号码(SSN)找到一个学生的记录并渲染在浏览器中(同样,是不是使用浏览器并不重要,你也可以很容易地写入控制台、数据库或文件)。本书会涉及并扩展这个程序,因为它是一个典型的、真实的场景,其中包含了很多与外部的本地对象存储结构(例如一个对象数组)和不同层次的IO交互而产生的副作用。
清单1.3 命令式的 showStudent 函数以及产生的副作用
function showStudent(ssn) {
var student = db.get(ssn); <---在对象存储中通过SSN查找学生。请假设这个操作现在是同步的,之后我会处理异步的情况
if(student !== null) {
document.querySelector(`#${elementId}`).innerHTML = <---读取函数外的elementId变量
`${student.ssn},
${student.firstname},
${student.lastname}`;
}
else {
throw new Error('Student not found!'); <---当学生信息错误时抛出异常
}
}
showStudent('444-44-4444'); <---使用SSN号444-44-4444作为参数执行函数,结果会显示在页面上
进一步分析这段代码。这个函数显然将一些副作用暴露到其作用域之外:
- 该函数为访问数据,与一个外部变量(
db)进行了交互,因为该函数签名中并没有声明该参数。在任何一个时间点,这个引用可能为null,或在调用间隔改变,从而导致完全不同的结果并破坏了程序的完整性。 - 全局变量
elementId可能随时改变,难以控制。 - HTML 元素被直接修改了。HTML 文档(DOM)本身是一个可变的、共享的全局资源。
- 如果没有找到学生,该函数可能会抛出一个异常,这将导致整个程序的栈回退并突然结束。
一方面,清单1.3中的函数依赖了外部资源,使得代码很不灵活,很难维护并且难以测试。另一方面,使用纯函数,其函数签名对所描述的所有形参(输入集)都有明确的约定,使其更易于理解和使用。
再回到函数式的世界,用在简单的 printMessage 程序中学到的东西来应对这种真实的情况。在阅读本书时,你会逐渐适应函数式,而本书会不断地改进并应用新技术来实现这个任务。目前可以改进以下两点。
- 将这个长函数分离成多个具有单一职责的短函数。
- 通过显式地将完成功能所需的依赖都定义为函数参数来减少副作用的数量。
首先分离屏幕显示与获取学生记录的行为。当然,与外部存储系统和 DOM 交互所造成的副作用是不可避免的,但至少可以通过将其从主逻辑中分离出来的方式使它们更易于管理。要做到这一点,需要引入一种常见的函数式编程技巧——柯里化 。使用柯里化,可以允许部分地传递函数参数,以便将函数的参数减少为一个。就像在清单1.4中显示的那样,可以使用 curry 减少 find 和 append 的参数,使其成为可以与 run 组合的一元函数。
清单1.4 showStudent 程序的分解
var find = curry(function (db, id) { <---函数find需要对象存储的引用和ID来查找学生
var obj = db.get(id);
if(obj === null) {
throw new Error('Object not found!');
}
return obj;
});
var csv = (student) { <---将学生对象转换成用逗号分隔的字符串
return `${student.ssn}, ${student.firstname}, ${student.lastname}`;
};
var append = curry(function (elementId, info) { <---为了在屏幕上显示学生信息,这里需要elementId以及学生的数据
document.querySelector(elementId).innerHTML = info;
});
读者并不需要现在就理解如何柯里化,但要看到很重要的一点,那就是通过减少这些函数的长度,可以将 showStudent 编写为这些小函数的组合:
var showStudent = run(
append('#student-info'), <---部分设置HTML元素的ID
csv,
find(db)); <---部分设置查找对象为学生表
showStudent('444-44-4444');
尽管这个程序只有些许的改进,但是它开始展现出许多的优势。
- 它灵活了很多,因为现在有三个可以被重用的组件。
- 这种细粒度函数的重用是提高工作效率的一种手段,因为你可以大大减少需要主动维护的代码量。
- 声明式的代码风格提供了程序需要执行的那些高阶步骤的一个清晰视图,增强了代码的可读性。
- 更重要的是,与 HTML 对象的交互被移动到一个单独的函数中,将纯函数从不纯的行为中分离出来。柯里化以及如何管理纯与不纯的代码将在第4章进一步解释。
这个程序仍然有一些枝节问题需要解决,但减少副作用能够在修改各种外部条件时使程序不那么脆弱。如果仔细看一下 find 函数,就会发现它有一个可以产生异常的检查 null 值的分支。由于许多我们会在后续了解的原因,能够确保一个函数有相同的返回值是一个优点,它使得函数的结果是一致的和可预测的。这是纯函数的一个特质,称为引用透明 。
1.2.3 引用透明和可置换性
引用透明是定义一个纯函数较为正确的方式。纯度 在这个意义上表明一个函数的参数和返回值之间映射的纯的关系。因此,如果一个函数对于相同的输入始终产生相同的结果,那么就说它是引用透明 的。例如,之前看到的那个有状态的函数increment 不是引用透明的,因为其返回值严重依赖外部变量counter 。再看一下这段代码:
var counter = 0;
function increment() {
return ++counter;
}
为了使其引用透明,需要删除其依赖的外部变量这一状态,使其成为函数签名中显式定义的参数。可以将其转换为 ES6 lambda 的形式:
var increment = counter => counter + 1;
现在这个函数是稳定的,对于相同的输入每次都返回相同的输出结果。否则,该函数的返回值总会受到一些外部因素的影响。
我们之所以追求这种函数的这种特质,是因为它不仅能使代码更易于测试,还可以让我们更容易推理整个程序 。引用透明(又称为等式正确性) 来自数学概念,但编程语言中的函数的行为和数学中的函数不同,所以引用透明必须由我们来实现。通过再次使用神奇的 run 函数,图1.2展示了increment 函数的命令式与函数式版本的对比。

图1.2 increment 函数的命令式与函数式版本的比较。命令式版本的结果是不可预测的,并且可能是不一致的。外部变量counter 随时会改变,这影响了函数连续调用的结果。而引用透明的函数式版本中,函数总是等式正确的,因此不可能出现任何错误
构建这样的程序更容易推理,因为可以在心中形成一个状态系统的模型,并通过重写 或替换 来达到期望的输出。具体来讲,假设任何程序可以被定义为一组的函数,对于一个给定的输入,会产生一个输出,则可表示为:
Program = [Input] + [func1, func2, func3, ...] -> Output
如果函数 [func1, func2, func3, ...] 都是纯的,则可以轻易地将由其产生的值来重写这个程序——[val1, val2, val3, ...] ——而不改变结果。考虑计算学生的平均成绩这样一个简单的例子:
var input = [80, 90, 100];
var average = (arr) => divide(sum(arr), size(arr));
average (input); //-> 90
由于函数 sum 和 size 都是引用透明的,对于如下的给定输入,可以很容易地重写这个表达式。
var average = divide(270, 3); //-> 90
由于 divide 总是纯的,因此可以利用其数学符号进一步改写,所以对于当前输入,平均值永远是 270/3=90 。引用透明使得开发者可以用这种系统的甚至是数理的方法来推导程序。整个程序可如下实现:
var sum = (total, current) => total + current;
var total = arr => arr.reduce(sum); <---又一新函数:reduce。跟map一样,reduce遍历整个集合。通过sum函数,可以将叠加集合中的数
var size = arr => arr.length;
var divide = (a, b) => a / b;
var average = arr => divide(total(arr), size(arr)); <---在第4章中,我们会用新的方式组合average函数
average(input); //-> 90
尽管本书并不打算对每个程序进行这种等价推导,但应该知道这种形式隐式地存在于任何纯函数的程序,但对于有副作用的函数来说,这却是不可能的。在中,我们会在函数式单元测试的上下文中重识其重要性。虽然可以通过定义函数形参的方式来避免在大多数情况下的副作用,但是在用引用来传递对象时,一定要谨慎,不要在不经意间改变它们。
1.2.4 存储不可变数据
不可变数据 是指那些被创建后不能更改的数据。与许多其他语言一样,JavaScript中的所有基本类型(String 、Number 等)从本质上是不可变的。但是其他对象,例如数组,都是可变的——即使它们作为输入传递给另一个函数,仍然可以通过改变原有内容的方式产生副作用。考虑一个简单的数组排序代码:
var sortDesc = function (arr) {
return arr.sort(function (a, b) {
return b - a;
});
}
乍一眼看去,这段代码看起来完全正常,并没有副作用。它确实如所期望的那样——给一个数组,返回以降序排序的相同数组:
var arr = [1,2,3,4,5,6,7,8,9];
sortDesc(arr); //-> [9,8,7,6,5,4,3,2,1]
不幸的是,array.sort 函数是有状态的,会导致在排序过程中产生副作用,因为原始的引用被修改了。这是语言的一个缺陷,我们将在后续的章节中克服它。
现在,读者已经了解了函数式编程的一些基本原则(如声名式的、纯的和不可变的),就可以更简洁地描述它:函数式编程是指为创建不可变的程序,通过消除外部可见的副作用,来对纯函数的声明式的求值过程。 ——还是比较拗口。之前只是通过编写函数式应用来获取一些显式的实践优势,但现在读者应该开始明白用函数式思考的意义了。
大多数 JavaScript 开发人员面临的问题都是由大量使用严重依赖外部共享变量的、存在太多分支的以及没有清晰的结构大函数所造成的。然而,这正是许多 JavaScript 应用今天的处境——即便是一些由很多文件组成并执行得很成功的应用,也会形成一种共享的可变全局数据网,难以跟踪和调试。
强迫自己去思考纯的操作,将函数看作永不会修改数据的闭合功能单元 ,必然可以减少这种潜在bug的可能性。理解这些核心的原则非常重要,它可以让代码发挥出函数式的诸多优势,从而引导你走向克服复杂性的函数式编程之路。
1.3 函数式编程的优点
为了从函数式编程中受益,你必须学会函数式的思考并掌握合适的工具。在本节中,为了增强函数式编程的意识 ,也就是将问题看作许多简单函数组合来提供完整解决方案的直觉,笔者将介绍一些工具箱中不可或缺的核心技术,还会简单地介绍一下本书的一些后续章节。如果某个概念现在很难把握,请不用担心,它将会在你阅读后续章节的过程中变得更加清晰明了。
现在来宏观地了解一下函数式能为JavaScript应用程序带来的好处。
- 促使将任务分解成简单的函数。
- 使用流式的调用链来处理数据。
- 通过响应式范式降低事件驱动代码的复杂性。
1.3.1 鼓励复杂任务的分解
从宏观上讲,函数式编程实际上是分解(将程序拆分为小片段)和组合(将小片段连接到一起)之间的相互作用。正是这种二元性,使得函数式程序如此模块化和高效。正如上文提到的,这里的模块化单元(或称为功能单元 ),就是函数本身。函数式思维的学习通常始于将特定任务分解为逻辑子任务(函数)的过程,图1.3所示的是对showStudent的分解。
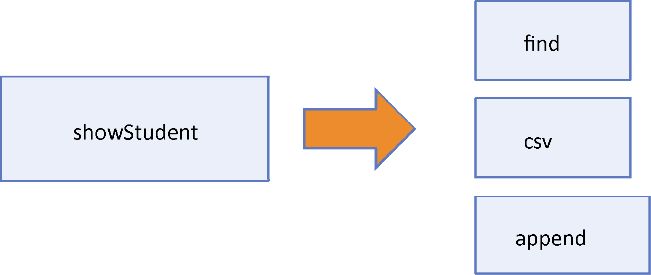
图1.3 将 showStudent 分解为小片段的过程。这些子任务是相互独立并易于
理解的,这样在组合时,可以有助于解决最终的问题
如果需要,这些子任务可以进一步分解,直到成为一个个简单的、相互独立的纯函数功能单元。请记住,这是笔者在重构清单1.4 中showStudent时采用的思维方式。函数式编程的模块化的概念与单一职责 原则息息相关,也就是说,函数都应该拥有单一的目的——之前例子中的 average 函数正体现了这一原则。纯度和引用透明会促使你这样思考问题,因为为了将函数组合在一起,它们必须在输入和输出的形式上形成一致。通过引用透明的概念能够看出,函数的复杂性往往与其接收的参数数量相关(这更多是来自实际观察的结果,函数的参数越少就越简单并不是绝对的)。
笔者一直在使用run 函数来组合各种函数,从而实现整个程序。现在是时候揭秘这个黑魔法了。在现实中,run 函数是一个极为重要的技术的别名:组合 。两个函数的组合是一个新的函数,它拿到一个函数的输出,并将其传递到另一个函数中。假设有两个函数 f 和 g ,形式上,其组合可以如下描述:
f • g = f(g(x))
这个公式读作“f 组合上g ”,它在g 的返回值与f 的参数之间构建了一个松耦合的且类型安全的联系。两个函数能够组合的条件是,它们必须在参数数目及参数类型上形成一致(见第3章)。现在用compose 构建组合函数 showStudent ,其结构如图1.4所示。
var showStudent = compose(append('#student-info'), csv, find(db));
showStudent('444-44-4444');

图1.4 两个函数组合后的数据流。函数 find 的返回值必须与函数 csv 的参数在类型和数量上相兼容,而之后的返回值又必须是 append 函数可以使用的信息。
注意:为了使数据流明晰,函数调用的顺序被翻转了
了解compose 是学习如何实现函数式应用的模块化和可重用性的关键——笔者会在第4章详细讨论。函数式的组合表明了整个表达式的意义可以从其各个部分分别去理解,这是其他编程范式所难以实现的特性。
此外,函数式的组合提高了抽象的层次,可以清晰地勾勒代码的所有步骤,但又不暴露任何底层细节在此代码执行的所有步骤。由于 compose 接收其他函数为参数,这被称为高阶函数 。但组合并不是构建流式的、模块化的代码的唯一方式。在本书中,读者还将学习如何通过连接各种操作来构建链式的运行序列。
1.3.2 使用流式链来处理数据
除了map ,开发者可以通过导入一些功能强大的、最优化的函数式类库来获得更多的高阶函数。在第3章和第4章中,我们将介绍很多实现于像 Lodash.js 和 Ramda.js 这种流行的 JavaScript 工具包中的高阶函数。尽管它们在某些方面有所重叠,但每一个都带来了独特的、可简化函数链式装配的功能。
如果读者以前写过一些 jQuery 代码,那么可能熟悉一个词语——链。链 指的是一连串函数的调用,它们共享一个通用的对象返回值(如 $ 或 jQuery 对象)。就像组合一样,链有助于写出简明扼要的代码,而且它通常多用于函数式和响应式的JavaScript类库(后面会见到更多)。为了说明这一点,下面来解决一个不同的问题。假设需要用程序计算那些选了多门课程的学生的平均成绩。已知选课数据的数组:
let enrollment = [
{enrolled: 2, grade: 100},
{enrolled: 2, grade: 80},
{enrolled: 1, grade: 89}
];
命令式的实现可能是这样的:
var totalGrades = 0;
var totalStudentsFound = 0;
for(let i = 0; i < enrollment.length; i++) {
let student = enrollment [i];
if(student !== null) {
if(student.enrolled > 1) {
totalGrades+= student.grade;
totalStudentsFound++;
}
}
}
var average = totalGrades / totalStudentsFound; //-> 90
与之前一样,用函数式的思维来分解这个问题,可以发现有三个主要步骤。
- 选择合适的(选课数量大于1的)学生。
- 获取他们的成绩。
- 计算出他们的平均成绩。
这样就可以用 Lodash 缝合表征这些步骤的函数,形成一个清单1.5所示的函数链(如果想知道其中每一个函数的详细说明,可以查看附录中的相应文档)。函数链是一种惰性计算 程序,这意味着当需要时才会执行。这对程序性能是有利的,因为可以避免执行可能包含一些永不会使用的内容的整个代码序列,节省宝贵的CPU计算周期。这有效地模拟了其他函数式语言的按需调用 的行为。
清单1.5 使用函数链编程
_.chain(enrollment)
.filter(student => student.enrolled > 1)
.pluck('grade')
.average()
.value(); //-> 90 <---调用 _.value() 会触发整个链上的所有操作
目前不要太在意这段代码中发生的一切。当下,请与其命令式的版本进行比较,并注意如何消除变量的声明和变化,以及循环和 if-else 语句。正如你将在第7章所学的,诸如循环和逻辑分支这样的很多命令式控制流机制,会提高函数的复杂程度,因为它们会根据某些条件不同而执行不同的路径,非常难以测试。
公平地说,这个例子略过了一些真实世界程序中典型的错误处理代码。而上文提到抛出异常是产生副作用的一个原因。异常尽管不会存在于理论上的函数式编程之中,但在现实生活中,你将无法避免它们。其实,纯粹的错误处理和异常处理是有区别的。本书的目标是尽可能多地使用纯粹的错误处理,并在像之前描述的那些真正需要异常的情况下抛出异常。
幸运的是,利用一些纯函数式的设计模式,你将不需要通过牺牲函数链的描述性来为代码提供强大的错误处理逻辑。我们将在第5章讨论这个话题。
到目前为止,读者已经看到了如何使用函数式编程来帮助创建模块化的、可测试的以及可扩展的应用程序了。但如何利用函数式编程与来自用户输入、远程Web请求、文件系统或持久化存储的基于异步或事件驱动的数据进行交互呢?
1.3.3 复杂异步应用中的响应
如果读者还记得最近一次请求远程数据、处理用户输入或与本地存储交互的情况,也许能够想起是如何将整个业务逻辑放入回调函数的嵌套序列之中的。这种回调模式打破了线性的代码流,使代码变得难以阅读,因为它的成功处理和错误处理的逻辑混杂在一起。而这一切将得以改变。
正如之前所说,学习函数式编程,尤其是对于如今的JavaScript 开发人员是极其重要的。当构建大型应用程序时,大家关注的焦点从像 Backbone.js 这样的面向对象框架逐渐转移到像采用响应式编程范式这样的框架上。像 Angular.js 这样的 Web 框架今天仍然广为使用;但像 RxJS 这样的新成员,也在通过函数式编程赋予的力量解决着很多极具挑战的任务。
响应式编程可能是函数式编程最令人兴奋和感到有趣的应用之一。JavaScript 开发人员每天都需要处理那些在服务端或客户端中的异步和事件驱动的代码,而你可以使用响应式编程来大幅降低这些代码的复杂性。
采用响应式范式的主要好处是,它能够提高代码的抽象级别,使你忘记与异步和事件驱动程序创建的相关样板代码,从而更专注于具体的业务逻辑。此外,这种新兴范式能够充分利用函数式编程中函数链和组合的优势。
事件有很多种:鼠标点击、文本变化、焦点变化、新HTTP请求的处理、数据库查询以及文件写入,等等。假设需要读取并验证学生的社会保险号(SSN),那么典型的命令式代码可能是清单1.6所示的这样:
清单1.6 读取并验证学生的SSN 的命令式程序
var valid = false;
var elem = document.querySelector('#student-ssn');
elem.onkeyup = function(event) {
var val = elem.value; <---访问函数作用域外的数据会产生副作用
if(val !== null && val.length !== 0) {
val = val.replace(/^\s*|\s*$|\-s/g, ''); <---裁剪并清理输入,直接改变数据
if(val.length === 9) { <---嵌套的分支逻辑
console.log(`Valid SSN: ${val}!`);
valid = true; <---访问函数作用域外的数据会产生副作用
}
}
else {
console.log(`Invalid SSN: ${val}!`);
}
};
对于这样一个简单的任务,从一开始就变得复杂,并且代码缺乏一种将所有业务逻辑模块化的能力。此外,由于依赖于外部状态,该函数无法被重用。由于基于函数式编程,响应式编程也是使用像 map 、reduce 以及简洁的lambda表达式这样的纯函数来处理数据的。所以学习响应式编程的第一部分就是学习函数式编程!这种编程范式使用了一个叫作observable 的概念。observable 能够订阅一个数据流,让开发者可以通过使用组合和链式操作来优雅地处理数据。下面来看它的实际应用——订阅一个学生的 SSN 字段的简单输入,如清单1.7所示。
清单1.7 读取并验证学生 SSN 的函数式程序
Rx.Observable.fromEvent(document.querySelector('#student-ssn'), 'keyup')
.map(input => input.srcElement.value)
.filter(ssn => ssn !== null && ssn.length !== 0)
.map(ssn => ssn.replace(/^\s*|\s*$|\-/g, ''))
.skipWhile(ssn => ssn.length !== 9)
.subscribe(
validSsn => console.log(`Valid SSN ${validSsn}`)
);
能看出清单1.7和采用链式编程的清单1.5的相似性吗?这说明,无论是处理集合元素序列或是用户输入序列,一切都被抽象了出来,这使得可以使用相同的方式去处理(本书第8章将会详细介绍)。
其中一个最重要的知识点是,所有清单1.7中的操作都是完全不可变的,并且所有的业务逻辑被分隔成单独的函数。并不是必须 要响应式地使用函数,但函数式的思维会迫使 开发者这样做。一旦这样做了,将解开一个基于函数式响应式编程 (FRP)的非常了不起的架构。
函数式编程是一种编程范式的转变,可以改变开发者对任何编程挑战的解决方式。那么,能说函数式编程是更为流行的面向对象设计的替代品么?幸运的是,就如本章开始 Michael Feathers 所说的,函数式编程对代码来说不是一个全有或全无的方案。事实上,很多采用面向对象架构的应用依然可以受益于函数式编程。由于对不可变性及状态共享的严格把控,函数式编程可以使得多线程编程更加简单。但由于 JavaScript 是单线程运行的,本书不会涵盖多线程编程。下一章会重点介绍一些函数式和面向对象设计的主要区别,帮助读者更容易地适应函数式的思维方式。
本章简要介绍了将在整本书中细致讨论的各个主题,让读者从思维方式上深入了解函数式的意境。不必担心遗漏一些东西,只要能够理解上述的所有概念,那么就很不错,这说明你选择了一本正确的书。在传统的面向对象编程中,读者习惯于采用命令式/过程式的编程风格。要改变这一点,思维过程需要有巨大的转变,要开始使用函数式的方式去解决问题。
1.4 总结
- 使用纯函数的代码绝不会更改或破坏全局状态,有助于提高代码的可测试性和可维护性。
- 函数式编程采用声明式的风格,易于推理。这提高了应用程序的整体可读性,通过使用组合和lambda表达式使代码更加精简。
- 集合中的数据元素处理可以通过链接如
map和reduce这样的函数来实现。 - 函数式编程将函数视为积木,通过一等高阶函数来提高代码的模块化和可重用性。
- 可以利用响应式编程组合各个函数来降低事件驱动程序的复杂性。
[1] 更多关于这个临时的run函数的细节,请访问http://mng.bz/nmax 。
第2章 高阶JavaScript
本章内容
- 为什么说JavaScript是适合函数式的编程语言
- JavaScript语言的多范型开发
- 不可变性和变化的对策
- 理解高阶函数和一等函数
- 闭包和作用域的概念探讨
- 闭包的实际使用
自然语言是没有主导范式的,JavaScript 也同样没有。开发者可以从过程式、函数式和面向对象的“大杂烩”中选择自己需要的,再适时地把它们融为一体。
——Angus Croll,《If Hemingway Wrote JavaScript》
当应用程序变得越来越庞大,其复杂性也随之增加。无论你觉得自己有多么了不起,如果没有一个适合的编程模型,也少不了麻烦。第1章解释了为什么函数式编程是一个值得采用的编程范式。但范式本身也仅仅是编程模型,需要借助合适的宿主语言才能在现实中应用。
本章将带领读者快速领略JavaScript 这门集面向对象和函数式为一体的混合语言。当然,这决不是广泛地学习语言本身。相反,笔者将把重点放在JavaScript的函数式特性及其不足。其中一个例子就是缺乏对不可变性的支持。此外,本章还涵盖高阶函数和闭包,它们是编写函数式风格JavaScript的支柱。
2.1 为什么要使用JavaScript?
首先回答“为什么使用函数式?”这个问题。而这与另一个问题息息相关,“为什么要使用JavaScript?”,其答案也很简单:它无所不在。JavaScript是一种动态类型、面向对象且极具语法表现力的一门通用语言。它是有史以来应用最为广泛的程序语言之一,在移动应用、网站、网络服务器、桌面应用、嵌入式应用甚至是数据库的开发中都能够看到。作为Web语言 ,鉴于其应用之广泛,JavaScript成为有史以来使用最为广泛的函数式编程语言也就理所当然了。
尽管 JavaScript 拥有类似 C 语言的语法,其设计灵感有很多则来自像 Lisp 和 Scheme 这样的函数式语言。作为这些语言的共同点,对高阶函数、闭包、数组字面量以及其他特性的支持,使得JavaScript成为一个应用函数式技术的理想平台。事实上,函数是 JavaScript 中主要的工作单元 ,这意味着它们不仅用于驱动应用程序的行为,也用于定义对象、创建模块以及处理事件。
JavaScript 是一门积极演变与改进的语言。在 ECMAScript(ES)的标准支持下,它的下一个主要版本 ES6 增加了更多的语言特性:箭头函数、常量、迭代器、Promise 以及其他能够很好地配合函数式编程的特性。
尽管JavaScript有许多强大的函数式特征,但更重要的是了解到它既是面向对象的,也是函数式的。然而,后者鲜有人知。大多数开发人员都在使用可变的操作、命令式的控制结构以及对实例对象状态的改变,而这些都是在函数式风格的代码中需要尽可能避免的行为。不过,我还是觉得应该花一些时间先谈谈作为一种面向对象语言的 JavaScript,从而更好地区分两种范式之间的关键差异。这将让你更轻松地跃入函数式编程。
2.2 函数式与面向对象的程序设计
无论是函数式还是面向对象编程(OOP)都可以用来开发中到大型的软件系统。诸如Scala和F#这样的混合语言能够将两种范式融入一种语言。JavaScript也具有类似的能力,因此要精通它需要学习如何将二者结合在一起,也要学会根据个人喜好和待解决问题的需求在二者之间寻求平衡。了解函数式和面向对象方案的共性及差异可以帮助你从一种范式过渡到另一种范式,或用任意一种范式来思考。
考虑一个简单的涉及Student 对象的学习管理系统模型。从类或类型层次的角度来看,我们能够很自然地想到 Student 应该作为 Person 的一个子类型,其中包括像姓、名、地址等基本属性。
面向对象的 JavaScript
当说到一个对象与另一个对象之间具有子类型或派生类型的关系时,指的是它们之间存在的原型关系。有必要指出,尽管 JavaScript 是面向对象的,但其并不具备像 Java 这样的语言中典型的继承关系。
在ES6中,可以通过使用像关键字
class和extends这样的语法糖来建立对象之间的原型链接(尽管很多情况下这样做是不对的)。这样的特性使得定义对象之间的继承更加简单,但却隐藏了 JavaScript 强大的原型机制的真实行为。本书将不过多介绍 JavaScript 的面向对象编程(本章的最后将推荐一本深入讨论该话题的书)。
如果进一步将 Student 派生为更具体的类型,例如CollegeStudent ,就可以再添加一些额外的功能。面向对象的核心,就是将创建派生对象作为程序中代码重用的主要手段。因此,CollegeStudent 将会重用从其父类继承而来的所有数据与行为。但这使得在原对象中添加更多功能变得很棘手,因为它的后代们并不一定会适用于这些新功能。虽然 firstname 和 lastname 适用于 Person 及其所有的子类型,但可以说让 workAddress 作为(从 Person 派生的)Employee 对象的一部分比起 Student 对象要更合理一些。之所以举这样的例子,是为了解释在数据(对象属性)与行为(函数)的组织上,面向对象和函数式的主要差别。
面向对象的应用程序大多是命令式的,因此在很大程度上依赖于使用基于对象的封装来保护其自身和继承的可变状态的完整性,再通过实例方法来暴露或修改这些状态。其结果是,对象的数据与其具体的行为以一种内聚的包裹的形式紧耦合在一起。而这就是面向对象程序的目的,也正解释了为什么对象是抽象的核心。
再看函数式编程,它不需要对调用者隐藏数据,通常使用一些更小且非常简单的数据类型。由于一切都是不可变的,对象都是可以直接拿来使用的,而且是通过定义在对象作用域外的函数来实现的。换句话说,数据与行为是松耦合的。正如在图2.1中看到的,函数式代码使用的是可以横切或工作于多种数据类型之上的更加粗粒度的操作,而不是一些细粒度的实例方法。在这种范式中,函数成为抽象的主要形式 。

图2.1 面向对象的程序设计通过特定的行为将很多数据类型逻辑地连接在一起,函数式编程则关注如何在这些数据类型之上通过组合来连接各种操作。因此存在一个两种编程范式都可以被有效利用的平衡点。使用如Scala、F#和JavaScript这样的混合语言就可以这么做
如图2.1所示,两种范式的差别随着横竖坐标的增长逐渐显现。在实践中,一些极好的面向对象代码均使用了两种编程范式——正是在这个相交的平衡点上。要做到这一点,你需要把对象视为不可变的实体或值,并将它们的功能拆分成可应用在该对象上的函数。因此,如下的一个Person 中的方法
get fullname() {
return [this._firstname, this._lastname].join(' '); <---比如在方法中,会推荐使用this来访问对象的状态
}
可以拆分出如下的函数:
var fullname =
person => [person.firstname, person.lastname].join(' '); <---函数中this可以替换为传入的参数对象
众所周知,JavaScript是一种动态类型语言(也就是无须在对象引用时显示指定类型),因此fullname() 可以适用于任何派生自Person 的对象(其实是任何拥有 firstname 和lastname 属性的对象),如图2.2所示。
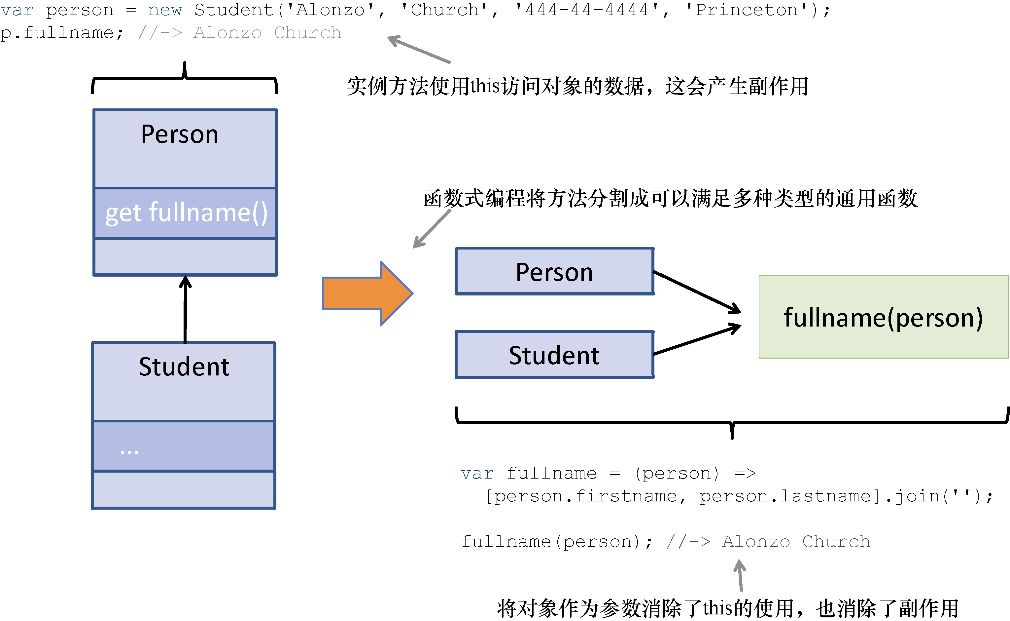
图2.2 面向对象的关键是创建继承层次结构(如继承Person 的Student 对象)并将方法与数据紧密的绑定在一起。函数式编程则更倾向于通过广义的多态函数交叉应用于不同的数据类型,同时避免使用this
鉴于 JavaScript 的动态特性,其支持使用广义的多态函数。换句话说,使用基类引用的函数(如Person )也能应用在派生类型的对象上(如Student 或CollegeStudent )。
从图2.2中可以看出,将fullname() 分离至独立的函数,可以避免使用 this 引用来访问对象数据。使用this 的缺点是它给予了超出方法作用域的实例层级的数据访问能力,从而可能导致副作用。使用函数式编程,对象数据不再与代码的特定部分紧密耦合,从而更具重用性和可维护性。
可以通过将其他函数作为参数的形式(而不是通过创建一堆的派生类型)来扩展当前函数的行为。为了说明这一点,我们在下面定义一个简单的数据模型,其中包含由 Person 类派生而来的类 Student 。本书的大部分例子都采用了这个模型,如清单2.1所示。
清单 2.1 Person 类与 Student 类的定义
class Person {
constructor(firstname, lastname, ssn) {
this._firstname = firstname;
this._lastname = lastname;
this._ssn = ssn;
this._address = null;
this._birthYear = null;
}
get ssn() {
return this._ssn;
}
get firstname() {
return this._firstname;
}
get lastname() {
return this._lastname;
}
get address() {
return this._address;
}
get birthYear() {
return this._birthYear;
}
set birthYear(year) { <---使用setter方法并不代表要改变对象,而只是创建含有不同属性的对象,而且无需长参数构造函数的方式。在创建并设置好对象后,它们的状态将不会改变(本章之后的部分会解释处理方式)
this._birthYear = year;
}
set address(addr){ <---使用setter方法并不代表要改变对象,而只是创建含有不同属性的对象,而且无需长参数构造函数的方式。在创建并设置好对象后,它们的状态将不会改变(本章之后的部分会解释处理方式)
this._address = addr;
}
toString() {
return `Person(${this._firstname}, ${this._lastname})`;
}
}
class Student extends Person {
constructor(firstname, lastname, ssn, school) {
super(firstname, lastname, ssn);
this._school = school;
}
get school() {
return this._school;
}
}
寻找并运行代码示例
本书的代码示例可以在www.manning.com/books/functional-programming-in-javascript和 https://github.com/luijar/functional-programming-js 找到。你可以随时找出这些项目代码,并开始练习函数式编程。我建议你先运行一下单元测试,然后再使用不同的程序实现去通过它。在写这本书的时候,并非所有的 JavaScript ES6 特性都已在各个浏览器中实现,因此我用 Babel(以前叫 6to5)转译器将 ES6 的代码转换成等效的 ES5 代码。
还有一些特性并不需要转换,只需开启如 Chrome 的“启用实验性 JavaScript”这样的浏览器设置就可以了。如果你正运行在试验模式,非常重要的一点是,要启用严格模式,请将 ‘use strict’ ;这段声明代码放在 JavaScript 文件的开头。
目前的一个任务是找到与给定的学生生活在同一国家的所有朋友。另一个任务则是找到与给定的学生生活在同一个国家且在同一所学校上学的所有学生。以下面向对象的解决方案中,使用this 和super 将各种操作与当前对象以及父对象紧紧地耦合在一起:
// Person class
peopleInSameCountry(friends) {
var result = [];
for (let idx in friends) {
var friend = friends [idx];
if (this.address.country === friend.address.country) {
result.push(friend);
}
}
return result;
};
// Student class
studentsInSameCountryAndSchool(friends) {
var closeFriends = super.peopleInSameCountry(friends); <---使用super调用父类的数据
var result = [];
for (let idx in closeFriends) {
var friend = closeFriends[idx];
if (friend.school === this.school) {
result.push(friend);
}
}
return result;
};
然而,由于函数式编程是纯的且引用透明,通过从状态中分离行为的方式,我们可以使用定义和组合新函数的办法来增加更多可以用于目标类型的操作。而这样,最终只会有一些负责存储数据的简单对象,以及数个以这些对象为参数且可组合实现特定功能的通用函数。尽管目前我们还没有介绍函数式的组合(见第4章),但了解编程范式之间的这些基本区别是非常重要的。从本质上讲,面向对象的继承和函数式中的组合都是为了将新的行为应用于不同的数据类型当中[ 1] 。若要运行此代码,则需要使用以下数据集:
var curry = new Student('Haskell', 'Curry',
'111-11-1111', 'Penn State');
curry.address = new Address('US');
var turing = new Student('Alan', 'Turing',
'222-22-2222', 'Princeton');
turing.address = new Address('England');
var church = new Student('Alonzo', 'Church',
'333-33-3333', 'Princeton');
church.address = new Address('US');
var kleene = new Student('Stephen', 'Kleene',
'444-44-4444', 'Princeton');
kleene.address = new Address('US');
面向对象方法使用 Strudent 上的成员方法来找出同一所学校的所有其他学生:
church.studentsInSameCountryAndSchool([curry, turing, kleene]);
//-> [kleene]
函数式的解决方案则将问题分解为很多小的函数:
function selector(country, school) { <---创建selector函数,用来比较学生的国籍与学校
return function(student) {
return student.address.country() === country && <---访问对象。我会在本章后面的部分展示访问对象的更好方式
student.school() === school;
};
}
var findStudentsBy = function(friends, selector) { <---使用filter用selector过滤数组
return friends.filter(selector);
};
findStudentsBy([curry, turing, church, kleene],
selector('US', 'Princeton'));
//-> [church, kleene]
通过应用函数式思想,我们创建了一个更易于应用的全新函数find-StudentsBy 。请注意,这个新的函数对任何由Person 衍生的对象有效,同时支持任意学校和国家的组合查询。
这一点清楚地表明了两种模式之间的差异。面向对象的设计着重于数据及数据之间的关系,函数式编程则关注于操作如何执行,即行为。表2.1汇总了其他值得关注的主要区别,这些点将在本章和后续章节深入讨论。
表2.1 面向对象和函数式编程一些重要性质的比较。这些性质是贯穿本书的主题
| 函数式 | 面向对象 | |
|---|---|---|
| 组合单元 | 函数 | 对象(类) |
| 编程风格 | 声明式 | 命令式 |
| 数据和行为 | 独立且松耦合的纯函数 | 与方法紧耦合的类 |
| 状态管理 | 将对象视为不可变的值 | 主张通过实例方法改变对象 |
| 程序流控制 | 函数与递归 | 循环与条件 |
| 线程安全 | 可并发编程 | 难以实现 |
| 封装性 | 因为一切都是不可变的,所以没有必要 | 需要保护数据的完整性 |
尽管它们之间存在差异,但有效构建应用程序的方法是混合两种范式。一方面,可以使用与组成类型之间存在自然关系的富领域模型;另一方面,可以拥有一组能够应用于这些类型之上的纯函数。其中界限的确定取决于代码编写者是否对任一编程范式应用自如。由于 JavaScript 既是面向对象的,又是函数式的,因此在编写函数式代码时,需要特别注意控制状态的变化。
2.2.1 管理JavaScript对象的状态
程序的状态 可以定义为在任一时刻存储在所有对象之中的数据快照。可惜的是,JavaScript 是在对象状态安全方面做得最差的语言之一。JavaScript 的对象是高度动态的,其属性可以在任何时间被修改、增加或删除。在清单2.1中,如果期望 _address (下划线的使用是纯句法的)被封装于 Person 之内,那么就大错特错了。在类型作用域之外,开发者拥有对该属性的完全访问权限来执行任何想做的操作,甚至是将其删除。
自由的代价是重大的责任。尽管这会让你自由地去做一些如动态创建属性这样的灵活的事情,但在中大型项目中,这也会使得代码极难维护。
第1章提到,使用纯函数会使代码更易于维护和推理。那么是否存在“纯对象”这种事物呢?可以认为一个包含不可变功能的不可变对象是纯的。相应地,可应用于函数的推理过程也可以应用于简单对象。在寻求函数式地使用 JavaScript 语言的过程中,状态管理至关重要。尽管后续章节探讨了一些可以用来管理不可变性的实践与模式,但完整的数据封装和保护将在实践道路上占很大比重。
2.2.2 将对象视为数值
字符串和数字可能是任何编程语言中最简单的数据类型了。那为什么会这样认为呢?部分原因在于,在传统意义上,这些原始类型本身就是不可变的,而这给我们的内心带来了其他自定义类型所无法给予的平和。在函数式编程中,我们将具有此种行为的类型称为数值 。在第1章中,我们学到,要做到不可变的思考,就需要将任何对象视为数值。而这样做可以让函数将对象传来传去,而不用担心它们被篡改。
虽然 ES6 在类上添加了很多语法糖,但 JavaScript 的对象也只是可在任意时间添加、删除和更改的属性包而已。那么,能做些什么来解决这个问题呢?许多编程语言支持让对象属性不可变的语法结构。其中一个例子就是 Java 的final 关键字。同时,像 F# 这样的语言,除非特别声明,否则其变量默认就是不可变的。但是到目前为止,JavaScript 中还没有如此炫酷的语言特性。尽管 JavaScript 的原始类型是不能改变的,但引用原始类型的变量状态是可以被更改的。因此,提供或者至少模拟对数据的不可变引用,才能使得自定义对象具有近似不可变的行为。
ES6 使用const 关键字来创建常量引用。这确实指对了方向,因为常量是不能被重新赋值或声明的。在实践函数式编程时,如果需要,可以使用 const 关键字来声明一些简单的配置数据(URL字符串、数据库名称等)。尽管读取外部变量会有副作用,但由于语言平台提供了这种具有特殊语义的常量,因此它们不会在函数调用之间被篡改。下面是声明一个常量的例子:
const gravity_ms = 9.806;
gravity_ms = 20; <--- JavaScript会在运行时阻止再赋值
但仅仅如此并不能达到函数式编程所需要的不可变性的支持水平。你可以防止一个变量被重新赋值,但如何防止对象内部状态的改变呢?比如以下代码是完全可以通过的:
const student = new Student('Alonzo', 'Church',
'666-66-6666', 'Princeton');
student.lastname = 'Mourning'; <---属性已经变了
这里需要的是一个更加严格的不可变策略,而封装是一个防止篡改的不错策略。对于一些简单的对象结构,一个好的方法是采用值对象 模式。值对象是指其相等性不依赖于标识或引用,而只基于其值,一旦声明,其状态可能不会再改变。除了数字和字符串,值对象的一些实例还包括tuple 、pair 、point 、zipCode 、coordinate 、money 、date 以及其他类型。以下是一个邮编的实现代码:
function zipCode(code, location) {
let _code = code;
let _location = location || '';
return {
code: function () {
return _code;
},
location: function () {
return _location;
},
fromString: function (str) {
let parts = str.split('-');
return zipCode(parts[0], parts[1]);
},
toString: function () {
return _code + '-' + _location;
}
};
}
const princetonZip = zipCode('08544', '3345');
princetonZip.toString(); //-> '08544-3345'
在 JavaScript 中,可以使用函数来保障 ZIP code 的内部状态访问权限,通过返回一个对象字面接口 来公开一小部分方法给调用者,这样就可以将_code 和_location 视为伪私有变量。在后续章节中能够看到,这些变量只能通过闭包的方式由对象的字面定义中访问。
返回的对象可以表现出像原始类型一样没有可变方法的行为。因此[ 2] ,尽管toString 方法不是纯函数,但其行为与纯函数无异,就是该对象的纯字符串表示。值对象是一种可简单应用于面向对象和函数式编程的轻量级方式。与关键字const 组合在一起使用,我们就可以创建具有与字符串或数字类似语义的对象。下面来看一个例子:
function coordinate(lat, long) {
let _lat = lat;
let _long = long;
return {
latitude: function () {
return _lat;
},
longitude: function () {
return _long;
},
translate: function (dx, dy) {
return coordinate(_lat + dx, _long + dy); <---返回翻译过的坐标副本
},
toString: function () {
return '(' + _lat + ',' + _long + ')';
}
};
}
const greenwich = coordinate(51.4778, 0.0015);
greenwich.toString(); //-> '(51.4778, 0.0015)'
让方法返回一个新的副本(例如 translate )是另一种实现不可变性的方式。在该对象上应用一次平移操作,将产生一个新的 coordinate 对象:
greenwich.translate(10, 10).toString(); //-> '(61.4778, 10.0015)'
值对象是一个由函数式编程启发而来的面向对象设计模式。这是语言范式之间如何优雅地相得益彰的另一个例子。这种模式是理想的,但无法解决所有的现实世界问题。在实践中,代码很可能需要处理层次化数据(例如之前的 Person 和 Student ),也可能需要和历史遗留对象进行交互。幸运的是,JavaScript 可以使用 Object.freeze 机制来模拟这些问题。
2.2.3 深冻结可变部分
尽管 JavaScript 新的类定义语法中不存在能够将字段标记为不可变量的关键字,但它拥有一种内部机制,可以通过控制一些如 writable 的隐藏对象元属性来实现。JavaScript 的 Object.freeze() 函数可以通过将该属性设置为 false 来阻止对象状态的改变。让我们冻结 Person 对象,如清单2.1所示:
var person = Object.freeze(new Person('Haskell', 'Curry', '444-44-4444'));
person.firstname = 'Bob'; <---不被允许
执行第一行代码使得 person 的属性变成只读。任何试图改变其值的操作(如 _firstname 这一行)将导致错误:
TypeError: Cannot assign to read only property '_firstname' of #<Person>
Object.freeze() 也可以冻结继承而来的属性。因此,也可以用同样的方式冻结Student 的实例,该机制会根据对象的原型链保护所有由 Person 继承而来的属性。但是,它不能被用于冻结嵌套对象属性,如图2.3所示。
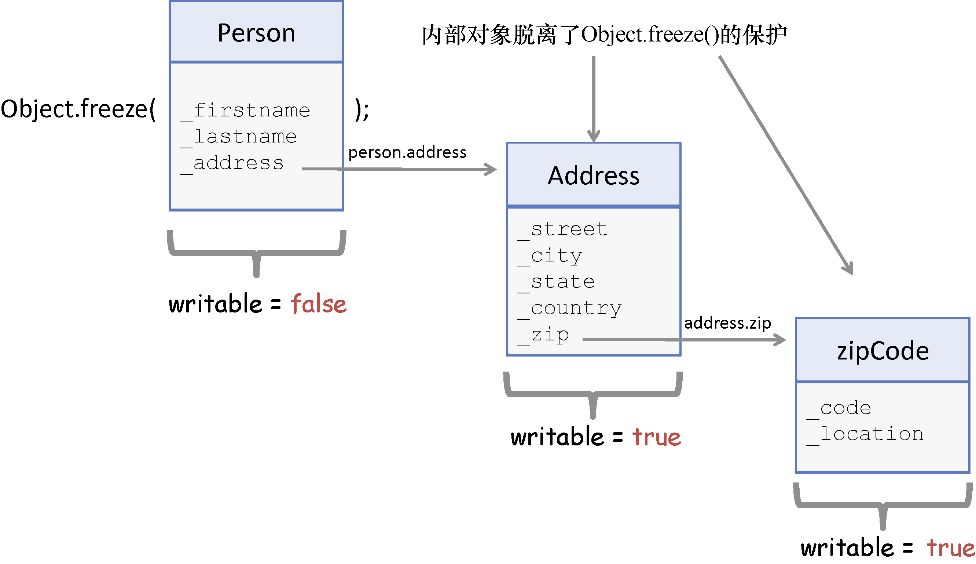
图2.3 尽管 Person 已被冻结,但其内部对象属性(如_address )并不会被冻结,因此 person.address.country 可以随时改变。这是由于只有顶层变量会被冻结,也就是说,该机制是浅冻结
Address 类型的定义如下:
class Address {
constructor(country, state, city, zip, street) {
this._country = country;
this._state = state;
this._city = city;
this._zip = zip;
this._street = street;
}
get street() {
return this._street;
}
get city() {
return this._city;
}
get state() {
return this._state;
}
get zip() {
return this._zip;
}
get country() {
return this._country;
}
}
然而,以下代码并不会报错:
var person = new Person('Haskell', 'Curry', '444-44-4444');
person.address = new Address(
'US', 'NJ', 'Princeton',
zipCode('08544','1234'), 'Alexander St.');
person = Object.freeze(person);
person.address._country = 'France'; //-> allowed!
person.address.country; //-> 'France'
Object.freeze() 是一种浅操作。要解决该问题,需要手动冻结对象的嵌套结构,如清单2.2所示。
清单2.2 使用递归函数来深冻结对象
var isObject = (val) => val && typeof val === 'object';
function deepFreeze(obj) {
if(isObject(obj) <---遍历所有属性并递归调用Object.freeze()(使用第3章介绍的map)
&& !Object.isFrozen(obj)) { <---跳过已经冻结过的对象,冻结没有被冻结过的对象
Object.keys(obj). <---跳过所有的函数,即使从技术上说,函数也可以被修改,但是我们更希望注意在数据的属性上
forEach(name => deepFreeze(obj[name])); <---递归地自调用(第3章会介绍递归)
Object.freeze(obj); <---冻结根对象
}
return obj;
}
上述的一些技巧可以用来增强代码中的不可变性水平,但要创建一个永不改变任何状态的应用是不现实的。因此,在由原对象创建新对象(如coordinate.translate() )时,使用这些严格的策略能够有效降低JavaScript应用的复杂性。接下来,我们将讨论使用一种称为Lenses的函数式方法来不可变地集中管理对象的变化。
2.2.4 使用Lenses定位并修改对象图
面向对象编程通常是通过调用对象方法来更改对象的内部状态的。这种方式的缺点是无法保证检索状态的输出一致,并可能破坏部分的期望该对象保持不变的系统功能。你也可以选择自行实现写时复制 策略,在每次方法调用时返回一个新的对象。但至少可以说,这是一个烦琐且容易出错的过程。Person 类的简单setter方法会是这样的:
set lastname(lastname) {
return new Person(this._firstname, lastname, this._ssn); <---需要将对象中所有的属性状态复制到新的实例(太糟糕了)
};
现在想象一下,在领域模型中,每个类型的每个属性都要做同样的事。开发者需要一个能以不可变的方式修改拥有状态对象的解决方案,它应该既不唐突,也不需要到处都硬编码同样的样板代码。Lenses也被称为函数式引用 ,是函数式程序设计中用于访问和不可改变地操纵状态数据类型属性的解决方案。从本质上讲,Lenses 与写时复制策略的工作方式类似,即采用一个能够合理管理和赋值状态的内部存储部件。然而,开发者不需要自行实现,而是可以使用一个称为 Ramda.js 的函数式 JavaScript 库(附录中包含使用该库以及其他库的详细信息)。默认情况下,Ramda 使用全局对象 R 来公开所有的功能。可以使用 R.lensProp 来创建一个包装了Person 的 lastname 属性的 Lens:
var person = new Person('Alonzo', 'Church', '444-44-4444');
var lastnameLens = R.lenseProp('lastName');
可以使用R.view 来读取该属性的内容:
R.view(lastnameLens, person); //-> 'Church'
从实践角度看,它类似于一个 get_lastname() 方法。目前还没有什么令人印象深刻的东西。那么,如何实现setter 呢?这里就是其神奇魔力的所在。调用R.set 时,它创建并返回一个全新的对象副本,其中包含一个新的属性值,并保留原始实例状态(免费的写时复制!):
var newPerson = R.set(lastnameLens, 'Mourning', person);
newPerson.lastname; //-> 'Mourning'
person.lastname; //-> 'Church'
Lenses 之所以有价值,是因为其提供了一种不那么烦琐的操作对象的机制,即使是一些历史遗留对象或超出控制范围的对象。Lenses 还支持嵌套属性,如 Person 的 address 属性:
person.address = new Address(
'US', 'NJ', 'Princeton', zipCode('08544','1234'),
'Alexander St.');
创建一个包装了 address.zip 属性的 Lens:
var zipPath = ['address', 'zip'];
var zipLens = R.lens(R.path(zipPath), R.assocPath(zipPath)); <---定义getter和setter行为
R.view(zipLens, person); //-> zipCode('08544', '1234')
由于 Lenses 实现了不可变的 setter 方法,因此即便改变内嵌对象,仍然会返回一个新的 Person 对象:
var newPerson = R.set(zipLens, person, zipCode('90210', '5678'));
R.view(zipLens, newPerson); //-> zipCode('90210', '5678')
R.view(zipLens, person); //-> zipCode('08544', '1234')
newPerson !== person; //-> true
这是个不错的进展,现在已经有了函数式getter和setter的语义了。除了提供一种不可变的保护性的包装器之外,Lenses 也与函数式编程的分离对象与字段访问逻辑的哲学思想非常契合,即消除了对this 的依赖,并提供了很多能够操作对象内容的强大函数。
既然已经知道该如何合理地使用对象了,我将转变方式来谈谈函数这一主题。函数驱动着应用程序的变化部分,它是函数式编程的核心。
2.3 函数
函数是函数式编程的工作单元与中心。函数 是任何可调用且可通过() 操作求值的表达式。函数会向调用者返回一个经过计算的值或是 undefined (无值函数)。函数式程序的工作方式与数学很像,函数只有在返回一个有价值的结果 (而不是 null 或者 undefined )时才有意义。反之,它就会更改外部数据并产生副作用。为了达到学习目的,我们需要区分表达式 (如返回一个值的函数)和语句 (如不返回值的函数)。命令式编程和过程式程序大多是由一系列有序的语句组成的,而函数式编程完全依赖于表达式,因此无值函数在该范式下并没有意义。
JavaScript 函数有两个支柱性的重要特性:一等的和高阶的。我们接下来会详细探讨这两个特性。
2.3.1 一等函数
在JavaScript中,术语是一等的 ,指的在语言层面将函数视为真实的对象。或许读者经常看到如下的函数声明:
function multiplier(a,b) {
return a * b;
}
其实,JavaScript提供了更多的方式。就像对象一样,函数也可以:
- 作为匿名函数或lambda表达式给变量赋值(第3章将详细介绍lambda)。
var square = function (x) { <---匿名函数
return x * x;
}
var square = x => x * x; <--- lambda表达式
- 作为成员方法给对象的属性赋值。
var obj = {
method: function (x) { return x * x; }
};
由于需要使用() 运算符调用函数,如square(2) ,因此可以像如下代码一样打印出函数对象:
square;
// function (x) {
// return x * x;
// }
函数还可以通过构造函数来实例化,尽管这并不常见,但它能够证明其在JavaScript 中的一等性。构造函数以函数形参,函数体为参数,并需要使用new 关键字,如:
var multiplier = new Function('a', 'b', 'return a * b');
multiplier(2, 3); //-> 6
在 JavaScript 中,任何函数都是 Function 类型的一个实例。函数的 length 属性可以用来获取形参的数量,而像apply() 和call() 方法可以用来调用函数并加入上下文(更多相关知识将在下一节讨论)。
匿名函数表达式的右侧是一个具有空 name 属性的函数对象。可以通过将匿名函数作为参数的方式来扩展或者定制化当前函数的行为。JavaScript 原生的 Array.sort(comparator) 就需要一个函数对象作为比较器。默认情况下,sort 会将值转换为字符串,再利用其 Unicode 值进行自然排序。但这往往不是我们期望的行为。下面来看几个例子:
var fruit = ['Coconut', 'apples'];
fruit.sort(); //->['Coconut', 'apples'] <---大写字母的unicode编码会在小写字母之后
var ages = [1, 10, 21, 2];
ages.sort(); //->[1, 10, 2, 21] <---数组会被转换成字符串,并比较unicode编码
其实,sort() 通常需要一个预定义的comparator 函数来驱动其行为,其本身用处并不大。可以使用一个自定义函数参数来实现按名单人员年龄的数字大小排序:
people.sort((p1, p2) => p1.getAge() - p2.getAge());
该comparator 函数的两个参数p1 和p2 具有以下约束。
- 如果
comparator的返回值小于0,p1应在p2之前。 - 如果
comparator返回0,p1与p2的顺序不变。 - 如果
comparator的返回值大于0,p1应在p2之后。
像sort() 这样可以接收其他函数作为参数的JavaScript函数,均属于一种函数类型——高阶函数 。
2.3.2 高阶函数
鉴于函数的行为与普通对象类似,其理所当然地可以作为其他函数的参数进行传递,或是由其他函数返回。这些函数则称为高阶函数 。目前我们已经看到了 Array.sort() 的comparator函数,让我们再来快速浏览其他一些例子。
下面的代码片段显示函数是可以传入其他函数中的。其中的 applyOperation 函数可以将任意的opt 函数应用于前两个参数:
function applyOperation(a, b, opt) { <--- opt()函数可以作为参数传入其他函数中
return opt(a,b);
}
var multiplier = (a, b) => a * b;
applyOperation(2, 3, multiplier); // -> 6
在下面的例子中,add 函数接收一个参数,并返回另一个接收第二个参数并把它们加在一起的函数:
function add(a) {
return function (b) { <---一个返回其他函数的函数
return a + b;
}
}
add(3)(3); //-> 6
因为函数的一等性和高阶性,JavaScript 函数具有值的行为 ,也就是说,函数就是一个基于输入的且尚未求值的不可变的值。这一原则将贯穿整个函数式编程的学习,尤其体现在第3章将要介绍的函数链的内容中。函数链的建立基于一些指向不同代码片段的函数名,它们将作为整个表达式的各部分被执行。
通过组合一些小的高阶函数来创建有意义的表达式,可以简化很多烦琐的程序。例如,假设需要打印住在美国的人员名单。一开始的实现很可能是这样的命令式代码:
function printPeopleInTheUs(people) {
for (let i = 0; i < people.length; i++) {
var thisPerson = people[i];
if(thisPerson.address.country === 'US') {
console.log(thisPerson); <---隐式调用对象的toString方法
}
}
}
printPeopleInTheUs([p1, p2, p3]); <--- p1、p2和p3 是Person的实例
现在假设还需要支持打印生活在其他国家的人。通过高阶函数,我们可以很好地抽象出应用于每个人的操作,这里就是控制台的打印逻辑。可以给高阶函数 printPeople 提供任何 action 函数:
function printPeople(people, action) {
for (let i = 0; i < people.length; i++) {
action (people[i]);
}
}
var action = function (person) {
if(person.address.country === 'US') {
console.log(person);
}
}
printPeople(people,action);
JavaScript 语言中显著的命名模式之一是使用如 multiplier 、comparator 以及 action 这样的受事名词。这也是因为这些函数是一等的,可以给变量赋值,并在之后再执行。基于函数的高阶特性将 printPeople 重构一下:
function printPeople(people, selector, printer) {
people.forEach(function (person) { <--- forEach是函数式推荐的循环方式。本章之后的部分讨论这个话题
if(selector(person)) {
printer(person);
}
});
}
var inUs = person => person.address.country === 'US';
printPeople(people, inUs, console.log); <---通过使用高阶函数,开始呈现出声明式的模式。表达式清晰地描述了程序需要做的事情
它需要一个完全拥抱函数式编程的心态。而从上例可以看出,这段代码可以变得比一开始灵活得多,因为现在可以轻松地改变选择条件以及打印的方式。第3章和第4章将紧紧围绕这个主题,使用一些特殊的库将一些简单的操作流式地链接在一起,来构建复杂的程序。
展望未来
这里笔者想暂停一下对核心 JavaScript 内容的讨论,结合一些已经简单介绍过的概念,进一步地讨论本节的程序。尽管对于现在来说,这是有点高级的技巧,但是很快,读者就会了解如何通过这种方式使用函数式编程来构建程序。可以使用 Lens 来创建可以访问对象属性的函数:
var countryPath = ['address', 'country']; var countryL = R.lens(R.path(countryPath), R.assocPath(countryPath)); var inCountry = R.curry((country, person) => R.equals(R.view(countryL, person), country));这样的代码比之前的更加函数式了:
people.filter(inCountry('US')).map(console.log);如上述代码所示,国家名变成另一个可以是任意值的参数。这个值得期待的特性将在后续章节中介绍。
在JavaScript中,函数不仅能够被调用,还可以被应用。下面介绍JavaScript的函数调用机制这一特质。
2.3.3 函数调用的类型
JavaScript 的函数调用机制与其他语言的不同,是语言中一个十分有趣的部分。JavaScript 给予了我们完全的自由来指定调用函数的运行上下文,也就是函数体中 this 的值。因此,JavaScript 的函数可以使用许多不同的方式来调用。
- 作为全局函数 ——其中
this的引用可以是global对象或是undefined(在严格模式中):
function doWork() {
this.myVar = 'Some value'; <---在全局上下文调用doWork()会造成this引用到全局对象上
}
doWork(); <---在全局上下文调用doWork()会造成this引用到全局对象上
- 作为方法 ——其中
this的引用是方法的所有者。这是 JavaScript 的面向对象特性的重要部分:
var obj = {
prop: 'Some property',
getProp: function () {return this.prop} <---调用对象中的方法时,this指向该对象
};
obj.getProp(); <---调用对象中的方法时,this指向该对象
- 作为构造函数与 new 一起使用 ——这种方式会返回新创建对象的引用:
function MyType(arg) {
this.prop = arg; <---使用new关键字会把this引用到新创建的对象上
}
var someVal = new MyType('some argument'); <---使用new关键字会把this引用到新创建的对象上
正如从例子中看到的,不同于其他编程语言,this 的引用取决于函数式如何使用的(如全局的、或是作为对象方法、或是作为构造函数等),而不是取决于函数体中的代码。由于需要特别关注函数是如何被执行的,因此这会导致代码难于理解。
作为一个 JavaScript 开发,了解这些内容是非常重要的,但正如上文不断指出的,在函数式代码中很少会使用this (事实上,应不惜一切代价来避免使用它)。但在一些库和工具中,它被大量使用,以在一些特殊情形下改变语言环境来实现一些难以置信的功能。这些往往会涉及 apply 方法以及 call 方法。
2.3.4 函数方法
JavaScript 支持通过使用函数原型链上的函数方法(类似元函数)call 和 apply 来调用函数本身。两个函数方法都广泛应用于脚手架代码的构建中,这样 API 用户就可以通过现有的函数去创建新的函数。下面来看如何写一个 negate 函数:
function negate(func) { <---高阶函数negate接收一个函数作为输入,并返回取反其结果的函数
return function() {
return !func.apply(null, arguments); <---使用fun.apply()来使用原来的参数调用函数
};
}
function isNull(val) { <---定义isNull函数
return val === null;
}
var isNotNull = negate(isNull); <---定义isNull函数的反,即isNotNull函数
isNotNull(null); //-> false
isNotNull({}); //-> true
该 negate 函数创建了一个新的函数,它会调用其参数,再取结果的倒数。上例使用了 apply 方法,但也可以使用 call 函数。不同之处在于前者接收一个参数组成的数组,而后者接收参数列表。第一个参数 thisArg 可用于按需修改函数的上下文。它们的函数签名如下:
Function.prototype.apply(thisArg, [argsArray])
Function.prototype.call(thisArg, arg1,arg2,...)
如果 thisArg 是一个对象,它表示该函数将作为该对象的成员方法被调用。如果 thisArg 为 null ,则表示该函数的上下文为全局对象,该函数的行为就像一个全局函数。但是,如果该方法是严格模式下定义的函数,null 才是实际被传入的值。
通过 thisArg 修改函数上下文可以灵活地应用在许多不同的技术中。但函数式编程并不鼓励这样,因为它永远不会依赖于函数的上下文状态(前面讲过,所有的数据都应以参数的形式提供给函数),所以我们不再过多讨论该功能。
尽管全局共享以及对象上下文的概念在函数式JavaScript编程中没太大用处,但有一个特殊的上下文概念我们应当注意,即函数上下文。要了解它,必须先理解闭包和作用域。
2.4 闭包和作用域
在 JavaScript 出现之前,闭包只存在于函数式编程语言中,用于编写某些特殊的应用程序。JavaScript 是第一个在主流开发中应用闭包的语言,显著地改变了开发者编写代码的方式。再重温一下 zipCode 这个类型:
function zipCode(code, location) {
let _code = code;
let _location = location || '';
return {
code: function () {
return _code;
},
location: function () {
return _location;
},
...
};
}
如果仔细观察这段代码,就会发现,zipCode 函数返回的对象似乎能够完全访问其作用域之外声明的变量。也就是说,zipCode 执行完毕后,生成的对象仍然可以看到在这个封闭函数中声明的信息:
const princetonZip = zipCode('08544', '3345');
princetonZip.code(); //-> '08544'
这有点难以想象,都归功于在 JavaScript 中形成于对象和函数声明周围的闭包。能够这样访问数据具有很好的实用价值,我们在本节中将会看到如何使用闭包来模拟私有成员变量、如何从服务器获取数据以及创建块作用域变量。
闭包 是一种能够在函数声明过程中将环境信息与所属函数绑定在一起的数据结构。它是基于函数声明的文本位置的,因此也被称为围绕函数定义的静态作用域 或词法作用域 。闭包能够使函数访问其环境状态,使得代码更清晰可读。你很快就会看到,闭包不仅应用于函数式编程的高阶函数中,也可用于事件处理和回调、模拟私有成员变量,还能用于弥补一些 JavaScript 的不足。
支配函数闭包行为的规则与 JavaScript 的作用域规则密切相关。作用域能够将一组变量绑定,并定义变量定义的代码段。从本质上讲,闭包就是函数继承而来的作用域,这类似于对象方法是如何访问其继承的实例变量的,它们都具有其父类型的引用。在内嵌函数中能够很清楚地看到闭包,示例如下:
function makeAddFunction(amount) {
function add(number) { <--- add函数可以通过词法绑定访问到amount变量
return number + amount;
}
return add;
}
function makeExponentialFunction(base) {
function raise (exponent) { <--- raise()函数也可以通过词法绑定访问到base
return Math.pow(base, exponent);
}
return raise;
}
var addTenTo = makeAddFunction(10);
addTenTo(10); //-> 20
var raiseThreeTo = makeExponentialFunction(3);
raiseThreeTo(2); //-> 9
值得注意的是,尽管两个函数中的变量amount 和base 并不在返回函数的活动作用域中,但通过调用返回函数仍然可以访问它们。从本质上讲,可以想象内嵌函数add 和raise 在声明式中不仅包含其计算逻辑,也包含其周围所有变量的快照。更一般地,如图2.4所示,函数的闭包包括以下内容。

图2.4 闭包包含了在外部(全局)作用域中声明的变量、在父函数内部作用域中声明的变量、父函数的参数以及在函数声明之后声明的变量。函数体中的代码可以访问这些作用域中定义的变量和对象。而所有函数都共享全局作用域
- 函数的所有参数(在本例中是
params和params2)。 - 外部作用域的所有变量(当然也包括所有的全局变量),包括那些如
additional Vars这样在函数后声明的变量。
再看一个真实代码中闭包的例子,如清单2.3所示。
清单 2.3 真实代码中的闭包
var outerVar = 'Outer'; <---声明全局变量outerVar
function makeInner(params) {
var innerVar = 'Inner'; <---调用makeInner会得到inner函数
function inner() {
console.log( <---声明inner:innerVar和outerVar在inner闭包内
`I can see: ${outerVar}, ${innerVar}, and ${params}`);
}
return inner;
}
var inner = makeInner('Params'); <---声明局部变量makeInner
inner(); <---函数inner生命周期比外部函数还长
运行此代码会打印出如下输出:
'I can see: Outer, Inner, and Params'
乍看起来,这似乎并不直观,还有点神秘。这个局部变量 innerVar 应该不复存在,或者在 makeInner 返回后被垃圾回收,从而打印出 undefined 。其实,这正是闭包的神奇之处。从 makeInner 返回的函数会在其声明时记住其作用域内的所有变量,并防止它们被回收。由于全局作用域内也是闭包的一部分,因此返回的函数也能够访问 outerVar 。第7章将继续闭包以及函数上下文的内容的讨论。
或许读者想知道为什么函数声明之后声明的变量(如 additionalVars )也可以作为闭包的一部分。要回答这个问题,读者需要明白 JavaScript 的3种类型的作用域:全局作用域、函数作用域以及伪块作用域。
2.4.1 全局作用域
全局作用域是最简单的作用域,但也是最差的。任何对象和在脚本最外层声明的(不在任何函数中的)变量都是全局作用域 的一部分,并且可以被所有 JavaScript 代码访问。函数式编程的目的是为了防止任何可被观测的变化影响到函数之外的部分,然而在全局作用域内,每执行一行都会导致明显变化。
尽管使用全局变量很容易,但是它们会被所有加载到页面中的脚本所共享。如果 JavaScript 代码不是以模块打包的,那么这样很容易导致命名空间冲突。全局命名空间的污染会导致很多问题,很容易导致不同文件中定义的变量和函数被重写。
全局数据也会使得程序难以推理,因为你需要时刻谨记所有的变量。这也是为什么随着代码量的增加,程序越来越复杂的原因之一。全局数据也会引发副作用,因为在读取或写入时,会不可避免地形成外部依赖。由此显而易见,在函数式编程时,我们应该不惜一切代价地避免使用全局变量。
2.4.2 函数作用域
这是 JavaScript 主推的作用域机制。在函数中声明的任何变量都是局部且外部不可见的。同时,在函数返回后,其声明的任何局部变量都会被删除。所以,在函数中,变量 student 和 address 被绑定在 doWork() 中,无法被外界访问。如图2.5所示,变量名称解析与之前所述的原型名称解析链非常相似。它会首先检查最内层作用域,并逐渐向外。JavaScript 的作用域机制如下。
function doWork() {
let student = new Student(...);
let address = new Address(...);
// do more work
};

图2.5 JavaScript 的名称解析顺序,在最近的作用域查找到变量,并逐层向外扩展。
它首先检查函数(局部)作用域,然后移动到(倘若存在的)父作用域,最终移动至
全局作用域。如果无法找到变量x ,该函数将返回 undefined
① 首先检查变量的函数作用域。
② 如果不是在局部作用域内,那么逐层向外检查各词法作用域,搜索该变量的引用,直到全局作用域。
③ 如果无法找到变量引用,那么JavaScript将返回undefined 。
考虑下面的代码示例:
var x = 'Some value';
function parentFunction() {
function innerFunction() {
console.log(x);
}
return innerFunction;
}
var inner = parentFunction();
inner();
当 inner 被调用时,JavaScript 运行时会按照图2.5中所示的顺序进行查找 x 。
2.4.3 伪块作用域
如果读者有任何其他编程语言的开发经验,很可能已经适应了函数作用域。但由于 JavaScript 类似 C 的语法,读者很可能也期望块作用域会以类似的方式工作。
遗憾的是,标准 ES5 JavaScript 并不支持块级作用域,这些块包裹在括号{} 中,隶属于各种控制结构,如 for 、while 、if 和 switch 语句。唯一的例外是传递到 catch 块的错误变量。语句 with 与块作用域类似,但它已不被建议使用,并且在严格模式下被禁止。在类似C的其他语言中,在 if 语句中声明的变量(即本例中的 myVar ),
if (someCondition) {
var myVar = 10;
}
是无法从代码块外部访问的。因此,对于已经习惯该风格的 JavaScript 入门开发人员来说会比较困惑。因为拥有函数作用域的 JavaScript 语言能够在函数中的任何地方访问一个在代码块中声明的变量。尽管这可能是 JavaScript 开发人员的噩梦,但还是有办法来克服的。来看看下面的问题:
function doWork() {
if (!myVar) {
var myVar = 10;
}
console.log(myVar); //-> 10
}
doWork();
变量 myVar 是在 if 语句中声明的,但它是块外部可见的。奇怪的是,该代码运行后打印的结果是 10 。这很令人困惑,特别是对于那些用惯了块级作用域的开发者来说。JavaScript 有一个内部机制将所有声明的变量和函数提取至当前作用域的顶部,本例中是函数作用域。这会使得循环不再安全,注意清单2.4所示的例子。
清单 2.4 有歧义的循环计数器问题
var arr = [1, 2, 3, 4];
function processArr() {
function multipleBy10(val) {
i = 10;
return val * i;
}
for(var i = 0; i < arr.length; i++) {
arr[i] = multipleBy10(arr[i]);
}
return arr;
}
processArr(); //-> [10, 2, 3, 4]
该循环计数器 i 被移动到函数的顶部,并成为 multipleBy10 函数闭包的一部分。在 i 的声明中忘记使用关键字 var 导致在 multiplyBy10 的局部作用域创建了一个已经存在于作用域的变量,不慎将循环计数器修改为 10 。该循环计数器的声明被提取置顶,并被设置为 undefined ,之后在执行循环时被赋值为0 。在第8章中,你会在处理循环中的非阻塞操作中再次看到这种有歧义的代码问题。
良好的IDE和代码检查工具可以缓和这些问题,但当面对几百行代码时,即便是这些工具也爱莫能助。在下一章中,我们将会了解到一些更好的解决方案,它们更加优雅,比起标准的循环也更不易出错,能够充分地利用高阶函数来克服这些语言缺陷。正如本章所述的,JavaScript ES6 提供了 let 关键字通过将循环计数器与循环块绑定的方式来解决这个问题:
for(let i = 0; i < arr.length; i++) { <--- let关键字解决了置顶问题(hoisting problem),i被定义在正确的作用域中。循环外部为定义i
// ...
}
i; // i === undefined
这是一个进步,也是我为什么更推荐使用let 而不是var 来声明作用域变量的原因。然而,标准的代码循环还有一些其他缺点,我们将在下一章对此进行讨论。现在,既然你已经了解了函数闭包的组成以及其工作机制,让我们来看看一些闭包的实际应用。
2.4.4 闭包的实际应用
闭包在很多大型的 JavaScript 实际场景中都有十分重要的应用。尽管它们并不全是函数式编程项目,但都对 JavaScript 的以下函数作用机制充分加以利用。
- 模拟私有变量。
- 异步服务端调用。
- 创建人工块作用域变量。
1.模拟私有变量
与JavaScript不同,很多其他语言提供了一个内置的机制,通过设置访问修饰符(如 private )来定义对象的内部属性。JavaScript 并没有一个固有的关键字来限定在对象作用域中私有变量和函数的访问。这种封装特性有利于程序的不可变性,因为你无法修改不能访问的东西。
我们可以使用闭包来模仿这种行为。其中一个例子就是像之前的 zipCode 和 coordinate 函数一样返回一个对象。这些函数返回一个字面的对象,尽管其中包含了一些可访问任何外部函数局部变量的方法,但并不会公开这些变量,因此可以有效地使这些变量私有化。
闭包还可以用来管理的全局命名空间,以免在全局范围内共享数据。一些库和模块还会使用闭包来隐藏整个模块的私有方法和数据。这被称为模块模式 ,它采用了立即调用函数表达式(IIFE) ,在封装内部变量的同时,允许对外公开必要的功能集合,从而有效减少了全局引用。
注意
将所有的功能代码包裹在良好封装的模块之中是一个通用的最佳实践。你可以将在本书中学到的所有函数式编程核心原则用在模块之中。
以下是一个模块框架的简单示例[ 3] :
var MyModule = (function MyModule(export) { <---给IIFE一个名字,这样有用的信息更方便栈追踪
let _myPrivateVar = ...; <---无法从外部访问到这个私有变量,但对内部的两个方法可见
export.method1 = function () { <---需要暴露的方法,这里给予了伪命名空间
// do work
};
export.method2 = function () { <---需要暴露的方法,这里给予了伪命名空间
// do work
};
}(MyModule || {})); <---一个单例对象,用来私有的封装所有的状态和方法。可以通过MyModule.method1()调用到method1()
对象 MyModule 是在全局作用域创建的,之后被传递给一个用function 关键字创建的函数表达式中,并会在脚本加载时被立即执行。由于JavaScript的函数作用域,变量_myPrivateVar 和其他私有变量都是包裹函数的局部变量。围绕这两个公开方法的闭包使得返回的对象能够安全地访问模块中的所有内部属性。能够在暴露一个包含大量被封装的状态和行为的对象的同时,尽可能地减少对全局的污染,这种能力确实引人注目。该模块模式被应用于本书涉及的每一个函数式库之中。
2.异步服务端调用
JavaScript中的一等高阶函数可以作为回调函数传递到其他函数中。回调函数和钩子一样,能够非侵入式地处理各种事件。假设需要对服务器发起一次请求,并期望在数据被接收到时得到通知。常用的方式就是提供一个回调函数来处理服务器响应:
getJSON('/students',
(students) => {
getJSON('/students/grades',
grades => processGrades(grades), <---处理两个返回结果
error => console.log(error.message)); <---处理获取评分等级时发生的错误
},
(error) =>
console.log(error.message) <---处理获取学生时发生的错误
)
getJSON 是一个高阶函数,它接收两个回调作为参数——一个处理成功的函数和一个处理错误的功能。一种伴随异步事件处理代码的常见现象是,当需要进行多次远程请求的情况下,很容易落入多层嵌套的函数调用中,这些回调会形成糟糕的“回调厄运金字塔”。正如你可能经历过的,代码在嵌套过深时会变得难以理解。在第8章,你将学到一些最佳实践,通过使用更加流式和声明式的表达式,并将其连接在一起来到替代这种代码嵌套。
3.模拟块作用域变量
闭包为代码示例2.4中的循环计数器问题提供了一个替代解决方案。正如前面提到的,问题的根本是JavaScript缺乏块作用域的语义,因此需要人为地制造出块作用域。该怎么做呢?使用let 确实可以缓解许多传统的循环机制问题,然而使用一种基于forEach 的函数式方法则可以对闭包以及 JavaScript 的函数作用域加以利用。这样就无须考虑如何将循环计数器以及其他变量约束在作用域之中,而可以在循环体内包裹一个函数作用域来模拟块作用域。后面还会看到,这可以帮助在遍历集合时进行异步调用:
arr.forEach(function(elem, i) {
...
});
本章所涵盖的仅仅是JavaScript的基础知识,来帮助读者了解它的一些局限性,为后续深入了解函数式技术做好准备。如果想更加深入地了解语言,读者应参考一本深刻讲解对象、继承以及闭包等概念的书籍。
想要成为一个 JavaScript 忍者吗?
本章涉及对象、函数、作用域以及闭包等主题,这对成为一名 JavaScript 专家至关重要。但本章仅仅介绍了一些皮毛,因为这可以使读者可以更加专注于函数式编程。如果想要获得更多的信息,精进JavaScript技能水平,建议您阅读John Resig*、* Bear Bibeault 以及 Josip Maras所著的《JavaScript 忍者秘籍》(第2版)(2016,www.manning.com/books/secrets-of-the- javascript-ninja-second-edition,中文版由人民邮电出版社于2018年2月出版,ISBN978-7- 115-47326-4,定价69元)。
现在读者已经有了坚实的JavaScript基础,在下一章中,我们将看看如何使用如map 、reduce 以及filter 等操作以及递归的方法来进行数据处理。
2.5 总结
- JavaScript 是一种用途广泛的、具有强大面向对象和函数式编程特性的语言。
- 使用不可变的实现方式可以使函数式与面向对象编程很好地结合在一起。
- 一等高阶的函数使得 JavaScript 成了函数式编程的中坚力量。
- 闭包具有很多实际用途,如信息隐藏、模块化开发,并能够将参数化的行为跨数据类型地应用于粗粒度的函数之上。
[1] 该引用更适用于面向对象的实践者而不是语言范式本身。包括Gang of Four在内的许多该领域的专家,都更倾向于使用对象组合而不是基于里氏替换原则的类型继承。
[2] 尽管该对象的内部状态得到了保护,但其行为仍然可变,因为可以动态地删除或替换它的任何方法。
[3] 对于模块模式的不同种类的更进一步的说明,请参阅Ben Cherry在Adequately Good 中发表的文章:《JavaScript Module Pattern: In-Depth》,2010年3月12日,http://mng.bz/H9hk。
第二部分 函数式基础
第一部分回答了本书的两个最根本的问题:为什么要选择函数式以及为什么要选择JavaScript。既然明白了函数式编程给 JavaScript 开发带来的好处,我们会继续深入讲解。第二部分将探讨一些实用概念,应用函数式编程来解决现实问题。在这一部分中,读者会了解到“函数式”的意义。
第 3 章通过让读者了解通用函数式程序中如 map、 reduce 和 filter 这样的命令式抽象函数,来学习如何创建易于推断的代码。本章还涵盖了函数式风格中用于数据迭代的重要手段,即递归的使用。
第 4 章将着眼于第 3 章中的概念应用,学习如何采用 Pointfree 风格基于流式的函数构建来简化软件开发。读者将了解到,将复杂任务拆分为独立的、粒度较小的组件是构建函数式代码的核心。而这些组件最终会通过函数式中的组合原则拼接在一起,形成最终的模块化可重用的解决方案。
第 5章将介绍如何应用一些基本的设计模式来克服程序复杂性的增加以及错误处理等问题。一些抽象数据类型,如 Functor 和 Monad,可以提供一个在异常条件下可容错的弹性抽象层,使用它们可以使函数的组合更加稳定可靠。
第二部分中的技术会完全改变读者编写 JavaScript 代码的方式,同时也为在第三部分中使用函数式技术解决如异步数据以及事件这样的复杂 JavaScript 问题打下基础。
第3章 轻数据结构,重操作
本章内容
- 理解程序的控制流
- 更易理解的代码与数据
- 命令抽象函数map、reduce 以及filter
- Lodash.js 及函数链
- 递归的思考
计算过程是计算机中的一种抽象存在,在其演化的过程中,这些过程会去控制另一种被称为数据的抽象存在。
——Harold Abelson,Gerald Jay Sussman(《Structure and Interpretation
of Computer Programs, MIT Press, 1979年》
本书第一部分完成了两个重要目标:一方面,其中的章节教读者如何用函数式思考,同时介绍了一些函数式编程中需要用到的工具;另一方面,让读者了解了许多核心的 JavaScript 特性,尤其是高阶函数——它们都会在本章和本书的其余部分频繁用到。现在,读者应该已经了解到如何使函数变得更纯,是该学习如何连接它们的时候了。
本章将介绍一些使用的操作,如map 、reduce 以及filter ,它们能够连续地遍历并变换各种数据结构。这些操作十分重要,几乎所有的函数式程序都会以各种方式来使用它们。它们也用于去除代码中的循环——大多数循环都是可由这些函数处理的一些具体案例。
读者还将在本章学习JavaScript 函数库 Lodash.js。它不但能够处理应用程序的结构,还能够处理各种数据结构。此外,本章还将讨论在函数式编程中具有重要作用的递归,以及用递归思考的优势。基于这些概念,你将能够编写出简洁的、可扩展的、声明式的程序代码,并能够使代码中的主逻辑与控制流清晰地分离。
3.1 理解程序的控制流
程序为实现业务目标所要行进的路径被称为控制流。命令式程序需要通过暴露所有的必要步骤才能极其详细地描述其控制流。这些步骤通常涉及大量的循环和分支,以及随语句执行变化的各种变量。简单的命令式程序大致可以这样描述:
var loop = optC();
while(loop) {
var condition = optA();
if(condition) {
optB1();
}
else {
optB2();
}
loop = optC();
}
optD();
图3.1显示了上述程序的简单流程图。
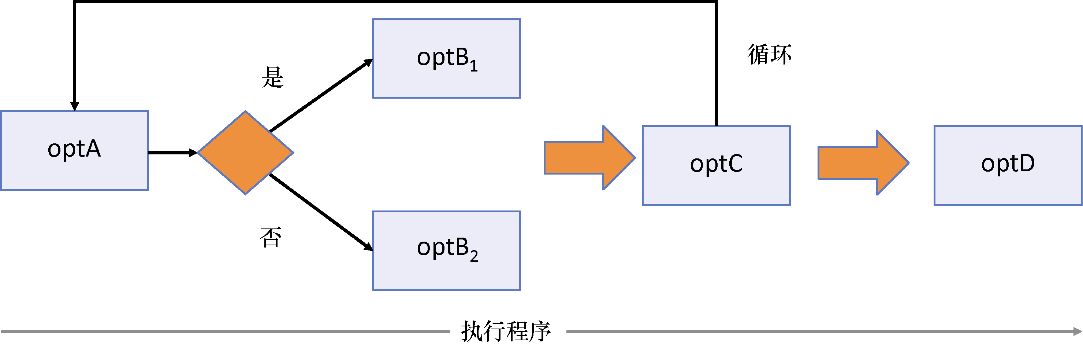
图3.1 通过分支和循环控制操作(或语句)组成的命令式程序
然而,声明式程序,特别是函数式程序,则多使用以简单拓扑连接的独立黑盒操作组合而成的较小结构化控制流,从而提升程序的抽象层次。这些连接在一起的操作只是一些能够将状态传递至下一个操作的高阶函数,如图3.2所示。使用函数式开发风格操作数据结构,其实就是将数据与控制流视为一些高级组件的简单连接。

图3.2 连接黑盒操作的函数式控制流程。信息在一个操作与下一个(独立的纯函数)操作 之间独立地流动。高阶抽象使得分支和迭代明显减少或甚至被消除
使用这种方式可以形成类似这样的代码:
optA().optB().optC().optD(); <--- 这样用点连接表示有共同的对象上定义过这些方法
采用这种链式操作能够使程序简洁、流畅并富有表现力,能够从计算逻辑中很好地分离控制流,因此可以使得代码和数据更易推理。
3.2 链接方法
方法链 是一种能够在一个语句中调用多个方法的面向对象编程模式。当这些方法属于同一个对象时,方法链又称为方法级联 。尽管该模式大多出现在面向对象的应用程序中,但在一些特定条件下,如操作不可变对象时,也能很好地用于函数式编程中。既然在函数式代码中是禁止修改对象的,又如何能使用这种方法链模式呢?让我们来看一个字符串处理的例子:
'Functional Programming'.substring(0, 10).toLowerCase() + ' is fun';
在该例中,substring 和 toLowerCase 都是(通过 this )在隶属的字符串对象上操作并返回一个新字符串的方法。JavaScript 中字符串的加号(+ )运算符被重载为连接字符串操作的语法糖,它也会返回一个新的字符串。通过一系列变换后的结果与原先字符串毫无引用关系,而原先的字符串也不会有任何变化。这种行为是理所当然的,因为按照设计,字符串是不可变的。从面向对象的角度来看,这没有什么特别的。但从函数式编程的角度来看,这是一种理想行为,因为不需要使用 Lenses 来进行字符串变换了。
如果用更加函数式的风格重构上面的代码,它会像这样:
concat(toLowerCase(substring('Functional Programming', 1, 10))),' is fun');
这段代码符合函数式风格,所有参数都应在函数声明中明确定义,而且它没有副作用,也不会修改的原有对象。但可以说,这样的代码写起来并没有方法链流畅。而且它也更难阅读,因为需要一层层地剥离外部函数,才能知晓内部真正发生的事情。
只要遵守不可变的编程原则,函数式中也会应用这种隶属于单个对象实例的方法链。能用该模式来处理数组变换吗?其实 JavaScript 也将这种字符串的行为推广到数组上了,大多数人之所以还在用for 循环作为权宜之计,是因为他们并不了解这些特性。
3.3 函数链
面向对象程序将继承作为代码重用的主要机制。回忆之前章节中,Student 类继承了父类 Person 的所有状态和方法。读者也许在一些纯面向对象的语言中更多见到的是这种模式,特别是在数据结构的实现代码中。例如在 Java 中,有一大堆继承于基础接口 List 的各种实体List 类,如ArrayList 、LinkedList 、DoublyLinkedList 、CopyOnWrite ArrayList 等,它们都源自共同的父类,并各自添加了一些特定的功能。
函数式编程则采用了不同的方式。它不是通过创建一个全新的数据结构类型来满足特定的需求,而是使用如数组这样的普通类型,并施加在一套粗粒度的高阶操作之上,这些操作是底层数据形态所不可见的。这些操作会作如下设计。
- 接收函数作为参数,以便能够注入解决特定任务的特定行为。
- 代替充斥着临时变量与副作用的传统循环结构,从而减少所要维护以及可能出错的代码。
让我们仔细研究一下。本章中的示例都是基于一个 Person 对象的集合。为了方便起见,我们只声明四个对象,但相同的概念同样适用于较大的集合:
const p1 = new Person('Haskell', 'Curry', '111-11-1111');
p1.address = new Address('US');
p1.birthYear = 1900;
const p2 = new Person('Barkley', 'Rosser', '222-22-2222');
p2.address = new Address('Greece');
p2.birthYear = 1907;
const p3 = new Person('John', 'von Neumann', '333-33-3333');
p3.address = new Address('Hungary');
p3.birthYear = 1903;
const p4 = new Person('Alonzo', 'Church', '444-44-4444');
p4.address = new Address('US');
p4.birthYear = 1903;
3.3.1 了解lambda表达式
lambda表达式 (在JavaScript中也被称为箭头函数 )源自函数式编程,比起传统的函数声明,它可以采用相对简洁的语法形式来声明一个匿名函数。尽管 lambda 函数也可以写成多行形式,但就像在第2章中见到的,单行是最普遍的形式。使用 lambda 表达式或普通函数声明语法一般只会影响到代码的可读性,其本质是一样的。下面是一个可用于提取个人姓名的示例函数:
const name = p => p.fullname;
console.log(name(p1)); //-> 'Haskell Curry'
(P) => p.fullname 这种简洁的语法糖表明它只接收一个参数p 并隐式地返回p.fullname 。图3.3显示了这种新语法的结构。
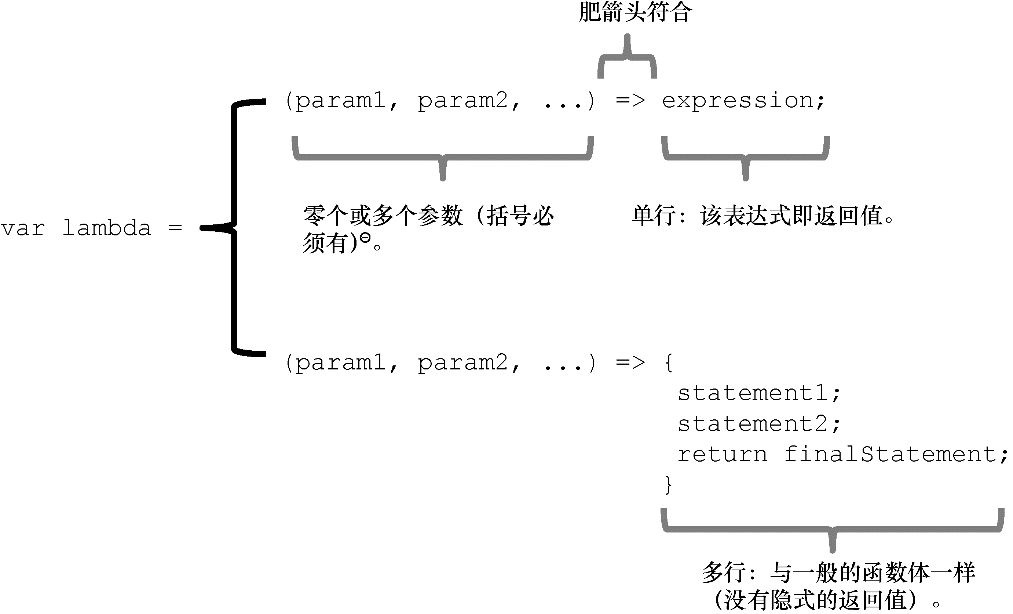
图3.3 箭头函数的结构。lambda函数的右侧可以是一个表达式或是一个封闭的多个语句块[ 1]
lambda表达式适用于函数式的函数定义,因为它总是需要返回一个值。对于单行表达式,其返回值就是函数体的值。另一个值得注意的是一等函数与lambda表达式之间的关系。函数名代表的不是一个具体的值,而是一种(惰性计算的)可获取其值的描述。换句话说,函数名指向的是代表着如何计算该数据的箭头函数。这就是在函数式编程中可以将函数作为数值使用的原因。我们将在本章进一步讨论它,并在第7章讨论惰性计算函数。
此外,函数式编程中鼓励使用的map 、reduce 以及 filter 等核心高阶函数都能够与 lambda 表达式良好地配合使用。很多函数式的 JavaScript 代码都需要处理数据列表,这也就是衍生 JavaScript 的函数式语言鼻祖起名为 LISP(列表处理)的原因。JavaScript 5.1 本身就提供特定版本的该类操作——称为函数式array extras 。但为了能够联合其他相似操作以提供完整的解决方案,本书会选择使用 Lodash.js 函数式库中提供的此类操作。它的工具包包含丰富的能够处理常见编程任务的基础函数(安装方法见附录),因此非常利于编写函数式程序。安装之后,就可以通过全局的 _ (下画线符号)对象来访问其功能。下面先来介绍 _.map 。
Lodash 中的下画线
Lodash 之所以使用下画线约定,是因为它是从著名且广泛使用的 Undesrscore.js 项目中衍生而来(http://underscorejs.org/)。为了能够直接替换 Underscore,Lodash 仍然保持与其一致的 API。但从本质上讲,为了能够以更为优雅的方式构建函数链,本书将完全重写lodash,这也伴随着一些性能的提升(我们将在第7章深入了解)。
3.3.2 用_.map做数据变换
假设需要对一个较大数据集合中的所有元素进行变换,例如,从一个学生对象的列表中提取每个人的全名。你曾经有多少次不得不写出这样的语句?
var result = [];
var persons = [p1, p2, p3, p4];
for(let i = 0; i < persons.length; i++) {
var p = persons[i];
if(p !== null && p !== undefined) {
result.push(p.fullname); <--- 命令式的方案会假设fullname是Student的方法
}
}
高阶函数 map (也称为collect )能够将一个迭代函数有序地应用于一个数组中的每个元素,并返回一个长度相等的新数组。以下是使用_.map 的函数式风格版本:
_.map(persons,
s => (s !== null && s !== undefined) ? s.fullname : '' <--- 通过高阶函数去掉了所有var声明
);
该操作的标准定义如下:
map(f, [e0, e1, e2...]) -> [r0, r1, r2...]; 其中, f(en) = rn
如果整个集合元素需要进行变换,map 函数是极其有用的——再也不必编写循环,并处理奇怪的作用域问题了。此外,由于其是不可变的,因此输出是一个全新的数组。map 需要以一个函数f 以及拥有*n*个元素的集合作为输入,由左到右对每个元素应用函数f 后,返回一个长度为*n*的新数组。该行为如图3.4所示。
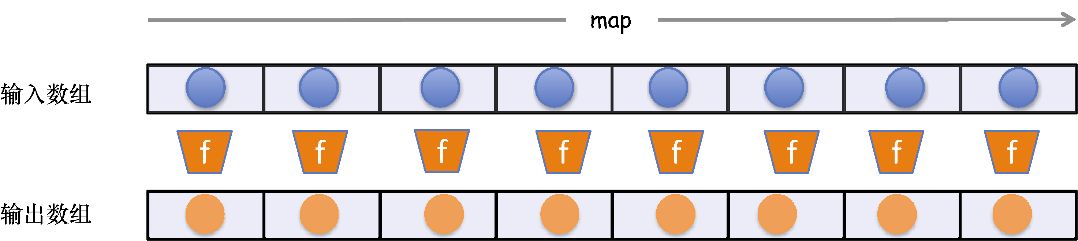
图3.4 操作 map 对数组的每个元素应用迭代函数 f ,并返回一个等长的数组
在 _.map 的例子中,我们遍历了学生的对象数组并提取出他们的名字。可以用 lambda 表达式作为迭代函数(这是通常的做法)。原有的数组不会被改变,而新返回的数组包含以下元素:
['Haskell Curry', 'Barkley Rosser', 'John von Neumann', 'Alonzo Church']
理解抽象层次背后的事情永远是有好处的,下面来看 map 是如何实现的(见清单3.1)。
清单3.1 Map的实现
function map(arr, fn) { <--- 接收一个函数和一个数组,应用函数到数组中的每一个元素,然后返回同样大小的新数组
let idx = 0,
len = arr.length,
result = new Array(len); <--- 结果:一个与输入数组同样长度的数组
while (++idx < len) {
result[index] = fn(array[idx], idx, arr); <--- 应用函数fn到数组中的每一个元素,再把结果放入数组
}
return result;
}
如上所示,_.map 也是基于标准循环的。该函数已经处理了迭代的逻辑,因此无须为一些如循环变量或边界检查这样的琐事而操心,只需关注在迭代函数中功能逻辑的合理性即可。这个例子展示了函数式库如何辅助开发者写出纯函数式的代码。
map 是一个只会从左到右遍历的操作,对于从右到左的遍历,必须先反转数组。JavaScript 中的 Array.reverse() 操作是不能在这里使用的,因为它会改变原数组。可以将Lodash中功能等价的 reverse 操作与 map 连接起来写成一行:
_(persons).reverse().map(
p => (p !== null && p !== undefined) ? p.fullname : ''
);
请注意该例子中语法的细小区别。Lodash 提供了一种不错的非侵入式的方式来与代码继承。开发者所需要做的就是用符号_(...) 将要操作的对象包起来,这样就拥有了其强大功能的完全控制,可以实现任何想要的变换。
容器的映射
将数据结构(即例子中的数组)映射为转换后的值,这个理念具有更加深远的意义。正如可以用任意函数映射一个数组,也可以用函数映射一个对象(见第5章)。
现在可以在数据上应用一个变换函数了。如果能够基于新的结构得出某个结果就更好了。这就是 reduce 函数要做的事了。
3.3.3 用_.reduce 收集结果
转换数据之后,如何从中收集具有意义的结果呢?假设要从一个 Person 对象集合中计算出人数最多的国家,就可以使用 reduce 函数来实现。
高阶函数reduce 将一个数组中的元素精简为单一的值。该值是由每个元素与一个累积值通过一个函数计算得出的,如图3.5所示。

图3.5 将数组 reduce 为单一值。每次迭代都会计算出基于先前结果的累积值,
直至到达数组的末尾。reduce 的最终结果始终是单一值
图3.5可以更正式地表示为以下描述:
reduce(f,[e0, e1, e2, e3],accum) -> f(f(f(f(acc, e0), e1, e2, e3)))) -> R
现在来看一个 reduce 函数的简单实现,如清单3.2所示。
清单3.2 reduce 的实现
function reduce(arr, fn,[accumulator]) {
let idx = -1,
len = arr.length;
if (!accumulator && len > 0) { <--- 如果不提供累加值,就会用第一个元素作为累加值
accumulator = arr[++idx];
}
while (++idx < len) {
accumulator = fn(accumulator, <--- 应用fn到每一个元素,将结果放到累加值中
arr[idx], idx, arr);
}
return accumulator; <--- 返回累加值
}
reduce 需要接收以下参数。
fn——迭代函数会应用于数组的每个元素,其参数包含累积值、当前值、当前索引以及数组本身。- 累加器——累积初始值,之后会用于存储每次迭代函数的计算结果,并不断被传入子函数中。
下面写一个简单的程序来收集一个 Person 对象数组的一些统计数据。假设要找住在某个特定国家的人数,如清单3.3所示。
清单3.3 国家人数计算
_(persons).reduce(function (stat, person) {
const country = person.address.country; <--- 抽取国家信息
stat[country] = _.isUndefined(stat[country]) ? 1 : <--- 记录人数, 初始为 1,每当找到同样国家的同学则加 1
stat[country] + 1;
return stat; <--- 返回累加值
}, {}); <--- 以空对象作为初始累加器
这段代码能够将输入的数组转换为表征各国人数的单一对象:
{
'US' : 2,
'Greece' : 1,
'Hungary': 1
}
为进一步简化,可以使用普适的 map-reduce 组合。通过链接这些函数,并提供具有特定行为的函数参数,就可以提高 map 和 reduce 函数的威力。抽象地讲,该程序流将具有如下结构:
_(persons).map(func1).reduce(func2);
其中,func1 和func2 用于实现所需的特定行为。清单3.4展示了将业务函数与控制流分离的方法。
清单3.4 结合map 与reduce 进行统计计算
const getCountry = person => person.address.country;
const gatherStats = function (stat, criteria) {
stat[criteria] = _.isUndefined(stat[criteria]) ? 1 :
stat[criteria] + 1;
return stat;
};
_(persons).map(getCountry).reduce(gatherStats, {});
清单 3.4 中使用 map 将对象数组进行预处理,提取出所有国家信息。之后,再使用 reduce 来收集最终的结果。这段代码与清单 3.3具有完全相同的输出,但更加清晰并更具可扩展性。与其直接去访问对象属性,不如考虑(使用Ramda)提供的lens来访问 address.city 属性:
const cityPath = ['address','city'];
const cityLens = R.lens(R.path(cityPath), R.assocPath(cityPath));
这样就能够很容易地基于人们所处的城市计算出结果:
_(persons).map(R.view(cityLens)).reduce(gatherStats, {});
此外,还可以使用 _.groupBy 函数以一种更加简洁的方式来获得同样的结果:
_.groupBy(persons, R.view(cityLens));
与 map 不同,由于 reduce 依赖于累积的结果,如果不使用满足交换率的操作,从左到右与从右到左的计算可能产生不同的结果。为了说明这一点,考虑一个数组求和的简单程序:
_([0,1,3,4,5]).reduce(_.add); //-> 13
使用反向的操作 _.reduceRight 函数也能够获得同样的结果。这是因为加法是一种满足交换律的运算,反之则有可能产生完全不同的结果,比如采用除法运算。如果使用之前的符号描述,_.reduceRight 可以作如下表示:
reduceRight(f, [e0, e1, e2],accum) -> f(e0, f(e1, f(e2, f(e3,accum)))) -> R
举例来说,以下两个使用 _.divide 的程序将计算出完全不同的结果:
([1,3,4,5]).reduce(_.divide) !== ([1,3,4,5]).reduceRight(_.divide);
此外,reduce 是一个会应用到所有元素的操作,这意味着没有办法将其“短路”来避免其应用于整个数组。假设需要对一组输入值进行校验,也许你会想用 reduce 将其转换为一个布尔值来表示所有参数是否合法。但是,使用 reduce 会比较低效,因为它会访问列表中的每一个值。其实,一旦找到了一个无效的输入,就不必继续校验剩下的值了。让我们看看如何使用 _.some 以及其他如 _.isUndefined 和_.isNull 这样的有趣函数来进行更高效的验证。当要应用于列表中的每个元素时,_.some 函数能够在找到第一个真值(true )后立即返回:
const isNotValid = val => _.isUndefined(val) || _.isNull(val); <--- undefined 与 null 时为不合法
const notAllValid = args => (_(args).some(isNotValid)); <--- 函数 some 会在遍历到第一个 true 时返回, 这在寻找数组中是否存在合法值时非常有用
validate (['string', 0, null, undefined]) //-> false
validate (['string', 0, {}]) //-> true
还可以使用与非全真的逻辑非(也就是全真)函数 _.every ,无论对单个元素返回 true 与否,都会检查所有元素。
const isValid = val => !_.isUndefined(val) && !_.isNull(val);
const allValid = args => _(args).every(isValid);
allValid(['string', 0, null]); //-> false
allValid(['string', 0, {}]); //-> true
正如前面所看到的,无论是 map 还是 reduce 都会遍历整个数组。通常并不想处理数据结构中的所有元素,而是期望跳过任何为 null 或 undefined 的值。要是在计算之前有一个能够去除或过滤掉列表中某些元素的方法就更好了。下面介绍_.filter 函数。
3.3.4 用_.filter 删除不需要的元素
在处理较大的数据集合时,往往需要删除部分不能参与计算的元素。例如,需要计算只生活在欧洲国家的人或是出生在某一年的人。与其在代码中到处用 if-else 语句,不如用 _.filter 来实现。
filter (也称为select )是一个能够遍历数组中的元素并返回一个新子集数组的高阶函数,其中的元素由谓词函数 p 计算得出的 true 值结果来确定。正式的符号描述如图3.6所示。
filter(p, [d0, d1, d2, d3...dn]) -> [d0,d1,...dn] (输入的子集)
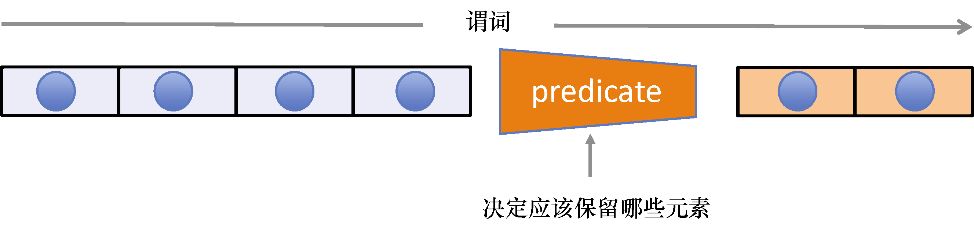
图3.6 filter 操作以一个数组为输入,并施加一个选择条件 p ,从而产生一个可能较
原数组更小的子集。条件p 也称为函数谓词
一种 filter 的实现如清单3.5所示。
清单3.5 filter 的实现
function filter(arr, predicate) {
let idx = -1,
len = arr.length,
result = []; <--- 结果数组为原数组的子集
while (++idx < len) {
let value = arr[idx];
if (predicate(value, idx, this)) { <--- 调用谓词函数,如果结果为真,则保留,否则略过
result.push(value);
}
}
return result;
}
除了需要提供数组外,filter 需要接收一个可用于测试数组中每个元素的 predicate 谓词函数。如果谓词为 true ,则将该元素保留在结果中,否则略过。这就是为什么通常会用 filter 从数组中删除无效数据:
_(persons).filter(isValid).map(fullname);
但它的应用不止如此。假设需要从 Person 对象集合中提取生于1903年的人,那么用_.filter 要比使用条件语句更简单明了:
const bornIn1903 = person => person.birthYear === 1903;
_(persons).filter(bornIn1903).map(fullname).join(' and ');
//-> 'Alonzo Church and Haskell Curry'
数组推导式
map和filter都是能够根据当前数组生成新数组的高阶函数。很多如 Haskell 和 Clojure 等函数式语言中都能看到它们的身影。组合map和filter的另一种方法是使用数组推导式 ——也被称为列表推导式 。这是一种使用关键字for…of和if的简明语法并能够将map和filter的功能封装在一起的函数式特性:[for (x of iterable) if (condition) x]在撰写本文时,ECMAScript 7 中存在一个增加数组推导式的提议。它能用简洁的表达式来组装新数组(这也就是为什么整个表达式被包裹在
[]中)。例如,之前的代码可以如下重构:[for (p of people) if (p.birthYear === 1903) p.fullname] .join(' and ');
这些技术的应用都基于这些具有扩展性和强大功能的函数,它们不仅有助开发者写出干净的代码,还能够提高开发者对数据的理解。使用声明式的编程风格,开发者可以专注于应用程序的输出,而不是其实现,从而更深地理解应用程序。
3.4 代码推理
回想一下,在JavaScript中,共享着一个全局命名空间的成千上万行代码被一次性加载到单个页面中。尽管最近业务逻辑的模块划分领域得到了越来越多的重视,但仍有数以千计生成中的项目没有这么做。
那么“代码推理”到底是什么意思呢?之前的章节用“松散”这个词来表征分析一个程序任何一个部分,并建立相应心智模型的难易程度。该模型分为两部分:动态部分包括所有变量的状态和函数的输出,而静态部分包含可读性以及设计的表达水平。两个部分都很重要。读者将在本书中了解到,不可变性和纯函数会使得该模型的构建更加容易。
之前的内容强调将高阶操作链接起来构成程序的价值。命令式的程序流与函数式的程序流有着本质的不同。函数式的控制流能够在不需要研究任何内部细节的条件下提供该程序意图的清晰结构,这样就能更深刻地了解代码,并获知数据在不同阶段是如何流入和流出的。
3.4.1 声明式惰性计算函数链
第1章中提到,函数式程序是由一些简单函数组成的,尽管每个函数只完成一小部分功能,但组合在一起就能够解决很多复杂的任务。本节将介绍一种能够连接一组函数来构建整个程序的方法。
函数式编程的声明式模型将程序视为对一些独立的纯函数的求值,从而在必要的抽象层次之上构建出流畅且表达清晰的代码。这样就可以构成一个能够清晰表达应用程序意图的本体或词汇表。使用如 map 、reduce 和 filter 这样的基石来搭建纯函数,可使代码易于推理并一目了然。
这个层次的抽象的强大之处在于,它会使开发者开始认识到各种操作应该对所采用的底层数据结构不可见。从理论上说,无论是使用数组、链表、二叉树还是其他数据结构,它都不应该改变程序原本的语义。正是出于这个原因,函数式编程选择更关注于操作而不是数据结构。
例如,假设需要对一组姓名进行读取、规范化、去重,最终进行排序。首先写一个命令式的版本,然后再重构成函数式的风格。
这个格式不一致的姓名字符串数组可以表示为:
var names = ['alonzo church', 'Haskell curry', 'stephen_kleene',
'John Von Neumann', 'stephen_kleene'];
其命令式的程序如清单3.6所示。
清单3.6 对数组进行一系列操作(命令式风格)
var result = [];
for (let i = 0; i < names.length; i++) { <--- 遍历数组中的所有名字
var n = names[i];
if (n !== undefined && n !== null) { <--- 检查所有词是否都合法
var ns = n.replace(/_/, ' ').split(' '); <--- 数组包含格式不一致的数据。这是规范化(修复)元素的步骤
for(let j = 0; j < ns.length; j++) {
var p = ns[j];
p = p.charAt(0).toUpperCase() + p.slice(1);
ns[j] = p;
}
if (result.indexOf(ns.join(' ')) < 0) { <--- 检查是否已存在于结果中,以去除重复的元素
result.push(ns.join(' '));
}
}
}
result.sort(); <--- 数组排序
这段代码能够产生所需的输出:
['Alonzo Church', 'Haskell Curry', 'Jon Von Neumann', 'Stephen Kleene']
命令式代码的缺点是限定于高效地解决某个特定的问题。例如,清单 3.6 只能用于解决上述的问题。因此,比起函数式代码,其抽象水平要低得多。抽象层次越低,代码重用的概率就会越低,出现错误的复杂性和可能性就会越大。
此外,函数式的实现不过是将各种黑盒组件连接在一起,将重任赋予如清单3.7列出的这些成熟且经过测试的API。请注意,级联排列的函数调用可以使该代码更易阅读。
清单3.7 数组的(函数式)序列操作
_.chain(names) <--- 初始化函数链(该话题会马上涉及)
.filter(isValid) <--- 去除非法值
.map(s => s.replace(/_/, ' ')) <--- 规范化值
.uniq() <--- 去掉重复元素
.map(_.startCase) <--- 大写首字母
.sort()
.value();
//-> ['Alonzo Church', 'Haskell Curry', 'Jon Von Neumann', 'Stephen Kleene']
_.filter 和 _.map 函数承担了在 names 数组中迭代出有效索引的责任。开发者唯一的工作就是在剩下的步骤中给出指定的行为。先使用 _.uniq 函数去掉重复的条目,再用 _.startCase 函数大写所有的单词,最后对结果进行排序。
读者是不是也更期望阅读和编写像清单3.7这样的程序呢?不仅是因为代码量的减少,还因为其结构简单明了。
下面继续探索 Lodash。重拾清单3.4,它从一个 Person 对象数组中计算所有国家的计数。为了本例的目的,增加了一个 gatherStats 函数:
const gatherStats = function (stat, country) {
if(!isValid(stat[country])) {
stat[country] = {'name': country, 'count': 0};
}
stat[country].count++;
return stat;
};
现在返回一个具有以下结构的对象:
{
'US' : {'name': 'US', count: 2},
'Greece' : {'name': 'Greece', count: 1},
'Hungary' : {'name': 'Hungary', count: 1}
}
采用这种结构保证了每个国家拥有唯一的条目。为了再让它变得有趣一些,下面再给本章一开始给出的 Person 数组注入一些数据:
const p5 = new Person('David', 'Hilbert', '555-55-5555');
p5.address = new Address('Germany');
p5.birthYear = 1903;
const p6 = new Person('Alan', 'Turing', '666-66-6666');
p6.address = new Address('England');
p6.birthYear = 1912;
const p7 = new Person('Stephen', 'Kleene', '777-77-7777');
p7.address = new Address('US');
p7.birthYear = 1909;
接下来的任务是建立一个程序,返回该数据集中人数最多的国家。通过使用 _.chain() 和一些其他组件,再次将这些函数连接起来,如清单3.8所示。
清单3.8 Lodash惰性计算函数链
_.chain(persons) <--- 创建惰性计算函数链来处理给定的数组
.filter(isValid)
.map(_.property('address.country')) <--- 使用 _.property 抽取 person 对象的address.country 属性。这是 Ramda 的R.view() 的 Lodash 对应版本,虽然Lodash 的版本没有那么功能丰富
.reduce(gatherStats, {})
.values()
.sortBy('count')
.reverse()
.first()
.value() <--- 执行函数链中的所有函数
.name; //-> 'US'
_.chain 函数可以添加一个输入对象的状态,从而能够将这些输入转换为所需输出的操作链接在一起。与简单地将数组包裹在_(…) 对象中不同,其强大之处在于可以链接序列中的任何函数。尽管这是一个复杂的程序,但仍然可以避免创建任何变量,并且有效地消除所有循环。
使用 _.chain 的另一个好处是可以创建具有惰性计算能力的复杂程序,在调用 value() 前,并不会真正地执行任何操作。这可能会对程序产生巨大的影响,因为在不需要其结果的情况下,可以跳过运行所有函数(见第7章中关于惰性计算的讨论)。该程序的控制流程如图3.7所示。
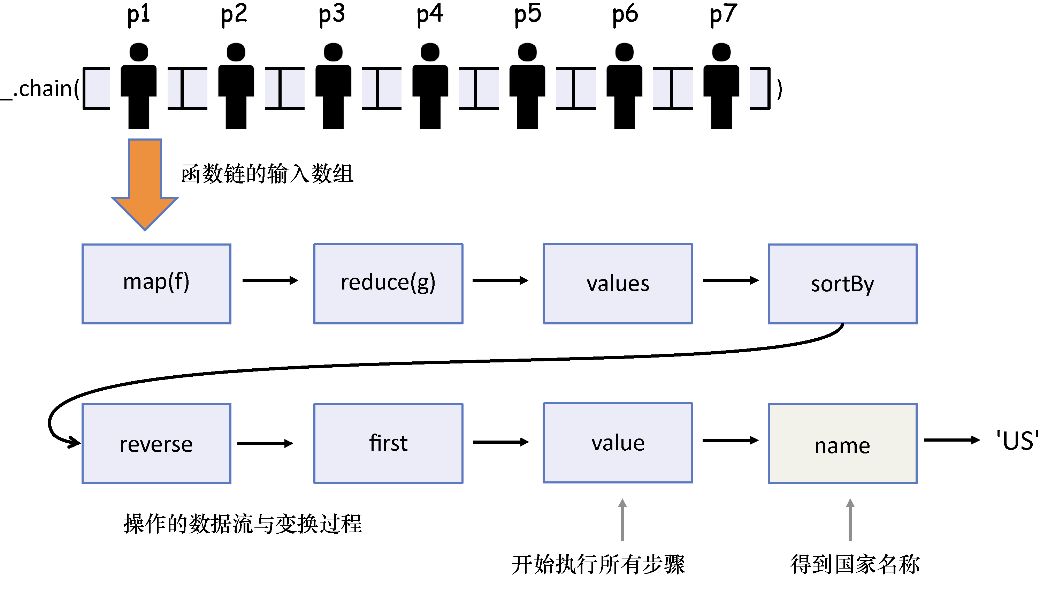
图3.7 Lodash 函数链程序的控制流程。通过一系列操作对person对象数组进行处理。 数据沿着函数链传递,并最终转化为单一值
现在读者应该开始明白为什么函数式的程序是如此优越的了。而相应的命令式版本留给读者去思考。清单3.8能够写得如此流畅与函数式编程中的纯性以及无副作用的基本原则息息相关。链中的每个函数都以一种不可变的方式来处理由上一个函数构建的新数组。Lodash 利用函数链这种模式,通过调用 _.chain() 提供了一种基础功能,以满足各种需求。这有助于过渡到对point-free 编程风格的理解。point-free是函数式编程的特色,将在下一章中介绍。
能够惰性地定义程序的管道不止有可读性这一个好处。由于以惰性计算方式编写的程序会在运行前定义好,因此可以使用数据结构重用或者方法融合等技术对其进行优化。这些优化不会减少执行函数本身所需的时间,但有助于消除不必要的调用。第7章研究函数式程序性能时,会更详细地进行讨论。
在清单3.8中,数据从一个节点流向下一个节点。声明式地使用高阶函数,使得节点中数据变换显而易见,从而揭示了更多对数据的认识。
3.4.2 类SQL的数据:函数即数据
本章已经介绍了各种各样的函数,比如map 、reduce 、filter 、groupBy 、sortBy 、uniq 等。将这些函数组成一个列表,可用来梳理数据相关的信息。如果在更高层面细细思考,就会发现这些函数与SQL相似,这不是偶然的。
开发者惯于使用SQL及其功能来了解和梳理数据的含义。例如,可以用表3.1所示的内容来表示person对象的集合。
表3.1 表格化的person数据表示
| id | firstname | lastname | country | birthYear |
|---|---|---|---|---|
| 0 | Haskell | Curry | US | 1900 |
| 1 | Barkley | Rosser | Greece | 1907 |
| 2 | John | Von Neumann | Hungary | 1903 |
| 3 | Alonzo | Church | US | 1903 |
| 4 | David | Hilbert | Germany | 1862 |
| 5 | Alan | Turing | England | 1912 |
| 6 | Stephen | Kleene | US | 1909 |
事实证明,在构建程序时,使用查询语言来思考与函数式编程中操作数组类似——使用通用关键字表或代数方法来增强对数据及其结构的深层次思考。下面的SQL查询语句
SELECT p.firstname, p.birthYear FROM Person p
WHERE p.birthYear > 1903 and p.country IS NOT 'US'
GROUP BY p.firstname, p.birthYear
使开发者能够清楚地看到运行此代码后数据是什么样子的。在实现此程序的 JavaScript 版本之前,先设置一些函数别名来辅助说明这一点。Lodash支持一种称为mixins 的功能,可以用来为核心库扩展新的函数,并使得它们可以以相同的方式连接:
_.mixin({'select': _.pluck,
'from': _.chain,
'where': _.filter,
'groupBy': _.sortByOrder});
应用此 mixin 对象后,就可以编写出如清单3.9所示的程序。
清单3.9 编写类似 SQL 的 JavaScript 代码
_.from(persons)
.where(p => p.birthYear > 1900 && p.address.country !== 'US')
.groupBy(['firstname', 'birthYear'])
.select('firstname', 'birthYear')
.value();
//-> ['Alan', 'Barkley', 'John']
清单3.9创建了一个SQL关键字到对应别名函数的映射,从而可以更深刻地理解一个查询语言的函数式特性。
JavaScript中的mixin
mixin 是定义与特定类型(也就是上例中 SQL 命令)相关的函数的抽象子集对象。该对象在代码中不会被直接使用,而是作为对另一个对象行为的扩展(它有点类似于其他编程语言中的特质)。目标对象则能够使用 mixin 中的各种功能。
在面向对象的世界中,除了继承或者在不支持的语言中(比如 JavaScript 就是其中之一)模拟地多重继承,mixin是另一种代码重用的方式。本书中过多地介绍mixin,但如果能够正确使用,它会很强大。更多关于mixin的信息,参见https://javascriptweblog.wordpress.com/ 2011/05/31/a-fresh-look-at-javascript-mixins/。
现在读者应该相信,函数式编程的抽象能力比命令式代码更加强大。还有比使用查询语言的语义来处理和解析数据更好的方法吗?像SQL一样,上面的 JavaScript 代码以函数的形式对数据进行建模,也就是函数即数据 。因为它是声明式的,描述了数据输出是什么 ,而不是数据是如何得到的 。到目前为止,并不需要任何常见的循环语句——本书的其余部分也不打算使用它们。相反,应该用高阶抽象代替循环。
另一种用于替换循环的常见技术是递归,尤其当处理一些“自相似”的问题时,可以用其来抽象迭代。对于这些类型的问题,序列函数链会显得效率低下或不适用。而递归实现了自己的处理数据的方式,从而大大缩短了标准循环的执行时间。
3.5 学会递归地思考
有时,要解决的问题是困难且复杂的。这种情况下,开发者应该立刻去寻找方法来分解它。如果问题可以分解成较小的问题,就可以逐个解决,再将这些结论组合起来构建出整个问题的解决方案。在Haskell、Scheme和Erlang这样的纯函数编程语言中,数组遍历是不能没有递归的,因为这些语言根本没有循环结构。
而在JavaScript中,递归具有许多应用场景,例如解析XML、HTML文档或图形等。本节将解释什么是递归,然后通过一个练习教读者如何去递归地思考,最后将概述可以使用递归解析的几种数据结构。
3.5.1 什么是递归?
递归是一种旨在通过将问题分解成较小的自相似问题来解决问题本身的技术,将这些小的自相似问题结合在一起,就可以得到最终的解决方案。递归函数包含以下两个主要部分。
- 基例(也称为终止条件)。
- 递归条件。
基例是能够令递归函数计算出具体结果的一组输入,而不必再重复下去。递归条件则处理函数调用自身的一组输入(必须小于原始值)。如果输入不变小,那么递归就会无限期地运行,直至程序崩溃。随着函数的递归,输入会无条件地变小,最终到达触发基例的条件,以一个值作为递归过程的终止。
第2章使用递归来深度冻结整个嵌套的对象结构。如果遇到的对象是基本类型或已经被冻结,就会触发基例;否则,就会继续遍历对象结构,因为发现了更多未被冻结的对象。递归很适合处理这种问题,因为在任何一个层次上,要解决的任务是完全一样的。但是,递归思考可能会是一个挑战,下面开始吧。
3.5.2 学会递归地思考
递归不是一个容易掌握的概念。与函数式编程一样,最难的部分是忘记常规的方法。本书的重点不是让读者成为一个递归大师,因为它不是一种常用的技术手段。但重要的是,本书期望通过它来锻炼读者的大脑,并帮助读者更好地学习如何分析可递归的问题。
递归地思考需要考虑递归自身以及自身的一个修改版本。递归对象是自定义的。例如,想象将树枝组合成一棵树。一个树枝有叶子以及其他的树枝,而它们又有更多的叶子和更多的树枝。这个过程将无限地持续下去,只有在达到外部限制时才会停止,本例中就是树的大小。
下面基于这一思想来解决一个简单的问题:对数组中的所有数求和。先实现命令式的版本,再实现函数式的版本。命令式的大脑可以自然而然地形成一个解决方案,遍历数组并不断地累积一个值:
var acc = 0;
for(let i = 0; i < nums.length; i++) {
acc += nums[i];
}
通常开发者会使用一个累加器,因为要计算一个总和时,这绝对是必要的。但是需要使用循环吗?在这一点上,开发者很清楚可以使用函数式的武器(例如_.reduce ):
_(nums).reduce((acc, current) => acc + current, 0);
将循环抽成框架,可以将应用程序代码抽象出来。但是可以做得更好,从代码中彻底移除迭代。使用函数 _.reduce 无须考虑循环,甚至是数组的大小。可以通过将第一个元素添加到其余部分来计算结果,从而实现递归思维。这种思想过程可以想象成如下的序列求和操作,这被称为横向思维:
sum[1,2,3,4,5,6,7,8,9] = 1 + sum[2,3,4,5,6,7,8,9]
= 1 + 2 + sum[3,4,5,6,7,8,9]
= 1 + 2 + 3 + sum[4,5,6,7,8,9]
递归和迭代是一枚硬币的两面。在不可变的条件下,递归提供了一种更具表现力、强大且优秀的迭代替代方法。事实上,纯函数式语言甚至没有标准的循环结构,如 do 、for 和 while ,因为所有循环都是递归完成的。递归使代码更易理解,因为它是以多次在较小的输入上重复相同的操作为基础的。清单3.10中的递归解决方案使用 Lodash 的 _.first 和 _.rest 函数分别访问数组的第一个元素和剩余元素。
清单3.10 递归求和
function sum(arr) {
if(_.isEmpty(arr)) { <--- 基例(终止条件)
return 0;
}
return _.first(arr) + sum(_.rest(arr)); <--- 递归条件:使用更小一些的输入集调用自身。这里通过_.first和_.rest 缩减输入集
}
sum([]); //-> 0
sum([1,2,3,4,5,6,7,8,9]); //->45
空数组会满足基例,返回 0。而对于非空数组,就会继续将第一个元素与数组的其余部分递归地求和。从底层来看,递归调用会在栈中不断堆叠。当算法满足终止条件时,运行时就会展开调用栈并执行加操作,因此所有返回语句都将被执行。递归就是通过语言运行时这种机制代替了循环。以下是算法实现的步骤视图:
1 + sum[2,3,4,5,6,7,8,9]
1 + 2 + sum[3,4,5,6,7,8,9]
1 + 2 + 3 + sum[4,5,6,7,8,9]
1 + 2 + 3 + 4 + sum[5,6,7,8,9]
1 + 2 + 3 + 4 + 5 + sum[6,7,8,9]
1 + 2 + 3 + 4 + 5 + 6 + sum[7,8,9]
1 + 2 + 3 + 4 + 5 + 6 + 7 + sum[8,9]
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + sum[9]
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + sum[]
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 0 -> halts, stack unwinds
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9
1 + 2 + 3 + 4 + 5 + 6 + 7 + 17
1 + 2 + 3 + 4 + 5 + 6 + 24
1 + 2 + 3 + 4 + 5 + 30
1 + 2 + 3 + 4 + 35
1 + 2 + 3 + 39
1 + 2 + 42
1 + 44
45
看到这里,自然要考虑一下递归和迭代的性能问题。毕竟,编译器在处理循环的优化问题上是非常强大的。JavaScript 的 ES6 带来了一种称之为尾调用优化 的优化功能,可以使递归和迭代的性能表现更加接近。考虑一个稍微有所不同的sum 实现:
function sum(arr, acc = 0) {
if(_.isEmpty(arr)) {
return 0;
}
return sum(_.rest(arr), acc + _.first(arr)); <--- 发生在尾部的递归调用
}
这个版本的实现将递归调用作为函数体中最后的步骤,也就是尾部位置 。在第7章讨论函数式优化问题时,我们会探索这样做的好处。
3.5.3 递归定义的数据结构
读者可能想知道person 对象示例数据中的那些名字。20世纪 20 年代,函数式编程(lambda 演算、范畴论等)背后的数学社区非常活跃。大部分发表的研究成果都是融合一些由Alonzo Church 这样的知名大学教授提出的思想和定理。事实上,许多数学家,如Barkley Rosser、Alan Turing和Stephen Kleene等,都是Church 的博士生。后来他们也有了自己的博士生。图3.8为这种师徒关系(的一部分)的示意图。
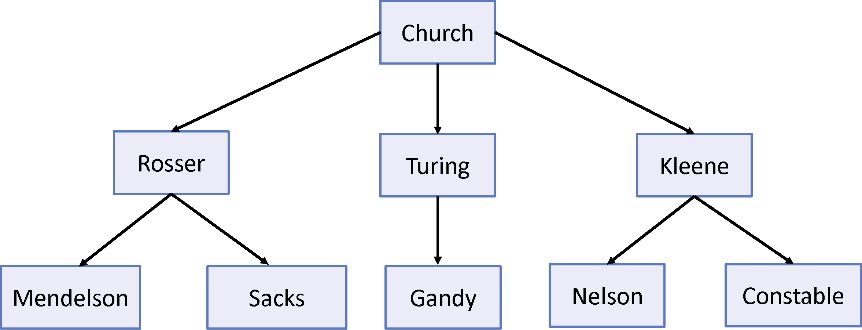
图3.8 函数式编程发展历程中具有杰出贡献和影响力的数学家。树形结构中从父节点到 子节点的连线代表了“是其学生”这种关系
这种结构在软件中是很寻常的,它可用于建模XML文档、文件系统、分类法、种别、菜单部件、逐级导航、社交图谱等,所以学习如何处理它们至关重要。图3.8显示了一组节点,其连线表示了导师-学生这一关系。到目前为止,本书已经利用函数式技术解析过一些扁平化的数据结构,如数组。但这些操作对树形数据是无效的。因为 JavaScript 没有内置的树型对象,所以需要基于节点创建一种简单的数据结构。节点是一种包含了当前值、父节点引用以及子节点数组的对象。在图3.8中,Rosser 的父节点是 Church ,其子节点有 Mendelson 和 Sacks 。如果一个节点没有父节点,比如 Church ,则被称为根节点。以下是节点 类型的定义,代码如清单3.11所示。
清单3.11 节点对象
class Node {
constructor(val) {
this._val = val;
this._parent = null;
this._children = [];
}
isRoot() {
return isValid(this._parent); <--- 之前创建的函数
}
get children() {
return this._children;
}
hasChildren() {
return this._children.length > 0;
}
get value() {
return this._val;
}
set value(val) {
this._val = val;
}
append(child) {
child._parent = this; <--- 设置父节点
this._children.push(child); <--- 将孩子节点加入孩子列表中
return this; <--- 返回该节点(便于方法级联)
}
toString() {
return `Node (val: ${this._val}, children:
${this._children.length})`;
}
}
可以这样创建一个新节点:
const church = new Node(new Person('Alonzo', 'Church', '111-11-1111'));// <--- 重复树中的所有节点
树是包含了一个根节点的递归定义的数据结构:
class Tree {
constructor(root) {
this._root = root;
}
static map(node, fn, tree = null) { <--- 使用静态方法以免与Array.prototype.map 混淆。静态方法也能像单例函数一样高效
node.value = fn(node.value); <--- 调用遍历器函数,并更新树中的节点值
if(tree === null) {
tree = new Tree(node); <--- 与 Array.prototype.map 类似。结果是一个新的结构
}
if(node.hasChildren()) { <--- 如果节点没有孩子,则返回(基例)
_.map(node.children, function (child) { <--- 将函数应用到每一个孩子节点
Tree.map(child, fn, tree); <--- 递归地调用每一个孩子节点
});
}
return tree;
}
get root() {
return this._root;
}
}
节点的主要逻辑在于 append 方法。要给一个节点追加一个子节点,需要将该节点设置为子节点的 parent 引用,并把子节点添加至该节点的子节点列表中。通过从根部不断地将节点链接到其他子节点来填充一棵树,由 church 开始:
church.append(rosser).append(turing).append(kleene);
kleene.append(nelson).append(constable);
rosser.append(mendelson).append(sacks);
turing.append(gandy);
每个节点都包裹着一个 person 对象。递归算法执行整个树的先序遍历,从根开始并且下降到所有子节点。由于其自相似性,从根节点遍历树和从任何节点遍历子树是完全一样的,这就是递归定义。为此,可以使用与 Array.prototype.map 语义类似的高阶函数 Tree.map ——它接收一个对每个节点求值的函数。可以看出,无论用什么数据结构来建模(这里是树形数据结构),该函数的语义应该保持不变。从本质上讲,任何数据类型都可以使用map并保持其结构不变。本书第5章会更正式地介绍这种保持数据结构的映射函数。
树的先序遍历按照以下步骤执行,从根节点开始。
1)显示根元素的数据部分。
2)通过递归地调用先序函数来遍历左子树。
3)以相同的方式遍历右子树。
图3.9显示了算法采用的路径。
图3.9 递归的先序遍历,从根节点开始,一直向左下降,然后再向右移动
函数 Tree.map 有两个必需的输入:根节点(即树的开始)以及转换每个节点数值的迭代函数:
Tree.map(church, p => p.fullname);
它以先序方式遍历树,并将给定的函数应用于每个节点,输出以下结果:
'Alonzo Church', 'Barkley Rosser', 'Elliot Mendelson', 'Gerald Sacks', 'Alan
Turing', 'Robin Gandy', 'Stephen Kleene', 'Nels Nelson', 'Robert Constable'
在操作不可变、无副作用的数据类型时,封装数据以控制其访问的思想是函数式编程的关键。本书第5章将进一步介绍这一思想。解析数据结构是软件和函数式编程最基本的方面之一。本章更深入地探讨了利用可扩展函数库(即Lodash)中的函数式特性来进行函数式风格的 JavaScript 开发。这种风格有利于流式建模,将包含业务逻辑的高阶操作连接在一起,从而达到最终的业务目的。
不可否认的是,编写流式风格的代码也有利于可重用性和模块化,但目前的讨论还比较浅显。本书第4章更深入地介绍流式编程,将重点放在构建真正的函数管道上。
3.6 总结
- 使用
map、reduce和filter等高阶函数来编写高可扩展的代码。 - 使用Lodash进行数据处理,通过控制链创建控制流与数据变换明确分离的程序。
- 使用声明式的函数式编程能够构建出更易理解的程序。
- 将高阶抽象映射到SQL语句,从而深刻地认识数据。
- 递归能够解决自相似问题,并解析递归定义的数据结构。
[1] 只有一个参数时其实括号是可以省略的。——译者注
第4章 模块化且可重用的代码
本章内容
- 函数链与函数管道的比较
- Ramda.js 函数库
- 柯里化、部分应用(partial application)和函数绑定
- 通过函数式组合构建模块化程序
- 利用函数组合子增强程序的控制流
一个复杂的工作系统总是从一个简单的系统发展而来的。
——John Gall,《The System Bible》(General Systemantics Press,2012年)
模块化是大型软件项目最重要的特性之一,它代表了将程序分成较小独立部分的程度。模块化程序的独特之处在于,其含义来自于其组成部分的性质。这些部分(或称为子程序)都是可重复使用的组件,并可以合并为一个系统整体或单独在其他系统中使用。这使代码更加可读和可维护,同时使开发更加高效。举一个简单的例子,UNIX脚本程序的编写:
tr 'A-Z' 'a-z' <words.in | uniq | sort
即便没有UNIX编程的经验,也可以清楚地看到,这行代码包括对字符的一系列变换:将大写转换为小写,删除重复字符,最终进行排序。管道操作符“| ”用于连接这些命令。令人惊奇的是,通过明确地描述命令输入和输出的约定,一些小程序就可以合在一起来解决更为复杂的任务。假设用传统的命令式JavaScript来编写这个程序,可能需要几个循环、字符串比较,或许还需要一些条件语句以及一些全局变量来记录状态。这应该不是很模块化的,对吧?在编程中,开发者倾向于先将问题分解成较小的部分,再重建这些部分以形成整体的解决方案。
第3章通过一个被包裹对象上的紧耦合级联方法链解决了类似的问题。本章将进一步扩展该思路,通过函数组合创建松耦合的管道,以便能够使用独立组件更灵活地构建整个程序。这些组件可以像函数一样小,也可以像整个模块一样大。分开来看,它们并没有太大的价值,但组合在一起就会颇具意义。
创建模块化的代码也不是一件很容易的事情。本章将借助Ramda.js函数框架来了解一些重要的函数式技术,如部分求值和组合,通过将代码抽象到合理的层次,以便构建出一种声明式管道的point-free风格的解决方案。
4.1 方法链与函数管道的比较
第3章提到了连接一系列函数的方法链,从而揭示了一种与众不同的函数式编程风格。还有一种称为管道 的方法也可以用来连接函数。
函数的输入和输出对于了解函数本身是十分重要的。Haskell中使用一种符号来描述函数,这常见于各种地方,例如一些函数式社区(见图4.1)。
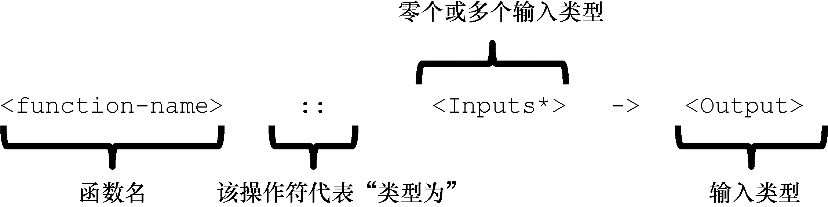
图4.1 Haskell中定义函数的符号。该符号先给出了函数的名称, 随后用一个操作符来设置函数的输入和输出类型
请记住,在函数式编程中,函数是输入和输出类型之间的数学映射,如图4.2所示。举例来说,一个简单的函数,如isEmpty ,它接收一个字符串并返回一个布尔值,使用该符号表示如下:
isEmpty :: String -> Boolean
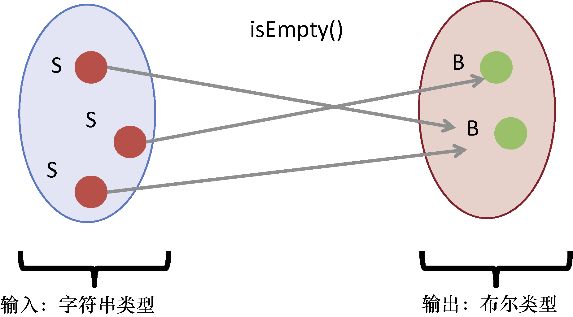
图4.2 函数**isEmpty**是所有String类型输入值的集合到所有Boolean类型输出值的集合之间的引用透明映射
该函数是所有String 类型输入值到所有Boolean 值之间的引用透明映射。该函数JavaScript的lambda描述形式如下:
// isEmpty :: String -> Boolean
const isEmpty = s => !s || !s.trim();
了解函数作为类型映射的性质是理解如何将函数链接和管道化的关键。
- 方法链接(紧耦合,有限的表现力)。
- 函数的管道化(松耦合,灵活)。
4.1.1 方法链接
回想一下,在第3章中,map 和filter 函数都以一个数组作为输入并返回一个新的数组。这些函数都可以通过Lodash封装的隐式对象紧密地连接在一起,从而在后台实现对新数据结构的创建。这是第3章中的一个例子:
_.chain(names)
.filter(isValid) <--- 每一个“点”后只能调用 Lodash 提供的方法
.map(s => s.replace(/_/, ' '))
.uniq()
.map(_.startCase)
.sort()
.value();
比较命令式代码,这的确是一个能够极大提高代码可读性的语法改进。然而,它与方法所属的对象紧紧地耦合在一起,限制链中可以使用的方法数量,也就限制了代码的表现力。这样就只能够使用由Lodash提供的操作,而无法轻松地将不同函数库的(或自定义的)函数连接在一起。
注意
尽管使用mixin的方法可以扩展一个对象的功能,但这就需要自己去管理mixin对象本身。本书并未过多涉及mixin的讨论,但读者可以在《重新审视的JavaScript Mixins》(Angus Croll,2011年5月30日,http://mng.bz/15Zj)一书中了解更多。
从高阶函数角度来看,可以一组对数组操作的简单方法序列表示为图4.3所示的形式。打破函数链的约束就能够自由地排列所有独立的函数操作,而可以使用函数管道来实现这一目的。

图4.3 数组的方法链需要通过调用所属对象中的方法来实现。而从 内部来看,每个方法都会返回一个含有调用结果的新数组
4.1.2 函数的管道化
函数式编程能够消除方法链中存在的限制,使得任何函数的组合都更加灵活。管道是松散结合的有向函数序列,一个函数的输出会作为下一个函数的输入。图4.4抽象地说明了以不同类型对象作为输入的函数的连接方式。

图4.4 函数管道始于具有类型**A**参数的函数**f**,产生一个类型**B**的对象,
随后按序传入函数**g**,并以输出的类型**C**对象作为最终结果。函数
**f** 和**g**既可以来自于任何函数库,也可以是自定义的函数
本章将介绍如何将函数调用组织成图4.4所示的简洁高阶函数管道。如果觉得该图表很熟悉,那是因为该模式就是许多企业应用程序中都能够看到的面向对象设计模式中的管道与过滤器模式,它是从函数式编程衍变而来的(其中的过滤器就是各个函数)。
比较图4.3和图4.4就会发现一个关键的区别:方法链接通过对象的方法紧密连接;而管道以函数作为组件,将函数的输入和输出松散地连接在一起。但是,为了实现管道,被连接的函数必须在元数(arity)和类型上相互兼容。
4.2 管道函数的兼容条件
面向对象的编程在一些特定情况下(其中之一是认证与授权)偶尔会使用管道。而函数式编程将管道视为构建程序的唯一方法。通常来说,对于不同的任务,问题的定义与解决方案间总是存在很大的差异。因此,特定的计算必须在特定的阶段进行。这些阶段由不同的函数表征,而所选函数的输入和输出需要满足以下两个兼容条件。
- 类型——函数的返回类型必须与接收函数的参数类型相匹配。
- 元数——接收函数必须声明至少一个参数才能处理上一个函数的返回值。
4.2.1 函数的类型兼容条件
在设计函数管道时,函数的返回类型与函数的接收参数之间具有一定程度的兼容性是极其重要的。由于JavaScirpt是弱类型语言,因此从类型角度来看,无须像使用一些静态类型语言一样太过关注类型。因此,如果一个对象在应用中表现得像某个特定类型,那么它就是该类型。这也被称为鸭子类型:“如果走起来像鸭子,并且像鸭子一样叫,那这就是一只鸭子。”
注意
静态类型语言的优势是使用类型系统在无须运行代码的情况下发现潜在的问题。类型系统是函数式编程中的一个重要课题,但本书不会涉及。
JavaScript的动态调度机制会尝试在对象中查找属性与方法,而不关注类型信息。虽然这非常灵活,但开发者仍然需要了解一个函数所期望的参数类型。使用清晰的定义(例如在代码中使用Haskell符号标记)可以使程序更易理解。
正式地讲,仅当f 的输出类型等同于函数g 的输入时,两个函数f 和g 是类型兼容的。举例来说,一个处理学生社会安全号码的简单程序:
trim :: String -> String <--- 截掉首末空白符
normalize :: String -> String <--- 去除横线
此时,normalize 的输入与trim 的输出服从兼容性的对应关系,因此可以像清单4.1所示的代码一样,在一个简单的管道序列中调用它们。
清4.1 使用 trim 和normalize 手动构建函数管道
// trim :: String -> String
const trim = (str) => str.replace(/^\s*|\s*$/g, '');
// normalize :: String -> String
const normalize = (str) => str.replace(/\-/g, '');
normalize(trim(' 444-44-4444 ')); //-> '444444444' <--- 手动构建系列管道调用两个函数(之后会涉及如何自动化这一过程)。使用带有首末空白符的输入测试
类型固然重要,但在JavaScript中,更关键的是函数元数的兼容性。
4.2.2 函数与元数:元组的应用
元数定义为函数所接收的参数数量,也被称为函数的长度(length)。尽管在其他编程范式中,元数是最基本的,但在函数式编程中,引用透明的必然结果就是,声明的函数参数数量往往与其复杂性成正比。例如,操作一个字符串的函数很可能比具有3个或4个参数的函数简单得多:
// isValid :: String -> Boolean
function isValid(str) { <--- 使用简单
...
}
// makeAsyncHttp:: String, String, Array -> Boolean
function makeAsyncHttp (method, url, data) { <--- 难以使用,因为必须先计算出所有参数
...
}
只具有单一参数的纯函数是最简单的,因为其实现目的非常单纯,也就意味着职责单一。因此,应该尽可能地使用具有少量参数的函数,这样的函数更加灵活和通用。然而,总是使用一元函数并非那么容易。例如,在真实世界中,isValid 函数可能会额外返回一个描述错误信息的值:
isValid :: String -> (Boolean, String) <--- 返回含有验证状态或错误信息的结构体
isValid(' 444-444-44444'); //-> (false, 'Input is too long!')
但如何返回两个不同的值呢?函数式语言通过一个称为元组 的结构来做到这一点。元组是有限的、有序的元素列表,通常由两个或三个值成组出现,记为(a, b,c) 。由此,可以使用一个元组作为isValid 函数的返回值——它将状态与可能的错误消息捆绑,作为单个实体返回,并随后传递到另一个函数中(如果需要的话)。下面详细探讨一下元组。
元组是不可变的结构,它将不同类型的元素打包在一起,以便将它们传递到其他函数中。将数据打包返回的方式还包括字面对象或数组等:
return {
status : false, or
return [false, 'Input is too long!'];
message: 'Input is too long!'
};
但当涉及函数间的数据传输时,元组能够具有更多的优点。
- 不可变的——一旦创建,就无法改变一个元组的内部内容。
- 避免创建临时类型——元组可以将可能毫不相关的数据相关联。而定义和实例化一些仅用于数据分组的新类型使得模型复杂并令人费解。
- 避免创建异构数组——包含不同类型元素的数组使用起来颇为困难,因为会导致代码中充满大量的防御性类型检查。传统上,数组意在存储相同类型的对象。
此外,元组的行为与第2章中显示的数值对象极为相似。一个具体的用例是 Status ,它是一个包含状态标志和一条消息的简单数据类型:(false, 'Some error occurred!') 。与其他函数式语言(如Scala)不同,JavaScript并不原生地支持Tuple 数据类型。例如,给定一个Scala中的元组定义:
var t = (30, 60, 90)
可以像这样访问各个元素:
var sumAnglesTriangle = t._1 + t._2 + t._3 = 180
但是,JavaScript已经提供了实现元组所需的所有工具,如清单4.2所示。
清单4.2 Tuple 数据类型
const Tuple = function( /* types */ ) {
const typeInfo = Array.prototype.slice.call(arguments, 0); <--- 读取参数作为元组的元素类型
const _T = function( /* values */ ) { <--- 声明内部类型_T,以保障类型与值匹配
const values = Array.prototype.slice.call(arguments, 0); <--- 提取参数作为元组内的值
if(values.some((val) => <--- 检查非空值。函数式数据类型不允许空值
val === null || val === undefined)) {
throw new ReferenceError('Tuples may not have
any null values');
}
if(values.length !== typeInfo.length) { <--- 按照定义类型的个数检查元组的元数
throw new TypeError('Tuple arity does not
match its prototype');
}
values.map(function(val, index) { <--- 使用 checkType 检查每一个值都能匹配其类型定义。其中的元素都可以通过_n 获取, n 为元素的索引(注意是从 1 开始)
this['_' + (index + 1)] = checkType(typeInfo[index])(val);
}, this);
Object.freeze(this); <--- 让元组实例不可变
};
_T.prototype.values = function() { <--- 提取元组中的元素,也可以使用 ES6 的解构赋值把元素赋值到变量上
return Object.keys(this).map(function(k) {
return this[k];
}, this);
};
return _T;
};
清单4.2中定义的元组对象是不可变且长度固定的数据结构,是可用于在函数间通讯的存储了n 个不同类型值的异构集合。举例来说,可以用元组来快速构建如Status 这样的值对象:
const Status = Tuple(Boolean, String);
下面利用元组来完成学生的SSN验证,代码如清单4.3所示。
清单4.3 使用了元组的isValid 函数
// trim :: String -> String
const trim = (str) => str.replace(/^\s*|\s*$/g, '');
// normalize :: String -> String
const normalize = (str) => str.replace(/\-/g, '');
// isValid :: String -> Status
const isValid = function (str) {
if(str.length === 0){
return new Status(false, <--- 声明包含状态( Boolean)和消息( String)的类型Status
'Invald input. Expected non-empty value!');
}
else {
return new Status(true, 'Success!');
}
}
isValid(normalize(strim('444-44-4444'))); //-> (true, 'Success!')
在软件开发过程中,二元组出现得非常频繁,将其设定为一等的对象非常具有实际意义。在JavaScript ES6解构赋值特性的支持下,可以简明地将元组值映射到变量中。清单4.4所示的代码使用元组创建了一个名为StringPair 的对象。
清单4.4 StringPair 类型
const StringPair = Tuple(String, String);
const name = new StringPair('Barkley', 'Rosser');
[first, last] = name.values();
first; //-> 'Barkley'
last; //-> 'Rosser'
const fullname = new StringPair('J', 'Barkley', 'Rosser'); <--- 抛出元素不匹配的错误
元组是减少函数元数的方式之一,但还可以使用更好的方式去应对那些不适于元组的情况。通过引入函数柯里化不仅可以降低元数,还可以增强代码的模块化和可重用性。
4.3 柯里化的函数求值
将函数的返回值作为参数传递给一元函数是十分容易的,但如果目标函数需要更多参数呢?为了理解JavaScript的柯里化,首先必须了解柯里化的求值和常规(非柯里化的)求值之间的区别。JavaScript是允许在缺少参数的情况下对常规或非柯里化函数进行调用的。换句话说,如果定义一个函数f(a, b, c) ,并只在调用时传递a ,JavaScript运行时的调用机制会将b 和c 设为undefined ,如图4.5所示。这并不是一件好事,也是JavaScript语言不能原生支持柯里化的最有可能的原因。可以想象,如果在函数声明时不定义任何参数,而仅依赖于函数中的arguments 对象,则会使问题变得更糟。

图4.5 在缺少参数的情况下调用非柯里化函数会导致缺失参数的实参变成 **undefined**
再看柯里化函数,它要求所有参数都被明确地定义,因此当使用部分参数调用时,它会返回一个新的函数,在真正运行之前等待外部提供其余的参数。图4.6能够直观地表现这一点。
图4.6 柯里化函数**f**的求值。只有提供了所有参数,该函数才会输出具体的结果,
否则它会返回另一个等待参数传递的函数
柯里化是一种在所有参数被提供之前,挂起或“延迟”函数执行,将多参函数转换为一元函数序列的技术。具有三个参数的柯里化函数的定义如下:
curry(f) :: (a,b,c) -> f(a) -> f(b)-> f(c)
以上符号描述表明,curry是一种从函数到函数的映射,将输入(a, b, c) 分解为多个分离的单参数调用。在纯函数式编程语言中(如Haskell),柯里化是原生特性,是任何函数定义中的组成部分。由于JavaScript本身不支持自动柯里化函数,因此需要编写一些代码来启用它。在了解自动柯里化之前,让我们先从二元参数的手动柯里化例子开始,代码如清单4.5所示。
清单4.5 二元参数的手动柯里化
function curry2(fn) {
return function(firstArg) { <--- 第一次调用 curry2,获得第一个参数
return function(secondArg) { <--- 第二次调用获得第二个参数
return fn(firstArg, secondArg); <--- 将两个参数应用到函数 fn 上
};
};
}
如上所示,柯里化是一种词法作用域(闭包),其返回的函数只不过是一个接收后续参数的简单嵌套函数包装器。以下是一个简单应用:
const name = curry2(function (last, first) {
return new StringPair('Barkley', 'Rosser');
});
[first, last] = name('Curry')('Haskell').values(); <--- 当给定两个参数时,函数会完全求值
first;//-> 'Curry'
last; //-> 'Haskell'
name('Curry'); //-> Function <--- 当只提供一个参数时,返回一个函数,而不是将第二个参数当作 undefined
下面再来看使用curry2 以及清单4.2中的Tuple 类型实现一个checkType 函数。这次会用到函数式库Ramda.js中的函数。
另一个函数库?
像 Lodash 一样,Ramda.js拥有众多可用于连接函数式程序的有用函数,并且对纯函数式编码风格提供了支持。之所以使用它,是因为可以很容易地实现参数柯里化、惰性应用和函数组合(参见本章后面的内容)。有关使用Ramda的更多详细信息,请参阅附录。
安装完毕后,就可以使用全局变量R 来访问其所有功能,例如R.is :
// checkType :: Type -> Type -> Type | TypeError
const checkType = curry2(function(typeDef, actualType) {
if(R.is(typeDef, actualType)) { <--- 使用 R.is()检查类型信息
return actualType;
}
else {
throw new TypeError('Type mismatch.
Expected [' + typeDef + '] but found
[' + typeof actualType + ']');
}
});
checkType(String)('Curry'); //-> String
checkType(Number)(3); //-> Number
checkType(Date)(new Date()); //-> Date
checkType(Object)({}); //-> Object
checkType(String)(42); //-> Throws TypeError
curry2 能够胜任简单的任务,但是当构建更复杂的功能时,就需要能够自动处理任意数量参数的柯里化函数。通常会介绍函数的内部实现,但由于curry 是一个很长且复杂的函数,因此与其去解释它令人头疼的实现,不如讨论更为有用的东西(读者可以在Lodash和Ramda中找到curry 及其另两个版本curryRight 和curryN 的实现)。
可以使用R.curry 对任意数量参数的函数进行自动的柯里化。可以将自动柯里化想象为基于声明参数的数量人工创建对应嵌套函数作用域的过程。柯里化fullname 函数如下所示:
// fullname :: (String, String) -> String
const fullname = function (first, last) {
...
}
多个参数会被通过如下形式转换成多个一元函数:
// fullname :: String -> String -> String
const fullname =
function (first) {
return function (last) {
...
}
}
现在来看一些柯里化的实际应用。尤其是,它可以用于实现以下两种流行的设计模式。
- 仿真函数接口。
- 实现可重用模块化函数模板。
4.3.1 仿真函数工厂
在面向对象世界中,接口是用于定义子类必须实现的契约抽象类型。如果创建的接口包含函数findStudent(SSN) ,那么实体类必须实现此函数。下面这段“简短的”Java示例代码说明了这一点:
public interface StudentStore {
Student findStudent(String ssn);
}
public class DbStudentStore implements StudentStore {
public Student findStudent(String ssn) {
// ...
ResultSet rs = jdbcStmt.executeQuery(sql);
while(rs.next()){
String ssn = rs.getString("ssn");
String name = rs.getString("firstname") +
rs.getString("lastanme");
return new Student(ssn, name);
}
}
}
public class CacheStudentStore implements StudentStore {
public Student findStudent(String ssn) {
// ...
return cache.get(ssn);
}
}
这段代码很冗长(不过Java就是这么啰嗦!)。这段代码显示了同一个接口的两个实现:一个从数据库读取;另一个从缓存读取。但是从调用代码的角度来看,它只关心方法的调用而并不关心来自哪个对象。这就是面向对象设计模式中工厂方法模式的美妙之处。只要使用一个函数工厂就可以了:
StudentStore store = getStudentStore();
store.findStudent("444-44-4444");
当然,函数式编程的实现是不容错过的,其解决方案就是柯里化。通过分别创建在存储数据和数组中查找学生对象的函数,就能够将这段Java代码翻译为JavaScript:
// fetchStudentFromDb :: DB -> (String -> Student)
const fetchStudentFromDb = R.curry(function (db, ssn) { <--- 在 DB对象中查找
return find(db, ssn);
});
// fetchStudentFromArray :: Array -> (String -> Student)
const fetchStudentFromArray = R.curry(function (arr, ssn) { <--- 在数组中查找
return arr[ssn];
});
由于这两个函数都是柯里化的,因此可以使用一个通用工厂方法 findStudent 将函数的定义与求值分离,而其具体的实现细节可能是任意一个查找函数:
const findStudent = useDb ? fetchStudentFromDb(db)
: fetchStudentFromArray(arr);
findStudent('444-44-4444');
现在,findStudent 可以传递给其他模块,而其调用者无须了解其具体实现(这对于第6章单元测试中模拟与对象存储交互的讨论至关重要)。从可重用的角度来看,柯里化也能够帮助开发者创建函数模板。
4.3.2 创建可重用的函数模板
假设开发者需要配置不同的日志函数来处理应用程序中的不同状态,比如错误、警告以及调试信息等。函数模板会根据创建时的参数数量来定义一系列的相关函数。本节例子中将使用流行的JavaScript库Log4js—— 一个远远优于传统console.log的日志框架。读者可以在附录中找到其安装信息。以下是一些基本设置:
const logger = new Log4js.getLogger('StudentEvents');
logger.info('Student added successfully!');
在Log4js的辅助下,还可以做到更多。假设需要在弹出的窗口中显示消息,可以通过配置一个 appender 来实现:
logger.addAppender(new Log4js.JSAlertAppender());
也可以通过配置一个布局,使其输出 JSON 而不是纯文本格式:
appender.setLayout(new Log4js.JSONLayout());
开发者可能设置很多的配置,而将这些代码复制并粘贴到每个文件中会导致大量重复。使用柯里化来定义一个可重用的函数模板(如清单4.6所示的日志函数模板),将带来最大的灵活性和重用性。
清单4.6 创建一个日志函数模板
const logger = function(appender, layout, name, level, message) {
const appenders = { <--- 预设 appenders
'alert': new Log4js.JSAlertAppender(),
'console': new Log4js.BrowserConsoleAppender()
};
const layouts = { <--- 预设布局layouts
'basic': new Log4js.BasicLayout(),
'json': new Log4js.JSONLayout(),
'xml' : new Log4js.XMLLayout()
};
const appender = appenders[appender];
appender.setLayout(layouts[layout]);
const logger = new Log4js.getLogger(name);
logger.addAppender(appender);
logger.log(level, message, null); <--- 使用配置好的logger 打印消息
};
通过柯里化logger ,可以集中管理和重用适用于任何场合的日志配置:
const log = R.curry(logger)('alert', 'json', 'FJS'); <--- 只会应用第一个参数到函数 logger
log('ERROR', 'Error condition detected!!');
// -> this will popup an alert dialog with the requested message
如果要在一个函数或文件中记录多条错误日志,可以灵活地设置除最后一个参数之外的其他参数:
const logError = R.curry(logger)('console', 'basic', 'FJS', 'ERROR');
logError('Error code 404 detected!!');
logError('Error code 402 detected!!');
curry 函数的后续调用在后台被执行,最终生产一个一元函数。事实上,可以通过现有的函数创建新函数,并将任意数量的参数传递给它们,从而逐步实现函数构建。
除了能够有效提升代码的可重用性之外,将多元函数转换为一元函数才是柯里化的主要动机。柯里化的可替代方案是部分应用和函数绑定,它们受到JavaScript语言的适度支持,以产生更小的功能,在插入功能管道时也能很好地工作。
4.4 部分应用和函数绑定
部分应用是一种通过将函数的不可变参数子集初始化为固定值来创建更小元数函数的操作。简单来说,如果存在一个具有五个参数的函数,给出三个参数后,就会得到一个、两个参数的函数。
和柯里化一样,部分应用也可以用来缩短函数的长度,但又稍有不同。因为柯里化的函数本质上是部分应用的函数,所以这两种技术往往会被互相混淆。它们的主要区别在于参数传递的内部机制与控制。
- 柯里化在每次分步调用时都会生成嵌套的一元函数。在底层,函数的最终结果是由这些一元函数的逐步组合产生的。同时,
curry的变体允许同时传递一部分参数。因此,可以完全控制函数求值的时间与方式。 - 部分应用将函数的参数与一些预设值绑定(赋值),从而产生一个拥有更少参数的新函数。该函数的闭包中包含了这些已赋值的参数,在之后的调用中被完全求值。
现在,既然已经明确两者的不同,下面继续研究partial 函数可能的实现方式,如清单4.7所示。
清单4.7 partial的函数实现
function partial() {
let fn = this, boundArgs = Array.prototype.slice.call(arguments);
let placeholder = <<partialPlaceholderObj>>; <--- 库中的具体占位符实现,像 Lodash 会使用下画线对象作为占位符。其他的实现使用 undefined 来表示应该略过该参数
let bound = function() { <--- 使用部分应用的参数创建新的函数
let position = 0, length = args.length;
let args = Array(length);
for (let i = 0; i < length; i++) {
args[i] = boundArgs[i] === placeholder <--- 其中 placeholder 对象略过了定义函数的参数
? arguments[position++] : boundArgs[i];
}
while (position < arguments.length) {
args.push(arguments[position++]);
}
return fn.apply(this, args); <--- 使用 fn.apply()给定函数合适的上下文,并将参数列表应用到函数的参数上
};
return bound;
});
对于部分应用和函数绑定的讨论,再次使用Lodash,因为它对函数绑定提供了比Ramda更好的支持。然而从表面来看,_.partial 与R.curry 的使用方式非常相似,并且都支持使用各自的占位符对象对参数进行占位。应用于之前看到的logger 函数,就通过部分应用部分参数来创建更具体的行为:
const consoleLog = _.partial(logger, 'console', 'json', 'FJS Partial');
下面用该函数加强对curry 与partial 之间差异的认识。在应用了三个参数之后,生成的consoleLog 函数会在调用时接收另外的两个参数(一次性的,而不是一步一步地传入)。与柯里化不同,只使用一个参数调用consoleLog 并不会返回一个新的函数,而是会以undefined 作为最后一个参数来执行。但是,可以像下面这样继续使用_.partial 将部分参数应用于consoleLog :
const consoleInfoLog = _.partial(consoleLog, 'INFO');
consoleInfoLog('INFO logger configured with partial');
柯里化是一种部分应用的自动化使用方式,这是它与partial 本身的主要区别。另一种类似的JavaScript原生技术称为函数绑定,即Function.prototype.bind() [1] 。但其作用与partial 有所不同:
const log =_.bind(logger, undefined, 'console', 'json', 'FJS Binding');
log('WARN', 'FP is too awesome!');
_.bind 的第二个参数undefined 是什么呢?使用绑定能够创建绑定函数,该函数可在一个所属对象的上下文中执行(传递undefined 表示该函数将在全局作用域中运行)。来看看_.partial 和_.bind 的一些实际用途:
- 核心语言扩展。
- 惰性函数绑定。
4.4.1 核心语言扩展
在增强语言的表现力方面,部分应用可用于扩展如 String 或 Number 这样的核心数据类型的实用功能。注意,如果语言中加入了可造成冲突的新方法,以这种方式扩展语言可能会使代码很难在平台升级的过程中移植。考虑下面的例子:
// Take the first N characters
String.prototype.first = _.partial(String.prototype.substring, 0, _); <--- 使用占位符,可以部分应用 substring一个参数 0,从而创建期待一个偏移量参数的函数
'Functional Programming'.first(3); // -> 'Fun'
// Convert any name into a Last, First format
String.prototype.asName =
_.partial(String.prototype.replace, /(\w+)\s(\w+)/, '$2, $1'); <--- 部分应用参数来创建具体的行为
'Alonzo Church'.asName(); //-> 'Church, Alonzo'
// Converts a string into an array
String.prototype.explode =
_.partial(String.prototype.match, /[\w]/gi); <--- 部分应用 match 方法,给定具体的正则表达式,得到能将字符串转换成数组的函数
'ABC'.explode(); //-> ['A', 'B', 'C']
// Parses a simple URL
String.prototype.parseUrl = _.partial(String.prototype.match, <--- 部分应用 match 方法,给定具体的正则表达式,得到能将字符串转换成数组的函数
/(http[s]?|ftp):\/\/([^:\/\s]+)\.([^:\/\s]{2,5})/);
'http://example.com'.parseUrl(); // -> ['http', 'example', 'com']
在实现自己的函数之前,首先要进行存在性检查,以便适用于新的语言版本升级:
if(!String.prototype.explode) {
String.prototype.explode = _.partial(String.prototype.match, /[\w]/gi);
}
在一些特定情况下,部分应用会失效,例如当用于(如setTimeout )延迟函数时。这时就需要使用函数绑定来实现。
4.4.2 延迟函数绑定
当期望目标函数使用某个所属对象来执行时,使用函数绑定来设置上下文对象就变得尤为重要。例如,浏览器中的setTimeout 和setInterval 等函数,如果不将this 的引用设为全局上下文,即window 对象,是不能正常工作的。传递undefined 在运行时正确设置它们的上下文。例如,setTimeout 可用于创建一个简单的调度对象来执行延迟的任务。以下是使用_.bind 和_.partial 的示例:
const Scheduler = (function () {
const delayedFn = _.bind(setTimeout, undefined, _, _);
return {
delay5: _.partial(delayedFn, _, 5000),
delay10: _.partial(delayedFn, _, 10000),
delay: _.partial(delayedFn, _, _)
};
})();
Scheduler.delay5(function () {
consoleLog('Executing After 5 seconds!')
});
使用Scheduler ,可以将任何一段代码包含在函数体中延迟的执行(运行时是无法确保计时器的精准的,但这是另一个问题)。由于bind 和partial 都是返回另一个函数的函数,因此可以很容易地嵌套使用。如前面的代码所示,每一个延迟操作都基于函数绑定和部分应用函数的组合。在函数式编程中,函数绑定并不像部分应用那么有用,而且使用起来也比较投机,因为它会重新设置函数的上下文。之所以在这里介绍它,也只是为了防止读者在自学时陷入其中。
部分应用和柯里化都是十分有用的技术。柯里化技术使用得非常广泛,通常用于创建可抽象函数行为的函数包装器,可预设其参数或对其部分求值。其优势源于具有较少参数的纯函数比较多参数的函数更易使用。两种方法都有助于向函数提供正确的参数,这样函数就不必在减少为一元函数时公然地访问其作用域之外的对象。这种分离参数获取逻辑的方式使得函数具有更好的可重用性。更重要的是,它简化了函数的组合。
4.5 组合函数管道
在第1章中,我们讨论了将问题分解成更小、更简单的子问题(或子任务),再将其组装起来以达到业务目标的重要性,就像拼图中的一个个小块一样。函数式程序的目标就是找到那些可以被组合的结构,这正是函数式编程的核心。现在读者应该明白了,纯且无副作用的函数使得组合成为一种非常强大的技术。回想一下,无副作用的函数不会依赖于任何外部数据。函数所需要的一切都必须以参数的形式提供。而为了能够正确地使用组合,所选的函数必须是无副作用的。
此外,一个由纯函数构建的程序本身也是纯的,因此能够进一步组合成更为复杂的解决方案,而不会影响系统的其他部分。了解这一点非常重要,因为这一思想将贯穿本书始终。因此,在深入学习函数组合之前,让我们通过一个在 HTML 页面中组合小部件的具体示例加深对其的理解。
4.5.1 HTML部件的组合
组合的概念是很直观的,也不是函数式编程所独有的。看看 HTML 页面中的部件是如何组织的。复杂的部件都是由简单的部件组合而来,而反过来又可以用于构建更大的部件。例如,将3个输入文本组件与一个空容器组合起来可以得到一个简单的学生表单,如图4.7所示。

图4.7 将3个简单的文本组件与一个空容器组合以创建一个简历表单组件
现在,学生表单也成为一个组件,可以与其他组件组合成更复杂的结构,从而一步步创建出一个完整的学生控制台表单(见图4.8)。现在读者应该明白了,如果需要,学生控制台表单还可以添加到更复杂的信息面板中。在本例中,控制台表单是地址表单和简历表单的组合。具有简单行为(即没有外部依赖关系)的对象易于组合,可以用于构建更为复杂的结构,就像垒砖块一样。

图4.8 由地址表单、简历表单、按钮和一个容器等小部件组合的学生控制台表单
为了演示,下面创建一个叫作Node 的递归结构的元组:
const Node = Tuple(Object, Tuple);
它可用于保存一个对象以及对另一个节点(元组)的引用。本质上,这是一个元素列表的函数式定义:由头部和尾部递归组合而成。通过柯里化的element 函数
const element = R.curry(function(val, tuple) {
return new Node(val, tuple);
});
读者可以创建以null 终止的任一类型的列表。图4.9显示了一个简单的数字列表。

图4.9 由头部和尾部构成的数字列表。函数式语言中的数组已经具有head和tail两个函数
这基本就是列表在ML和Haskell等语言中的构造。然而,与外部对象高度耦合的复杂对象就没有比较明确的组合规则,可能会非常难以使用。当存在副作用和改变时,函数式组合也可能会这样。好了,是时候深入了解函数组合了。
4.5.2 函数组合:描述与求值分离
从本质上讲,函数组合是一种将已被分解的简单任务组织成复杂行为的整体过程。本书第1章对其进行了简要的定义,现在来进行具体的解释。我们来看一个使用Ramda的R.compose 函数组合两个纯函数的小例子:
const str = `We can only see a short distance
ahead but we can see plenty there
that needs to be done`;
const explode = (str) => str.split(/\s+/); <--- 将句子分割成单词数组
const count = (arr) => arr.length; <--- 单词数量
const countWords = R.compose(count, explode);
countWords(str); //-> 19
可以说,这段代码很容易阅读,从函数的组成部分一眼就能看出其行为。这段程序最有趣的是,直到countWords 被调用才会触发求值。换句话说,用其名称传递的函数(explode 和count )在组合中是静止的。组合的结果是一个等待指定参数调用的另一个函数countWords 。这是函数式组合的强大之处:将函数的描述与求值分开。
下面来解释一下后台发生了什么。countWords(str) 的调用触发了函数 explode 的执行并将其输出(一个字符串数组)传给count 以计算该数组的长度。组合将输入与输出相连接,创建出函数管道。组合的一个更正式的定义是,考虑两个函数f 和g 以及其各自的输入和输出类型:
g :: A -> B <--- g 是由类型 A 到B 的函数
f :: B -> C <--- f 是由类型 B到 C的函数
图4.10是由箭头连接的各分组。该符号表示了一个(箭头)函数f ,接收类型B 的参数并返回C 类型。另一个(箭头)函数g 接收类型A 的参数并返回B 。因此,g :: A -> B 与 f :: B -> C 的组合(叫作“f 由g 组合”)会形成另一个函数A->C ,如图4.11所示。更正式的表示为:
f·g = f(g) = compose :: (B -> C) -> (A -> B) -> (A -> C)
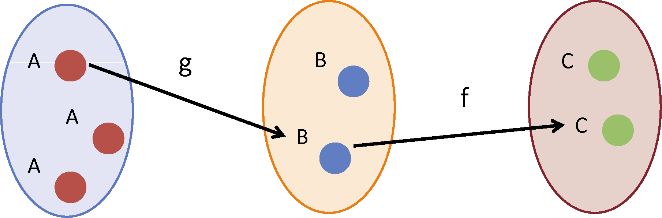
图4.10 函数**f**和**g**的输入和输出类型表示。函数**g**将**A**类型的值映射为**B**类型的值,而函数
**f** 将**B**类型的值映射为**C**类型的值。组合之所以能够实现,是因为**f**和**g**是相互兼容的

图4.11 两个函数的组合是一个将第二个函数的输入直接映射到第一个函数的 输出的新函数。组合后的函数也是输入和输出之间的引用透明映射
回想一下引用透明的概念,函数也不过是连接一组对象到另一组对象的箭头而已。
这也是另一个重要的软件开发原则模块化系统的支柱。由于组合能够松散地将类型兼容函数的边界(即输入和输出)相互绑定,因此满足面向接口编程的原则。在前面的例子中,函数 explode :: String -> [String] 与函数count :: [String] -> Number 组合,各函数只知道和关心下一个函数的接口,而不是其实现。虽然compose 不是JavaScript语言的一部分,但可以自然而然地表示为一个高阶函数,如清单4.8所示。
清单4.8 compose 的实现
function compose(/* fns */) {
let args = arguments;
let start = args.length - 1;
return function() { <--- 组合的输出是真正接收实际参数的函数
let i = start;
let result = args[start].apply(this, arguments); <--- 动态应用接收的参数到函数
while (i--)
result = args[i].call(this, result); <--- 循环调用系列函数,以前一个函数的输出作为下一个函数的输入
return result;
};
}
幸好Ramda提供了R.compose ,所以无须自己实现。我们编写一个验证程序来检查一个SSN格式是否合法(我们会在本书中多次重用这些帮助函数):
const trim = (str) => str.replace(/^\s*|\s*$/g, ''); <--- 移除输入中的首末空格
const normalize = (str) => str.replace(/\-/g, ''); <--- 移除所有横线
const validLength = (param, str) => str.length === param; <--- 检查字符串长度
const checkLengthSsn = _.partial(validLength, 9); <--- 设置长度为 9,来验证 SSN
利用这些函数,还可以创建其他的函数:
const cleanInput = R.compose(normalize, trim); <--- 组合 normalize 和 trim,得到 cleanInput 函数
const isValidSsn = R.compose(checkLengthSsn, cleanInput); <--- 组合 cleanInput 和checkLengthSsn, 得到新函数 isValidSsn
cleanInput(' 444-44-4444 '); //-> '444444444'
isValidSsn(' 444-44-4444 '); //-> true
进一步地,如图4.12所示,整个程序都可以通过简单函数的组合来构建。
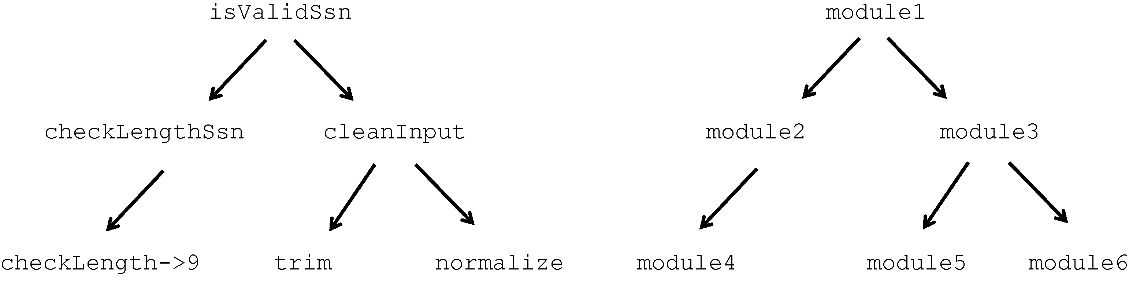
图4.12 复杂的函数可以通过简单函数的组合来构建。正如函数组合一样,由不同的 (包含更多函数的)模块组成的程序,也可以通过这种组合的方式来构建
组合的概念不仅限于函数,整个程序都可以由无副作用的纯的程序或模块组合而成(基于之前的函数定义,本书将不严格区分函数、程序和模块这3个术语,它们均表示具有输入和输出的可执行单元)。
组合是一种合取操作,这意味着其元素使用逻辑与运算连接。例如,函数isValidSsn 由checkLengthSsn 和cleanInput 组成。因此,程序实际上由其各部分的总和得出。第5章将解决需要返回两个结果之一(即A或B)这样的具有析取性质的表达式问题。
同时,还可以将compose 增加到JavaScript的Function 原型中。下面是以第3章中函数链风格实现的具有完全相同行为的逻辑:
Function.prototype.compose = R.compose;
const cleanInput = checkLengthSsn.compose(normalize).compose(trim); <--- 可以链式地组合函数
如果读者更喜欢这种风格,也可以随意使用。在下一章中,读者将了解到,方法链接机制在叫作monad的代数数据类型中非常普遍。就个人而言,笔者建议使用更加函数式的形式,因为它更加简洁与灵活,并且与函数式库结合得更好。
4.5.3 函数式库的组合
使用诸如Ramda这种函数式库的好处之一是,所有的函数已经被正确地柯里化,在组合函数管道时更具有通用性。再来看一个例子,以下是一个班中各学生的名单和成绩:
const students = ['Rosser', 'Turing', 'Kleene', 'Church'];
const grades = [80, 100, 90, 99];
假设需要找到班里成绩最高的学生。从第3章了解到,使用数据集合是函数式编程的基石之一。清单4.9由组合的多个柯里化函数构成,每个函数都能够以特定的方式对数据进行变换。
R.zip——通过配对两个数组的内容来创建一个新数组。本例中,配对两个数组能够得到[['Rosser', 80], ['Turing', 100], ...]。R.prop——指定在排序中要使用的值。本例中,以 1 作为参数指明使用子数组的第二个元素(成绩)。R.sortBy——通过给定的属性执行数组的自然升序排序。R.reverse——反转整个数组以获得第一个元素的最高数字。R.pluck——通过抽取指定索引处的元素构建数组。传递参数 0 表示提取元素为学生姓名。R.head——获取第一个元素。
清单4.9 获取最聪明的学生
const smartestStudent = R.compose(
R.head,
R.pluck(0),
R.reverse,
R.sortBy(R.prop(1)),
R.zip); <--- 用 Ramda 的一系列函数组合成新函数smartestStudent
smartestStudent(students, grades); //-> 'Turing' <--- 传给第一个函数 R.zip()两个数组。每一步对数据进行不可变的变换,直到最后一个函数 R.head(),返回结果
尤其当刚刚熟悉的框架或刚开始理解问题域时,使用组合可能会比较难。笔者在工作中使用组合时,经常发现自己需要思考从何处入手。同样,最难的部分是将任务分解成较小的部分。一旦完成了这一工作,就能用组合对这些函数进行重组。
另外,一个令人开始意识到并开始爱上函数式组合的原因是,它能够让开发者自然地用一两行简洁的代码来描述整个解决方案。因为已经创建了映射到算法中不同阶段的函数,所以需要构建描述这一部分解决方案的本体表达式,从而使得其他团队成员能够更快地了解该代码。清单4.10所示的代码与第3章中的练习类似。
清单4.10 使用描述性函数别名
const first = R.head;
const getName = R.pluck(0);
const reverse = R.reverse;
const sortByGrade = R.sortBy(R.prop(1));
const combine = R.zip;
R.compose(first, getName, reverse, sortByGrade, combine);
尽管上述代码更容易阅读,但由于这些函数与具体的业务任务相关,所以这段代码并没有提升程序的可重用性。因此,笔者建议去熟悉像head 、pluck 、zip 等其他的函数式词汇,以便通过实践获得所选函数式框架的综合知识。由于都使用了相同的命名约定,这会使代码更容易过渡到其他框架或函数式语言。它会很快地提高开发者的生产力。
清单4.9和清单4.10都使用了纯函数来描述整个解决方案,但这并不总是办得到的。应用程序开发者会经常面临读取本地存储、远程HTTP请求等任务的需求,不可避免地产生副作用,为此必须能从纯的代码中分离不纯的部分。正如读者将在第6章中看到的,这将使得测试非常容易。
4.5.4 应对纯的代码和不纯的代码
不纯的代码在运行后会导致外部可见的副作用,导致访问的数据超出函数的作用域,导致外部依赖关系。只要有一个函数是不纯的,整个程序都会被影响。
但是,并不需要总保证100%的纯函数以获得函数式编程的好处。理想情况下,开发者需要尽可能地分离纯的行为与不纯的行为,而且最好是在同一个函数中。之后,再使用组合来将纯的与不纯的片段粘在一起。第1章中提到,一开始实现showStudent 函数的要求是这样的:
const showStudent = compose(append, csv, findStudent);
无论怎样,大多数函数都是通过其参数引发副作用的。
findStudent使用了对象存储或一些外部数组的引用。append直接改写了HTML元素。
继续改进这个程序,通过curry 对各函数的不变参数进行部分求值。再通过添加代码来清理输入参数,并使用更细粒度的函数重构对HTML的操作。最后,可以通过将find 操作从对象存储解耦,来使其更加函数式。代码如清单4.11所示。
清单4.11 使用柯里化和组合的showStudent 程序
// findObject :: DB -> String -> Object
const findObject = R.curry(function (db, id) { <--- 重构的 find()函数更容易组合
const obj = find(db, id);
if(obj === null) {
throw new Error('Object with ID [' + id + '] not found');
}
return obj;
});
// findStudent :: String -> Student
const findStudent = findObject(DB('students')); <--- 使用部分求值 fetchRecord 得到固定在 students 对象存储中查找的新函数 findStudent
const csv = (student) =>
`${student.ssn}, ${student.firstname}, ${student.lastname}`;
// append :: String -> String -> String
const append = curry(function (elementId, info) {
document.querySelector(elementId).innerHTML = info;
return info;
});
// showStudent :: String -> Integer
const showStudent = R.compose( <--- 组合函数以完成整个程序
append('#student-info'),
csv,
findStudent,
normalize,
trim));
showStudent('44444-4444'); //-> 444-44-4444, Alonzo, Church
清单4.11中定义了组成showStudent 的4个函数(为它们加上了类型签名,就可以更轻松地了解到每个连续调用之间的对应关系)。这段代码将一个函数的输出与下一个函数的输入相连接,以trim 函数作为开始,直到函数 append 。但还有一个问题:记得在本章一开始的UNIX程序吗?该程序使用UNIX内置的管道操作符| ,由左到右地执行每个函数。因此,管道函数的执行顺序与组合相反(见图4.13)。

图4.13 一个简单的Unix shell程序,将一系列函数用管道组合在一起
如果觉得函数式组合这种自然反转的执行顺序很奇怪,或者将程序视为左结合的序列,那么就可以使用Ramda compose 的镜像函数pipe 来获得相同的结果:
R.pipe(
trim,
normalize,
findStudent,
csv,
append('#student-info'));
从F#原生就提供管道运算符|> ,就能看出这有多么重要了。在JavaScript中,并没有这种优待,但可以使用功能库来完成相同的工作。注意,在使用R.pipe 和R.compose 时,不必像原来一样正式地声明参数来创建新的函数。函数式组合鼓励这种写作风格,它被称为point-free。
4.5.5 point-free编程
仔细阅读清单4.10,就能够发现它并没有像传统函数声明一样使用任何显式的参数。再看一下这行代码:
R.compose(first, getName, reverse, sortByGrade, combine);
使用compose (或者pipe )就意味着永远不必再声明参数了(称为函数的points),这无疑会使代码更加声明式、更加简洁,或更加point-free。
point-free编程使JavaScript的函数式代码更接近于Haskell和UNIX的理念。它可以用来提高抽象度,促使开发者关注高级组件的组合,而不是低级的函数求值的细节。柯里化在这里也起着很重要的作用,因为它能够灵活地部分定义一个只差最后一个参数的内联函数。这种编码风格也被称为Tacit编程。下面代码正如本章一开始介绍的UNIX程序一样,以point-free风格编写。
清单4.12中的程序仅由一些point-free函数的名称组成(其中一些是带有参数的部分定义),而没有表明这些函数所接收的参数类型。在将组合改为这种编码风格时,要记住,过度的使用会使得程序晦涩且令人费解。并不是要去除所有的参数。在某些情况下,将函数组合分解成2个或3个表达式会更好。
清单4.12 使用Ramda函数编写的,UNIX程序的point-free版本
const runProgram = R.pipe(
R.map(R.toLower),
R.uniq,
R.sortBy(R.identity)); <--- identity 函数返回其接收到的参数。虽然功能不起眼,但是非常实用(下一节会进一步解释)
runProgram(['Functional', 'Programming', 'Curry',
'Memoization', 'Partial', 'Curry', 'Programming']);
//-> [curry, functional, memoization, partial, programming]
point-free代码可能会对错误处理和调试造成影响。比如,在有异常抛出并产生副作用时,是否应该在组合函数中返回null 来解决呢?尽管可以在函数中检查null ,但会导致很多的代码重复、样板代码以及为了程序进行而返回的合理默认值。同时,该怎样尝试调试出现在一行的所有命令呢?这些都需要关注的问题会在下一章中予以解决。我们将看到更多的point-free程序,包括支持自动错误处理的程序。
另一个重要的问题是,如何处理需要使用条件逻辑或者按某种方式执行多个函数的情况。下一节将介绍能够管理应用程序控制流的实用程序。
4.6 使用函数组合子来管理程序的控制流
在第 3 章中,我们比较了命令式程序和函数式程序中的控制流程,并强调了二者的显著差异。命令式代码能够使用如if-else 和for 这样的过程控制机制,函数式则不能。所以,这需要一个替代方案——可以使用函数组合子。
组合器是一些可以组合其他函数(或其他组合子),并作为控制逻辑运行的高阶函数。组合子通常不声明任何变量,也不包含任何业务逻辑,它们旨在管理函数式程序的流程。除了compose 和pipe ,还有无数的组合子,一些最常见的组合子如下。
identitytapalternationsequencefork(join)
4.6.1 identity(I-combinator)
identity 组合子是返回与参数同值的函数:
identity :: (a) -> a
它广泛使用于函数数学特性的检验,但也有很多其他的实际用途。
- 为以函数为参数的更高阶函数提供数据,如之前清单4.12中的point-free代码。
- 在单元测试的函数组合器控制流中作为简单的函数结果来进行断言(将在第 6章讨论)。例如,可以使用identity函数来编写
compose的单元测试。 - 函数式地从封装类型中提取数据(将在下一章详述)。
4.6.2 tap(K-组合子)
tap 非常有用,它能够将无返回值的函数(例如记录日志、修改文件或HTML页面的函数)嵌入函数组合中,而无须创建其他的代码。它会将所属对象传入函数参数并返回该对象。以下是该函数的签名:
tap :: (a -> *) -> a -> a
该函数接收一个输入对象a 和一个对a 执行指定操作的函数。它使用提供的对象调用给定的函数,然后再返回该对象。例如,可以使用一个如debugLog 这样的void函数来调用R.tap ,
const debugLog = _.partial(logger, 'console', 'basic', 'MyLogger',
'DEBUG');
并在一些函数组合中嵌入它。以下是一些例子:
const debug = R.tap(debugLog);
const cleanInput = R.compose(normalize, debug, trim);
const isValidSsn = R.compose(debug, checkLengthSsn, debug, cleanInput);
无论如何,(基于R.tap )调用debug 都不会改变程序的结果。实际上,该组合器会忽略其函数参数的执行结果(如果存在的话)。以下代码既能够记录调试信息,又能够输出函数结果:
isValidSsn('444-44-4444');
// output
MyLogger [DEBUG] 444-44-4444 // clean input
MyLogger [DEBUG] 444444444 // check length
MyLogger [DEBUG] true // final result
4.6.3 alt(OR-组合子)
alt 组合子能够在提供函数响应的默认行为时执行简单的条件逻辑。该组合器以两个函数为参数,如果第一个函数返回值已定义(即,不是false 、null 或undefined ),则返回该值;否则,返回第二个函数的结果。可以按照如下方式实现:
const alt = function (func1, func2) {
return function (val) {
return func1(val) || func2(val);
}
};
也可以使用curry 和lambda表达式写得更简洁:
const alt = R.curry((func1, func2, val) => func1(val) || func2(val));
可以将该组合子用在showStudent 程序中,来处理当获取操作不成功的情况,从而创建一个新的学生:
const showStudent = R.compose(
append('#student-info'),
csv,
alt(findStudent, createNewStudent));
showStudent('444-44-4444');
若要了解发生了什么,可以假设该代码模拟了一个简单的if-else{/0 } 语句,等同于以下的命令式条件逻辑:
var student = findStudent('444-44-4444');
if(student !== null) {
let info = csv(student);
append('#student-info', info);
}
else {
let newStudent = createNewStudent('444-44-4444');
let info = csv(newStudent);
append('#student-info', info);
}
4.6.4 seq(S-组合子)
seq 组合子用于遍历函数序列。它以两个或更多的函数作为参数并返回一个新的函数,会用相同的值顺序调用所有这些函数。该组合子的实现如下:
const seq = function(/*funcs*/) {
const funcs = Array.prototype.slice.call(arguments);
return function (val) {
funcs.forEach(function (fn) {
fn(val);
});
};
};
有了它,就可以序列化地执行相关但独立的多个操作。例如,在找到学生对象后,可以使用seq 将它们呈现在HTML页面上并将其输出到控制台。所有函数都以同一学生对象作为参数顺序执行:
const showStudent = R.compose(
seq(
append('#student-info'),
consoleLog),
csv,
findStudent));
seq 组合子不会返回任何值,只会一个一个地执行一系列操作。如果要将其嵌入函数组合之间,可以使用R.tap 将它与其余部分进行桥接。
4.6.5 fork(join)组合子
fork 组合子用于需要以两种不同的方式处理单个资源的情况。该组合子需要以3个函数作为参数,即以一个join函数和两个fork函数来处理提供的输入。两个分叉函数的结果最终传递到的接收两个参数的join 函数中,如图4.14所示。
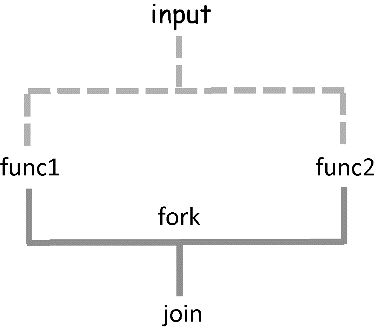
图4.14 **fork** 组合子接收三个函数: 一个**join**函数和两个**fork**函数。**fork**函数根据所提供的输入执行, 然后通过**join**函数将结果结合起来
注意
这与Java中的多任务处理框架fork-join不同,不要相互混淆。其实现来自Haskell和其他函数式工具包中的
fork组合子。
该组合子的实现如下:
const fork = function(join, func1, func2){
return function(val) {
return join(func1(val), func2(val));
};
};
现在来看看该组合子的使用方法。让我们重新通过一组数字形式的成绩计算出平均的字母形式的成绩。可以使用fork 来组织3个计算函数的求值:
const computeAverageGrade =
R.compose(getLetterGrade, fork(R.divide, R.sum, R.length));
computeAverageGrade([99, 80, 89]); //-> 'B'
下面的例子用于检查均值和集合的中位数是否相等:
const eqMedianAverage = fork(R.equals, R.median, R.mean);
eqMedianAverage([80, 90, 100])); //-> True
eqMedianAverage([81, 90, 100])); //-> False
有些人将组合视为约束,但看来恰恰相反:组合子使代码编写更加灵活,并有利于point-free风格编程。因为组合子都是纯函数,它们也能够结合其他组合子使用,为任何类型的应用程序提供无数的替代方案并减少复杂度。我们会在后续章节中再次使用它们。
基于不可变性和纯性,函数式编程可以有效提高程序代码的模块化和可重用性水平。在第2章中,我们了解到JavaScript中的函数也可以模块化。同理,也可以像使用函数一样组合和重用整个模块。这一内容留待读者独立思考。
模块化的函数式程序由一些抽象的函数构成,可以单独地理解并重用,其功能与组合的具体规则相关。在本章中,我们了解到纯函数的组合是函数式编程的支柱。这些组合技术均利用了函数式抽象的特性,(通过柯里化或部分应用)对各种纯函数进行组合。不过到目前为止,还没有涉及错误处理,这是任何可容错应用的重要组成部分,我们将在后续章节中加以讨论。
4.7 总结
- 用于连接可重用的、模块化的、组件化程序的函数链与管道。
- Ramda.js是一个功能强大的函数库,适用于函数的柯里化与组合。
- 可以通过部分求值和柯里化来减少函数元数,利用对参数子集的部分求值将函数转化为一元函数。
- 可以将任务分解为多个简单的函数,再通过组合来获得整个解决方案。
- 以point-free的风格编写,并用函数组合子来组织的程序控制流,可解决现实问题。
[1] 请参阅“Function.prototype.bind()”,Mozilla开发者网络,http://mng.bz/MY75。
第5章 针对复杂应用的设计模式
本章内容
- 命令式处理异常方式的问题
- 使用容器,以防访问无效数据
- 用Functor的实现来做数据转换
- 利于组合的Monad数据类型
- 使用Monadic类型来巩固错误处理策略
- Monadic类型的组合与交错
空引用是一个价值数十亿美元的错误。
——Tony Hoare,InfoQ
有人可能以为函数式编程范式只适用于学术问题,却忽视了其在真实世界问题的作用。然而近年来人们发现,函数式编程可以把错误处理得比任何其他开发风格更为优雅。
软件中的许多问题都是由于数据不经意地变成了null 或undefined``、 出现了异常、失去网络连接等情况造成的。代码需要顾及所有此类问题,因此增加了复杂性。这样一来,就需要花大量的时间来确保所有抛出的异常都能被适当地捕获,并且在所有能想到的地方检查值是否为null 。最后的结果是什么呢?——越来越长、不能扩展、推理起来又很费劲的庞大复杂的代码。
开发者需要更聪明地工作,而不是辛苦地工作。本章将介绍Functor这一可以简单映射函数的数据类型。应用Functor可以创建多种包含不同错误处理行为的Monad数据类型。由于出自范畴论,Monad是函数式编程中最难以把握的概念之一。不过请放心,本书不会讲到范畴论,而会把重点放到实际问题上。话虽如此,本章还是会旁敲侧击地先介绍几个基本概念,之后将会展示如何用Monad来创建与组合容错函数,而这些都是命令式编程无法做到的。
5.1 命令式错误处理的不足
在许多情况下都会发生JavaScript错误,特别是在与服务器通信时,或是在试图访问一个为null 对象的属性时。此外,第三方库也有可能抛出异常来表示某些特定的错误。因此,开发者在编程时总是需要做好最坏的打算。值得一提的是,在命令式编程世界中,异常是通过try-catch 处理的。
5.1.1 用try-catch处理错误
JavaScript的异常处理机制通常会以大多数现代语言都有的try-catch 语句来完成:
try {
// code that might throw an exception in here
}
catch (e) {
// statements to handle any exceptions
console.log('ERROR' + e.message);
}
以该语句包裹住你认为不太安全的代码,一旦有异常发生,JavaScript会立即终止程序,并创建导致该问题的指令的函数调用堆栈跟踪。有关错误的具体细节,如消息、行号和文件名,被填充到Error 类型的对象中,并传递到catch 块中。catch 块就像程序的避风港,例如前面提到的函数findObject 和findStudent :
// findObject :: DB, String -> Object
const findObject = R.curry(function (db, id) {
const result = find(db, id)
if(!result) {
throw new Error('Object with ID [' + id + '] not found');
}
return result;
});
// findStudent :: String -> Student
const findStudent = findObject(DB('students'));
由于这些函数有可能会抛出异常,实践中会在调用它们的地方用try-catch 块包裹起来:
try {
var student = findStudent('444-44-4444');
}
catch (e) {
console.log('ERROR' + e.message);
}
正如用函数抽象循环和条件语句那样,也需要对错误处理进行抽象。但是,显然使用try-catch 后的代码将不能组合或连在一起,这将会严重影响代码设计。
5.1.2 函数式程序不应抛出异常
命令式的JavaScript代码结构有很多缺陷,而且也会与函数式的设计有兼容性问题。会抛出异常的函数存在以下问题。
- 难以与其他函数组合或链接。
- 违反了引用透明性,因为抛出异常会导致函数调用出现另一出口,所以不能确保单一的可预测的返回值。
- 会引起副作用,因为异常会在函数调用之外对堆栈引发不可预料的影响。
- 违反非局域性的原则,因为用于恢复异常的代码与原始的函数调用渐行渐远。当发生错误时,函数离开局部栈与环境。
try {
var student = findStudent('444-44-4444');
... more lines of code in between
}
catch (e) {
console.log('ERROR: not found');
// Handle error here
}
- 不能只关注函数的返回值,调用者需要负责声明
catch块中的异常匹配类型来管理特定的异常。 - 当有多个异常条件时会出现嵌套的异常处理块。
var student = null;
try {
student = findStudent('444-44-44444');
}
catch (e) {
console.log('ERROR: Cannot locate students by SSN');
try {
student = findStudentByAddress(new Address(...));
}
catch (e) {
console.log('ERROR: Student is no where to be found!');
}
}
说到这里,可能有人会怀疑,“函数式编程真的不需要抛出异常吗?”笔者不这么认为。在实践中,很多因素是在控制范围之外的,而且依赖库也有抛出异常的可能。
对于某些边缘情况,使用异常可能颇有效率。在第4章的checkType 中,使用了异常来表示API被滥用。同时,像RangeError: Maximum call stack size exceeded 这种不可修复的异常情况,会在第7章更多地讨论。异常应该由一个地方抛出,而不应该随处可见。其中一个常见的场景是JavaScript中因在null 对象上调用函数所产生的臭名昭著的TypeError 。
5.1.3 空值(null)检查问题
另一种跟抛出异常一样烦人的错误是null 返回值。虽然null返回值保证了函数的出口只有一个,但是也并没有好到哪去——给使用函数的用户带来需要null 检查的负担。比如获取学生地址与国家的getCountry 函数:
function getCountry(student) {
let school = student.getSchool();
if(school !== null) {
let addr = school.getAddress();
if(addr !== null) {
var country = addr.getCountry();
return country;
}
return null;
}
throw new Error('Error extracting country info');
}
这个函数似乎很容易实现,毕竟它只是提取对象的属性。本来可以简单地创建一个lens来获取该属性,若是null 即返回undefined, 但它并不会打印任何错误信息。
这使代码需要大量的判空检查代码。不管是使用try-catch 还是null 检查,都是被动的解决方式。若是能既轻松处理错误,又不需要这些啰嗦的防守代码该多好!
5.2 一种更好的解决方案——Functor
函数式以一种完全不同的方法应对软件系统的错误处理。其思想说起来也非常简单,就是创建一个安全的容器,来存放危险代码(见图5.1)。

图5.1 其实**try-catch**也可以看作存放着会抛出异常的
函数的保险箱。而保险箱可以看作一种容器
在函数式编程中,仍然会包裹这些危险代码,但可以不用try-catch 块。使用函数式数据类型是解决不纯性的主要手段。不过,首先从最简单的类型开始。
5.2.1 包裹不安全的值
将值包裹起来是函数式编程的一个基本设计模式,因为它直接地保证了值不会被任意篡改。这有点像给值身披铠甲,只能通过map 操作来访问该容器中的值。实际上第3章已经介绍过数组的map,而数组也是值的容器。本章将继续扩展更广义的map的概念。
其实,可以映射函数到更多类型,而不仅仅是数组。在函数式JavaScript中,map只不过是一个函数,由于引用透明性,只要输入相同,map永远会返回相同的结果。当然,还可以认为map是可以使用lambda表达式变换容器内的值的途径。比如,对于数组,就可以通过map 转换值,返回包含新值的新数组。
下面用Wrapper 好好地解释一下这个概念,如清单5.1所示。该类型看似简单,但是认真理解其中的原理,会为学习下一节做出非常好的铺垫。
清单5.1 包裹值的函数式数据类型
class Wrapper {
constructor(value) { <--- 存储任意类型值的简单类型
this._value = value;
}
// map :: (A -> B) -> A -> B
map(f) { <--- 用一个函数来 map 该类型(就像数组一样)
return f(this.val);
};
toString() {
return 'Wrapper (' + this.value + ')';
}
}
// wrap :: A -> Wrapper(A)
const wrap = (val) => new Wrapper(val); <--- 能够根据值快速创建Wrapper 的帮助函数
要访问包裹内的对象,唯一办法是map 一个第4章中提到的identity 函数(注意,Wrapper类型并没有get 方法)。虽然JavaScript允许用户方便地访问这个值,但重要的是,一旦该值进入容器,就不应该能被直接获取或转化(就像一个虚拟的屏障),如图5.2所示。
图5.2 Wrapper类型使用map安全地访问和操作值。在这种情况下, 通过映射 identity 函数就能在容器中提取值
下面是获取值的例子:
const wrappedValue = wrap('Get Functional');
wrappedValue.map(R.identity); //-> 'Get Functional' <--- 值的提取
其实还可以映射任何函数到该容器,比如记录日志或是变换该值:
wrappedValue.map(log);
wrappedValue.map(R.toUpper); //-> 'GET FUNCTIONAL' <--- 对内部值应用函数
如此一来,所有对值的操作都必须借助Wrapper.map “伸入”容器,从而使值得到一定的保护。但是null 或者undefined 的情况仍然存在,还是需要在映射的函数中去处理。不过不用心急,下面马上介绍解决的方法:
const wrappedNull = wrap(null);
wrappedNull.map(doWork); <--- doWork 被赋予了空值检查的责任
就像这个例子,由于直接调用函数,完全可以交给Wrapper类型来做错误处理。换句话说,可以在调用函数之前,检查null 、空字符串或者负数,等等。因此,Wrapper.map 的语义就由具体的Wrapper类型来确定。
不妨放慢进度,来看看map 的变种——fmap :
// fmap :: (A -> B) -> Wrapper[A] -> Wrapper[B]
Wrapper.prototype.fmap = function (f) {
return wrap(f(this.val)); <--- 先将返回值包裹到容器中,再返回给调用者
};
fmap 知道如何在上下文中应用函数值。它会先打开该容器,应用函数到值,最后把返回的值包裹到一个新的同类型容器中。拥有这种函数的类型称为Functor。
5.2.2 Functor定义
从本质上讲,Functor 只是一个可以将函数应用到它包裹的值上,并将结果再包裹起来的数据结构。下面是fmap 的一般定义:
fmap :: (A -> B) -> Wrapper(A) -> Wrapper(B) <--- Wrapper 可以是任何容器类型
fmap 函数接受一个从A->B 的函数,以及一个Wrapper(A) Functor,然后返回包裹着结果的新Functor Wrapper(B) 。图5.3显示了用increment 函数作为A->B 的映射函数,只是这里的A和B为同一类型。
图5.3 **Wrapper**内的值1,在应用函数**increment**后再次包裹成新的容器
要注意的是,fmap 在每次调用都会返回一个新的副本,这跟第2章的lenses 类似,都是不可变的。例如图5.3中的第2个Wrapper 就是一个全新的对象。在开始解决更实际的问题之前,再来看一个简单的例子。试用Functor来完成简单的2 + 3 = 5 。首先柯里化add 函数,这样就得到了plus3的 函数:
const plus = R.curry((a, b) => a + b);
const plus3 = plus(3);
现在可以把数字2放到Wrapper 中:
const two = wrap(2);
再调用fmap 把plus3 映射到容器上:
const five = two.fmap(plus3); //-> Wrapper(5) <--- 返回一个具有上下文包裹的值
five.map(R.identity); //-> 5
fmap 返回同样类型的结果,可以通过映射R.identity 来提取它的值。不过需要注意的是,值会一直在容器中,因此可以 fmap 任意次函数来转换值。
two.fmap(plus3).fmap(plus10); //-> Wrapper(15)
光看代码可能不够直观,图5.4更清楚地解释了如何fmapplus3 。
图5.4 **Wrapper**容器中的值是2。Functor会将其打开,
应用fmap的函数,再包裹函数的返回值到新的容器中
fmap 函数会返回同样的类型,这样就可以链式地继续使用fmap 。比如清单5.2所示的这个例子,它会在映射plus3 之后再打印结果。
清单5.2 通过链接Functor在给定的上下文中添加行为
const two = wrap(2);
two.fmap(plus3).fmap(R.tap(infoLogger)); //-> Wrapper(5)
在控制台上运行这段代码会打印出以下信息:
InfoLogger [INFO] 5
这种链式的函数调用是不是非常眼熟?其实很多人一直在使用Functor却没有意识到而已。比如Array的map 和filter 方法(参见3.3.2节和3.3.4节):
map :: (A -> B) -> Array(A) -> Array(B)
filter :: (A -> Boolean) -> Array(A) -> Array(A)
map 和filter 都返回同样类型的Functor,因此可以不断地链接。来看看另一个Functor:compose 。正如第4章提到的,这是从一个函数到另一个函数的映射(也保持类型不变):
compose :: (B -> C) -> (A -> B) -> (A -> C)
与其他函数式编程的神器一样,Functor有如下一些重要的属性约束。
- 必须是无副作用的。若映射
R.identity函数可以获得上下文中相同的值,即可证明Functor是无副作用的:
wrap('Get Functional').fmap(R.identity); //-> Wrapper('Get Functional')
- 必须是可组合的。这个属性的意思是
fmap函数的组合,与分别fmap函数是一样的。比如,下面表达式的效果就跟清单5.2的一致:
two.fmap(R.compose(plus3, R.tap(infoLogger))).map(R.identity); //-> 5
Functor的这些属性并不奇怪。遵守这些规则,可以免于抛出异常、篡改元素或者改变函数的行为。其实际目的只是创建一个上下文或一个抽象,以便可以安全地应用操作到值,而又不改变原始值。这也是map 可以将一个数组转换到另一个数组,而不改变原数组的原因。而Functor就是这个概念的推广。
Functor本身并不需要知道如何处理null 。例如Ramda中的R.compose, 在收到为null 的函数引用时就会抛出异常。这完全是预期的行为,并不是设计上的缺陷。因为Functor映射从一个类型到另一类型的函数。还有一个更为具体化的函数式数据类型——Monad。Monad可以简化代码中的错误处理,进而更流畅地进行函数组合。但是它跟Functor有什么关系呢?其实,Monad就是Functor“伸入”的容器。
请不要因为听到术语Monad就开始气馁,如果读者写过jQuery代码,那么应该觉得Monad很面熟。Monad只是给一些资源提供了抽象,例如一个简单的价值,一个DOM元素、事件或AJAX调用,这样就可以安全地处理其中包含的数据。比如,jQuery就可以看作DOM的Monad:
$('#student-info').fadeIn(3000).text(student.fullname());
这段代码的行为之所以像Monad,是因为jQuery可以将fadeIn 和text 行为安全地应用到DOM上。如果student-info 面板不存在,将方法应用到空的jQuery对象上只会什么也不发生,而不会抛出任何异常。Monad旨在安全地传送错误,这样应用才具有较好的容错性。下一节将更深入地介绍Monad。
5.3 使用Monad函数式地处理错误
Monad用于函数式地解决传统错误处理的问题。但在深入这个话题之前,先来了解使用Functor的局限性。使用Functor可以安全地应用函数到其内部的值,并且返回一个不可变的新Functor。但如果它遍布在代码中,就会有一些让人不那么顺心的地方。下面来看一个通过SSN获取学生地址的例子。对于这个例子,大概需要两个函数——findStudent 和getAddress ,这两个函数都给值包裹上一个安全的上下文:
const findStudent = R.curry(function(db, ssn) {
return wrap(find(db, ssn)); <--- 包裹对象获取逻辑,以避免找不到对象所造成的问题
});
const getAddress = function(student) {
return wrap(student.fmap(R.prop('address'))); <--- 用 Ramda 的 R.prop()函数来map 对象以获取其地址, 再将结果包裹起来
}
然后把这两个函数组合在一起:
const studentAddress = R.compose(
getAddress,
findStudent(DB('student'))
);
虽然成功地避免了所有的错误处理代码,但是结果却出乎意料。返回的值是被包裹了两层的address对象:
studentAddress('444-44-4444'); //-> Wrapper(Wrapper(address))
为了提取这个值,需要两次应用R.identity 函数:
studentAddress('444-44-4444').map(R.identity).map(R.identity); <--- Ugh!
当然,有的读者在自己的代码中见到两层这样的代码还可以勉强接受,如果出现三四层呢?这个时候,Monad可以成为更好的解决方案。
5.3.1 Monad:从控制流到数据流
Monad和Functor类似,但在处理某些情况时可以带来一些特殊的逻辑。下面就用简单的例子来看看Monad到底有什么特殊的功能。假如有一个函数half::Number ->Number (见图5.5):
Wrapper(2).fmap(half); //-> Wrapper(1)
Wrapper(3).fmap(half); //-> Wrapper(1.5)
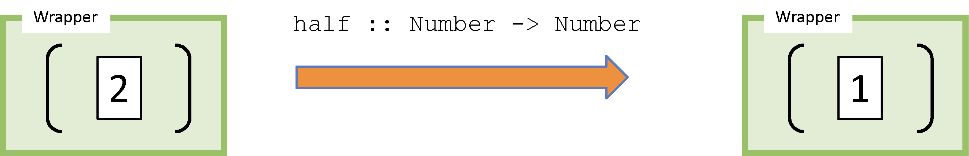
图5.5 Functor可以将函数应用到包裹的值上。例子中包裹的值会被2除
不过,Functor只管应用函数到值并将结果包裹起来,并不能加额外的逻辑。如果想要限制half 只应用到偶数,而输入是一个奇数,该怎么办?或许可以返回null 或抛出异常,但更好的策略是让该函数能给合法的数字返回正确的结果,并忽略不合法的数字。
现在假设有一个名为Empty 的类似Wrapper 的容器:
const Empty = function (_) {
; <--- 无操作。 Empty 不会存储任何值,其代表着“空”或“无”的概念
};
// map :: (A -> B) -> A -> B
Empty.prototype.map = function() { return this; }; <--- 类似,将函数 map到 Empty上会跳过该操作
// empty :: _ -> Empty
const empty = () => new Empty();
为了实现half 以满足新的需求,可以通过以下方式完成(见图5.6):
const isEven = (n) => Number.isFinite(n) && (n % 2 == 0); <--- 区分奇偶数的工具函数
const half = (val) => isEven(val) ? wrap(val / 2) : empty(); <--- half 函数只会操作偶数,否则会返回一个空的容器
half(4); //-> Wrapper(2)
half(3); //-> Empty

图5.6 函数half可以根据输入返回一个包裹好的值或空容器
Monad用于创建一个带有一定规则的容器,而Functor并不需要了解其容器内的值。Functor可以有效地保护数据,然而当需要组合函数时,即可以用Monad来安全并且无副作用地管理数据流。在前面的例子中,对于奇数会返回Empty 而不是null 。所以此后如果想应用函数,就不必在意可能会出现的异常:
half(4).fmap(plus3); //-> Wrapper(5)
half(3).fmap(plus3); //-> Empty <--- 容器知道该如何应用函数,即便其值是非法的
除此之外,Monad还适用于解决其他问题。但是本章只讨论如何使用Monad来解决命令式错误处理的问题,从而使代码更可读、更易于推理。
理论上,Monad依赖于语言的类型系统。很多人觉得显式的类型更有助于理解Monad,例如Haskell。但是其实无类型语言,如JavaScript,也可以使得Monad更易读,并且还不需要担心复杂的类型系统。
以下两个概念非常重要。
- Monad——为Monadic操作提供抽象接口。
- Monadic类型——该接口的具体实现。
Monadic类型类似于本章介绍的Wrapper 对象。不过每个Monad都有不同的用途,可以定义不同的语义便于确定其行为(例如map 或fmap )。使用这些类型可以进行链式或嵌套操作,但都应遵循下列接口定义。
- 类型构造函数——创建Monadic类型(类似于
Wrapper的构造函数)。 - unit函数——可将特定类型的值放入Monadic结构中(类似于
wrap和前面看到的empty函数)。对于Monad的实现来说,该函数也被称为of函数。 - bind函数——可以链式操作(这就是Functor的
fmap[1] ,也被称为flatmap)从现在开始,后文将使用更简短的map。顺便说一句,这个bind函数与第4章提到的“函数绑定”概念完全是两回事。 - join函数——将两层Monadic结构合并成一层。这会对嵌套返回Monad的函数特别有用。
将这一个接口应用到Wrapper 类型,就可以重构成清单5.3所示的这种形式。
清单5.3 Wrapper monad
class Wrapper { <--- 类型构造器
constructor(value) {
this._value = value;
}
static of(a) { <--- unit 函数
return new Wrapper(a);
}
map(f) { <--- bind 函数( Functor)
return Wrapper.of(f(this.value));
}
join() { <--- 压平嵌套的Wrapper
if(!(this.value instanceof Wrapper)) {
return this;
}
return this.value.join();
}
toString() { <--- 返回一个当前结构的文本描述
return `Wrapper (${this.value})`;
}
}
Wrapper 使用Functor的map 将数据提升到容器中,这样就可以无任何副作用。通常还可以用_.identity 函数来检查其内容:
Wrapper.of('Hello Monads!')
.map(R.toUpper)
.map(R.identity); //-> Wrapper('HELLO MONADS!')
map 操作被视为一种中立的functor,因为它无非只是映射函数到对象,然后关闭它。之后,Monad给map 加入特殊的功能。join 函数用于逐层扁平化嵌套结构,就像剥洋葱一样。这可以用来消除之前用functor时发现的问题,如清单5.4所示。
清单5.4 扁平化Monadic结构
// findObject :: DB -> String -> Wrapper
const findObject = R.curry(function(db, id) {
return Wrapper.of(find(db, id));
});
// getAddress :: Student -> Wrapper
const getAddress = function(student) {
return Wrapper.of(student.map(R.prop('address')));
}
const studentAddress = R.compose(getAddress, findObject(DB('student')));
studentAddress('444-44-4444').join().get(); // Address
清单5.4返回一组嵌套的wrapper,其中join 操作用于将这种嵌套结构压平成单一的层:
Wrapper.of(Wrapper.of(Wrapper.of('Get Functional'))).join();
//-> Wrapper('Get Functional')
图5.7为join操作的示意图。
图5.7 使用**join**操作递归扁平化嵌套结构的Monad,像剥洋葱一样
相对于数组(也是可以map的容器),R.flatten 操作如下:
R.flatten([1, 2, [3, 4], 5, [6, [7, 8, [9, [10, 11], 12]]]]);
//=> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
Monad通常有更多的操作,这里提及的最小接口只是其整个API的子集。一个Monad本身只是抽象,没有任何实际意义。只有实际的实现类型才有丰富的功能。幸运的是,大多数函数式编程的代码只用一些常用的类型就可以消除大量的样板代码,同时还能完成同样的工作。下面来看丰富的Monad实例:Maybe 、Either 和IO。
5.3.2 使用Maybe Monad和Either Monad来处理异常
除了用来包装有效值,Monadic的结构也可用于建模null 或undefined 。函数式编程通常使用Maybe和Either来做下列事情。
- 隔离不纯。
- 合并判空逻辑。
- 避免异常。
- 支持函数组合。
- 中心化逻辑,用于提供默认值。
这两种类型都以不同的方式提供了这些好处。下面先来介绍Maybe 。
1.用Maybe合并判空
Maybe Monad侧重于有效整合null -判断逻辑。Maybe 是一个包含两个具体字类型的空类型(标记类型)。
Just(value)——表示值的容器。Nothing()——表示要么没有值或者没有失败的附加信息。当然,还可以应用函数到Nothing上。
这些子类型实现了之前提到的所有monad的属性,而且附加了一些独特的行为。Maybe 的实现,如清单5.5所示。
清单5.5 Maybe Monad 及其子类 Maybe Either
class Maybe { <--- 容器类型(父类)
static just(a) {
return new Just(a);
}
static nothing() {
return new Nothing();
}
static fromNullable(a) {
return a !== null ? just(a) : nothing(); <--- 由一个可为空的类型创建 Maybe(即构造函数)。如果值为空,则创建一个 Nothing;否则,将值存储在 Just 子类型中来表示其存在性
}
static of(a) {
return just(a);
}
get isNothing() {
return false;
}
get isJust() {
return false;
}
}
class Just extends Maybe { <--- Just 子类型用于处理存在的值
constructor(value) {
super();
this._value = value;
}
get value() {
return this._value;
}
map(f) {
return of(f(this.value)); <--- 将映射函数应用于 Just,变换其中的值,并存储回容器中
}
getOrElse() {
return this.value; <--- Monad 提供默认的一元操作,用于从中获取其值
}
filter(f) {
Maybe.fromNullable(f(this.value) ? this.value : null);
}
get isJust() {
return true;
}
toString () { <--- 返回该结构的文本描述
return `Maybe.Just(${this.value})`;
}
}
class Nothing extends Maybe { <--- Nothing子类型用于为无值的情况提供保护
map(f) {
return this;
}
get value() {
throw new TypeError('Can't extract the value
of a Nothing.'); <--- 任何试图从 Nothing 类型中取值的操作会引发表征错误使用 Monad的异常(后文会予以介绍)
}
getOrElse(other) {
return other; <--- 忽略值,返回 other
}
filter() {
return this.value; <--- 如果存在的值满足所给的断言,则返回包含值的 Just,否则,返回 Nothing
}
get isNothing() {
return true;
}
toString() {
return 'Maybe.Nothing'; <--- 返回结构的文本描述
}
}
Maybe 显式地抽象对“可空”值(null 和undefined) 的操作,可让开发者关注更重要的事情。如上述代码所示,Maybe 是Just 和Nothing 的抽象,Just 和Nothing 各自包含自己的Monadic的实现。正如前面提到的,对于Monadic操作的实现最终取决于具体类型给予的语义。例如,map 的行为具体取决于该类型是 Nothing 还是Just 。例如,Maybe 结构可以用来存储学生对象(见图5.8):
图5.8 Maybe结构有两个子类型: Maybe和Either调用findStudent返回 有值的容器或者没有值的Nothing
// findStudent :: String -> Maybe(Student)
function findStudent(ssn)
通常开发者会在遇到不确定的调用时使用这种Monad,比如查询数据库、在集合中查找值、从服务器请求数据等。清单 5.4 所示的是抽取学生对象的address 属性的方法。因为目标记录可能不存在,所以可以给Maybe 的变量加上safe 前缀:
// safeFindObject :: DB -> String -> Maybe
const safeFindObject = R.curry(function(db, id) {
return Maybe.fromNullable(find(db, id));
});
// safeFindStudent :: String -> Maybe(Student)
const safeFindStudent = safeFindObject(DB('student'));
const address = safeFindStudent('444-44-4444').map(R.prop('address'));
address; //-> Just(Address(...)) or Nothing
使用Monad的另一个好处是,它可以修饰函数签名,以表征其返回值的不确定性。Maybe.fromNullable是个非常有用的函数,可用于你处理null 判断。如果有合法值,调用safeFindStudent 会产生一个Just(Address(...)) ,否则返回Nothing 。将R.prop map到Monad上的行为跟我们想的一样。此外,它还做了些检测程序错误和API滥用的工作:也可以用它来当参数的前提条件。如果一个无效的值被传递到Maybe.fromNullable, 它会产生Nothing 类型,这样调用 get() 来打开容器将抛出一个异常:
TypeError: Can't extract the value of a Nothing.
使用Monad应该首先想到将函数map上去,而不是直接去提取其内容。也可以使用getOrElse 安全地获取其内容,如果是Nothing,则返回默认值。想想给表单字段添值的例子,如果没有数据可以添一个默认值:
const userName = findStudent('444-44-4444').map(R.prop('firstname'));
document.querySelector('#student-firstname').value =
username.getOrElse('Enter first name');
如果提取操作成功,则会显示学生的用户名;否则,else 分支会返回默认字符串。
Maybe的其他形式
读者可能已经见过其他形式的
Maybe,如Java 8和Scala中使用Optional或Option类型。它们将Just与Nothing称为Some和None。语义上,它们其实做的是同样的事情。
现在重温前面提到的面向对象悲剧的反模式的 null 判断。来看getCountry 函数:
function getCountry(student) {
let school = student.school();
if(school !== null) {
let addr = school.address();
if(addr !== null) {
return addr.country();
}
}
return 'Country does not exist!';
}
这也太麻烦了。如果函数返回'Country does not exist!' ,到底是哪句话引起的异常?在这段代码中,很难辨别是哪一行有问题。如果写出这样的代码,风格和正确性已经不是关键,实际上在用各种补丁来保护函数调用。如果没有Monadic的特质(trait),那么基本上需要到处放置这种null 检查以防TypeError 异常。Maybe 则能够以可重用的方式封装了这种行为。看看下面这个例子:
const country = R.compose(getCountry, safeFindStudent);
由于safeFindStudent 返回一个包含Student对象的容器,现在可以删掉所有的防守代码,即使有非法值也可以安全地传递下去。看看新的getCountry:
const getCountry = (student) => student
.map(R.prop('school'))
.map(R.prop('address'))
.map(R.prop('country'))
.getOrElse('Country does not exist!'); <--- 如果任何一步返回Nothing,所有的后续操作都会被跳过
不管是在哪一步返回null ,这个错误还是可以安全地作为Nothing 传递下去,所有后续操作都优雅地跳过Nothing。代码现在不但更声明式、更优雅,而且更容错。
提升函数
仔细看看这个函数:
const safeFindObject = R.curry(function(db, id) { return Maybe.fromNullable(find(db, id)); });注意到名字的前缀是
safe,返回值是Monad。这是一个很好的实践,因为明确了该函数包含着潜在危险。但难道所有函数都需要这么包成Monad吗?答案是不一定。一种名为函数提升的技术,可以把任意普通函数变化成能操作Monad的函数,使其成为一个“安全”的函数。这是一个非常方便的工具,因为无须改变现有的实现。const lift = R.curry(function (f, value) { return Maybe.fromNullable(value).map(f); });这样就不需要直接在函数体里面使用Monad了。
const findObject = R.curry(function(db, id) { return find(db, id); });
lift会把函数放到容器中:const safeFindObject = R.compose(lift, findObject); safeFindObject(DB('student'), '444-44-4444');这种提升可以用在任何函数上!
很明显,Maybe 擅长于集中管理的无效数据的检查,但它没有(双关Nothing )提供关于什么地方出了错的信息。我们需要一个更积极的,可以知道失败原因的解决方案。解决这个问题,要最好的工具是Either monad。
2.使用Either从故障中恢复
Either 跟Maybe 略有不同。Either 代表的是两个逻辑分离的值a 和b ,它们永远不会同时出现。这种类型包括以下两种情况。
Left(a)——包含一个可能的错误消息或抛出的异常对象。Right(b)——包含一个成功的值。
Either 通常操作右值,这意味着在容器上映射函数总是在Right(b)子类型上执行。它类似于Maybe 的Just 分支。
Either 的常见用法是为失败的结果提供更多的信息。在不可恢复的情况下,左侧可以包含一个合适的异常对象。清单5.6所示的列表显示了Either Monad的实现。
清单5.6 包含Left和Right子类的Either Monad
class Either {
constructor(value) { <--- Either 类型的构造函数,接收一个异常或合法的值(主右的)
this._value = value;
}
get value() {
return this._value;
}
static left(a) {
return new Left(a);
}
static right(a) {
return new Right(a);
}
static fromNullable(val) { <--- 若值非法则返回 Left,否则返回 Right
return val !== null ? right(val): left(val);
}
static of(a){ <--- 创建一个包含值的Right 实例
return right(a);
}
}
class Left extends Either {
map(_) { <--- 通过映射函数对 Right 结构中的值进行变换,对 Left 不进行任何操作
return this; // noop
}
get value() { <--- 尝试提取 Right 结构中的值,否则抛出 TypeError
throw new TypeError('Can't extract the
value of a Left(a).');
}
getOrElse(other) {
return other; <--- 提取 Right 的值,如果不存在,则返回给定的默认值
}
orElse(f) {
return f(this.value); <--- 将给定函数应用于 Left 值,不对Right 进行任何操作
}
chain(f) { <--- 将给定函数应用于 Right值并返回其结果,不对 Left 进行任何操作。这是 chain 方法第一次出现(将在后面解释)
return this;
}
getOrElseThrow(a) { <--- 如果为 Left, 通过给定值抛出异常; 否则,忽略异常并返回 Right 中的合法值
throw new Error(a);
}
filter(f) { <--- 如果为 Right 且给定的断言为真,返回包含值的 Right 结构;否则,返回空的 Left
return this;
}
toString() {
return `Either.Left(${this.value})`;
}
}
class Right extends Either {
map(f) { <--- 通过映射函数对 Right 结构中的值进行变换,对 Left 不进行任何操作
return Either.of(f(this.value));
}
getOrElse(other) {
return this.value; <--- 提取 Right 的值,如果不存在,则返回给定的默认值
}
orElse() { <--- 将给定函数应用于 Left 值上,不对 Right 进行任何操作
return this;
}
chain(f) { <--- 将给定函数应用于 Right 值上并返回其结果,不对 Left 进行任何操作。这是 chain 方法首次出现
return f(this.value);
}
getOrElseThrow(_) { <--- 如果为 Left,通过给定值抛出异常;否则,忽略异常并返回 Right中的合法值
return this.value;
}
filter(f) { <--- 如果为 Right且给定的断言为真时,返回包含值的 Right 结构; 否则, 返回空的 Left
return Either.fromNullable(f(this.value) ? this.value : null);
}
toString() {
return `Either.Right(${this.value})`;
}
}
注意,Maybe 和Either 类型都有的一些操作是空的(无操作)。这是故意为之,目的是充当占位符,遇到特定Monad时可以跳过。
现在试试Either 。用这个Monad可以实现另一个版本的safeFindObject :
const safeFindObject = R.curry(function (db, id) {
const obj = find(db, id);
if(obj) {
return Either.of(obj); <--- 也可以使用 Either.fromNullable()来抽象 if-else 语句。代码中之所以这样写,是为了更好的诠释
}
return Either.Left(`Object not found with ID: ${id}`); <--- Left 结构也可以包含值
});
如果数据存取操作是成功的,学生对象会存储在右侧;否则,在左侧设置错误信息,如图5.9所示。
图5.9 **Either** 的结构可以存储对象(到右侧)或带有堆栈信息的错误
(到左侧)。这样可以返回单一的值,或者在发生故障的情况下返回错误消息
读者可能会好奇:“为什么不使用在第4章讲过的2元组tuple(或Pair )类型来捕捉对象和消息呢?”一个微妙的原因是:元组代表product类型,这意味着它的操作数之间的逻辑关系是与。在错误处理的情况下,更适合使用互斥类型来建模,因为不会同时存在正常和错误两种情况。
使用Either ,也可以通过getOrElse (一定要提供合适的默认值)提取结果:
const findStudent = safeFindObject(DB('student'));
findStudent('444-44-4444').getOrElse(new Student()); //->Right(Student)
但是不同于Maybe.Nothing 结构,Either.Left 结构包含一个可以应用函数的值。如果findStudent 没有返回一个对象,则可以使用Left 的orElse 函数来记录错误:
const errorLogger = _.partial(logger, 'console', 'basic', 'MyErrorLogger',
'ERROR');
findStudent('444-44-4444').orElse(errorLogger);
这会将如下信息打印到控制台:
MyErrorLogger [ERROR] Student not found with ID: 444-44-4444
Either 结构也可用于把代码与可能会抛出异常(由开发者自己或其他人实现的)的函数隔离开来。这样的函数更加类型安全——在早期将异常消除,而不会到处传递下去。比如JavaScript的decodeURI-Component 函数,就可以产生一个URI错误:
function decode(url) {
try {
const result = decodeURIComponent(url); <--- 抛出一个 URIError
return Either.of(result);
}
catch (uriError) {
return Either.Left(uriError);
}
}
这段代码还将错误的堆栈信息放到了Either.Left中,如果有必要,可以将这个异常对象抛出。假设需要解码并跳转到一个URL。下面的函数对于合法和非法输入都能够正常工作:
const parse = (url) => url.parseUrl(); <--- 该函数创建于 4.4.2 节
decode('%').map(parse); //-> Left(Error('URI malformed'))
decode('http%3A%2F%2Fexample.com').map(parse);
//-> Right(true)
函数式编程可以避免以往动不动就抛出异常的问题。可以通过将异常对象存储到Left结构来延迟异常的抛出。当需要打开Left结构时再处理该异常:
...
catch (uriError) {
return Either.Left(uriError);
}
现在读者应该已经学会用Monad效仿try-catch 的机制了。Scala用类似的类型Try 来替代try-catch 。虽然不是一个完整的Monad,但是Try 代表着计算有可能会导致异常或返回一个结果。Try 也包括两个类型Success 和Failure ,这在语义上跟Either 是等价的。
值得探索的函数式编程项目
这两章的大多数话题,如部分应用、元组、函数组合、Functor和Monad以及后面会提及的概念,都在Fantasy Land中有规范(https://github.com/fantasyland)。Fantasy Land定义了如何实现的JavaScript代数数据结构。尽管本书一直在使用像Lodash和Ramda这些易于使用的函数式库,但Fantasy Land或者Folktale(http://folktalejs.org/)也是很值得深入探讨的。
Monad可以帮助你应对软件开发中的不确定性和可能出现的异常。但该如何与外界交互呢?
5.3.3 使用IO Monad与外部资源交互
Haskell被视为唯一在很大程度上依赖于IO Monad的编程语言,比如文件的读取/写入、打印,等等。其实这可以简单地翻译成JavaScript,代码看起来像这样:
IO.of('An unsafe operation').map(alert);
虽然这是一个简单的例子,但是可以看到一段错综复杂IO被塞进惰性的Monadic操作,然后交给平台运行(在例子中,只是发一个简单的警报)。但是JavaScript不可避免地需要能够与不断变化的、共享的、有状态的DOM相互作用。其结果是,对DOM进行任何操作,无论是读还是写,都会产生副作用,违反引用透明性。先从最基础的IO操作开始:
const read = function(document, id) {
return document.querySelector(`\#${id}`).innerHTML; <--- 多次调用 read 可能产生不同的结果
}
const write = function(document, id, val) {
document.querySelector(`\#${id}`).innerHTML = value; <--- 不返回任何值,显然会造成改变(不安全操作)
};
当分开执行时,这些函数的输出得不到保证。不但执行顺序很关键,而且调用多次read 也可以产生不同的结果,比如在此期间DOM被另一个write 调用修改。记住,把不纯的代码隔离出来,就像第4章中的showStudent 一样,就是为了要始终保证一致的结果。
虽然不能避免改变或消除副作用,但至少从应用的角度把IO操作当作不可变的。可以将 IO操作提升到Monadic的链式调用中,让Monad主导数据流。要做到这一点,可以使用清单5.7所示的IO Monad。
清单5.7 IO Monad
class IO {
constructor(effect) { <--- IO 构造器包含读和写的操作(比如读写 DOM)。该操作由 effect 函数表示
if (!_.isFunction(effect)) {
throw 'IO Usage: function required';
}
this.effect = effect;
}
static of(a) { <--- Unit 函数用于将值或函数提升至IO Monad 中
return new IO( () => a );
}
static from(fn) { <--- Unit 函数用于将值或函数提升至IO Monad 中
return new IO(fn);
}
map(fn) { <--- 映射 Functor
var self = this;
return new IO(function () {
return fn(self.effect());
});
}
chain(fn) {
return fn(this.effect());
}
run() {
return this.effect(); <--- 执行 IO 的惰性调用链
}
}
这个Monad跟其他的不太一样,因为它包装的是effect函数,而不是一个值。记住,一个函数可以看作一个等待计算的惰性的值。有了这个Monad,可以将任何DOM操作都链接成一个“伪”引用透明的操作,并能确保所有引起副作用的函数的调用顺序不会跑偏。
在展示这一点之前,先将write 和read 重构成柯里化函数:
const read = function (document, id) {
return function () {
return document.querySelector(`\#${id}`).innerHTML;
};
};
const write = function(document, id) {
return function(val) {
return document.querySelector(`\#${id}`).innerHTML = val;
};
};
为了避免将document 对象传来传去,把它部分应用到这两个函数上:
const readDom = _.partial(read, document);
const writeDom = _.partial(write, document);
改完之后,readDom 和writeDom 都可以链式地调用(也可以组合)。做这些是为了之后可以与IO操作连接在一起。考虑这样一个简单的例子,从HTML元素读取一个学生的姓名,并将单词的第一个字母大写:
<div id="student-name">alonzo church</div>
const changeToStartCase =
IO.from(readDom('student-name')).
map(_.startCase). <--- 可以在这里映射任何变换操作
map(writeDom('student-name'));
然后写入DOM中。注意,链中的最后一个操作不是纯的。所以,changeToStartCase 应该输出什么呢?使用Monad的好处是保持了纯函数的规定。就像任何其他Monad,map 的输出是Monad本身,IO 的一个实例,这意味着在这一阶段什么都还未执行。这里只是声明式地描述了一段IO操作。最后,运行下面的代码:
changeToStartCase.run();
看看DOM,会发现:
<div id="student-name">Alonzo Church</div>
可见这是符合引用透明性的IO操作!IO Monad最重要的好处是,它很明显地将不纯分离了出来。正如changeToStartCase 的定义所示的,IO容器上映射的转换函数完全从读写操作中隔离出来。完全可以根据需要任意改变HTML元素的内容。同时,由于这一切都在同一刻执行,因此可以保证发生在读写操作之间什么都不发生,不会导致不可预测的结果。
Monad只不过是链式表达式或链式计算。它可以构建流水线上的每一步,像传送带一样对每个步骤进行处理。但链式操作并不是使用Monad的唯一方式。使用Monadic容器作为返回类型既保持了函数的一致和类型的安全,也保留了引用透明性。如第4章提到的,这完全满足了组合链式函数的要求。
5.4 Monadic链式调用及组合
如前所述,Monad控制了充满副作用的世界,使得开发者可以在可组合的结构中使用它们。第4章中提到,组合是降低复杂性的关键技术,但当时并没有费心去检查无效数据。如果findStudent 已经返回null, 整个应用就失败了,如图5.10所示。

图5.10 函数findStudent和append的组合。如果没有适当的检查, 前者如果产生null的返回值,后者将会失败,抛出TypeError异常
幸运的是,只需很少的代码,就可以将Monad制成可组合的,从而可以享受流畅的、富有表现力的错误处理机制。如果让管道中的函数能够优雅地避开null 陷阱,不是很好吗?
如图5.11所示,首先是确保将要执行的第一个函数把结果包裹成一个适当的Monad:Maybe 和Either 在这种情况下都适用。在函数式编程中,结合函数有两种方式:链和组合。上一章提到,showStudent 有3个部分。

图5.11 图5.10中的两个函数使用Monad来传递null (Maybe或Either都可以),从而优雅地处理错误
- 规范化用户输入。
- 查找学生记录。
- 将学生信息添加到HTML页面。
甚至还可以添加输入验证的组合,使之更加复杂。因此,这个方案有两个地方可能失败:验证错误或者学生的取操作失败。可以简单地重构一下,用Either Monad给出相应的错误消息,如清单5.8所示。
清单5.8 用Either重构函数
// validLength :: Number, String -> Boolean
const validLength = (len, str) => str.length === len;
// checkLengthSsn :: String -> Either(String)
const checkLengthSsn = function (ssn) { <--- 除了可以将这些函数提升至 Either中,还可以直接使用Monad , 并根据错误来提供指定的错误信息
return Either.of(ssn).filter(_.bind(validLength, undefined, 9))
.getOrElseThrow(`Input: ${ssn} is not a valid SSN number`);
};
// safeFindObject :: Store, string -> Either(Object)
const safeFindObject = R.curry(function (db, id) {
return Either.fromNullable(find(db, id)) <--- 除了可以将这些函数提升至 Either中,还可以直接使用Monad , 并根据错误来提供指定的错误信息
.getOrElseThrow(`Object not found with ID: ${id}`);
});
// finStudent :: String -> Either(Student)
const findStudent = safeFindObject(DB('students'));
// csv :: Array => String
const csv = arr => arr.join(','); <--- 重构过的 csv 函数由一个数组返回一个字符串
由于这些函数都已经柯里化,可以部分地求值,构造出新的函数,就像之前那样,再加些日志函数:
const debugLog = _.partial(logger, 'console', 'basic',
'Monad Example', 'TRACE');
const errorLog = _.partial(logger, 'console', 'basic',
'Monad Example', 'ERROR');
const trace = R.curry((msg, val)=> debugLog(msg + ':' + val));
完成!在Monadic式的操作确保数据可以轻松地通过函数调用,不需要任何额外的成本。来看看应该如何使用Either 和Maybe 自动处理showStudent 的错误,如清单5.9所示。
清单5.9 使用自动错误处理的单子showStudent
const showStudent = (ssn) => <--- map 和 chain 函数可以用于在 Monad 中对数据进行变换。 Map 返回一个 Monad,而为了避免嵌套,将 chain 与 map 交叉使用来保证在调用过程始终都是单层的 Monad
Maybe.fromNullable(ssn)
.map (cleanInput)
.chain(checkLengthSsn)
.chain(findStudent)
.map (R.props(['ssn', 'firstname', 'lastname'])) <--- 从对象中将选择的属性提取为一个数组
.map (csv)
.map (append('#student-info'));
清单5.9显示了如何使用chain 函数。这只不过使用map 然后join 的快捷方式,从而防止Monad出现嵌套的层次结构。跟map 一样,但是 chain 在应用完函数后不会再包多余的一层Monad类型。
此外,需要注意这两个Monad可以无缝地交错(interleave)。这是因为Either 或者Maybe 实现了相同的Monad接口。现在,可以试着调用如下代码:
showStudent('444-44-4444').orElse(errorLog);
这会产生两种结果:如果学生对象成功找到,就追加学生信息到HTML:
Monad Example [INFO] Either.Right('444-44-4444, Alonzo,Church')
否则,跳过整个操作,并使用OrElse 子句:
Monad Example [ERROR] Student not found with ID: 444444444
使用链并不是唯一的模式。也可以很容易地通过函数组合引入错误处理逻辑。要做到这一点,就要把面向对象的那些方法转换成多态的函数,让这些函数可以应用在任何Monad类型上(按照里氏替换原则)。具体的,例如创建通用的map 和chain 函数,如清单5.10所示。
清单5.10 通用的map和chain函数
// map :: (ObjectA -> ObjectB), Monad -> Monad[ObjectB]
const map = R.curry(function (f, container) {
return container.map(f);
});
// chain :: (ObjectA -> ObjectB), M -> ObjectB
const chain = R.curry(function (f, container) {
return container.chain(f);
});
现在可以使用这些函数将Monad注入函数组合好的表达式中。清单5.11的结果会和清单5.9一样。由于Monad控制了表达式到下一表达式的数据流,这种编程方式也被称为可编程逗号(programmable commas),也就是point-free。在这种情况下,逗号用来分割表达式,就像JavaScript中用分号来分割语句一样。此外,大量trace 语句的使用可以明示数据流过函数的过程(日志记录语句对于调试来说也非常有用)。
清单5.11 Monad用作可编程逗号
const showStudent = R.compose(
R.tap(trace('Student added to HTML page'))
map(append('#student-info')),
R.tap(trace('Student info converted to CSV')),
map(csv),
map(R.props(['ssn', 'firstname', 'lastname'])),
R.tap(trace('Record fetched successfully!')),
chain(findStudent),
R.tap(trace('Input was valid')),
chain(checkLengthSsn),
lift(cleanInput));
运行代码后,控制台会打印出以下的日志消息:
Monad Example [TRACE] Input was valid:Either.Right(444444444)
Monad Example [TRACE] Record fetched successfully!: Either.Right(Person
[firstname: Alonzo| lastname: Church])
Monad Example [TRACE] Student converted to row: Either.Right(444-44-4444,
Alonzo, Church)
Monad Example [TRACE] Student added to roster: Either.Right(1)
追踪程序
清单5.11展示了这段代码多么容易追踪。无须把代码嵌入函数体上,可以通过日志代码描述调用前和调用后的函数,这非常有利于整个程序的问题追踪和定位。如果写成面向对象的风格,就不可能做到这一点,除非修改实际函数或者使用切面编程,但是这些代价都过于庞大。然而函数式编程中,这一切都这么轻松!
最后归纳一下整个流程,如图5.12所示。图5.13描述的是findStudent 不成功的情况下程序的行为。

图5.12 在findStudent成功地找到了SSN的学生 对象情况下,showStudent函数的数据流
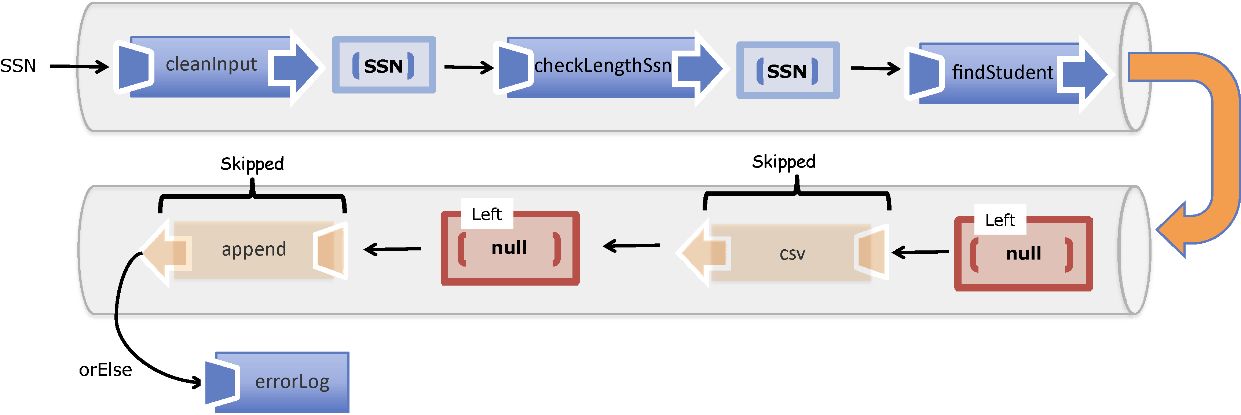
图5.13 在findStudent不成功的情况下,对其余部分的影响。 管道中任何组件的故障都会被优雅地跳过
那么,showStudent 是不是就止步于此了?不尽然。从前面IO Monad的讨论来看,还可以在DOM的读写上有所改进:
map(append('#student-info')),
由于append 已经自动柯里化,很容易映射到IO 。接下来要做的事情是把值提升到csv ,通过映射R.identity 函数到IO 来提取其内容,然后连接两个操作:
const liftIO = function (val) {
return IO.of(val);
};
这将产生清单5.12所示的程序。
清单5.12 完整的showStudent程序
const showStudent = R.compose(
map(append('#student-info')),
liftIO,
map(csv),
map(R.props(['ssn', 'firstname', 'lastname'])),
chain(findStudent),
chain(checkLengthSsn),
lift(cleanInput));
结合了Io monad,能使所实现的这一切变得更棒。可以看到,showStudent(SSN) 已经贯穿了验证和获取学生记录的所有逻辑。接下来只需运行并等程序跑完把数据写到屏幕上。因为已经提升了数据到IO Monad,需要真正调用它的run 函数,才能把惰性的计算都进行求值,最终把结果刷新到屏幕上:
showStudent(studentId).run(); //-> 444-44-4444, Alonzo, Church
使用IO 的常用模式是把所有不纯的操作都累积到最后。这样生成的程序可以一步一个脚印地完成所有必要的业务逻辑,留下最后“端盘子上菜”的杂活留给IO Monad来完成,这样做既声明式,又无副作用。
回顾一下非函数式版本的showStudent ,就能体会到函数式的代码是多么易于推理:
function showStudent(ssn) {
if(ssn != null) {
ssn = ssn.replace(/^\s*|\-|\s*$/g, '');
if(ssn.length !== 9) {
throw new Error('Invalid Input');
}
let student = db.get(ssn);
if (student) {
document.querySelector(`#${elementId}`).innerHTML =
`${student.ssn},
${student.firstname},
${student.lastname}`;
}
else {
throw new Error('Student not found!');
}
}
else {
throw new Error('Invalid SSN!');
}
}
由于有副作用、缺乏模块化以及命令式的错误处理,这段代码很难使用和测试。我们将在下一章更仔细地分析这一点。所以函数组合用于控制程序的流程,Monad则用于控制数据流。在函数式编程生态系统中,二者可能是最重要的概念了。
随着本章的结束,第二部分也接近尾声了。希望开发者的工具箱中已经配备了所有现实世界需要的函数式解决方案。
5.5 总结
- 面向对象抛异常的机制让函数变得不纯,把大部分的责任都推到了调用者的尝试——
try-catch逻辑上。 - 把值包裹到容器中的模式是为了构建无副作用的代码,把可能不纯的变化包裹成引用透明的过程。
- 使用Functor将函数应用到容器中的值,这是无副作用地、不可变地访问和修改操作。
- Monad是函数式中用来降低应用复杂度的设计模式,通过这种模式可以将函数编排成安全的数据流程。
- 交错的组合函数和Monadic类型是非常有弹性而且强大的,如
Maybe、Either和IO。
[1] 这不是Functor的fmap,bind是flatmap,flatmap是flat与map的组合。——译者注
第三部分 函数式技能提升
在第一部分和第二部分中,我们介绍了函数式编程应用到现实世界问题所需要的工具。读者应该从中学到了一些新技术和新的设计模式,这所有的一切都以消除副作用为目的,这样才能使代码模块化、可扩展、易于推理。这一部分将会使用这些知识来解决JavaScript应用单元测试的挑战,将函数式作为代码的保护伞,处理异步事件带来的复杂数据。
第6章的重点是命令式的单元测试,以及探究为什么函数式编程本质上是更可测试的、更简单的。引用透明带来的好处是可以进行基于属性的测试(property-based testing)。
第7章探讨了JavaScript的函数上下文,以及深层嵌套函数闭包和递归时应考虑到的性能。为了提高整体应用性能,读者应了解惰性求值、记忆化及尾递归调用优化。
第 8 章会介绍更多针对复杂应用的 Monadic 设计模式。本章着重关注两个常见的JavaScript任务:异步地从服务器或数据库获取数据;使用RxJS响应式的编程方式替代传统的函数式回调。
完成本书的学习后,读者应能自如地在职业领域中运用函数式编程技术。
第6章 坚不可摧的代码
本章内容
- 函数式编程会如何改变测试方式
- 认识到测试命令式代码的挑战
- 使用QUnit测试函数式代码
- JSCheck探索属性测试
- 使用Blanket测量程序的复杂性
有好篱笆,才有好邻居。
——Robert Frost,《Mending Wall》
通过学习第一部分和第二部分的内容,读者应该已经注意到了本书的中心主题:函数式编程使代码更容易理解、阅读和维护。甚至可以说,函数式编程的声明式特性使代码自成文档。
现在,如何证明所写的函数式代码能工作?换句话说,如何确保它满足客户的要求?唯一的办法就是编写一个测试来验证代码的结果是否符合预期。函数式的思考方式会对应用级别的代码产生很深的影响,所以,测试也不例外。
创建单元测试,以确保代码满足问题的说明,并涵盖各种可能会导致其失败的边界条件。写过单元测试的读者可能已经发现,编写命令式程序的测试,特别是在大型代码库中,会是一个艰巨的任务。由于存在副作用,当命令式代码做出对全局状态的假设失误时,就会引发错误。同样,有些测试还不能单独运行,必须要保持正确的调用顺序,才会得到一致的结果。这些因素通常导致大多数测试都是代码写完之后补的,甚至不加测试。
本章将探究为什么函数式代码本质上就是可测的,而在大多数其他范式就必须通过刻意的设计使之易于测试。有很多关于测试的最佳实践,例如消除外部依赖,使函数可预测之类的,其实都是函数的核心原则。引用透明的纯函数带来了更先进的测试方法——基于属性的测试。在开始之前,先来了解函数式编程对不同类型测试的影响,并把重点放在最有帮助的“单元测试”之上。
6.1 函数式编程对单元测试的影响
通常有3种测试类型:单元测试、集成测试和验收测试。在测试金字塔(见图6.1)中,从验收测试(顶部)到单元测试(底部),函数式编程的影响越来越大。这是非常显而易见的,因为函数式编程是一种专注于函数和模块,及其组合的软件开发模式。
图6.1 函数式编程是着重于代码的软件模式,其影响力主要集中于单元测试的设计, 对集成测试影响并不大,对验收测试不太有影响
虽然Web应用程序的外观、易用性和适航性测试对用户很重要,但这些离代码都非常远,无论代码用函数式还是命令式写并不是很重要。这种情况更适合用自动化测试框架。对于集成测试,正如第4章提到的,函数式编程把应用程序分割成不同的组件再组合,毫无疑问,前提是需要知道它们的联系。因此,只需要遵循函数式编程范式,集成测试将能节省大量的时间。
函数式编程的真正重点当然是函数、模块单元以及它们之间的交互。本书选取的测试库是流行的 QUnit。本书不会介绍如何搭建这个测试环境。如果之前配置过任何单元测试库,那么搭建QUnit将是十分简单的任务。当然,读者也可以在本书的附录中找到更多细节。
单元测试的基本结构如下:
QUnit.test('Test Find Person', function(assert) {
const ssn = '444-44-4444';
const p = findPerson(ssn);
assert.equal(p.ssn, ssn);
});
测试代码都不会混在应用代码中,而是放在另一个JavaScript文件中,然后把所有需要的函数导入即可。由于副作用和突变的存在,单元测试命令式的代码非常具有挑战性。下面来看一些测试命令式代码的“痛点”。
6.2 测试命令式代码的困难
测试命令式代码和写命令式代码一样难受。测试命令式代码是真正的挑战,因为它基于全局状态与变化,而不是控制数据流,再在其中加入计算。设计单元测试的其中一个主要原则是隔离。单元测试应该不需要察觉到周围其他测试或数据,但代码中的副作用使得这一原则很难履行。
命令式代码的特点如下。
- 很难识别或拆分成简单任务。
- 依赖于共享资源,使得测试结果不一致。
- 强行预定义求值的顺序。
下面具体来看其中的一些挑战。
6.2.1 难以识别和分解任务
单元测试本应测试应用程序中非常小的部分。在过程式的程序中,确定模块的单位是非常困难的,因为从一开始就没有以直观分割的方式设计。在这种情况下,测试单元是封装了业务逻辑的函数。例如,本书前面提到的showStudent 的命令式版本。图6.2尝试将它分割成一些部分。

图6.2 showStudent 中的单一功能函数。为了简化编写测试,这些部分应分成与验证、
IO和错误处理相独立的函数
可以看到,该程序由紧密耦合的业务逻辑组成,业务在各个方面都与程序相互联系。完全没有理由让数据验证、获取学生记录以及修改DOM耦合在一起。这些完全可以拆成单独的业务单元再组合进来。此外,通过第5章的介绍,错误处理逻辑应该用Monad来分离处理。
Monad和错误处理
第5章介绍了一些设计模式,比如如何删除错误处理代码,同时仍保持它们的容错。通过使用
Maybe Monad和Either Monad,开发者可以写出point-free风格的代码,让错误在组件间安全地传递,确保程序保持响应。
为了提高函数式的可测试性,开发者需要想办法按纯与不纯将代码分割成松散耦合的组件。由于有副作用,比如对DOM或外部存储的读写操作,不纯的代码会很难测试。
6.2.2 对共享资源的依赖会导致结果不一致
第2章中提到,用JavaScript自由访问全局数据是有多么不明智。测试具有副作用的代码需要格外小心,因为需要负责管理函数相关的所有状态。很多情况下,增加一个新的测试会导致其他很多不相关的测试失败。为什么会这样?为了使测试可靠,必须保证每个测试自包含并独立于其他测试,这意味着每个单元测试基本上运行在其自己的沙箱中,保持系统的状态完全不受影响。违反此规则的测试可能不会每次都产生相同的结果。
下面用一个简单点的例子进行说明。回想一下命令式的increment 函数:
var counter = 0; // (global)
function increment() {
return ++counter;
}
可以写一个简单的单元测试,使其返回1。但是如果运行100次,返回的还是1吗?因为该函数修改依赖来自外部的数据(见图6.3)。

图6.3 重复命令式的increment 函数的单元测试是不可能通过的,因为函数依赖了外部的计数器变量
因为第一次修改了外部计数器变量,依赖于同样变量的第二次测试自然不会再返回1,所以第二次测试失败了。同理,有副作用的函数也容易因顺序变化而发生错误。下面就此进行验证。
6.2.3 按预定义顺序执行
单元测试应该是符合交换律的,意思是说,即使改变测试运行的顺序,也不应该对结果有任何影响。跟前面的原因一样,不纯的函数也不符合这一原则。要解决此问题,单元测试库,例如QUnit含有一些在建立和关闭时可以配置全局测试环境的外部机制。但一个测试的设置可能会跟另一个完全不同的,所以不得不在每个测试开始时设立先决条件。这也意味着,对于每个测试,测试人员需要负责识别被测代码中的所有副作用(外部依赖)。
为了说明这一点,先创建一个increment 的简单测试来验证其对负数、零和正数的行为(见图6.4)。在第一次运行时(左侧图),所有测试都通过了。当随机打乱测试(右侧图)的顺序后,第二测试失败。这是因为测试运行在建立好的周边状态的假设上。
图6.4 在错误的系统的全局状态设定下,会直接导致测试失败。左侧图显示了所有测试完全执行, 因为每个测试在执行时的状态均正确。但如果打乱测试(右侧图),测试状态的假设就不成立了
就算把每一个测试的状态都设置正确,让测试通过,但也不能保证它们的位置。只需要简单换一下位置,就足以让所有断言失效。
运用函数式的思维有助于构建可靠的测试。如果代码是函数式风格,这些好处将不请自来。预期往测试代码中硬塞函数式原则,还不如一开始就投入时间写函数式的代码。下面来看测试函数式代码的好处。
6.3 测试函数式代码
无论是测试命令式还是函数式代码,很多单元测试的最佳实践,如隔离、可预测性和可重复性,都可以通过函数式编程获得。因为每一个函数都明确规定所有输入参数,所以只需简单地使用边界条件作为参数输入验证函数中的所有路径即可。相对于副作用,像前面的章节提到的意义,所有不纯的代码都可以放到Monad中,纯的代码都可以简单明确地定义。
此外,循环完全可以通过诸如map 、reduce 、filter 和递归,或者一些无副作用的函数式库替代。这些技术和设计模式有助于有效地抽象复杂代码,从而只需集中精力测试主要的业务逻辑部分。
测试函数式代码的好处如下。
- 把函数当作黑盒子。
- 专注于业务逻辑,而不是控制流。
- 使用Monadic隔离纯和不纯的代码。
- Mock外部依赖。
6.3.1 把函数当作黑盒子
函数式编程鼓励以松耦合的方式对一组输入做处理,使其与应用程序的其余部分相独立。这些函数无副作用,引用透明,因此不管调用多少次,也不管以什么样的顺序测试,都可以很容易地预测测试结果。这样就可以把函数作为黑盒子,只专注于由给定的输入断言相应的输出。测试showStudent 函数的代价与测试increment 函数是一个级别的,如图6.5所示。

图6.5 针对increment 函数的测试,可以重复或以不同的顺序进行,而不改变其结果
第1章中提到,在函数签名中明确地声明所有参数,会使其更可配置,从而使得测试更为简单——因为调用时显然知道应该给什么样的参数,返回什么样的结果。简单函数通常只有一两个参数,这样很容易组合成功能更丰富的函数。
6.3.2 专注于业务逻辑,而不是控制流
本书始终贯彻把任务分解成简单函数的模式。第1章提到,编写函数式代码时,会花大部分的时间来分解问题,这是非常具有挑战性的。剩下的事情只是将函数组合在一起。幸运的是,Lodash和Ramda库为JavaScript提供了像curry 和compose 这样的函数黏合剂。在结合 4.6 节的组合子,前期分解问题所花费的时间将会在测试阶段收到回报。唯一的任务就是测试这些组成主要逻辑的一个个函数。下面开始编写函数式版本的computeAverageGrade 的测试。该函数的代码如清单6.1所示。
清单6.1 测试computeAverageGrade 程序
const fork = function(join, func1, func2){
return function(val) {
return join(func1(val), func2(val));
};
};
const toLetterGrade = function (grade) {
if (grade >= 90) return 'A';
if (grade >= 80) return 'B';
if (grade >= 70) return 'C';
if (grade >= 60) return 'D';
return 'F';
};
const computeAverageGrade =
R.compose(toLetterGrade, fork (R.divide, R.sum, R.length));
QUnit.test('Compute Average Grade', function(assert) {
assert.equal(computeAverageGrade([80, 90, 100]), 'A');
});
该程序用了许多简单的函数,如Ramda的R.divide 、R.sum 和R.length, 还用了自定义函数组合子fork ,再将其结果与toLetterGrade 组合。Ramda提供的函数已经测试过了,因此没有必要自己再测一遍。这也是使用函数式库带来的好处,所以剩下需要做的只是写toLetterGrade 的单元测试:
QUnit.test('Compute Average Grade: toLetterGrade', function (assert) {
assert.equal(toLetterGrade(90), 'A');
assert.equal(toLetterGrade(200),'A');
assert.equal(toLetterGrade(80), 'B');
assert.equal(toLetterGrade(89), 'B');
assert.equal(toLetterGrade(70), 'C');
assert.equal(toLetterGrade(60), 'D');
assert.equal(toLetterGrade(59), 'F');
assert.equal(toLetterGrade(-10),'F');
});
由于toLetterGrade 是纯的,因此可以随意地运行任何多次,用不同的输入来覆盖所有边界条件。而且由于它是引用透明的,因此还可以随意调整测试数据,不用害怕结果会发生任何变化。本书后续章节会介绍如何自动生成输入。但现在只需要关注该函数对一系列输入都能返回期望的结果。现在程序的各个部分都已经测试了,可以安全地设定程序作为一个整体也是可以正常工作的,因为它是由函数组成和函数组合子完成的。
那么fork 是什么 ?函数式组合子并没有什么业务逻辑,只是单纯地安装应用的数据流编排函数调用,因此也不需要太多的测试。4.6节提到的组合子完全可以替代控制语句,如if-else() 和循环。
一些库实现了很多好用的组合子,例如R.tap 。但是像自定义的(如fork ),也完全可以独立于应用程序的业务逻辑来进行测试。为了完整起见,让我们给fork 写一个测试,而且这是一个使用R.identity 的好地方:
QUnit.test('Functional Combinator: fork', function (assert) {
const timesTwo = fork((x) => x + x, R.identity, R.identity);
assert.equal(timesTwo(1), 2);
assert.equal(timesTwo(2), 4);
});
再次强调,只需这样一个简单的测试即可,因为组合子与程序业务是完全无关的,只会受到参数影响。使用函数式库,函数组合和组合子使开发和测试变得简单,但是处理不纯的行为就容易导致混乱。
6.3.3 使用Monadic式从不纯的代码中分离出纯函数
前面的章节提到,大多数程序都有纯的和不纯的部分。特别是在客户端的JavaScript,它的存在就是为了跟DOM交互。在服务器上,数据库或文件读取也是不纯的部分。前面介绍了使用纯或不纯的函数组合成程序的方法。但是,它们仍然不纯。开发者可以依靠IO Monad把纯度再扩大一些,从应用程序的角度看,这样能得到引用透明性,使程序更声明式、更易推理。除了IO, 还会用其他Monad(如Maybe 或Either )建立能在异常情况下依然正常响应的程序。有了这些技术,开发者已经可以控制大多数的副作用。但是当JavaScript代码需要读写DOM时,如何保证测试仍然保持隔离和可重复的?
回想一下非函数式版本的showStudent ,分离其中不纯的部分还挺麻烦的:一个缺点是,所有逻辑都混在一起,在测试时只能当作一个整体。这样毫无效率可言,因为所要验证的只是逻辑,却要每次都运行整个应用,比如db.get(ssn) 。另一个缺点是,不能彻底地测试它,因为所有语句紧密耦合着。例如,第一个代码块就有可能因为验证不通过而退出函数,这样测试数据就到不了db.get(ssn) 这一步。
此外,函数式编程的目的是让业务减少导致副作用的函数(如IO),这样就可以增加应用程序逻辑的可测范围,同时解耦不需要负责的IO边界测试。再来看showStudent 的函数式版本:
const showStudent = R.compose(
map(append('#student-info')),
liftIO,
getOrElse('unable to find student'),
map(csv),
map(R.props(['ssn', 'firstname', 'lastname'])),
chain(findStudent),
chain(checkLengthSsn),
lift(cleanInput));
仔细对照函数式版本和非函数式版本的代码,就会发现函数式版本是如何使用组合和Monad来拆分命令式版本的。这样做立刻扩大了showStudent 的可测试范围,并且清楚地识别与分离了纯和不纯的函数(见图6.6)。
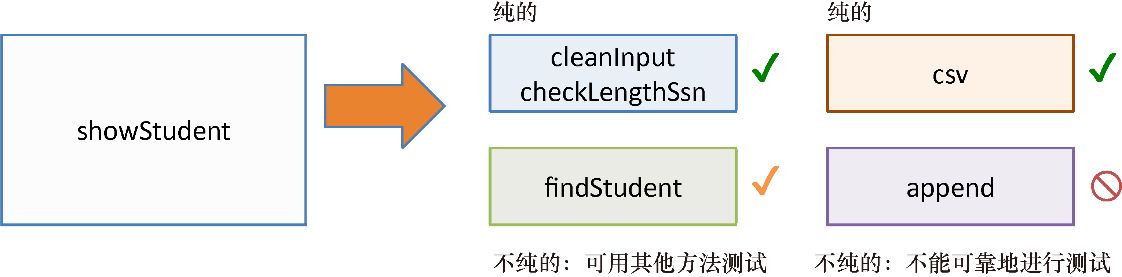
图6.6 识别showStudent 程序的可测试区域。执行IO中的组件是不纯的,含有副作用,
所以不能可靠地进行测试。除了这个不纯的部分,整个程序的可测试范围依然很高
下面来分析showStudent 组件的可测试性。5个函数中,只有3个能够可靠地测试:cleanInput 、checkLengthSsn 和CSV。 虽然findStudent 阅读来自外部资源的数据时有副作用,但本节后面会解决这个问题。余下的append 函数没有真正的业务逻辑,因为它只是简单地把给它的数据放到DOM上而已。这个函数并不需要关注,测试DOM API这种事情完全可以留给浏览器厂商。函数式编程可用于可以把一个难以测试的程序拆分成高度可以测试的一些小部分。
现在来对比清单6.2中的非函数式、紧耦合的代码。在函数式版本中,可以可靠测试的程序大约占90%,而在命令式的版本中,会面临与increment 函数类似的命运——打乱测试顺序会“挂掉”测试。
清单6.2显示了图6.6中对每个可测组件的单元测试。
清单6.2 单元测试showStudent 纯的部分
QUnit.test('showStudent: cleanInput', function (assert) {
const input = ['', '-44-44-', '44444', ' 4 ', ' 4-4 ']; <---以不同长度并包含空格的字符串作为输入
const assertions = ['', '4444', '44444', '4', '44'];
assert.expect(input.length);
input.forEach(function (val, key) {
assert.equal(cleanInput(val), assertions[key]);
});
});
QUnit.test('showStudent: checkLengthSsn', function (assert) {
assert.ok(checkLengthSsn('444444444').isRight); <---以 Either.isLeft 或Either.isRight 来检测Monad 中的内容
assert.ok(checkLengthSsn('').isLeft);
assert.ok(checkLengthSsn('44444444').isLeft); <---以 Either.isLeft 或Either.isRight 来检测Monad 中的内容
assert.equal(checkLengthSsn('444444444').chain(R.length), 9);
});
QUnit.test('showStudent: csv', function (assert) {
assert.equal(csv(['']), '');
assert.equal(csv(['Alonzo']), 'Alonzo');
assert.equal(csv(['Alonzo', 'Church']), 'Alonzo,Church');
assert.equal(csv(['Alonzo', '', 'Church']), 'Alonzo,,Church,');
});
由于这些函数都是分离的、自我可测的(稍后会介绍如何自动生成测试数据),因此可以随意地进行重构而不用担心破坏其他的部分。
还有最后一个函数的测试:findStudent。 这个函数是从不纯的safeFindObject 抽出来的,用来从外部存储中查找学生记录。此函数所产生的副作用可以通过mock的技术控制。
6.3.4 mock外部依赖
mock是一种流行的测试技术,用来模拟和控制函数的外部依赖,可以用来处理某些副作用。如果mock对象的期望没有达到,就会导致测试失败。它们就像一种可编程虚拟方法(或存根stub),这样就可以在测试断言前配置与这个对象的预期行为。在这种情况下,mock数据库对象就可以提供这个外部资源的完全控制权,从而创造更多可预测的、一致的测试。具体来讲,会使用QUnit的mock插件Sinon.JS(关于如何设置该插件的详细信息参见附录)。
Sinon.JS可以使用sinon对象来创建模拟环境中所有可访问对象的mock版本。对于前述示例,需要mock DB 对象:
const studentDb = DB('students');
const mockContext = sinon.mock(studentDb);
通过这种mock上下文环境,开发者可以为它设计多个期望的行为,比如应该调用多少次、应该接收到什么样的参数以及返回什么样的返回值。为了验证Either Monad返回safeFindObject 的行为,可以创建两个单元测试:一个返回Either.Right 类型,另一种返回Either.Left 。使用findStudent 的柯里化版本,可以方便地注入任何存储的实现,类似于在第4章中工厂方法的模式。如清单6.3所示,这个函数调用存储对象的get 方法,现在可以方便地控制其返回所需的返回值。
清单6.3 mockfindStudent 的外部依赖
var studentStore, mockContext;
QUnit.module('CH06',
{
beforeEach: function() {
studentDb = DB('students'); <---为所有单元测试预备 mock 的上下文
mockContext = sinon.mock(studentDb);
},
afterEach: function() { <---在测试完后,清除上下文状态
mockContext.verify(); <---验证 mock 在上下文中配置的断言
mockContext.restore();
}
});
QUnit.test(showStudent: findStudent returning null',
function (assert) {
mockContext.expects('get').once().returns(null); <---第一个单元测试中,被 mock 对象的 get 方法能够模拟地被调用(有且仅有)一次并返回 null
const findStudent = safefetchRecord(studentStore);
assert.ok(findStudent('xxx-xx-xxxx').isLeft); <---检查返回值应被包裹在 Either.Left 中
});
QUnit.test('showStudent: findStudent returning valid object',
function (assert) {
mockContext.expects('get').once().returns( <---第二个单元测试中,被mock 对象的 get 方法允许模拟地被调用一次并返回一个合法的结果
new Student('Alonzo', 'Church', 'Princeton').
setSsn('444-44-4444'));
const findStudent = safefetchRecord(studentStore);
assert.ok(findStudent('444-44-4444').isRight); <---检查返回值应被包裹在 Either.Right 中
});
showStudent可测试部分的QUnit和sinon.JS的测试结果如图6.7所示。
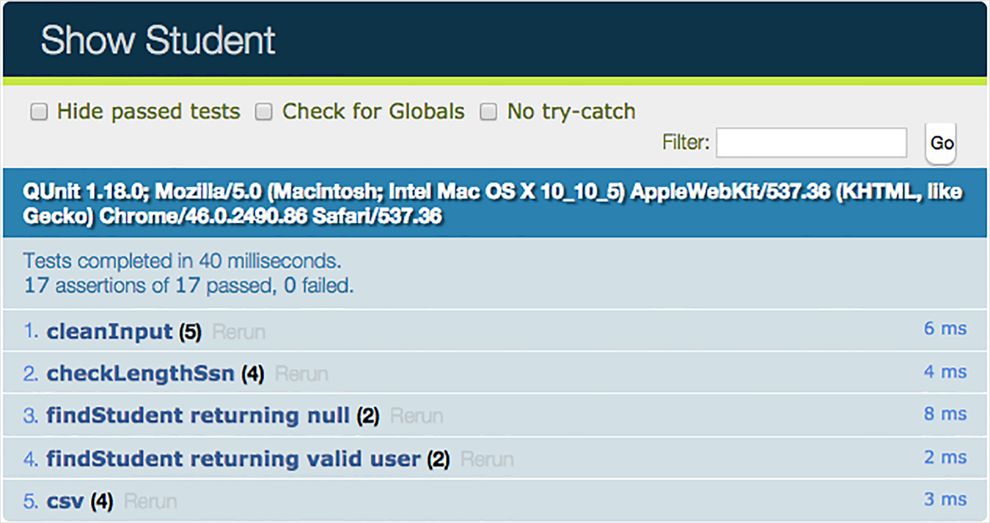
图6.7 运行showStudent 程序的所有单元测试。测试3和4使用的是QUnit和Sinon.JS,
因为它们需要mock获取学生记录的功能
函数式代码比命令式代码更好测试的主要原因可以归结为一个原则:引用透明。断言的本质就是验证其满足引用透明性:
assert.equal(computeAverageGrade([80, 90, 100]), 'A');
后文还会涉及很多关于引用透明性的概念。这个概念也可以扩展到软件开发的其他领域,如程序规格。毕竟,测试的唯一目的是验证系统的规格是否得到满足。
6.4 通过属性测试制定规格说明
单元测试可以作为文档,因为它包含函数的运行规范,比如computeAverageGrade :
QUnit.test('Compute Average Grade', function (assert) {
assert.equal(computeAverageGrade([80, 90, 100]),'A');
assert.equal(computeAverageGrade([80, 85, 89]), 'B');
assert.equal(computeAverageGrade([70, 75, 79]), 'C');
assert.equal(computeAverageGrade([60, 65, 69]), 'D');
assert.equal(computeAverageGrade([50, 55, 59]), 'F');
assert.equal(computeAverageGrade([-10]), 'F');
});
读者应该能由此想象出一个简单的文档。
- 如果学生的平均分是90或以上,可授予A。
- 如果学生的平均分是80和89之间,授予B。
- ……
系统规范通常用自然语言描述,但自然语言表达需要一定的上下文,否则很容易在翻译代码时产生歧义。这样导致开发者会不断地向产品经理确认一些含糊的规范。造成模糊的主要原因是采用了命令行式风格来编写文档,比如if-then的条件语句:if是A情况,then系统应该做B。这种方法的缺点是,它并没有描述全部的边界条件。如果情况A不发生怎么办?系统应该要做什么?
良好的规格说明不应该基于条件,而应该是通用的、普遍的。看看下面这两个语句措辞的略微不同。
- 如果学生的平均分是90以上,授予A。
- 只有平均90分以上的奖学生可以获得A。
通过拆除命令式的条件语句,第二条语句显得更加完整。它不仅表示当学生达到90以上会发生什么,也表明了限制条件为制定数值范围外的情况都不会是A。但是这一点不能从第一句话得出。
更通用的要求更容易实现,因为它们不依赖于系统中任何时间点的状态。就像单元测试,良好的规格既没有副作用,也不会对上下文做出任何假设。
引用透明的规范有助于对函数及其输入条件做出清晰的定义。由于引用透明的函数对一定输入的返回永远是一致的,因此可以很轻易地用自动化测试来覆盖。这样就引入了基于属性测试这种更加引人注目的测试方式。属性测试需要描述函数对某些类型的输入会得到某些类型的输出。测试框架的规范或参考实现为Haskell的QuickCheck。
QuickCheck:Haskell的属性测试库
QuickCheck可以为Haskell库程序基于属性随机生成测试数据。比如在程序中定义好函数应该满足的属性,QuickCheck生成符合属性的测试用例,并生成一个报告。更多信息参见https://hackage.haskell.org/package/QuickCheck。
JavaScript也有一个类似QuickCheck的库,名为JSCheck(见附录的配置信息),作者是Douglas Crockford[ 1] ,他是《JavaScript语言精粹》的作者(O’Reilly出版,2008)。JSCheck是为函数或程序创建引用透明性规范的技术手段。它通过生成大量的随机测试来保证函数所有路径都被覆盖。
此外,基于属性的测试也可以很好地防止重构的代码引入bug。JSCheck工具的主要优点是,它生成测试数据的算法。它所生成的某些边界情况很有可能是开发者自行编写测试代码时很难想到的。
JSCheck模块封装在全局对象JSC 里:
JSC.claim(name, predicate, specifiers, classifier)
该库的核心是需要创建claims和verdicts。claim是由以下部分组成。
- 命名 ——claim的描述(类似于QUnit的测试说明)。
- 谓词 ——返回为
false或者true的函数。 - 说明符 ——描述输入参数的类型以及生成随机数据集的规范。
- 分类器(可选) ——可用于拒绝对某些不适用的测试用例。
claims会被传递到JSCheck.check 来运行随机测试用例。claim可以通过JSCheck.test 构造。下面简单地写一个computeAverageGrade 的JSCheck规范,就按照例子的规格:“只有平均90分或以上的学生可以获得A”。代码如清单6.4所示。
清单6.4 computeAverageGrade 基于属性的测试
JSC.clear(); <---以 JSC.clear 作为开始来初始化一个全新的测试上下文
JSC.on_report((str) => console.log(str));
JSC.test(
'Compute Average Grade', <---claim 的描述
function (verdict, grades, grade) { <---谓词函数会传递verdict 对象来定义测试的条件
return verdict(computeAverageGrade(grades) === grade);
},
[
JSC.array(JSC.integer(20), JSC.number(90,100)), <---签名数组用来描述生成得 A 平均值的规则
'A'
],
function (grades, grade) {
return 'Testing for an ' + grade + ' on grades: ' + grades; <---分类器会在每个测试中调用,因此可以用来将数据附加到测试报告中
}
);
在清单6.4中,使用声明说明符来表达程序的属性。
JSC.array——描述该函数接收Array类型的输入。JSC.integer(20)——描述此函数能操作的最大长度。虽然可以是任意数字,但在这种情况下,20个就足够了。JSC.number(90, 100)——描述数组元素中的类型。在这种情况下,它们是范围从90到100的数字(包括整数和浮点数)。
谓词函数有些难以理解。当claim成立时,谓词函数返回true ,而谓词函数中的逻辑是需要根据具体程序来决定的。verdict函数除了会宣布测试的结果外,还可以在这里得到生成的随机输入和预期的输出。这样就可以宣布computeAverageGrade 能返回预期等级——A。本例使用了几种说明符,读者可以到该项目的网站查一下,也可以创建自己的说明符。
现在读者大概已经明白了这个程序的含义,下面运行一下。JSCheck报告会非常冗长,因为JSCheck将默认根据提供的说明产生100个随机测试用例。这里选取其中一部分作为例子:
Compute Average Grade: 100 classifications, 100 cases tested, 100 pass
Testing for an A on grades:
90.042,98.828,99.359,90.309,99.175,95.569,97.101,92.24 pass 1
Testing for an A on grades:
90.084,93.199, pass 1
// and so on 98 more times
Total pass 100, fail 0
JSCheck代码自成文档。读者可以很容易地描述函数输入输出的契约,这是平常的单元测试所做不到的,而且可以发现JSCheck报告的详细程度。JSCheck程序可单独运行,也可以嵌入QUnit测试中,这样一来,就成了测试套件的一部分。这些库之间的集成如图6.8所示。

图6.8 JSCheck和QUnit:主要部件的集成。QUnit测试封装了JSCheck测试规格。
规格和函数测试都提供给verdict 函数,JSCheck引擎会运行并回调QUnit的
通过/失败接口。这些回调会触发QUnit断言
下面的例子将使用JSCheck测试checkLengthSsn 程序,它具有以下规格。
一个合法的社会保障号码必须满足以下条件。
- 不含空格
- 不含破折号
- 长度为9个字符
- 遵循ssa.gov列举的格式,需要这3个部分组成。
- 前3个数字称为区号。
- 中间两位数字称为分组号码。
- 最后4位称为序列号。
请看清单6.5所示的代码。后文会对相关部分做出解释。
清单6.5 checkLengthSsn 的JSCheck测试
QUnit.test('JSCheck Custom Specifier for SSN', function (assert) {
JSC.clear();
JSC.on_report((report) trace('Report'+ str));
JSC.on_pass((object) => assert.ok(object.pass));
JSC.on_fail((object) => <---使用 JSC.on_fail 来确保参数长度不为 9 时测试一定会失败
assert.ok(object.pass || object.args.length === 9,
'Test failed for: ' + object.args));
JSC.test(
'Check Length SSN',
function (verdict, ssn) { <---由于函数本身返回值为Boolean 类型,可以将结果直接传给 verdict 函数
return verdict(checkLengthSsn(ssn));
},
[
JSC.SSN(JSC.integer(100, 999), JSC.integer(10, 99),
JSC.integer(1000,9999)) <---JSC.SSN是一个自定义的说明符,由 JSC.interger 说明符组合而成。JSC.interge 能够从一个指定的区间随机取值
],
function (ssn) {
return 'Testing Custom SSN: ' + ssn;
}
);
)};
该程序通过JSC.on_fail 和JSC.on_pass 函数把JSCheck继承到了QUnit,这两个函数可以给QUnit报告任何满足或者失败的断言。由于说明符
JSC.SSN(JSC.integer(100, 999), JSC.integer(10, 99), JSC.integer(1000,9999))
描述的合法SSN的契约,这段程序需要一直输出形式为XXX-XX-XXXX 的任意组合:
Check Length SSN:
100 classifications, 100 cases tested, 100 pass
Testing Custom SSN: 121-76-4808 pass 1
Testing Custom SSN: 122-87-7833 pass 1
Testing Custom SSN: 134-44-6044 pass 1
Testing Custom SSN: 139-47-6224 pass 1
...
Testing Custom SSN: 992-52-3288 pass 1
Testing Custom SSN: 995-12-1487 pass 1
Testing Custom SSN: 998-46-2523 pass 1
Total pass 100
这里并没有什么特殊的东西,但也可以调整规格,看看输入一些3位的分组号码时会发生什么:
JSC.SSN(JSC.integer(100, 999),JSC.integer(10, 999),JSC.integer(1000,9999))
运行QUnit与JSCheck标记发现会失败。图6.9所示的是单个故障的输出。

图6.9 非法的输入会很快被QUnit报出来,JSCheck算法具有足够 把握这些随机生成的输入能覆盖所有边缘的情况
JSC.SSN 是从哪儿来的?JSCheck说明符可以像函数一样组合起来,变成更具体的说明符。在这个例子中,JSC.SSN 是由3个JSC.integer 的说明符共同定义的,如清单6.6所示。
清单6.6 自定义JSC.SSN说明符号
/**
* Produces a valid social security string (with dashes)
* @param param1 Area Number -> JSC.integer(100, 999)
* @param param2 Group Number -> JSC.integer(10, 99)
* @param param3 Serial Number -> JSC.integer(1000,9999)
* @returns {Function} Specifier function
*/
JSC.SSN = function (param1, param2, param3) { <---将 SSN 作为 JSC 对象的一部分以保持使用的一致性
return function generator() {
const part1 = typeof param1 === 'function' <---SSN 数字的每个部分可以是一个常数,或一个能够让 JSCheck 用来生成随机数的函数
? param1(): param1;
const part2 = typeof param2 === 'function'
? param2(): param2;
const part3 = typeof param3 === 'function'
? param3(): param3;
return [part1 , part2, part3].join('-'); <---三部分数据结合成一个合法的 SSN 号码
};
};
JSCheck只对纯的程序有用,所以可能不能完全地测试showStudent ,但是开发者可以分别测试单个组件。这就当作留给读者的一个练习吧。属性测试厉害的地方是它可以让函数发挥到极致。在笔者看来,属性测试适合用来验证代码是否引用透明,比如契约和判决一致时看是否还能保持一致。但是,为什么要把代码提交给这么复杂的程序?答案很简单:使测试更有效。
6.5 通过代码覆盖率衡量有效性
如果没有适当的工具,将很难保证测量单元测试的有效性。因为涉及研究测试的覆盖率这项艰巨的任务。获取覆盖信息包括程序的所有控制流的路径是否得到覆盖。其中一种方式是通过函数的边界条件来研究代码的控制流。
当然,代码覆盖率并不是质量的指标,但在某种程度上反映了函数被测试的程度,这与好的质量是相关的。谁也不会将从未见过天日的代码直接部署到产品上的。
代码覆盖分析可以发现没有测试过的区域。通常,这些代码是很容易忘记测试的错误处理代码。使用代码覆盖率可以衡量单元测试覆盖的代码行数的百分比。推荐使用Blanket.js库作为代码覆盖工具。它是专门设计来提供代码覆盖率数据,帮助补全单元测试的。它的工作原理分为以下3个阶段。
1.载源文件。
2.在代码中加入跟踪。
3.在测试运行后回调输出coverage细节。
Blanket在收集覆盖率信息时会捕获有关执行的语句。读者可以在QUnit报告看到非常友好的覆盖率信息。具体的Blanket配置信息可以在附录中找到。可以通过脚本中include 这行的data-covered 属性来配置任何JavaScript模块或程序。通过分析覆盖率,读者会发现函数式代码比命令式的更容易测试。
6.5.1 衡量函数式代码测试的有效性
通过学习本章的内容,你会发现函数式程序更容易测试,这是因为大的任务会被拆解成原子的、可验证的单元。但是,光靠我说可能不可信口说无凭,读者可以通过showStudent 程序的覆盖率分析来衡量一下。首先来看最简单的测试案例:一个正向测试。
1.衡量有效输入的函数式代码的有效性
首先看一下命令式showStudent 的代码覆盖统计数据(见清单6.2)。用Blanket和QUnit对这段代码进行测试。
<script src="imperative-show-student-program.js" data-cover></script>
现在运行下面的测试。
QUnit.test('Imperative showStudent with valid user', function (assert) {
const result = showStudent('444-44-4444');
assert.equal(result, '444-44-4444, Alonzo, Church');
});
图6.10所示的QUnit /Blanket输出表明,语句的覆盖百分比为80%。

图6.10 用QUnit /Blanket运行命令式showStudent 的合法数据测试,带阴影的行
表示没有覆盖的语句。由于15行中有12行都运行到了,所以覆盖率是80%
完全不出乎意料,错误处理代码被全部漏掉。对于命令式代码,能达到75%~80%的代码覆盖率就已经非常不错了。所以这个单元测试能达到80%的覆盖率已经很不错了。再来试试测试函数式代码:
<script src="functional-show-student-program.js" data-cover></script>
同样,只测试正常情况,但这次的覆盖率高达100%,如图6.11所示。

图6.11 针对函数showStudent 的单元测试达到100%的行覆盖率,
即任何一行业务逻辑都是可以测试的
但是如果只用合法数据来测试,为什么错误处理的逻辑也能覆盖到呢?这就是Monad的神奇之处,它可以无缝地在整个程序中传递空值(使用Either.Left 或者Maybe.Nothing ),因此每个函数得以运行,但映射函数中的逻辑被跳过。
函数式代码的灵活性和鲁棒性都非常显著。现在衡量无效输入的测试。
2.衡量无效输入的命令式代码和函数式代码的有效性
下面来衡量两个程序在输入数据无效(例如输入为null )时的有效性,如图6.12所示,命令式代码覆盖率一般(毫不奇怪):
QUnit.test('Imperative Show Student with null', function (assert) {
const result = showStudent(null);
assert.equal(result, null);
});
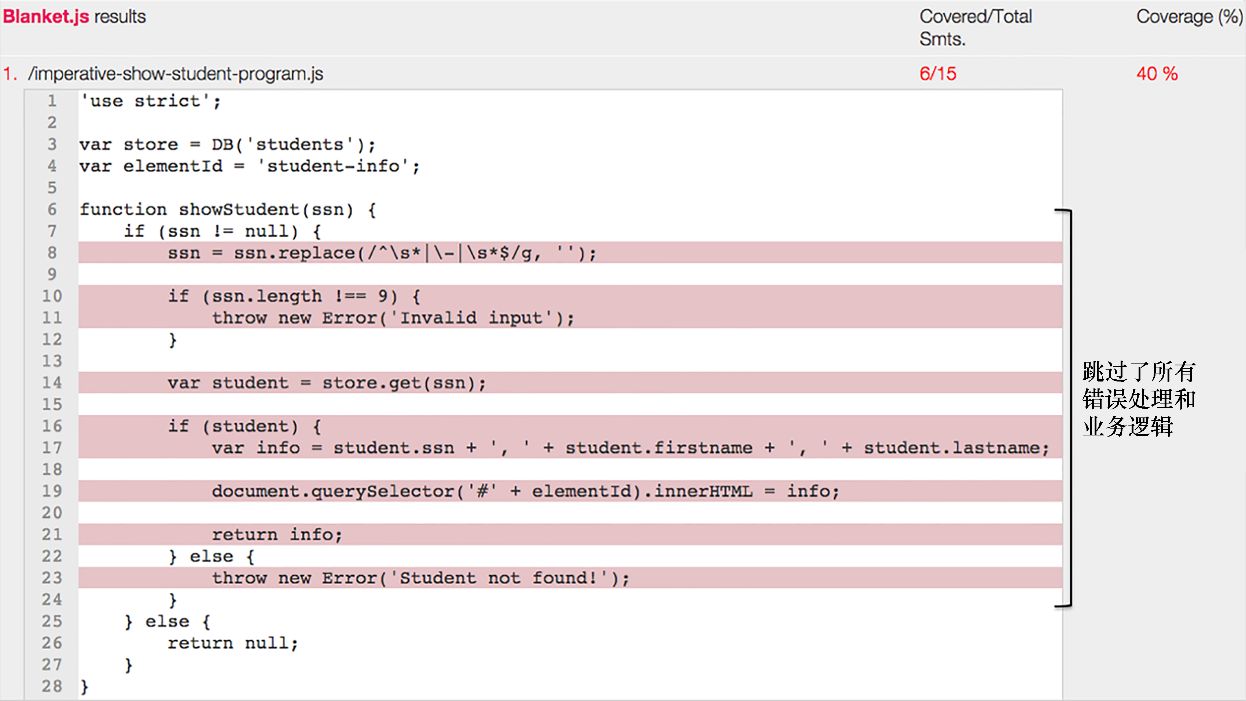
图6.12 showStudent 的代码跳过了所有合法输入的路径,得到了非常低的40%的覆盖率
出现这种结果是因为控制流的if-else 块的存在,它导致了不同的分支,也导致了函数的复杂。
相比之下,函数式的null 处理更为优雅些,因为它避免了直接处理非法输入(比如null )的逻辑。整个程序的结构(函数之间的交互)都无须做出任何调整,就可以成功地进行调用和测试。一旦有错误,函数式代码的输出会是Nothing 。开发者完全不必要检查null 输出,只需要下面这个测试就足够了:
QUnit.test('Functional Show Student with null', function (assert) {
const result = showStudent(null).run();
assert.ok(result.isNothing);
});
所有被跳过的逻辑区域如图6.13所示。
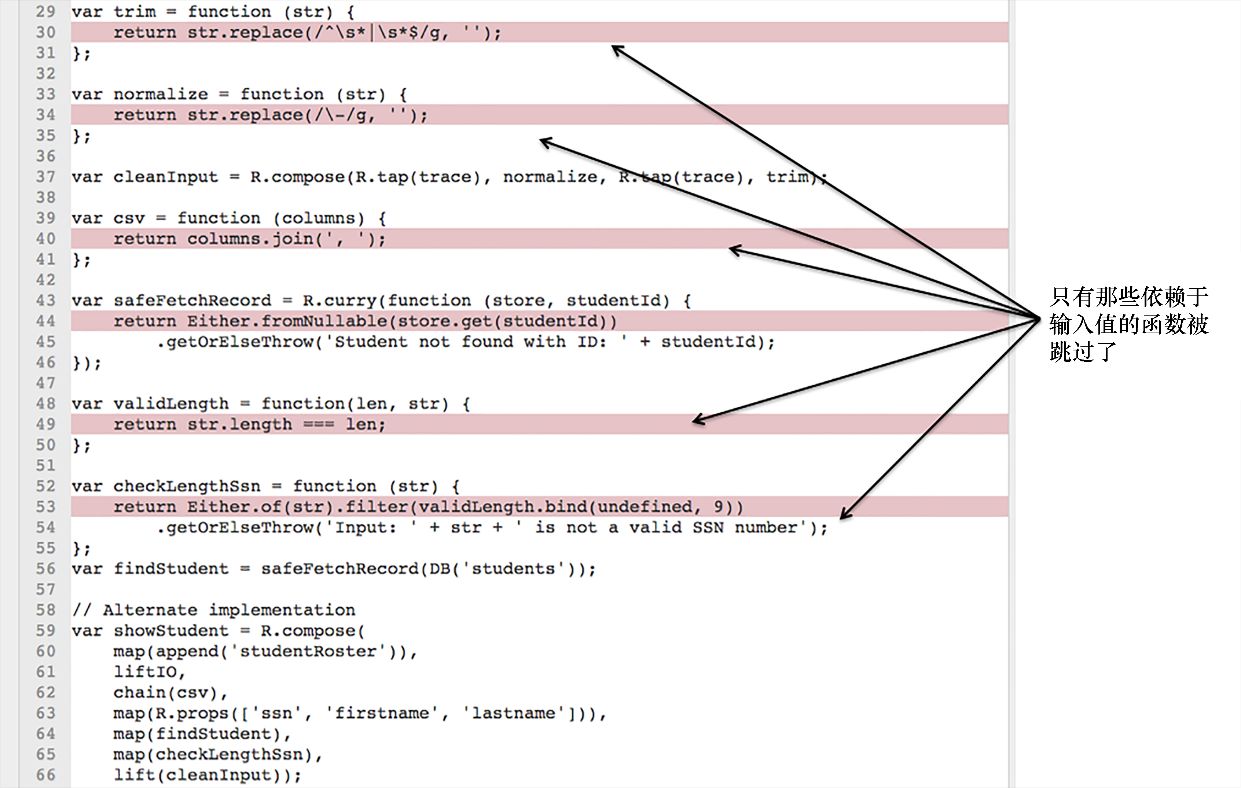
图6.13 函数式版本的showStudent 跳过操作数据的区域,这些区域对于合法输入会执行
但即使对于无效数据,函数式程序也不仅仅是跳过整段代码的执行。它优雅地、安全地在Monad中传递无效状态,覆盖率仍然能达到80%(两倍命令式代码),如图6.14所示。

图6.14 函数showStudent 对于无效输入仍然能达到高覆盖率
由于高可测性,函数式代码会让开发者对部署到生产环境更有信心,这都可以归功于不可变性和消除的副作用。之前可能提到过,命令式的条件语句与循环不仅使得测试复杂,也更难以推理,而且会给之后扩展函数带来不小的复杂性。那么,该如何衡量复杂性?
6.5.2 衡量函数式代码的复杂性
可以通过仔细检查其控制流来衡量程序的复杂性。更简单的验证方式是,如果看到一段代码而不知道它到底在做什么,就说明这段代码的复杂性很高。函数式编程在视觉上呈现出很好的声明式。这相当于开发者视角上的复杂性。在本节中,读者还会看到函数式代码的算法复杂度更低。
有许多因素可以导致代码复杂,比如条件与循环,甚至这些东西还会嵌套于其他结构中。分支逻辑是相互排斥的,它根据一个布尔条件把控制流逻辑分成两个独立的分支。很多的if-else 会导致很难在代码块中追踪。当条件再依赖于外部因素时,追踪过程就更加困难了。条件块与嵌套条件块的数量越多,函数就越难进行测试,所以让函数尽可能简单是非常重要的。这也是函数式编程的理念是将函数分解成简单的lambda表达式,再用组合和Monad将它们结合起来的原因。
圈复杂度(CC) 用于衡量该函数的线性独立路径的数量。从这个概念来验证函数的边界条件,以确保通过函数的所有可能路径都被测试到。这可以通过使用图论中简单的节点与边来保证(见图6.15)。
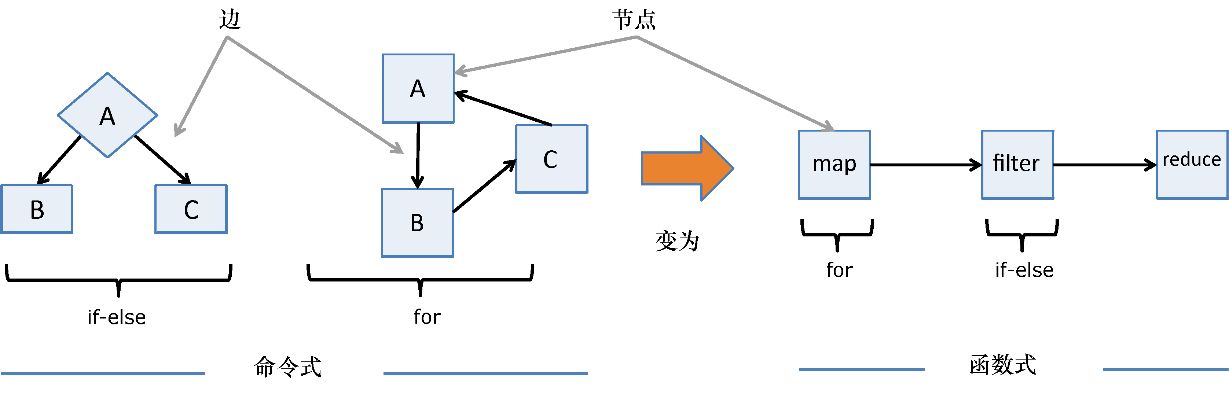
图6.15 命令式的if-else 块和for 循环可以被翻译成函数式的map 、filter 和reduce
- 节点对应不可分割的代码块。
- 如果第二块会在第一块后执行,用有向边连接这两个代码块。
第3章研究了命令式控制流的图与函数式控制流的图,以及函数式如何使用map 和filter 的高阶操作消除这些分支与循环,如高阶操作之间的差异。
这对圈复杂度有什么帮助呢?在数学上,任何程序的复杂性可以计算为M = E − N + P ,其中E 表示控制流的边数,N 表示节点或块的数量,P 表示有退出点的节点数,
所有控制结构都会反映到圈复杂度,所以值越小越好。条件块对复杂度的影响最大,因为它把控制流分成两个线性无关的路径。因此,控制条件数量越多,圈复杂度也就越大,程序也越难测试。
再来重温一下命令式showStudent 的控制流。为了更简单地描绘流程,这里在图6.16中给语句都标上了节点号。运用圈复杂度的公式,该图有11条边、10个节点和3个出口。所以M =E − N + P = 11 − 10 + 3 = 4。
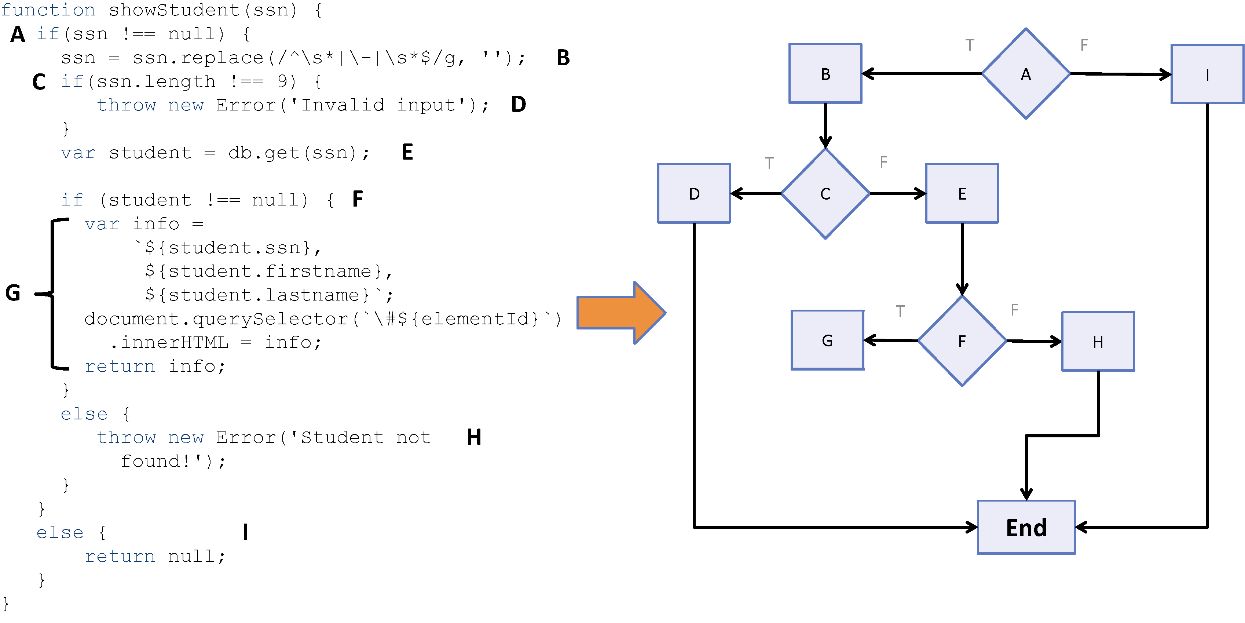
图6.16 命令式showStudent 的潜在节点。这些标签已转换成流程图中的节点,
其中边描述了条件语句引擎的线性独立的不同路径数量
衡量函数式程序的圈复杂度更为简单,因为函数式编程倾向于尽可能地使用高阶函数、函数组合子和其他抽象,而避免循环和条件语句。这导致节点和边都相对减少。因此,函数式程序的圈复杂度往往能接近1。所以函数式showStudent 能组成完全不包含节点和边(只是单个出口点)的图,使得其圈复杂度为M = E − N + P = 0 − 0 + 1 = 1。在复杂的领域中,还有一些相关指标同样值得关注(见表6.1)。读者可以通过网站http://jscomplexity.org来进行衡量。
表6.1 函数式与命令式静态代码其他指标的比较
| 命令式 | 函数式 |
|---|---|
| 圈复杂度:4圈复杂度密度:29%可维护性指数:100 | 圈复杂度:1圈复杂度密度:3%可维护性指数:148 |
圈复杂密度反映了圈复杂度对应到代码行数的比例,函数式代码对此依然能保持很低的数值。这些指标在一定程度上跟程序的设计是否良好密切相关。简单地说,越模块化的代码,越容易进行测试。函数式代码本身带有这一优势,因为函数就是模块化的最小单位。
函数式编程在很大程度想要通过高阶函数消除循环,用组合替代命令式代码的顺序计算,还用柯里化建立更高抽象,而这一切都可能会影响性能,真可谓是鱼和熊掌不可兼得。
6.6 总结
- 依赖于简单函数抽象的程序是模块化的。
- 基于纯函数的模块化的代码很容易测试,还可以使用更严格的类型测试方法,如基于属性的测试。
- 可测试的代码一定是简单的控制流。
- 简单的控制流可以降低整个程序的复杂度,这可以通过复杂度测量工具进行验证。
- 降低复杂度的代码更容易推理。
[1] Douglas Crockford是很受欢迎的程序员、作家和演讲者,他以积极推进JavaScript语言、推广JSON和创建JSLint、JSMin和JSCheck等闻名。他也是《JavaScript语言精粹》一书的作者。
第7章 函数式优化
本章内容
- 如何识别高性能的函数式代码
- JavaScript函数执行的内部机制
- 嵌套函数的背景和递归
- 通过惰性求值优化函数调用
- 使用记忆化(memoization)加速程序执行
- 使用尾递归函数展开递归调用
97%的时候我们应该忽略效率……过早的优化是一切罪恶的根源。然而,我们决不能错过这关键的3%的优化机会。
——Donald Knuth,《The Art of Computer Programmin》
既然说是要把优化留到最后。通过前面章节的学习,读者应该学会了如何编写和测试函数式代码。现在已经接近这段奇妙旅程的尾声,我们来看看如何优化它。没有任何单一的编程范式是圣杯,它们各有其在性能与抽象上的取舍,例如函数式编程提供流畅而描述性的抽象层。哪怕用柯里化、递归、Monadic封装和组合来解决最简单的问题,函数式代码能跟命令式代码一样保证性能吗?
的确,现代的Web应用程序,除了游戏,减少几个毫秒并不能带来什么价值。计算机已经非常快而且编译器技术也先进得惊人,这保证了代码性能。因此函数式不仅不比命令式性能低,还有别的闪光点。
不理解其运行环境就使用新的范式是不明智的。因此,本章将解释函数式JavaScript代码处理大量数据时尤其需要注意的地方。本章将涉及一些JavaScript核心功能,如闭包,所以读者应确保已经阅读并理解了第2章的内容。本章还会讨论一些有趣的优化技术,如惰性求值、记忆化和递归调用。
函数式编程不会加快单个函数的求值速度。相反,它的理念是避免重复的函数调用以及延迟调用代码,把求值延迟到必要的时候,这可能会使应用程序的整体加速。在纯函数式语言中,平台内置了这些优化,所以大多数情况下并不需要开发者关心优化问题。然而在JavaScript中,开发者需要通过自定义代码或函数式库来做到这些优化。在深入介绍上述内容之前,先来看一下函数式JavaScript性能优化所面临的挑战。
7.1 函数执行机制
由于FP依赖于函数求值,了解每一个函数调用时发生了什么对于性能和优化函数是很必要的,也必须了解每个函数调用的推移。在JavaScript中,每个函数调用其实都会在函数上下文堆栈中创建记录(帧)。
注意:
栈是一个基本的数据结构,它的插入和取出顺序是后进先出(LIFO)。可以想象成一个个堆叠在一起的碟子:所有操作都只能从最顶部的碟子开始。
JavaScript编程模型中的上下文堆栈负责管理函数执行以及关闭变量作用域(参见2.4 节的闭包)。堆栈始终从全局执行上下文帧开始,其包含所有全局变量,如图7.1所示。

图7.1 JavaScript执行上下文栈的初始化。取决于页面上要加载多少脚本, 全局上下文可能有大量的变量和函数
全局上下文帧永远驻留在堆栈的底部。每个函数的上下文帧都占用一定量的内存,实际取决于其中的局部变量的个数。如果没有任何局部变量,一个空帧大约48个字节。每个数字或布尔类型的局部变量和参数会占用8字节。所以,函数体声明越多的变量,就需要越大的堆栈帧。每一帧大致包含以下信息[ 1] :
executionContextData = {
scopeChain, <---包含当前函数的 variableObject 以及父执行上下文的 variableObject
variableObject, <---包括当前函数的参数、内部变量以及函数声明
this <---函数对象的引用(任何函数在系统中都是对象)
}
从这个结构可以提取出一些重要的见解。首先,variableObject 属性是决定堆栈帧大小的关键因素,因为它包含类数组类型的函数参数arguments 对象(第2章提过)以及所有局部变量和函数。其次,函数的作用域链引用这个函数的父函数的执行上下文(我会稍后具体解释作用域链)。不管是直接还是间接,所有函数的作用域链最终都链接到全局上下文。
注意:
函数的作用域链与JavaScript对象的原型链不是一回事。虽然两者表现得很类似,但是原型链通过
prototype属性建立对象继承的链接,而作用域链是指内部函数能访问到外部函数的闭包。
堆栈的行为由下列规则确定。
- JavaScript是单线程的,这意味着执行的同步性。
- 有且只有一个全局上下文(与所有函数的上下文共享)。
- 函数上下文的数量是有限制的(对客户端代码,不同的浏览器可以有不同的限制)。
- 每个函数调用会创建一个新的执行上下文,递归调用也是如此。
函数式编程将函数发挥到了极致,我们鼓励把问题分解为尽可能多的函数和尽可能的柯里化函数,以获得更多的灵活性和重用性。但使用柯里化函数会对上下文堆栈有影响。
7.1.1 柯里化与函数上下文堆栈
笔者个人而言非常喜欢柯里化。如果JavaScript能够自动柯里化所有函数,那是再好不过了。但这种额外的抽象可能会导致大量上下文堆栈的开销。为了更好地理解这个问题,下面来看一个JavaScript柯里化函数调用的背后到底发生了什么。
回忆第4章的柯里化函数时,把一次函数执行变成了多次执行的函数(每次消费一个参数)。换句话说,第4章的logger 函数
const logger = function (appender, layout, name, level, message)
柯里化后会变成如下嵌套结构:
const logger =
function (appender) {
return function (layout) {
return function (name) {
return function (level) {
return function (message) {
...
嵌套结构的函数会使用更多的堆栈。先来解释logger 函数的非柯里化的执行。由于JavaScript的同步执行机制,调用logger 会暂停全局上下文的执行,好让logger 运行,创建新的活跃上下文,并引用全局上下文中的所有变量,如图7.2所示。
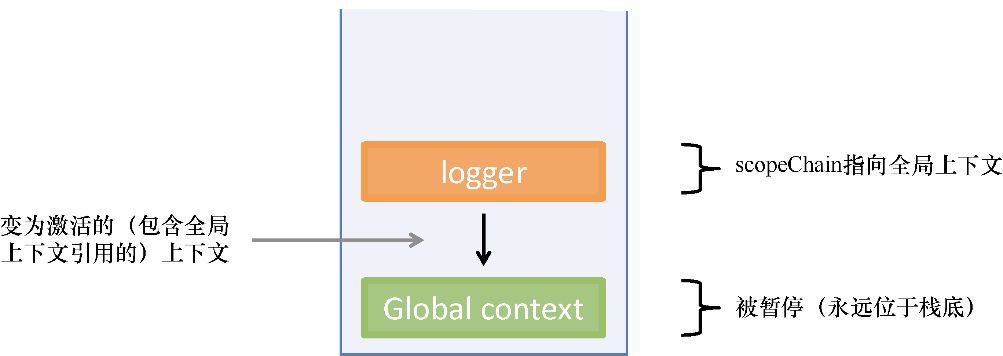
图7.2 调用任何函数时,如logger ,单线程JavaScript运行时会暂停当前全局上下文并激活
新函数创建的上下文。此时,还会通过scopeChain 创建到全局上下文的链接。
一旦logger 返回,它的执行上下文也会被弹出堆栈,全局上下文将恢复
当logger函数调用其他函数(如Log4js)时,会在堆栈上产生新函数的上下文(如果没听过Log4js,请查看附录中的相关信息)。由于JavaScript的闭包,内部函数调用的上下文会在外部函数上下文堆栈的上面占用分配给它的存储器,并经由scopeChain 链接起来(见图7.3)。
图7.3 运行嵌套函数时函数上下文的变化。因为每个函数会产生新的堆栈帧, 所以堆栈增长跟函数嵌套的层级成正比。柯里化与递归都依赖于嵌套的函数调用
一旦Log4js代码运行完,它就会被弹出堆栈;logger 函数也会在之后被弹出,运行时环境恢复到只有全局上下文的状态(见图7.1)。这就是JavaScript的闭包背后的魔法。
虽然这种方法强大,但是嵌套深的函数会消耗大量的内存。第8章介绍如何用RxJS来处理异步代码的功能库。最新版本的RxJS 5着重提升性能,其中最为关键的就是要减少闭包的数量。
现在来看柯里化版本的logger 函数,如图7.4所示。
图7.4 柯里化将每一个参数都转换成内部嵌套调用。可以连续提供参数 带来了灵活性,却额外占用了堆栈空间
柯里化所有函数看起来是不错的主意,但是过度使用会导致其占用较大的堆栈空间,进而导致程序运行速度显著降低。不妨试试下面这个简单的测试程序:
const add = function (a, b) {
return a + b;
};
const c_add = curry2(add);
const input = _.range(80000);
addAll(input, add); //->511993600000000
addAll(input, c_add); //-> browser halts
function addAll(arr, fn) {
let result= 0;
for(let i = 0; i < arr.length; i++) {
for(let j = 0; j < arr.length; j++) {
result += fn(arr[i], arr[j]);
}
}
return result;
}
这个程序会创建80000个数的数组。非柯里化版本只需要几秒就可以返回正确的结果,而柯里化版本会导致浏览器停止。毫无疑问,柯里化是有代价的,但是大多数应用也很少会处理这么大型的数据。
这还不是导致堆栈增长的唯一原因。效率低下或不正确的递归也会导致堆栈的溢出。
7.1.2 递归的弱点
函数调用自己时也会创建新的函数上下文。所以不正确的递归调用,例如永远无法满足结束条件,很容易导致堆栈溢出。幸运的是,递归通常要么能工作要么有问题,这是很快就能知道的。如果你见过错误Range Error: Maximum Call Stack Exceeded or too much recursion ,就会知道递归有问题了。通过下面这个简单的脚本,可以测试浏览器函数堆栈大概的大小:
function increment(i) {
console.log(i);
increment(++i);
}
increment(1);
不同的浏览器的堆栈错误会有不同:例如在某台计算机上,Chrome会在17500次递归后触发异常,而Firefox的会递归大约213000次。不要以这些数值作为递归函数的上界!这些数字只是为了说明递归是有限制的。代码预设应该要远远低于这些阈值,否则递归肯定是有问题的。
如果碰巧使用递归处理超大量的数据,可能会导致堆栈呈数组大小的比例增长。看看这个寻找数字中最长字符串的例子:
function longest(str, arr) {
if(R.isEmpty(arr)) {
return str;
else {
let currentStr = R.head(arr).length >= str.length
? R.head(arr): str;
return longest(currentStr, R.tail(arr));
}
}
用来找世界上192个国家的最长名字是没有问题的,但如果用来找全球250万个城市,就可能会导致应用程序失败,如图7.5所示(但是这个算法在ES6上是不会失败的,稍后会解释原因)。
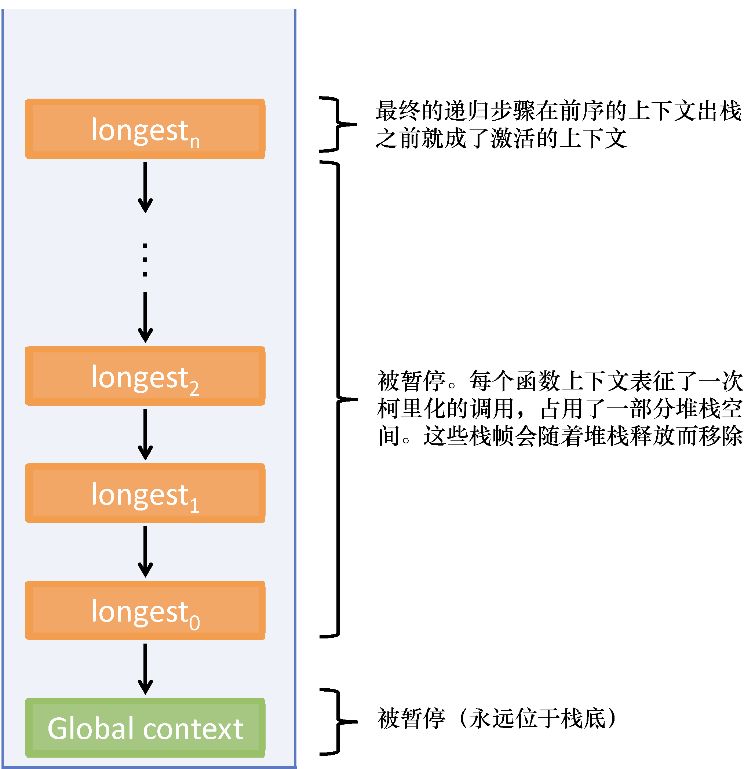
图7.5 longest 函数,为了在大小为n 的数组中找到最长字符串,需要插入n 帧到上下文堆栈
遍历这种异常巨大的数组的另一种方式就是利用到第3章提到的高阶函数,如map 、filter 以及reduce 。使用这些函数不会产生嵌套的函数调用,因为堆栈在每次迭代循环后都能得到回收。
虽然柯里化和递归导致更多的内存占用,但是鉴于它们带来的灵活性和复用性以及递归解决方案固有的正确性,又感觉这些额外的内存花费是值得的。
函数式编程还提供了其他范式没有的优化。大量函数推入堆栈会增加程序的内存占用,那么为什么不避免不必要的调用?
7.2 使用惰性求值推迟执行
当输入很大但只有一个小的子集有效时,避免不必要的函数调用可以体现出许多性能优势,例如函数式语言Haskell就内置了惰性函数求值 。惰性求值的方法有很多,但是目的都相同,即尽可能地推迟求值,直到依赖的表达式被调用。
但是,JavaScript使用的是更主流的函数求值策略——及早求值 。及早求值会在表达式绑定到变量时求值,不管结果是否会被用到,所以也称为贪婪求值 。例如获取数组子集的函数,如图7.6所示。
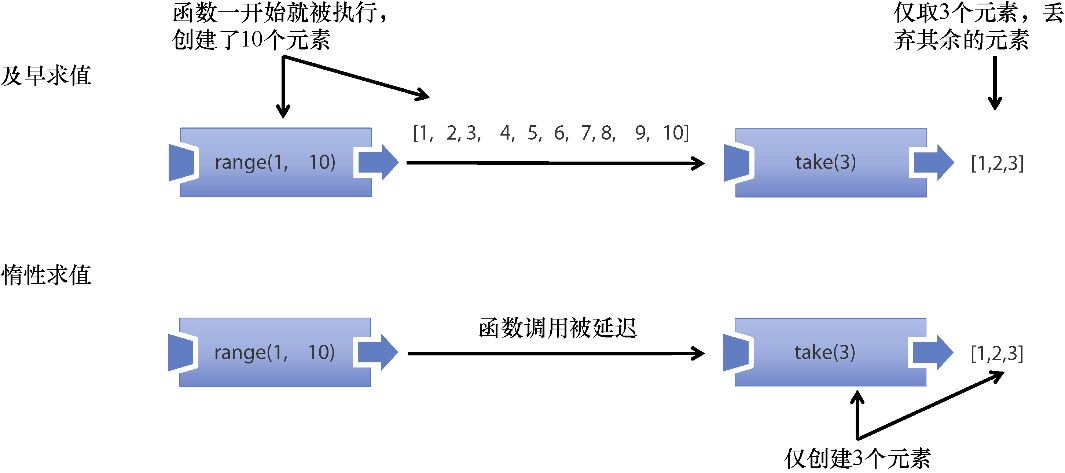
图7.6 函数range (生成给定范围的数组)与take (读取前n个 元素)的组合。对于及早求值,range 函数在调用时就执行,结果传给take 。而惰性求值的range ,调用时不会产生结果,直到take 执行
如图7.6所示,及早求值的方案会首先执行range 函数,再将其结果传递给take 。然而take只需要一个子集,剩下的部分会被丢弃。试想如果生成的元素数量较多,这会多么浪费。对于惰性求值,range 会推迟到take 真的取值时再执行。知道函数的最终目的之后,range 函数可以只生成所需数量的元素。考虑另一个涉及Maybe Monad的例子:
Maybe.of(student).getOrElse(createNewStudent());
乍一眼看上去,这里Maybe 很像是下面这段表达式:
if(!student) {
return createNewStudent();
}
else {
return student;
}
但是由于JavaScript用的是及早求值方案,因此getOrElse 中的createNewStudent 函数不管怎么样都会执行。如果是惰性求值,这两段代码中的createNewStudent 就只有student对象合法时执行。所以,到底应该如何利用惰性求值呢?本节将介绍下列技巧和窍门。
- 避免不必要的计算。
- 使用函数式类库。
7.2.1 使用函数式组合子避免重复计算
其实可以模拟惰性求值来实现纯函数语言的好处。在最简单的情况下,可以通过只传递函数引用(或名称),然后有条件地选择调用或不调用。第4章介绍过alt 函数式组合子,它类似于或|| (OR)运算符,先计算func1 ,如果返回值为false 、null 或undefined ,再调用func2 。这里再举一个例子:
const alt = R.curry((func1, func2, val) => func1(val) || func2(val));
const showStudent = R.compose(append('#student-info'),
alt(findStudent, createNewStudent)); <---没有函数会过早地调用,因为组合子使用的只是它们的函数引用
showStudent('444-44-4444');
由于函数式组合子负责编排调用,这个代码就相当于命令式的条件逻辑:
var student = findStudent('444-44-4444');
if(student !== null) {
append('#student-info', student);
}
else {
append('#student-info', createNewStudent('444-44-4444'));
}
这是避免不必要计算的简单方法之一。本章后面会介绍一个更强大的方法memoization 。同时,如果在运行前就定义好程序,就可以使用函数式库的shortcut fusion 技术来优化。
7.2.2 利用shortcut fusion
第3章介绍了Lodash的_.chain 函数,该函数可以用于包装和执行一系列的函数,然后通过value() 函数提取结果。这不仅可以分离程序的描述与执行,还可以让Lodash推断出可优化的地方,比如合并执行或优化存储。下面是一个按国家人口排序生成列表的例子:
_.chain([p1, p2, p3, p4, p5, p6, p7])
.filter(isValid)
.map(_.property('address.country')) .reduce(gatherStats, {})
.values()
.sortBy('count')
.reverse()
.first()
.value()
声明式编程的模式意味着开发者不必担心具体函数如何执行,只需提前描述好要做些什么事情。在某些情况下,Lodash会使用shortcut fusion对程序进行优化。这是一种函数级别的优化,它通过合并函数执行,并压缩计算过程中使用的临时数据结构。处理大集合时,创建更少的数据结构能有效地降低内存占用。
之所以能这样做,都是因为函数式编程的引用透明性带来的数学与代数的正确性。例如,compose(map(f), map(g)) 可以由表达式map(compose(f, g)) 完全代替。同样,compose(filter(p1), filter(p2)) 等同于filter((x) => p1(x) && p2(x)) ,前面chain中的filter 和map 也能做同样的优化。而且,只有纯函数才能以这种数学方式进行系列操作。再来看清单7.1所示的例子,可能会更能说明这一点。
清单7.1 Lodash的惰性求值与和shortcut fusion
const square = (x) => Math.pow(x, 2);
const isEven = (x) => x % 2 === 0;
const numbers = _.range(200); <---生成一个从 1 到 200 的数值数组
const result =
_.chain(numbers)
.map(square)
.filter(isEven)
.take(3) <---仅会处理前三个满足 filter(和 map)条件的数字
.value(); //-> [0,4,16]
result.length; //-> 5
清单7.1有几个可以优化的地方:首先,take(3) 告诉Lodash只需担心前三个通过map和filter的值,而不用把时间浪费在剩余的195个元素上。其次,shortcut fusion技术可以把map 和filter 融合到compose(filter(isEven), map(square)) 。可以简单地通过把跟踪日志(使用Ramda提供的tap 组合子)加到square 和isEven 函数来证明这一点:
square = R.compose(R.tap(() => trace('Mapping')), square);
isEven= R.compose(R.tap(() => trace('then filtering')), isEven);
控制台打印5次下面这一对消息:
Mapping
then filtering
这证实了map 和filter 的合并。使用函数式库不仅能简化测试,还能提高代码运行时效率。Lodash还有一些其他带有shortcut fusion优化的函数,如_.drop 、_.dropRight 、_.dropRightWhile 、_.dropWhile 、_.first 、_.initial 、_.last 、_.pluck 、_.reject 、_.rest 、_.reverse 、_.slice 、_.takeRight 、.takeRightWhile 、_.takeWhile 和_.where 。
除此之外,函数式还有另一种避免重复计算的技术:记忆化 (memorization)。
7.3 实现需要时调用的策略
加快应用程序执行的方法之一是避免计算重复值,特别是当这些计算的代价昂贵时。在传统的面向对象系统中,这可以通过在函数调用前检查高速缓存或代理层来实现。在返回时,给函数的结果赋予唯一的键值并持久化到缓存中。缓存 作为耗时操作之前查询的中介或记忆体。在Web应用程序中,这种技术还用于图像、文档、编译的代码、HTML页面、查询结果等。考虑下面这个简单缓存层的实现:
function cachedFn (cache, fn, args) {
let key = fn.name + JSON.stringify(args); <---基于函数名称和参数分配一个键值来表明函数的结果
if(contains(cache, key)) { <---首先在缓存中检查该函数
return get(cache, key); <---如果执行过, 则返回缓存值(缓存命中)
}
else {
let result = fn.apply(this, args); <---否则,执行函数(函数未命中)
put(cache, key, result); <---再缓存执行的结果
return result;
}
}
可以用该函数包裹findStudent 的执行:
var cache = {};
cachedFn(cache, findStudent, '444-44-4444'); <---第一次会导致缓存未命中,从而执行 findStudent
cachedFn(cache, findStudent, '444-44-4444'); <---第二次的结果直接来自于缓存
该cachedFn 函数相当于介于函数调用缓存结果之间的代理。但是用这个来包裹所有函数调用显然过于繁琐而且不易于阅读。更糟糕的是,这个函数是有副作用的,它依赖于一个全局共享的缓存对象。我们需要的是一个更普遍适用的解决方案,能在享受到缓存的好处的同时,保持对代码和测试都透明的机制。在函数式语言,这种机制被称为记忆化 (memoization)。
7.3.1 理解记忆化
记忆化的方案与之前的缓存类似。它就像以前的代码中,基于函数的参数创建与之对应的唯一的键,并将结果值存储到对应的键上,当再次遇到相同参数的函数时,立即返回存储的结果。能够用存储的结果来替代函数调用的结果,这要归功于函数式的引用透明性原则。首先来研究一下记忆化对于简单函数调用的益处。
7.3.2 记忆化计算密集型函数
纯函数式语言自带记忆化。其他诸如JavaScript和Python的语言,可以在需要时选择使用记忆化函数。当然,计算密集型函数很大程度上可以受益于缓存层。考虑rot13 函数的计算,将字符串编码成ROT13格式(将26个ASCII字符旋转13个字符位置)的例子。虽然这是一个简单的算法,但实际上是很多简单优惠码或者谜题答案的解决方案:
var discountCode = 'functional_js_50_off';
rot13(discountCode); //-> shapgvbany_wf_50_bss
ROT13算法的详细实现如下:
var rot13 = s =>
s.replace(/[a-zA-Z]/g, c =>
String.fromCharCode((c <= 'Z' ? 90 : 122)
>= (c = c.charCodeAt(0) + 13) ? c : c - 26));
(c = c.charCodeAt(0) + 13) ? c : c - 26);
});
};
理解这个算法与此处的讨论并不相关,重要的是同样的输入一定会输出同样的结果(引用透明函数),这意味着通过记忆化提高了这段算法的性能。在展示memoize 函数的代码之前,先来介绍以下两种记忆化的用法:
- 通过调用函数对象上的方法。
var rot13 = rot13.memoize();
- 通过包裹函数。
var rot13 = (s =>
s.replace(/[a-zA-Z]/g, c =>
String.fromCharCode((c <= 'Z' ? 90 : 122)
>= (c = c.charCodeAt(0) + 13) ? c : c - 26))).memoize();
通过使用记忆化,遇到相同的输入会立即触发内部缓存命中直接返回结果。为了说明这一点,下面使用JavaScript的高分辨率时间API(也称为性能API),以产生比传统函数如Date.now() 和console.time() 更精确的时间戳,来测量函数调用的精确时间。可以用IO Monad把计时语句加入测试前后。整个程序需要先构造包裹着performance.now 副作用的start和end函数,再用tap在测试时调用。清单7.2所示的是时间测量的代码。后面会对该例中的代码进行简化。
清单7.2 使用tap 调用性能时间戳函数
const start = () => performance.now(); <---使用 start 和 end 函数来测量时间
const end = function (start) {
let end = performance.now();
return (end - start).toFixed(3); <---使用 performance API 来获取3 个小数点毫秒的测量精度
};
const test = function (fn, input) {
return () => fn(input);
};
const testRot13 =
IO.of(start)
.map(R.tap(start('rot13')))
.map(R.tap(test( <---通过 tap 组合子在 Monad 中生成算法开始时间的信息(这样做是因为并不关心函数的结果,而是得出结果所花费的时间)
rot13,
'functional_js_50_off'
)))
.map(end);
testRot13.run(); // 0.733 ms
testRot13.run(); // second time: 0.021 ms
如上述代码所示,第二次调用rot13 只需片刻就能得到结果。虽然JavaScript没有自动记忆化的原生支持,但是可以给Function 对象添加这个方法,如清单7.3所示。
清单7.3 给Function添加记忆化
Function.prototype.memoized = function () { <---内部的工具方法负责为当前函数实例创建缓存逻辑
let key = JSON.stringify(arguments); <---将参数字符串化以获得对当前函数调用的键值。可以通过检测输入类型来创建更加鲁棒的键值生成方法。这只是一个简单的例子
this._cache = this._cache || {}; <---为当前函数实例创建一个内部的缓存
this._cache[key] = this._cache[key] ||
this.apply(this, arguments); <---先试图读取缓存, 通过输入来判断是否计算过。 如果找到对应的值, 则跳过函数调用直接返回;否则,执行计算
return this._cache[key];
};
Function.prototype.memoize = function () { <---激活函数的记忆化
let fn = this;
if (fn.length === 0 || fn.length > 1) {
return fn; <---只尝试记忆化一元函数
}
return function () {
return fn.memoized.apply(fn, arguments); <---将函数实体包裹在记忆化函数中
};
};
通过扩展Function 对象,这样可以随时使用记忆化,还消除了全局共享的缓存。此外,抽象到函数的内部缓存机制,使其完全与测试无关,这意味着不需要在代码中测试缓存的功能,只需要关心函数的行为是什么即可。
为了能有更直观的认识,下面来看rot13 记忆化的详细序列图,如图7.7所示。第一次查询缓存会失败,于是开始计算ROT13消息。接下来,结果会以参数为键存入缓存,之后同样参数的调用就可以在缓存中查询到结果而不需要重新计算了。
图7.7 使用同一参数functional_js_50_off两次调用rot13 。第一次调用,缓存为空,需要计算ROT13码。其结果会以参数为键存储在缓存中。第二次调用会命中缓存:于是没有发生计算就直接返回结果
注意:
这里的memoize记忆化只有一个参数。那么如何处理多个参数的函数呢?这个问题留给读者作为练习。基本上需要遵循两个策略。其一,创建一个多维缓存(数组的数组);其二,生成参数组合的唯一字符串密匙。
清单7.3中的代码仅限于一元函数。这样做是为了简化生成密匙的逻辑。如果需要记忆化多个参数的函数,那么制订正确的缓存键生成逻辑可能会比较复杂。在某些情况下,柯里化可以解决这个问题。
7.3.3 有效利用柯里化与记忆化
更复杂的函数或涉及多个参数的函数,即使是纯函数,也很难缓存。这是由于在产生正确的唯一键时逻辑的复杂度增加了,但是缓存层又不应该给函数增加额外的开销和复杂度。柯里化是上述问题的解决方法之一。第4章提到,柯里化可以将一个多元函数变成一元函数。例如,柯里化可以记忆化safeFindObject 函数:
const safeFindObject = R.curry(function (db, ssn) { <---该函数并不具备引用透明性,但实践中一般会使用缓存来降低查询和 HTTP 请求的代价
// expensive IO lookup operation
});
const findStudent = safeFindObject(DB('students')).memoize();
findStudent('444-44-4444');
DB 对象仅用于数据访问,但是对唯一区分findStudent 没什么帮助,然而上述代码的目的是找到具有唯一ID的学生,所以只需要记忆化带有ID参数的函数。这就体现出了柯里化的好处,即不仅易于组合,还可以在组合之前方便地选择将部分函数进行记忆化。下一节会重点讨论分解与记忆化。
7.3.4 通过分解来实现更大程度的记忆化
记忆化和分解的关系可以用一个简单的化学原则来解释。读者可能在高中学习化学中的溶解度原则时听过溶质和溶剂的概念。溶质是在溶剂中溶解的物质。溶解速度由多个因素决定,表面积 是其中一个因素。举例来说,如果准备溶解糖到水里,糖粉和糖块哪一个溶解得更快?当糖溶解时,只有其表面与水接触。因此,溶质的表面积越大,溶解得越快。
记忆化跟这个道理类似,问题拆分得越小,越容易记忆化。代码粒度越细,越能更大程度地享受记忆化带来的好处。每个函数都有内部缓存机制在加快程序,就像拥有更大的表面积一样。
以showStudent 为例,如果之前就验证过某些输入,何苦再验证一遍?同样,如果已经通过本地存储cookie,甚至是服务器端调用找到SSN对应的学生对象,且其实它们不会有所改变,为什么要浪费宝贵的时间再查找一次?在findStudent 的例子中,可以记忆化查询,保留已经查找到的对象以便下次快速访问。记忆化把函数当作一个惰性计算的返回值。为了说明这一点,下面用记忆化的函数来组合成showStudent 函数(通常是给记忆化函数加上前缀m_ ):
const m_cleanInput = cleanInput.memoize();
const m_checkLengthSsn = checkLengthSsn.memoize();
const m_findStudent = findStudent.memoize();
const showStudent = R.compose(
map(append('#student-info')),
liftIO,
chain(csv),
map(R.props(['ssn', 'firstname', 'lastname'])),
map(m_findStudent),
map(m_checkLengthSsn),
lift(m_cleanInput));
showStudent('444-44-4444').run(); //-> 9.2 ms on average (no memoization)
showStudent('444-44-4444').run(); //-> 2.5 ms on average (with memoization)
这些函数被分解成更小的任务,第二次运行的速度比第一次快75%!
递归是另一种类型的分解,像是程序被分为自相似的、更小的、可记忆化的子任务。同样,记忆化也可以让一个缓慢的递归算法变得非常快。
7.3.5 记忆化递归调用
递归可能会导致浏览器卡顿或者抛出异常。这些往往都是由输入过大时堆栈的增加失控导致的。在某些情况下,记忆化可以减轻此问题。正如第3章讲过的,递归是将任务分解成更小版本的自己的机制。通常情况下,每次递归调用都在一个更小的子集解决“同样的问题”,直至达到递归的基例情况,然后释放堆栈返回结果。如果每一个子任务的结果都能缓存,就可以减少重复同样的计算,从而提高性能。
为了说明这一点,下面使用计算n 的阶乘的例子。n 的阶乘(表示为N !) 也就是比n 小的正整数的乘积:
*n* ! = *n* * (*n* – 1) * (*n* – 2) * … * 3 * 2 * 1
例如:
3! = 3 * 2 * 1 = 6
4! = 4 * 3 * 2 * 1 = 4 * 3! = 24 <—注意:阶乘数是可以通过更小的阶乘数递归定义的,比如 4!=4*3!
这很容易翻译成记忆化的递归函数:
const factorial = ((n) => (n === 0) ? 1
: (n * factorial(n - 1))).memoize();
factorial(100); //-> Takes .299 ms <---执行整个计算100*99*98*… *3*2*1
factorial(101); //-> Second time, takes .021 ms <---使用之前的缓存来加快计算,仅计算到 101*100!
由于记忆化了阶乘函数,在第二次迭代时吞吐量有显著的提升。在第二次运行时,函数“记住”了使用公式“101!= 101×100!”,并且可以重复使用factorial(100) 的值,使得整个算法立即返回,并对栈帧的管理以及污染堆栈方面都有好处,如图7.8所示。

图7.8 运行记忆化的factorial(100) 在第一次会创建100的堆栈帧,因为它需要计算100!在第二次调用101的阶乘时通过记忆化能够重复使用factorial(100) 的结果,所以只会创建2个栈帧
如图7.8所示,factorial(100) 的第一个运行会贯穿整个算法,创造了100帧函数堆栈。这是一些递归解决方案的缺点:它们往往不注意堆栈空间,尤其是在factorial 这种情况下,堆栈帧的数量跟输入的大小是相同比例。但如果使用记忆化,就可以显著减少计算下一个数所需堆栈帧的数目。
记忆化不是优化递归调用的唯一方法,还存在其他的方法,比如编译器级别的优化。
7.4 递归和尾递归优化
读者应该发现了,递归程序使用堆栈的情况会比非递归程序更严重一些。有些函数式语言甚至没有内置的循环机制,需要依靠递归和缓存来实现高效的迭代。但是有时记忆化也无能为力,比如输入不断变化,就会导致内部高速缓存层一直派不上用场。递归到底能达到标准循环的效率吗?事实证明,当使用尾递归时,编译器有可能帮助你做尾部调用优化 (TCO)。本节会讲解如何用尾递归重写阶乘函数。
const factorial = (n, current = 1) =>
(n === 1) ? current
: factorial(n - 1, n * current); <---函数最后一条语句是下一次递归(即处于尾部)
跟之前略有不同的是,递归发生在最后,运行起来可以跟命令式版本一样快:
var factorial = function (n) {
let result = 1;
for(let x = n; x > 1; x--) {
result *= x;
}
return result;
}
TCO也称为尾部调用消除 ,是ES6添加的编译器增强功能。同时,在最后的位置调用别的函数也可以优化(虽然通常是本身),该调用位置称为尾部位置 (尾递归因此而得名)。
这为什么算是一种优化?函数的最后一件事情如果是递归的函数调用,那么运行时会认为不必要保持当前的栈帧,因为所有工作已经完成,完全可以抛弃当前帧。在大多数情况下,只有将函数的上下文状态作为参数传递给下一个函数调用(正如在递归阶乘函数处看到的),才能使递归调用不需要依赖当前帧。通过这种方式,递归每次都会创建一个新的帧,回收旧的帧,而不是将新的帧叠在旧的上。因为factorial 是尾递归的形式,所以factorial(4) 的调用会从典型的递归金字塔:
factorial(4)
4 * factorial(3)
4 * 3 * factorial(2)
4 * 3 * 2 * factorial(1)
4 * 3 * 2 * 1 * factorial(0)
4 * 3 * 2 * 1 * 1
4 * 3 * 2 * 1
4 * 3 * 2
4 * 6
return 24
变为图7.9所示的扁平结构,相对于如下上下文堆栈:
factorial(4)
factorial(3, 4)
factorial(2, 12)
factorial(1, 24)
factorial(0, 24)
return 24
return 24
图7.9 尾递归factorial(4) 求值的详细视图。函数只使用了一帧。TCO负责抛弃当前帧,
为新的帧让路,就像factorial 在循环中求值一样
这种扁平化结构可以更有效地利用栈,不再需要保留N 帧。接下来看看将非尾递归的factorial 函数转换成尾递归函数的详细处理步骤。
将非尾递归转换成尾递归
下面优化一下factorial ,以便能够利用JavaScript的TCO机制。递归实现factorial 大概最直接的实现是:
const factorial = (n) =>
(n === 1) ? 1
: (n * factorial(n - 1));
递归调用并没有发生在尾部,因为最后返回的表达式是n * factorial(n - 1) 。切记,最后一个步骤一定要是递归,这样才会在运行时TCO将factorial 转换成一个循环。改成尾递归只需要两步。
1)将当前乘法结果当作参数传入递归函数。
2)使用ES6的默认参数给定一个默认值(也可以部分地应用它们,但默认参数会让代码更整洁)。
const factorial = (n, current = 1) =>
(n === 1) ? current :
factorial(n - 1, n * current);
现在,这个阶乘函数运行起来跟标准循环没什么区别,没有额外创建堆栈帧,同时仍保留了它原本的数学声明的感觉。之所以能够做这种转换,是因为尾递归函数跟循环有着共同的特点,如图7.10所示。

图7.10 标准循环(左)及其等效的尾递归函数之间的相似之处。在这两个代码示例中, 读者可以很容易地找到基例、事后操作、累计参数和结果
来看另一个例子。在第3章中,有一个递归计算数组元素总和的函数:
function sum(arr) {
if(_.isEmpty(arr)) {
return 0;
}
return _.first(arr) + sum(_.rest(arr));
}
最后一个调用_.first(arr) + sum(_.rest(arr)) 也不是尾调用。接下来重构代码并优化它的内存消耗。这次,所有需要分享给之后调用的数据都将以参数的方式传递下去:
function sum(arr, acc = 0) {
if(_.isEmpty(arr)) {
return 0;
}
return sum(_.rest(arr), acc + _.first(arr));
}
尾递归带来递归循环的性能接近于for循环。所以对于有尾递归优化的语言,比如ES6,就可以在保持算法的正确性和mutation的控制,同时还能保持不会拖累性能。不过尾调用也不仅限于尾递归。也可以是调用另一个函数,这种情况在JavaScript代码中也很常见。不过要注意的是,这是个新的JavaScript标准,即便ES4就开始起草,很多浏览器也没有广泛实现。事实上,在编写本节的时候,还没有任何浏览器实现了TCO,这就是笔者一直在用Babel transpiler的原因。
ES5中模仿尾递归调用
目前主流的JavaScript实现ES5并不具备尾调用优化支持。ES6将其加入被称为适当尾调用的提案(在ECMA-262规范的14.6部分)。还记得第2章中使用的Babel转译器(源代码到源代码的编译器)吗?那是用来测试语言新特性的绝佳方式。
还有一种解决方式是使用trampolining 。trampolining可以用迭代的方式模拟尾递归,所以可以非常理想、容易地控制JavaScript的堆栈。
trampoline是一个接受函数的函数,它会多次调用函数,直到满足一定的条件。一个可反弹或者重复的函数被封装在thunk 结构中。thunk只不过是多了一层函数包裹。在函数式JavaScript背景下,可以用thunk及简单的匿名函数包裹期望惰性求值的值。
thunk和trampolining的话题已经超出了本书的范围,如果读者非常希望用这些技术来优化递归函数,可以从这个概念开始展开研究。
要检查TCO和其他ES6特性的兼容性,可以登录:https://kangax.github.io/compat- table/es6/。
如果需要一个图形渲染一个大型的数据,那么性能就成为一项关键要求。在这种情况下,开发者就可能需要做出取舍,即可能不需要编写优雅、可扩展的代码,而需要快速地完成工作。如果是这样,建议使用标准循环。但对于大多数的应用需求,函数式编程仍然可以保持代码的性能。但需要注意的是,尽量把优化工作放到最后。再者,在需要额外毫秒级别的性能优化时,可以随时使用任何本章中的技术增强性能。
每个软件决策都很难权衡,但对于大多数的应用而言,牺牲效率以获得更高的可维护性是值得考虑的。应该让代码更容易阅读和调试,即使它不是最快的。正如Knuth所说:“对于你写的97%的代码,多上几毫秒并不会有什么区别,特别是相对代码的可维护性来说。”
函数式编程是一个完整的范式。它提供了丰富的抽象层次以及有趣的提高效率的方法。到现在为止,读者应学会了如何通过链接或组合函数来创建线性数据流的函数式程序。但是,众所周知,JavaScript程序会混合许多非线性或异步行为,例如处理用户输入或进行远程HTTP请求。第8章将带领读者直面这些挑战并了解响应式编程——这是一种基于函数式编程的范式。
7.5 总结
- 在某些情况下,函数式代码可能比与其等效的命令式代码更慢或消耗的内存更多。
- 可以利用交替组合子以及函数式库(如Lodash)中提供的支持来实施延迟策略。
- memoization(内部函数级缓存策略)可用于避免重复对潜在费时函数进行求值。
- 将程序分解成简单的函数不仅可以创建可扩展代码,还可以通过记忆化来使其更高效。
- 递归可以通过分解把问题化为更简单的自相似问题,继而充分利用记忆化优化上下文堆栈的使用。
- 将函数转换为尾递归形式,就可以借助编译器优化消除尾调用。
[1] 源自David Shariff的优秀博客文章《什么是JavaScript的执行上下文和堆栈?》2012年6月19日,http://mng.bz/mqTu。
第8章 管理异步事件以及数据
本章内容
- 编写异步代码的挑战
- 通过函数式技术避免嵌套回调
- 使用Promise简化异步代码
- 用函数生成器惰性地生成数据
- 响应式编程
- 应用响应式编程来处理事件驱动的代码
程序员之所以认为函数式编程比其他编程更高效,是因为函数式程序的代码量往往会少一个数量级。
——John Hughes,《Why Functional Programming Matters》[ 1]
到目前为止,本书一直在向读者介绍如何函数式思考,以及如何使用函数式技术来编写、测试和优化JavaScript代码。所有这些技术都旨在解决中型和大型Web应用程序所固有的复杂性,因为这些复杂性很容易导致程序越来越难以维护。许多年前,与Web应用程序的交互仅限于提交大型表单然后一次性渲染整个页面。应用程序随着用户需求的发展而发展。如今,人们都期望页面的行为能像本地应用程序那样实时做出响应和反应。
在客户端JavaScript的世界中,开发者所面临的挑战多于任何其他环境。这很大程度上是因为客户端代码不仅需要与传统Web中间件关联,还需要有效地与用户输入交互,通过AJAX与远程服务器通信,并在屏幕上显示数据。本书倾向于使用函数式编程这一解决方案,因为它对于需要保持高完整性的系统而言是理想的,尽管可能在某些方面还存在问题。
本章将应用函数式编程来解决与异步数据流相关的JavaScript编程挑战,其中代码与程序的执行不是线性关系。有些示例会使用浏览器技术,如AJAX和本地存储请求。本章的目标是将函数式编程与ES6 Promise结合使用,并引入响应式编程,这两种方式可以将凌乱的回调代码转换成优雅流畅的表达式。读者可能发现响应式编程非常眼熟,这是因为用它解决问题的思路跟函数式编程密切相关。
想保证异步行为正确是很棘手的。与正常函数不同,异步函数不能将数据返回给调用者,而要依靠长时间运行的计算,如数据库提取或远程HTTP调用后的通知这种臭名昭著的回调模式。还可以使用回调来响应用户交互来处理诸如点击、按键和移动手势之类的浏览器事件。开发者需要构建代码来响应程序运行后发生的这些事件,这对于函数式的设计构成了许多挑战,因为很难保持数据可预测并在正确的时间内返回。毕竟,谁也不知道如何将未来会发生的行为组合或链接成函数。
8.1 异步代码的挑战
现代JavaScript程序很少在单个请求中加载。最常见的是,数据通过响应用户需求的多个异步请求逐渐加载到页面上。一个简单的用例是电子邮件客户端。用户的收件箱可以有数千条长的电子邮件线程,但只会与最近的电子邮件进行交互。花费几秒甚至几分钟等待整个收件箱加载是没有意义的。JavaScript开发人员经常涉及实现某种形式的非阻塞异步调用的问题,但这可能会带来以下挑战。
- 在函数之间创建时间依赖关系。
- 不可避免地陷入回调金字塔。
- 同步和异步代码的不兼容。
8.1.1 在函数之间创建时间依赖关系
想象一下发送AJAX请求以从服务器获取学生对象列表的函数。在图8.1中,由于getJSON 是异步的,函数在发送请求后立即返回,并将控制权返回给程序,随后调用showStudents 。但是在这个时候,students 对象仍然是null ——因为较慢的远程请求还没有完成。确保正确的事件顺序发生的唯一方法是在异步代码和下一步采取的操作之间创建时间依赖关系 。所以需要在回调函数中包含showStudents,以便它在正确的时间执行。
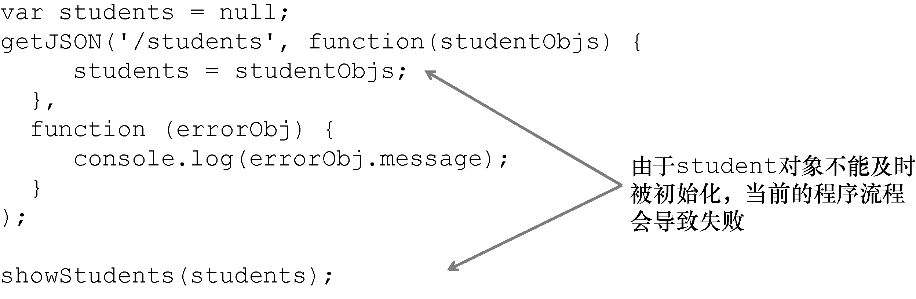
图8.1 这段代码有一个很大的问题。发现了吗?因为需要异步地获取数据,
所以students 对象永远不会及时地被填充到列表中
当某些函数的执行在逻辑上分组在一起时,会发生时间耦合 或时间内聚 。这意味着函数需要等待数据可用或需要等待其他函数运行结束才能完成操作。无论是依赖于数据还是时间,这样做都会产生副作用。
因为执行远程IO操作明显比其他的代码慢,所以将它们委托给可以请求数据的“非阻塞”进程,然后“等待”它返回。当接收到数据时,将调用用户提供的回调函数。这正是清单8.1所示的getJSON 要做的事情。
清单8.1 使用原生集XMLHttpRequest 函数实现的getJSON
const getJSON = function (url, success, error) {
let req = new XMLHttpRequest();
req.responseType = 'json';
req.open('GET', url);
req.onload = function() {
if(req.status == 200) {
let data = JSON.parse(req.responseText);
success(data);
}
else {
req.onerror();
}
}
req.onerror = function () {
if(error) {
error(new Error(req.statusText));
}
};
req.send();
};
回调函数在JavaScript中非常常见。但是,当需要加载更多数据时,读者会发现它们很难扩展,这将导致出现常见的回调模式。
8.1.2 陷入回调金字塔
回调的主要用途是避免阻塞UI,防止用户长时间等待IO进程完成。接受回调而不是返回值的函数实现了一种控制反转 的形式:“不要打电话给我,我会打给你的”。一旦事件发生,例如数据可用或用户单击按钮,数据会作为参数来调用回调函数,函数中的同步代码才开始运行:
var students = null;
getJSON('/students',
function(students) {
showStudents(students);
},
function (error) {
console.log(error.message);
}
);
在发生错误的情况下,会调用相应的错误回调函数,以便有机会报告错误并恢复。但是,这种控制反转跟函数式程序的设计有所冲突——函数式任务函数应该彼此独立,并且期望立即向调用者返回结果。如前所述,如果需要在已经嵌套的回调中添加更多的异步逻辑,则这种情况会更糟。
为了表明这一点,考虑一下稍微复杂的情况。假设从服务器获取学生列表之后,还需要获取成绩,但只需要居住在美国的学生。然后,该数据按SSN排序并显示在HTML页面上,如清单8.2所示。
清单8.2 嵌套的JSON调用,其中还有自己的成功和错误回调
getJSON('/students',
function (students) { <---第一层嵌套用于包含成功和失败回调的 AJAX 请求
students.sort(function(a, b){
if(a.ssn < b.ssn) return -1;
if(a.ssn > b.ssn) return 1;
return 0;
});
for (let i = 0; i < students.length; i++) {
let student = students[i];
if (student.address.country === 'US') {
getJSON(`/students/${student.ssn}/grades`,
function (grades) { <---收到每个学生的成绩后,需要改写该函数来支持在表格中一个一个地增加学生及其成绩信息
showStudents(student, average(grades)); <---第二层嵌套用于包含其成功和失败回调的学生成绩获取请求
},
function (error) { <---收到每个学生的成绩后,需要改写该函数来支持在表格中一个一个地增
加学生及其成绩信息
console.log(error.message);
});
}
}
},
function (error) {
console.log(error.message); <---第一层嵌套用于包含成功和失败回调的 AJAX 请求
}
);
在阅读本书之前,这段代码看起来可能还可以接受,但是一个函数式程序员会感觉非常凌乱(稍后章节会给出一个完整的函数式版本的代码)。处理事件时也会出现类似的问题。清单8.3中交织着用户输入处理及AJAX调用。比如监听点击和鼠标事件,从服务器获取多条数据,并在DOM上呈现数据。
清单8.3 按照SSN从服务器检索学生记录
var _selector = document.querySelector;
_selector('#search-button').addEventListener('click',
function (event) {
event.preventDefault();
let ssn = _selector('#student-ssn').value;
if(!ssn) {
console.log('WARN: Valid SSN needed!');
return;
}
else {
getJSON(`/students/${ssn}`, function (info) {
_selector('#student-info').innerHTML = info;
_selector('#student-info').addEventListener('mouseover',
function() {
getJSON(`/students/${info.ssn}/grades`,
function (grades) {
// ... process list of grades for this
// student...
});
});
})
.fail(function() {
console.log('Error occurred!');
});
}
});
而且这段代码非常难懂。比如,一系列的回调使代码变得像图8.2所示的金字塔。这也被称为“回调地狱(callback hell)”或“厄运圣诞树(Christmas tree of doom)”,很容易出现在处理许多异步代码和用户/ DOM行为的时候。
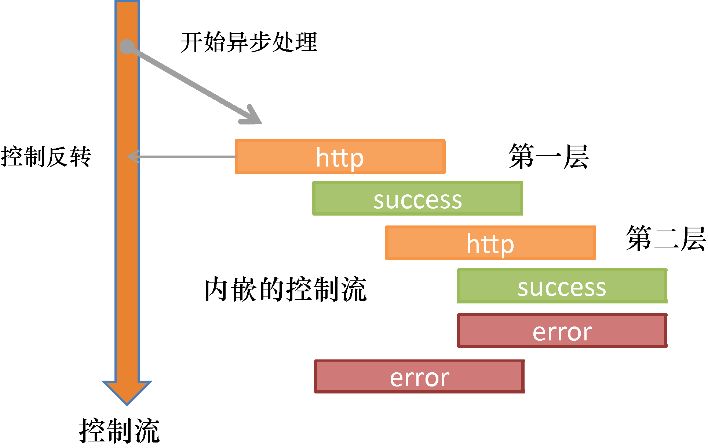
图8.2 一个简单的控制流变成一个像“厄运圣诞树”一样水平生长的金字塔
一旦开始采取这种形式,程序将依赖于间距和句法组织来提高可读性。但这并没什么用。下面来看函数式如何能够改变这种情况。
8.1.3 使用持续传递式样
清单8.3是尚未正确分解的程序的另一个示例。嵌套回调函数不仅难以阅读,还可以闭包作用域上的变量与函数。嵌套函数的唯一原因是内部函数的计算依赖其外部变量。但是在这种情况下,内部的回调函数仍然保持着不必要的外部引用。对于这段代码,解决方案是使用持续传递式样 (CPS)。清单8.4是CPS重构后的代码。
清单8.4 使用CPS重构学生检索
var _selector = document.querySelector;
_selector('#search-button').addEventListener('click', handleMouseMovement);
var processGrades = function (grades) {
// ... process list of grades for this student...
};
var handleMouseMovement = () =>
getJSON(`/students/${info.ssn}/grades`, processGrades);
var showStudent = function (info) {
_selector('#student-info').innerHTML = info;
_selector('#student-info').addEventListener(
'mouseover', handleMouseMovement);
};
var handleError = error =>
console.log('Error occurred' + error.message);
var handleClickEvent = function (event) {
event.preventDefault();
let ssn = _selector('#student-ssn').value;
if(!ssn) {
alert('Valid SSN needed!');
return;
}
else {
getJSON(`/students/${ssn}`, showStudent).fail(handleError);
}
};
这里只是将内部回调分离为单独的函数或lambda表达式。CPS是一种用于非阻塞程序的编程风格,它鼓励开发者将程序分成单个组件,因此它是函数式编程的中间形式。在这种情况下,回调函数被称为当前的延续 (current continuation),它们由调用者在返回值上提供。CPS[ 2] 的一个重要优点是其在上下文堆栈方面的效率(参见第7章有关JavaScript函数堆栈的信息)。如果程序完全在CPS(如清单8.4)中,持续计算会清除当前函数的上下文,并准备一个新的函数来支持继续程序流程的功能——每个函数基本上都是尾部调用形式。
使用CPS还可以修复清单8.2中同步和异步行为交错的问题。主要的问题是嵌套循环来发送AJAX请求检索每个学生的成绩并计算其平均值:
for (let i = 0; i < students.length; i++) {
let student = students[i];
if (student.address.country === 'US') {
getJSON(`/students/${student.ssn}/grades`,
function (grades) {
showStudents(student, average(grades));
},
function (error) {
console.log(error.message);
}
);
}
}
乍一看好像代码应该可以工作,打印出学生Alonzo Church和Haskell Curry[ 3] 的名字及其各自的信息(该段代码使用HTML表来附加每个学生的所有数据,但也可以是一个文件或数据库插入)。然而,运行结果如图8.3所示。
图8.3 异步函数与同步循环混合的错误命令式代码的运行结果。在获取远程数据时, 函数调用将始终引用最后迭代的(闭包中的)学生记录,无论并打印多少次
这当然不是期望的结果。为什么同一个学生打印了两次?这个错误主要是由使用了同步的循环执行异步函数getJSON 所导致的。循环并不会等待getJSON 完成。即使用了块作用域的let 关键字,所有对showStudents(student, average(grades)) 的内部调用都将只能看到闭包中的最后一个学生对象引用。第2章曾讨论了这个问题,这种奇怪的循环问题证明函数的闭包不是其封闭环境的一个副本,而是实际的引用。注意,成绩仍然是正确的。这是因为获取的值是通过回调作为参数传递进去的。
正如第2章中提到的,解决这个问题的方法是将student 对象放入产生AJAX请求的函数中。在这种情况下,使用CPS并不像以前那样简单,因为处理成绩的嵌套回调函数也取决于student 对象。记住,这是副作用。CPS的实现需要使用第4章中关于currying的内容,以帮助链接函数输入和输出:
const showStudentsGrades = R.curry(function (student, grades) { <---使用柯里化将该函数转化为一元函数
appendData(student, average(grades)); <---appendData 函数能够将行信息添加至HTML 表格中
});
const handleError = error => console.log(error.message);
const processStudent = function (student) {
if (student.address.country === 'US') {
getJSON(`/students/${student.ssn}/grades`,
showStudentsGrades(student), handleError); <---柯里化函数 showStudentsGrades(student)最终被回调并传入成绩数据
}
};
for (let i = 0; i < students.length; i++) {
processStudent(students[i]); <---将循环的对象传递给函数能够有效的将当前 students的引用保存在闭包中
}
这段新代码计算出了正确的结果,如图8.4所示。
图8.4 将当前student 对象作为参数设置到函数的闭包中,解决了
在循环中远程调用导致的歧义
采用延续传递风格有助于打破代码中的时间依赖性,并将异步流程伪装成线性的函数求值。但是当一个不熟悉这段代码的人看到时,他可能会对这些函数的执行顺序感到迷惑,所以需要一个让这种耗时操作成为一等公民的对象。
8.2 一等公民Promise
上面的代码比本章开头所用的命令式异步程序要稍微好一些,但还不够函数式。函数式程序还需要具备以下性质。
- 使用组合和point-free编程。
- 将嵌套结构扁平化为更线性的流程。
- 抽象时间耦合的概念,这样就不需要关心它。
- 将错误处理整合到单个函数,而不是多个错误回调遍布在业务代码中。
每当提及扁平结构、组合和巩固行为时,开发者都应该考虑一种设计模式——Monad。先看看Promise Monad,想象一个包含长时间计算的Monad容器(真实的Promise 并不是这样,这只是一个比喻):
Promise.of(<long computation>).map(fun1).map(fun2);//-> Promise(result)
与本书介绍的其他Monad不同,Promise“知道”需要等待长时间计算的完成。就这样,这个数据类型解决了异步调用中存在的延迟问题。就像Maybe 和Either 适用于不确定的返回值一样,Promise适用于需要等待的数据。与传统的基于回调的方法相比,它还更容易执行、编写和管理异步操作。
可以使用Promise来包装将来要处理的值或函数(如果读者有一些Java经验,就会发现这与Future 对象很类似)。耗时操作可能是一个复杂的计算,从数据库或服务器获取数据、读取文件等。在失败的情况下,Promise允许开发者使用与Maybe 和Either 类似的方法来处理错误。Promise可以提供有关工作状态的信息,因此可以提出以下问题:数据是否已成功获取?或者,操作中是否有任何错误?
如图8.5 所示,Promise 可以是以下任何一个状态:pending、fulfilled、rejected或者settled。它以状态pending (也称为unresolved )开始。根据耗时操作的结果,Promise会进入fulfilled (resolve 被调用)或rejected 的状态(reject 被调用)。一旦Promise已经变为状态fulfilled,它可以将数据已经到达的消息通知给其他对象(延续或回调),或者在错误的情况下调用已注册的失败回调函数。这时Promise会处于settled 状态。
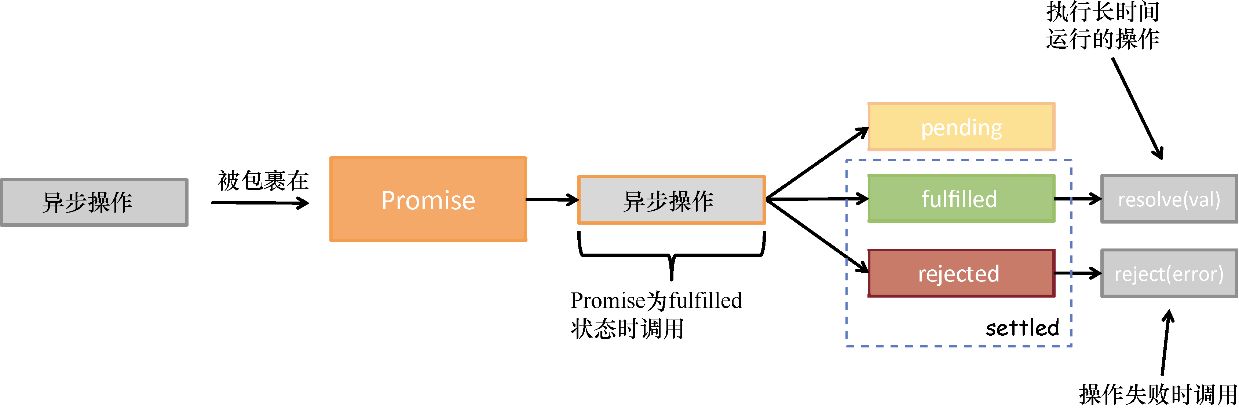
图8.5 异步操作被封装在Promise中 并提供两个回调:一个用于resolve ,
另一个用于reject 。Promise开始于pending状态,然后在fulfilled或rejected时
分别调用函数resolve 或reject ,然后变为settled状态
使用Promise可以更方便推理程序,并松解回调的耦合。就像Maybe 用来消除代码中判空产生的嵌套if-else 条件的数量一样,Promise 可以将一系列嵌套回调函数转换为一系列动作,类似于Monad的map functor。
ES6采用了Promises/A +标准,浏览器制造商也实现了这一开放标准。参考文件可以在https://promisesaplus.com找到。推荐读者阅读,以更多地了解该复杂协议及其术语。可以简单地构建一个Promise 对象:
var fetchData = new Promise(function (resolve, reject) {
// fetch data async or run long-running computation
if (<success>) {
resolve(result);
}
else {
reject(new Error('Error performing this operation!'));
}
});
Promise构造函数接收一个包含异步操作的函数(称为action 函数),该函数需要两个回调(你可以将其视为延续),即resolve 和reject ,分别在fulfilled或rejected时执行。注意,它受到Either设计模式的强烈影响。来看一个简单的例子,该例用了Promise与第4章中的简单Scheduler :
var Scheduler = (function () {
let delayedFn = _.bind(setTimeout, undefined, _, _);
return {
delay5: _.partial(delayedFn, _, 5000),
delay10: _.partial(delayedFn, _, 10000),
delay: _.partial(delayedFn, _, _)
};
})();
var promiseDemo = new Promise(function(resolve, reject) {
Scheduler.delay5(function () { <---设置一个延迟函数来模拟长时间运行的操作
resolve('Done!'); <---resolve该promise
});
});
promiseDemo.then(function(status) {
console.log('After 5 seconds, the status is: ' + status); <---5秒后 resolve该 promise
});
就像一个Monad的map 一样,Promise提供了一种机制来转换一个尚未存在的值。
8.2.1 链接将来的方法
Promise 对象定义了一个then 方法(类似于函子的fmap ),它对一个Promise中返回的值应用一个操作,并将其关闭并返回Promise 。与Maybe.map(f) 类似,Promise.then(f) 可以用于链接数据转换和添加函数,从而在函数之间抽象时间耦合。因此,可以线性链接多级依赖异步行为,而不会创建新的嵌套,如图8.6所示。
图8.6 通过then 方法加入一系列的Promise。每一个then 满足后,会等待
下一个Promise的值fulfilled
then 方法接收两个可选参数:分别是成功回调与错误回调。在每个then 块中提供错误回调可以报告详细的错误信息,但也可以使用一系列成功回调,把错误处理逻辑延迟到最后的catch 方法。在开始链接Promise之前,先利用Promise 来重构getJSON ——这个过程叫Promise 化。代码如清单8.5所示。
清单8.5 Promise化getJSON
var getJSON = function (url) {
return new Promise(function(resolve, reject) {
let req = new XMLHttpRequest();
req.responseType = 'json';
req.open('GET', url);
req.onload = function() { <---在 AJAX 函数返回后调用
if(req.status == 200) {
let data = JSON.parse(req.responseText);
resolve(data); <---如果是成功响应( 200 的响应码),则分解该 Promise
}
else {
reject(new Error(req.statusText)); <---如果响应码并非200 或者建立连接出错,则丢弃该 Promise
}
};
req.onerror = function () {
if(reject) {
reject(new Error('IO Error')); <---如果响应码并非200 或者建立连接出错,则丢弃该 Promise
}
};
req.send(); <---发送一个远程请求
});
};
Promise化API是好的实践。这样代码比传统的回调更简单。因为Promise旨在包装任何类型的耗时操作,而不仅仅是获取数据,所以它们可以与任何实现then方法的对象(称为thenable)一起使用。很快,所有JavaScript库都会兼容Promise。
Promise与jQuery
如果读者是jQuery用户,那么可能使用过Promise。jQuery的
$.getJSON操作(以及JQuery$.ajax调用的任何变体)都会返回Deferred对象(Promise的非标准版本),该对象实现Promise接口,并具有一个then方法。因此,可以跟使用Promise一样将Promise.resolve()应用到Deferred:Promise.resolve($.getJSON('/students')).then(function () ...);这个对象现在就像任何promisified对象一样thenable 。不过本书还是选择在清单8.5中的
getJSON来说明如何重构API调用以使用Promise的过程。
首先来看一个简单的例子,用新的Promise的getJSON 从服务器获取学生数据,然后获取成绩:
getJSON('/students').then(
function(students) {
console.log(R.map(student => student.name, students));
},
function (error) {
console.log(error.message);
}
);
现在用Promise重构清单8.2。以下是新的清单8.2:
getJSON('/students',
function (students) {
students.sort(function(a, b){
if(a.ssn < b.ssn) return -1;
if(a.ssn > b.ssn) return 1;
return 0;
});
for (let i = 0; i < students.length; i++) {
let student = students[i];
if (student.address.country === 'US') {
getJSON(`/students/${student.ssn}/grades`,
function (grades) {
showStudents(student, average(grades));
},
function (error) {
console.log(error.message);
});
}
}
},
function (error) {
console.log(error.message);
}
);
清单8.6中进行了以下函数式的更改。
- 使用Promise抽象代码的异步部分,并用
then将它们连接在一起,来替代异步嵌套调用。 - 用lambda函数替代所有变量声明和状态改变。
- 利用Ramda的柯里化函数创建简洁的数据转换,如排序、过滤和映射。
- 将错误处理逻辑整合到最终的catch函数中。
- 将数据提升到
IOMonad中,以无副作用的方式将数据写入DOM。
清单8.6 通过异步调用获取学生和成绩数据
getJSON('/students')
.then(hide('spinner')) <---隐藏 spinner。由于该函数并不返回任何值, Promise 中依附的值会被传入下一个 then 中
.then(R.filter(s => s.address.country == 'US')) <---去除不属于美国的学生
.then(R.sortBy(R.prop('ssn'))) <---根据 SSN排序剩下的对象
.then(R.map(student => { <---使用另一个 getJSON请求来获取每个学生的成绩。对于每一个获取的学生对象,都会分别生成一个Promise 来处理结果
return getJSON('/grades?ssn=' + student.ssn)
.then(R.compose(Math.ceil, <---使用函数式组合子和 Ramda 函数来计算平均值
forkJoin(R.divide, R.sum, R.length)))
.then(grade =>
IO.of(R.merge(student,
{'grade': grade})) <---使用 IO Monad 将学生和成绩信息添加到 DOM 中
.map(R.props(['ssn', 'firstname',
'lastname', 'grade']))
.map(csv)
.map(append('#student-info')).run())
);
}))
.catch(function(error) {
console.log('Error occurred: ' + error.message);
});
因为Promise会隐藏处理异步调用的细节,这样像是每个函数都一个接一个地执行,无须关心内部的计算是正在从外部服务器请求数据还是其他耗时操作。Promise隐藏异步工作流,但强调then的时间概念。换句话说,可以轻松地将getJSON(url) 与允许的本地存储调用交换,比如getJSON(db) ,代码还能正常工作。这种灵活性称为位置透明度 (location transparency)。还要注意,该代码具有point-free样式。图8.7描述了该程序的行为。
清单8.6的代码会提取每个学生的信息,并将它们一个接一个地添加到DOM中。但是通过序列化操作来获取成绩,这将失去一些宝贵的时间。Promise 其实还能够利用浏览器的多个连接一次获取多个项目。先来改一下需求。假设要计算同一组学生的平均成绩。在这种情况下,哪种顺序获取数据或哪些结果首先到达其实无关紧要,所以可以同时执行,为此可以使用Promise.all() ,如清单8.7所示。
图8.7 使用Promise链接产生的工作流。每个块包含一个函数,用于转换通过它的数据。
虽然这个程序是无缺陷的,而且实现了所有功能,但效率很低。因为瀑布式地
按序列调用getJSON 来获取每个学生的成绩
清单8.7 使用Promise.all() 一次获取多个数据
const average = R.compose(Math.ceil,
forkJoin(R.divide, R.sum, R.length)); <---均值函数被使用多次,因此提为独立的函数
getJSON('/students')
.then(hide('spinner'))
.then(R.map(student => '/grades?ssn=' + student.ssn))
.then(gradeUrls =>
Promise.all(R.map(getJSON, gradeUrls))) <---并发地下载所有的学生信息
.then(R.map(average)) <---计算每个学生的平均成绩
.then(average) <---计算班级的平均成绩
.then(grade => IO.of(grade).map(console.log).run()) <---使用 IOMonad 写入控制台
.catch(error => console.log('Error occurred: ' + error.message));
使用Promise.all 可以利用浏览器一次下载多项数据。数组中的所有Promise一旦分解,整个Promise就会分解。清单8.7汇集了函数式代码的两个基本要素:将程序分解成简单的函数,然后通过Monadic数据类型组合来编制整个程序的执行过程。这个过程的示意图如图8.8所示。
但是,Monads 不仅仅用于组成方法链。正如前几章中提到的,它们也可用于组合。
图8.8 通过使用Promise.all() 链接线性和并发的Promise工作流。每个thenable块包含一个函数,用于转换通过它的数据。该程序是高效的,因为它可以产生几个并行连接以一次获取所有数据
8.2.2 组合同步和异步行为
想象一下组合函数时输入和输出连接在一起的画面,读者肯定会觉得它们会一个接一个线性地执行。但是,使用Promise可以做到执行时分离,但仍然保留着类似同步程序的外观。这个概念有点难以把握,下面用例子来阐释。
前面用同步版本的find(db, ssn) 来实现showStudent 。为简单起见,假设find 是同步的。现在用浏览器的本地存储IndexedDB来实现异步版本。IndexedDB 可用于存储特定密钥(SSN)。如果读者从未用过此API,也不用担心,因为这里会用Promise来实现find ,如清单8.8所示。这里需要注意的一点是,如果student 对象存在,这个Promise将会被分解,否则将会被丢弃。
清单8.8 使用浏览器的本地存储实现find 函数
// find :: DB, String -> Promise(Student)
const find = function (db, ssn) {
let trans = db.transaction(['students'], 'readonly');
const store = trans.objectStore('students');
return new Promise(function(resolve, reject) { <---将获取任务的结果包裹在 Promise 中
let request = store.get(ssn);
request.onerror = function() {
if(reject) {
reject(new Error('Student not found!')); <---查找对象失败的事件会导致丢弃该 Promise
}
};
request.onsuccess = function() {
resolve(request.result); <---如果查找对象成功,分解该 Promise并将匹配的学生对象传递下去
};
});
};
这里省略了设置db 对象的细节,因为它们与此讨论无关。读者可以通过这篇文档了解如何初始化和使用索引本地存储API:https://developer.mozilla.org/en-US/docs/Web/API/ IndexedDB_API。注意,文档中读取和写入API都是异步的——都依赖于回调。那么,如何组合在不同时刻执行的函数呢?到目前为止,find 函数一直是同步的。幸运的是,Promise抽象异步代码的执行,这样一来就跟组合函数没什么区别。在实现代码之前,先创建一些帮助函数:
// fetchStudentDBAsync :: DB -> String -> Promise(Student)
const fetchStudentDBAsync = R.curry(function (db, ssn) {
return find(db, ssn);
});
// findStudentAsync :: String -> Promise
const findStudentAsync = fetchStudentDBAsync(db); <---柯里化对象获取函数,以用于后续的函数组合
// then :: f -> Thenable -> Thenable
const then = R.curry(function (f, thenable) { <---在 thenable 类型(即实现了 then 方法的对象,比如Promise)上启用链接操作
return thenable.then(f);
});
// catchP :: f -> Promise -> Promise
const catchP = R.curry(function (f, promise) { <---为 Promise对象提供错误处理逻辑
return promise.catch(f);
});
// errorLog :: Error -> void
const errorLog = _.partial(logger, 'console', 'basic',
'ShowStudentAsync', 'ERROR'); <---建立一个命令行日志记录器
使用R.compose来组合这些函数会得到清单8.9所示的代码。
清单8.9 showStudent的异步版本
const showStudentAsync = R.compose(
catchP(errorLog), <---捕获所有错误
then(append('#student-info')), <---then 等价于 Monad 的map 方法
then(csv),
then(R.props(['ssn', 'firstname', 'lastname'])),
chain(findStudentAsync), <---将同步操作与异步操作相链接的关键点(后文解释)
map(checkLengthSsn),
lift(cleanInput));
这样,读者应该可以体会到组合与Promise的力量。如图8.9所示,当findStudentAsync 运行时,会按照compose顺序等待异步函数的执行,以便继续执行其余的函数。在这种情况下,可以把Promise作为进入异步部分的网关。而且它也是声明式的,因为这个程序中没有显示函数的异步性质,或是内部回调的使用。因此,compose 仍然可以用point-free风格编排这些不同步执行的函数。
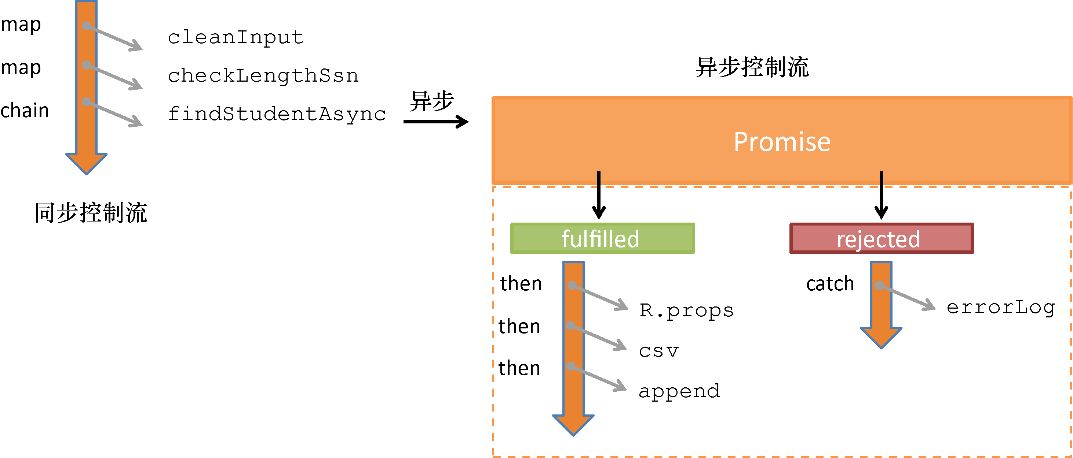
图8.9 同步控制流转换成异步的关键,是控制在Promise类型范围内发生的时间相关的事件序列
这里还添加了错误处理逻辑;现在showStudentAsync('444-44-4444') 可以成功地将学生记录附加到页面。否则,如果Promise被丢弃,该错误将在整个程序中安全的传播,直到catch 子句打印出以下内容:
[ERROR] Error: Student not found!
现在程序是复杂的,但是可以通过整合本书中的许多概念来保持其函数式式风格,如组合、高阶函数、Monad、容器化、映射、链接等。此外,等待或yield 数据的概念也被引入ES6 JavaScript中(后文会讲到)。
8.3 生成惰性数据
ES6最强大的功能之一是可以通过暂停函数执行而不用一次运行完。这带来了许多(可能无限的)机会,比如函数可以生成惰性数据,而不必一次处理大量的数据。
一方面,可以拥有大量对象集——需要根据业务规则进行转换(这一切可以通过map 、filter 、reduce 等完成);另一方面,还可以指定可管理如何创建数据的规则。例如,在数学意义上,函数x => x * x 只不过是所有平方数(1、4、9、16、25等)的规范。这称为生成器 (generator)。
生成器函数通过语言级别的function* 符号定义(是的,带有星号的函数)。这种新型函数可以使用新的关键字yield 退出,随后还可以重新进入该上下文(所有本地变量绑定)。如果读者不熟悉函数的执行上下文,请参阅第7章的相关内容。与典型的函数调用不同,生成函数的执行上下文可以暂时暂停,然后随意恢复。
惰性求值语言可以根据程序的要求生成任意大小的列表。如果JavaScript也是惰性求值,理论上可以做如下的事情:
R.range(1, Infinity).take(1); //-> [1]
R.range(1, Infinity).take(3); //-> [1,2,3]
这当然只是概念。正如第 7 章提到的那样,JavaScript 属于及早求值,所以对R.range(1, Infinity) 的调用将无法完成,并会溢出浏览器的函数栈。生成器被调用时会在内部产生一个迭代器(iterator) ,以此提供惰性行为。迭代器会在每次被调用时通过yield 返回相应数据,如图8.10所示。
图8.10 在循环中执行range 生成器。循环的每次迭代都会使生成器
暂停并产生新的数据。因此,生成器与迭代器具有相似的语义
下面来看一个简单的例子,该例只取前3个元素,而不会产生无数的列表:
function *range(start = 0, finish = Number.POSITIVE_INFINITY) {
for(let i = start; i < finish; i++) {
yield i; <---返回给调用者, 同时记住所有局部变量的状态
}
}
const num = range(1);
num.next().value; //-> 1
num.next().value; //-> 2
num.next().value; //-> 3
// or
for (let n of range(1)) { <---生成器是 iterable 类型的,也就是说,可以像数组一样在循环语句中使用(下文会介绍)。ES6 引入一个可用于生成器的新循环结构 for… of
console.log(n);
if(n === threshold) { <---阈值判断, 防止无限循环
break;
}
}// -> 1,2,3,...
使用生成器,可以惰性地从无限集中取一定数量的元素:
function take(amount, generator) {
let result = [];
for (let n of generator) {
result.push(n);
if(n === amount) {
break;
}
}
return result;
}
take(3, range(1, Infinity)); //-> [1, 2, 3]
除了一些限制,生成器的行为与任何标准函数调用非常相似。可以通过给它传递参数,(也许是一个函数)来操作生成的值:
function *range(specification, start = 0,
finish = Number.POSITIVE_INFINITY) {
for(let i = start; i < finish; i++) {
yield specification(i); <---将 specification 函数应用于生成的每一个值上
}
}
for (let n of range(x => x * x, 1, 4)) { <---生成器与高阶函数一样,能够通过参数实现特定的行为。在这里,生成器用于生成一系列平方数字
console.log(n);
}// -> 1,4,9,16
生成器函数的另一个优点就是可以递归地使用。
8.3.1 生成器与递归
就像任何函数调用一样,也可以在生成器中调用其他生成器。这对于将嵌套对象集合扁平化非常有用,比如树的遍历。因为可以用for…of 遍历生成器,调用另一个生成器就类似于合并两个集合并遍历。回顾第3章的学徒图,如图8.11所示。
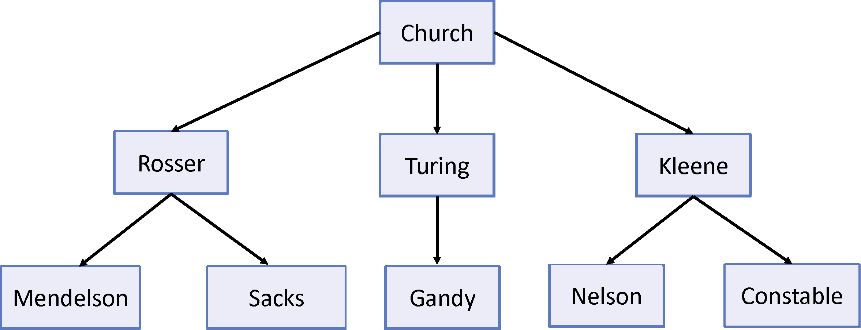
图8.11 重新审视第3章的学徒图,每个节点代表一个student 对象,每个箭头代表“学生关系”
可以使用生成器轻松地对这棵树进行建模(稍后将显示运行此程序的打印结果):
function* AllStudentsGenerator(){
yield 'Church';
yield 'Rosser';
yield* RosserStudentGenerator(); <---使用 yield* 关键字将调用请求代理到另一个生成器上
yield 'Turing'; <---可以用这种方式来交错调用其他生成器
yield* TuringStudentGenerator();
yield 'Kleene';
yield* KleeneStudentGenerator();
}
function* RosserStudentGenerator(){
yield 'Mendelson';
yield 'Sacks';
}
function* TuringStudentGenerator(){
yield 'Gandy';
yield 'Sacks';
}
function* KleeneStudentGenerator(){
yield 'Nelson';
yield 'Constable';
}
for(let student of AllStudentsGenerator()){ <---该循环的执行机制就如同处理一个单独的大生成器一样
console.log(student);
}
因为递归是函数式编程的一个重要组成部分,尽管发生器背后有特殊的语义,但我还是想证明,它们表现得很像标准函数调用,可以自己调用自己。下面的代码使用递归遍历这棵树(每个节点包含一个Person 对象):
function* TreeTraversal(node) {
yield node.value;
if (node.hasChildren()) {
for(let child of node.children) {
yield* TreeTraversal(child); <---使用 yield*将调用请求代理给生成器自身
}
}
}
var root = node(new Person('Alonzo', 'Church', '111-11-1231')); <---第 3 章中提到, 树的根对象由 Church节点开始
for(let person of TreeTraversal(root)) {
console.log(person.lastname);
}
运行此代码的输出与之前是一样的:Church 、Rosser 、Mendelson 、Sacks 、Turing 、Gandy 、Kleene 、Nelson 和Constable 。如上述代码所示,控制传给了其他生成器,一旦完成,将返回给调用者。然而,从循环的角度来看,它只是调用一个内部迭代器,直到遍历完数据,并不会在意递归的发生。
8.3.2 迭代器协议
生成器与另一个称为迭代器 的ES6特性紧密相连,这也是可以像遍历其他数据结构(如数组)一样遍历生成器的原因。事实上,生成函数返回符合迭代器协议的Generator 对象。这意味着它实现一个名为next() 的方法,该方法返回使用yield 关键字return 的值。此对象具有以下属性。
done——如果迭代器到达序列结尾,则值为true;否则,值为false,表示迭代器还可以生成下一个值。value——迭代器返回的值。
这足以让读者了解生成器的工作原理。再来看看如何以这种方式实现range 生成器:
function range(start, end) {
return {
[Symbol.iterator]() { <---表明返回的对象是一个(实现了迭代器协议的) iterable 对象
return this;
},
next() {
if(start < end) {
return { value: start++, done:false }; <---生成器的主要逻辑实现。如果还有可生成的数据,返回一个包含了生成值和 done标志为 false 的对象;否则,done 会被置为 true
}
return { done: true, value:end }; <---生成器的主要逻辑实现。如果还有可生成的数据,返回一个包含了生成值和 done标志为 false 的对象;否则,done 会被置为 true
}
};
}
可以以这种形式创建符合某种规范的数据。例如平方生成器:
function squares() {
let n = 1;
return {
[Symbol.iterator]() {
return this;
},
next() {
return { value: n * n++ };
}
};
}
JavaScript中有许多内含@@iterator属性的可迭代对象。数组是可以这样使用的:
var iter = ['S', 't', 'r', 'e', 'a', 'm'][Symbol.iterator]();
iter.next().value; // S
iter.next().value; // t
字符串也可以迭代:
var iter = 'Stream'[Symbol.iterator]();
iter.next().value// -> S
iter.next().value// -> t
笔者欲提出将数据作为流的想法,当被探测时产生离散的事件或值序列。比如这些值流入一系列纯高阶函数,并转换为期待的输出。这种思维方式至关重要,并引出了另一种称为响应式编程的编程范式(基于函数式编程)。
8.4 使用RxJS进行函数式和响应式编程
前面提到,Web应用程序的性质之所以发生了巨大变化,主要是受AJAX的影响。当人们推动网络到极致时,用户的期望不仅是更多的数据,还需要有更多的交互性。应用程序需要能够处理来自不同来源的用户输入,例如按钮按压、文本字段、鼠标移动,手指手势、语音命令等、并且能够以一致的方式进行这些交互很重要。
本节将介绍一个名为Reactive Extensions for JavaScript(RxJS)的响应式库,以用于优化组合异步和基于事件的程序(有关安装信息参见附录)。RxJS的工作方式类似于本章前面所介绍的Promise的示例,但它提供了更高程度的抽象和更强大的操作。在开始之前,读者必须了解Observable 的概念。
8.4.1 数据作为Observable序列
Observable是可以订阅的数据对象。应用程序可以订阅如读取文件、Web服务调用、查询数据库、推送系统通知、处理用户输入、遍历元素集合或甚至解析简单字符串而发出的异步事件。响应式编程使用Rx.Observable 为这些数据提供统一的名为可观察的流(observable stream)的概念。流是随时间发生的有序事件的序列 。要提取其值,必须先订阅它。下面来看一些例子:
Rx.Observable.range(1, 3)
.subscribe( <---订阅方法需要 3 个回调函数:序列处理函数、异常终止函数和完成终止函数
x => console.log(`Next: ${x}`),
err => console.log(`Error: ${err}`),
() => console.log('Completed')
);
运行上述代码将创建一个会发出值为1 、2 、3 的Observable序列。结束时,会回调第三个参数打印出Completed:
Next: 1
Next: 2
Next: 3
Completed
考虑使用先前的squares 生成器函数,如果改成Observable(需要添加一个参数来生成有限数量的正方形):
const squares = Rx.Observable.wrap(function* (n) {
for(let i = 1; i <= n; i++) {
return yield Observable.just(i * i);
}
});
squares(3).subscribe(x => console.log(`Next: ${x}`));
Next: 1
Next: 4
Next: 9
从这些示例可以看出,可以使用Rx 以完全相同的方式处理任何类型的数据,因为Rx.Observable 将数据转换为流。Rx.Observable 包装或提升任何可观察对象,然后可以映射和应用不同的函数,最后将其中的值转换为所需的输出。因此,这是一个Monad 。
8.4.2 函数式编程与响应式编程
Rx.Observable 对象将函数式编程与响应式编程结合在一起。它实现了第 5章中提到的最小Monadic 接口(map 、of 和join )以及流操作特有的许多方法。示例如下:
Rx.Observable.of(1,2,3,4,5)
.filter(x => x%2 !== 0)
.map(x => x * x) <---过滤掉偶数
.subscribe(x => console.log(`Next: ${x}`));
//-> Next: 1
Next: 9
Next: 25
图8.12显示了所发生的转换。
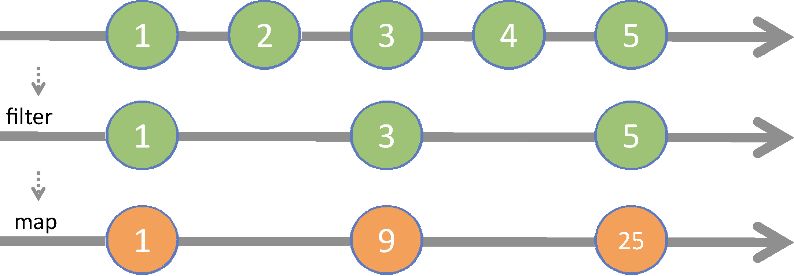
图8.12 从Observable应用函数filter 和map 的过程
如果读者之前没有阅读过任何一本函数式编程书,那么会觉得响应式编程最难的部分是如何学习“响应式思维”。但响应式思维与函数式思维没有什么不同,只是使用不同的工具集而已。实际上,大部分网络上的响应式编程的文档都是通过介绍函数式编程技术开始的。流带来的是声明式的代码和链式计算。因此,响应式编程倾向于和函数式编程一起使用,从而产生函数式响应式编程 (Functional Reactive Programming,FRP)。
建议阅读
自2013年以来,响应式编程开始受到关注,因此有相当多和FRP相关的内容。本书并非要教读者掌握响应式编程,而是要表明响应式编程实际上是把函数式编程应用到异步和基于事件的问题。
如果读者想了解更多有关响应式编程和FRP的信息,可以查看Stephen Blackheath和Anthony Jones的《Functional Reactive Programming》(Manning,2016),这本书可以在https://www.manning.com/books/functional-reactive-programming 找到。如果读者有兴趣了解更多RxJS与函数式编程的内容,可以阅读Paul Daniels和Luis Atencio的 《RxJS in Action》(Manning,2017年出版)。
现在既然了解了Observable,下面就使用RxJS来处理用户输入。当需要处理许多不同来源的交互和事件时,很容易写出纠结又难以阅读的代码。比如读取和验证SSN字段的简单示例:
document.querySelector('#student-ssn')
.addEventListener('change', function (event) {
let value = event.target.value;
value = value.replace(/^\s*|\-|\s*$/g, '');
console.log(value.length !== 9 ? 'Invalid' : 'Valid'));
});
//-> 444 Invalid
//-> 444-44-4444 Valid
因为change 事件是异步发生的,所有业务逻辑就不得不写入单个回调函数中。如本章前面所述,如果继续为页面上的每个按钮、字段和链接堆积更多的事件处理代码,这段代码会很难缩放规模。唯一的重构方式是从回调中抽出一些核心逻辑。那么当更多的业务逻辑到来时,如何保证代码复杂度不会成比例增长?
与异步代码一样,函数式编程很难与传统的基于事件的函数结合——这两种范例是不一样的。类似于Promise解决了函数和异步函数之间的不匹配,Rx.Observable 提供的抽象层将事件与函数式联系起来。随着用户更新学生SSN 输入字段,随时间触发的change 事件可以建模成流(见图8.13)。

图8.13 把SSN输入字段的change 事件创建成可观察的流
通过这种思想,开发者可以使用FRP重构先前基于事件的代码,这样就可以订阅事件,并使用纯函数来实现所有业务逻辑:
Rx.Observable.fromEvent(
document.querySelector('#student-ssn'), 'change') <---订阅 change事件
.map(x => x.target.value) <---提取出事件对象中的值
.map(cleanInput) <---规范化输入的 SSN(见上一章)
.map(checkLengthSsn) <---规范化输入的 SSN(见上一章)
.subscribe( <---检查验证后的输出是 Either.Right 还是 Either.Left,从而确定是否合法
ssn => ssn.isRight ? console.log('Valid') : console.log('Invalid'));
上述代码重用了前几章的函数,因此传入subscribe 的值为Right(SSN) 或Left(null) 的Either 类型。RxJS不仅擅长链接线性异步数据流来处理事件,还将Promise纳入其强大的API,这样就可以用一种编程模型来操作异步的所有事情。
8.4.3 RxJS和Promise
RxJS可以将任何Promises / A +兼容的对象转换成可观察的序列。这意味着可以包装耗时的getJSON 函数,将其值转换为流。比如在美国居住的学生排序列表的示例:
Rx.Observable.fromPromise(getJSON('/students'))
.map(R.sortBy(R.compose(R.toLower, R.prop('firstname')))) <---不区分大小写地根据名字对所有学生对象排序
.flatMapLatest(student => Rx.Observable.from(student)) <---将学生对象数组转换为可观测的学生序列
.filter(R.pathEq(['address', 'country'], 'US')) <---过滤不在美国的学生
.subscribe(
student => console.log(student.fullname), <---打印结果
err => console.log(err)
);
// -> Alonzo Church
Haskell Curry
可以看到,这段代码保留了很多关于Promise的知识,只是稍有区别。注意,subscribe 中的集中错误处理逻辑。如果Promise无法进入fulfilled状态,比如正在访问的Web服务关闭,就会传递错误并调用错误回调中的打印(这很Monad风格):
Error: IO Error
如果没有异常,学生对象的列表被排序(这里会按照名字顺序),并传递给将响应对象转换成可观察的学生数组的flatMapLatest 函数。最后,筛选出不在美国境内的学生,并打印结果。RxJS工具包提供了很多的功能,这里只是涉及皮毛而已。有关更深入的信息,请访问https://xgrommx.github.io/rx-book。
本书们使用函数式编程来处理所有不同类型的具有挑战性的JavaScript问题,包括处理集合、使用AJAX请求、数据库调用、处理用户事件等。至此,本章已经详细地探讨了理论以及函数式的一些实际应用。读者一旦掌握了函数式的核心思维,就很容易将其应用到真实世界的程序中。
8.5 总结
- Promise为回调驱动的设计提供了函数式的解决方案。长期以来,回调一直是JavaScript程序的一大困扰。
- Promise提供链接和组合“未来”函数的可能,抽象出时间依赖代码,并降低复杂性。
- 生成器则采用另一种方法来抽象异步代码,即通过惰性迭代器可以yield还未准备好的数据。
- 函数式响应式编程提升了抽象的层次,这样就可以将事件视为独立的逻辑单元。这可以让开发者更专注于任务,而不是处理复杂的实现细节。
[1] 来自《Research Topics in Functional Programming》, ed. D. Turner (Addison-Wesley, 1990), 17–42, http://mng.bz/Zr02.
[2] 事实上CPS应该是调用者通过参数传入continuations。——译者注
[3] 不是随便两个学生的名字,他们分别是lambda算子之父与函数式语言之父。——译者注
附录 本书中使用的JavaScript库
函数式JavaScript库
因为JavaScript不是纯粹的函数式语言,所以开发者必须依靠第三方库的帮助。开发者可以将其加载到项目中,以模拟诸如柯里化、组合、记忆化、惰性求值、不变性等这些纯粹的函数式语言(如Haskell)的核心特性。使用这些库,就不需要自己实现这些特性,因此开发者可以更专注于编写业务逻辑功能,并将此编排代码的事情委托给这些库。本附录列出了本书中使用的函数式库。这些库旨在提供如下特性。
- 填补其他语言结构和高级实用函数与标准JavaScript环境的空白,从而可以使用简单的函数编写代码。
- 在客户端上使用JavaScript时,确保了不同浏览器的功能一致。
- 以一致的方式抽象出函数式编程技术的内部结构,如柯里化、组合、部分应用、惰性求值等
对于每个库,本附录将给出浏览器和服务器(Node.js)环境的安装说明。
Lodash
这个实用程序库是Underscore.js的分支。Underscore过去为函数式JavaScript程序员广泛采用,并且是重要的JavaScript框架,如Backbone.js的依赖。Lodash保持着Underscore API,但是内部实现已被完全重写,还包括了其他的性能增强。本书主要使用Lodash构建模块化的函数式链。
- 版本:3.10.1
- 安装:
- z浏览器。
</ script> - Node。
$npm i –-save lodash
- z浏览器。
Ramda
Ramda是专门为函数式编程设计的工具库,有助于创建函数管道。Ramda的所有函数都是不可变的、无副作用的。此外,所有函数都已自动柯里化,参数的设计都方便柯里化与组合。Ramda还包含了本书中使用的Lens,通过它可以用不可变的方式读取/写入对象的属性。
- 版本:0.18.0
- 安装:
- 浏览器。
</ script> - Node。
$npm install ramda
- 浏览器。
RxJS
全称为Reactive Extensions for JavaScript,其实现了一种称为响应式编程的范式。这种范式结合了观察者模式、迭代器模式和函数式编程的思想,有助于编写异步和基于事件的程序。
- 版本:4.0.7
- 安装:
- 浏览器。可以从任何JavaScript存储库下载所需的软件包。本书所需的包为:
rx-async、rx-dom和rx-binding。 - Node。
$npm install rx-node
- 浏览器。可以从任何JavaScript存储库下载所需的软件包。本书所需的包为:
使用的其他库
本书还使用非函数式库来处理软件开发的其他一些方面,如日志记录、测试和静态代码分析等。
Log4js
Log4JavaScript是一个客户端日志记录框架,遵循与其他语言(如Log4j(Java),log4php(PHP)等)相同的“Log4X”设计。该库通常用于企业级日志记录,比典型的console.log强大得多。
- 版本:1.0.0
- 安装:
- 浏览器。
</ script> - Node。
$npm install log4js
- 浏览器。
QUnit
QUnit是一个强大、轻量且易于使用的JavaScript单元测试框架。它用于jQuery等流行项目,并且能够测试通用的JavaScript代码。
- 版本:1.20.0
- 安装:
- 浏览器。
</ script> - Node。
$npm install –-save-dev qunitjs
- 浏览器。
Sinon
Sinon.JS是JavaScript的一个stub和mock框架。在本书中,它与QUnit结合使用,以mock上下文和API来扩展测试环境。
- 版本:1.17.2
- 安装:
- 浏览器。
</ script></ script> - Node。
$npm install sinon$npm install sinon-qunit
- 浏览器。
Blanket
Blanket.js是JavaScript的代码覆盖工具。它旨在通过代码覆盖率统计补充现有的JavaScript单元测试(QUnit测试)。代码覆盖率为通过单次测试所通过的代码执行行数的百分比。它分三个阶段工作。
1)加载源文件。
2)给代码添加跟踪代码。
3)在测试运行后回调并输出coverage细节。
- 版本:1.1.5
- 安装:
- 浏览器。
</ script> - Node。
$npm install blanket
- 浏览器。
JSCheck
JSCheck是由Douglas Crockford编写的,由Haskell的QuickCheck项目启发的规范驱动(基于属性)的JavaScript测试库。通过对函数d的属性描述,生成试图证明这些属性的随机测试用例。
- 安装:
- 浏览器。
</ script> - Node。
$npm install jscheck
- 浏览器。